
In the 1974 film classic Blazing Saddles, Mel Brooks, playing Governor William J. LePetomaine, struts around his office complaining, “Harrumph, Harrumph, Harrumph...” When one of his cohorts does not reply, he adds, “Hey! I didn’t get a harrumph outta that guy!!” To us, this scene epitomizes the current state of enterprise architecture. There’s a lot of complaining going on, and we have a big menu of issues that we can harrumph about if we choose to. For almost everyone in the architecture field, today represents an agonizing best-of-times/worst-of-times scenario. There is so much we want to do with our architecture, so much we need to do, and indeed, so much we can do—if we can solve certain core architectural problems.
Event-driven architecture (EDA)—and by this, we mean the modern, dynamic, and agile kind—presents a superb solution to a range of major organizational IT challenges. Yet, despite its desirability, its attainment has been frustratingly out of reach for many years. This has changed, though, with the advent of service-oriented architecture (SOA).
We see the EDA as existing in a kind of systemic vortex at the present moment. There are those who want EDA, and there are forces that block its realization, namely tightly coupled integration and interoperation. To set the stage for the rest of this book, then, this first chapter is devoted to establishing a thorough and workable definition of EDA, and explores the reasons it can be an effective solution to many business and IT challenges. This chapter also describes how an EDA works, what it can do, and what it might be able to do as the paradigm matures. At the same time, this chapter introduces the subject of interoperability and integration of systems, the area of IT that has stymied those of us who seek EDA. The purpose of this chapter is to refine your sense of that goal of EDA—where we are headed (we hope) and the obstacles that stand in the way, to be solved as we progress in the sophistication of SOA.
As we noted in the Introduction, an event-driven architecture is one that has the ability to detect events and react intelligently to them. Brenda Michelson, a technology analyst, writes, “In an event-driven architecture, a notable thing happens inside or outside your business, which disseminates immediately to all interested parties (human or automated). The interested parties evaluate the event, and optionally take action.”1 To be able to learn about how EDAs work and how we can build them, though, we need a more specific and workable definition of what Michelson’s definition means in concrete terms. This book refrains from technologically specific concepts or brand names, as these terms (such as enterprise service bus [ESB]) tend to distract us from gaining a useful working definition of EDA and drag us into debates that take us off course.
First, let’s define what we mean by an event. In life, an event is something that happens: a car drives by, a ball flies through your window, someone falls asleep—an action occurs. Alternatively, for our purposes, an event can also be an expected action that does not occur. If the temperature does not go down at night, that could be an event. In systemic terms, an event generally refers to a change in state. A change in state typically means that a data value has changed.
For example, if you exceed your allowance of minutes of cellular phone time, your wireless carrier bills you for the overage. In EDA terms, the state of your minutes goes from “Under” to “Over,” and that change in state triggers the billing of the overage charge. The value of your account balance changes as you exceed the minute allowance. The shift from minutes = under to minutes = over is an event.
An event has three levels of detail. At one level, there is the basic fact that an event has occurred. An event has either occurred or not. This takes us to the second level of detail, which is the event definition. To recognize an event, an EDA must have a definition of what the event is. In the cell phone example, the EDA must work with a definition of an event that says, in effect, a “change in minutes” event has occurred whenever the allowance limit is exceeded. Then, there is the detail of the specific event. By how much has the minute allowance been exceeded? In our example, the three levels of event detail would look like this: (1) An event has occurred, based on the following definition, (2) an event is defined as “minutes=over,” and (3) the event detail says “So-and-so’s minutes have been exceeded. Amount =10 minutes.” All three factors—event notification, event definition, and event detail—are necessary when designing an EDA.
For an event to occur in an EDA, it must be in a form that a computer can understand. However, that does not mean that an EDA is exclusively the preserve of digital information. A change in state can also result from nondigital information being translated into digital form. For example, a digital thermometer typically has some kind of analog temperature sensor that inputs temperature information into the sensor and results in a digital value equated to temperature. The edges of an EDA might be full of analog information that is translated into digital data to trigger events.
A key learning point here is to understand that virtually anything can be an event or trigger an event. Rainfall in Chad could be an event, if it is quantified and made available as a source of data. Stock market activity in Tokyo could absolutely be an event, assuming you know why you are interested. The examples are endless. An ideal EDA can be easily adapted to recognize events that occur anywhere. The trickiest word in the preceding sentence was easily, a simple idea that can generate a lot of discussion and complexity.
Armed with a sense of what an event can be, we can now add some flesh to the basic EDA definition. If an event is any “notable thing” that happens inside or outside our businesses, then an EDA is the complete array of architectural elements, including design, planning, technology, organization, and so on, which enables the ability to disseminate the event immediately to all interested parties, human or automated. The EDA also provides the basis for interested parties to “evaluate the event, and optionally take action.”
The reason that EDA is a challenging concept is that it is so potentially broad. Just as almost any piece of data, analog or digital, can be an event, and any system in the universe can potentially be part of your EDA, where do you begin to draw the boundaries and definition of an EDA that makes sense to your organization? Though there is no bullet-proof way to answer the question, we think that it makes sense to identify the main ingredients of an EDA, and build the definition from these constructs.
To have an EDA, you must first have events. That might seem obvious, but a lot of otherwise sophisticated discussions of EDA either neglect or muddle up this central enabling concept. The EDA cannot work unless it has the ability to perceive that an event has occurred. For that to happen, the event must be created and then disseminated for consumption to EDA components called listeners (see next section) to “hear” them.
The technologies that do this are known as event publishers or event producers. With the broad definition of an event, event publishers can take many different forms. Most are software programs, though an event publisher can also be a dedicated piece of hardware that translates analog data into digital form and feeds it into software that can detect an event. You should keep the following core ideas in mind about event publishers.
Event publishers can be anywhere. Because events can occur outside of your enterprise, event publishers that relate to your EDA can be pretty much any place. Imagine the relationship between an airline EDA and the FAA radar tower. The radar tower, which serves many purposes, one of which is to be an event publisher, is completely separate from the airline’s systems, yet it is part of the EDA.
Event publishers might or might not originate the data that is contained in the event itself. In their purest form, an event publisher generates a piece of data that is formatted to be “heard” as an event in accordance with the EDA’s setup for this process. For example, a credit card processing system typically generates data that is EDA ready—it contains the card holder’s identifiers, the time of the transaction, the amount, the merchant name, and so on. Of course, the data was created for the purpose of charging the card, not feeding the EDA, but it serves that purpose quite readily. In contrast, other event publishers need to translate data into a format that constitutes an event according to what the EDA requires. For example, there is no inherent event pattern in the Tokyo stock exchange index unless you specifically instruct an event publisher to transmit data about the index in a manner that makes sense to your EDA’s purposes.
Like event publishers, event listeners can be anywhere. In theory, the event listener (or consumer) has a communication link with the event publishers. That is not always the case, but we will work under that assumption for now. The event listener is a piece of technology—typically software based, but also hardware—that “knows” how to differentiate an event, as it is defined, from other data it receives.
In the simplest form of EDA, the event listener can only receive the specific event data that it is meant to hear. For example, an EDA for building security might be based on a burglar alarm whose event listeners can only hear one kind of event—the kind created by a break-in. Window monitoring hardware will produce a break-in event in the occurrence of a breakage for the burglar alarm system to consume. The real world, of course, is more complex, and as we progress, we get into more involved EDA setups.
Event listeners also need to know what they are listening for. An application that reads the data stream of the Tokyo stock market average is not an event listener until it has been instructed to listen for some specific type of event. For instance, the event listener must know that a gain of 5% or more in the average is an event. A 4% gain is not an event. The event listener must be able to detect the event and be capable of interpreting the event. The criteria for interpretation are known as business rules.
After an event has occurred, and after the event has been published and consumed by an event listener, it must be processed. By processing, we mean determining the event’s potential impact and value and deriving the next action to take. It does little good to have an event that is perceived, but not handled. An EDA without event processors is like the Tower of Babel—lots of event voices chattering at each other without interpretation yields nothing. An EDA should have the capacity to interpret the events it hears.
An event processor is invariably a piece of software. Although it might or might not be part of some larger, more comprehensive suite of applications, an event processor is distinctive because it has the ability to assess events, determine their importance, and generate a reaction of some kind, even if the reaction is “do nothing.”
Following our chain of activities, we have an event, which is published by an event producer, heard by an event listener, and processed by an event processor. Then, something (or nothing) needs to happen. Because “something happening” is inherently more interesting than “nothing happening,” let’s look at event reactions that require action.
Reactions to an event in an EDA vary widely, from automated application responses, to automated notifications sent either to applications or people, to purely human reactions based on business processes that occur outside of the EDA itself. In the purely automated application response category, we might see an EDA that reacts to an event by initiating an application-level process. For example, in the credit card fraud example, the EDA might modify a variable value from Normal to Warning based on an event that suggests that fraud is occurring. If this reaction is coded into the event reaction, it happens without any human involvement. Following this, another related branch of processes might handle new charge requests on the account differently based on a Warning value than it would in a Normal state. Event processors and reactions can be linked and interdependent.
The event reaction might be machine-to-human. Continuing with our example, imagine that there is a customer service representative who sees all the new Warning value changes and is prompted to call the cardholder to inquire about the status of their card. This approach to EDA is dependent on the human reaction to an event, a situation that might be good or bad, depending on the desired outcome. For example, many intrusion detection systems that monitor networks for unauthorized access attempts generate a great deal of false positives. Indeed, there are many intrusion detections that are not monitored at all. What these defectively implemented systems do is generate logs consisting of thousands of possible intrusion records, which are essentially useless. The takeaway here is that the human reaction might be very much part of the EDA design, even though it does not involve technology per se.
Finally, there are EDAs where the event reaction is based on an entirely human set of processes, following the detection and processing of the original event. For example, an EDA might generate a number of alerts that arise from a number of stock market indicators. An investor then reviews the alerts and decides whether to buy or sell. Once again, the EDA design must take into account the human reaction as part of its eventual success or failure. And, with this type of complex human decision making, it can be quite challenging to determine what the “right” reaction should be. Experts might differ on how to react to identical sets of event alerts. As they say on Wall Street, these differences of opinion make for a good horse race...
The final core component of an EDA is the messaging backbone, the communication infrastructure—inclusive of hardware, software, network protocols, and message formats—that enables each piece of the EDA to communicate with one another. To serve an EDA effectively, a messaging backbone must have several characteristics. These characteristics are explored in great detail throughout the rest of the book, but for now, at a high level, let’s use the following baseline to describe an optimal EDA messaging backbone.
The EDA messaging backbone does not necessarily have to be one single piece of infrastructure. Rather, the backbone refers to the ability of any number of separate pieces of messaging infrastructure to exchange messages using either common message transports or translators. For the purposes of illustration and simplicity, the backbone is shown in the illustrations in this book as a single connector, though the messaging backbone in real life might comprise many different pieces.
An EDA messaging backbone needs to be as near to universal as possible, meaning that it should enable messaging across multiple network transport protocols and data formats. In other words, it should be standards based, or have the ability to mediate across multiple messaging standards. It should be pervasive, that is, far-reaching and universally accessible. In reality, this means that it might be based on the Internet for EDAs that span multiple enterprises or on an IP-based corporate network for EDAs that exist within a single enterprise. It should be highly reliable and inexpensive to develop, maintain, and modify—which is, perhaps, a lot easier said than done, but this is a critical. Cost is the “invisible hand” that has killed many great EDA initiatives. Finally, it should enable a high level of decoupling between event producers and event consumers. In reality, this usually translates into a publish/subscribe or pub/sub setup.
The messaging backbone is arguably the most essential piece of the EDA puzzle, for without it, there can be no EDA. Without the ability to communicate, the event listeners, producers, processors, or reaction processes, cannot work. Now, you might be thinking, “Yes, of course they can—you can always create communication interfaces between systems.” Of course, this has been true for many years. The reality, though, is that proprietary interfaces, which have been the traditional way to achieve connections, are costly to develop, maintain, and modify. So costly, in fact, that they have rendered the concept of a dynamic EDA virtually impossible to realize. This is now changing, and this shift is discussed in great detail throughout the book.
To get to the paradigmatic EDA—the one we use as the reference point for the rest of this book—involves connecting event producers, event listeners, event processors, and event reactions using a common messaging backbone. Figure 1.1 shows what this looks like in the plainest terms. Obviously, things can get wildly more complex in real life, but it is best to start with a very stripped-down paradigm example.
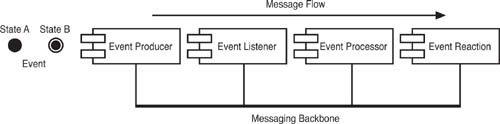
Like our “enterprise nervous system” that we discussed in the Introduction, the EDA works as a whole, taking in signal inputs in the form of event data, processing it, and reacting to it based on some kind of intelligent model. Like the nerve endings that tell us when we are hot or cold, being touched, or falling through the air, event listeners in the EDA quantify information from the world and order it into a form that the EDA can understand. The messaging backbone of the EDA is like the nerve cells themselves, transmitting signals back and forth from various places in the body and toward the brain. The brain is like the EDA’s event processing components. It takes in event data and decides how to respond to it. The event reaction components are like our limbs. Based on the input, we take action, or not.
There’s an old joke about Las Vegas, where a guy wants to be seated at a restaurant and is asked, “Which section would you prefer, smoking or chain smoking?” EDA is the same. Almost every type of computer system has some degree of event orientation in it. After all, computing is essentially a matter of input, processing, and output, much like an EDA. Following from this, discussions of what an EDA actually looks like can be confusing because they tend to get overly broad and encompass, well, just about everything in the IT universe. To keep our focus, let’s look at several prime models of EDA that are in use today.
Dr. Manas Deb, a thought-leader in the Oracle Fusion and middleware space, once suggested that there are two essential types of EDA: explicit and implicit. In an explicit EDA, the event publishers send event data to known event listeners, perhaps even by direct hard-coding of the event listener destination right into the event producer. Many current implementations of EDA are either partly or wholly explicit. As such, they tend to rely on tight coupling of event producers and event listeners.
In contrast, an implicit EDA does not specify any dedicated connections between event producers and event listeners. The event listeners, or the event processors even, may determine the events to which they want to listen. The coupling between the event producers and listeners will be loose, or even completely decoupled in an implicit EDA. As you might imagine, an implicit EDA is more flexible and dynamic than an explicit EDA. Historically, they have proved too complex to implement. This has changed with the advent and adoption of open standards.
Of the two types, the implicit EDA is more agile; however, that agility comes with a price. As we implicitly process events, it becomes difficult to predict the outcome and monitor the success. For example, this form would not be ideal for processing multiphase transactions because the atomicity cannot be guaranteed due to the implicit processing—that is, the unknown processor of the state change can make it harder to understand or validate the origin of the state change.
Within EDAs themselves, there are three basic patterns of event processing: simple event processing, event stream processing, and complex event processing, which is known as CEP. In simple event processing, the EDA is quite narrow and simple. The event producer’s function is to generate event data and send it to the event listener, which, in turn, processes it in whatever manner is required. The thermostat example is emblematic of a simple event processing design. The furnace gets the signal and switches on or off, and that’s about it.
Event stream processing involves event processors receiving a number of signals from event producers (via the event listeners) but only reacting when certain criteria are met. For example, the thermometer might send the temperature data every two seconds, but the event processor (thermostat) ignores all but the relevant “switch on” data point, which activates the furnace only when it is observed.
Complex event processing (CEP) takes the EDA to another level, enabling it to react to multiple events under multiple logical conditions. So, for the sake of argument, let’s say that we only want to buy U.S. Treasury bonds when the Nikkei hits a certain number, and unemployment figures dip below 5%. The CEP listens to multiple event streams, and knows how to correlate them in a logical manner according to the objectives of the EDA. In other words, the CEP starts to “think” like a person, taking in data from unrelated sources on the fly, differentiating between useful and useless information, and acting accordingly. This is the ideal of the complex, implicit, dynamic EDA.
In another example, complex event processing can also be instructed to do, in essence, the reverse of the previous example—meaning the processor could be instructed to determine the events that caused a particular outcome. In this case, the processor monitors for a particular outcome then derives the causality of the event or event sequence that created the desired event. This is highly valuable in proving hypothetical situations through simulation.
Without going too far off subject, we want to point out here that there is a natural match between CEP and artificial intelligence (AI). AI systems have the capacity to recognize patterns of information and suggest reactions to patterns of events. Later in the book, we delve into this under the rubric of business rules and automation of corporate decision making using CEP.
Older EDAs have typically been event-stream or simple-event oriented and reliant on explicit or nearly explicit designs. Complex event processing, married with implicit capabilities, is really what most people mean when they talk about modern or futuristic EDAs. When you hear someone talk about how, for example, the Department of Homeland Security should be able to instantly know that John Smith, who has bought a one-way ticket for cash, has a fingerprint that matches that of a known criminal based on records kept in Scotland Yard—we are talking about an implicit CEP EDA.
This last example highlights why people are so interested in EDA. The paradigm has the potential to serve many business and organizational needs that are now unmet with existing enterprise architecture. The pressure to build EDAs comes from a desire to bring together information from disparate and unpredictable sources and process it in intelligent ways—even if the information is not in digital form at its creation. In business, the desired result might be agility, or improved profitability. In government, the goal might be tighter security or improved knowledge of the economy.
In addition, the EDAs that everyone seems to want are not only CEP based and implicit, but also highly malleable and dynamic. The world is not static, so EDAs can never stand still. It seems like a lot of hoops for an architectural paradigm to jump through, but the demand for the capability is quite real and the value that an EDA can realize is not hard to discern. However, we are not quite there yet. Though the future is looking pretty bright for complex, implicit, dynamic EDAs, a few enormous challenges exist, mostly residing in the world of system interoperation and integration, the gating technological factors of EDA.
Years ago, one of us got profoundly lost while on vacation in the tropics. Driving a rented Jeep, he pulled into a small village and asked someone how to get to the rental cottage on the other side of the island. The local man gave him a funny look and said, “You can’t get there in a vehicle.” That concept, of being stuck in a place from which you can’t get to your desired destination, should resonate with anyone who has contemplated transitioning an existing set of systems into an EDA or building one from scratch.
Taking a huge step back to gain perspective, let’s identify the one architectural feature that you need to have an EDA. That feature is interoperability. Interoperability—the sum total of software and hardware that enables applications, systems, machines, and networks to connect with one another and communicate productively—is either an inhibitor or enabler of EDA. Without simple, cost-effective interoperability, there simply cannot be any EDA. Or, at least, there cannot be the kind of dynamic, implicit, complex EDA that we want now and in the future.
Given that EDAs are utterly reliant on interoperation between systems to work, we need to know where we, as architects, stand in the realm of interoperation. We must have a good grasp of how we have progressed (and not progressed) in the whole endeavor. To get started, we need to first agree on where we are now. That way, when we hear that we “can’t get there from here,” we will know that it is likely an untrue statement. There is always a way to get from here to there. It’s all about knowing what path to take and how to move yourself.
We often tell our children, “Don’t cry over spilled milk.” In enterprise architecture, we should take that sentiment to heart. If your enterprise is anything like the ones we’ve seen in our 50 years combined experience, it’s not quite spilled milk in that data center. It’s more like a dairy that got hit by a tornado. You’re drowning in spilled milk—and, you probably weren’t the one who did the spilling. That guy is playing golf at a retirement community in Tucson while you tear your hair out.
Don’t blame him, though. The current state of enterprise IT is not anyone’s fault, and that’s kind of the problem. Most of us are coping with the legacy, in the broadest sense of the term, of years of poorly thought through decisions and imperfect management. A lot of smart people made the best choices they could under the circumstances they were in at the time. We are living in the misshapen structures that their architecture afforded them. We call this accidental architecture, and it’s all around us.
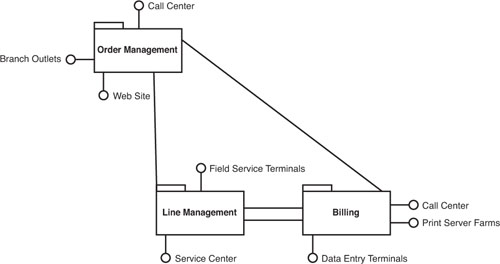
To illustrate accidental architecture, take the example of a phone company. As shown in Figure 1.2, this highly simplified phone company has three groups of systems, one for each of its core areas of operation: order management, line management (the provisioning and management of phone lines and service), and billing. At some point in the primordial past, the architecture of the phone company looked something like this. The order management systems connected with customized clients used in call centers and branch outlets. The order management systems connected with a service center and field service terminals used by traveling line installation personnel. The billing system connected with call centers, print server farms, and data entry terminals. In the dark ages when these systems were created, transfers of data from one system to another were either manual or completely hardwired. An order for phone service would be entered in the order system, but the request for phone service would be sent to the line management system and its personnel in a paper form. A hardwired connection transferred line use data to the billing system for output of printed phone bills.

In the enterprise architecture shown in Figure 1.2, it made little difference how each group of systems was developed or configured. Each group could run using operating systems, programming languages, or message formats that were completely incompatible with the others. There is nothing inherently wrong with this kind of setup, either. It’s just a nuisance when you want information or procedures from one group to be available with another. That’s interoperation.
The milk got spilled when well-meaning IT people used the best tools and knowledge at their disposal to try and get such separate, incompatible systems to work together. Before we get into the mechanics of how interoperation has worked traditionally, and the reasons it can cause difficulty for IT today, we want to first go over the drivers of interoperability. After all, interoperability and its various clumsy incarnations over the years have all been done in the name of serving business needs.
We say we want interoperability. Okay, but what is it, exactly? At its essence, interoperability is just what its name implies. It’s two or more systems performing an operation together. If you and a friend pick up a heavy box together, you are interoperating. Both of your efforts are needed to lift the box. The reason we go over this seemingly obvious explanation is because interoperation in IT is often confused with integration.
For many of us, there is no distinction between interoperation and integration. The two concepts are often linked, and deeply related. However, we like to differentiate between the two because understanding how EDA components such as event listeners and event processors work together becomes easier when the two ideas are treated separately.
Interoperation means making two or more systems communicate or exchange information together, whether or not the systems are connected by any dedicated integration interfaces. In contrast, integration is a scenario where two or more systems are linked by a software interface that bridges the two systems. Integration is the technically specific means of getting two applications to connect, whereas interoperation is the broader scope view of the entire situation. To relate it to a real-world parallel, think about the difference between driving a car and taking a vacation. Of course, you might drive a car to take your vacation. Yet, there is far more to the trip than just sticking the key into the ignition and turning the steering wheel. To go on vacation, you need to know where you are going, why you want to go there, how to get there, and so on. In enterprise architecture, interoperation is the complete set of business and technology factors that make two applications come together. Integration is the conventional, but not exclusive means to that end. In essence, integration can be thought of as “interoperability by any means necessary.”
Figure 1.3 shows a basic point-to-point interoperation scenario at the phone company. For reasons that we explore in the next section, the company finds it necessary to make the order management, line management, and billing systems work together to accomplish specific business functions. There already was one point-to-point interface between the line management and billing systems, but the company wants more connections to serve more business needs. The specific ways that the interoperation is achieved might involve application-to-application connections, network connections, physical connections, user interfaces, database updating, and so on.
Having a discussion about interoperability issues in IT can often feel like walking in on a movie halfway through. You kind of understand why Mel Gibson is slapping the perp around, but you missed the part where he took the bribe.... In all of our nerdy ruminations about architecture, we often forget a core truth: IT systems and solutions we develop for interoperability all serve some kind of business objective. “Of course,” you say. “That’s obvious.” Yes, it is, but interoperation can get so complex that it becomes its own topic, evolving in its own separate domain.
Although there are myriad reasons why IT needs to get systems to interoperate, we find that there are two essential groups of business requirements that drive the need for interoperability. Business functional requirements are a major driver of interoperation between systems. Business functional requirements are business situations that demand that two or more systems or applications work together to achieve a business objective. In the phone company example, a goal of providing real-time access to any customer account activity, whether it is related to a new order, a billing problem, or a service problem, necessitates interoperation between multiple separate and incompatible systems.
The second driver of interoperation is what we call business extension. Business extension is a situation where management wants to take advantage of data or system functionality to increase the scope of services offered or drive sales growth. For example, the phone company in our example might want to conduct telemarketing of cell phone plans to its landline customers. To attain an optimal marketing result on an ongoing basis, it would make sense for the telemarketers to be able to update the landline account holders’ records with their marketing activities. Assuming the telemarketers were using the order management system as their basis of interacting with customers, the requirement to have the telemarketers update landline customer records—who was called, whether they wanted cell service, and so forth—could result in a requirement for interoperation between the order management and line management systems.
Classic solutions to these requirements are in the form of an abstraction layer—either product-based or custom—that pulls information from (and populates) a shared data store. These solutions are typically specific to a given business function and might not provide the generic interoperability required for long-term agility in an enterprise or product environment.
There is no law of nature that commands us to integrate systems that need to interoperate. We could always rebuild everything and achieve interoperation by smashing separate systems into one, new, unified system. Although that is sometimes the best path to take, it is usually not the one we choose because it is too costly and time consuming. Thus, short of unifying the systems through a significant rebuild effort, some forward-thinking IT organizations defined enterprise integration strategies to allow applications and systems to share data and functionality to better meet the needs of the business community. Historically, such strategies were built around vendor-based enterprise application integration (EAI) suites, also known as middleware. Figure 1.4 shows a basic middleware component that connects the order management, line management, and billing systems in our phone company example.
Figure 1.4 Integration typically involves the use of middleware, as shown by the enterprise application integration (EAI) module that connects the order management, line management, and billing systems at the phone company. The EAI approach contrasts with the point-to-point approach shown in Figure 1.3.

Middleware introduced an isolation tier to buffer the application changes from the integration logic. Typically message-bus based, this form of integration led to the idea of loosely coupled composite systems. The concept was simple, but initially the effort associated with bus-enabling an application proved to be difficult. Developers had to have in-depth knowledge of the target system to build bus connectors, just as they did for case-specific interfaces. Middleware vendors recognized the drawback, and in an effort to promote adoption, built application connectors to give their customers a cheaper alternative to hand-coding connectors. Of course, buying prebuilt connectors meant buying the vendor’s middleware software, and although often cheaper initially than building from scratch, this investment led to long-term business constraints, including limited ability to upgrade or modify applications, insurmountable connector functionality restrictions, and classic vendor lock in. Figure 1.5 shows these adapters and connections in a perhaps more realistic version of what Figure 1.4 presents.

Integrating a middleware suite has typically required deep pockets and willingness to endure significant technical difficulty and organizational fallout. It is unfortunate, but the pain associated with incorporating these middleware suites into an enterprise architecture has prejudiced many technical managers against today’s integration suites, including those based on industry standards (like the Java 2 Enterprise Edition [J2EE] Connector Architecture) and including frameworks that implement common integration design patterns.
To understand how complex and costly EAI can get, look at Figure 1.6, which represents a classic “islands of integration” problem. As is often the case, especially in companies with highly autonomous divisions or postmerger situations, there might be multiple EAI vendors in place in the enterprise architecture. Each EAI suite requires its own adapters to connect to each system. Thus, in the example shown in Figure 1.6, connecting the order management system to the line management system requires the use of an adapter from Vendor B, while connecting that same system to the billing system requires one from Vendor A. License and maintenance fees can add up quickly in this scenario, but the biggest cause of trouble is usually the personnel required to keep it all going and scheduling lags caused by multiple layers of integration and testing.
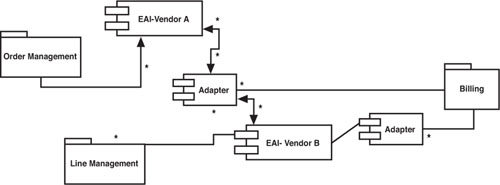
The kind of situation shown in Figure 1.6 is quite common, and it is generally referred to as a tightly coupled architecture. The applications are bound with one another tightly, and making changes can be costly and time consuming. As a result, the expensive and painful lesson learned by many technical managers and architects is that banking an enterprise integration strategy on a proprietary vendor product can show a very small, if any, return on investment (ROI), and can ultimately limit the agility of an architecture.
As integration strategies evolved to include process integration, middleware vendor software suites began to include business process management (BPM) or workflow-oriented integration. Promoting the idea that integration is driven by the business processes, these packages provided a better way to think about combining system functionality. However, as the sophistication of each integration approach increased, the complexity introduced also increased. The increased complexity required more implementation time and resources with a high skill level.
As Figure 1.7 shows, it is possible with certain EAI suites to map business process steps to the specific IT system that supports that step. The process shown in the figure is deliberately blank—we have shown it to get across the general concept. If it helps, you could imagine the process describes how to open a cell phone account as an add-on to a landline account, for example. The process touches each of the company’s major systems.

Business process modeling tools and technologies are helpful because they enable businesspeople and IT people to come together with a common communication vehicle that helps lay out specific requirements and solve business issues in ways that are often more streamlined than conventional discovery and requirement iterations. The added complexity that adding BPM to EAI creates, though, can drive cost and delays to an unsustainable pitch.
Ultimately, costs for such configurations increased to the point where leveraging existing components (reuse) became a priority. Relying on reuse to decrease implementation time is a valid approach, but without clearly identified techniques (like those introduced by SOA and EDA) is a pipe dream.
All of this brings us back to our spilled milk scenario. The unplanned growth in information systems and IT organizations in the ‘90s and the tactical, short-term-focused culture of this decade have combined today to create a consistent situation among enterprises of any meaningful scope: multiple disparate systems in various production environments supporting an organization’s business goals. The sharing of data and functionality between applications might be today’s primary technical architectural challenge for IT groups. The default solution for interoperability is often a point-to-point implementation optimized for a particular case; application teams seldom have the appropriate authority to define an overarching solution for more than the case at hand. The problem is that without an application interoperability strategy, point-to-point integration is often the standard and the coordination of decisions and processes across an enterprise becomes unmanageable over time.
Figure 1.8 shows what a lot of enterprises have come to resemble over the years. Integration between systems is excessively complex and poorly governed. Dependencies between systems that interoperate are either unknown, invisible, or very challenging to modify—resulting in a situation where something will always get “broken” when the IT department attempts to change system architecture in response to shifting business requirements.

The bottom line with the spaghetti approach is that it wreaks havoc on agility and the potential for a complex, dynamic EDA. Business needs requiring visibility or coordination between disparate systems become more difficult (and more costly) to meet. As a result, a general dissatisfaction with IT groups abounds in the business community. Business managers grow frustrated with IT for being “slow,” and IT gets stressed with business clients who seem to change their plans too much. Those tasked with managing all the interfaces that connect the pieces together get weary of the constant struggle to keep it all running right as unfinished changes pile up in queue. This hinders developing new revenue opportunities ultimately limiting business growth.
We have all probably wished at one point or another for some kind of IT version of the ultra low-carb diet that will forever banish spaghetti from our lives. If only such a thing existed. What we have actually found, though, is that a lot of us can’t even articulate what it is we would want in its place. To set the stage for the rest of the book, then, let’s try to think about what an ideal enterprise architecture might look like.
If you’ve ever looked at a personal ad, you’ve probably seen how picky people can be about a potential mate. Everyone is looking for that magic someone: tall, handsome, nonsmoker, football fan who loves his mother but not too much...right? Maybe that’s crazy, but in our situation, we think it is healthy to dream about what IT could actually be like if things were different. How would your enterprise architecture “personal ad” read?
If it were up to us, our personal ad might say something like:
“Seeking: An enterprise architecture that’s flexible; highly performant; adapts to changes easily, cheaply, and quickly; enables access to data in near-real-time; enables agility; can scale without pain; and doesn’t require maintenance overhead that breaks the bank. Availability, resilience, security, supportability, testability required. ‘High maintenance’ is a turn off.”
Whew, talk about picky! To put it succinctly, to get to the EDA we want, we ought to be looking for enterprise architecture solutions that are flexible and cost effective to change. The big challenge for most of us, though, is to understand the underlying architectural, technological, and organizational factors that have to come together to realize the level of flexibility and cost effectiveness we desire.
To relate flexibility and cost effectiveness to a concept that your line-of-business clients might understand, it might help to think in terms of business agility. As we mentioned in the preface to the book, agility is the lifeblood of business management today. Executives are preoccupied with being able to make strategic and operational changes to suit their shifting management objectives. As your IT architecture becomes more flexible and cost effective to maintain and change, you will be more able to enable agility than you are in your current spaghetti state.
Just how we get to that state of flexibility is a matter of lengthy discussion throughout the book. But, at least now we know what we want. We might never be swept off our feet by Prince Charming of the IT world, vendor pledges of eternal love notwithstanding. Yet, the exercise of thinking out loud about what we want is educational because it gives us a baseline of requirements against which we can measure proposed solutions and approaches to enterprise architecture. The process can also guide us as we think about designing and updating our existing architecture.
The important takeaway here is that any future architecture plan for EDA should ideally be matched up with this idea of flexibility and cost effectiveness before it is put into action. You might think, “Of course—this is so obvious,” but if you take a look around your department, you will probably see quickly that it hasn’t been so obvious to everyone. Or, to be fair, the technologies just haven’t been available to make it all work. The first important step to take, though, is to understand how to assess the myriad underlying factors that come into play in discovering the optimal architectural state for an enterprise.
For purpose of focus, we concentrate on IT governance, policy definition and enforcement, system development life cycle, business process modeling, and standards. Though these factors might seem to be a layer removed from the goals of flexibility and cost effectiveness, they are, in fact, the foundations of these capabilities. Although we can say with confidence that the SOA approach and the EDA implementation of SOA are the paradigms most able to deliver the optimal architecture, the path that will make an SOA/EDA right for your enterprise will depend on how underlying factors relate to the unique circumstances of your enterprise.
For example, you cannot attain a state of agile application integration if you have not tackled IT governance. If your systems are poorly governed, or governed by an inappropriate set of policies, people, and organizational structures, it will be difficult to modify systems and their interoperation with any flexibility or cost effectiveness. Only you will understand how this relates to your specific situation.
Continuing on this thread, the system development life cycle must take interoperation into account throughout its entire process chain. Otherwise, attempts to introduce new systems, integrate existing ones, or make changes to integrations will experience delays and uncertainty (translating into costly problems). Business process modeling is a basic necessity for getting to a state of flexible, cost-effective enterprise architecture. There has to be a way for business and technology stakeholders to communicate with one another and map requirements to IT assets.
Finally, standards are the glue that holds it all together. Governing enterprise architectures should include adherence to the standards adopted by the enterprise so that the EDA model can evolve unencumbered. To be flexible and cost effective, an enterprise architecture must evolve based on standards, or at the very least have the ability to be tolerant of differences in the capabilities of its constituents to mediate and resolve impedances between systems with differing standards.
The remainder of this book is devoted to showing you, through a mixture of theory and practice, how to move from where you are now (we guess in the spaghetti bowl) toward an EDA, using the SOA approach. With that goal in mind, we now turn to a theme that will recur through the rest of the book: the need for a unified architecture planning process to ensure progress toward the objectives of SOA and EDA as they best suit your enterprise needs.
It’s important to understand that interoperability between applications and components is difficult to achieve without overarching, uniform technical direction. With the assessment of our underlying factors in mind, there are some things that your application groups can do now to promote interoperability before your formal strategy is in place. Your application group needs to define coarsely grained, cohesive interfaces (service-based integration). If the predicted evolution includes interaction with other systems, interfaces should be designed to support that direction. Some of these steps in the right direction will become clear to you as you read this book.
Regardless of the interoperability mechanism(s) available to you in your architecture, building your systems with interoperability in mind from the start is the easiest way to achieve long-term system integration. Of course, few of us have the luxury of starting with a blank slate because most enterprises rely on proprietary or homegrown legacy business-critical systems. Unfortunately, interoperability is one of the more difficult things to add to an existing architecture (hence the popularity of middleware solutions).
So how can we tailor our application and system design activities to promote long-term interoperability? As is often the case, the first thing we need is a plan. An effective enterprise interoperability and integration strategy is typically the result of a joint effort between the technical and business architects in your organization. It is the job of the technical leadership in an organization to understand how new and existing systems or products will evolve over time, based on their understanding of both market trends and emerging technology. Understanding this predicted evolution will help you determine the appropriate structure of your system, whether it should be service-oriented and/or event-driven, whether it will leverage enterprise service bus (ESB) technology, whether it should support dynamic discovery of services, whether it must leverage Java Connector Architecture (JCA)-based (or other) integration technology, how the architecture will be monitored and governed, and the like.
The questions of how services and components will be governed and managed and what interface requirements each new component or application will need to meet—such as what policies should be applied to Web Services Description Language documents (WSDLs) or interfaces, what test cases must be applied per interface, and so on—are typically in the domain of the technical architect. These details can be defined after the overall strategy is defined.
This book strives to clear up the confusion associated with defining an optimal strategy for your case. If your organization is like most, your physical infrastructure maps closely to your organizational layout. In an organization with many silos, systems in a single silo are tightly coupled and heavily interdependent, and the level of reliability, maintainability, and extensibility varies widely between silos. When systems need to interoperate across silos, integration is achieved on a case-by-case basis. Alternatively, if your organization is matrixed or “flat,” every system might be independent of the others, with integration techniques defined and applied for specific endpoints. In both cases, business logic is buried deep inside of the applications and exposed only on a case-by-case basis to other applications. Interestingly, this holds true for large software product companies as well. You’ll notice vendor products sold as consolidated suites that might not share underlying frameworks—usually the result of disparate development teams building the products in a given suite or platform.
In either case, defining a service-oriented architecture requires overarching technical direction and visibility into the multiple silos or application groups as well as a good understanding of the business needs per group. If your organization falls into either category and does not have an enterprise architecture team, you have your work cut out for you. Achieving an elegant enterprise architecture environment through grassroots activity across a large organization can be done, but takes an inordinate amount of time and relies on the goodwill of key people in the right places. In either case, applying SOA principles in the context of a business solution is a necessary step in the journey to enterprisewide SOA and achieving the promise of an EDA. Applying SOA scoped to a specific business problem, distributing your work, and evangelizing the methods will go a long way toward defining a cross-functional strategy. Ultimately, it’s far better to aim for a business-driven, solution-specific SOA rather than one that mirrors a siloed approach to IT. Much of one’s success or failure in this area depends on the way that the EDA/SOA is managed and governed.
You will hear references to the process and organizational impact of defining an SOA. The impact is felt in a number of ways, but most painfully in the world of management and governance. Later in this book, we look at specific examples of management and governance issues, but for now we consider them at a high level. Good governance is about applying the minimal set of constraints required to encourage the desired behavior required for a targeted business outcome or regulatory requirement. Management and governance pose the biggest challenge for organizations planning to implement an SOA-based EDA, mainly because of the changes that might be required to the existing development processes. Before we talk about the challenges, let’s describe what managing and governing an SOA can entail.
The term governance is commonly used to define “...the processes and systems by which an organization or society operates.”1
Information technology governance (or IT governance) is a subset discipline of corporate governance focused on information technology systems and their performance and risk management. Weill and Ross have further refined this definition as follows: “Specifying the decision rights and accountability framework to encourage desirable behavior in the use of IT.”
In contrast, the IT Governance Institute expands the definition to include underpinning mechanisms: “...the leadership and organizational structures and processes that ensure that the organization’s IT sustains and extends the organization’s strategies and objectives.”
Accordingly, SOA Governance can be thought of as
![]() A decision rights and accountability framework
A decision rights and accountability framework
![]() Specifying a set of domain-specific extensions to commonly utilized IT governance methodologies (such as Information Technology Infrastructure Library [ITIL], Control Objectives for Information and Related Technology [COBIT], COSO [from the Committee of Sponsoring Organizations of the Treadway Commission], and so on)
Specifying a set of domain-specific extensions to commonly utilized IT governance methodologies (such as Information Technology Infrastructure Library [ITIL], Control Objectives for Information and Related Technology [COBIT], COSO [from the Committee of Sponsoring Organizations of the Treadway Commission], and so on)
SOA governance is most effective when
![]() The decision rights and accountability framework is combined with the effective operationalization of processes and supporting systems.
The decision rights and accountability framework is combined with the effective operationalization of processes and supporting systems.
![]() It is required to encourage the desirable behavior of participating constituents in the use of IT-enabled capabilities in a service-oriented enterprise environment.
It is required to encourage the desirable behavior of participating constituents in the use of IT-enabled capabilities in a service-oriented enterprise environment.
In short, we can describe SOA governance as
![]() The models and structures we use to create balance between constituent needs typically satisfied by an SOA CoE (Center-of-Excellence)
The models and structures we use to create balance between constituent needs typically satisfied by an SOA CoE (Center-of-Excellence)
![]() The mechanisms utilized to achieve visibility and coordination typically satisfied by an Integrated SOA Governance Automation solution
The mechanisms utilized to achieve visibility and coordination typically satisfied by an Integrated SOA Governance Automation solution
![]() The key decisions we make, record, and (in some cases) digitally execute in support of the guiding principles for an IT organization in the form of plan-time, design-time, change-time, and run-time policies
The key decisions we make, record, and (in some cases) digitally execute in support of the guiding principles for an IT organization in the form of plan-time, design-time, change-time, and run-time policies
Additionally, SOA governance systems would be expected to support the end-to-end life cycle of an SOA—including planning, analysis, design, construction, change, and retirement of services—combined with the requisite mechanisms (processes, systems, and infrastructure) that support the definition, negotiation, mediation, validation, administration, enforcement, control, observation, auditing, optimization, and evolution of policies and service contracts in an SOA environment.
Whereas service contacts represent the scope of a contextual binding between the constituents leveraging a set of capabilities in an SOA environment, the policies represent the constraints (or checks and balances) governing the relationships, interactions, and best interests (or motivations and incentives for behavioral change) of the participating constituents, processes, and systems.
Governance of an SOA/EDA includes the definition and enforcement of policies and best practices. The definition of best practices can be achieved through the creation of templates, design patterns, common or shared components, semantic guidelines, and the like. Enforcing the usage of these practices, often a step toward measuring compliance, can be achieved through the definition of policies that are applied to services as they are designed, developed, and deployed. Governance toolsets may have their own method of defining a policy (typically through the use of assertions to be applied to WSDLs at various stages of the development process), or you could create your own through an assertion-based policy definition and application approach (not recommended). In any case, a governance vehicle of some sort should be defined as part of your SOA strategy, and this typically involves an architecture team responsible for defining best practices and policies.
After teams or individuals are assigned responsibility for best-practice definition and ongoing governance of the services, your software deployment process must adapt to include the application of policies to the services developed by your application teams. In other words, a review process, preferably a programmatic review, must be executed to ensure conformance to the policies set by your design team.
Management of an SOA includes a number of things: registries in which services can be referenced, service brokers or buses, service-level monitors, intermediaries or agents to support the abstraction of nonfunctional or enterprise concerns from the application layer, directory servers, and the like. Vendors offer product suites with all or many of these components for management of an SOA, but as mentioned earlier, applying any solution requires careful architectural design, definition of optimization goals, and clear assignment of responsibility and ownership. Managing an SOA is just as complex as a network management solution or a systems monitoring.
To summarize, the primary differences between management and governance of an SOA can be viewed as follows: SOA management focuses on whether the systems and processes (machines) in your SOA environment are behaving correctly relative to operational governance policies that have been specified. Are the machines behaving correctly? SOA governance focuses on whether the people, policies, processes, and metrics supporting the SOA program (people AND machines) are producing the desired business outcomes. Is the organization doing the right things? Both are important, and an integrated model tends to work best.
![]() The pursuit of event-driven architecture (EDA) brings into focus a tension between the goals of many IT organizations—including flexibility and EDA—and the realities of system interoperation, which must be solved to proceed to EDA.
The pursuit of event-driven architecture (EDA) brings into focus a tension between the goals of many IT organizations—including flexibility and EDA—and the realities of system interoperation, which must be solved to proceed to EDA.
![]() An EDA working definition is as follows: EDA is an approach to enterprise architecture that enables systems to hear events and react to them intelligently.
An EDA working definition is as follows: EDA is an approach to enterprise architecture that enables systems to hear events and react to them intelligently.
![]() An event is an occurrence, in either the digital or analog world, that is of interest to the EDA.
An event is an occurrence, in either the digital or analog world, that is of interest to the EDA.
![]() For an EDA to work, it must be able to detect events and react to them. To do this, an EDA requires several components, including the following:
For an EDA to work, it must be able to detect events and react to them. To do this, an EDA requires several components, including the following:
![]() Event producers—software/hardware/logic that either generates event data or transforms it into a format that the EDA can understand
Event producers—software/hardware/logic that either generates event data or transforms it into a format that the EDA can understand
![]() Event listeners—software/hardware/logic that can hear the event producer’s output
Event listeners—software/hardware/logic that can hear the event producer’s output
![]() Event processors—processor that interprets the events and generates responses, if one is required
Event processors—processor that interprets the events and generates responses, if one is required
![]() Event reactions—entities that translate the event processor’s response into an action; can be an application or a person
Event reactions—entities that translate the event processor’s response into an action; can be an application or a person
![]() EDAs can be either implicit or explicit. An explicit EDA is deliberately set up to process event data. In contrast, an implicit EDA may be based on a number of system elements that were not specifically designed to be an EDA. An implicit EDA is a great deal more dynamic and agile.
EDAs can be either implicit or explicit. An explicit EDA is deliberately set up to process event data. In contrast, an implicit EDA may be based on a number of system elements that were not specifically designed to be an EDA. An implicit EDA is a great deal more dynamic and agile.
![]() There are three basic types of EDA processing:
There are three basic types of EDA processing:
![]() Simple event processing—for example, a thermostat; the event leads to a direct action.
Simple event processing—for example, a thermostat; the event leads to a direct action.
![]() Event stream processing—the EDA must listen for specific event data and react.
Event stream processing—the EDA must listen for specific event data and react.
![]() Complex event processing (CEP)—the EDA hears events from multiple sources and processes them according to dynamic rule sets.
Complex event processing (CEP)—the EDA hears events from multiple sources and processes them according to dynamic rule sets.
![]() When we talk about EDA today, we are really talking about modern, implicit, CEP EDAs. They offer the most potential for EDA, though they are the hardest to develop mostly because of constraints on system interoperability.
When we talk about EDA today, we are really talking about modern, implicit, CEP EDAs. They offer the most potential for EDA, though they are the hardest to develop mostly because of constraints on system interoperability.
![]() Interoperability and integration are related concepts in IT that can cause confusion because they are commonly misunderstood. Although in the old days, systems might have existed in a state of isolation, today, it is necessary much of the time for one system to exchange data or function procedures with multiple other systems. This is known as interoperation, and it can be achieved through a variety of technological modes, including direct integration of systems. Integration is a type of interoperation that has each system with a specific, technological “hook” into another system or systems.
Interoperability and integration are related concepts in IT that can cause confusion because they are commonly misunderstood. Although in the old days, systems might have existed in a state of isolation, today, it is necessary much of the time for one system to exchange data or function procedures with multiple other systems. This is known as interoperation, and it can be achieved through a variety of technological modes, including direct integration of systems. Integration is a type of interoperation that has each system with a specific, technological “hook” into another system or systems.
![]() There is nothing new about integration and interoperation. Over the years, most large enterprises have seen their systems connected by a multitude of technological approaches, including a direct point-to-point arrangement, as well as enterprise application integration (EAI) hubs and adapters that connect systems on a common platform. Though there is nothing inherently wrong with these approaches, they tend to result in complex, overly interdependent enterprise architectures that resemble spaghetti. Changing one element in such an environment can set off a chain reaction of related changes and modifications—a situation that slows down agility and adds costs to IT budgets.
There is nothing new about integration and interoperation. Over the years, most large enterprises have seen their systems connected by a multitude of technological approaches, including a direct point-to-point arrangement, as well as enterprise application integration (EAI) hubs and adapters that connect systems on a common platform. Though there is nothing inherently wrong with these approaches, they tend to result in complex, overly interdependent enterprise architectures that resemble spaghetti. Changing one element in such an environment can set off a chain reaction of related changes and modifications—a situation that slows down agility and adds costs to IT budgets.
![]() To get at a solution for the spaghetti problem, we establish objectives for an enterprise architecture that is both flexible and cost effective to maintain and change. The objectives are, in turn, supported by underlying factors that include IT governance, policy definition and enforcement, system development life cycle, business process modeling, and standards. We recommend an architectural approach to attaining SOA/EDA that is based on assessing your enterprise for its unique characteristics for these key underlying factors.
To get at a solution for the spaghetti problem, we establish objectives for an enterprise architecture that is both flexible and cost effective to maintain and change. The objectives are, in turn, supported by underlying factors that include IT governance, policy definition and enforcement, system development life cycle, business process modeling, and standards. We recommend an architectural approach to attaining SOA/EDA that is based on assessing your enterprise for its unique characteristics for these key underlying factors.
![]() Overall, with the assumption that SOA/EDA is the approach to enterprise architecture that can deliver the desired flexibility and cost effectiveness (also known as business agility), in this chapter we begin to define how architecture can promote integration. Specifically, we begin a discussion of how an enterprise must identify and embrace a unified approach to planning and executing architecture design and subsequent implementations. This theme continues throughout the rest of the book.
Overall, with the assumption that SOA/EDA is the approach to enterprise architecture that can deliver the desired flexibility and cost effectiveness (also known as business agility), in this chapter we begin to define how architecture can promote integration. Specifically, we begin a discussion of how an enterprise must identify and embrace a unified approach to planning and executing architecture design and subsequent implementations. This theme continues throughout the rest of the book.
1. Michelson, Brenda. “Event Driven Architecture Overview.” Paper published by Patricia Seybold Group (2/2/2006).