
Chapter 7
Predicting the Future Using Data Classification
IN THIS CHAPTER
Introducing data classification
Making better decisions by using data classification
Getting an overview of widely used data classification algorithms
Using data classification algorithms to predict future behavior of customers
Leveraging basic decision trees to assess business opportunities
Introducing the fundamentals of deep learning
Applying data classification as a way to make business predictions
This chapter introduces an easy and widely used concept that can help you predict the future: data classification, a data-mining technique used to make sense of overwhelmingly large and humanly unmanageable datasets to uncover hidden patterns in the data. That could be one possible first step in the direction of building a predictive model.
Predictive models that use this technique are called classification models, often referred to as classifiers. Behind the scenes of these classifiers is a set of sophisticated machine-learning algorithms that learn from experience — as represented by the historical data — to discover hidden patterns and trends in the data. When these unseen relationships come to light, the model can predict the outcome (a category (class label), or numerical value) based on newly input data.
For instance, most financial institutions that issue loans to individuals or corporate entities use risk modeling to predict whether the loan will be paid back (or, in the case of mortgage loans, paid back early). Often these models use a classification algorithm. In essence, a classification algorithm predicts the class or category of an unknown event, phenomenon, or future numerical value. The categories or classes are extracted from the data. One way to organize data into categories of similar data objects is by using data clustering (covered in detail in Chapter 6).
Financial analysts, mortgage bankers, and underwriters depend heavily on such predictive models when they decide whether to grant loans. Most people have heard of the FICO Score — as noted in the accompanying sidebar, it’s a number that represents your credit history and creditworthiness. It’s also a classic example of the output you get from a classification model.
Besides providing just a number (or score) as output, a classifier may place a credit applicant in one of several categories of risk — such as risky, not risky, or moderately risky. It’s up to the modeler or analyst to determine whether the output will be a discrete number or a category. Thus a classification model may play a major role in whether someone buys that new house or car. The predictive model utilizes historical credit data of the user, labels the user as belonging to a specific category, and speculates on the user’s future behavior if his or her loan application is approved.
Classification can be also used in fraud detection, spam e-mail identification, medical diagnosis, image recognition, targeted marketing, text analytics, and many other practical applications.
This chapter explains the underlying concepts behind data classification and illustrates techniques used to build classification-based predictors. You also get a look at a general approach to incorporating data classification into your business.
Explaining Data Classification
In data mining, data classification is the process of labeling a data item as belonging to a class or category. A data item is also referred to (in the data-mining vocabulary) as data object, observation, or instance.
 Data clustering (see Chapter 6) is different from data classification:
Data clustering (see Chapter 6) is different from data classification:
- Data clustering is used to describe data by extracting meaningful groupings or categories from a body of data that contains similar elements.
- Data classification is used to predict the category or the grouping that a new and incoming data object belongs to.
You can use data classification to predict new data elements on the basis of the groupings discovered by a data clustering process. The following section walks you through the use of data classification to solve a practical problem.
Lending
A loan can serve as an everyday example of data classification. The loan officer needs to analyze loan applications to decide whether the applicant will be granted or denied a loan.
One way to make such a critical decision is to use a classifier to assist with the decision-making process. In essence, the classifier is simply an algorithm that contains instructions that tell a computer how to analyze the information mentioned in the loan application, and how to reference other (outside) sources of information on the applicant. Then the classifier can label the loan application as fitting one of these sample categories, such as “safe,” “too risky,” or “safe with conditions” assuming that these exact categories are known and labeled in the historical data.
By removing most of the decision process from the hands of the loan officer or underwriter, the model reduces the human work effort and the company’s portfolio risk. This increases return on investment (ROI) by allowing employees to originate more loans and/or get better pricing if the company decides to resell the higher-quality loan.
If the classifier comes back with a result that labels an applicant as “safe with conditions,” then the loan processor or officer can request that the applicant fulfill the conditions in order to get the loan. If the conditions are met, then the new data can be run through the classifier again for approval. Using machine learning, the loan application classifier will learn from past applications, leverage current information mentioned in the application, and predict the future behavior of the loan applicant.
As ever, predicting the future is about learning from the past and evaluating the present. Data classification relies on both past and current information — and speeds up decision making by using both faster.
Marketing
To illustrate the use of classifiers in marketing, consider a marketer who has been assigned to design a smart marketing strategy for a specific product. Understanding the customers’ demographics drives the design of an effective marketing strategy. Ultimately it helps the company select suitable products to advertise to the customers most likely to buy them.
For instance, one of the criteria you can use to select targeted customers is specific geographical location. You may have an unknown store (or a store that isn’t known for selling a particular product — say, a housewares store that could start selling a new food processor) and you want to start a marketing campaign for the new product line.
Using data you collected or bought from a marketing agency, you can build your classifier. You can design a classifier that anticipates whether customers will buy the new product. For each customer profile, the classifier predicts a category that fits each product line you run through it, labeling the customer as (say) “interested,” “not interested,” or “unknown.”
Using the analysis produced by the classifier, you can easily identify the geographical locations that have the most customers who fit the “interested” category. Your model discovers for example that the population of San Francisco includes a large number of customers who have purchased a product similar to what you have for sale.
You jump at this chance to take action on the insight your model just presented to you. You may send an advertisement for that cool new gadget to those customers — and only to them.
To limit operating and marketing costs, you must avoid contacting uninterested customers; the wasted effort would affect your ROI. For that matter, having too much unnecessary contact with customers can dilute the value of your marketing campaigns and increase customer fatigue till your solicitations seem more like a nuisance. You don’t want your glossy flyers to land immediately in the garbage can or your e-mails to end up in the spam folder.
 As a marketer, you might want to use data about potential customers’ profiles that has been collected from different sources or provided by a third party. Such sources include social media and databases of historical online transactions by customers.
As a marketer, you might want to use data about potential customers’ profiles that has been collected from different sources or provided by a third party. Such sources include social media and databases of historical online transactions by customers.
Healthcare
In the medical field, a classifier can help a physician settle on the most suitable treatment for a given patient. It can be designed to analyze the patient data, learn from it, and classify the patient as belonging to a category of similar patients. The classifier can approve recommending the same treatment that helped similar patients of the same category in the past.
As in the examples previously described, the classifier predicts a label or class category for the input, using both past and current data. In the case of healthcare, the predictive model can use more data, more quickly, to help the physician arrive at an effective treatment.
To help physicians prescribe individualized medicine, the classifier would assist them in determining the specific stage of a patient’s disease. Hypothetically, the data (say, genetic analysis from a blood sample) could be fed to a trained classifier that could label the stage of a new patient’s illness. In the case of cancer (for example), the classifier could have such labels — describing the following classes or groupings — as “healthy,” “benign,” “early stage,” “metastatic,” or “terminal.”
What’s next?
Future uses of classifiers promise to be even more ambitious. Suppose you want to predict how much a customer will spend on a specific date. In such a case, you design a classifier that predicts numerical values rather than specified category names. Of course, numeric predictors can be developed using not only statistical methods such as regression but also other data-mining techniques such as neural networks (covered later in this chapter). Given sufficiently sophisticated designs, classifiers are commonly used in fields such as presidential elections, national security, and climate change. Chapter 5 also presents some current examples of predictive analytics using classification-based modeling.
Introducing Data Classification to Your Business
Getting back down to earth, if your business has yet to use data classification, maybe it’s time to introduce it as a way to make better management or operating decisions. This process starts with an investigative step: Identifying a problem area in the business where ample data is available but currently isn’t being used to drive business decisions.
One way to identify such a problem area is to hold a meeting with your analysts, managers, and other decision-makers to ask them what risky or difficult decisions they repeatedly make — and what kind of data they need to support their decisions. If you have data that reflects the results of past decisions, be prepared to draw on it. This process of identifying the problem is called the discovery phase.
After the discovery phase, you’ll want to follow up with individual questionnaires addressed to the business stakeholders. Consider asking the following types of questions:
- What do you want to know from the data?
- What action will you take when you get your answer?
- How will you measure the results from the actions taken?
If the predictive analytical model’s results produce meaningful insights, then someone must do something with it — take action. Obviously, you’ll want to see whether the results of that action add business value to the organization. So you’ll have to find a method of measuring that value — whether in terms of savings from operational costs, increased sales, or better customer retention.
As you conduct these interviews, seek to understand why certain tasks are done and how they’re being used in the business process. Asking why things are the way they are may help you uncover unexpected realizations. No point in gathering and analyzing data just for the sake of creating more data. You want to use that data to answer specific business needs.
For the data scientist or modeler, this exercise defines what kinds of data must be classified and analyzed — a step essential to developing a data classification model. A basic distinction to begin with is whether the data you’ll use to train the model is internal or external:
- Internal data is specific to your company, usually draws from your company’s data sources, and can include many data types — such as structured, semi-structured, or unstructured.
- External data comes from outside the company, often as data bought from other companies.
Regardless of whether the data you use for your model is internal or external, you’ll want to evaluate it first. Several questions are likely to crop up in that evaluation:
- How critical and accurate is the data in question? If it’s too sensitive, it may not serve your purposes.
- How accurate is the data in question? If its accuracy is questionable, then its utility is limited.
- How do company policy and applicable laws allow the data to be used and processed? You may want to clear the use of the data with your legal department for any legal issues that could arise. (See the accompanying sidebar for a famous recent example)
When you’ve identified data that is appropriate to use in the building of your model, the next step is to classify it — to create and apply useful labels to your data elements. For instance, if you’re working on data about customers’ buying behavior, the labels could define data categories according to how some groups of customers buy, along these lines:
- Seasonal customers could be those who shop regularly or semi-regularly.
- Discount-oriented customers could be those who tend to shop only when major discounts are offered.
- Faithful customers are those who have bought many of your products over time.
Predicting the category that a new customer will fit can be of great value to the marketing team. The idea is to spend time and money efficiently on identifying which customers to advertise to, determining which products to recommend to them, and choosing the best time to do so. A lot of time and money can be wasted if you target the wrong customers, probably making them less likely to buy than if you hadn’t marketed to them in the first place. Using predictive analytics for targeted marketing should aim not only at more successful campaigns, but also at the avoidance of pitfalls and unintended consequences.
Exploring the Data-Classification Process
At a brass-tacks level, data classification consists of two stages:
- The learning stage entails training the classification model by running a designated set of past data through the classifier. The goal is to teach your model to extract and discover hidden relationships and rules — the classification rules from historical (training) data. The model does so by employing a classification algorithm.
- The prediction stage that follows the learning stage consists of having the model predict class labels or numerical values that classify data it has not seen before (that is, test data).
To illustrate these stages, suppose you’re the owner of an online store that sells watches. You’ve owned the online store for quite a while, and have gathered a lot of transactional data and personal data about customers who purchased watches from your store. Suppose you’ve been capturing that data through your site by providing web forms, in addition to the transactional data you’ve gathered through operations.
You could also purchase data from a third party that provides you with information about your customers outside their interest in watches. That’s not as hard as it sounds; there are companies whose business model is to track customers online and collect and sell valuable information about them. Most of those third-party companies gather data from social media sites and apply data-mining methods to discover the relationship of individual users with products. In this case, as the owner of a watch shop, you’d be interested in the relationship between customers and their interest in buying watches.
You can infer this type of information from analyzing, for example, a social network profile of a customer, or a microblog comment of the sort you find on Twitter. To measure an individual’s level of interest in watches, you could apply any of several text-analytics tools that can discover such correlations in an individual’s written text (social network statuses, tweets, blog postings, and such) or online activity (such as online social interactions, photo uploads, and searches).
After you collect all that data about your customers’ past transactions and current interests — the training data that shows your model what to look for — you’ll need to organize it into a structure that makes it easy to access and use (such as a database).
At this point, you’ve reached the second phase of data classification: the prediction stage, which is all about testing your model and the accuracy of the classification rules it has generated. For that purpose, in many cases you’ll need additional historical customer data, referred to as test data (which is different from the training data). You feed this test data into your model and measure the accuracy of the resulting predictions. You count the times that the model predicted correctly the future behavior of the customers represented in your test data. You also count the times that the model made wrong predictions.
At this point, you have only two possible outcomes: Either you’re satisfied with the accuracy of the model or you aren’t:
- If you’re satisfied, then you can start getting your model ready to make predictions as part of a production system.
- If you’re not happy with the prediction, then you’ll need to retrain or redesign your model with a new training dataset, revisit the data preparation phase for the original training dataset or try another predictive model.
If your original training data was not representative enough of the pool of your customers — or contained noisy data that threw off the model’s results by introducing false signals — then there’s more work to do to get your model up and running. Either outcome is useful in its own way.
Using Data Classification to Predict the Future
When your data is divided into clusters of similar objects, your model is in a better position to make reliable predictions. This section examines a handful of common algorithms used to classify data in predictive analytics.
Decision trees
In this section, you will be introduced to the basics of using decision trees to make decision. The following section provides a step-by-step algorithm that's widely used to generate a decision tree from raw historical data.
A decision tree is an approach to analysis that can help you make decisions. Suppose, for example, that you need to decide whether to invest a certain amount of money in one of three business projects: a food-truck business, a restaurant, or a bookstore. A business analyst has worked out the rate of failure or success for each of these business ideas as percentages (shown in Table 7-1) and the profit you’d make in each case (shown in Table 7-2).
TABLE 7-1 Business Success Percentages
Business |
Success Rate |
Failure Rate |
Food Truck |
60 percent |
40 percent |
Restaurant |
52 percent |
48 percent |
Bookstore |
50 percent |
50 percent |
TABLE 7-2 Business Value Changes
Business |
Gain (USD) |
Loss (USD) |
Food Truck |
20,000 |
-7,000 |
Restaurant |
40,000 |
-21,000 |
Bookstore |
6,000 |
-1,000 |
From past statistical data shown in Table 7-1, you can construct a decision tree, as shown in Figure 7-1.

FIGURE 7-1: Decision tree for three business ideas.
Using such a decision tree to decide on a business venture begins with calculating the expected value for each alternative — a numbered rank that helps you select the best one on average.
The expected value is calculated in such a way that includes all possible outcomes for a decision. Calculating the expected value for the food-truck business idea looks like this:
Expected value of food-truck business = (60 percent x 20,000 (USD)) + (40 percent * -7,000 (USD)) = 9,200 (USD)
Here the expected value reflects the average gain from investing in a food-truck business. In this scenario — working with hypothetical numbers, of course — if you attempt to invest in food-truck businesses several times (under the same circumstances each time), your average profit will be 9,200 (USD) per business.
Accordingly, you can calculate the expected values of a restaurant business and bookstore the same way, as follows:
- Expected value of restaurant business = (52 percent x 40,000 (USD)) + (48 percent * -21,000 (USD)) = 10,720 (USD)
- Expected value of bookstore business = (50 percent x 6,000 (USD)) + (50 percent * -1,000 (USD)) = 2,500 (USD)
The expected value of a restaurant business represents a prediction of how much profit you’d make (on average) if you invested in a restaurant business several times. Therefore, the expected value becomes one of the criteria you figure into your business decision making. In this example, the expected values of the three alternatives might incline you to favor investing in the restaurant business.
Decision trees can also be used to visualize classification rules (such as those mentioned in the earlier example of the online watch store).
In the watch-store example mentioned in the previous section, you want to predict whether a given customer will buy a watch from your store; the decision tree will be, essentially, a flow chart (refer to Figure 7-1): Each node of the decision tree represents an attribute identified in the data matrix. The leaves of the tree are the predicted decisions, as shown in Figure 7-2.

FIGURE 7-2: Decision tree that predicts customer interest in buying watches.
This decision tree predicts whether a customer might buy a given watch at the online store. The nodes in this decision tree represent some of the attributes you’re analyzing; each is a score — of customer interest in watches, customer age, and customer salary.
Applying the model to a new Customer X, you can trace a path from the root of the tree down to a decision tree’s leaf (yes or no) that indicates and maps how that customer would behave toward the watch being advertised.
In the preceding example, we showed you how a decision tree can be used as a useful management tool to make decisions. The following section will walk you through a step-by-step algorithm to generate a decision tree from raw customer data.
Algorithms for Generating Decision Trees
The longtime senior executive for the Walt Disney Company, Roy Disney once said: “It's not hard to make decisions when you know what your values are.” This is indeed true especially when you have a decision tree in front of you, so how do can we automatically generate decision trees from historical data in order to predict the future?
A recent CNNMoney article titled “Would you wear a tracker to get an insurance discount?” explained that for the first time in the United States of America insurance companies are trying activity trackers for discounted rates. In other words, insurance companies may offer you a discount if you wear a fitness tracker that measures your lifestyle.
Imagine that you decided to wear the fitness tracker to get an insurance discount. The fitness tracker captures your personal data, your heart rate, your sleeping hours, your locations, your gym visits, and your favorite exercises among others. This data can be combined into a simple mathematical function that can generate a score to determine if you are maintaining a healthy lifestyle.
Imagine the insurance company has collected historical data, as shown in Table 7-3 (this is an imaginary dataset for the purpose of explaining the decision tree algorithm).
TABLE 7-3 Sample Historical Customer Personal and Fitness Tracker Data
Customer Name |
Zip Code |
Age |
Lifestyle (Health) |
Discount |
Sarah |
10036 |
30-40 |
Average |
1%-5% |
Ana |
10020 |
20-30 |
Good |
1%-5% |
Mariah |
10018 |
30-40 |
Good |
6%-15% |
Mike |
10011 |
40-50 |
Average |
1%-5% |
Zach |
20052 |
20-30 |
Average |
1%-5% |
John |
20037 |
30-40 |
Good |
6%-15% |
As shown in Table 7-3, the table represents each customer's name, zip code, age, lifestyle label (as inferred from the health tracker device), and awarded discount range.
Consider this new customer to whom the insurance company is about to award a discount:
{customer name = David, age 20-30, lifestyle=good, discount=?}
The insurance company wants to decide what discount will be awarded to David. For that purpose, we will use the data in Table 7-3 to create a decision tree that will help in making this decision.
Before we dive into how we can automatically create a decision tree, you need to know an important concept known as entropy that is widely used in algorithms that generate decision trees.
In the world of information theory, the entropy measures the amount of information in a random variable. For instance, we can calculate the entropy of the variables (attribute) Lifestyle or Age shown in Table 7-3 to see how much information they can tell to predict the discount range for a given customer. The entropy can be used to select the nodes that will make the decision tree. In general, high entropy of an attribute X means that the attribute is from a uniform distribution; if the entropy of X is low, it means that the variable is from a varied and interesting distribution.
The entropy of a variable X can be calculated as follows:
Where P(d) is the probability that represent the number of data items for decision (label) d divided by the total number of items.
In Table 7-3, there are two possible decisions to be taken for a given customer either to award them 6-15 percent discount or 1-5 percent discount. In order to better understand how to calculate the entropy of an attribute, here's the Age attribute as an example. It can be calculated as follows for three classes for ages: 20-30, 30-40, and 40-50. Based on Age, we can divide the data elements (rows) into three subsets. We will compute the entropy for each subset:
- For ages 20-30, two customers received 1-5 percent discount. We are using log base two in the calculation below.

The entropy is zero because the outcome (discount) is certain along the age (20-30) dimension for the dataset shown in table 7-3.
- For ages 30-40, two customers received 6-15 percent discount and one customer received 1-5 percent.
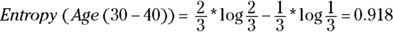
- For ages 40-50, one customer received 1-5 percent discount.

 The log used in these the calculations is of base two.
The log used in these the calculations is of base two.
The overall conditional entropy for attribute Age is:

In order to construct a decision tree, it is important to determine which attributes (such as age and lifestyle) are most discriminating between the data classes. The following measure, Information Gain, can reveal the importance of a given attribute that can lead to the creation of the decision tree.
The zip code attribute was discarded in this analysis because in the sample data in Table 3-7 there is no clear mapping between zip values and discount (at least in the sample data). In a real data set ZIP code would almost always have too many possible categories to be useful as a nominal variable.
Where
The information gain for the age attribute is
Similarly, the information gain for the Lifestyle attribute is
In this example, both attributes Lifestyle and Age are of the same information gain. In other cases, you might have different values for attributes. Because both features “Lifestyle” and “Age” have the same values of information gain, we can start with either one as a first node in the decision tree. We will choose Lifestyle as the root of the tree.
Because the variable “Lifestyle” has two possible values average and good, we will have two branches coming out of the root of the tree as shown in Figure 7-3.

FIGURE 7-3: Decision tree deciding on customer’s insurance discount.
If the Lifestyle is average, then it's clear from historical data in Table 7-3 that discount is 1 percent to 5 percent, regardless of the age. If the Lifestyle is good, the discount will depend on the age attribute:
- If the age is between 20 and 30, the discount is between 1 percent and 5 percent.
- If the age is between 30 and 40, the discount is between 6 percent and 15 percent.
Because the historical data doesn't support the case where the lifestyle is good and the age is between 40-50, we assume that the discount is 6 percent to 15 percent (because most of the outcomes for good lifestyle are 6 percent to 15 percent).
The final decision tree is shown in Figure 7-3. Now that we derived the decision tree, we can easily decide on the discount we will give to customer David (introduced earlier):
If we follow the decision tree shown in Figure 7-3, David will be awarded a discount in the range of 1 percent to 5 percent.
Multiple algorithms that can automatically learn a decision from large amount of data. Some of the most widely used algorithms are
- ID3 (Iterative Dichotomiser 3)
- C4.5 (successor of ID3)
- CART (Classification and Regression Tree)
Most of these algorithms are implemented in R, RapidMiner, and Weka. With a matter of clicks, you can build a decision tree after you upload your historical data.
Support vector machine
The support vector machine (SVM) is a data-classification algorithm that assigns new data elements to one of labeled categories
SVM is, in most cases, a binary classifier; it assumes that the data in question contains two possible target values. Another version of the SVM algorithm, multiclass SVM, augments SVM to be used as classifier on a dataset that contains more than two classes (grouping or category). SVM has been successfully used in many applications such as image recognition, medical diagnosis, and text analytics.
Suppose you’re designing a predictive analytics model that will automatically recognize and predict the name of an object in a picture. This is essentially the problem of image recognition — or, more specifically, face recognition: You want the classifier to recognize the name of a person in a photo.
Well, before tackling that level of complexity, consider a simpler version of the same problem: Suppose you have pictures of individual pieces of fruit and you’d like your classifier to predict what kind of fruit appears in the picture. Assume you have only two types of fruit: apples and pears, one per picture.
Given a new picture, you’d like to predict whether the fruit is an apple or a pear — without looking at the picture. You want the SVM to classify each picture as apple or pear. As with all other algorithms, the first step is to train the classifier.
Suppose you have 200 pictures of different apples, and 200 pictures of pears. The learning step consists of feeding those pictures to the classifier so it learns what an apple looks like and what a pear looks like. Before getting into this first step, you need to transform each image into a data matrix, using (say) the R statistical package (which is covered in detail in Chapter 14). A simple way to represent an image as numbers in a matrix is to look for geometric forms within the image (such as circles, lines, squares, or rectangles) and also the positions of each instance of each geometric form. Those numbers can also represent coordinates of those objects within the image, as plotted in a coordinate system.
As you might imagine, representing an image as a matrix of numbers is not exactly a straightforward task. A whole distinct area of research is devoted to image representation.
Figure 7-4 shows how a support vector machine can predict the class of a fruit (labeling it mathematically as apple or pear), based on what the algorithm has learned in the past.

FIGURE 7-4: A support vector machine that predicts a fruit class.
Suppose you’ve converted all the images into data matrices. Then the support vector machine takes two main inputs:
- Previous (training) data: This set of matrices corresponds to previously seen images of apples and pears.
- The new (unseen) data consists of an image converted to a matrix. The purpose is to predict automatically what is in the picture — an apple or a pear.
The support vector uses a mathematical function, often called a kernel function which is a math function that matches the new data to the best image from the training data in order to predict the unknown picture’s label (apple or pear).
In comparison to other classifiers, support vector machines produce robust, accurate predictions, are less affected by noisy data, and are less prone to overfitting (see Chapter 15 for more about overfitting). Keep in mind, however, that support vector machines are most suitable for binary classification — when you have only two categories (such as apple or pear).
Ensemble Methods to Boost Prediction Accuracy
As in the real world, so with the multiplicity of predictive models: Where there is unity, there is strength. Several models can be combined in different ways to make predictions. You can then apply the combined model — called an ensemble model — at the learning stage, at the classification stage, or at both stages.
Here’s one way to use an ensemble model:
- Split the training data into several sets.
- Have each of the individual models that make up the ensemble model process parts of the data and learn from it.
- Have each model produce its learning outcome from that data.
So far, so good. But in order to get the ensemble model to predict a future class or category label for new data and make a decision, you have to run the new data through all of the trained models; each model predicts a class label. Then, on the basis of the collective classification or prediction, you can generate an overall prediction.
You can generate that overall prediction by simply implementing a voting mechanism that decides the final result. One voting technique could use the label that the majority of the models predict as the label that the ensemble model produces as its result.
Suppose you want to build a model that will predict whether an incoming e-mail is spam. Assume that the training data consists of a set of e-mails in which some are spam and others are not. Then you can distribute that dataset to a number of models for training purposes.
Then the trained models process an incoming e-mail. If the majority of the models classify it as spam, then the ensemble model gives the e-mail the final label of spam.
Another way to implement an ensemble model is to weigh the accuracy of each model you’re building into the ensemble model against the accuracy of all the other models in the set:
You assign a specific weight (accuracy) to each model.
This weight will vary from one dataset to the next and from one business problem to the next.- After the models are trained, you can use test data where you know the classification of each data point in the test data.
- Evaluate the prediction made by each model for each test case.
- Increase the weight for the models that predicted correctly and decrease the weight for the models that classified the data incorrectly.
Naïve Bayes classification algorithm
Naïve Bayes is a data-classification algorithm that is based on probabilistic analysis. The term probability is often associated with the term event. So you often hear statements along these lines: “The probability of Event X is so and so.”
Well, the probability of Event X is a numerical value. You can calculate this numerical value by dividing the number of times Event X can occur by the number of events that are possible in the same circumstances.
Probability as a grab bag
Consider a bag that contains seven fruits: three apples and four oranges. Imagine that you’ll be pulling one fruit at a time out of the bag, without looking at the bag. What is the likelihood (the probability) that you’ll pull out an orange? In this case, following the definition just mentioned, Event X is picking an orange out of a bag that contains seven fruits.
- The number of times that the Event X in question could happen is four because there are four oranges in the bag.
- The total number of possible events that can occur is seven because there are seven fruits in the bag.
- Each time you pull a fruit out of the bag, it’s considered an event. Thus the probability of picking an orange is four divided by seven.
- If you follow the same reasoning, you can deduce that the probability of pulling an apple out of the fruit bag is the result of dividing three by seven.
- The probability of pulling out a banana from the same bag is zero because the number of times such an event can happen is zero, the total number of possible events is seven, and zero divided by seven equals zero.
Naïve Bayes algorithm and Bayes’ Theorem
The Naïve Bayes classification algorithm is based on basic probabilities and on Bayes’ Theorem, a powerful formula that can be used to calculate the probability of an event based on previous knowledge. Such previous knowledge is often referred to as evidence.
Let X be the event you want to calculate the probability for; let Y be the prior event that has happened (evidence). Bayes’ Theorem states that
The same equation can be also written as follows: ![]()
where
- P (X) is the probability that Event X will happen.
- P (not_X) is the probability that Event X will not happen.
- P (X|Y) is the probability that Event X will happen, given that Event Y has happened.
- P (Y|X) is the probability that Event Y will happen, given that Event X has happened.
- P (Y|not_X) is the probability that Event Y will happen, given that X has not happened.
In practice, the preceding equation in the list is the one most often used when applying Bayes’ Theorem.
Fundamentals of the Naïve Bayes classifier
Consider the scenario where you want to advertise Product X to a customer. You’ve gathered information about your customers, as shown in Figure 7-5. You want to predict whether the customer in question will buy Product X.

FIGURE 7-5: Customer data.
Figure 7-5 shows customer data you could possibly gather. Each customer has an ID, income, a credit rating, and a purchase history of similar products. Each customer record also has sentiment analysis of his or her social media text about Product X.
Consider the following probabilities definitions and notations:
- P(X) is the probability of X being purchased.
- P(not_X) is the probability of X not being purchased.
- P(CR_fair|X) is the probability that a customer’s credit rating is fair, given the customer purchases Product X.
- P(CR_excellent|X) is the probability that a customer’s credit rating is excellent, given the customer purchases Product X.
- P(CR_poor|X) is the probability that a customer’s credit rating is poor, given the customer purchases Product X.
- P(CR_fair|not_X) is the probability that a customer’s credit rating is poor, given the customer did not purchase Product X.
- P(CR_excellent|not_X) is the probability that a customer’s credit rating is excellent, given the customer did not purchase Product X.
- P(CR_poor|not_X) is the probability that a customer’s credit rating is poor, given the customer did not purchase Product X.
- P(I_medium|X) is the probability that a customer’s income is medium, given the customer did purchase Product X.
- P(I_high|X) is the probability that a customer’s income is high, given the customer did purchase Product X.
- P(I_poor|X) is the probability that a customer’s income is poor, given the customer did purchase Product X.
- P(I_medium|not_X) is the probability that a customer’s income is medium, given the customer did not purchase Product X.
- P(I_high|not_X) is the probability that a customer’s income is high, given the customer did not purchase Product X.
- P(I_poor|not_X) is the probability that a customer’s income is poor, given the customer did not purchase Product X.
- P(SA_neutral|X) is the probability that a customer’s sentiment on social media is neutral about Product X, give the customer did purchase Product X.
- P(SA_positive|X) is the probability that a customer’s sentiment on social media is positive about Product X, given the customer did purchase Product X.
- P(SA_negative|X) is the probability that a customer’s sentiment on social media is negative about Product X, given the customer did purchase Product X.
- P(SA_neutral|not_X) is the probability that a customer’s sentiment on social media is neutral about Product X, given the customer did not purchase Product X.
- P(SA_positive|not_X) is the probability that a customer’s sentiment on social media is positive about Product X, given the customer did not purchase Product X.
- P(SA_negative|not_X) is the probability that a customer’s sentiment on social media is negative about Product X, given the customer did not purchase Product X.
- P(SP_yes|X): the probability that a customer has purchased a product similar to X, given the customer did purchase Product X.
- P(SP_no|X) is the probability that a customer has not purchased a product similar to X, given the customer did purchase Product X.
- P(SP_yes|not_X) is the probability that a customer has purchased a product similar to X, given the customer did not purchase Product X.
- P(SP_no|not_X) is the probability that a customer has not purchased a product similar to X, given the customer did not purchase Product X.
Those probabilities can be calculated as follows, using the basic explanation of probabilities described at the beginning of this section:
- P(X) = 6/10 = 0.6
- P(not_X) = 4/10 = 0.4
- P(CR_fair|X) = 4/6 = 0.67
- P(CR_excellent|X)=2/6 = 0.33
- P(CR_poor|X)=0/6 = 0
- P(CR_fair|not_X)= 1/4 = 0.25
- P(CR_excellent|not_X)=1/4 = 0.25
- P(CR_poor|not_X)=2/4 = 0.5
- P(I_medium|X)=2/6 = 0.33
- P(I_high|X)=3/6 = 0.5
- P(I_poor|X)= 1/6 = 0.17
- P(I_medium|not_X) = 1/4 = 0.25
- P(I_high|not_X) = 2/4 = 0.5
- P(I_poor|not_X) = 1/4 = 0.25
- P(SA_neutral|X) =1/6 = 0.17
- P(SA_positive|X)=4/6 = 0.67
- P(SA_negative|X)=1/6 = 0.17
- P(SA_neutral|not_X)=0/4 = 0
- P(SA_positive|not_X)=3/4 = 0.75
- P(SA_negative|not_X)=1/4 = 0.25
- P(SP_yes|X)=4/6 = 0.67
- P(SP_no|X)=2/6 = 0.33
- P(SP_yes|not_X)=2/4 = 0.5
- P(SP_no|not_X)=2/4 = 0.5
Here comes a new customer, whose ID is 3356 and who has the features (evidence) shown in Figure 7-6.

FIGURE 7-6: New customer data.
Figure 7-6 shows the data belonging to the new customer (#3356). You want to know whether the company should spend money on advertising Product X to this new customer. In other words, you want to know the probability that the customer will purchase Product X, given what you know already: that the customer is of medium income, has a poor credit rating, has a positive sentiment analysis on social media about Product X, and has a history of purchasing similar products.
The classifier uses historical data (as shown in Figure 7-6) and Bayes’ Theorem (mentioned earlier in this section) to label the new customer as a potential buyer of Product X … or not.
- Let P(X|Customer#3356) be the probability that Product X will be purchased by Customer#3356, given the customer’s features.
- Let P(not_X|Customer#3356) be the probability that Product X will not be purchased by Customer#3356, given the customer’s features.
Following Bayes’ Theorem, the following probabilities can be calculated:
- P (X|Customer#3356) =
- [P(X) * P(Customer#3356|X)] / [P(X) * P(Customer#3356|X) + P (not_X) * P (Customer#3356|not_X)]
- P(not_X|Customer#3356) = [P(not_X) * P(Customer#3356|not_X)] /
- [P (not_X) * P (Customer#3356|not_X) +P(X) * P(Customer#3356|X)]
Notice that those probabilities have the same denominator. Thus we focus on comparing the numerators, as follows:
- P(Customer#3356|X) is the probability of having customers like Customer#3356, knowing that Customer#3356 purchased Product X.
- P(Customer#3356|X) = P(CR_fair|X) * P(I_medium|X) * P(SA_positive|X) * P(SP_yes|X)
- =0.67 * 0.33 * 0.67 * 0.67 = 0.0993
- P(Customer#3356|not_X) = P(CR_fair|not_X) * P(I_medium|not_X) * P(SA_positive|not_X) * P(SP_yes|not_X)
- =0.25 * 0.25 * 0.75 * 0.5 = 0.0234
- P(X|Customer#3356) = [P(X) * P(Customer#3356|X)] /
- [P(X) * P(Customer#3356|X) + P (not_X) * P (Customer#3356|not_X)]
- =0.6 * 0.0993 / [P(X) * P(Customer#3356|X) + P (not_X) * P (Customer#3356|not_X)]
- P(not_X|Customer#3356) = [P(not_X) * P(Customer#3356|not_X)] / [P(X) * P(Customer#3356|X) + P (not_X) * P (Customer#3356|not_X)]
- =0.4 * 0.0234 / [P(X) * P(Customer#3356|X) + P (not_X) * P (Customer#3356|not_X)]
Notice that both probabilities P(not_X/Customer#3356) and P(X/Customer#3356) have the same numerator. Through comparing the numerators, the following inequality can be deduced:
- P(X|Customer#3356) > P(not_X|Customer#3356)
Thus we can conclude that Customer#3356 is more likely to buy Product X.
The Markov Model
The Markov Model is a statistical model that relies heavily on probability theory. (It’s named after a Russian mathematician whose primary research was in probability theory.)
Here’s a practical scenario that illustrates how it works: Imagine you want to predict whether Team X (let’s say a soccer team) will win tomorrow’s game. The first thing to do is collect previous statistics about Team X. The question that might arise is how far back you should go in history. Let’s assume you were able to get to the last 10 past game outcomes in sequence. You want to know the probability of Team X winning the next game, given the outcomes of the past 10 games (for example, Team X won 3 times and then lost 7 times). The problem is that the further back in history you want to go, the harder and more complex the data collection and probability calculations become.
Believe it or not, the Markov Model simplifies your life by providing you with the Markov Assumption, which looks like this when you write it out in words:
The probability that an event will happen, given n past events, is approximately equal to the probability that such an event will happen given just the last past event.
Written as a formula, the Markov Assumption looks like this:
Either way, the Markov Assumption means that you don’t need to go too far back in history to predict tomorrow’s outcome. You can just use the most recent past event. This is called the first-order Markov prediction because you’re considering only the present event to predict the future event. A second order Markov prediction includes just the last two events that happen in sequence. From the equation just given, the following widely used equation can also be derived:
This equation aims to calculate the probability that some events will happen in sequence: event1 after event2, and so on. This probability can be calculated by multiplying the probability of each event t (given the event previous to it) by the next event in the sequence. For instance, suppose you want to predict the probability that Team X wins, then loses, and then ties.
A typical Markov Model prediction
Here’s how a typical predictive model based on a Markov Model would work. Consider the same example: Suppose you want to predict the results of a soccer game to be played by Team X. The three possible outcomes — called states — are win, loss, or tie.
Assume that you’ve collected past statistical data on the results of Team X’s soccer games, and that Team X lost its most recent game. You want to predict the outcome of the next soccer game. It’s all about guessing whether Team X will win, lose, or tie — relying only on data from past games. So here’s how you use a Markov Model to make that prediction.
Calculate some probabilities based on past data.
For instance, how many times has Team X lost games? How many times has Team X won games? For example, imagine if Team X won 6 games out of ten games in total. Then, Team X has won 60 percent of the time. In other words, the probability of wining for Team X is 60 percent. You arrive at this figure by taking the number of victories and dividing by 10 (the total number of games), which results in a probability of 60 percent.
- Calculate the probability of a loss, and then the probability of a tie, in the same way.
Use the probability equation mentioned in the previous Naïve Bayes section to calculate probabilities such as the following:
- The probability that Team X will win, given that Team X lost the last game.
- The probability that Team X will lose, given that Team X won the last game.
Let’s arbitrarily assign those probabilities. Note that you can easily calculate P(X|Y) — the probability of X given Y — as shown earlier in the Naïve Bayes section of this chapter.
Calculate the probabilities for each state (win, loss, or tie).
Assuming that the team plays only one game per day, the probabilities are as follows:
- P (Win|Loss) is the probability that Team X will win today, given that it lost yesterday.
- P (Win|Tie) is the probability that Team X will win today, given that it tied yesterday.
- P(Win|Win) is the probability that Team X will win today, given that it won yesterday.
Using the calculated probabilities, create a chart like the one shown in Figure 7-7.
A circle in this chart represents a possible state that Team X could attain at any given time (win, loss, tie); the numbers on the arrows represent the probabilities that Team X could move from one state to another.

FIGURE 7-7: Team X’s possible states (win, loss, tie) and past probabilities.
For instance, if Team X has just won today’s game (its current state = win), the probability that the team will win again is 60 percent; the probability that they’ll lose the next game is 20 percent (in which case they’d move from current state = win to future state = loss).
Suppose you want to know the chances that Team X will win two more games in a row and lose the third one. As you might imagine, that’s not a straightforward prediction to make.
However, using the chart just created and the Markov assumption, you can easily predict the chances of such an event occurring. You start with the win state, walk through the win state twice, and record 60 percent twice; then you move to the loss state and record 20 percent. The chances that Team X will win twice and lose the third game become simple to calculate: 60 percent times 60 percent times 20 percent which equals 7.2 percent.
Using hidden Markov Models
A hidden Markov Model is a Markov Model in which a previous state from which the current state originated can be hidden or unknown. The main inputs to the model are the states transition probabilities and a number of observations. A hidden Markov Model takes observation states into consideration. Let us walk you through an example that predicts a future state on the basis of a previous state and some observations.
Suppose you’re currently watching a game that Team X is playing and you make the following observation:
Team X is winning, so far, by 1 goal to zero (the current score over the first 30 minutes of the game).
Based on only one present observation, you want to predict a hidden future state: Will Team X win, lose, or tie?
Assume you know the past statistical probabilities for Team X, as mentioned earlier in the previous section (refer to Figure 7-7). Here are the steps to predict the next hidden (unknown) state — whether Team X will win, lose, or tie — on the sole basis of your current observation.
The first phase (as mentioned earlier) is the learning phase: You learn about Team X from past data and the outcomes of Team X’s games. The following facts turn up:
- Team X won 55 percent of its past games, lost 40 percent of those games, and tied 5 percent of the time.
- In all past games, Team X won 60 percent of the time when they scored a goal within the first 30 minutes.
- In all past games, Team X lost 35 percent of the time when they scored a goal within the first 30 minutes.
- In all past games, Team X tied 5 percent of the time when they scored a goal within the first 30 minutes.
The statistics that reflect the learning outcomes from past games can be summarized like this:
Win |
Loss |
Tie |
|
P(X) |
55 percent |
40 percent |
5 percent |
The following table shows the probabilities of an outcome X, given observation Z.
Z = scored a goal within the first 30 minutes |
|
X=win |
60 percent |
X=loss |
35 percent |
X=tie |
5 percent |
Using a probability rule known as Bayes’ Theorem (mentioned in the Naïve Bayes section) and the Markov Assumption just mentioned in the previous section, you can easily calculate the probability that Team X will win if you’re currently observing that the team has scored a goal within the first 30 minutes of the game. Similarly, you can calculate the probability that Team X will lose if you observe that the team has scored a goal within the first 30 minutes of the game. Also, assume that Team X ties in the previous game, and that the prior probability of Team X scoring in the first 30 minutes in any game is 40 percent. Given these facts and observations, what is the probability Team X will win the game?
Here’s how to calculate the probability that Team X will win, given that Team X tied in the last game and you observe that the team scored within the first 30 minutes of the current game. This probability can be written as follows:
For simplicity in the equations, consider the following notations:
Now you can write that same probability — that Team X will win, given that Team X tied in the last game and you observe that the team scored within the first 30 minutes of the current game, and also given that Y and Z are independent — like this:
- P(X|Y, Z) = P(X,Y|Z) / P(Y|Z)
- = P(X,Y|Z) / P(Y)
Applying the Naïve Bayes rules explained earlier, we get this:
- = P(Z|Y, X) * P(X, Y) / [ P(Y) * P (Z)]
Applying Markov’s Assumption equation (mentioned in the previous section) gives you this result:
- = P(Z|X) * P(X, Y) / [ P(Y) * P (Z)]
- = P(Z|X) * P(X|Y) * P(Y) / [ P(Y) * P (Z)]
- = P(Z|X) * P(X|Y) / P (Z)
- = (60 percent * 30 percent) / 40 percent = 45 percent
Written out, it looks like this:
Hidden Markov Models have been successfully used in time series predictions and in practical applications such as speech recognition and biological sequence analysis.
Linear regression
Linear regression is a statistical method that analyzes and finds relationships between two variables. It can be used to predict a future numerical value of a variable.
Consider an example of data that contains two variables: past data consisting of the arrival times of a train and its corresponding delay time. Suppose you want to predict what the delay would be for the next train. If you apply linear regression to these two variables — the arrival and delay times — you can generate a linear equation such as
Delay = a + (b * Arrival time) + d
This equation expresses the relationship between delay time and arrival time. The constants a and b are the model’s parameters. The variable d is the error term (also known as the remainder) — a numerical value that represents the mismatch between the two variables delay and arrival time.
If you’re sitting at the train station, you can simply plug the arrival time into the preceding equation and you can compute the expected delay, using the linear regression model’s given parameters a, b, and d.
Linear regression can be very sensitive toward outliers in the data points. The outliers in your data can have a significant impact on the model (for more about outliers, see Chapter 15). We recommend that you carefully remove those outliers from the training set if you’re planning to use linear regression for your predictive model.
Neural networks
A complex algorithm, the neural network, is biologically inspired by the structure of the human brain. A neural network provides a very simple model in comparison to the human brain, but it works well enough for our purposes.
Widely used for data classification, neural networks process past and current data to estimate future values — discovering any complex correlations hidden in the data — in a way analogous to that employed by the human brain.
Neural networks can be used to make predictions on time series data, such as weather data. A neural network can be designed to detect pattern in input data and produce an output free of noise.
Figure 7-8 illustrates the structure of a neural-network algorithm and its three layers:
- The input layer feeds past data values into the next (hidden) layer. The black circles represent nodes of the neural network.
- The hidden layer encapsulates several complex functions that create predictors; often those functions are hidden from the user. A set of nodes (black circles) at the hidden layer represents mathematical functions that modify the input data; these functions are called neurons.
- The output layer collects the predictions made in the hidden layer and produces the final result: the model’s prediction.

FIGURE 7-8: Neural networks create predictors in the second (hidden) layer of a three-layer structure.
Here’s a closer look at how a neural network can produce a predicted output from input data. The hidden layer is the key component of a neural network because of the neurons it contains; they work together to do the major calculations and produce the output.
Each neuron takes a set of input values; each is associated with a weight (more about that in a moment) and a numerical value known as bias. The output of each neuron is a function of the output of the weighted sum of each input plus the bias.
Most neural networks use mathematical functions to activate the neurons. A function in math is a relation between a set of inputs and a set of outputs, with the rule that each input corresponds to an output. (For instance, consider the negative function where a whole number can be an input and the output is its negative equivalent.) In essence, a function in math works like a black box that takes an input and produces an output.
Neurons in a neural network can use sigmoid functions to match inputs to outputs. When used that way, a sigmoid function is called a logistic function and its formula looks like this:
Here f is the activation function that activates the neuron, and e is a widely used mathematical constant that has the approximate value of 2.718.
You might wonder why such a function is used in neurons. Well, most sigmoid functions have derivatives that are positive and easy to calculate. They’re continuous, can serve as types of smoothing functions, and are also bounded functions. This combination of characteristics, unique to sigmoid functions, is vital to the workings of a neural network algorithm — especially when a derivative calculation (such as the weight associated with each input to a neuron) is needed.
The weight for each neuron is a numerical value that can be derived using either supervised training or unsupervised training, such as data clustering (see Chapter 6):
- In the case of supervised training, weights are derived by feeding sample inputs and outputs to the algorithm until the weights are tuned (that is, there’s a near-perfect match between inputs and outputs).
- In the case of unsupervised training, the neural network is only presented with inputs; the algorithm generates their corresponding outputs. When we present the algorithm with new-but-similar inputs and the algorithm produces new outputs that are similar to previous outputs, then the neurons’ weights have been tuned.
Neural networks tend to have high accuracy, even if the data has a significant amount of noise. That’s a major advantage; when the hidden layer can still discover relationships in the data despite noise, you may be able to use otherwise-unusable data.
Deep Learning
Deep learning algorithms are among the latest state-of-the-art innovations made in the field of machine learning.
Think of a deep learning algorithm as a black box that makes predictions. Consider a scenario where you have a picture that is first being converted to numbers and pixels. A deep learning algorithm can run a series of mathematical functions on those numbers and returns different numbers that can reveal the nature of the object in the image.
These mathematical functions are based on the neurons’ parameters in a neural network. The biggest challenge with using neural networks has been to teach and train them on massive sets of inputs in order to derive the right neuron’s parameters. This would lead to a better prediction accuracy.
The renaissance of neural networks
Deep learning algorithms are here to improve neural networks’ ability to detect complex patterns. In fact, one of the key phases in the predictive analytics lifecycle involves the process of Feature Extraction explained in Chapter 9.
Feature Extraction, also known as Feature Engineering, is a time-consuming process that has to take place, in most cases, before applying a predictive model. It is also a process in the predictive analytics pipeline that has a lot of influence on the final model’s accuracy.
Deep learning algorithms are designed so that they skip the feature extraction step of predictive analytics and machine learning. Automatic learning of features relevant to the training data is a major advantage of deep learning. In many cases, especially in the field of image pattern recognition, deep learning has outperformed the model accuracy of traditional feature extraction engineering algorithms.
Like any other predictive model, the choice of the training data set has a major effect on the accuracy of the deep learning algorithm.
Introducing deep learning
Deep learning is a novel sub-field of machine learning. It is often referred to as deep structure learning, deep machine learning, or hierarchical learning. Deep learning consists of algorithms that try to automatically learn multiple levels of abstractions of data. Those abstractions can help in the process of extracting insights and forward-insights.
Deep learning is about neural networks. As explained in the preceding section, a neural network is a graph of nodes called “neurons” that have edges between them. A neural network takes a set of numbers as inputs, then applies complex mathematical computations on those inputs and produces a set of outputs that could be used for data classification.
As we mention in the preceding section, a neural net is a network of nodes that are organized in layers. The first layer is called the input layer and the last layer is called the output layer. The layers in between are known as “hidden layers.” Every node in the hidden layer can be seen as a classifier that takes an input and returns an output (which is also the input to another neuron in the subsequent hidden layers). The last outputs are a combination of the outputs from many neurons on the hidden layers of the neural network. This process of passing inputs from one layer to another through hidden layers until they reach the final output at the output layer is known as forward propagation.
You might wonder why each node in the hidden layers is producing a different output. The reason is that every node is associated with two values: a bias and weight. A weight is a numerical value by which an input is being multiplied; a bias is another numerical value that is being added to the output at every node. The weights and biases are critical to the classification accuracy in a neural network.
A neural network needs to be trained, like any other predictive model. Cross validation, for example, can be used to train the model. In other words, the ground truth output is compared to the output generated by the neural net, and the bias and weight values are adjusted accordingly each time there is a mistake on the output. The ultimate goal behind training a neural net is to reduce costs; the cost is the difference between the predicted value generated by the neural net and the actual known value in the training data.
The biases and weights are adjusted and tweaked through running the neural network across a large number of training data samples.
The reason why neural nets are complex is because multiple neurons, which can be viewed as classifiers, are being trained. For datasets of very complex patterns, neural nets tend to provide better prediction accuracy when compared with other classifiers, at the cost of training the neural network. However, with recent advancements in computing power, neural nets can be trained in relatively short amount of time.
Deep learning takes a divide-and-conquer approach to detect very complex patterns. In fact, a deep learning algorithm tries to break up the problem of detecting complex patterns into smaller parts. It does this by detecting a set of less complex sub-patterns that, collectively, will lead it to discover the original pattern.
In the previous fruits example, consider the data classification problem where the goal is to classify and determine whether the image is of a banana. In simple terms, a deep learning algorithm will try to detect the edges of the object, the shape, and the color. Next, it will calculate an output score that reflects a decision of whether this is a picture of a banana.
An analogy would be how we, as human beings, detect complex patterns. We tend to detect such patterns by finding smaller, simpler patterns that will lead us to make final decisions. Interestingly, the design of a deep neural network was inspired by the architecture of the human brain.
Deep learning algorithms are very robust and in most cases outperform all classifiers for detecting very complex patterns. However, deep learning networks take a very long time to be trained. For example, in some cases it might take about a week to train a deep network.
A neural network is trained through calculating a cost value. The cost is the difference between the actual value (ground truth and labeled training data) and the predictive value produced by the neural net. The cost is minimized by running several iterations of the training. The weights and biases at each neuron are adjusted accordingly to lower the cost.
The training process of neural networks utilizes a mathematical function called gradient. This measures how much the cost will change with respect to a change in biases, values, and weights. Back propagation is the process of training neural networks. This process can be seen as the reverse of forward propagations (discussed previously in this section). It starts with the last layer and moves towards the first layer. The gradients are being multiplied throughout the back propagation process. As the network becomes more complex, back propagation takes a lot of time to train the neural network and the accuracy deteriorates. While training a deep net, researchers have encountered a major problem known as the vanishing gradient. The vanishing gradient problem occurs as the values of the gradients become very small (multiplying numbers ranging from 0 to 1) until they vanish as we propagate back over the network.
These problems were addressed by researchers like Professor Yann LeCun, of New York Univerty’s Courant Institute of Mathematical Sciences. He is also the director of Artificial Intelligence at Facebook.
Results from deep learning researchers’ work and other teams led to the creation of the Restricted Boltzmann Machine (RBM). An RBM is considered a feature extractions neural network. In simple terms, an RBM is a neural network of two layers: the visible layer and the hidden layer. Each neuron (node) in the visible layer is connected to every neuron in the hidden layer. Nodes from the same layer can't be connected. The RBM converts the set of inputs into outputs in the forward pass, and tries to reconstruct the inputs from the output on the backward pass. Through this process, weights and biases on an RBM are being adjusted, and the RBM is trying to learn which inputs are more important than others through several iterations of backward and forward passes. An RBM doesn't necessarily require labeled data. The RBM has performed well for mining and classifying videos and images.
Combining multiple RBMs together can partially address the vanishing gradient problem. A set of combined RBMs can construct deep belief networks, another deep learning algorithm in the family of deep learning. Each RBMs’ hidden layer is considered a visible layer of the subsequent RBM in the deep belief net structure. Because of its structure, deep belief networks would only need a reasonably small dataset to train.
There exist multiple deep learning algorithms known to work for different applications. Follow these guidelines to get started and make selections from available algorithms:
- Recurrent nets algorithms are suitable for time series analysis.
- Recursive neural tensor network algorithms are suitable for text mining problems for supervised learning.
- In many cases, Deep belief networks and convolutional neural networks algorithms tend to perform well for supervised learning problems for image and object recognition.
- Restricted Boltzmann Machine and auto-encoder algorithms are suitable for unsupervised learning, unlabeled data for the purpose of feature extraction.
- Deep belief networks and rectified linear units (ReLU) algorithms are good for general-purpose data classification.
Remember:
- In deep learning algorithms, data is being passed through a sequence of layers. Each layer takes some numbers and interprets those numbers, which are passed to another layer.
- Each layer is trying to identify a subset of features in the input data. This data could be text, video, or images.
- A neural network is being trained by calculating a cost value. The cost is the difference between the actual value (ground truth and labeled training data) and the predictive value produced by the neural net.
- The cost is minimized through running several iterations of training. The weights and bias at each neuron are being adjusted accordingly to lower the cost.
- For simple pattern detection, you might not need to use neural networks or deep learning algorithms; a simple classifier like linear regression or support vector machine would do the job.
- For complex tasks such as facial recognition, deep learning algorithms are more appropriate.
- To properly train a convolutional neural network (repeats), you need millions of images; otherwise, you may overfit the model.
- Deep learning can be used in real-time speech recognition, natural language processing, text mining, video stream mining, and image recognition.