
Chapter 7
Development and Calibration of a Large-Scale Agent-Based Model of Individual Tax Reporting Compliance
Kim M. Bloomquist
7.1 Introduction
Since the publication of the groundbreaking theoretical work by Allingham and Sandmo (1972) and Srinivasan (1973), much has been learned about the determinants of taxpayer compliance.1 Despite these advances, progress has lagged in transforming this knowledge into computational tools that tax officials can use to conduct in silico tests of proposed tax service and enforcement programs prior to implementation on potentially millions of taxpayers. Alm (1999) suggests that the key reason for this lack of progress is the inability of existing analytical (i.e., mathematical) models to incorporate sufficient real-world taxpayer behavior and he goes on to point out that past efforts to introduce greater realism into the standard rational choice model of taxpayer decision-making have tended only to increase the ambiguity of the model's predictions. A similar observation has been made by Janssen and Ostrom (2006) and Axtell (2000) for complex social and ecological systems in general. Increasingly, researchers are concluding that agent-based modeling and simulation (ABMS) is a methodology that is well suited for modeling complex social phenomena, of which taxpayer compliance is a prime example (see Alm, 2010).
This chapter describes the development and calibration of a large-scale ABM that simulates the income tax reporting behavior of a community of 85,000 individual taxpayers. The Individual Reporting Compliance Model (IRCM) includes many enforcement mechanisms used by tax agencies, such as audits and information reporting, as well as detailed information on the reporting compliance for major income and offset2 items. A more detailed description of the IRCM is found in Bloomquist (2012). Other articles featuring the IRCM are Bloomquist (2013) and Bloomquist and Koehler (2015).
The decision to use ABMS (i.e., an object-oriented approach) to model taxpayer reporting behavior over a variable-oriented approach such as system dynamics (Cioffi-Revilla, 2014) was made based on reasoning similar to that outlined in Rand and Rust (2011). In their paper, Rand and Rust cite six characteristics of a social system that make it suitable for analysis using ABMS. The one necessary feature is that the system must be one that is temporally dynamic as it can (or has the potential to) give rise to multiple equilibria over time. Therefore, the system must be one that is temporally dynamic. Adapting to changing environmental conditions (i.e., exhibiting learning behavior) is a characteristic of social systems that the authors see as sufficient for analysis using ABMS as adaptive agents. Four other characteristics are seen as indicative of social systems that are suited for analysis using ABMS. They are the following:
- 1. Heterogeneity. Individuals or groups of individuals that exhibit different responses to identical environmental conditions or that are subject to different constraints. For example, among individual taxpayers the opportunity to evade varies greatly for employees whose earnings are reported to the Internal Revenue Service (IRS) by employers, and sole proprietors that are subject to little or no third-party information reporting.
- 2. Local and Potentially Complex Interactions. When individuals exchange information through networked interaction with other individuals or businesses, this can substantially alter behavior over time and space. Stolen identity tax refund schemes is an example of such behavior.
- 3. Rich Environment. An environment that is “rich” in detail is one that captures a broad range of situations that potentially influence behavior. Among taxpayers this can be interactions with the tax agency itself, tax preparers, family members, acquaintances, coworkers, and professional organizations.
- 4.
Medium Numbers. Rand and Rust correctly point out that ABM is not an appropriate tool when only one or two agents are involved since such small-scale interactions are better analyzed using game theory. The IRCM itself may be classified as a medium- to large-scale model since it investigates the tax reporting behavior of approximately
 agents. However, ABMs with millions of agents are now being built,3
agents. However, ABMs with millions of agents are now being built,3 - and limiting the scope of ABMs to “medium-size” systems seems an artificial limitation.
The goal for the design of the IRCM was to have a model that would represent the major real-world features and institutions of modern tax administration. Modeling an entire community of taxpayers makes it possible to represent social networks that empirical research has shown to significantly influence tax compliance behavior (Bernard et al., 2007). The IRCM does this by including formal (and observable) relationships between taxpayers and commercial tax preparers and employers as well as informal (and less directly observable) social networks among taxpayers in both workplace and residential settings. Links between taxpayers and paid preparers and taxpayers (employees) and employers were based directly on tax return data but all unique identifying information (including the identity of the study area itself) has been removed. Tax return information for all 85,000 taxpayers is amply detailed with each tax return containing 180 distinct elements. Misreporting behavior (both over and underreporting) is based on results from random taxpayer audits conducted by the IRS for tax year (TY) 2001 (Internal Revenue Service, 2007). Last, but not least importantly, the IRCM provides the main tax enforcement tools including taxpayer audits, third-party information reporting, and tax withholding.
7.1.1 Taxpayer Dataset
To preserve taxpayer anonymity and yet facilitate model verification and validation, the IRCM uses a dataset of artificial taxpayers. The dataset of artificial taxpayers was created by substituting cases from the US IRS Statistics of Income (SOI) Public Use File (PUF) for actual tax returns of the 85,000 taxpayers featuring in the study area. Although most fields in the PUF are derived from tax forms, SOI modifies the data in order to protect the identity of individuals. Substitution was performed by first partitioning tax return and PUF records and selecting (with replacement) the PUF record that most closely matches each taxpayer record in the study area. Further details on the statistical matching algorithm are provided in Bloomquist (2012). Table 7.1 compares the resulting dataset of artificial taxpayers to the actual tax return data by major income and offset item.
Table 7.1 Comparison of actual versus artificial taxpayer data for study region
| Actual data | Artificial data | Percent | ||||
| Income item | N (non-zero) | Sum ($1000) | N (non-zero) | Sum ($1000) | differencein sums (%) | |
| Wages | 72,058 | $2,744,170 | 71,773 | $2,738,049 | ||
| Interest | 47,768 | $138,156 | 42,582 | $125,803 | ||
| Dividends | 22,951 | $77,716 | 19,590 | $65,905 | ||
| Tax refunds | 14,955 | $6,098 | 10,764 | $7,287 | 19.5 | |
| Alimony | 238 | $2,748 | 155 | $2,071 | ||
| Schedule C | 8,728 | $92,480 | 7,610 | $90,104 | ||
| Capital gains | 17,636 | $95,117 | 14,520 | $89,043 | ||
| Other gains | 930 | $81 | 690 | $802 | 887.6 | |
| IRA | 6,820 | $68,681 | 5,315 | $59,328 | ||
| Pensions | 18,604 | $277,083 | 16,597 | $269,574 | ||
| Schedule E | 8,769 | $116,042 | 7,185 | $120,370 | 3.7 | |
| Schedule F | 1,143 | $1,154 | 841 | $2,252 | 95.2 | |
| Unemp. comp. | 6,203 | $19,783 | 4,774 | $15,311 | ||
| Social security | 8,461 | $73,374 | 7,821 | $68,003 | ||
| Other income | 4,576 | $9,194 | 4,573 | $222 | ||
| Total AGI | 84,842 | $3,695,035 | 84,846 | $3,635,509 | ||
| Deductions | 84,851 | $731,363 | 84,907 | $743,302 | 1.6 | |
| Exemptions | 75,870 | $455,524 | 75,905 | $453,310 | ||
From Table 7.1 it can be seen that for the largest line items (e.g., wages, interest, Schedule C income, capital gains, pension income, Schedule E income, deductions, exemptions, and total adjusted gross income (AGI)) there is close agreement in the number of returns (with non-zero values) and total dollar amount.4 In addition, in 20 of 21 postal code zones that make up the study region (not shown in Table 7.1), the percentage difference in Total AGI between the actual and artificial data is in low single digits (Bloomquist, 2012).
7.1.2 Agents
Figure 7.1 graphically displays the IRCM agent architecture.5 A single Region is composed of multiple non-overlapping zones (e.g., a postal code zone). Each Zone is the place of residence for a group of filers. Each Zone also includes any tax preparers and employers operating within its borders. A Preparer agent prepares tax returns for its Filer clients. Employer agents represent firms having one or more employee tax filers. The TaxReturn class defines the characteristics of all tax returns, which are reviewed by a tax agency (an instance of the TaxAgency class) and may be selected for an audit.

Figure 7.1 IRCM agent hierarchy
The interaction between filers and the tax agency is illustrated in Figure 7.2.6 The filer either self-prepares or uses a paid preparer. The tax agency reviews all filed tax returns to determine if any discrepancies are present on items having third-party information reporting. If a return is audited and underreporting is detected (or automated review reveals misreporting) the detected misreported amount is recorded. In each time period, individuals reassess how much income and/or offsets they will report in the next time period, but only for items having little or no third-party information reporting (mainly business and investment-related income). If audited, the filer may re-evaluate reporting on all major income and offset items, including those items with extensive information reporting (e.g., wage income).

Figure 7.2 Interaction between filer and tax agency
7.1.3 Tax Agency
One of the important enforcement functions of the tax agency is to conduct taxpayer audits. In the IRCM, the user specifies the number of audits to perform7 and the tax agency selects returns to audit and completes the audit before the next tax return is filed. The assumption that tax audits are completed prior to filing the next tax return is an abstraction from reality. Typically, there is a two-year lag from the time a taxpayer files a return, the return is selected for audit, and the audit is completed. However, since audits are conducted on a continuous basis, the assumption that audits are completed during the same filing year is not believed to be a significant departure from real-world conditions.
The IRCM provides three ways to select tax returns for audit: simple random selection, fixed number, and constrained maximum yield. By default, the IRCM uses simple random selection. For the other two audit selection methods, the model randomly selects tax returns to audit from 17 pre-specified classes based on selected return characteristics: deduction type (standard or itemized), reported business income (or not), income greater than (or less than or equal to) $100,000, and preparation mode (self or paid-preparer). The final audit class is defined as taxpayers with zero-reported taxable income. Under fixed audit selection, the user specifies the number of audits in each of the 17 categories (with any unallocated audits selected randomly). The constrained maximum yield audit strategy attempts to increase the total amount of tax collected given a fixed number (including zero) of non-random audits. This is accomplished by identifying, at each time step, the audit class with the lowest and the highest average yield (average yield = tax collected/number of audits performed). The tax agency reallocates a single audit case from the class with the lowest yield to the class with the highest yield. The process of reallocating a single audit case for the next time step continues until the minimum coverage for the lowest yielding audit class is reached. The tax agency then repeats this same process with the second lowest yielding audit class and so on. Similarly, if the user-specified maximum coverage rate is reached the tax agency reallocates audits to the second highest yielding class, and so on.
In addition to performing audits, the tax agency in the IRCM also performs automatic checks of taxpayer reported income using available third-party information documents. In fact, although infrequently discussed in the academic literature on tax evasion, the most effective means for promoting high levels of voluntary compliance is, in fact, the existence of third-party information reporting. Figure 7.3 displays the relationship between reporting non-compliance and amount of information reporting for a weighted representative sample of TY 2006 US individual taxpayers (Black et al., 2012). In Figure 7.3, the “Underreporting Gap” refers to the dollar amount of underreported tax and “net misreporting percentage” (NMP) is a measure that allows for the comparison of relative non-compliance among the various line items.8 Wage and salary income is least likely to be misreported (NMP equal to 1%) because it is subject to both third-party information reporting and withholding. Items subject to third-party information reporting, but not to withholding (e.g., pension income, social security income, and interest and dividend income), have an NMP of 8%. Items subject to partial reporting by third parties (e.g., capital gains) have a still higher NMP of 11%. Lastly, items not subject to withholding or third-party information reporting (e.g., sole proprietor income and “other” income) are the least visible and, therefore, are most likely to be misreported. The NMP for this group of line items is 56%. The main conclusion to be drawn from Figure 7.3 is that non-compliance is most prevalent where the opportunities for underreporting are greatest.9

Figure 7.3 Tax year 2006 individual income tax underreporting gap
The IRCM is able to explore the impact of a change in information reporting on income items either directly by changing the default values for information coverage and/or withholding or indirectly by mapping the reporting characteristics of one item based on the reporting behavior of the taxpayer on another line item. Under the direct method, the user changes the information coverage and withholding parameters for one or more line items using drop-down menus and check boxes. With this approach, the reporting behavior of all taxpayers is potentially changed (with random variation) to reflect the new information reporting for the selected line item(s). Under the indirect approach, the user tells the IRCM to assign user reporting behavior for one line item to another line item. For example, let us say the analyst wants to use the indirect approach to apply observed reporting behavior for dividend income (with substantial information reporting) to capital gains income (with only some information reporting). The IRCM determines the new capital gains reporting behavior for each filer as follows:
- 1. If the filer has dividend income, then assume that the current reporting rate for this filer's dividend income applies to capital gains income.
- 2. If the filer does not have dividend income, then query the members of the filer's neighbor reference group to see if someone has dividend income. Use the reporting characteristics of the first neighbor reference group member with dividend income.
- 3. If no one in the filer's neighbor reference group has dividend income, then query the members of the filer's coworker reference group. Use the first coworker's dividend income reporting behavior, if one is found.
- 4. If no coworker has dividend income (or the filer has no coworkers, i.e., self-employed), then query the clients of the filer's tax preparer (if not self-prepared). Use the first client's dividend income reporting behavior, if one is found.
- 5. If no neighbor, coworker, or preparer client has dividend income, randomly query other filers in the region until someone with dividend income is found. Use the dividend income reporting characteristics of the randomly selected filer as this filer's capital gains reporting characteristics.
Once the user finishes specifying the level of information reporting for selected line items, IRCM uses these up-dated parameters to recalculate reported amounts prior to running a simulation. Figure 7.4 shows the IRCM's Information Reporting Parameters Screen that allows a user to make changes to information reporting and withholding for the major income line items.

Figure 7.4 IRCM information reporting parameters screen
7.1.4 Taxpayer Reporting Behavior
In the IRCM, taxpayer reporting behavior is modeled using either the SOI reporting regime (default) or the rule-based reporting regime. When the SOI reporting regime is selected, the IRCM uses values from the PUF data to instantiate filer reported income and offset amounts. The SOI reporting regime option is useful for performing model validation, for example, by comparing the line item NMPs calculated by the model to NMPs in published IRS studies on the tax gap (Internal Revenue Service, 2007). The SOI reporting regime also provides a benchmark for model calibration (discussed later in this chapter). The baseline reporting rate calculated using the SOI reporting regime is assumed to be the individual filer's preferred reporting behavior given the enforcement environment in effect at time ![]() = 0. If never audited or if the filer's coworkers or neighbors are never audited, then the baseline reporting rate on each line item remains unchanged throughout the filing “lifetime” of the individual.
= 0. If never audited or if the filer's coworkers or neighbors are never audited, then the baseline reporting rate on each line item remains unchanged throughout the filing “lifetime” of the individual.
By selecting the rule-based reporting regime the user tells the IRCM to determine filer reported amounts and baseline reporting behavior using six user-specified parameters. The user sets the values of these parameters using sliders on the Filer Parameters screen (Figure 7.5). The top three sliders set the probability of misreporting success for income and offset items characterized by the extent of third-party information reporting (No Information Reporting, Some Information Reporting, or Substantial Information Reporting). For example, if the Substantial Information Reporting slider is set to a value of 10, then the model assumes 10% of filers believe that misreporting on items with substantial information reporting will be successful and 90% of filers hold the opinion that misreporting will not succeed. This difference in perception among filers may stem from different levels of knowledge and experience or due to qualitative differences in information reporting within a given income or offset line item.

Figure 7.5 IRCM filer parameters screen
The second row of sliders in the Reporting Regime section of the Filer Parameters screen defines additional influences on filers' reporting behavior. The “Withholding marginal impact” slider sets the marginal impact of withholding on reporting compliance. For example, Figure 7.3 above suggests that the marginal impact of withholding is between 80 and 90% based on the reduction in NMP from 8% for items subject to substantial misreporting (e.g., unemployment compensation, dividends and interest income) to an NMP of 1% for wage and salary income.10 The “% deontological filers” slider sets the percentage of filers whose reporting compliance is motivated by non-economic factors. While the term “deontological” suggests that the primary motivating principle is duty-based influences, equity or personal integrity can be included here as well. If this slider is set to a value of 30, then IRCM randomly selects 30% of filers to become deontological filers. Such filers are assumed to fully and accurately report all income and offset items.11 Finally, the slider de minimis amount is used to set a minimum threshold amount for reporting for items with no information reporting. If the calculated reported amount for a given live item falls below the de minimis threshold, the filer is assumed to report zero for that item. More detail on the procedure the IRCM uses to derive line item-specific reporting rates is available in Bloomquist (2012).
7.1.5 Filer Behavioral Response to Tax Audit
Since taxpayers cannot know for certain that actions they take (or not take) will cause the tax agency to select their tax return for an audit, the reporting behavior of these taxpayers is modeled as a partially observable Markov decision process (POMDP) (Ghallab et al., 2004).
A POMDP is a five-tuple ![]() where:
where:
 is a finite set of states (audited or not audited)
is a finite set of states (audited or not audited) is a finite set of compliance responses (perfect, increase, decrease, no change)
is a finite set of compliance responses (perfect, increase, decrease, no change) is a probability distribution where for each
is a probability distribution where for each  , if there exists
, if there exists  and
and  such that
such that  , we have
, we have 
 is the cost/reward (or expected cost/reward) experience from transition to state
is the cost/reward (or expected cost/reward) experience from transition to state 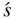 from state
from state  with transition probability
with transition probability  . The quantity
. The quantity  is the probability that if response
is the probability that if response  is taken in state
is taken in state  , then state
, then state  will result. For example, if a taxpayer decides to increase compliance following a tax audit, one can infer that the action is being taken in order to reduce the probability of being selected for an audit (and the associated costs) in future time periods.
will result. For example, if a taxpayer decides to increase compliance following a tax audit, one can infer that the action is being taken in order to reduce the probability of being selected for an audit (and the associated costs) in future time periods. is a set of observations with probabilities
is a set of observations with probabilities  , for any
, for any  ,
,  , and
, and  .
.  represents the probability of observing
represents the probability of observing  in state
in state  after taking response
after taking response  . Finally, it is required that the sum of probabilities over the set of observations is 1, that is,
. Finally, it is required that the sum of probabilities over the set of observations is 1, that is,  .
.
Since the observations in a POMDP represent probability distributions, rather than exact states of the system, the probability distributions are called belief states and are updated using Bayes rule. The use of Bayes rule implies that the probabilities represented by ![]() are not static but change as knowledge of the enforcement environment changes.
are not static but change as knowledge of the enforcement environment changes.
In the IRCM, neither the belief states (![]() ) nor the cost functions (
) nor the cost functions (![]() ) of individual filers are modeled explicitly but are implied by filers' stochastically modeled “choices.” Stochastic choice modeling is used since relatively little is known about how taxpayers perceive the tax enforcement environment and what factors motivate changes in observed behavior.
) of individual filers are modeled explicitly but are implied by filers' stochastically modeled “choices.” Stochastic choice modeling is used since relatively little is known about how taxpayers perceive the tax enforcement environment and what factors motivate changes in observed behavior.
Figure 7.6 graphically illustrates the POMDP for the filer's response to a tax audit. The two states are not audited (![]() ) and audited (
) and audited (![]() ). A taxpayer is in one of these two states in each time period. The filer's belief about the probability of audit is defined as
). A taxpayer is in one of these two states in each time period. The filer's belief about the probability of audit is defined as ![]() , implying that a filer's perceived probability of being selected for a tax audit depends on her belief about how the baseline audit probability (
, implying that a filer's perceived probability of being selected for a tax audit depends on her belief about how the baseline audit probability (![]() ) changes with a change in reporting behavior (response)
) changes with a change in reporting behavior (response) ![]() .
.

Figure 7.6 POMDP of the filer's response to the tax audit environment
In Figure 7.6 it is assumed ![]() no change in reporting compliance,
no change in reporting compliance, ![]() an increase in reporting compliance,
an increase in reporting compliance, ![]() decrease in reporting compliance and
decrease in reporting compliance and ![]() perfect reporting compliance.12 If not audited in time
perfect reporting compliance.12 If not audited in time ![]() , the filer may start or increase underreporting in time
, the filer may start or increase underreporting in time ![]() on income subject to little or no information reporting, assuming the filer has such income from one or more sources. If the filer is audited in time
on income subject to little or no information reporting, assuming the filer has such income from one or more sources. If the filer is audited in time ![]() , the decision to select a response
, the decision to select a response ![]() is determined in the IRCM by a random draw and the user-specified probabilities
is determined in the IRCM by a random draw and the user-specified probabilities ![]() . Although the IRCM models the filer's response as a stochastic process, actual filers are presumed to select an action
. Although the IRCM models the filer's response as a stochastic process, actual filers are presumed to select an action ![]() based on their (heterogeneous and non-stationary) beliefs about the expected cost associated with that action.
based on their (heterogeneous and non-stationary) beliefs about the expected cost associated with that action.
7.1.6 Model Execution
The steps followed in executing a simulation using the IRCM are shown in Figure 7.7. The model reads tax return data for the population of artificial taxpayers and instantiates agents. During instantiation, the IRCM estimates a true amount for the largest income and offset items. The true amount is the amount reported plus imputed misreporting.13 Imputed amounts are based on audit results from the TY 2001 National Research Program (NRP) study. Details of the imputation methodology are described in Bloomquist (2012).

Figure 7.7 IRCM execution sequence: top-level view
Each time step represents one filing cycle (year). Tax calculations are performed twice for all taxpayers, first using reported amounts and again using estimated true amounts. The difference in calculated tax using true and reported amounts is the tax gap for each filer. By default, the IRCM assumes that the difference between the true and reported tax amounts is the amount identified by the tax auditor. An option is provided to account for underreporting not detected by examiners.14
Tax audits are performed at the penultimate step in each time loop. During wrap up, the tax agency issues notices to taxpayers who are not audited but where computer checking of tax returns against information documents detects some underreporting.15 In addition, filers who stop filing, either because they leave the region or because they no longer have an obligation to file, are replaced by a new filer having identical income and network relationships as the “stop filer” being replaced, but with reporting behavior and memory reset to baseline levels (i.e., no memory of a prior audit experience or audits of reference group members, if that option is selected). The reporting behavior of filers who are not “stop filers” is also updated at each time step, as is the audit selection strategy of the tax agency.16 Finally, data collection occurs during the wrap-up phase. When the user-specified number of time steps has completed the model generates output in the form of tables and charts that can be reviewed and saved for further analysis.17
7.2 Model Validation and Calibration
A two-stage approach is used to validate and calibrate the IRCM. In stage 1 (validation), the model is executed using values from the PUF (the “SOI reporting regime” option) and the output is compared to IRS estimates of reporting non-compliance published tax gap studies. The method of comparison follows Axtell and Epstein's (1994) hierarchical approach consisting of four increasingly detailed levels of validation. A model with Level 0 validity is considered to be a caricature of reality. At this level the model needs to show only that the system as a whole exhibits behavior that is consistent with the available data (e.g., the aggregate response of agents to changing environmental conditions is in the appropriate direction). At Level 1, the model is expected to be in qualitative agreement with empirical macro-structures. This is demonstrated by comparing the distributional characteristics of the actual population to the modeled population. To be valid at Level 2 the model must show quantitative agreement with empirical macro-structures. Finally, at Level 3, the model exhibits quantitative agreement with empirical micro-structures, as determined from cross-sectional and longitudinal analysis of the agent population.
IRCM's on-board graphical and statistical routines are used to demonstrate model validity through Level 2. Validation at Level 3 requires panel data on an individual's tax reporting behavior, which is a standard not yet available to researchers. Table 7.2 summarizes results for a Level 2 validation that compares line item NMPs produced by the model to NMPs calculated by IRS in the TY 2001 tax gap study (Internal Revenue Service, 2007).18 Focusing on the column in Table 7.2 labeled “SOI” we see that the model overestimates the NMPs on some items (e.g., Schedule C (sole proprietor) income, taxable IRA income, unemployment compensation, taxable social security benefits, and other income) and underestimates on others (e.g., Schedule E (partnership/small corporation) income, Schedule F (farm) income, deductions, and exemptions). The model-generated NMP for total tax is within one percentage point of the IRS estimate for the SOI regime and two percentage points for the Rule-Based regime. One reason for this difference is a lack of data on the PUF specific to children eligible for the EIC. Another reason is an overall average effective tax rate for the study area, which is slightly lower than the national average.19
Table 7.2 Line item net misreporting percentages: IRS versus IRCM
| Net misreporting percentage | |||
| IRCM reporting regime | |||
| Income item | IRS | SOI | Rule-based |
| Wages | 1 | 1 | 1 |
| Interest | 4 | 3 | 5 |
| Dividends | 4 | 4 | 5 |
| Tax refunds | 12 | 14 | 7 |
| Schedule C | 57 | 63 | 63 |
| Capital gains | 12 | 13 | 24 |
| IRA | 4 | 7 | 4 |
| Pensions | 4 | 3 | 5 |
| Schedule E | 35 | 28 | 28 |
| Schedule F | 72 | 63 | 62 |
| Unemp. comp. | 11 | 15 | 6 |
| Social security | 6 | 10 | 5 |
| Other income | 64 | 82 | 63 |
| Taxable income | 11 | 13 | 12 |
| Tax | 18 | 17 | 16 |
| Adjustments | −21 | −24 | −41 |
| Deductions | 5 | 3 | 5 |
| Exemptions | 5 | 4 | 5 |
The goal in stage 2 (calibration) is to find a combination of values for the six “rule-based reporting regime” parameters20 that can closely replicate IRCM output using the “SOI reporting regime” option. Formally, it is preferable to minimize the sum of differences in reported incomes between the SOI and rule-based reporting regimes:
In Eq. (7.1), ![]() is the calculated reported amount using the rule-based reporting regime in IRCM for income type
is the calculated reported amount using the rule-based reporting regime in IRCM for income type ![]() and
and ![]() is the calculated reported amount for income type
is the calculated reported amount for income type ![]() using the SOI reporting regime. A solution for Eq. (7.1) is found by inspection using multi-stage Monte Carlo simulation, the details of which are described in Bloomquist (2012). The column of Table 7.2 labeled “rule-based” shows the resulting line item NMPs for model calibration.
using the SOI reporting regime. A solution for Eq. (7.1) is found by inspection using multi-stage Monte Carlo simulation, the details of which are described in Bloomquist (2012). The column of Table 7.2 labeled “rule-based” shows the resulting line item NMPs for model calibration.
7.3 Hypothetical Simulation: Size of the “Gig” Economy and Taxpayer Compliance
Recently, much attention has been focused on the growing number of people employed in the so-called “Gig” Economy. Gig workers typically are self-employed as independent contractors or freelancers and are often associated with services marketed online. Some better-known examples of Gig Economy firms include: Uber, Lyft, and Airbnb. Other categories of jobs associated with the Gig Economy include “contingent” workers such as agency temps, on-call workers, contract company workers, and part-time laborers. Although little official data exists on the number of gig workers, a recent estimate using the broadest definition of the US gig workforce finds that contingent workers accounted for over 40% of the total labor force in 2010 (U.S. Government Accountability Office, 2015) and grew twice as fast as overall employment (14.4% vs 7.2%) from 2002 to 2014 (Rinehart and Gitis, 2015).
From a tax compliance perspective, why does it matter that gig workers seem to be accounting for an increasing share of the labor force? In short, it matters if jobs performed by gig workers as independent contractors are substitutes for jobs previously performed by full-time employees. By law, employers are responsible for their employees' tax withholding and information reporting whereas independent contractors are responsible for their own withholding and are not subject to third-party information reporting.21 IRS random audit studies have conclusively established that incomes subject to information reporting are reported by taxpayers at much higher levels than incomes not subject to information reporting. For example, Figure 7.3 shows the NMP for income subject to substantial information (e.g., interest income, pension income) was 8% compared to 56% for sole proprietor income (no information reporting). The NMP for wage income, subject to both information reporting and withholding, is only1%.
The IRCM was used to simulate the impact on tax reporting compliance of a shift in the composition of the labor force to include progressively larger shares of gig economy workers. Figure 7.8 shows the model output for tax NMP for the baseline and three alternative scenarios that represent a shift of 5%, 10%, and 15% of current full-time employees to gig workers. In all scenarios simulations are performed using default values for the rule-based reporting regime. The values displayed in Figure 7.8 are averages for five independent simulations using different random number seeds.

Figure 7.8 Model time series of tax NMPs for alternative increases in share of gig economy workers
Figure 7.8 shows that from a baseline tax NMP of about 16% (84% reporting compliance rate), each five percentage point increase in the share of gig workers causes the tax NMP to increase by about two percentage points. At the national level in the United States each additional percentage point of voluntary compliance brings in approximately $30 billion in tax receipts (Koskinen, 2015). Thus, when considered from a national perspective, even small reductions in the relative size of the full-time employee labor force can result in significant losses in tax revenue.
7.4 Conclusion and Future Research
The purpose of this chapter has been to demonstrate the feasibility of using ABMs to simulate a taxpayer reporting compliance while incorporating the complexities of real-world tax systems. The major features of the IRCM are: (i) a community-based approach that allows network relations to be modeled explicitly, (ii) imputation of misreported income and offsets using results from random taxpayer audits thus enabling micro-level analysis of taxpayer reporting behavior, and (iii) the creation of a dataset of artificial taxpayers that can be used to independent model verification and validation. In fact, the IRCM has undergone independent verification and validation testing by analysts at The MITRE Corporation. The model, originally written in Java using Repast Simphony 1.0 (North et al., 2007), has been ported successfully to both Windows and Mac-OS platforms running Repast 2.0 and MASON (Cline et al., 2014).
The IRCM is capable of performing a wide range of “what–if” analyses involving various aspects of taxpayer reporting compliance. This capability was demonstrated in a simulation experiment that estimated the impact on voluntary reporting compliance of progressively larger relative shares of so-called “gig economy” workers. The simulation found that switching 5% of the labor force from full-time employees to gig workers lowers the voluntary compliance rate by roughly two percentage points. In the United States, each percentage point of voluntary compliance translates to approximately $30 billion in tax receipts.
The value of a model such as the IRCM increases as our knowledge of taxpayer behavior improves. Specific topics that would improve the predictive capability of ABMs for taxpayer compliance use include (i) research on the indirect effect of taxpayer audits, (ii) research on attitudinal and social factors associated with tax morale, and (iii) how the provision of taxpayer services interacts with tax enforcement to achieve observed levels of voluntary compliance. Finally, building a massive-scale ABM ![]() taxpayers) is now feasible due to the availability of multi-processor computing environments and software, such as Repast HPC, designed for such platforms (see also Chapter 8). The development of the IRCM shows that building such national-scale models is a goal that is now within reach.
taxpayers) is now feasible due to the availability of multi-processor computing environments and software, such as Repast HPC, designed for such platforms (see also Chapter 8). The development of the IRCM shows that building such national-scale models is a goal that is now within reach.
Acknowledgments
The author is grateful to Professors Robert L. Axtell and Claudio Cioffi-Revilla for their guidance and encouragement on this project, which was done in partial fulfillment of his Ph.D. in Computational Social Science at George Mason University, Fairfax, Virginia.
References
- Allingham, M.G. and Sandmo, A. (1972) Income tax evasion: a theoretical analysis. Journal of Public Economics, 1, 323–338.
- Alm, J. (1999) Tax compliance and administration, in Handbook on Taxation (eds W.B. Hildreth and J.A. Richardson), Mercel Dekker, New York, pp. 741–768.
- Alm, J. (2010) Testing behavioral public economics theories in the laboratory. National Tax Journal, 63, 635–658.
- Alm, J., Bloomquist, K.M., and McKee, M. (2015) On the external validity of laboratory tax compliance experiments. Economic Inquiry, 53, 1170–1186.
- Andreoni, J., Erard, B., and Feinstein, J. (1998) Tax compliance. Journal of Economic Literature, 36, 818–860.
- Axtell, R.L. (2000) Why Agents? On the Varied Motivations for Agent Computing in the Social Sciences, Center on Social and Economic Dynamics Working Paper No. 27, Brookings Institution, Washington, DC.
- Axtell, R.L. (2013) Team dynamics and the empirical structure of U.S. firms, Department of Computational Social Science Working Paper, George Mason University, http://tinyurl.com/jee8anf (accessed 20 June 2016).
- Axtell, R.L. and Epstein, J.M. (1994) Agent-based modeling: understanding our creations. Bulletin of the Santa Fe Institute, 9 (2), 28–32.
- Bernard, F., Lacroix, G., and Villeval, M.C. (2007) Tax evasion and social interactions. Journal of Public Economics, 91, 2089–2112.
- Black, T., Bloomquist, K.M., Emblom, E. et al. (2012) Federal tax compliance research: tax year 2006 tax gap estimation. IRS Research, Analysis & Statistics working paper, https://www.irs.gov/pub/irs-soi/06rastg12workppr.pdf (accessed 17 June 2016).
- Bloomquist, K.M. (2012) Agent-based simulation of tax reporting compliance. Doctoral dissertation. George Mason University, http://digilib.gmu.edu/xmlui/handle/1920/7927 (accessed 17 June 2016).
- Bloomquist, K.M. (2013) Incorporating Indirect Effects in Audit Case Selection: An Agent-Based Approach, The IRS Research Bulletin, Publication 1500, pp. 103–116.
- Bloomquist, K.M. and Koehler, M. (2015) A large-scale agent-based model of taxpayer reporting compliance. Journal of Artificial Societies and Social Simulation, 18, 20, http://jasss.soc.surrey.ac.uk/18/2/20.html (accessed 17 June 2016).
- Cioffi-Revilla, C. (2014) Introduction to Computational Social Science: Principles and Applications, Springer-Verlag, London.
- Cline, J.S., Bloomquist, K.M., Gentile, J.E. et al. (2014) From Thought to Action: Creating Tax Compliance Models at National Scales. Paper presented at the 11th International Conference on Tax Administration, Sydney, Australia.
- Erard, B. and Feinstein, J.S. (2011) The Individual Income Reporting Gap: What We See and What We Don't, The IRS Research Bulletin, Publication 1500, pp. 129–142.
- Gemmell, N. and Ratto, M. (2012) Behavioral responses to taxpayer audits: evidence from random taxpayer inquiries. National Tax Journal, 65, 33–58.
- Ghallab, M., Nau, D., and Traverso, P. (2004) Automated Planning: Theory and Practice, Morgan Kaufmann Publishers Inc., San Francisco, CA.
- Grimm, V., Berger, U., Bastiansen, F., Eliassen, S., Ginot, V., Giske, J., Goss-Custard, J., Grand, T., Heinz, S., Huse, G., Huth, A., Jepsen, J.U., Jørgensen, C., Mooij, W.M., Müller, B., Pe'er, G., Piou, C., Railsback, S.F., Robbins, A.M., Robbins, M.M., Rossmanith, E., Rüger, N., Strand, E., Souissi, S., Stillman, R.A., Vabø, R., Visser, U., and DeAngelis, D.L. (2006) A standard protocol for describing individual-based and agent-based models. Ecological Modelling, 198, 115–126.
- Grimm, V., Berger, U., DeAngelis, D.L., Polhill, G., Giske, J., and Railsback, S.F. (2010) The ODD protocol: a review and first update. Ecological Modelling, 221, 2760–2768.
- Internal Revenue Service (2007) Reducing the Federal Tax Gap: A Report on Improving Voluntary Compliance, https://www.irs.gov/pub/irs-news/tax_gap_report_final_080207_linked.pdf (accessed 17 June 2016).
- Internal Revenue Service (2015) Third Party Reporting Information Center - Information Documents, http://tinyurl.com/zudmhob (accessed 17 June 2016).
- Janssen, M.A. and Ostrom, E. (2006) Empirically based, agent-based models. Ecology and Society, 11 (2), 37.
- Koskinen, J.A. Written testimony of Koskinen, J.A. (2015) Commisioner, Internal Revenue Service, before the House Oversight and Government Reform Committee on the Government Accountability Office's High-Risk List, http://tinyurl.com/judgku7 (accessed 17 June 2016).
- North, M.J., Tatara, E., Collier, N.T., and Ozik, J. (2007) Visual Agent-Based Model Development with Repast Simphony. Proceedings of the 2007 Conference on Complex Interaction and Social Emergence, Argonne National Laboratory, Argonne, IL.
- Rand, W. and Rust, R.T. (2011) Agent-based modeling in marketing: guidelines for rigor. International Journal of Research in Marketing, 28, 181–193.
- Rinehart, W. and Gitis, B. (2015) Independent Contractors and the Emerging Gig Economy, American Action Forum, http://tinyurl.com/zevgo4s (accessed 17 June 2016).
- Sandmo, A. (2005) The theory of tax evasion: a retrospective view. National Tax Journal, 58, 643–663.
- Slemrod, J. (2007) Cheating ourselves: the economics of tax evasion. Journal of Economic Perspectives, 21, 25–48.
- Srinivasan, T.N. (1973) Tax evasion: a model. Journal of Public Economics, 2, 339–346.
- U.S. Government Accountability Office (2015) Contingent Workforce: Size, Characteristics, Earnings, and Benefits, GAO-15-168R, http://www.gao.gov/assets/670/669899.pdf (accessed at 17 June 2016).
Appendix 7A Overview, Design Concepts, and Details (ODD)
7A.1 Purpose
The Individual Reporting Compliance Model (IRCM) is designed to enable tax administrators to explore alternative enforcement strategies (e.g., audit case selection, computerized validation through use of third-party information reporting) for improving the compliance of individual taxpayers.
7A.2 Entities, State Variables, and Scales
The IRCM has five major types of entities: Region, Filer, Tax Agency, Preparer, and Employer. A Region is an integral unit of geography (e.g., state, county, or city) that is composed of one or more Zone entities. Zones are nonoverlapping areal subunits located entirely within the Region (e.g., postal zip code zones). A Filer in an IRCM represents an individual tax filer. In the current version of the IRCM, there are 84,912 filers who reside in the test-bed region. Each filer files a tax return (an instance of the TaxReturn class) which, in turn, contains 180 items (elements). A Preparer prepares a client's tax returns unless the filer self-prepares. An Employer employs filers, except for the self-employed. Filers, preparers, and employers are allocated to zones based on identifiers contained in actual tax return data. A single tax agency (an instance of the TaxAgency class) reviews and validates filed tax returns for accuracy against available third-party information documents and audits tax returns. Each simulation time step represents a tax filing year. The number of time steps is a user input.
7A.3 Process Overview and Scheduling
The main process is tax return filing, which is performed once per time step. A second set of processes involves the actions of the tax agency, which reviews all filed tax returns and selects returns for audit. The tax agency's review of tax returns involves comparing the amount reported on each major line item with the amount reported on third-party information documents, if they exist for a given item. Discrepancies are flagged and a notice is issued if the discrepancy exceeds a user-specified threshold. There are three types of audit selection strategies: Random, Fixed, and Constrained Maximum Yield (CMY). The number of audits to perform (![]() ) is a user input. Under Random selection the tax agency selects
) is a user input. Under Random selection the tax agency selects ![]() returns at random. Under Fixed selection the tax agency selects a user-specific fixed number of returns in each of 17 nonoverlapping audit classes. The CMY selection strategy uses a simple greedy-type algorithm that targets taxpayers in audit classes having the highest average yield (tax). The order in which the returns are filed or processed is unimportant; therefore, scheduling is not a consideration in the IRCM.
returns at random. Under Fixed selection the tax agency selects a user-specific fixed number of returns in each of 17 nonoverlapping audit classes. The CMY selection strategy uses a simple greedy-type algorithm that targets taxpayers in audit classes having the highest average yield (tax). The order in which the returns are filed or processed is unimportant; therefore, scheduling is not a consideration in the IRCM.
7A.4 Design Concepts
7A.4.1 Basic Principles
People exhibit heterogeneous reporting behaviors when filing their tax returns. Some appear to behave as rational decision makers, others comply out of a sense of duty or fear, and some pattern their reporting behavior by taking cues from family and friends. In addition to varying motivational factors, taxpayers have different opportunities for evasion based largely on the source of their income. Finally, taxpayers learn through repeated interactions with other taxpayers and with paid preparers what types of behaviors are more likely to draw the tax agency's attention. Analytical models in the tradition of Allingham and Sandmo (1972) and Srinivasan (1973) assume that taxpayers are independent, rational, and self-interested actors motivated to comply solely due to probability of detection and associated fines. However, empirical evidence from laboratory experiments, field studies, and random taxpayer audits suggests that a variety of noneconomic considerations also influence taxpayer reporting decisions. Agent-based models, such as the IRCM, are capable of incorporating both rational and behavioral motivations in a heterogeneous population of taxpayers.
7A.4.2 Emergence
The main emergent feature is a stochastically stable level of compliance (for major line items and total tax) that reflects user-specified assumptions for the level, quality, and effectiveness of tax agency enforcement activities and individuals' behavioral and filing characteristics.
7A.4.3 Adaptation
Filers adapt their reporting behavior to the perceived enforcement environment as determined from repeated interactions with the tax agency and (optionally) with their neighbors and coworkers.
7A.4.4 Objectives
The overall objective for each filer is to achieve a level of tax compliance consistent with their perception of the tax enforcement environment as well as their individual behavioral and filing characteristics.
7A.4.5 Learning
Filers may adjust their reporting behavior if they are audited or someone they know (e.g., a neighbor or coworker) is audited. This learning behavior is modeled as a partially observable Markov decision process (POMDP) ![]() , where
, where
 is a finite set of states (audited or not audited)
is a finite set of states (audited or not audited) is a finite set of compliance responses (perfect, increase, decrease, no change)
is a finite set of compliance responses (perfect, increase, decrease, no change) is a probability distribution where for each
is a probability distribution where for each  , if there exists
, if there exists  and
and  such that
such that  , we have
, we have 
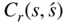 is the cost/reward (or expected cost/reward) experience from transition to state
is the cost/reward (or expected cost/reward) experience from transition to state  from state
from state  with transition probability
with transition probability  . The quantity
. The quantity  is the probability that if response
is the probability that if response  is taken in state
is taken in state  , then state
, then state  will result. For example, if a taxpayer decides to increase compliance following a tax audit, one can infer that the action is being taken in order to reduce the probability of being selected for an audit (and the associated costs) in future time periods.
will result. For example, if a taxpayer decides to increase compliance following a tax audit, one can infer that the action is being taken in order to reduce the probability of being selected for an audit (and the associated costs) in future time periods. is a set of observations with probabilities
is a set of observations with probabilities  , for any
, for any  ,
,  , and
, and  .
.  represents the probability of observing
represents the probability of observing  in state
in state  after taking response
after taking response  .
.
The IRCM does not explicitly model costs (![]() ) and belief states (
) and belief states (![]() ) but assumes that these are implicit in the stochastically determined “choices” made by filers. These elements could be added to the model when better data on taxpayer decision-making becomes available. The IRCM allows users to provide independent sets of choice probabilities (
) but assumes that these are implicit in the stochastically determined “choices” made by filers. These elements could be added to the model when better data on taxpayer decision-making becomes available. The IRCM allows users to provide independent sets of choice probabilities (![]() ) to reflect different degrees of responsiveness by filers to a tax audit of themselves or someone in a reference group (see Section B.4.10).
) to reflect different degrees of responsiveness by filers to a tax audit of themselves or someone in a reference group (see Section B.4.10).
7A.4.6 Prediction
The IRCM makes no predictions about future taxpayer behavior but simply models the presumed behavior of taxpayers given certain enforcement conditions.
7A.4.7 Sensing
Sensing occurs when filers become aware that someone in either their coworker or neighbor reference groups has been audited. This “sensing” is achieved by a filer polling her reference group members. If a reference group member has been audited, it is assumed that this information is openly communicated to all other reference group members. Lastly, the tax agency can use audits as a sensing mechanism if the CMY selection strategy is used.
7A.4.8 Interaction
The main types of interactions in the model that can potentially influence the behavior of individuals include (i) tax agency audits of filers and (ii) filers polling members of their reference groups to determine if someone was audited in the previous time period. Implied interactions occur between tax preparers and their clients. However, these preparer–client “interactions” are implied only because they appear as differences in estimated coefficients used to impute misreported amounts for paid prepared and self-prepared taxpayers.
7A.4.9 Stochasticity
Stochasticity is an integral feature of an IRCM. One way the model uses stochasticity is to determine which filers become “stop filers” at each time step. If the stop filer option is activated (the default setting) a uniform random number is drawn and compared to a fixed probability of becoming a stop filer as determined from analyzing filing behavior in the study area. Stop filer probabilities are specific to filing status. Another use of stochasticity is determining which filers are audited at each time step. Audit cases may be selected completely at random or by using one of two targeted strategies. The IRCM has 17 pre-determined audit classes used for targeted audits. These audit classes are groups of filers that share certain characteristics. These include filing status (single, married filing joint/qualified widow(er), head of household, married filing separate, dependent filer), children at home (yes/no), itemized or standard deduction, adjusted gross income (AGI) greater than the median (by filing status), and wage income more than one-half of AGI. Targeted audits may either be fixed in number or use a search algorithm (i.e., CMY) that assigns cases to audit classes with the highest average tax yield. A third use of stochasticity involves modeling filers' response to being audited. The user defines a vector of response probabilities (e.g., perfect compliance, increase compliance, decrease compliance, no change) and the model generates a uniform random number to determine which category of response the filer “selects.” When the rule-based reporting regime is selected, the IRCM uses a stochastic process to assign line item reporting behavior to each taxpayer. The model first determines if a filer is a “deontological” filer meaning that the filer has perfect compliance. If a line item is subject to information reporting and/or withholding the IRCM determines how much the filer will report using separate random draws for information reporting and withholding, depending on which conditions apply. Stochasticity is also involved in the process of imputing misreported income and offset amounts. These values are imputed from estimated equations that are fit to empirical cumulative distribution functions (ECDFs). Uniform [0, 1] random numbers are generated and used to select imputed amounts from these equations. Finally, creating reference groups involves stochasticity. Members of a filer's coworker and neighbor reference groups may be structured as either random or “small world” networks. In the former, reference group members are assigned using random selection from a filer's coworkers and neighbors. The process of creating “small world” networks is the same as random except one individual (the “hub”) is known to all of a firm's employees or residents of a given zone. The “hub” is determined by random selection.
7A.4.10 Collectives
There are two types of filer reference groups: neighbor and coworker. These are determined at the time of instantiation. Both groups assume the same (user specified) fixed size. If the “stop filer” option is activated (the default setting), then reference group stop filers are replaced over time; however, this does not affect group size or member relationships. Preparer networks are a third type of collective that may be optionally specified. At present, preparer networks only become relevant for scenarios that simulate a preparer-based tax scheme.
7A.4.11 Observation
The IRCM generates an output in the form of tables and figures. These can be copied and pasted into other applications for further analysis. The main interface screen also has a “map” of the study region and component zones. Options are provided that allow a user to drill down to view model output for individual preparers and employers by zone. This capability is especially useful for model verification and validation.
7A.5 Initialization
All agents are instantiated when the user selects a data file to read. The order in which agents are instantiated is as follows:
- 1. Regions and zones
- 2. Employers
- 3. Preparers
- 4. Filers
- 5. Tax agency.
Once these entities have been created and default values assigned the following relationships are added:
- 1. Filer + Zone
- 2. Filer (client) + Preparer
- 3. Filer (employee) + Employer
- 4. Preparer + Zone
- 5. Employer + Zone
Last, preparer networks and filer reference groups are created (see Section B.4.10).
7A.6 Input Data
The IRCM uses tax return information from the Statistics of Income (SOI) to describe the filing characteristics of taxpayers in the study region. Public Use File (PUF) records are substituted for the tax returns of filers in the study region using statistical matching (performed outside of the model). In addition to the PUF data, filer data includes pseudo-values for the paid preparer taxpayer identification number (TIN), employer identification number (EIN) and zone id as well as a calculated ratio of primary to secondary earnings and an estimate of the number of children living at home under the age of 17. These non-PUF values are derived from filers' tax returns and are used to preserve key filer relationships that influence reporting behavior and tax calculation. Once the data set is constructed, the name of the data file becomes an input parameter to the model. The IRCM allows the user to create and save all model parameters used to define a scenario in an xml (.xml) file. This facilitates the re-creation of scenarios for sensitivity testing and model verification and validation.
7A.7 Submodels
Submodels are provided to analyze alternative behavioral assumptions for paid preparers and employers. The paid preparer submodel enables the user to change the reporting compliance of filers using a paid preparer up or down relative to default levels for all preparers (region) or only for preparers in a specific zone. Networks of preparers (conceptually similar to filer reference groups) can also optionally be created by specifying the network size and the proportion of network members located in the same “home” zone for a given preparer. A fraction of preparers also may be resistant to network influences and an option is available to indicate this as well. The employer submodel permits the user to explore the impact on compliance if some fraction of firms converts their workers from employees to independent contractors (ICs). Conversion of employees to ICs has several advantages for firms; for instane, employers are no longer responsible for making payments of state unemployment tax or withholding of employees' income tax. In addition, ICs, not firms, become responsible for paying the employers' share of Social Security and Medicare taxes. The model represents the conversion of employees to ICs by converting wage income to Schedule C income, determining the baseline reporting rate on this income (based on National Research Program (NRP) random audit data), and using the tax calculator to determine income tax and employment tax liabilities.