
Oracle Coherence is a distributed data grid solution, keeping data available in memory, and using sophisticated distribution algorithms and protocols to synchronize and transfer information between its nodes. This model gives us amazing access times by having data readily available and improved reliability by distributing the data between several instances and machines, adding redundancy to avoid loss of information.
The most recent version of WebLogic, 12.1.2, comes with the newest Coherence version, also numbered 12.1.2, and tighter integration between the two products; Coherence is now enabled by default at the server's classpath, working as a regular subsystem like JMS, for instance.
Also, we are able to create and configure Coherence clusters from the administration console (and related technologies such as JMX and WLST). Finally, there's a new deployment package, Grid ARchive (GAR), that encapsulates Coherence configuration files, for instance, cache declarations and operational parameters, into a consistent unit, making administrative tasks more streamlined.
Tip
For more details on this, check out the documentation at http://docs.oracle.com/middleware/1212/wls/WLCOH/create-application.htm.
As you may recall, we configured the web applications to use in-memory HTTP Session replication when configuring a WebLogic cluster. Another alternative for session replication on WebLogic is to use Coherence*Web. This module enables WebLogic session data to be distributed (replicated) among multiple machines, which is basically the same functionality provided by the in-memory session replication feature, but using Coherence as the engine. This allows different applications and even servers to access session data, and, as we can configure standalone Coherence servers to be part of a cluster (each running on their own JVM instance), the application server heap space isn't cluttered with session data.
Tip
Coherence*Web can be used with several other application servers, such as Oracle Glassfish and Apache Tomcat among others. For a complete list of benefits and the possibilities of Coherence*Web, check out the product's documentation at http://docs.oracle.com/middleware/1212/coherence/COHCW/start.htm.
We are going to configure an in-process topology for Coherence*Web, meaning that Coherence is going to share the JVM of a WebLogic server, running as its subsystem.
Note
Up to Version 12.1.1, this integration wasn't available out of the box. It was possible to set it up, but the process involved copying libraries around. Now, coherence.jar and coherence-web.jar (the files that enable Coherence*Web) are loaded by default at server startup, making the configuration process easier.
To use this feature, we need to enable a Coherence cluster, configure a WebLogic instance to be Coherence's data repository, and, finally, we must adjust the web application that will use this mechanism.
To show how to use Coherence*Web, we're going to use the default cluster configuration provided by Coherence.
Note
Using the default configuration is a great way to get up and running quickly, but keep in mind that for real-world systems this is not an option; aspects like environment isolation and network latency must be addressed by specific configurations. You can find more information about the parameters available by checking the official documentation at http://docs.oracle.com/cd/E24290_01/coh.371/e22837/cluster_setup.htm.
These are the steps to add a Coherence cluster to the domain:
- At the administration console, expand the Environment section at the Domain Structure box and then click on Coherence Clusters.
- On the Summary screen, click on New.
- Enter
sessionDataClusterin the Name field and then click on Next. - We don't need to change the way Coherence instances communicate, so just click on Next here.
- Add both the loadBalancer server (or AdminServer if you didn't create the dedicated instance) and WebLogic's ticketsCluster cluster to it by selecting the appropriate entries.

- Click on Finish and it's done.
Another change introduced by Version 12.1.2 is that every WebLogic Server is now potentially also a Coherence node; as the libraries are enabled at the server's classpath, all we have to do to start using Coherence is to add a server to a Coherence cluster.
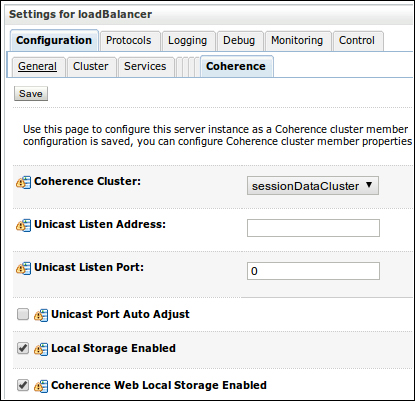
The most important configuration associated with this step is deciding if that specific server will hold data in it or if it will act as a client in relation to data; in other words, we have to decide if the instance will have local storage enabled. Also, there's a specific Coherence*Web parameter that indicates if the node will act as a storage tier for this feature.
When a server is added to a Coherence cluster, local storage is enabled by default and Coherence*Web storage isn't. To edit Coherence-related parameters of a specific server, the following steps must be followed:
- In the administration console, select the desired server from the Servers list.
- In the Configuration tab, click on the last inner tab Coherence.
- As we want to store all data into the node loadBalancer, we must configure it to allow Coherence*Web by enabling the parameter Coherence Web Local Storage Enabled.
- If the servers are already running, restart them.
Now that we already have a server configured to store session data, we need to modify the application deployment descriptors and change the actual HTTP session state replication mechanism to use Coherence*Web:
- Start Eclipse and open the file
weblogic.xmlunder/WebContent/WEB-INFin the project Store. - Change the value of the entry
persistent-store-typetocoherence-webto instruct WebLogic to use Coherence*Web and add a new tag,coherence-cluster-ref, to reference the cluster we created in the previous section.<wls:session-descriptor> <wls:persistent-store-type> coherence-web </wls:persistent-store-type> </wls:session-descriptor> <wls:coherence-cluster-ref> <wls:coherence-cluster-name> sessionDataCluster </wls:coherence-cluster-name> </wls:coherence-cluster-ref>
- Save the file.
- Make sure that the server configured as Coherence*Web storage is running; at least one node of the Coherence cluster we specified at the deployment descriptor must be up when deploying an application that uses it or else the deployment procedure will fail.
- Deploy the project to the cluster.
In order to test that your sessions are now stored on an external cache server, put some information on the session, shutdown one or both Managed Servers, and start them again. Since the data persists outside these servers, the cache kept the data, even though the application went down.
Tip
Due to the resource limitations of a normal developer workstation or laptop (physical memory, basically), the example used only one node to hold session data. On a production system, or when the memory or number of servers aren't constraints, you can follow the same procedures to scale the cache to use multiple nodes, giving it better performance and increased reliability. As Coherence's is naturally a distributed data grid, having more nodes will contribute to the overall experience.
TopLink Grid is a feature that enables Java Persistence API (JPA) to use Coherence to cache object instances, bringing performance gains to an application.
As you may remember, TopLink is WebLogic's JPA implementation, so enabling this cache function basically involves deciding which kind of caching is a best fit for the business scenario and configuring it.
There are a few different strategies that can be used when attaching Coherence to the JPA layer. Here's a quick description of each one:
- Grid Cache: This is the simplest way to integrate JPA and Coherence, where the latter acts as an L2 cache; data is read from the database and stored at the cache and subsequent queries can use data from there, speeding up response times.
- Grid Read: On this topology, Coherence is promoted to a more central role, being the source of data when JPA runs a query. The cache is loaded with object instances read from the database and the idea is that they should remain there longer, eventually serving all queries using only in-memory data. When an instance is updated, JPA does it first at the database, and then automatically updates Coherence.
- Grid Entity: This is an evolution of the Grid Read topology, where all queries and updates are made directly to Coherence. Insertions and updates are sent to Coherence, and this layer propagates them to the database, ideally using its write-behind capability to get even better response times.
Tip
If you want to read details about each topology, check out the following document: http://docs.oracle.com/middleware/1212/coherence/COHIG/tlg_integrate.htm.
The following figure shows how such a configuration would work; Coherence would be at the front of the database, intercepting and serving requests from or to it.
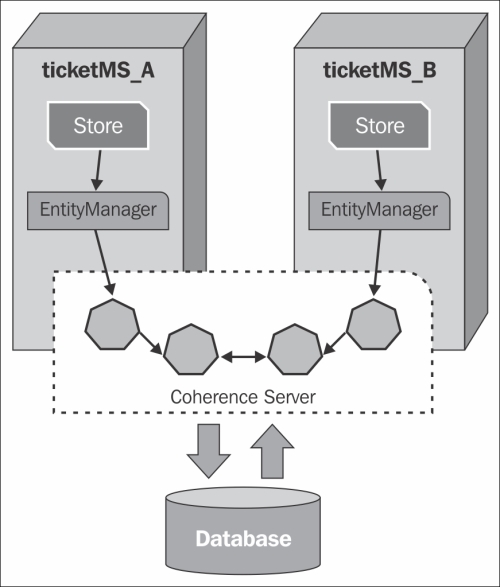
Since this is considered an advanced feature of a more complex WebLogic topology, the configuration of such features is out of the scope of this book, but at the following URL you can find documentation and step-by-step instructions on how to enable it: http://docs.oracle.com/cd/E24290_01/coh.371/e23131/toc.htm.
This integration between JPA and Coherence is a powerful feature when scaling up your application, but keep in mind that a new set of considerations must be taken, such as how many Coherence instances must be set up, how to distribute the load over them, for how long a specific object must be kept in the cache, how to invalidate it, and so on.