
B.1 Overview
Database systems technology has advanced a great deal during the past five decades from the legacy systems based on network and hierarchical models to relational database systems to object databases and more recently big data management systems. We consider a database system to include both the database management system (DBMS) and the database (see also the discussion in [DATE90]). The DBMS component of the database system manages the database. The database contains persistent data. That is, the data are permanent even if the application programs go away.
We have discussed database systems in this appendix as it is at the heart of big data technologies. For example, the supporting technologies discussed in Part I of this book have their roots in database systems (e.g., data mining, data security, big data management). Also, big data management systems have evolved from database query processing and transaction management that were initially developed in the 1970s. Furthermore, some of the experimental systems we have discussed in this book such as cloud-centric assured information sharing have evolved from the concepts in federated databases systems. Therefore, an understanding of database systems is essential to master the concepts discussed in this book.
The organization of this chapter is as follows. In Section B.2, relational data models, as well as entity-relationship models are discussed. In Section B.3, various types of architectures for database systems are described. These include architecture for a centralized database system, schema architecture, as well as functional architecture. Database design issues are discussed in Section B.4. Database administration issues are discussed in Section B.5. Database system functions are discussed in Section B.6. These functions include query processing, transaction management, metadata management, storage management, maintaining integrity and security, and fault tolerance. Distributed database systems are the subject of Section B.7. Heterogeneous database integration aspects are summarized in Section B.8. Object models are discussed in Section B.9. Other types of database systems and their relevance to BDMA are discussed in Section B.10. The chapter is summarized in Section B.11. More details on database systems can be found in [THUR97].
B.2 Relational and Entity-Relationship Data Models
B.2.1 Overview
In general, the purpose of a data model is to capture the universe that it is representing as accurately, completely, and naturally as possible [TSIC82]. In this section, we discuss the essential points of the relational data model, as it is the most widely used model today. In addition, we discuss the entity-relationship data model, as some of the ideas have been used in object models and, furthermore, entity-relationship models are being used extensively in database design.
Many other models exist such as logic-based models, hypersemantic models, and functional models. Discussion of all of these models is beyond the scope of this book. We do however provide an overview of an object model in Section B.15 as object technology is useful for data modeling as well as for database integration.
B.2.2 Relational Data Model
With the relational model [CODD70], the database is viewed as a collection of relations. Each relation has attributes and rows. For example, Figure B.1 illustrates a database with two relations: EMP and DEPT. EMP has four attributes: SS#, Ename, Salary, and D#. DEPT has three attributes: D#, Dname, and Mgr. EMP has three rows, also called tuples, and DEPT has two rows. Each row is uniquely identified by its primary key. For example, SS# could be the primary key for EMP and D# for DEPT. Another key feature of the relational model is that each element in the relation is an atomic value such as an integer or a string. That is, complex values such as lists are not supported.

Various operations are performed on relations. The SELECT operation selects a subset of rows satisfying certain conditions. For example, in the relation EMP, one may select tuples where the salary is more than 20K. The PROJECT operation projects the relation onto some attributes. For example, in the relation EMP, one may project onto the attributes Ename and Salary. The JOIN operation joins two relations over some common attributes. A detailed discussion of these operations is given in [DATE90] and [ULLM88].
Various languages to manipulate the relations have been proposed. Notable among these languages is the ANSI Standard SQL (Structured Query Language). This language is used to access and manipulate data in relational databases [SQL3]. There is wide acceptance of this standard among database management system vendors and users. It supports schema definition, retrieval, data manipulation, schema manipulation, transaction management, integrity and, security. Other languages include the relational calculus first proposed in the INGRES project at the University of California at Berkeley [DATE90]. Another important concept in relational databases is the notion of a view. A view is essentially a virtual relation and is formed from the relations in the database.
B.2.3 Entity-Relationship Data Model
One of the major drawbacks of the relational data model is its lack of support for capturing the semantics of an application. This resulted in the development of semantic data models. The entity-relationship (ER) data model developed by Chen [CHEN76] can be regarded to be the earliest semantic data model. In this model, the world is viewed as a collection of entities and relationships between entities. Figure B.2 illustrates two entities, EMP and DEPT. The relationship between them is WORKS.

Relationships can be either one–one, many–one, or many–many. If it is assumed that each employee works in one department and each department has one employee, then WORKS is a one–one relationship. If it is assumed that an employee works in one department and each department can have many employees, then WORKS is a many–one relationship. If it is assumed that an employee works in many departments, and each department has many employees, then WORKS is a many–many relationship.
Several extensions to the entity-relationship model have been proposed. One is the entity-relationship-attribute model where attributes are associated with entities as well as relationships, and another has introduced the notion of categories into the model (see, e.g., the discussion in [ELMA85]). It should be noted that ER models are used mainly to design databases. That is, many database CASE (computer-aided software engineering) tools are based on the ER model, where the application is represented using such a model and subsequently the database (possibly relational) is generated. Current database management systems are not based on the ER model. That is, unlike the relational model, ER models did not take off in the development of database management systems.
B.3 Architectural Issues
This section describes various types of architectures for a database system. First we illustrate a centralized architecture for a database system. Then we describe a functional architecture for a database system. In particular, the functions of the DBMS component of the database system are illustrated in this architecture. Then we discuss the ANSI/SPARC’s (American National Standard Institute) three-schema architecture, which has been more or less accepted by the database community [DATE90]. Finally, we describe extensible architectures.
Figure B.3 is an example of a centralized architecture. Here, the DBMS is a monolithic entity and manages a database which is centralized. Functional architecture illustrates the functional modules of a DBMS. The major modules of a DBMS include the query processor, transaction manager, metadata manager, storage manager, integrity manager, and security manager. The functional architecture of the DBMS component of the centralized database system architecture (of Figure B.3) is illustrated in Figure B.4.


Schema describes the data in the database. It has also been referred to as the data dictionary or contents of the metadatabase. Three-schema architecture was proposed for a centralized database system in the 1960s. This is illustrated in Figure B.5. The levels are the external schema which provides an external view, the conceptual schema which provides a conceptual view, and the internal schema which provides an internal view. Mappings between the different schemas must be provided to transform one representation into another. For example, at the external level, one could use ER representation. At the logical or conceptual level, one could use relational representation. At the physical level, one could use a representation based on B-Trees.

There is also another aspect to architectures and that is extensible database architectures. For example, for many applications, a DBMS may have to be extended with a layer to support objects or to process rules or to handle multimedia data types or even to do mining. Such an extensible architecture is illustrated in Figure B.6.

B.4 Database Design
Designing a database is a complex process. Much of the work has been on designing relational databases. There are three steps which are illustrated in Figure B.7. The first step is to capture the entities of the application and the relationships between the entities. One could use a model such as the entity-relationship model for this purpose. More recently, object-oriented data models which are part of object-oriented design and analysis methodologies are becoming popular to represent the application.

The second step is to generate the relations from the representations. For example, from the entity-relationship diagram of Figure B.2, one could generate the relations EMP, DEPT, and WORKS. The relation WORKS will capture the relationship between employees and departments.
The third step is to design good relations. This is the normalization process. Various normal forms have been defined in the literature (see, e.g., [MAIE83] and [DATE90]). For many applications, relations in third normal form would suffice. With this normal form, redundancies, complex values, and other situations that could cause potential anomalies are eliminated.
B.5 Database Administration
A database has a Database Administrator (DBA). It is the responsibility of the DBA to define the various schemas and mappings. In addition, the functions of the administrator include auditing the database as well as implementing appropriate backup and recovery procedures.
The DBA could also be responsible for maintaining the security of the system. In some cases, the System Security Officer (SSO) maintains security. The administrator should determine the granularity of the data for auditing. For example, in some cases there is tuple (or row) level auditing while in other cases there is table (or relation) level auditing. It is also the administrator’s responsibility to analyze the audit data.
Note that there is a difference between database administration and data administration. Database administration assumes there is an installed database system. The DBA manages this system. Data administration functions include conducting data analysis, determining how a corporation handles its data, and enforcing appropriate policies and procedures for managing the data of a corporation. Data administration functions are carried out by the data administrator. For a discussion of data administration, we refer to [DMH96, DMH97]. Figure B.8 illustrates various database administration issues.

B.6 Database Management System Functions
B.6.1 Overview
The functional architecture of a DBMS was illustrated in Figure B.4 (see also [ULLM88]). The functions of a DBMS carry out its operations. A DBMS essentially manages a database and it provides support to the user by enabling him to query and update the database. Therefore, the basic functions of a DBMS are query processing and update processing. In some applications such as banking, queries, and updates are issued as part of transactions. Therefore, transaction management is also another function of a DBMS. To carry out these functions, information about the data in the database has to be maintained. This information is called the metadata. The function that is associated with managing the metadata is metadata management. Special techniques are needed to manage the data stores that actually store the data. The function that is associated with managing these techniques is storage management. To ensure that the above functions are carried out properly and that the user gets accurate data, there are some additional functions. These include security management, integrity management, and fault management (i.e., fault tolerance).
This section focuses on some of the key functions of a DBMS. These are query processing, transaction management, metadata management, storage management, maintaining integrity, and fault tolerance. We discuss each of these functions in Sections B.6.2 to B.6.7. In Section B.6.8 we discuss some other functions.
B.6.2 Query Processing
Query operation is the most commonly used function in a DBMS. It should be possible for users to query the database and obtain answers to their queries. There are several aspects to query processing. First of all, a good query language is needed. Languages such as SQL are popular for relational databases. Such languages are being extended for other types of databases. The second aspect is techniques for query processing. Numerous algorithms have been proposed for query processing in general and for the JOIN operation in particular. Also, different strategies are possible to execute a particular query. The costs for the various strategies are computed and the one with the least cost is usually selected for processing. This process is called query optimization. Cost is generally determined by the disk access. The goal is to minimize disk access in processing a query.
Users pose a query using a language. The constructs of the language have to be transformed into the constructs understood by the database system. This process is called query transformation. Query transformation is carried out in stages based on the various schemas. For example, a query based on the external schema is transformed into a query on the conceptual schema. This is then transformed into a query on the physical schema. In general, rules used in the transformation process include the factoring of common subexpressions and pushing selections and projections down in the query tree as much as possible. If selections and projections are performed before the joins, then the cost of the joins can be reduced by a considerable amount.
Figure B.9 illustrates the modules in query processing. The user-interface manager accepts queries, parses the queries, and then gives them to the query transformer. The query transformer and query optimizer communicate with each other to produce an execution strategy. The database is accessed through the storage manager. The response manager gives responses to the user.

B.6.3 Transaction Management
A transaction is a program unit that must be executed in its entirety or not executed at all. If transactions are executed serially, then there is a performance bottleneck. Therefore, transactions are executed concurrently. Appropriate techniques must ensure that the database is consistent when multiple transactions update the database. That is, transactions must satisfy the ACID (Atomicity, Consistency, Isolation, and Durability) properties. Major aspects of transaction management are serializability, concurrency control, and recovery. We discuss them briefly in this section. For a detailed discussion of transaction management, we refer to [KORT86] and [BERN87].
Serializability: A schedule is a sequence of operations performed by multiple transactions. Two schedules are equivalent if their outcomes are the same. A serial schedule is a schedule where no two transactions execute concurrently. An objective in transaction management is to ensure that any schedule is equivalent to a serial schedule. Such a schedule is called a serializable schedule. Various conditions for testing the serializability of a schedule have been formulated for a DBMS.
Concurrency Control: Concurrency control techniques ensure that the database is in a consistent state when multiple transactions update the database. Three popular concurrency control techniques which ensure the serializability of schedules are locking, time-stamping and validation (which is also called optimistic concurrency control).
Recovery: If a transaction aborts due to some failure, then the database must be brought to a consistent state. This is transaction recovery. One solution to handling transaction failure is to maintain log files. The transaction’s actions are recorded in the log file. So, if a transaction aborts, then the database is brought back to a consistent state by undoing the actions of the transaction. The information for the undo operation is found in the log file. Another solution is to record the actions of a transaction but not make any changes to the database. Only if a transaction commits should the database be updated. This means that the log files have to be kept in stable storage. Various modifications to the above techniques have been proposed to handle the different situations.
When transactions are executed at multiple data sources, then a protocol called two-phase commit is used to ensure that the multiple data sources are consistent. Figure B.10 illustrates the various aspects of transaction management.

B.6.4 Storage Management
The storage manager is responsible for accessing the database. To improve the efficiency of query and update algorithms, appropriate access methods and index strategies have to be enforced. That is, in generating strategies for executing query and update requests, the access methods and index strategies that are used need to be taken into consideration. The access methods used to access the database would depend on the indexing methods. Therefore, creating and maintaining an appropriate index file is a major issue in database management systems. By using an appropriate indexing mechanism, the query-processing algorithms may not have to search the entire database. Instead, the data to be retrieved could be accessed directly. Consequently, the retrieval algorithms are more efficient. Figure B.11 illustrates an example of an indexing strategy where the database is indexed by projects.

Much research has been carried out on developing appropriate access methods and index strategies for relational database systems. Some examples of index strategies are B-Trees and Hashing [DATE90]. Current research is focusing on developing such mechanisms for object-oriented database systems with support for multimedia data as well as for web database systems, among others.
B.6.5 Metadata Management
Metadata describes the data in the database. For example, in the case of the relational database illustrated in Figure B.1, metadata would include the following information: the database has two relations, EMP and DEPT; EMP has four attributes and DEPT has three attributes, etc. One of the main issues is developing a data model for metadata. In our example, one could use a relational model to model the metadata also. The metadata relation REL shown in Figure B.12 consists of information about relations and attributes.

In addition to information about the data in the database, metadata also includes information on access methods, index strategies, security constraints, and integrity constraints. One could also include policies and procedures as part of the metadata. In other words, there is no standard definition for metadata. There are, however, efforts to standardize metadata (see, e.g., the IEEE Mass Storage Committee efforts as well as IEEE Conferences on Metadata [MASS]. Metadata continues to evolve as database systems evolve into multimedia database systems and web database systems.
Once the metadata is defined, the issues include managing the metadata. What are the techniques for querying and updating the metadata? Since all of the other DBMS components need to access the metadata for processing, what are the interfaces between the metadata manager and the other components? Metadata management is fairly well understood for relational database systems. The current challenge is in managing the metadata for more complex systems such as digital libraries and web database systems.
B.6.6 Database Integrity
Concurrency control and recovery techniques maintain the integrity of the database. In addition, there is another type of database integrity and that is enforcing integrity constraints. There are two types of integrity constraints enforced in database systems. These are application independent integrity constraints and application specific integrity constraints. Integrity mechanisms also include techniques for determining the quality of the data. For example, what is the accuracy of the data and that of the source? What are the mechanisms for maintaining the quality of the data? How accurate is the data on output? For a discussion of integrity based on data quality, we refer to [DQ]. Note that data quality is very important for mining and warehousing. If the data that is mined is not good, then one cannot rely on the results.
Application independent integrity constraints include the primary key constraint, the entity integrity rule, referential integrity constraint, and the various functional dependencies involved in the normalization process (see the discussion in [DATE90]). Application specific integrity constraints are those constraints that are specific to an application. Examples include “an employee’s salary cannot decrease” and “no manager can manage more than two departments.” Various techniques have been proposed to enforce application specific integrity constraints. For example, when the database is updated, these constraints are checked and the data are validated. Aspects of database integrity are illustrated in Figure B.13.

B.6.7 Fault Tolerance
The previous two sections discussed database integrity and security. A closely related feature is fault tolerance. It is almost impossible to guarantee that the database will function as planned. In reality, various faults could occur. These could be hardware faults or software faults. As mentioned earlier, one of the major issues in transaction management is to ensure that the database is brought back to a consistent state in the presence of faults. The solutions proposed include maintaining appropriate log files to record the actions of a transaction in case its actions have to be retraced.
Another approach to handling faults is checkpointing. Various checkpoints are placed during the course of database processing. At each checkpoint it is ensured that the database is in a consistent state. Therefore, if a fault occurs during processing, then the database must be brought back to the last checkpoint. This way it can be guaranteed that the database is consistent. Closely associated with checkpointing are acceptance tests. After various processing steps, the acceptance tests are checked. If the techniques pass the tests, then they can proceed further. Some aspects of fault tolerance are illustrated in Figure B.14.

B.6.8 Other Functions
In this section we will briefly discuss some of the other functions of a database system. They are: security, real-time processing, managing heterogeneous data types, view management, and backup and recovery.
Security: Note that security is a critical function. Therefore, both discretionary security and mandatory security will be discussed throughout this book.
Real-time processing: In some situations, the database system may have to meet real-time constraints. That is, the transactions will have to meet deadlines.
Heterogeneous data types: The database system may have to manage multimedia data types such as voice, video, text, and images.
Auditing: The databases may have to be audited so that unauthorized access can be monitored.
View management: As stated earlier views are virtual relations created from base relations. There are many challenges related to view management.
Backup and Recovery: The DBA has to back-up the databases and ensure that the database is not corrupted. Some aspects were discussed under fault tolerance. More details are given in [DATE90].
B.7 Distributed Databases
Although many definitions of a distributed database system have been given, there is no standard definition. Our discussion of distributed database system concepts and issues has been influenced by the discussion in [CERI84]. A distributed database system includes a distributed database management system (DDBMS), a distributed database, and a network for interconnection. The DDBMS manages the distributed database. A distributed database is data that is distributed across multiple databases. Our choice architecture for a distributed database system is a multi-database architecture which is tightly coupled. This architecture is illustrated in Figure B.15. We have chosen such an architecture that can explain the concepts for both homogeneous and heterogeneous systems based on this approach. In this architecture, the nodes are connected via a communication subsystem and local applications are handled by the local DBMS. In addition, each node is also involved in at least one global application, so there is no centralized control in this architecture. The DBMSs are connected through a component called the distributed processor (DP). In a homogeneous environment, the local DBMSs are homogeneous while in a heterogeneous environment, the local DBMSs may be heterogeneous.

Distributed database system functions include distributed query processing, distributed transaction management, distributed metadata management and enforcing security and integrity across the multiple nodes. The DP is an essential component of the DDBMS. It is this module that connects the different local DBMSs. That is, each local DBMS is augmented by a DP. The modules of the DP are illustrated in Figure B.16. The components are the Distributed Metadata Manager (DMM), the Distributed Query Processor (DQP), the Distributed Transaction Manager (DTM), the Distributed Security Manager (DSP), and the Distributed Integrity Manager (DIM). DMM manages the global metadata. The global metadata includes information on the schemas, which describe the relations in the distributed database, the way the relations are fragmented, the locations of the fragments, and the constraints enforced. DQP is responsible for distributed query processing; DTM is responsible for distributed transaction management; DSM is responsible for enforcing global security constraints; and DIM is responsible for maintaining integrity at the global level. Note that the modules of DP communicate with their peers at the remote nodes. For example, the DQP at node 1 communicates with the DQP at node 2 for handling distributed queries.

B.8 Heterogeneous and Federated Data Management
Figure B.17 illustrates an example of interoperability between heterogeneous database systems. The goal is to provide transparent access, both for users and application programs, for querying and executing transactions (see, e.g., [IEEE98 and [WIED92]). Note that in a heterogeneous environment, the local DBMSs may be heterogeneous. Furthermore, the modules of the DP have both local DBMS specific processing as well as local DBMS independent processing. We call such a DP a heterogeneous distributed processor (HDP).

There are several technical issues that need to be resolved for the successful interoperation between these diverse database systems. Note that heterogeneity could exist with respect to different data models, schemas, query processing techniques, query languages, transaction management techniques, semantics, integrity, and security. There are two approaches to interoperability. One is the federated database management approach where a collection of cooperating, autonomous and possibly heterogeneous component database systems, each belonging to one or more federations, communicates with each other. The other is the client–server approach where the goal is for multiple clients to communicate with multiple servers in a transparent manner. We discuss both federated and client–server approaches in Sections B.9 and B.10.
The development in heterogeneous data management was then extended into federated data management in the 1990s. As stated by Sheth and Larson [SHET90], a federated database system is a collection of cooperating but autonomous database systems belonging to a federation. That is, the goal is for the database management systems, which belong to a federation, to cooperate with one another and yet maintain some degree of autonomy. Note that to be consistent with the terminology, we distinguish between a federated database management system and a federated database system. A federated database system includes both a federated database management system, the local DBMSs, and the databases. The federated database management system is that component which manages the different databases in a federated environment.
Figures B.18 illustrates a federated database system. Database systems A and B belong to federation F1 while database systems B and C belong to federation FB. We can use the architecture illustrated in Figure B.18 for a federated database system. In addition to handling heterogeneity, the HDP also has to handle the federated environment. That is, techniques have to be adapted to handle cooperation and autonomy. We have called such an HDP an FDP (Federated Distributed Processor). An architecture for an FDS is illustrated in Figure B.19.


Figure B.20 illustrates an example of an autonomous environment. There is communication between components A and B and between B and C. Due to autonomy, it is assumed that components A and C do not wish to communicate with each other. Now, component A may get requests from its own user or from component B. In this case, it has to decide which request to honor first. Also, there is a possibility for component C to get information from component A through component B. In such a situation, component A may have to negotiate with component B before it gives a reply to component B. The developments to deal with autonomy are still in the research stages. The challenge is to handle transactions in an autonomous environment. Transitioning the research into commercial products is also a challenge.

B.9 Object Data Model
Several object data models were proposed in the 1980s. Initially these models were to support programming languages such as Smalltalk. Later these models were enhanced to support database systems as well as other complex systems. This section provides an overview of the essential features of object models. While there are no standard object models, the Unified Modeling Language (UML) proposed by the prominent object technologists (Rumbaugh, Booch and Jacobson) has gained increasing popularity and has almost become the standard object model in recent years. Our discussion of the object model has been influenced by much of our work in object database systems as well as the one proposed by Won Kim et al. [BANE87]. We call it an object-oriented data model.
The key points in an object-oriented model are encapsulation, inheritance, and polymorphism. With an object-oriented data model, the database is viewed as a collection of objects [BANE87]. Each object has a unique identifier called the object ID. Objects with similar properties are grouped into a class. For example, employee objects are grouped into EMP class while department objects are grouped into DEPT class as shown in Figure B.21. A class has instance variables describing the properties. Instance variables of EMP are SS#, Ename, Salary, and D#, while the instance variables of DEPT are D#, Dname, and Mgr. The objects in a class are its instances. As illustrated in the figure, EMP has three instances and DEPT has two instances.

A key concept in object-oriented data modeling is encapsulation. That is, an object has well-defined interfaces. The state of an object can only be accessed through interface procedures called methods. For example, EMP may have a method called Increase-Salary. The code for Increase-Salary is illustrated in Figure B.22. A message, say Increase-Salary(1, 10K), may be sent to the object with object ID of 1. The object’s current salary is read and updated by 10K.
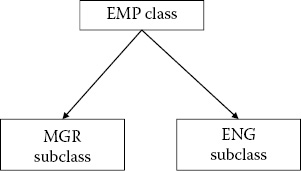
A second key concept in an object model is inheritance where a subclass inherits properties from its parent class. This feature is illustrated in Figure B.22 where the EMP class has MGR (manager) and ENG (engineer) as its subclasses. Other key concepts in an object model include polymorphism and aggregation. These features are discussed in [BANE87]. Note that a second type of inheritance is when the instances of a class inherit the properties of the class.
A third concept is polymorphism. This is the situation where one can pass different types of arguments for the same function. For example, to calculate the area, one can pass a sphere or a cylinder object. Operators can be overloaded also. That is, the add operation can be used to add two integers or real numbers.
Another concept is the aggregate hierarchy also called the composite object or the is-part-of hierarchy. In this case an object has component objects. For example, a book object has component section objects. A section object has component paragraph objects. Aggregate hierarchy is illustrated in Figure B.23.

Objects also have relationships between them. For example, an employee object has an association with the department object which is the department he is working in. Also, the instance variables of an object could take integers, lists, arrays, or even other objects as values. Many of these concepts are discussed in the book by Cattell [CATT91]. Object Data Management Group has also proposed standards for object data models [ODMG93].
Relational database vendors are extending their system with support for objects. In one approach the relational model is extended with an object layer. The object layer manages objects while the relational database system manages the relations. Such systems are called extended relational database systems. In another approach, the relational model has objects as its elements. Such a model is called an object-relational data model and is illustrated in Figure B.24. A system based on the object-relational data model is called an object-relational database system.

B.10 Other Database Sysyems
This section briefly discusses various other database systems as illustrated in Figure B.25. Some of the systems discussed in this book have evolved from such systems.

Real-time database systems: These are systems where the queries and transactions will have to meet timing constraints. Details are given in [RAMA93]. Some of our works on real-time stream-based analytics systems have evolved from real-time database systems.
Deductive database systems: These are systems that use logic as a data model. These are essentially logic programming systems that manage data. More details can be found in [FROS86] and [LLOY87]. Our work on inference control as well as cloud-based inference control has evolved from logic programming systems.
Multimedia database systems: These are database systems that manage multimedia data such as text, audio, video, and images. Details can be found in [PRAB97]. Some of our work on big data management such as managing massive amounts of data as well as social media systems has evolved from multimedia database systems.
Spatiotemporal Database Systems: For applications such as geospatial information systems and motion data management, one needs to model objects with spatial and temporal properties. Therefore, managing spatiotemporal data structures is important for such applications. Some of our work on stream data analytics as well as big data management has evolved from spatiotemporal database systems.
Parallel database systems: These systems use parallel processing techniques for executing queries and transactions so that the speed can be improved. More details can be found in [DEWI90]. Some of our work on cloud-query processing systems has evolved from parallel database systems.
Functional database systems: These systems were developed in the early 1980s. The database is viewed as a collection of functions and query evaluation amounts to function execution. Details can be found in [BUNE82]. Functional systems have impacted data warehousing systems due to the OLAP (on-line analytical processing) models. OLAP models in turn have influenced data mining systems.
Data warehousing is one of the key data management technologies to support data mining and data analysis. As stated by Inmon [INMO93], data warehouses are subject oriented. Essentially data warehouses carry out analytical processing for decision-support functions of an enterprise. For example, while the data sources may have the raw data, the data warehouse may have correlated data, summary reports, and aggregate functions applied to the raw data. Big data analytics has evolved from such data warehouse systems.
We have discussed only a sample of the database systems that have been developed over the past 40 years. The challenge is to develop data models, query and transaction processing techniques as well as security and integrity for database systems that manage zettabyte- and exabyte-sized databases,
B.11 Summary and Directions
This chapter has discussed various aspects of database systems and provided some background information to understand the various chapters in this book. We began with a discussion of various data models. We chose relational and entity-relationship models as they are more relevant to what we have addressed in this book. Then we provided an overview of various types of architectures for database systems. These include functional and schema architectures. Next we discussed database design aspects and database administration issues. We also provided an overview of the various functions of database systems. These include query processing, transaction management, storage management, metadata management, integrity, and fault tolerance. Next we discussed briefly distributed databases and interoperability. This was followed by a discussion of object models. Finally, we provided an overview of the various types of database systems that have been developed. Many of the chapters in this book have their roots in database management systems.
Various texts and articles have been published on database systems and we have referenced them throughout the book. There are also some major conferences on database systems and these include ACM SIGMOD conference series [SIGM], Very Large Database Conference series [VLDB], IEEE Data Engineering Conference series [DE], and the European Extended Database Technology Conference series [EDBT].
References
[BANE87]. J. Banerjee et al. “A Data Model for Object-Oriented Applications,” ACM Transactions on Office Information Systems, 5 (1), 3–26, 1987.
[BERN87]. P. Bernstein et al. Concurrency Control and Recovery in Database Systems. Addison-Wesley, MA, 1987.
[BUNE82]. P. Buneman et al. “An Implementation Technique for Database Query Languages,” ACM Transactions on Database Systems, 7 (2), 1982, 164–180.
[CATT91]. R. Cattel, Object Data Management Systems. Addison-Wesley, MA, 1991.
[CERI84]. S. Ceri and G. Pelagatti, Distributed Databases, Principles and Systems. McGraw-Hill, NY, 1984.
[CHEN76]. P. Chen, “The Entity-relationship Model—Toward a Unified View of Data,” ACM Transactions on Database Systems, 1 (1), 9–36, 1976.
[CODD70]. E.F. Codd, “A Relational Model of Data for Large Shared Data Banks,” Communications of the ACM, 13 (6), 377–387, 1970.
[DATE90]. C. Date, An Introduction to Database Systems. Addison-Wesley, Reading, MA, 1990.
[DE]. Proceedings of the IEEE Data Engineering Conference Series, IEEE Computer Society Press, CA.
[DEWI90]. D.J. Dewitt et al. “The Gamma Database Machine Project,” IEEE Transactions on Knowledge and Data Engineering, 2 (1), 44–62, 1990.
[DMH96]. B. Thuraisingham, editor. Data Management Handbook Supplement. Auerbach Publications, NY, 1996.
[DMH97]. B. Thuraisingham, editor. Data Management Handbook. Auerbach Publications, NY, 1997.
[DQ]. MIT Total Data Quality Management Program, http://web.mit.edu/tdqm/www/index.shtml
[EDBT]. Proceedings of the Extended Database Technology Conference Series, Springer Verlag, Heidelberg, Germany.
[ELMA85]. R. Elmasri et al. “The Category Concept: An Extension to the Entity-relationship Model,” Data and Knowledge Engineering Journal, 1 (2), 75–116, 1985.
[FROS86]. R. Frost, On Knowledge Base Management Systems. Collins Publishers, UK, 1986.
[IEEE98]. IEEE Data Engineering Bulletin, 21 (2), 1998.
[INMO93]. W. Inmon, Building the Data Warehouse. John Wiley & Sons, NY, 1993.
[KDN]. Kdnuggets, www.kdn.com
[KORT86]. H. Korth, and A. Silberschatz, Database System Concepts. McGraw-Hill, NY, 1986.
[LLOY87]. J. Lloyd, Foundations of Logic Programming. Springer-Verlag, Heidelberg, Germany, 1987.
[MAIE83]. D. Maier, Theory of Relational Databases. Computer Science Press, MD, 1983.
[MASS]. IEEE Mass Storage Systems technical Committee, http://www.msstc.org/
[ODMG93]. Object Database Standard: ODMB 93, Object Database Management Group. Morgan Kaufmann, CA, 1993.
[PRAB97]. B. Prabhakaran, Multimedia Database Systems. Kluwer Publications, MA, 1997.
[RAMA93]. K. Ramaritham, “Real-Time Databases,” Journal of Distributed and Parallel Systems, 1 (2),
199–226, 1993.
[SHET90]. A. Sheth and J. Larson, “Federated Database Systems for Managing Distributed, Heterogeneous, and Autonomous Databases,” ACM Computing Surveys, 22 (3), 183–236, 1990.
[SIGM]. Proceedings of the ACM Special Interest Group on Management of Data Conference Series, ACM Press, New York, NY.
[SQL3]. SQL3, American National Standards Institute, Draft, 1992.
[THUR97]. B. Thuraisingham, Data Management Systems Evolution and Interoperation. CRC Press, FL, 1997.
[TSIC82]. D. Tsichritzis, and F. Lochovsky, Data Models. Prentice-Hall, NJ, 1982.
[ULLM88]. J. D. Ullman, Principles of Database and Knowledge Base Management Systems. Volumes I and II, Computer Science Press, MD 1988.
[VLDB]. Proceedings of the Very Large Database Conference Series, Morgan Kaufman, San Francisco, CA.
[WIED92]. G. Wiederhold, “Mediators in the Architecture of Future Information Systems,” IEEE Computer, 25 (3), March 1992.