
Elements of a CIRT Plan
CIRTs can vary in the elements that are included. However, a CIRT commonly includes information on the membership of the CIRT, policy information, and details on communications methods and incident response procedures. The following sections outline these common elements.
 NOTE
NOTE
This section isn’t intended to indicate that these are the only elements of the CIRT plan. Neither is it intended to say that these elements must exist. The CIRT plan will meet the needs of the specific organization, and organizations differ widely.
CIRT Members
Although a CIRT plan identifies CIRT members, these members will likely be involved in its creation. CIRT members include IT and security professionals, who understand the risks that threaten networks and systems. When developing a CIRT, identifying the roles, responsibilities, and accountabilities of the team members is important.
Different models can be used for developing a CIRT. The National Institute of Standards and Technology (NIST) regularly releases special publications (SPs). NIST SP 800-61 Rev. 2 identifies the following team models:
- Central incident response team—Organizations in a single location can use a single team, which will respond to all incidents. A single team may even cover multiple locations, and all members will have remote access to all of them. They will also be available at any time to provide flyaway support, if needed.
- Distributed incident response teams—If the organization has major computing facilities in multiple locations, it might choose to have a single team in each location with all teams centrally managed. For example, if the organization has multiple regional locations with teams at each location, personnel at the headquarters location will still centrally manage the teams.
- Coordinating team—This team includes knowledgeable personnel who provide advice to other teams. Team members don’t have any authority over the other teams. However, when incidents occur at outlying locations, team members provide assistance as needed.
NOTE
The members of the CIRT are usually identified by title, rather than by name, within the plan.
Roles
A CIRT needs a balanced set of skills. The overall goal is to ensure that the team has members with a variety of skills from different areas of the organization. Team members might fill a single role or multiple roles. Some of the roles held by the team members are:
- Team leader—The team leader is responsible for the team’s actions and is usually a senior manager with expertise in security. However, some CIRTs identify the team leader as the first team member who arrives on the scene. This person takes charge of the incident and directs other member activities.
- Information security members—These individuals could be experts on boundary protection, which includes firewalls and routers on the edge of the network. They are able to identify the source of breaches and recommend solutions. These members could also be experts in intrusion detection systems (IDSs) and other systems that include audit logs and audit trails.
- Network administrators—Network administrators understand the details of a network, such as what systems are connected and how they’re connected and what systems are accessible from the Internet. They know what normal traffic flow is and can recognize abnormal traffic.
- Physical security—Because attackers can be social engineers and might be on company property, physical security personnel need to be on the team. They know what physical security controls the organization uses, where they are located, and their purpose. They also know the different types of surveillance methods used within the organization, such as video cameras and their capabilities.
- Legal—Legal personnel provide advice on the organization’s legal responsibilities and legal remedies before, during, and after an incident. Legal personnel understand what legal actions are possible against the attackers and the requirements necessary to pursue legal actions.
- Human resources (HR)—If the attack originated from an employee, HR needs to be involved because HR understands the organization’s policies and is aware of the available enforcement methods. For example, if an employee violates the AUP, the first offense may result in a formal written warning, and a second or third offense may result in termination. HR personnel would know whether the employee had been previously warned.
- Communications—Public relations (PR) personnel become the face of the organization if the incident becomes public. They help to present an image of resolve, even if everything is not quite under control. If PR reps aren’t used, team members might express frustration or confusion about the attack, which can present a poor image to customers, vendors, and stockholders of the organization.
Responsibilities
The CIRT has several responsibilities, such as helping to develop the plan, respond to incidents, and document the incidents. Each member of the team has special skills and responsibilities to the team. However, the team as a whole also has specific responsibilities.
Some of the primary responsibilities of the CIRT include:
- Developing incident response procedures—These procedures can be generic procedures to respond to any type of incident or detailed checklists for different types of incidents. For example, malware infections and DoS attacks may each have its own checklist.
- Investigating incidents—When an incident occurs, the CIRT is responsible for responding to and investigating it. Depending on the priority and impact of the incident, a single team member may respond. For high-priority, high-impact incidents, the entire team may respond.
- Determining the cause of incidents—One of the goals of an investigation is to determine the cause because, by understanding the cause, the CIRT is better able to determine the best response. For example, a user brings in an infected universal serial bus (USB) flash drive from home. After plugging it into the system, the antivirus software detects and quarantines it. Thus, the cause was from the user transferring the virus from home to the work computer via the USB drive. Luckily, the antivirus software detected it, but, unfortunately, some viruses bypass the antivirus software. This type of incident has caused many organizations to outlaw USB flash drives on their networks.
- Recommending controls to prevent future incidents—CIRT members often know the best solution to prevent the same incident again. Even if they don’t know it already, they have the expertise and experience to identify a control, which may be as simple as upgrading the security policy or more complex and require the purchase and installation of hardware or software. Either way, the CIRT members provide the recommendation.
- Protecting collected evidence—Evidence should not be modified when it’s collected. For example, police officers don’t walk through the blood at a crime scene because doing so would affect the evidence. Similarly, CIRT members should not modify the evidence, such as accessing files or turning off the computers, unless they’ve captured the RAM content if that is desired. They use bit copy tools to copy hard drives to get a complete copy without modifying the data.
- Using a chain of custody—CIRT members are responsible for managing the evidence as soon as they collect it. A chain of custody helps ensure that the evidence presented later is the same evidence that was originally collected. It should be established when evidence is seized and maintained throughout the life of the evidence. The chain of custody log documents who had the evidence at any moment and when the evidence has been secured in a semipermanent storage location.
The CIRT plan at any organization may spell out the previously listed responsibilities, and it could list additional responsibilities of the CIRT, based on its needs or expectations. For example, members may be expected to subscribe to different security bulletins or take other steps to ensure that they stay aware of current risks.
Accountabilities
The CIRT is also accountable to the organization to provide a proactive response to any incident. Although incidents can’t be avoided, the team is expected to minimize the impact of any incident.
Organizations often invest a lot of time and money in team members. The goal is to ensure they are trained and capable of handling the incidents. However, serious incidents don’t happen often, which doesn’t mean that team members don’t think about security very often. The team members are expected to keep up to date on security threats and possible responses, which requires dedication on the part of each of the team members.
CIRT Policies
A CIRT plan also includes CIRT policies. These policies may be simple statements or contained in appendixes at the end of the plan. They provide the team with guidance in the midst of any incident.
One of the primary policies to consider is whether or not CIRT members can attack back. In other words, during the investigation of an incident, team members may have the opportunity to launch an attack on the attacker. Should they?
The answer is almost always a resounding no. First, legal ramifications may exist. Even though thieves steal from a company, the company can’t use that as an excuse to steal from them because, if the company is caught, it can be prosecuted. A defense of “but he did it first” won’t impress a judge. Similarly, even if the attacker broke laws attacking the company’s network, no justification exists for the company to break laws to attack back.
If a company attacks back, it also runs the risk of escalating an incident between itself and the attacker. For example, if a person bumps into another person on a busy street, both of them could say excuse me, and the incident is over. Even if one person is rude and purposely bumps into another person, if the person bumped says excuse me and moves on, the incident is over. However, the incident is not over if the person bumped turns on the other person and flails their arms, pushes, and yells. Instead, the incident is escalated into a conflict, the result of which may depend on which party is willing to cause the most harm to the other.
Similarly, if an attacker attacks a company’s network and fails, he or she might just move on to an easier target. However, if the company attacks the attacker, the incident will be escalated. The attacker might now consider the company’s attack as being personal, and he or she becomes intent on breaking into the network and causing as much damage as possible.
With this in mind, considering how many work hours an attacker may spend attacking is worthwhile. If personal gains are at stake, such as millions of dollars, 12-hour days or 80-hour workweeks are doable in the short term. Similarly, if the attacker has a personal vendetta against an organization that had the audacity to attack back, he or she might devote all of his or her waking time to satisfying the vendetta.
In short, the best practice is not to escalate an attack into a two-sided conflict. Leave any retribution to law enforcement. Attackers can inflict higher damage and costs to an organization than the organization can to the attacker, leaving little reason for an organization to invite more of the same. This is not to say that an organization should never attack back. Police, government, and military agencies may have specific units that are trained to attack to gather evidence on criminal activities or to carry out purposeful cyberwarfare against a government’s enemies. However, if this isn’t the organization’s mission, refrain from attacking back.
Other policies included in the CIRT may include those related to evidence, communications, and safety. Evidence collected during an investigation may need to be used to prosecute people in the future. However, specific rules exist that govern the collection and storage of evidence, and the CIRT plan can include policies to define these rules.
Communications with media can be challenging for anyone who doesn’t have experience in this area. However, a CIRT should have a PR person. A simple policy may state that the only person who may talk to the media about any incident is the PR person. If the media query anyone else, the response is to refer the query to the public relations office or a specific PR person.
Although computer incidents aren’t as dangerous as disasters, such as hurricanes or earthquakes, some danger could be involved. A CIRT plan often states that the safety of personnel is most important and that actions should not be taken that risk the safety of any personnel.
Incident Handling Process
A CIRT plan identifies the incident handling process, which can be a large part of the plan, depending on its detail. NIST SP 800-61 Rev. 2, Computer Security Incident Handling Guide, outlines four phases of an incident. FIGURE 15-2 shows these four phases as an incident response life cycle.

FIGURE 15-2 Incident response life cycle.
The four phases outlined in NIST SP 800-61 Rev. 2 are described as follows:
- Preparation—Preparation involves creating a CIRT plan, defining incidents, and creating CIRTs. The team members are trained and have specific roles and responsibilities. They know how to recognize, contain, and mitigate incidents.
- Detection and analysis—This phase uses various controls to detect incidents, which include IDSs and antivirus software. Because some detected events may not actually be incidents, they need to be investigated and analyzed to determine whether they are actual incidents or false positives.
- Containment, eradication, and recovery—After an incident has been detected, it needs to be contained as quickly as possible. This containment can be as simple as removing the cable from the network interface card (NIC) on the affected system, which removes the source of the attack. For example, if a system is infected with malware, the malware should be quarantined or removed. Then, the system can be returned to normal operations. Attacks often include several elements. After eradicating one element, the detection and analysis step must often be repeated. This process is repeated until verification has been obtained that all the malicious elements have been eradicated. Only then is the postincident recovery phase initiated.
- Postincident recovery—This phase includes an after-action review, whereby the incident and the response are examined to determine where the response could be improved. When warranted, the CIRT plan is modified accordingly.
The preparation phase is the same for any type of incident in that personnel within the organization take the time to plan and prepare. Similarly, the postincident recovery phase is the same for any incident. However, the two middle phases are often different. The following sections discuss different types of incidents and include methods of preventing, detecting, and responding to them.
Handling DoS Attack Incidents
DoS attacks attempt to prevent a system or network from providing a service by overwhelming it to consume its resources. Any system has four primary resources: processor, memory, disk, and bandwidth. When these resources are responding to an attack, they can’t be used for normal operations.
A DDoS attack is launched from multiple systems, and these systems are often controlled in a botnet. FIGURE 15-3 shows multiple zombies, or clone computers, that have been infected by malware and are now controlled by an attacker from a command-and-control center. When the attacker issues a command, the zombies attack.
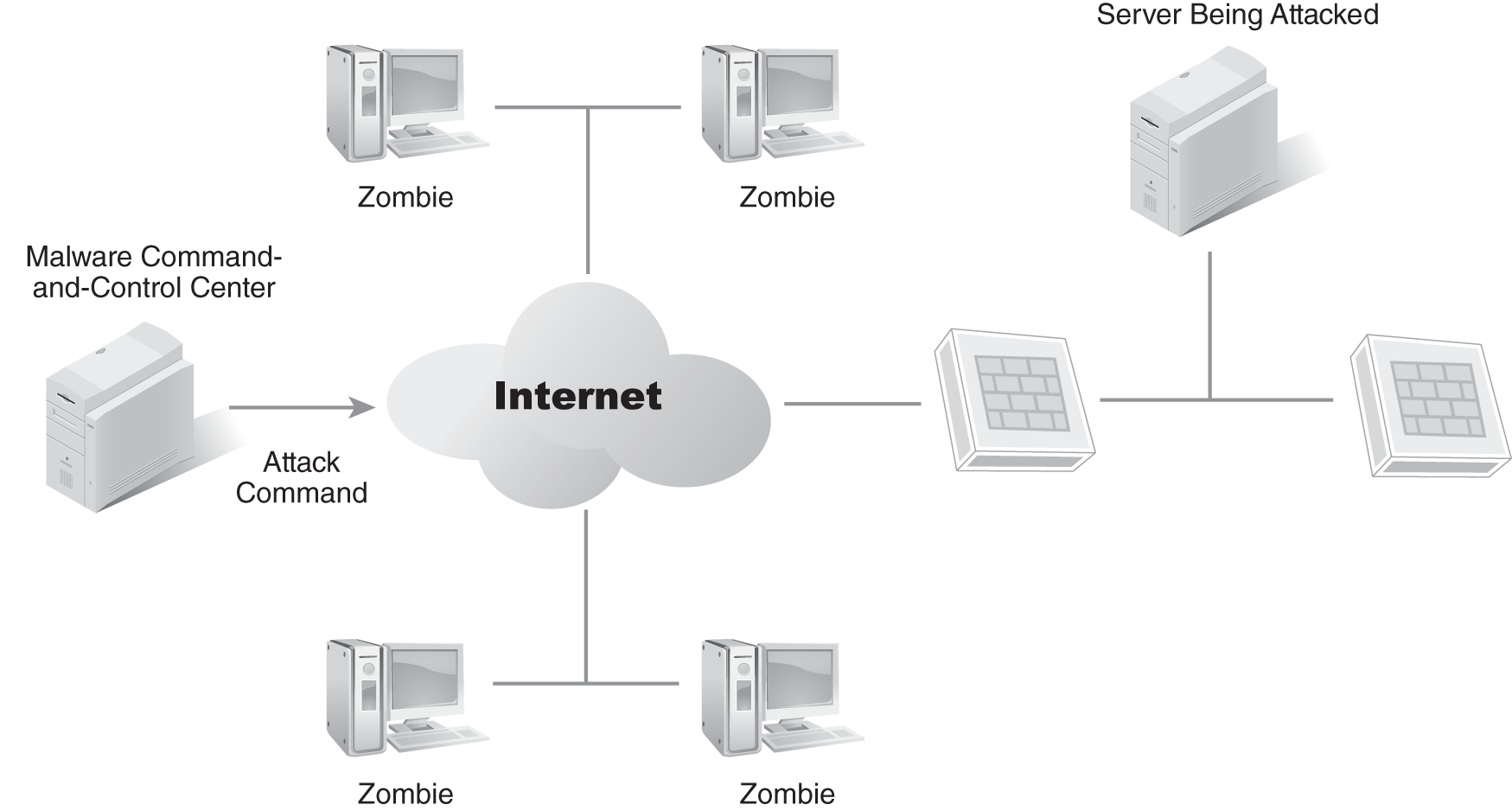
FIGURE 15-3 DDoS attack launched from a botnet.
NOTE
Botnets often include tens of thousands of computers. Cybercriminals manage the botnets and rent access to them to other criminals. For example, an attacker can rent access to launch a DDoS attack on a specific server.
DoS attacks attack a single system. Several indications indicate that a DoS attack is occurring. These include:
- User reports of system unavailability
- IDS alerts on the attack
- Increased resource usage on the attacked system
- Increased traffic through the firewall to the attacked system
- Unexplained connection losses
- Unexplained system crashes
A suspected attack can be confirmed by reviewing available logs. System logs include information on system activity, firewall logs can show network traffic to the system, and logs gathered by the IDS can identify many specific types of attacks.
The response depends on the type of attack. If the attack is due to a vulnerability, such as an unpatched system, the primary response should be to fix the vulnerability, in this case, patch the system. Many attacks can be blocked at the network firewall, and other attacks can be blocked at the system firewall.
Many IDSs include automated response capabilities, such as changing firewall rules to block specific types of traffic. For example, if the attack is Internet Control Message Protocol (ICMP) based, the IDS can configure the firewall to block ICMP traffic. If the attack is a synchronized (SYN) flood attack that is withholding the third packet of a Transmission Control Protocol (TCP) handshake, the IDS can configure the firewall to block traffic from the attacking IP.
If an IDS system doesn’t automatically respond to the attack, changes can be made manually. The goal is to identify the source of the attack and modify the firewall rules to block the traffic. Basic packet-filtering rules can be modified on routers or firewalls. Traffic can be blocked based on IP addresses; ports; and some protocols, such as ICMP.
The Internet service provider (ISP) can also be recruited to assist with the response by filtering the traffic so the attack doesn’t even reach the network.
NOTE
Although the SYN flood attack is an older DoS attack, attackers still use it. They launch SYN flood attacks via the Internet.
 TIP
TIP
NIST SP 800-83 Rev. 1, Guide to Malware Incident Prevention and Handling for Desktops and Laptops, includes details on how to address malware incidents.
Handling Malware Incidents
Malware incidents are the result of any malicious software, such as viruses and worms. Many types of malware exist, and new ones appear daily. Some of the varieties include:
- Viruses—Viruses attach themselves to applications and execute when the application executes. They have three phases: replication, activation, and objective. Their first goal is to replicate to other applications, and, at some point, they activate to launch the objective, which is the virus payload. This is the most dangerous part of the program, where the virus inflicts damage on the system or network. In some cases, the objective can be to contact a control server in a botnet to download additional malware.
- Worms—Worms are self-replicating programs. They don’t need a host application as a virus does, but they do commonly have a virus component. They travel over the network using the worm component and, then, when they arrive at a system, they install a virus.
- Mobile code—Mobile code includes different types of malware that execute when a user visits a website or opens an email. Some of the languages and methods used are Java, ActiveX, JavaScript, and VBScript.
- Trojan horses—A Trojan horse appears to be something useful, but it also includes a malicious component. For example, it may look like a game or a screen saver, but it also includes malware. Some Trojan horses will keep the malicious software installed even if the original application is uninstalled.
FYI
Trojan horses are named after the wooden horse in Greek mythology. This wooden horse looked like a gift from the gods to the people of Troy, so the residents of Troy rolled the horse through the gates to the city and partied all day and night celebrating their good fortune. But, when the city slept, hidden attackers climbed out of the horse and opened the gates to let the attacking army in, which promptly sacked the city of Troy. The lesson is the same today as it was then: Beware of gifts from unknown sources.
The primary protection against malware is antivirus software, and many organizations use it in a three-pronged approach. First, antivirus software is installed on all the systems in the organization; second, it is installed on email servers, which blocks malware delivered via email; and third, it is often installed at the boundary of the network, which is where the intranet meets the Internet and can filter all traffic for potential malware.
Additionally, signature files on the antivirus software must be updated regularly. Most organizations use automated techniques to install the antivirus software, and these automated techniques also update the signatures regularly.
A secondary protection is to train and educate users because many of them are unaware of how malware is delivered, and they don’t recognize the extent of damage possible from it. Routine training educates users about the types of malware threats and what to do if malware infects their system.
Some organizations create checklists that identify what users should do if their systems are infected, and they post them where users can regularly see them. The first step after identifying the virus is to contain the threat, perhaps by removing the NIC.
If malware infects an email server, isolating the email server is the best thing to do until the malware can be contained. Depending on the extent of the malware, this may require IT personnel to shut down the email server and rebuild it. It could also mean simply removing the cable at the NIC until the malware has been removed.
Moreover, many organizations configure web browsers and email readers to prevent the execution of malicious mobile code. For example, Microsoft domains can use Group Policy to configure all the systems in the network. Group Policy settings can be set once to restrict execution of scripts or unsigned ActiveX controls on all user systems.
Handling Unauthorized Access Incidents
An unauthorized access incident occurs when a person gains access to resources even though that person does not have authorized access. Sometimes, unauthorized access can be gained accidentally. For example, if an administrator grants a user too many privileges, the user might stumble upon classified data. However, the focus in this section is on attackers gaining unauthorized access, which they can do by gaining access through social engineering or technical attacks.
Once they have gained access, attackers try to exploit it, often by using privilege escalation techniques to gain additional access. Examples of unauthorized access incidents include:
- Attacking and defacing a web server
- Uploading or downloading data from a File Transfer Protocol (FTP) server
- Using an unattended workstation without permission
- Viewing or copying sensitive data without authorization
- Using social engineering techniques to collect organization data
- Guessing or cracking passwords and logging on with these credentials
- Running a packet sniffer, such as Wireshark, to capture data transmitted on the network
The majority of these types of attacks originate from attackers outside the organization. Because Internet-facing servers are the most vulnerable to Internet-based attacks, attackers often access servers or other internal resources through the Internet.
One of the basic protection steps that can be taken is to ensure that all servers are hardened. Steps to harden a server include:
- Reducing the attack surface—If services are not used, disable them. If protocols are not used, remove them. If an attacker launches an attack using a protocol that isn’t installed on the server, the server is protected.
- Keeping systems up to date—Software vendors release patches and updates to eliminate bugs that cause security vulnerabilities. These updates must be applied regularly to protect the systems.
- Enabling firewalls—Firewalls filter all traffic to ensure that unwanted traffic does not reach vulnerable systems. Network-based firewalls provide one layer of protection for the computers in the network, and host-based firewalls provide another layer of protection. Therefore, both types of firewalls should be enabled.
- Enabling IDSs—IDSs detect attacks either passively or actively. A passive IDS detects the attack and then provides notification, whereas an active IDS can modify the environment and stop attackers before any damage is done.
Moreover, basic access controls also provide protection. These controls ensure that all users authenticate on the network before gaining access to resources. Additionally, the principle of least privilege ensures that users have access to only the data they need and no more.
Without credentials to authenticate on the network, outside attackers won’t have any success gaining access. However, their lack of access doesn’t prevent them from using social engineering tactics to discover network credentials by tricking or conning users into giving up valuable information, such as their usernames and passwords, which they can then use to launch an attack.
Unauthorized access incidents can be detected through several methods. IDSs often provide warnings about reconnaissance activity before an attack. For example, an attacker may scan a server for open ports to determine what protocols are running. The data thus gained in the reconnaissance attack is then later used in the access attack.
Educated users can detect social engineering attempts by recognizing the conning and trickery that a social engineer uses to get them to give up their secrets. Once users recognize these attempts, they can then report them to administrators. Of course, uneducated users often give up their secrets without realizing what they’ve done because most people are helpful by nature, and this trait is exploited by social engineers.
Some attacks are not detected, though, because an attacker can access data in a database and disappear before anyone even notices. Even if the access is logged, the actual event may go undetected. Oftentimes, the realization that the unauthorized access has occurred isn’t discovered until later when a problem is noticed. The stolen data may have been research and development data, which is now being used by a competitor, or customer credit card information. As an example, the attack against Target continued for several weeks in late 2013, but Target didn’t discover the breach until the U.S. Justice Department notified the company.
The response depends on the attack, but the most important element of any attack is containment. If the attack is detected in progress, the goal is to isolate the affected system, but not necessarily from all users. Instead, the system can be isolated from only the attacker. For example, firewall rules can be modified to block the attacker’s IP address.
If the problem is from a compromised account, the account can be disabled, but, if the account is an elevated account, such as one with elevated permissions, other accounts may have been created with it. For example, an attacker may steal the credentials of an administrator account, and, right after logging on, he or she creates another account with administrative permissions. Therefore, even if the first account is locked out, the attacker can still use the second account.
Handling Inappropriate Usage Incidents
Inappropriate usage incidents occur when users violate internal policies, but these incidents usually aren’t as serious as external ones. However, depending on the activity, the incidents can be quite serious and result in loss of money for the organization.
TIP
Attackers commonly scan systems to determine which ports are open because many protocols use well-known ports. If the port is open, the attacker realizes the associated protocol is probably running on the server. For example, if port 80 is open, Hypertext Transfer Protocol (HTTP) is most likely running on the server, which indicates that the server is most likely a web server.
Examples of inappropriate usage include users who:
- Spam coworkers
- Access websites that are prohibited
- Purposely circumvent security policies
- Use file sharing or P2P programs
- Send files with sensitive data outside the organization
- Launch attacks from within the organization against other computers
A security policy helps prevent many of these incidents and often requires an AUP, which identifies what is and is not acceptable usage. For example, the AUP may specify that using email to advertise a personal business or using the Internet to access gambling or pornographic sites is prohibited. Similarly, the policy often prohibits the use of anonymizer sites. Most proxy servers can detect and block access to anonymizers. Organizations commonly reprimand users who violate AUPs.
AUPs typically restrict the use of P2P software, which people often use to download and share pirated music, videos, and applications. However, one of the main problems with P2P software is data leakage, which occurs when the P2P software shares user data without the user’s knowledge. For example, users might have files with personal data, such as passwords or credit card information, on their computers, and the P2P software might include steps to protect these files. But, if users don’t protect these files, the P2P program might share the files with anyone else using the same P2P program. Similarly, the user could be sharing proprietary data if a P2P program is installed on the user’s computer.
Technical TIP
An anonymizer site attempts to hide a user’s activity. When a user visits the anonymizer site and then visits other sites through it, the anonymizer retrieves the webpages but serves them as if they had originated from it. For example, a user could visit a gambling site via the anonymizer, and, if the internal proxy server tracked the user’s activity, it would identify the traffic from the anonymizer but not the traffic from the gambling site. Just the use of an anonymizer alone is considered to be a serious offense by many organizations.
Inappropriate usage incidents can be discovered through several methods, which include alerts, log reviews, and reports by other users. Because firewalls and proxy servers log all the traffic going through them, they can be scanned to determine whether users are violating the policies. Additionally, an IDS can be configured to automatically detect and report prohibited activities.
Many organizations also use data loss prevention (DLP) software, which administrators can configure with keywords associated with proprietary data and to look for personally identifiable information (PII). For example, Social Security numbers include nine numbers and two dashes. A DLP scanner can look for text matching a mask like this: ###-##-####. It scans all traffic going in and out of a network, and, when it detects a match, it sends an alert.
Another way to detect inappropriate usage is through other users. For example, employees may receive spam from another employee advertising a business or promoting a religion, or they may view inappropriate images on an offender’s computer. The organization responds to these incidents when the employees report them.
The primary response is based on the existing policies, which include the security policy and the AUP. If policies don’t exist, they need to be created. If an employee violates the policy, the employee is at fault, but, if a policy doesn’t exist, the organization may be at fault.
In addition to having policies, it’s worth stating the obvious: They must be enforced. Some organizations go through the motions of creating policies, but, when it comes time to enforce them, they look the other way. In this situation, employees quickly realize that there are dual policies: One is written but not followed, and the other is unwritten and is the norm.
Handling Multiple Component Incidents
A multiple component incident is a single incident that includes two or more other incidents, which are related to each other but not always immediately apparent. For example, in the first incident of a multiple component incident, a user in an organization receives an email with a malware attachment, and, when it is opened, it infects the user’s system.
The malware has three objectives. First, it releases a worm component that seeks out computers on the organization’s network and infects them. This is the second incident.
Next, the malware contacts a server on the Internet that is managing a botnet. In this role, the organization’s infected system acts as a zombie. It waits for a command from the botnet control server and then does whatever it’s commanded to do.
Because the organization’s infected system has infected other systems on the network, multiple systems could easily be infected, and each of these systems is looking for other systems to infect. They are also acting as zombies in the botnet.
Next, the botnet control server issues a command to all the infected systems, directing them to launch an attack on an Internet server. All the zombies in the infected network then attack, which is the third incident.
From the perspective of the attacked server, the infected organization looks like it is attacking. The party being attacked may query the infected organization’s ISP and report the attacks. The ISP may then threaten to discontinue the infected organization’s service. Notice that the ISP contact may be the first indication that the infected organization has a problem because the problem may not have been noticeable before then.
In this case, the primary protection is antivirus software and ensuring the antivirus software is up to date. Up-to-date antivirus software reduces the likelihood that systems will be infected. However, up-to-date antivirus software doesn’t guarantee that a system won’t be infected. It simply reduces the likelihood. A system is always susceptible to new and emerging threats.
NOTE
The Computer Security Institute completes regular surveys identifying IT security trends. In its 2010/2011 report, respondents indicated that malware attack was the most common attack. Over 45 percent of respondents reported that they had been the subject of a targeted attack. Regulatory compliance appeared to have helped many of these organizations, although over 45 percent of organizations did not seem to use cloud computing in 2010/2011. Cyber Security Trends’ 2019 report indicated that 75 percent of executives surveyed reported that artificial intelligence (AI) helps to respond to breaches and another 69 percent said that AI was necessary for response. Attacks originating in the mobile channel are also on the increase with 70 percent of executives confirming this, according to RSA’s 2019 “state of cybercrime” survey.
Anomaly-based IDSs may notice the increased activity on the network. It starts with a baseline of normal activity, and, when activity increases outside the established threshold, the IDS alerts on the anomaly.
TIP
A behavior-based IDS is the same as an anomaly-based IDS. Both systems start with a baseline of regular activity, which is monitored and compared with intrusion activities.
When a multiple component incident is discovered, the root cause must be identified, which, in the preceding example, is the initial malware. If the root cause can be removed, the other issues may be eliminated. However, any one of the individual components in a multiple component incident can take on a life of its own and can launch another multiple component incident.
Communication Escalation Procedures
When someone determines an event is an incident, he or she declares it to be so, which is known as escalation. One of the first steps to take when declaring an incident is to recall one or more CIRT members, which can be done by a phone tree or any other type of traditional recall.
But incidents can get worse. For example, the initial report may have been a virus on a single computer, but a CIRT member may discover that the malware is being delivered from the email server to every client in the network. What looked like a small problem now has the potential to become catastrophic. In this case, the CIRT member can escalate the response, and, if necessary, the organization can activate the full CIRT.
Communication is very important during the incident, but it may be hampered. For example, email or instant messaging systems might not be available. If these are the primary methods of communication with no backup plan, communication will be challenging.
DRPs often include solutions for potential communication problems, which can also be used for computer incidents. For example, CIRT members can be issued push-to-talk phones or walkie-talkies, or a war room can be set up for face-to-face communications. The war room could be staffed constantly, and team members could report findings to personnel there.
Incident Handling Procedures
When an incident is suspected, checklists can be used to guide actions. They can be included in the CIRT plan as procedures to use in response to incidents. IT professionals and CIRT members can use the checklists when responding to incidents.
Although checklists can’t be created to respond to every possible incident, they can be tailored to the different types of incidents. For example, a generic checklist can be created to match most incidents, and then, other checklists can be created to identify what do for the different types of incidents.
Calculating the Impact and Priority
One of the important steps when handling an incident is to identify its impact and priority, and the CIRT plan can include tools to help personnel determine both. Members can then refer to these tools for clarification during the incident.
For example, data in TABLE 15-1 identifies the effect of an attack. A CIRT member compares the actual effect of the risk to the definition, which provides a value or a rating. For example, an organization has multiple locations spread around the country. No effect on any location is a minimal effect. A severe effect on a single location is a medium effect. A severe effect on multiple locations is considered critical. Each of these ratings is assigned a numerical value.
| DEFINITION | RATING | VALUE |
|---|---|---|
| No effect on any locations or the critical infrastructure | Minimal | 10 |
| Severe effect on a single location or minimal effect on multiple locations | Medium | 50 |
| Severe effect on multiple locations | Critical | 90 |
The values in Table 15-1 are used to determine both current and projected effects. For example, a DoS attack may be launched against one of several web servers in a web farm. The effect may be minimal as long as only one server is being attacked. However, if the attack isn’t resolved soon, it may affect all the servers in the web farm. The projected effect may be considered medium.
NOTE
The checklists in this section are derived from information in NIST SP 800-61 Rev. 2, Computer Security Incident Handling Guide.
TABLE 15-2 can be used to determine how critical the attack is, which is determined by the importance, or criticality, of the systems.
| DEFINITION | RATING | VALUE |
|---|---|---|
| Noncritical systems | Minimal | 10 |
| Systems that are mission-critical to a single location | Medium | 50 |
| Systems that are mission-critical to multiple locations | Critical | 90 |
NOTE
The definitions, values, and ratings used in these examples can be expanded to fit any organization. For example, an organization could have five values and ratings instead of three. Different values, ratings, and even definitions, based on the organization’s needs, can also be used.
Next, the ratings from Tables 15-1 and 15-2 are used to determine an overall score. Whenever possible, the current and the projected effect should be determined:
- Current effect rating—Minimal because the attack is currently affecting only one web server in the web farm. Score of 10. This rating will be used for 25 percent, or one-quarter, of the overall impact score (10 × .25 = 2.5).
- Projected effect rating—Medium because the attack has the potential to spread to more web servers in the web farm. Score of 50. This rating will be used for 25 percent, or one-quarter, of the overall impact score (50 × .25 = 12.5).
- Criticality rating—Medium because the web server does affect a mission-critical system in a single location. Score of 50. This rating will be used for 50 percent, or one-half, of the overall impact score (50 × .50 = 25).
The following formula can then be used to determine the impact:
(Current effect rating × .25) + (Projected effect rating × .25) + (Criticality rating × .50)
(10 × .25) + (50 × .25) + (50 × .50)
2.5 + 12.5 + 25
Incident impact score = 40
After the incident impact score has been identified, then the impact of the incident can be rated. Table 15-3 shows a sample incident rating table. Note that a score of 40 indicates that the incident has a medium impact rating.
| SCORE | RATING AND PRIORITY |
|---|---|
| 0 to 25 | Minimal, low priority |
| 26 to 50 | Medium, medium priority |
| 51 to 100 | Critical, high priority |
These numbers can be confusing, especially during a crisis, but a tool can be created to automate the calculation. For example, a spreadsheet can be created with check boxes next to the ratings. Creating the ratings requires doing some underlying calculations, but they can be hidden and locked. A CIRT member then only needs to open the spreadsheet and select the appropriate check boxes.
Using a Generic Checklist
Once the calculation for the impact and priority has been identified, then the checklists can be created. The following checklist is a sample generic checklist:
- Verifying that an incident has occurred—This verification ensures that the event is an actual incident and not just a false positive. For example, some IDSs send an alert on unusual activity when the activity is not an actual incident.
- Determining the type of incident—Whether the incident is a DoS, malware, unauthorized access, inappropriate usage, or a multiple type of incident is determined. If a checklist exists for an incident, retrieve it from the CIRT plan. Some incidents may require specialists, and, if they do, the appropriate specialists must be recalled.
- Determining the impact or potential impact of the incident—The extent of the attack is determined. For example, the attack could be a virus that has affected a single workstation, a worm that has affected multiple servers, or a DoS attack that has taken down a primary web server that is generating over $20,000 an hour in revenue. If the impact is high, the resulting response will be a high priority.
- Reporting the incident—If the person reporting the incident isn’t a member of the CIRT, he or she should report the incident to a member of the CIRT. The impact and severity of the incident should be included if possible and the incident reported to management. High-impact incidents should be reported as soon as possible, and lower-priority incidents can be reported after they have been contained.
- Acquiring any available evidence on the incident—Evidence must be preserved. Therefore, establishing a chain of custody should begin as soon as evidence has been collected. The chain of custody log should include the time, date, and name of the person who is receiving the evidence. If the evidence is passed from one person to another or into storage, the chain of custody log must be updated, and the evidence must not be modified. No files should be accessed or any system turned off because accessing files modifies the evidence and turning off a system deletes data in its memory.
- Containing the incident—The incident must be kept from spreading to other systems and the system isolated, which can be done by removing the NIC from the system or disabling it. If multiple systems are affected, the network must be isolated, which can be done by isolating all the systems on the network or isolating the network devices. For example, a router could be turned off or reconfigured to isolate a subnet.
- Eradicating the incident—The exploited vulnerabilities must be identified and the steps necessary to reduce the weaknesses determined. If malware was involved, it must be completely removed. If the attack was on a public-facing server, the server must be hardened to prevent another attack.
- Recovering from the incident—Once the incident has been eradicated, systems can be returned to normal operation. Depending on the system and the damage, the system may simply need to be rebooted, or it may need to be completely rebuilt or a system image reapplied. If the system is rebuilt, it must be patched and up to date before and then verified to be operating normally after it has been returned to operation.
- Documenting the incident—Documentation includes many elements, one of which is an after-action report describing the incident, which includes all the details gathered during the incident and all the steps taken to eradicate and recover from the incident. If a chain of custody was created, it must be maintained with any collected evidence, which may be needed later.
The following sections show information that can be used in checklists for other types of incidents. CIRT members can use either the generic checklist or the specific type of checklist when responding to an incident.
Handling DoS Attack Incidents
If the attack is a DoS attack, a checklist designed to address DoS attacks can be uses. The checklist can be designed to stand alone or to be used in conjunction with the generic checklist.
The following items should be considered when creating a checklist for DoS attacks:
- Containment—The DoS attack must be halted as soon as possible. One way to do this is to add filters at routers or firewalls to block the traffic based on the IP address, port, or protocol used in the attack. If the attack cannot be blocked in the network, the ISP may be able to help. Only as a last resort should the server be disconnected. Once it has been disconnected, the service is stopped, which is the primary objective of the DoS attack.
- Eradication—Vulnerabilities that allowed the DoS attack must be identified. For example, the vulnerability may have stemmed from a server that wasn’t adequately hardened because unused protocols may have been enabled on the system or the server may not have had up-to-date patches. After the vulnerabilities have been identified, steps need to be taken to mitigate them.
- Recovery—If the server has suffered long-term damage, it must be repaired. Because the attack may have installed malware, performing a malware scan with updated antivirus software would be advisable. After recovery, the system must be tested to ensure it is operating normally.
Handling Malware Incidents
If an incident was the result of malicious software, several additional steps can be taken, which are in addition to the steps in the generic checklist. If desired, a specific checklist can be created for malware incidents, or they could be combined into the generic checklist.
Consider the following items when creating a checklist for malware incidents:
- Containment—All the infected systems must be identified and disconnected from the network, and the reason the antivirus software didn’t detect the malware must be determined. For example, the antivirus software may have been disabled, or the antivirus signatures may have been out of date. Therefore, the antivirus signatures must be updated and the software enabled. If necessary, the firewall or router rules must be configured to block the malware from being transmitted to or from the infected system.
- Eradication—Full scans on the systems must be run. Antivirus software vendors, such as Symantec and McAfee, often host pages that show detailed steps for removing multipartite viruses and other advanced malware. If necessary, individual steps must be performed to remove all elements of the malware from the system, and infected files must be disinfected, quarantined, or deleted.
- Recovery—Any files that were deleted or quarantined and are needed for system operation must be replaced, and the system must be verified that it is no longer infected. If multiple steps were required to clean the system, running another full scan before returning the system to operation should be considered.
Handling Unauthorized Access Incidents
Several steps can be taken in response to unauthorized access incidents. Just as with other types of incidents, separate checklists can be created to cover unauthorized access incidents, and the generic checklist can be supplemented with a checklist for unauthorized access incidents.
NOTE
A multipartite virus is a virus that uses multiple infection methods. It often requires more steps or complex procedures to eradicate than simpler malware.
The following items should be considered when creating a checklist for unauthorized access incidents:
- Containment—If an in-progress attack is discovered, the attacked system must be identified and isolated from the network, which can be done by pulling the NIC cable or disabling the NIC. A host-based firewall can be used to block all traffic while logging all attempts to connect. If the incident was from an internal account, the account must be disabled and verified to have been under the principle of least privilege. The determination should be made as to whether an attacker hijacked the account as well and whether other systems were attacked, because attackers who succeed when attacking one system will usually try to attack other systems in the same network. Other systems can then be contained if necessary.
- Eradication—The weaknesses that allowed the attack to succeed must be identified, and all the steps to harden the server must be verified to have been completed and that they haven’t been modified. Strong passwords must be used and may need to be changed on the system. If additional accounts were created during the attack, they must be disabled and perhaps deleted.
- Recovery—After resolving the vulnerabilities, the systems can be reconnected and verified that they are operational. The systems should be tested to ensure they are operating as expected. Adding additional monitoring, such as an IDS, to identify future incidents as soon as possible may need to be considered.
When creating a follow-up report of unauthorized access, the data that was accessed during the attack needs to be considered. If it was private customer data, such as credit card data, the organization may have specific liabilities associated with the incident, which need to be determined and included in the report. Management will be responsible for determining how to handle these liabilities.
Handling Inappropriate Usage Incidents
Inappropriate usage incidents need specific responses to mitigate their effects. The steps to mitigate their effects can be combined with the steps in a generic checklist, or a separate checklist can be created to address inappropriate usage incidents individually.
As a reminder, an inappropriate usage incident occurs when an internal user violates the organization’s policies. The following items should be considered when creating a checklist for inappropriate usage incidents:
- Containment—The user’s account may be disabled until management takes action. For example, if a user is sending religious materials to everyone in the organization, the user’s email access can be disabled. Because an employee is unable to perform regular work duties if his or her network access is disabled, immediacy is brought to the problem for both the user and the user’s supervisor.
- Eradication—Some organizations require users to complete specific training before their access is returned, and other organizations require supervisors to document the activity in the employee’s record. If the employee is a repeat offender or the incident is considered severe enough, the employee may be terminated. For example, if a user installed P2P software on an employer-owned computer that resulted in the loss of valuable research and development data through data leakage, the employer may terminate the employee immediately.
- Recovery—If the account was disabled, it would be enabled after the appropriate action has been completed, for example, after the employee completes training or HR has documented the incident. If the employee is terminated, the account should be disabled or deleted, based on the organization’s policy.