
Chapter 11: The Administrator and Operations Views
We have spent a good proportion of time in this book so far understanding the components of the H2O machine learning at scale framework and deep diving to develop the skills to implement the framework for model building and model deployment on enterprise systems.
Success in machine learning requires skill with code and technology but in an enterprise, it also requires success with people and processes. Looked at in another way, the proverbial success is a team sport statement is all too true. Let's now begin looking at the personas or stakeholders that participate in bringing success to H2O machine learning at scale.
In this chapter, we will start by addressing the personas directly involved in this success: H2O administrators, the operations team, and the data scientist. We'll understand how the key stakeholders interact with H2O at scale model building and model deployment. We'll look at the H2O administrator view of H2O at scale and understand how Enterprise Steam is central to this view. We'll also look at the operations team view of H2O at scale model building and model deployment. Finally, we'll understand how data scientists are impacted by the H2O administrator and the operations team views.
In this chapter, we're going to cover the following main topics:
- A model building and deployment view: The personas on the ground
- View 1: Enterprise Steam administrator
- View 2: The operations team
- View 3: The data scientist
A model building and deployment view – the personas on the ground
Many personas or stakeholders are involved in the machine learning life cycle. The key personas involved in H2O at scale model building and deployment are the data scientist, the Enterprise Steam administrator, and the operations team. The focus of this chapter is on these personas. Let's get a high-level view of their activities as shown in the following diagram:
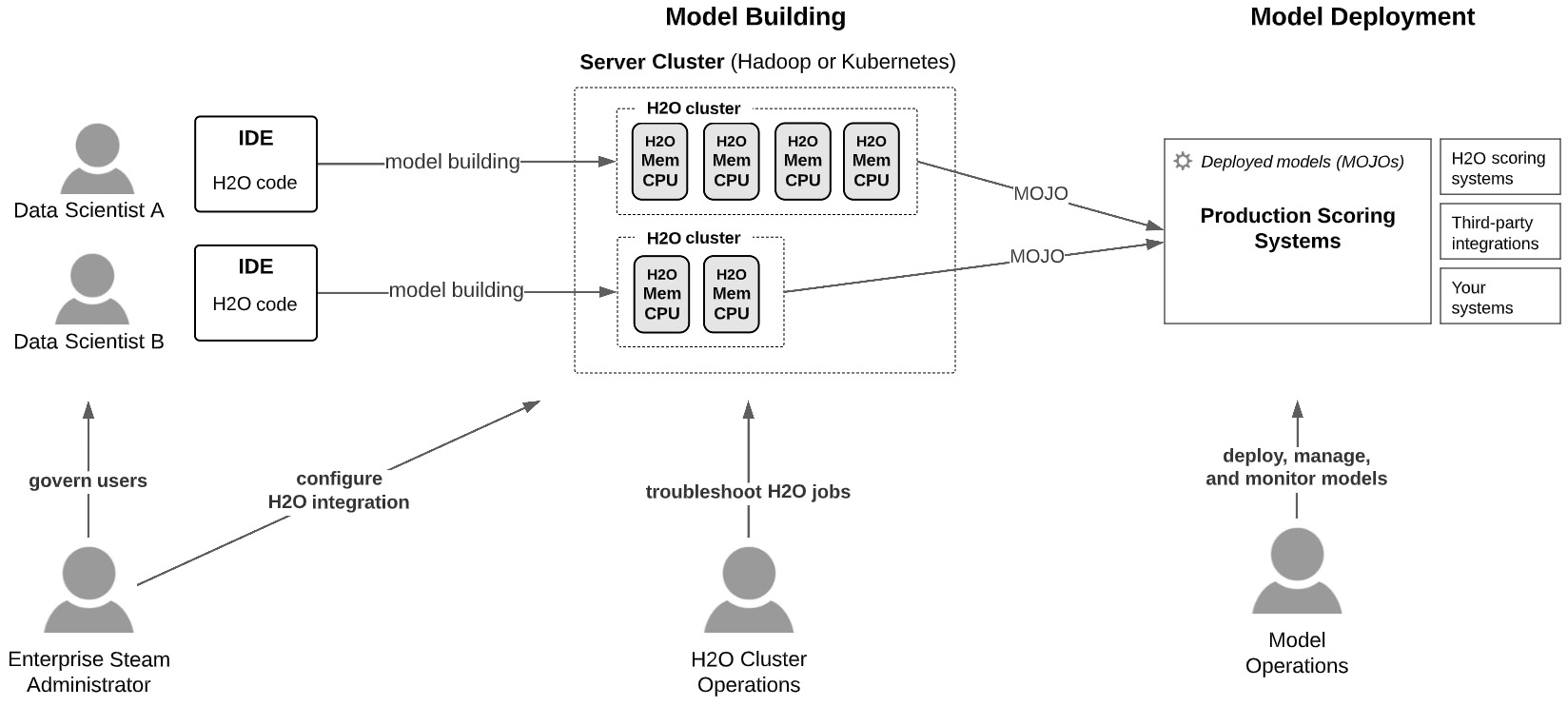
Figure 11.1 – Key personas involved in building and deploying H2O models at scale
A summary of these stakeholders and their high-level concerns are as follows:
- Enterprise Steam Administrator: Governs who launches H2O clusters on the multitenant enterprise server cluster and how many resources they are allowed to consume, and centralizes and manages H2O integration on the server cluster
- H2O Cluster Operations: Troubleshoots H2O jobs on the enterprise server cluster (either a Kubernetes or Hadoop cluster)
- Model Operations: Deploys, manages, and monitors models deployed to scoring environments
- Data Scientist: For the purpose of this chapter, knows how and why to interact with the aforementioned personas
The rest of this chapter will be dedicated to drilling down into each of these persona's views and activities when working on H2O machine learning at scale.
Let's get started.
View 1 – Enterprise Steam administrator
Let's first look at the concerns of the Enterprise Steam administrator before understanding their activities.
Enterprise Steam administrator concerns
The Enterprise Steam administrator has two broad concerns as shown in the following diagram:

Figure 11.2 – Enterprise Steam administrator concerns
The preceding diagram can be summarized as follows:
- H2O user governance: These concerns focus on governing data scientists, who launch H2O model building jobs on the enterprise server cluster. This includes authenticating these H2O users against the enterprise identity provider, defining roles for H2O users, and governing the resource consumption of H2O users in the enterprise server cluster environment.
- H2O system management: These concerns revolve around centralizing the integration of H2O technology with the enterprise server cluster and managing H2O software versions. This creates a separation of roles where now data scientists do not need to understand the complexities of this integration (which they would if Enterprise Steam were not implemented).
Enterprise Steam can be seen as a necessity in handling enterprise concerns.
Enterprise Steam's Value to the Enterprise
Enterprises tend to be careful in governing who uses enterprise systems, how users integrate with them, and how users use resources on them. Administrators use Enterprise Steam to build centralized safeguards to handle these concerns and to create uniformity and predictability of H2O usage. Enterprise Steam also makes it easier for data scientists because they do not need to know the technical complexities of integrating H2O with the enterprise system.
To appreciate the benefits of Enterprise Steam, it is useful to look at the role it plays in the workflow of data scientists building models at scale with H2O. This is summarized in the following diagram:

Figure 11.3 – Data science and administrator workflows through Enterprise Steam
Fundamentally, Enterprise Steam sits in front of all data scientists' access to H2O on the enterprise server cluster. Let's understand the benefits of this design in a step-by-step way:
- Data scientist authenticates through Enterprise Steam: All data scientists using H2O are authenticated through the enterprise identity provider, for example, LDAP. We will see later in the chapter that group membership returned from the identity provider is used to configure user capabilities specific to the group.
- Launch H2O cluster: The data scientist must go through Enterprise Steam to launch an H2O cluster on the enterprise server cluster. In doing so, the data scientist is given boundaries around the size of the H2O cluster (the number of server nodes, memory, and CPU per node) that can be launched and how long it can run before being shut down. We will see later in the chapter how the Enterprise Steam admin uses a profile to define these boundaries.
Note that there is a lot of complexity involved in configuring H2O to integrate with the specifics of the enterprise server cluster. This is taken care of by the Enterprise Steam administrator using Enterprise Steam's configuration workflow. Data scientists are shielded from this task and simply use the Enterprise Steam UI (or its API from the model building IDE) to quickly launch an H2O cluster.
- Build models: From the model building IDE, data scientists must use the Enterprise Steam API to authenticate before interacting with the H2O cluster that has been launched. After authenticating through Enterprise Steam, the data scientist will be able to connect to their H2O cluster and write code to build models on it.
Note that all the steps in the workflow just described can be done programmatically from the data scientist's IDE and do not require interaction with the Enterprise Steam UI.
The Enterprise Steam UI versus the API
It is convenient to manage one or more H2O clusters (launch, stop, re-launch, terminate) from the Enterprise Steam UI. Alternatively, this can be done from your IDE as well by using the same Enterprise Steam API required to authenticate to Enterprise Steam when connecting to your cluster from the IDE to build models. Thus, you can work entirely from your IDE if you wish.
Let's now return to the role of the Enterprise Steam administrator in governing H2O users and managing the H2O system and integration.
Enterprise Steam configurations
Let's go directly to the home configurations screen in Enterprise Steam. This will help us get the big picture before focusing on H2O user governance and H2O system management. This is shown in the following screenshot. Keep in mind that only Enterprise Steam administrators can see and access these configurations:

Figure 11.4 – Enterprise Steam configurations home page (administrator visibility only)
Let's organize this logically:
- H2O user governance: This is done using the ACCESS CONTROL configuration set. Note that these configurations also include user resource consumption governance and other guardrails.
- H2O System Management – integration: Configurations for integration with the enterprise cluster environment are done using the BACKENDS and PRODUCTS configuration sets. This includes management of H2O versions as well.
- H2O System Management – Steam: Configuring Enterprise Steam itself is done using the STEAM CONFIGURATION configuration set.
Driverless AI Can be Configured in Enterprise Steam (Wait, What?)
The focus of this book is machine learning at scale with H2O. From a model building perspective, this focuses on H2O-3 or Sparkling Water clusters training on massive datasets via the horizontally scaling architecture these create.
Driverless AI is an H2O product that is specialized for extreme AutoML (typically on datasets of less than 100-200 GB) leveraging extensive automation, a genetic algorithm to find the best models, and highly automated and exhaustive feature engineering. We will elaborate more on Driverless AI when covering H2O.ai's end-to-end machine learning platform in Chapter 13, Introducing H2O AI Cloud. We will see in that chapter how Driverless AI can augment the use of H2O-3 and Sparkling Water at scale. For now, know that Driverless AI can also be launched and managed through Steam (on a Kubernetes cluster).
Let's now elaborate on the previous bullets one by one.
H2O user governance from Enterprise Steam
Enterprise Steam administrators govern users of H2O clusters using the GENERAL > ACCESS CONTROL set of configurations. An overview of these configurations follows.
Authentication
User authentication to Enterprise Steam and thus to H2O clusters that are launched can be configured against the following enterprise identity providers:
- OpenID
- LDAP
- SAML
- PAM
Detailed and familiar settings are configured depending on which provider is selected.
Tokens
Tokens are alternatives to using passwords when using the Enterprise Steam API. Tokens are issued here for the logged-in user. Each time a token is generated the previously issued token is revoked. In the case of OIDC auth, the user must obtain a token to use the API (a single sign-on (SSO) password cannot be used).
Users
Users who have authenticated through Enterprise Steam are listed on this page. Users are listed by username, role, and authentication method. Users can be deactivated and reactivated from here.
Overrides of an individual user's role, authentication method, and profile assignments can be done here as well. Note that the user's role, authentication method, and profile are typically assigned via mapping to a group that they belong to and that is returned by the identity provider. Also note that a user configuration for enabled identity provider can be overridden here when the user exists in more than one enabled identity provider system.
Roles
There are two roles in Enterprise steam:
- Admin: Logged-in users with admin roles can make configuration changes as discussed in this chapter.
- Standard user: Logged-in users with standard user roles are data scientists who can launch clusters from Enterprise Steam as shown in Figure 11.3. This user experience is described more fully in Chapter 3, Fundamental Workflow – Data to Deployable Model.
Note that roles can be assigned by group name (returned from authentication against the identity provider). You may also provide a group name with the wildcard character * to assign a role to all authenticated users.
Profiles
This is where users are given boundaries on the resource consumption of their H2O clusters. These boundaries are assigned to a profile that is given a name, and profiles are mapped to one or more user groups or to individual users. The wildcard character * maps a profile to all users.
Users are constrained to these boundaries when they launch an H2O cluster. For example, an intern may only be allowed one concurrent H2O cluster comprising no more than 2 nodes each with 1 GB of memory, whereas an advanced user may be allowed 3 concurrent clusters each with up to 20 nodes and 50 GB of memory per node.
Profiles Govern User Resource Consumption
Profiles draw boundaries around each user's resource consumption on the shared server cluster. This is done by limiting the number of H2O clusters a user can manage concurrently, the size of each cluster (total server nodes, memory per node, CPU per node), and how long the cluster can run.
Profiles should not limit users but on the other hand, they should be appropriately sized for them. Without profiles, users tend toward maximum possible resource consumption while requiring far less. Multiplied by all users this typically creates unnecessary pressure to expand the server cluster (which has a significant cost) or to constrain the tenants that use it.
There are three profile types for H2O Core that can be configured and assigned to users:
- H2O: H2O-3 clusters on Hadoop.
- Sparkling Water – Internal Backend: Sparkling Water clusters on Hadoop where H2O and Spark DataFrames occupy the same memory space (that is, memory on the same server node).
- Hadoop: Sparkling Water – External Backend: Sparkling Water clusters on Hadoop where H2O and Spark DataFrames occupy separate memory space (memory on different server nodes). Note that this profile is used infrequently, typically only for Sparkling Water processing that lasts extremely long durations (typically over 24 hours). The external backend has the advantage of isolating H2O Sparkling Water clusters from disruption caused by Spark node termination or reassignment but has the disadvantage of requiring network (versus memory space) transfer of data between H2O and Spark DataFrames.
- H2O – Kubernetes: H2O-3 clusters on the Kubernetes cluster framework.
See Chapter 2, Platform Components and Key Concepts, to revisit the distinction between H2O-3 and Sparkling Water clusters. Also recall that H2O cluster refers to either an H2O-3 cluster or a Sparkling Water cluster.
Hadoop Spark versus a Pure Spark Cluster
Hadoop systems typically implement both MapReduce and Spark frameworks as distributed compute systems and jobs on these frameworks typically are managed by the YARN resource manager. Enterprise Steam manages H2O-3 clusters on the MapReduce framework of Hadoop/YARN and Sparkling Water clusters on the Spark framework of Hadoop/YARN.
Note that Spark can also be run alone outside of Hadoop and YARN. H2O Sparkling Water clusters can be run on this type of Spark implementation but currently, H2O does not integrate Enterprise Steam with these environments.
Kubernetes is an alternative framework for implementing distributed compute. Enterprise Steam also integrates with Kubernetes to launch and run H2O-3 clusters. Support for Enterprise Steam and Kubernetes for Sparkling Water is currently in progress.
Details differ for the four profile types listed previously, but they each share the following key configurations:
- Profile name: To assign to user groups.
- User groups: Who to assign the profile to.
- Cluster limit per user: The number of H2O clusters a user can concurrently run.
- Number of nodes: The number of server nodes comprising the distributed H2O cluster.
- Memory and CPU: The amount of memory and CPU per node to dedicate to the H2O cluster.
- Maximum idle time (hrs): The H2O cluster will automatically shut down when the H2O cluster is idle for longer than this duration.
- Maximum uptime (hrs): The H2O cluster will automatically shut down when the H2O cluster has been running longer than this duration, whether idle or not.
- Enable cluster saving: Saves cluster data when the cluster is shut down (either after the user manually shuts it down or after the maximum idle time or uptime is exceeded) so that the cluster can be restarted and resume with the same state as when it shut down.
Note that the preceding is not an exhaustive list but just a list of the key configurations to govern user resource usage on an H2O cluster.
Enterprise Steam configurations
Configurations to manage the Enterprise Steam server are made at GENERAL > STEAM CONFIGURATION. The configuration sets to do this are as follows.
License
Enterprise Steam requires a license from H2O.ai. This configuration page identifies the number of days remaining on the current license and provides ways to manage the license.
Security
This configuration page provides settings to harden the security of Enterprise Steam.Enterprise Steam only runs on HTTPS and Steam by default generates a self-signed certificate. This page allows you to configure the path to your own TLS certificate, among other security settings.
Logging
Enterprise Steam performs extensive logging of user authentication and H2O cluster usage. This page allows you to configure the log level and the log directory path. This is also where you can download the logs.
You can also download usage reports of H2O clusters at user-level granularity.
Import/export
This page facilitates the reuse of configurations by allowing the Enterprise Steam configuration to be exported as well as a configuration from another instance to be imported and loaded.
Server cluster (backend) integration
A theme of this book is that H2O Core (H2O-3 and Sparkling Water) is used to build models on massive data volumes. To achieve this, users launch H2O clusters, which distribute both data and compute in parallel across multiple separate servers. This allows, for example, XGBoost or Generalized Linear Model (GLM) algorithms to train against a terabyte of data.
Enterprise Steam allows the administrators to configure the integration of H2O clusters in these server cluster environments. This is done in the BACKENDS section of the configuration pages.
There are two types of server cluster backends that H2O clusters can be launched on and governed by Enterprise Steam:
- Hadoop: These are YARN-based distributed systems, for example, Cloudera CDH or CDP, or Amazon EMR.
- Kubernetes: This is a distributed framework architected around orchestrating pools of containers and is vendor-agnostic, though with vendor-specific offerings.
Configuration items are detailed and extensive for either backend to allow H2O clusters to run securely against these enterprise environments. See the H2O documentation for full details at https://docs.h2o.ai/enterprise-steam/latest-stable/docs/install-docs/backends.html.
H2O-3 and Sparkling Water management
Now that cluster backends have been configured, administrators can manage and configure H2O-3 or Sparkling Water, which users run on these backends. This is done in the PRODUCTS section of the configuration pages.
Both H2O-3 and Sparkling Water have the following pages:
- Configuration: This presents high-level configurations that will be constant for all H2O-3 or Sparkling Water clusters among users and profiles. For example, you can append a configured YARN prefix to the job name appearing for all H2O clusters listed in the YARN resource manager UI on the Hadoop system.
- Engines: Engines refers to H2O-3 or Sparkling Water library versions that are used to launch an H2O cluster. This configuration page lists all library versions (engines) maintained by Enterprise Steam. Each is available as a drop-down choice when the user launches an H2O cluster. Note that new library versions are either uploaded to the library (after first downloading from the H2O.ai website) or copied to the Enterprise Steam server local filesystem (for example, via the scp command from another server). Library versions can be added and removed on this configuration page.
Note on Upgrading H2O Versions
Upgrading H2O versions is easy: the user simply launches a new H2O cluster by selecting a new library version (that the administrator has uploaded or copied to Enterprise Steam as just described). This simple upgrade method works because (a) the H2O cluster architecture pushes the library from Enterprise Steam to the nodes on the server cluster when the H2O cluster is launched and removes the library when the H2O cluster is terminated, and (b) each H2O cluster is an isolated entity. Thus, user A can launch an H2O cluster using one H2O version and user B can do so using another version (or user A can launch multiple H2O clusters each with a different version).
A requirement in all cases is that the library version installed in your IDE environment matches the version the H2O cluster was launched with.
See the H2O.ai documentation for more in-depth details about using H2O-3 on Hadoop: https://docs.h2o.ai/h2o/latest-stable/h2o-docs/welcome.html#hadoop-users. Note that the list of Hadoop launch parameters listed at this link can be used to configure Enterprise Steam for all H2O-3 clusters.
Restarting Enterprise Steam
For some configuration changes, you will be prompted with a message stating that a restart of Enterprise Steam is necessary to apply these changes.
Restart Enterprise Steam by running the following command from the Enterprise Steam server command line:
sudo systemctl restart steam
Validate that Enterprise Steam is running after the restart by running the following command:
sudo systemctl status steam
The log for troubleshooting the Enterprise Steam service is found at the following path on the Enterprise Steam server: /opt/h2oai/steam/logs/steam.log.
Now that we have understood the Enterprise Steam administrator views of machine learning at scale with H2O, let's see what this means to the operations team.
View 2 – The operations team
The operations team maintains enterprise systems and monitors the workloads run on them. For H2O at scale, these operations focus on the following three areas:
- The Enterprise Steam server
- H2O model building jobs running on the enterprise cluster
- The models deployed to production scoring environments
Specific operations personas around these areas and their concerns are summarized in the following diagram:
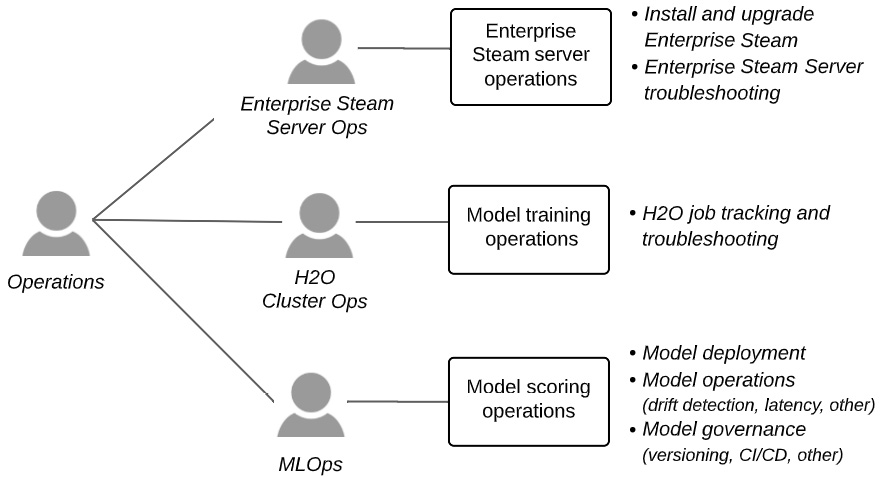
Figure 11.5 – Operations and persona concerns for H2O at scale
Let's look more closely at each operations persona and their concerns around H2O at scale.
Enterprise Steam server Ops
Ops around the Enterprise Steam server are focused on deploying and maintaining the server and the Enterprise Steam service that runs on it.
Enterprise Steam is a lightweight service that is mostly a web app with an embedded database to maintain state. There are no data science workloads that run on Enterprise Steam and no data science data passes through or resides on it. As discussed previously and summarized in Figure 11.3, Enterprise Steam launches the H2O cluster formation on the backend Hadoop or Kubernetes infrastructure where H2O workloads occur as driven by the data scientist's IDE.
H2O cluster Ops
H2O cluster ops are typically performed by Hadoop or Kubernetes administrators. On Hadoop, H2O clusters are run as native YARN MapReduce (for H2O-3 clusters) or Spark (for Sparkling Water clusters) jobs and are viewable as such in the YARN resource management UI. As noted in Chapter 2, Platform Components and Key Concepts, each YARN job maps to a single H2O cluster and runs for the duration that the cluster runs for.
MLOps
MLOps sometimes refers to operations on the full machine learning life cycle but we will focus on operations around deploying and maintaining models for scoring in production systems. These operations typically focus on the following:
- Model deployment: This concerns the actual deployment of the model to its scoring environment and is typically performed via automated continuous integration and continuous delivery (CI/CD) pipelines.
- Model monitoring (software focus): This is a traditional concern around asking how healthy the model is from a running software perspective. Typically, the model is monitored to see that it is running with no errors and that its scoring latencies are meeting service-level agreement (SLA) expectations.
- Model monitoring (machine learning focus): This is a set of concerns around model scoring outcomes specifically. It typically addresses whether data drift is occurring (whether the data distribution at scoring time has shifted from that of the training data), which is used to determine whether the model needs to be retrained or not. Other concerns may be monitoring for prediction decay (whether the prediction distribution of scores is shifting toward being less predictive), monitoring for bias (whether a model is predicting in an unfair or prejudiced way for a particular subset or demographic group), and monitoring for adversarial attacks (attempts to fool models with artificial data to create a mistaken prediction or to maliciously damage the model scoring).
- Model governance: This is a set of concerns that include managing model versions and tracing deployed models back to the details of model building (for example, the training and testing datasets used to build the model, configuration details of the trained model, the data science owner of the trained model, and so on). It also includes the ability to roll back or reproduce models and other concerns that may be specific to the organization. Note that the model documentation generated during the model building stage is an excellent asset for use in model governance. (See Chapter 7, Understanding ML Models, for details on generating H2O AutoDoc.)
Note that MLOps is a rapidly moving set of practices and implementations. Building an MLOPs framework on your own will likely result in great difficulty keeping up with the capabilities and ease of use of MLOps platforms offered by software vendors. We will see in Chapter 13, Introducing H2O AI Cloud, that H2O.ai offers a fully capable MLOps component as part of its end-to-end platform.
Now that we have understood the Enterprise Steam administrator and the operations views of machine learning at scale with H2O, let's see what this means to the data scientist.
View 3 – The data scientist
The primary ways that data scientists using H2O at scale interact with the Enterprise Steam administrator and the operations teams are shown in the following diagram:

Figure 11.6 – Data scientist interactions with administrator and operations stakeholders when using H2O at scale
Let's drill down into the key data scientist interactions with the Enterprise Steam administrator and with operations teams.
Interactions with Enterprise Steam administrators
Recall that data scientists authenticate through Enterprise Steam and launch H2O cluster sizes as defined by Enterprise Steam profiles. Data scientists may at times interact with Enterprise Steam administrators to solve authentication issues or to ask for profiles that size H2O clusters more appropriately to their needs. They may also request access to a different YARN queue than what is allowed in their profile, request a longer configured idle time for their profile, or request a new version of H2O for launching H2O clusters. There may of course be other H2O configuration and profile requests. Reviewing the View 1 – The Enterprise Steam administrator section will help data scientists understand how Enterprise Steam configurations affect them and perhaps should be changed.
Interactions with H2O cluster (Hadoop or Kubernetes) Ops teams
Data scientists rarely interact with H2O cluster operations teams. These teams are typically Hadoop or Kubernetes operations teams, depending on which server cluster backend H2O clusters are launched on.
When data scientists do interact with these teams, it is typically to help troubleshoot H2O jobs that are failing or performing badly. This interaction may involve requests for Hadoop or Kubernetes logs to send to the H2O support portal for troubleshooting on the H2O side.
Interactions with MLOps teams
Data scientists typically interact with the MLOps team to engage at the beginning of the model deployment process. This often involves staging the model scoring artifact known as the H2O MOJO (generated from model building) for deployment and possibly staging other assets to archive with the model for governance purposes (for example, H2O AutoDoc).
Data scientists may also interact with the MLOps team to determine whether data drift is occurring to decide on whether to retrain the model with more up-to-date training data. Depending on the MLOps system, this process may be automated so that an alert is sent to the data scientist and other stakeholders with content that identifies and describes the drift.
Summary
In this chapter, we learned that H2O administrators (working through Enterprise Steam) and the operations team (managing the enterprise server cluster environment where H2O model building is executed, and also managing, monitoring, and governing the models after they are deployed to a scoring environment) are key personas participating in H2O machine learning at scale. We also learned how data scientists who build models are impacted by these personas and why they may need to interact with them.
Let's move on to two additional personas who play a role in H2O machine learning at scale and who may impact the data scientist: the enterprise architect and the security stakeholders.