
Integration Points
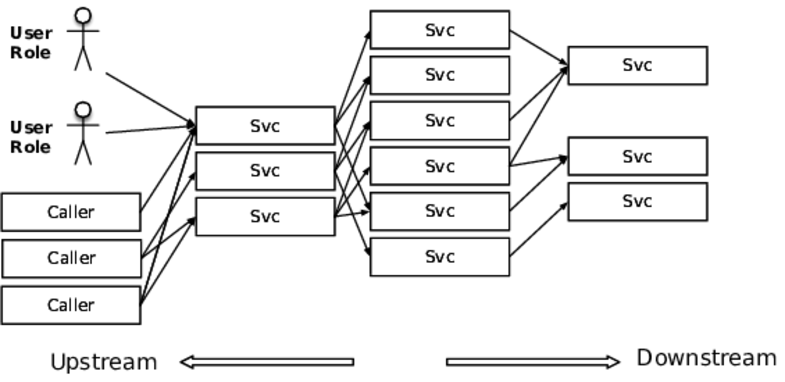
I haven’t seen a straight-up “website” project since about 1996. Everything is an integration project with some combination of HTML veneer, front-end app, API, mobile app, or all of the above. The context diagram for these projects will fall into one of two patterns: the butterfly or the spider. A butterfly has a central system with a lot of feeds and connections fanning into it on one side and a large fan out on the other side, as shown in the figure that follows.

Some people would call this a monolith, but that has negative connotations. It might be a nicely factored system that just has a lot of responsibility.
The other style is the spiderweb, with many boxes and dependencies. If
you’ve been diligent (and maybe a bit lucky), the boxes fall into ranks with
calls through tiers, as shown in the first figure. If not, then the web will be chaotic
like that of the black widow, shown in the second figure. The feature common to all of
these is that the connections outnumber the services. A butterfly style has 2N
connections, a spiderweb might have up to ![]() , and yours falls
somewhere in between.
, and yours falls
somewhere in between.

All these connections are integration points, and every single one of them is out to destroy your system. In fact, the more we move toward a large number of smaller services, the more we integrate with SaaS providers, and the more we go API first, the worse this is going to get.
Integration points are the number-one killer of systems. Every single one of those feeds presents a stability risk. Every socket, process, pipe, or remote procedure call can and will hang. Even database calls can hang, in ways obvious and subtle. Every feed into the system can hang it, crash it, or generate other impulses at the worst possible time. We’ll look at some of the specific ways these integration points can go bad and what you can do about them.
Socket-Based Protocols
Many higher-level integration protocols run over sockets. In fact, pretty much everything except named pipes and shared-memory IPC is socket-based. The higher protocols introduce their own failure modes, but they’re all susceptible to failures at the socket layer.
The simplest failure mode occurs when the remote system refuses connections. The calling system must deal with connection failures. Usually, this isn’t much of a problem, since everything from C to Java to Elm has clear ways to indicate a connection failure—either an exception in languages that have them or a magic return value in ones that don’t. Because the API makes it clear that connections don’t always work, programmers deal with that case.
One wrinkle to watch out for, though, is that it can take a long time to discover that you can’t connect. Hang on for a quick dip into the details of TCP/IP networking.
Every architecture diagram ever drawn has boxes and arrows, similar to the ones in the following figure. (A new architect will focus on the boxes; an experienced one is more interested in the arrows.)

Like a lot of other things we work with, this arrow is an abstraction for a network connection. Really, though, that means it’s an abstraction for an abstraction. A network “connection” is a logical construct—an abstraction—in its own right. All you will ever see on the network itself are packets. (Of course, a “packet” is an abstraction, too. On the wire, it’s just electrons or photons. Between electrons and a TCP connection are many layers of abstraction. Fortunately, we get to choose whichever level of abstraction is useful at any given point in time.) These packets are the Internet Protocol (IP) part of TCP/IP. Transmission Control Protocol (TCP) is an agreement about how to make something that looks like a continuous connection out of discrete packets. The figure shows the “three-way handshake” that TCP defines to open a connection.

The connection starts when the caller (the client in this scenario, even though it is itself a server for other applications) sends a SYN packet to a port on the remote server. If nobody is listening to that port, the remote server immediately sends back a TCP “reset” packet to indicate that nobody’s home. The calling application then gets an exception or a bad return value. All this happens very quickly, in less than ten milliseconds if both machines are plugged into the same switch.
If an application is listening to the destination port, then the remote server sends back a SYN/ACK packet indicating its willingness to accept the connection. The caller gets the SYN/ACK and sends back its own ACK. These three packets have now established the “connection,” and the applications can send data back and forth. (For what it’s worth, TCP also defines the “simultaneous open” handshake, in which both machines send SYN packets to each other before a SYN/ACK. This is relatively rare in systems that are based on client/server interactions.)
Suppose, though, that the remote application is listening to the port but is absolutely hammered with connection requests, until it can no longer service the incoming connections. The port itself has a “listen queue” that defines how many pending connections (SYN sent, but no SYN/ACK replied) are allowed by the network stack. Once that listen queue is full, further connection attempts are refused quickly. The listen queue is the worst place to be. While the socket is in that partially formed state, whichever thread called open is blocked inside the OS kernel until the remote application finally gets around to accepting the connection or until the connection attempt times out. Connection timeouts vary from one operating system to another, but they’re usually measured in minutes! The calling application’s thread could be blocked waiting for the remote server to respond for ten minutes!
Nearly the same thing happens when the caller can connect and send its request but the server takes a long time to read the request and send a response. The read call will just block until the server gets around to responding. Often, the default is to block forever. You have to set the socket timeout if you want to break out of the blocking call. In that case, be prepared for an exception when the timeout occurs.
Network failures can hit you in two ways: fast or slow. Fast network failures cause immediate exceptions in the calling code. “Connection refused” is a very fast failure; it takes a few milliseconds to come back to the caller. Slow failures, such as a dropped ACK, let threads block for minutes before throwing exceptions. The blocked thread can’t process other transactions, so overall capacity is reduced. If all threads end up getting blocked, then for all practical purposes, the server is down. Clearly, a slow response is a lot worse than no response.
The 5 A.M. Problem
One of the sites I launched developed a nasty pattern of hanging completely at almost exactly 5 a.m. every day. The site was running on around thirty different instances, so something was happening to make all thirty different application server instances hang within a five-minute window (the resolution of our URL pinger). Restarting the application servers always cleared it up, so there was some transient effect that tipped the site over at that time. Unfortunately, that was just when traffic started to ramp up for the day. From midnight to 5 a.m., only about 100 transactions per hour were of interest, but the numbers ramped up quickly once the East Coast started to come online (one hour ahead of us central time folks). Restarting all the application servers just as people started to hit the site in earnest was what you’d call a suboptimal approach.
On the third day that this occurred, I took thread dumps from one of the afflicted application servers. The instance was up and running, but all request-handling threads were blocked inside the Oracle JDBC library, specifically inside of OCI calls. (We were using the thick-client driver for its superior failover features.) In fact, once I eliminated the threads that were just blocked trying to enter a synchronized method, it looked as if the active threads were all in low-level socket read or write calls.
Abstractions provide great conciseness of expression. We can go much faster when we talk about fetching a document from a URL than if we have to discuss the tedious details of connection setup, packet framing, acknowledgments, receive windows, and so on. With every abstraction, however, the time comes when you must peel the onion, shed some tears, and see what’s really going on—usually when something is going wrong. Whether for a problem diagnosis or performance tuning, packet capture tools are the only way to understand what’s really happening on the network.
tcpdump is a common UNIX tool for capturing packets from a network interface. Running it in “promiscuous” mode instructs the network interface card (NIC) to receive all packets that cross its wire—even those addressed to other computers. Wireshark can sniff packets on the wire,[4] as tcpdump does, but it can also show the packets’ structure in a GUI.
Wireshark runs on the X Window System. It requires a bunch of libraries that might not even be installed in a Docker container or an AWS instance. So it’s best to capture packets noninteractively using tcpdump and then move the capture file to a nonproduction environment for analysis.
The following screenshot shows Wireshark (then called “Ethereal”) analyzing a capture from my home network. The first packet shows an address routing protocol (ARP) request. This happens to be a question from my wireless bridge to my cable modem. The next packet was a surprise: an HTTP query to Google, asking for a URL called /safebrowsing/lookup with some query parameters. The next two packets show a DNS query and response for the “michaelnygard.dyndns.org” hostname. Packets 5, 6, and 7 are the three-phase handshake for a TCP connection setup. We can trace the entire conversation between my web browser and server. Note that the pane below the packet trace shows the layers of encapsulation that the TCP/IP stack created around the HTTP request in the second packet. The outermost frame is an Ethernet packet. The Ethernet packet contains an IP packet, which in turn contains a TCP packet. Finally, the payload of the TCP packet is an HTTP request. The exact bytes of the entire packet appear in the third pane.

Running packet traces is an educational activity. I strongly recommend it, but I must offer two comments. First, don’t do it on a network unless you are specifically granted permission! Second, keep a copy of The TCP/IP Guide [Koz05] or TCP/IP Illustrated [Ste93] open beside you.
The next step was tcpdump and ethereal (now called Wireshark). The odd thing was how little that showed. A handful of packets were being sent from the application servers to the database servers, but with no replies. Also, nothing was coming from the database to the application servers. Yet monitoring showed that the database was alive and healthy. There were no blocking locks, the run queue was at zero, and the I/O rates were trivial.
By this time, we had to restart the application servers. Our first priority was restoring service. (We do data collection when we can, but not at the risk of breaking an SLA.) Any deeper investigation would have to wait until the issue happened again. None of us doubted that it would happen again.
Sure enough, the pattern repeated itself the next morning. Application servers locked up tight as a drum, with the threads inside the JDBC driver. This time, I was able to look at traffic on the databases’ network. Zilch. Nothing at all. The utter absence of traffic on that side of the firewall was like Sherlock Holmes’ dog that didn’t bark in the night—the absence of activity was the biggest clue. I had a hypothesis. Quick decompilation of the application server’s resource pool class confirmed that my hypothesis was plausible.
I said before that socket connections are an abstraction. They exist only as objects in the memory of the computers at the endpoints. Once established, a TCP connection can exist for days without a single packet being sent by either side. As long as both computers have that socket state in memory, the “connection” is still valid. Routes can change, and physical links can be severed and reconnected. It doesn’t matter; the “connection” persists as long as the two computers at the endpoints think it does.
In the innocent days of DARPAnet and EDUnet, that all worked beautifully well. Pretty soon after AOL connected to the Internet, though, we discovered the need for firewalls. Such paranoid little bastions have broken the philosophy and implementation of the whole Net.
A firewall is nothing but a specialized router. It routes packets from one set of physical ports to another. Inside each firewall, a set of access control lists define the rules about which connections it will allow. The rules say such things as “connections originating from 192.0.2.0/24 to 192.168.1.199 port 80 are allowed.” When the firewall sees an incoming SYN packet, it checks it against its rule base. The packet might be allowed (routed to the destination network), rejected (TCP reset packet sent back to origin), or ignored (dropped on the floor with no response at all). If the connection is allowed, then the firewall makes an entry in its own internal table that says something like “192.0.2.98:32770 is connected to 192.168.1.199:80.” Then all future packets, in either direction, that match the endpoints of the connection are routed between the firewall’s networks.
So far, so good. How is this related to my 5 a.m. wake-up calls?
The key is that table of established connections inside the firewall. It’s finite. Therefore, it does not allow infinite duration connections, even though TCP itself does allow them. Along with the endpoints of the connection, the firewall also keeps a “last packet” time. If too much time elapses without a packet on a connection, the firewall assumes that the endpoints are dead or gone. It just drops the connection from its table, as shown in the following figure. But TCP was never designed for that kind of intelligent device in the middle of a connection. There’s no way for a third party to tell the endpoints that their connection is being torn down. The endpoints assume their connection is valid for an indefinite length of time, even if no packets are crossing the wire.

As a router, the firewall could have sent an ICMP reset to indicate the route no longer works. However, it could also have been configured to suppress that kind of ICMP traffic, since those can also be used as network probes by the bad guys. Even though this was an interior firewall, it was configured under the assumption that outer tiers would be compromised. So it dropped those packets instead of informing the sender that the destination host couldn’t be reached.
After that point, any attempt to read or write from the socket on either end did not result in a TCP reset or an error due to a half-open socket. Instead, the TCP/IP stack sent the packet, waited for an ACK, didn’t get one, and retransmitted. The faithful stack tried and tried to reestablish contact, and that firewall just kept dropping the packets on the floor, without so much as an “ICMP destination unreachable” message. My Linux system, running on a 2.6 series kernel, has its tcp_retries2 set to the default value of 15, which results in a twenty-minute timeout before the TCP/IP stack will inform the socket library that the connection is broken. The HP-UX servers we were using at the time had a thirty-minute timeout. That application’s one-line call to write to a socket could block for thirty minutes! The situation for reading from the socket was even worse. It could block forever.
When I decompiled the resource pool class, I saw that it used a last-in, first-out strategy. During the slow overnight times, traffic volume was light enough that a single database connection would get checked out of the pool, used, and checked back in. Then the next request would get the same connection, leaving the thirty-nine others to sit idle until traffic started to ramp up. They were idle well over the one-hour idle connection timeout configured into the firewall.
Once traffic started to ramp up, those thirty-nine connections per application server would get locked up immediately. Even if the one connection was still being used to serve pages, sooner or later it would be checked out by a thread that ended up blocked on a connection from one of the other pools. Then the one good connection would be held by a blocked thread. Total site hang.
Once we understood all the links in that chain of failure, we had to find a solution. The resource pool has the ability to test JDBC connections for validity before checking them out. It checked validity by executing a SQL query like “SELECT SYSDATE FROM DUAL.” Well, that would’ve just make the request-handling thread hang anyway. We could also have had the pool keep track of the idle time of the JDBC connection and discard any that were older than one hour. Unfortunately, that strategy involves sending a packet to the database server to tell it that the session is being torn down. Hang.
We were starting to look at some really hairy complexities, such as creating a “reaper” thread to find connections that were close to getting too old and tearing them down before they timed out. Fortunately, a sharp DBA recalled just the thing. Oracle has a feature called dead connection detection that you can enable to discover when clients have crashed. When enabled, the database server sends a ping packet to the client at some periodic interval. If the client responds, then the database knows it’s still alive. If the client fails to respond after a few retries, the database server assumes the client has crashed and frees up all the resources held by that connection.
We weren’t that worried about the client crashing. The ping packet itself, however, was what we needed to reset the firewall’s “last packet” time for the connection, keeping the connection alive. Dead connection detection kept the connection alive, which let me sleep through the night.
The main lesson here is that not every problem can be solved at the level of abstraction where it manifests. Sometimes the causes reverberate up and down the layers. You need to know how to drill through at least two layers of abstraction to find the “reality” at that level in order to understand problems.
Next, let’s look at problems with HTTP-based protocols.
HTTP Protocols
REST with JSON over HTTP is the lingua franca for services today. No matter what language or framework you use, it boils down to shipping some chunk of formatted, semantically meaningful text as an HTTP request and waiting for an HTTP response.
Of course, all HTTP-based protocols use sockets, so they are vulnerable to all of the problems described previously. HTTP adds its own set of issues, mainly centered around the various client libraries. Let’s consider some of the ways that such an integration point can harm the caller:
-
The provider may accept the TCP connection but never respond to the HTTP request.
-
The provider may accept the connection but not read the request. If the request body is large, it might fill up the provider’s TCP window. That causes the caller’s TCP buffers to fill, which will cause the socket write to block. In this case, even sending the request will never finish.
-
The provider may send back a response status the caller doesn’t know how to handle. Like “418 I’m a teapot.” Or more likely, “451 Resource censored.”
-
The provider may send back a response with a content type the caller doesn’t expect or know how to handle, such as a generic web server 404 page in HTML instead of a JSON response. (In an especially pernicious example, your ISP may inject an HTML page when your DNS lookup fails.)
-
The provider may claim to be sending JSON but actually sending plain text. Or kernel binaries. Or Weird Al Yankovic MP3s.
Use a client library that allows fine-grained control over timeouts—including both the connection timeout and read timeout—and response handling. I recommend you avoid client libraries that try to map responses directly into domain objects. Instead, treat a response as data until you’ve confirmed it meets your expectations. It’s just text in maps (also known as dictionaries) and lists until you decide what to extract. We’ll revisit this theme in Chapter 11, Security.
Vendor API Libraries
It would be nice to think that enterprise software vendors must have hardened their software against bugs, just because they’ve sold it and deployed it for lots of clients. That might be true of the server software they sell, but it’s rarely true for their client libraries. Usually, software vendors provide client API libraries that have a lot of problems and often have stability risks. These libraries are just code coming from regular developers. They have all the variability in quality, style, and safety that you see from any other random sampling of code.
The worst part about these libraries is that you have so little control over them. If the vendor doesn’t publish source to its client library, then the best you can hope for is to decompile the code—if you’re in a language where that’s even possible—find issues, and report them as bugs. If you have enough clout to apply pressure to the vendor, then you might be able to get a bug fix to its client library, assuming, of course, that you are on the latest version of the vendor’s software. I have been known to fix a vendor’s bugs and recompile my own version for temporary use while waiting for the official patched version.
The prime stability killer with vendor API libraries is all about blocking. Whether it’s an internal resource pool, socket read calls, HTTP connections, or just plain old Java serialization, vendor API libraries are peppered with unsafe coding practices.
Here’s a classic example. Whenever you have threads that need to synchronize on multiple resources, you have the potential for deadlock. Thread 1 holds lock A and needs lock B, while thread 2 has lock B and needs lock A. The classic recipe for avoiding this deadlock is to make sure you always acquire the locks in the same order and release them in the reverse order. Of course, this helps only if you know that the thread will be acquiring both locks and you can control the order in which they are acquired. Let’s take an example in Java. This illustration could be from some kind of message-oriented middleware library:
| | public interface UserCallback { |
| | public void messageReceived(Message msg); |
| | } |
| | public interface Connection { |
| | public void registerCallback(UserCallback callback); |
| | |
| | public void send(Message msg); |
| | } |
I’m sure this looks quite familiar. Is it safe? I have no idea.
We can’t tell what the execution context will be just by looking at the code. You have to know what thread messageReceived gets called on, or else you can’t be sure what locks the thread will already hold. It could have a dozen synchronized methods on the stack already. Deadlock minefield.
In fact, even though the UserCallback interface does not declare messageReceived as synchronized (you can’t declare an interface method as synchronized), the implementation might make it synchronized. Depending on the threading model inside the client library and how long your callback method takes, synchronizing the callback method could block threads inside the client library. Like a plugged drain, those blocked threads can cause threads calling send to block. Odds are that means request-handling threads will be tied up. As always, once all the request-handling threads are blocked, your application might as well be down.
Countering Integration Point Problems
A stand-alone system that doesn’t integrate with anything is rare, not to mention being almost useless. What can you do to make integration points safer? The most effective stability patterns to combat integration point failures are Circuit Breaker and Decoupling Middleware.
Testing helps, too. Cynical software should handle violations of form and function, such as badly formed headers or abruptly closed connections. To make sure your software is cynical enough, you should make a test harness—a simulator that provides controllable behavior—for each integration test. (See Test Harnesses.) Setting the test harness to spit back canned responses facilitates functional testing. It also provides isolation from the target system when you’re testing. Finally, each such test harness should also allow you to simulate various kinds of system and network failures.
This test harness will immediately help with functional testing. To test for stability, you also need to flip all the switches on the harness while the system is under considerable load. This load can come from a bunch of workstations or cloud instances, but it definitely requires much more than a handful of testers clicking around on their desktops.
Remember This
- Beware this necessary evil.
-
Every integration point will eventually fail in some way, and you need to be prepared for that failure.
- Prepare for the many forms of failure.
-
Integration point failures take several forms, ranging from various network errors to semantic errors. You will not get nice error responses delivered through the defined protocol; instead, you’ll see some kind of protocol violation, slow response, or outright hang.
- Know when to open up abstractions.
-
Debugging integration point failures usually requires peeling back a layer of abstraction. Failures are often difficult to debug at the application layer because most of them violate the high-level protocols. Packet sniffers and other network diagnostics can help.
- Failures propagate quickly.
-
Failure in a remote system quickly becomes your problem, usually as a cascading failure when your code isn’t defensive enough.
- Apply patterns to avert integration point problems.
-
Defensive programming via Circuit Breaker, Timeouts (see Timeouts), Decoupling Middleware, and Handshaking (see Handshaking) will all help you avoid the dangers of integration points.