
Chapter 10: H2O Model Deployment Patterns
In the previous chapter, we learned how easy it is to generate a ready-to-deploy scoring artifact from our model-building step and how this artifact, called a MOJO, is designed to flexibly deploy to a wide diversity of production systems.
In this chapter, we explore this flexibility of MOJO deployment by surveying a wide range of MOJO deployment patterns and digging down into the details of each deployment pattern. We will see how MOJOs are implemented for scoring on either H2O software, third-party software including business intelligence (BI) tools, and your own software. These implementations will include scoring on real-time, batch, and streaming data.
Recall from Chapter 1, Opportunities and Challenges, how machine learning (ML) models achieve business value when deployed to production systems. The knowledge you gain in this chapter will allow you to find the appropriate MOJO deployment pattern for a particular business case. For example, it will allow analysts to perform time-series forecasting from a Microsoft Excel spreadsheet, technicians to respond to predictions of product defects made on data streaming from a manufacturing process, or business stakeholders to respond to fraud predictions scored directly on Snowflake tables.
The goal of this chapter is for you to implement your own H2O model scoring, whether from these examples, your web search, or your imagination, inspired by these examples.
So, in this chapter, we're going to cover the following main topics:
- Surveying a sample of MOJO deployment patterns
- Exploring examples of MOJO scoring on H2O software
- Exploring examples of MOJO scoring on third-party software
- Exploring examples of MOJO scoring on your target-system software
- Exploring examples of accelerators based on H2O Driverless AI integrations
Technical requirements
There are no technical requirements for this chapter, though we will be highlighting the technical steps to implement and execute MOJO deployment patterns.
Surveying a sample of MOJO deployment patterns
The purpose of this chapter is to overview the diverse ways in which MOJOs can be deployed for making predictions. Enough detail is given to provide an understanding of the context of MOJO deployment and scoring. Links are provided to find low-level details.
First, let's summarize our sample of MOJO scoring patterns in table form to get a sense of the many different ways you can deploy MOJOs. After this sample overview, we will elaborate on each table entry more fully.
Note that the table columns for our deployment-pattern summaries are represented as follows:
- Data Velocity: This refers to the size and speed of data that is scored and is categorized as either real-time (single record scored, typically in less than 100 milliseconds), batch (large numbers of records scored at one time), and streaming (a continuous flow of records that are scored).
- Scoring Communication: This refers to how the scoring is triggered and communicated—for example, via a REpresentational State Transfer (REST) call or a Structured Query Language (SQL) statement.
- MOJO Deployment: This is a brief description of how the MOJO is deployed on the scoring system.
Let's take a look at some of the deployment patterns. We will break these patterns into four categories.
H2O software
This is a sample of ways you can deploy and score MOJOs on software provided and supported by H2O.ai. The following table provides a summary of this:

We will see that deploying to H2O software is super easy since all you have to do is upload the MOJO (manually or programmatically).
Third-party software integrations
Here are a few examples of MOJO scoring with third-party software:

Note that some third-party integrations are done by consuming scoring from MOJOs deployed to a REST server. This has the advantage of centralizing your deployment in one place (the REST server) and consuming it from many places (for example, dozens of Tableau or MS Excel instances deployed on employee personal computers).
Other third-party integrations are accomplished by deploying MOJOs directly on the third-party software system. The Snowflake integration, for example, is implemented on the Snowflake architecture and allows batch scoring that performs at a Snowflake scale (it can score hundreds of thousands of rows per second).
Your software integrations
We will explore the following patterns for integrating MOJOs directly into your own software:

MOJO integration into your software requires a MOJO wrapper class. We learned how to do this in Chapter 9, Production Scoring and the H2O MOJO. Of course, you can take the alternative approach and integrate your software with MOJO scoring consumed from a REST endpoint.
Accelerators based on H2O Driverless AI integrations
This book focuses on H2O Core (H2O-3 and Sparkling Water) model-building technology for building models against large data volumes. H2O provides an alternative model-building technology called Driverless AI. Driverless AI is a specialized, automated ML (AutoML) engine that allows users to find highly accurate and trusted models in extremely short amounts of time. Driverless AI cannot train on the massive datasets that H2O Core can, though. However, Driverless AI also produces a MOJO, and its flavor of MOJO deploys similarly to the H2O Core MOJO. These similarities were covered in Chapter 9, Production Scoring and the H2O MOJO.
There are many examples available online for deploying Driverless AI MOJOs. These examples can be followed as a guide to deploying H2O Core MOJOs in the same pattern. Consider the following Driverless AI examples therefore as accelerators that can get you most of the way to deploying your H2O Core MOJOs, but some implementation details will differ:

The patterns shown in these four tables should provide a good sense of the many ways you can deploy MOJOs. They do not, however, represent the total set of possibilities.
A Note on Possibilities
The patterns shown here are merely a sample of H2O MOJO scoring patterns that exist or are possible. Other MOJO scoring patterns can be found through a web search, and you can use your imagination to integrate MOJO scoring in diverse ways into your own software. Additionally, H2O.ai is rapidly expanding its third-party partner integrations for scoring, as well as expanding its own MOJO deployment, monitoring, and management capabilities. This is a rapidly moving space.
Now that we have surveyed a landscape of MOJO deployment patterns, let's jump in and look at each example in detail.
Exploring examples of MOJO scoring with H2O software
The patterns in this section represent MOJOs deployed to H2O software. There are many advantages to deploying to H2O software. First, the software is supported by H2O and their team of ML experts. Second, this deployment workflow is greatly streamlined for H2O software since all you have to do is supply the MOJO in a simple upload (via a user interface (UI), an API, or a transfer method such as remote copy). Third, H2O scoring software has additional capabilities—such as monitoring for prediction and data drift—that are important for models deployed to production systems.
Let's start by looking at H2O's flagship model-scoring platform.
H2O MLOps
H2O MLOps is a full-featured platform for deploying, monitoring, managing, and governing ML models. H2O MLOps is dedicated to deploying models at scale (many models and model versions, enterprise-grade throughput and performance, high availability, and so on), and addressing monitoring, management, and governance concerns around models in production.
H2O MLOps and its relation to H2O's larger end-to-end ML platform will be reviewed in Chapter 13, Introducing H2O AI Cloud. See also https://docs.h2o.ai/mlops-release/latest-stable/docs/userguide/index.html for the MLOps user guide to better understand H2O MLOps.
Pattern overview
The H2O MLOps scoring pattern is shown in the following diagram:

Figure 10.1 – Model-scoring pattern for H2O MLOps
We'll elaborate on this next.
Scoring context
This is H2O.ai's flagship model-deployment, model-monitoring, and model-governance platform. It can be used to host and score both H2O and third-party (non-H2O) models.
H2O MLOps scores models in real time and in batches. Predictions optionally return reason codes. Models are deployed as single-model, champion/challenger, and A/B. See the Additional notes section for a full description of its capabilities.
Implementation
H2O MLOps is a modern Kubernetes-based implementation deployed using Terraform scripts and Helm charts.
Scoring example
The following code snippet shows a real-time scoring request sent using the curl command:
curl -X POST -H "Content-Type: application/json" -d @- https://model.prod.xyz.com/9c5c3042-1f9a-42b5-ac1a-9dca19414fbb/model/score << EOF
{"fields":["loan_amnt","term","int_rate","emp_length","home_ownership","annual_inc","purpose","addr_state","dti","delinq_2yrs","revol_util","total_acc","longest_credit_length","verification_status"rows":[["5000","36months","10.65","10",24000.0","RENT","AZ","27.650","0","83.7","9","26","verified"]]}EOF
And here is the result:
{"fields":["bad_loan.0","bad_loan.1"],"id":"45d0677a-9327-11ec-b656-2e37808d3384","score":[["0.7730158252427003","0.2269841747572997"]]}
From here, we see the probability of a loan default (bad_loan value of 1) is 0.2269841747572997. The id field is used to identify the REST endpoint, which is useful when models are deployed in champion/challenger or A/B test modes.
Additional notes
Here is a brief summary of key H2O MLOps capabilities:
- Multiple deployment models: Standalone; champion/challenger; A/B models
- Multiple model problems: Tabular; time-series; image; language models
- Shapley values: On deployment, specify whether to return Shapley values (reason codes) with the prediction
- Third-party models: Scores and monitors non-H2O models—for example, scikit-learn models
- Model management: Model registry; versioning; model metadata; promotion and approval workflow
- APIs: APIs and continuous integration and continuous delivery (CI/CD) integration
- Analytics: Optionally push scoring data to your system for your own analytics
- Lineage: Understand the lineage of data, experiment, and model
- Model monitoring: Data drift and prediction monitoring with alert management (bias and other types of monitoring are on the MLOps roadmap)
H2O MLOps versus Other H2O Model-Scoring Software
MLOps is H2O's flagship full-featured platform to deploy, monitor, and govern models for scoring. H2O supplies other software (overviewed next) that is specialized to address needs or constraints where MLOps may not fit.
Next, let's have a look at the H2O REST scorer.
H2O eScorer
H2O has a lightweight but powerful REST server to score MOJOs, called the H2O eScorer. This is a good alternative for serving MOJOs as REST endpoints without committing to larger infrastructure requirements of the H2O MLOps platform and therefore freeing deployment options to on-premises and lightweight deployments. Recall that third-party software often integrates with MOJOs by way of REST endpoint integration, so this is an effective way to achieve that.
Pattern overview
The H2O REST scorer pattern is shown in the following diagram:

Figure 10.2 – MOJO scoring pattern for H2O REST scorer
Here is an elaboration.
Scoring context
The H2O REST scorer makes real-time and batch predictions to a REST endpoint. Predictions optionally include reason codes.
Implementation
The H2O Rest scorer is a single Java ARchive (JAR) file holding an Apache Tomcat server hosting a Spring REST services framework. A properties file configures the application to host multiple REST scoring endpoints. MOJOs are loaded either by REST itself or by other means of transferring the MOJO to the server.
High throughput is achieved by placing multiple H2O REST scorers behind a load balancer.
Scoring example
Here are some examples of REST endpoints for real-time scoring:
http://192.1.1.1:8080/model?name=riskmodel.mojo &row=5000,36months,10.65,162.87,10,RENT,24000,VERIFIED-income,AZ,27.65,0,1,0,13648,83.7,0"
The REST scorer's REST API is quite flexible. For example, it includes multiple ways to structure the payload (for example, an observation input can be sent as comma-separated values (CSV), JavaScript Object Notation (JSON), or other structures with the scorer output returned in the same format, which is convenient when integrating with a BI tool).
Additional notes
Here is a summary of the H2O REST Scorer's set of capabilities:
- Each H2O Rest scorer can score multiple models (that is, MOJOs), each with its own REST endpoint.
- Typically, 1,000 scores per second are achieved for each CPU on an H2O REST scorer server.
- Security, monitoring, and logging settings are configurable in a properties file.
- Java Monitoring Beans (JMX) can be configured so that your own monitoring tool can collect and analyze runtime statistics. Monitoring includes scoring errors, scoring latency, and data drift.
- Security features include HTTPS, administrator authentication, authenticated endpoint URIs and limited access from IP prefix.
- There is extensive logging.
- There are extensive capabilities via the REST API, including obtaining model metadata, defining prediction output formats, defining logging verbosity, and managing MOJOs on the server.
- The REST API can generate an example request sent from different BI tools to score a model on the H2O REST scorer—for example, sample Python code to call a model for Power BI.
Next, we will have a look at the H2O batch database scorer.
H2O batch database scorer
The H2O batch database scorer is a client application that can perform batch predictions against tables using a Java Database Connectivity (JDBC) connection.
Pattern overview
The H2O batch database scorer pattern is shown in the following diagram:
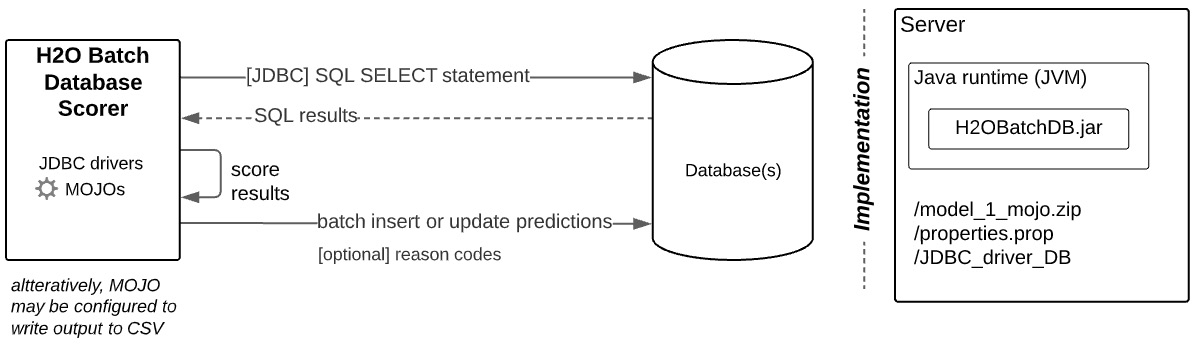
Figure 10.3 – MOJO scoring pattern for H2O batch database scorer
We'll elaborate on this next.
Scoring context
The H2O batch database scorer performs batch predictions against database tables. Predictions optionally include reason codes. Depending on how it is configured, predictions against table rows can be inserted into a new table or updated into the same table being scored. Alternatively, it can generate a CSV file of the prediction's outcome. This CSV output can be used to manually update tables or for other downstream processing.
Details of the processing sequence for H2O batch database scoring are shown in Figure 10.3.
Implementation
The H2O batch database scorer is a single JAR file that is available from H2O.ai. The JAR file uses a properties file to configure aspects of the database workflow.
More specifically, the property file contains the following:
- SQL connection string
- SQL SELECT statement to batch-score
- SQL INSERT or UPDATE statement to write prediction results
- Number of threads during batch scoring
- Path to MOJO
- Flag to write results to CSV or not
- Security settings
- Other settings
Scoring example
The following command shows how a batch job is run from the command line:
java -cp /PostgresData/postgresql-42.2.5.jar:H2OBatchDB.jar ai.h2o.H2OBatchDB
This, of course, can be integrated into a scheduler or a script to schedule and automate batch scores.
Note that this command does not include anything about the database or table. The program that is kicked off from this command finds the properties file, as described in the previous Implementation subsection, and uses the information there to drive batch scoring.
Additional notes
A single properties file holds all the information needed to run a single batch-scoring job (the properties file maps to a SQL statement against a table that will be scored).
If no properties file is stated in the Java command to score (see the Scoring example section), then the default properties file is used. Alternatively, a specific properties file can be specified in the Java command line to run a non-default scoring job.
Next, let's have a look at the H2O batch file scorer.
H2O batch file scorer
The H2O batch file scorer is an application that can perform batch predictions against records in a file.
Pattern overview
The H2O batch file scorer pattern is shown in the following diagram:

Figure 10.4 – MOJO scoring pattern for H2O batch file scorer
Scoring context
Scoring is batch against records in a file, and the output will be a file identical to the input file but with a scored field appended to each record. The output file remains on the H2O batch-scorer system until processed by another system (for example, copied to a downstream system for processing).
Implementation
The H2O batch file scorer is a single JAR file that is available from H2O.ai. Command-line arguments are used to specify the location of the model and input file, as well as any runtime parameters such as skipping the column head if one exists in the file.
Scoring example
The following command shows how a batch-file job is run from the command line:
java -Xms10g -Xmx10g -Dskipheader=true -Dautocolumns=true -classpath mojo2-runtime.jar:DAIMojoRunner_TQ.jar daimojorunner_tq.DAIMojoRunner_TQ pipeline.mojo LoanStats4.csv
A few notes are worth mentioning.
Additional notes
This scorer is ideal for processing extremely large files (> GB) as a single task, making it easy to use in a traditional batch-processing workflow. If the input file contains a header, then the scorer will select the correct columns to pass to the model, and if a header is not present, then the columns can be passed as command-line parameters.
Let's now take a look at the H2O Kafka scorer.
H2O Kafka scorer
The H2O Kafka scorer is an application that integrates with the score from Kafka streams.
Pattern overview
The H2O Kafka scorer pattern is shown in the following diagram:

Figure 10.5 – MOJO scoring pattern for H2O Kafka scorer
Scoring context
Scoring against streaming data is shown in Figure 10.5. Specifically, the H2O Kafka scorer pulls messages from a topic queue and publishes the score outcome to another topic.
Implementation
The H2O Kafka scorer is a JAR file that is implemented on the Kafka system. A properties file is used to configure which topic to consume (and thus which messages to score) and which to publish to (where to send the results). When the H2O Kafka scorer JAR file is started, it loads the MOJO and then listens for incoming messages from the topic.
Scoring example
Scoring is done when a message arrives at the upstream topic. A prediction is appended to the last field of the original message. This new message is then sent to a topic for downstream processing.
Additional notes
Scaling throughput is done using native Kafka scaling techniques inherent in its distributed parallelized architecture.
Finally, let's look at H2O batch scoring on Spark.
H2O batch scoring on Spark
H2O MOJOs can be deployed as native Spark jobs.
Pattern overview
The H2O batch scoring on Spark pattern is shown in the following diagram:

Figure 10.6 – MOJO scoring pattern for H2O batch scoring on Spark
Scoring context
Scoring is batch and on a Spark cluster. As such, the batch scoring is distributed and thus scales well to massive batch sizes.
Implementation
The required dependency to score MOJOs on the Spark cluster is distributed with the spark-submit command, as shown in the following section.
Scoring example
First, we'll create a PySparkling job similar to the following example. We will call this job myRiskScoring.py. The code is illustrated in the following snippet:
from pysparkling.ml import *
settings = H2OMOJOSettings(convertUnknownCategoricalLevelsToNa = True, convertInvalidNumbersToNa = True)
model_location="hdfs:///models/risk/v2/riskmodel.zip"
model = H2OMOJOModel.createFromMojo(model_location, settings")
predictions = model.transform(dataset)
// do something with predictions, e.g. write to hdfs
Then, submit your Spark job with the H2O scoring library, as follows:
./bin/spark-submit
--py-files py/h2o_pysparkling_scoring.zip
myRiskScoring.py
Note that the h2o_pysparkling_scoring.zip dependency will be distributed to the cluster with the job. This library is available from H2O.ai.
Additional notes
There are other scoring settings available in addition to those shown in the previous code sample. The following link will provide more details: https://docs.h2o.ai/sparkling-water/3.1/latest-stable/doc/deployment/load_mojo.html.
We have finished our review of some scoring patterns on H2O software. Let's now transition to scoring patterns on third-party software.
Exploring examples of MOJO scoring with third-party software
Let's now look at some examples of scoring that involve third-party software.
Snowflake integration
H2O.ai has partnered with Snowflake to integrate MOJO scoring against Snowflake tables. It is important to note that the MOJO in this integration is deployed on the Snowflake architecture and therefore achieves Snowflake's native scalability benefits. Combined with the low latency of MOJO scoring, the result is batch scoring on massive Snowflake tables in mere seconds, though real-time scoring on a smaller number of records is achievable as well.
Pattern overview
The Snowflake integration pattern is shown in the following diagram:

Figure 10.7 – MOJO scoring pattern for Snowflake Java user-defined function (UDF) integration
Let's elaborate.
Scoring context
Scoring is batch against Snowflake tables and leverages the scalability of the Snowflake platform. Thus, scoring can be made against any Snowflake table, including those holding massive datasets.
Scoring is done by running a SQL statement from a Snowflake client. This can be either a native Snowflake worksheet, SnowSQL, or a SQL client with a Snowflake connector.Alternatively, scoring can be done programmatically using Snowflake's Snowpark API.
Implementation
To implement your score, create a staging table and grant permissions against it. You then copy your MOJO and H2O JAR file dependencies to the staging table.
You can then use SQL to create a Java UDF that imports these dependencies and assigns a handler to the H2O dependency that does the scoring. This UDF is then referenced when making a SQL scoring statement, as shown next.
You can find H2O dependencies and instructions here: https://s3.amazonaws.com/artifacts.h2o.ai/releases/ai/h2o/dai-snowflake-integration/java-udf/download/index.html.
An integrated experience of using the UDF with Snowflake is also available online at https://cloud.h2o.ai/v1/latestapp/wave-snowflake.
Scoring example
This is an example of a SQL statement that performs batch scoring against a table:
select ID, H2OScore_Java('Modelname=riskmodel.zip', ARRAY_CONSTRUCT(loan_amnt, term, int_rate, installment, emp_length, annual_inc, verification_status, addr_state, dti, inq_last_6mths, revol_bal, revol_util, total_acc)) as H2OPrediction from RiskTable;Notice that the H2O Scoring UDF (loaded as shown in the Implementation section) is run and that the model name (the MOJO name) is referenced.
Additional notes
For a more programmatic approach, you can use the Snowpark API instead of a SQL statement to batch-score.
Alternative implementation – Scoring via a Snowflake external function
For cases where you do not want to deploy MOJOs directly to the Snowflake environment, you can implement an external function on Snowflake and then pass the scoring to an H2O eScorer implementation. Note that scoring itself is external to Snowflake, and batch throughput rates are determined by the H2O eScorer and not the Snowflake architecture. This is shown in the following diagram:

Figure 10.8 – MOJO scoring pattern for Snowflake external function integration
To implement this, we will use Snowflake on AWS as an example. Follow these steps:
- First, use the Snowflake client to create api_integration to aws_api_gateway. A gateway is required to secure the external function when communicating to the H2O eScorer, which will be outside Snowflake. You will need to have the correct role to create this.
- Then, use SQL to create an external function on Snowflake—for example, named H2OPredict. The external function will reference the api_integration.
- You are now ready to batch score a Snowflake table via an external function pass-through to an H2O eScorer. Here is a sample SQL statement:
select ID, H2OPredict('Modelname=riskmodel.zip', loan_amnt, term, int_rate, installment, emp_length, annual_inc, verification_status, addr_state, dti, inq_last_6mths, revol_bal, revol_util, total_acc) as H2OPrediction from RiskTable;
Let's have a look at Teradata integration.
Teradata integration
H2O.ai has partnered with Teradata to implement batch or real-time scoring directly against Teradata tables. This is done as shown in the following diagram:

Figure 10.9 – MOJO scoring pattern for Teradata integration
Scoring context
Scoring is batch against Teradata tables and leverages the scalability of the Teradata platform. Thus, scoring can be made against any Teradata table, including those holding massive datasets. This is similar in concept to the Snowflake UDF integration, but only in concept: the underlying architectures and implementations are fundamentally different.
Scoring against Teradata tables is done by running a SQL statement from a Teradata client. This can be either a native Teradata Studio client or a SQL client with a Teradata connector.
Implementation
To implement, you first must install Teradata Vantage Bring Your Own Model (BYOM). Then, you use SQL to create a Vantage table to store H2O MOJOs. You then use SQL to load MOJOs into the Vantage table. Details can be found at https://docs.teradata.com/r/CYNuZkahMT3u2Q~mX35YxA/WC6Ku8fmrVnx4cmPEqYoXA.
Scoring example
Here is an example SQL statement to batch score a Teradata table:
select * from H2OPredict(
on risk_table
on (select * from mojo_models where model_id=riskmodel) dimension
using Accumulate('id')) as td_alias;
In this case, the code assumes all risk_table fields are used as input into the MOJO.
Additional notes
Your SQL statement to batch score may include options to return reason codes, stage probabilities, and leaf-node assignments.
BI tool integration
A powerful use of MOJO scoring is to integrate into BI tools. The most common way is to implement MOJO scoring either on a REST server or against a database, as shown in the following diagram. Note that in this pattern, MOJOs are not deployed on the BI tool itself, but rather, the tool integrates with an external scoring system. The low-latency nature of MOJO scoring allows users to interact in real time with MOJO predictions through this pattern:

Figure 10.10 – MOJO scoring patterns for BI tool integration
Scoring context
BI tools integrate real-time predictions from external scorers.
Implementation
An external REST or database MOJO scoring system is implemented. Integration with the external scorer is implemented in the BI tool. These integrations are specific to each BI tool, and often, a single BI tool has multiple ways to make this integration.
Scoring example – Excel
The following code block shows a formula created in a cell of an Excel spreadsheet:
=WEBSERVICE(CONCAT("http://192.1.1.1:8080/modeltext?name=riskmodel.mojo&row=",TEXTJOIN(","FALSE, $A4:$M4))))This web service is called when the formula is applied to the target cell, or whenever a value changes in any of the cells referenced in the formula. A user can then drag the formula down a column and have predictions fill the column.
Note in the preceding formula that the REST call composes the observation to be scored as CSV and not as JSON. The structuring of this payload is specific to the REST API and its endpoint.
We can integrate MOJO scoring into other third-party software using REST endpoints in a similar fashion, though the semantics of the endpoint construction differ. Let's see how to do it in Tableau.
Scoring example – Tableau
Tableau is a common dashboarding tool used within enterprises to present information to a variety of different users within the organization.
Using the Tableau script syntax, a model can be invoked from the dashboard. This is very powerful as now, a business user can get current prediction results directly in the dashboard on demand. You can see an example script here:
SCRIPT_STR(
'name'='riskmodel.mojo',
ATTR([./riskmodel.mojo]),
ATTR([0a4bbd12-dcad-11ea-ab05-024200eg007]),
ATTR([loan_amnt]),
ATTR([term]),
ATTR([int_rate]),
ATTR([installment]),
ATTR([emp_length]),
ATTR([annual_inc]),
ATTR([verification_status]),
ATTR([addr_state]),
ATTR([dti]),
ATTR([inq_last_6mths]),
ATTR([revol_bal]),
ATTR([revol_util]),
ATTR([total_acc]))
The script reads the values as attributes (ATTR keyword) and passes them to a script in the Tableau environment when a REST call is made to the model. Using the REST call allows a centralized model to be deployed and managed, but different applications and consumers invoke the model based on their specific needs.
Now, let's see how to build a REST endpoint in Power BI.
Scoring example – Power BI
Here is a scoring example for Power BI. In this case, we are using a Web.Contents Power Query M function. This function is pasted to the desired Power BI element in your Power BI dashboard:
Web.Contents(
"http://192.1.1.1:8080",
[
RelativePath="modeltext",
Query=
[
name="riskmodel.mojo",
loan_amnt=Loan_Ammt,
term=Term,
int_rate=Int_Rate,
installment=Installments,
emp_length=Emp_Length,
annual_inc=Annual_Inc,
verification_status=Verification_Status,
addr_state=Addr_State,
dti=DTI,
inq_last_6mths= Inq_Last_6mths,
revol_bal=Revol_Bal,
revol_util=Revol_Util,
total_acc=Total_Acc
]
]
)
Let's generalize a bit from these specific examples.
Additional notes
Each BI tool integrates with a REST endpoint or database in its own way and often provides multiple ways to do so. See your BI tool documentation for details.
UiPath integration
UiPath is an RPA platform that automates workflows based on human actions. Making predictions and responding to these predictions is a powerful part of this automation, and thus scoring models during these workflow steps is a perfect fit. You can see an example of this in the following diagram:

Figure 10.11 – MOJO scoring pattern for UiPath integration
Scoring context
UiPath integrates with external MOJO scoring similar to what was shown for BI tools in the previous section. In the case of UiPath, a workflow step is configured to make a REST call, receive a prediction, and respond to that prediction.
Implementation
MOJO scoring is implemented externally on a REST server, and the UiPath Request Builder wizard is used to configure a REST endpoint to return a prediction. Details can be seen here: https://www.uipath.com/learning/video-tutorials/application-integration-rest-web-service-json.
Scoring example
This video shows how to automate a workflow using H2O MOJO scoring: https://www.youtube.com/watch?v=LRlGjphraTY.
We have just finished our survey of some MOJO scoring patterns for third-party software. Let's look at a few scoring patterns with software that your organization builds itself.
Exploring examples of MOJO scoring with your target-system software
In addition to deploying MOJOs for scoring on H2O and third-party software, you can also take a Do-It-Yourself (DIY) approach and deploy scoring in your own software. Let's see how to do this.
Your software application
There are two ways to score from your own software: integrate with an external scoring system or embed scoring directly in your software system.
The following diagram shows the pattern of integrating with an external scoring system:
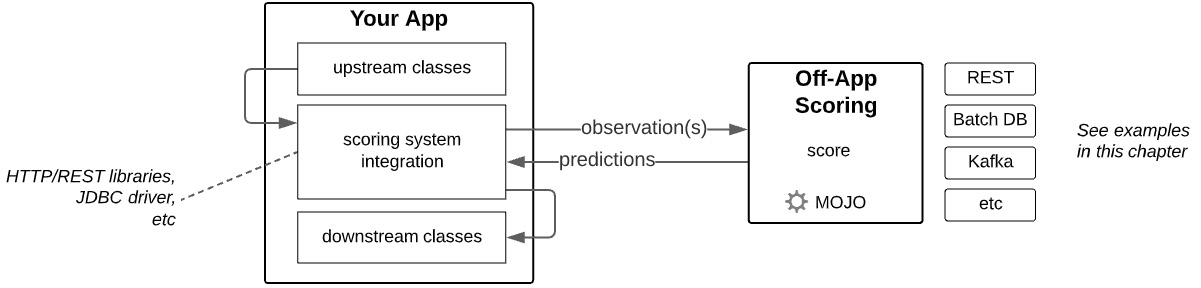
Figure 10.12 – MOJO application-scoring pattern for external scoring
This pattern should look familiar because it is fundamentally the same as what we saw with scoring from BI tools: your software acts as a client to consume MOJO predictions made from another system. The external prediction system can be a MOJO deployed on a REST server (for example, an H2O REST scorer) or batch database scorer (for example, a Snowflake Java UDF or an H2O batch database scorer) or another external system, and your application needs to implement the libraries to connect to that system.
In contrast, the following diagram shows the pattern of embedding MOJO scoring directly into your application itself:

Figure 10.13 – MOJO application-scoring pattern for embedded scoring
Doing so requires your application to implement a Java wrapper class that uses the H2O MOJO API to load the MOJO and score data with it. This was shown in detail in Chapter 9, Production Scoring and the H2O MOJO.
When should you use the external versus embedded scoring pattern? There are, of course, advantages and disadvantages to each pattern.
The external scoring pattern decouples scoring from the application and thus allows each component and the personas around it to focus on what it does best. Application developers, for example, can focus on developing the application and not deploying and monitoring models. Additionally, an external scoring component can be reused so that many applications and clients can connect to the same deployed model. Finally, particularly in the case of on-database scoring (for example, Java UDF and Teradata integration) and streaming scoring with extreme batch size or throughput, it would be difficult or foolish to attempt to build this on your own.
The embedded scoring pattern has the advantage of eliminating the time cost of sending observations and predictions across the network. This may or may not be important depending on your service-level agreements (SLAs). It certainly simplifies the infrastructure requirements to perform scoring, especially when network infrastructure is unavailable or unreliable. Finally, and often for regulatory reasons, it may be desirable or necessary to manage the model deployment and the application as a single entity, thus demanding the coupling of the two.
On-device scoring
MOJOs can be deployed to devices, whether they be an office scanner/printer, a medical device, or a sensor. These can be viewed as mini-applications, and the same decision for external or embedded scoring applies to devices as with applications, as discussed previously. In the case of devices, however, the advantages and disadvantages of external versus embedded scoring can be magnified greatly. For example, devices such as internet of things (IoT) sensors may number in the thousands, and the cost of deploying and managing models on each of these may outweigh the cost of greater latency resulting from network communication to a central external scorer.
Important Note
A rule of thumb is that the available device memory needs to be over two times the size of the MOJO.
Exploring examples of accelerators based on H2O Driverless AI integrations
This book thus far has focused on building models at scale using H2O. We have been doing this with H2O Core (often called H2O Open Source), a distributed ML framework that scales to massive datasets. We will see in Chapter 13, Introducing H2O AI Cloud, that H2O offers a broader set of capabilities represented by an end-to-end platform called H2O AI Cloud. One of these capabilities is a highly focused AI-based AutoML component called Driverless AI, and we will distinguish this from H2O Core in Chapter 13, Introducing H2O AI Cloud.
Driverless AI is like H2O Core because it also generates ready-to-deploy MOJOs with a generic MOJO runtime and API, though for Driverless AI a license file is required for MOJO deployment, and the MOJO and runtime are named differently than for H2O Core.
The reason for mentioning this here is that several integrations of Driverless AI have been built and are well documented but have not analogously been built for H2O Core. These integrations and their documentation can be used as accelerators to do the same for H2O Core. Just bear in mind the lack of license requirement for deploying H2O Core MOJOs, and the differently named MOJOs and runtime.
Approach to Describing Accelerators
Accelerators are overviewed here and links are provided to allow you to understand their implementation details. As noted, these accelerators represent the deployment of MOJOs generated from the H2O Driverless AI AutoML tool. Please review Chapter 9, Production Scoring and the H2O MOJO to understand how MOJOs generated from H2O Core (H2O-3 or Sparkling Water) are essentially the same as those generated from Driverless AI but with differences in naming and the MOJO API. This knowledge will allow you to implement the Driverless AI MOJO details shown in the links for H2O Core MOJOs.
Let's take a look at some examples.
Apache NiFi
Apache NiFi is an open source software (OSS) designed to program the flow of data in a UI and drag-and-drop fashion. It is built around the concept of moving data through different configurable processors that act on the data in specialized ways. The resulting data flows allow forking, merging, and nesting of sub-flows of processor sequences and generally resemble complex directed acyclic graphs (DAGs). The project's home page can be found here: https://nifi.apache.org/index.html.
NiFi processors can be used to communicate with external REST, JDBC, and Kafka systems and thus can leverage the pattern of scoring MOJOs from external systems.
You can, however, build your own processor that embeds the MOJO in the processor to score real-time or batch. This processor requires only configurations to point to the MOJO and its dependencies. The following link shows how to do this for Driverless AI and can be used as an accelerator for doing the same with H2O Core: https://github.com/h2oai/dai-deployment-examples/tree/master/mojo-nifi.
Apache Flink
Apache Flink is a high throughput distributed stream- and batch-processing engine with an extensive feature set to run event-driven, data analytics, and data pipeline applications in a fault-tolerant way.
The following link shows how to embed Driverless AI MOJOs to score data directly against Flink data streams and can be used as an accelerator for doing the same with H2O Core: https://github.com/h2oai/dai-deployment-examples/tree/master/mojo-flink.
AWS Lambda
AWS Lambda is a serverless computing service that lets you run code without the need to stand up, manage, and pay for underlying server infrastructure. It can perform any computing task that is short-lived and stateless, and thus is a nice fit for processing scoring requests. The following accelerator shows how to implement an AWS Lambda as a REST endpoint for real-time or batch MOJO scoring: https://h2oai.github.io/dai-deployment-templates/aws_lambda_scorer/.
AWS SageMaker
AWS SageMaker can be used to host and monitor model scoring. The following accelerator shows how to implement a REST endpoint for real-time MOJO scoring: https://h2oai.github.io/dai-deployment-templates/aws-sagemaker-hosted-scorer/.
And now, we have finished our survey of scoring and deployment patterns for H2O MOJOs. The business value of your H2O-at-scale models is achieved when they are deployed to production systems. The examples shown here are just a few possibilities, but they should give you an idea of how diverse MOJO deployments and scoring can be.
Let's summarize what we've learned in this chapter.
Summary
In this chapter, we explored a wide diversity of ways to deploy MOJOs and consume predictions. This included scoring against real-time, batch, and streaming data and scoring with H2O software, third-party software (such as BI tools and Snowflake tables), and your own software and devices. It should be evident from these examples that the H2O model-deployment possibilities are extremely diverse and therefore able to fit your specific scoring needs.
Now that we have learned how to deploy H2O models to production-scoring environments, let's take a step back and start seeing through the eyes of enterprise stakeholders who participate in all the steps needed to achieve success with ML at scale with H2O. In the next section, we will view H2O at scale through the needs and concerns of these stakeholders.