
Bulkheads
In a ship, bulkheads are partitions that, when sealed, divide the ship into separate, watertight compartments. With hatches closed, a bulkhead prevents water from moving from one section to another. In this way, a single penetration of the hull does not irrevocably sink the ship. The bulkhead enforces a principle of damage containment.
You can employ the same technique. By partitioning your systems, you can keep a failure in one part of the system from destroying everything. Physical redundancy is the most common form of bulkheads. If there are four independent servers, then a hardware failure in one can’t affect the others. Likewise, if there are two application instances running on a server and one crashes, the other will still be running (unless, of course, the first one crashed because of some external influence that would also affect the second).
Redundant virtual machines are not quite as robust as redundant physical machines. Most VM provisioning tools do not allow you to enforce physical isolation, so more than one VM may end up running on the same physical box.
At the largest scale, a mission-critical service might be implemented as several independent farms of servers, with certain farms reserved for use by critical applications and others available for noncritical uses. For example, a ticketing system could provide dedicated servers for customer check-in. These would not be affected if other, shared servers are overwhelmed with “flight status” queries (as sometimes happens during severe weather). Such a partitioning would have allowed the airline in Chapter 2, Case Study: The Exception That Grounded an Airline, to keep checking in passengers at airports, even if channel partners could not look up fares for that day’s flights.
In the cloud, you should run instances in different divisions of the service (e.g., across zones and regions in AWS). These are very large-grained chunks with strong partitioning between them. When using functions as a service, basically every function invocation runs in its own compartment.
In the figure that follows, Foo and Bar both use the enterprise service Baz. Because both depend on a common service, each system has some vulnerability to the other. If Foo suddenly gets crushed under user load, goes rogue because of some defect, or triggers a bug in Baz, Bar—and its users—also suffer. This kind of unseen coupling makes diagnosing problems (particularly performance problems) in Bar very difficult. Scheduling maintenance windows for Baz also requires coordination with both Foo and Bar, and it may be difficult to find a window that works for both clients.
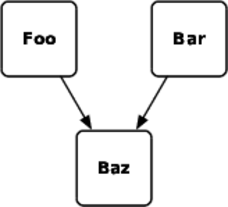
Assuming both Foo and Bar are critical systems with strict SLAs, it’d be safer to partition Baz, as shown in this revised figure. Dedicating some capacity to each critical client removes most of the hidden linkage. They probably still share a database and are, therefore, subject to deadlocks across instances, but that’s another antipattern.

Of course, it would be better to preserve all capabilities. Assuming that failures will occur, however, you must consider how to minimize the damage caused by a failure. It is not an easy effort, and one rule cannot apply in every case. Instead, you must examine the impact to the business of each loss of capability and cross-reference those impacts against the architecture of the systems. The goal is to identify the natural boundaries that let you partition the system in a way that is both technically feasible and financially beneficial. The boundaries of this partitioning may be aligned with the callers, with functionality, or with the topology of the system.
With cloud-based systems and software-defined load balancers, bulkheads do not need to be permanent. With a bit of automation, a cluster of VMs can be carved out and the load balancer can direct traffic from a particular consumer to that cluster. This is similar to A/B testing, but as a protective measure rather than an experiment. Dynamic partitions can be made and destroyed as traffic patterns change.
At smaller scales, process binding is an example of partitioning via bulkheads. Binding a process to a core or group of cores ensures that the operating system schedules that process’s threads only on the designated core or cores. Because it reduces the cache bashing that happens when processes migrate from one core to another, process binding is often regarded as a performance tweak. If a process goes berserk and starts using all CPU cycles, it can usually drag down an entire host machine. I’ve seen eight core servers consumed by a single process. If that process is bound to a core, however, it can use all available cycles only on that one core.
You can partition the threads inside a single process, with separate thread groups dedicated to different functions. For example, it’s often helpful to reserve a pool of request-handling threads for administrative use. That way, even if all request-handling threads on the application server are hung, it can still respond to admin requests—perhaps to collect data for postmortem analysis or a request to shut down.
Bulkheads are effective at maintaining service, or partial service, even in the face of failures. They are especially useful in service-oriented architectures, where the loss of a single service could have repercussions throughout the enterprise. In effect, a service inside an SOA represents a single point of failure for the enterprise.
Remember This
- Save part of the ship.
-
The Bulkheads pattern partitions capacity to preserve partial functionality when bad things happen.
- Pick a useful granularity.
-
You can partition thread pools inside an application, CPUs in a server, or servers in a cluster.
- Consider Bulkheads particularly with shared services models.
-
Failures in service-oriented or microservice architectures can propagate very quickly. If your service goes down because of a Chain Reaction, does the entire company come to a halt? Then you’d better put in some Bulkheads.