
Chapter 4. Making Authorization Decisions
Authorization is arguably the most important process occurring within a zero trust network, and as such, making an authorization decision should not be taken lightly. Every flow and/or request will ultimately require that a decision be made.
The databases and supporting systems we will discuss here are the key systems that come together to make and affect those decisions. Together, they are authoritative for access control and thus need to be rigorously isolated from each other. Careful distinction should be made between these responsibilities, particularly when deciding whether to collapse them into a single system, which should generally be avoided if possible.
Taking reality into account, this chapter will focus on high-level architectural arrangement of the components required to make zero trust authorization decisions, as well as how they fit together and enforce said decisions.
Authorization Architecture
The zero trust authorization architecture comprises four main components, as shown in Figure 4-1:
-
Enforcement
-
Policy engine
-
Trust engine
-
Data stores
These four components are distinct in their responsibilities, and as a result, we treat them as separate systems. From a security standpoint, it is highly desirable that these components be isolated from each other. These systems represent the practical crown jewels of the zero trust security model, so special care should be taken in their maintenance and security posture. It is critical from an implementation standpoint that isolation exists among these components so that a breach of one does not automatically lead to a breach of the entire system, both from a security and availability standpoint. This is typically handled by cloud-based systems, where SaaS-based services allow isolation based on various factors while services remain available under a single vendor’s umbrella. Another common pattern is the use of microservices, in which various services are distributed across providers and are exposed via well defined APIs. Because software systems are typically heavily distributed these days, planning for isolation should be prioritized early on.
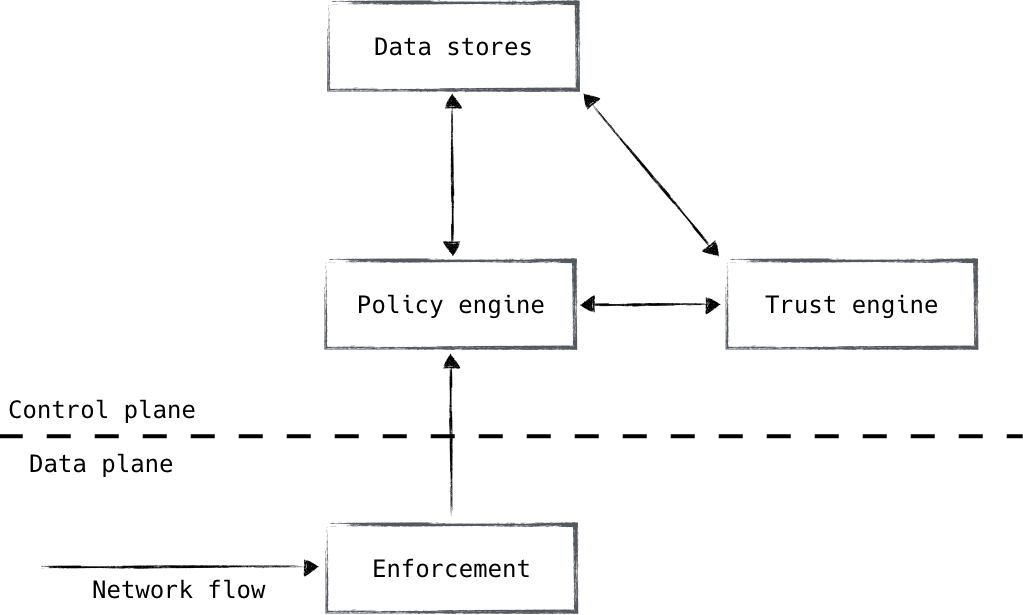
Figure 4-1. Zero trust authorization systems
The enforcement component should exist in large numbers throughout the system and should be as close to the workload as possible. This is the component that actually affects the outcome of the authorization decision. It is typically manifested as a load balancer, proxy, or even a firewall. This component interacts with the policy engine, which is the piece that we use to make the actual decision. The enforcement component ensures that clients are authenticated, and passes the context of each flow/request to the policy engine. The policy engine compares the request and its context to policy, and informs the enforcer whether the request will be permitted or not.
The trust engine is leveraged by the policy engine for risk analysis purposes. It leverages multiple data sources in order to compute a risk score, similar to a credit score. This score can be used to protect against unknown unknowns, and helps keep policy strong and robust without complicating it with edge cases and signatures. It is used by the policy engine as an additional component by which an authorization decision can be made. Google’s BeyondCorp is widely recognized as having pioneered this technology.
Finally, the various data stores represent the source of truth for the data being used to inform authorization. This data is used to paint a full contextual picture of a particular flow/request, using small authenticated bits of data as the primary lookup keys (i.e., a username or a device’s serial number). These data stores, be they user data, device data, or otherwise, are heavily leveraged by both the policy engine and trust engine, and represent the backing against which all decisions are measured.
Enforcement
The enforcement component (depicted in Figure 4-2) is a natural place to start. It sits on the “front line” of the authorization flow and is responsible for carrying out decisions made by the rest of the authorization system.
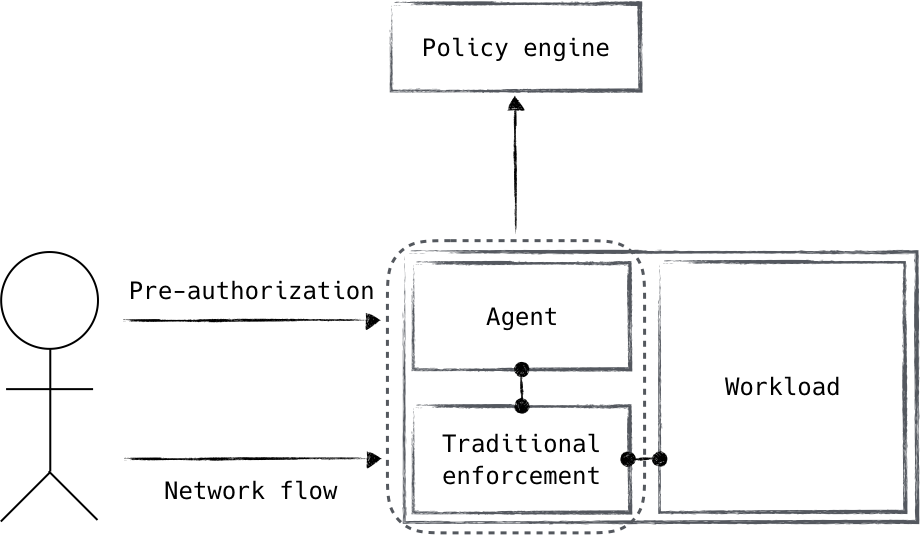
Figure 4-2. An agent receives a pre-authorization signal to grant access to a system using traditional enforcement mechanisms. These systems together form the enforcement component.
Enforcement can be broken down into two primary responsibilities. First, an interaction with the policy engine must occur. This is generally the authorization request itself (e.g., a load balancer has received a request and needs to know whether it is authorized or not). The second is the actual installation and ongoing enforcement of the decision. While these two responsibilities represent a single component in the zero trust authorization architecture, you can choose whether they are fulfilled together or separately.
The way you choose to handle this will likely depend on your use case. For instance, an identity-aware proxy can call the policy engine to actively authorize a request it has received, and in the same step use the response to either service or reject the request. This is an example of treating the concerns as unified. Alternatively, perhaps a pre-authorization daemon receives a request for access to a particular service, which then calls the policy engine for authorization. Upon successful authorization,
the daemon can manipulate local firewall rules to allow the specific request. With this approach, we rely on “standard” enforcement mechanisms that are informed/ programmed by the zero trust control plane. It should be noted, however, that this approach requires a client-side hook in order to notify the control plane of the authorization request. This may or may not be acceptable, depending on the level of control over your devices and applications.
Placement of the enforcement component is very important. Since it represents our control point within the data plane, we must ensure that enforcement components are placed as close to the endpoints as possible. Otherwise, trust can pool “behind” the enforcement component, undermining zero trust security. Luckily, the enforcement component can be modeled as a client of sorts and applied liberally throughout the system. This is in contrast to the rest of the authorization components, which are modeled as services.
Policy Engine
The policy engine is the component that has the power to make a decision. It compares the request coming from the enforcement component against policy in order to determine whether the request is authorized or not. Once determined, the result is returned to the enforcement piece for actual realization.
The arrangement of the enforcement layer and policy engine allows for dynamic, point-in-time decisions to be made, allowing revocation to occur rapidly. As such, it is important that these components be considered separately and independently. That is not to say, however, that they cannot be co-located.
Depending on a number of factors, a policy engine may be found hosted side by side with the enforcement mechanism. An example of this might be a load balancer that authorizes requests through inter-process communication (IPC) instead of a remote call. The most attractive benefit of this architecture is the lower latency to authorize the request. A low-latency authorization system enables fine-grained and comprehensive authorization of network activity; for example, individual HTTP requests could be authorized instead of the session-level authorization that commonly is deployed. It should be noted that it is best to maintain process-level isolation between the policy engine and enforcement layer. The enforcement layer, being in the user’s data path, is more exposed; therefore, integrating the policy engine in the same process could expose it to unwanted risk. Deploying the policy engine as its own process goes a long way to ensure that bugs in the enforcement layer don’t result in a policy engine compromise.
Policy Storage
The rules referenced by the policy engine need to be stored. These policy rules are ultimately loaded into the policy engine, but it is strongly recommended that the rules are captured outside of the policy engine itself. Storing the policy rules in a version control system is ideal and provides several benefits:
-
Changes to policy can be tracked over time.
-
Rationale for changing policy is tracked in the version control system.
-
The expected current policy state can be validated against the actual enforcement mechanisms.
Many of these benefits have historically been implemented using rigorous change management procedures. In that system, changes to the system’s configuration are requested and approved before ultimately being applied. The resulting change management log can be used to determine why the system is in the current state.
Moving policy definitions into version control is the logical conclusion of change management procedures when the system can be configured programmatically. Instead of relying on human system administrators to load desired policy into the system, we can instead capture the policy as data that a program can read and apply. In many ways, loading policy is then similar to deployable software. As a result, system administrators can use standard software development procedures (namely code review and promotion pipelines) to manage the changes in policy.
What Makes Good Policy?
Policy in a zero trust network is in some ways similar to traditional network security, and in other ways substantially different.
Zero Trust Policy Is Still Not Standardized
The reality today is that zero trust policy is still not standardized in the same way as a network-oriented policy. As a result, defining the standard policy language used in a zero trust network is a great opportunity.
Let’s look at what’s similar first. Good policy in a zero trust network is fine-grained. The level of granularity will vary based on the maturity of the network, but the desired goal is policy that is scoped to the individual resource being secured. This is not very different from a traditional network security model that aims to segment the network to decrease attack surface area.
The zero trust model starts to diverge from traditional network security in the control mechanisms that are used to define policy. Instead of defining policy in terms of network implementation details (such as IP addresses and ranges), policy is best defined in terms of logical components in the network. These components will generally consist of:
-
Network services
-
Device endpoint classes
-
User roles
Defining policy from logical components that exist in the network allows the policy engine to calculate the enforcement decisions based on its knowledge of the current state of the network. To put this in concrete terms, a web service running on one server today might be on a different server tomorrow, or might even move between servers automatically as directed by a workload scheduler. The policy that we define needs to be divorced from these implementation details to adapt to this reality. An example of this style of policy from the Kubernetes project is shown in Figure 4-3.

Figure 4-3. A snippet from a Kubernetes network policy. These policies use workload labels, computing the underlying IP-based enforcement rules when and where necessary.
Although there is no single way or standard for defining policies, they are typically configured in JSON or YAML format and are easy to understand semantically. Consider Google’s cloud custom access level policy, shown below, which defines conditions for known devices, such as corporate-owned and admin-approved devices running a known operating system.
{
"name": "example_custom_level",
"title": "Example custom level",
"description": "An example custom access level.",
"custom": {
"expr": {
"expression": "device.is_corp_owned == true || (device.os_type !=
OsType.OS_UNSPECIFIED &&
device.is_admin_approved_device == true)",
"title": "Check for known devices",
"description": "Permits requests from corp-owned devices and admin-approved
devices with a known OS."
}
}
}Policy in a zero trust network also leans on trust scores to anticipate unknown attack vectors. By defining policy with a trust score component, administrators are able to mitigate risk that otherwise can’t be captured with a specific policy. Therefore, most policies should include a trust score component. Check out the example below of a conditional access policy in Microsoft’s Azure cloud that requires any user with a risk score of “medium” or “high” to perform mandatory multifactor authentication when signing in to an HR application (MFA).The trust score is covered in detail later in this chapter.
{
"displayName": "Require MFA For High/Medium Sign-in Risk",
"state": "enabled",
"conditions": {
"signInRiskLevels": ["high", "medium"],
"clientAppTypes": [
"all"
],
"users": {
"includeUsers": ["*"]
}
},
"grantControls": {
"operator": "OR",
"builtInControls": [
"mfa"
]
}
}Lack of Policy Standards
At the time of writing, there is no industry-wide standard for defining policies; however, efforts by organizations such as National Cybersecurity Center of Excellence (NCCoE) to create a publicly available description of the practical steps required to implement the cybersecurity reference designs for zero trust aid in understanding the various components of zero trust, including policies. You can read more about it by visiting their website.
Policy should not rely on trust score alone. Specific characteristics of the request being authorized can also be part of the policy definition. An example of this might be certain user roles should only have access to a particular service.
Who Defines Policy?
Zero trust network policy should be fine-grained, which can place an extraordinary burden on system administrators to keep the policy up to date. To help spread the load of this configuration burden, most organizations decide to distribute policy definition across the teams so they can help maintain policy for the services they own. Opening up policy definition to an entire organization can present certain risks, like well-meaning users who create overly broad policies, thereby increasing the attack surface area of the system they intended to constrain. Zero trust systems lean on two organizational workflows to counteract this exposure.
Policy Reviews
First, since policy is typically stored under version control, having another person review changes to the policy helps ensure that changes are well considered. Security teams can additionally review the changes and ask probing questions to ensure that the policy being defined is as tightly scoped as possible. Since the policy is defined using logical intent instead of physical components, the policy will change less rapidly than if it was defined in physical terms.
The second organizational measure used is to layer broad infrastructure policy on top of fine-grained policy. For example, an infrastructure group might rightly require that only a certain set of roles be allowed to accept traffic from the internet. The infrastructure team will therefore define policy that enforces that restriction, and no user defined policy will be allowed to circumvent it. Enforcing this constraint could take several forms: an automated test of proposed policy, or perhaps a policy engine that will simply refuse overly broad policy assertions from untrusted sources. Such enforcement can also be useful for compliance and regulatory requirements.
Trust Engine
The trust engine is the system in a zero trust network that performs risk analysis against a particular request or action. This system’s responsibility is to produce a numeric assessment of the riskiness of allowing a particular request/action, which the policy engine uses to make an ultimate authorization decision.
The trust engine will frequently pull from data contained in authoritative inventory systems to check attributes of an entity when computing its score. A device inventory, for example, could provide the trust engine with information like the last time a device was audited, scanned for compliance, or whether it has a particular hardware security feature.
Creating a numeric assessment of risk is a difficult task. A simple approach would be to define a set of ad hoc rules that score an entity’s riskiness. For example, a device that is missing the latest software patches could have its score reduced. Similarly, a user who is continually failing to authenticate could have their trust score reduced. While ad hoc trust scoring might be simple to get started with, a set of statically defined rules will be insufficient to meet the desired goal of defending against unexpected attacks. As a result, in addition to using static rules, mature trust engines use machine learning techniques to derive a scoring function.
Machine learning derives a scoring function by calculating observable facts from a subset of activity data known as training data. The training data is raw observations that have been associated with trusted or untrusted entities. From this data, features are extracted and used to derive a computer-generated scoring function. This scoring function, a model in machine learning terms, is then run against a set of data that is in the same format as the training data. The resulting scores are compared against human-defined risk assessments, and the model’s quality can then be refined based on its ability to correctly predict risk of the data being analyzed. A model that has sufficient accuracy can then be said to be predictive of the riskiness of yet unseen requests in the network.
Machine learning models can learn from a variety of attributes, like the user’s IP address, geo-location, device, and so on, to evaluate whether a current user request is anomalous or typical in the current context. Keep in mind that “false-positives” can occur anytime. This is because there are legitimate situations where the user activity in question is normal, but the prediction tends to be anomalous. In real life, an example of false-positive can be seen when a user travels to a new location, perhaps for a vacation, and makes an access request. In this case, the machine learning model has not yet been trained against this new user’s location, so it will most likely identify this as an anomalous pattern. Dealing with false-positives is a hot topic in machine learning, and it’s usually improved by adjusting factors such as learning period, precision, and recall, among others.
While machine learning is increasingly used to solve hard computational problems, it does not obviate the need for more explicit rules in the trust engine. Whether due to limitation of the derived scoring models or for desired customization of the scoring function, trust engines will typically use a mixture of ad hoc and machine learning scoring methods.
What Entities Are Scored?
Deciding which components of a zero trust network should be scored is an interesting consideration. Should scores be calculated for each individual entity (user, device, and application), for the network agent as a whole, or for both? Let’s look at some Scenarios.
Using Network Agents For Scoring
Imagine a user’s credentials are being brute forced by a malicious third party. Some systems will mitigate this threat by locking the user’s account, which can present a denial-of-service attack against that particular user. If we were to score a user negatively based on that activity, a zero trust network would suffer the same problem. A better approach is to realize that we’re authenticating the network agent, and so the attacker’s network agent is counteracted, leaving the legitimate user’s network agent unharmed. This scenario makes a case that the network agent is the entity that should be scored.
Using Devices for Scoring
But just scoring the network agent can be insufficient against other attack vectors. Consider a device that has been associated with malicious activity. A user’s network agent on that device may be showing no signs of malicious behavior, but the fact that the agent is being formed with a suspected device should clearly have an impact on the trust score for all requests originating from that device. This scenario strongly suggests that the device should be scored.
Finally, consider a malicious human user (the infamous internal threat) is using multiple kiosk devices to exfiltrate trade secrets. We’d like the trust engine to recognize this behavior as the user hops across devices and to reflect the decreasing level of trust in their trust score for all future authorization decisions. Here again, we see that scoring the network agent alone is insufficient for mitigating common threats. Taken as a whole, it seems like the right solution is to score both the network agent itself and the underlying entities that make up the agent. These scores can be exposed to the policy engine, which can choose the correct component(s) to authorize based on the policy being written.
Presenting so many scores for consideration when writing policy, however, can make the task of crafting policy more difficult and error prone. In an ideal world, a single score would be sufficient, but that approach presents extra availability requirements on the trust engine. A system that tries to create a single score would likely need to move to an online model, where the trust engine is interactively queried during the policy decision making. The engine would be given some context about the request being authorized so it could choose the best scoring function for that particular request. This design is clearly more complex to build and operate. Additionally, for policy where a system administrator specifically wishes to target a particular component (say, only allow deployments from devices with a score above X), it seems rather roundabout.
Exposing Scores Considered Risky
While the scores assigned to entities in a zero trust network are not considered confidential, exposing the scores to end users of the system should be avoided. Seeing one’s score could be a signal to would-be attackers that they are increasing or decreasing their trustworthiness in the system. This desire to withhold information should be balanced against the frustration of end users’ ability to understand how their actions are affecting their own trust in the system. A good compromise from the fraud industry is to show users their scores infrequently, and to highlight contributing factors to their score determination.
Data Stores
The data stores used to make authorization decisions are very simply the sources of truth for the current and past state of the system. Information from these data stores flows through the control plane systems, providing a large portion of the basis on which authorization decisions are made, as demonstrated in Figure 4-4.
We previously spoke about the trust engine leveraging these data stores in order to produce a trust score, which in turn is considered by the policy engine. In this way, information from control plane data stores has flowed through the authorization system, finally reaching the policy engine where the decision was made. These data stores are used by the policy engine, both directly and indirectly, but they can be useful to other systems that need authoritative data about the state of the network.
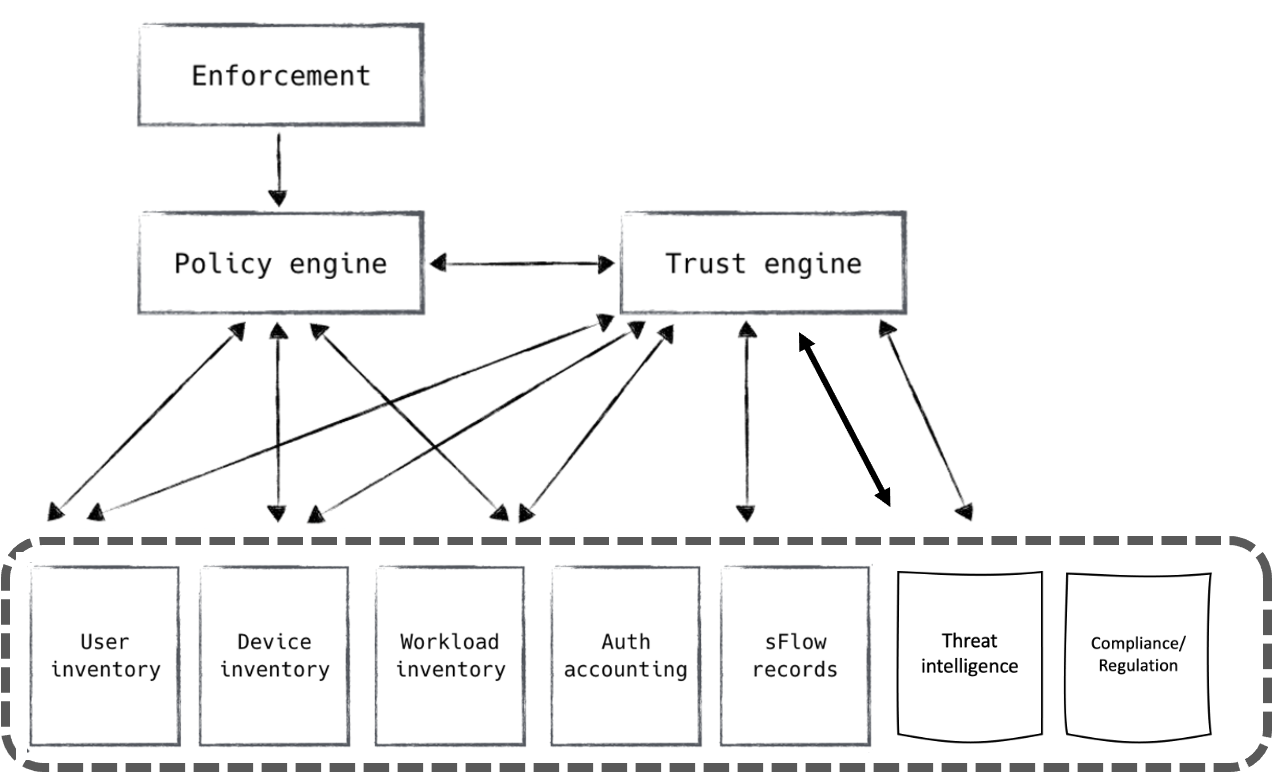
Figure 4-4. Authoritative data stores are used by the policy engine both directly and indirectly through the trust engine
Zero trust networks tend to have many data stores, organized by function. There are two primary types: inventory and historical. An inventory is a single consistent source of truth, recording the current state of the resource(s) it represents. An example is a user inventory that stores all user information, or a device inventory that records information about devices known to the company.
In an inventory, a primary key exists which uniquely represents the tracked entity. In the case of a user, the likely choice is the username; for a device, perhaps it’s a serial number. When a zero trust agent undergoes authentication, it is authenticating its identity against this primary key in the inventory. Think about it like this: a user authenticates against a given username. The policy engine gets to know the username, and that the user was successfully authenticated. The username is then used as the primary key for lookup against the user inventory. Keeping this flow and purpose in mind will help you choose the right primary keys, depending on your particular implementation and authentication choices.
A historical data store is a little bit different. Historical data stores are kept primarily for risk analysis purposes. They are useful for examining recent/past behavior and patterns in order to assess risk as it relates to a particular request or action. Trust engine components are most likely to be consuming this data, as trust/risk determinations are the engine’s primary responsibility.
One can imagine many types of historical data stores, and when it comes to risk analysis, the sky’s the limit. Some common examples include user accounting records and sFlow data. Regardless of the data being stored, it must be queryable using the primary key from one of the inventory systems. We will talk about various inventory and historical data stores as we introduce related concepts throughout this book.
Threat intelligence gathered from both internal and external third-party sources, such as Open Source Intelligence (OSINT), provides valuable insights that trust engines can use to determine a trust score. Consider a scenario in which a user’s credentials were leaked on the dark web as a result of a recent data breach. In this case, the trust engine can use threat intelligence to calculate the trust score against the user, which may lead to the policy engine denying the request or granting it limited access.
Compliance and regulatory standards like General Data Protection Regulation (GDPR), Federal Risk and Authorization Management Program (FedRAMP) etc. have an impact on the policy engine’s decision-making process when analyzing a request. Organizations typically maintain a versioned system for maintaining compliance and regulatory requirements that can be used to create policies, ideally entirely automated, but most likely requiring final human review before release. The end result is a robust system in which the policy engine can query the compliance and regulatory store to determine if a request should be granted or rejected.
Scenario Walkthrough
Before we wrap up this chapter, let’s consider a simple but real-world scenario that will help you understand the various components discussed in this and earlier chapters, plus how they interact with one another. Later chapters will expand on the scenario as we delve deeper into various aspects of zero trust, such as users, devices, applications, and traffic.
Let’s look at a typical workflow for a user named Bob, who works as a business manager for Wayne Corporation and is attempting to access a resource, such as a printer. Figure 4-5 depicts a high-level breakdown of the zero trust components in this scenario.
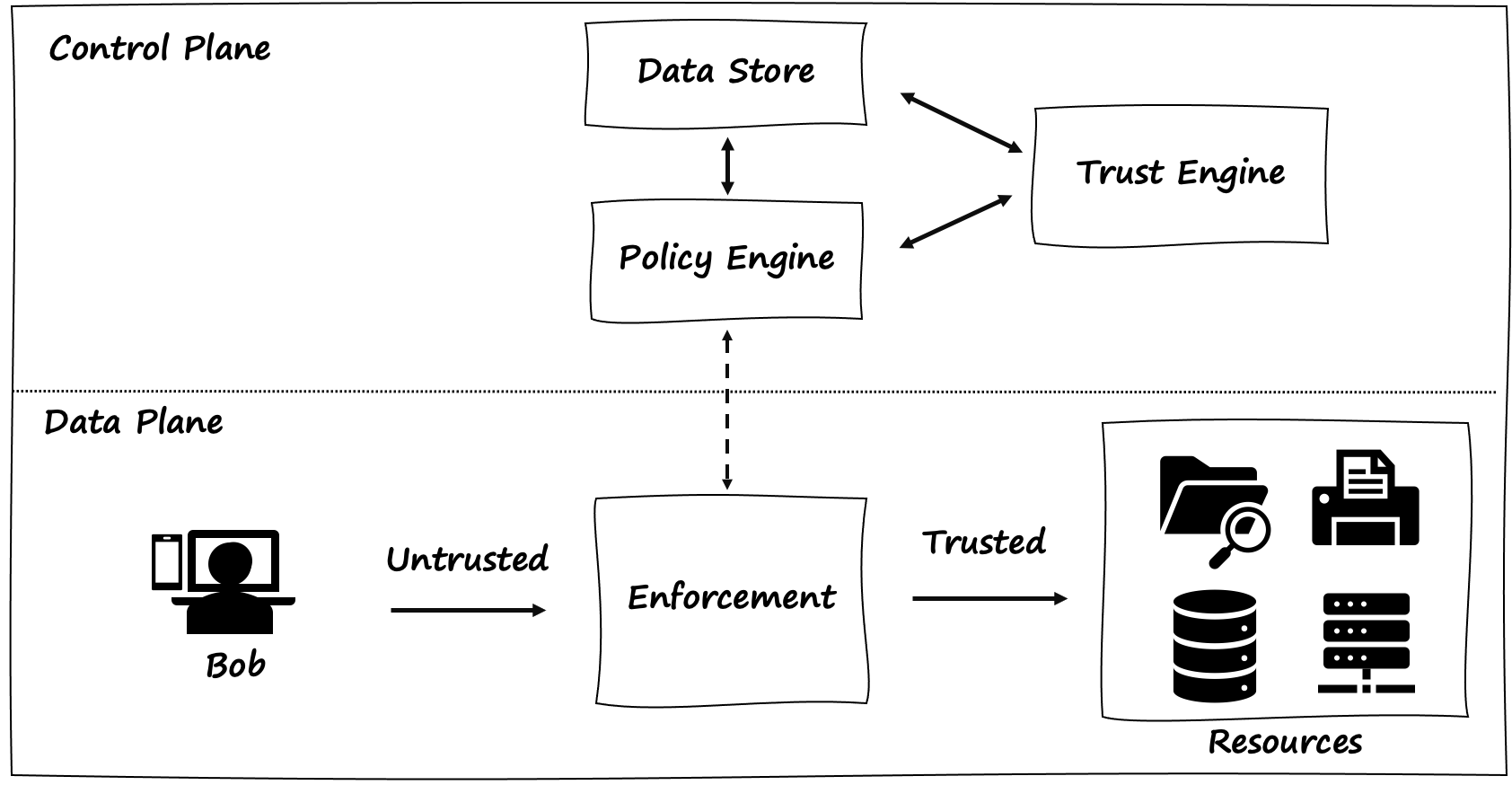
Figure 4-5. A logical view of zero trust security model with control plane, data plane, user, and resources.
First, examine the components in the control plane, as shown in Figure 4-6. Bob’s personal information, such as his name, IP address, and location, is stored in the user store. The device data includes details such as the operating system and whether or not Bob’s devices have received the most recent security patch. Finally, activity logs record every interaction he has, including the timestamp (in unix format), IP address, and location.
The trust engine employs a machine learning model to dynamically calculate the trust score by looking for anomalous behavior in Bob’s activity logs. Its primary responsibility is to calculate and communicate the trust score to the policy engine.
The policy engine, which is at the heart of the control plane, uses trust score and compliance policies to determine whether Bob’s request should be granted or denied.
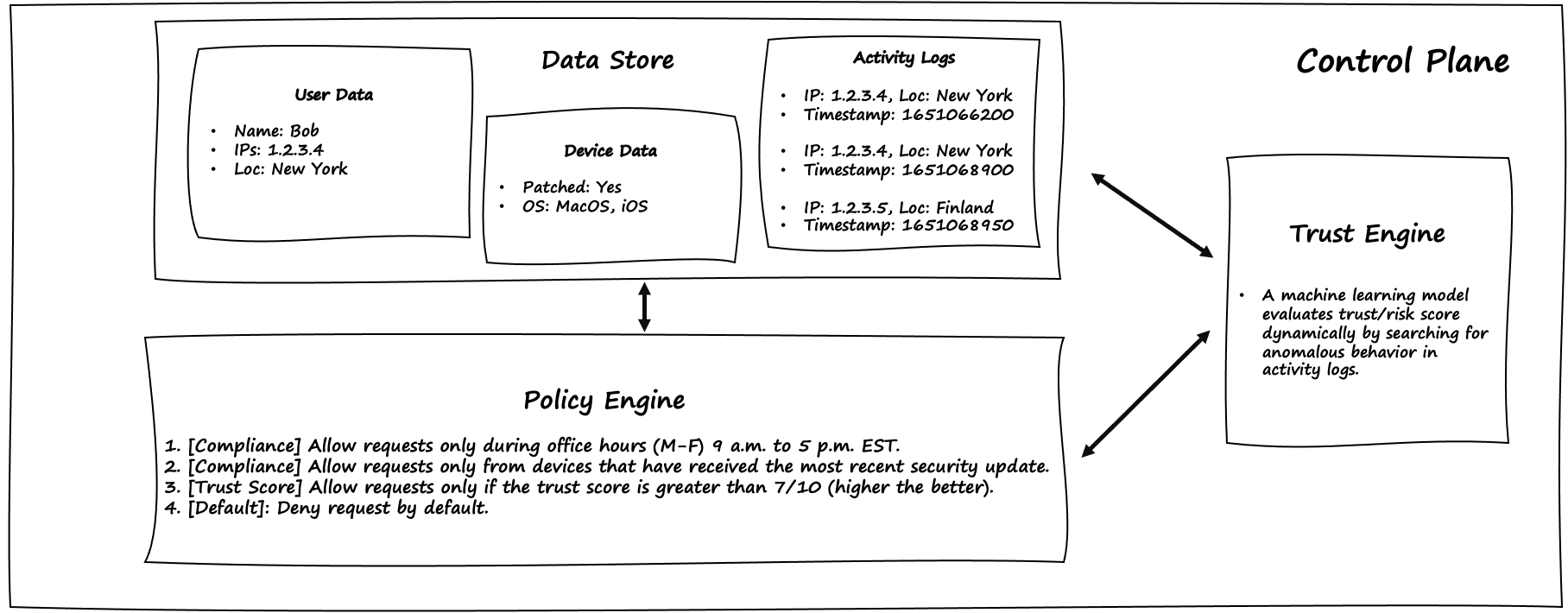
Figure 4-6. To make an authorization decision against an access request, the policy engine utilizes a trust score as well as compliance rules.
We’ll now take a closer look at the policy rules that govern the policy engine’s behavior. The first two are compliance-related, ensuring that the system always adheres to regulatory and operational business requirements. The third adds a trust score as a dynamic input to the policy, ensuring that requests are only granted if the score exceeds a certain threshold. Finally, if no other policy rule applies, the default behavior is set to deny the authorization request, ensuring that access must be denied unless a policy rule explicitly grants it.
-
Compliance: Allow requests only during office hours, Monday through Friday between 9am to 5pm Eastern Time Zone (EST).
-
Compliance: Allow requests only from devices that have received the most recent security update. The goal is to ensure that devices are patched and less vulnerable to exploits.
-
Trust Score: Allow requests only if the trust score is greater than 7/10. A higher trust score inspires more confidence in this case, so a value of 7 is used. Typically, trust score values in policies are configurable and adjusted over time to ensure a balance; a low score allows malicious requests to slip through the cracks, while a high score may negatively impact genuine access requests.
-
Default: If no other policy rule is applied, this is the catch-all (thus default) rule that takes effect.. This rule is important because it is recommended to deny by default rather than allow by default. This is useful because there is no inherent trust in a zero-trust system, each request is evaluated on its own merits and is treated equally maliciously.
Next, consider the data plane, which includes enforcement, resources (printers, file shares, and so on), and the user Bob, who requests access to a resource (fileshare in this case). Figure 4-7 depicts the control plane as well as the data plane.
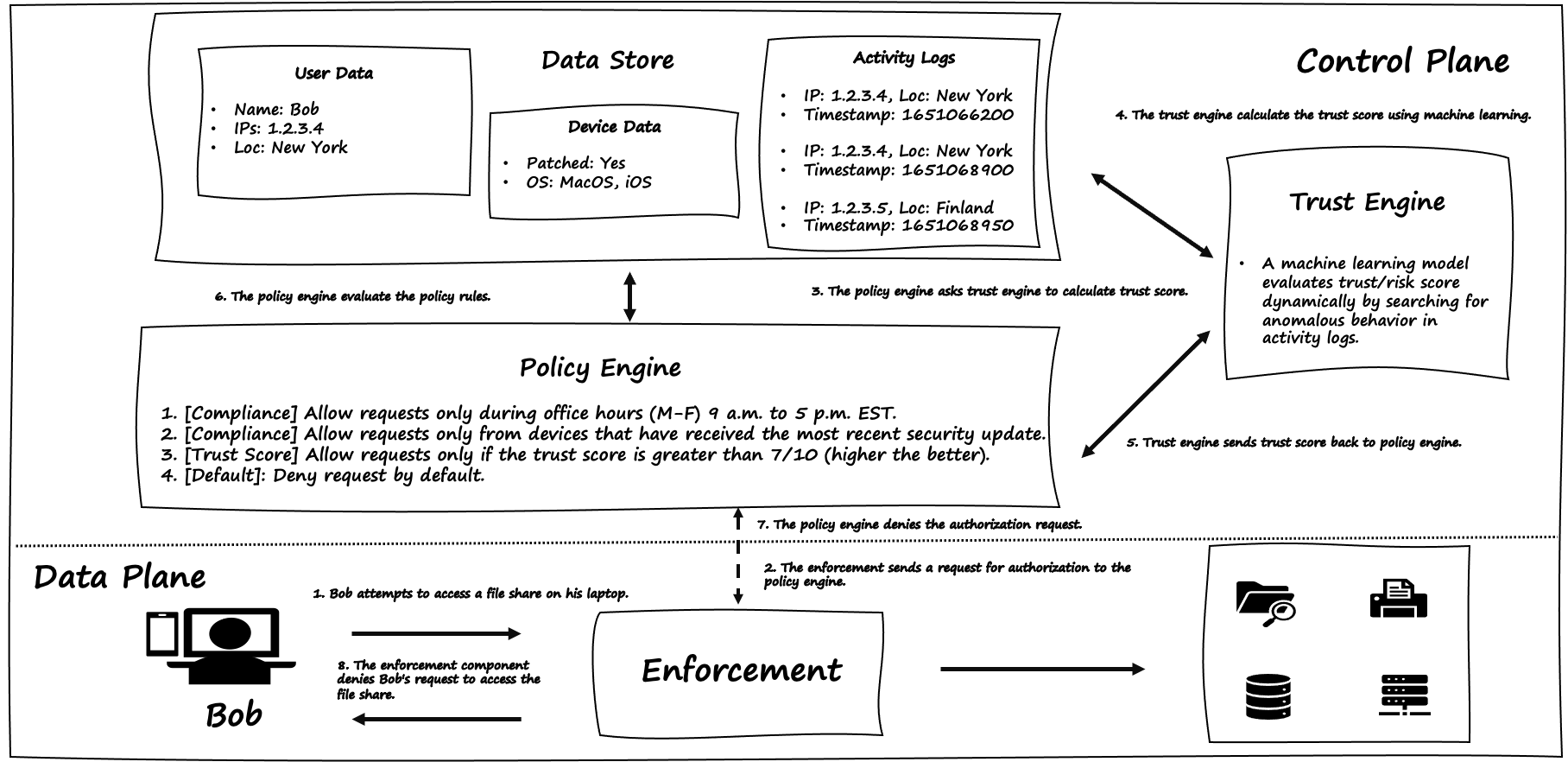
Figure 4-7. Bob’s request to access the file share is denied after the policy engine evaluates the request using the trust score and other policy rules.
Here’s a step-by-step analysis of Bob’s request:
-
On Monday, at 9.30 a.m. Eastern Time Zone (EST), Bob requests access to the file share from his laptop. The laptop is fully patched and runs MacOS.
-
The enforcement component intercepts the request and sends it to the policy engine for authorization.
-
The policy engine receives the request and consults with the trust engine to determine the request’s trust score.
-
The trust engine uses a machine learning model to calculate the trust score based on the activity logs. Anomalies are detected because Bob’s IP address of 1.2.3.5 and location in Finland are unusual. Moreover, given that the requests were made from New York and Finland and are only a few seconds apart, the time stamps between the last two activities appear impossible for a human to match. The machine learning model decides that the request should be assigned a trust score of 3, indicating a low level of trust, and sends the score to the policy engine.
-
Policy engine receives the trust score from the trust engine.
-
For authorization, the policy engine compares the request to all policy rules:
-
This first rule results in a grant (or allow) action because the request is made during the permissible hours on Monday.
-
The second rule results in grant (or allow) action because the request is made using a device that has been fully patched with the most recent security update.
-
The third rule results in a deny action because the request received a trust score of 3, whereas the policy requires a trust score of 7 or higher to grant access. Because deny action is a final action, policy no longer processes any additional rules.
-
-
The policy engine sends a deny action to the enforcement component. It also sends additional information about the result, which can aid in understanding the reason for the denial of the requested action.
-
The enforcement component receives the policy engine’s result and denies Bob’s request, preventing him from accessing the file share. It also sends Bob a helpful message about how to improve his chances of gaining access to the resource if he decides to do so in a future request.
While basic in nature, the scenario walkthrough in this section provides a functional understanding of various components in the control plane and data plane working together to deny Bob’s request to access the file share. The key takeaway is that the system in place does not make authorization decisions based on ad hoc basics, but rather takes the overall context of the access request into account when making decisions.
Summary
This chapter focused on the systems that are responsible for making the ultimate decision of whether a particular request should be authorized in a zero trust network. This decision is a critical component of such a network, and therefore should be carefully designed and isolated to ensure it is trustworthy.
We broke this responsibility down into four key systems: enforcement, policy engine, trust engine, and data stores. These components are logical areas of responsibility. While they could be collapsed into fewer physical systems, the authors prefer an isolated design.
The enforcement system is responsible for ensuring that the policy engine’s authorization decision takes effect. This system, being in the data path of user traffic, is best implemented in a manner where the policy decision is referenced and then enforced. Depending on the architecture chosen, the policy engine might be notified before a request occurs, or during the processing of that same request.
The policy engine is the key system that computes the authorization decision based on data available to it and the policy definitions that have been crafted by the system administrators. This system should be heavily isolated. The policy that is defined should ideally be stored separately from the engine and should use good software development practices to ensure that changes are understood, reviewed, and not lost as the policy moves from being proposed to being implemented. Furthermore, since zero trust networks expect to have much finer-grained policy, mature organizations choose to distribute the responsibility of defining that policy into the organization with security teams reviewing the proposed changes.
The trust engine is a new concept in security systems. This engine is responsible for calculating a trust score of components of the system using static and inferred algorithms derived from past behavior. The trust score is a numerical determination of the trustworthiness of a component and allows the policy writers to focus on the level of trust required to access some resource instead of the particular details of what actions might reduce that trust.
The final component of this part of the system is the authoritative data sources that capture current and historical data that can be used to make the authorization decision. These data stores should focus on being sources of truth. The policy engine, the trust engine, and perhaps third-party systems can leverage this data so the collection of this data will have a decent return on investment from capturing it.
The scenario walkthrough demonstrated how various control and data plane components interact to make the system work. In our scenario, the request from user Bob to access a file share was evaluated based on the overall context of the request, which included both a dynamic trust score calculation and various policies in place by the business to make a final authorization decision. This scenario walkthrough will be expanded upon in later chapters.
The next chapter will dig into how devices gain and maintain trust.