
Chapter 8. Lean, Eliminating Waste, and Seeing the Whole
Lean is a mindset—a mental model of how the world works.
Mary and Tom Poppendieck, The Lean Mindset: Ask the Right Questions
So far in this book, you’ve learned about Scrum and XP. Each of those methodologies has practices that you and your team can put in place, and values and principles that help everyone on the team reach an effective mindset. You can tell that you’re on a team doing Scrum because you’re attending a Daily Scrum, using sprints, and working with a Product Owner and Scrum Master. The same goes for XP: if you’re refactoring mercilessly, doing test-driven development, continuously integrating, and doing incremental design, your team is using XP.
But one thing that XP and Scrum have in common is that if you and your team don’t understand their values and principles, then you’ll end up going through the motions and getting better-than-not-doing-it results. As Ken Schwaber pointed out, if you don’t understand collective commitment and self-organization, you don’t “get” scrum, and the Scrum values help you understand those things. Ditto for XP: without understanding its values like simplicity and energized work, you’ll end up treating the practices like a checklist—your team won’t truly embrace change, and you’ll end up with complex software that’s difficult to maintain.
Lean is different. Unlike Scrum and XP, Lean doesn’t include a set of practices. Lean is a mindset, and just like with the mindset for Scrum or XP, Lean comes with values and principles (which, in Lean terminology, are called “thinking tools”). The mindset of lean is sometimes called lean thinking. The term “lean” has been applied to manufacturing for many decades; it was adapted for software development by Tom and Mary Poppendieck in the first decade of the twenty-first century. We’ll use the capital-L term “Lean” to refer to this adaption of lean ideas to agile software development.
In this chapter, you’ll learn about Lean, the values that help you get into the lean thinking mindset, and the thinking tools that help your team identify waste and eliminate it, and see the whole system that you use to build software.
Lean Thinking
Lean is a mindset. This is an interesting idea—giving a name to a mindset—and it’s very useful.
We saw earlier in the book that to effectively adopt Scrum, a team needs to have a specific mindset. And we saw that the Scrum values of commitment, focus, openness, respect, and courage help the team get into that mindset. We also saw that XP requires a mindset of its own, and that an XP team uses the values of simplicity, communication, feedback, respect, and courage in the same way.
So it shouldn’t be surprising that Lean comes with its own set of values, and that a team looking to adopt lean thinking starts with those values.
The Lean values are:
- Eliminate waste
-
Find the work that you’re doing that doesn’t directly help to create valuable software and remove it from the project.
- Amplify learning
-
Use feedback from your project to improve how you build software.
- Decide as late as possible
-
Make every important decision for your project when you have the most information about it—at the last responsible moment.
- Deliver as fast as possible
-
Understand the cost of delay, and minimize it using pull systems and queues.
- Empower the team
-
Establish a focused and effective work environment, and build a whole team of energized people.
- Build integrity in
-
Build software that intuitively makes sense to the users, and which forms a coherent whole.
- See the whole
-
Understand the work that happens on your project—and take the right kind of measurements to make sure you’re actually seeing everything clearly, warts and all.
Each value comes with thinking tools to help you apply the values to real-world situations for your team. Each of these thinking tools is roughly analogous to an XP principle—they’re used in exactly the same way.As we explain these values, we’ll show you their associated thinking tools and how you use them to help your team get into the Lean mindset.
You Already Understand Many of These Values
An organization will get what it values, and the Agile Manifesto does us a great service in shifting our perception of value from process to people, from documentation to code, from contracts to collaboration, from plans to action.
Tom and Mary Poppendieck, Lean Software Development: An Agile Toolkit
Does it surprise you that you’ve already encountered many of the Lean values and thinking tools? It shouldn’t. Lean is an important part of agile. When the Poppendiecks were adapting ideas from lean manufacturing to software development, they borrowed from other parts of agile, including XP. But more importantly, the manufacturing ideas that they used have been an important part of engineering and quality management for decades. Ken Schwaber drew on many of the same quality ideas when developing Scrum—we saw this when learning about how the Daily Scrum is a formal inspection.
Because this book covers several agile methodologies, we’ve already covered some important parts of Lean. We’ll go through them here—the only reason they don’t take up much space in this chapter is because you’ve learned about them in depth already. They’re still core elements to lean thinking.

Figure 8-1. You already know a lot about Lean, because there’s a lot of overlap between the values of lean thinking and the values of Scrum and XP.
Take another look at the list of Lean values. At least one of them should jump out at you: decide as late as possible. Both Scrum and XP heavily rely on the idea of making decisions at the last responsible moment. This Lean value is exactly the same idea. Scrum teams apply this idea to planning. So do XP teams, and they also apply it to design and coding. Lean practitioners do this too—in fact, this value even has a thinking tool called the last responsible moment, which is identical to the concept that you’ve already learned about.
There’s another value that you’ve learned about already: amplify learning—and you know that you’ve already learned it because its first two thinking tools are feedback and iterations.These are exactly the same concepts that you learned about with both Scrum and XP. This value also has two other thinking tools: synchronization and set-based development. Synchronization is very similar to continuous integration and collective ownership in XP, and we’ll cover set-based development in just a minute.
Finally, you’ve also learned about the value empower the team, and its thinking tools self-determination, motivation, leadership, and expertise. These ideas are almost identical to the ideas behind the XP practices of whole team and energized work—especially avoiding long days and long nights because they have a severe and negative impact on the software. You learned in Chapter 4 that Scrum teams also value this, as part of the Scrum value of focus. A team whose members have control over their lives will build better software. And you’ll learn later that an important aspect of seeing the whole is sharing information about the project with everyone, including managers—this is exactly why Scrum teams value openness.
Commitment, Options Thinking, and Set-Based Development
Here’s something we said back in Chapter 4—it’s worth reading again:
Plans don’t commit us. Our commitments commit us: the plan is just a convenient place to write those commitments down. Commitments are made by people, and documented in project plans. When someone points to a project plan to show that a commitment was made, it’s not really the piece of paper that the person is pointing to. It’s the promise that’s written down on it that everyone is thinking about.
So what does that really mean? It means that when you make a plan, first you make the commitment, and then you write it down.
Now have another look at Figure 8-1. We added a footnote to commitment about how it’s part of Lean and XP, because even though it’s only explicitly called out in the Scrum values, commitment is an important part of both the XP mindset and lean thinking. But Lean goes further and adds nuances to the ideas of commitment: options thinking, or seeing the difference between something that you’re committed to and something that you have the right (but not the obligation) to do; and set-based development, or running a project in a way that gives you more options by having the team follow several paths simultaneously to build alternatives that they can compare.
Scrum teams commit to delivering value, but give themselves options for how to do it
Teams should make commitments,65 right?
For example, when a Scrum team member is asked about delivering a specific feature in a few months, he can’t just tell the users and managers, “This is Scrum, so I don’t have to commit to anything beyond the end of this sprint. Talk to me two months from now.” Instead, Scrum teams use a product backlog, so that they can work with the business to understand what’s valuable. They make a commitment to deliver valuable software at the end of this sprint, the next sprint, and every sprint for the next few months.
Contrast this with a command-and-control project manager who creates a very detailed project plan that commits people to working on specific tasks months ahead of time. When a team makes a commitment up front to deliver a specific feature with a lot of detailed planning, that gives everyone the illusion that everything is under control. The project manager can point to a specific task that a developer is going to be working on, say, Tuesday at 10:30 a.m. four weeks from now; that gives everyone a feeling that the team has already thought through all of the options and committed to the best path. The problem is that they haven’t really committed to anything. They don’t have enough information to have done that. In fact, there’s only one thing that they actually know in this situation: that whatever the plan says the programmer will be doing on Tuesday at 10:30 a.m. four weeks from now is almost certainly wrong.66
So instead of planning each task in detail and committing to those detailed tasks, Scrum teams self-organize, and collectively commit to delivering value. And instead of committing to having a specific developer perform a specific task at, say, Tuesday at 10:30 a.m. four weeks from now, they leave decisions to a later responsible moment (probably a Daily Scrum meeting in four weeks).
However, the Scrum team does not make a commitment to deliver specific backlog items until the sprint has started. And even after the sprint has started, the Product Owner can take items out of the sprint if they no longer make sense. By making a smaller commitment—to deliver value—instead of committing to specific backlog items, they leave those decisions and commitments to a later responsible moment.
When the sprint starts, the items in the sprint backlog may feel like commitments to the team, because they were discussed during the sprint planning session and put on the task board. But they’re not commitments. They’re options. You know that they’re not commitments because the Product Owner can remove them from the sprint. And if the team discovers near the end of the sprint that it won’t be “done done” by the end of the timebox, they’ll push it to the next sprint. This is one reason that Scrum works so well: it separates true commitments (delivering valuable working software at the end of a timeboxed sprint) from options (delivering a specific feature at a specific date).
Getting people to think about options instead of commitments can be difficult, because it’s not always easy to think clearly about what it means to commit. Nobody likes being forced to make a commitment on the spot. Most of us have been in a meeting where a boss demands a date from a team member, and the team member shifts uncomfortably in his seat and gives a non-committal, non-answer. This situation happens when bosses or project managers feel like they’ve been “burned” by a team that made a commitment and then failed to meet it. Their gut reaction is to micromanage the team by demanding many commitments from individual team members about many short-term tasks. This creates an environment where developers are afraid of making commitments.
How do projects get to the point where bosses and project managers feel like they don’t trust the team, and that they’ve repeatedly failed to meet their commitments? This happens because even though individual people may shy away from commitments (especially under pressure in front of the boss), teams have a tendency to overcommit. Sometimes this is due to heroics—like an overeager developer who promises more than he can deliver. Other times, it’s because commitment is rewarded: it’s practical for someone to commit today and apologize later for unforeseen circumstances that knock the project off track. (“There’s no way we could have predicted that!”) In a company with a culture of blame and CYA, the commit-and-apologize-later approach, while not particularly effective for delivering software, is often the most effective way to get a higher salary or to keep your job.
It’s worth repeating the main idea here: bosses often have a tendency to demand commitment, and teams often have a tendency to overcommit.
Incremental design, set-based development, and other ways to give your team options
A task on a Scrum task board goes through three states: to do, in progress, and done. When a task is in the “to do” column, it’s still an option, not a commitment. And even while the task is in progress, the team can decide at a Daily Scrum to change direction if it makes sense. In Chapter 4, we talked about how a Scrum team doesn’t spend a lot of time modeling and tracking dependencies between tasks, because those dependencies are mainly useful for projecting out a schedule. Instead, the team is free to add and remove tasks on the task board every day during the Daily Scrum. These tasks are options, not commitments: tasks don’t have due dates, and there’s no such thing as a “late” task that causes the rest of the project to blow a deadline. This encourages options thinking on the team, because they’ve only committed to the goal, and can change the tasks at any time to meet that goal more effectively based on any new information that they’ve uncovered.
Here’s an example of how Scrum teams use options thinking. Let’s say during sprint planning a Scrum team broke a story down into four tasks based on assumptions that they made about storing data in a database, and they included a database design task that would probably have to be done by a DBA. Two weeks into the sprint, a developer discovers that the data they need is already in the database in another format, and it makes more sense to build an object or service than gather the data into a form that the rest of the system can use. To the Scrum team, this is good news! They can pull tasks off of the task board at the next Daily Scrum, freeing up time in the sprint to add another backlog item or clear some technical debt.
In contrast, for a traditional waterfall team, discovering that a task should be done by someone else can be much more difficult to handle: now the project manager has to reallocate resources because the DBA is no longer needed for this task, and that can throw off many project dependencies and ripple through other projects. This is a problem if those project plans contained many commitments that now must be renegotiated. The project manager will be tempted to go back to the team and demand that they use the database anyway. Or a technical architect may feel like the team committed to using his design that depended on the database, and now that commitment is being broken.
Many developers recognize the feeling of being asked to make unnecessary or even counterproductive technical compromises by someone who is not close to the project, like that project manager or technical architect. From the developer’s perspective, the team is being asked to compromise the integrity of the software. From the project manager or architect’s perspective, the developer is breaking a commitment. Everyone has a cause to see the other person as a “bad guy.”
The real problem is that the design should never have been committed to in the first place—if everyone saw it as an option rather than a commitment, the team would be free to build the best software, and the project manager and architect would not have to change their plans or feel slighted.
So how do you get both the boss and the team members to make fewer commitments, and treat more “final” decisions as options?
XP gives us a good answer to this question: incremental design. When a team builds simple components, and each of those components does only one thing, that lets them combine those components in lots of different ways. The team uses refactoring and test-driven development to keep those components as independent as possible.
In other words, decoupled, independent components create options.
When new thinking arises, or a new requirement is discovered, if the components are very large and there are a lot of dependencies between them, the team will spend most of their effort ripping apart that code and performing shotgun surgery. But an XP team that used incremental design has kept their options open. They’ll add only the minimal code that they need to meet the new requirement, and they’ll keep refactoring and continue to use test-driven development. The team will add as few dependencies as possible, which will continue to keep as many options as possible open to them in the future.
So XP and Scrum teams practice options thinking in how they plan their work and design their software. But is there something that teams can do to explicitly build options into their project?
Yes, there is. When teams practice set-based development, they spend time talking about their options, and change the way that they work in order to give themselves additional options in the future. The team will do extra work to pursue more than one option, trusting that the extra work will pay for itself by giving the team more information so that they can make a better decision later.
Let’s say that a team has a business problem that has a number of possible technical solutions—for example, our Scrum team that discovered partway through the sprint that they don’t need the DBA to modify the database. What if the team doesn’t know whether the object-based solution is better than the database solution? This is very common in software projects. You often don’t know which solution is best until you build them both—or, at least, until you start building them.
When developers are tackling difficult problems, they don’t really understand what’s involved in solving them until they get their hands dirty. Every developer recognizes the situation where they started working on a “simple” problem that turned out to be much more complicated or subtle than they expected. This is a fact of life for software teams. If the team made a commitment because they assumed that a problem was simple, discovering that it’s much more complex than expected gives the team two choices: break the commitment, or deliver hacky, kludgey code and rack up technical debt.
Set-based development will help our Scrum team cope with the fact that they don’t know which of the two solutions will work out best. Instead of choosing one path (building the data model) or the other (creating an object-based solution), the team adds tasks to the task board to pursue both options. This may seem like it might be wasteful at first, but it can actually save the team a lot of effort in the long run. If one of those approaches truly leads to a much better solution, while the other one leads to a hacky solution with lots of technical debt, then it’s worth it for the team to pursue both options—at least long enough for developers on both paths to think through their solutions. This gives them much more information to make a better decision, and the responsible moment for making that decision is after they’ve spent time working on the problem.
Another example of set-based development that teams use regularly is A/B testing. This is a practice commonly found when developing user interfaces and improving user experience, and has been used with a lot of success at Amazon, Microsoft, and many other companies. In A/B testing, the team builds two or more solutions—for example, two different layouts or decision paths for a web-based user interface (an “A” layout and a “B” layout). The team will then randomly assign either the A or B option to beta testers—or, for some projects, to live users—and monitor their usage and success rates. Companies have found repeatedly that while it takes more time and effort to build two different complete solutions, it’s well worth it in the long run because they can take measurements and prove that one of those solutions was more successful. Not only that, but often the less successful solution still has useful lessons, like features that they can later incorporate into the final product.
These examples show how teams use set-based development and options thinking in the real world. More importantly, they show you how the ideas that you’ve already learned in Scrum and XP give you a foothold for learning about Lean and lean thinking.
Act I: Just One More Thing...
“Come on, everyone. Buck up and do it.”
Catherine was sick of hearing that from her boss. She had just finished a meeting with him, and he was not happy with the team’s progress on a new feature he’d asked them to add. Two of the developers had run into a problem that would cause it to take longer, and he wouldn’t give them more time to finish. He hadn’t exactly said that they would face consequences if they didn’t get it done when he expected it done, but it was clear to everyone that delays were a bad thing.
Catherine was much happier last year, when she worked at a small company with just one programming team. They all worked on a single product, a mobile phone app that added features to the phone’s camera. The team was small, but they were highly innovative, and everyone knew how to work well together.
They were also very highly regarded by the rest of the industry. So it only seemed natural that a large Internet conglomerate would express interest in buying the company. Catherine and her teammates had been very excited about this, because they’d read all about that company’s relaxed working environment, fridges full of soda, flexible work hours, and other perks. When the deal finally went through, they all got big bonuses (she paid off her student loans!), and the whole team moved to their new, beautiful offices downtown.
“How did we end up this way, Timothy?” asked Catherine, walking out of her boss’s office. “This used to be fun. What happened?”
Timothy was a programmer, and had been on the team almost as long as Catherine. “I don’t know, Catherine,” he said. “It seems like everything takes twice as long as it should.”
“I don’t mind working longer hours,” said Catherine. “But it feels like no matter how long or hard we work, we’re always behind.”
“I know,” said Timothy. “And we’ll never get out from under it all.”
“Hey, Cathy! Tim! Do you guys have a minute?”
Catherine and Timothy looked at each other. “This doesn’t sound good,” she said. Their boss, Dan, was calling them back into his office.
“I just got off the phone with one of senior managers at our company’s social networking site, and I’ve got great news.” (Somehow, all new requests for the team were “great news.”) “He had an idea for integrating their social network data with our camera app. I want you guys to get on it immediately. I’ll send you an email with a list of features we need to add, and make sure they get into our next sprint.”
Timothy said, “OK. We’re halfway through the sprint. What should we remove?”
Catherine shot him a dagger of a stare. She knew this wouldn’t end well.
Dan had been looking at his screen while talking to them. He slowly looked up at Timothy. “Don’t you think you’ve got enough resources to get it in this cycle, Tim?”
Timothy started to respond. “Well, uh, no, we’ve got four other features, and one of them is already behind—”
Dan cut him off. “That’s an excuse. I don’t see anyone staying late or working real hard these days. I was here at 6 this morning, and nobody else was here. You’re telling me we can’t put a little more time in? This isn’t a big request. I could code it myself in a day.”
Catherine knew where this was heading. She’d heard this whole exchange before, and it didn’t end well last time. They’d barely gotten that other “great news” request from Dan into the software, and they only got it there by skipping the unit tests and racking up technical debt. And the users noticed—their four- and five-star online reviews dropped to two and three stars after that release.
“Just tell everyone to buck up and do it. It’ll be quick, and we’ll get a lot of recognition for it in the company.”
Creating Heroes and Magical Thinking
There’s a school of thought among many managers that if you set very high goals for people, it will motivate them, and they’ll work hard to meet those goals. If you give each individual team member aggressive goals and a tight timeline, everyone will rise to the occasion. There’s a gut feeling that this “rugged individualism” approach to building teams will eliminate bureaucracy. Each person is individually empowered to solve his or her own problems, and that leads to a highly effective team of problem solvers.
The rugged individualist manager congratulates heroics. The developer who stays late, works weekends, and brings complete solutions back to the team gets the most recognition, and rises to the top of the team. The hero developer rises to the top not because of teamwork, not because of making the whole product better or improving how the team builds software, but because of what he did, alone, after hours.
This is counterproductive. It’s traditional thinking, but time and time again teams have found that this “individualist” thinking leads to worse software. Why is that the case?
The best software is created when teams work together. We’ve already seen a heavy focus on teamwork in both Scrum (with self-organization and collective commitment) and XP (creating an energized environment where the people come together as a whole team). Many agile teams in the real world have seen over and over again how improving their teamwork and giving themselves sane, relaxed working conditions helped them build better software.
So why do so many bosses gather groups of “rugged individuals” instead of building real teams of people who work together and collaborate?
Try to put yourself into this manager’s shoes for a minute. It’s easy for you to look at the team as a sort of “black box” that creates software. You’ll tell the team what to build, wait for a few days, and somehow software appears. If one of your developers is especially good at working on his own, and is willing to work late nights and weekends, he’ll immediately stand out to you as someone who can push software out the door. This person is a gift to you as a manager: pile work on him, and it gets done. You’ll reward that person, and maybe others will step up to the plate and work the same way.
It seems like the more pressure that you put on the team, the more work you’ll get out of them. The more that you reward the late-night workers and the people who can scramble the fastest through the chaos, the more software gets built. And how do you put pressure on people? You’ll make sure that they know that there’s always more work to be done, and that whatever is currently being worked on needs to get out the door as fast as possible.
It’s important for us to be charitable to this boss, even if he’s created a distinctly un-energized work environment where every team member feels like he or she doesn’t have time to think, and just needs to get work done now. We’ve got the luxury of having seen from XP exactly how this causes the team to build software that’s poorly designed and difficult to change. This boss, on the other hand, doesn’t think that way.
This boss uses magical thinking.
When a manager has magical thinking, anything is possible. The team can take on any project, no matter how big. Every new project is “just a little feature” or “no big deal, my team can handle it” because a trained group of smart people can accomplish anything. No matter how much work they’ve taken on this week, next week they can take on even more. You can always add an extra task to the team’s plate, and it will somehow get done without affecting any of the other work. If it means that the team needs to pull a “power week” where they work an extra 20 hours, or a few developers have to work over the weekend, that’s OK—they’ll get the job done. Like magic.
It’s not just managers who have magical thinking. There’s a symbiosis with the hero—he’s willing to work overtime to pull off “miracles” for recognition, a leadership position, and possibly a higher salary. He becomes the measuring stick against which all other team members are valued. The boss doesn’t really look very closely at how the software is actually designed and built, or how many poorly constructed stopgaps are turned into long-term solutions. So the number of hours worked per week becomes the main measure of how valuable a team member is.
Magical thinking feels good. You feel like you’ve solved a big problem, whether you’re a manager “motivating” a team or a hero team member who worked very hard to get software out the door. But software built with magical thinking causes more problems than it solves long term: technical debt piles up, software is never “done done,” and quality and testing are always considered “nice-to-haves”: bugs are injected often and usually found by users after the software has been released. And eventually the team slows to a crawl because they spend more and more time fixing bugs and maintaining lousy code than they do building new features.
With both Scrum and XP, we’ve talked about how the best software is produced most quickly by teams who are given enough time to do the work (through timeboxed iterations), the ability to focus on one task at a time, and an environment of collaboration where they can help each other get over obstacles. This is why agile does not thrive alongside magical thinking or hero developers.
So how do we avoid magical thinking?
This is one of the main goals of Lean. Instead of treating the team as a black box, lean thinking helps you understand exactly what the team does day by day and week by week to build software. A Lean mindset has you look beyond the team, and clearly see what happens before the team starts working and after they deliver—because magical thinking happens there, too. Lean thinking helps you strip away the little white lies that bosses tell teams, that managers tell each other, and that we tell ourselves—lies that keep us from building the best software we can, as quickly as possible. Lean attempts to get rid of those falsehoods, and helps teams work together to think about how to provide real value rather than just burn effort.
Eliminate Waste
It’s not always easy to see waste, or even recognize that you and your team spend hours or days doing something that has no practical value for the project. The Lean value eliminate waste is about finding project activities that don’t add value and eliminating them.
Most teams don’t really think about how they build software. There’s usually a “way we do things here” that’s shared between team members, and which new people pick up when they join the team. It’s unusual for most of us to stop and take stock of how we actually get software from concept to production—in fact, it’s almost strange to even think about how the team works. Everyone is used to the way things are done. If you always start a project with a big spec, then it would seem strange to the team to try to build software without one. If everyone always uses a build framework that was written three years ago, then your next project will almost certainly use it, too.
Your job, if you’re on a team, is to get software out the door, right? Nobody really has time to stop and question the meaning and purpose of life, or of specifications.
In XP, we learned that when teams get into the habit of constantly refactoring their code, they end up with much more flexible designs. The same idea applies to thinking about the way your whole team works in general: if you get into the habit of continuously “refactoring” the way you run your project, you’ll end up with a more flexible and capable team.
So how do you “refactor” the way the team runs projects?
The first step in refactoring code is looking for antipatterns. In lean thinking, antipatterns for running projects are called waste. That makes sense: waste is anything that your team does that doesn’t actively help them build better software.
Think about the last few projects that you worked on. Can you think of things that your team did that didn’t actually help the project? What about things that everyone was expected to do, never got around to doing, but still feels bad about skipping? Did you have to write a specification that never got read? Or were you handed a spec but never actually used it? Did you intend to write unit tests or do code reviews, but somehow they never got done? Maybe you did code reviews, but they were done just before the release—so people were hesitant to bring up any issues for fear of delaying the production release, and any issues that were found were merely tagged for repair later.
There’s often a lot of work that gets done on a project, but doesn’t actually cause the software to get better. For example, a project manager may put a lot of time and effort into a large Gantt chart or other project plan that never accurately represents reality, because it’s based on estimates and early information that have changed significantly between when the plan was written and when the team starts working on building software. What’s worse, that project manager may put a lot of work into updating the plan after the fact so that it’s up to date for periodic status meetings. Clearly that won’t help the software, because by the time the plan is brought up to date the software is out the door. Now, maybe this project manager doesn’t intend to put effort into something that isn’t used by the team. It could be that a senior manager might freak out if the plan says anything other than “100% on time and under budget.” Everyone—including the project manager—might be perfectly aware that it’s not helping the project.
This is an example of waste: work done by a project manager on a plan that never reflects reality, and isn’t actually used by the software team. Not every project plan is like this—not even on waterfall projects. Plenty of waterfall projects have effective planning (or, at least, planning that’s as effective as can be done in an inefficient organization). But if you’ve been a project manager or developer on a project like this, you’ll recognize this antipattern. It will be clear to you that it’s waste.
When you take a hard, objective look at what you and your team actually do every day, you can start to spot all kinds of waste. Maybe you’ve got a binder of specifications that’s never been opened, and is gathering dust on a shelf. The work that went into building those documents is waste. If you spend a few hours a week sitting through code reviews that focus entirely on superficial errors or personal preferences but don’t affect design or catch real bugs, then that’s waste. Some waste happens before your project even begins, like writing an extensive statement of work that the team needs to spend a day reviewing but which gets thrown out when the work starts. Are you spending hours debugging deployment problems that could be taken care of with scripts? That’s waste too. Useless status meetings where people take turns reciting their individual status so a project coordinator can write it into meeting minutes that are never looked at? Waste.
A Scrum team—even one that gets better-than-not-doing-it results—that replaces the useless status meeting with a Daily Scrum has eliminated that waste. And you’ve seen throughout this book how the other examples of waste that we just listed can also be eliminated.
If something is waste from a software development perspective, that doesn’t mean that it’s not useful. It’s just not useful for building software. Maybe a senior manager needs that project plan so that she can convince shareholders to keep funding the project. Or maybe the meeting minutes are required for regulators. A statement of work may not be useful for the team, but it could be a required part of a contracting process. Those things may all still be required, but they’re not useful for the project itself. That makes them waste.
The Lean value of eliminating waste starts with seeing waste, the first thinking tool for this value.
It’s often hard to see wasteful activities as waste because they’re almost always someone else’s priority: a project manager who’s not part of the team, a contracting officer, a senior manager. Some waste is accepted by the team—maybe everyone knows that the budgeting process is time consuming and doesn’t include any activities that directly result in the software being built. Other waste is so familiar that it’s essentially invisible—like your team is spread out across three different, disconnected parts of the floor, so it takes an extra five minutes to walk over to your teammate and have a discussion.
The Poppendiecks came up with an idea called the Seven Wastes of Software Development. Like much of Lean, this is adapted from ideas developed at Toyota in the middle of the last century. They discovered that these ideas can help you and your team to see the waste on your software project:
- Partially done work
-
When you’re doing iteration, you only deliver work that’s “done done” because if it’s not 100% complete and working, then you haven’t delivered value to your users. Any activity that doesn’t deliver value is waste.
- Extra processes
-
An example of an extra process is the project management antipattern from Chapter 7, where the team spends 20% of their time giving status and creating estimates that aren’t used for anything other than updating a status sheet. All that extra effort going through the process of tracking and reporting time doesn’t create any value.
- Extra features
-
When the team builds a feature that nobody has asked for instead of one that the users actually need, that’s waste. Sometimes this happens because someone on the team is very excited about a new technology, and wants an opportunity to learn it. This might be valuable to the person who improved their skillset, and that might even be valuable in the future for the team. But it doesn’t directly help build valuable software, so it’s all waste.
- Task switching
-
Some teams are expected to multitask, and often this multitasking gets out of hand. Team members feel like they already have a full-time job (like building software), plus many additional part-time tasks added on (like support, training, etc.)—and every bit of work is critical and top priority. The Scrum value of Focus helped us see that switching between projects, or even between unrelated tasks on the same project, adds unexpected delays and effort, because context switching requires a lot of cognitive overhead. Now we have another word for this: waste.
- Waiting
-
There are so many things that professional software developers have to sit around and wait for: someone needs to finish reviewing a specification, or approve access to some system that the project uses, or fix a computer problem, or obtain a software license... these are all waste.
- Motion
-
When the team doesn’t sit together, people literally have to stand up and walk to their team members in order to have a discussion. This extra motion can actually add days or even weeks to a project if you add up all of the time team members spend walking around.
- Defects
-
Test-driven development prevents a lot of defects. Every developer who is “test infected” had that “a ha” moment where a unit test caught a bug that would have been very painful to fix later, and realized that it took a lot less time to write all of the tests than it would have to track down that one bug—especially if a user discovers the bug after the software is released. On the other hand, when the team needs to stay late scrambling to fix bugs that could have been prevented, that’s waste.
Do some of these things that we’re calling “waste” seem like they’re useful? Even when something is waste, it’s usually useful (or, at least, it seems useful) to someone. Even the developers’ seat layout that’s spread across the floor inefficiently probably helped the office manager who planned it to solve a different organizational problem. What seeing waste does is help you understand those motives, and lets you objectively evaluate whether they’re more important than getting your project done efficiently.
Even when they’re useful to someone, all of these things are wasteful for building a product that delivers value to the users and the company. Lean thinking involves clearly seeing activities done by people inside and outside of the team that do not add value to the specific goals of the project.
The framework trap in Chapter 7 is a good example of waste that the team has trouble spotting. If the developers build a large framework to address a problem that can be solved with much less code, that framework is waste—which is ironic, considering that the original purpose of the framework was to avoid waste by automating repetitive tasks or eliminating duplicate code. Even worse, that framework often becomes an obstacle in the future, because the team needs to either extend it or work around it whenever they need to add features that aren’t explicitly support by it. That extra effort is also waste.
A team that can see waste clearly can see that the framework prevents value from being added to the project. That team understands that waste affects how they do their work every day, and clearly sees that waste in their daily work—and even when that waste is deemed necessary for the company, they see it as waste because it doesn’t add value to the product.
Use a Value Stream Map to Help See Waste Clearly
In Lean Software Development, Mary and Tom Poppendieck recommend a simple pencil-and-paper exercise to help you find waste. It’s called a value stream map, and you can build one for any process. Like many techniques used in conjunction with Lean, it originated in manufacturing, but it makes sense for software teams as well.
It shouldn’t take you more than half an hour to build a value stream map for your project. Here’s how to do it. Start with a small unit of value that the team has already built and delivered to the customers or users. Try to find the smallest unit possible—this is an example of a minimal marketable feature (MMF), or the smallest “chunk” of the product that the customers are willing to prioritize. Think back through all of the steps that the unit went through from inception to delivery. Draw a box for every one of these steps, using arrows to connect the boxes. Because you’re drawing the actual path that a real feature took through your project, this will be a straight line—there are no decision points or forks in the path, because it represents the actual history of a real feature.
The concept of a minimal marketable feature is important here. Luckily, it’s a concept that you’ve already learned about. When the Product Owner of a Scrum team manages items in the backlog, those items are typically MMFs. An MMF often takes the form of a user story, requirement, or feature request.
Next, estimate how much time it took to do the work for the first step, and how much time elapsed before the next step to start. Repeat this for each of the steps, and draw lines underneath the boxes to represent the work and wait times.
Figure 8-2 shows an example of a value stream map for a real feature going through a traditional waterfall process.

Figure 8-2. This value stream map shows how a feature in a software project moves through a traditional project management cycle. A team can use it to see more clearly where time is wasted.
The value stream map clearly shows how much wait time was involved during the process. It took a total of 71 days from the time the team started work on it to the time that it was deployed. Of those 71 days, 35.5 were spent waiting rather than working. That waiting time could be caused by many different things: the requirements document may take a long time to circulate to all reviewers, or an estimation meeting had to wait because everyone’s schedule was booked, or plans are always reviewed by a committee that only meets once a week. The value stream map shows the cumulative effect of those delays on the feature, without bogging you down with the details of why those delays happened. Seeing the overall impact helps you delve into which delays are waste, and which ones are necessary for the project.
To the team, it may not have seemed like they were waiting a long time for the plan to get approved, because they were probably working on another feature during the waiting time. But the customer who needs the feature doesn’t necessarily know about all of the other priorities that the team is focusing on. And, to be honest, he doesn’t really care—all he knows is that for his feature, a total of 71 days elapsed between the time the team started building it and the time that it was delivered.
Imagine how the boss might react when he sees how much waiting was involved, especially if he had to deal with the increasingly impatient and angry customer. If the team can find a way to cut down on waste and reduce the waiting time, they can significantly improve the delivery time for future features. That will make the customer happier, which will make the boss happier too. And that’s how visualizing the waste makes it easier to convince everyone—especially the boss—that something needs to change.
Gain a Deeper Understanding of the Product
Perceived integrity means that the totality of the product achieves a balance of function, usability, reliability, and economy that delights customers. Conceptual integrity means that the system’s central concepts work together as a smooth, cohesive whole.
Mary and Tom Poppendieck, Lean Software Development: An Agile Toolkit
When your team has a lean thinking mindset, it means more than just thinking clearly about how they do their work, and seeing waste. It also means clear thinking about the software product that they’re building, and how that product delivers value to the users. When the team thinks about how that product delivers value, they’re thinking about integrity. This leads us to the next Lean value: build integrity in. A software team that has a lean thinking mindset always thinks about how they build integrity into their software.
There are actually two aspects to this: internal and external integrity. The software needs to have integrity from the users’ perspective (external), but it also needs to have integrity from the perspective of the developers (internal). Lean includes two thinking tools to help us understand internal integrity: refactoring and testing. These are exactly the same things that you learned about in Chapter 7. In fact, a very effective way to build a system with a high degree of internal integrity is to use XP, especially test-driven development, refactoring, and incremental design.
In this chapter, we’ll concentrate on external integrity—what makes software more valuable to users. That means understanding how the users think.
This can seem very abstract. Luckily, Lean has two thinking tools to help you get your brain around integrity. The first tool is perceived integrity, or how well the product meets the needs of the person using it—and how well the person immediately sees that his or her needs are met.
Every good product is built to solve a problem or fill a need. Sometimes that need is matter-of-factly and businesslike: an accounting firm needs a tax and accounting system that includes changes to this year’s tax code, so that their clients’ deductions are legal. Other times, that need is harder to put your finger on: a video game needs to be really fun.
If software is buggy and crashes a lot, it clearly has a perceived integrity problem. But once you get past the software simply working, perceived integrity can be more subtle. There’s a major news website, for example, that has repeatedly had perceived integrity problems over the years. For a long time, it was difficult to copy text from articles and paste it into documents or emails. At first, attempting to click and drag to copy and paste would cause the website to pop up a definition of the word that the user clicked on. Eventually that definition feature was disabled, and users were allowed to copy and paste. But a redesign of the website blocked text selection entirely, and attempting to select text would cause the website to pop up a related article in a different window.
This website’s clicking, selecting, copying, and pasting behavior was inconsistent and frustrating. It may have had a real purpose: news organizations often want to prevent people from copying their intellectual property and pasting it into emails, and would prefer that users use the “Email this article” feature to share the articles. However, this didn’t change the fact that the website did not work the way that the users expected it to. This is an example of poor perceived integrity.
The second thinking tool to help you understand integrity is conceptual integrity, or how well the features of the software work together to form a single, unified product. When you and your team understand the perceived and conceptual integrity of your software, you can make it more valuable to your users.
There’s a great example of how conceptual integrity affected an entire industry: the evolution of video games over the course of the first decade of the twenty-first century. In the late 1990s, the majority of people who were playing video games were pretty savvy. There were far fewer casual video game players, and many of them were frustrated because they’d buy the latest game only to discover that it was way too hard for them. On the other hand, the hardest of hardcore gamers routinely complained that many new games were too easy.
Video games became increasingly popular over the following decade. And as they did, the industry found ways to design games for both audiences. How did they do this?
The first thing they had to realize was that casual gamers and hardcore gamers need conceptual integrity in their games. Fun, casual games like Tetris, Angry Birds, and Candy Crush need to slowly increase in difficulty over many levels. Casual gamers value this steady increase in difficulty, combined with a continual feeling of accomplishment. If Angry Birds started with five easy levels, and then confronted the player with a level that was extremely difficult, people would stop playing because there would be an obvious break in conceptual integrity. A break like that is called dissonance.
Hardcore gamers don’t like games with a slow, steady learning curve or being constantly rewarded for progress that they didn’t earn. They often get more satisfaction from “grinding,” or being required to engage in repetitive and often frustrating tasks before getting rewarded with progress.
A fun video game shouldn’t have a frustrating level; a “grinding” video game shouldn’t have an easy level. Games like Flappy Bird, Super Meat Boy, and many of the Final Fantasy games are lauded by hardcore gamers for their difficulty, and for the number of times that many levels need to be repeated before it can be mastered. An easy level in a grinding video game would cause as much dissonance to a hardcore gamer as a nearly impossible level in a relatively easy game would for a casual gamer.
Teams building video games ran into a lot of trouble with conceptual integrity as the video game industry grew over the first few years of the twenty-first century. There were many games that got poor reviews because they were seen as too easy by hardcore gamers, or too difficult by casual gamers. Those teams learned to include features in their games that improved conceptual integrity for both of these audiences. For example, most games aimed at both markets now have a difficulty setting. If your character keeps dying, a game will prompt you to lower the difficulty. A hardcore gamer would never choose this option—and a game with good conceptual integrity won’t continue to ask him if he wants an easier game, because simply asking that question is incongruous with a difficult game. But there is also recognition in the industry that casual and hardcore gamers represent two distinct markets, and there are many games that are marketed to only one group or the other.
All of these developments are about increasing the value that the game brings to the player by understanding how he or she plays the game, and designing games with conceptual integrity in their difficulty level. Video game teams changed the way that they work, making changes to how they design games in order to improve conceptual integrity. It is now very common for software teams to decide at the beginning of the project whether they’re building for casual gamers, hardcore gamers, or both. They’ll include testing tasks that target the intended audience, and work with their marketing departments to make sure that the games are marketed to the right audience. These are examples of how a team can change the way work is done in order to increase conceptual integrity.
See the Whole
When you work on a software team, you don’t work in a vacuum. How your team and your company are structured can have a big impact on how you do your work. And there are all sorts of barriers and stumbling blocks in any organization that can impact your projects as well. For example, you may need to get half a dozen specification approvals from managers before you can start working on a new feature of your software. Maybe a few negative comments from a user cause a product owner to panic and start scheduling your weekends for you. Your boss could fall in love with an overly complex workflow in a ticketing system, and now you need to push every ticket through eight phases before you can start working on it. These are just a few examples—you can probably think of your own examples of inefficient activities that are baked into the way you and your team work.
We saw earlier how these things are waste, but we also saw that sometimes they serve a purpose that may not benefit your project, but are needed by the project or the company. For example, you and your team may waste time (from the project’s perspective) filling out reports that don’t help the project, but if they’re required by a regulator then they’re worth it to the company. How do we know which activities are genuinely useful?
That’s where the next Lean value comes in: see the whole. To really understand whether your team is working efficiently and effectively, you need to take a step back and understand the whole system, because you need to see the whole objectively: it’s easy to become emotionally invested in a solution. For example, say a project manager created a timesheet system that requires every developer to fill out a daily timesheet in 15-minute increments. She might be really happy with the constant status updates that she’s getting. But she might not be aware of how taxing it is on the team—and it’s a lot easier to convince her to give up those extra updates if you can show that they’re costing the team, say, 5% of their productivity.
But while recognizing the nature of the system that the team works in may sound straightforward, it isn’t always easy to do. Each person on a team may feel good or bad about a project depending on how satisfying it was to work on, or how they see their individual contribution. For example, a developer might find a project very satisfying if she solved an interesting coding problem. A project manager will be more satisfied with a project if the team came in ahead of every deadline—but if the developer had to give up her nights and weekends to meet that deadline, she might feel like the project was less successful.
This is why Lean teams take measurements—another Lean thinking tool—so that everyone can see the project the same way. There are many things that a software team can measure, and choosing the right measurement helps the team get a better picture of the project. They’ll take different measurements depending on what problem they want to solve. Everyone on the project has a different perspective, and taking objective measurements helps get everyone to see the project on the same terms.
For people who haven’t spent a lot of time measuring a system—especially the system that a team uses to build software—this can seem very abstract. Let’s make it concrete with an example.
Users care very much about how responsive teams are to their needs. Businesspeople and users want their requests to make it into the software quickly. They’re much happier when a team can give them one new feature a month than when they have to wait three months for all three features. This is why both Scrum and XP use iterations, and it’s why agile teams use shorter feedback loops.
Imagine that you’re a business owner paying for a software project. How do you know if you’re spending your money wisely? Let’s say that you’ve gotten a steady flow of status reports from your project manager telling you that the project is coming in on schedule and under budget, and that everything is going very well. He has many dashboards, reports, and completed tasks on project plans that are full of green dots to show how each of the past four releases has been almost entirely on track.
This sounds like incontrovertible evidence that the project team is building software very well, and is delivering features that the users requested. Even more, the project manager can point to buffers in the schedule, a tidy risk register, and a ticketing system to show that the project is fully under control, and that allowances have been made for known and unknown risks in the future. As the boss, this gives you a warm, fuzzy feeling: you have control over the project, a good idea of how it runs, and a way to handle unexpected problems that pop up.
But what if you hear from several of your customers who use the software that they made simple requests months ago, and still have not seen them added as features to the software? What if you’re starting to lose customers because they’re switching to a competitor that they perceive as more responsive to their needs? Would you say that the project is a success? Clearly there’s a serious problem, and you need to work with the team to fix it.
How would you work with the team to get them to respond to the most important requests more quickly? Let’s say that you try to confront the team, but they point to their positive status reports and tell you that the project is going just fine for them. How do you get them to see the problem?
An objective measurement can help with this. Many teams will measure lead time for each feature. This is a measurement of the average time elapsed between when a feature is requested and when it’s delivered.
Here’s how to calculate it. Any time a user makes a request, record the start date. When a version of the software is released that includes that request, record the end date. The amount of time elapsed between the start date and the end date is the lead time for each request. Add up the lead times for all of the requests in the release and divide by the number of features to calculate the average lead time for the release.67
If you ask all the team members what they think the average lead time will be, what do you think they’ll say? If the team releases software every month, they’ll probably guess that it’s between one and two months. That could be an acceptable lead time—most of your users could be satisfied with that, and maybe you just heard a few “squeaky wheel” stories from especially disgruntled users.
But what if the lead time turns out to be a lot longer than your users will accept? What if it takes six months for even a simple user request to make it into the software, and this is not acceptable? Is it the team’s fault? Is it something that you’re doing? Or is the long lead time an unavoidable side effect of how your business is run? You don’t know yet. But now you know that there’s a problem, and because you took measurements, you can help the team understand that there’s a problem too.
Now when you confront your team about the complaints, if the project manager points to the status reports and tells you that there are no problems, you can point to the objective lead time measurement and prove to the team there is a problem after all. This is much better than just saying, “I’m the boss, fix it,” because now there’s a clear, objective goal that everyone can work toward. It’s not an arbitrary decision, and it’s not magical thinking.
Find the Root Cause of Problems That You Discover
Taking measurements and seeing the objective truth about your project and your team is only the first part of seeing the whole. The second part is understanding the root cause, or the actual reason that the problem is happening.
Back at the end of Chapter 6, we said that we’d get back to root-cause analysis, because in addition to being an important part of lean thinking, it’s also one of the corollary practices of XP teams. XP teams and Lean teams both utilize a technique called Five Whys to figure out the root cause of a problem. Like much of lean thinking, this technique originated with Japanese auto manufacturing, but has found a home among agile teams. In this simple practice, the team members ask why a problem happened, and when they answer the question they continue to ask why (usually around five times) until they discover a root cause.
In our example, the team can use the Five Whys technique to find the root cause of their long lead time by asking questions like this:
-
Why is the average lead time so long? Because it’s taking over six months for most users’ feature requests to make it into the software.
-
Why is it taking over six months for users’ requests to make it into the software? Because those feature requests are almost always pushed back to make room on the schedule for last-minute changes.
-
Why are there so many last-minute changes? Because before the team can release software to the users, they need to do a review with senior managers, and those senior managers almost always ask for basic, foundational changes.
-
Why do the senior managers almost always ask for basic, foundational changes? Because they all have very specific opinions about how the software should look, how it needs to function, and sometimes even the technical tools that should be used to build it, but the team doesn’t hear those opinions until after they’ve built all of the code and have demoed it to the senior managers.
-
Why doesn’t the team hear those opinions until after they’ve built all of the code and given a demo? Because the senior managers are too busy to talk to the team early in the project, so they’ll only attend the final demo—and send the team back to the drawing board after the software is finished.
Aha! Now we know why it takes so long for the team to respond to user requests. Taking measurements and looking for the root cause helped us to see that this wasn’t the team’s fault at all. It turns out that the team finishes many of the features, but when they give the demo to the senior managers, they’re asked to make a lot of changes. Maybe it turns out that these changes are necessary, and those managers had good ideas. But even necessary changes require that this particular project manager do an impact analysis, update her project plan, and reschedule the changed features for a later release. This is what led to the very long lead time that was measured. And it gets worse—some feature requests were already scheduled for the next release; now they need to be bumped to the following release to make room for the changes made by the managers. And it turns out that those requests’ especially long lead times caused some of the users to switch to the competitors.
Understanding the root cause of the long lead times gives us several potential solutions. The team can build software more iteratively, and ask the managers to attend demos at the end of each iteration, rather than at the end of each major release. Or the managers can delegate their approval to someone (like a Product Owner) who stays more involved with the project and meets with the team more often, and trust that person to make the right decisions. Or the team and managers can keep building software the same way and live with the long lead times, but bring in account managers to work with the users and clients to manage their expectations.
To sum up: the team started with a problem—not responding quickly enough to users’ feature requests. By taking measurements and looking for the root cause, they were able to see the whole. They understood where their project fit in with the rest of the company, and could identify several possible fixes that would lead to a long-term solution. And most importantly, the team and the boss now both have the same objective information, and can make decisions together.
Deliver As Fast As Possible
There’s one more Lean value: deliver as fast as possible.
When you read that, what comes to mind? Do you think of a pushy boss or project manager prodding the team to work late and get code out the door? Does “deliver as fast as possible” mean cutting out tests, low-priority features, and anything else that is deemed “extraneous” or low-priority? Maybe it makes you think of a heroic developer working late nights and weekends or putting in quick-and-dirty hacks to get an important feature out the door. This is where most managers’ minds go when they hear the phrase, “deliver as fast as possible,” and many developers, testers, and other software engineers think the same thing.
Agile teams know that those things cause your team to deliver more slowly, not more quickly. This idea is why we have the agile principle of promoting sustainable development (“The sponsors, developers, and users should be able to maintain a constant pace indefinitely”—this is one of the principles that you learned about in Chapter 3). Taking shortcuts, cutting corners, and working very long hours costs more time and money than it saves. Teams deliver better work more quickly when they have time to do things right.
But while this is true, it’s also abstract and somewhat high-minded. The Scrum principle of Focus and the XP practice of Energized Work help to make it more concrete. Scrum and XP gave us insight into how to realistically achieve this optimal pace for delivery with iterations and flow. Lean takes this idea further by giving us three thinking tools to help teams deliver as fast as possible: pull systems, queuing theory, and the cost of delay.
The purpose of queuing theory is to make sure that people are not overloaded with work, so that they have time to do things the right way. A queue is a list of tasks, features, or to-do items for a team or for an individual developer. Queues have an order, and are typically first-in, first-out—meaning unless someone explicitly changes the order, the item that has been on the queue the longest is the next one that a team member will pull off of the queue to work on. Queuing theory is the mathematical study of queues, and one of the areas of queuing theory involves predicting the impact that adding queues early in a system can have on its outcome. Lean tells us that making a team’s queue of work public, and making it central to the decision-making process, helps teams to deliver more quickly.
Use an Area Chart to Visualize Work in Progress
How do you know if you’re delivering as fast as possible?
Lean thinking gives us an answer to this question: measurement. And an effective way to measure how your team delivers valuable products is to use a work-in-progress (WIP) area chart. This is a simple diagram that shows how the minimal marketable features are flowing through your value stream.
If you’ve created a value stream map, then you can build a WIP area chart, which is an area chart that shows how features, products, or other measures of value flow through every part of the value stream. This works best if you use MMFs, because they represent the minimally sized “chunk” of value that’s created.
Let’s take a look at an example of a value stream map that shows how a web development shop handles most of their MMFs.

Figure 8-3. We’ll use this value stream map to build a work-in-progress (WIP) area chart.
The goal of the WIP area chart is to show a complete history of the work in progress—all of the valuable features that the team is currently working on. The chart will show us how many MMFs were in progress on any date, and how those MMFs broke down across the various value stream stages. The work in progress is a measurement of features, not tasks. In other words, it shows the number of features or parts of the product that are being worked on, not the specific tasks that the team does to produce them. Back in the Scrum chapter, you saw how features relate to tasks when the team broke stories down into tasks that moved across a task board. A story is a good way to represent an MMF because it’s a small, self-contained “chunk” of value that’s delivered to the user. The story would appear in the WIP area chart; the tasks that the team uses to build the story don’t.
To build the WIP area chart, start with an x-axis that shows the date, and a y-axis that shows the number of MMFs. The chart has a line for each of the boxes in the value stream map. The lines divide the chart into areas for boxes in the value stream map.
There are no MMFs in progress before the project starts, so there’s just a single dot at X=0 at the lefthand side of the diagram (day 0). Let’s say that when the project starts, the team starts working with the users on nine user stories, and they’re using those user stories as MMFs for their project. Then a few days later, they add three more stories. You’ll draw a dot at 9 for the first day, then another at 9 + 3 = 12 when those new MMFs were added, and you’ll connect them.

Figure 8-4. Start building up the WIP area chart by creating a line chart of MMFs (like user stories) in the first stage of the value stream, and shading the area underneath it.
A few days later, the programmers start working on creating the design wireframes for four of the stories, so those four stories have progressed to the next stage in the value stream. The total number of MMFs in the system is still 12, but now they’re divided into 8 still being worked on—or waiting, because the value stream map tracks both work and wait time—in the first stage of the value stream, and 4 in the second stage. So you can add dots at 4 and 12 to represent this.
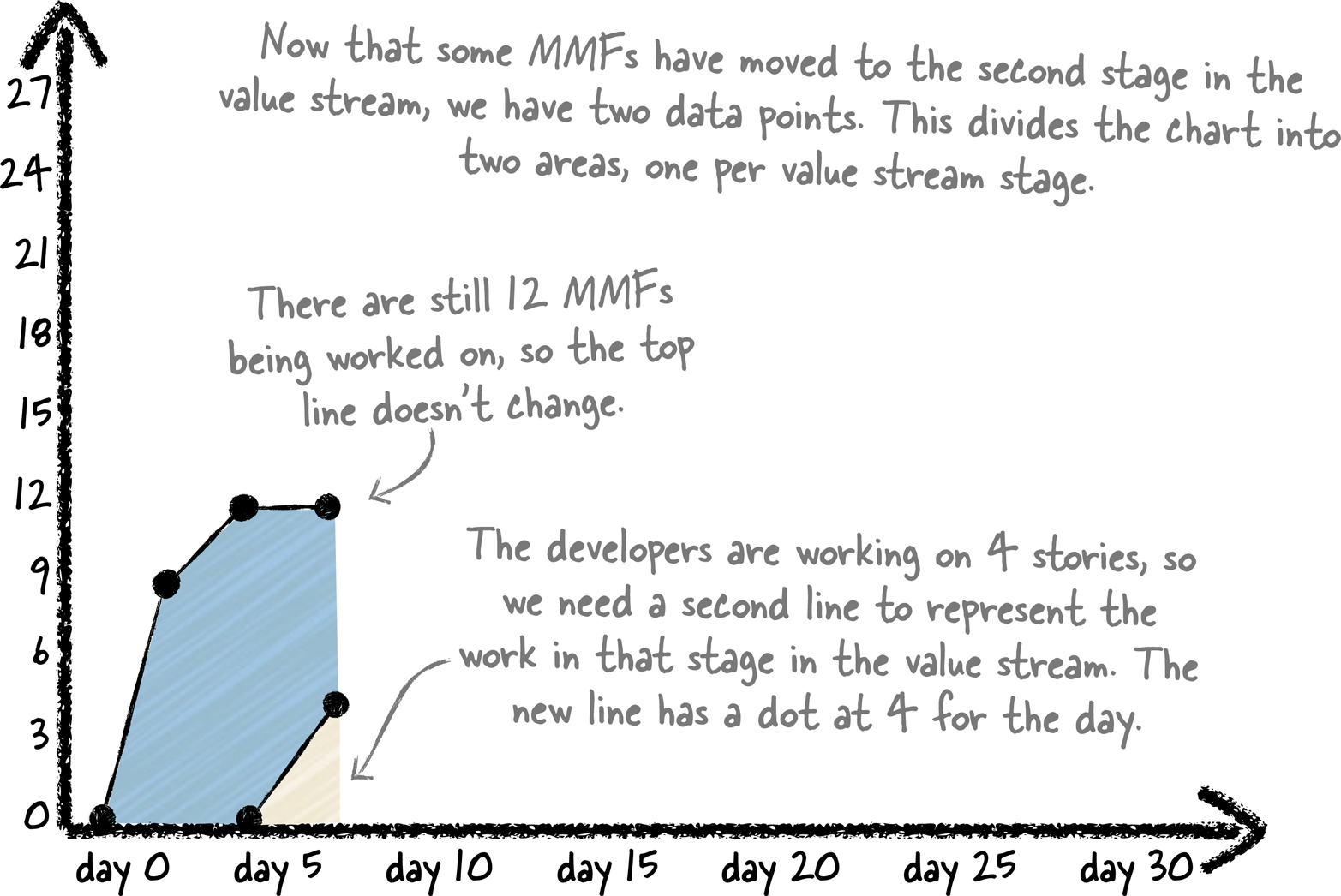
Figure 8-5. When work progresses to the next stage in the value stream, a new line for that stage is added to the WIP area chart, dividing it into two areas. The top line still represents the total number of MMFs in in progress, and the space between it and the new line represents the number of MMFs in the first stage.
As MMFs move through the value stream, the total number of tasks grows, and over time the WIP area chart acquires stripes for each stage in the value stream map.

Figure 8-6. The WIP area chart shows you how work in progress changes over time.
What happens when MMFs are completed? If you keep them on the chart, eventually the number of “done” MMFs grows to a size that dwarfs all of the other columns. This makes the active MMFs resemble a ribbon on top of a mountain.

Figure 8-7. When a team wants to show the boss how much work they’ve accomplished, they’ll leave the “done” tasks on the chart because it looks impressive. Unfortunately, that makes it a lot more difficult to use the chart to measure work in progress.
This is showing growth, not flow. And while it makes for a great status report item to impress a senior manager—because it shows that the team has gotten an enormous amount of work done—it’s not particularly useful for managing flow. Removing the “done” work from the diagram gives a clearer visualization of how value flowed down the value stream over time.

Figure 8-8. It’s useful to remove the “done” tasks from the chart, and use different shades for each stripe to make it easy to figure out which columns they correspond to.
This is why most WIP area charts do not include completed tasks. That way, if your project stabilizes over time, your WIP area chart looks stable too.68 When a MMF moves from one stage in the value stream to the next, the stripe for the old stage it moved from gets thinner, and the stripe for the new one to gets thicker. This makes it easy to spot trends—like when many MMFs move from one column to another (or out of the value stream entirely) at the same time.

Figure 8-9. The WIP area chart helps you see how the work flows through the value stream, and makes it easier to spot delays and other potential waste—like stories that took a very long time to deploy to production.
Control Bottlenecks by Limiting Work in Progress
An important idea that uses queuing theory is called the theory of constraints, introduced by a physicist turned management guru named Eliyahu M. Goldratt. One of the ideas behind the theory of constraints is that a particular constraint (like work piling up behind an overburdened team) limits the total amount of work that can get through the system. When the constraint is resolved, another constraint becomes the critical one. The theory of constraints tells us: every overloaded workflow has at least one constraint.
When a constraint causes work to pile up at a specific point in a workflow, people will often call it a bottleneck. Removing one bottleneck from the system—maybe by changing the process or adding people—will cause work to flow more smoothly. The theory of constraints tells us that there will still be another critical constraint or bottleneck somewhere else in the system. However, we can reduce the total amount of waste by systematically tracking down the critical constraint and eliminating it.
What does it feel like to work on a team that has to deal with one of these constraints on a day-to-day basis? In other words, what does it feel like when you and your team are the bottleneck?
When you’re the bottleneck in the system, you’re always expected to multitask, constantly switching between your normal full-time job and many smaller part-time ones. Keep in mind that plenty of healthy teams usually have many tasks due at the same time but don’t call it “multitasking”; people typically use the term “multitasking” in order to mask the fact that the team is simply overloaded. Splitting the work up and telling the team to multitask often keeps you from recognizing that you simply have more work than time, especially when you consider the extra time and cognitive effort required to switch between tasks.
For example, a team that already has 100% of their time already devoted to development work may have a boss with magical thinking who asks them to “multitask” and spend several hours a week that they don’t have on support, training, maintenance, meetings, or other work. It’s difficult for them to necessarily see that they have more work than time, especially if that extra work is added a bit at a time. They’ll just start to feel overloaded, and because it’s called “multitasking” they won’t necessarily realize why they feel that way; it will just feel as if they have many part-time jobs that they’re having trouble keeping up with. We can help that team by applying queuing theory to gain insight into the problem. Now we know that more and more of their work is piling up in a bottleneck somewhere in their workflow, and that growing pile of work is weighing on them.
Pull Systems Help Teams Eliminate Constraints
And I have a philosophy that I live by. Everybody that works with me knows this; it’s on the wall: “If stupid enters the room, you have a moral duty to shoot it, no matter who’s escorting it.”
Keoki Andrus, Beautiful Teams (Chapter 6)
A pull system is a way of running a project or a process that uses queues or buffers to eliminate constraints. This is another concept that originated with Japanese auto manufacturing, but has since found its place in software development. Car manufacturers—specifically Toyota in the 1950s and 1960s—started to look at their warehouses of parts, and tried to find ways to reduce the number of parts that they needed to have lying around. After a lot of experimentation, they discovered that even if you had almost all of the parts needed to assemble cars available in the warehouse, a shortage of just a few parts could hold up the entire line. Entire assembly teams would end up waiting for those missing parts to be delivered. The cost of delay became important: if a part was in short supply, a delay in getting that part to the assembly line was very expensive; if the part was abundant, the cost of delay was low.
Teams at Toyota found that they could reduce their costs and deliver cars much more quickly if they could figure out which parts the teams needed right now, and deliver only those parts to the line. To fix this, they came up with the Toyota Production System (or TPS)—this was the precursor of lean manufacturing, which the Poppendiecks adapted to create lean software development.
At the heart of TPS is the idea that there are three types of waste that create constraints in the workflow and must be removed:
-
Muda (無駄), which means “futility; uselessness; idleness; superfluity; waste; wastage; wastefulness”
-
Mura (斑), which means “unevenness; irregularity; lack of uniformity; nonuniformity; inequality
-
Muri (無理), which means “unreasonableness; impossible; beyond one’s power; too difficult; by force; perforce; forcibly; compulsorily; excessiveness; immoderation”
Anyone who’s been on a poorly managed, poorly run software project—especially one that used an ineffective process—is intimately familiar with the ideas of futility, unevenness, and unreasonableness. This is true of ineffective waterfall processes, but anyone who’s been on, say, a team that was only able to get better-than-not-doing-it results (or worse) by forcing Scrum or XP practices on a team with the wrong mindset will also recognize these things.
Do any of these things feel familiar?
-
It takes a very long time to get everyone to sign off on a specification, and in the meantime developers are sitting around waiting for the project to start. Once it does start, they’re already late.
-
It takes management forever to secure the budget. By the time the project is given the green light, it’s already late.
-
Halfway through development, the team recognizes that an important part of the software design or architecture needs to be changed, but that will cause very large problems because so many other things depend on it.
-
The QA team doesn’t start testing the software until every feature is complete. They find a major bug or a serious performance problem, and the team has to scramble to fix it.
-
The analysis and design take so long that by the time coding begins, everyone needs to work nights and weekends to meet the deadline.
-
A software architect designs a large, beautiful, complex system that’s impractical to implement.
-
Even the smallest change to a specification, a document, or a plan needs to go through a burdensome change control process. People find ways to work around the process by putting even sweeping, large-scale changes into a ticketing or bug tracking system instead.
-
The project is running late, so the boss adds extra people to the team for the last few weeks. Instead of making the project go faster, this move creates confusion and chaos.69
Think back to your own projects that ran into problems because of things that you knew were stupid. They may have been stupid rules that you had to live with (or work around) that were imposed by a boss or were part of your company’s culture. Maybe there were stupid, unnecessary deadlines that were arbitrarily set in order to motivate you.
These things aren’t random. Take a minute to look back at the definitions of muda, mura, and muri. Then look at the list of familiar project problems, as well as the problems you’ve seen on your own projects. See if you can fit each of these problems into one of these three categories. Were there things you had to do that were futile, useless, or superfluous? This is muda—work you had to do that didn’t add value. What about times when you were sitting around idle, anxiously waiting for someone to get back to you so you could get your work done? This is mura—unevenness, or work that happens in fits and starts. Those times that you had to stay late or work weekends because you were expected to do more work than was humanly possible? That’s muri—overburdening, or being expected to do unreasonable or impossible things.
Even though there are many differences between software development and car manufacturing, the Poppendiecks recognized that these ideas from lean manufacturing also affect software projects. So it stands to reason that if software teams face problems similar to those in manufacturing, the solutions that worked for manufacturers will also work for software teams. For manufacturing, that solution is a pull system (also known as “just-in-time production”).
The manufacturing team at Toyota in the 1950s, led by engineer Taiichi Ohno, recognized that it was difficult to predict in advance which parts would be in short supply in the future—it often seemed like different parts were in short supply. This was an important root cause of waste (muda, mura, and muri). So they came up with a system where stations on each assembly line would signal that they’re ready for more parts, with a team set up to deliver parts based on those signals. Each station would have a small queue of parts that they needed. Instead of having a warehouse that pushed parts onto a line, they had a line that pulled parts from a warehouse, and only took parts when the queue got low.
This is called a pull system because it consists of independent teams or team members that pull only those parts that they need (rather than having a large stockpile of parts pushed on them and routinely topped off). Toyota and other car manufactures found that it made their entire assembly process much faster and cheaper, because it cut out a huge amount of waste and waiting time. In fact, every time a specific bit of waste was identified, they were able to make a small change to their process in order to eliminate it.
Pull systems are very useful for building software—maybe not surprisingly, for exactly the same reason that they’re useful in manufacturing. Instead of having users, managers, or product owners push tasks, features, or requests down to a team, they’ll add those requests to a queue that the team pulls from. When work backs up and causes unevenness partway through the project, they can create a buffer to help smooth it out. The team may have several different queues and buffers throughout their project. And as it turns out, this is a very effective way of reducing waiting time, cutting out waste, and helping users, managers, product owners, and software teams decide on what software is built.
Here’s a very simple example of how a pull system might solve a familiar problem: the software team that has to wait until every single feature is written into a large specification that must then go through a cumbersome review process. Maybe the process is a way to get all of the perspectives from every person; it may just be a way to provide CYA to bosses and stakeholders who are afraid to make a real commitment; or it might just be how the company always did business, and it never occurred to anyone that it’s wasteful. What would it look like if we replaced this with a simple pull system?
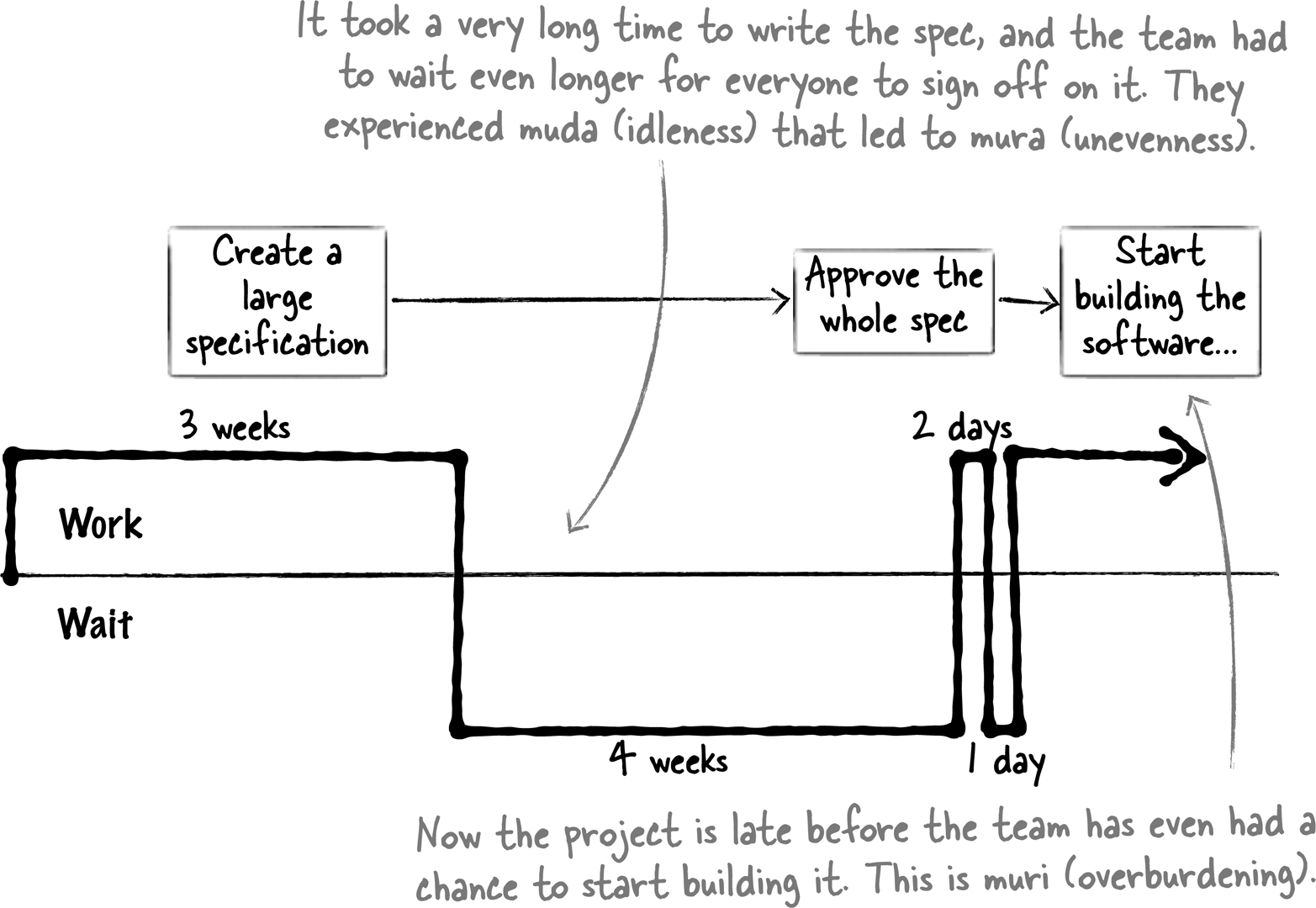
Figure 8-10. This value stream map shows the waste that happens when the team is waiting for a large specification to be created and approved.
This is a very familiar problem, and in the real world many teams have found ways to work around it. For example, the designers and architects might do “prework” based on an early draft of the spec, and their best guess as to what they’ll eventually be building. But while the team will find ways to eliminate the waste from the project—“shooting stupid when it enters the room”—they can only do so much. There will still be waste, often a lot of it, especially if they guess wrong and now have to undo some of the prework.
A pull system is a better way to remove this unevenness and prevent the overburdening.
The first step in creating a pull system is to break the work down into small, pullable chunks. So instead of building a large spec, the team can break it into minimal marketable features—say, individual stories, and maybe a small amount of documentation to go with each story. Those stories would then be approved individually. Typically, when a spec review process is held up for a long time, it’s because people have problems with some of the features. (Can you see how breaking the work down into smaller MMFs gives the team more options? That’s options thinking.) Approving individual MMFs should allow at least a few features to get approved quickly. As soon as the first MMF has been approved, the team can start working on it. Now the team doesn’t have to guess. Instead, there’s a real discussion of the work that needs to be done. There may be a real reason for the approval process (like a regulatory requirement, or a genuine need to get everyone’s perspective); now the team can get a real sign-off before starting the work.
This is how all the parts of lean thinking—seeing the whole, identifying the waste, and setting up a pull system of eliminate the unevenness and overburdening—can come together to help a team improve the way they do work. But that’s just the beginning. In the next chapter, you’ll learn about how to apply the mindset of Lean to improve the way your team builds software.
Here are a few things that you can try today on your own or with your team:
-
Identify all of the MMFs on your project. How are they managed? Do you write user stories on cards or sticky notes and put them on a task board? Do you have individual requirements in a specification? Find a larger feature or story and see if you can break it down into smaller chunks.
-
Look for waste in your project. Write down examples of muda, mura, and muri.
-
Find any MMFs that you and your team completed already and create a value stream map for them. See if you can get your whole team to do it together. Then create a value stream map for another MMF. What are the similarities and differences between the two value streams?
-
Find a bottleneck that your team routinely hits. (Your value stream map can be very helpful for doing this.) Have a discussion about what you can do to alleviate it in the future.
-
Look at the dates that you and your team are currently committed to. Have you really made the commitments that you think you’ve made? Are there options to deliver something different, while still meeting those commitments?
65 There’s a great resource for learning about options thinking. It’s a graphic novel called Commitment, by Olav Maassen, Chris Matts, and Chris Geary. You can thank David Anderson for recommending it to us!
66 If you have a background in finance, you may recognize that when it comes to options thinking, there is a lot of overlap with the world of financial services. Traders and portfolio managers buy and sell options, or instruments that give one party the option to buy or sell an underlying stock or commodity (like oil or wheat) on a certain date at a specific price. This gives them the ability to pursue a strategy to buy that stock or commodity without having to completely commit to owning it. In other words, they can keep their options open.
67 There are other ways to calculate lead time—for example, you can calculate it so that large features are weighed more heavily than small features. We chose a very simple method of calculating lead time for this example to make it clear how measurements can help this team.
68 Did you look at this chart and wonder why we aren’t calling it a cumulative flow diagram, or CFD? In Chapter 9, we’ll explain the difference between a WIP area chart and a CFD.
69 In The Mythical Man Month, Fred Brooks gave us Brooks’s Law: “Adding manpower to a late project makes it later.” Think about that while you’re reading about muda, mura, and muri.