
![]()
Consistency Models
For changes to be of any true value, they’ve got to be lasting and consistent.
—Tony Robbins, motivational speaker
Consistency is contrary to nature, contrary to life. The only completely consistent people are dead.
—Aldous Huxley
One of the biggest factors powering the nonrelational database revolution is a desire to escape the restrictions of strict ACID consistency. It’s widely believed that the new breed of nonrelational databases provide only weak or at best eventual consistency, and that the underlying consistency mechanisms are simplistic. This belief represents a fundamental misunderstanding of nonrelational database systems. Nonrelational systems offer a range of consistency guarantees, including strict consistency, albeit at the single-object level. And in fact, there are some complex architectures required to balance an acceptable degree of consistency when we lose the strict and predictable rules provided by the ACID transaction model.
In the absence of the ACID transaction model, a variety of approaches to consistency have emerged: these include relatively familiar concepts such as eventual consistency and various tunable consistency models. Many nonrelational databases are, in fact, strictly consistent with respect to individual objects, even if they don’t support strict multi-object consistency. And although ACID transactions are absent, systems such as Cassandra support a simpler, lightweight transaction model.
Consistency models have a huge effect on database concurrency—the ability for multiple users to access data simultaneously—and on availability. Understanding how a database system treats consistency is essential in order to determine whether that database can meet the needs of an application.
Types of Consistency
Ironically, there is significant variation in how the term “consistency” is used in the database community. Consistency might mean any of the following:
- Consistency with other users: If two users query the database at the same time, will they see the same data? Traditional relational systems would generally try to ensure that they do, while nonrelational databases often take a more relaxed stance.
- Consistency within a single session: Does the data maintain some logical consistency within the context of a single database session? For instance, if we modify a row and then read it again, do we see our own update?
- Consistency within a single request: Does an individual request return data that is internally coherent? For instance, when we read all the rows in a relational table, we are generally guaranteed to see the state of the table as it was at a moment in time. Modifications to the table that occurred after we began our query are not included.
- Consistency with reality: Does the data correspond with the reality that the database is trying to reflect? For example, it’s not enough for a banking transaction to simply be consistent at the end of the transaction; it also has to correctly represent the actual account balances. Consistency at the expense of accuracy is not usually acceptable.
Relational databases responded to the requirements of consistency using two major architectural patterns: ACID transactions and multi-version concurrency control (MVCC).
We’ve covered ACID transactions extensively already in this book. To recap, ACID transactions should be:
- Atomic: The transaction is indivisible—either all the statements in the transaction are applied to the database or none are applied.
- Consistent: The database remains in a consistent state before and after transaction execution.
- Isolated: While multiple transactions can be executed by one or more users simultaneously, one transaction should not see the effects of other in-progress transactions.
- Durable: Once a transaction is saved to the database (in SQL databases via the COMMIT command), its changes are expected to persist even if there is a failure of operating system or hardware.
![]() Note Even relational databases such as Oracle don’t implement the strict isolation between transactions that ACID demands by default. The overhead for completely isolating all transactions is usually too high.
Note Even relational databases such as Oracle don’t implement the strict isolation between transactions that ACID demands by default. The overhead for completely isolating all transactions is usually too high.
The easiest way to implement ACID consistency is with locks. Using lock-based consistency, if a session is reading an item, no other session can modify it, and if a session is modifying an item, no other session can read it. However lock-based consistency leads to unacceptably high contention and low concurrency.
To provide ACID consistency without excessive locking, relational database systems almost universally adopted the multi–version concurrency control (MVCC) model. In this model, multiple copies of data are tagged with timestamps or change identifiers that allow the database to construct a snapshot of the database at a given point in time. In this way, MVCC provides for transaction isolation and consistency while maximizing concurrency.
For example, in MVCC, if a database table is subjected to modifications between the time a session starts reading the table and the time the session finishes, the database will use previous versions of table data to ensure that the session sees a consistent version. MVCC also means that until a transaction commits, other sessions do not see the transaction’s modifications—other sessions look at older versions of the data. These older copies of the data are also used to roll back transactions that do not complete successfully.
Figure 9-1 illustrates the MVCC model. A database session initiates a transaction at time t1 (1). At time t2, the session updates data in a database table (2); this results in a new version of that data being created (3). At about the same time, a second database session queries the database table, but because the transaction from the first session has not yet been committed, they see the previous version of the data (4). After the first session commits the transaction (5), the second database session will read from the modified version of the data (6).

Figure 9-1. Multi-version concurrency control (MVCC)
The big advantage of MVCC is a reduction in lock overhead. In the example shown in Figure 9-1, without MVCC the update would have created a blocking lock that would have prevented the second session from reading the data until the transaction was completed.
Global Transaction Sequence Numbers
MVCC can use transaction timestamps to determine which versions of data should be made visible to specific queries. However, most databases use a global transaction ID rather than an explicit timestamp. This is called the system change number (SCN) in Oracle and the transaction sequence number in Microsoft SQL Server.
This sequence number is incremented whenever a transaction is initiated, and it is recorded in the structure of modified rows (or database blocks). When a query commences, it looks for rows that have a sequence number less than or equal to the value of the sequence number that was current when the query began. If the query encounters a row with a higher sequence number, it knows it must request an older version of that row.
Two-phase Commit
MVCC works in concert with the ACID transaction model to provide isolation between transactions running on a single system. Transactions that span databases in a distributed RDBMS are achieved using a two-phase-commit (2PC) protocol.
The two phases of 2PC are:
- Commit-request phase, in which the coordinator asks other nodes to prepare the transaction. Typically, the preparation phase involves locking the table rows concerned and applying changes without a commit.
- Commit phase, in which the coordinator signals all nodes to commit their transactions if the commit-request phase succeeded across all nodes. Alternatively, if any node experiences difficulties, a rollback request is sent to all nodes and the transaction fails.
It’s possible for a problem to occur between the two phases, in which case the transaction may succeed on some nodes but not others; in this case, in-doubt transactions are created and need to be reconciled by the database administrator.
Other Levels of Consistency
The multi-table ACID transaction model is somewhat of a high-water mark in database consistency. While many next-generation databases continue to support ACID, none attempts to provide a higher level of transactional consistency, while many offer lower consistency guarantees.
The first and most significant reduction in consistency is to limit its scope to a single operation or object. In an RDBMS, we can maintain consistency across multiple statements; for instance, we can delete a row in one table and insert a row in another table as an atomic operation. In most relational databases we can require that a set of queries accessing multiple tables return a consistent view of the data from the moment the query commenced. Almost no nonrelational systems support this level of multi-object consistency.
Even within single-object operations, there are a variety of consistency levels that we can expect. In practice, the most significant levels of consistency are:
- Strict consistency: A read will always return the most recent data value.
- Causal consistency: Reads may not return the most recent value, but will not return values “out of sequence.” This implies that if one session created updates A, B, and C, another session should never see update C without also being able to see update B.
- Monotonic consistency: In this mode, a session will never see data revert to an earlier point in time. Once we read a data item, we will never see an earlier version of that data item.
- Read your own writes: This is a form of eventual consistency in which you are at least guaranteed to see any operations you executed.
- Eventual consistency: The system may be inconsistent at any point in time, but all individual operations will eventually be consistently applied. If all updates stop, then the system will eventually reach a consistent state.
- Weak consistency: The system makes no guarantee that the system will ever become consistent—if, for instance, a server fails, an update might be lost.
In practice, nonrelational systems implement either strict or eventual consistency while RDBMS systems offer ACID consistency. Causal or monotonic consistency levels are not directly supported in most nonrelational systems.
By default—in a single-server deployment—a MongoDB database provides strict single-document consistency. When a MongoDB document is being modified, it is locked against both reads and writes by other sessions.
However, when MongoDB replica sets are implemented, it is possible to configure something closer to eventual consistency by allowing reads to complete against secondary servers that may contain out-of-date data.
MongoDB Locking
Consistency for individual documents is achieved in MongoDB by the use of locks. Locks are used to ensure that two writes do not attempt to modfy a document simultaneously, and also that a reader will not see an inconsistent view of the data.
We saw earlier how a multi-version concurrency control (MVCC) algorithm can be used to allow readers to continue to read consistent versions of data concurrently with update activity. MVCC is widely used in relational databases because it avoids blocking readers—a reader will read a previous “version” of a data item, rather than being blocked by a lock when an update is occurring. MongoDB does not implement an MVCC system, and therefore readers are prevented from reading a document that is being updated.
The granularity of MongoDB locks has changed during its history. In versions prior to MongoDB 2.0, a single global lock serialized all write activity, blocking all concurrent readers and writers of any document across the server for the duration of any write.
Lock scope was increased to the database level in 2.2, and to the collection level in 2.8. In the MongoDB 3.0 release, locking is applied at the document level, providing the collection is stored using the WiredTiger storage engine. When document-level locking is in effect, an update to a document will only block readers or writers who wish to access the same document.
Locking is a controversial topic in MongoDB; the original “global” lock and lack of MVCC compared poorly with the mechanisms familiar in relational databases. Now that lock scope is limited to the document level, these concerns have been significantly reduced.
Replica Sets and Eventual Consistency
In a single-server MongoDB configuration—and in the default multi-server scenario—MongoDB provides strict consistency. All reads are directed to the primary server, which will always have the latest version of a document.
However, we saw in the previous chapter that we can configure the MongoDB read preference to allow reads from secondary servers, which might return stale data. Eventually all secondary servers should receive all updates, so this behavior can loosely be described as “eventually consistent.”
HBase provides strong consistency for individual rows: HBase clients cannot simultaneously modify a row in a way that would cause it to become inconsistent. This behavior is similar to what we see in relational systems that generally use row-level locking to prevent any simultaneous updates to a single row. However, the implementation is more complex in HBase because rows may contain thousands of columns in multiple column families, which may have distinct disk storage. During an update to any column or column family within a row, the entire row will be locked by the RegionServer to prevent a conflicting update to any other column.
Read operations do not acquire locks and reads are not blocked by write operations. Instead, read operations use a form of multi-version concurrency control (MVCC), which we discussed earlier in this chapter. When read and write operations occur concurrently, the read will read a previous version of the row rather than the version being updated.
HBase uses a variation on the SCN pattern that we discussed earlier to achieve MVCC. When a write commences, it increments a write number that is stored in the cell (e.g., specific column value within the row) being modified. When the read commences, it is assigned a read point number that corresponds to the highest completed write point. The read can then examine data items to ensure it does not read a cell whose write number suggests it was updated since the read began.
Eventually Consistent Region Replicas
In earlier versions of HBase, strong consistency for all reads was guaranteed—you were always certain to read the most recently written version of a row. However, with the introduction of region replicas, introduced in Chapter 8, the possibility of a form of eventual consistency is presented.
Region replicas were introduced in order to improve HBase availability. A failure of a RegionServer would never result in data loss, but it could create a minor interruption in performance while a new RegionServer was instantiated. Region replicas allow immediate failover to a backup RegionServer, which maintains a copy of the region data.
By default, in HBase all reads are directed to the primary RegionServer, which results in strictly consistent behavior. However, if consistency for a read is configured for timeline consistency, then a read request will first be sent to the primary RegionServer, followed shortly by duplicate requests to the secondary RegionServer. The first server to return a result completes the request. Remember that the primary gets a head start in this contest, so if the primary is available it will usually be the first to return.
The scheme is called timeline consistency because the secondary RegionServer always receives region updates in the same sequence as the primary. However, this architecture does not guarantee that a secondary RegionServer will have up-to-date information; and if there are multiple secondary RegionServers, then it’s possible that reads will return writes out of order, since there may be race conditions occurring among the multiple secondary servers and the primary.
Figure 9-2 illustrates RegionServer replica processing. An HBase client is issuing writes in sequential order to the master RegionServer (1). These are being replicated asynchronously to the secondary RegionServers (2); at any given moment in time some of these replications may not yet have completed (3). If a client is using timeline consistency, then it may read data from the master, but if the master is unresponsive, it may read data from one of the secondary RegionServers (4). Successive reads may return data from either of the secondaries or from the primary—so data can be returned in any sequence. The “timeline” nature of the consistency only applies to an individual secondary, not to the system as a whole.

Figure 9-2. HBase timeline consistency with RegionServer replicas
![]() Note Timeline consistency is not the default in HBase. By default, a client will read from the master RegionServer, in which case HBase will provide strong consistency.
Note Timeline consistency is not the default in HBase. By default, a client will read from the master RegionServer, in which case HBase will provide strong consistency.
Cassandra uses the Amazon Dynamo model of tunable consistency. This tunable consistency provides a variety of consistency levels, most of which can be specified at the level of individual requests.
We touched on the Dynamo consistency model in Chapter 3. At a high level, this model allows the following three variables to be configured independently to provide a variety of outcomes:
- N is the number of copies of each data item that the database will maintain.
- W is the number of copies of the data item that must be written before a write can return control to the application.
- R is the number of copies that the application will access when reading the data item.
As we saw in Chapter 3, these variables can be configured to allow for strong consistency, weak consistency, and to balance read and write performance.
Cassandra follows the Dynamo model pretty closely, but has its own unique implementation. So while the following discussion should be broadly applicable to other Dynamo systems such as Riak or DynamoDB, the details are specific to Cassandra.
Replication Factor
The replication factor determines how many copies of the data will be maintained across multiple nodes. This is specified at the keyspace (roughly equivalent to a schema) level and is equivalent to the “N” in Dynamo NRW notation.
As we saw in the previous chapter, various replication strategies can be established to ensure that replicas are distributed across multiple racks or data centers
Write Consistency
Each write operation can specify a write consistency level. The write consistency level controls what must happen before Cassandra can complete a write request. Some of the more common levels are:
- ALL: The write must be propagated to all nodes. This results in very strong consistency, but should a node be unavailable, the write cannot complete.
- ONE|TWO|THREE: The write must be propagated to the specified number of nodes. A level of ONE maximizes write performance but possibly at the expense of consistency. Depending on the read consistency settings and replication factor, TWO and THREE may or may not provide stronger consistency guarantees.
- QUORUM: The write must complete to a quorum of replica nodes. A quorum requires the majority of replicas accept the write before the write operation completes.
- EACH_QUORUM: The write must complete to a quorum of replica nodes in each data center. So if there are two data centers with three replicas each, at least two replicas from each data center must complete the write request before the operation can complete.
- LOCAL_QUORUM: Requires that a quorum of replicas be written in the current data center only.
- ANY: The write will succeed providing it is written to any node, even if that node is not responsible for storing that particular data item. If no node directly responsible for storing a replicas of the data item can be reached, then a hinted handoff—described in detail later in this chapter—on any node will be sufficient to complete the write. This is an extremely low reliability setting, since by default hinted handoffs are deleted after three hours; the best you could say about this setting is that data might be written.
Some additional write consistency levels are described in the section on lightweight transactions below.
Read consistency levels are similar to write consistency levels. The key words are identical, though the semantics are of course somewhat different. A setting for write consistency does not imply any particular read consistency setting, though as we shall see it is the interaction between the two that determines the overall behavior of the database.
The most common consistency levels for reads are:
- ALL: All replicas are polled.
- ONE|TWO|THREE: Read requests will be propagated to the “closest” ONE, TWO, or THREE nodes. “Closeness” is determined by a snitch (see Chapter 8).
- LOCAL_ONE: The read request will be sent to the closest node in the current data center.
- QUORUM: The read completes after a quorum has returned data: a quorum involves a majority of replicas across all data centers.
- EACH_QUORUM: The read completes after a quorum of replicas in each data center have responded.
- LOCAL_QUORUM: The read completes after a quorum of replicas in the local data center respond.
Some additional read consistency levels are described in the section on lightweight transactions that follows.
Note that when requesting a read from multiple replicas, Cassandra does not need to see the entire data content from each node. Instead, the coordinator will often request a digest of the data. The digest is a hashed representation of the data that can be used to determine if two sets of returned data are identical. We’ll discuss this further in the sections on read repair and hinted handoff.
Interaction between Consistency Levels
The settings of read and write consistency interact to create a variety of performance, consistency, and availability outcomes. Strong consistency and high availability can be configured at the cost of lower performance; high availability and performance can be configured at the cost of consistency; or consistency and performance can be achieved at the cost of availability. Some of these trade-offs were illustrated in Figure 3-6. Table 9-1 describes some of the combinations and their implications.
Table 9-1. Interaction between Read and Write Consistency Levels in Cassandra

Hinted Handoff and Read Repair
We spoke about hinted handoff and read repair in the context of Cassandra clustering in the previous chapter, but since they form an important part of Cassandra’s consistency story, some further discussion is in order.
Unless the write consistency level is set to ALL, inconsistencies will collect within the Cassandra cluster. Network partitions or temporary node downtime (from reboots, for instance) will prevent some replica writes from completing. Over time these inconsistencies will build up, creating disorder and chaos—what is often referred to as entropy in thermodynamics. Anti–entropy mechanisms in Cassandra and other Dynamo-based databases seek to actively return the system to a consistent state.
Hinted handoffs allow a node to store an update that is intended for another node if that node is temporarily unavailable. If the node comes back online within a short interval (by default, three hours), the write will be transmitted. If the node does not come back online within that period, the hinted handoff is deleted. A hinted handoff can substitute for a successful write if the consistency level is set to ANY.
Read repair is a mechanism that Cassandra can use to repair inconsistencies that might arise, for instance, when a node is down longer than the hinted handoff limit. When Cassandra assembles a read from multiple nodes, it will detect any nodes that have out-of-date data. An update will be sent to the out-of-date replicas to correct the inconsistency.
As noted earlier, Cassandra does not request the entire data value from all replicas during a multi-node read. Instead, one node is issued a direct read request for the actual data, while other nodes are sent requests for hashed digests of the data. If the results are inconsistent, the most recent data is retrieved by a direct read, and a read repair instruction is issued to the out-of-date nodes.
Figure 9-3 provides an example of a read-repair operation. A coordinator node requests a direct read (e.g., the actual data) from one replica (1) and digests (e.g., hashes) from two other replicas (2). One of the replicas has out-of-date data (3). After returning the correct result to the client (4), the coordinator issues a read repair to the out-of-date replica (5).

Figure 9-3. Read repair in Cassandra
As noted in the previous chapter, there is also the ability to schedule or manually invoke batch read-repair operations that find inconsistencies across entire keyspaces. This mechanism will be discussed further in Chapter 10, when we discuss compaction strategies.
Cassandra uses timestamps to determine which replica is the most up to date. Other Dynamo systems such as Riak use a different algorithm, known as a vector clock, which we’ll discuss in the next section.
The Cassandra approach involves comparing the timestamps of conflicting writes and choosing the one with the highest timestamp; this strategy is referred to as last write wins.
The last write wins approach has some potential drawbacks when applied to large, complex objects such as you would find in a document database or in a key-value store. One user might modify the user’s email address while seconds later another user modifies the user’s date of birth. We don’t want the date-of-birth modification to obliterate the email address update. MongoDB and HBase lock the entire document or row during an update to avoid this potential problem.
The issue is addressed in Cassandra by making the unit of modification, concurrency, and conflict resolution the individual cell: the intersection of row and column. This means that two users can happily modify the same row simultaneously, providing they are not modifying the same column. If one user updates the date of birth and another user updates the email address for a row, neither update will conflict with the other.
Vector Clocks
Cassandra uses timestamps to work out which is the “latest” transaction. If there are two conflicting modifications to a column value, the one with the highest timestamp will be considered the most recent and the most correct.
Other Dynamo systems use a more complex mechanism known as a vector clock. The vector clock has the advantage of not requiring clock synchronization across all nodes, and helps us identify transactions that might be in conflict.
Despite its name, the vector clock does not include any timestamps. Rather, it is composed of a set of counters. These counters are incremented when operations complete, in a way that’s similar to the traditional system change number pattern discussed earlier. The set contains one counter for each node in the cluster. Whenever an operation occurs on a node, that node will increment its own counter within its vector clock. Whenever a node transmits an operation to another node, it will include its vector clock within the request. The transmitted vector clock will include the highest counter for the transmitting node and the highest counters from other nodes that the transmitting node has ever seen.
When a node receives possibly conflicting updates from other nodes, it can compare the vector clocks to determine the relative sequencing of the requests. There is a defined set of vector clock operations that can tell if:
- The two vector clocks come from nodes that are completely in sync.
- One node is out of date with respect of the other node.
- The clocks are concurrent in that each node has some information that is more up to date than the other node. In this case, we can’t choose which update is truly the more correct.
Vector clocks are notoriously difficult to understand, though the underlying algorithm is really quite simple. Figure 9-4 shows an example of three vector clocks incrementing across three nodes. The algorithm is somewhat simplified to improve clarity.
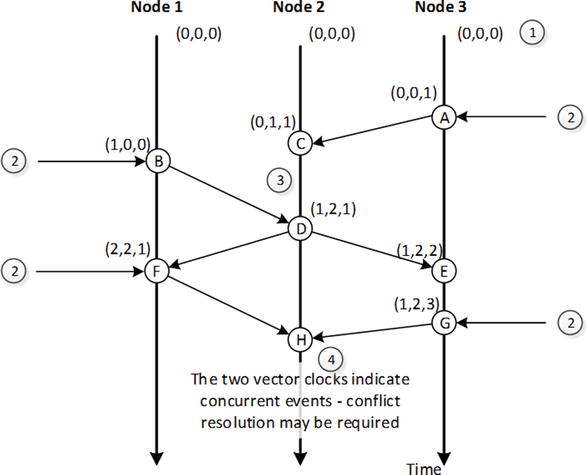
Figure 9-4. Vector clock example
In Figure 9-4, the vector clocks start out set to 0 for all nodes (1). Updates to nodes from external clients cause the nodes to increment their own element of the vector clock (2). When these changes are propagated to other nodes, the receiving node updates its vector clock and merges the vector clocks from the other nodes (3). Event (H) occurs when node 2 receives the vector clock (F) from node 1 and (G) from node 3 (4). Each of these vector clocks contains elements higher than the other; vector clock (F) has the higher value for node 1, while vector clock (G) has the higher value for node 3. There is no way for node 2 to be sure which of the two vector clocks represents the most up-to-date data—each of the sending nodes “knows” something that the other node does not, and consequently it’s not clear which of the two nodes “knows” best.
The vector clock in Figure 9-4 tells us that version (G) and version (F) are conflicting—each contains information from unique updates that could both contain important information. What, then, is the system to do? Here are some of the options:
- Revert to last write wins: Two updates are unlikely to have occurred at the exact same nanosecond, so one will have a higher timestamp value. We could decide that the highest timestamp “wins.”
- Keep both copies: This requires that the application or the user resolve the conflict.
- Merge the data: This is the approach taken by the original Dynamo, which managed Amazon’s shopping cart. If there are two conflicting shopping carts, they are merged and the worst that can happen (from Amazon’s point of view) is that you buy some things twice. Another merge can occur with things like counters; rather than having one counter increment overwrite another, we can deduce that both operations wanted to increment the counter and increment it twice. A special class of data types— conflict-free replicated data type (CRDT)—exists that allows these sorts of merges to be predefined.
There are advocates for the vector clock and advocates for the timestamp system used in Cassandra. Neither party disputes the concrete implications of the two approaches; they differ on the desirability of the consequences. Last write wins represents a simpler model for the application developer and administrator, while vector clocks allow for conflicts to be identified but that must then be resolved.
Cassandra is a lockless architecture, which uses conflict resolution rather than locking to allow high availability and performance. However, sometimes operations need to atomically combine a read operation and a write operation. For instance, consider the scenario shown in Figure 9-5: a familiar transactional operation modifying two account balances. Two Cassandra sessions issue Cassandra Query Language (CQL) statements to retrieve the current balance of an account (1). Based on this information, the first session applies an interest payment (2) and momentarily afterwards the second session increases the balance to process a deposit (3). The second update overwrites the first update and the interest payment is lost.

Figure 9-5. Lost update problem
Of course, the lack of ACID transactions is one of the reasons Cassandra might not be suitable for this sort of banking application. However, it is common in almost all applications for some form of atomic operation to be required, and Cassandra offers lightweight transactions (LWT) to support these requirements.
Cassandra transactions are called “lightweight” because they apply to only a single operation and support only a compare-and-set (CAS) pattern. A CAS operation is an atomic operation that checks a value, and if the value is as expected, sets another value.
In Cassandra, the lightweight transactions are expressed in the Cassandra Query Language using the IF clause. Figure 9-6 illustrates how this could solve the lost update scenario that we encountered in Figure 9-5.

Figure 9-6. Solving lost updates with lightweight transactions
As before, each session queries the current balance (1). The first session applies the interest payment, which succeeds because the balance specified in the IF clause is correct (2). However, the second transaction that attempts to add a $100 deposit fails because the balance has changed since the time it was first read (3). The new balance is returned in the failure message, allowing the session to retry the transaction successfully (4).
Those familiar with relational database transactions will recognize the scenario in Figure 9-6 as the optimistic locking pattern.
Cassandra’s lightweight transactions use a quorum-based transaction protocol called Paxos. The Paxos protocol is notoriously difficult to describe and is complicated in implementation, but it resembles a form of the Two Phase Commit (2PC) protocol discussed earlier in the context of distributed relational database transactions. The key difference with Paxos is that it uses a quorum—that is, a majority—to determine success or failure rather than requiring that every node successfully apply the change.
The modified Cassandra Paxos protocol works in four phases:
- Prepare/promise. Any node may propose a modification; this node is referred to as the leader. The leader sends a proposal to all replica nodes. Nodes can respond in three ways:
- They may promise to accept this proposal and not to accept any subsequent proposals.
- If the node already is in possession of an earlier proposal, then the earlier proposal will be included with its promise. If the majority of nodes reply with an earlier proposal, then that earlier proposal will have to be applied before the new proposal can be processed.
- The node may decline the proposal because it has already promised to apply a later proposal.
- Read current value. The current value of the data item will be requested from each node to confirm that the value conforms to the IF clause in the UPDATE or INSERT statement.
- Propose/accept. The new value is proposed to all nodes and nodes reply if they are able to apply the new value.
- Commit/acknowledge. If the propose/accept step succeeds, then the leader will indicate to all nodes that the transaction can be completed. The proposed value is applied to normal Cassandra storage and is visible to everyone.
Remember that Paxos is a quorum-based protocol, which means that each step succeeds providing a majority of replicas agree. Replicas that cannot be reached or can for other reasons not participate will be corrected at a later time through normal anti-entropy mechanisms.
The Cassandra lightweight transaction implementation involves a significantly larger number of round trips than the nontransactional alternatives—four times as many round trips are involved in a simple case, and could be potentially more should multiple conflicting proposals need to be reconciled.
Figure 9-7 shows a simplified sequence of events in a successful Cassandra lightweight transaction. In phase 1, the leader proposes a change to a data item and replicas promise not to accept any earlier proposals. In phase 2, the leader checks that the value of the data is what is expected and as specified in the CQL IF clause. In phase 3, the leader proposes the new value for the data item and replicas accept the proposal. In phase 4, the leader commits the proposal and each replica acknowledges that the commit succeeded.

Figure 9-7. Cassandra lightweight transaction processing
Conclusion
Many next-generation systems—generally those described as NewSQL—employ the time-tested consistency models of the traditional RDBMS, most significantly ACID transactions and multi-version concurrency control (MVCC).
Next-generation databases of the NoSQL variety have an undeserved reputation for offering only simplistic consistency controls. In fact, as we have seen in this chapter, maintaining a predictable yet flexible consistency model while meeting availability and scalability requirements of a distributed database requires architectures at least as complicated as those we have come to know in the relational world.
We have concentrated in this chapter on three approaches employed in the NoSQL world. MongoDB employs a relatively traditional pessimistic locking model that preserves consistency by blocking conflicting operations. HBase employs only very short-lived locks, instead relying on a version of MVCC to allow high-frequency mutations to occur without creating row-level inconsistencies. Cassandra employs the Dynamo model of tunable consistency, which allows the application to choose among consistency, availability, and performance. Cassandra also adds a lightweight Paxos-based transaction.
In the next chapter, we’ll see how the consistency concepts of this chapter and distributed database architectures of the previous chapter are supported by data models and storage systems.