
CHAPTER NINE
Panda, Penguin, and Penalties
Search engines use many techniques for measuring search quality, including manual penalties, algorithmic penalties, and ranking algorithms. Sometimes these algorithms and penalties can have a major impact on your organic traffic. Significant decreases in the search engine traffic to your website can be devastating to a business. As shown in Figure 9-1, sometimes these drops in traffic can be quite large.
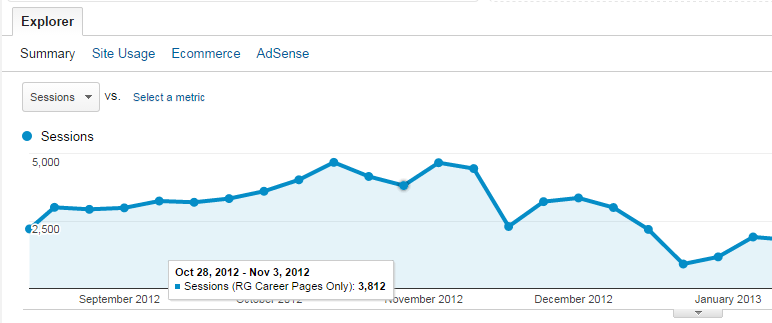
Figure 9-1. Major loss in traffic
If the business shown in Figure 9-1 generates all of its revenue from organic search traffic, this would represent a devastating blow. This type of loss of revenue can mean laying off employees, or even closing the business.
For that reason, you need to have a working understanding of the potential causes of these traffic losses, and if you have already suffered such a loss, know how you can figure out what the cause is and what you need to do to recover.
Diagnosing the Cause of a Traffic Loss
The first step to identifying the cause of a traffic loss is to check your analytics data to see if the drop is in fact a loss of organic search engine traffic. If you have Google Analytics on your site, make sure you check your traffic sources, and then isolate just the Google traffic.
If you confirm that it is a drop in Google organic search traffic, then the next step is to check if you have received a message in Google Search Console indicating that you have been penalized by Google. Figure 9-2 shows an example of a manual penalty message from Google. This is what Google refers to as a manual action.
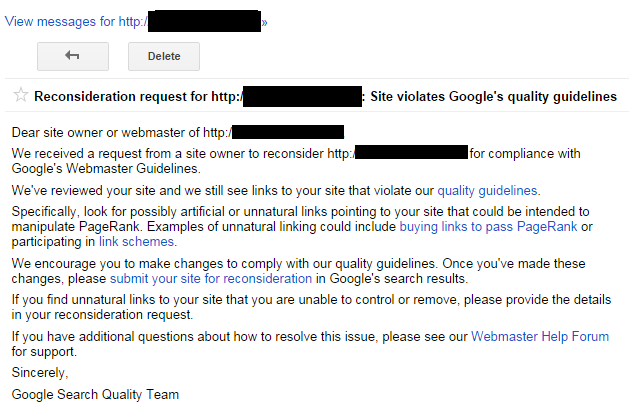
Figure 9-2. Penalty message in Google Search Console
If you have received such a message, you now know what the problem is and you can get to work fixing it. It is not fun to have the problem, but knowing what you are dealing with is the first step in recovery.
If you don’t have such a message, you will need to dig deeper to determine the source of your problem. The next step is to determine the exact date on which your traffic dropped. For example, if that date was April 24, 2012, take note of that. Then go to the Moz Google Algorithm Update Page and see if you can find the date of your traffic drop listed there.
Using our example of April 24, 2012, Figure 9-3 shows that sites that suffered traffic losses on this date were probably hit by Google’s Penguin 1.0 algorithm release.
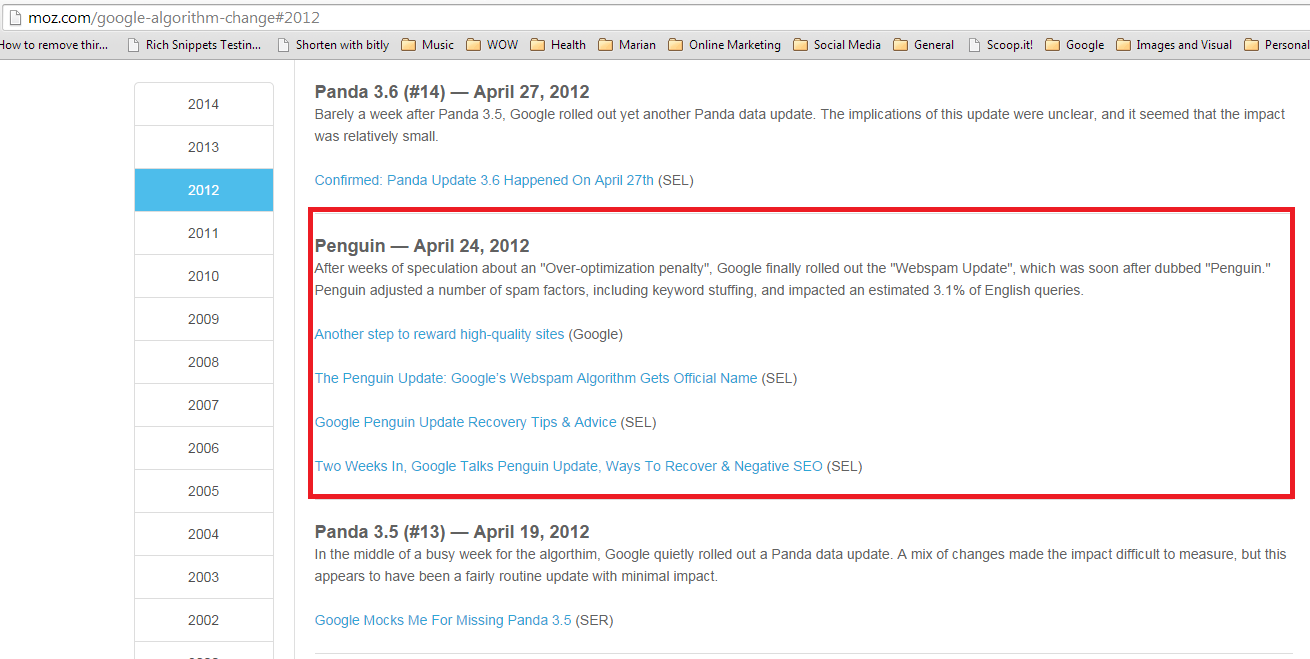
Figure 9-3. Moz Google algorithm update page showing Penguin 1.0
Barracuda Digital also offers a tool called the “Panguin Tool” that will overlay the Google algorithm updates on your Google Analytics data to make this date comparison analysis easier for you.
If you haven’t gotten a message in Google Search Console, and the date of your traffic loss does not line up with a known Google algorithm update, the process of figuring out how to recover is much harder, as you don’t know the reason for the drop.
Google does make smaller changes to its algorithms on a daily basis. From its perspective, these are smaller changes and not major updates. Such tweaks may be much harder to recover from as well. The best strategy is to focus on the best practices outlined in Chapter 6 and Chapter 7, or if you can afford SEO advice, bring in an expert to help you figure out what to do next.
Summary of Major Google Algorithms
The two most famous Google algorithms released since February 2011 are Panda and Penguin, but there are several others that Google has also released in that timeframe. Panda and Penguin are examined in detail later in this chapter. Here is a summary of some of the other major algorithms released by Google:
- Top Heavy Update
-
Released on January 19, 2012, this update impacts sites that have too many ads above the fold. This is true even if the ads are AdSense ads (from Google’s own advertising programs). To avoid this penalty, avoid placing lots of ads near the top of your web pages. A banner ad is probably fine, as is something on the right rail of your site, but anything more than that starts to run into trouble with this algorithm. This algorithm was updated on October 9, 2012.
- DMCA Penalty (a.k.a. Pirate)
-
Announced on August 10, 2012, this update applies penalties to sites that receive too many valid DMCA takedown requests. DMCA stands for Digital Millennium Copyright Act. You can file a DMCA takedown request if someone has stolen your content and published it as his own. Of course, to avoid this penalty, you should publish only your own original content. If you hire people to write for you, ensure that they are writing original content as well.
- Exact-Match Domain (EMD)
-
With the release of this update on September 27, 2012, Google started to change the way it values exact-match domains. An example of an exact-match domain might be http://www.blue-widgets.com (note that this is not currently a real site, and is in fact a parked page), which historically would have had an advantage in ranking for the search phrase blue widgets. The purpose of this update was to reduce or eliminate that advantage.
- Payday Loan (spammy sites)
-
Released on June 11, 2013, this algorithm targeted sites that it considered to be in particularly spammy market spaces. Google specifically mentioned payday loans, casinos, and pornography as targeted markets. This algorithm was updated on May 16, 2014.
- Hummingbird
-
Announced on September 26, 2013, Hummingbird was not really an algorithm update, but instead a rewrite of Google’s search platform, with a design goal of making the overall search engine more flexible and adaptable for the future. Part of the design of this rewrite included more support for natural language queries and semantic search.
These are some of the major releases, but as we’ve noted, Google makes many smaller changes as well. In August 2014, the head of search quality for Google, Amit Singhal, indicated that it had made 890 changes in the past year.1
Panda
Google’s Panda algorithm shook up the search landscape when it came out on February 24, 2012. In their announcement of the release, Google said the following:
Many of the changes we make are so subtle that very few people notice them. But in the last day or so we launched a pretty big algorithmic improvement to our ranking—a change that noticeably impacts 11.8% of our queries—and we wanted to let people know what’s going on. This update is designed to reduce rankings for low-quality sites—sites which are low-value add for users, copy content from other websites, or sites that are just not very useful. At the same time, it will provide better rankings for high-quality sites—sites with original content and information such as research, in-depth reports, thoughtful analysis, and so on.
Other information also came out pretty quickly about this release, which Danny Sullivan of Search Engine Land initially called the Farmer update.2 Between this additional information and the initial announcement, several aspects of Panda quickly became clear:
-
This was a very large change. Very few algorithm updates by Google impact more than 10% of all search queries.
-
This algorithm is focused on analyzing content quality.
-
Scraper sites were targeted.
-
Sites lacking substantial unique information were also targeted. In particular, content farms were part of what Google was looking to address—a move that Eric Enge predicted would happen three weeks before this release.3
-
Google clearly states a strong preference for new research, in-depth reports, and thoughtful analysis.
-
The Panda algorithm does not use the link graph as a ranking factor.
The second release of Panda came out on April 11, 2011. What made this release particularly interesting is that it incorporated data gathers from Google’s Chrome Blocklist Extension. This extension to Chrome allowed users to indicate that they wanted pages removed from the search results. Figure 9-4 illustrates what this looks like in action.
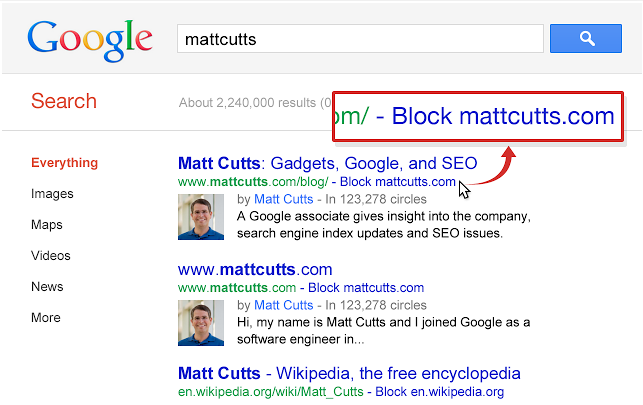
Figure 9-4. Chrome Blocklist Extension
This was the first time that Google ever publicly confirmed that it was using a form of direct user input as a ranking factor in any of its algorithms.
Initially, Panda was focused only on the United States, but was rolled out internationally on August 12, 2011, to most of the rest of the world except Japan, China, and Korea.
Google has done many releases for Panda since the initial one. Table 9-1 provides a full list of all known Panda releases.
| Panda release | Date | Notes |
|---|---|---|
| Panda 1.0 | February 23, 2011 | Impacted 11.8% of search results. |
| Panda 2.0 | April 11, 2011 | Added use of the Chrome Blocklist Extension. |
| Panda 2.1 | May 9, 2011 | |
| Panda 2.2 | June 21, 2011 | |
| Panda 2.3 | July 23, 2011 | |
| Panda 2.4 | August 12, 2011 | Rolled out internationally; impacted 6–9% of queries internationally. |
| Panda 2.5 | September 28, 2011 | |
| Panda “Flux” | October 5, 2011 | Called “Flux” as a result of a Matt Cutts tweet; impacted 2% of queries. |
| Minor update | October 11, 2011 | |
| Panda 3.1 | November 18, 2011 | Naming skipped an official 3.0 release. |
| Panda 3.2 | January 18, 2012 | |
| Panda 3.3 | February 27, 2012 | |
| Panda 3.4 | March 23, 2012 | Impacted 1.6% of results. |
| Panda 3.5 | April 19, 2012 | |
| Panda 3.6 | April 27, 2012 | |
| Panda 3.7 | June 8, 2012 | Impacted less than 1% of queries. |
| Panda 3.8 | June 25, 2012 | |
| Panda 3.9 | July 24, 2012 | Impacted about 1% of queries. |
| Panda #18 | August 20, 2012 | Industry agreed on nomenclature change to counting the release number. |
| Panda #19 | September 18, 2012 | |
| Panda #20 | September 27, 2012 | Impacted 2.4% of queries. |
| Panda #21 | November 5, 2012 | Impacted 1.1% of queries. |
| Panda #22 | November 21, 2012 | |
| Panda #23 | December 21, 2012 | Impacted 1.3% of queries. |
| Panda #24 | January 22, 2012 | Impacted 1.2% of queries. |
| Panda #25 | March 14, 2013 | Date estimated by Moz. Google announced Panda would be made part of the core algorithm. As of this date, rolling updates are no longer announced, but happen monthly and roll out over 10 days or so. |
| Panda #26 | June 11, 2013 | |
| Panda #27 | July 18, 2013 | Rumored to soften Panda’s impact. |
| Panda 4.0 | May 20, 2014 | Major update confirmed by Google. Also appeared to soften Panda’s impact on many sites, but new sites were also hit. |
As of March 14, 2013, Google announcements of Panda updates became relatively rare, and Table 9-1 shows only the announced updates. However, these updates appear periodically as unannounced data refreshes and roll out over a period of more than a week.
Since that time, Google has confirmed only three Panda updates, with the most recent one being Panda 4.0 on May 20, 2014.
To track all Google updates over time, you can check the Google algorithm change history page on the Moz website.
Target Areas of Panda
Google has historically offered relatively vague information on how the Panda algorithm works to determine the quality of a site. For example, on May 6, 2011, Amit Singhal offered his advice on building high-quality sites. In it, he suggested a list of questions that you could use to determine if you were on such a site:
-
Would you trust the information presented in this article?
-
Is this article written by an expert or enthusiast who knows the topic well, or is it more shallow in nature?
-
Does the site have duplicate, overlapping, or redundant articles on the same or similar topics with slightly different keyword variations?
-
Would you be comfortable giving your credit card information to this site?
-
Does this article have spelling, stylistic, or factual errors?
-
Are the topics driven by genuine interests of readers of the site, or does the site generate content by attempting to guess what might rank well in search engines?
-
Does the article provide original content or information, original reporting, original research, or original analysis?
-
Does the page provide substantial value when compared to other pages in search results?
-
How much quality control is done on content?
-
Does the article describe both sides of a story?
-
Is the site a recognized authority on its topic?
-
Is the content mass-produced by or outsourced to a large number of creators, or spread across a large network of sites, so that individual pages or sites don’t get as much attention or care?
-
Was the article edited well, or does it appear sloppy or hastily produced?
-
For a health-related query, would you trust information from this site?
-
Would you recognize this site as an authoritative source when mentioned by name?
-
Does this article provide a complete or comprehensive description of the topic?
-
Does this article contain insightful analysis or interesting information that is beyond obvious?
-
Is this the sort of page you’d want to bookmark, share with a friend, or recommend?
-
Does this article have an excessive amount of ads that distract from or interfere with the main content?
-
Would you expect to see this article in a printed magazine, encyclopedia, or book?
-
Are the articles short, unsubstantial, or otherwise lacking in helpful specifics?
-
Are the pages produced with great care and attention to detail versus less attention to detail?
-
Would users complain when they see pages from this site?
There are a few key points that can be extracted from this advice, and the industry has been able to determine and clarify a number of Panda’s target areas. These include:
- Thin content
-
As you might expect, this is defined as pages with very little content. Examples might be user profile pages on forum sites with very little information filled in, or an ecommerce site with millions of products, but very little information provided about each one.
- Unoriginal content
-
These may be scraped pages, or pages that are only slightly rewritten, and Google can detect them relatively easily. Sites with even a small number of these types of pages can be impacted by Panda.
- Nondifferentiated content
-
Even if you create all original articles, this may not be enough. If every page on your site covers topics that have been written about by others hundreds or thousands of times before, then you really have nothing new to add to the Web with your site. Consider, for example, the number of articles in the Google index about making French toast, as shown in Figure 9-5. There are over 30,000 pages on the Web that include the phrase how to make french toast in their title. From Google’s perspective, it don’t need another web page on that topic.
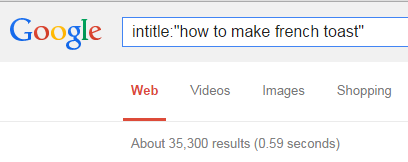
Figure 9-5. There are tens of thousands of pages on “how to make french toast”
- Poor-quality content
-
This is content that is inaccurate or poorly assembled. In many cases, this may be hard to detect, but as mentioned in Amit Singhal’s article, one indicator is content that includes poor grammar or a lot of spelling mistakes. Google could also potentially use fact checking as another way to determine poor-quality content.
- Curated content
-
Sites that have large numbers of pages with lists of curated links do get hit by Panda. Content curation is not inherently bad, but if you are going to do it, it’s important to incorporate a significant amount of thoughtful commentary and analysis. Pages that simply include lots of links will not do well, nor will pages that include links and only a small amount of unique text. Content curation is explored in depth in “Content Curation & SEO: A Bad Match?”.
- Thin slicing
-
This was believed to be one of the original triggers for the Panda algorithm, as it was a popular tactic for content farms. Imagine you wanted to publish content on the topic of schools with nursing programs. Content farm sites would publish many articles on the same topic, with titles such as: “nursing schools,” “nursing school,” “nursing colleges,” “nursing universities,” “nursing education,” and so forth. There is no need for all of those different articles, which prompted Google to target this practice with Panda.
- Database-generated content
-
The practice of using a database to generate web pages is not inherently bad, but many companies were doing it to an excessive scale. This led to lots of thin-content pages or poor-quality pages, so many of these types of sites were hit by Panda.
Importance of Diversity in Rankings
Diversity is important to overall search quality for Google. One simple way to illustrate this is with the search query Jaguar. This word can refer to an animal, a car, a guitar, an operating system, or even an NFL team. Normal ranking signals might suggest the results shown in Figure 9-6.
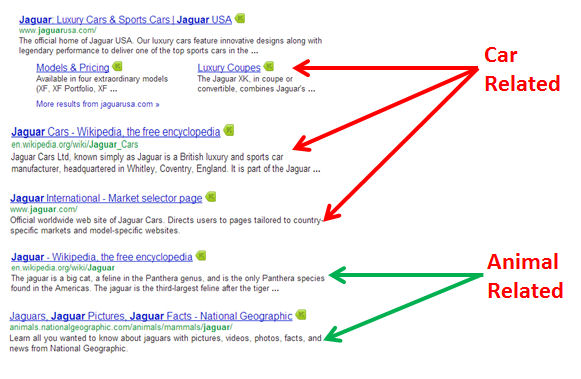
Figure 9-6. Normal ranking signals may show these results for “Jaguar”
Note that the search results at the top all focus on the car, which may be what the basic ranking signals suggest the searcher is looking for. However, if the searcher is looking for information on the animal, those results are pushed down a bit. As a result, Google may use other signals to decide to alter the results to look more like those shown in Figure 9-7.
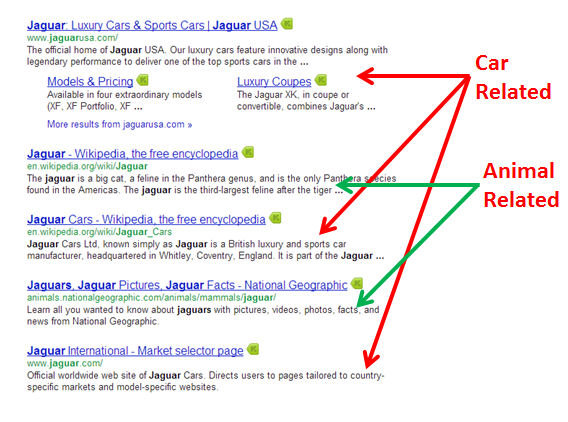
Figure 9-7. “Query Deserves Diversity” may alter the results for “Jaguar”
In this version of the results, one of the animal-related results has been pushed into the second position. Google makes these types of adjustments to the SERPs using a concept known as Query Deserves Diversity.
Google makes these adjustments by measuring user interaction with the search results to determine what ordering of the results provides the highest levels of user satisfaction. For example, even if traditional ranking signals would put another page for the car next, it might make sense for the next result to be about the animal.
Role of Authority in Rankings
Consider again the search query how to make French toast we showed in Figure 9-5. While Google has plenty of results on the topic, there are, of course, some sites that rank highly for this search query. How is their rank determined?
Very high-authority sites are likely to do fine when publishing content on a topic that is already well covered on the Internet. There are a few possible reasons why this is the case:
-
Reputation and authority is a big factor. For example, if the New York Times Lifestyle section posted a new article on how to make French toast, even though it is not particularly unique, readers might respond well to it anyway. User interaction signals with the search result for that content would probably be quite strong, simply because of the site’s reputation.
-
High-authority sites probably got to be that way because they don’t engage in much of the behavior that Google does not like. Chances are that you won’t find a lot of thin content, “me too” content, thin slicing, or any of the issues that are Panda triggers.
-
Google may simply be applying looser criteria to a high-authority site than it does to other sites.
Exactly what factors allow higher-authority sites to have more leeway is not clear. Is it that Google is measuring user interaction with the content, the quality of the content itself, the authority of the publisher, or some combination of these factors? There are probably elements of all three in what Google does.
Impact of Any Weak Content on Rankings
Weak content on even one single section of a larger site can cause Panda to lower the rankings for the whole site. This is true even if the content in question makes up less than 20% of the pages for the site. When you are putting together a plan to recover from Panda, it is important to take this into account.
Path to Recovery
The road to recovery from a Panda penalty may be a long one. Oftentimes it requires a substantial reevaluation of your site’s business model. You need to be prepared to look at your site with a highly critical eye, and this is often very hard to do with your own site. Thus, it’s a good idea to consider bringing in an external perspective to evaluate your site. You need someone who is willing to look you in the eye and tell you that your baby is ugly.
Once you go through this reevaluation process, you may realize that even the basic premise of your site is broken, and that you need to substantially restructure it. Making these types of decisions is quite hard, but you need to be prepared to do it.
As you consider these tough choices, it can be helpful to look at your competition that did not get hit. Understand, however, that you may see instances of thin content, weak content, “me too” content, and other poor-quality pages on competitors’ sites that look just as bad as the content penalized on your site, and they may not appear to have been impacted by Panda. Don’t let this type of analysis deter you from making the hard choices. There are so many factors that Google uses in its ranking algorithms that you will never really know why your site was hit by Panda and your competitor’s site was not.
What you do know is that Google’s Panda algorithm does not like something about your site. This may include complex signals based on how users interact with your listings in the search results, which is data you don’t have access to.
To rebuild your traffic, it’s best to dig deep and take on hard questions about how you can build a site full of fantastic content that gets lots of user interaction and engagement. While it is not believed that social media engagement is a factor in Panda, there is likely a strong correlation between high numbers of social shares and what Google considers to be good content.
Highly differentiated content that people really want, enjoy, share, and link to is what you want to create on your site (the article “After Google Panda, Standout Content Is Essential” expands on this concept). There is a science to creating content that people will engage with. We know that picking engaging titles for the content is important, and that including compelling images matters too. Make a point of studying how to create engaging content that people will love, and apply those principles to every page you create. In addition, measure the engagement you get, test different methods, and improve your ability to produce great content over time.
Ways to address weak pages
As you examine your site, a big part of your focus should be addressing its weak pages. They may come in the form of an entire section of weak content, or a number of pages interspersed among the higher-quality content on your site. Once you have identified those pages, there are a few different paths you can take to address the problems you find:
-
Improve the content. This may involve rewriting the content on the page, and making it more compelling to users who visit.
-
Add the
noindexmeta tag to the page (you can read about how to do this in Chapter 6). This will tell Google to not include these pages in its index, and thus will take them out of the Panda equation. -
Delete the pages altogether, and 301-redirect visitors to other pages on your site. Use this option only if there are quality pages that are relevant to the deleted ones.
-
Delete the pages and return a 410 HTTP status code when someone tries to visit the deleted page. This tells the search engine that the pages have been removed from your site.
-
Use the URL removal tool to take the page out of Google’s index. This should be done with great care. You don’t want to accidentally delete other quality pages from the Google index!
Expected timeline to recovery
Even though they are no longer announced, Panda releases come out roughly once per month. However, once you have made the necessary changes, you will still need to wait. Google has to recrawl your site to see what changes you have made. It may take Google several months before it has seen enough of the changed or deleted pages to tilt the balance in your favor.
What if you don’t recover?
Sadly, if your results don’t change, this usually means that you have not done enough to please the Panda algorithm. It may be that you were not strict enough in deleting poorer-quality content from your site. Or, it may mean that Google is not getting enough signals that people really care about what they find on your site.
Either way, this means that you have to keep working to make your site more interesting to users. Go beyond viewing this process as a way to deal with Panda, and instead see it as a mission to make your site one of the best on the Web.
This requires substantial vision and creativity. Frankly, it’s not something that everybody can accomplish without making significant investments of time and money. One thing is clear: you can’t afford to cut corners when trying to address the impact of the Panda algorithm.
If you have invested a lot of time and made many improvements, but you still have content that you know is not so great, chances are pretty good that you haven’t done enough. You will likely find yourself four months later wishing that you had kept at the recovery process.
In addition, the Panda algorithm is constantly evolving. Even if you have not been hit by this algorithm, the message from Google is clear: it is going to give the greatest rewards to sites that provide fantastic content and great user experiences. Thus, your best path forward is to be passionate about creating a site that offers both. This is how you maximize your chances of recovering from Panda, and from being impacted by future releases.
Successful Panda recovery example
In Figure 9-1, we showed an example of a site suffering a major traffic loss. The site in question, called The Riley Guide, is dedicated to providing information on jobs and careers. A thorough examination of the site showed that it had two major problems:
-
The content on careers was too similar to the type of content you can find on a major government website, http://www.bls.gov. Even though The Riley Guide’s content was not copied from that location, it did not offer any unique differentiation or value to the Web.
-
The content on the rest of the site mainly consisted of links to resources for job information elsewhere on the Web. This content was structured like a librarian’s index, with links and short commentaries on each. In some cases, the commentary was copied from the target website.
In short, the original site structure did not offer a lot of value. The publishers of The Riley Guide took the site through a complete overhaul. This was a lengthy process, as about 140 pages had to be rewritten from scratch, and another 60 or so pages had the noindex tag applied.
Figure 9-8 shows the results of this effort. Not only did the site recover from Panda, but it is now hitting new highs for traffic.
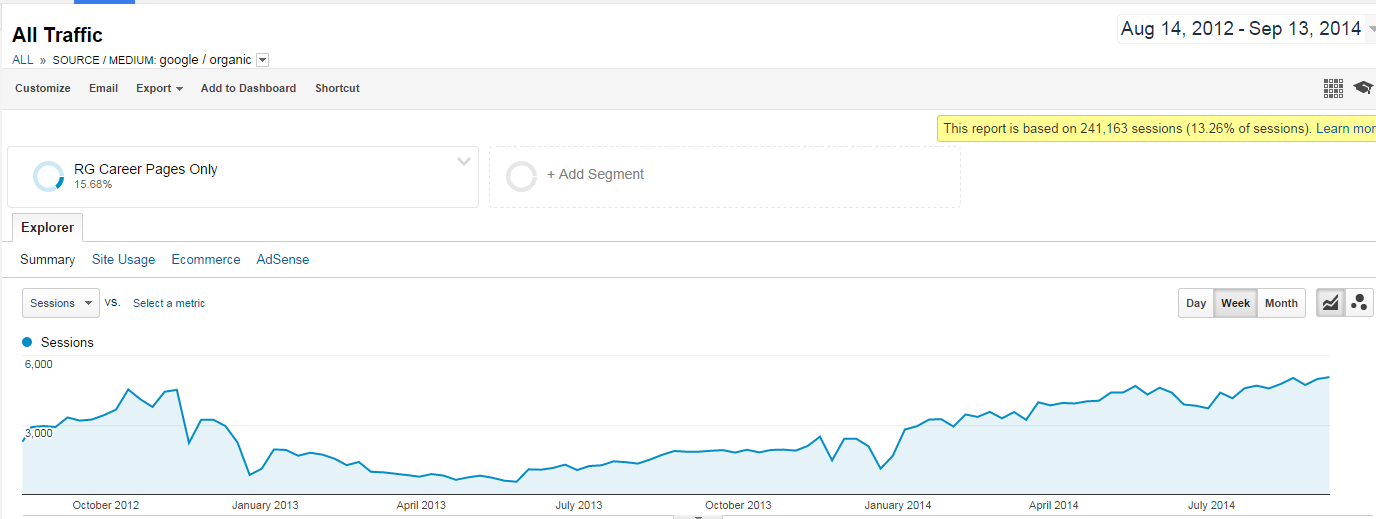
Figure 9-8. Panda traffic recovery
Penguin
Google’s Penguin algorithm was first released to the world on April 24, 2012. It was the first major algorithm implemented by Google to address bad links. Like Panda before it, the Penguin release shook up the search landscape. Since the initial release of this algorithm, there have been several incremental releases, and an expansion of the scope of the types of links addressed.
Penguin algorithm hits are generally reasonably easy to detect, as there have only been five total releases of Penguin. These are the only dates on which you may have been hit by the alogrithm, and unfortunately, also appear to be the only dates on which you can recover from it. Table 9-2 lists all of the releases of Penguin as of June 2015.
| Penguin release | Date | Notes |
|---|---|---|
| Penguin 3.0 | October 17, 2014 | Impacted 1.0% of queries |
| Penguin 2.1 | October 4, 2013 | |
| Penguin 2.0 | May 22, 2013 | Began targeting links more at the page level. |
| Penguin 1.2 | October 5, 2012 | Impacted about 0.3% of queries. |
| Penguin 1.1 | May 25, 2012 | |
| Penguin 1.0 | April 24, 2012 | Impacted 3.1% of U.S. search queries. |
As you can see, the releases are quite rare, and this is one of the more jarring aspects of Penguin. Once you have been hit by it, you have to wait until the next release to have a chance to recover. That could be as long as one full year!
For purposes of diagnosis, if your traffic experiences a significant drop on one of the dates listed in Table 9-2, it’s likely that you have been hit by Penguin.
Target Areas of Penguin
As you will see in the section “Links Google Does Not Like”, there are many different types of links that are considered bad links. However, Penguin appears to focus on a more limited set of link types. These are:
- Article directories
-
From the very first release of Penguin, Google targeted sites that obtained links from article directories. While these links may not always reflect manipulative intent by the publisher, Google found that people who leveraged article directories tended to operate lower-quality sites.
- Cheap directories
-
These were also targeted in the very first release of Penguin. There are a few directories that are genuinely high quality, such as the Yahoo! Directory, DMOZ, Business.com, Best of the Web, and perhaps a few others specific to your industry vertical. Stay away from the rest.
- Excessive rich anchor text
-
Excessive use of rich anchor text was also a part of the initial release of Penguin. Specifically, Penguin targeted too many instances of the same anchor text pointing to any of the URLs on your site. Google does not expect, or want, all links to say, “click here,” but it sees it as a signal of spammy behavior when the exact same keyword-rich anchor text is used repeatedly.
- Low-relevance international links
-
While it is not confirmed that this target area is a part of any Penguin release, anecdotal evidence suggests it might be. Consider any links from countries where you don’t sell your products or services as a potential problem, unless they come from truly high-quality sites.
- Comment spam
-
Excessively implementing links in comments on other people’s blog posts and forums is also a problem for Penguin.
There may be more types of links that are a part of the Penguin algorithm or that could be included in future releases. A complete summary of problem links is discussed in “Links Google Does Not Like”.
Path to Recovery
The first step on the road to recovery from a Penguin hit is to realize that Penguin releases are rare. As they happen roughly twice per year, you don’t want to get cute and try to save some of your questionable links. Be aggressive and clean up every possible problem. Certainly, address the types of links listed in “Target Areas of Penguin”, but you should also seriously consider dealing with all of the link problems listed in “Links Google Does Not Like”.
Do not file a reconsideration request, as it is a waste of time. In fact, you can’t file one unless you have a manual penalty on your site. Google does not have the mechanisms in place to adjust how the Penguin algorithm impacts you.
After you have addressed the bad links to your site, you must wait. Once the next Penguin release arrives, you will know whether you have done enough. If you are not successful in recovering during that release, you have no choice but to figure out which links you failed to clean up and try again for the next release. If you are successful, congratulations!
Penalties
There are two types of penalties, algorithmic and manual. Algorithmic penalties do not involve any human component, whereas manual penalties do. While the details of what prompts Google to perform a manual review of a website are not always evident, there appear to be several ways that manual reviews can be triggered. Figure 9-9 illustrates how a manual review might be triggered in the case of a site that has problems with its link profile.
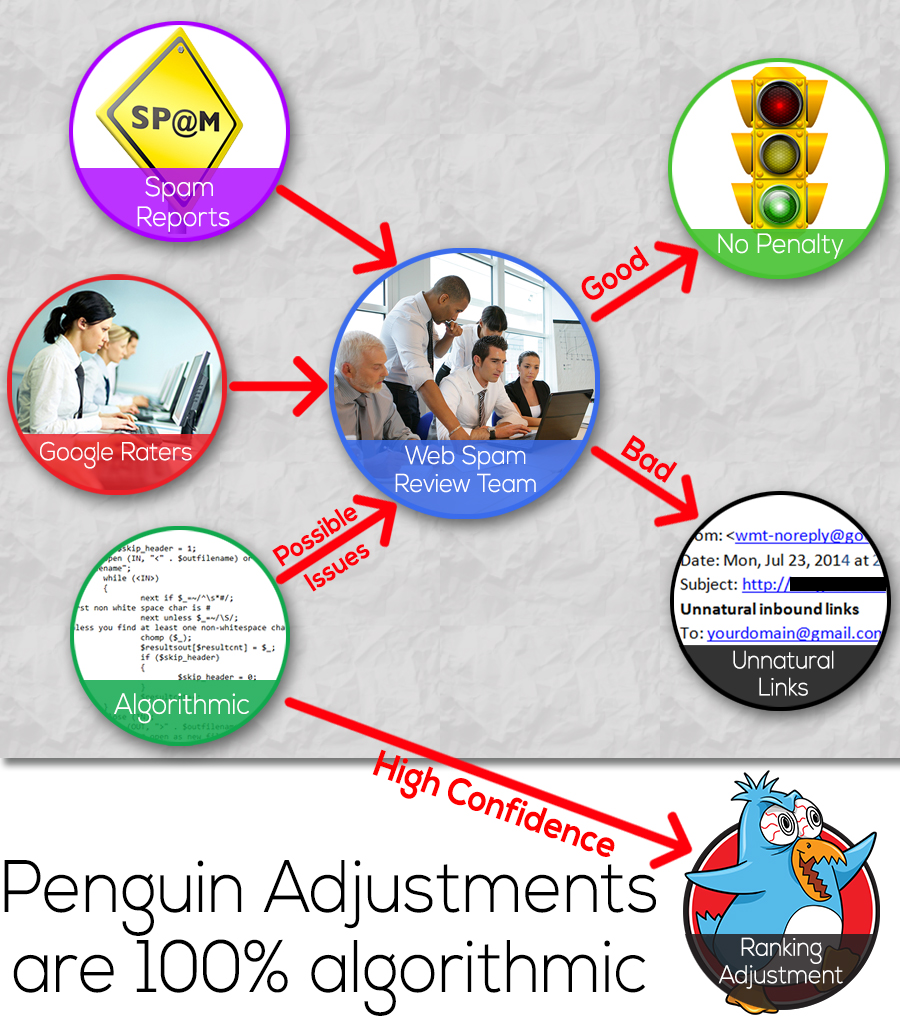
Figure 9-9. Possible ways that Google manual reviews may be triggered
Note that in some cases an algorithm may trigger an algorithmic ranking adjustment (as shown in Figure 9-9, algorithmic adjustments are made only when Google’s confidence in the signals is very high; if the confidence level is not high but there are indications of a problem, a manual review might be initiated). Here is a summary of the major potential triggers:
- Spam report
-
Any user (including your competitor) can file a spam report in Google. Google receives large volumes of these reports every day. Google evaluates each report, and if it finds one credible (it may run some type of algorithmic verifier to determine that), then it conducts a manual review.
- Algorithmically triggered review
-
While this approach has never been verified by Google, it’s likely that Google uses algorithms to trigger a manual review of a website. The premise is that Google uses algorithms like Panda, Penguin, and others that identify large quantities of sites whose behavior is bad, but not bad enough for Google to algorithmically penalize them, so these sites would be queued for manual review. Google could also implement custom algorithms designed to flag sites for review.
- Regular search results reviews
-
Google maintains a large team of people who perform manual reviews of search results to evaluate their quality.4 This effort is primarily intended to provide input to the search quality team at Google that they can use to help them improve their algorithms. However, it is quite possible that this process could also be used to identify individual sites for further scrutiny.
Once a review is triggered, the human reviewer uses a set of criteria to determine if a penalty is merited. Whatever the outcome of that review, it is likely that Google keeps the notes from the review in a database for later use. Google most likely keeps a rap sheet on all webmasters and their previous infractions, whether they result in a penalty or not.
Google Search Console Messages
As of April 2012, Google has maintained a policy of sending all publishers that receive a manual penalty a message in their Search Console describing the nature of the penalty. These messages describe the penalty in general terms, and it is up to the publisher to figure out how to resolve it. Generally, the only resource that Google provides to help with this is its Webmaster Guidelines. If you receive such a message, then the reconsideration request option in Google Search Console becomes available.
Types of Manual Penalties
Manual penalties come in many forms. The most well-known types of penalties are link related, but you can also get a variety of other penalties. Some of the most common types of manual penalties are discussed in the following sections.
Thin-content penalties
This penalty relates to pages that don’t add enough value to users in Google’s opinion. Figure 9-10 shows an example of a thin-content message from Google in Search Console.
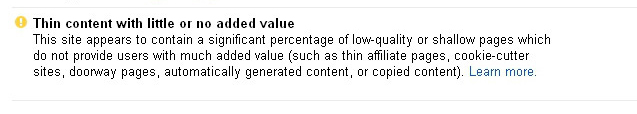
Figure 9-10. Thin-content penalty message
Unfortunately, when you receive this type of penalty, Google doesn’t provide any guidance on what the cause might be. It does tell you that it is a thin-content penalty, but the rest is up to you. There are four primary triggers for thin-content penalties:
- Pages with little useful content
-
As the name of the penalty suggests, pages with very little content are potential triggers for this penalty. This is especially true if there are a large number of these pages, or if there is a particular section on the site that has a significant percentage of its pages deemed thin.
- Thin slicing
-
This happens to publishers who implement pages that are really designed to just garner search traffic. What these publishers often do is build pages for each potential search query a visitor might use, even if the variations in the content are quite small or insignificant. To use an earlier example, imagine a site with information on nursing schools with different pages with the following titles:
-
Nursing schools
-
Nursing school
-
Nursing colleges
-
Nursing universities
-
Best nursing schools
-
-
Sometimes publishers do this unintentionally, by autogenerating content pages based on queries people enter when using the search function for the website. If you decide to do something like this, then it’s critical to have a detailed review process for screening out these thin-slicing variants, pick one version of the page, and focus on it.
- Doorway pages
-
These are pages that appear to be generated just for monetizing users arriving from search engines. One way to recognize these types of pages is that they are usually pretty much standalone pages with little follow-on information available, and/or they are pages that are largely written for search engines and not users.
-
The user arriving on these pages basically has two choices: buy now, or leave.
- Poor integration into the overall site
-
Another issue to look for is whether parts of your site are not well integrated into the rest of the site. Is there a simple way for users to get to these pages from the home page, from the main navigation of the site, or at least from a major section of the site?
-
If you have a section that appears to be isolated from the rest of your site, that could result in a thin-content penalty.
Once you believe you have resolved these issues, you need to submit a reconsideration request. You can read more about this in “Filing reconsideration requests”. Once you have filed this request, you simply wait until Google provides a response. This process normally takes two to three weeks.
If you are successful, then you are in good shape and just need to make sure not to overstep your boundaries again in the future. Otherwise, it’s back to the drawing board to see what you might have missed.
Partial link penalties
Another possible manual penalty is a partial link penalty. This is sometimes called an “impacts links” penalty, as that term is part of the message you get from Google (see Figure 9-11). These penalties indicate that one or a small number of your pages have been flagged for bad linking behavior.
Normally, only the rankings and traffic for those particular pages suffer as a consequence of this penalty.
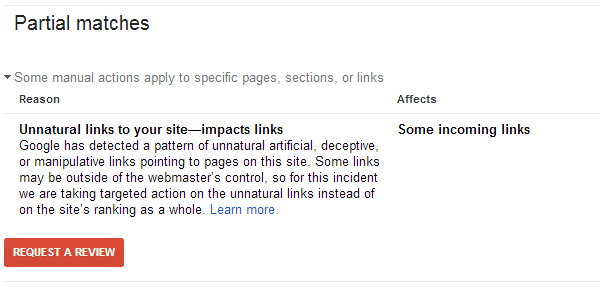
Figure 9-11. Partial link penalty message
Unfortunately, Google does not tell you which of your pages is receiving the penalty, so you have to determine that for yourself. This penalty is normally caused by too many questionable or bad links to pages other than your home page.
The cause is often a link-building campaign focused on bringing up the rankings and search traffic to specific money pages on your site. One of the more common problems is too many links with keyword-rich anchor text pointing to those pages, but other types of bad links can be involved as well. The steps to recover from this type of penalty are:
-
Pull together a complete set of your links as described in “Sources of Data”.
-
Look for pages on your site, other than the home page, that have the most links.
-
Examine these pages for bad links as described in “Links Google Does Not Like”.
-
Use the process described in “Link Cleanup Process” to deal with the bad links.
-
Submit a reconsideration request as described in “Filing reconsideration requests”.
Once you have sent in the reconsideration request, the only thing you can do is wait. As noted previously, it normally takes two to three weeks before you get a response. Google will either let you know you have succeeded and confirm that it has removed the penalty, or it will tell you that you have failed, in which case you have to take a deeper look at your links and figure out what you missed in your previous attempt.
Sitewide link penalties
Manual link penalties can also be applied on a sitewide basis. This usually means more than a few pages are involved, and may well also involve the home page of the site. With this type of penalty, rankings are lowered for the publisher on a sitewide basis.
As a consequence, the amount of lost traffic is normally far more than it is for a partial link penalty. Figure 9-12 shows an example of a sitewide link penalty message.
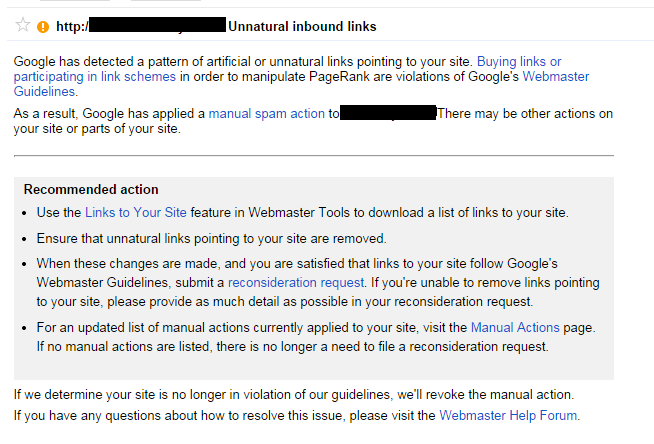
Figure 9-12. Sitewide link penalty message
The steps to recover from this type of penalty are:
-
Pull together a complete set of your links as described in “Sources of Data”.
-
Examine this list for bad links as described in “Links Google Does Not Like”.
-
Use the process described in “Link Cleanup Process” to deal with the bad links.
-
Submit a reconsideration request as described in “Filing reconsideration requests”.
Once you have sent in the reconsideration request, the only thing you can do is wait. It normally takes two to three weeks before you get a response. Google will either let you know you have succeeded and confirm that it has removed the penalty, or it will tell you that you have failed, in which case you have to take a deeper look at your links and figure out what you missed in your previous attempt.
Other types of manual penalties
Some of the other manual penalties include:
- Cloaking and/or sneaky redirects
-
You can get this message if Google believes you are showing different versions of pages to Googlebot than you show to users. To diagnose this, use the “Fetch and Render as Google” tool in Search Console to retrieve the page. Use the tool to load the same page in another browser window and compare the two pages.
-
If you see differences, invest the time and effort to figure out how to remove the differing content. You should also check for URLs that redirect and send people to pages that are not in line with what they expected to see—for example, if they click on anchor text to read an article about a topic of interest but instead find themselves on a spammy page trying to sell them something.
-
Another potential source of this problem is conditional redirects, where users coming from Google search, or a specific range of IP addresses, are redirected to different pages than other users.
- Hidden text and/or keyword stuffing
-
This message is generated if Google believes you are stuffing keywords into your pages for the purpose of manipulating search results—for example, if you put content on a page with a white background using a white font, so it’s invisible to users but search engines can still see it.
-
Another way to generate this message is to simply repeat your main keyword for a page over and over again in hopes of influencing search results.
- User-generated spam
-
This type of penalty is applied to sites allowing user-generated content (UGC) that are perceived to not be doing a good job of quality control on that content. It’s very common that sites with UGC become targets for spammers uploading low-quality content with links back to their own sites.
-
The short-term fix for this is to identify and remove the spammy pages. The longer-term fix is to implement a process for reviewing and screening out spammy content to prevent it from getting on your site in the first place.
- Unnatural links from your site
-
This is an indication that Google believes you are selling links to third parties, or participating in link schemes, for the purposes of passing PageRank. The fix is simple: remove the links on your site that look like paid links, or add a
nofollowattribute to those links. - Hacked site
-
Google will communicate this penalty by sending you a message in Search Console and/or by showing indications that your site has been hacked (and is dangerous to visit) in the search results. The most common cause for this penalty is failing to keep up with updates to your content management system (CMS).
-
Spammers take advantage of vulnerabilities in the CMS to modify your web pages, most often for the purpose of inserting links to their own sites, but sometimes for more nefarious purposes such as accessing credit card data or other personally identifiable information.
-
To resolve the problem, you will need to determine how your site has been hacked. If you don’t have technical staff working for you, you may need to get help to detect and repair the problem. To minimize your exposure going forward, always keep your CMS on the very latest version possible.
- Pure spam
-
Google will give you this message in Search Console if it believes that your site is using very aggressive spam techniques. This can include things such as automatically generated gibberish or other tactics that appear to have little to do with trying to add value for users.
-
If you get this message, there is a strong chance that you should simply shut down the site and start with a new one.
- Spammy freehosts
-
Even if your site is clean as a whistle, if a large percentage of the sites using your hosting company are spamming, Google may take action against all of the sites hosted there. Take care to make sure you are working with a highly reputable hosting company!
For any of these problems, you need to address the source of the complaints. When you believe you have done so, follow the procedure outlined in “Filing reconsideration requests”.
Links Google Does Not Like
To understand the types of links that Google does not like, we need only review Larry Page and Sergey Brin’s original thesis, “The Anatomy of a Large-Scale Hypertextual Web Search Engine”). At the beginning of the thesis is this paragraph:
The citation (link) graph of the web is an important resource that has largely gone unused in existing web search engines. We have created maps containing as many as 518 million of these hyperlinks, a significant sample of the total. These maps allow rapid calculation of a web page’s “PageRank,” an objective measure of its citation importance that corresponds well with people’s subjective idea of importance. Because of this correspondence, PageRank is an excellent way to prioritize the results of web keyword searches.
The concept of a citation is critical. Consider the example of an academic research paper, which might include citations similar to those shown in Figure 9-13.

Figure 9-13. Academic citations
The paper’s author uses the citation list to acknowledge major sources he referenced as he wrote the paper. If you did a study of all the papers on a given topic area, you could fairly easily identify the most important ones, because they would have the most citations (votes) by other papers.
Generally speaking, you do not buy placement of a citation in someone else’s research paper. Nor do you barter such placements (“I will mention you in my paper if you mention me in yours”), and you certainly would not implement some tactic to inject mentions of your work in someone else’s research paper without the writer’s knowledge.
You would also not publish dozens or hundreds of poorly written papers just so you could include more mentions of your work in them. In principle, you can’t vote for yourself. Nor would you upload your paper to dozens or hundreds of sites created as repositories for such papers if you knew no one would ever see it there, or if such repositories contained a lot of illegitimate papers that you would not want to be associate with.
Of course, all of these examples have happened on the Web with links. All of these practices run counter to the way that search engines want to use links, as they are counting on the links they find being ones that were earned by merit.
This means that search engines don’t want you to purchase links for the purpose of influencing their rankings. You can buy ads, of course—there is nothing wrong with that—but search engines would prefer those ad links have the nofollow attribute so they know not to count them.
Additionally, pure barter links are valued less or ignored altogether. From 2000 to 2005, it was quite popular to send people emails that offered to link to them if they linked to you, on the premise that this helped with search engine rankings. Of course, these types of links are not real citations either.
Google will not place any value on the links from user-generated content sites, such as social media sites, either. Anywhere people can link to themselves is a place that search engines will simply discount, or even potentially punish if they detect patterns of abusive behavior.
Here is a list of some of the types of links that Google may consider less valuable, or not valuable at all:
- Article directories
-
These are sites that allow you to upload an article to them, usually with little or no editorial review. The articles can contain links back to your site, so the simple act of uploading the article results in a link. The problem is that this is a form of voting for yourself, and Google started punishing sites that actively obtained links from article directories with the Penguin 1.0 release on April 24, 2012.
- Cheap directories
-
Many directories have sprung up all over the Web that exist only to collect fees from as many sites as possible. These types of directories have little or no editorial review, and the owner’s only concern is to collect as many listing fees as possible. There are a few quality directories, such as the Yahoo! directory, Business.com, and a few others. These are discussed in more detail in Chapter 7.
NOTE
These comments on directories are not meant to apply to local business directories, whose dynamics are quite different. These are discussed more in Chapter 10.
- Links from countries where you don’t do business
-
If your company does business only in Brazil, there is no reason you should have large numbers of links from Poland and Russia. There is not much you can do if people choose to give you links you did not ask for, but there is certainly no reason for you to proactively engage in activities that would result in your getting links from such countries.
- Links from foreign sites with a link in a different language
-
Some aggressive SEO professionals actively pursue getting links from nearly anywhere. As shown in Figure 9-14, there is no reason to have a “Refinance Your Home Today” link on a page where the rest of the text is in Chinese.
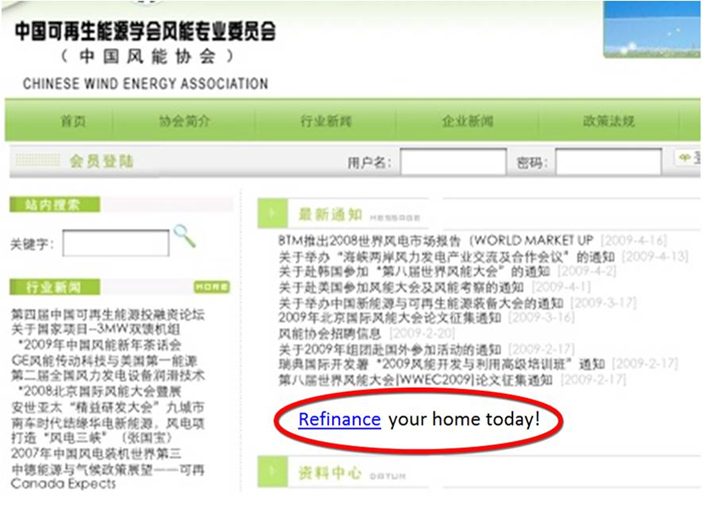
Figure 9-14. Foreign language mismatch
- Comment spam
-
Another popular technique in the past was to drop links in comments on forums and blog posts. This practice became much less valuable ever since Google introduced the
nofollowattribute, but aggressive spammers still pursue it. In fact, they make use of bots that drop comments on an automated basis on blog posts and forums all over the Web. They may post 1 million or more comments this way, and even if only .001% of 1 percent of those links are notnofollowed, it still nets the spammers 1,000 links. - Guest post spam
-
These are generally poorly written guest posts that add little value for users and have been written just to get a link back to your own site. Consider the example in Figure 9-15, where the author was looking to get a link back to his site with the anchor text “buy cars.” He could not even take the time to work that phrase into a single sentence!

Figure 9-15. Guest post spam
- Guest posts not related to your site
-
This is a type of guest post spam where the article written does not really relate to your site. If you sell used cars, you should not expect Google to see any value in a guest post you write about lacrosse equipment that links back to your site. There is no relevance.
- In-context guest post links
-
Another form of guest posting that Google frowns upon is posts that include links in the body of the article back to you, particularly if those links are keyword-rich, and if they don’t add a lot of value to the post itself. Figure 9-16 shows a fictional example of what this might look like.

Figure 9-16. Embedded keyword-rich anchor text links
- Advertorials
-
This is a form of guest post that is written like it’s an ad. Given the structure, it’s highly likely that the site posting it was influenced to do so in some manner. If you are going to include guest posting as part of your strategy, focus on sites that don’t permit these types of guest posts.
- Widgets
-
One tactic that became quite popular is building useful or interesting tools (widgets), and allowing third-party websites to publish them on their own sites. These normally contained a link back to the widget creator’s site. If the content is highly relevant, there is nothing wrong with this idea in principle, but the problem is that the tactic was abused by SEOs, resulting in Google wanting to discount many of these types of links.
- Infographics
-
This is another area that could in theory be acceptable, but was greatly abused by SEOs. It is not clear what Google does with these links at this point, but you should create infographics only if they are highly relevant, highly valuable, and (of course) accurate.
- Misleading anchor text
-
This is a more subtle issue. Imagine an example where the anchor text of a link says “information about golf courses,” but the page receiving the link is about tennis rackets. This is not a good experience for users, and is not something that search engines will like.
- Sites with malware
-
Of course, Google looks to discount these types of links. Sites containing malware are very bad for users, and hence any link from them is of no value, and potentially harmful.
- Footer links
-
Once again, there is nothing inherently wrong with a link from the footer of someone’s web page, but as these links are less likely to be clicked on or viewed by users, Google may discount their value. For more on this topic, you can read Bill Slawski’s article Google’s Reasonable Surfer: How the Value of a Link May Differ Based Upon Link and Document Features and User Data”, which discusses Google’s “reasonable surfer” patent.
- Links in a list with unrelated links
-
This can be a sign of a purchased link. Imagine you find a link to your “Travel Australia” website mixed in a list of links with an online casino site, a mortgage lead generation site, and a lottery ticket site. This does not look good to Google.
- Links from poor-quality sites
-
The links that have the most value are the ones that come from very high-quality sites that show substantial evidence of strong editorial control. Conversely, as quality drops, editorial control tends to as well, and Google may not count these links at all.
- Press releases
-
It used to be quite popular to put out lots of press releases, complete with keyword-rich text links back to your site. Of course, this is a form of voting for yourself, and this is not the way that press releases should be used to promote your site. As shown in Figure 9-17, a much better way to use press releases is to get your news in front of media people and bloggers, and hope that it’s interesting enough that they will write about you or share your news on social media.
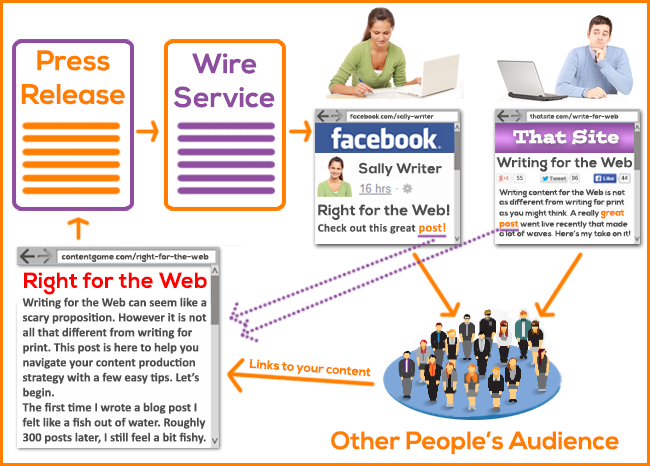
Figure 9-17. The right way to use press releases
- Bookmark sites
-
There are many quality sites for saving interesting links for your own benefit, such as Delicious, Evernote, Diigo, and many others. However, as these are user-generated content sites, their links are
nofollowed and thus have no value in ranking your site.
Not all of the types of links in the preceding list will necessarily result in your site bring penalized, but they are all examples of links that Google may not want to count.
Link Cleanup Process
The first part of the link cleanup process is to establish the right mindset. As you review your backlink profile, consider how Google looks at your links. Here are some rules of thumb to help you determine whether a link has real value:
-
Would you want that link if Google and Bing did not exist?
-
Would you proudly show it to a prospective customer right before she is ready to buy?
-
Was the link given to you as a genuine endorsement?
As you review your backlinks, you may find yourself at times trying to justify a link’s use. This is usually a good indicator that it’s not a good link. High-quality links require no justification—it’s obvious that they are good links.
Sources of Data
Google provides a list of external links in the Search Console account for your site. Figure 9-18 shows the steps to navigate to that report.
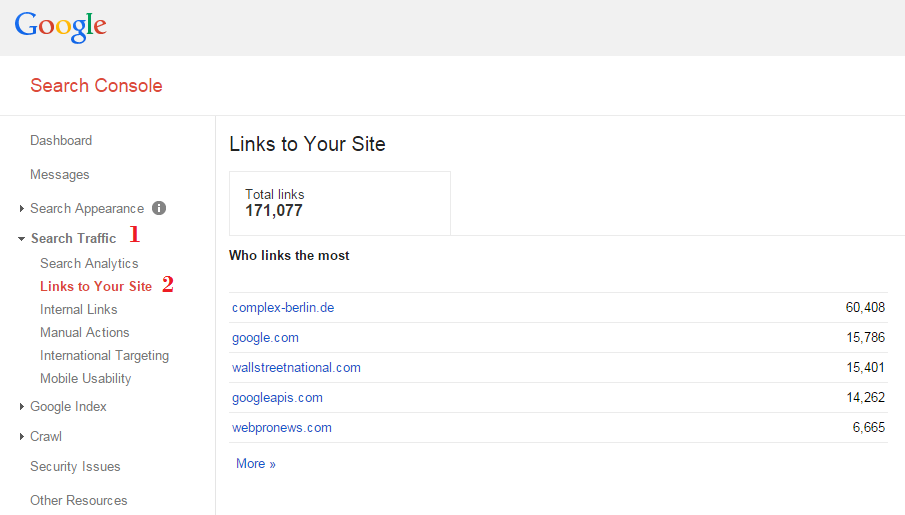
Figure 9-18. Steps to obtain the Search Console list of links
The problem with this list is that it tends to be incomplete, thus we recommend that you also pull links from several other sources. Some of the best additional sources include Open Site Explorer, Majestic SEO, Ahrefs, and LinkResearchTools.
The combination of data from all of these tools will show a more complete list of links. Of course, there will also be a lot of overlap in what they show, so make sure to deduplicate the list.
However, even the combination of all these sources is not comprehensive. Google shares only a portion of the links it is aware of in Search Console. The other link sources are reliant on the crawls of their individual companies, and crawling the entire Web is a big job that they simply do not have the resources for.
Using Tools
There are tools available to help speed up link removal by automating the process of identifying bad links. These include Remove’em and Link Detox. These tools can potentially help you identify some of your bad links. However, it is a good idea to not rely solely on these tools to do the job for you.
Each tool has its own algorithms for identifying problem links, and this can save you time in doing a full evaluation of all your links. However, keep in mind that Google has spent more than 15 years developing its algorithms for evaluating links and it’s a core part of its business to evaluate them effectively, including detecting link spam. Third-party tools won’t be as sophisticated as Google’s algorithm. They can detect some of the bad links, but not necessarily all of the ones you will need to address. You should plan on evaluating all of the links—not only the sites labeled as toxic, but also any that are merely suspicious or even innocuous. Use your own judgment, and don’t just rely on the tools to decide for you what is good or bad.
The Disavow Links tool
Google provides a tool to allow you to disavow links. The Disavow Links tool tells Google that you no longer wish to receive any PageRank (or other benefit) from certain links. This gives you a method for eliminating the negative impact of bad links pointing to your site. Figure 9-19 shows what the tool’s opening screen looks like.
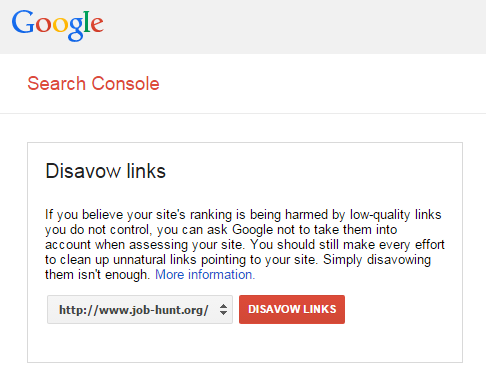
Figure 9-19. Opening screen of Google’s Disavow Links tool
Note that Google includes the following text: “You should still make every effort to clean up unnatural links pointing to your site. Simply disavowing them isn’t enough.” This is good advice, as Google employees who review reconsideration requests like to see that you have invested time in getting the bad links to your site removed.
Once you select a site (blacked out in Figure 9-19) and click the Disavow Links button, you are taken to another screen that includes the following warning:
This is an advanced feature and should only be used with caution. If used incorrectly, this feature can potentially harm your site’s performance in Google’s search results. We recommend that you only disavow backlinks if you believe that there are a considerable number of spammy, artificial, or low-quality links pointing to your site, and if you are confident that the links are causing issues for you.
On this screen, you need to click Disavow Links again, after which you’ll be taken to a third and final screen, shown in Figure 9-20.
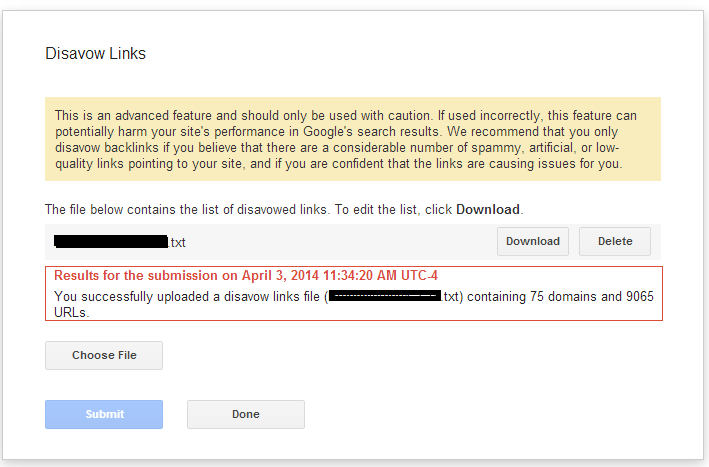
Figure 9-20. Final screen of Google’s Disavow Links tool
The sample screen in Figure 9-20 shows that the current disavow file for this site (the name is blacked out) is disavowing 75 domains and 9,065 URLs.
One important tip: considering that the link data you have is incomplete (as described in “Sources of Data”), it is best practice to disavow entire domains. In other words, if you see one bad link coming to you from a domain, it is certainly possible that there are other bad links coming to you from that domain, and that some of these bad links are not in the data available to you.
An example would be a guest post that you want to disavow. Perhaps you have done only one guest post on that site, but the post will also appear in category pages and date-based archives on that blog. If you disavow only the post page, you still have many other bad links from that site that Google has found.
In the example shown in Figure 9-20, it is quite likely that this publisher has not solved his problem and that many (if not all) of the disavowed URLs should be made into full disavowed domains. That is usually the safest course of action.
Refer to the Google help page for more specifics on formatting the disavow file.
The Link Removal Process
The most important part of the link removal process is recognizing the need to be comprehensive. Losing a lot of your traffic is scary, and being impatient is natural. If there is a manual link penalty on your site you will be anxious to send in your reconsideration request, but as soon as you do, there’s nothing you can do but wait.
If you don’t do enough to remove bad links, Google will reject your reconsideration request, and you have to go through the whole process again. If you end up filing a few reconsideration requests without being successful, Google may send you a message telling you to pause for a while. Make a point of being very aggressive in removing and disavowing links, and don’t try to save a lot of marginal ones. This almost always speeds up the process in the end. In addition, those somewhat questionable links that you’re trying to save often are not helping you much anyway.
As we have discussed, the Penguin algorithm is updated only once or twice per year. If you have been hit by that algorithm and fail to recover during an update, that means waiting another 6 to 12 months before you have another chance.
NOTE
Google has indicated that it intends to speed up the Penguin update process in the future.
With all this in mind, you also want to be able to get through the process as quickly as possible. Figure 9-21 is a visual outline of the link removal process.
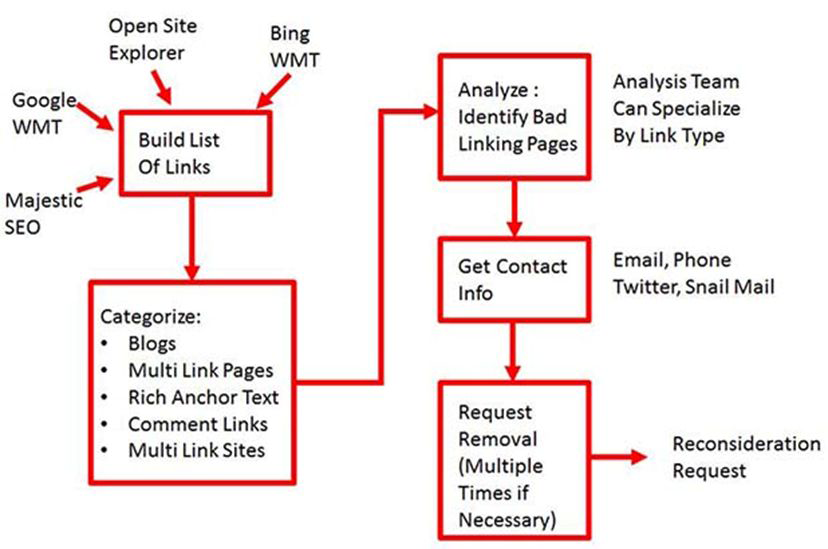
Figure 9-21. Process for removing links
Precategorizing the links is quite helpful in speeding up this process. For example, you can identify many of the blogs simply by using the Excel filter function and filtering on “blog.” This will allow you to more rapidly review the links for problems. Tools such as Remove’em and Link Detox will do this for you as well.
This step is especially helpful if you know you have been running an aggressive guest posting campaign, or worse, paying for guest post placements. Some additional tips include:
-
You do not need to worry about links that are marked as
nofollow. -
Links from sites with very low PageRank for their home page probably are adding little to no value to your site.
-
Links from very low-relevance pages are not likely to be adding much value either.
In addition, contacting sites directly and requesting that they remove links can be quite helpful. Google likes to see that you’re putting in the effort to clean up those bad links.
Remember that reconsideration requests are reviewed by members of the webspam team at Google. This introduces a human element that you can’t ignore. The members of this team make their living dealing with sites that have violated Google’s guidelines, and you are one of them.
As we noted in “Sources of Data”, even when you use all the available sources of link data, the information you have is incomplete. This means that it’s likely that you will not have removed all the bad links when you file your reconsideration request, even if you are very aggressive in your review process, simply because you don’t have all the data. Showing reviewers the good faith effort to remove some of the bad links is very helpful, and can impact their evaluation of the process.
However, there is no need to send link removal requests to everyone in sight. For example, don’t send them to people where the link to you is marked with nofollow.
Once the process is complete, if you have received a manual penalty, you are ready to file a reconsideration request. If you have been hit by Penguin, all you can do is wait, as reconsideration requests won’t help you there. The only way to recover from Penguin penalties is to wait for the next algorithm update.
Filing reconsideration requests
The first thing to realize about your reconsideration request is that a person will review it, and that person likely reviews large numbers of them every single day. Complaining about what has happened to your business, or getting aggressive with the reviewer, is not going to help your cause at all.
The best path is to be short and to the point:
-
Briefly define the nature of the problem. Include some statistics if possible.
-
Explain what went wrong. For example, if you were ignorant of the rules, just say so, and tell them that you now understand. Or, if you had a rogue SEO firm do bad work for you, say that.
-
Explain what you did to clean it up:
-
If you had a link penalty, let them know how many links you were able to get removed.
-
If you did something extraordinary, such as removing and/or disavowing all of your links from the past year, tell them that. Statement actions such as this can have a strong impact and improve your chances of success.
-
-
Clearly state that you intend to abide by the Webmaster Guidelines going forward.
As already noted, keep your reconsideration short. Briefly cover the main points and then submit it using the Search Console account associated with the site that received the penalty. In fact, you can’t send it from an account without a manual penalty.
Conclusion
Traffic losses due to manual penalties or algorithmic updates can be devastating to your business. One defense against them is to reduce your overall dependence on Google traffic, but for nearly any business, traffic from Google is one of the largest opportunities available.
For that reason, it is critical that you conduct your SEO efforts in a way that is in line with Google’s expectations of publishers—creating compelling websites and then promoting them effectively in accordance with Google’s Webmaster Guidelines).
1 Barry Schwartz, “Google Made 890 Improvements To Search Over The Past Year,” Search Engine Land, August 19, 2014, http://bit.ly/890_improvements.
2 Danny Sullivan, “Google Forecloses On Content Farms With ‘Panda’ Algorithm Update,” Search Engine Land, February 24, 2011, http://bit.ly/panda_update.
3 Eric Enge, “The Rise And Fall Of Content Farms,” Search Engine Land, January 31, 2011, http://bit.ly/content_farms.
4 Danny Goodwin, “Google’s Rating Guidelines Adds Page Quality to Human Reviews,” Search Engine Watch, September 6, 2012, http://bit.ly/rating_guidelines.