
10. The Liskov Substitution Principle (LSP)

© Jennifer M. Kohnke
The primary mechanisms behind the Open/Closed Principle are abstraction and polymorphism. In statically typed languages, such as C#, one of the key mechanisms that supports abstraction and polymorphism is inheritance. It is by using inheritance that we can create derived classes that implement abstract methods in base classes.
What are the design rules that govern this particular use of inheritance? What are the characteristics of the best inheritance hierarchies? What are the traps that will cause us to create hierarchies that do not conform to OCP? These are the questions addressed by the Liskov Substitution Principle (LSP).
Barbara Liskov wrote this principle in 1988.1 She said:
What is wanted here is something like the following substitution property: If for each object o1 of type S there is an object o2 of type T such that for all programs P defined in terms of T, the behavior of P is unchanged when o1 is substituted for o2 then S is a subtype of T.
The importance of this principle becomes obvious when you consider the consequences of violating it. Presume that we have a function f that takes as its argument a reference to some base class B. Presume also that when passed to f in the guise of B, some derivative D of B causes f to misbehave. Then D violates LSP. Clearly, D is fragile in the presence of f.
The authors of f will be tempted to put in some kind of test for D so that f can behave properly when a D is passed to it. This test violates OCP because now, f is not closed to all the various derivatives of B. Such tests are a code smell that are the result of inexperienced developers or, what’s worse, developers in a hurry reacting to LSP violations.
Violations of LSP
A Simple Example
Violating LSP often results in the use of runtime type checking in a manner that grossly violates OCP. Frequently, an explicit if statement or if/else chain is used to determine the type of an object so that the behavior appropriate to that type can be selected. Consider Listing 10-1.
Listing 10-1. A violation of LSP causing a violation of OCP
struct Point {double x, y;}
public enum ShapeType {square, circle};
public class Shape
{
private ShapeType type;
public Shape(ShapeType t){type = t;}
public static void DrawShape(Shape s)
{
if(s.type == ShapeType.square)
(s as Square).Draw();
else if(s.type == ShapeType.circle)
(s as Circle).Draw();
}
}
public class Circle : Shape
{
private Point center;
private double radius;
public Circle() : base(ShapeType.circle) {}
public void Draw() {/* draws the circle */}
}
public class Square : Shape
{
private Point topLeft;
private double side;
public Square() : base(ShapeType.square) {}
public void Draw() {/* draws the square */}
}
Clearly, the DrawShape function in Listing 10-1 violates OCP. It must know about every possible derivative of the Shape class, and it must be changed whenever new derivatives of Shape are created. Indeed, many rightly view the structure of this function as anathema to good design. What would drive a programmer to write a function like this?
Consider Joe the Engineer. Joe has studied object-oriented technology and has concluded that the overhead of polymorphism is too high to pay.2 Therefore, he defined class Shape without any abstract functions. The classes Square and Circle derive from Shape and have Draw() functions, but they don’t override a function in Shape. Since Circle and Square are not substitutable for Shape, DrawShape must inspect its incoming Shape, determine its type, and then call the appropriate Draw function.
The fact that Square and Circle cannot be substituted for Shape is a violation of LSP. This violation forced the violation of OCP by DrawShape. Thus, a violation of LSP is a latent violation of OCP.
A More Subtle Violation
Of course there are other, far more subtle ways of violating LSP. Consider an application that uses the Rectangle class as described in Listing 10-2.
public class Rectangle
{
private Point topLeft;
private double width;
private double height;
public double Width
{
get { return width; }
set { width = value; }
}
public double Height
{
get { return height; }
set { height = value; }
}
}
Imagine that this application works well and is installed in many sites. As is the case with all successful software, its users demand changes from time to time. One day, the users demand the ability to manipulate squares in addition to rectangles.
It is often said that inheritance is the IS-A relationship. In other words, if a new kind of object can be said to fulfill the IS-A relationship with an old kind of object, the class of the new object should be derived from the class of the old object.
For all normal intents and purposes, a square is a rectangle. Thus, it is logical to view the Square class as being derived from the Rectangle class. (See Figure 10-1.)
Figure 10-1. Square inherits from Rectangle

This use of the IS-A relationship is sometimes thought to be one of the fundamental techniques of object-oriented analysis, a term frequently used but seldom defined. A square is a rectangle, and so the Square class should be derived from the Rectangle class. However, this kind of thinking can lead to some subtle yet significant problems. Generally, these problem are not foreseen until we see them in code.
Our first clue that something has gone wrong might be the fact that a Square does not need both height and width member variables. Yet it will inherit them from Rectangle. Clearly, this is wasteful. In many cases, such waste is insignificant. But if we must create hundreds of thousands of Square objects—such as a CAD/CAE program in which every pin of every component of a complex circuit is drawn as a square—this waste could be significant.
Let’s assume, for the moment, that we are not very concerned with memory efficiency. Other problems ensue from deriving Square from Rectangle. Square will inherit the Width and Height settter properties. These properties are inappropriate for a Square, since the width and height of a square are identical. This is a strong indication that there is a problem. However, there is a way to sidestep the problem. We could override Width and Height as follows:
public new double Width
{
set
{
base.Width = value;
base.Height = value;
}
}
public new double Height
{
set
{
base.Height = value;
base.Width = value;
}
}
Now, when someone sets the width of a Square object, its height will change correspondingly. And when someone sets the height, its width will change with it. Thus, the invariants—those properties that must always be true regardless of state—of the Square remain intact. The Square object will remain a mathematically proper square:
Square s = new Square();
s.SetWidth(1); // Fortunately sets the height to 1 too.
s.SetHeight(2); // sets width and height to 2. Good thing.
But consider the following function:
void f(Rectangle r)
{
r.SetWidth(32); // calls Rectangle.SetWidth
}
If we pass a reference to a Square object into this function, the Square object will be corrupted, because the height won’t be changed. This is a clear violation of LSP. The f function does not work for derivatives of its arguments. The reason for the failure is that Width and Height were not declared virtual in Rectangle and are therefore not polymorphic.
We can fix this easily by declaring the setter properties to be virtual. However, when the creation of a derived class causes us to make changes to the base class, it often implies that the design is faulty. Certainly, it violates OCP. We might counter this by saying that forgetting to make Width and Height virtual was the real design flaw and that we are simply fixing it now. However, this is difficult to justify, since setting the height and width of a rectangle are exceedingly primitive operations. By what reasoning would we make them virtual if we did not anticipate the existence of Square?
Still, let’s assume that we accept the argument and fix the classes. We wind up with the code in Listing 10-3.
Listing 10-3. Rectangle and Square that are self consistent
public class Rectangle
{
private Point topLeft;
private double width;
private double height;
public virtual double Width
{
get { return width; }
set { width = value; }
}
public virtual double Height
{
get { return height; }
set { height = value; }
}
}
public class Square : Rectangle
{
public override double Width
{
set
{
base.Width = value;
base.Height = value;
}
}
public override double Height
{
set
{
base.Height = value;
base.Width = value;
}
}
}
The real problem
Square and Rectangle now appear to work. No matter what you do to a Square object, it will remain consistent with a mathematical square. And regardless of what you do to a Rectangle object, it will remain a mathematical rectangle. Moreover, you can pass a Square into a function that accepts a Rectangle, and the Square will still act like a square and will remain consistent.
Thus, we might conclude that the design is now self-consistent and correct. However, this conclusion would be amiss. A design that is self-consistent is not necessarily consistent with all its users! Consider function g:
void g(Rectangle r)
{
r.Width = 5;
r.Height = 4;
if(r.Area() != 20)
throw new Exception("Bad area!");
}
This function invokes the Width and Height members of what it believes to be a Rectangle. The function works just fine for a Rectangle but throws an Exception if passed a Square. So here is the real problem: The author of g assumed that changing the width of a Rectangle leaves its height unchanged.
Clearly, it is reasonable to assume that changing the width of a rectangle does not affect its height! However, not all objects that can be passed as Rectangles satisfy that assumption. If you pass an instance of a Square to a function like g, whose author made that assumption, that function will malfunction. Function g is fragile with respect to the Square/Rectangle hierarchy.
Function g shows that there exist functions that take Rectangle objects but that cannot operate properly on Square objects. Since, for these functions, Square is not substitutable for Rectangle, the relationship between Square and Rectangle violates LSP.
One might contend that the problem lay in function g, that the author had no right to make the assumption that width and height were independent. The author of g would disagree. The function g takes a Rectagle as its argument. There are invariants, statements of truth, that obviously apply to a class named Rectangle, and one of those invariants is that height and width are independent. The author of g had every right to assert this invariant.
It is the author of Square who has violated the invariant. Interestingly enough, the author of Square did not violate an invariant of Square. By deriving Square from Rectangle, the author of Square violated an invariant of Rectangle!
Validity is not intrinsic
The Laskov Substitution Principle leads us to a very important conclusion: A model, viewed in isolation, cannot be meaningfully validated. The validity of a model can be expressed only in terms of its clients. For example, when we examined the final version of the Square and Rectangle classes in isolation, we found that they were self-consistent and valid. Yet when we looked at them from the viewpoint of a programmer who made reasonable assumptions about the base class, the model broke down.
When considering whether a particular design is appropriate, one cannot simply view the solution in isolation. One must view it in terms of the reasonable assumptions made by the users of that design.3
Who knows what reasonable assumptions the users of a design are going to make? Most such assumptions are not easy to anticipate. Indeed, if we tried to anticipate them all, we’d likely wind up imbuing our system with the smell of needless complexity. Therefore, as with all other principles, it is often best to defer all but the most obvious LSP violations until the related fragility has been smelled.
ISA is about behavior
So, what happened? Why did the apparently reasonable model of the Square and Rectangle go bad? After all, isn’t a Square a Rectangle? Doesn’t the IS-A relationship hold?
Not as far as the author of g is concerned! A square might be a rectangle, but from g’s point of view, a Square object is definitely not a Rectangle object. Why? Because the behavior of a Square object is not consistent with g’s expectation of the behavior of a Rectangle object. Behaviorally, a Square is not a Rectangle, and it is behavior that software is really all about. LSP makes it clear that in OOD, the IS-A relationship pertains to behavior that can be reasonably assumed and that clients depend on.
Design by contract
Many developers may feel uncomfortable with the notion of behavior that is “reasonably assumed.” How do you know what your clients will really expect? There is a technique for making those reasonable assumptions explicit and thereby enforcing LSP. The technique is called design by contract (DBC) and is expounded by Bertrand Meyer.4
Using DBC, the author of a class explicitly states the contract for that class. The contract informs the author of any client code of the behaviors that can be relied on. The contract is specified by declaring preconditions and postconditions for each method. The preconditions must be true in order for the method to execute. On completion, the method guarantees that the postcondition are true.
We can view the postcondition of the Rectangle.Width setter as follows:
assert((width == w) && (height == old.height));
where old is the value of the Rectangle before Width is called. Now the rule for preconditions and postconditions of derivatives, as stated by Meyer, is: “A routine redeclaration [in a derivative] may only replace the original precondition by one equal or weaker, and the original post-condition by one equal or stronger.”5
In other words, when using an object through its base class interface, the user knows only the preconditions and postconditions of the base class. Thus, derived objects must not expect such users to obey preconditions that are stronger then those required by the base class. That is, users must accept anything that the base class could accept. Also, derived classes must conform to all the postconditions of the base. That is, their behaviors and outputs must not violate any of the constraints established for the base class. Users of the base class must not be confused by the output of the derived class.
Clearly, the postcondition of the Square.Width setter is weaker6 than the postcondition of the Rectangle.Width setter, since it does not enforce the constraint (height == old.height). Thus, the Width property of Square violates the contract of the base class.
Certain languages, such as Eiffel, have direct support for preconditions and postconditions. You can declare them and have the runtime system verify them for you. C# has no such feature. In C#, we must manually consider the preconditions and postconditions of each method and make sure that Meyer’s rule is not violated. Moreover, it can be very helpful to document these preconditions and postconditions in the comments for each method.
Specifying contracts in unit tests
Contracts can also be specified by writing unit tests. By thoroughly testing the behavior of a class, the unit tests make the behavior of the class clear. Authors of client code will want to review the unit tests in order to know what to reasonably assume about the classes they are using.
A Real-World Example
Enough of squares and rectangles! Does LSP have a bearing on real software? Let’s look at a case study that comes from a project I worked on a few years ago.
Motivation
In the early 1990s I purchased a third-party class library that had some container classes.7 The containers were roughly related to the Bags and Sets of Smalltalk. There were two varieties of Set and two similar varieties of Bag. The first variety was called bounded and was based an array. The second was called unbounded and was based on a linked list.
The constructor for BoundedSet specified the maximum number of elements the set could hold. The space for these elements was preallocated as an array within the BoundedSet. Thus, if the creation of the BoundedSet succeeded, we could be sure that it had enough memory. Since it was based on an array, it was very fast. There were no memory allocations performed during normal operation. And since the memory was preallocated, we could be sure that operating the BoundedSet would not exhaust the heap. On the other hand, it was wasteful of memory, since it would seldom completely utilize all the space that it had preallocated.
UnboundedSet, on the other hand, had no declared limit on the number of elements it could hold. So long as heap memory was avaliable, the UnboundedSet would continue to accept elements. Therefore, it was very flexible. It was also economical in that it used only the memory necessary to hold the elements that it currently contained. It was also slow, because it had to allocate and deallocate memory as part of its normal operation. Finally, a danger was that its normal operation could exhaust the heap.
I was unhappy with the interfaces of these third-party classes. I did not want my application code to be dependent on them, because I felt that I would want to replace them with better classes later. Thus, I wrapped the third-party containers in my own abstract interface, as shown in Figure 10-2.
Figure 10-2. Container class adapter layer

I created an interface, called Set, that presented abstract Add, Delete, and IsMember functions, as shown in Listing 10-4.8 This structure unified the unbounded and bounded varieties of the two third-party sets and allowed them to be accessed through a common interface. Thus, some client could accept an argument of type Set and would not care whether the actual Set it worked on was of the bounded or unbounded variety. (See the PrintSet function in Listing 10-5.)
Listing 10-4. Abstract Set class
public interface Set
{
public void Add(object o);
public void Delete(object o);
public bool IsMember(object o);
}
void PrintSet(Set s)
{
foreach(object o in s)
Console.WriteLine(o.ToString());
}
It is a big advantage not to have to know or care what kind of Set you are using. It means that the programmer can decide which kind of Set is needed in each particular instance, and none of the client functions will be affected by that decision. The programmer may choose an UnboundedSet when memory is tight and speed is not critical or may choose a BoundedSet when memory is plentiful and speed is critical. The client functions will manipulate these objects through the interface of the base class Set and will therefore not know or care which kind of Set they are using.
Problem
I wanted to add a PersistentSet to this hierarchy. A persistent set is can be written out to a stream and then read back in later, possibly by a different application. Unfortunately, the only third-party container that I had access to that also offered persistence was not acceptable. It accepted objects that were derived from the abstract base class PersistentObject. I created the hierarchy shown in Figure 10-3.
Figure 10-3. PersistentSet hierarchy
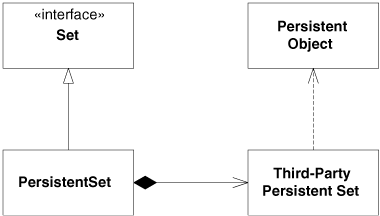
Note that PersistentSet contains an instance of the third-party persistent set, to which it delegates all its methods. Thus, if you call Add on the PersistentSet, it simply delegates that to the appropriate method of the contained third-party persistent set.
On the surface, this might look all right. However, there is an implication that is rather ugly. Elements that are added to the third-party persistent set must be derived from PersistentObject. Since PersistentSet simply delegates to the third-party persistent set, any element added to PersistentSet must therefore derive from PersistentObject. Yet the interface of Set has no such constraint.
When a client is adding members to the base class Set, that client cannot be sure whether the Set might be a PersistentSet. Thus, the client has no way of knowing whether the elements it adds ought to be derived from PersistentObject.
Consider the code for PersistentSet.Add() in Listing 10-6. This code makes it clear that if any client tries to add an object that is not derived from the class PersistentObject to my PersistentSet, a runtime error will ensue. The cast will throw an exception. None of the existing clients of the abstract base class Set expect exceptions to be thrown on Add. Since these functions will be confused by a derivative of Set, this change to the hierarchy violates LSP.
Listing 10-6. Add method in PersistentSet
void Add(object o)
{
PersistentObject p = (PersistentObject)o;
thirdPartyPersistentSet.Add(p);
}
Is this a problem? Certainly. Functions that never before failed when passed a derivative of Set may now cause runtime errors when passed a PersistentSet. Debugging this kind of problem is relatively difficult, since the runtime error occurs very far away from the logic flaw. The logic flaw is the decision either to pass a PersistentSet into a function or to add an object to the PersistentSet that is not derived from PersistentObject. In either case, the decision might be millions of instructions away from the invocation of the Add method. Finding it can be a bear. Fixing it can be worse.
A solution that does not conform to the LSP
How do we solve this problem? Several years ago, I solved it by convention, which is to say that I did not solve it in source code. Rather, I instated a convention whereby PersistentSet and PersistentObject were kept hidden from the application. They were known only to one particular module.
This module was responsible for reading and writing all the containers to and from the persistent store. When a container needed to be written, its contents were copied into appropriate derivatives of PersistentObject and then added to PersistentSets, which were then saved on a stream. When a container needed to be read from a stream, the process was inverted. A PersistentSet was read from the stream, and then the PersistentObjects were removed from the PersistentSet and copied into regular, nonpersistent, objects, which were then added to a regular Set.
This solution may seem overly restrictive, but it was the only way I could think of to prevent PersistentSet objects from appearing at the interface of functions that would want to add nonpersistent objects to them. Moreover, it broke the dependency of the rest of the application on the whole notion of persistence.
Did this solution work? Not really. The convention was violated in several parts of the application by developers who did not understand the necessity for it. That is the problem with conventions: they have to be continually resold to each developer. If the developer has not learned the convention or does not agree with it, the convention will be violated. And one violation can compromise the whole structure.
An LSP-compliant solution
How would I solve this now? I would acknowledge that a PersistentSet does not have an IS-A relationship with Set, that it is not a proper derivative of Set. Thus, I would separate the hierarchies but not completely. Set and PersistentSet have features in common. In fact, it is only the Add method that causes the difficulty with LSP. Thus, I would create a hierarchy in which both Set and PersistentSet were siblings beneath an interface that allowed for membership testing, iteration, and so on (see Figure 10-4). This would allow PersistentSet objects to be iterated and tested for membership, and so on, but would not afford the ability to add objects that were not derived from PersistentObject to a PersistentSet.
Figure 10-4. An LSP-compliant solution
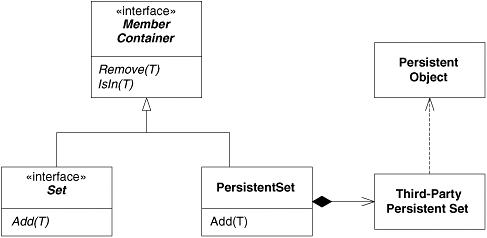
Factoring Instead of Deriving
Another interesting and puzzling case of inheritance is the case of Line and LineSegment.9 Consider Listings 10-7 and 10-8. At first, these two classes appear to be natural candidates for inheritance. LineSegment needs every member variable and every member function declared in Line. Moreover, LineSegment adds a new member function of its own, Length, and overrides the meaning of the IsOn function. Yet these two classes violate LSP in a subtle way.
public class Line
{
private Point p1;
private Point p2;
public Line(Point p1, Point p2){this.p1=p1; this.p2=p2;}
public Point P1 { get { return p1; } }
public Point P2 { get { return p2; } }
public double Slope { get {/*code*/} }
public double YIntercept { get {/*code*/} }
public virtual bool IsOn(Point p) {/*code*/}
}
public class LineSegment : Line
{
public LineSegment(Point p1, Point p2) : base(p1, p2) {}
public double Length() { get {/*code*/} }
public override bool IsOn(Point p) {/*code*/}
}
A user of Line has a right to expect that all points that are colinear with it are on it. For example, the point returned by the YIntercept property is the point at which the line intersects the Y-axis. Since this point is colinear with the line, users of Line have a right to expect that IsOn(YIntercept) == true. In many instances of LineSegment, however, this statement will fail.
Why is this an important issue? Why not simply derive LineSegment from Line and live with the subtle problems? This is a judgment call. There are rare occasions when it is more expedient to accept a subtle flaw in polymorphic behavior than to attempt to manipulate the design into complete LSP compliance. Accepting compromise instead of pursuing perfection is an engineering trade-off. A good engineer learns when compromise is more profitable than perfection. However, conformance to LSP should not be surrendered lightly. The guarantee that a subclass will always work where its base classes are used is a powerful way to manage complexity. Once it is forsaken, we must consider each subclass individually.
In the case of the Line and LineSegment, a simple solution illustrates an important tool of OOD. If we have access to both the Line and LineSegment classes, we can factor the common elements of both into an abstract base class. Listings 10-9, 10-10, and 10-11 show the factoring of Line and LineSegment into the base class LinearObject.
public abstract class LinearObject
{
private Point p1;
private Point p2;
public LinearObject(Point p1, Point p2)
{this.p1=p1; this.p2=p2;}
public Point P1 { get { return p1; } }
public Point P2 { get { return p2; } }
public double Slope { get {/*code*/} }
public double YIntercept { get {/*code*/} }
public virtual bool IsOn(Point p) {/*code*/}
}
public class Line : LinearObject
{
public Line(Point p1, Point p2) : base(p1, p2) {}
public override bool IsOn(Point p) {/*code*/}
}
public class LineSegment : LinearObject
{
public LineSegment(Point p1, Point p2) : base(p1, p2) {}
public double GetLength() {/*code*/}
public override bool IsOn(Point p) {/*code*/}
}
Representing both Line and LineSegment, LinearObject provides most of the functionality and data members for both subclasses, with the exception of the IsOn method, which is abstract. Users of LinearObject are not allowed to assume that they understand the extent of the object they are using. Thus, they can accept either a Line or a LineSegment with no problem. Moreover, users of Line will never have to deal with a LineSegment.
Factoring is a powerful tool. If qualities can be factored out of two subclasses, there is the distinct possibility that other classes will show up later that need those qualities, too. Of factoring, Rebecca Wirfs-Brock, Brian Wilkerson, and Lauren Wiener say:
We can state that if a set of classes all support a common responsibility, they should inherit that responsibility from a common superclass.
If a common superclass does not already exist, create one, and move the common responsibilities to it. After all, such a class is demonstrably useful—you have already shown that the responsibilities will be inherited by some classes. Isn’t it conceivable that a later extension of your system might add a new subclass that will support those same responsibilities in a new way? This new superclass will probably be an abstract class.10
Listing 10-12 shows how the attributes of LinearObject can be used by an unanticipated class: Ray. A Ray is substitutable for a LinearObject, and no user of LinearObject would have any trouble dealing with it.
public class Ray : LinearObject
{
public Ray(Point p1, Point p2) : base(p1, p2) {/*code*/}
public override bool IsOn(Point p) {/*code*/}
}
Heuristics and Conventions
Some simple heuristics can give you some clues about LSP violations. These heuristics all have to do with derivative classes that somehow remove functionality from their base classes. A derivative that does less than its base is usually not substitutable for that base and therefore violates LSP.
Consider Figure 10-13. The f function in Base is implemented but in Derived is degenerate. Presumably, the author of Derived found that function f had no useful purpose in a Derived. Unfortunately, the users of Base don’t know that they shouldn’t call f, and so there is a substitution violation.
Listing 10-13. A degenerate function in a derivative
public class Base
{
public virtual void f() {/*some code*/}
}
public class Derived : Base
{
public override void f() {}
}
The presence of degenerate functions in derivatives is not always indicative of an LSP violation, but it’s worth looking at them when they occur.
Conclusion
The Open/Closed Principle is at the heart of many of the claims made for object-oriented design. When this principle is in effect, applications are more maintainable, reusable, and robust. The Liskov Substitution Principle is one of the prime enablers of OCP. The substitutability of subtypes allows a module, expressed in terms of a base type, to be extensible without modification. That substitutability must be something that developers can depend on implicitly. Thus, the contract of the base type has to be well and prominently understood, if not explicitly enforced, by the code.
The term IS-A is too broad to act as a definition of a subtype. The true definition of a subtype is substitutable, where substitutability is defined by either an explicit or implicit contract.
Bibliography
[Liskov88] “Data Abstraction and Hierarchy,” Barbara Liskov, SIGPLAN Notices, 23(5) (May 1988).
[Meyer97] Bertrand Meyer, Object-Oriented Software Construction, 2d. ed., Prentice Hall, 1997.
[Wirfs-Brock90] Rebecca Wirfs-Brock et al., Designing Object-Oriented Software, Prentice Hall, 1990.