
In this chapter, we will have an overview of Cassandra Query Language and take a detailed look into the wealthy set of data types supported by Cassandra. We will walk through the data types to study what their internal storage structure looks like. If you want to know how Cassandra implements them behind the scenes, the Java source code of Cassandra can be referenced. For those of you who have not installed and set up Cassandra, you can refer to Chapter 5, First-cut Design and Implementation, for a quick procedure.
Cassandra introduced Cassandra Query Language (CQL) in release 0.8 as a SQL-like alternative to the traditional Thrift RPC API. As of the time of this writing, the latest CQL version is 3.1.7. I do not want to take you through all of its old versions and therefore, I will focus on version 3.1.7 only. It should be noted that CQL Version 3 is not backward compatible with CQL Version 2 and differs from it in many ways.
CQL Version 3 provides a model very similar to SQL. Conceptually, it uses a table to store data in rows of columns. It is composed of three main types of statements:
CQL is case insensitive, unless the word is enclosed in double quotation marks. It defines a list of keywords that have a fixed meaning for the language. It distinguishes between reserved and non-reserved keywords. Reserved keywords cannot be used as identifiers. They are truly reserved for the language. Non-reserved keywords only have a specific meaning in certain contexts but can be used as identifiers. The list of CQL keywords is shown in DataStax's documentation at http://www.datastax.com/documentation/cql/3.1/cql/cql_reference/keywords_r.html.
Cassandra bundles an interactive terminal supporting CQL, known as cqlsh. It is a Python-based command-line client used to run CQL commands. To start cqlsh, navigate to Cassandra's bin directory and type the following:
- On Linux, type
./cqlsh - On Windows, type
cqlsh.batorpython cqlsh
As shown in the following figure, cqlsh shows the cluster name, Cassandra, CQL, and Thrift protocol versions on startup:

cqlsh connected to the Cassandra instance running on the local node
We can use cqlsh to connect to other nodes by appending the host (either hostname or IP address) and port as command-line parameters.
If we want to create a keyspace called packt using SimpleStrategy (which will be explained in Chapter 6, Enhancing a Version) as its replication strategy and setting the replication factor as one for a single-node Cassandra cluster, we can type the CQL statement, shown in the following screenshot, in cqlsh.
This utility will be used extensively in this book to demonstrate how to use CQL to define the Cassandra data model:

Create keyspace packt in cqlsh
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/supportand register to have the files e-mailed directly to you.
CQL Version 3 supports many basic data types for columns. It also supports collection types and all data types available to Cassandra. The following table lists the supported basic data types and their corresponding meanings:
Table 1. CQL Version 3 basic data types
If we look into the Cassandra's Java source code, the CQL Version 3 native data types are declared in an enum called Native in the org.apache.cassandra.cql3.CQL3Type interface, as shown in the following screenshot:

Cassandra source code declaring CQL Version 3 native data types
It is interesting to know that TEXT and VARCHAR are indeed both UTF8Type. The Java classes of AsciiType, LongType, BytesType, DecimalType, and so on are declared in the org.apache.cassandra.db.marshal package.
Note
Cassandra source code is available on GitHub at https://github.com/apache/cassandra.
Knowing the Java implementation of the native data types allows us to have a deeper understanding of how Cassandra handles them. For example, Cassandra uses the org.apache.cassandra.serializers.InetAddressSerializer class and java.net.InetAddress class to handle the serialization/deserialization of the INET data type.
These native data types are used in CQL statements to specify the type of data to be stored in a column of a table. Now let us create an experimental table with columns of each native data type (except counter type since it requires a separate table), and then insert some data into it. We need to specify the keyspace, packt in this example, before creating the table called table01, as shown in the following screenshot:
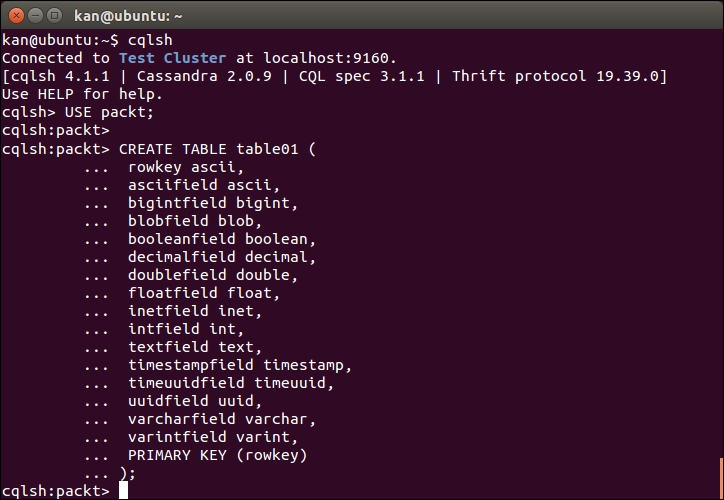
Create table01 to illustrate each native data type
We create the table using the default values, but, there are other options to configure the new table for optimizations, including compaction, compression, failure handling, and so on. The PRIMARY KEY clause, which is on only one column, could also be specified along with an attribute, that is, rowkey ascii PRIMARY KEY. Then insert a sample record into table01. We make it with an INSERT statement, as shown in the following screenshot:

Insert a sample record into table01
We now have data inside table01. We use cqlsh to query the table. For the sake of comparison, we also use another Cassandra command-line tool called Cassandra CLI to have a low-level view of the row. Let us open Cassandra CLI on a terminal.
Note
Cassandra CLI utility
Cassandra CLI is used to set storage configuration attributes on a per-keyspace or per-table basis. To start it up, you navigate to Cassandra bin directory and type the following:
- On Linux,
./cassandra-cli - On Windows,
cassandra.bat
Note that it was announced to be deprecated in Cassandra 3.0 and cqlsh should be used instead.
The results of the SELECT statement in cqlsh and the list command in Cassandra CLI are shown in the following screenshot. We will then walk through each column one by one:
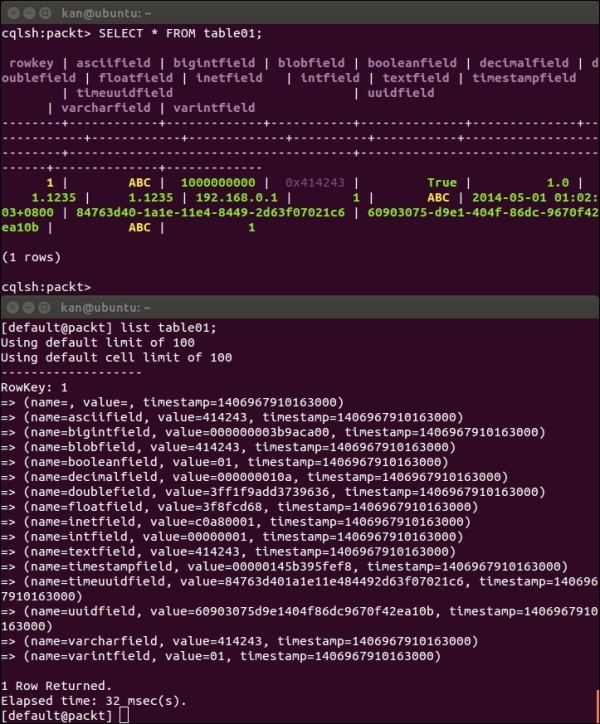
Comparison of the sample row in cqlsh and Cassandra CLI
Internally, a data value 'ABC' is stored as the byte values in hexadecimal representation of each individual character, 'A', 'B', and 'C' as 0x41, 0x42, and 0x43 respectively.
This one is simple; the hexadecimal representation of the number 1000000000 is 0x000000003b9aca00 of 64-bit length stored internally.
A BLOB data type is used to store a large binary object. In our previous example, we inserted a text 'ABC' as a BLOB into the blobfield. The internal representation is 414243, which is just a stream of bytes in hexadecimal representation.
Obviously, a BLOB field can accept all kinds of data, and because of this flexibility it cannot have validation on its data value. For example, a data value 2 may be interpreted as either an integer 2 or a text '2'. Without knowing the interpretation we want, a BLOB field can impose a check on the data value.
Another interesting point of a BLOB field is that, as shown in the SELECT statement in the previous screenshot in cqlsh, the data value of blobfield returned is 0x414243 for 'ABC' text. We know from the previous section that 0x41, 0x42, 0x43 are the byte values of 'A', 'B', and 'C', respectively. However, for a BLOB field, cqlsh prefixes its data value with '0x' to make it a so-called BLOB constant. A BLOB constant is a sequence of bytes in their hexadecimal values prefixed by 0[xX](hex)+ where hex is a hexadecimal character, such as [0-9a-fA-F].
CQL also provides a number of BLOB conversion functions to convert native data types into a BLOB and vice versa. For every <native-type> (except BLOB for an obvious reason) supported by CQL, the <native-type>AsBlob function takes an argument of type <native-type> and returns it as a BLOB. Contrarily, the blobAs<Native-type> function reverses the conversion from a BLOB back to a <native-type>. As demonstrated in the INSERT statement, we have used textAsBlob() to convert a text data type into a BLOB.
Note
BLOB constant
BLOB constants were introduced in CQL version 3.0.2 to allow users to input BLOB values. In older versions of CQL, inputting BLOB as string was supported for convenience. It is now deprecated and will be removed in a future version. It is still supported only to allow smoother transition to a BLOB constant. Updating the client code to switch to BLOB constants should be done as soon as possible.
A boolean data type is also very intuitive. It is merely a single byte of either 0x00, which means False, or 0x01, which means True, in the internal storage.
A decimal data type can store a variable-precision decimal, basically a BigDecimal data type in Java.
The float data type is a single-precision 32-bit IEEE 754 floating point in its internal storage.
Note
BigDecimal, double, or float?
The difference between double and float is obviously the length of precision in the floating point value. Both double and float use binary representation of decimal numbers with a radix which is in many cases an approximation, not an absolute value. double is a 64-bit value while float is an even shorter 32-bit value. Therefore, we can say that double is more precise than float. However, in both cases, there is still a possibility of loss of precision which can be very noticeable when working with either very big numbers or very small numbers.
On the contrary, BigDecimal is devised to overcome this loss of precision discrepancy. It is an exact way of representing numbers. Its disadvantage is slower runtime performance.
Whenever you are dealing with money or precision is a must, BigDecimal is the best choice (or decimal in CQL native data types), otherwise double or float should be good enough.
The inet data type is designed for storing IP address values in IP Version 4 (IPv4) and IP Version 6 (IPv6) format. The IP address, 192.168.0.1, in the example record is stored as four bytes internally; 192 is stored as 0xc0, 168 as 0xa8, 0 as 0x00, and 1 as 0x01, respectively. It should be noted that regardless of the IP address being stored is IPv4 or IPv6, the port number is not stored. We need another column to store it if required.
We can also store an IPv6 address value. The following UPDATE statement changes the inetfield to an IPv6 address 2001:0db8:85a3:0042:1000:8a2e:0370:7334, as shown in the following screenshot:
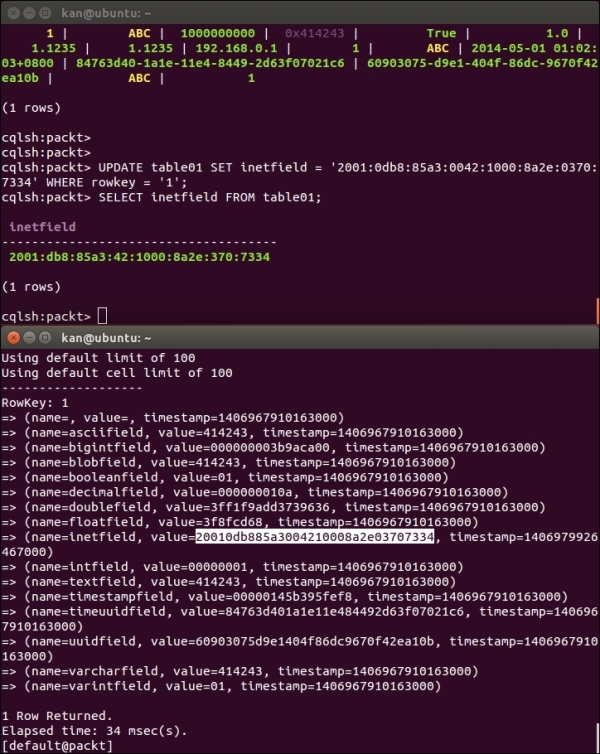
Comparison of the sample row in cqlsh and Cassandra CLI in inetfield
Note
Internet Protocol Version 6
Internet Protocol Version 6 (IPv6) is the latest version of the Internet Protocol (IP). It was developed by the IETF to deal with the long-anticipated problem of IPv4 address exhaustion.
IPv6 uses a 128-bit address whereas IPv4 uses 32-bit address. The two protocols are not designed to be interoperable, making the transition to IPv6 complicated.
IPv6 addresses are usually represented as eight groups of four hexadecimal digits separated by colons, such as 2001:0db8:85a3:0042:1000:8a2e:0370:7334.
In cqlsh, the leading zeros of each group of four hexadecimal digits are removed. In Cassandra's internal storage, the IPv6 address value consumes 16 bytes.
The text data type is a UTF-8 encoded string accepting Unicode characters. As shown previously, the byte values of "ABC", 0x41, 0x42, and 0x43, are stored internally. We can test the text field with non-ASCII characters by updating the textfield as shown in the following screenshot:
The text data type is a combination of non-ASCII and ASCII characters. The four non-ASCII characters are represented as their 3-byte UTF-8 values, 0xe8b584, 0xe6ba90, 0xe68f90, and 0xe4be9b.
However, the ASCII characters are still stored as byte values, as shown in the screenshot:
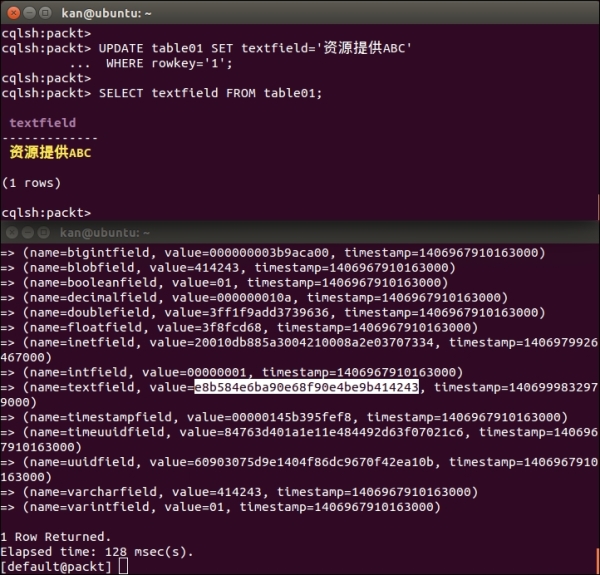
Experiment of the textfield data type
The value of the timestampfield is encoded as a 64-bit signed integer representing a number of milliseconds since the standard base time known as the epoch: January 1, 1970, at 00:00:00 GMT. A timestamp data type can be entered as an integer for CQL input, or as a string literal in ISO 8601 formats. As shown in the following screenshot, the internal value of May 1, 2014, 16:02:03, in the +08:00 timezone is 0x00000145b6cdf878 or 1,398,931,323,000 milliseconds since the epoch:
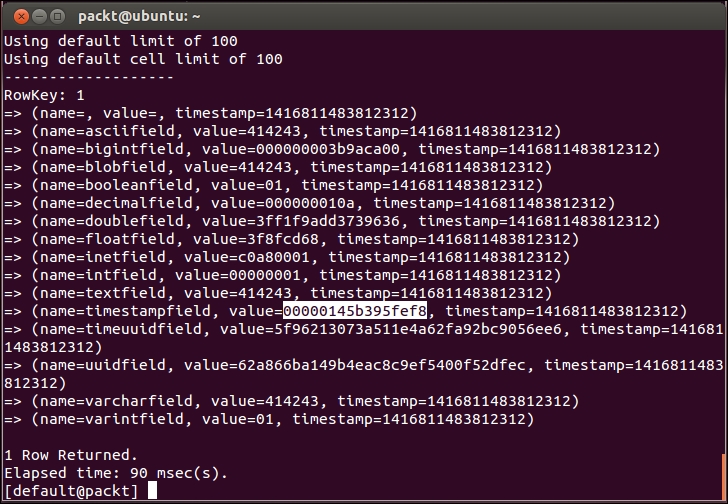
Experiment of the timestamp data type
A timestamp data type contains a date portion and a time portion in which the time of the day can be omitted if only the value of the date is wanted. Cassandra will use 00:00:00 as the default for the omitted time of day.
Note
ISO 8601
ISO 8601 is the international standard for representation of dates and times. Its full reference number is ISO 8601:1988 (E), and its title is "Data elements and interchange formats – Information interchange – Representation of dates and times."
ISO 8601 describes a large number of date/time formats depending on the desired level of granularity. The formats are as follows. Note that the "T" appears literally in the string to indicate the beginning of the time element.
- Year: YYYY (e.g. 1997)
- Year and month: YYYY-MM (e.g. 1997-07)
- Date: YYYY-MM-DD (e.g. 1997-07-16)
- Date plus hours and minutes: YYYY-MM-DDThh:mmTZD (e.g. 1997-07-16T19:20+01:00)
- Date plus hours, minutes and seconds: YYYY-MM-DDThh:mm:ssTZD (e.g. 1997-07-16T19:20:30+01:00)
- Date plus hours, minutes, seconds and a decimal fraction of a second: YYYY-MM-DDThh:mm:ss.sTZD (e.g. 1997-07-16T19:20:30.45+01:00)
Where:
- YYYY = four-digit year
- MM = two-digit month (01=January, etc.)
- DD = two-digit day of month (01 through 31)
- hh = two digits of hour (00 through 23) (am/pm NOT allowed)
- mm = two digits of minute (00 through 59)
- ss = two digits of second (00 through 59)
- s = one or more digits representing a decimal fraction of a second
- TZD = time zone designator (Z or +hh:mm or -hh:mm)
Times are expressed either in Coordinated Universal Time (UTC) with a special UTC designator "Z" or in local time together with a time zone offset in hours and minutes. A time zone offset of "+/-hh:mm" indicates the use of a local time zone which is "hh" hours and "mm" minutes ahead/behind of UTC.
If no time zone is specified, the time zone of the Cassandra coordinator node handing the write request is used. Therefore the best practice is to specify the time zone with the timestamp rather than relying on the time zone configured on the Cassandra nodes to avoid any ambiguities.
A value of the timeuuid data type is a Type 1 UUID which includes the time of its generation and is sorted by timestamp. It is therefore ideal for use in applications requiring conflict-free timestamps. A valid timeuuid uses the time in 100 intervals since 00:00:00.00 UTC (60 bits), a clock sequence number for prevention of duplicates (14 bits), and the IEEE 801 MAC address (48 bits) to generate a unique identifier, for example, 74754ac0-e13f-11e3-a8a3-a92bc9056ee6.
CQL v3 offers a number of functions to make the manipulation of timeuuid handy:
- dateOf(): This is used in a
SELECTstatement to extract the timestamp portion of atimeuuidcolumn - now(): This is used to generate a new unique
timeuuid - minTimeuuid() and maxTimeuuid(): These are used to return a result similar to a UUID given a conditional time component as its argument
- unixTimestampOf(): This is used in a
SELECTstatement to extract the timestamp portion as a raw 64-bit integer timestamp of atimeuuidcolumn
The following figure uses timeuuidfield of table01 to demonstrate the usage of these timeuuid functions:

Demonstration of timeuuid functions
The UUID data type is usually used to avoid collisions in values. It is a 16-byte value that accepts a type 1 or type 4 UUID. CQL v3.1.6 or later versions provide a function called uuid() to easily generate random type 4 UUID values.
Note
Type 1 or type 4 UUID?
Type 1 uses the MAC address of the computer that is generating the UUID data type and the number of 100-nanosecond intervals since the adoption of the Gregorian calendar, to generate UUIDs. Its uniqueness across computers is guaranteed if MAC addresses are not duplicated; however, given the speed of modern processors, successive invocations on the same machine of a naive implementation of a type 1 generator might produce the same UUID, negating the property of uniqueness.
Type 4 uses random or pseudorandom numbers. Therefore, it is the recommended type of UUID to be used.
A counter data type is a special kind of column whose user-visible value is a 64-bit signed integer (though this is more complex internally) used to store a number that incrementally counts the occurrences of a particular event. When a new value is written to a given counter column, it is added to the previous value of the counter.
A counter is ideal for counting things quickly in a distributed environment which makes it invaluable for real time analytical tasks. The counter data type was introduced in Cassandra Version 0.8. Counter column tables must use counter data type. Counters can be stored in dedicated tables only, and you cannot create an index on a counter column.
Tip
Counter type don'ts
- Don't assign the
counterdata type to a column that serves as the primary key - Don't use the
counterdata type in a table that contains anything other thancounterdata types and primary keys - Don't use the
counterdata type to generate sequential numbers for surrogate keys; use thetimeuuiddata type instead
We use a CREATE TABLE statement to create a counter table. However, INSERT statements are not allowed on counter tables and so we must use an UPDATE statement to update the counter column as shown in the following screenshot.
Cassandra uses counter instead of name to indicate that the column is of a counter data type. The counter value is stored in the value of the column.
This is a very good article that explains the internals of how a counter works in a distributed environment http://www.datastax.com/dev/blog/whats-new-in-cassandra-2-1-a-better-implementation-of-counters.
The following screenshot shows that counter value is stored in the value of the column:
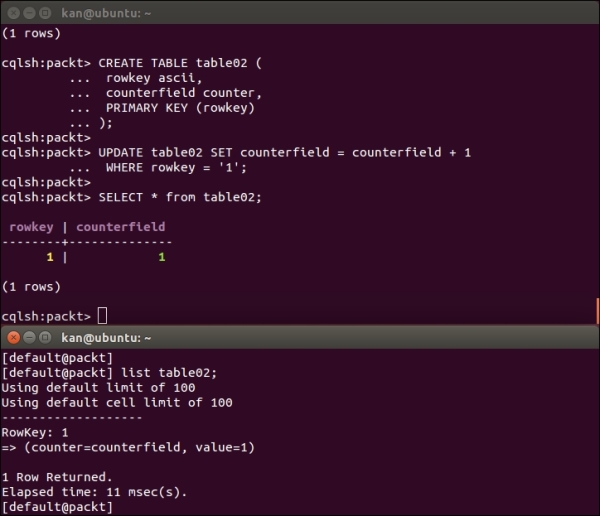
Experiment of the counter data type