
7
Handling Data for Each Microservice with the Database per Service Pattern
In the previous chapter, we explored the concepts of event sourcing and event stores. Event sourcing patterns help us to reconcile changes made to our data stores across our microservices. An operation in one microservice might require that data be sent to other microservices. For efficiency reasons, we create an event store as an intermediary area to which microservices can subscribe for changes and will be able to get the latest version of the data as needed.
This concept revolves around the assumption that each microservice has its own database. This is the recommended approach in a microservice architecture, given the fundamental requirement that each microservice needs to be autonomous in its operations and data requirements.
Building on this notion, we will explore best practices and techniques for handling data for each microservice.
After reading this chapter, you will know how to do the following:
- How to make use of the Database-per-Service pattern
- How to develop a database
- How to implement the repository pattern
Technical requirements
The code references used in this chapter can be found in the project repository, which is hosted on GitHub at https://github.com/PacktPublishing/Microservices-Design-Patterns-in-.NET/tree/master/Ch07.
How to make use of the Database-Per-Service pattern
A core characteristic of microservices architecture is loose coupling between our services. We need to maintain the independence and individuality of each service and allow them to autonomously interact with the data they need when they need it. We want to ensure that one service’s manipulation of data does not inhibit another service’s ability to use its own data.
Each microservice will be left to define its own data access layers and parameters and, unless deliberately implemented, no two services will have direct access to the same data store. Data is not persisted across two services and the overall decoupling that comes with this pattern means that one database failure will not inhibit the operation of the other services.
We also need to bear in mind that microservices architecture allows us to select different development technologies that best meet the needs of the service being implemented. Different technologies tend to work better with or support specific databases. Therefore, this pattern may be more of a requirement than a suggestion given that we will want to use the best database technology to support the needs of a service.
As usual, where there is a pro, there is a con. We need to consider the costs involved with this kind of heterogenous architecture and how we might need to adapt our knowledge base and team to support several databases and, by extension, various database technologies. We now have to account for additional maintenance, backup, and tuning operations, which might lead to maintenance overheads.
There are several approaches that can be taken in implementing this pattern and some of the approaches reduce our infrastructure needs and help us to save costs. We discuss those options in the next section.
A single database technology per service
Ultimately, we need to establish clear boundaries between the source of truth for each service. This doesn’t mean that you absolutely need to have different databases, but you can take advantage of features of relational data stores such as the following:
- Tables-per-service: We can define tables that are optimized for the data to be stored for each service. We will model these tables in the microservice code and ensure that we only include these tables. In this model, it is common that some tables are denormalized representations of data that can be found in other tables, as the service they are created for requires the data in this format.
- Schema-per-service: Relational databases allow us to specify schema values to categorize our tables. A schema is an organizational unit in a database that helps us to categorize tables. We can use these to organize tables per service. Like the tables-per-service pattern, the tables in each schema are optimized based on the needs of the matching microservice. We also have a better opportunity to tune access rights and restrictions per schema and reduce the security administration overhead.
- Database-per-service: Each microservice has its own database. This can be taken a step further by placing each database on its own server to reduce the infrastructural dependencies.
Figure 7.1 shows multiple services connected to one database.
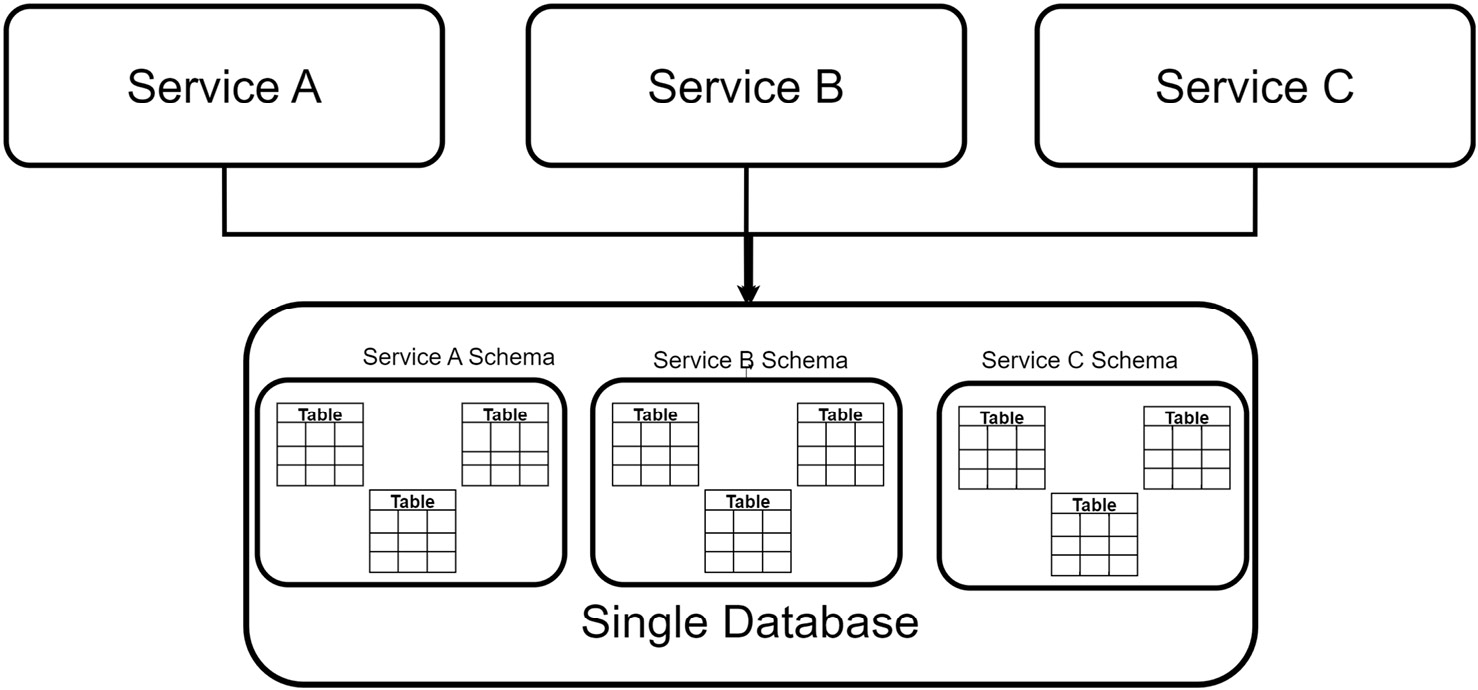
Figure 7.1 – Multiple services share one database, but schemas are created for each service to preserve segregation and data autonomy
Implementing tables and schemas per service has the lowest resource requirements since it would be the same thing as building one application on top of one database. The downside is that we retain a single point of failure and do not adequately scale the varied service demands.
In the Database per Service approach, we can still use one server but provision each microservice with its own database. This approach matches the name of the pattern more appropriately, but infrastructurally maintains a common choke point that has all the databases on the same server. The most appropriate implementation to maintain service autonomy and reduce infrastructural dependencies would be to have each database and its reliant microservice in its own fault domain.
Looking at this issue from another dimension, we can see that we have the flexibility to choose the best database technology for each service. Some services might favor a relational data store, while others might use a document data store more efficiently. We will discuss this further in the next section.
Using different database technologies per service
Databases are the foundation of any application. A good or poor database design can determine how efficient your application is, how easily it can be extended, and how efficiently you can write your code.
The use of the database-per-service pattern allows us to choose the best database for the operation that each microservice might complete. It would be ideal for a more homogenous technology stack that all developers can identify with and easily maintain. Attempting to remain homogenous, however, has led to shortcuts and extensive integration projects in the past, where the need to use one technology overshadowed the opportunity to use the best technology for the problem being addressed.
Figure 7.2 shows multiple services connected to individual databases.

Figure 7.2 – Multiple services can be built using different technologies alongside the most appropriate development framework technology
Microservices allow us to have multiple teams that can choose the best technology stack to implement the solution and, by extension, they can use the best type of database technology to complement the technology and the problem. Some development frameworks tend to work best with certain database technologies, and this makes it easier to select the entire stack that is to be used for a particular microservice.
Now that we have reviewed our database-per-service options, let us review some disadvantages of using this development pattern for our microservices architecture.
Disadvantages of this pattern
We could spend all day singing the praises of this pattern and pointing out why it is the ideal path to take during the microservices development process. Despite all these advantages, however, we can point to potential pitfalls that we must overcome or learn to mitigate during runtime:
- Additional costs: When we talk about having fewer infrastructural dependencies between our services, we talk about introducing more robust networking software and hardware, more servers, and more software licenses for the supporting software. Using a cloud platform might more easily offset some of the infrastructural and software costs, but even this approach will have a modest price tag.
- Heterogenous development stack: This is an advantage from the perspective of attempting to meet the business needs of the microservice as appropriately as possible. The bigger picture, however, comes when we need to source talent to maintain certain technologies that might have been used. Cross-training between teams is recommended but not always effective and a company can risk having a microservice built by past staff members that none of the current ones can maintain.
- Data synchronization: We have already discussed the issue of Eventual Consistency, which leads us down the path of implementing contingencies to deal with data being out of sync across multiple databases. This comes with additional code and infrastructure overhead to properly implement it.
- Transactional handling: We are unable to ensure ACID transactions across databases, which can lead to inconsistent data between data stores. This will lead us to need another coding pattern called the Saga Pattern, which we will discuss further in the next chapter.
- Communication failure: Because one microservice cannot directly access another’s database, we may need to introduce synchronous microservice communication to complete an operation. This introduces more potential failure points in the operation at hand. These can be mitigated using the Circuit Breaker Pattern, which will be discussed in subsequent chapters.
It is always important to remember that with every pattern, we have pros and cons. We should never do an implementation solely because it is the recommended way to go. We should always properly assess the problems that need to be addressed and choose the most appropriate solutions and patterns to ensure full coverage and at the best price.
Now that we have discussed the dos and don’ts for our Database-per-Service pattern, let us move on to discuss best practices when designing a database.
Developing a database
The ability to develop a capable database is paramount to a developer’s career. This role was once given to the database developer in a team, whose sole purpose was to do all things database. The application developer would simply write code to interact with the database based on the application’s needs.
More recently, the role of a typical application developer evolved into what is now called a full stack developer role. This means that the modern developer needs to have as much application development knowledge as they do database development knowledge. It is now very common to see teams of two to three developers who work on a microservice team, and who can develop and maintain the user interface, application code, and database.
Developing a database transcends one’s comfort level with the technology being used. In fact, that is the easy part. Many developers neglect to consult the business and fully understanding the business requirements before they start implementing the technology. This often leads to poor design and rework, and additional maintenance in the lifetime of the application.
Since we are in the realm of microservices, we have the unique opportunity to build much smaller, target data stores, for tranches of the entire application. This makes it easier for us to ingest and analyze the storage needs of the service that we are focusing on and reduces the overall complexity of building a large database as a catch-all, thus reducing the margin for error during the design phase. As discussed previously, we can make better choices about the most appropriate database, which influences the design considerations that we make.
Some services need relational integrity based on the nature of the data they process; others need to produce results fast more than they need to be accurate; some only need a key-value store. In the next section, we will compare the pros and cons of relational and non-relational data stores and when it is best to use each one.
Databases are an integral part of how well an application performs and it is important to make the correct decision on which technology is used for which microservice. In the next section, start by assessing the pros and cons of using relational databases.
Relational databases
Relational databases have been a mainstay for years. They have dominated the database technology landscape for some time and for good reason. They are built on rigid principles that complement clean and efficient data storage while ensuring a degree of accuracy in what is stored.
Some of the most popular relational database management systems include the following:
- SQL Server: This is Microsoft’s flagship relational database management system, which is widely used by individuals and enterprises alike for application development.
- MySQL / MariaDB: MySQL is a traditionally open source and free-to-use database management system that is mostly used for PHP development. MariaDB was forked from the original MySQL code base and is maintained by a community of developers to maintain the free-to-use policy.
- PostgreSQL: A free and open source database management system that is robust enough to handle a wide range of workloads, from individual projects to data warehouses.
- Oracle Database: This is Oracle Corporation’s flagship database management system, which is designed to handle a wide range of operations, from real-time transaction processing to data warehousing and even mixed workloads.
- IBM DB2: Developed by IBM on top of one of the most reliable systems for high transaction and traffic enterprise settings. This database supports relational and object-relational structures.
- SQLite: A free and lightweight database storage option for a quick and easy database. Unlike most alternatives that require a server, oftentimes a dedicated machine, SQLite databases can live in the same filesystem as the app it is being integrated into, making it an excellent choice for mobile-first apps.
Through a process called normalization, data is efficiently shared across multiple tables, with references or indexes created between each table. Good design principles encourage you to have a primary key column present in each table, which will always have a unique value, to uniquely identify a record. This unique value is then referenced by other tables in the form of a foreign key, which helps to reduce the number of times data repeats across tables.
These simple references go a long way to ensure that the data is accurate across tables. Once this association is created between the primary and foreign keys, we have created what we call a relationship, which introduces a constraint or restriction on what values are possible in the foreign key column. This is also referred to as referential integrity.
Relationships can be further defined by their cardinality. This refers to the nature by which the primary key values will be referenced in the other table. The most common cardinalities are as follows:
- One-to-one: This means that a primary key value is referenced exactly once in another table as a foreign key. For instance, if a customer can only have one address on record. The table storing the address cannot have multiple records that refer to the same customer.
- One-to-many: This means that the primary key value can be referenced multiple times in another table. For instance, if a customer has made multiple orders, then we have one customer’s ID referenced multiple times in the orders table.
- Many-to-many: This means that a primary key can be referenced multiple times as a foreign key in another table, and that table’s primary key can be referenced multiple times in the original table. This can get confusing and implementing it as it is described will directly violate the referential integrity that we are fighting hard to maintain. This is where a linker table is introduced as an intermediary to associate the different combinations of key values from either table.
Using the example of our health care management system, if we revisit how appointments are tracked relative to the customer who has made them, we will see that we implemented a reference point between the customer’s ID, their primary key, and the appointment. This ensures that we do not repeat the customer’s information every time an appointment is booked. An appointment also cannot be created for a customer who is not already in the system.
Figure 7.3 shows a typical relationship.

Figure 7.3 – An example of a one-to-many relationship where one customer is referenced many times in the appointments table
Many-to-many relationships do occur often and it is important to recognize them. Building on the example of customers and their appointments, we can expand and see that we also have a need to associate a customer with a room for an appointment. The same room is not always guaranteed, which leads us to realize that many customers will book appointments, and appointments might happen in many rooms. If we try a direct association, then details of either the customer or the room will need to be repeated to reflect the many possible combinations of customers, rooms, and appointments.
Ideally, we would have a table storing rooms and the associated details, a table storing customers, and an appointments table sitting between the two, which seeks to associate them on the day as needed.
Figure 7.4 shows a typical many-to-many relationship.
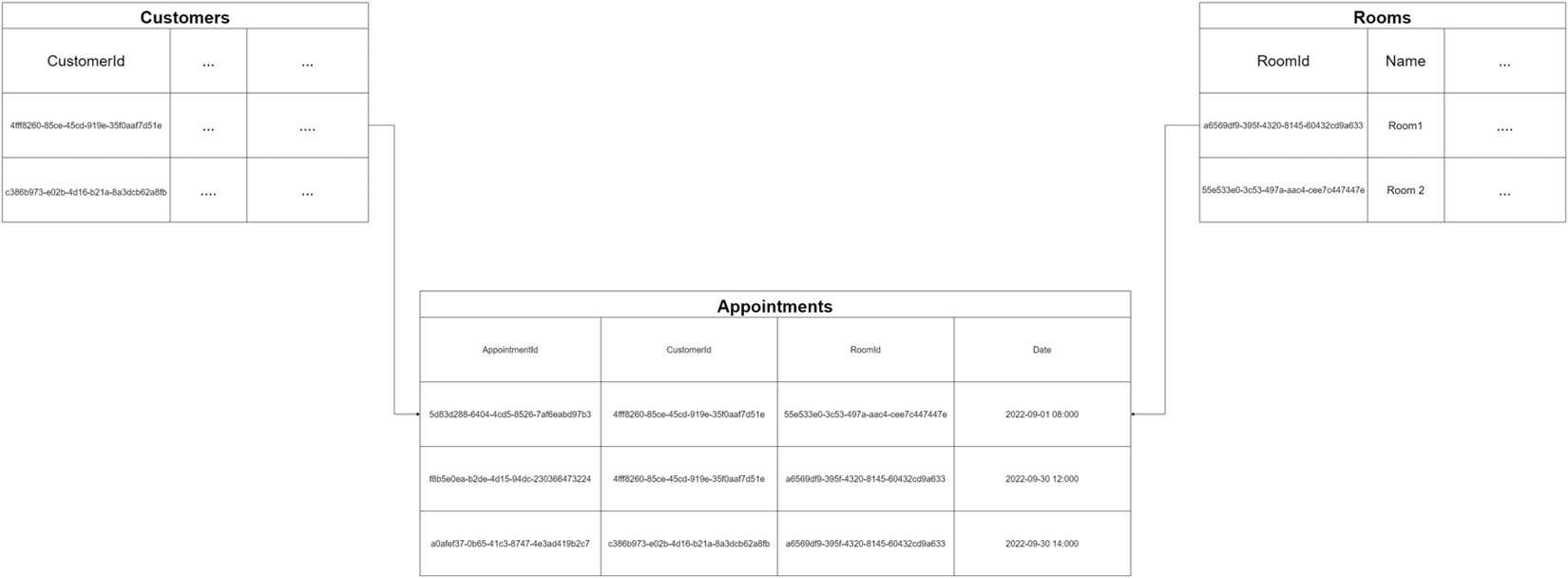
Figure 7.4 – An example of a many-to-many relationship where we associate many records from two different tables using an intermediary linker table
We have already discussed ACID principles and why they are important. Relational databases are designed to ensure that these principles can be observed as a default mode of operation. This makes changing the layout and references of tables relatively difficult, especially if the changes involve changing how tables are related to each other.
Another potential drawback of relational database storage comes in terms of performance with large datasets. Relational databases are typically efficient in data storage, retrieval, and overall speed. They are built to manage large workloads, so the technology itself is hardly at fault, but our design will either complement speed or inhibit it.
These are trade-offs of proper relational database design and upholding relational integrity. Design principles favor normalization, where bits of data are spread across multiple tables, and this is good until we need the data and need to traverse multiple tables with potentially thousands of records to get it. Considering this deficiency, NoSQL or document storage databases have become more and more popular, as they seek to store data in one place, making the retrieval process much faster.
We discuss the use of non-relational databases in the next section.
Non-relational databases
Non-relational databases took the database world by storm. That might be a naive assessment of the impact that they have had, but the fact remains that they introduced a dimension to data storage that was not very popular or widely used. They came along and proposed a far more flexible and scalable data storage technique that favored a more agile development style.
Agile development hinges on the ability to morph a project as we go along. This means that the excess amounts of scoping and planning that would be recommended when using a relational data store would not be necessary upfront. Instead, we could start with an idea of a system and begin using a non-relational data store to accommodate that tiny part, and as the system evolves, so could the data store, with minimal risk of data loss or attrition.
Non-relational databases are also referred to as NoSQL databases, or not only SQL, and they favor a non-tabular data storage model. The most popular NoSQL databases use a document style of storage, where each record is stored in one document, containing all the details needed for that record. This directly violates the principles of normalization, which would have us spread the data to reduce possible redundancy. The major advantage of this model, however, is the speed with which we can write and retrieve data since all the details are in one place.
Using the example of our health care appointment management system, if we were to store an appointment in the form of a document, it would look something like this:
{
"AppointmentId":"5d83d288-6404-4cd5-8526-7af6eabd97b3",
"Date":"2022-09-01 08:000",
"Room":{
"Id":"4fff8260-85ce-45cd-919e-35f0aaf7d51e",
"Name":"Room 1"
},
"Customer": {
"Id":"4fff8260-85ce-45cd-919e-35f0aaf7d51e",
"FirstName":"John",
"LastName":"Higgins"
}
}Unlike with the relational model, where these details were split across multiple tables and simply referenced, we have the opportunity to include all the details needed to fully assess what an appointment entails.
Types of NoSQL databases include the following:
- Document database: Stores data in the form of JavaScript Object Notation (JSON) objects. This JSON document outlines fields and values and can support a hierarchy of JSON objects and collections all in one document. Popular examples include MongoDB, CosmosDB, and CouchDB.
- Key-value database: Stores data in simple key-value pairs. Values are usually stored as string values, and they do not natively support storing complex data objects. They are usually used as quick lookup storage areas, like for application caching. A popular example of this is Redis.
- Graph database: Stores data in nodes and edges. A node stores information on the object, such as a person or place, and the edges represent relationships between the nodes. These relationships link how data points relate to each other, as opposed to how records relate to each other. A popular example of this is Neo4j.
The clear advantages of using NoSQL document databases come from the way that data is stored. Unlike with the relational model, we do not need to traverse many relationships and tables to get a fully human-readable record of data. As seen in the preceding example, we can store all the details in one document and simply scale from there. This comes in handy when we might need to do fast read operations and do not want to compromise system performance with complex queries.
A clear disadvantage, however, comes from how storage is handled. Document databases do very little, if anything at all, to reduce the risk of data redundancy. We will end up repeating details of what would have been related data, which means that the maintenance of this data, in the long run, could become a problem. Using our customer records as examples, if we needed to add a new data point for each customer that has booked an appointment, we would need to traverse the appointment records to make one change. This would be a much easier and more efficient operation using a relational model.
Now that we have discovered some of the advantages and disadvantages of relational and non-relational database stores, let us discuss scenarios where either would be a good choice.
Choosing a database technology
When choosing the best technology for anything, we are faced with several factors:
- Maintainability: How easy is this technology to maintain? Does it have excessive infrastructural and software requirements? How often are updates and security patches produced for the technology? Ultimately, we want to ensure that we do not regret our selection weeks into starting the project.
- Extensibility: To what extent can I use this technology to implement my software? What happens when the requirements change and the project needs to adapt? We want to ensure that our technology is not too rigid and can support the dynamics of the business needs.
- Supporting technologies: Is the technology stack that I am using the best fit? We are often forced to take shortcuts and implement methods, sometimes contrary to best practices, to facilitate matching technologies that are not the best fit for each other. With more libraries being produced to support integrations of heterogenous technology stacks, this is becoming less of an issue, but is still something that we want to take into consideration from day one.
- Comfort level: How comfortable are you and the team with the technology? It is always nice to use new technology and expand your scope and experience, but it is important to recognize your limitations and knowledge gaps. These can just as easily be addressed with training, but we always want to ensure that we can handle the technology that we choose and are not prone to surprises in the long run.
- Maturity: How mature is the technology? In some development circles, technology lives for months at a time. We don’t want to embrace new technology the day it is released without doing our due diligence. Seek to choose more mature technologies that have been tried and proven and have strong enterprise or community support and documentation.
- Appropriateness: Lastly, how appropriate is the technology for the application? We want to ensure that we use the best technology possible to do the job at hand. This sometimes gets compromised considering the bigger picture, which includes budget constraints, the type of project, team experience, and the business’ risk appetite, but as much as possible, we want to ensure that the technology we choose can adequately address the needs of the project.
Now let us narrow this down to database development. We have gone through the pros and cons of the different types of database models and the different technology providers for each. While we are not limited to the options outlined, they serve as guidelines to help us make out assessments from the most unbiased point of view possible.
Within the context of microservices, we want to choose the best database for the service’s needs. There are no hard and fast rules surrounding which storage mechanism should be used outright, but there are recommendations that can help to guide you during the system design.
You can consider using relational databases in the following situations:
- Working with complex reports and queries: Relational databases can run efficient queries across large datasets and are a much better storage option for generating reports.
- Working with a high transaction application: Relational databases are a good fit for heavy-duty and complex transaction operations. They do a good job of ensuring data integrity and stability.
- You require ACID compliance: Relational databases are based on ACID principles, which can go a long way in protecting your data and ensuring accuracy and completeness.
- Your service will not evolve rapidly: If your service doesn’t have changing requirements, then a database should be easy to design and maintain in the long run.
You can consider using a non-relational database in the following situations:
- Your service is constantly evolving, and you need a flexible data store that can adapt to new requirements without too much disruption.
- You anticipate that data may not be clean or meet a certain standard all the time. Given the flexibility that we have with non-relational data stores, we accommodate data of varying levels of accuracy and completeness.
- You need to support rapid scaling: This point goes hand in hand with the need to evolve the data store based on the needs of the business, so we can ensure that the database can be changed with minimal code changes and low costs.
Now that we have explored some of the major considerations regarding choosing a database technology, let us review our options for interacting with a database with code.
Choosing an ORM
Choosing an ORM is an important part of the design process. This lays a foundation for how our application will communicate with our database. The abbreviation ORM is short for Object Relational Mapping.
Every language has support for some form of ORM. Sometimes this is built into the language, and sometimes developers and architects alike contract the use of an external package or library to support database-related operations. In the context of .NET, we have several options, and each has its pros and cons. The most popular options are as follows:
- Entity Framework Core: The most popular and obvious choice of .NET developers. It is a Microsoft-developed and maintained ORM that is packaged with .NET. It implements a C# query-like syntax called LINQ, which makes it easy to write C# code that will execute a query at runtime on the developer’s behalf and has support for most relational and non-relational database technologies.
- Dapper: Dapper is considered a MicroORM as it is a fast, lightweight ORM for .NET. It provides a clean and extendable interface for constructing SQL queries and executing them in a secure and efficient manner. Its performance has always rivaled that of Entity Framework.
- NHibernate: NHibernate is an open source ORM that has been widely used as an alternative to Entity Framework. It has wide support for database technologies and offers alternative methods of handling object mapping and query construction that developers have come to prefer.
There are other ORMs, but these are arguably the most popular and widely used options.
Entity Framework Core has undergone constant improvement and is currently open source and provides excellent interfaces and abstractions that reduce the need for specific code to be written based on the database being accessed. This is a significant feature as it allows us to reuse code across different database technologies and helps us to be flexible in terms of the database technology being used. We can easily change the database technology without affecting the main application and its operations. Barring the presence of any obvious bias on why we should use Entity Framework in our .NET projects, it does help that we can keep our technology stack homogenous.
To integrate Entity Framework Core, or EF Core for short, into our .NET application, we would need to add the package that is designed for our preferred database technology. For this example, we can use SQLite given its versatility. The commands to add the packages would look like this:
dotnet add package Microsoft.EntityFrameworkCore.Sqlite dotnet add package Microsoft.EntityFrameworkCore.Design
The first command adds all the core and supporting EF Core libraries needed to communicate with a SQLite database and the Microsoft.EntityFrameworkCore.Design package adds support for design time logic for migrations and other operations. We will investigate migrations in the next section.
The next thing we need is a data context class, which serves as a code-level abstraction of the database and the tables therein. This context file will outline the database objects that we wish to access and refer to them. So, if our SQLite database should have a table that stores patient information, then we need a class that is modeled from how the patient table should look as well.
Our data context file looks like this:
public class ApplicationDatabaseContext : DbContext
{
public DbSet<Patient> Patients { get; set; }
protected override void OnConfiguring
(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlite("Data Source=patients.db");
}
}This ApplicationDatabaseContext class inherits from DbContext, which is a class provided by EF Core that gives us access to the database operations and functions. We also have a property of type DbSet, which requires a reference type and a name. The reference type will be the class that models a table, and the name of the property will be the code-level reference point for the table. A DbSet represents the collection of records in the referenced table. Our OnConfiguring method sets up the connection string to our database. This connection string will vary based on the type of database we are connecting to.
Now, our patients table will have a few fields and we need a class called Patient, which has C# properties that represent the column names and data types as accurately as possible, relative to how they are presented in the database:
public class Patient
{
// EF Core will add auto increment and Primary Key
constraints to the Id property automatically
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string TaxId { get; set; }
// Using ? beside a data type indicates to the database
that the field is nullable
public DateTime? DateOfBirth { get; set; }
}Our Patient class is a typical class. It simply represents what we want a patient record to look like both in the database and in our application. This way, we abstract much of the database-specific code and use a standard C# class and standard C# code to interact with our tables and data.
A simple database query to retrieve and print all the records from the patients table would look like this:
// initialize a connection to the database
using var context = new ApplicationDatabaseContext();
// Go to the database a retrieve a list of patients
var patients = await context.Patients.ToListAsync();
// Iterate through the list and print to the screen
foreach (var patient in patients)
{
Console.WriteLine($"{patient.FirstName}
{patient.LastName}");
}We can see how cleanly we can use the LINQ syntax in C# and execute a query. EF Core will attempt to generate the most efficient SQL syntax, carry out the operation, and return the data in the form of objects fashioned by the class that models the table. We can then interact with the records as standard C# objects.
EF Core gives us a complete way to interact with our database and carry out our operations without needing to break much from our C# syntax. To go beyond the example shared above, EF Core has full support for dependency injection, which makes connection management and garbage collection almost a non-issue.
A fundamental step that was not addressed above comes in the form of database development techniques that govern how we can create our database in our project. We also have the issue of migrations. We will discuss those in the next section.
Choosing a database development technique
There are best practices and general guidelines that govern how databases are designed. In this section, we are not going to explore or contest those, but we will discuss the possible approaches that exist to materialize a database to support our application.
There are two popular types of development techniques:
- Schema-first: Also called Database-First, this technique sees us creating the database using the usual database management tools. We then scaffold the database into our application. Using Entity Framework, we will get a database context class that represents the database and all the objects within, as well as classes per table and view.
- Code-first: This technique allows us to model the database more fluently alongside our application code. We create the data models using standard C# classes (as we saw in the previous section) and manage the changes to the data models and eventual database using migrations.
Whether we intend to scaffold a database or use the code-first approach, we can use dotnet CLI commands that are made available via the Microsoft.EntityFrameworkCore.Tools package. You can add this package to your project using the dotnet add package command.
To scaffold a database, the commands look like this:
dotnet ef dbcontext scaffold "DataSource=PATH_TO_FILE" Microsoft.EntityFrameworkCore.Sqlite -o Models
This command simply states that we wish to generate a dbcontext based on the database that is located at the connection string that is provided. Based on the technology of the target database (SQL Server, Oracle, and so on), this connection string will be different, but in this example, we’re looking at scaffolding an SQLite database in our application. We then specify the database provider package that is most appropriate for the target database and output the generated files to a directory in our project called Models. This command is also agnostic to the IDE being used.
This command can also look like this, and this format is more popularly used when working in Visual Studio:
Scaffold-DbContext "DataSource=PATH_TO_FILE" Microsoft.EntityFrameworkCore.Sqlite --output-dir Models
Either command needs to be executed within the directory of the project being worked on. Each time a change is made to the database, we need to rerun this command to ensure that the code reflects the latest version of the database. It will overwrite the existing files accordingly.
One limitation here is that we are not always able to track all the changes that are happening in the database and adequately track what changes each time we run this command. Therefore, code-first is a very popular option for database development and its use of migrations helps us to solve this problem.
The concept of migrations is not unique to EF Core, but it is present in several other frameworks in other languages as well. It is a simple process that tracks all the changes being made to a data model as we write our applications and the tables and objects evolve. A migration will evaluate the changes being applied to the database and generate commands (which eventually become SQL scripts) to effect those changes against the database.
Unlike with the database-first model, where we need to use source control with a dedicated database project, migrations are natively available in our code base and tell the story of every adjustment that is made to the database along the way.
Following the example of using EF Core to add a database to our application, we already created the database context class as well as a patient class. So, a direct translation of the code would be that our database context is the database, and Patient.cs is our table. To materialize the database with the table, we need to create a migration that will generate the assets as outlined. We need the same Microsoft.EntityFrameworkCore.Tools package to run our command-line commands and the command to create our first migration will look like this:
dotnet ef migrations add InitialCreate
Or, it will look like this:
Add-Migration InitialCreate
Here, we simply generate a migration file and give it the name InitialCreate. Naming our migrations helps us to visibly track what might have changed in that operation and helps our team as well. Each time we make a change to a data model and/or the database context class, we need to create a new migration, which will produce commands that outline the best possible interpretations of what has changed since the last known version of the database.
This command will generate a class with Up and Down methods that outline what changes are to be applied, and what will be undone if the migration is reversed. This makes it convenient for us to make sure that the changes we intended are what will be carried out and we can remove a migration and make corrections before these changes are applied. Migrations can only be removed before they are applied to the database and the command for that looks like this:
dotnet ef migrations remove
Or, it looks like this:
Remove-Migration
When we are satisfied that a migration correctly outlines the changes that we intend to make, we can apply it using the simple database update command:
dotnet ef database update
Or, we can use the following:
Update-Database
If source control is being used with your project, then migrations will always be included in the code base for other team members to see and evaluate if necessary. It is important to collaborate with team members when making these adjustments as well. It is possible to have migration collisions if changes are not coordinated and this can lead to mismatched database versions if a central database is being used. Ultimately, if we need a fresh copy of the database as of the latest migrations, we can simply change our connection string to target a server and an intended database name, run the Update-Database command, and have EF Core generate a database that reflects the most recent version of our database.
Now that we understand how to use EF Core to either reverse engineer a database into our application or create a new database using migrations, let us investigate writing extensible database querying code on top of the interfaces provided by EF Core.
Implementing the repository pattern
By definition, a repository is a central storage area for data or items. In the context of database development, we use the word repository to label a widely used and convenient development pattern. This pattern helps us to extend the default interfaces and code given to us by our ORM, making it reusable and even more specific for certain operations.
One side effect of this pattern is that we end up with more code and files, but the general benefit is that we can centralize our core operations. As a result, we abstract our business logic and database operations away from our controllers and eliminate repeating database access logic throughout our application. It helps us to maintain the single responsibility principle in our code base as we seek to author clean code.
In any application, we need to carry out four main operations against any database table. We need to create, read, update, and delete data. In the context of an API, we need a controller per database table, and we would have our CRUD code repeating in every controller, which is good for getting started, but becomes dangerous as our application code base grows. This means that if something changes in the way that we retrieve records from every table, we have that many places that we need to change code in.
An API controller with a GET operation for our patients table would look like this without using the repository pattern:
[Route("api/[controller]")]
[ApiController]
public class PatientsController : ControllerBase
{
private readonly ApplicationDatabaseContext
_context;
public PatientsController
(ApplicationDatabaseContext context)
{
_context = context;
}
// GET: api/Patients
[HttpGet]
public async Task<ActionResult<Ienumerable
<Patient>>> GetPatients()
{
if (_context.Patients == null)
{
return NotFound();
}
return await _context.Patients.ToListAsync();
}
}We simply inject the database context into the controller and use this instance to carry out our queries. This is simple and efficient as the query logic is not very complicated. Now imagine that you have several controllers with similar GET operations. All is well until we get feedback that we need to add paging to our GET operations for all endpoints. Now, we have that many places that need to be refactored with a far more complex query, which may also change again in the future.
For scenarios like this, we need to centralize the code as much as possible and reduce the rework that becomes necessary across the application. This is where the repository pattern can come to our rescue. We typically have two files that contain generic templating code, then, we derive more specific repositories for each table where we can add custom operations as needed.
Our generic repository includes an interface and a derived class. They look something like this:
public interface IGenericRepository<T> where T : class
{
Task<T> GetAsync(int? id);
Task<List<T>> GetAllAsync();
Task<PagedResult<T>> GetAllAsync<T>(QueryParameters
queryParameters);
}Here, we only outline methods for read operations, but this interface can just as easily be extended to support all CRUD operations. We use generics as we are prepared to accept any type of class that represents a data model. We also outline a method for a GET operation that returns paged results in keeping with the recent requirement. Our derived class looks like this:
public class GenericRepository<T> : IGenericRepository<T>
where T : class
{
protected readonly ApplicationDatabaseContext
_context;
public GenericRepository(ApplicationDatabaseContext
context)
{
this._context = context;
}
public async Task<List<T>> GetAllAsync()
{
return await _context.Set<T>().ToListAsync();
}
public async Task<PagedResult<T>> GetAllAsync<T>
(QueryParameters queryParameters)
{
var totalSize = await _context.Set<T>()
.CountAsync();
var items = await _context.Set<T>()
.Skip(queryParameters.StartIndex)
.Take(queryParameters.PageSize)
.ToListAsync();
return new PagedResult<T>
{
Items = items,
PageNumber = queryParameters.PageNumber,
RecordNumber = queryParameters.PageSize,
TotalCount = totalSize
};
}
public async Task<T> GetAsync(int? id)
{
if (id is null)
{
return null;
}
return await _context.Set<T>().FindAsync(id);
}
}We see here that we are injecting the database context into the repository and then we can write our preset queries in one place. This generic repository can now be injected into the controllers that need to implement these operations:
[Route("api/[controller]")]
[ApiController]
public class PatientsController : ControllerBase
{
private readonly IGenericRepository<Patient>
_repository;
public PatientsController(IGenericRepository<Patient>
repository)
{
_repository = repository;
}
// GET: api/Patients
[HttpGet]
public async Task<ActionResult<Ienumerable
<Patient>>> GetPatients()
{
return await _repository.GetAllAsync();
}
// GET: api/Patients/?StartIndex=0&pagesize=25
&PageNumber=1
[HttpGet()]
public async Task<ActionResult< PagedResult
<Patient>>> GetPatients([FromQuery]
QueryParameters queryParameters)
{
return await _repository.GetAllAsync
(queryParameters);
}Now we can simply call the appropriate method from the repository. The repository gets instantiated in our controller relative to the class that is used in its injection and the resulting query will be applied against the related table. This makes it much easier to standardize our queries across multiple tables and controllers. We need to ensure that we register our GenericRepository service in our Program.cs file like this:
builder.Services.AddScoped(typeof(IGenericRepository<>), typeof(GenericRepository<>));
Now we may need to implement operations that are specific to our patient table and are not needed for other tables. This means that the generic approach will not be best moving forward, as we would end up cluttering it with custom logic for our tables. We can now extend it and create a specific interface for our table and write our custom logic:
public interface IPatientsRepository : IGenericRepository
<Patient>
{
Task<Patient> GetByTaxIdAsync(string id);
}
public class PatientsRepository : GenericRepository
<Patient>, IPatientsRepository
{
public PatientsRepository(ApplicationDatabaseContext
context) : base(context)
{}
public async Task<Patient> GetByTaxIdAsync(string id)
{
return await _context.Patients.FirstOrDefaultAsync
(q => q.TaxId == id);
}
}Now we can register this new service in the Program.cs file like this:
builder.Services.AddScoped<IPatientsRepository, PatientsRepository>();
And then we can inject it into our controller instead of GenericRepository and use it like this:
public class PatientsController : ControllerBase
{
private readonly IPatientsRepository _repository;
public PatientsController(IPatientsRepository
repository)
{
_repository = repository;
}
// GET: api/Patients
[HttpGet]
public async Task<ActionResult<IEnumerable<Patient>>>
GetPatients()
{
return await _repository.GetAllAsync();
}
// GET: api/Patients/taxid/1234
[HttpGet("taxid/{id}")]
public async Task<ActionResult<Patient>>
GetPatients(string id)
{
var patient = await _repository.GetByTaxIdAsync
(id);
if (patient is null) return NotFound();
return patient;
}
// GET: api/Hotels/?StartIndex=0&pagesize=25
&PageNumber=1
[HttpGet()]
public async Task<ActionResult<PagedResult<Patient>>>
GetPatients([FromQuery] QueryParameters
queryParameters)
{
return await _repository.GetAllAsync
(queryParameters);
}
}Here, we can cleanly call the custom code while maintaining access to the base functions that we implemented in the generic repository.
There are debates as to whether this pattern saves us time and effort or just makes our code base more complicated. There are pros and cons to this pattern but ensure that you do a fair assessment of the benefits and pitfalls before you choose to include it in your project.
Summary
Databases are a critical part of application development, and we need to ensure that we make the right decisions as early as possible. The technology, type of storage mechanism, and supporting application logic all play a large role in making our application as effective as possible in implementing business requirements. In this chapter, we explored the different considerations involved when developing supporting databases for microservices, the best type of database to use and when, and choosing a pattern of development that helps us to reduce redundant code.
In the next chapter, we will investigate implementing transactions across multiple services and databases using the saga pattern, since this is a big issue when we choose the database-per-service approach to microservice architecture.