
Objectives of a Business Impact Analysis
The overall objective of a BIA is to identify the impact of outages. More specifically, the goal is to identify the critical functions that can affect the organization. After the critical functions have been identified, the critical resources that support these functions can be identified.
Each resource has an MAO and an impact if it fails. The ultimate goal is to identify the recovery requirements. FIGURE 12-3 shows these overall steps: Input is gathered from process owners and experts to help identify the CBFs and the critical resources that support them, the impact and MAO of the resources are identified, and the recovery requirements from the MAO are determined.
FIGURE 12-3 Objectives of a BIA.
An indirect objective of the BIA is to justify funding. After the recovery requirements in the BIA have been identified, controls to support these requirements in the BCP are identified. If the impact is high, spending money to prevent the outage would be cost effective.
NIST SP 800-34 Rev. 1 includes a diagram similar to that in FIGURE 12-4. It shows the relationship between costs and the time of an outage. The line labeled Cost of Disruption indicates that the cost of a disruption is very low immediately after an outage occurs. However, as the outage time increases, the cost of the disruption also increases. The other line identifies the Cost to Recover from an outage. To be able to recover from an outage almost immediately, the costs are high. However, if a longer outage time is acceptable, the costs to recover are lower.
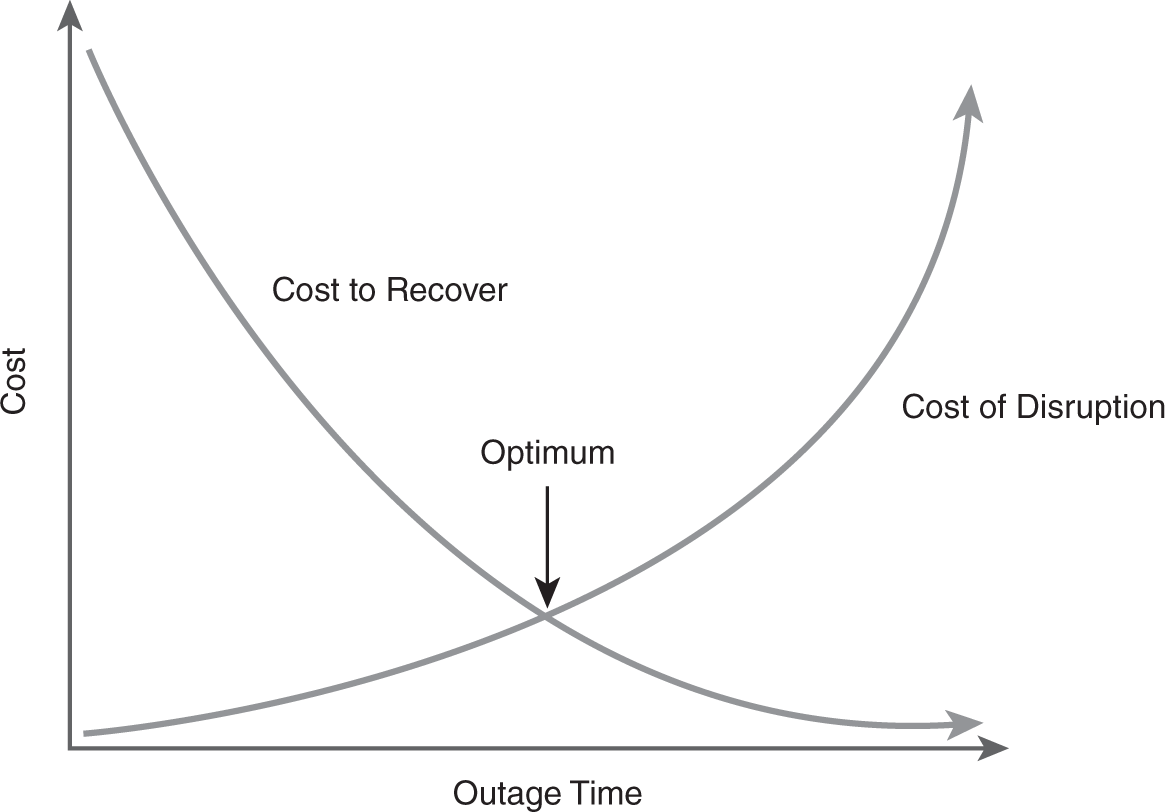
FIGURE 12-4 Relationship of costs.
For example, if a website that sells products online fails for 60 seconds, the cost of the disruption would be very low, whereas, if the outage lasts for days, the cost of the disruption would be very high. Controls can be implemented that allow the website to recover immediately from a 60-second outage, but the cost would be very high. In contrast, spending very little money on recovery controls would result in a longer outage time.
These considerations help to identify the optimum cost point. At this point, the company would spend the minimum amount on recovery controls while still minimizing the costs of disruption.
The following sections cover the objectives of a BIA in more detail.
Identifying Critical Business Functions
To an IT specialist, the CBFs are not always apparent. For example, a security expert may not know the CBFs of a website. To him or her, the web server would be an obvious component, but there are others.
Interviewing or surveying the experts can help in gaining insight into all the components that support the web server, and identifying the underlying steps of CBFs is often useful. For example, the following list details the steps of an online website purchase:
- The customer visits the website—The customer accesses the website using a web browser. The website is hosted on a web server located in the organization’s demilitarized zone (DMZ), and a firewall provides security while also providing access to the web server.
- The customer browses the product catalog—The website sends queries to a back-end database when users search for specific products. The database server is on the internal network behind a second firewall. The web server uses the database query results to build a webpage, which it sends back to the customer.
- The customer picks a product—While browsing, the customer can add products into a shopping cart.
- The customer checks out—When the customer is ready to complete the purchase, he or she clicks on the checkout button, which starts a secure session. Existing customers can log on to access previously used information, such as their address and credit card numbers. This information is available from a back-end database server behind the second firewall. New customers are prompted to enter their customer data. The web server sends the new customer’s data to the back-end database server for storage. After the order has been completed, the web server sends an acknowledgment email to the customer.
- A message is sent to the order processing application—The database server sends a message to the order processing application, which is hosted on a different server in the internal network. This application handles the shipment of the product, which is a separate process.
- The order is processed—The order processing application tracks the order and sends the customer’s order to a warehouse application for shipping. It also accepts status data from the warehouse application. Warehouse personnel ship the order and enter information into the warehouse application. The order processing application sends emails to customers letting them know the status of their orders, which includes when an order ships and follow-up emails for shipment problems, such as delays.
 TIP
TIP
Identifying CBFs first is a top-down approach followed by identifying the critical IT services and infrastructure that support the CBFs. A bottom-up approach would likely miss important elements, for example, trying to determine what functions a server supports.
In this example, the CBFs are:
- The customer’s accessing the website
- The web server’s accessing the database server
- The order processing application’s tracking the order
With this information, the critical resources can be identified.
Identifying Critical Resources
Critical resources are those that are required to support the CBFs. Once the CBFs have been identified, they can be analyzed to determine the critical resources for each.
The example of the website shows how to identify critical resources from the CBFs. One of the website CBFs is the customer’s accessing the website. The following IT resources are required to support this function:
- Internet access
- Web server
- Web application
- Network connectivity
- Firewall on the Internet side of the DMZ
 NOTE
NOTE
This isn’t the only way the process could be designed. The product database could be hosted on a server in the DMZ so that data could be retrieved more quickly, and the customer database could be hosted separately in the internal network. The DMZ could be designed differently too. Many design possibilities exist, which is why asking the experts is important. They will know how the process is configured.
The second CBF is the web server’s ability to access the database server. The database server hosts both product and customer information. The customer information is used when a customer makes a purchase and to target advertising for the returning customer. The following IT resources are required to support this function:
- Web server
- Web application
- Database server
- Network connectivity
- Firewall on the internal side of the DMZ
The third CBF is the order processing application. It needs to receive orders from the database server and be able to track the order until delivery. The following IT resources are required to support this function:
- Server hosting the order processing application
- Database server
- Warehouse application
- Network connectivity
- Internet access
In many instances, the critical resources will overlap. In other words, a critical resource required for one function may also be required for another function. For example, the web server is required for two of the functions, and facility support (e.g., power, heating, and air-conditioning) is required for all of them.
A resource can be listed one time for all the functions or with each function. In the case of IT resources, listing each of the resources with each of the functions is the better idea. For example, all IT resources require facility support. They could be listed one time as follows:
- Power—Uninterruptible power supplies and generators are required to ensure systems remain operational during power outages.
- Heating and air-conditioning—Heating and air-conditioning are required to ensure that all systems can operate.
Identifying the MAO and Impact
Once the CBFs and IT resources that support them have been identified, the next item to consider is the MAO and impact. The MAO is also referred to as the maximum tolerable period of disruption (MTPD). The MAO helps to determine which CBFs need to be recovered and restarted as soon as possible after a disaster, identifies the specific resources needed to restart the CBF, and helps to determine how soon these systems need to be recovered.
The other consideration in this process is the impact on the business, which is monetary but doesn’t need to be expressed as money. Instead, the impact is often expressed as a relative value such as high, medium, or low, but it can also be expressed as a number, such as 1 through 4.
Once the impact level has been identified, it can be matched with an MAO. TABLE 12-1 shows an example of how impact value levels can be defined in an organization. Each level is matched to the MAO to identify how long the system can be down before the impact is felt.
| IMPACT VALUE LEVEL | MAXIMUM ACCEPTABLE OUTAGE AND IMPACT |
|---|---|
| Level 1 Business functions must be available during all business hours. Online systems must be available 24 hours a day, seven days a week. |
Two hours Any outage will have an almost immediate impact on the business. |
| Level 2 Business processes can survive without the business function for a short time. |
One day If the outage lasts more than a day, it will have an impact on the business. |
| Level 3 Business processes can survive without the business functions for one or more days. |
Three days The outage won’t have an impact on the business if the outage lasts as long as three days. |
| Level 4 Business processes can survive without the business functions for extended periods. |
One week The outage won’t have a significant impact on the business unless it lasts longer than a week. |
When calculating the MAO for an organization, both direct and indirect costs must be considered.
Direct Costs
NOTE
The MAO values are assigned internally by each organization, which means that the values and recovery objectives used by one organization can be completely different from those used by another organization.
The direct costs are usually easier to calculate than the indirect costs. Some of these costs are readily apparent, and others are not. The following list shows some of the direct costs:
- Loss of immediate sales and cash flow—This is the most obvious loss. During the outage, the company won’t be able to sell its products or services, and it loses the normal cash flow from these sales.
- Equipment replacement costs—If equipment is damaged, it needs to be repaired or replaced. Depending on the equipment, these costs can be substantial.
- Building replacement costs—If a building is lost due to a fire or natural disaster, it needs to be rebuilt or replaced. Although insurance covers most of the costs, it rarely covers all of them, and the organization must make up the difference.
- Penalty costs for late delivery—Service level agreements (SLAs) specify expected levels of service and often impose penalties if the service is not met, which should be calculated as direct costs for an outage.
- Penalty costs for noncompliance issues—Some laws impose penalty costs for noncompliance. If a failure results in noncompliance with a law, this cost should be included.
- Costs to re-create or recover data—Data lost during an outage needs to be re-created or restored. Some data may need to be re-created manually, whereas other data may be recoverable using existing backups. Labor costs may be associated with recovering data.
- Salaries paid to staff who are idled due to outage—If an outage prevents normal work, workers will still be on the clock, which means they will still be paid to perform jobs they can’t perform.
Indirect Costs
Identifying indirect costs is more difficult than identifying direct costs, but they must be identified because their value also affects the impact value. The following list shows some of the indirect costs that need to be considered:
- Loss of customers—Customers who can’t purchase from the company may purchase from a competitor, and, in doing so, they may find the experience satisfying and never come back. Attracting new customers to replace those lost costs a significant amount of money.
- Loss of public goodwill—The outage may cause the organization to look less desirable to the public. For example, if an outage results in the compromise of customers’ personally identifiable information, they may begin to distrust the organization, and, if their credit card data is compromised, they may no longer do business with the organization.
- Costs to regain market share—When customers and goodwill are lost, the company loses market share, which its competitors gain. Most companies realize that keeping a customer is much easier than attracting a new one.
- Costs to regain positive brand image—If the company’s brand is tarnished, the company must take steps to repair it. Repairing a tarnished reputation takes a lot of advertising money, and some companies never recover.
- Loss of credit or higher costs for credit—When an outage affects a company’s cash flow, it can also affect the company’s credit rating. A lower credit rating results in higher costs, and, worse, a company may lose its existing credit.
- Lost opportunities during recovery—While an organization is dealing with the outage, employees spend their time addressing it. These same employees may have been working on projects to attract new business, which means the new business becomes a lost opportunity.
Identifying Recovery Requirements
The recovery requirements establish the time frame in which systems must be recoverable and identify the data that must be recovered. For example, some data loss might be acceptable, whereas other data loss is not.
Two primary terms related to recovery requirements are recovery time objective (RTO) and recovery point objective (RPO). Although the RTO applies to systems or functions, the RPO applies only to data. More specifically, the RPO addresses data housed in databases.
The RTO is the time in which the system or function must be recovered and would be equal to or less than the MAO. For example, if the MAO is one hour, the RTO needs to be one hour or less.
The RPOs identify the maximum amount of data loss an organization can accept, which is the acceptable data latency. For example, a database may record hundreds of sales transactions a minute. The organization may need to recover this data up to the moment of failure, which would be an expensive process, but, because each transaction represents revenue, the cost is justified. On the other hand, another database may import data only once a week; to ensure nothing is lost, the only data that would need to be restored would be the data that had been added since the last import, which is a much less expensive process.
RTO can also be thought of as time critical and RPO as mission critical. The RTO identifies the time when the system is restored, and the RPO identifies data that is mission critical. Some processes must be restored in a timely manner, which requires a short RTO. Restoration of other processes can be delayed as long as all the data is recovered.
TIP
Although lower RTOs are achievable, they are much more expensive. Therefore, when interviewing stakeholders, connecting the cost with the RTO is important. For example, ensuring that a database is recoverable up to the moment of failure is possible, even after major disasters, such as earthquakes, but would require a separate site, separate servers, and immediate data replication, all of which are expensive. Once stakeholders recognize the costs, they may decide on a different RTO.
After the MAO has been identified, identifying the recovery time objectives becomes easy. TABLE 12-2 adds an additional column, the recovery objectives, to Table 12-1 and shows that the recovery objective is directly related to the MAO.
| IMPACT VALUE LEVEL | MAXIMUM ACCEPTABLE OUTAGE | RECOVERY OBJECTIVE |
|---|---|---|
| Level 1 Business functions must be available during all business hours. Online systems must be available 24 hours a day, seven days a week. |
Two hours Any outage will have an almost immediate impact on the business. |
Two hours or less Functions in this category must be recovered in less than two hours. |
| Level 2 Business processes can survive without the business function for a short amount of time. |
One day If the outage lasts more than a day, it will have an impact on the business. |
24 hours or less Functions in this category must be recovered within 24 hours. |
| Level 3 Business processes can survive without the business functions for one or more days. |
Three days The outage won’t have an impact on the business if the outage lasts as long as three days. |
72 hours or less Functions in this category must be recovered within 72 hours. |
| Level 4 Business processes can survive without the business functions for extended periods. |
One week The outage won’t have a significant impact on the business unless it lasts longer than a week. |
Seven days or less Functions in this category must be recovered within one week. |
Looking at impact value level 4, the question could be asked, if an organization can do without a function for up to a week, why include it in the BIA at all? This level can be thought of as encompassing minor desirable functions. Although the organization won’t fail without them, it would be able to operate with fewer problems with them functional. For example, an organization may not use Internet access for mission-critical tasks, but having Internet access may make it easier for employees to perform other jobs.
The RPO isn’t calculated directly from the MAO. Instead, personnel will need to be interviewed to determine what data loss is acceptable, which would vary in different types of databases. Commonly, acceptable data loss is measured in minutes, such as 15 minutes.
A database used to record sales can’t accept much data loss because every minute of data loss represents lost sales revenue. On the other hand, other databases may not change as much, and their changes may be manually reproduced. If there aren’t many changes and they can easily be reproduced, more data loss can be accepted. For example, a database is manually updated about five times a week, and the updates have a paper trail that shows what needs to be reproduced. Therefore, data loss of a week could easily be accepted in the database. Because the updates have a paper trail, the database can be restored and the updates reproduced.