
One method of achieving parallelism is for multiple processes to cooperate and synchronize through shared memory or message passing. An alternative approach uses multiple threads of execution in a single address space. This chapter explains how threads are created, managed and used to solve simple problems. The chapter then presents an overview of basic thread management under the POSIX standard. The chapter discusses different thread models and explains how these models are accommodated under the standard.
A blocking read operation causes the calling process to block until input becomes available. Such blocking creates difficulties when a process expects input from more than one source, since the process has no way of knowing which file descriptor will produce the next input. The multiple file descriptor problem commonly appears in client-server programming because the server expects input from multiple clients. Six general approaches to monitoring multiple file descriptors for input under POSIX are as follows.
A separate process monitors each file descriptor (Program 4.11)
select(Program 4.12 and Program 4.14)poll(Program 4.17)Nonblocking I/O with polling (Example 4.39)
POSIX asynchronous I/O (Program 8.14 and Program 8.16)
A separate thread monitors each file descriptor (Section 12.2)
In the separate process approach, the original process forks a child process to handle each file descriptor. This approach works for descriptors representing independent I/O streams, since once forked, the children don’t share any variables. If processing of the descriptors is not independent, the children may use shared memory or message passing to exchange information.
Approaches two and three use blocking calls (select or poll) to explicitly wait for I/O on the descriptors. Once the blocking call returns, the calling program handles each ready file descriptor in turn. The code can be complicated when some of the file descriptors close while others remain open (e.g., Program 4.17). Furthermore, the program can do no useful processing while blocked.
The nonblocking strategy of the fourth approach works well when the program has “useful work” that it can perform between its intermittent checks to see if I/O is available. Unfortunately, most problems are difficult to structure in this way, and the strategy sometimes forces hard-coding of the timing for the I/O check relative to useful work. If the platform changes, the choice may no longer be appropriate. Without very careful programming and a very specific program structure, the nonblocking I/O strategy can lead to busy waiting and inefficient use of processor resources.
POSIX asynchronous I/O can be used with or without signal notification to overlap processing with monitoring of file descriptors. Without signal notification, asynchronous I/O relies on polling as in approach 4. With signal notification, the program does its useful work until it receives a signal advising that the I/O may be ready. The operating system transfers control to a handler to process the I/O. This method requires that the handler use only async-signal-safe functions. The signal handler must synchronize with the rest of the program to access the data, opening the potential for deadlocks and race conditions. Although asynchronous I/O can be tuned very efficiently, the approach is error-prone and difficult to implement.
The final approach uses a separate thread to handle each descriptor, in effect reducing the problem to one of processing a single file descriptor. The threaded code is simpler than the other implementations, and a program can overlap processing with waiting for input in a transparent way.
Threading is not as widely used as it might be because, until recently, threaded programs were not portable. Each vendor provided a proprietary thread library with different calls. The POSIX standard addresses the portability issue with POSIX threads, described in the POSIX:THR Threads Extension. Table E.1 on page 860 lists several additional extensions that relate to the more esoteric aspects of POSIX thread management. Section 12.2 introduces POSIX threads by solving the multiple file descriptor problem. Do not focus on the details of the calls when you first read this section. The remainder of this chapter discusses basic POSIX thread management and use of the library. Chapter 13 explains synchronization and signal handling with POSIX threads. Chapters 14 and 15 discuss the use of semaphores for synchronization. Semaphores are part of the POSIX:SEM Extension and the POSIX:XSI Extension and can be used with threads. Chapters 16 and 17 discuss projects that use threads and synchronization.
Multiple threads can simplify the problem of monitoring multiple file descriptors because a dedicated thread with relatively simple logic can handle each file descriptor. Threads also make the overlap of I/O and processing transparent to the programmer.
We begin by comparing the execution of a function by a separate thread to the execution of an ordinary function call within the same thread of execution. Figure 12.1 illustrates a call to the processfd function within the same thread of execution. The calling mechanism creates an activation record (usually on the stack) that contains the return address. The thread of execution jumps to processfd when the calling mechanism writes the starting address of processfd in the processor’s program counter. The thread uses the newly created activation record as the environment for execution, creating automatic variables on the stack as part of the record. The thread of execution continues in processfd until reaching a return statement (or the end of the function). The return statement copies the return address that is stored in the activation record into the processor program counter, causing the thread of execution to jump back to the calling program.
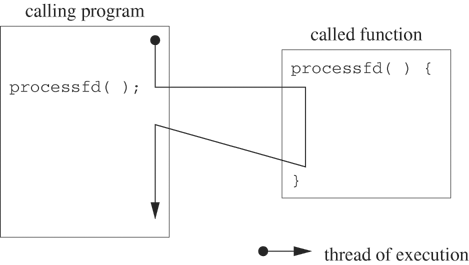
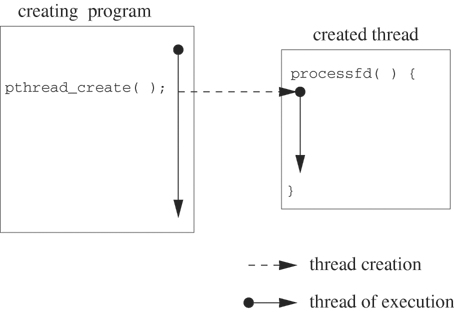
Figure 12.2 illustrates the creation of a separate thread to execute the processfd function. The pthread_create call creates a new “schedulable entity” with its own value of the program counter, its own stack and its own scheduling parameters. The “schedulable entity” (i.e., thread) executes an independent stream of instructions, never returning to the point of the call. The calling program continues to execute concurrently. In contrast, when processfd is called as an ordinary function, the caller’s thread of execution moves through the function code and returns to the point of the call, generating a single thread of execution rather than two separate ones.
We now turn to the specific problem of handling multiple file descriptors. The processfd function of Program 12.1 monitors a single file descriptor by calling a blocking read. The function returns when it encounters end-of-file or detects an error. The caller passes the file descriptor as a pointer to void, so processfd can be called either as an ordinary function or as a thread.
The processfd function uses the r_read function of Program 4.3 instead of read to restart reading if the thread is interrupted by a signal. However, we recommend a dedicated thread for signal handling, as explained in Section 13.5. In this case, the thread that executes processfd would have all signals blocked and could call read.
Example 12.1. processfd.c
The processfd function monitors a single file descriptor for input.
#include <stdio.h>
#include "restart.h"
#define BUFSIZE 1024
void docommand(char *cmd, int cmdsize);
void *processfd(void *arg) { /* process commands read from file descriptor */
char buf[BUFSIZE];
int fd;
ssize_t nbytes;
fd = *((int *)(arg));
for ( ; ; ) {
if ((nbytes = r_read(fd, buf, BUFSIZE)) <= 0)
break;
docommand(buf, nbytes);
}
return NULL;
}
Example 12.1.
The following code segment calls processfd as an ordinary function. The code assumes that fd is open for reading and passes it by reference to processfd.
void *processfd(void *); int fd; processfd(&fd);
Example 12.2.
The following code segment creates a new thread to run processfd for the open file descriptor fd.
void *processfd(void *arg); int error; int fd; pthread_t tid; if (error = pthread_create(&tid, NULL, processfd, &fd)) fprintf(stderr, "Failed to create thread: %s ", strerror(error));
The code of Example 12.1 has a single thread of execution, as illustrated in Figure 12.1. The thread of execution for the calling program traverses the statements in the function and then resumes execution at the statement after the call. Since processfd uses blocking I/O, the program blocks on r_read until input becomes available on the file descriptor. Remember that the thread of execution is really the sequence of statements that the thread executes. The sequence contains no timing information, so the fact that execution blocks on a read call is not directly visible to the caller. The code in Example 12.2 has two threads of execution. A separate thread executes processfd, as illustrated in Figure 12.2.
The function monitorfd of Program 12.2 uses threads to monitor an array of file descriptors. Compare this implementation with those of Program 4.14 and Program 4.17. The threaded version is considerably simpler and takes advantage of parallelism. If docommand causes the calling thread to block for some reason, the thread runtime system schedules another runnable thread. In this way, processing and reading are overlapped in a natural way. In contrast, blocking of docommand in the single-threaded implementation causes the entire process to block.
If monitorfd fails to create thread i, it sets the corresponding thread ID to itself to signify that creation failed. The last loop uses pthread_join, described in Section 12.3, to wait until all threads have completed.
Example 12.2. monitorfd.c
A function to monitor an array of file descriptors, using a separate thread for each descriptor.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void *processfd(void *arg);
void monitorfd(int fd[], int numfds) { /* create threads to monitor fds */
int error, i;
pthread_t *tid;
if ((tid = (pthread_t *)calloc(numfds, sizeof(pthread_t))) == NULL) {
perror("Failed to allocate space for thread IDs");
return;
}
for (i = 0; i < numfds; i++) /* create a thread for each file descriptor */
if (error = pthread_create(tid + i, NULL, processfd, (fd + i))) {
fprintf(stderr, "Failed to create thread %d: %s
",
i, strerror(error));
tid[i] = pthread_self();
}
for (i = 0; i < numfds; i++) {
if (pthread_equal(pthread_self(), tid[i]))
continue;
if (error = pthread_join(tid[i], NULL))
fprintf(stderr, "Failed to join thread %d: %s
", i, strerror(error));
}
free(tid);
return;
}
A thread package usually includes functions for thread creation and thread destruction, scheduling, enforcement of mutual exclusion and conditional waiting. A typical thread package also contains a runtime system to manage threads transparently (i.e., the user is not aware of the runtime system). When a thread is created, the runtime system allocates data structures to hold the thread’s ID, stack and program counter value. The thread’s internal data structure might also contain scheduling and usage information. The threads for a process share the entire address space of that process. They can modify global variables, access open file descriptors, and cooperate or interfere with each other in other ways.
POSIX threads are sometimes called pthreads because all the thread functions start with pthread. Table 12.1 summarizes the basic POSIX thread management functions introduced in this section. The programs listed in Section 12.1 used pthread_create to create threads and pthread_join to wait for threads to complete. Other management functions deal with thread termination, signals and comparison of thread IDs. Section 12.6 introduces the functions related to thread attribute objects, and Chapter 13 covers thread synchronization functions.
Table 12.1. POSIX thread management functions.
POSIX function | description |
|---|---|
| terminate another thread |
| create a thread |
| set thread to release resources |
| test two thread IDs for equality |
| exit a thread without exiting process |
| send a signal to a thread |
| wait for a thread |
| find out own thread ID |
Most POSIX thread functions return 0 if successful and a nonzero error code if unsuccessful. They do not set errno, so the caller cannot use perror to report errors. Programs can use strerror if the issues of thread safety discussed in Section 12.4 are addressed. The POSIX standard specifically states that none of the POSIX thread functions returns EINTR and that POSIX thread functions do not have to be restarted if interrupted by a signal.
POSIX threads are referenced by an ID of type pthread_t. A thread can find out its ID by calling pthread_self.
SYNOPSIS #include <pthread.h> pthread_t pthread_self(void); POSIX:THR
The pthread_self function returns the thread ID of the calling thread. No errors are defined for pthread_self.
Since pthread_t may be a structure, use pthread_equal to compare thread IDs for equality. The parameters of pthread_equal are the thread IDs to be compared.
SYNOPSIS #include <pthread.h> pthread_t pthread_equal(thread_t t1, pthread_t t2); POSIX:THR
If t1 equals t2, pthread_equal returns a nonzero value. If the thread IDs are not equal, pthread_equal returns 0. No errors are defined for pthread_equal.
The pthread_create function creates a thread. Unlike some thread facilities, such as those provided by the Java programming language, the POSIX pthread_create automatically makes the thread runnable without requiring a separate start operation. The thread parameter of pthread_create points to the ID of the newly created thread. The attr parameter represents an attribute object that encapsulates the attributes of a thread. If attr is NULL, the new thread has the default attributes. Section 12.6 discusses the setting of thread attributes. The third parameter, start_routine, is the name of a function that the thread calls when it begins execution. The start_routine takes a single parameter specified by arg, a pointer to void. The start_routine returns a pointer to void, which is treated as an exit status by pthread_join.
SYNOPSIS #include <pthread.h> int pthread_create(pthread_t *restrict thread, const pthread_attr_t *restrict attr, void *(*start_routine)(void *), void *restrict arg); POSIX:THR
If successful, pthread_create returns 0. If unsuccessful, pthread_create returns a nonzero error code. The following table lists the mandatory errors for pthread_create.
error | cause |
|---|---|
| system did not have the resources to create the thread, or would exceed system limit on total number of threads in a process |
|
|
| caller does not have the appropriate permissions to set scheduling policy or parameters specified by |
Do not let the prototype of pthread_create intimidate you—threads are easy to create and use.
Example 12.4.
The following code segment creates a thread to execute the function processfd after opening the my.dat file for reading.
void *processfd(void *arg);
int error;
int fd;
pthread_t tid;
if ((fd = open("my.dat", O_RDONLY)) == -1)
perror("Failed to open my.dat");
else if (error = pthread_create(&tid, NULL, processfd, &fd))
fprintf(stderr, "Failed to create thread: %s
", strerror(error));
else
printf("Thread created
");
When a thread exits, it does not release its resources unless it is a detached thread. The pthread_detach function sets a thread’s internal options to specify that storage for the thread can be reclaimed when the thread exits. Detached threads do not report their status when they exit. Threads that are not detached are joinable and do not release all their resources until another thread calls pthread_join for them or the entire process exits. The pthread_join function causes the caller to wait for the specified thread to exit, similar to waitpid at the process level. To prevent memory leaks, long-running programs should eventually call either pthread_detach or pthread_join for every thread.
The pthread_detach function has a single parameter, thread, the thread ID of the thread to be detached.
SYNOPSIS #include <pthread.h> int pthread_detach(pthread_t thread); POSIX:THR
If successful, pthread_detach returns 0. If unsuccessful, pthread_detach returns a nonzero error code. The following table lists the mandatory errors for pthread_detach.
error | cause |
|---|---|
|
|
| no thread with ID |
Example 12.5.
The following code segment creates and then detaches a thread to execute the function processfd.
void *processfd(void *arg); int error; int fd pthread_t tid; if (error = pthread_create(&tid, NULL, processfd, &fd)) fprintf(stderr, "Failed to create thread: %s ", strerror(error)); else if (error = pthread_detach(tid)) fprintf(stderr, "Failed to detach thread: %s ", strerror(error));
Example 12.6. detachfun.c
When detachfun is executed as a thread, it detaches itself.
#include <pthread.h>
#include <stdio.h>
void *detachfun(void *arg) {
int i = *((int *)(arg));
if (!pthread_detach(pthread_self()))
return NULL;
fprintf(stderr, "My argument is %d
", i);
return NULL;
}
A nondetached thread’s resources are not released until another thread calls pthread_join with the ID of the terminating thread as the first parameter. The pthread_join function suspends the calling thread until the target thread, specified by the first parameter, terminates. The value_ptr parameter provides a location for a pointer to the return status that the target thread passes to pthread_exit or return. If value_ptr is NULL, the caller does not retrieve the target thread return status.
SYNOPSIS #include <pthread.h> int pthread_join(pthread_t thread, void **value_ptr); POSIX:THR
If successful, pthread_join returns 0. If unsuccessful, pthread_join returns a nonzero error code. The following table lists the mandatory errors for pthread_join.
error | cause |
|---|---|
|
|
| no thread with ID |
Example 12.7.
The following code illustrates how to retrieve the value passed to pthread_exit by a terminating thread.
int error; int *exitcodep; pthread_t tid; if (error = pthread_join(tid, &exitcodep)) fprintf(stderr, "Failed to join thread: %s ", strerror(error)); else fprintf(stderr, "The exit code was %d ", *exitcodep);
Example 12.8.
What happens if a thread executes the following?
pthread_join(pthread_self());
Answer:
Assuming the thread was joinable (not detached), this statement creates a deadlock. Some implementations detect a deadlock and force pthread_join to return with the error EDEADLK. However, this detection is not required by the POSIX:THR Extension.
Calling pthread_join is not the only way for the main thread to block until the other threads have completed. The main thread can use a semaphore or one of the methods discussed in Section 16.6 to wait for all threads to finish.
The process can terminate by calling exit directly, by executing return from main, or by having one of the other process threads call exit. In any of these cases, all threads terminate. If the main thread has no work to do after creating other threads, it should either block until all threads have completed or call pthread_exit(NULL).
A call to exit causes the entire process to terminate; a call to pthread_exit causes only the calling thread to terminate. A thread that executes return from its top level implicitly calls pthread_exit with the return value (a pointer) serving as the parameter to pthread_exit. A process will exit with a return status of 0 if its last thread calls pthread_exit.
The value_ptr value is available to a successful pthread_join. However, the value_ptr in pthread_exit must point to data that exists after the thread exits, so the thread should not use a pointer to automatic local data for value_ptr.
SYNOPSIS #include <pthread.h> void pthread_exit(void *value_ptr); POSIX:THR
POSIX does not define any errors for pthread_exit.
Threads can force other threads to return through the cancellation mechanism. A thread calls pthread_cancel to request that another thread be canceled. The target thread’s type and cancellability state determine the result. The single parameter of pthread_cancel is the thread ID of the target thread to be canceled. The pthread_cancel function does not cause the caller to block while the cancellation completes. Rather, pthread_cancel returns after making the cancellation request.
SYNOPSIS #include <pthread.h> int pthread_cancel(pthread_t thread); POSIX:THR
If successful, pthread_cancel returns 0. If unsuccessful, pthread_cancel returns a nonzero error code. No mandatory errors are defined for pthread_cancel.
What happens when a thread receives a cancellation request depends on its state and type. If a thread has the PTHREAD_CANCEL_ENABLE state, it receives cancellation requests. On the other hand, if the thread has the PTHREAD_CANCEL_DISABLE state, the cancellation requests are held pending. By default, threads have the PTHREAD_CANCEL_ENABLE state.
The pthread_setcancelstate function changes the cancellability state of the calling thread. The pthread_setcancelstate takes two parameters: state, specifying the new state to set; and oldstate, a pointer to an integer for holding the previous state.
SYNOPSIS #include <pthread.h> int pthread_setcancelstate(int state, int *oldstate); POSIX:THR
If successful, pthread_setcancelstate returns 0. If unsuccessful, it returns a nonzero error code. No mandatory errors are defined for pthread_setcancelstate.
Program 12.3 shows a modification of the processfd function of Program 12.1 that explicitly disables cancellation before it calls docommand, to ensure that the command won’t be canceled midstream. The original processfd always returns NULL. The processfdcancel function returns a pointer other than NULL if it cannot change the cancellation state. This function should not return a pointer to an automatic local variable, since local variables are deallocated when the function returns or the thread exits. Program 12.3 uses a parameter passed by the calling thread to return the pointer.
Example 12.3. processfdcancel.c
This function monitors a file descriptor for input and calls docommand to process the result. It explicitly disables cancellation before calling docommand.
#include <pthread.h>
#include "restart.h"
#define BUFSIZE 1024
void docommand(char *cmd, int cmdsize);
void *processfdcancel(void *arg) { /* process commands with cancellation */
char buf[BUFSIZE];
int fd;
ssize_t nbytes;
int newstate, oldstate;
fd = *((int *)(arg));
for ( ; ; ) {
if ((nbytes = r_read(fd, buf, BUFSIZE)) <= 0)
break;
if (pthread_setcancelstate(PTHREAD_CANCEL_DISABLE, &oldstate))
return arg;
docommand(buf, nbytes);
if (pthread_setcancelstate(oldstate, &newstate))
return arg;
}
return NULL;
}
As a general rule, a function that changes its cancellation state or its type should restore the value before returning. A caller cannot make reliable assumptions about the program behavior unless this rule is observed. The processfdcancel function saves the old state and restores it rather than just enabling cancellation after calling docommand.
Cancellation can cause difficulties if a thread holds resources such as a lock or an open file descriptor that must be released before exiting. A thread maintains a stack of cleanup routines using pthread_cleanup_push and pthread_cleanup_pop. (We do not discuss these here.) Although a canceled thread can execute a cleanup function before exiting (not discussed here), it is not always feasible to release resources in an exit handler. Also, there may be points in the execution at which an exit would leave the program in an unacceptable state. The cancellation type allows a thread to control the point when it exits in response to a cancellation request. When its cancellation type is PTHREAD_CANCEL_ASYNCHRONOUS, the thread can act on the cancellation request at any time. In contrast, a cancellation type of PTHREAD_CANCEL_DEFERRED causes the thread to act on cancellation requests only at specified cancellation points. By default, threads have the PTHREAD_CANCEL_DEFERRED type.
The pthread_setcanceltype function changes the cancellability type of a thread as specified by its type parameter. The oldtype parameter is a pointer to a location for saving the previous type. A thread can set a cancellation point at a particular place in the code by calling pthread_testcancel. Certain blocking functions, such as read, are automatically treated as cancellation points. A thread with the PTHREAD_CANCEL_DEFERRED type accepts pending cancellation requests when it reaches such a cancellation point.
SYNOPSIS #include <pthread.h> int pthread_setcanceltype(int type, int *oldtype); void pthread_testcancel(void); POSIX:THR
If successful, pthread_setcanceltype returns 0. If unsuccessful, it returns a nonzero error code. No mandatory errors are defined for pthread_setcanceltype. The pthread_testcancel has no return value.
The creator of a thread may pass a single parameter to a thread at creation time, using a pointer to void. To communicate multiple values, the creator must use a pointer to an array or a structure. Program 12.4 illustrates how to pass a pointer to an array. The main program passes an array containing two open file descriptors to a thread that runs copyfilemalloc.
Example 12.4. callcopymalloc.c
This program creates a thread to copy a file.
#include <errno.h>
#include <fcntl.h>
#include <pthread.h>
#include <stdio.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#define PERMS (S_IRUSR | S_IWUSR)
#define READ_FLAGS O_RDONLY
#define WRITE_FLAGS (O_WRONLY | O_CREAT | O_TRUNC)
void *copyfilemalloc(void *arg);
int main (int argc, char *argv[]) { /* copy fromfile to tofile */
int *bytesptr;
int error;
int fds[2];
pthread_t tid;
if (argc != 3) {
fprintf(stderr, "Usage: %s fromfile tofile
", argv[0]);
return 1;
}
if (((fds[0] = open(argv[1], READ_FLAGS)) == -1) ||
((fds[1] = open(argv[2], WRITE_FLAGS, PERMS)) == -1)) {
perror("Failed to open the files");
return 1;
}
if (error = pthread_create(&tid, NULL, copyfilemalloc, fds)) {
fprintf(stderr, "Failed to create thread: %s
", strerror(error));
return 1;
}
if (error = pthread_join(tid, (void **)&bytesptr)) {
fprintf(stderr, "Failed to join thread: %s
", strerror(error));
return 1;
}
printf("Number of bytes copied: %d
", *bytesptr);
return 0;
}
Program 12.5 shows an implementation of copyfilemalloc, a function that reads from one file and outputs to another file. The arg parameter holds a pointer to a pair of open descriptors representing the source and destination files. The variables bytesp, infd and outfd are allocated on copyfilemalloc’s local stack and are not directly accessible to other threads.
Program 12.5 also illustrates a strategy for returning values from the thread. The thread allocates memory space for returning the total number of bytes copied since it is not allowed to return a pointer to its local variables. POSIX requires that malloc be thread-safe. The copyfilemalloc function returns the bytesp pointer, which is equivalent to calling pthread_exit. It is the responsibility of the calling program (callcopymalloc) to free this space when it has finished using it. In this case, the program terminates, so it is not necessary to call free.
Example 12.5. copyfilemalloc.c
The copyfilemalloc function copies the contents of one file to another by calling the copyfile function of Program 4.6 on page 100. It returns the number of bytes copied by dynamically allocating space for the return value.
#include <stdlib.h>
#include <unistd.h>
#include "restart.h"
void *copyfilemalloc(void *arg) { /* copy infd to outfd with return value */
int *bytesp;
int infd;
int outfd;
infd = *((int *)(arg));
outfd = *((int *)(arg) + 1);
if ((bytesp = (int *)malloc(sizeof(int))) == NULL)
return NULL;
*bytesp = copyfile(infd, outfd);
r_close(infd);
r_close(outfd);
return bytesp;
}
Example 12.9.
What happens if copyfilemalloc stores the byte count in a variable with static storage class and returns a pointer to this static variable instead of dynamically allocating space for it?
Answer:
The program still works since only one thread is created. However, in a program with two copyfilemalloc threads, both store the byte count in the same place and one overwrites the other’s value.
When a thread allocates space for a return value, some other thread is responsible for freeing that space. Whenever possible, a thread should clean up its own mess rather than requiring another thread to do it. It is also inefficient to dynamically allocate space to hold a single integer. An alternative to having the thread allocate space for the return value is for the creating thread to do it and pass a pointer to this space in the argument parameter of the thread. This approach avoids dynamic allocation completely if the space is on the stack of the creating thread.
Program 12.6 creates a copyfilepass thread to copy a file. The parameter to the thread is now an array of size 3. The first two entries of the array hold the file descriptors as in Program 12.4. The third array element stores the number of bytes copied. Program 12.6 can retrieve this value either through the array or through the second parameter of pthread_join. Alternatively, callcopypass could pass an array of size 2, and the thread could store the return value over one of the incoming file descriptors.
Example 12.6. callcopypass.c
A program that creates a thread to copy a file. The parameter of the thread is an array of three integers used for two file descriptors and the number of bytes copied.
#include <errno.h>
#include <fcntl.h>
#include <pthread.h>
#include <stdio.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#define PERMS (S_IRUSR | S_IWUSR)
#define READ_FLAGS O_RDONLY
#define WRITE_FLAGS (O_WRONLY | O_CREAT | O_TRUNC)
void *copyfilepass(void *arg);
int main (int argc, char *argv[]) {
int *bytesptr;
int error;
int targs[3];
pthread_t tid;
if (argc != 3) {
fprintf(stderr, "Usage: %s fromfile tofile
", argv[0]);
return 1;
}
if (((targs[0] = open(argv[1], READ_FLAGS)) == -1) ||
((targs[1] = open(argv[2], WRITE_FLAGS, PERMS)) == -1)) {
perror("Failed to open the files");
return 1;
}
if (error = pthread_create(&tid, NULL, copyfilepass, targs)) {
fprintf(stderr, "Failed to create thread: %s
", strerror(error));
return 1;
}
if (error = pthread_join(tid, (void **)&bytesptr)) {
fprintf(stderr, "Failed to join thread: %s
", strerror(error));
return 1;
}
printf("Number of bytes copied: %d
", *bytesptr);
return 0;
}
The copyfilepass function of Program 12.7 uses an alternative way of accessing the pieces of the argument. Compare this with the method used by the copyfilemalloc function of Program 12.5.
Example 12.7. copyfilepass.c
A thread that can be used by callcopypass to copy a file.
#include <unistd.h>
#include "restart.h"
void *copyfilepass(void *arg) {
int *argint;
argint = (int *)arg;
argint[2] = copyfile(argint[0], argint[1]);
r_close(argint[0]);
r_close(argint[1]);
return argint + 2;
}
Example 12.10.
Why have copyfilepass return a pointer to the number of bytes copied when callcopypass can access this value as args[2]?
Answer:
If a thread other than the creating thread joins with copyfilepass, it has access to the number of bytes copied through the parameter to pthread_join.
Program 12.8 shows a parallel file-copy program that uses the thread in Program 12.7. The main program has three command-line arguments: an input file basename, an output file basename and the number of files to copy. The program creates numcopiers threads. Thread i copies infile.i to outfile.i.
Example 12.11.
What happens in Program 12.8 if a write call in copyfile of copyfilepass fails?
Answer:
The copyfilepass returns the number of bytes successfully copied, and the main program does not detect an error. You can address the issue by having copyfilepass return an error value and pass the number of bytes written in one of the elements of the array used as a parameter for thread creation.
When creating multiple threads, do not reuse the variable holding a thread’s parameter until you are sure that the thread has finished accessing the parameter. Because the variable is passed by reference, it is a good practice to use a separate variable for each thread.
Example 12.8. copymultiple.c
A program that creates threads to copy multiple file descriptors.
#include <errno.h>
#include <fcntl.h>
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#define MAXNAME 80
#define R_FLAGS O_RDONLY
#define W_FLAGS (O_WRONLY | O_CREAT)
#define W_PERMS (S_IRUSR | S_IWUSR)
typedef struct {
int args[3];
pthread_t tid;
} copy_t;
void *copyfilepass(void *arg);
int main(int argc, char *argv[]) {
int *bytesp;
copy_t *copies;
int error;
char filename[MAXNAME];
int i;
int numcopiers;
int totalbytes = 0;
if (argc != 4) {
fprintf(stderr, "Usage: %s infile outfile copies
", argv[0]);
return 1;
}
numcopiers = atoi(argv[3]);
if ((copies = (copy_t *)calloc(numcopiers, sizeof(copy_t))) == NULL) {
perror("Failed to allocate copier space");
return 1;
}
/* open the source and destination files and create the threads */
for (i = 0; i < numcopiers; i++) {
copies[i].tid = pthread_self(); /* cannot be value for new thread */
if (snprintf(filename, MAXNAME, "%s.%d", argv[1], i+1) == MAXNAME) {
fprintf(stderr, "Input filename %s.%d too long", argv[1], i + 1);
continue;
}
if ((copies[i].args[0] = open(filename, R_FLAGS)) == -1) {
fprintf(stderr, "Failed to open source file %s: %s
",
filename, strerror(errno));
continue;
}
if (snprintf(filename, MAXNAME, "%s.%d", argv[2], i+1) == MAXNAME) {
fprintf(stderr, "Output filename %s.%d too long", argv[2], i + 1);
continue;
}
if ((copies[i].args[1] = open(filename, W_FLAGS, W_PERMS)) == -1) {
fprintf(stderr, "Failed to open destination file %s: %s
",
filename, strerror(errno));
continue;
}
if (error = pthread_create((&copies[i].tid), NULL,
copyfilepass, copies[i].args)) {
fprintf(stderr, "Failed to create thread %d: %s
", i + 1,
strerror(error));
copies[i].tid = pthread_self(); /* cannot be value for new thread */
}
}
/* wait for the threads to finish and report total bytes */
for (i = 0; i < numcopiers; i++) {
if (pthread_equal(copies[i].tid, pthread_self())) /* not created */
continue;
if (error = pthread_join(copies[i].tid, (void**)&bytesp)) {
fprintf(stderr, "Failed to join thread %d
", i);
continue;
}
if (bytesp == NULL) {
fprintf(stderr, "Thread %d failed to return status
", i);
continue;
}
printf("Thread %d copied %d bytes from %s.%d to %s.%d
",
i, *bytesp, argv[1], i + 1, argv[2], i + 1);
totalbytes += *bytesp;
}
printf("Total bytes copied = %d
", totalbytes);
return 0;
}
Program 12.9 shows a simple example of what can go wrong. The program creates 10 threads that each output the value of their parameter. The main program uses the thread creation loop index i as the parameter it passes to the threads. Each thread prints the value of the parameter it received. A thread can get an incorrect value if the main program changes i before the thread has a chance to print it.
Example 12.12.
Run Program 12.9 and examine the results. What parameter value is reported by each thread?
Answer:
The results vary, depending on how the system schedules threads. One possibility is that main completes the loop creating the threads before any thread prints the value of the parameter. In this case, all the threads print the value 10.
Example 12.9. badparameters.c
A program that incorrectly passes parameters to multiple threads.
#include <pthread.h>
#include <stdio.h>
#include <string.h>
#define NUMTHREADS 10
static void *printarg(void *arg) {
fprintf(stderr, "Thread received %d
", *(int *)arg);
return NULL;
}
int main (void) { /* program incorrectly passes parameters to threads */
int error;
int i;
int j;
pthread_t tid[NUMTHREADS];
for (i = 0; i < NUMTHREADS; i++)
if (error = pthread_create(tid + i, NULL, printarg, (void *)&i)) {
fprintf(stderr, "Failed to create thread: %s
", strerror(error));
tid[i] = pthread_self();
}
for (j = 0; j < NUMTHREADS; j++)
if (pthread_equal(pthread_self(), tid[j]))
continue;
if (error = pthread_join(tid[j], NULL))
fprintf(stderr, "Failed to join thread: %s
", strerror(error));
printf("All threads done
");
return 0;
}
Example 12.13.
For each of the following, start with Program 12.9 and make the specified modifications. Predict the output, and then run the program to see if you are correct.
1 | Run the original program without any modification. |
2 | Put a call to |
3 | Put a call to |
4 | Put a call to |
5.-8. | Repeat each of the items above, using |
Answer:
The results may vary if it takes more than a second for the threads to execute. On a fast enough system, the result will be something like the following.
Output described in Exercise 12.12.
Each thread outputs the value 10, the value of
iwhenmainhas finished its loop.Each thread outputs the correct value since it executes before the value of
ichanges.Same as in Exercise 12.12.
All threads output the value 0, the value of
iwhenmainwaits for the first thread to terminate. The results may vary.Same as 5.
Same as 3.
Same as 4.
Example 12.14. whichexit.c
The whichexit function can be executed as a thread.
#include <errno.h>
#include <pthread.h>
#include <stdlib.h>
#include <string.h>
void *whichexit(void *arg) {
int n;
int np1[1];
int *np2;
char s1[10];
char s2[] = "I am done";
n = 3;
np1[0] = n;
np2 = (int *)malloc(sizeof(int *));
*np2 = n;
strcpy(s1, "Done");
return(NULL);
}
Which of the following would be safe replacements for NULL as the parameter to pthread_exit? Assume no errors occur.
n&n(int *)nnp1np2s1s2"This works"strerror(EINTR)
Answer:
The return value is a pointer, not an integer, so this is invalid.
The integer
nhas automatic storage class, so it is illegal to access it after the function terminates.This is a common way to return an integer from a thread. The integer is cast to a pointer. When another thread calls
pthread_joinfor this thread, it casts the pointer back to an integer. While this will probably work in most implementations, it should be avoided. The C standard [56, Section 6.3.2.3] says that an integer may be converted to a pointer or a pointer to an integer, but the result is implementation defined. It does not guarantee that the result of converting an integer to a pointer and back again yields the original integer.The array
np1has automatic storage class, so it is illegal to access the array after the function terminates.This is safe since the dynamically allocated space will be available until it is freed.
The array
s1has automatic storage class, so it is illegal to access the array after the function terminates.The array
s2has automatic storage class, so it is illegal to access the array after the function terminates.This is valid in C, since string literals have static storage duration.
This is certainly invalid if
strerroris not thread-safe. Even on a system wherestrerroris thread-safe, the string produced is not guaranteed to be available after the thread terminates.
A hidden problem with threads is that they may call library functions that are not thread-safe, possibly producing spurious results. A function is thread-safe if multiple threads can execute simultaneous active invocations of the function without interference. POSIX specifies that all the required functions, including the functions from the standard C library, be implemented in a thread-safe manner except for the specific functions listed in Table 12.2. Those functions whose traditional interfaces preclude making them thread-safe must have an alternative thread-safe version designated with an _r suffix.
An important example of a function that does not have to be thread-safe is strerror. Although strerror is not guaranteed to be thread-safe, many systems have implemented this function in a thread-safe manner. Unfortunately, because strerror is listed in Table 12.2, you can not assume that it works correctly if multiple threads call it. We use strerror only in the main thread, often to produce error messages for pthread_create and pthread_join. Section 13.7 gives a thread-safe implementation called strerror_r.
Another interaction problem occurs when threads access the same data. The individual copier threads in Program 12.8 work on independent problems and do not interact with each other. In more complicated applications, a thread may not exit after completing its assigned task. Instead, a worker thread may request additional tasks or share information. Chapter 13 explains how to control this type of interaction by using synchronization primitives such as mutex locks and condition variables.
Table 12.2. POSIX functions that are not required to be thread-safe.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
| |
|
|
|
In traditional UNIX implementations, errno is a global external variable that is set when system functions produce an error. This implementation does not work for multithreading (see Section 2.7), and in most thread implementations errno is a macro that returns thread-specific information. In essence, each thread has a private copy of errno. The main thread does not have direct access to errno for a joined thread, so if needed, this information must be returned through the last parameter of pthread_join.
The two traditional models of thread control are user-level threads and kernel-level threads. User-level threads, shown in Figure 12.3, usually run on top of an existing operating system. These threads are invisible to the kernel and compete among themselves for the resources allocated to their encapsulating process. The threads are scheduled by a thread runtime system that is part of the process code. Programs with user-level threads usually link to a special library in which each library function is enclosed by a jacket. The jacket function calls the thread runtime system to do thread management before and possibly after calling the jacketed library function.
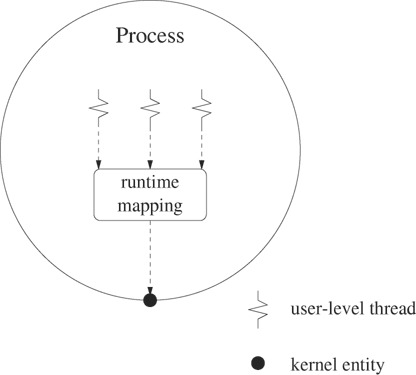
Functions such as read or sleep can present a problem for user-level threads because they may cause the process to block. To avoid blocking the entire process on a blocking call, the user-level thread library replaces each potentially blocking call in the jacket by a nonblocking version. The thread runtime system tests to see if the call would cause the thread to block. If the call would not block, the runtime system does the call right away. If the call would block, however, the runtime system places the thread on a list of waiting threads, adds the call to a list of actions to try later, and picks another thread to run. All this control is invisible to the user and to the operating system.
User-level threads have low overhead, but they also have some disadvantages. The user thread model, which assumes that the thread runtime system will eventually regain control, can be thwarted by CPU-bound threads. A CPU-bound thread rarely performs library calls and may prevent the thread runtime system from regaining control to schedule other threads. The programmer has to avoid the lockout situation by explicitly forcing CPU-bound threads to yield control at appropriate points. A second problem is that user-level threads can share only processor resources allocated to their encapsulating process. This restriction limits the amount of available parallelism because the threads can run on only one processor at a time. Since one of the prime motivations for using threads is to take advantage of multiprocessor workstations, user-level threads alone are not an acceptable approach.
With kernel-level threads, the kernel is aware of each thread as a schedulable entity and threads compete systemwide for processor resources. Figure 12.4 illustrates the visibility of kernel-level threads. The scheduling of kernel-level threads can be almost as expensive as the scheduling of processes themselves, but kernel-level threads can take advantage of multiple processors. The synchronization and sharing of data for kernel-level threads is less expensive than for full processes, but kernel-level threads are considerably more expensive to manage than user-level threads.
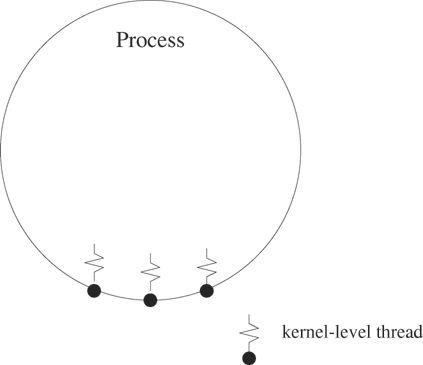
Figure 12.4. Operating system schedules kernel-level threads as though they were individual processes.
Hybrid thread models have advantages of both user-level and kernel-level models by providing two levels of control. Figure 12.5 illustrates a typical hybrid approach. The user writes the program in terms of user-level threads and then specifies how many kernel-schedulable entities are associated with the process. The user-level threads are mapped into the kernel-schedulable entities at runtime to achieve parallelism. The level of control that a user has over the mapping depends on the implementation. In the Sun Solaris thread implementation, for example, the user-level threads are called threads and the kernel-schedulable entities are called lightweight processes. The user can specify that a particular thread be run by a dedicated lightweight process or that a particular group of threads be run by a pool of lightweight processes.
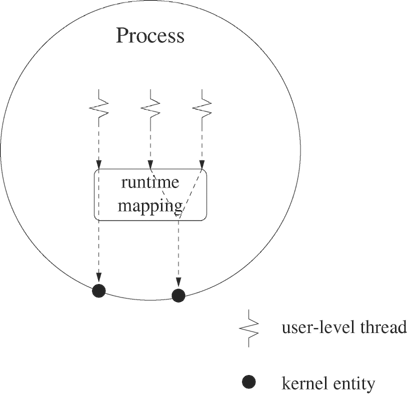
Figure 12.5. Hybrid model has two levels of scheduling, with user-level threads mapped into kernel entities.
The POSIX thread scheduling model is a hybrid model that is flexible enough to support both user-level and kernel-level threads in particular implementations of the standard. The model consists of two levels of scheduling—threads and kernel entities. The threads are analogous to user-level threads. The kernel entities are scheduled by the kernel. The thread library decides how many kernel entities it needs and how they will be mapped.
POSIX introduces the idea of a thread-scheduling contention scope, which gives the programmer some control over how kernel entities are mapped to threads. A thread can have a contentionscope attribute of either PTHREAD_SCOPE_PROCESS or PTHREAD_SCOPE_SYSTEM. Threads with the PTHREAD_SCOPE_PROCESS attribute contend for processor resources with the other threads in their process. POSIX does not specify how such a thread contends with threads outside its own process, so PTHREAD_SCOPE_PROCESS threads can be strictly user-level threads or they can be mapped to a pool of kernel entities in some more complicated way.
Threads with the PTHREAD_SCOPE_SYSTEM attribute contend systemwide for processor resources, much like kernel-level threads. POSIX leaves the mapping between PTHREAD_SCOPE_SYSTEM threads and kernel entities up to the implementation, but the obvious mapping is to bind such a thread directly to a kernel entity. A POSIX thread implementation can support PTHREAD_SCOPE_PROCESS, PTHREAD_SCOPE_SYSTEM or both. You can get the scope with pthread_attr_getscope and set the scope with pthread_attr_setscope, provided that your POSIX implementation supports both the POSIX:THR Thread Extension and the POSIX:TPS Thread Execution Scheduling Extension.
POSIX takes an object-oriented approach to representation and assignment of properties by encapsulating properties such as stack size and scheduling policy into an object of type pthread_attr_t. The attribute object affects a thread only at the time of creation. You first create an attribute object and associate properties, such as stack size and scheduling policy, with the attribute object. You can then create multiple threads with the same properties by passing the same thread attribute object to pthread_create. By grouping the properties into a single object, POSIX avoids pthread_create calls with a large number of parameters.
Table 12.3 shows the settable properties of thread attributes and their associated functions. Other entities, such as condition variables and mutex locks, have their own attribute object types. Chapter 13 discusses these synchronization mechanisms.
Table 12.3. Summary of settable properties for POSIX thread attribute objects.
property | function |
|---|---|
attribute objects |
|
| |
state |
|
| |
stack |
|
| |
| |
| |
scheduling |
|
| |
| |
| |
| |
| |
| |
|
The pthread_attr_init function initializes a thread attribute object with the default values. The pthread_attr_destroy function sets the value of the attribute object to be invalid. POSIX does not specify the behavior of the object after it has been destroyed, but the variable can be initialized to a new thread attribute object. Both pthread_attr_init and pthread_attr_destroy take a single parameter that is a pointer to a pthread_attr_t attribute object.
SYNOPSIS #include <pthread.h> int pthread_attr_destroy(pthread_attr_t *attr); int pthread_attr_init(pthread_attr_t *attr); POSIX:THR
If successful, pthread_attr_destroy and pthread_attr_init return 0. If unsuccessful, these functions return a nonzero error code. The pthread_attr_init function sets errno to ENOMEM if there is not enough memory to create the thread attribute object.
Most of the get/set thread attribute functions have two parameters. The first parameter is a pointer to a thread attribute object. The second parameter is the new value of the attribute for a set operation or a pointer to location to hold the value for a get operation. The pthread_attr_getstack and pthread_attr_setstack each have one additional parameter.
The pthread_attr_getdetachstate function examines the state of an attribute object, and the pthread_attr_setdetachstate function sets the state of an attribute object. The possible values of the thread state are PTHREAD_CREATE_JOINABLE and PTHREAD_CREATE_DETACHED. The attr parameter is a pointer to the attribute object. The detachstate parameter corresponds to the value to be set for pthread_attr_setdetachstate and to a pointer to the value to be retrieved for pthread_attr_getdetachstate.
SYNOPSIS #include <pthread.h> int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate); int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate); POSIX:THR
If successful, these functions return 0. If unsuccessful, they return a nonzero error code. The pthread_attr_setdetachstate function sets errno to EINVAL if detachstate is invalid.
Detached threads release their resources when they terminate, whereas joinable threads should be waited for with a pthread_join. A thread that is detached cannot be waited for with a pthread_join. By default, threads are joinable. You can detach a thread by calling the pthread_detach function after creating the thread. Alternatively, you can create a thread in the detached state by using an attribute object with thread state PTHREAD_CREATE_DETACHED.
Example 12.15.
The following code segment creates a detached thread to run processfd.
int error, fd;
pthread_attr_t tattr;
pthread_t tid;
if (error = pthread_attr_init(&tattr))
fprintf(stderr, "Failed to create attribute object: %s
",
strerror(error));
else if (error = pthread_attr_setdetachstate(&tattr,
PTHREAD_CREATE_DETACHED))
fprintf(stderr, "Failed to set attribute state to detached: %s
",
strerror(error));
else if (error = pthread_create(&tid, &tattr, processfd, &fd))
fprintf(stderr, "Failed to create thread: %s
", strerror(error));
A thread has a stack whose location and size are user-settable, a useful property if the thread stack must be placed in a particular region of memory. To define the placement and size of the stack for a thread, you must first create an attribute object with the specified stack attributes. Then, call pthread_create with this attribute object.
The pthread_attr_getstack function examines the stack parameters, and the pthread_attr_setstack function sets the stack parameters of an attribute object. The attr parameter of each function is a pointer to the attribute object. The pthread_attr_setstack function takes the stack address and stack size as additional parameters. The pthread_attr_getstack takes pointers to these items.
SYNOPSIS #include <pthread.h> int pthread_attr_getstack(const pthread_attr_t *restrict attr, void **restrict stackaddr, size_t *restrict stacksize); int pthread_attr_setstack(pthread_attr_t *attr, void *stackaddr, size_t stacksize); POSIX:THR,TSA,TSS
If successful, the pthread_attr_getstack and pthread_attr_setstack functions return 0. If unsuccessful, these functions return a nonzero error code. The pthread_attr_setstack function sets errno to EINVAL if stacksize is out of range.
POSIX also provides functions for examining or setting a guard for stack overflows if the stackaddr has not been set by the user. The pthread_attr_getguardsize function examines the guard parameters, and the pthread_attr_setguardsize function sets the guard parameters for controlling stack overflows in an attribute object. If the guardsize parameter is 0, the stack is unguarded. For a nonzero guardsize, the implementation allocates additional memory of at least guardsize. An overflow into this extra memory causes an error and may generate a SIGSEGV signal for the thread.
SYNOPSIS #include <pthread.h> int pthread_attr_getguardsize(const pthread_attr_t *restrict attr, size_t *restrict guardsize); int pthread_attr_setguardsize(pthread_attr_t *attr, size_t guardsize); POSIX:THR,XSI
If successful, pthread_attr_getguardsize and pthread_attr_setguardsize return 0. If unsuccessful, these functions return a nonzero error code. They return EINVAL if the attr or guardsize parameter is invalid. Guards require the POSIX:THR Extension and the POSIX:XSI Extension.
The contention scope of an object controls whether the thread competes within the process or at the system level for scheduling resources. The pthread_attr_getscope examines the contention scope, and the pthread_attr_setscope sets the contention scope of an attribute object. The attr parameter is a pointer to the attribute object. The contentionscope parameter corresponds to the value to be set for pthread_attr_setscope and to a pointer to the value to be retrieved for pthread_attr_getscope. The possible values of the contentionscope parameter are PTHREAD_SCOPE_PROCESS and PTHREAD_SCOPE_SYSTEM.
SYNOPSIS #include <pthread.h> int pthread_attr_getscope(const pthread_attr_t *restrict attr, int *restrict contentionscope); int pthread_attr_setscope(pthread_attr_t *attr, int contentionscope); POSIX:THR,TPS
If successful, pthread_attr_getscope and pthread_attr_setscope return 0. If unsuccessful, these functions return a nonzero error code. No mandatory errors are defined for these functions.
Example 12.16.
The following code segment creates a thread that contends for kernel resources.
int error;
int fd;
pthread_attr_t tattr;
pthread_t tid;
if (error = pthread_attr_init(&tattr))
fprintf(stderr, "Failed to create an attribute object:%s
",
strerror(error));
else if (error = pthread_attr_setscope(&tattr, PTHREAD_SCOPE_SYSTEM))
fprintf(stderr, "Failed to set scope to system:%s
",
strerror(error));
else if (error = pthread_create(&tid, &tattr, processfd, &fd))
fprintf(stderr, "Failed to create a thread:%s
", strerror(error));
POSIX allows a thread to inherit a scheduling policy in different ways. The pthread_attr_getinheritsched function examines the scheduling inheritance policy, and the pthread_attr_setinheritsched function sets the scheduling inheritance policy of an attribute object.
The attr parameter is a pointer to the attribute object. The inheritsched parameter corresponds to the value to be set for pthread_attr_setinheritsched and to a pointer to the value to be retrieved for pthread_attr_getinheritsched. The two possible values of inheritsched are PTHREAD_INHERIT_SCHED and PTHREAD_EXPLICIT_SCHED. The value of inheritsched determines how the other scheduling attributes of a created thread are to be set. With PTHREAD_INHERIT_SCHED, the scheduling attributes are inherited from the creating thread and the other scheduling attributes are ignored. With PTHREAD_EXPLICIT_SCHED, the scheduling attributes of this attribute object are used.
SYNOPSIS #include <pthread.h> int pthread_attr_getinheritsched(const pthread_attr_t *restrict attr, int *restrict inheritsched); int pthread_attr_setinheritsched(pthread_attr_t *attr, int inheritsched); POSIX:THR,TPS
If successful, these functions return 0. If unsuccessful, they return a nonzero error code. No mandatory errors are defined for these functions.
The pthread_attr_getschedparam function examines the scheduling parameters, and the pthread_attr_setschedparam sets the scheduling parameters of an attribute object. The attr parameter is a pointer to the attribute object. The param parameter is a pointer to the value to be set for pthread_attr_setschedparam and a pointer to the value to be retrieved for pthread_attr_getschedparam. Notice that unlike the other pthread_attr_set functions, the second parameter is a pointer because it corresponds to a structure rather than an integer. Passing a structure by value is inefficient.
SYNOPSIS #include <pthread.h> int pthread_attr_getschedparam(const pthread_attr_t *restrict attr, struct sched_param *restrict param); int pthread_attr_setschedparam(pthread_attr_t *restrict attr, const struct sched_param *restrict param); POSIX:THR
If successful, these functions return 0. If unsuccessful, they return a nonzero error code. No mandatory errors are defined for these functions.
The scheduling parameters depend on the scheduling policy. They are encapsulated in a struct sched_param structure defined in sched.h. The SCHED_FIFO and SCHED_RR scheduling policies require only the sched_priority member of struct sched_param. The sched_priority field holds an int priority value, with larger priority values corresponding to higher priorities. Implementations must support at least 32 priorities.
Program 12.10 shows a function that creates a thread attribute object with a specified priority. All the other attributes have their default values. Program 12.10 returns a pointer to the created attribute object or NULL if the function failed, in which case it sets errno. Program 12.10 illustrates the general strategy for changing parameters—read the existing values first and change only the ones that you need to change.
Example 12.17.
The following code segment creates a dothis thread with the default attributes, except that the priority is HIGHPRIORITY.
#define HIGHPRIORITY 10
int fd;
pthread_attr_t *tattr;
pthread_t tid;
struct sched_param tparam;
if ((tattr = makepriority(HIGHPRIORITY))) {
perror("Failed to create the attribute object");
else if (error = pthread_create(&tid, tattr, dothis, &fd))
fprintf(stderr, "Failed to create dothis thread:%s
", strerror(error));
Threads of the same priority compete for processor resources as specified by their scheduling policy. The sched.h header file defines SCHED_FIFO for first-in-first-out scheduling, SCHED_RR for round-robin scheduling and SCHED_OTHER for some other policy. One additional scheduling policy, SCHED_SPORADIC, is defined for implementations supporting the POSIX:SS Process Sporadic Server Extension and the POSIX:TSP Thread Sporadic Server Extension. Implementations may also define their own policies.
Example 12.10. makepriority.c
A function to create a thread attribute object with the specified priority.
#include <errno.h>
#include <pthread.h>
#include <stdlib.h>
pthread_attr_t *makepriority(int priority) { /* create attribute object */
pthread_attr_t *attr;
int error;
struct sched_param param;
if ((attr = (pthread_attr_t *)malloc(sizeof(pthread_attr_t))) == NULL)
return NULL;
if (!(error = pthread_attr_init(attr)) &&
!(error = pthread_attr_getschedparam(attr, ¶m))) {
param.sched_priority = priority;
error = pthread_attr_setschedparam(attr, ¶m);
}
if (error) { /* if failure, be sure to free memory */
free(attr);
errno = error;
return NULL;
}
return attr;
}
First-in-first-out scheduling policies (e.g., SCHED_FIFO) use a queue for threads in the runnable state at a specified priority. Blocked threads that become runnable are put at the end of the queue corresponding to their priority, whereas running threads that have been preempted are put at the front of their queue.
Round-robin scheduling (e.g., SCHED_RR) behaves similarly to first-in-first-out except that when a running thread has been running for its quantum, it is put at the end of the queue for its priority. The sched_rr_get_interval function returns the quantum.
Sporadic scheduling, which is similar to first-in-first-out, uses two parameters (the replenishment period and the execution capacity) to control the number of threads running at a given priority level. The rules are reasonably complex, but the policy allows a program to more easily regulate the number of threads competing for the processor as a function of available resources.
Preemptive priority policy is the most common implementation of SCHED_OTHER. A POSIX-compliant implementation can support any of these scheduling policies. The actual behavior of the policy in the implementation depends on the scheduling scope and other factors.
The pthread_attr_getschedpolicy function gets the scheduling policy, and the pthread_attr_setschedpolicy function sets the scheduling policy of an attribute object. The attr parameter is a pointer to the attribute object. For the function pthread_attr_setschedpolicy, the policy parameter is a pointer to the value to be set; for pthread_attr_getschedpolicy, it is a pointer to the value to be retrieved. The scheduling policy values are described above.
SYNOPSIS #include <pthread.h> int pthread_attr_getschedpolicy(const pthread_attr_t *restrict attr, int *restrict policy); int pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy); POSIX:THR
If successful, these functions return 0. If unsuccessful, they return a nonzero error code. No mandatory errors are defined for these functions.
This section develops a parallel file copy as an extension of the copier application of Program 12.8. Be sure to use thread-safe calls in the implementation. The main program takes two command-line arguments that are directory names and copies everything from the first directory into the second directory. The copy program preserves subdirectory structure. The same filenames are used for source and destination. Implement the parallel file copy as follows.
Write a function called
copydirectorythat has the following prototype.void *copydirectory(void *arg)
The
copydirectoryfunction copies all the files from one directory to another directory. The directory names are passed inargas two consecutive strings (separated by a null character). Assume that both source and destination directories exist whencopydirectoryis called. In this version, only ordinary files are copied and subdirectories are ignored. For each file to be copied, create a thread to run thecopyfilepassfunction of Program 12.7. For this version, wait for each thread to complete before creating the next one.Write a
mainprogram that takes two command-line arguments for the source and destination directories. Themainprogram creates a thread to runcopydirectoryand then does apthread_jointo wait for thecopydirectorythread to complete. Use this program to test the first version ofcopydirectory.Modify the
copydirectoryfunction so that if the destination directory does not exist,copydirectorycreates the directory. Test the new version.Modify
copydirectoryso that after it creates a thread to copy a file, it continues to create threads to copy the other files. Keep the thread ID and open file descriptors for eachcopyfilepassthread in a linked list with a node structure similar to the following.typedef struct copy_struct { char *namestring; int sourcefd; int destinationfd; int bytescopied; pthread_t tid; struct copy_struct *next; } copyinfo_t; copyinfo_t *head = NULL; copyinfo_t *tail = NULL;After the
copydirectoryfunction creates threads to copy all the files in the directory, it does apthread_joinon each thread in its list and frees thecopyinfo_tstructure.Modify the
copyfilepassfunction of Program 12.7 so that its parameter is a pointer to acopyinfo_tstructure. Test the new version ofcopyfilepassandcopydirectory.Modify
copydirectoryso that if a file is a directory instead of an ordinary file,copydirectorycreates a thread to runcopydirectoryinstead ofcopyfilepass. Test the new function.Devise a method for performing timings to compare an ordinary copy with the threaded copy.
If run on a large directory, the program may attempt to open more file descriptors or more threads than are allowed for a process. Devise a method for handling this situation.
See whether there is a difference in running time if the threads have scope
PTHREAD_SCOPE_SYSTEMinstead ofPTHREAD_SCOPE_PROCESS.
A number of books on POSIX thread programming are available. They include Programming with POSIX(R) Threads by Butenhof [19], Pthreads Programming: A POSIX Standard for Better Multiprocessing by Nichols et al. [87], Multithreaded Programming with Pthreads by Lewis and Berg [72] and Thread Time: The Multithreaded Programming Guide by Norton and DiPasquale. All these books are based on the original POSIX standard. The book Distributed Operating Systems by Tanenbaum [121] presents an understandable general discussion of threads. Approaches to thread scheduling are discussed in [2, 12, 32, 78]. Finally, the POSIX standard [49, 51] is a surprisingly readable account of the conflicting issues and choices involved in implementing a usable threads package.