
Now, we'll see how entropy TAML works step by step:
- Let's say we've a model
 parameterized by a parameter
parameterized by a parameter  and we've a distribution over tasks
and we've a distribution over tasks  . First, we randomly initialize the model parameter,
. First, we randomly initialize the model parameter,  .
. - Sample a batch of tasks from a distribution of tasks—that is,
 . Say, we've sampled three tasks then:
. Say, we've sampled three tasks then:  .
. - Inner loop: For each task
 in tasks
in tasks 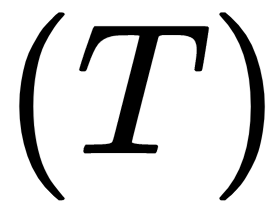 , we sample k data points and prepare our train and test datasets:
, we sample k data points and prepare our train and test datasets:


Then, we calculate the loss on our training set  , minimize the loss using gradient descent, and get the optimal parameters:
, minimize the loss using gradient descent, and get the optimal parameters:

So, for each of the tasks, we sample k data points, prepare the train dataset, minimize the loss, and get the optimal parameters. Since we sampled three tasks, we'll have three optimal parameters:  .
.
- Outer loop: We perform meta optimization. Here, we try to minimize the loss on our meta training set,
 . We minimize the loss by calculating the gradient with respect to our optimal parameter
. We minimize the loss by calculating the gradient with respect to our optimal parameter  and update our randomly initialized parameter
and update our randomly initialized parameter  ; along with this, we'll add the entropy term. So our final meta objective becomes the following:
; along with this, we'll add the entropy term. So our final meta objective becomes the following:
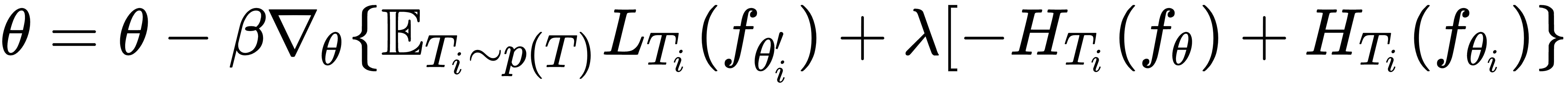
- We repeat steps 2 to 4 for n number of iterations.