
17 Toward Accurate Simulation of Large-Scale Systems via Time Dilation
James Edmondson and Douglas C. Schmidt
CONTENTS
17.2.1 Formal Composition Techniques
17.3.1 Ethernet Capture Effect
17.4 Applying Time Dilation with Diecast
17.4.1.1 Time Dilation Factor (TDF) and Scale Factor (SF)
17.4.1.2 Paravirtualized vs. Fully Virtualized VMs
17.4.2 Application to Motivating Scenarios
17.5 Addressing Issues of Time Dilation in Physical Memory
17.1 Introduction
Distributed systems, particularly heterogeneous systems, have been historically hard to validate [1]. Even at small scales—and despite significant efforts at planning, modeling, and integrating new and existing systems into a functional system-of-systems—end users often experience unforeseen (and often undesirable) emergent behavior on the target infrastructure. Some types of unexpected emergent behaviors include unwanted synchronization of distributed processes, deadlock and starvation, and race conditions in large-scale integrations or deployments [2].
Deadlock and starvation are not just limited to large-scale systems and can occur when connecting just a few computers or computer systems together. Phenomenon such as the Ethernet Capture Effect [2,3] (which is a type of race condition involving a shared bus and accumulating back-off timers on resending data) once occurred on networks as small as two computers, despite decades of previous protocol use and extensive modeling. If problems like this can occur during small integrations or technology upgrades, the challenges of integrating large-scale systems containing thousands of computers, processing elements, software services, and users are even more daunting. Ideally, all technological upgrades and new protocols could be tested on the actual target infrastructure at full scale and speeds, but developers and system integrators are often limited to testing on smaller-scale testbeds and hoping that the behavior observed in the testbeds translates accurately to the target system.
Consequently, what we need are technologies and methodologies that support representative “at-scale” experiments on target infrastructure or a faithful simulation, including processor time and disk simulation, as well as network simulation. These technologies and methodologies should allow application developers to incorporate their application or infrastructure software into the simulator unmodified, and so they run precisely as expected on the target system. There are many network simulators available for use—some of which we discuss in this chapter—but we also explore a new simulation technology that was introduced by Gupta et al. and is called time dilation [4].
The term time dilation has roots in the theory of relativity, pioneered by Albert Einstein in the early twentieth century [5]. In physics, time dilation is a set of phenomena that describe how two observers moving through space relative to each other or at different positions relative to objects with gravitational mass will observe each other as having erroneous clocks, even if the clocks are of identical construction. Relative velocity time dilation, the phenomenon described by two bodies observing each other’s clocks while moving at different velocities, is the best parallel for the definitions and usage of the terminology in the work on simulation by Gupta et al.
Gupta et al. specifically coin the term time dilation in simulation to describe the process of altering time sources, clocks, and disk and network transactions to allow accurate simulation of multiple virtual machines (VM) on a single host, and we use this new definition throughout this chapter. This new usage fits with the original definitions by Einstein since a simulator and the actual operating system running the simulator will see time flowing at different rates due to context switching and other modern operating system techniques, despite both using equivalent clock mechanisms. The time dilation mechanism in the simulation context attempts to correct this clock drift from the simulator and operating system perspective to allow for closer approximation of target behavior by simulated tests.
Simulations based on time dilation allow system integrators and planners to run unmodified executables, services, and processing elements to accurately emulate CPU, network, disk, and other resources for large-scale systems in much smaller testbeds. A prototype of this time dilation technology called DieCast [6] has been implemented by researchers at the University of California at San Diego. This chapter explores the benefits of this technology to date, summarizes what testers must consider when using DieCast, and describes future work necessary to mature time dilation techniques and tools for simulation of large-scale distributed systems. This chapter presents a survey of the work to date by Gupta et al. in the application of time dilation to simulation in DieCast. It also motivates future work on memory management considerations for time dilation and the need for additional improvements to conventional time dilation implementations to address particular types of race conditions (such as the Ethernet Capture Effect) that may not be covered by time dilation.
17.2 Background
In general, large-scale distributed systems are difficult to validate. Though some simulators, such as USSF described in Section 17.2, can emulate networks consisting of millions of nodes, simulation technologies that scale to this level often deviate from the performance and characteristics of target large-scale systems. This section describes related work on validating distributed systems and summarizes the pros and cons of current validation techniques with respect to their ability to address the role of time dilation in large-scale system validation. We divide related background material into two main areas: formal composition and simulation techniques.
17.2.1 Formal Composition Techniques
Formal composition is typically associated with modeling a target system in a computer-aided manner that ensures the distributed system is validated based on validated components and will execute properly on the target system [7]. When constructing mission and safety-critical distributed real time and embedded systems, such as flight avionics computers and nuclear power plant control systems, software developers often use formal composition techniques and tools, such as Step-Wise Refinement [8], Causal Semantics [9], Behavioral Modeling [10], and Object Modeling Technique [7], to validate their software before it goes into production.
Formal composition techniques are often time consuming to validate, however, and can be tightly coupled to a particular development context and domain. Moreover, many formal composition methods require developers to model everything (e.g., from processors to operating systems to the application logic) to validate the target system. When composing systems-of-systems with formal composition techniques in this manner, it is difficult to ensure a meaningful composition of heterogeneous components that interoperate correctly [11]. Progress is being made in this area of expertise–including a recent Turing Award awarded to Edmund Clarke, Allen Emerson, and Joseph Sifakis in 2007 for their work in the field of model checking [12], but formal composition of heterogeneous hardware, software, and platforms generally remains an open challenge, especially for large-scale distributed systems.
The main thrust of current development in this area of expertise is the domain-specific modeling language (DSML) [13], which requires developers to tailor a visual modeling language to a specific knowledge domain, allowing business logic programmers to create an application, device driver, etc. for a specific application need (e.g., a device driver for a particular type of hardware). DSMLs can shield developers from many tedious and error-prone hardware and operating system concerns, allowing them to focus on modeling the business application logic and allow further validation by tools developed by researchers and engineers experienced in the target domain.
Though DSMLs can simplify validation of certain software/hardware artifacts (such as device drivers on an airplane) for application developers, it is much more difficult to make a DSML that encompasses all hardware, device drivers, operating systems, etc. for an Internet-connected application or even a small network of application processes. One issue that hinders modeling languages from being able to completely validate arbitrary application and infrastructure software is the sheer variety of orthogonal personal computer architectures and configurations that must be expressed to ensure proper validation.
Validating an application can be simplified somewhat for homogenous configurations (e.g., all personal computers are Dell T310 with a certain number and type of processors, all running a specific version and configuration of Windows, etc.), but complexities remain because of randomized algorithms used in many components of operating systems such as page replacement and queuing. Threading presents additional challenges, even in homogonous hardware configurations, since composing multiple threads has no formally recognized semantic definition that fits all possible compositions [11].
When heterogeneous hardware, operating systems, and software must be supported, validating software with formal composition techniques becomes even harder. Formally composing legacy systems with closed-source implementations into a large-scale system may be aided by solutions that allow descriptions of behaviors by the legacy system, but it is still difficult to ensure that an entire large-scale system is formally composed in a semantically meaningful way. Because of these issues, we do not discuss formal composition techniques in this chapter, but instead focus on a separate vector of validation: simulation.
17.2.2 Simulation Techniques
Simulation is the process of reproducing the conditions of a target platform [14], and because of its flexibility, simulation has been the de facto method for validating many networked and distributed applications. A popular simulation model is discrete event simulation, where business application logic, operating system logic, etc. are treated as distinct, discrete events that are processed by a simulator engine [15,16,17,18]. Though simulation has evolved quite a bit in recent decades, simulators often make approximations that bring testing closer to a target system but do not precisely match what is being simulated, especially when the network connectivity, processing elements, or activities performed that are being simulated experience failures, intermittent behavior, or scarce resources.
Simulation technologies are particularly problematic in highly connected distributed or networked applications where Internet connections with high failure rates or resends are frequent. Although simulating the Internet is generally considered infeasible [19,20], many network emulators exist that attempt to emulate Internet access times, intermittency, network congestion, etc., and local area network testing. Examples of these simulators include Emulab and its derivatives Netlab [21] and ISIS Lab at Vanderbilt University [22], which can simulate dozens to hundreds of processing elements and their interconnections.
Emulab and its derivatives allow swapping in operating system images, applications, and test script setup to enable automated testing. They also provide robust network emulation including bandwidth restriction, packet loss, etc. Accuracy of the simulation is left as an exercise to the developer or user and how they configure operating system images, scripts, etc. Moreover, Emulab does not explicitly support multiple VMs per host, though if a user must scale a small testbed to a larger target system, operating system–specific VM managers, such as Xen [23], may be used.
Other simulators such as Modelnet [24] and USSF [19] enable explicit virtualization of hosts and also include robust network emulators. Modelnet separates a testbed infrastructure into edge nodes and nodes that act as switches between the edge nodes. Vahdat et al. [24] showed that a host emulating Gigabit Ethernet in Modelnet can result in approximations of networked application performance during simulation. The throughput difference between the emulation and real-world performance shown in their results, however, can differ by as much as 20%. Closer performance is possible if more than just networking is emulated, as shown in Section 17.4, via time dilation.
USSF is a simulation technology based on Time Warp and built on top of the WARPED [25] parallel discrete-event simulator that claims to simulate large-scale target systems of over 100,000 nodes [26]. USSF is complicated to use and develop for, requiring the creation of topology models and generation from application model to application code. Developers then tailor their application to the simulator, which may be unacceptable for existing code, particularly complex code that interfaces with undocumented legacy systems.
Working with USSF requires parsing a USSF model into a Topology Specification Language and then code generation via static analysis to reduce memory consumption—a major issue in WARPED libraries. The resulting code then links to WARPED libraries and the USSF kernel, which interfaces to the user application. Although USSF does allow simulation of potentially millions of nodes, there is no guarantee (or even an established working estimate) that the simulation will match a physical target system because USSF development has been prioritized to operate on reduced memory per VM, high cache hit ratios via file-based caching with a least-recently-used policy for cache replacement, etc. and not accuracy of simulation.
17.3 Motivating Scenarios
To provide a solid motivation for time dilation and simulation of large-scale systems in general, this section presents several testing scenarios that require scalable and sound validation techniques. These examples focus on system environments where the computer infrastructure is mission-critical. Before we deploy large-scale mission-critical computer systems, it is essential to accurately simulate such systems in a smaller, less critical infrastructure where typical functional and performance problems can be observed, analyzed, and ultimately resolved before production deployment occurs.
We first discuss a smaller situation (connecting two computers together) and specifically look into a phenomenon known as the Ethernet Capture Effect [2,3] that can manifest itself when connecting just two computers together, at least one of which is constantly sending information over an Ethernet connection. To identify the Ethernet Capture Effect during simulation requires the simulator adhering closely to actual performance on a target architecture. We next review Application Services, which are collections of interdependent systems, such as database servers, front end servers, etc. We then expand the second scenario to include collections of such services, which is our targeted large-scale scenario. We refer to these three motivating scenarios when discussing the capacities and capabilities of modeling or simulation techniques.
17.3.1 Ethernet Capture Effect
The Ethernet Capture Effect [2,3] is a form of emergent misbehavior that plagued system integrators during the 1990s and caused unfairness in a networking system once Ethernet hardware became fast enough to support resend frequencies that approached optimal speeds indicated in the Ethernet protocol standard. Though specific to Ethernet, similar problems during integration and scaling can occur with any other system with a shared bus. To replicate this behavior requires just two hosts, both of which send information frequently.
During the 1990s, when a collision occurred between Ethernet connected hosts, all hosts involved in the collision would randomly generate a back-off time to allow the selection of a winner to send information across the Ethernet. The winner of this contest for the shared resource would have its back-off timer reset, while the loser or losers of this contest would essentially accumulate back-off timers until they successfully sent information.
The problem of the Ethernet Capture Effect manifested itself when the winner of these contests had a distinct amount of information to send and the Ethernet hardware was fast enough to allow for the winner to send its next information immediately (see Figure 17.1 for losing hosts increasing their back-off timers). Since its timer had been reset, this host or service would be allowed to win each contest, indefinitely, while the losing hosts would be essentially starved until the winning process or service finished. If the winning process never died, the starvation would be indefinite or last until a developer or technician reset the nodes involved.

FIGURE 17.1 Example of the Ethernet Capture Effect in a four host system where one host is publishing constantly and three hosts are being forced to increase their back-offs indefinitely to avoid collisions. This race condition occurred despite extensive modeling of the Ethernet protocol and decades of practical use.
Ethernet had been modeled extensively before the problem became apparent. Moreover, Ethernet devices had been in service for decades before the Ethernet Capture Effect manifested itself in any type of scale. The protocol had been standardized and validated by thousands of users across the world, but small increases in hardware capabilities caused this emergent misbehavior to cripple previously functioning networks or integrations between seemingly compatible Ethernet networks of services, processes, and hosts.
The Ethernet Capture Effect represents emergent behaviors that should be caught during simulation on a testbed before deployment. If a simulator cannot catch such behaviors, major problems could manifest themselves in the production deployments. Time dilation does not solve this issue. Instead, the Ethernet Capture Effect scenario is presented as a potential motivator of future work.
17.3.2 Application Services
Amazon, Google, and various other companies maintain thousands of servers providing software services for millions of end users every year. Application Services can range from a dozen to thousands of hosts (see Figure 17.2 for an example of deployment). Though most of these service providers have proprietary networks and systems, there are other open-source auction, e-commerce, and specialty sites for general testing. Many of these proprietary and legacy systems are closed-source, meaning that formal composition methods may not be feasible for most of the utilized systems (e.g., other than a brief description of what the legacy software does, a developer may not be able to completely model much less formally compose the system without the original developer providing the completed formal model).

FIGURE 17.2 Example of a medium-scale Application Service with application gateways communicating over local area connections to web servers and databases. Internet connections can be a large part of Application Services, as depicted by the advertisement servers’ interactions.
Consequently, Modelnet, Emulab, or similar simulators can be used to gauge and validate a target Application Service, though simulation technologies such as USSF (see Section 17.2) may require too much modification for the simulation to be accurate enough for validation before deployment.
17.3.3 Large-Scale Systems
Large-scale systems are complex systems of systems that evolve over time. For the purposes of this chapter, the motivating scenario here is an integration of a dozen or more Application Services into one large-scale system of 2000 nodes and is comprised of heterogeneous hardware and services. Moreover, we envision a large-scale system to have subsystems linked together via a combination of Internet connections and local area networks.
Consequently, the motivating scenarios presented in this chapter cover simulation needs from a very small network of two to three nodes (e.g., Ethernet Capture Effect) to a medium-sized network of a few dozen nodes (e.g., Application Services) to a large network of thousands of nodes (e.g., large-scale systems). In Section 17.4.2, we show how time dilation can be used to accurately simulate these latter two scenarios by intrinsically maintaining both accuracy and scale. The Ethernet Capture Effect and race conditions like it will require additional refinements to the time dilation simulation process (discussed more in Section 17.4.3).
17.4 Applying Time Dilation With Diecast
Previous sections have examined formal composition and simulation technologies that are being used to approximate and validate large-scale networks. This section expands on these technologies to include descriptions and results of the DieCast simulator system, which is based on the time dilation principle.
17.4.1 Overview
17.4.1.1 Time Dilation Factor (TDF) and Scale Factor (SF)
As mentioned in Section 17.1, time dilation has roots in the theory of relativity as the description of a phenomenon where two observers might view each other as having erroneous clocks, even if both clocks are of equivalent scale and construction [5]. In work by Gupta et al. [4,6], time dilation is the process of dividing up real time by the scale of the target system that will be emulated on a particular host. The reasoning for this partitioning is simple. Each host machine will potentially emulate numerous other hosts via VMs in an environment called Xen [23], preferably all requiring the same hardware, resources, and timing mechanisms found on the host machine.
A first instinct for emulating nine hosts might be to create nine VMs of the same operating system image and run them with regular system time mechanisms on the testbed hosts. An equivalent to this situation is shown in Figure 17.3. This approach, however, does not emulate the timing of the physical target system because the testing system will be sharing each physical second between the emulated hosts or services, resulting in each VM believing a full second of computational time has passed when the VM was really only able to run for a ninth of that time. This sharing can cause problems in emulation, for example, it can affect throughput to timer firings, sleep statements, etc. Time dilation allows the system developer to adjust the passage of time to more accurately reflect the actual computational time available to each VM. How time dilation affects the simulation of nine VMs on a single host is shown in Figure 17.4.
SF specifically refers to the number of hosts being emulated, while the TDF refers to the scaling of time. Gupta et al. [6] mentioned that these factors may be set to different values, but for the purpose of experimentation in the paper, TDF and SF are both set to the same values.

FIGURE 17.3 Most simulators do not modify time sources for virtual machines according to processor time actually used by a virtual machine. This can cause a simulation to drift from actual operation on target hardware because of queuing of timer-related events.

FIGURE 17.4 Basics of time dilation. When running nine virtual machines on a single host, programmable interrupt timers, time sources, and other timer-related events for each individual VM should only increment by the amount of processor time used by the VM.
17.4.1.2 Paravirtualized vs. Fully Virtualized VMs
To accomplish disk input/output emulation, Gupta et al. had to deal with the intricacies of two different types of VMs: paravirtualized and fully virtualized. A paravirtualized VM is a virtualized OS image that was limited to certain flavors of Linux and was soft-emulated on the host. Fully virtualized, in contrast, requires hardware support via Intel Virtualization Technology or AMD Secure VM, but does allow for any operating system image to be emulated directly on the hardware—rather than just a certain type of supported OS.
In their previous work on paravirtualized images [4], Gupta et al. created mechanisms that sat between the disk device driver and the OS, allowing emulation of disk latencies, write times, etc. with time dilation mechanisms. For the fully virtualized model of emulation, Gupta et al. used a disk simulator called DiskSim to emulate a disk drive in memory, which provided more control over buffering of read/write tasks. DiskSim gave the DieCast developer the ability to take the number of VMs into account and partition the read/write queuing accordingly.
The fully virtualized VM implementations give DieCast users the ability to plug in any operating system into the underlying Xen hypervisor and emulate a functional host according to the time slices allocated to each VM via time dilation. Together with changes to the time sources, CPU scheduling, and network emulation, fully virtualized VMs give developers a lot more options and control over what they are going to be testing and amazing scalability (concerning VMs accurately simulated per host). The divergence of a simulation from the target environment (which we call the “overestimation factor”) without taking time dilation into account is shown in Figure 17.5, which is based on Figure 17.2c from Gupta [6]. This overestimation factor in the simulation is a multiple of the correct target system (i.e., simulating 10 VMs per host results in inaccurate simulation by a factor of 9 on disk throughput). We also experienced this same phenomenon when simulating multiple subscribers and publishers per host in our own testing of the Quality-of-Service (QoS)-Enabled Dissemination (QED) middleware [27].

FIGURE 17.5 Analysis of the overestimation of disk throughput without time dilation versus using CPU and disk time dilation scaling.
17.4.1.3 CPU Scheduling
To implement properly scaled CPU scheduling, Gupta et al. had to intercept and scale a number of time sources appropriately. Timer interrupts (e.g., the Programmable Interrupt Timer), specialized counters (e.g., TSC on Intel platforms), and external time sources (e.g., Network Time Protocol) were intercepted and scaled before being handed to VMs.
Timing is more intricate, however, than just allotting 1/(time dilation factor) time to each VM. For IO bound VMs, they may not use their full CPU allocation and this could skew the non-IO-bound VM CPU usage upwards and affect all timing dependent aspects of the emulation. Consequently, Gupta et al. devised a credit-based CPU scheduler in Xen to support a debit/credit scheme, where IO-bound VMs could relinquish CPU, but no VM used more than its exact allocated share of a real time unit. If a VM did not use its share before blocking, the VM received a debit to put towards its next time slice, and the CPU scheduler took into account total usage over a second to make sure that non-IO-bound VMs were not monopolizing the CPU and skewing results.
17.4.1.4 Network Emulation
Network emulation in the DieCast implementation is accomplished via capturing all network traffic and routing it through a network emulator. Though Gupta et al. mention that DieCast has been tested with Dummynet, Modelnet, and Netem, all experiments presented in their work used Modelnet as the network emulator. Since time dilation scales time down, emulating network throughput and latency turns out to be a relatively straightforward task (compared to CPU scheduling). To emulate a 1 Gbps network on a scaled host with time dilation factor of 10, the emulator simply ships 100 Mpbs (1/10 that total) to the host within a second. Latencies are easy to mimic also, since each VM is slowed down to 1/10 speed, and consequently, a system requiring 100 μs latency on the target system could be emulated with data arriving every 1 ms.
Time dilation is a powerful, robust mechanism for network emulation. The first paper on time dilation by Gupta et al. [4] shows how time dilation can even be used to emulate network throughput and speeds that are larger than the network capacity available over a link. As a result, not only can a tester using DieCast simulate ultra high network capacities internal to nodes (e.g., when all VMs are on the same host and the network link is completely emulated), but testers may also scale the number of VMs per host while simultaneously scaling the network capacity between hosts, if required. The key to this ability, once again, is effectively slowing down each VM according to a TDF. If all VMs are operating at that time scale, then the network can be emulated at a factor equal to the TDF.
17.4.2 Application to Motivating Scenarios
Earlier work has focused on time dilation in two scenarios: scaling network characteristics [4] and validating large-scale applications [6]. In the first paper [4] covering time dilation in networked applications, Gupta et al. scale network bandwidth and response time when needed via time dilation in both CPU and network emulation. This work outlined many results concerning how time dilation brought TCP throughput and response times between a simulated and baseline system into harmony in tests between two machines. These results show that time dilation can accurately simulate traffic characteristics (network capacity, response time, and traffic flows down to the TCP layer). As a first step in reflecting our motivating scenarios, therefore, time dilation can accurately simulate scaling the number of VMs and reflecting a target system when the target system is small—down to 1 to 2 machines if needed.
On the surface, this would appear to signal that the DieCast implementation of time dilation would be able to mimic the Ethernet Capture Effect, presented in Section 17.3, between two or more Ethernet capable hosts. Ethernet is at a lower OSI layer than TCP, however, and it is unlikely that a race condition like the Ethernet Capture Effect, which is essentially a hardware-related phenomenon that requires ultra fast publication to manifest, will occur when a simulator is slowing down publication rates by splitting processor time between multiple VMs. Consequently, the Ethernet Capture Effect and phenomenon like it demonstrate problems in current time dilation implementations and the need for future work to address low level (e.g., hardware level) race conditions that are difficult to emulate in a software environment.
In another paper on time dilation, Gupta et al. [4] performed testing in two different types of scenarios: (1) a baseline that is run without time dilation on the actual hardware—40 machines on their testbed—and (2) a scaled version running on much less hardware—usually 4 machines scaled to 40 machines via a TDF of 10. Several types of distributed systems were tested in the papers on time dilation, but we will be focusing on specific tests that reflect our motivating scenarios: RUBiS (an academic tool that resembles an auction site, along with automatable item auctioning, comments, etc.), Isaac (a home-grown Internet service architecture that features load balancers, front end servers, database servers, and clients and application servers), and PanFS (a commercial file system used in clustering environments).
In Ref. [4], Gupta et al. experimented with the DieCast system with TDFs of 10 (meaning that 10 VMs were running per host) and showed the effects of turning off CPU scheduling, disk IO, etc. to see how the system diverged from the actual baseline when time dilation was not applied in each of the time dilation mechanisms. When CPU and disk IO time dilation were turned off, the graphs diverge drastically for all experiments—often deviating by factors of two or more in perceived network throughput, disk IO, etc. These particular results demonstrate problems with using only network emulation to validate target systems—namely that these testbed systems may misrepresent the target systems by not just small error ratios but factors of error. Consequently, this result extends to experiments using Modelnet, Emulab, or other network emulation frameworks while simulating multiple VMs per node with ns, VMWare, Xen, or other systems without time dilation. This differential in network throughput, disk throughput, or latency could mean developers missing emergent behaviors on the testbed that will occur on the actual target hardware.
The RUBiS [30] completion times for file sharing and auctions on scaled systems closely mirrored the actual baselines for time dilation, while the non-TDF enforced versions of Xen did not. The testing data for RUBiS in particular is abundant with Gupta et al. showing results for CPU usage, memory profiling, throughput, and response times closely mirroring the baseline target system.
As the number of user sessions increased to 5000 or more, the deviation by non-time-dilation-scaled systems in response time grew to 5 to 7 times more than the target systems. Moreover, the average requests-per-second was less than half the corresponding statistic on the target system when not using time dilation with only 10 VMs per host. This inaccuracy in messaging throughput means that without time dilation, the simulation was attempting to put the testbed under less than half of the load that would be experienced on the actual target system. The time dilation tests, however, closely approximated both response time and requests-per-second.
The more complicated Isaac scenario, consisting of load balancers and multiple tiered layers of hosts and services, not only mimicked low-level metrics such as request completion time, but also resembled the base system on high-level application metrics such as time spent at each tier or stage in the transaction. DieCast also matched target systems closely during IO-bound transactions and CPU-bound ones.
The Isaac scenario also demonstrated the ability of time dilation to approximate target systems in fault situations. The DieCast developers caused failures to occur in the database servers in the Isaac scenario at specific times and compared the baseline performance to the time-dilated and non-time-dilated simulations. Without time dilation, the simulated experiments did not follow the baseline experiments. In addition, when requests through the Isaac system were made more CPU-intensive (generating large amounts of SHA-1 hashes) or more database-intensive (each request caused 100 times larger database access), the time dilation simulation was within 10% deviation of the baseline at all times, while non-dilated ended up requiring 3× more time than the baseline to complete the CPU stress tests.
The final tests on the commercial PanFS system showed similar aggregate file throughput to the baseline and also allowed Panasas, the company that makes PanFS, to more accurately test their file system according to target client infrastructures before deployment, which they had not previously been able to do due to their clients having much larger clustering infrastructures than the company had available for testing. While RUBiS and Isaac represent classic application services scenarios, the PanFS results were especially interesting because PanFS is regularly used by clients with thousands of nodes (i.e., large-scale systems). To validate the time dilation work in PanFS, Gupta et al. tested the system on 1000 hosts against time dilation on just 100 hosts and closely mirrored the performance of a deployed system, validating that the PanFS servers were reaching peak theoretical throughput bottlenecks. The PanFS results demonstrate that time dilation may be ready to make the leap to larger testing configurations, perhaps into tens of thousands and hundreds of thousands of target system nodes.
17.4.3 Future Work
Though DieCast provides an accurate approximation of a large-scale distributed system, time dilation technologies may mask timing-related race conditions (such as the Ethernet Capture Effect and TCP Nagle algorithm problems noted by Mogul [2]) due to DieCast slowing the entire system down and potentially missing boundary conditions that could have happened, for instance, in between real target timer events (which were instead queued up and fired in quick succession in a time dilation system). One of our motivating scenarios, the Ethernet Capture Effect, may not have been caught by systems using time dilation because by slowing down the Ethernet traffic resend rate of an application (by interrupting its resends to run other VMs), we may have allowed the back-off accumulator to reset. The lesson here is that, despite close approximation of the actual target system, DieCast and time dilation may not help catch all types of race conditions and unexpected emergent behavior. Other simulation solutions may be required to catch these types of low-level issues.
Gupta et al. admit that DieCast may not be able to reproduce certain race conditions or timing errors in the original services [6]. The system also has no way to scale memory usage or disk storage, and this can be a large limiting factor when a testbed host system is unable to emulate the time dilation factor of the target system (e.g., 100 hosts on the testbed with 4 GB of RAM trying to emulate 1000 hosts each requiring 1 GB of dedicated RAM a piece). Moreover, Gupta et al. appear to arbitrarily set the TDF to 10 for all experiments, noting that they had empirically found this value was the most accurate for their tests. No formal methods or description appear in their work to instruct how others may find the optimal TDF for target systems or the TDF corresponding to the number of simulated processes, the maximum delays expected from IO operations, or any other metric of the system. For time dilation to gain widespread acceptance and usage, this matter of obtaining an appropriate TDF for experiments should be addressed.
Potential vectors of interest may include augmenting the DiskSim to allow virtualization of memory on disk (possibly by further scaling down of time) to allow for the increased latency of disk drives emulating RAM memory access times. DieCast may also be a good vehicle to implement emergent “signatures” detection algorithms [2] into the testing phases and development cycles of large scale system development.
17.5 Addressing Issues of Time Dilation In Physical Memory
Section 17.4 discussed how DieCast can be used to validate large-scale network topologies for production applications. DieCast has built-in support for scaling disk input/output, networking characteristics, and time sources, but it has no mechanisms for scaling memory. This section, therefore, discusses options available to developers when memory scaling is necessary, including how to determine memory requirements to support scaled experiments and custom modifications that may be made to DieCast or VM managers such as Xen to enable scaling memory.
17.5.1 Overview
One aspect of validation that the DieCast implementation of time dilation does not solve is the situation where a host cannot emulate the physical memory required by the user-specified number of VMs per host. Physical memory is a scarce resource, and if it runs out during emulation of the target infrastructure, VM managers like Xen will begin to emulate physical memory using hard drive memory (virtual memory) on the host. Virtual memory is typically set aside from a hard drive, which has orders of magnitude worse fetch time than physical memory.
Although emulating in virtual memory will not stop the VMs from functioning (unless virtual memory is similarly exhausted), it may result in major timing differences between the testbed system and the target system. If the TDF were set to 10 (e.g., for 10 VMs hosted per host) and we only had enough physical memory to mimic target system performance for 5 of those VMs properly before virtual memory was used, we would likely miss race conditions, deadlock, and other types of emergent misbehavior during testing.
When using time dilation solutions, users should have options to address this issue. We evaluate potential solutions in this section.
17.5.2 Solutions
17.5.2.1 More Memory or More Hosts
Adding more physical memory may be possible, especially with increased adoption of 64-bit architectures and the ability of modern operating systems to support more than 4 GB of physical memory. This solution is attractive, and though processor speeds appear to have plateaued recently, availability of larger, inexpensive physical memory continues to increase. Users of time dilation systems or any other simulation system need to make sure that the amount of available memory exceeds the memory profiles required by all individual VMs. We discuss a reliable method for doing so here.
One available option is to profile physical memory usage of a single VM using Linux’s top utility, the Task Manager of Microsoft Windows, or any other type of monitoring tool. To properly conduct such a memory profile, the VM must not only be up and running when profiling the memory, but also performing in the same type of role that it will be used in on the target system (e.g., serving as a database system during memory profiling). Developers would then have to multiply this maximum physical memory used during the memory profiling session by the number of VMs that the host will be running and add an additional physical memory overhead required by the Xen VM Manager in the case of DieCast, or whatever technology is managing the VMs, and the actual host operating system.
Once these memory overheads are calculated, developers should be able to arrive at the required physical memory for host systems. If implementers or validation testers are unsure of the amount of overhead required by host operating system and the VM manager, it may be best to multiply the amount required by a certain percentage, and remember the following: it is much better to have more physical memory than required than not enough when trying to get an accurate simulation of a target system with time dilation or any simulation system.
Adding more hosts may also be a feasible solution to this scenario if developers can afford to add more hosts to the testbed system. Gupta et al. recommend a TDF of 10 [6], and although there was not much reasoning or testing presented in the work to support this TDF, developers using DieCast may be best served by following this advice and keeping the host to VM ratio at 10 or less (i.e., 10 VMs per host at a maximum).
These two solutions (adding more memory or adding more hosts) are feasible for the vast majority of validation requirements. The next proposed solution tries to cover the other portion of testbed emulation of a target infrastructure.
17.5.2.2 Memory Emulation
This solution requires the most augmentation to a time dilation system like DieCast and is the most likely to deviate from a target system. This solution, however, may be the only option available when obtaining sufficient physical memory is infeasible.
As an example of such a scenario, consider a situation where a testbed system is composed of 10 hosts and a target infrastructure has 1000 nodes. If we were to equally distribute the 1000 VMs required over the 10 hosts, we would require each host to emulate 100 VMs, requiring at least a TDF of 100 to accurately mimic operation of the target system. Assuming that each VM requires a physical memory profile of 4 GB to accurately reflect operation of a target system, a total of 400 GB of physical memory must be installed on each host, before taking into account the memory required by the host operating system and VM manager.
Assuming an overhead of 20% of the VM requirement for the latter (400 GB × 0.2 = 80 GB for a total of 480 GB required per host), if our hosts actually have only 4 GB of installed memory, this situation will result in a simulation that does not accurately reflect timing of target systems, due to virtual memory being much slower than the physical memory used on the target system. A potential solution to this situation is to completely emulate the instruction set for all VMs on the host and run most of the VMs on virtual memory with a TDF that reflects usage of virtual memory instead of physical memory. This solution will result in a significant increase in the amount of time an experiment will require to run.
Figure 17.6 shows the difference between accessing physical memory and a hard drive for memory needs. The difference between access time in physical memory and hard drive data is typically six orders of magnitude. Consequently, emulating all VMs in virtual memory and adjusting the time dilation accordingly to the access time difference could lead to a time dilation simulation taking over 1 million times longer with emulation on hard disks and over 10 thousand times longer with emulation on a flash memory type drive (shown as SSD for Solid-State Drive in Figure 17.6). SSD flash cards or hard drives are currently able to supplement system memory with over 64 GB of flash memory. There has also been recent success with using SSD memory for virtual memory in enterprise database applications and large clusters [28,29]. Obtaining the 480 GB of additional memory for the ten thousand times longer run time system could potentially be possible via USB hubs or similar technologies.
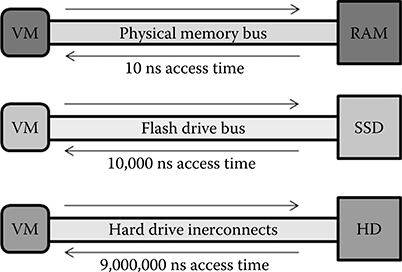
FIGURE 17.6 Memory access time comparison between physical memory (RAM), SSD flash drives, and traditional hard drives. All numbers are approximations to provide scale.
17.6 Concluding Remarks
Time dilation is a versatile emerging technology that helps developers and testers ease the validation of medium- to large-scale systems. Earlier work on DieCast has provided developers with CPU scheduling, network emulation, and disk emulation informed by time dilation mechanisms, resulting in accurate test runs on reduced hardware. DieCast does not require developers to remodel their business application logic, piggyback unrelated libraries, generate simulation glue code, or do many things required by other simulation frameworks and technologies typically used for large- to ultra large-scale target architectures. Instead, it allows for developers to compile their projects and code as they normally would do, harness the power of the Xen hypervisor—a stable, well supported VM manager for Linux—and run multiple VMs per machine in a way that more accurately reflects the true performance of a target system.
Though time dilation shows promise, it does not identify all types of problems that affect mission-critical distributed systems. This chapter explained how Ethernet problems, such as the Ethernet Capture Effect, may be masked by slowing down the host and not witnessing some of the race conditions that can appear in target systems because of queuing of timer firings and other related issues. Time dilation also currently has a higher memory footprint than some network simulators that are able to reduce memory requirements via shared data structures, operating system emulation, etc. While these network simulators might be useful to determine if the target system works if provided with certain operating systems or configurations and modeling of environments, implementations of time dilation such as DieCast allow developers to test their business logic for distributed or networked applications on actual operating systems with excellent approximations of time source progression, disk queuing, and network throughput and latency.
References
1. Basu, A., M. Bozga, and J. Sifakis. 2006. “Modeling Heterogeneous Real-Time Components in BIP.” In Fourth IEEE International Conference on Software Engineering and Formal Methods, Pune, India 3–12.
2. Mogul, J. C. 2006. “Emergent (Mis)behavior vs. Complex Software Systems.” 2006. In 1st ACM SIGOPS/EuroSys European Conference on Computer Systems, 293–304. Belgium: Leuven.
3. Ramakrishnan, K. R. and H. Yang. 1994. “The Ethernet Capture.” In Proceedings of IEEE 19th Local Computer Networks Conference. Minneapolis, MN.
4. Gupta, D., K. Yokum, M. McNett, A. C. Snoeren, G. M. Voelker, and A. Vahdat. 2006. “To Infinity and Beyond: Time-Warped Network Emulation.” In Proceedings of the 3rd USENIX Symposium on Networked Systems Design and Implementation, San Jose, CA.
5. Einstein, A. 1905. “Zur Elektrodynamik bewegter Körper.” Annalen der Physik 17: 891.
6. Gupta, Diwaker, Kashi V. Vishwanath, and Amin Vahdat. 2008. “DieCast: Testing Distributed Systems with an Accurate Scale Model.” In 5th USENIX Symposium on Networked System Design and Implementation, 407–22. San Francisco, CA.
7. Cheng, B. H. C., L. A. Campbell, and E. Y. Wang. 2000. “Enabling Automated Analysis through the Formalization of Object-Oriented Modeling Diagrams.” In International Conference on Dependable Systems and Networks, New York, 305–14.
8. Batory, Don, Jacob Neal Sarvela, and Axel Rauschmayer. 2004. “Scaling Step-Wise Refinement.” IEEE Transactions on Software Engineering. Vol. 30:6, Piscataway, NJ.
9. Bliudze, S. and J. Sifakis. 2008. “Causal Semantics for the Algebra of Connectors.” In Formal Methods for Components and Objects, Sophia Antipolis, France, 179–99.
10. Engels, G., J. M. Küster, R. Heckel, and L. Groenewegen. 2001. “A Methodology for Specifying and Analyzing Consistency of Object-Oriented Behavioral Models.” ACM SIGSOFT Software Engineering Notes 26 (5): 186–95.
11. Henzinger, T. and Sifakis, J. 2006. “The Embedded Systems Design Challenge.” In Lecture Notes in Computer Science, Springer, 1–15.
12. Clarke, E., A. Emerson, and J. Sifakis. 2009. “Model Checking: Algorithmic Verification and Debugging.” In Communications of the ACM, New York, 74–84.
13. Schmidt, D. 2006. “Model-Driven Engineering.” In IEEE Computer Society, Piscataway, NJ, 25–32.
14. Oxford English Dictionary. 2010. Oxford, UK: Oxford University Press.
15. Wainer, G. and Mosterman, P. 2010. Discrete-Event Modeling and Simulation: Theory and Applications. Boca Raton, FL: CRC Press.
16. Fujimoto, R. M., K. Perumalla, A. Park, H. Wu, M. H. Ammar, and G. F. Riley. 2003. “Large-Scale Network Simulation: How Big? How Fast?” In 11th IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunications Systems, 116–23. Orlando, FL.
17. Varga, A. 2001. “The OMNeT++ Discrete Event Simulation System.” In Proceedings of the European Simulation Multiconference (ESM). Prague, Czech Republic.
18. Banks, J., J. Carson, B. Nelson, and D. Nicol. 2009. Discrete-Event System Simulation. 5th ed. Upper Saddle River, NJ: Prentice Hall.
19. Rao, D. M. and P. A. Wilsey. 2002. “An Ultra-Large-Scale Simulation Framework.” Journal of Parallel and Distributed Computing 62 (11): 1670–93.
20. Riley, G. F. and Ammar, M. H. 2002. “Simulating Large Networks—How Big Is Big Enough?” In Grand Challenges in Modeling and Simulation.
21. White, B., Lepreau, J., Stoller, L., Ricci, R., Guruprasad, S., Newbold, M., Hibler, M., Barb, C., and Joglekar, A. 2002. “An Integrated Experimental Environment for Distributed Systems and Networks.” In 5th Symposium on Operating Systems Design and Implementation (OSDI). Boston, MA.
22. Hill, J., J. Edmondson, A. Gokhale, and D. C. Schmidt. 2010. “Tools for Continuously Evaluating Distributed System Qualities.” IEEE Software, Vol, 27:4, 65–71.
23. Barham, P., et al. 2003. “Xen and the Art of Virtualization.” In Proceedings of the 19th ACM Symposium on Operating System Principles.
24. Vahdat, A., et al. 2002. “Scalability and Accuracy in a Large-Scale Network Emulator.” In Proceedings of the 5th Symposium on Operating Systems Design and Implementation, 271–84.
25. Martin, D. E., McBrayer, T. J., and Wilsey, P. A. 1996. “WARPED: A Time Warp Simulation Kernel for Analysis and Application Development.” In 29th Hawaii Internetional Conference on System Sciences.
26. Rao, D. M. and P. A. Wilsey. 1999. “Simulation of Ultra-large Communication Networks.” In Seventh IEEE International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunications Systems, 112–9.
27. Loyall, J., et al. 2009. “QoS Enabled Dissemination of Managed Information Objects in a Publish-Subscribe-Query Information Broker.” In SPIE Defense Transformation and Net-Centric Systems Conference. Orlando.
28. Lee, S., Moon, B., Park, C., Kim, J., Kim, S. 2008. “A Case for Flash Memory SSD in Enterprise Database Applications.” In ACM SIGMOD International Conference on Management of Data. Vancouver.
29. Caulfield, A. M., Grupp, L. M., Swanson, S. 2009. “Gordon: Using Flash Memory to Build Fast, Power-Efficient Clusters for Data-Intensive Applications.” In 14th International Conference on Architectural Support for Programming Languages and Operating Systems. Washington, D.C.
30. RUBiS. 2012. http://rubis.objectweb.org.