
Mobile Cloud Security: Attribute-Based Access Control
At the end of the day, the goals are simple: safety and security.
Jodi Rell
Abstract
The scalability of secure access control is extremely challenging for edge cloud connected to millions of IoT and mobile devices. Traditional data access control approaches such as Role-Based Access Control (RBAC) require establishing a trusted group for access/credential management beforehand, which is not scalable for supporting a large number of data providers and consumers. Attribute-Based Access Control (ABAC) provides a scalable approach to make the access control focus on data access policies instead of managing access entities. Attribute-Based Encryption (ABE) approaches provide the building blocks to establish an ABAC framework. Due to the access policies incorporated into the data, ABE-based ABAC approach can isolate the access control function from the storage services providers, which makes the data service mobile and flexible. In this chapter, a basic ABE-based ABAC approach is presented to address the scalability issues of mobile cloud data access. In addition, ABE-enabled named networking, multidomain attribute management, and security computation offloading approaches are also described as starting points for readers to further investigate ABAC-based secure data access control solutions.
Keywords
Attribute-Based Access Control (ABAC); Attribute-Based Encryption (ABE); Information Centric Networking (ICN); Ontology-based attribute management; Federated IDM; Secure offloading
Attribute-Based Encryption (ABE) [271] and its supported data access models have made big strides in the access control and cryptography areas. There are, however, important research questions that need to be investigated to make ABE more suitable and applicable in real data access control scenarios.
Recent Attribute-Based Access Control (ABAC) reference model developed by NIST [135] provides a flexible access control framework to handle various access management scenarios based on scrutinized attributes assigned to both subjects and objects. ABAC is an advanced method for managing access rights for people and systems connecting to networks and assets. Its dynamic capabilities offer greater efficiency, flexibility, scalability and security than traditional access control methods, without burdening administrators or users.
In fact, Gartner recently predicted that by 2020, 70% of enterprises will use ABAC as the dominant mechanism to protect critical assets, up from less than 5% since 2014 [113]. ABE approaches have the capability to realize various access control features demanded by ABAC; and as a result, they have become good candidates as the fundamental building blocks to enable ABAC. Thus, determining how to use ABE approaches to realize ABAC becomes an active and promising research area.
In this chapter, we first present the foundation of ABAC and ABE in Section 7.1, and then present a few case studies using ABAC/ABE in mobile cloud application scenarios, including Information Centric Networking (ICN) naming scheme in Section 7.2, ontology-based attribute management in Section 7.3, and mobile cloud computing storage solution using security offloading in Section 7.4.
7.1 Attribute-Based Access Control
Attribute-Based Encryption (ABE) and its supported data access models have made big strides in the access control and cryptography areas. There are, however, important research questions that need to be investigated to make ABE more suitable and applicable in mobile cloud application scenarios. ABE approaches have the capability to realize various access control features demanded by ABAC; and as a result, they have become good candidates as the fundamental building blocks to enable ABAC. Thus, how to use ABE approaches to realize ABAC becomes an active and promising research area.
User Group and Application Scenarios
The confidentiality and integrity of data distributed in mobile clouds are of the utmost importance. For example, in an enterprise environment, one critical data sharing feature should assist organizations in ensuring that sensitive documents can be shared and accessed securely from any mobile device. A secure data sharing solution must be a document-centric security platform that allows users to easily and effectively access, share and control all their important documents across the extended enterprise on any tablet, smartphone, or PC – even those outside the corporate firewall. ABE-based ABAC model fits in such a secure data sharing application scenario really well. A secure data sharing solution can be deployed in multiple ways, as a cloud-based solution, as a dedicated private cloud, or as an on-premises virtual appliance, where data sharing is focused on security policies and theres is a lack of a trusted third party to build a secure communication group during the application runtime. The secure data sharing service can be applied to many organizations worldwide in various industries including financial services, pharmaceutical and biotechnology, legal, energy, healthcare, manufacturing, insurance, real estate, technology and government agencies.
In December 2011, the FICAM Roadmap and Implementation Plan v2.0 [122] called ABAC a recommended access control model for promoting information sharing between diverse and disparate organizations. ABAC is a logical access control model that is distinguishable because it controls access to objects by evaluating rules against the attributes of the entities (subject and object) actions and the environment relevant to a request. Attributes may be considered characteristics of anything that may be defined and to which a value may be assigned. In its most basic form, ABAC relies upon the evaluation of attributes of the subject, attributes of the object, environment conditions, and a formal relationship or access control rule defining the allowable operations for subject–object attribute and environment condition combinations. All ABAC solutions contain these basic core capabilities to evaluate attributes and environment conditions, and enforce rules or relationships between those attributes and environment conditions.
For example, in an ABE-enabled ABAC application scenario, a trusted authority is required to predistribute private keys (SK, as shown in Fig. 7.1) corresponding to each attribute assigned to individual users. An object's (e.g., a document's) attributes are usually not used directly to design the data access policy. Instead, they are maintained at an information level for data owner to specify what policies for data receivers to comply with, i.e., attributes assigned to receivers. In the presented example, Bob has an attribute director and Kevin has an attribute marketing. Based on the logic gates (i.e., internal nodes of the policy tree), Bob can access the root, where the Data Encrypting Key (DEK) resides; however, Kevin cannot. This policy tree was generated by the data owner, and the data owner does not even need to know who can access the data, just specifying the data access policy and using ABE to encrypt the DEK suffice. Once Bob has derived the DEK, he can access the data encrypted by this crypto key.

Access Control for Data Sharing Applications
In the presented ABAC reference model, document owners (or data owner) can maintain control over their documents at all times – even after they have been sent and downloaded to a recipient's PC, smartphone, or tablet. Data access control allows applying granular permissions to documents, enabling or restricting recipients from viewing a document based on recipients' access privileges, which is decided by attributes assigned to a recipient. Further, additional controls can be applied according to document's expiration time and location constraints, etc. Additional software running framework is needed to enforce the attributes-based policy and environment (location and time) controls.
7.1.1 ABAC Reference Model
FICAM Roadmap and Implementation Plan v2.0 [122] called ABAC a recommended access control model for promoting information sharing between diverse and disparate organizations. In 2014, NIST proposed an ABAC reference model [135], which includes subjects (such as human) and objects (such as data) having their associated attributes to describe their access properties. In addition, security and privacy policies are predefined according to nonchangeable features associated with subjects and objects, which include standardized regulations such as FISMA Compliance [14], HIPPA Compliance [15], FERPA Compliance [13], etc., and any organizational level of security policies. The situations of access control can be changed according to dynamic impact factors, such as time, location, ad hoc decisions, etc. When a subject tries to access the data, the ABAC Decision Module (DM) needs to process the request by considering attributes owned by subjects and objects, security and privacy policies, and situations to make a decision if access is or is not granted.
ABAC Data Access Model
To realize ABAC reference model [135], in this section, we present an ABAC solution for objective storage service, which is presented in Fig. 7.2. ABAC is a logical access control model that is distinguishable because it controls access to objects by evaluating rules against the attributes of the entities (subject and object) actions and the environment relevant to a request. Attributes may be considered characteristics of anything that may be defined and to which a value may be assigned. In its most basic form, ABAC relies upon the evaluation of attributes of the subject, attributes of the object, environment conditions, and a formal relationship or access control rule defining the allowable operations for subject–object attribute and environment condition combinations. All ABAC solutions contain these basic core capabilities to evaluate attributes and environment conditions, and enforce rules or relationships between them.

The presented ABAC reference model includes a typical 4-step data access protocol, which is illustrated as follows:
(1) Request (interests,ID) – The requester describes data of interest to access with his unique ID, e.g., interests can be medical records, X-ray picture, blood test results, etc., and the user's ID can be a user's e-mail address, etc.
(2) Challenges (C,PT) – The storage server sends a randomly selected challenge C, and a policy tree (PT) that had been used to secure the data according to the requester's interests. A ![]() is an attribute-tree where internal nodes are logical gates and leave nodes are descriptive attributes including static attributes
is an attribute-tree where internal nodes are logical gates and leave nodes are descriptive attributes including static attributes ![]() such as Doctor, Nurse, Nutritionist, etc., and dynamic attributes
such as Doctor, Nurse, Nutritionist, etc., and dynamic attributes ![]() such as time duration, ranking range, etc. Usually, the PT is given by the data owner or originator when he/she stores the data in the storage service.
such as time duration, ranking range, etc. Usually, the PT is given by the data owner or originator when he/she stores the data in the storage service.
(3) Response (proof(PT/A, ID)) – Based on the challenge C, the requester generates proofs to validate his/her attributes (A) that can satisfy the required static policy tree portion (![]() ). The requester also needs to prove own ID for the strong auditing purpose. The proof of dynamic attributes
). The requester also needs to prove own ID for the strong auditing purpose. The proof of dynamic attributes ![]() is optional. It can be simply done by sending the challenge C: the storage server can send it in an encrypted form by using
is optional. It can be simply done by sending the challenge C: the storage server can send it in an encrypted form by using ![]() as the public key. In step 3, the requester needs to use his/her dynamic attributes, e.g., a date range attribute, and can successfully decrypt the challenge and then reply to the storage server.
as the public key. In step 3, the requester needs to use his/her dynamic attributes, e.g., a date range attribute, and can successfully decrypt the challenge and then reply to the storage server.
(4) Encrypted Data – If the verification of message (3) passes, the storage service sends a block of ciphertext to the requester by encrypting the data using PT (in practice, PT is the public key, and it is used to encrypt an AES Data Encrypting Key (DEK); and the AES key is the actual key to encrypt the data). Then, the requester can decrypt the data by using corresponding private keys for both ![]() and
and ![]() .
.
ABAC Building Blocks
In order to establish the ABAC model presented in Fig. 7.2, we need to investigate a few cryptography and protocol design approaches that can be used to realize the functions/features related to the transmitted messages (1)–(4) and corresponding processing and verification procedures:
(i) ID and Attribute-Based Signature (ABS) can be used to verify users' privilege, i.e., to validate both user's ID and his/her owned attributes that can fulfill a given PT. This feature will provide a strong auditing feature in the system to know who had accessed the system with what access privileges. Messages (2) and (3) are used for this purpose.
(ii) Comparable Attribute-Based Encryption [270] will be used to realize message (4). After verifying users' credentials, the system will encrypt the data by using PT, which will include both static and dynamic attributes. The comparable ABE is used to have an effective attribute-based encryption system that can easily handle a comparison ranging as an attribute.
(iii) Multiauthority Attribute Management is required to make sure that the users' attributes can be used in a different administrative domain. Moreover, we should be able to interface the presented ABAC to existing well-developed federated ID management system, such as InCommon [16].
7.1.2 Federated IDM and ABAC
Federation profiles define the syntax and semantics of the data being federated. These technologies leverage widely accepted, open web communication languages, like the Security Assertion Markup Language (SAML) standard [144], which utilizes Extensible Markup Language (XML) [69], or the OpenID [232] and InCommon [16]. Connect standard is built upon JavaScript Object Notation (JSON) [88]. Federation profiles allow identity and attribute information to be sent over HTTP in a manner that can be understood and used by the receiving organization (hereafter referred to as the Relying Party (RP)) to make access control decisions.
Using such profiles, identity information can be federated from a trusted third-party entity that has issued subject credentials known as an Identity Provider (IdP). Attributes associated with a specific identity may be federated by an IdP, but can also be obtained from a trustworthy or authoritative external source known as an Attribute Provider (AP). Often, an AP's authority applies only to its domain.
Institutions looking to participate in federation must have a degree of trust with the organization from which they are receiving identity and attribute information. To facilitate these trust relationships, nonprofit organizations such as the Kantara Initiative [148] and the Open Identity Exchange (OIX) [191] have proposed trust framework specifications that provide a complete set of contracts, regulations, and commitments that enable parties of a trust relationship to rely on identity and attribute assertions from external entities.
To date, few demonstrations of ABAC utilizing federated identity and attribute information exist, which is still an open research issue.
7.1.3 Using Attribute-Based Cryptography to Build ABAC
Traditionally, access control is based on the identity of a user, either directly or through predefined attributes types, e.g., roles or groups assigned to that user. However, practitioners have noted that this access control approach usually needs cumbersome management and identity, groups, as well as roles, which are not sufficient in expressing the access control policies in the real world. Therefore, a new approach which is referred to as Attribute-Based Access Control (ABAC) was proposed [134]. With ABAC, whether a user's request is granted or not is decided by the attributes of the user, selected attributes of the object, and environment conditions that can be globally recognized. Compared with role-based access control, ABAC provides the following nice properties. First, ABAC is more expressive. Second, ABAC enables access control policy enforcement without prior knowledge of the specific subjects. Because of its flexibility, ABAC is nowadays the fastest-growing access control model [133,135,136]. ABAC considers attributes as users' credentials for composing access control policies, and as a result using ABE as the foundation to realize ABAC is a promising approach.
Current State-of-the-Art of ABE
The research on Attribute-Based Encryption (ABE) originated from Identity-Based Encryption (IBE) in [66], in which an identity can be considered as an attribute in ABE. In IBE, an identity or an ID is a descriptive term used as the user's public key. The user can acquire a private key corresponding this ID from a trusted authority, a.k.a., the private key generator. ABE extends the IBE scheme by enabling expressive logics, such as AND, OR, k out of n, etc., among multiple attributes (i.e., descriptive terms) for data access control [142].
The ABE scheme was originally proposed by Sahai and Waters [235] in 2005, as a fuzzy version of identity-based encryption with a single threshold gate, whereby an identity is represented by a set of descriptive attributes. Since then ABE has received much attention in cryptographic access control, with plenty of research works of ABE derivation as presented in [63,77,112,120,158,216,294]. Goyal et al. [120] first defined two complimentary forms of ABE, namely Key Policy ABE (KP-ABE) and Ciphertext-Policy ABE (CP-ABE), and provided the first construction for KP-ABE. Bethencourt et al. [63] then gave the first construction for a CP-ABE scheme in the generic group model. Comparatively, CP-ABE is more compelling than KP-ABE in that CP-ABE is compliant with role-based access control model. In addition, there have been numerous solutions proposed to improve the efficiency of CP-ABE in [49,97,99,104,128,271].
CP-ABE is more suitable for enforcing data access control over data stored on the cloud servers. CP-ABE allows data owners to define an access structure on attributes and upload the data encrypted under this access structure to the cloud servers. Therefore, CP-ABE enables users to define the attributes a data user needs to possess in order to access the data. Based on ABE, various security protocols have been proposed. For example, Yu et al. [288] proposed a new design to integrate CP-ABE and centralized flat table together for secure group management. Nabeel et al. [210] proposed a new attribute-based group key management construction based on an optimized version of the Access Control Vector Broadcast Group Key Management [240]. Lewko et al. [181] proposed a new multiauthority ABE system wherein any party can become an authority, without any requirement for global coordination other than the creation of an initial set of common reference parameters.
As promising as it is, CP-ABE suffers from user revocation problem. This issue was first addressed in [287] as a rough idea. There were also several researches [145,184,284,288] that are not suitable for user revocation. Boldyreva et al. [65] proposed an identity-based scheme with efficient user revocation capability. It applies key updates with significantly reduced computational cost based on a binary tree data structure, which is also applicable to KP-ABE and fuzzy IBE user revocation. However, its applicability to CP-ABE is not clear. Libert et al. [185] proposed an IBE scheme with stronger adaptive-ID sense to address the selective security issue of [65]. Lewko et al. [180] proposed two novel broadcast encryption schemes with effective user revocation capability. EASiER [150] architecture is described to support fine-grained access control policies and dynamic group membership based on attribute-based encryption. It relies on a proxy to participate in the decryption and to enforce revocation, such that the user can be revoked without reencrypting ciphertexts or issuing new keys to other users. Chen et al. [74] presented an IBE scheme based on lattices to realize efficient key revocation. In the literature, a few important ABE solutions can be summarized as follows:
Efficient Group Communication: Comparable ABE. In [283], the authors presented a dual comparative expression of integer ranges to extend the power of attribute expression for implementing various temporal constraints. This work presented a comparative ABE scheme with high flexibility and improved over the bitwise-comparison method in BSW scheme [63]. To demonstrate how to use the comparable ABE scheme, a Location-Based Service (LBS) [299] was presented, where according to users' comparable location attributes (e.g., GPS location range information), the users' access could be granted or denied.
Performance Enhancement of ABE. In [294], a privacy preserving ABE scheme was presented, such that the lightweight devices can securely outsource heavy encryption and decryption operations to cloud service providers. In [296], we presented an efficient CP-ABE scheme that provides the following features: (1) the ciphertext is constant regardless of the number of involved attributes; (2) it provides a unique bit-assignment approach to achieve efficient secure group communication. In this scheme, a bit-assignment is a position in a user's ID representing three possible states, A, ![]() , and
, and ![]() (i.e., Yes, No, and Don't Care) of an attribute. Using the bit-assignment and corresponding attributes, we can establish secure group communication groups efficiently.
(i.e., Yes, No, and Don't Care) of an attribute. Using the bit-assignment and corresponding attributes, we can establish secure group communication groups efficiently.
ABE-based Policy Management. To address the conversion from RBAC to ABAC, in [298], the authors introduced an attribute lattice approach for ABE to define a seniority relation among all values of an attribute. This scheme implements an efficient comparison operation between attribute values on a poset derived from attribute lattice with high flexibility. In [143,295], the policies were discovered layer by layer in a skewed policy tree structure. In this way, a user can reveal the security policies by decrypting the policy-tree level by level to protect the policy information. To enable multiple trust authorities issue private keys for users, in [184], a distributed ABE-based trust authority framework was presented to relax the reliance on a centralized trust authority to manage attributes. In this approach, trust authority's functions are delegated and distributed amongst network entities. To manage the attributes managed by multiple authorities, an ontology-based approach [183] was presented to address the inconsistency of using attributes among multiple administrative domains.
Privacy for ABE. To anonymize users' ID, in [137], a variant of IBE wherein the PKG (Private Key Generator) was removed and the anonymous users could derive their own private keys based on public parameters and pseudonyms. In [293,296], a new construction of CP-ABE, named Privacy Preserving Constant CP-ABE was presented, which leveraged a hidden policy construction. To provide privacy protection of attributes in the attribute policy tree, in [143,295], an attribute graduate exposure approach was constructed. Based on the available attributes, users could reveal attributes one by one from the attribute policy tree structure. A powerful user, who owns more privileged attributes, can reveal all the attributes in a secure policy tree for ABE.
Besides the above mentioned research, various application scenarios using ABE solutions, such as secure mobile cloud data storage [294], vehicular networking [139], healthcare [270], etc., have been studied. They significantly reduced the ciphertext to constant size with any given number of attributes.
7.1.4 ABE-Based ABAC Example
Role-Based Access Control (RBAC) is widely adopted by various information systems (such as Windows/Active Directory) and requires associating capabilities directly to users or their roles, which is often cumbersome to manage and insufficient for capturing real-world access control policies. For example, RBAC usually needs cumbersome management and identity, groups, as well as roles, which are not sufficient in expressing the access control policies in the real world. In a personal health information system, since data is collected from multiple sources with different health care providers, whether a data access request is granted or not is usually decided by the attributes of the requester, selected attributes of the object, and environment conditions that can be globally recognized. At times, access control policy enforcement is performed even without prior knowledge of the specific subjects, where ABAC perfectly fits these desired requirements.
Trust and Threat Model
Trust model. A Trusted Authority (TA) is required to predistribute private keys (SK, as shown in Fig. 7.3) corresponding to each attribute assigned to individual users. There may be multiple TAs such as ![]() and
and ![]() , and Bob (e.g., a cardiologist doctor working at Mayo Clinic [23] from Monday to Wednesday) and Kevin (e.g., a medical director working for TGEN [34] from Monday to Friday) derived their private keys from them, respectively. An object's (e.g., a document's) attributes are usually not used directly to design the data access policy. Instead, they are maintained at an information level for the data owner to specify the policies for data receivers to comply with, i.e., attributes assigned to receivers. In the presented example, Bob has four attributes:
, and Bob (e.g., a cardiologist doctor working at Mayo Clinic [23] from Monday to Wednesday) and Kevin (e.g., a medical director working for TGEN [34] from Monday to Friday) derived their private keys from them, respectively. An object's (e.g., a document's) attributes are usually not used directly to design the data access policy. Instead, they are maintained at an information level for the data owner to specify the policies for data receivers to comply with, i.e., attributes assigned to receivers. In the presented example, Bob has four attributes: ![]() {Mayo Clinic, Cardiologist} and
{Mayo Clinic, Cardiologist} and ![]() {Doctor, Mon to Wed}. In this example, Bob can satisfy the logical gates based on his
{Doctor, Mon to Wed}. In this example, Bob can satisfy the logical gates based on his ![]() to the root of
to the root of ![]() . In order to get to the root level of the PT, he also needs to satisfy the dynamic
. In order to get to the root level of the PT, he also needs to satisfy the dynamic ![]() . Suppose
. Suppose ![]() {Mon to Tuesday, <nurse, doctor, director>}, then Bob can access the root of the PT, and thus he can access the data.
{Mon to Tuesday, <nurse, doctor, director>}, then Bob can access the root of the PT, and thus he can access the data.

Using the ABAC framework presented in Fig. 7.2, a subject (or user) may have been assigned a set of attributes, and they are assigned by a TA. The object (or data, such as a file or a document) may also have a number of attributes, which can be assigned by the data's owner. Thus, data owners can maintain control over their data and they decide how and where to store the data, and what attributes are assigned to it.
Threat Model. We assume attackers can be system users and their goal is to access the data that they should not have the privilege to access, which means that they cannot fulfill the required data access policy – a PT specified for the data. A storage service provider is generally trusted. However, it can be “honest but curious” and it tries to learn data content stored in objective storage servers. The honest but curious scenario will address data owners' concern when they store their data on an external storage service provider. An attacker can also try to hide his/her data access activities, thus auditing is a desired function of the access control model.
7.2 Using Information Centric Networking and ABAC to Support Mobile Cloud Computing
There is a clear trend showing that the number of wireless connected devices is growing steadily, with IoT devices and users' personal devices representing the biggest share. By 2020 the total number of wireless connected devices will increase beyond 10 billion worldwide, with smartphones and IoT devices collectively accounting for 66% of this number [83]. Interestingly, IoT devices show the largest percentage increase across all devices types, from 8% in 2015 up to 26% by 2020. This results in an emerging scenario recently called immersed human [68], which is represented in Fig. 7.4. In this view, there is a tight and continuous interaction between the human users, their personal devices, and the “things” embedded in the physical environment (sensory swarm). These interactions are primarily information-centric, with IoT and personal devices constantly generating data that is transferred between sources (things and users' devices), places where it can be stored and elaborated, and sent back to the users. Mobile applications that will be more and more data intensive, also in the IoT domain (e.g., IoT multimedia applications).

To fully exploit the potential of the data available in such an environment, cloud computing and Information-Centric Networking (ICN) are currently considered cornerstone technologies. Cloud computing provides a scalable approach to store data generated by things and users devices, and, most importantly, to extract information and knowledge from raw data, providing value-added services to the users. Moreover, ICN is one promising approach to turn the Internet into an information-centric network that natively supports access to data, irrespective of where it is stored or generated, also overcoming possible disconnections of data providers.
ICN technology has changed the requirements for relatively static hosts in network communications. It is designed to provide better support to large scale multicast services. Traditional host-based architecture works well in end-to-end communications between a pair of users. However, in multicast scenarios, where one source is sending the same data to multiple recipients, performance can be further improved. According to [82], most of the current network traffic is video sharing, from 64% in 2014 up to 80% by 2019. To further improve the overall network performance, several different ICN network architectures are proposed.
In a typical ICN network, data is represented as contents. Different contents have different identifiers/names. They are transmitted through the network in the publisher–subscriber model. When a network party publishes a content, it registers the content name to a naming service. Through this naming service, a subscriber who is interested in such content will be notified with the name of the content. Here, names are unique identifiers to contents in the network. Once a subscriber gets the name of the content, he/she is able to retrieve a copy of the content using the name through a name-based routing scheme. Copies of the same content may be scattered all over the network, existing in network caches for a certain period of time, depending on what caching algorithm they are running. Typically, if a copy of a certain content is transmitted from one entity to another, all the network caches along the path will keep a copy of it. In this way, the next time when another entity requests the same content, the network is able to locate a nearby network cache, which maintains a copy of the content, but has a shorter distance from the user.
The name based routing scheme uses content names as identifiers to route a copy of content to its consumers. In traditional session based networking environment, each network party is tagged with a unique identifier, for example, IP address. Network traffic is routed based on the entity's identifier. In ICN network, it is the content that is tagged with a unique identifier. Routers along the network path use the content identifiers to forward traffic. In other words, in a traditional network, a routing decision is made based on the destination address of the traffic, while in ICN network, it is based on the content identifier to make such decisions. In the following subsections, the presented ABE scheme to support ICN naming scheme is based on the research article [182]. For detailed cryptographic constructive of ABE scheme, please refer to Appendix C.1.
7.2.1 Attribute-Based Access Control for ICN Naming Scheme
In traditional networking schemes, if a network entity wants to access some information content, it has to locate and connect to the server that provides such service following network routing protocols. As a result, the information is tightly associated with the location of the server. The entire network is centered around the connections between content consumers and content providers, making connection status an important factor to the network.
Witnessed by the fact that most of the network traffic is file sharing, especially video sharing [82], various ICN architectures [71,95,111,167,290] have been proposed. In ICN architecture, the focus is shifted from consumer–server to consumer–content connections. Thus, instead of identifying the content owner's address, the network changes to identify authentic content copies. In this way, the consumers do not need to know where the content is located, i.e., the IP address of the content owner. The content name is sufficient to direct the consumer to a content copy. Content owners publish the content, which can be copied and stored in the network using network caches [230,258]. This design enables contents being efficiently delivered to consumers.
Though the design is efficient in retrieving content, it brings great challenges to security issues during content caching and retrieving. One of them is that traditional RBAC access control mechanisms cannot be easily enforced. This is because, in ICN, content owners and consumers are not directly connected. Content owners have no control over the distributed network caches. To enforce access control to the content, several frameworks have been proposed [110,248]. Most of them require additional authorities or secure communication channels in network to authenticate each content consumer. These schemes are sound but have too much reliance on traditional control schemes, making them inefficient in practice.
Using ABE, we present an attribute-based access control for ICN naming scheme [182]. The scheme can be divided into two levels. At the upper-level, to address the attribute management problem, we present an ontology-based attribute management solution to manage the distributed attributes in ICN network. In this scheme, attributes defined by different authorities can be synchronized more efficiently than traditional approaches. Content consumers do not need to negotiate their attribute keys when they request contents from other authorities.
At the lower-level, we propose an ABE-based naming scheme. This approach is inspired by Attribute Based Encryption (ABE) schemes [63,181,287]. In this approach, each network entity is assigned with a set of attributes with the help of a Trusted Third Party (TTP) according to their real identities. The access control policy is enforced according to the content names instead of the contents. Moreover, privacy-preservation is provided for the content access policies. This feature can greatly improve the privacy protection on ICN data when it is distributed in the public domain. In this way, a user is able to identify its eligibility of the accessed contents through the encrypted names before actually accessing the data content.
An Illustrative Example
In the example of Fig. 7.5, there are three subjects: a Nurse, a Physician, and a Patient. Their attributes are as shown in the figure. The patient publishes his MRI report in the network as the content. He, as the content owner, specifies an access policy as shown in Fig. 7.6 for the MRI report. Its object attributes are listed in Fig. 7.5.
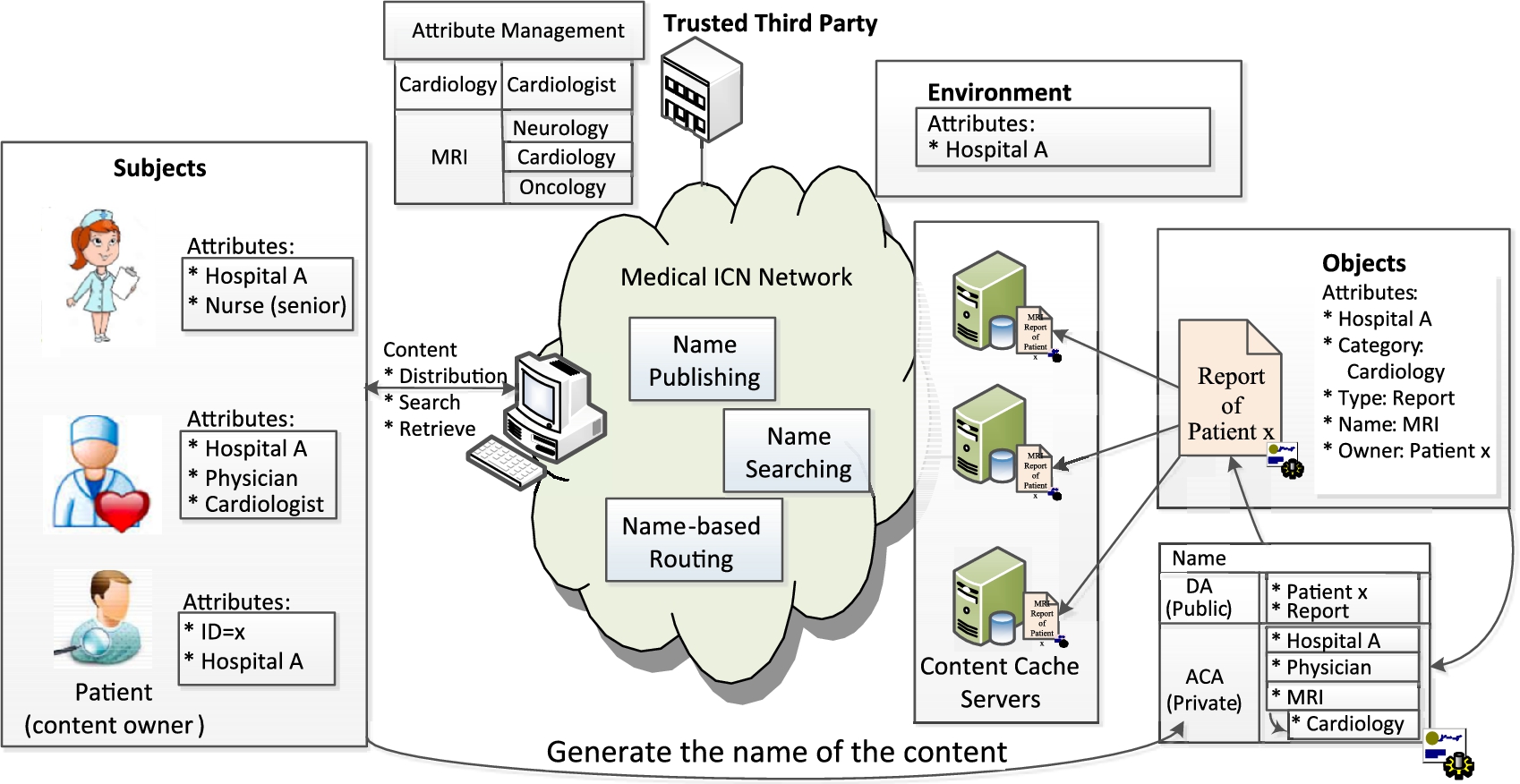

The content name is created following the procedure in Fig. 7.7, which will be further illustrated in Section 7.2.2. When the nurse tries to access this content, she can successfully use her ![]() attribute to decrypt the first node but will get stuck at
attribute to decrypt the first node but will get stuck at ![]() , meaning this content is not intended for her. When the Physician accesses the content, he/she can successfully decrypt the entire decryption process from the leaf to the root level-by-level to reveal the random data encrypting key. Here,
, meaning this content is not intended for her. When the Physician accesses the content, he/she can successfully decrypt the entire decryption process from the leaf to the root level-by-level to reveal the random data encrypting key. Here, ![]() is substituted with
is substituted with ![]() since
since ![]() is a subattribute. This is shown with the arrow in Fig. 7.6. Also,
is a subattribute. This is shown with the arrow in Fig. 7.6. Also, ![]() equals to
equals to ![]() in this case. Then, the Physician uses the NR system to get the nearest copy of the content and uses the random data encrypting key derived from the name to decrypt the MRI report.
in this case. Then, the Physician uses the NR system to get the nearest copy of the content and uses the random data encrypting key derived from the name to decrypt the MRI report.

7.2.2 Creating a Content
Initially, the TTP sets up global parameters for the entire network. Then, any entity in the network can create attributes and assign them to other entities. The detailed process on how attributes are distributed is out of the scope of this work. An interested reader can refer to allocation problem solutions such as [64]. Once the attributes are assigned, entities are able to create contents. As shown in Fig. 7.7, when an entity publishes a file, as the content owner, it creates an access policy for the content. The policy is represented as a combination of related attributes with AND and OR gates. For example, if a content owner wants to create a record accessible only to physicians and nurses working at hospital A, the policy can be ![]() . In this way, the owner does not need to know explicitly who should access the content. All he needs is to identify the attributes and the combination so that as long as a consumer satisfies the policy, he/she is able to access the content. Any entity who does not satisfy the policy will not be able to access the file with this content.
. In this way, the owner does not need to know explicitly who should access the content. All he needs is to identify the attributes and the combination so that as long as a consumer satisfies the policy, he/she is able to access the content. Any entity who does not satisfy the policy will not be able to access the file with this content.
After creating the policy, the owner generates a random data encrypting key and uses it to encrypt the file. The encryption result is set as the data part of the content item. The metadata includes public parameters to decrypt the data and data integrity related information. Then the owner creates a name for the content. He/she uses the proposed scheme to encrypt the random key under the policy he/she has specified. The result is used as the content name. Here we need to emphasize that the generated name hides the content access policies so that no one can get the entire policy from the name.
A consumer who needs this file can get the content by its name. Before he/she gets the content, he/she uses his/her assigned attributes to decrypt the name. If his/her attributes satisfy the hidden policy in the name, he/she can get the random data-encrypting key protected in the name. The data of the content then can be decrypted using the random key to get the original file. If a consumer cannot successfully decrypt the content name, it implies the consumer is not allowed to access the original file. Thus, even if he/she downloads the content, he/she still does not have the random data encrypting key to decrypt the content.
7.3 Ontology-Based Attribute Management
In this section, we describe the ontology-based attribute management scheme in details. This scheme is suitable for managing attribute names and values for both ACAs and DAs in a distributed manner, which is very suitable for ICN architecture.
Ontology defines various classes of users, data and object properties that are part of the attribute schema. Data properties are the attributes of the users, and object properties are attributes of user classes that relate a user object to objects of another class. We can query Web Ontology Language (OWL) [61] ontologies using the SPARQL language [43] that takes into account the ontology structure while executing. Information about different attributes can be merged and integrated. This aggregation is useful to determine facts which cannot be acquired from any individual parties in decentralized environment.
In the ICN example presented in Fig. 7.5, we need a scheme for negotiating the attributes to be used by the users to encrypt and decrypt data, so that these processes can occur coherently. The same attribute can have different names while having the same meaning in real life like synonyms. Sometimes we also need to restrict the possible values for a particular attribute to a realistic range.
In our design, the TTP specifies an Attribute Ontology that defines the set of attributes that the users can use. Users composite the access policies with these attributes for the content they publish over the network. Our design uses the following approach that distinguishes it from the current systems.
7.3.1 Attribute Equivalence
The main advantage of using ontologies to define attributes is that they allow us to declare equivalent attributes. For example, if we declare attributes (or properties) A and A' as equivalent, some users can use the property name A for defining their policy and others can use A' for their policy. The ontology ensures that both properties map to the same attribute, i.e., the same mathematical elements in ABE algorithm. A formal definition for such a equivalence is:
![]() iff
iff ![]() .
.
Here, ![]() are mathematical elements used in the proposed naming scheme as in Section 7.2.
are mathematical elements used in the proposed naming scheme as in Section 7.2.
Equivalent properties can be specified in an OWL document using the owl:equivalentProperty element. We can define two attributes attribute1 and attribute2 as data type properties. In any one of these attributes we can declare the equivalence by adding the owl:equivalentProperty element in the property definition [61]. Once the equivalent set of attributes is defined, the users can use either of the attributes from the set for sharing as well as accessing data since all of them map to the same attribute. For example, if we have equivalent attributes ![]() ≡
≡ ![]() and they map to a unique triplet of
and they map to a unique triplet of ![]() , then this unique triplet can be used to encrypt the data using the ABE based naming scheme.
, then this unique triplet can be used to encrypt the data using the ABE based naming scheme.
7.3.2 Attribute Hierarchy
Another advantage of using ontologies for defining attributes is that we can define a hierarchy of attributes. One attribute can be defined as a subattribute of another. For example, in a hospital, a user can have the attribute ![]() . We can define an attribute
. We can define an attribute ![]() as a sub-attribute of
as a sub-attribute of ![]() . This means that a “Nurse” is also an “Employee” and he/she can have more properties than other “Employees.” This is done by using the rdfs:subPropertyOf element in the OWL specification [61]. The advantage is that if the access policies specify that all users having attribute
. This means that a “Nurse” is also an “Employee” and he/she can have more properties than other “Employees.” This is done by using the rdfs:subPropertyOf element in the OWL specification [61]. The advantage is that if the access policies specify that all users having attribute ![]() can access a particular data, the attribute hierarchy specified in the ontology will also allow a
can access a particular data, the attribute hierarchy specified in the ontology will also allow a ![]() to get it, but any other “Employee” cannot access the data that requires the user to be a “Nurse” to access it. In Appendix C.1.4, an attribute ranking capacity is enabled through the proposed naming scheme. The connection and difference between this example and the one in Section C.1.4 is that:
to get it, but any other “Employee” cannot access the data that requires the user to be a “Nurse” to access it. In Appendix C.1.4, an attribute ranking capacity is enabled through the proposed naming scheme. The connection and difference between this example and the one in Section C.1.4 is that:
• In this example, ![]() and
and ![]() are two values in the category of
are two values in the category of ![]() , or
, or ![]() ;
;
• In Appendix C.1.4, ![]() has fewer privileges than
has fewer privileges than ![]() , or
, or ![]() .
.
Here we can treat ![]() as a set of some ordinal attributes.
as a set of some ordinal attributes.
In fact, with the attribute hierarchy, a user is able to define the set relationship between attributes. In Appendix C.1.4, the users can further define the ordinal relationship among all the attributes within a set.
7.3.3 Distributed Policy Specification
Since our design assumes multiple trusted attribute authorities, we need an initial negotiation between these authorities to decide the structure of attributes and properties to be specified in the attribute ontology. This can be achieved with the help of the TTP. Once this agreement is established, the users can access this ontology from any of the attribute authorities and design the access policy for their shared data. This policy can then be translated to an equivalent ABE compatible form to be used for encrypting the contents. This approach allows the access policies to be generated in a distributed manner by the users themselves. As long as these access policies satisfy the established ontology, they can be used over the entire network.
7.3.4 Apply ABE-Based Naming Scheme in ICN
With the above naming scheme, we can achieve the following capabilities:
• Specification of the access control policy without knowing the consumers' keys;
• Full preservation of the policy confidentiality from leaking to adversaries;
• Step-by-step attribute exposure for consumers to determine their eligibility efficiently in computation;
• Flexible attribute management.
Using this scheme, any entity that wants to publish data needs to create the content following the process in Fig. 7.7.
The owner firstly creates a random symmetric key K. Then the data to be published is encrypted using K. The resulting ciphertext C is then used to generate metadata of C. Both the metadata and C are parts of the final content. Then the owner needs to specify an access policy P of attributes to define what an authentic consumer should satisfy. Then the owner uses this policy to encrypt K following Encrypt algorithm. The result is used as the content name.
In this way, the owner does not need to know individual public keys of all the potential consumers in advance, which is required in traditional methods.
7.3.5 Performance Analysis and Evaluation
In this section, we firstly evaluate the performance of the attribute management scheme. Then, the computation and communication performance for the privacy-preserving naming scheme is analyzed. The security strength of the proposed naming scheme is evaluated in the last part.
7.3.5.1 Evaluation and Analysis on the Attribute Management
In this section we create an application scenario to demonstrate the effectiveness of ontology-based attribute management. Evaluation in this section is carried out in NDN environment [290]. We implemented ndn-cxx v0.3.1 library [211] together with NDF 0.3.1 [212] on Ubuntu 12.04 systems. As mentioned in Section 7.2, users are able to define their own name structure in NDN network, which makes it quite suitable for evaluating the proposed naming scheme in this chapter.
In an ICN healthcare network, there are hospitals, clinics, and medical institutions that share information and data. Each institution defines its own users and attributes. A trusted Attribute Authority (AA) is set for each institution to generate attributes for users and assign them correctly when new users join the system. It also generates the private keys to be used for ABE operations by the users and securely transfers them to intended user(s). An institution defines its own setup like the various departments, employees, patients, etc. We assume that each institution will use its own nomenclature so that the same department can have a different name in different institutions. The users can have a hierarchy among themselves, for example, Nurse < Resident < Consultant < Surgeon < Head of Department < Chief Medical Officer.
Medical Records Transfer
When a patient is being transferred from one hospital to another for better treatment, his/her medical records need to be transferred as well. Since these are highly sensitive data, they are stored in encrypted form (in our case the encryption is ABE-based) and only medical personnel having the required privileges can access and decrypt this data. Let ![]() be the time taken to encrypt data and
be the time taken to encrypt data and ![]() be the time to decrypt it.
be the time to decrypt it.
If no ontology has been specified by the two hospitals and no attributes are shared among them, the attributes used to encrypt the data by the first hospital would be invalid in the second hospital. Therefore, the data has to be decrypted first, and then encrypted using the attributes defined in the second hospital. If we also consider the initial encryption of the data, it accounts for two encryptions and one decryption: ![]() .
.
Now we consider using an ontology that maps the attributes of one hospital to its equivalent attributes in another hospital over the ICN network. Since the attributes are already mapped, we don't need to encrypt/decrypt the data again. Only the initial encryption is required to be performed in this case: ![]() .
.
A comparison of the two cases is illustrated in Fig. 7.8. As shown in the figure, using ontology based management can save about 75% in time when the number of attributes is more than 6, which is significant in real life.

Applying User Hierarchy to Access Policy
When certain data is to be shared with all doctors, irrespective of their rankings, without ontology, the person who issues the policy will need to know all the possible “ranks” of the doctors and then specify a DNF of all these ranks as the access policy specification. If we have an ontology where the hierarchy is specified, i.e., all the various ranks of doctors (Resident, Surgeon, etc.) are structured as subtypes of a parent type Doctor, the policy specifier only specifies Doctor as the access privilege and the ontology ensures that all the subtypes also satisfy this access requirement. In this way, if we are able to provide a proper parent type for the cases where a large combination of roles are included in the access policy, the size of the policy as well as the corresponding computation, communication, and storage cost will be greatly reduced. For such a gain, the cost is merely one additional level in the attribute hierarchy.
Storage Overhead and Its Effect on Network Throughput
When N institutions are sharing data without using an ICN network, it results in N copies of the data, one for each institution and encrypted using its own set of attributes. Using ICN networking without the attribute management scheme can help improve the network efficiency in file sharing and content distribution, but no benefits will be provided in terms of storage overhead. With the use of ICN network in our design along with ontology-based management to specify relation between the attribute sets of all the different institutions, we reduce the storage overhead to a single copy of the encrypted data. Any eligible user from the various institutions can decrypt the encrypted data, thereby removing the need for multiple copies.
Due to the large differences in caching strategies and hardware capacities, we cannot provide a concrete network performance improvement from the reduced storage overhead. Instead, we calculate the numerical network throughput improvement using a demonstration scenario. Here, we assume that there are m domains with n entities in each domain. A file of k bits is to be shared from one single source to all the entities. The caching capacity for each network cache is m, meaning all the m copies of one single file can be cached at the same time. We also assume that the entities of each domain are evenly distributed in the network. The time needed for distributing one single copy is t seconds. When no inter-domain attribute management scheme is involved, the throughput of the network is  bps. However, when the ontology-based management scheme is applied, the throughput is increased to
bps. However, when the ontology-based management scheme is applied, the throughput is increased to ![]() bps. Such an increase is due to the reduced amount of copies need to be transferred in the network.
bps. Such an increase is due to the reduced amount of copies need to be transferred in the network.
7.3.5.2 Evaluation of the Naming Scheme
In this section, the ABE-based naming scheme is evaluated from the performance aspect. We analyze its computation and communication (storage) overhead.
From the computation perspective, we tested the time consumption for key generation, encryption and decryption processes. In a real application, we are more concerned with the time consumption for a consumer to decrypt the content's name. This is because each content is encrypted once but decrypted by multiple users. Therefore, we also compare the decryption overhead with existing ABE solutions: CP-ABE [63], CN scheme [77], NYO scheme (the 2nd construction in [216]), YRL scheme [287], and GIE scheme [142]. The idea is to compare the number of most time-consuming operations needed in each scheme.
We use a machine with a four-core 2.80 GHz processor and 4 GB memory running Ubuntu 10.04 for the experiment. PBC Library [192] is used to handle the pairing computations. We generated a type-A1 curve [193] using the parameter generating tools included in this library for the following tests. It randomly generates the prime numbers used for the curve, with a length of 512 bits for each of them. We run each operation ten times for key generation, encryption and decryption (Fig. 7.9). Here the policies are set to be a conjunctive clause of different number (shown on the x-axis) of attributes. This is because given a number of attributes, this form requires the most time for computation. The reason why encryption consumes more time when attributes are fewer is that the cost for computing C in Algorithm C.5 requires an additional pairing computation which is independent of the number of attributes. When few attributes are involved, this additional pairing takes a high portion of the time consumption. This portion reduces as the attribute numbers grow.

In theory, the time consumption should be linear in the number of attributes involved. The curve in Fig. 7.9 is not perfectly linear, but it meets our expectation. There are several reasons why it is not strictly linear. Before decrypting attribute by attribute, in our program, there are some necessary steps to initialize global parameters, read files, and allocate memory space. Similarly, at the end of the algorithm, we have some clean-up work, such as writing files and releasing memory space. Such time consumption is related to the number of attributes involved but not strictly proportional. Also, at step 4 of Decryption algorithm, there is one additional pairing operation. Thus, when the number of attributes is small, this additional operation takes a larger portion of the total time than when the number of attributes is large. If we further consider the possible variance introduced by system level factors, for instance, the resource consumption from other processes, the variance in the figures is reasonable in practice.
For comparison purpose, we test every operation for 50 times and choose the average value as basics for our comparison. Results of our experiment (Table 7.1) show that pairing operation takes longer than any other operations. Therefore, our comparison metric is set to be the number of pairing operations in the decryption process.
Table 7.1
Time-consumption of different operations (in milliseconds)
| Pairing | Exponentiation | Multiplication | Inversion | |
| Time | 7.675 | 0.491 | 0.029 | 0.024 |

Following the above-mentioned idea, we use ![]() to denote the number of attributes a consumer has,
to denote the number of attributes a consumer has, ![]() , as the total number of attributes defined in the network (
, as the total number of attributes defined in the network (![]() ). The proposed naming scheme is denoted as ICN-ABE in the rest of this paper. Since the policy is publicly known in CP-ABE and CN, decrypters are able to decide what attributes to use in decryption. Therefore, for those who satisfy the policy, the time taken for decryption is proportional to the number of attributes involved, which is denoted as
). The proposed naming scheme is denoted as ICN-ABE in the rest of this paper. Since the policy is publicly known in CP-ABE and CN, decrypters are able to decide what attributes to use in decryption. Therefore, for those who satisfy the policy, the time taken for decryption is proportional to the number of attributes involved, which is denoted as ![]() ,
, ![]() . It is obvious that inauthentic decrypters would not bother to try decryption, which is why it takes no time. An inauthentic decrypter in GIE and ICN-ABE is not able to proceed with the decryption process if it cannot meet the next attribute. In this situation, we use
. It is obvious that inauthentic decrypters would not bother to try decryption, which is why it takes no time. An inauthentic decrypter in GIE and ICN-ABE is not able to proceed with the decryption process if it cannot meet the next attribute. In this situation, we use ![]() to denote the number of attributes that the consumer has already decrypted, where
to denote the number of attributes that the consumer has already decrypted, where ![]() . The result of our test is shown in Table 7.2.
. The result of our test is shown in Table 7.2.
Table 7.2
Comparison of computation cost in decryption
| Scheme | Hidden Policy | Number of Pairings |
| CP-ABE | No | 2Ninvo + 1 or 0 |
| CN | No | Nall + 1 or 0 |
| NYO | Yes | 2Nattr + 1 |
| YRL | Yes | 2Nattr + 2 |
| GIE | Yes | 3Ninvo or 3Npart |
| ICN-ABE | Yes | 2Ninvo + 1 or 2Npart |
To evaluate the communication costs, we compare the size of the name in various schemes, which are sumarized in Table 7.3. In PBC library [192], a data structure element_t with size of 8 bytes is used to represent an element. For our scheme, we need 24 bytes to store the network name. Compared with this name size, a content in CBCB [71] is identified by a set of attributes determined by the content owners. Thus, we can model the names as a human-readable string of an undetermined size. NDN [290] shares a similar problem with the name size. As mentioned before, DONA [167], NetInf [95], and PURSUIT [111] share the same naming scheme. Therefore, we only use the size of DONA's name for comparison. In [167], the size of the name is confined to 40 bytes in its protocol header. Thus, the network name size in our scheme is small enough to fit in existing ICN solutions.
Table 7.3
Comparison of ciphertext size
| Scheme | Ciphertext Size |
| CP-ABE |
|
| CN |
|
| NYO |
|
| YRL |
|
| GIE |
|
| ICN-ABE |
|
7.3.5.3 Security Analysis
From the security perspective of the proposed solution, we analyze the performance based on the attack model presented in below.
Attack Model. We assume that the attackers have two goals in compromising the ICN access control scheme: (1) acquiring unauthorized privilege to the data; (2) retrieving constitutional information of access policies to gain more information about the content, the owner, and the consumers. The information includes but is not limited to the identity of the owner or consumers, the sensitivity of the content and the potential value of data in the content. For the first goal, the attackers have to break the confidentiality mechanism of the protected data. Possible methods include collusion attacks and vulnerability exploitation. For the second goal, attackers need to analyze the proposed ABE-based scheme to identify possible ways to reveal the policy.
Theorem 1
The proof for this theorem is provided in Appendix C.1.5. In the proof, it is verified that the attacker cannot break the encryption algorithm to get any data exposed. Furthermore, it is also proved that attackers cannot conduct collusion attacks onto the system.
For the second attack goal, the attacker will stop at the first attribute, ![]() , that he/she doesn't own in the decryption process. If he/she can get to know this additional attribute, he/she must get it from step 3 in Algorithm C.6. This means that the attacker possesses the secret key
, that he/she doesn't own in the decryption process. If he/she can get to know this additional attribute, he/she must get it from step 3 in Algorithm C.6. This means that the attacker possesses the secret key ![]() of the attribute
of the attribute ![]() , which contradicts to the assumption that he/she does not possess this attribute.
, which contradicts to the assumption that he/she does not possess this attribute.
7.4 Secure Computation Offloading
With the fast development of wireless technology, mobile cloud computing has become an emerging cloud service model [80,138], where mobile devices and sensors are used as the information collecting and processing nodes for the cloud infrastructure. This new trend demands researchers and practitioners to construct a trustworthy architecture for mobile cloud computing that includes a large numbers of lightweight, resource-constrained mobile devices. In such a mobile cloud sensing environment, cloud users may inquiry the data from sensing devices. A simple solution to protect the data is to encrypt the sensing data with a group key and broadcast the encrypted data; only legitimate users can reveal the data content with the predistributed group key. However, this approach demands high key management overhead and it is vulnerable to single point failure problems.
In this chapter, we present the basis of CP-ABE schemes [63,77,158] to facilitate key management and cryptographic access control in an expressive and efficient way, and then, we present it how to use ABE scheme to establish an ABAC access control model. Particularly, we presented an example using ABE to support ICN naming scheme that supports edge cloud mobile networking and data distribution services.
To illustrate the application scenario, we consider a mobile remote health sensing scenario, where a doctor using a mobile device (e.g., smart phone) to inquire the sensing data collected from a set of body sensors attached on a patient at home. It is convenient to encrypt the data and enforce data access policies that only eligible users can decrypt it. To this end, the sensed data can be encrypted using the following policy:
In this example, doctors who are working at Saint Luke hospital on 12/8/2016 can decrypt the data. Using CP-ABE scheme, the sensor can use the above described policies to encrypt the data, and the data inquirers must satisfy the given policies in order to decrypt the data.
To establish the highlighted mobile cloud data inquiry services, several research challenges need to be addressed:
• With the CP-ABE enabled mobile cloud data inquiry services, the main challenge originates from the fact that CP-ABE schemes always require intensive computing resources for sensors or mobile devices to run the encryption and decryption algorithms.
• Given the sensitivity of data and multitenancy nature of the public cloud, critical customer secrets should not be exposed to the cloud.
• Another major challenge is how to upload/download and update encrypted data stored in the mobile cloud system. Frequent upload/download operations will cause tremendous overhead for resource constrained wireless devices.
To address the above described research challenges, users may securely offload computation intensive CP-ABE encryption and decryption operations to the cloud without revealing data content and secret keys. In this way, lightweight and resource constrained devices can access and manage data stored in the cloud data store. This approach requires users' attributes to be organized in a carefully constructed hierarchy so that the cost of membership revocation can be minimized; and it is suitable for mobile computing to balance communication and storage overhead, thus reducing the cost of data management operations (such as upload, updates, etc.) for both the mobile cloud nodes and storage service providers.
7.4.1 Overview of Secure Computation Offloading
In this section, we denote the data owner as DO. A DO can be a mobile wireless device such as a smart phone or an environmental sensor that can request and/or store encrypted information from/in the cloud storage. The data are encrypted using the presented Partitioning CP-ABE (P-CP-ABE). Other than DO, there are many DRs (Data Requesters or Receivers) who can inquire the information from the storage services of the mobile cloud. For example, a user may want to inquire current pollution map of a particular city area. Since the data provided by DOs can be proprietary, it should be encrypted and only pollution map service subscribers can retrieve the data. In this case, the mobile cloud system only provides a service platform and it should not be able to access the data content from the DOs. Here, the focus is on the encryption and decryption model to support the described application scenario; thus, due to the space limit, we do not describe how exactly the application is established in details. The presented system model should provide the following properties:
1. The data must be encrypted before sending to a Storage Service Provider (SSP);
2. The Encryption Service Provider (ESP) provides encryption service to the data owner without knowing the actual Data Encryption Key (DEK);
3. The Decryption Service Provider (DSP) provides decryption service to data inquirers without knowing the data content;
4. Even if ESP, DSP, and SSP collude, the data content cannot be revealed;
As shown in Fig. 7.10, the SSP, ESP, and DSP form the core components of the proposed system. A DR inquires the data provided by a DO. ESP and DSP provide P-CP-ABE services and SSP, e.g., Amazon S3, provides storage services. The cloud is semitrusted, in which the cloud only provides computing and storage services with the assistance on data security; however, the data is blinded to the cloud. In particular, more powerful PCs and mobile phones can work as communication proxy for sensors that collect information.

Essentially, the basic idea of P-CP-ABE to outsource intensive but noncritical part of the encryption and decryption algorithm to the service providers while retaining critical secrets. As we can prove later in this chapter, the outsourcing of computation does not reduce the security level compared with original CP-ABE schemes, where all computations are performed locally.
The encryption complexity of CP-ABE grows linearly in the size of access policy. During the encryption, a master secret is embedded into ciphertext according to the access policy tree in a recursive procedure, where, at each level of the access policy, the secret is split to all the subtrees of the current root. However, the security level is independent on the access policy tree. In other words, even if the ESP possesses secrets of most but not all parts of the access policy tree, the master secret is still information theoretically secure given there is at least one secret that is unknown to ESP. Thus, we can safely outsource the majority of encryption complexity to ESP by just retaining a small amount of secret information, which is processed locally.
As for the decryption, the CP-ABE decryption algorithm is computationally expensive since bilinear pairing operations over ciphertext and private key are computationally intensive operations. P-CP-ABE addresses this computation issue by securely blinding the private key and outsourcing the expensive pairing operations to the DSP. Again, the outsourcing will not expose the data content of the ciphertext to the DSP. This is because the final step of decryption is performed by the decryptors.
The mathematical construction of P-CP-ABE is presented in Appendix C.2.
7.4.2 Use Case: Attribute Based Data Storage
In this section, we present an Attribute Based Data Storage (ABDS) scheme for mobile cloud computing that is based on P-CP-ABE to enable efficient, scalable data management and sharing.
The frequent data updates will cause additional expense for file management, for example, to update existing files, e.g., change certain data fields of an encrypted database, in which the encrypted data need to be downloaded from SSP to DSP for decryption. Upon finishing the updates, the ESP needs to reencrypt and upload the data to the SSP. Thus, the reencryption process requires downloading and uploading the data, which may incur high communication and computation overhead, and as a result, will cost more for DOs.
To address the described cost issue, it is reasonable to divide a file into independent blocks that are encrypted independently. To update files, the DO can simply download the particular blocks to be updated. In this way, we can avoid reencrypting the entire data. Moreover, data access control can be enforced on individual blocks using “lazy” reencryption strategy. For example, when the data access memberships to a particular file are changed (i.e., the access tree is changed), this event can be recorded but no file changes are invoked. If the data content needs to be updated, the reencryption is performed using the proposed P-CP-ABE scheme.
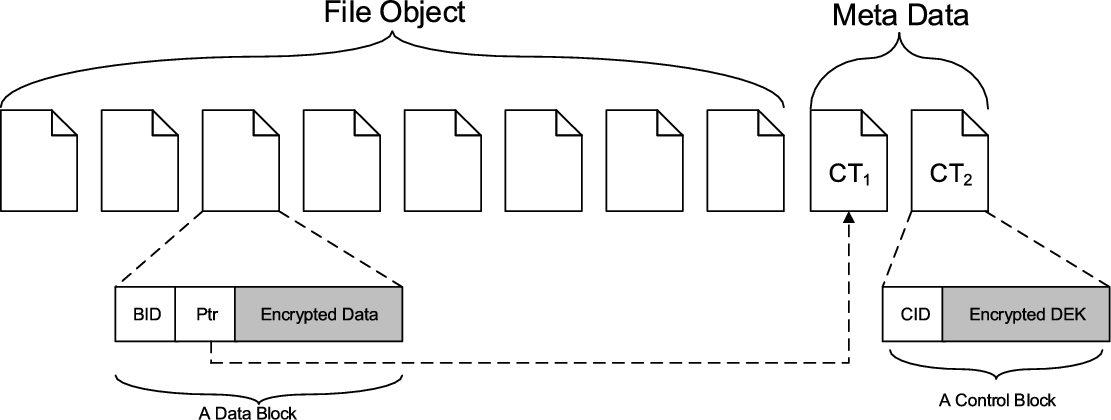
Partitioning the data into multiple small blocks also introduces addition overhead. This is because the extra control information needs to be attached for each data block for data management. For example, the control message should include a block ID and a pointer to its corresponding data access tree ![]() . In Fig. 7.11, we depicted a sample file stored in SSP. Each file is divided into blocks. A block is a tuple {BID, Ptr, Encrypted Data}, where BID is the unique identification of the block; Ptr is the pointer to the control block CT; and data is encrypted with a DEK. A control block {CID, Encrypted DEK} has a control block ID, i.e., CID and DEK encrypted by using P-CP-ABE scheme.
. In Fig. 7.11, we depicted a sample file stored in SSP. Each file is divided into blocks. A block is a tuple {BID, Ptr, Encrypted Data}, where BID is the unique identification of the block; Ptr is the pointer to the control block CT; and data is encrypted with a DEK. A control block {CID, Encrypted DEK} has a control block ID, i.e., CID and DEK encrypted by using P-CP-ABE scheme.
The ABDS system should determine what the appropriate data block size is to be partitioned with a known file size. In this work, our goal is to minimize the storage and communication overhead with the considerations of the following simple assumptions:
1. Every data update should only affect a small amount of data, e.g., updating certain data fields in the database;
2. In each unit time period, the number of blocks to be updated is known;
3. Each data block has the same probability to be updated;
Based on the above discussions, we can model the total cost C in a unit time period as follows:
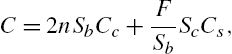
where n is the number of updated blocks in a unit time period and 2n stands for an update includes one encryption and one decryption that require two transmissions; ![]() is the size of block;
is the size of block; ![]() is the cost rate of data transmission that is charged by both cloud storage providers and wireless communication service providers; F is the size of file;
is the cost rate of data transmission that is charged by both cloud storage providers and wireless communication service providers; F is the size of file; ![]() is the size of control data for each data block, and
is the size of control data for each data block, and ![]() is the charging rate of storage. To minimize cost C, DO can minimize (7.1) and derive the optimal block size:
is the charging rate of storage. To minimize cost C, DO can minimize (7.1) and derive the optimal block size:
7.4.3 Setup
P-CP-ABE enables expressive policy with descriptive attributes to enforce data access control on the stored data. For example, if Alice wants to share a file to all CS students, she can specify the policy “CS AND Student.” All the users whose attributes satisfy this policy can decrypt the data.
Besides the set of descriptive attributes enabled in the system, each user is assigned a unique binary ID: ![]() . We can define the term “bit-assignment attribute” that is represented as “
. We can define the term “bit-assignment attribute” that is represented as “![]() ” or “
” or “![]() ” to indicate the binary value at position i in the ID.
” to indicate the binary value at position i in the ID. ![]() indicates that the ith bit of an ID is 1;
indicates that the ith bit of an ID is 1; ![]() indicates that the ith bit of an ID is 0. If the length of an ID is n, then the total number of bit-assignment attributes is 2n. This means that two binary values are mapped to one bit position (one for value 0 and one for value 1). Thus, a DO with ID u is uniquely identified by the set of bit-assignments
indicates that the ith bit of an ID is 0. If the length of an ID is n, then the total number of bit-assignment attributes is 2n. This means that two binary values are mapped to one bit position (one for value 0 and one for value 1). Thus, a DO with ID u is uniquely identified by the set of bit-assignments ![]() . Also, multiple DOs may have a common subset of bit-assignments. For example, a DO
. Also, multiple DOs may have a common subset of bit-assignments. For example, a DO ![]() 's ID is 000 and a DO
's ID is 000 and a DO ![]() 's ID is 001,
's ID is 001, ![]() and
and ![]() and
and ![]() . Bit-assignment attributes can be used when the DO wants to share data to any arbitrary set of DOs. In this case, it may be hard to describe the set of DOs efficiently using descriptive attributes.
. Bit-assignment attributes can be used when the DO wants to share data to any arbitrary set of DOs. In this case, it may be hard to describe the set of DOs efficiently using descriptive attributes.
7.4.4 Uploading New Files
Before uploading new files to the SSP, both ESP and DO are required determining the encryption parameters such as the block size. DO then invokes ESP with an access policy ![]() , which is the access policy to be enforced on the uploaded files. Here, we define some terms used in the following presentation:
, which is the access policy to be enforced on the uploaded files. Here, we define some terms used in the following presentation:
• Literal – A variable or its complement, e.g., ![]() ,
, ![]() , etc.
, etc.
• Product Term – Literals connected by AND, e.g., ![]() .
.
• Sum-of-Product Expression (SOPE) – Product terms connected by OR, e.g., ![]() .
.
Given the set of shared data receivers S, the membership function ![]() , which is in the form of SOPE, specifies the list of receivers:
, which is in the form of SOPE, specifies the list of receivers:

For example, if the subgroup ![]() is considered, then
is considered, then ![]() .
.
Then, the DO runs the Quine–McCluskey algorithm [195] to reduce ![]() to minimal SOPE
to minimal SOPE ![]() . The reduction can consider do not care values ⁎ on those IDs that are not currently assigned to any DO to further reduce the number of product terms in the membership function. For example, if
. The reduction can consider do not care values ⁎ on those IDs that are not currently assigned to any DO to further reduce the number of product terms in the membership function. For example, if ![]() , then
, then ![]() .
.
Finally, DO uploads the data blocks and the control block to SSP, where each data block is encrypted by the DEK, and DEK is protected by the access policy in the control block.
7.4.5 Data Updates
Now, we investigate how to efficiently handle the data updates, i.e., how to modify encrypted data with or without changing data access control policy.
Data Updates with Access Policy Change
At the beginning of Section 7.4.2, we described the “lazy” reencryption strategy adopted by DOs. Using the “lazy” reencryption scheme, the DO continuously records the revoked data receivers. When there is a need to modify the data, the DO will choose a new data access tree that can revoke all previously recorded data receivers.
When DO updates a data block with access policy change, we need to consider the following cases:
• If there is no control block associated with the latest access policy, i.e., no data updates occurred after the latest access policy change event, the DO encrypts a new random DEK associated with the latest access policy with P-CP-ABE and attaches a new control block to the end of the file, see Fig. 7.11.
• If there exists a control block associated with the latest access policy, i.e., at least one data block was encrypted with the newest access policy, the DO can simply redirect the control block pointer, see Fig. 7.11, to the control block associated with the latest access policy.
• If a control block is not pointed by any data block, this control block should be deleted.
Updates without Access Policy Change
If no change is required to the access policy, DO can simply perform the P-CP-ABE scheme and upload the updated data block in the SSP. The block ID and the pointer to control the block are not changed.