
6.1 IP Networks
The backbone of today's widespread networking is the Internet technology that can be better characterized as a packet-switched, store-and-forward, communication network running the Internet family of protocols at the network and transport layers. This single-sentence description entails several key concepts that will be described in the following subsections. More detailed information on these topics can be found on the many very good current textbooks on networking, such as [1], [2] and [3].
6.1.1 Packet Networks
With the development of communication networks came the need to develop switching techniques so as to connect one network node to another network node through the communication process. In early networks, the adopted techniques followed a paradigm known as “circuit switching”. This paradigm is based on establishing at the beginning of a call, a connection between the communicating nodes that is maintained for the duration of the call. In this way, the resources needed for a communication session are exclusively reserved for that session for as long as it lasts. Probably the best example of a circuit switched system is the plain old telephone system (POTS), where the connection is established during dialing, and its resources are reserved until the call ends. An important property to note for circuit switching networks is that the reservation of resources for a connection effectively establishes a state within the network. Connection setup and tear-down procedures manage these states within the network.
After several decades of circuit switching dominance, network switching saw the emergence of a new paradigm, called “packet switching” or “store-and-forward” networks. In this paradigm, the information to be communicated is separated into blocks, usually called the “data payload”. Before transmission of any of the blocks, they are appended to a “header”. The header is a block of metadata, this is, information about the data in the payload. The combined payload data along with its associated metadata in the header is called a “packet”.
The purpose of the information contained in the packet header is to ensure that the payload could be communicated from the sending node to the destination node. As such, a critical element of the metadata contained in the header is the identification of the destination node. While the payload data is, of course, important for the destination node, the metadata is used to control the protocols running in the network nodes involved in the communication process. Importantly, the information contained in the header should be sufficient to ensure that a packet can be treated and processed as an independent element in all network nodes. To see this important point, let's suppose that a communication process sends a packet from a source node to a destination node, visiting in between a number of other intermediate nodes, which will simply help route the packet through the network, toward the destination node. At any of the intermediate nodes, the metadata in the header allows the node to find out what is the node destination and, based on this information, forward the node to another node in the direction of the destination. The information in the header also allows a packet to be temporarily stored in the memory of a node until it can be processed for routing.
6.1.2 Layered Network Protocols Architecture
A network can be seen as an infrastructure that supports the distributed execution of software. The software can be the application itself, which in this book consists of a 3D video playback system. As such, at the transmitter side, the software performs operations such as source and channel encoding, buffering, and data framing. At the receiver side, it is common to also find buffering operations and the decoding operations to match the encoding at the transmitter. The two main components in the network infrastructure are the nodes, which generate, forward, or receive data, and the links that interconnect the nodes.
Another key component needed to form a network is the protocols. Protocols are a set of coordinating rules that establish the format and structure by which two separate ends of distributed software interact. For example, in a routing algorithm the transmitter side needs to specify what the address of the destination is, in a format that is understood by the intermediate nodes executing an algorithm to route the data packet.
The network protocols are divided into “layers”, where each layer is specialized on a set of functions. The layers are organized into a stack, with the layers piled up one on top of the other. Viewed at the transmitter side, the functions of a layer provide services to the layers immediately above in the stack. Therefore, the lower the layer is in the stack, the more basic are the communication functions that are provided by the associated protocol. The aggregated result from all stacked protocols at different layers is the complete set of functions required by the networking process.
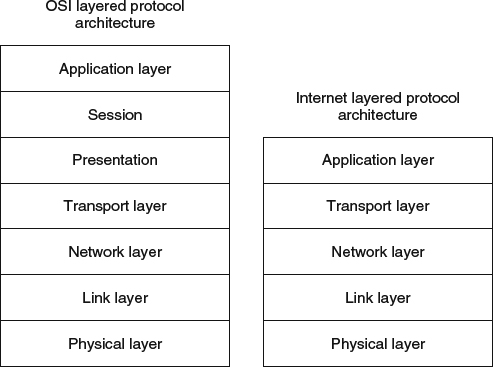
Figure 6.1 OSI and Internet layered protocol architectures.
The idea for a network protocols architecture where they are divided into stacked layers was introduced in 1980 by the International Organization for Standardization (ISO) through the “Open Systems Interconnection” (OSI) reference model [4]. As shown in Figure 6.1, this model introduced an architecture with seven layers. Today's modern networks, included wireless networks, are based on an architecture based on the Internet protocol stack. As seen in Figure 6.1, this architecture has five layers: the physical layer (also called Layer 1, or the PHY layer), the data link layer (also called Layer 2), the network layer (or Layer 3), the transport layer (or Layer 4) and the application layer (or Layer 5). The function of these layers is as follows:
- Physical layer: This provides to the upper layer those services related to the transmission of unstructured bit streams over a physical medium, by performing a mapping from bits or groups of bits into electrical signals. This layer also provides, at times, forward error control (FEC) services.
- Data link layer: This is one of the most complex layers in terms of the breadth of services provided to upper layers. Because of this, it is frequently divided into sublayers. One common such sublayer is the logical link control (LLC) sublayer, which provides node-to-node flow control, error detection, forward error control (when not implemented at the physical layer or complementing the FEC scheme at the physical layer) and retransmission procedures of link layer frames with errors (ARQ – automatic repeat request). Another very common sublayer is the medium (or media) access control (MAC) sublayer, which provides the means for multiple stations to share access to the transmission medium. Regardless of its internal structure, two characteristics differentiate the data link layer. One is that the layer is the lowest in the stack to provide structure into the transmitted bit stream, forming sequences of bits into frames. The second important characteristic is that the data link layer, as its name indicates, provides services exclusively related to links. Here, a link is the direct connection between two nodes, without having any other node in between. Because of this, it is said in summary that the function of the data link layer is to provide reliable transfer of information on a link.
- Network layer: This layer is the lowest in the stack providing services that encompass more than just a link and with a network-wide scope. As such, this layer provides the upper layers in the stack with the services needed to switch and route information through the network, enabling a packet to be routed through network nodes from a source to a destination. In the Internet protocol stack, the network layer protocol is the Internet Protocol (IP), today used in the two versions IPv4 and IPv6.
- Transport layer: This layer provides reliable transfer of information between end points in a connection. As such, it provides end-to-end congestion and flow control, as well as services for the retransmission of data that is missing or received with errors. At first sight, this layer may seem to provide services very similar to those of the data link layer, but the key difference here is that while the data link layer provides link-oriented services, the transport layer provides services operating on the end-to-end connection established between sender and receiver of data. In terms of Internet technology, while the data link layer can be seen as providing services for a wireless link or the link of an Ethernet local area network, the transport layer would provide services for an end-to-end connection that may include multiple types of links and networks. The best known two examples for Internet transport layer protocols are the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP).
- Application layer: This layer encompasses protocols that enable the distributed execution of an application. As such, there exist many application layer protocols, such as those used for file transfer (e.g., FTP), email (e.g., SMTP, IMAP, POP), hypermedia-based Internet browsing (e.g., HTTP), etc.