
Chapter
7
Foundations
In the last chapter, the operations team, my client, and I narrowly avoided a financial disaster. It was a difficult situation, and the “solution” was not exactly ideal. All of us would have been happier if it’d never happened. My team couldn’t fix the underlying problem—the delivery scheduling servers were outside our control. But I was able to diagnose the problem, and the operations center partially mitigated its effects. That was only possible because we already had good visibility into the running system. There certainly wasn’t time to add a bunch of logging calls inside the application. With runtime visibility, though, new logging wasn’t necessary. The applications revealed their problems. To apply the solution, we exercised control over the running system. There’s no way we could have recovered if we’d had to reboot the servers after every configuration change.
The next few chapters cover those key ingredients, leading us to a concept of “design for production.” Design for production means thinking about production issues as first-class concerns. That includes the production network, which might be considerably different from your development environment. It also includes logging and monitoring, runtime control, and security. Design for production also means designing for the people who do operations, whether they are a dedicated ops team or integrated with development. Operators are users, too. They may not be logged in to a beautifully designed front-end application, but they get to interact with your system through its configuration, control, and monitoring interfaces. If your system’s front end is Disney World, then operators get to use the secret tunnels beneath the park.
In the next several chapters, we will work through layers of concerns. As you can see in the figure, everything starts with the physical infrastructure. We’ll discuss that in this chapter. The next chapters each zoom out one step at a time to encompass wider, more distributed concerns as we go.
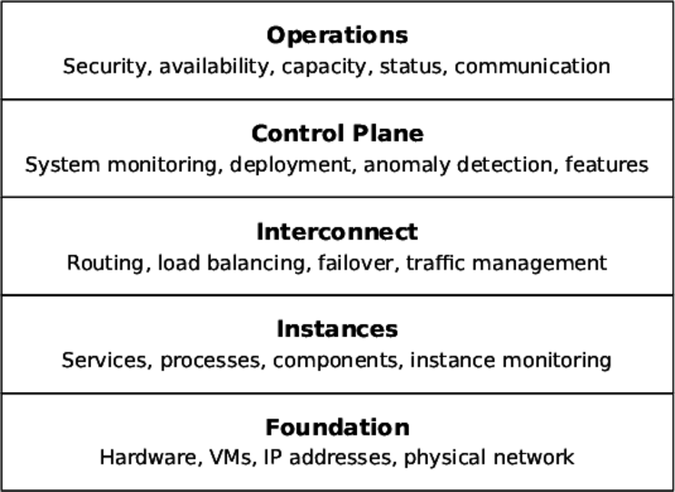
You may notice that the words “as a service” don’t appear anywhere in the diagram above. The distinctions between “Infrastructure as a Service” and “Platform as a Service” were never strong to begin with. As vendors have sliced, diced, and triangulated their way across the landscape, those classifications have broken down completely. It’s more useful to look at different technology platforms in terms of those layers of responsibility: Which layers do they drive/does the platform drive completely by API? Which responsibilities move from operations to developers, and in which layers? What responsibilities remain application-level concerns and what is moved behind software-driven abstractions?
This chapter starts with the first layer. Operations leads us into design for production considerations by looking at the physical fundamentals of the system: the machines and wires that everything else builds upon. The first order of business is to clear up some things about networks, hostnames, and IP addresses. After that, it’s time to talk about the code holders: physical hosts, virtual machines, and containers. Each kind of deployment has its own set of concerns that software designs must account for. Finally, we’ll look at some special concerns that arise when a system spans multiple data centers.