
Chapter 22: Working with Files
We have seen how to get data to and from the console via output and input streams. The next step in our exploration of input and output streams is to be able to access a persistent storage mechanism, one where we can save our data, exit the program, and then use it later. Data stored persistently, from one invocation of a program to the next, is saved in a file via standard file operations. Persistently stored data – that is, files – not only exists from one program invocation to the next but also remains in existence after a computer is turned off and then restarted.
In persistent storage, files are the basic entity of storage. In this chapter, we will present the essential properties of files and some basic manipulations that can be performed on them. We will also consider some of the functions that are unique to file manipulations. We will touch briefly on the function of the filesystem, the part of the operating system that manages the organization of files on persistent media.
In this chapter, we are going to explore the very basics of file manipulation in our own C program. In the next chapter, we will perform more interesting and useful file Input/Output (I/O) operations. This chapter should be considered a prerequisite for Chapter 23, Using File Input and File Output.
The following topics will be covered in this chapter:
- Expanding our knowledge of streams
- Understanding the properties of FILE streams
- Introducing opening and closing streams
- Understanding various operations on each type of stream
- Differentiating between operations on text and binary files
- Introducing filesystem concepts
- Understanding file paths and filenames
- Performing basic open/close operations on files
Technical requirements
Continue to use the tools you chose from the Technical requirements section of Chapter 1, Running Hello, World!.
The source code for this chapter can be found at https://github.com/PacktPublishing/Learn-C-Programming-Second-Edition/tree/main/Chapter22.
Understanding basic file concepts
Up to this point, data inputs and outputs have moved into and out of our C programs via streams through scanf(), printf(), or other related I/O functions. However, most data exists on computers in files. Files represent persistent data storage in that they exist between invocations of any programs and exist even when a computer is turned off.
Any file will have been created because a program captured input from the user and saved it to a storage medium. The files could've been modified by another program and then saved, they could have been copied by any number of programs, or they could have been created from other files by yet another program. Ultimately, nothing happens to a file unless a program does something to it.
Revisiting file streams
A stream is the means of transferring data, specifically bytes, between any device and a program. Streams are device-oriented. Devices, as we have seen, include a keyboard and screen. These are associated with the stdin and stdout predefined streams. A file is an abstract data storage device. Other devices include hard disks, Solid-State Drives (SSDs), printers, Compact Discs (CDs), Digital Versatile Discs (DVDs), and magnetic tape devices, among others.
For the movement of data – that is, a stream – to exist, there needs to be a connection from one device to a program; this connection must be opened for the data transfer to take place. When we run a C program, the connections to stdin, stdout, and stderr have already been made by the C runtime library for us. For any other kind of stream, we must explicitly make that connection and open a stream.
C supports two types of streams – a text stream and a binary stream. A text stream consists of lines of bytes, primarily printable characters in the range of 32 to 126; these are readable to humans. The added constraint is that each line of bytes should end with ' '.
Text streams are sometimes called sequential-access streams because each line of text can vary in length, so it would be nearly impossible to position the file at the beginning of any one line with a simple offset. The file must be read sequentially from beginning to end to be properly interpreted.
A binary stream is byte-oriented (using the full 8 bits) and is only intelligible to other programs. We have been using both of these stream types from the very beginning of this book. We generated text streams with scanf(), printf(), and other related functions. Binary streams were used when we created executable files and ran them on the console.
A binary stream can either be a collection of binary data, such as an executable file, or it can be a collection of fixed-length records or blocks of data, in which case it is sometimes called a random-access stream. A random-access stream is very much like an array of structures, where an offset to the beginning of any structure can be a simple calculation of the x record number and the size of the record. The retrieval of individual records is done directly and, therefore, relatively quickly (compared to sequential-access files). Random-access files are common in transaction-oriented processing systems, such as banking systems, airline reservation systems, and point-of-sale systems.
So, while there are various types of files, files and streams are closely related. Through the creation of a stream, data moves to and from a file and is persistently stored for later use.
Understanding the properties of FILE streams
We encountered the FILE structure in Chapter 21, Exploring Formatted Input. This structure consists of information needed to control a stream. It holds the following:
- A current position indicator: This is relevant if the device has a beginning and an end, such as a file.
- An End-of-File (EOF) indicator: To show whether we are at the end of the file or not.
- An error indicator: To show whether an error occurred.
- A data buffer: When in buffer mode, data is temporarily stored here.
- A buffer state: Indicates what kind of buffering is in use.
- I/O mode: Indicates whether this is input, output, or an update stream. An update stream performs both input and output; it requires advanced file manipulations to use properly.
- Binary or text mode: To show whether the stream is a text stream or a binary stream.
- An I/O device identifier: A platform-specific identifier of an associated I/O device.
We never access these fields directly. Instead, each field, if accessible, has an associated file function – for instance, to check the EOF, call the feof() function; to check for any error conditions, call the ferror() function; and to clear any error condition, call the clearerr() function.
Note
Recall from our ASCII table that there is no EOF character. The state of EOF is a property of the file structure, and its state is returned by a call to feof().
Also, note that when we've gotten input from the console, we have not checked for EOF. In reality, many systems simulate an EOF for stdin, but it does not make sense, since stdin is a stream, not a file. Furthermore, checking for EOF can be unreliable, depending upon which of the three character types is being used. The EOF_IntVsUnsignedChar.c program is provided for you to explore further.
To summarize, only check EOF for files, not streams.
Some of these properties are set when the file stream is opened, and others are updated as the file stream is manipulated.
A file stream, declared as a FILE* variable, is also known as a file descriptor.
Opening and closing a file
To create a file stream, a filename (described in the following section) and an I/O mode must be specified.
There are three general I/O modes that are specified with character strings, as follows:
- r: Opens an existing file for reading. It fails if the filename does not exist.
- w: Opens a file for writing. If the file exists, existing data is lost; otherwise, the file is created.
- a: Opens a file for appending. If the file exists, writing commences at the end of the file; otherwise, the file is created.
These are all one-way modes – that is, a file opened for reading with r can only be read; it cannot be updated. Two-way modes exist by appending + to each of the preceding modes – for example, r+, w+, and a+. When files are opened for reading and writing, care must be exercised to re-position the current file position so as not to inadvertently overwrite existing data. We will look at the file reposition functions in the next section.
To open a binary stream, b can be appended either after the first character or at the end of the string. The following are the possible binary access modes:
- One-way modes: rb, wb, and ab
- Two-way modes: r+b, w+b, a+b, rb+, wb+, and ab+
Note that some systems ignore the b specifier; in these cases, it is provided for backward compatibility.
A stream can be manipulated with the following functions:
- fopen(): Using an absolute or relative filename and mode, this creates/opens a stream.
- freopen(): This closes the given stream and reopens it using the new filename.
- fclose(): This closes a stream.
- fflush(): For output or update streams, this flushes any content in the buffer to the file/device.
Note
fflush() is only intended for the output stream buffer. It would be handy to have a C standard library function to also clear the input stream buffer. Some systems offer the non-standard fpurge() function, which discards anything still in the stream buffer. Other systems allow non-standard behavior for fflush() to also flush the input stream buffer. Your system may offer yet another non-standard method to flush the input buffer. However, it is generally considered a bad practice to use fflush() on stdin, the input stream.
fopen() will fail if the user does not have permission to read or write the file. It will also fail if a file opened for reading (only) does not exist.
It is a good idea to always close files before exiting a program. It is also a good practice to flush the buffers of output files before closing them. This will be demonstrated in all of the example programs later in this chapter.
Understanding file operations for each type of stream
Because there are two types of file streams – text streams and binary streams – there are also different sets of functions to manipulate them.
We have already seen most of the functions that are useful for text streams. They are as follows:
- fprintf(): Writes formatted text to the output stream
- fscanf(): Reads and interprets formatted text from the input stream
- fputs(): Writes an unformatted line to the output stream
- fgets(): Reads an unformatted line from the input stream
There are also some single-character functions that we have come across:
- fgetc(): Reads a single character from the input stream
- fputc(): Writes a single character to the output stream
- ungetc(): Puts a single character back into the input stream
These single-character functions are particularly handy when processing input one character at a time. Numbers or words can be assembled into strings. If a whitespace or delimiter character is encountered, it can either be processed or pushed back into the input stream for additional processing.
There is a set of functions intended specifically for record- or block-oriented file manipulations. These are as follows:
- fread(): Reads a block of data of a specified size from a file
- fwrite(): Writes a block of data of a specified size to a file
- ftell() or fgetpos(): Gets the current file position
- fseek() or fsetpos(): Moves the current file position to a specified position
In block-oriented file processing, whole records are read at once. These are typically read into a structure. They may also be read into a buffer and then parsed for their individual parts.
Finally, there are some common file stream functions, as follows:
- rewind(): Moves the current position to the beginning of the file
- remove(): Deletes a file
- rename(): Renames a file
With these functions, we can create programs to manipulate files in any number of ways.
C doesn't impose a structure on the content of a file. That is left up to the program and the type of data that is to be preserved in the file. These functions enable a wide variety of ways to create, modify, and delete not only the content of files but also the files themselves.
Before we can put these functions into action, we need to introduce the filesystem and how it fits in with the C standard library.
Introducing the filesystem essentials
A filesystem is a component of an operating system that controls how files are stored and retrieved. The filesystem typically provides a naming and organization scheme to enable the easy identification of a file. We can think of a file as a logical group of data stored as a single unit. A filesystem provides the ability to manage an extremely large number of files of a wide range of sizes, from very small to extremely large.
There are many different kinds of filesystems. Some are specific to a given operating system while others offer a standard interface and appear identical across multiple operating systems. Nonetheless, the underlying mechanisms of a filesystem are meant to guarantee various degrees of speed, flexibility, security, size, and reliable storage.
The filesystem is meant to shield both the operating system and programs that run on it from the underlying physical details of the associated storage medium. There is a wide variety of media, such as hard drives, SSDs, magnetic tapes, and optical discs. The filesystem can provide access to local data storage devices – devices connected directly to the computer – as well as remote storage devices – devices connected to another computer accessible over a network connection.
Getting acquainted with the filesystem
We can think of the filesystem as the interface between the actual storage medium and our program. Despite the underlying complexity and details of any filesystem, its interface is quite simple. C provides a standard set of file manipulation functions that hide the underlying complexities of any filesystem. These complexities are encapsulated in each implementation of the C standard library. From the perspective of a C program, once we can identify a file by name and, optionally, by its location, very little else is of concern to the program.
So, the main aspects of filesystems that we need to care about are how files are named and their location. As much as I would like to say that there is only one way to name and locate files, I cannot say that. Not all filesystems have the same file organization or naming schemes.
Each file has two aspects to its name – its location or file path and its filename.
Understanding a file path
A file path can be either an absolute file path or a relative file path. In an absolute file path, the base of the file hierarchy is specified, along with the name of each directory and subdirectory to the final directory where the filename exists. The base of the file hierarchy is also called the root of the file hierarchy tree. In a relative file path, only the portions of the path relative to the current program location are required.
The structure of an absolute file path varies from one filesystem to another. It may have a generic root or it may begin with the name of the device where the file hierarchy exists – for instance, on Unix and Linux systems, all files exist somewhere in the file hierarchy with the root beginning with /. On Windows, the root of a file hierarchy typically begins with a device identifier, such as D:.
Thankfully, there are many common features that we can rely upon. Once the base of the file hierarchy, or the root, is identified, various parts of the way a file location is specified are common.
Not all files live at the root. There can be many directories at the root, and each directory itself may have numerous sub-directories. Traversing this hierarchy to the desired file is called the path. Each layer in the hierarchy can be separated by a forward slash (/) in C, even though this may not be the case in the native filesystem. Also, the current working directory, regardless of its path, is identified by a dot (.). Furthermore, if the current directory has a dot (.), then the parent of this directory – or whatever the layer is when we go up one level in the hierarchy – can be specified by two dots (..).
Default path attributes apply if no path attributes are given – for instance, if there is no path, the current directory location is the default path.
In our example programs, we will assume that the data files are in the same directory as the executable program. This is a simplified assumption. Very often, paths to data files are stored in a file with the .init or .config extension, which is read and processed when the program starts.
Understanding a filename
A filename identifies a unique file within a directory. Each filename is typically unique within a directory. We think of this directory as the location where the file exists. A directory name is part of the file path.
A filename can take many forms, depending on the filesystem. In Windows, Unix, and Linux filesystems, a filename consists of one or more alphabetic characters with an optional extension. A file extension consists of one or more characters with a separating dot (.) between it and the name. The combination of the name and extension must be unique within a directory. We have already seen this with our source files that have a .c extension, our header files that have a .h extension, and our executable files, which, by convention, have no extension.
With these concepts in mind, we are now ready to begin manipulating files in C.
Opening files for reading and writing
We can now create a program to open a file for reading and another file for writing. This is where our file I/O exploration will begin and continue through the remaining chapters of this book. The following program is our starting point:
#include <stdio.h>
#include <stdlib.h> // for exit()
#include <string.h> // for strerror()
#include <sys/errno.h> // for errno
int main( void ) {FILE* inputFile;
FILE* outputFile;
char inputFilename[] = "./input.data";
char outputFilename[] = "./output.data";
inputFile = fopen( inputFilename , "r" );
if( NULL == inputFile ) {fprintf( stderr, "input file: %s: %s ",
inputFilename , strerror( errno ) );
exit( EXIT_FAILURE );
}
outputFile = fopen( outputFilename , "w" );
if( NULL == outputFile ) {fprintf( stderr, "input file: %s: %s ",
outputFilename , strerror( errno ) );
exit( EXIT_FAILURE );
}
fprintf( stderr,""%s" opened for reading. ",inputFilename );
fprintf( stderr,""%s" opened for writing. ",outputFilename );
fprintf( stderr,"Do work here. " );
fprintf( stderr , "Closing files. " );
fclose( inputFile );
fflush( outputFile );
fclose( outputFile );
fprintf( stderror , "Done. " );
return 0;
}
In this program, we are not only introducing minimal file operations; we are also introducing a very basic system-error reporting mechanism. With this mechanism, we do not need to reinvent the error message; we let the system report its own error message. To do that, we need to include string.h and sys/errno.h. If we can't open our files for any reason, we need to exit, so we also need to include stdlib.h.
We are not (yet) using any input from the command line, so the parameters to main() are ignored by setting them to void. We then declare input and an output file descriptor for each file we will open.
The next two lines set the file path ("./") and filenames ("input.data" and "output.data") for the files we will soon try to open. For now, we will hardcode these names. In later versions of this program, we'll get a bit more practical with the user input of filenames.
Now, we are ready for the real work of this program. First, we call fopen() to open inputFilename for reading; if this succeeds, the file descriptor is set. If the file descriptor is NULL, we print an error message to stderr and exit. Note that we are using fprintf() with stderr to provide feedback to the user. This is a good practice, one that we will continue for the remainder of this book.
If a C standard library function fails, it typically sets the value of a system-global variable named errno. In this case, when fopen() fails, the fprintf() function uses the strerror(errno) function to convert errno into a human-readable string. These are defined in the <sys/errno.h> file. It is worthwhile to find that file on your system, open it, and peruse the errors defined there. However, don't try to understand everything you see there all at once. So, what we are showing here is a very handy way to display known system errors to the user. This is an extremely useful programming pattern to incorporate into your own programs.
If the first fopen() group succeeds, we move on to the next fopen() group. This is similar to the first group, except we are opening a file for writing. This will usually succeed, but we need to also be able to handle a situation where it might not.
The next three fprintf() statements provide the simple status of the program. These are not really necessary because, most often, we can assume the success of system function calls and only need to check and report when they fail.
Finally, the program closes the input file, flushes the output file (even though we haven't done anything yet), and closes the output file.
Create a file named open_close_string.c. Type in the preceding program, save it, compile it, and run it. You should see the following output:

Figure 22.1 – A screenshot of the open_close_string.c output (no input file)
Oh, darn! Our input file needs to exist before we can open it. Alright – in your console window, you can create an empty file with the touch input.data Unix command, or with your editor, create a file named input.data in the same directory as open_close_string.c and save it (it doesn't have to have anything in it; it just has to exist). Run the program again and you should see the following:

Figure 22.2 – A screenshot of the open_close_string.c output (the input file exists)
Terrific! We now have a very basic file I/O program that we can use when input and output files are known and fixed.
This technique is handy to use when filenames never change. However, very often, filenames will change, so we need more flexible ways to get filenames as input.
Before we finish this chapter, we'll present two simple ways to get filenames from the user. The first will be via input from within the program, and the second will be by using the rather limited argv arguments via the command line.
Getting filenames from within a program
Copy open_close_string.c into open_close_fgetstr.c and open the following program:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/errno.h> // for errno
char* safe_gets(char* buf, int size ) { if( fgets( buf , size , stdin ) ) { for( int i = 0; i < size ; i++ ) { if( '
' == buf[i] ) {buf[i] = '�';
break;
}
}
return buf;
} else {return NULL;
}
}
int main( void ) {FILE* inputFile;
FILE* outputFile;
printf( "FILENAME_MAX on this system is %d bytes " ,
FILENAME_MAX ); // FILENAME_MAX is defined in
// stdio.h
char* inputFilename = (char*)calloc( FILENAME_MAX , 1 );
char* outputFilename = (char*)calloc( FILENAME_MAX , 1 );
fprintf( stdout , "Enter name of input file: " );
safe_gets( inputFilename , FILENAME_MAX );
inputFile = fopen( inputFilename , "r" );
if( NULL == inputFile ) {fprintf( stderr, "input file: %s: %s ",
inputFilename , strerror( errno ) );
exit( EXIT_FAILURE );
}
fprintf( stdout , "Enter name of output file: " );
safe_gets( outputFilename , FILENAME_MAX );
outputFile = fopen( outputFilename , "w" );
if( NULL == outputFile ) {fprintf( stderr, "input file: %s: %s ",
outputFilename , strerror( errno ) );
exit( EXIT_FAILURE );
}
fprintf( stdout,""%s" opened for reading. ",inputFilename );
fprintf( stdout,""%s" opened for writing. ",outputFilename );
fprintf( stderr , "Do work here. " );
fprintf( stderr , "Closing files. " );
fclose( inputFile );
fflush( outputFile );
fclose( outputFile );
free( inputFilename );
free( outputFilename );
fprintf( stderr , "Done. " );
return 0;
}
For this program, we've added safe_gets(), as we've seen in the previous chapter. Another change is that the valid length of filenames varies from system to system. That size is defined in stdio.h. On my system, this is a somewhat large array. So, instead of simply declaring two large arrays, the buffer for each filename is allocated on the heap with calloc(). Remember that we will have to use free()on this memory before we exit. Finally, the last difference in this program is a prompt for the user and the call to safe_gets() to get the filename from the user. Save, compile, and run this program. If you enter input.data and output.data at the prompt, you should see the following output:
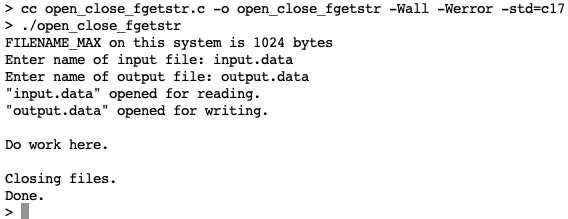
Figure 22.3 – A screenshot of the open_close_fgets.c output
With this program, after prompting the user, we can get the relevant filenames each time the program runs. Possibly even more convenient is the next method, where filenames are given on the command line.
Getting filenames from the command line
Next, copy the program into open_close_argv.c and modify it to match the following program:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/errno.h> // for errno
void usage( char* cmd ) {fprintf( stderr ,
"usage: %s inputFileName
outputFileName " , cmd );
exit( EXIT_SUCCESS );
}
int main( int argc, char *argv[] ) {FILE* inputFile = NULL;
FILE* outputFile = NULL;
if( argc != 3 ) usage( argv[0] );
if( NULL == ( inputFile = fopen( argv[1] , "r") ) ) {fprintf( stderr, "input file: %s: %s ",
argv[1], strerror(errno));
exit( EXIT_FAILURE );
}
if( NULL == ( outputFile = fopen( argv[2] , "w" ) ) ) {fprintf( stderr, "output file: %s: %s ",
argv[2], strerror(errno));
exit( EXIT_FAILURE );
}
fprintf( stderr , "%s opened for reading. " , argv[1] );
fprintf( stderr , "%s opened for writing. " , argv[2] );
fprintf( stderr , "Do work here. " );
fprintf( stderr , "Closing files. " );
fclose( inputFile );
fflush( outputFile );
fclose( outputFile );
fprintf( stderr , "Done " );
return 0;
}
In this program, we added the usage() function. Next, we added argc and argv to the main() parameters because here, we'll get input from the command line.
Before we start to open any files, we need to make sure we have three parameters – the program name, the input filename, and the output filename. When opening each file, use the appropriate argv[] string for each one. Note that once we have opened the filenames given in argv[], we really don't need them again for the remainder of the program.
Edit, save, compile, and run this program. You should see the following output:

Figure 22.4 – A screenshot of the open_close_argv.c output
As you can see, the first time that open_close_argv is run, no command-line arguments are given, and the usage() function is called. The next time that open_close_argv is run, only one argument is given, and the usage() function is again called. Only when open_close_argv is called with two arguments is usage() no longer called, and we can attempt to open the named files. Note that when opening a file for input, the file must exist or an error will occur. However, if you open a file for writing or appending that does not exist, a new file with that name will be created. In this case, input.data already exists, so opening the file is successful.
We now have several ways to get filenames to open file descriptors.
Summary
In this chapter, we expanded our knowledge of file streams to include text streams and binary streams. We learned about the various file stream properties and briefly explored file functions that manipulate text streams and binary streams. We also learned about some common file functions, including fopen(), fflush(), and fclose(). These functions were demonstrated in three different programs that obtained input and output filenames in various ways. The first way hardcoded filenames into the program. The second way gave the user a prompt for each file and read the filenames with safe_gets(). The last way received filenames from command-line arguments via argv.
With the knowledge we have gained from covering these topics, we are ready to start with the next chapter, where we'll begin working on these simple programs, enhancing the command-line argument process, and performing useful work on input to generate meaningful output. We'll start with these programs to first create an unsorted name file and then use them again to read that unsorted name file and write out a sorted name file.
Questions
- What is the difference between a stream and a file?
- What are the three basic modes for file streams?
- How does data flow for a stream opened for reading?
- How does data flow for a stream opened for writing or appending?
- Name various streaming devices (whether they have files or not).