
The Foundation
SUMMARY
Cloud deployments combine management innovation and technical innovation. They require network bandwidth and connectivity, software that will support flexible and scalable remote operation, and hardware designed for cloud datacenters. Cloud success depends on both technology and management to achieve its goals of technical efficiency and capacity as well as opening new potential for IT-based business. From the view of service management, cloud deployments and even private clouds are form of outsourcings. Clouds must be managed like outsourced services. ITIL guidance on outsourcing applies to clouds. Cloud deployments also require increased cooperation between technical and business specialists in several areas. Cloud deployments, especially SaaS deployments, have generated requirements for rapid incremental releases and have driven evolving software development methodologies that fit well with ITIL continual service improvement.
Information Technology Information Library (ITIL) and service management were introduced in Chapter 3. This chapter goes into some of the unique aspects of ITIL, service management, and cloud implementations and the criteria that often contribute to decisions about developing and deploying cloud services. This includes examining cloud implementations as outsourced services and the relationship between the ITIL service cycle and the development methodologies applied to cloud computing.
Cloud services are, almost by definition, outsourced services—services performed by an external entity. Even when an internal organization provides and manages a cloud, the relationship between the consumer and provider is a form of outsourcing because the consumer has handed over responsibility for the cloud service to the provider. Communications are usually simpler and more collegial when the consumer and provider are in the same organization, but the relationship is still an example of outsourcing. This chapter examines the nature of cloud outsourcing and the relationship between cloud consumer and provider.
Introduction
Chief information officers (CIOs)1 and other IT executives are continually asked to make strategic decisions regarding the efficiency of the IT department and to balance costs against the quality and robustness of IT services. They must deliver increased IT functionality and contain IT costs. Sometimes they are fortunate enough to do both at the same time; at other times, functionality languishes and costs soar.
SUNK INVESTMENTS
A sunk investment is money that has been spent and cannot be recovered. A sunk investment cannot be withdrawn and reinvested somewhere else. Management can withdraw an investment that is not sunk and transfer it from one project to another. Salaries and wages are an example of a classic sunk investment; after they are paid, they cannot be withdrawn and used for another purpose. Money invested in physical IT infrastructure is sunk unless it can be sold at near or greater than its purchase price. For example, after IT purchases a server, the investment typically sinks quickly because little of the purchase price can be recovered by selling the used server.
Sunk investments can contribute to planning mistakes. Human nature tends to hold on to expensive projects with large sunk investments because humans often regret losing sunk investments more than they see value in change. What they may not realize is that whether a project is preserved or ended, the sunk investments are already lost. In IT, overvaluing sunk investments in infrastructure can contribute to wrong decisions. All other things being equal, hanging on to a sunk investment in on-premises infrastructure is a strategic mistake when an investment in cloud services will yield a greater return.
A sure way to guarantee the latter situation, low functionality at high cost, is an inflexible infrastructure that loses its value quickly. The IT department cannot readily repurpose an inflexible infrastructure to support new or enhanced functionality. This puts a drag on IT innovation, and when IT has no choice but to deliver increased functionality, it comes at a high cost in new infrastructure.
This is a bitter downside of the rapid growth of the capacity of computing technology and its relative decrease in cost. The other side of rapidly improving computing is that infrastructure ages fast and rapidly becomes a sunk investment. New functionality, designed to run on current hardware, always demands up-to-date equipment. PC gamers know that the latest games are no fun without the latest and fastest graphics. The same applies to the newest corporate functionality, and both gamers and CIOs are in a tough bind when the budget is limited.
CIOs have an option that gamers don’t have: they can outsource.2 Sometimes a decision to outsource is a way out of continual pressure to acquire newer technology by shifting responsibility for equipment to outsourcers. IT departments have always outsourced services when it makes economic sense.
Cloud computing is a form of outsourcing that can lessen the sting of sinking hardware investments and that can deliver other benefits to IT. Therefore, it is useful to examine outsourcing in general before examining cloud outsourcing. Much of what is unique about managing cloud services stems from its nature as outsourcing.
Outsourcing is both popular and controversial. (See the following definition.) Offshore outsourcing is even more controversial. Outsourcing is often a type of creative destruction in which management replaces inefficient or outmoded internal capacity with services from an external provider.3 Like all creative destruction, disruption is almost a given, and a perfect outcome is rare; however, careful outsourcing is often a sound long-term decision.
OUTSOURCING DEFINED
The essential characteristic of outsourcing is the involvement of an external provider. An external third-party service provider performs an outsourced service. The act of outsourcing transfers a service from an internal to external implementation or establishes a new service via an external provider. When the service provider is located outside national boundaries, the practice is sometimes called offshoring. However, services provided by offshore service providers are not always outsourced. In multinational organizations, the offshore provider may be part of the parent organization.
There are many incentives to delegate the performance of a service to a third party.
Cost
A commonly cited incentive is cost. When an organization uses a service only lightly, maintaining the service internally can be expensive because the service resources remain idle when the service is not used, or an outsourced service may be cheaper because the outsourcer is more efficient at performing the service. This can be because the outsourcer has achieved economies of scale or because they have developed greater expertise in delivering the service. Perhaps vigorous competition between outsourcers has reduced the price. In many cases, outsourcers take advantage of lower labor costs in certain areas. Often, an outsourced service price is temptingly low. However, before a final decision, consider carefully whether the outsourced service will fully replace the in-house service and supply the same quality of service. If the outsourced service does not, hidden costs may drive up the real cost significantly.
Cost-cutting is frequently cited as the reason for offshore outsourcing, and offshoring is often blamed for eliminating local jobs, but offshoring can also increase local jobs. Some companies are finding that offshore services offer an opportunity to expand local resources. A company is not a zero-sum game with a fixed pool of resources in which a gain for one player must cause a loss for another player. Instead, in a well-managed enterprise, allocating resources offshore increases the overall resource pool and opens opportunities that cause other groups to expand. For example, when a software company adds an offshore development team, the company may be able to combine offshore and local teams to deliver innovative and timely products and grow rather than shrink the local development team.
Flexibility
Cost is not the only factor in an outsourcing decision. An outsourced service can offer significant flexibility that an in-house service cannot supply. Growing and shrinking an outsourced service is usually quick and painless. An outsourcer that covers several time zones can offer extended hours that would be difficult to supply in-house at a single location. An outsourcer may be able to offer better coverage during peak times than an in-house organization with a fixed staff.
Focus
The decision to outsource can also be a decision to concentrate on skills and capacities that are core to the mission of the organization. An aeronautics company may decide that datacenter operations skills are not strategic skills in their industry. Instead, they want their IT department to concentrate on developing aeronautics-specific computing applications. Outsourcing datacenter operations can free IT resources to give them the competitive edge needed to be successful and therefore can justify the decision to outsource, even when the outsourced datacenter operation is more expensive.
Skills
Yet another justification for outsourcing appears when an enterprise must quickly ramp up a particular set of skills to meet some contingency. The enterprise may regard the skills as critical and therefore want to develop them internally, but the ramp-up time is too long to meet the contingency. Under those circumstances, they may decide to acquire the skills via outsourcing, at least temporarily until they can build up the skills internally.
For example, a retail company may need to start using big data techniques to analyze their customer buying records. These analysis skills have become mission critical for them in the current environment, and developing internal big data analysis skills are part of their strategic plan, but they need results immediately to compete. Therefore, they may conclude that outsourcing from a firm that specializes in retail big data analysis is tactically wise, even though it runs contrary to their longer-term strategy.
Outsourcing has risks. Although outsourcing often brings flexibility to an organization, one of the worst risks is loss of flexibility. This happens in two interrelated ways.
Lock-in and Dependence
Lock-in is a risk common to many third-party relationships. When a company finds itself in a position where it must purchase goods or services from a single vendor, it is locked in. It can no longer choose its vendor. If the company must use a product or service from a certain vendor or face a major redesign of its services, it has lost the flexibility to choose a more desirable vendor. When an enterprise cannot switch outsourcers without a major disruption, it has also lost its flexibility in vendor choice.
Dependence is another way to lose flexibility. A single vendor may not have the enterprise locked in, but the enterprise can still become so dependent on an outsourced service that it is constrained in its decisions. For example, the aeronautics company that decided to outsource its datacenter operations might decide that an application it developed requires specialized graphics hardware on servers in the datacenter. They may not find an outsourcer prepared to operate the graphics hardware. If the department has reached the point that it lacks the expertise and facilities to deploy and maintain the hardware itself, the options are few and costly. It must either redevelop its datacenter management talent or pay a premium to an outsourcer to supply the specialized service.
Organizations contemplating outsourcing often have to consider their own processes and infrastructure. For example, an outsourced service desk should use diagnostic tools that are compatible with the organization’s own tools or waste time transferring and interpreting diagnostic data. Similarly, if the reports produced by the outsourced service do not fit in with the organization’s reports and report distribution system, they must invest resources to train users and develop a distribution system.
Governance
Whenever another party enters a business relationship, the relationship becomes more complicated, and there are more opportunities for it to go awry. Governing an IT department is straightforward. Executive management sets policies and goals, managers guide people and processes according to the policies and goals, and employees reporting to the manager carry out the processes and roll out the products and services.
In this situation, accountability is clear. When executives set well-chosen goals and policies that result in profits and meeting other enterprise goals, boards and stockholders reward them. When managers permit policies to be broken or goals to go unmet, executives hold managers accountable. Managers hold their employees accountable for their duties. This simple system with clear lines of responsibility and accountability is relatively easy to govern. All the roles are members of the same organization and ultimately answerable to the same management. Tools like responsibility assignment (see the “Responsibility Assignment” sidebar) can be used to analyze roles in performing tasks.
RESPONSIBILITY ASSIGNMENT
Responsibility assignment matrices are useful in analyzing roles in service management and business in general. The goal is to identify the role of each person involved in a task.
- Responsibility: The person responsible for a task does the work to complete the task.
- Accountability: The single person accountable for a task approves the work to signify that it is completed satisfactorily and is liable to upper management for the results of the task.
- Consult: A consultant, usually a subject-matter expert and sometimes an external contractor, comments on a task before it is complete but usually is not a decision maker.
- Informed: Informed individuals receive reports after decisions are made but do not provide input to decisions.
Analyzing these roles in a task is often helpful in spotting bottlenecks and points of confusion in service delivery.4
When a service is outsourced, responsibility and accountability are not so simple. The service provider has managers who are accountable for the execution of the services delivered by the provider, but they are accountable to the service provider management. The external service provider is accountable to its own management, which has its own goals that seldom align exactly with the interests of the consumer of the outsourced service. When something goes wrong, there is no “single throat to choke,” or an individual accountable for the service.
Consider the example of an outsourced service desk. Service is bad. The service desk ignores high-severity incidents disrupting a line of business. When the service desk is internal, the manager of the disrupted business would call the service desk manager. If a call did not remedy the situation, the next step would be a call to the service desk manager’s manager, perhaps the chief information officer. If that didn’t work, there is always the chief executive officer (CEO). At some point in the escalation, the service quality improves or there are adverse effects on careers.
The escalation follows a different path when the service desk is outsourced. The service desk manager is not in the company directory for business managers to call. Different organizations handle outsourcing differently, but a hard-charging business manager would probably go directly to the CIO, and the CIO would have to sort out the situation. A CIO does not have anyone on his or her team directly responsible for the conduct of an outsourced service because that responsibility lies with the outsourced service provider, but the CIO probably does have someone who manages the service relationship. That person may have contacts in the outsource service provider and may be able to smooth over the problem, but the service relationship manager does not have the same kind of leverage with the outsourcer’s manager as the internal business manager has over the internal service desk manager. The service relationship manager is a diplomat negotiating with a foreign entity, not a boss giving orders. If the problem represents a real clash of interests, the only recourse is to go to the service contract and service level agreements and enter into legal discussions.
In this environment, even simple issues can become complicated. If the service contract is not written carefully and the outsourcer is not eager to accommodate its consumers, trivial issues can become major annoyances. This represents an important risk in all forms of outsourcing: resolving misunderstandings and conflicts between the consumer and provider. It also depends upon a diligent inspection of the outsourcer’s practices and reputation as well as a carefully prepared service contract and service level agreement before the relationship begins. Business relationships are seldom without issues. Without a clear and efficient method for resolving issues, blindly entering into an outsourcing agreement can be disastrous.
Diligent examination of outsourcers and the preparation of service contracts and service level agreements may seem remote from the responsibilities of the technical members of the IT department. Nevertheless, engineers will often be the first line in dealing with outsourcers. They have an interest in dealing with reliable and cooperative outsourcers with a solid contract that addresses technical relationships as well as business relationships. Service level agreements are a special point of engineering concern, particularly when the outsourced service is not directly exposed to the lines of business. When the IT department is accountable for a service that is performing poorly or unreliably because an outsourced service is misbehaving, the IT department is in a painful bind if its service level agreements do not allow IT to put pressure on the outsourcer. The bind is especially tight when the outsourcer’s business manager is talking about profitable business agreements with the consuming business manager while the IT department is desperately trying to convince the business managers that the outsourced technology is at fault.
IT employees involved in outsourcing must develop some skills that they may not have had before. Researching outsourcer reputations, for example, is a long stretch from coding and writing specifications. It is usually the realm of corporate procurement negotiators. Nevertheless, the engineers of the IT department are sometimes the only people in the organization who can recognize inferior or questionable technical practices. In addition, determining appropriate metrics and thresholds for service level agreements is often a challenging technical problem and can determine both the cost and ultimate success of an outsourcing project.
Liability
Outsourcing can become a liability issue. In many cases, organizations are required by either regulation or business practice to retain end-to-end control of their business processes. Placing a portion of a process in the hands of an outsourcer does not alter the need for end-to-end control. Organizations outsourcing services must keep the need for control in mind, especially in the service contract and service level agreements.
The complex chain of responsibility in an outsourced service can become an issue for those concerned with due responsibility for the organization’s assets and critical processes. When a department store uses an outsourcer to back up credit card and customer data, the department store remains responsible for the customer data. If a malefactor breaches the outsourcer’s security, the department store, not the outsourcer, is answerable to their customers for damages. The provisions in the service contract will probably determine the liability of the outsourcer, and the outsourcer may or may not have the assets to compensate the department store and their customers. To avoid situations like this, an auditor may require that the outsourcer offer a bond or submit to additional controls in order to protect the department store’s investors from damage.
Security
Security is another risk involved with outsourcing that is closely related to liability. If the service contract between the consumer and the outsourcer shifts all liability to the outsourcer, as unlikely as that may be, the consumer can still be harmed by a security breach. For example, the outsourced service provider may pay all the direct costs of a security breach, but a reputation for lax security may settle on the organization that outsourced the service. This topic will be treated in more detail when discussing security for outsourcing clouds.
Outsourcing Cloud
Outsourcing to clouds is a specialized form of outsourcing and shares many characteristics with outsourcing in general. The advantages and risks that come with outsourcing in general apply to cloud deployments on external providers, but clouds also have their own special advantages and risks.
Incentives
The incentives for entering into a cloud-outsourcing project are a superset of the incentives for outsourcing in general, but they have special technical aspects.
Cost Reduction
Like outsourcing in general, cost reduction is frequently cited as a reason to outsource services on clouds. Some of the ways in which clouds reduce costs have been discussed in previous chapters. Many of these are economies of scale similar to the gains from other forms of outsourcing, but there are gains that come from the technical nature of cloud. The scale and diverse loads of cloud datacenters help provide services that are resilient in the face of variations in load and datacenter faults. Consequently, clouds can supply reliable services while limiting expensive redundancy and under-utilization at a lower cost than a local installation that has to allocate extra equipment capacity to cope with occasional peak loads. Datacenters designed for energy efficiency produce greater computing capacity with less energy than smaller installations. Large datacenters can also locate close to energy sources. They can also be located and designed for efficient cooling. These all add up to substantial cost reductions.
Costs based on metered usage can also generate savings for cloud consumers that may not be available with other forms of outsourcing. Many forms of outsourcing help replace capital investment with operational expenses, which makes a service easier to manage financially. Usage-based costing adds to these benefits by aligning operational expenses to fluctuations in business.
Availability of Capacity
Outsourcing to the cloud provides opportunities to use technologies that require more computing capacity than an organization could obtain on its own. This is similar to a small local government unit that hires a professional economist to perform a strategic economic analysis. The organization does not have the resources to perform the analysis itself. Without the economist consultant, the organization would have to go without the analysis and expose itself to strategic blunders. In the case of cloud outsourcing, the critical resources are computing capacity for special projects.
Big data analysis is a good example of this in the cloud. Big data requires big computing resources, orders of magnitude larger than a small or medium business is likely to have. Even large enterprises seldom have the facilities to take advantage of big data. The data sources for big data analysis come in terabytes and petabytes, not the gigabytes that organizations are accustomed to managing. Rapid analysis of data of this magnitude requires thousands of computing processors. By using cloud resources, organizations of all sizes can obtain the capacity to perform big data analysis that they could not perform on their own equipment. These analyses can yield patterns and insights for many purposes including tailoring their services to customers that offer advantages over competitors who do not analyze. In this case, although the cost of cloud computing resources is less than on-premises resources, the need for the results rather than cost savings drives the decision.
Flexibility
Enterprises struggle with flexibility. Large and successful enterprises have a long string of products and services that have done well in their marketplace. However, times and environments change. In 1985, a stand-alone word processor that could perform basic editing and formatting functions was a killer application. Today, that product would compete against free products and well-established products that go far beyond basic word-processing functions. If the vendor of a 1985 word processor wanted to compete today, it would need to have the flexibility to add many features even to match the free open source offerings. An enterprise that is not able to respond positively to a changing environment struggles.
Small enterprises and startups face similar problems. They are looking at the future, the products that consumers will want a year or five years in the future. But crystal balls are murky. Every innovation and every social and political movement changes our vision of the future. Successful small enterprises roll with change and change their plans and goals as the perceived future changes.
Organizations competing in this changing environment retrain, reallocate, grow, and shrink their personnel frequently to keep up with change. However, their investment in physical infrastructure is not so easily changed. Both large and small enterprises are in a continual scramble to wring value from their sunk investments in depreciating hardware. Outsourcing to cloud computing offers a way out of this scramble. Instead of investing in rapidly sinking assets, cloud computing provides services that can scale up for business peaks and down for less active periods. This pay-as-you-go model can be very efficient, especially for smaller businesses with less capital.
Each service model affects the distribution of skills in the IT department differently. Outsourcing infrastructure following an IaaS model eliminates the need for skills in managing physical hardware, but it accentuates the need to manage applications running on virtual systems. These skills have some resemblances to physical hardware management, but they are also profoundly different. Instead of worrying about physical factors such as cabling and cooling, virtual system managers have to track images and configurations of virtual machines, which can change faster and with less authorization than physical systems. Patch management takes on new dimensions when patches to running both machines and their images must be managed. Instead of rushing out to the datacenter floor to replace a failing component, they must contact the cloud provider when signs of physical failure appear, which can be hard to detect in a virtual environment. Sometimes diplomacy has to replace technical skill. The total effort required to manage a cloud IaaS deployment will free physical hardware management skills for core activities, but some training may be required to deal with the virtual environment.
A PaaS deployment simplifies development and deployment by supplying development tools and utilities that the consumer does not have to install or maintain. This simplifies administration by shifting responsibility for these tools and utilities from the local staff to the cloud provider. This allows the consumer staff to focus on the unique aspects of the software needed for their enterprise.
SaaS takes this a step further and removes responsibility for the installation, maintenance, and administration of the SaaS-supplied software. This means that the local staff can concentrate on the process the application supports rather than managing the application.
The flexibility offered by cloud computing can be the difference between success and failure for an organization. It can move them out of the sunk hardware investment bind. Large organizations can avoid irrecoverable hardware investment. Smaller organizations avoid large outlays for computing assets. Cloud flexibility also often permits small organizations to operate with some of the efficiencies of a large organization without difficulties that come with size.
Risks
Like incentives to cloud outsourcing, the risks involved in cloud outsourcing are all similar to the risks of outsourcing in general, but the technical nature of cloud computing adds a layer of technical issues. Therefore, outsourced cloud deployments usually require more technical input than typical outsourcing agreements. Outsourcing to a cloud provider deals with a specific commodity: computing capacity, which is a technical resource that most enterprises use to solve business problems.5 Unfortunately, business managers may misunderstand and over- or under-estimate its importance.
Two kinds of risks are involved in outsourcing to cloud. The first involves the cloud environment. A crash or performance degradation of a cloud datacenter exemplifies this kind of hazard.
Another kind of hazard lies in cloud outsourcing agreements, which are often more technical and less business oriented than other outsourcing agreements. A traditional service desk outsourcing agreement has provisions such as hours of operation, length of call queues, issue resolution expectations, and so on, which are all easily understood by a business manager. Adoption of SaaS service desk software is different. The requirements for an outsourced service desk for the most part remain with the SaaS consumer. The local service desk agents determine the hours the service desk will open incidents. Keeping the call queue down depends on the number of local agents assigned, not the SaaS provider, and the speed and quality of incident resolution depends on agent knowledge and diligence.
Or so it seems. When the SaaS service is performing as expected, the local service desk department is responsible. But services do not always perform as expected. Servers crash. Patches can be misapplied. Configuration changes can be botched. When these unfortunate events occur, the service desk may be inaccessible during normal operating hours, call queues can lengthen, and incident resolution can fall or cease, through no fault of the local agents.
A robust cloud agreement should contain service level metrics, which may be difficult for business managers to translate into terms that affect their business. If the same service desk were to retain their service desk staff but subscribe to a SaaS service desk product, the service agreement would take into account the technical aspects of the outsourced software and hardware operations. If they do not receive adequate technical input, the metrics could be ignored or set too low to effectively protect business interests.
Security
All outsourcing, including cloud outsourcing, expands the security surface; that is, the points of security vulnerability increase. Adding an outsourcer brings all the points of vulnerability in the outsourcer’s organization and infrastructure to the table in addition to the vulnerabilities of the outsourcing consumer. Expanding the security surface does not imply that an organization becomes less secure. It only means that the organization has new points that must be secured.
Sometimes, security itself is outsourced. A non-IT example of outsourcing security is hiring a commercial security service to supply guards at a company event. Hiring guards may increase security, but the company hiring the security service has extended its security surface to include the integrity of the guards from the service. If those guards are not prepared to do their job, the event might become less rather than more secure. In choosing security services, a prudent consumer seeks to avoid dangers from the extended security surface by choosing a reputable firm with well-trained and certified personnel.
Using outsourced cloud services is much the same. The security surface expands to the personnel, processes, and infrastructure of the cloud provider. The security surface may expand, but the level of security will increase if the cloud provider supplies well-secured services. It is the job of the cloud consumer to decide whether the services are secure.
Service Contracts and Service Level Agreements
In outsourcing services, the service contract and the service level agreement6 are the most important documents for evaluating the safety and security of a service. Cloud services, SaaS especially, often do not have explicit service contracts or service level agreements. The cloud consumer must be cautious. Services used for some purposes will cause serious harm if they are unavailable, lose data, or allow unauthorized access. The extent of the harm depends on the business and the purpose. Services that are designed for casual noncritical use can get by without guarantees or contracts, but it can be dangerous to rely on them when their failure will cause damage.
Cloud backup services provide a good example. In some circumstances, losing data can be troublesome but not threatening. Losing the data on a personal computer used for recreation is annoying but scarcely an existential threat. On the other hand, authors losing their manuscript collection may result in both legal and financial trouble. The author must scrutinize a backup service carefully; a recreational user should too, but the need is not as great.
A number of reputable services provide secure and reliable backups. A consumer is tempted to think that these services will completely replace their local backups. This may be true, but some reputable cloud backup services do not fully replace similar on-premises services. These services synchronize on-premises files with files on cloud servers. The files are available on any computer connected to the Internet to anyone with the proper credentials and authorizations. These files are not dependent on the on-premises facilities. A disaster on the organization premises will not affect these files. Especially for home users, this may be better than a local backup that may be destroyed along with the computer in a home disaster.
Nevertheless, the service may not protect the files from a common cause of having to restore files from backup: files deleted by user mistake. Most users hit the Delete key at the wrong time more often than disks crash or tornados strike. On operating systems such as Windows, the trash receptacle is some protection, but sometimes users delete the trash permanently before they realize not all the content is trash. However, even when a file is deleted permanently, the file can still be restored from a recent local backup.
If there is no local backup and the synchronization backup service permanently deletes a file on the server when the user permanently deletes a file locally, the file is likely to be gone forever.
In addition, many consumers consider synchronized permanent deletion to be a desirable feature rather than a defect: if the service charges by the volume of data stored, permanently deleting files from the server avoids paying for storing unwanted data. In addition, permanent deletion is the ultimate privacy. However, if a consumer blindly assumes a cloud backup service can restore permanently deleted files like an on-premises backup, they are vulnerable to inadvertent loss.
To avoid unfortunate events like this, cloud service consumers have to make an effort to understand thoroughly the cloud service they are subscribing to and what the provider warrants. Above all, avoid assuming that a cloud service will provide the exact features and level of service of the on-premises version. Cloud services can be more secure and reliable than on-premises services, but they are also dangerous for the unwary.
Certification
An effective way for a cloud consumer to protect itself from a provider’s vagaries is to look for provider certification. There are a number of forms of certification available. Not all are helpful to every consumer. Aspects of a cloud service that are critical to one consumer are not to another. A legal firm subscribing to a cloud e-mail service will probably be concerned about electronic discovery in which prompt and complete removal of documents designated for deletion is paramount. A healthcare firm is likely to be concerned about the Healthcare Insurance Portability and Accountability Act (HIPAA) privacy regulations. Certification satisfactory for a law firm may not be helpful to a healthcare organization, and vice versa.
Consumers have to be cautious with certification in several ways. International Organization for Standardization (ISO) 27001 is an important general service management standard that applies in many different circumstances. However, consumers have to be aware that ISO27001 certifies the processes that the cloud provider uses to establish security controls, not the security controls themselves. ISO27001 is an important standard and providers that have obtained ISO27001 certification have taken an important step toward security, but the security controls they have developed under ISO27001-compliant processes may not be the controls needed by any given consumer.7 The consumer has to be aware of what has been certified as well as the certificate.
Another important certification is the Service Organization Controls (SOC) 1, 2, and 3 auditor’s reports. SOC 1, 2, and 3 are guidance issued to auditors by the American Institute of Certified Public Accountants (AICPA) in its Statement on Standards for Attestation Engagements No. 16 (SSAE16). SSAE16 replaced SAS 70 in 2011.8,9
SOC 1 is roughly the equivalent of SAS-70. It does not mandate that specific controls be in place, only that the controls that are included in an audit report be satisfactorily auditable. It is up to the consumer’s auditors to determine the effectiveness of the controls for the consumer’s purposes. SOC 1 is useful to sophisticated service consumers who perform their own audits of the provider controls, but it is less useful to consumers who do not plan to execute their own audits.
SOC 2 and 3 are more specific and suited to the needs of less knowledgeable consumers with fewer resources for evaluating a provider. These reports address controls. The SOC 2 report was designed to be private and disclosed only to limited stakeholders. Nevertheless, a SOC 2 report is much more useful for consumers who do not plan their own audits.
The SOC 3 report was designed to be a public document and applies directly to cloud services. It can be posted on a web site and distributed freely. The SOC 3 does not report on the tests run or other details of the system, only the results of examinations of controls on security, availability, processing integrity, confidentiality, and privacy of services. A SOC 3 report is suitable for consumers who do not have the capacity or need to evaluate a provider’s service in detail.
There are organizations that offer provider certification for specific purposes without the support of any legal or standards status. For example, there is no public standard for HIPAA compliance certification, but some organizations offer compliance certificates. These certificates can be useful, but the consumer must do their own due diligence on the value of the certificate.10
Identity and Access Management
Access and identity management (AIM) requires attention when outsourcing to cloud. Most organizations have robust AIM to control access to departmental and corporate IT systems.11 The employee onboarding and offboarding process usually handles entering and removing employees from AIM. Since clouds are often new additions to the IT system, cloud access and authorization may not be included in corporate AIM.
A robust AIM collects all an employee’s system privileges in one place. An employee’s identity is established and verified following consistent corporate standards, and when all authorizations are kept in one place, there is less chance for inconsistent authorizations. When cloud access is not in AIM, someone has to manage a separate cloud access system and keep it aligned with corporate AIM, which often ends up as an error-prone manual task. When an employee changes jobs within the organization, someone or some process has to change both the corporate AIM and the cloud AIM. The solution to this challenge depends on circumstances. Occasionally, simple communication is adequate; the cloud administrator and the AIM manager keep in communication and keep the systems aligned.
In organizations of any size, a more sophisticated system is required. This will depend on the sophistication of the corporate AIM and the cloud. Security Assertion Markup Language (SAML)–based federation offers an elegant solution.12 Using SAML, corporate, and cloud identities and authorizations appears interchangeable. An employee logged in to the corporate system is also identified to the cloud system, and a person attempting to log in to the cloud system must be identified in the corporate system. SAML also supports sharing authorizations.
Unfortunately, the federation of corporate and cloud AIM is not always possible. Both the corporate and cloud systems must support some form of federation, which is not always available. Then a process or practice must support federation. Sometimes even that is difficult. When a department or an individual obtains cloud access without corporate involvement, the onus falls outside the IT department. Perhaps the worst possibility is that of an off-boarded employee who remains in the cloud AIM, giving a potentially disgruntled nonemployee access to corporate assets, which is a well-known security disaster scenario.
Iterative and Incremental Development and ITIL Service Management
The Deming Plan-Do-Check-Act cycle is the foundation of ITIL continual service improvement. Understanding the ITIL interpretation of the Deming cycle is the key to the practice of cloud service management. A robust service improves as it responds to the necessities of production and a changing environment.
Unfortunately, the ITIL approach sometimes appears to run counter to trends in development methodologies. Many developers look at the ITIL service management cycle and the division of service development into segmented stages with some skepticism. Superficially, and as it is too often practiced, service development appears to follow the waterfall development model that was once held up as the ideal development methodology but has been criticized for some time.13
This is a serious discrepancy. ITIL practices have driven the improvement of IT services for decades. At the same time, waterfall development methodologies have been identified as a cause of development failures. In place of the waterfall, more iterative and incremental methodologies (see the following definition) have become much more important, especially in cloud implementations. Continually updated SaaS implementations are often held up as examples of the iterative style of development. Large web commerce sites are usually developed iteratively and incrementally. The difficulties in rolling out such sites as healthcare exchanges can be at least partially attributed to adherence to a waterfall model.
ITERATIVE AND INCREMENTAL DEVELOPMENT DEFINED
Beginning software classes teach a simple methodology: determine what the software is intended to do, consider ways in which code could perform the task and choose the best, write the code, test it, and hand in the assignment. This methodology works well for classroom exercises and not so well for large projects. An alternative method that scales well is to build the software a small part at a time, delivering a possibly incomplete but usable and defect-free product at regular intervals until the deliverable meets project goals. Each incomplete product represents an increment. The process used to develop each incomplete product is an iteration.
Nevertheless, the ITIL cycle and iterative development are based on similar principles, and they are reconcilable. Iterative and incremental approaches such as Agile development14 are also based on the Deming cycle of repeated designing, testing, and improving. In other words, both iterative development and ITIL have the same foundation.
Waterfall Development
The name waterfall comes from projects organized into stages with barriers between each stage. Each waterfall project stage ends with a waterfall that marks a point of no return. When the project progresses from one stage to the next—“goes over the waterfall”—there is no going back. For better or for worse, the project team must now complete the next stage. When the project misses a deadline for a phase, managers must extend the delivery date or invest additional resources into the next phase of the project to make up the lost time. In an all too familiar failure scenario, the investment in each phase is fixed, and pats on the back and bonuses are handed out when a phase is on time and budget. To achieve this, problems are sometimes glossed over and passed on to the next phase.15 The gap between plan and reality builds as each phase is marked complete. Eventually, the planned completion date slides by. At that point, a crisis is declared. Eventually, either the incomplete deliverables are accepted, more is invested to bring the project to true completion, or the project is abandoned.
A waterfall project follows a clear progression: analyze before specifying requirements; design only after requirements are locked down; don’t write a line of code until the design is approved; no system tests until the unit tests are complete16; when the project passes system tests, roll out the entire project in a big bang.
All too frequently, the big bang is a bomb. The code is unstable, functionality is missing, and the cost overrun is staggering. Large government software projects traditionally followed a strict waterfall model, and the waterfall model still influences many projects. This has led to some notable apparent failures such as the 2013 rollout of online health insurance exchanges.17 A disastrous big-bang rollout of a large project followed by a frenzy of activity to patch the failing software has been a common in the software industry.
Why does this happen? There are many reasons. Tossing problems down the waterfall is only one aspect of the problem. Software is complex, and the environment in which it operates is even more complex. Test beds seldom completely reproduce the environment in which a production service must operate, and differences between the real and test environments can let defects pass through that render a service unstable or unusable in production. The larger than expected volumes of users that bring down web sites during Super Bowl halftimes can be held up as an example of an inadequate test environment.18 Software developers can misinterpret finely nuanced designs. Outright design flaws may appear only in hindsight. Requirements often change faster than software can be developed. The user base may be larger, smaller, or less well trained than the product was designed to support, or there may be unanticipated performance requirements or network issues.
There is a truism: software changes the requirements that the software was designed to meet. When automation eliminates one bottleneck, the next one appears. When automation eliminates one source of errors, it reveals a previously hidden source. Automating one process step brings to light a weakness in another step that cannot handle the automated volume. A business manager may see that an automated voice recognition unit achieves its goal of expediting telephone call handling, but it alienates customers. In other words, a perfectly planned and executed waterfall software project may still fail because it changes its own requirements.
These problems, and others, with waterfall development models have been evident for a long time, and many development organizations have chosen to move away from a waterfall model. There are many alternative methodologies in use, but the one that has gotten the most attention recently is iterative and incremental Agile software development.
Agile takes apart the requirements-design-code-test-rollout sequence and turns it into what Agile calls sprints. A sprint is a short (usually a month or less) flurry of activity that addresses a few requirements and builds a deliverable that could be acceptable to a customer with that set of requirements. During the sprint, all the traditional participants—analysts, designers, coders, testers, onsite installers and trainers, and customers—work together to produce a product that may have limited functionality but is deliverable. Ideally, customers in a real production environment test the product of the sprint. In earlier sprints, the deliverable may not be placed into production, but customers and those close to the customer, not just quality assurance specialists, examine the results of each sprint.
Each sprint builds on previous sprints adding features and meeting requirements that were not addressed in the previous sprint. The work of the sprint itself may reveal new requirements and valuable potential features. Old requirements may be discovered to be irrelevant during a sprint. Designs change to meet the evolving circumstances, and the product is exposed to real environments as soon as possible. Reliability, functionality, and desirability of the product to real customers measure the progress of sprints. As the product becomes more complete and rich in function, it may be rolled out to more and more customers. When the project reaches completion, it is likely to be in use by a portion of the user base and ready to roll out to the entire user base, without the unpleasant surprises that come with a traditional big bang. In addition, this method of development fosters products that can be rolled out in phases by new customers to minimize the effects in their environments.
Hypothetical Iterative Rollout
A hypothetical iterative rollout might occur like this. The project is to develop an online life insurance sales site. The first public rollout might be a display-only web site that lists life insurance products and sends customers to agents on phones. In the second phase, the developers add a sign-on. Customers can now sign on and leave their phone numbers for agents to call them. In the next phase, customers can enter their own health information that agents use to price policies. The next phase might automatically price each policy based on the entered health information. In the final phase, the customer can complete the entire insurance purchase online. After a number of customers have purchased insurance smoothly and without issues, the site is widely announced with full publicity.
In the background, the development team steadily gains knowledge of the behavior of their product in increasingly complex circumstances. Instead of a waterfall, the process is iterative in which each phase, or sprint, executes all the phases of the old waterfall model. Before the site starts accepting substantial data from the customer, the developers know their sign-in works smoothly. Before the site begins using health information, the developers become familiar with the data that real customers enter. They check their ability to calculate prices accurately before they sell policies. When they complete the project, the final rollout is an anticlimax because the software has already proven itself in a real environment.
There are many variations on the iterative development theme. However, in one form or another, iterative development is widely used today. Large web commerce sites are usually built incrementally, feature by feature, and tested incrementally with segments of the customer base rather than rolling out the entire site at once.
ITIL Cycle
The Deming Plan-Do-Check-Act (PDCA) cycle is the foundation of ITIL continual service improvement. This cycle is the underpinning strategy for ITIL practices. Without the cycle, service management is a static set of rules that could not keep up with the rapid improvements in computing and infrastructure that characterizes IT today.
The ITIL interpretation of the Deming cycle is the key to the practice of service management in general and cloud service management in particular. Technology has improved at an ever-increasing rate, forcing IT change to accelerate proportionately. A robust service undergoing continual improvement responds to the necessities of production and changing environments. ITIL practices provide a systematic approach to establishing a robust policy of continual IT improvement.
ITIL has prescribed activities and processes for the phases in the ITIL cycle. In most ITIL implementations, humans, not software, execute most of the activities and processes of each phase. In these implementations, software may play a role, but the activity is primarily human. For example, in change management, a software-implemented configuration management database (CMDB) is usually required for ITIL change management, but it is a tool used by humans in a larger change management process, which plays a crucial role in service operations. The ITIL practice addresses a CMDB, but it is more concerned with the humans using the CMDB in change management, not the CMDB software. This is sometimes confusing to developers who are used to implementing designs in software rather than building software into a management practice.
If a service is established and placed into production in a single iteration of the ITIL cycle, ITIL looks like a waterfall model. When the ITIL cycle functions over a longer period, it becomes clear that the phases are iterative rather than a waterfall. The same applies to iterative development. If a project were required to be completed in a single Agile sprint, it would be difficult to distinguish the single iteration from waterfall development. However, such single-cycle projects violate both the spirit of ITIL and iterative development.
From a development standpoint, the ITIL cycle can be nearly invisible. Typically, software developers are called in during the ITIL transition phase, after both the strategy and design phases have completed. When the software project is complete (in other words, when it passes all the tests that were passed down from design and strategy) and all the test deployments are complete, the developers go on to another project and the service proceeds to the operations phase.
Developers see this as a waterfall followed by a big bang. The developers may feel that they have a set of immutable requirements thrown over a waterfall by the ITIL strategy and design phases. Development has only one chance to get the software and hardware right before final testing. When testing is satisfactorily completed, the project flows over another waterfall into operations. The only redeeming feature is that ITIL transition testing is extensive and involves test implementations; never mind the practical caution that testing is the first thing to go when projects lag.
This is not the way ITIL is supposed to work. Continual improvement assumes that improvement is always possible and the environment in which the service performs is always changing, requiring changes to the service. This applies to software as well as human-conducted processes. See Figure 6-1.
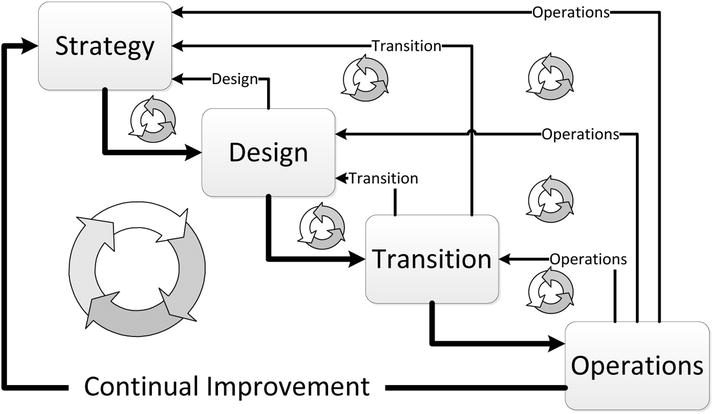
Figure 6-1. ITIL phases have nested cycles
Following best practices, each ITIL phase represents an overlapping team. Some members of the strategy team are likely to also participate in the design and transition teams, even the operations team. These teams do not disappear when a service moves to another phase. Although the size of these teams may ebb and flow with the needs of the organization, they all function simultaneously and are likely to contribute to a range of services. This persistence of teams is generally not characteristic of waterfall models in which teams tend to disband after their task is complete. Instead, ITIL works in cycles within cycles.
DevOps, a portmanteau of “development” and “operations,” is a development methodology, an organizational plan, and a collection of tools. It has arisen in response to demands for more rapid and reliable software development, especially software deployed on clouds. The purpose of DevOps is to speed the development cycle and make it more reliable while tailoring applications more closely to operational requirements. The foundation of DevOps lies in Agile principles that insist that all stakeholders be active in the development process. DevOps goes a step further and suggests that development and operations in an IT department should meld into a single group. Operations people should contribute to design, code, and testing, and developers should directly experience the challenges of operations.19 The combined development and operations group concentrates on relatively small, incremental releases targeted on specific issues. The combined group produces these incremental releases and places them into production to a brisk cadence.
DevOps also involves tooling. Rapid releases are impossible without automated builds and testing. There is no extra time for assembling and disassembling test environments that emulate production, although realistic test environments are critical to software quality. With an assembled test bed, engineers should build effective tests for new features, not execute critical but tedious regression tests. There are commercial products for addressing all these tooling issues. CA’s ca DevCenter portfolio is an example.20
Strategy
ITIL service strategy was discussed in Chapter 3. It is usually thought of as the first stage in the continual improvement cycle. The important tool of service strategy is the service portfolio, a master list of all the services the IT department offers, plans to offer, and has offered in the past. The service portfolio places all the information for developing an overall strategy into a single repository. It identifies all the stakeholders in a service and the requirements for the success of a service that provides an optimal solution for the entire organization. A service strategy addresses the full life cycle of a service from its inception to its eventual removal from operations.
The incentives and risks involved in cloud deployment are part of strategic decisions. Cloud deployment models—private, community, private, and hybrid—often are an important part of service strategy because they reflect high-level investment policy. Choice of service model (IaaS, PaaS, and SaaS) may be strategic, although they are more likely to be part of the service design.
Design
The ITIL service design phase can be confused with software design. Although service design can involve software design, the service design phase is more concerned with people and processes as much or more than software. During the service design phase, business managers, service managers, and other stakeholders translate strategy into a design to implement in the transition phase. Software design, in the sense of choosing code patterns and software architecture, is usually left to the next phase, transition. For software, the output of the design phase describes what the software does, not how it should do it. The output may be a set of use cases or other forms of requirements that the software design must implement.
The design phase provides feedback to the previous strategy phase and, unlike a waterfall model, may initiate a change in strategy.
Transition
Transition is the phase in which services are implemented and put into production. This is the phase in which the software is developed, tested, and rolled out. Often, developers see only the ITIL transition phase in action. However, the transition phase offers feedback to both the design and strategic groups, continuing to hone strategies and designs as the service transitions from a design to a working service. This means that software designs may iterate all the way back to strategy as they are incrementally developed.
ITIL practices are often applied to services that affect the mission of the organization with large numbers of users relying on the service for critical activities. Failed rollouts for services like this can be costly. As a consequence, ITIL transition practices contain much guidance on how to test a service before putting it into operation. These tests include software, people, and process and range from software unit testing to testing user-training systems. The consequences of a failed test may be a software defect repair, a service design change, and even a strategy shift, and all of this may take place at the same time.
Operations
When a service has been fully transitioned into production, it enters the operation phase. ITIL has several concerns during operations. The goal is to keep the service working at peak efficiency while it meets the needs of the service consumers and efficiently meets enterprise goals. ITIL includes several functions for achieving this, including service desks, change management procedures, and application management. One of the most important functions is monitoring operations. The operations team is charged with monitoring the deployed process to determine whether it is meeting the goals and requirements laid out by the strategy and design teams. Operations works with the transition team to determine whether the service meets production requirements. The operations team often works with business teams to measure user satisfaction with the service. In this role as the monitor of production services, operations provides important input to the strategy team and completes the ITIL Deming cycle.
Continual Improvement
The continual improvement aspect of ITIL means the Deming PDCA cycle never ends. Services may be stable for long periods, but service managers must always be on the alert for changing requirements and opportunities for improvement. Iterative development is also a form of a Deming PDCA cycle. Each iteration is a repetition of the cycle. The iterative team plans the sprint. Developers, product managers, business managers, users, and other interested parties all participate. Next, in the Do stage, the team implements the software for the sprint. This includes code from previous sprints as well as new code. As the team members code, they operate the software and check its behavior against their goals, executing the Check phase. When they understand the behavior of what they have built, they act on their conclusions and begin a new cycle with planning for the next sprint, which may involve requirement and overall design changes as a result of the experience of the previous sprint.
ITIL and Iterative Development
The ITIL Service Strategy, Design, Transition, Operation cycle is not far from an iterative development cycle.
The ITIL cycle starts further back in the history of a project and stretches further into the future. Usually, certainly not always, iterative software projects start with a distinct end already determined, such as “build a new asset management system with these characteristics” or “create a SaaS version of this on-premises application.” There were undoubtedly many hours of discussion and planning before the iterative project began. Business and technical leaders determined the feasibility and desirability of the project. Someone thought about how the project would combine with and integrate with existing technology. The finance department worked on budget and financing plans. Marketing had their say. This preproject planning is the content of the ITIL Service Strategy phase.
The ITIL cycle for a service ends only when the service ceases to operate, and even then, it lives as history in the service portfolio. Agile projects usually end when their goals are complete.
ITIL and iterative development combine well. In ITIL practices, developers, as subject-matter experts on the software used in a service, have a voice in each of the ITIL service lifecycle phases. However, since ITIL is concerned with services in a broad context that includes both people and processes as well as technology, software development is only one aspect of the service lifecycle, unlike development methodologies that touch lightly on the other aspects of a service but concentrate on software.
Iterative development and ITIL both are based on an improvement cycle, and both deal with a living cycle in which every stage contributes to every other stage and no stage disappears because its single job is done. Strict waterfall development, on the other hand, in its rigid stages, violates the spirit of ITIL, which is always prepared to respond to changing circumstances.
Developing cloud services can benefit from ITIL practices. ITIL practice recommends processes for gathering all the important input on developing a service and organizing the input into a usable form that supports a well-organized and responsive IT department. In addition, ITIL practices have clear feedback paths to support a continuous improvement cycle that goes beyond software development. Within ITIL practices, iterative software development is well supported.
ITIL practices are particularly important for cloud development because cloud computing is as much a business approach as a technological breakthrough. Technology and business must cooperate to make a cloud deployment successful both technically and for business. ITIL has a record of accomplishment for bringing business and technology together in a well-organized and sustainable way.
Conclusion
In some ways, cloud services are business as usual for service management. A cloud deployment outsources an aspect of IT that has not commonly been outsourced before. All the discipline that goes into managing any outsourced service is necessary for successfully managing a cloud service. However, cloud deployments have special requirements. Although they may look like a business agreement, they are also a highly technical shift and require technical input to be properly managed. Without technical input, service contracts and service level agreements may not adequately represent an organization’s interests.
One way of ensuring that both business and technology are well represented is to follow ITIL service lifecycle practices along with an iterative and incremental development approach.
EXERCISES
- What is the key difference between outsourcing in general and cloud outsourcing?
- Discuss the dangers of click-through licensing in an enterprise environment.
- Do certifications, such as SOC 3, guarantee that a cloud service will meet enterprise requirements for reliability and security? Why or why not?
- Contrast waterfall development with iterative incremental development.
- What are the four phases of the ITIL service life cycle?
- How do the ITIL phases relate to iterative development?
1I will use the term CIOs to represent all high-level IT decision makers, even though they may have a range of titles and shared responsibilities.
2This situation is changing for gamers. At least two systems, Nvidia Grid and Sony PlayStation Now, offer streaming games. Both have some hardware requirements, but they have reduced the requirements for computing and storage capacity on the local device.
3In many cases, especially for offshore outsourcing, the remedied inefficiency is cost. This has smudged the reputation of outsourcing, especially when quality is compromised.
4For more information on responsibility assignment, see the following: Michael Smith, James Erwin. “Role & Responsibility Charting (RACI).” https://pmicie.org/images/downloads/raci_r_web3_1.pdf. Accessed September, 2015.
5Technical and scientific enterprises are the exception. They may use cloud resources for business, but they also use cloud resources on technical projects.
6A service contract is a contract to deliver services and sets up the rules both parties will follow such as fees, billing schedules, and hours of operation, and it describes the service to be supplied. A service level agreement specifies thresholds for penalties and incentives for levels of service. The documents overlap, and sometimes a service contract will contain service level agreements, or vice versa. The combined documents should cover all significant aspects of the service. Terms of service are similar to the combined service contract and service-level agreement documents and are commonly used in click-through consumer web sites rather than service contracts and service level agreements, which are typically individually negotiated.
7For more information on ISO27001 and its companion standard, ISO2717, see my book Cloud Standards (also from Apress).
8SAS-70, Statement on Auditing Standards No. 70: Service Organizations, is an older service organization standard similar to SOC 1. For more detail on SAS 70, see my book Cloud Standards (also from Apress).
9AICPA. “Illustrative Type 2 SOC 2 Report with the Criteria in the Cloud Security Alliance (CSA) Cloud Controls Matrix (CCM).” April 2014. Accessed May 2014. https://www.aicpa.org/InterestAreas/FRC/AssuranceAdvisoryServices/DownloadableDocuments/SOC2_CSA_CCM_Report.pdf. This is a useful example of what an SOC 2 report could contain.
10U.S Department of Health and Human Services. “What You Should Know About OCR HIPAA Privacy Rule Guidance Materials.” Web site. Accessed May 2015. www.hhs.gov/ocr/privacy/hipaa/understanding/coveredentities/misleadingmarketing.html.
11Security best practice separates identity authentication from authorization. Users are authenticated when they supply proof of identity such as a correct password or personal characteristic such as a fingerprint or retinal scan. After authentication, users receive the authorizations they are assigned by the system. Some older systems do not separate authentication from authorization, and users must be given a separate login for each set of privileges they are given.
12Federated systems exchange information but remain distinct. SAML is a protocol for sharing access and authorization data between AIM systems.
13Craig Larman, Victor R. Basili. “Iterative and Incremental Development: A Brief History.” IEEE Computer Society, Computer 36 (6). pp 47–56. www.craiglarman.com/wiki/downloads/misc/history-of-iterative-larman-and-basili-ieee-computer.pdf. Accessed May 2014. Iterative and incremental development may actually predate waterfall, but waterfall development was held up as the ideal through the end of the 20th century.
14The putative beginning for Agile was the Agile Manifesto formulated in 2001. See “The Agile Manifesto.” Agile Alliance, 2001. www.agilealliance.org/the-alliance/the-agile-manifesto/. Accessed May 2014. Also see “The Twelve Principles of Agile Software.” Agile Alliance, 2001. www.agilealliance.org/the-alliance/the-agile-manifesto/the-twelve-principles-of-agile-software/. Accessed May 2014. The Twelve Principles reveal more of the details of Agile methodology. However, Agile is based on many principles that were evident in the development community long before 2001.
15Programmers sometimes call this practice “tossing the dead rat over the fence.”
16Unit tests evaluate individual modules. System tests evaluate groups of modules working together.
17I have no knowledge of the healthcare rollout other than what I read in the media. I am only an external observer.
18Under-estimating traffic volumes is endemic in the software industry. During every Super Bowl, a few web sites crash from the traffic generated by the ads. You can argue that these are dunderhead mistakes, but perhaps it is misguided modesty in estimating the popularity of a site.
19This is an example of the time-honored principle that developers should “eat their own dog food.” In other words, developers should have to use the software that they create. DevOps takes this a step further by suggesting that operations people should also experience the frustrations of developers.