
Chapter 12: Other Topics
Standard for Exchange of Non-Clinical Data
FDA Janus Clinical Trials Repository
This book has primarily focused on the use of SAS products for the creation and use of data that conforms to CDISC standards, specifically the SDTM and ADaM. In this chapter, we introduce you to other CDISC standards and related initiatives that have less of a direct impact on the typical roles of data managers, SAS programmers, and biostatisticians involved with clinical research. As a result, these standards and initiatives might have little to do with SAS software, at least for now. In the future, however, they could become important topics for understanding the flow of data from outside sources to clinical trials, and vice versa.
Standard for Exchange of Non-Clinical Data
The Standard for Exchange of Non-Clinical Data, or SEND, is detailed in version 3.0 of the SEND Implementation Guide (SENDIG), which was released in May 2011. (See http://www.cdisc.org/standards/foundational/send.) The SENDIG is intended to guide the organization, structure, and format of standard non-clinical tabulation data sets for interchange between organizations such as sponsors and CROs and for submission to the FDA. The current version of the IG is designed to support single-dose general toxicology, repeat-dose general toxicology, and carcinogenicity studies. For non-clinical animal data, the SEND standard is closely related to the SDTM. It contains many of the same domains used for clinical data, in addition to ones specific to non-clinical studies such as death diagnosis (DD), body weight (BW) and body weight gain (BG), and food and water consumption (FW).
Because of the similarities between SEND data and the SDTM, the conversion process from raw data to the SEND standard would presumably be similar to the processes outlined in Chapters 3, 4, and 5, with a similar up-front attention to metadata outlined in Chapter 2. The FDA’s study data specifications document has information about acceptance and expectations of the SEND standard in regulatory submissions.
Dataset-XML
Dataset-XML is a relatively new CDISC standard that was developed by the CDISC XML Technologies team as an exchange format for study data sets. Like the Define-XML CDISC standard, the Dataset-XML model is based on the ODM, as depicted in the following figure.
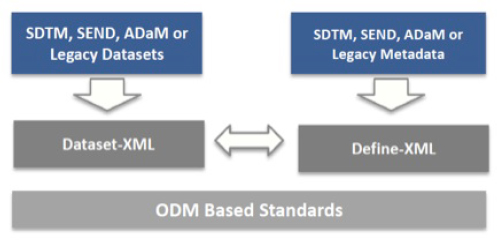
Source: http://www.cdisc.org/dataset-xml.
The idea behind Dataset-XML is for it to serve as an alternative exchange format to the Version 5 SAS Transport (XPT) file format for data sets. It has the advantage of fewer limitations with respect to variable name and label lengths, data set name and label lengths, and text field lengths. In 2014, FDA published a Federal Register Notice requesting participation in a pilot project to evaluate CDISC Dataset XML. FDA envisioned several pilot projects to evaluate new transport formats. As part of the Dataset XML pilot, FDA requested sponsors to prepare and submit previously submitted study data sets using the Dataset XML transport format. The testing period ended in November 2014, and a report was posted online on April 8, 2015 (http://www.fda.gov/downloads/ForIndustry/DataStandards/StudyDataStandards/UCM443327.pdf). The results of the pilot were encouraging, although one limitation discovered during the testing was that of substantial file size inflation when converting data sets to XML from XPT (one sponsor’s data set increased 269%, from <5 gigabytes to >17 gigabyes).
FDA envisions conducting several pilots to evaluate new transport formats before a decision is made to support a new format. In the meantime, there are already tools that can be used to convert XPT files to the Dataset-XML format, including some SAS tools. (These tools are summarized on the CDISC wiki at http://wiki.cdisc.org/display/PUB/CDISC+Dataset-XML+Resources.)
Version 1.7 of the Clinical Standards Toolkit support Dataset-XML, but this is a later version than that used for this book. SAS also provides free macros to support the conversion Dataset-XML directly from SAS data sets, which can circumvent the need to create XPT files beforehand. However, an accompanying define.xml file is required (since the define.xml contains information about the data that Dataset-XML does not, such as data set labels). You can learn more about these macros at http://support.sas.com/kb/53/447.html.
There is another tool covered in this book that supports Dataset-XML. Pinnacle 21 Community can convert your XPT files to XML with a straightforward interface.

Whether SAS programmers are involved in this transformation process is unclear at the moment. Ideally, the transformation from CDISC-formatted SAS data sets to an approved XML format will be handled by a simple application such as a SAS procedure or something similar that can make the process as seamless as that from native SAS to the version 5 transport file format.
BRIDG Model
BRIDG is an acronym that stands for the Biomedical Research Integrated Domain Group. You can study this model in depth at http://bridgmodel.org. The BRIDG model was conceived by CDISC in 2003 as a way to not only integrate, or bridge, the CDISC models with HL7, but also as a way to harmonize the various internal and disparate CDISC models. BRIDG today is intended to serve as an informational bridge between CDISC, HL7, FDA, and the National Cancer Institute at NIH and its Cancer Biomedical Informatics Grid (caBIG). The main target of BRIDG is to achieve semantic harmonization of information for protocol-driven research across these organizations.
The mechanism of harmonization that BRIDG uses is called a Domain Analysis Model or DAM. A DAM in BRIDG is a general area of interest specified in both Unified Modeling Language (UML) as well as the HL7 Reference Information Model (RIM). For example, the CDISC SDTM and CDASH have been modeled into the BRIDG via DAM processes. You can download the current BRIDG model from their website and see via UML how those models are mapped into the BRIDG and by extension how those models relate to HL7 and the NCI caBIG models.
Over the past two years, a group of individuals has been working on building a BRIDG Statistics DAM. The idea is to map the processes that we perform in clinical trials analysis and reporting and to express that in UML. As part of that effort, the CDISC ADaM model has been translated and mapped into the overarching BRIDG model as well. The hope is that the BRIDG Statistics DAM will enable CDISC, HL7, NCI, and FDA to speak about clinical trials statistics with the same semantic understanding.
Protocol Representation Model
Continuing with the BRIDG initiative, CDISC has released standards that support the BRIDG model. An example of this is the Protocol Representation Model (PRM). (See http://www.cdisc.org/standards/foundational/protocol.) The PRM was developed to capture the elements of a clinical trial protocol such as entry criteria, study objectives, information about study sites, planned activities, and the requirements for ClinicalTrials.gov and World Health Organization (WHO) registries. Much of the SDTM trial design data, which we introduced in Chapter 2, has been mapped to the PRM. In the future, this should take the burden off SAS programmers as the providers of such data. As a follow-up to the PRM itself, CDISC released a PRM toolset. The initial release of this toolset contained two tools: a template for study outline documents and a template for the study outline concept list. The study outline template is a straightforward Word document that can be used to capture all of the key elements of a study. The study outline concept list is an Excel file that contains each study outline concept along with a description, notes, and a mapping of the concept to an element in the SDTM Trial Summary (TS) domain. A desired next step is to create a web tool that can capture each concept and, in turn, create output files such as a PDF version of the study outline, SDTM domain data sets (such as TS and TI), and corresponding ODM XML files.
Some third-party organizations are developing their own template-driven software that can create a Microsoft Word version of a protocol using PRM data elements. The success of such systems should accelerate the uptake of this standard within the clinical research industry.
FDA Janus Clinical Trials Repository
In 2003, the FDA began the task of building a clinical data warehouse called the Janus Clinical Trial Repository (CTR) (http://www.fda.gov/ForIndustry/DataStandards/StudyDataStandards/ucm155327.htm). After several and sometimes recursive stages of development, it finally became operational as a pilot at the FDA’s White Oak Data Center in January of 2015. As of February 4, 2016, it is in full production mode at the FDA with 172 studies loaded. This is a substantial increase from the previous year when 61 studies had been loaded in an operational pilot. The idea behind Janus is to give FDA personnel who are responsible for approval and surveillance of medical products an integrated clinical data repository that can enhance their ability to carry out the mission of protecting the public health. For example, Janus can be mined to study the comparative effectiveness of interventions or to study the safety of interventions across a class of similar compounds.
It is expected that the FDA requirements to have sponsors electronically submit their marketing applications with standardized (and validated) study data will greatly accelerate the uptake of study data into the CTR, which will ultimately transform how the FDA manages and analyzes clinical trial data and fulfills its mission of protecting the public health.
CDISC Model Versioning
A critical topic worthy of your organization’s consideration is how to handle CDISC model versioning. Versioning is the process by which your organization either updates or implements new versions of the CDISC standards. We have not addressed this issue in this book so far, but it is worth serious thought before you implement CDISC models. Some questions that you should be considering are:
● When will the FDA and your customers accept or require the new standard?
If you adopt the new CDISC model version, will your customer or the FDA be ready for it? You might not want to adopt the new standard before your end users can use it.
● How will the new standard impact your internal systems?
How will adoption of the new standard impact your internal systems and software? Does your environment allow for multiple standards in production at the same time? How does use of the new standard impact the associated older dependent standards? How will you handle multiple CDISC model versions used within a submission?
As an example of this problem, while producing this book, we encountered the release of “Amendment 1 to the Study Data Tabulation Model (SDTM) v1.2 and the SDTM Implementation Guide: Human Clinical Trials V3.1.2.” So we had to decide what to do with it. Recognizing that the CDISC models will constantly be in a state of update and revision and seeing that this particular SDTM amendment did not add much value to the examples in this book, we chose to ignore it for now. You are going to face similar situations in your work, and you and your organization should have governance plans for how to handle the evolving CDISC models.
Future CDISC Directions
In what direction is CDISC heading? There seem to be two paths. One is focused on CDISC’s core expertise—standards for clinical trial data (the type that is captured on a CRF). Another is for continued interoperability with other healthcare standards.
Regarding CDISC’s core expertise, one hot topic has been the development of SDTM models for specific therapeutic areas. An example of this is the oncology domains that are modeled to capture tumor data. Models have also been created to capture data specific to Alzheimer's disease, tuberculosis, and cardiovascular endpoints. Similar progress is being made with the ADaM standard, mostly through the release of documents that demonstrate examples of how to use existing ADaM models for specific types of analyses, such as time-to-event analysis or categorical data analysis.
Regarding the path of interoperability with other healthcare data standards, CDISC members are actively supporting and developing the BRIDG model (as evidenced by the release of the Protocol Representation Model and the Statistics DAM discussed previously). Another example of this direction is CDISC’s Healthcare Link Initiative (see http://www.cdisc.org/healthcare-link), which involves a collaboration with an organization called Integrating the Healthcare Enterprise (IHE). Through this initiative, a method has been established for linking electronic health record data to critical secondary uses such as safety reporting (and biosurveillance), clinical research, and disease registries.
Chapter Summary
The realm of CDISC standards continues to evolve and expand. CDISC standards have expanded to include SDTM domains specific to certain therapeutic areas such as oncology, Alzheimer's disease, and tuberculosis. They have evolved from focusing on standards for clinical trial data intended for an ultimate FDA submission to standards for non-clinical data and clinical trial information that goes beyond what is typically captured on a case report form, such as protocol data.
Despite these evolutions, the roles of SAS programmers, biostatisticians, and data managers are unlikely to be affected to any great degree (at least for the time being). These roles will continue to be instrumental in helping organizations adopt CDISC standards and for the development of tools to make the use of CDISC data more automatic. We do, however, expect to see the tools that we use improve and evolve as the CDISC standards are adopted and implemented across our industry. In the future, we expect to see the development of protocol authoring tools, improved standards-based data collection tools, and statistical computing environments that are based on the efficient use of the CDISC model standards.