
Chapter 8. strings, string_views, Text Files, CSV Files and Regex

Objectives
In this chapter, you’ll:
■ Determine string characteristics.
■ Find, replace and insert characters in strings.
■ Use C++11 numeric conversion functions.
■ See the C++20 update to how string member function reserve modifies string capacity.
■ Use C++17 string_views for lightweight views of contiguous characters.
■ Write and read sequential files.
■ Perform input from and output to strings in memory.
■ Do an objects-natural case study using an object of an open-source-library class to read and process data about the Titanic disaster from a CSV (comma-separated values) file.
■ Do an objects-natural case study using C++11 regular expressions (regex) to search strings for patterns, validate data and replace substrings.
Outline
8.2 string Assignment and Concatenation
8.6.1 C++20 Update to string Member-Function reserve
8.7 Finding Substrings and Characters in a string
8.8 Replacing Characters in a string
8.9 Inserting Characters into a string
8.10 C++11 Numeric Conversions
8.13 Creating a Sequential File
8.14 Reading Data from a Sequential File
8.15 C++14 Reading and Writing Quoted Text
8.16 Updating Sequential Files
8.19 Objects Natural Case Study: Reading and Analyzing a CSV File Containing Titanic Disaster Data
8.19.1 Using rapidcsv to Read the Contents of a CSV File
8.19.2 Reading and Analyzing the Titanic Disaster Dataset
8.20 Objects Natural Case Study: Introduction to Regular Expressions
8.1 Introduction
17 This chapter discusses additional std::string features and introduces C++17 string_views, text file-processing, CSV file processing and regular expressions.
std::strings
20 We’ve been using std::string object since Chapter 2. Here, we introduce many more std::string manipulations, including assignment, comparisons, extracting substrings, searching for substrings, modifying std::string objects and converting std::string objects to numeric values. We also introduce a C++20 change to the mechanics of the std::string member function reserve.
C++17 string_views
17 We introduce C++17’s string_views, which are read-only views of C-strings or std::string objects. Like std::span, a string_view does not own the data it views. You’ll see that string_views have many similar capabilities to std::strings, making them appropriate for many cases in which you do not need modifiable strings.
Text Files
Data storage in memory is temporary. Files are used for data persistence—permanent retention of data. Computers store files on secondary storage devices, such as flash drives, and frequently today, in the cloud. In this chapter, we explain how to build C++ programs that create, update and process sequential text files. We also show how to output data to and read data from a std::string in memory using ostringstreams and istringstreams.
Objects Natural Case Study: CSV Files and the Titanic Disaster Dataset
In this chapter’s first objects-natural case study, we introduce the CSV (comma-separated values) file format. CSV is popular for datasets used in big data, data analytics and data science, and artificial intelligence applications like natural language processing, machine learning and deep learning.
DS One of the most commonly used datasets for data analytics and data science beginners is the Titanic disaster dataset. It lists all the passengers and whether they survived when the ship Titanic struck an iceberg and sank on its maiden voyage April 14–15, 1912. We use a class from the open-source rapidcsv library to create an object that reads the Titanic dataset from a CSV file. Then, we view some of the data and perform some basic data analytics.
Objects Natural Case Study: Using Regular Expressions to Search Strings for Patterns, Validate Data and Replace Substrings
11 In this chapter’s second objects-natural case study, we introduce regular expressions, which are particularly crucial in today’s data-rich applications. We’ll use C++11 regex objects to create regular expressions then use them with various functions in the <regex> header to match patterns in text. In earlier chapters, we mentioned the importance of validating user input in industrial-strength code. The std::string, string stream and regular expression capabilities presented in this chapter are frequently used to validate data.
8.2 string Assignment and Concatenation
Figure 8.1 demonstrates std::string assignment and concatenation.
1// fig08_01.cpp2// Demonstrating string assignment and concatenation.3#include <iostream>4#include <string>5#include "fmt/format.h" // In C++20, this will be #include <format>6using namespace std;7 8int main() {
Fig. 8.1 Demonstrating string assignment and concatenation.
String Assignment
Lines 9–11 create the strings s1, s2 and s3. Line 13 uses the assignment operator to copy the contents of s1 into s2. You also can specify two arguments, as in
string bar{8, '*'}; // string of 8 '*' characters
which creates a string containing eight '*' characters.
9 string s1{"cat"}; 10 string s2; // initialized to the empty string 11 string s3; // initialized to the empty string 12 13 s2 = s1; // assign s1 to s2 14 s3.assign(s1); // assign s1 to s3 15 cout << fmt::format("s1: {} s2: {} s3: {} ", s1, s2, s3); 16
s1: cat s2: cat s3: cat
Line 14 uses member function assign to copy s1’s contents into s3. This particular version of assign is equivalent to using the operator, but assign also has many overloads that enable you to assign characters to an existing string object. For details of each, see
https://en.cppreference.com/w/cpp/string/basic_string/assign
std::string also provides an overloaded version of member function assign that copies a specified number of characters, as in
target.assign(source, start, numberOfChars);
where source is the string to copy, start is the starting index, and numberOfChars is the number of characters to copy.
Accessing String Elements By Index
Lines 17 and 18 use the string member function at to assign 'r' to s2 at index 0 (forming "rat") and to assign 'r' to s3 at index 2 (forming "car").
17 s2.at(0) = 'r'; // modify s2 18 s3.at(2) = 'r'; // modify s3 19 cout << fmt::format("After modifications: s2: {} s3: {}", s2, s3); 20
After modifications: s2: rat s3: car
You also can use the member function at to get the character at a specific index in a string. As with std::array and std::vector, a std::string’s at member function performs range checking and throws an out_of_range exception if the index is not within the string’s bounds. The subscript operator, [], also is available for strings, but does not provide checked access. This is consistent with its use with std::array and std::vector. You also can iterate through the characters in a string using range-based for as in
for (char c : s3) { cout << c; }
which ensures that you do not access any elements outside the string’s bounds.
Accessing String Elements By Index
Line 22 initializes s4 to the contents of s1 followed by "apult". For std::string, the + operator denotes string concatenation. Line 23 uses member function append to concatenate s1 and "acomb". Next, line 24 uses the overloaded addition assignment operator, +=, to concatenate s3 and "pet". Then line 30 appends the string "comb" to empty string s5. The arguments are the std::string to retrieve characters from (s1), the starting index (4) and the number of characters to append (s1.size() - 4).
21 cout << " After concatenations: "; 22 string s4{s1 + "apult"}; // concatenation 23 s1.append("acomb"); // create "catacomb" 24 s3 += "pet"; // create "carpet" with overloaded += 25 cout << fmt::format("s1: {} s3: {} s4: {} ", s1, s3, s4); 26 27 // append locations 4 through end of s1 to 28 // create string "comb" (s5 was initially empty) 29 string s5; // initialized to the empty string 30 s5.append(s1, 4, s1.size() - 4); 31 cout << fmt::format("s5: {}", s5); 32 }
After concatenations: s1: catacomb s3: carpet s4: catapult s5: comb
8.3 Comparing strings
std::string provides member functions for comparing strings (Fig. 8.2). Throughout this example, we call function displayResult (lines 8–18) to display each comparison’s result. The program declares four strings (lines 21–24) and outputs each (line 26).
1// fig08_02.cpp2// Comparing strings.3#include <iostream>4#include <string>5#include "fmt/format.h" // In C++20, this will be #include <format>6using namespace std;7 8void displayResult(const string& s, int result) {9if (result == 0) {10cout << s + " == 0 ";11}12else if (result > 0) {13cout << s + " > 0 ";14}15else { // result < 016cout << s + " < 0 ";17}18}19 20int main() {21const string s1{"Testing the comparison functions."};22const string s2{"Hello"};23const string s3{"stinger"};24const string s4{s2}; // "Hello"25 26cout << fmt::format("s1: {} s2: {} s3: {} s4: {}", s1, s2, s3, s4);27
s1: Testing the comparison functions.s2: Hellos3: stingers4: Hello
Fig. 8.2 Comparing strings.
Comparing Strings with the Relational and Equality Operators
Strings may be compared with the relational and equality operators—each returns a bool. Comparisons are performed lexicographically—that is, based on the integer values of each character (see Appendix B, ASCII Character Set). Line 29 tests whether s1 is greater than s4 using the overloaded > operator. In this case, s1 starts with a capital T, and s4 starts with a capital H. So, s1 is greater than s4 because T has a higher numeric value than H.
28 // comparing s1 and s4 29 if (s1 > s4) { 30 cout << " s1 > s4 "; 31 } 32
s1 > s4
Comparing Strings with Member Function compare
Line 34 compares s1 to s2 using std::string member function compare. This member function returns 0 if the strings are equal, a positive number if s1 is lexicographically greater than s2 or a negative number if s1 is lexicographically less than s2. Because a string starting with 'T' is considered lexicographically greater than a string starting with 'H', result is assigned a value greater than 0, as confirmed by the output.
33 // comparing s1 and s2 34 displayResult("s1.compare(s2)", s1.compare(s2)); 35 36 // comparing s1 (elements 2-5) and s3 (elements 0-5) 37 displayResult("s1.compare(2, 5, s3, 0, 5)", 38 s1.compare(2, 5, s3, 0, 5)); 39 40 // comparing s2 and s4 41 displayResult("s4.compare(0, s2.size(), s2)", 42 s4.compare(0, s2.size(), s2)); 43 44 // comparing s2 and s4 45 displayResult("s2.compare(0, 3, s4)", s2.compare(0, 3, s4)); 46 }
s1.compare(s2) > 0 s1.compare(2, 5, s3, 0, 5) == 0 s4.compare(0, s2.size(), s2) == 0 s2.compare(0, 3, s4) < 0
The call to compare in line 38 compares portions of s1 and s3 using an overloaded version of member function compare. The first two arguments (2 and 5) specify the starting index and length of the portion of s1 ("sting") to compare with s3. The third argument is the comparison string. The last two arguments (0 and 5) are the starting index and length of the portion of the comparison string being compared (also "sting"). The two pieces being compared here are identical, so compare returns 0 as confirmed in the output.
Line 42 uses another overloaded version of function compare to compare s4 and s2. The first two arguments are the starting index and length. The last argument is the comparison string. The pieces of s4 and s2 being compared are identical, so compare returns 0.
Line 45 compares the first 3 characters in s2 to s4. Because "Hel" begins with the same first three letters as "Hello" but has fewer letters overall, "Hel" is considered less than "Hello" and compare returns a value less than zero.
8.4 Substrings
std::string’s member function substr (Fig. 8.3) returns a substring from a string. The result is a new string object that’s copied from the source string. Line 9 uses member function substr to get a substring from s starting at index 3 and consisting of 4 characters.
1// fig08_03.cpp2// Demonstrating string member function substr.3#include <iostream>4#include <string>5using namespace std;6 7int main() {8const string s{"airplane"};9cout << s.substr(3, 4) << endl; // retrieve substring "plan"10}
planFig. 8.3 Demonstrating string member function substr.
8.5 Swapping strings
std::string provides member function swap for swapping strings. Figure 8.4 swap (line 14) to exchange the values of first and second.
1// fig08_04.cpp2// Using the swap function to swap two strings.3#include <iostream>4#include <string>5#include "fmt/format.h" // In C++20, this will be #include <format>6using namespace std;7 8int main() {9string first{"one"};10string second{"two"};11 12cout << fmt::format(13"Before swap: first: {}; second: {}", first, second);14first.swap(second); // swap strings15cout << fmt::format(16" After swap: first: {}; second: {}", first, second);17}
Before swap:first: one; second: twoAfter swap:first: two; second: one
Fig. 8.4 Using the swap function to swap two strings.
8.6 string Characteristics
std::string provides member functions for gathering information about a string’s size, capacity, maximum length and other characteristics:
• A string’s size is the number of characters currently stored in the string.
• A string’s capacity is the number of characters that can be stored in the string before it must allocate more memory to store additional characters. A string performs memory allocation for you behind the scenes. The capacity of a string must be at least equal to the current size of the string, though it can be greater. The exact capacity of a string depends on the implementation.
• The maximum size is the largest possible size a string can have. If this value is exceeded, a length_error exception is thrown.
Figure 8.5 demonstrates string member functions for determining these characteristics. Function printStatistics (lines 9–12) receives a string and displays its capacity (using member function capacity), maximum size (using member function max_size), size (using member function size), and whether the string is empty (using member function empty).
1// fig08_05.cpp2// Printing string characteristics.3#include <iostream>4#include <string>5#include "fmt/format.h" // In C++20, this will be #include <format>6using namespace std;7 8// display string statistics9void printStatistics(const string& s) {10cout << fmt::format("capacity: {} max size: {} size: {} empty: {}",11s.capacity(), s.max_size(), s.size(), s.empty());12}13 14int main() {
Fig. 8.5 Printing string characteristics.
The program declares empty string string1 (line 15) and passes it to function printStatistics (line 18). The initial call to printStatistics indicates that string1’s initial size is 0—it contains no characters. Recall that the size and length are always identical. On Visual C++, the maximum size (shown in the output) is 2,147,483,647. On GNU C++, the maximum is 9,223,372,036,854,775,807 and on Apple Clang it’s 18,446,744,073,709,551,599. Object string1 is an empty string, so function empty returns true.
15 string string1; // empty string 16 17 cout << "Statistics before input: "; 18 printStatistics(string1); 19
Statistics before input: capacity: 15 max size: 2147483647 size: 0 empty: true
Line 21 inputs a string (in this case, "tomato"). Line 24 calls printStatistics to output updated string1 statistics. The size is now 6, and string1 is no longer empty.
20 cout << " Enter a string: "; 21 cin >> string1; // delimited by whitespace 22 cout << "The string entered was: " << string1; 23 cout << " Statistics after input: "; 24 printStatistics(string1); 25
Enter a string: tomato The string entered was: tomato Statistics after input: capacity: 15 max size: 2147483647 size: 6 empty: false
Line 27 inputs another string (in this case, "soup") and stores it in string1, thereby replacing "tomato". Line 30 calls printStatistics to output updated string1 statistics. Note that the length is now 4.
26 cout << " Enter a string: "; 27 cin >> string1; // delimited by whitespace 28 cout << "The string entered was: " << string1; 29 cout << " Statistics after input: "; 30 printStatistics(string1); 31
Enter a string: soup The string entered was: soup Statistics after input: capacity: 15 max size: 2147483647 size: 4 empty: false
Line 33 uses += to concatenate a 46-character string to string1. Line 36 calls print-Statistics to output updated string1 statistics. Because string1’s capacity was not large enough to accommodate the new string size, the capacity was automatically increased to 63 elements, and string1’s size is now 50.
32 // append 46 characters to string1 33 string1 += "1234567890abcdefghijklmnopqrstuvwxyz1234567890"; 34 cout << " string1 is now: " << string1; 35 cout << " Statistics after concatenation: "; 36 printStatistics(string1); 37
Statistics after resizing to add 10 characters: capacity: 63 max size: 2147483647 size: 60 empty: false
Line 38 uses member function resize to increase string1’s size by 10 characters. The additional elements are set to null characters. The printStatistics output shows that the capacity did not change, but the size is now 60.
38 string1.resize(string1.size() + 10); // add 10 elements to string1 39 cout << " Statistics after resizing to add 10 characters: "; 40 printStatistics(string1); 41 cout << endl; 42 }
Statistics after resizing to add 10 characters: capacity: 63 max size: 2147483647 size: 60 empty: false
8.6.1 C++20 Update to string Member-Function reserve
20 You can change the capacity of a string without changing its size by calling string member function reserve. If its integer argument is greater than the current capacity, the capacity is increased to greater than or equal to the argument value. As of C++20, if reserve’s argument is less than the current capacity, the capacity does not change. Before C++20, reserve optionally would reduce the capacity and, if the argument were smaller than the string’s size, optionally would reduce the capacity to match the size.
8.7 Finding Substrings and Characters in a string
std::string provides member functions for finding substrings and characters in a string. Figure 8.6 demonstrates the find functions. String s is declared and initialized in line 9.
1// fig08_06.cpp2// Demonstrating the string find member functions.3#include <iostream>4#include <string>5#include "fmt/format.h" // In C++20, this will be #include <format>6using namespace std;7 8int main() {9const string s{"noon is 12pm; midnight is not"};10cout << "Original string: " << s;11
Original string: noon is 12pm; midnight is notFig. 8.6 Demonstrating the string find member functions.
Member Functions find and rfind
Lines 13–14 attempt to find "is" in s using member functions find and rfind, which search from the beginning and end of s, respectively. If "is" is found, the index of the starting location of that string is returned. If the string is not found, the string find-related functions return the constant string::npos to indicate that a substring or character was not found in the string. The rest of the find functions presented in this section return the same type unless otherwise noted.
12 // find "is" from the beginning and end of s 13 cout << fmt::format(" s.find("is"): {} s.rfind("is"): {}", 14 s.find("is"), s.rfind("is")); 15
s.find("is"): 5
s.rfind("is"): 23
Member Function find_first_of
Line 17 uses member function find_first_of to locate the first occurrence in s of any character in "misop". The searching is done from the beginning of s. The character 'o' is found in element 1.
16 // find 'o' from beginning 17 int location = s.find_first_of("misop"); 18 cout << fmt::format(" s.find_first_of("misop") found {} at {}", 19 s.at(location), location); 20
s.find_first_of("misop") found o at 1
Member Function find_last_of
Line 22 uses member function find_last_of to find the last occurrence in s of any character in "misop". The searching is done from the end of s. The character 'o' is found in element 28.
21 // find 'o' from end 22 location = s.find_last_of("misop"); 23 cout << fmt::format(" s.find_last_of("misop") found {} at {}", 24 s.at(location), location); 25
s.find_last_of("misop") found o at 27
Member Function find_first_not_of
Line 27 uses member function find_first_not_of to find the first character from the beginning of s that is not contained in "noi spm", finding '1' in element 8. Line 33 uses member function find_first_not_of to find the first character not contained in "12noi spm". It searches from the beginning of s and finds ';' in element 12. Line 39 uses member function find_first_not_of to find the first character not contained in "noon is 12pm; midnight is not". In this case, the string being searched contains every character specified in the string argument. Because a character was not found, string::npos (which has the value –1 in this case) is returned.
26 // find '1' from beginning 27 location = s.find_first_not_of("noi spm"); 28 cout << fmt::format( 29 " s.find_first_not_of("noi spm") found {} at {}", 30 s.at(location), location); 31 32 // find '.' at location 13 33 location = s.find_first_not_of("12noi spm"); 34 cout << fmt::format( 35 " s.find_first_not_of("12noi spm") found {} at {}", 36 s.at(location), location); 37 38 // search for characters not in "noon is 12pm; midnight is not" 39 location = s.find_first_not_of("noon is 12pm; midnight is not"); 40 cout << fmt::format(" s.find_first_not_of(" + 41 ""noon is 12pm; midnight is not"): {}", location); 42 }
s.find_first_not_of("noi spm") found 1 at 8
s.find_first_not_of("12noi spm") found ; at 12
s.find_first_not_of("noon is 12pm; midnight is not"): -1
8.8 Replacing Characters in a string
Figure 8.7 demonstrates string member functions for replacing and erasing characters. Lines 10–14 declare and initialize string string1.
1// fig08_07.cpp2// Demonstrating string member functions erase and replace.3#include <iostream>4#include <string>5#include "fmt/format.h" // In C++20, this will be #include <format>6using namespace std;7 8int main() {9// compiler concatenates all parts into one string10string string1{"The values in any left subtree"11" are less than the value in the"12" parent node and the values in"13" any right subtree are greater"14" than the value in the parent node"};1516cout << fmt::format("Original string: {} ", string1);17
Original string:The values in any left subtreeare less than the value in theparent node and the values inany right subtree are greaterthan the value in the parent node
Fig. 8.7 Demonstrating string member functions erase and replace.
Line 18 uses string member function erase to erase everything from (and including) the character in position 62 to the end of string1. Each newline character occupies one character in the string.
18 string1.erase(62); // remove from index 62 through end of string1 19 cout << fmt::format("string1 after erase: {} ", string1); 20
string1 after erase: The values in any left subtree are less than the value in the
Lines 21–27 use find to locate each occurrence of the space character. Each space is then replaced with a period by a call to string member function replace. Function replace takes three arguments—the index of the character in the string at which replacement should begin, the number of characters to replace and the replacement string. Member function find returns string::npos when the search character is not found. In line 26, we add 1 to position to continue searching from the next character’s location.
21 size_t position = string1.find(" "); // find first space 22 23 // replace all spaces with period 24 while (position != string::npos) { 25 string1.replace(position, 1, "."); 26 position = string1.find(" ", position + 1); 27 } 28 29 cout << fmt::format("After first replacement: {} ", string1); 30
After first replacement: The.values.in.any.left.subtree are.less.than.the.value.in.the
Lines 31–38 use functions find and replace to find every period and replace every period and its following character with two semicolons. The arguments passed to this version of replace are:
• the index of the element where the replace operation begins,
• the number of characters to replace,
• a replacement character string from which a substring is selected to use as replacement characters,
• the element in the character string where the replacement substring begins and
• the number of characters in the replacement character string to use.
31 position = string1.find("."); // find first period 32 33 // replace all periods with two semicolons 34 // NOTE: this will overwrite characters 35 while (position != string::npos) { 36 string1.replace(position, 2, "xxxxx;;yyy", 5, 2); 37 position = string1.find(".", position + 1); 38 } 39 40 cout << fmt::format("After second replacement: {} ", string1); 41 }
After first replacement: The.values.in.any.left.subtree are.less.than.the.value.in.the After second replacement: The;;alues;;n;;ny;;eft;;ubtree are;;ess;;han;;he;;alue;;n;;he
8.9 Inserting Characters into a string
std::string provides overloaded member functions for inserting characters into a string (Fig. 8.8). Line 14 uses string member function insert to insert "middle " before element 10 of s1. Line 15 uses insert to insert "xx" before s2’s element 3. The last two arguments specify the starting and last element of "xx" to insert. Using string::npos causes the entire string to be inserted.
1// fig08_08.cpp2// Demonstrating std::string insert member functions.3#include <iostream>4#include <string>5#include "fmt/format.h" // In C++20, this will be #include <format>6using namespace std;7 8int main() {9string s1{"beginning end"};10string s2{"12345678"};11 12cout << fmt::format("Initial strings: s1: {} s2: {} ", s1, s2);13 14s1.insert(10, "middle "); // insert "middle " at location 10 in s115s2.insert(3, "xx", 0, string::npos); // insert "xx" at location 3 in s216 17cout << fmt::format("Strings after insert: s1: {} s2: {} ", s1, s2);18}
Initial strings:s1: beginning ends2: 12345678Strings after insert:s1: beginning middle ends2: 123xx45678
Fig. 8.8 Demonstrating std::string insert member functions.
8.10 C++11 Numeric Conversions
11 C++11 added functions for converting from numeric values to strings and from strings to numeric values.
Converting Numeric Values to string Objects
C++11’s to_string function (from header <string>) returns the string representation of its numeric argument. The function is overloaded for all the fundamental numeric types int, unsigned int, long, unsigned long, long long, unsigned long long, float, double and long double.
Converting string Objects to Numeric Values
11 C++11 provides eight functions (from the <string> header) for converting string objects to numeric values:
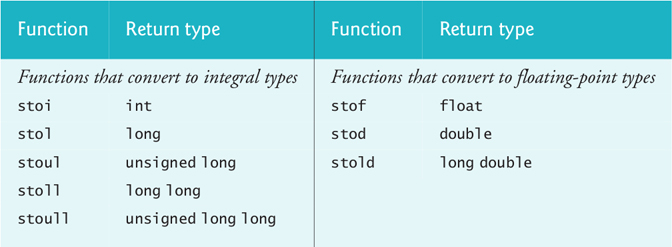
Each function attempts to convert the beginning of its string argument to a numeric value. If no conversion can be performed, each function throws an invalid_argument exception. If the result of the conversion is out of range for the function’s return type, each function throws an out_of_range exception.
Functions That Convert strings to Integral Types
Consider an example of converting a string to an integral value. Assuming the string:
string s("100hello");
the following statement converts the beginning of the string to the int value 100 and stores that value in convertedInt:
int convertedInt = stoi(s);
Each function that converts a string to an integral type receives three parameters—the last two have default arguments. The parameters are:
• A string containing the characters to convert.
• A pointer to a size_t variable. The function uses this pointer to store the index of the first character that was not converted. The default argument is nullptr, in which case the function does not store the index.
• An int from 2 to 36 representing the number’s base—the default is base 10.
So, the preceding statement is equivalent to
int convertedInt = stoi(s, nullptr, 10);
Given a size_t variable named index, the statement:
int convertedInt = stoi(s, &index, 2);
converts the binary number "100" (base 2) to an int (100 in binary is the int value 4) and stores in index the location of the string’s letter "h" (the first character that was not converted).
Functions That Convert strings to Floating-Point Types
The functions that convert strings to floating-point types each receive two parameters:
• A string containing the characters to convert.
• A pointer to a size_t variable where the function stores the index of the first character that was not converted. The default argument is nullptr, in which case the function does not store the index.
Consider an example of converting a string to a floating-point value. Assuming the string:
string s("123.45hello");
the following statement converts the beginning of the string to the double value 123.45 and stores that value in convertedDouble:
double convertedDouble = stod(s);
Again, the second argument is nullptr by default.
8.11 C++17 string_view
17 C++17 introduced string_views (header <string_view>), which are read-only views of C-strings or std::string objects. Like std::span, a string_view does not own the data it views. It contains:
• a pointer to the first character in a contiguous sequence of characters and
• a count of the number of characters.
![]() PERF CG
PERF CG string_views enable many std::string-style operations on C-strings without the overhead of creating and initializing std::string objects, which copies the C-string contents. The C++ Core Guidelines state that you should prefer std::string if you need to “own character sequences”—for example, to be able to modify std::string contents.1 If you simply need a read-only view of a contiguous sequence of characters, use a string_view.2
1. https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rstr-string.
2. https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rstr-view.
Creating a string_view
Figure 8.9 demonstrates several string_view features. Line 5 includes the header <string_view>. Line 11 creates the std::string s1 and line 12 copies s1 into s2. Line 12 initializes a string_view with the std::string s1 (line 12), but you can also initialize a string_view with a C-string.
1// fig08_09.cpp2// C++17 string_view.3#include <iostream>4#include <string>5#include <string_view>6#include "fmt/format.h" // In C++20, this will be #include <format>7using namespace std;8 9int main() {10string s1{"red"};11string s2{s1};12string_view v1{s1}; // v2 "sees" the contents of s113cout << fmt::format("s1: {} s2: {} v1: {} ", s1, s2, v1);14
s1: reds2: redv1: red
Fig. 8.9 C++17 string_view.
string_views “See” Changes to the Characters They View
Because a string_view does not own the sequence of characters it views, it “sees” any changes to the original characters. Line 16 modifies the std::string s1. Then line 17 shows s1’s, s2’s and the string_view v1’s contents.
15 // string_views see changes to the characters they view 16 s1.at(0) = 'R'; // capitalize s1 17 cout << fmt::format("s1: {} s2: {} v1: {} ", s1, s2, v1); 18
s1: Red s2: red v1: Red
string_views Are Comparable with std::strings or string_views
Like std::string, string_views are comparable with the relational and equality operators. You also can intermix std::strings and string_views as in the equality comparisons in line 21.
19 // string_views are comparable with strings or string_views 20 cout << fmt::format("s1 == v1: {} s2 == v1: {} ", 21 s1 == v1, s2 == v1); 22
s1 == v1: true s2 == v1: false
string_views Can Remove a Prefix or Suffix
![]() PERF You can easily remove a specified number of characters from the beginning or end of a
PERF You can easily remove a specified number of characters from the beginning or end of a string_view. These are fast operations for a string_view—they simply adjust the character count and, in the case of removing from the beginning, move the pointer to the first character in the string_view. Lines 24–25 call string_view member functions remove_prefix and remove_suffix to remove one character from the beginning and one from the end of v1, respectively. Note that s1 remains unmodified.
23 // string_view can remove a prefix or suffix 24 v1.remove_prefix(1); // remove one character from the front 25 v1.remove_suffix(1); // remove one character from the back 26 cout << fmt::format("s1: {} v1: {} ", s1, v1); 27
s1: Red v1: e
string_views Are Iterable
Line 29 initializes a string_view from a C-string. Like std::strings, string_views are iterable, so you can use them with the range-based for statement (as in lines 31–33).
28 // string_views are iterable 29 string_view v2{"C-string"}; 30 cout << "The characters in v2 are: "; 31 for (const char c : v2) { 32 cout << c << " "; 33 } 34
The characters in v2 are: C - s t r i n g
string_views Enable Various String Operations on C-Strings
Many std::string member functions that do not modify a string also are defined for string_views. For example, line 36 calls size to determine the number of characters in the string_view, line 37 calls find to get the index of '-' in the string_view. Line 38 uses the new C++20 starts_with function to determine whether the string_view starts with 'C'. For a complete list of string_view member functions, see
https://en.cppreference.com/w/cpp/string/basic_string_view
35 // string_views enable various string operations on C-Strings 36 cout << fmt::format(" v2.size(): {} ", v2.size()); 37 cout << fmt::format("v2.find('-'): {} ", v2.find('-')); 38 cout << fmt::format("v2.starts_with('C'): {} ", v2.starts_with('C')); 39 }
v2.size(): 8
v2.find('-'): 1
v2.starts_with('C'): true
8.12 Files and Streams
C++ views each file simply as a sequence of bytes:

Each file ends either with an end-of-file marker or at a specific byte number recorded in an operating-system-maintained administrative data structure. When a file is opened, an object is created, and a stream is associated with the object. The objects cin, cout, cerr and clog are created for you in the header <iostream>. The streams associated with these objects provide communication channels between a program and a particular file or device. The cin object (standard input stream object) enables a program to input data from the keyboard or other devices. The cout object (standard output stream object) enables a program to output data to the screen or other devices. The objects cerr and clog objects (standard error stream objects) enable a program to output error messages to the screen or other devices. Messages written to cerr are output immediately. In contrast, messages written to clog are stored in a memory object called a buffer. When the buffer is full, its contents are written to the standard error stream.
File-Processing Streams
To perform file processing in C++, headers <iostream> and <fstream> must be included. Header <fstream> includes the following definitions:
• ifstream is for file input that reads chars.
• ofstream is for file output that writes chars.
• fstream combines the capabilities of ifstream and ofstream.
The cout and cin capabilities we’ve discussed so far and the additional I/O features we describe in Chapter 18 also can be applied to file streams.
8.13 Creating a Sequential File
C++ imposes no structure on files. Thus, a concept like that of a record (Section 1.4) does not exist in C++. You must structure files to meet the application’s requirements. The following example shows how you can impose a simple record structure on a file.
Figure 8.10 creates a sequential file that might be used in an accounts-receivable system to help keep track of the money owed to a company by its credit clients. For each client, the program obtains the client’s account number, name and balance (i.e., the amount the client owes the company for goods and services received in the past). The data obtained for each client constitutes a record for that client.
1// fig08_10.cpp2// Creating a sequential file.3#include <cstdlib> // exit function prototype4#include <fstream> // contains file stream processing types5#include <iostream>6#include <string>7#include "fmt/format.h" // In C++20, this will be #include <format>8using namespace std;9 10int main() {11// ofstream opens the file12if (ofstream output{"clients.txt", ios::out}; output) {13cout << "Enter the account, name, and balance. "14<< "Enter end-of-file to end input. ? ";15 16int account;17string name;18double balance;19 20// read account, name and balance from cin, then place in file21while (cin >> account >> name >> balance) {22output << fmt::format("{} {} {} ? ", account, name, balance);23}24}25else {26cerr << "File could not be opened "; 27exit(EXIT_FAILURE);28}29}
Enter the account, name, and balance.Enter end-of-file to end input.? 100 Jones 24.98? 200 Doe 345.67? 300 White 0.00? 400 Stone -42.16? 500 Rich 224.62? ^Z
Fig. 8.10 Creating a sequential file.
Opening a File
Figure 8.10 writes data to a file, so we open the file for output by creating an ofstream object (line 12). Two arguments are used to initialize the ofstream—the filename and the file-open mode. For an ofstream object, the file-open mode can be
• ios::out (the default) to output data to a file or
• ios::app to append data to the end of a file (without modifying any data already in the file).
11 17 Line 12 creates the ofstream object output associated with the file clients.txt and opens it for output. We did not specify a path to the file (that is, its location), so it’splaced in the same directory as the program. Before C++11, the filename was specified as a pointer-based string. C++11 added specifying the filename as a string object. C++17 introduced the <filesystem> header with features for manipulating files and folders in C++. As of C++17, you also may specify the file to open as a filesystem::path object.
Since ios::out is the default, the second argument in line 12 is not required, so we could have used:
ofstream output{"clients.txt"}
Existing files opened with mode ios::out are truncated—all data in the file is discarded. If the file does not yet exist, the ofstream object creates the file. The following table lists the file-open modes—these modes can also be combined:

Opening a File via the open Member Function
You can create an ofstream object without opening a specific file. In this case, a file can be attached to the object later. For example, the statement
ofstream output;
creates an ofstream object that’s not yet associated with a file. The ofstream member function open opens a file and attaches it to an existing ofstream object as follows:
output.open("clients.txt", ios::out);
Again, ios::out is the default value for the second argument. Use caution when opening an existing file for output (ios::out), especially when you want to preserve the file’s contents, which will be discarded without warning.
Testing Whether a File Was Opened Successfully
11 After creating an ofstream object and attempting to open it, the if statement uses the file object output as a condition (line 12) to determine whether the open operation succeeded. For a file object, there is an overloaded operator bool (added in C++11) that implicitly evaluates the file object to true if the file opened successfully. Some possible reasons opening a file might fail are:
• attempting to open a nonexistent file for reading
• attempting to open a file for reading or writing in a directory that you don’t have permission to access, and
• ![]() Security opening a file for writing when no secondary storage space is available.
Security opening a file for writing when no secondary storage space is available.
If the condition indicates an unsuccessful attempt to open the file, line 26 outputs an error message, and line 27 invokes function exit to terminate the program. The argument to exit is returned to the environment from which the program was invoked. Passing EXIT_SUCCESS (defined in <cstdlib>) to exit indicates that the program terminated normally; passing any other value (in this case, EXIT_FAILURE) indicates that the program terminated due to an error.
Processing Data
If line 12 opens the file successfully, the program begins processing data. Lines 13–14 prompt the user to enter either the various fields for each record or the end-of-file indicator when data entry is complete. To enter end-of-file key on Linux or macOS type <Ctrl-d> (on a line by itself). On Microsoft Windows, type <Ctrl-z> then press Enter.
The while statement’s condition (line 21) implicitly invokes the operator bool member function on cin. The condition remains true as long as each input operation with cin is successful. Entering the end-of-file indicator causes the operator bool member function to return false. You also can call member function eof on the input object to determine whether the end-of-file indicator has been entered.
Line 21 extracts each set of data into the variables account, name and balance, and determines whether end-of-file has been entered. When end-of-file is encountered (that is, when the user enters the end-of-file key combination) or an input operation fails, the operator bool returns false, and the while statement terminates.
Line 28 writes a set of data to the file clients.txt, using the stream insertion operator << and the output object associated with the file at the beginning of the program. The data may be retrieved by a program designed to read the file (see Section 8.14). The file created in Fig. 8.10 is simply a text file—it can be viewed by any text editor.
Closing a File
Once the user enters the end-of-file indicator, the while loop terminates. At this point, the output object goes out of scope, which automatically closes the file. You should always close a file as soon as it’s no longer needed in a program. You also can close a file object explicitly, using member function close, as in:
output.close();
Sample Execution
In the sample execution of Fig. 8.10, the user enters information for five accounts, then signals that data entry is complete by entering end-of-file (^Z is displayed for Microsoft Windows). This dialog window does not show how the data records appear in the file. The next section shows how to create a program that reads this file and prints its contents.
8.14 Reading Data from a Sequential File
The previous section demonstrated how to create a sequential-access file. Figure 8.11 reads data sequentially from a file and displays the records from the clients.txt file that we wrote in Fig. 8.10. Creating an ifstream object opens a file for input. An ifstream is initialized with a filename and file-open mode. Line 12 creates an ifstream object called input that opens the clients.txt file for reading. If a file’s contents should not be modified, use ios::in to open it only for input to prevent unintentional modification of the file’s contents.
1// fig08_11.cpp2// Reading and printing a sequential file.3#include <cstdlib>4#include <fstream> // file stream5#include <iostream>6#include <string>7#include "fmt/format.h" // In C++20, this will be #include <format>8using namespace std;9 10int main() {11// ifstream opens the file12if (ifstream input{"clients.txt", ios::in}; input) {13cout << fmt::format("{:<10}{:<13}{} ",14"Account", "Name", "Balance");15 16int account;17string name;18double balance;19 20// display each record in file21while (input >> account >> name >> balance) {22cout << fmt::format("{:<10}{:<13}{:>7.2f} ",23account, name, balance);24}25}26else {27cerr << "File could not be opened ";28exit(EXIT_FAILURE);29}30}
Account Name Balance100 Jones 24.98200 Doe 345.67300 White 0.00400 Stone -42.16500 Rich 224.62
Fig. 8.11 Reading and printing a sequential file.
Opening a File for Input
Objects of class ifstream are opened for input by default, so
ifstream input("clients.txt");
opens clients.txt for input. An ifstream object can be created without opening a file—you can attach one to it later. Before attempting to retrieve data from the file, line 12 uses the input object as a condition to determine whether the file was opened successfully. The overloaded operator bool converts the ifstream object to a true or false value.
Reading from the File
Line 21 reads a set of data (i.e., a record) from the file. After line 21 executes the first time, account has the value 100, name has the value "Jones" and balance has the value 24.98. Each time line 21 executes, it reads another record into the variables account, name and balance. Lines 22–23 display the records. When the end of the file is reached, the implicit call to operator bool in the while condition returns false, the ifstream object goes out of scope (which automatically closes the file), and the program terminates.
File-Position Pointers
Programs often read sequentially from the beginning of a file and read all the data consecutively until the desired data is found. It might be necessary to process the file sequentially several times (from the beginning) during the execution of a program. istream and ost-ream provide member functions seekg (“seek get”) and seekp (“seek put”) to reposition the file-position pointer. This represents the byte number of the next byte in the file to be read or written. Each istream object has a get pointer, which indicates the byte number in the file from which the next input is to occur. Each ostream object has a put pointer, which indicates the byte number in the file at which the next output should be placed. The statement
input.seekg(0);
repositions the file-position pointer to the beginning of the file (location 0) attached to input. The argument to seekg is an integer. If the end-of-file indicator has been set, you’d also need to execute
input.clear();
to re-enable reading from the stream.
An optional second argument indicates the seek direction;
• ios::beg (the default) for positioning relative to the beginning of a stream,
• ios::cur for positioning relative to the current position in a stream or
• ios::end for positioning backward relative to the end of a stream.
The file-position pointer is an integer value that specifies the location in the file as the number of bytes from the file’s starting location. This is also referred to as the offset from the beginning of the file. Some examples of positioning the get file-position pointer are
// position to the nth byte of fileObject (assumes ios::beg)
fileObject.seekg(n);
// position n bytes in fileObject fileObject.seekg(n, ios::cur);
// position n bytes back from end of fileObject fileObject.seekg(n, ios::end);
// position at end of fileObject fileObject.seekg(0, ios::end);
The same operations can be performed using ostream member function seekp. Member functions tellg and tellp are provided to return the current locations of the get and put pointers, respectively. The following statement assigns the get file-position pointer value to variable location of type long:
location = fileObject.tellg();
8.15 C++14 Reading and Writing Quoted Text
14 Many text files contain quoted text, such as "C++20 for Programmers". For example, in files representing HTML5 web pages, attribute values are enclosed in quotes. If you’re building a web browser to display the contents of such a web page, you must be able to read those quoted strings and remove the quotes.
Suppose you need to read from a text file, as you did in Fig. 8.11, but with each account’s data formatted as follows:
100 "Janie Jones" 24.98
Recall that the stream extraction operator >> treats white space as a delimiter. So, if we read the preceding data using the expression in line 30 of Fig. 8.11:
input >> account >> name >> balance
the first stream extraction reads 100 into the int variable account, and the second reads only "Janie into the string variable name. The opening double quote would be part of the string in name. The third stream extraction fails while attempting to read a value for the double variable balance because the next token (i.e., piece of data) in the input stream—Jones"—is not a double.
Reading Quoted Text
14 C++14 added the stream manipulator quoted (header <iomanip>) for reading quoted text from a stream. It includes any white space characters in the quoted text and discards the double-quote delimiters. For example, if we read the preceding data, the expression:
input >> account >> quoted(name) >> balance
reads 100 into account, reads Janie Jones as one string into name, and reads 24.98 into balance. If the quoted data contains " escape sequences, each is read and stored in the string as the escape sequence "—not as ".
Writing Quoted Text
Similarly, you can write quoted text to a stream. For example, if name contains Janie Jones, the statement:
outputStream << quoted(name);
writes to the text-based outputStream:
"Janie Jones"
8.16 Updating Sequential Files
Data that is formatted and written to a sequential file, as shown in Section 8.13, cannot be modified in place without the risk of destroying other data in the file. For example, if the name “White” needs to be changed to “Worthington,” the old name cannot be overwritten without corrupting the file. The record for White was written to the file as
300 White 0.00
If this record were rewritten beginning at the same location in the file using the longer name, the record would be
300 Worthington 0.00
The new record contains six more characters than the original. Any characters after “h” in “Worthington” would overwrite 0.00 and the beginning of the next sequential record in the file. The problem with the formatted input/output model using the stream insertion operator << and the stream extraction operator >> is that fields—and hence records—can vary in size. For example, values 7, 14, –117, 2074, and 27383 are all ints, which store the same number of “raw data” bytes internally (typically four bytes on 32-bit machines and eight bytes on 64-bit machines). However, these integers become different-sized fields, depending on their actual values, when output as formatted text (character sequences). Therefore, the formatted input/output model usually is not used to update records in place.
Such updating can be done with sequential files, but awkwardly. For example, to make the preceding name change in a sequential file, we could:
• copy the records before 300 White 0.00 to a new file,
• write the updated record to the new file, then
• write the records after 300 White 0.00 to the new file.
Then we could delete the old file and rename the new one. This requires processing every record in the file to update one record. If many records are being updated in one pass of the file, though, this technique can be acceptable.
8.17 String Stream Processing
In addition to standard stream I/O and file stream I/O, C++ stream I/O includes capabilities for inputting from, and outputting to, strings in memory. These capabilities often are referred to as in-memory I/O or string stream processing. You can read from a string with istringstream and write to a string with ostringstream.
Class templates istringstream and ostringstream provide the same functionality as classes istream and ostream plus other member functions specific to in-memory formatting. Programs that use in-memory formatting must include the <sstream> and <iost-ream> headers. An ostringstream object uses a string object to store the output data. Its str member function returns a copy of that string.
One application of string stream processing is data validation. A program can read an entire line at a time from the input stream into a string. Next, a validation routine can scrutinize the string’s contents and correct (or repair) the data, if necessary. Then the program can input from the string, knowing that the input data is in the proper format.
11 To assist with data validation, C++11 added powerful pattern-matching regular-expression capabilities. For instance, in a program requiring a U.S. format telephone number (e.g., (800) 555-1212), you can use a regular expression to confirm that a string matches that format. Many websites provide regular expressions for validating e-mail addresses, URLs, phone numbers, addresses and other popular kinds of data. We introduce regular expressions and provide several examples in Section 8.20.
Demonstrating ostringstream
Figure 8.12 creates an ostringstream object, then uses the stream insertion operator to output a series of strings and numerical values to the object.
1// fig08_12.cpp2// Using an ostringstream object.3#include <iostream>4#include <sstream> // header for string stream processing5#include <string>6using namespace std;7 8int main() {9ostringstream output; // create ostringstream object10 11const string string1{"Output of several data types "};12const string string2{"to an ostringstream object:"};13const string string3{" double: "};14const string string4{" int: "};15 16constexpr double s{123.4567};17constexpr int i{22};18 19// output strings, double and int to ostringstream20output << string1 << string2 << string3 << d << string4 << i;21 22// call str to obtain string contents of the ostringstream23cout << "output contains: " << output.str();24 25// add additional characters and call str to output string26output << " more characters added";27cout << " after additional stream insertions, output contains: "28<< "" << output.str() << endl;29}
outputString contains:Output of several data types to an ostringstream object:double: 123.457int: 22after additional stream insertions, outputString contains:Output of several data types to an ostringstream object:double: 123.457int: 22more characters added
Fig. 8.12 Using an ostringstream object.
Line 20 outputs string string1, string string2, string string3, double d, string string4 and int i—all to output in memory. Line 23 displays output.str(), which returns the string created by output in line 20. Line 25 appends more data to the string in memory by simply issuing another stream insertion operation to output, then lines 27–28 display the updated contents.
Demonstrating istringstream
An istringstream object inputs data from a string in memory. Data is stored in an istringstream object as characters. Input from the istringstream object works identically to input from any file. The end of the string is interpreted by the istringstream object as end-of-file.
Figure 8.13 demonstrates input from an istringstream object. Lines 9–10 create string inputString containing the data and istringstream object input constructed to read from inputString, which consists of two strings ("Amanda" and "test"), an int (123), a double (4.7) and a char ('A'). These are read into variables s1, s2, i, d and c in line 18, then displayed in lines 20–21. Next, the program attempts to read from input again in line 24, but the operation fails because there is no more data in inputString. So the input evaluates to false, and the else part of the if…else statement executes.
1// fig08_13.cpp2// Demonstrating input from an istringstream object.3#include <iostream>4#include <sstream>5#include <string>6#include "fmt/format.h" // In C++20, this will be #include <format>7using namespace std;8 9int main() {10const string inputString{"Amanda test 123 4.7 A"};11istringstream input{inputString};12string s1;13string s2;14int i;15double d;16char c;17 18input >> s1 >> s2 >> i >> d >> c;19 20cout << "Items extracted from the istringstream object: "21<< fmt::format("{} {} {} {} {} ", s1, s2, i, d, c);22 23// attempt to read from empty stream24if (long value; input >> value) {25cout << fmt::format(" long value is: {} ", value);26}27else {28cout << fmt::format(" input is empty ");29}30}
Items extracted from the istringstream object:Amandatest1234.7Ainput is empty
Fig. 8.13 Demonstrating input from an istringstream object.
8.18 Raw String Literals
Recall that backslash characters in strings introduce escape sequences—like
for newline and for tab. If you wish to include a backslash in a string, you must use two backslash characters \, making some strings difficult to read. For example, Microsoft Windows uses backslashes to separate folder names when specifying a file’s location. To represent a file’s location on Windows, you might write:
string windowsPath{"C:\MyFolder\MySubFolder\MyFile.txt"}
11 For such cases, raw string literals (introduced in C++11) that have the format
R"(rawCharacters)"
are more convenient. The parentheses are required around the rawCharacters that compose the raw string literal. The compiler automatically inserts backslashes as necessary in a raw string literal to properly escape special characters like double quotes ("), backslashes (), etc. Using a raw string literal, we can write the preceding string as:
string windowsPath{R"(C:MyFolderMySubFolderMyFile.txt)"}
Raw strings can make your code more readable, particularly when using the regular expressions that we discuss in Section 8.20. Regular expressions often contain many backslash characters. We’ll also use raw strings in Section 8.19.2.
The preceding raw string literal can include optional delimiters up to 16 characters long before the left parenthesis, (, and after the right parenthesis,), as in
R"MYDELIMITER(J.*d[0-35-9]-dd-dd)MYDELIMITER"
The optional delimiters must be identical if provided.
Raw string literals may be used in any context that requires a string literal. They may also include line breaks, in which case the compiler inserts
escape sequences. For example, the raw string literal
R"(multiple lines of text)"
is treated as the string literal
"multiple lines
of text"
8.19 Objects Natural Case Study: Reading and Analyzing a CSV File Containing Titanic Disaster Data
The CSV (comma-separated values) file format, which uses the .csv file extension, is particularly popular, especially for datasets used in big data, data analytics and data science and in artificial intelligence applications like machine learning and deep learning. Here, we’ll demonstrate reading from a CSV file.
Datasets
There’s an enormous variety of free datasets available online. The OpenML machine learning resource site
https://openml.org
contains over 21,000 free datasets in comma-separated values (CSV) format. Another great source of datasets is:
https://github.com/awesomedata/awesome-public-datasets
account.csv
For our first example, we’ve included a simple dataset in accounts.csv in the ch08 folder. This file contains the account information shown in Fig. 8.11’s output, but in the format:
account,name,balance 100,Jones,24.98 200,Doe,345.67 300,White,0.0 400,Stone,-42.16 500,Rich,224.62
The first row of a CSV file typically contains column names. Each subsequent row contains one data record representing the values for those columns. In this dataset, we have three columns representing an account, name and balance.
8.19.1 Using rapidcsv to Read the Contents of a CSV File
The rapidcsv3 header-only library
https://github.com/d99kris/rapidcsv
provides class rapidcsv::Document that you can use to read and manipulate CSV files. Many other libraries have built-in CSV support. For your convenience, we provided rapidcsv in the example’s folder’s libraries/rapidcsv subfolder. As in earlier examples that use open-source libraries, you’ll need to point the compiler at the rapidcsv subfolder’s src folder so you can include "rapidcsv.h" (Fig. 8.14, line 7).
3. Copyright ©2017, Kristofer Berggren. All rights reserved.
1// fig08_14.cpp2// Reading from a CSV file.3#include <iostream>4#include <string>5#include <vector>6#include "fmt/format.h" // In C++20, this will be #include <format>7#include "rapidcsv.h"8using namespace std;9 10int main() {11rapidcsv::Document document{"accounts.csv"}; // loads accounts.csv12vector<int> accounts{document.GetColumn<int>("account")};13vector<string> names{document.GetColumn<string>("name")};14vector<double> balances{document.GetColumn<double>("balance")};15 16cout << fmt::format("{:<10}{:<13}{} ", "Account", "Name", "Balance");17 18for (size_t i{0}; i < accounts.size(); ++i) {19cout << fmt::format("{:<10}{:<13}{:>7.2f} ",20accounts.at(i), names.at(i), balances.at(i));21}22}
Account Name Balance100 Jones 24.98200 Doe 345.67300 White 0.00400 Stone -42.16500 Rich 224.62
Fig. 8.14 Reading from a CSV file.
Line 11 creates and initializes a rapidcsv::Document object named document. This statement loads the specified file ("accounts.csv"). Class Document’s member functions enable you to work with the CSV data by row, by column or by individual value in a specific row and column. In this example, lines 12–14 get the data using the class’s GetColumn template member function. This function returns the specified column’s data as a std::vector containing elements of the type you specify in angle brackets. Line 12’s call
document.GetColumn<int>("account")
returns a vector<int> containing the account numbers for every record. Similarly, the calls in line 13–14 return a vector<string> and a vector<double> containing all the records’ names and balances, respectively. Lines 16–21 format and display the file’s contents to confirm that they were read properly.
Caution: Commas in CSV Data Fields
Be careful when working with strings containing embedded commas, such as the name "Jones, Sue". If this name were accidentally stored as the two strings "Jones" and "Sue", that CSV record would have four fields, not three. Programs that read CSV files typically expect every record to have the same number of fields; otherwise, problems occur.
Caution: Missing Commas and Extra Commas in CSV Files
Be careful when preparing and processing CSV files. For example, suppose your file is composed of records, each with four comma-separated int values, such as:
100,85,77,9
If you accidentally omit one of these commas, as in:
100,8577,9
then the record has only three fields, one with the invalid value 8577.
If you put two adjacent commas where only one is expected, as in:
100,85,,77,9
then you have five fields rather than four, and one of the fields erroneously would be empty. Each of these comma-related errors could confuse programs trying to process the record.
8.19.2 Reading and Analyzing the Titanic Disaster Dataset
DS One of the most commonly used datasets for data analytics and data science beginners is the Titanic disaster dataset4. It lists all the passengers and whether they survived when the ship Titanic struck an iceberg and sank on its maiden voyage April 14–15, 1912. We’ll load the dataset in Fig. 8.15, view some of its data and perform some basic data analytics.
4. “Titanic” dataset on OpenML.org (https://www.openml.org/d/40945). Author: Frank E. Harrell, Jr. and Thomas Cason. Source: Vanderbilt Biostatistics (http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.html). The OpenML license terms (https://www.openml.org/cite) say, “You are free to use OpenML and all empirical data and metadata under the CC-BY license (http://creativecommons.org/licenses/by/4.0/), requesting appropriate credit if you do.”
1// fig08_14.cpp2 // Reading the Titanic dataset from a CSV file, then analyzing it. 3 #include <algorithm> 4 #include <cmath> 5 #include <iostream> 6 #include <numeric> 7 #include <ranges> 8 #include <string> 9 #include <vector> 10 #include "fmt/format.h" // In C++20, this will be #include <format> 11 #include "rapidcsv.h" 12 using namespace std; 13 14 int main() { 15// load Titanic dataset; treat missing age values as NaN16rapidcsv::Document titanic("titanic.csv",17rapidcsv::LabelParams{}, rapidcsv::SeparatorParams{},18 rapidcsv::ConverterParams{true}); 19
Fig. 8.15 Reading the Titanic dataset from a CSV file, then analyzing it.
‘To download the dataset in CSV format go to
https://www.openml.org/d/40945
and click the CSV download button in the page’s upper-right corner. This downloads the file phpMYEkMl.csv, which we renamed as titanic.csv. We assume that you’ll download the file, rename it as titanic.csv and place it in the chapter’s ch08 examples folder.
20 Figure 8.14 uses some C++20 ranges library features we introduced in Section 6.14. At the time of this writing, only GNU C++ 10.1 supports the ranges library.
Getting to Know the Data
Much of data analytics and data science is devoted to getting to know your data. One way is simply to look at the raw data. If you open the titanic.csv file in a text editor or spreadsheet application, you’ll see that the dataset contains 1309 rows, each containing 14 columns—often called features in data analytics. We’ll use only four columns here:
• survived: 1 or 0 for yes or no, respectively.
• sex: "female" or "male".
• age: The passenger’s age. Most values in this column are integers, but some children under 1 year of age have floating-point age values, so we’ll process this column as double values.
• pclass: 1, 2 or 3 for first class, second class or third class, respectively.
To learn more about the dataset’s origins and its other columns, visit:
http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3info.txt
Missing Data
Bad data values and missing values can significantly impact data analysis. The Titanic dataset is missing ages for 263 passengers. These are represented as ? in the CSV file. In this example, when we produce descriptive statistics for the passengers’ ages, we’ll filter out and ignore the missing values. Some data scientists advise against any attempts to insert “reasonable values.” Instead, they advocate clearly marking missing data and leaving it up to a data analytics package to handle the issue. Others offer strong cautions.5
5. This footnote was abstracted from a comment sent to us July 20, 2018 by one of our Python text-book’s academic reviewers, Dr. Alison Sanchez of the University of San Diego School of Business. She commented: “Be cautious when mentioning 'substituting reasonable values' for missing or bad values.' A stern warning: 'Substituting' values that increase statistical significance or give more 'reasonable' or 'better' results is not permitted. 'Substituting' data should not turn into 'fudging' data. The first rule students should learn is not to eliminate or change values that contradict their hypotheses. 'Substituting reasonable values' does not mean students should feel free to change values to get the results they want.”
Loading the Dataset
Lines 16–18 create and initialize a rapidcsv::Document object named titanic that loads "titanic.csv". The second and third arguments in line 17 are two of the default arguments used to initialize a Document object when you create it only by specifying the CSV file name. Recall from our discussion of default function arguments that when an argument is specified explicitly for a parameter with a default argument, all prior arguments in the argument list also must be specified explicitly. We provided the second and third arguments, so we can specify the fourth argument.
The rapidcsv::LabelParams{} argument specifies by default that the CSV file’s first row contains the column names. The rapidcsv::SeparatorParams{} argument specifies by default that each record’s fields are separated by commas. The fourth argument:
rapidcsv::ConverterParams{true}
enables RapidCSV to convert missing and bad data values in integer columns to 0 and floating-point columns to NaN (not a number). This enables us to load all the data in the age column into a vector<double>, including the missing values represented by ?.
Removing the Quotes from the Columns Containing Strings
Lines 21–24 use the rapidcsv::Document’s GetColumn member function to get each column by name. In the dataset, the column names are enclosed in double-quote characters, so they are required to load the columns. For example, in the raw string R"("survived")" represents the column name "survived" with the enclosing quotes.
20 // get data by column; ignoring column 0 in this example 21 auto survived{titanic.GetColumn<int>(R"("survived")")}; 22 auto sex{titanic.GetColumn<string>(R"("sex")")}; 23 auto age{titanic.GetColumn<double>(R"("age")")}; 24 auto pclass{titanic.GetColumn<int>(R"("pclass")")}; 25
Removing the Quotes from the Column Containing Strings
String values in the Titanic dataset are enclosed in double-quotes—e.g., "female" and "male". The rapidcsv::Document object includes the quotes in each such std::string it returns. Lines 27–29 remove these quotes from each value in the vector named sex. For the current item, line 28 calls std::string member function erase to remove the character at index 0 (a quote) in the string. The first argument is the index (0) at which to begin erasing characters. The second is the number of characters to erase (1). erase returns a reference to the modified std::string, which we use to the std::string’s pop_back member function. This removes the string’s last character (also a quote).
26 // lambda to remove the quotes from the strings 27 for (string& item : sex) { 28 item.erase(0, 1).pop_back(); 29 } 30
Viewing Some Rows in the Titanic Dataset
The 1309 rows each represent one passenger. According to Wikipedia, there were approximately 1317 passengers and 815 of them died.6 For large datasets, it’s not possible to display all the data at once. A common practice when getting to know your data is to display a few rows from the beginning and end of the dataset, so you can get a sense of the data. The code in lines 32–37 displays the first five elements of each column’s data:
31 // display first 5 rows 32 cout << fmt::format("First five rows: {:<10}{:<8}{:<6}{} ", 33 "survived", "sex", "age", "class"); 34 for (size_t i{0}; i < 5; ++i) { 35 cout << fmt::format("{:<10}{:<8}{:<6.1f}{} ", 36 survived.at(i), sex.at(i), age.at(i), passengerClass.at(i)); 37 } 38
First five rows: survived sex age class 1 female 29.0 1 1 male 0.9 1 0 female 2.0 1 0 male 30.0 1 0 female 25.0 1
6. https://en.wikipedia.org/wiki/Passengers_of_the_RMS_Titanic.
The code in lines 40–46 displays the last five elements of each column’s data. To determine the control variable’s starting value, line 42 calls the rapidcsv::Document’s GetRowCount member function. Then line 43 initializes the control variable to five less than the row count. Note the value in the age column for one of row is nan, indicating a missing value in the dataset.
39 // display last 5 rows 40 cout << fmt::format(" Last five rows: {:<10}{:<8}{:<6}{} ", 41 "survived", "sex", "age", "class"); 42 auto count{titanic.GetRowCount()}; 43 for (size_t i{count - 5}; i < count; ++i) { 44 cout << fmt::format("{:<10}{:<8}{:<6.1f}{} ", 45 survived.at(i), sex.at(i), age.at(i), pclass.at(i)); 46 } 47
Last five rows: survived sex age class 0 female 14.5 3 0 female nan 3 0 male 26.5 3 0 male 27.0 3 0 male 29.0 3
Basic Descriptive Statistics
DS 20 As part of getting to know a dataset, data scientists often use statistics to describe and summarize data. Let’s calculate several descriptive statistics for the age column, including the number of passengers for which we have age values, and the average, minimum, maximum and median age values. Before performing these calculations, we must remove nan values—calculations performed with nan result in nan. Lines 49–50 use the C++20 ranges filtering techniques from Section 6.14 to keep only the values in the age vector that are not nan. Function isnan (header <cmath>) returns true if the value is nan. Next, line 51 creates a vector<double> named cleanAge. The vector initializes its elements by iterating through the filtered results from begin(removeNaN) to end(removeNan).
48 // use C++20 ranges to eliminate missing values from age column 49 auto removeNaN = 50 age | views::filter([](const auto& x) {return !isnan(x);}); 51 vector<double> cleanAge{begin(removeNaN), end(removeNaN)}; 52
Basic Descriptive Statistics for the Cleaned Age Column
Now, we can calculate the descriptive statistics. Line 54 sorts cleanAge, which will help us determine the minimum, maximum and median values. To count the number of people for which we have valid ages, we simply get cleanAge’s size (line 55).
53 // descriptive statistics for cleaned ages column 54 sort(begin(cleanAge), end(cleanAge)); 55 size_t size{cleanAge.size()}; 56 double median{}; 57 58 if (size % 2 == 0) { // find median value for even number of items 59 median = (cleanAge.at(size / 2 - 1) + cleanAge.at(size / 2)) / 2; 60 } 61 else { // find median value for odd number of items 62 median = cleanAge.at(size / 2); 63 } 64 65 cout << " Descriptive statistics for the age column: " 66 << fmt::format("Passengers with age data: {} ", size) 67 << fmt::format("Average age: {:.2f} ", 68 accumulate(begin(cleanAge), end(cleanAge), 0.0) / size) 69 << fmt::format("Minimum age: {:.2f} ", cleanAge.front()) 70 << fmt::format("Maximum age: {:.2f} ", cleanAge.back()) 71 << fmt::format("Median age: {:.2f} ", median); 72
Descriptive statistics for the age column: Passengers with age data: 1046 Average age: 29.88 Minimum age: 0.17 Maximum age: 80.00 Median age: 28.00
Lines 56–63 determine the median. If cleanAge’s size is even, the median is the average of the two middle elements (line 59); otherwise, it’s the middle element (line 62). Lines 65–71 display the descriptive statistics. Line 68 calculates the average age by using the accumulate algorithm to total the ages, then dividing the result by size. The vector is sorted, so lines 69–70 determine the minimum and maximum values by calling the vector’s front and back member functions, respectively. The average and median are measures of central tendency. Each is a way to produce a single value that represents a “central” value in a set of values, i.e., a value which is, in some sense, typical of the others.
For the 1046 people with valid ages, the average age was 29.88 years old. The youngest passenger (i.e., the minimum) was just over two months old (0.17 * 12 is 2.04), and the oldest (i.e., the maximum) was 80. The median age was 28.
Determining Passenger Counts By Class
Let’s calculate each class’s number of passengers. Lines 74–79 define a lambda that
• filters the pclass column, keeping only the elements for the specified classNumber (line 76),
• maps each to the value 1 (line 77), then
• uses accumulate to total the mapped results, which gives us the count for the specified classNumber.
The lambda introducer [classNumber] in line 76 indicates that the lambda will use the variable classNumber (line 74 in the parameter list) in line 76’s lambda body. Known as capturing the variable, this is required to use a variable that’s not defined in the lambda. Lines 81–83 define constants for the three passenger classes. Lines 84–86 call countClass for each passenger class, and lines 88–90 display the counts.
73 // passenger counts by class 74 auto countClass = [](const auto& column, const int classNumber) { 75 auto filterByClass{column 76 | views::filter([classNumber](auto x) {return classNumber == x;}) 77 | views::transform([](auto x) {return 1;})}; 78 return accumulate(begin(filterByClass), end(filterByClass), 0); 79 }; 80 81 constexpr int firstClass{1}; 82 constexpr int secondClass{2}; 83 constexpr int thirdClass{3}; 84 const int firstCount{countClass(pclass, firstClass)}; 85 const int secondCount{countClass(pclass, secondClass)}; 86 const int thirdCount{countClass(pclass, thirdClass)}; 87 88 cout << " Passenger counts by class: " 89 << fmt::format("1st: {} 2nd: {} 3rd: {} ", 90 firstCount, secondCount, thirdCount); 91
Passenger counts by class: 1st: 323 2nd: 554 3rd: 2127
Basic Descriptive Statistics for the Cleaned Age Column
Let’s say you want to determine some statistics about people who survived. Line 93 filters the survived column, keeping only the survivors. Recall that this column contains 1 or 0 to represent survived or died, respectively. These also are values that C++ can treat as true (1) or false (0), so the lambda in line 93 simply returns the column value. If that value is 1, the filter operation keeps that value in the results. Line 94 uses the accumulate function to calculate the survivorCount by iterating over the results and totaling the 1s. To find out how many people died, we simply subtract survivorCount from the survived vector’s size. Line 99 calculates the percentage of people who survived.
92 // percentage of people who survived 93 auto survivors = survived | views::filter([](auto x) {return x;}); 94 int survivorCount{accumulate(begin(survivors), end(survivors), 0)}; 95 96 cout << fmt::format(" Survived count: {} Died count: {} ", 97 survivorCount, survived.size() - survivorCount); 98 cout << fmt::format("Percent who survived: {:.2f}% ", 99 100.0 * survivorCount / survived.size()); 100
Survived count: 500 Died count: 809 Percent who survived: 38.20%
Counting By Sex and By Passenger Class the Numbers of People Who Survived
14 Lines 102–122 iterate through the survived column, using its 1 or 0 value as a condition (line 109). For each survivor, we increment counters for the survivor’s sex (surviving-Women and survivingMen in line 110) and pclass (surviving1st, surviving2nd and surviving3rd in lines 112–120). We’ll use these counts to calculate percentages. In line 110, the literal value "female"s with the trailing s after the closing quote is a C++14 string object literal that treats "female" as a std::string rather than a C-string. So the == comparison is between two std::string objects.
101 // count who survived by male/female, 1st/2nd/3rd class 102 int survivingMen{0}; 103 int survivingWomen{0}; 104 int surviving1st{0}; 105 int surviving2nd{0}; 106 int surviving3rd{0}; 107 108 for (size_t i{0}; i < survived.size(); ++i) { 109 if (survived.at(i)) { 110 sex.at(i) == "female"s ? ++survivingWomen : ++survivingMen; 111 112 if (firstClass == pclass.at(i)) { 113 ++surviving1st; 114 } 115 else if (secondClass == pclass.at(i)) { 116 ++surviving2nd; 117 } 118 else { // third class 119 ++surviving3rd; 120 } 121 } 122 } 123
Calculating Percentages of People Who Survived
Lines 125–135 calculate and display the percentages of:
• women who survived,
• men who survived,
• first-class passengers who survived,
• second-class passengers who survived, and
• third-class passengers who survived.
Of the survivors, about two-thirds were women, and first-class passengers survived at a higher rate than the other passenger classes.
124 // percentages who survived by male/female, 1st/2nd/3rd class 125 cout << fmt::format("Female survivor percentage: {:.2f}% ", 126 100.0 * survivingWomen / survivorCount) 127 << fmt::format("Male survivor percentage: {:.2f}% ", 128 100.0 * survivingMen / survivorCount) 129 << fmt::format("1st class survivor percentage: {:.2f}% ", 130 100.0 * surviving1st / survivorCount) 131 << fmt::format("2nd class survivor percentage: {:.2f}% ", 132 100.0 * surviving2nd / survivorCount) 133 << fmt::format("3rd class survivor percentage: {:.2f}% ", 134 100.0 * surviving3rd / survivorCount); 135 }
Female survivor percentage: 67.80% Male survivor percentage: 32.20% 1st class survivor percentage: 40.00% 2nd class survivor percentage: 23.80% 3rd class survivor percentage: 36.20%
8.20 Objects Natural Case Study: Introduction to Regular Expressions
Sometimes you’ll need to recognize patterns in text, like phone numbers, e-mail addresses, ZIP Codes, web page addresses, Social Security numbers and more. A regular expression string describes a search pattern for matching characters in other strings.
Regular expressions can help you extract data from unstructured text, such as social media posts. They’re also important for ensuring that data is in the proper format before you attempt to process it.
Validating Data
Before working with text data, you’ll often use regular expressions to validate it. For example, you might check that:
• A U.S. ZIP Code consists of five digits (such as 02215) or five digits followed by a hyphen and four more digits (such as 02215-4775).
• A string last name contains only letters, spaces, apostrophes and hyphens.
• An e-mail address contains only the allowed characters in the allowed order.
• A U.S. Social Security number contains three digits, a hyphen, two digits, a hyphen and four digits, and adheres to other rules about the specific numbers that can be used in each group of digits.
You’ll rarely need to create your own regular expressions for common items like these. The following free websites
• https://www.regular-expressions.info
and others offer repositories of existing regular expressions that you can copy and use. Many sites like these also allow you to test regular expressions to determine whether they’ll meet your needs.
Other Uses of Regular Expressions
Regular expressions also are used to:
• Extract data from text (known as scraping)—e.g., locating all URLs in a web page.
• Clean data—e.g., removing data that’s not required, removing duplicate data, handling incomplete data, fixing typos, ensuring consistent data formats, removing formatting, changing text case, dealing with outliers and more.
• Transform data into other formats—e.g., reformatting tab-separated or space-separated values into comma-separated values (CSV) for an application that requires data to be in CSV format. We discussed CSV in Section 8.19.
8.20.1 Matching Complete Strings to Patterns
To use regular expressions, include the header <regex>, which provides several classes and functions for recognizing and manipulating regular expressions.
Matching Literal Characters
The <regex> function regex_match (Fig. 8.16) returns true if the entire string in its first argument matches the pattern in its second argument. By default, pattern matching is case sensitive—later, you’ll see how to perform case-insensitive matches. Let’s begin by matching literal characters—that is, characters that match themselves. Line 10 creates a regex object r1 for the pattern "02215" containing only literal digits that match themselves in the specified order. Line 13 calls regex_match for the strings "02215" and "51220". Each has the same digits, but only "02215" has them in the correct order for a match.
1 // fig08_16.cpp 2 // Matching entire strings to regular expressions. 3 #include <iostream> 4 #include <regex> 5 #include "fmt/format.h" // In C++20, this will be #include <format> 6 using namespace std; 7 8 int main() { 9 // fully match a pattern of literal characters 10 regex r1("02215"); 11 cout << "Matching against: 02215 " 12 << fmt::format("02215: {}; 51220: {} ", 13 regex_match("02215", r1), regex_match("51220", r1)); 14
Matching against: 02215 02215: true; 51220: false
Fig. 8.16 Matching entire strings to regular expressions.
Metacharacters, Character Classes and Quantifiers
Regular expressions typically contain various special symbols called metacharacters:
[] {} () * + ^ $ ? . |
The metacharacter begins each of the predefined character classes, several of which are shown in the following table with the groups of characters they match.

To match any metacharacter as its literal value, precede it by a backslash. For example, $ matches a dollar sign ($) and \ matches a backslash ().
Matching Digits
Let’s validate a five-digit ZIP Code. In the regular expression d{5} (created by the raw string literal in line 16), d is a character class representing a digit (0–9). A character class is a regular expression escape sequence that matches one character. To match more than one, follow the character class with a quantifier. The quantifier {5} repeats d five times, as if we had written ddddd, to match five consecutive digits. Line 19’s second call to regex_match returns false because "9876" contains only four consecutive digit characters.
15 // fully match five digits 16 regex r2(R"(d{5})"); 17 cout << R"(Matching against: d{5})" << " " 18 << fmt::format("02215: {}; 9876: {} ", 19 regex_match("02215", r2), regex_match("9876", r2)); 20
Matching against: d{5}
02215: true; 9876: false
Custom Character Classes
Characters in square brackets, [], define a custom character class that matches a single character. For example, [aeiou] matches a lowercase vowel, [A-Z] matches an uppercase letter, [a-z] matches a lowercase letter and [a-zA-Z] matches any lowercase or uppercase letter. Let’s use a custom character class to validate a simple first name with no spaces or punctuation.
21 // match a word that starts with a capital letter 22 regex r3("[A-Z][a-z]*"); 23 cout << "Matching against: [A-Z][a-z]* " 24 << fmt::format("Wally: {}; eva: {} ", 25 regex_match("Wally", r3), regex_match("eva", r3)); 26
Matching against: [A-Z][a-z]* Wally: true; eva: false
A first name might contain many letters. In the regular expression r3 (line 22), [A-Z] matches one uppercase letter, and [a-z]* matches any number of lowercase letters. The * quantifier matches zero or more occurrences of the subexpression to its left (in this case, [a-z]). So [A-Z][a-z]* matches "Amanda", "Bo" or even "E".
When a custom character class starts with a caret (^), the class matches any character that’s not specified. So [^a-z] (line 28) matches any character that’s not a lowercase letter:
27 // match any character that's not a lowercase letter 28 regex r4("[^a-z]"); 29 cout << "Matching against: [^a-z] " 30 << fmt::format("A: {}; a: {} ", 31 regex_match("A", r4), regex_match("a", r4)); 32
Matching against: [^a-z] A: true; a: false
Metacharacters in a custom character class are treated as literal characters—that is, the characters themselves. So [*+$] (line 34) matches a single *, + or $ character:
33 // match metacharacters as literals in a custom character class 34 regex r5("[*+$]"); 35 cout << "Matching against: [*+$] " 36 << fmt::format("*: {}; !: {} ", 37 regex_match("*", r5), regex_match("!", r5)); 38
Matching against: [*+$] *: true; !: false
* vs. + Quantifier
If you want to require at least one lowercase letter in a first name, replace the * quantifier in line 22 with +. This matches at least one occurrence of a subexpression to its left:
39 // matching a capital letter followed by at least one lowercase letter 40 regex r6("[A-Z][a-z]+"); 41 cout << "Matching against: [A-Z][a-z]* " 42 << fmt::format("Wally: {}; E: {} ", 43 regex_match("Wally", r6), regex_match("E", r6)); 44
Matching against: [A-Z][a-z]* Wally: true; E: false
Both * and + are greedy—they match as many characters as possible. So the regular expression [A-Z][a-z]+ matches "Al", "Eva", "Samantha", "Benjamin" and any other words that begin with a capital letter followed at least one lowercase letter.
Other Quantifiers
The ? quantifier matches zero or one occurrence of the subexpression to its left. In the regular expression labell?ed (line 46), the subexpression is the literal character "l". So in line 49’s regex_match calls, the regular expression matches labelled (the U.K. English spelling and labeled (the U.S. English spelling), but in line 50’s regex_match calls, the regular expression does not match the misspelled word labellled.
45 // matching zero or one occurrenctes of a subexpression 46 regex r7("labell?ed"); 47 cout << "Matching against: labell?ed " 48 << fmt::format("labelled: {}; labeled: {}; labellled: {} ", 49 regex_match("labelled", r7), regex_match("labeled", r7), 50 regex_match("labellled", r7)); 51
Matching against: labell?ed labelled: true; labeled: true; labellled: false
You can match at least n occurrences of a subexpression to its left with the {n,} quantifier. The regular expression in line 53 matches strings containing at least three digits:
52 // matching n (3) or more occurrences of a subexpression 53 regex r8(R"(d{3,})"); 54 cout << R"(Matching against: d{3,})" << " " 55 << fmt::format("123: {}; 1234567890: {}; 12: {} ", 56 regex_match("123", r8), regex_match("1234567890", r8), 57 regex_match("12", r8)); 58
Matching against: d{3,}
123: true; 1234567890: true; 12: false
You can match between n and m (inclusive) occurrences of a subexpression with the {n,m} quantifier. The regular expression in line 60 matches strings containing 3 to 6 digits:
59 // matching n to m inclusive (3-6), occurrences of a subexpression 60 regex r9(R"(d{3,6})"); 61 cout << R"(Matching against: d{3,6})" << " " 62 << fmt::format("123: {}; 123456: {}; 1234567: {}; 12: {} ", 63 regex_match("123", r9), regex_match("123456", r9), 64 regex_match("1234567", r9), regex_smatch("12", r9)); 65 }
Matching against: d{3,6}
123: true; 123456: true; 1234567: false; 12: false
8.20.2 Replacing Substrings
The header <regex> provides function regex_replace to replace patterns in a string. Let’s convert a tab-delimited string to comma-delimited (Fig. 8.17). The regex_replace (line 15) function receives three arguments:
• the string to be searched ("1 2 3 4")
• the regex pattern to match (the tab character " ") and
• the replacement text (",")
and returns a new string containing the modifications. The expression regex{R"( )"} in line 15 creates a temporary regex object, initializes it and immediately passes it to regex_replace. This is useful if you do not need to reuse a regex multiple times.
1 // fig08_17.cpp 2 // Regular expression replacements and splitting. 3 #include <iostream> 4 #include <regex> 5 #include <string> 6 #include <vector> 7 #include "fmt/format.h" // In C++20, this will be #include <format> 8 using namespace std; 9 10 int main() { 11 // replace tabs with commas 12 string s1("1 2 3 4"); 13 cout << "Original string: 1\t2\t3\t4 "; 14 cout << fmt::format("After replacing tabs with commas: {} ", 15 regex_replace(s1, regex{R"( )"}, ",")); 16 }
Original string: 1 2 3 4 After replacing tabs with commas: 1,2,3,4
Fig. 8.17 Regular expression replacements and splitting.
8.20.3 Searching for Matches
You can match a substring within a string using function regex_search (Fig. 8.18), which returns true if any part of an arbitrary string matches the regular expression. Optionally, the function also gives you access to the matching substring via an object of the class template match_results that you pass as an argument. There are match_results aliases for different string types:
• For searches in std::strings and string object literals, use an smatch (pronounced “ess match”).
• For searches on C-strings and string literals, you use a cmatch (pronounced “see match”).
1 // fig08_18.cpp 2 // Matching patterns throughout a string. 3 #include <iostream> 4 #include <regex> 5 #include <string> 6 #include "fmt/format.h" // In C++20, this will be #include <format> 7 using namespace std; 8 9 int main() { 10 // performing a simple match 11 string s1{"Programming is fun"}; 12 cout << fmt::format("s1: {} ", s1); 13 cout << "Search anywhere in s1: " 14 << fmt::format("Programming: {}; fun: {}; fn: {} ", 15 regex_search(s1, regex{"Programming"}), 16 regex_search(s1, regex{"fun"}), 17 regex_search(s1, regex{"fn"})); 18
s1: Programming is fun Search anywhere in s1: Programming: true; fun: true; fn: false
Fig. 8.18 Matching patterns throughout a string.
Finding a Match Anywhere in a String
The calls to function regex_search in lines 15–17, search in s1 ("Programming is fun") for the first occurrence of a substring that matches a regular expression—in this case, the literal strings "Programming", "fun" and "fn". Function regex_search’s two-argument version simply returns true or false to indicate a match.
Ignoring Case in a Regular Expression and Viewing the Matching Text
The regex_constants in the header <regex> can customize how regular expressions perform matches. For example, matches are case sensitive by default, but by using the constant regex_constants::icase, you can perform a case-insensitive search.
19 // ignoring case 20 string s2{"SAM WHITE"}; 21 smatch match; // store the text that matches the pattern 22 cout << fmt::format("s2: {} ", s2); 23 cout << "Case insensitive search for Sam in s2: " 24 << fmt::format("Sam: {} ", 25 regex_search(s2, match, regex{"Sam", regex_constants::icase})) 26 << fmt::format("Matched text: {} ", match.str()); 27
s2: SAM WHITE Case insensitive search for Sam in s2: Sam: true Matched text: SAM
Line 25 calls regex_search’s three-argument version in which the arguments are:
• the string to search (s2; line 20), which in this case contains all capital letters,
• the smatch object (line 21) that stores the match if there is one, and
• the regex pattern to match.
Here, we created the regex with a second argument
regex{"Sam", regex_constants::icase}
This regex matches the literal characters "Sam" regardless of their case. So, in s2, "SAM" matches the regex "Sam" because both have the same letters, even though "SAM" contains only uppercase letters. To confirm the matching text, line 26 gets the match’s string representation by calling its member function str.
Finding All Matches in a String
Let’s extract all the U.S. phone numbers of the form ###-###-#### from a string. The following code finds each substring in contact (line 29) that matches the regex phone (line 30) and displays the matching text.
28 // finding all matches 29 string contact{"Wally White, Home: 555-555-1234, Work: 555-555-4321"}; 30 regex phone{R"(d{3}-d{3}-d{4})"}; 31 32 cout << " Finding all phone numbers in: " << contact << " "; 33 while (regex_search(contact, match, phone)) { 34 cout << fmt::format(" {} ", match.str()); 35 contact = match.suffix(); 36 } 37 }
Finding all phone numbers in: Wally White, Home: 555-555-1234, Work: 555-555-4321 555-555-1234 555-555-4321
The while statement iterates as long as regex_search returns true—that is, as long as it finds a match. Each iteration of the loop
• displays the substring that matched the regular expression (line 34), then
• replaces contact with the result of calling the match object’s member function suffix (line 35), which returns the portion of the string that has not yet been searched. This new contact string is used in the next call to regex_search.
8.21 Wrap-Up
This chapter discussed more details of std::string, such as assigning, concatenating, comparing, searching and swapping strings. We also introduced several member functions to determine string characteristics, to find, replace and insert characters in a string, and to convert strings to pointer-based strings and vice versa. We performed input from and output to strings in memory, and introduced functions for converting numeric values to strings and for converting strings to numeric values.
We presented sequential text-file processing using features from the header <fstream> to manipulate persistent data, then demonstrated string stream processing. In our first objects-natural case study, we used an open source library to read the contents of the Titanic dataset from a CSV file, then performed some basic data analytics. In our second objects-natural case study, we introduced regular expressions for pattern matching.
We’ve now introduced the basic concepts of control statements, functions, arrays, vectors, strings and files. You’ve already seen in many of our objects natural case studies, that C++ applications typically create and manipulate objects that perform the work of the application.
In Chapter 9, you’ll learn how to implement your own custom classes and use objects of those classes in applications. We’ll begin discussing class-design and related software-engineering concepts.