
Visual Databases
12.1 INTRODUCTION
Databases of images and image sequences are becoming a subject of increasing relevance in multimedia applications. Archiving and retrieving these data requires different approaches from those used with traditional textual data. Specifically, the marked characterization of the information units managed in such systems, with the lack of a native structured organization and the inherent visuality of the information contents associated with pictorial data makes the use of conventional indexing and retrieval based on textual keywords unsuitable. Icons as picture indexes have been suggested to support image retrieval by contents from databases (Tanimoto, 1976), iconic indexes standing for objects, object features or relationships between objects in the pictures.
The use of iconic indexes naturally fits with visual querying by example to perform retrieval. In this approach, image contents are specified by reproducing on the screen of a computer system the approximated pictorial representation of these contents. Using pictures to query pictures, retrieval is thus reduced to a matching between the pictorial representation given by the user and the iconic indexes in the database. Visual queries by example make simpler the expression of image queries by contents. The cognitive effort which is required to the user in the expression of image contents through text is now reduced by resorting on the natural human capabilities in picture analysis and interpretation.
In the following, we will review several of the main approaches in pictorial data iconic indexing and visual retrieval. Single image indexing and retrieval is discussed in Section 12.2, with reference to different approaches to indexing and retrieval based on different facets of the informative contents of pictorial data, such as spatial relationships, color, textures and object shapes. The subject of sequence retrieval is discussed in Section 12.3 considering symbolic indexing and iconic retrieval.
12.2 SINGLE IMAGES
Pictorial indexing and querying of single images may take into account relative object spatial relationships, color and textural attributes, or shapes of the objects represented in the images.
12.2.1 Iconic indexing and querying based on spatial relationships
Spatial relationships between imaged objects play the most immediate and relevant role for the indexing of image data. The symbolic projection approach, initially proposed by Chang and Liu (1984) and Chang et al. (1987), and subsequently developed by many authors (Lee et al., 1989; Chang and Jungert, 1991; Costagliola et al., 1992; Jungert, 1992; Lee and Hsu, 1992; Del Bimbo et al., 1993a, 1994a), is a simple and effective way to provide iconic indexes based on spatial relationships and is also ideally suited to support visual interaction for the expression of queries by contents. In this approach, first, after preprocessing, the objects in the original image are recognized and enclosed in their minimum bounding rectangles. Then for each object, the orthogonal relation of objects with respect to the other objects are created. Objects are abstracted with their centroids. Orthogonal projections of the object centroids on the two image axes x and y are considered. Three spatial relational operators {<, =,: } are employed to describe relations between object projections. The symbol ‘<’ denotes the left-right or below-above spatial relationship, the symbol ‘=’ denotes the at the same spatial relation as, the symbol ‘:’ stands for in the same set as relation.
Image contents may be described through a 2D string (Chang and Liu, 1984). A 2D string (u, v) over a vocabulary of pictorial objects oi, is formally defined to be: (x1 op x2 op x3 op x4 op …, y1 op y2 op y3 op y4 op …), where op is one of the relational operators expounded above and xi and yi are the projections of the objects oi along the x- and y-axes, respectively.
A pictorial query can be expressed visually, by arranging icons over a screen to reproduce spatial relationships between objects and in turn reduced to a 2D string. In this way, the problem of pictorial information retrieval is reduced to the matching of two symbolic strings. Examples of visual retrieval according to the symbolic projection approach using 2D string encodings are reported in (Chang et al., 1988).
Among the developments of the original 2D-string approach, 2D G-strings with the cutting mechanism (Lee et al., 1989) overcome the limitations of 2D strings due to the inability to give a complete description of spatial relationships that occur in complex images. A 2D G-string is a five-tuple (V, C, E, e,〈−〉) where V is the vocabulary; C the cutting mechanism which consists of cutting lines at the extremal points of the objects; E = {<,=,!} is the set of extended spatial operators; e is a special symbol which represents an area of any size and any shape, called the empty space object, and ‘〈−〉’ is a pair of operators which is used to describe a local structure. The cutting mechanism defines how the objects in an image are segmented. The special empty space symbol and the operator pair ‘〈−〉’ provide the means to use generalized 2D strings to substitute for other representations.
Although 2D G-strings can represent the spatial relationships among objects in pictures, the number of segmented subparts of an object is dependent on the number of bounding lines of other objects which are completely or partially overlapped. Lee and Hsu (1992) define 2D C-strings, which preserve all spatial relations between objects with efficient segmentation. The knowledge structure of 2D C-string is a five-tuple (S, C, Rg, Rl, ()), where: S is the set of symbols in symbolic pictures of interest; C is the cutting mechanism which consists of cutting lines at the points with partial overlapping from x- and y-projection respectively. Cuttings are performed along the x- and y-axes independently, in a way that the 2D-C-string representation of a picture is unique and minimal. The set Rg = {<,!} is the set of global relational operators; considering two objects A and B operated with the above operators, they have the meaning of A disjoins B and A is edge to edge to B, respectively; Rl = {=, [,],%} is the set of local relational operators considering two objects A and B operated with the above operators, they have the meaning of A is the same as B, A contains B and they have the same begin-bound, A contains B and they have the same end-bound, A contains B and they have not the same bound, respectively; ( ) is a pair of separators which is used to describe a set of symbols as one body.
An extension of 2D strings to deal with three-dimensional imaged scenes was proposed by Del Bimbo et al. (1993a). The approach relies on the consideration that two-dimensional iconic queries and 2D-string-based representations are effective for the retrieval of images representing 2D objects or very thin 3D objects, but they might not allow an exact definition of spatial relationships for images representing scenes with 3D objects. In fact in this case, an incorrect representation of the spatial relationships between objects may result, due to two distinct causes. First, 2D icons cannot reproduce scene depth. 2D icon overlapping can be used only to a limited extent since it impacts on the intelligibility of the query. Second, as demonstrated by research in experimental and cognitive psychology, mental processes of human beings simulate physical world processes. Computer-generated line drawings representing 3D objects are regarded by human beings as 3D structures and not as image features, and they imagine spatial transformations directly in 3D space. Therefore an unambiguous correspondence is established between the iconic query and image contents if the spatial relationships referred to are those between the objects in the scene represented in the image, rather than those between the objects in the image. The dimensionality of data structures associated with icons must follow the dimensionality of the objects in the scene represented in the image. A 3D structure should be employed for each icon to describe a 3D scene. Representations of images are derived considering 3D symbolic projections of objects in the 3D imaged scene. Thirteen distinct operators, corresponding to the interval logic operators distinguish all the possible relationships between the intervals corresponding to the object projections on each axis.
Retrieval systems employing the ternary representation of symbolic projections have been expounded in Del Bimbo et al. (1993a) and Del Bimbo et al. (1994a). In the latter approaches, the user reproduces a three-dimensional scene by placing 3D-icons in a virtual space and sets the position of the camera in order to reproduce both the scene and the vantage point from which the camera was taken. A spatial parser translates the visual specification into the representation language and retrieval is again reduced to a matching between symbolic strings.
12.2.2 Iconic indexing and querying based on colors and textures
Indexing and query by contents based on picture colors or object textures has been proposed, among the others, by Hirata and Kato (1992), Binaghi et al. (1992) and Niblack et al. (1993). Generally speaking, image color distribution and textures are assumed to be the characterizing features of image contents and images are requested that contain objects whose color/texture is similar to the color/texture selected from some user menu, or that have global similarity as to color or textures.
In the QBIC system (Niblack et al., 1993) color space is represented by using average (R, G, B), (Y, i, q), (L, a, b) and the Mathematical Transform to Munsell coordinates (MTM) of each object. A color histogram is also evaluated. Color RGB space is quantized in 4096 cells. The MTM coordinates of each cell are computed and clustering is performed to obtain the best 256 colors. Color histogram is obtained as the normalized count of the number of pixels that fall in each of these colors. For average color, the distance between a query object and the database object is weighted Euclidean distance. Improved results are claimed when color matching is not made on average color but on distribution of colors occurring in an object or image. Queries representing images with distinct percentages of different colors are also allowed.
A similar approach is carried out by Hirata and Kato (1992). Iconic indexes are built following a complex procedure. Images are divided into several regions using edges (see the next section), color values of the pixels, texture values. The edge-detection step uses an adaptive differential filter in the RGB space based on the Weber–Fechner law of human vision. In the color measurement the image is divided into regions considering the distance in the hue, lightness and saturation space. Color and texture values are added to each region. Retrieval is obtained by measuring the similarity (through correlation functions) of shapes (see the next section), color and position between regions in the user sketch and the iconic indexes in the database.
12.2.3 Iconic indexing and querying based on object shapes
Several mathematical frameworks can be defined to measure shape similarity. The most straightforward way is to extract a number of features describing the shape and then make a number of measurements to determine the distance in the feature space between the model (the shape we draw) and the candidate (the part of the image that we are testing for the presence of the shape). Nevertheless, unlike other indexes like color or texture, shape does not have a mathematical definition that exactly matches what the user feels as a shape. It is not easy to understand what a human perceives as shape and, more importantly what should be considered a valid shape similarity measure. In particular, it often happens that shapes that a human feels as very similar are regarded by reasonable, mathematically-defined distance operators as completely different. Feature based approaches tend to be brittle in the presence of shape distortion and generally speaking a feature-based comparison between a model and an image just doesn’t work. Typical images span very high-dimensional subspaces in feature spaces, thus requiring the extraction of a great number of features to be reliably characterized, and, for most of these features, there is no warranty that our notion of closeness is mapped in the topological closeness in the feature space.
Retrieval by contents based on object shapes and sketches has been proposed by Hirata and Kato (1992) and in the QBIC system by the IBM research group in Almaden (Niblack et al., 1993). In the latter work, similarity retrieval is carried out by considering the local correlation between a linear sketch drawn by the user on a tablet and an abstract image in the database. Linear sketches are binarized sketches which passed a thinning and shrinking procedure to be reduced to a fixed size sketch (64 × 64). Abstract images are images that are converted to a single band luminance, passed a Canny edge extraction procedure, a thinning and shrinking procedure to be reduced to the standard 64 × 64 size. In the correlation process a local block is shifted in 2D directions to find the best match position between the sketch and the image.
In the QBIC system (Niblack et al., 1993), heuristic shape features are considered such as area (i.e. the number of pixels set in the binary image), the circularity, computed as the square perimeter over area, major axis orientation, computed as the direction of the largest eigenvector of the second order covariance matrix, and eccentricity, measured as the ratio between the smallest and the largest eigenvalues. Algebraic moment invariants are also considered that are computed from the first m central moments. Shape matching between the sketch and stored images is accomplished by considering a weighted Euclidean distance between the features in the two images.
Limitations of both the above approaches stand in the requirement that shapes drawn by the user must be close to the imaged shapes of the objects in the requested images, due to the rough parameterization used. Moreover, due to the distance function used, given a certain shape many images other than that containing the requested object are answered, thus forcing the user to perform a further analysis over a still large set of images. Since retrieval is only based on shapes, without any care of spatial relationships, in the case of images with multiple objects, the lack of pruning over the image database may lead to unmanageable sets of answered images.
Del Bimbo et al. (1994b) present a system for image retrieval by contents, following a different approach, based on shape matching with elastic deformations. In this system, the user sketches a drawing on the computer screen and the drawing is deformed to adapt to shapes of objects in the images. Differently from previous attempts in shape-based image retrieval, similar shapes are searched with no form of feature extraction.
In this system, images are collected and, while inserted in the database, a number of interesting rectangular areas are selected. Typically, these areas correspond to objects in the image. All the following searches are limited to the interesting areas. A query is again composed by drawing a sketch of one, or more, shapes on a graphic screen. A template, in the form of a 4th-order spline, is instantiated for each of the shapes. Image retrieval is based upon two considerations: a candidate image is retrieved and presented for browsing if it has two or more areas of interest in the same spatial relationship as the shapes drawn on the tablet and the shapes contained in the areas of interest match the shapes on the tablet with a certain degree.
To make a robust match even in the presence of deformations, we must allow the template to deform. The template must deform taking into account two opposite requirements: first, it must follow as closely as possible the edges of the image (R1); second, it must take into account the deformation of the template (R2): specifically a measure must be taken into account of the energy spent to locally stretch and bend the template. The elastic energy depends only on the first and second derivatives of the deformation. This allows not to penalize discontinuities and sharp angles that are already present in the template, but to penalize only the degree by which we depart from those discontinuities or angles. Also, since the energy depends only on the derivatives of deformation, pure translation of the template, for which deformation is constant, does not result in additive cost. This makes the scheme inherently translation invariant. The goal is to maximize R1 while minimizing R2. This can be achieved by minimizing a compound functional where the term R1 appears with plus sign and the term R2 with minus sign. A solution can be obtained as a solution of the Euler-Lagrange equations associated to this variational problem. Under suitable approximations the solution is a spline function with i knots. The match between the deformed sketch and the imaged objects, as well as the deformation energy of the sketch are taken into account to measure the similarity between the model and the image. Energy and match values at the end of the deformation process, together with a measure of the shape complexity (the number of zeroes of the curvature function) are used as an input to a neural classifier which derives a similarity ranking. Only images with the highest similarity rankings are displayed in response to the query. An example of retrieval by elastic matching is shown in Figure 12.1, where the rough sketch of a bottle is compared with images from the Morandi’s catalogue: the deformed template is shown superimposed with the six most similar images in the database. For queries including multiple objects, spatial relationships between the different objects are taken into account.
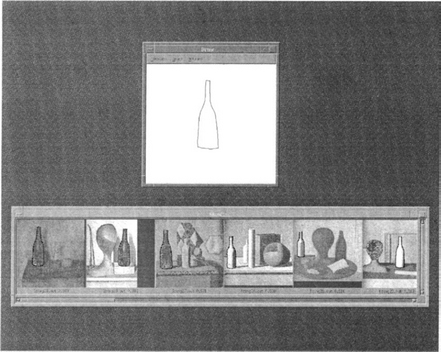
The elastic matching algorithm is computationally very demanding, and sets a serious burden on the capacity of the system it is implemented on. To make this system as effective as possible, it is important to make a preliminary filtering of the database, eliminating as many images as possible before applying the elastic matching algorithm.
12.3 IMAGE SEQUENCES
As opposite to the number of experiences on single images, only a few techniques have been proposed for indexing and querying of image sequences. Contents of frame sequences can be expressed by referring either to the temporal structure of the video, or to the occurrences in the individual frames. The first approach especially makes evident the editing process which has been applied to create the syntactic structure of the video; the second, points out the spatial occurrences of objects in the individual frames, or the temporal changes of spatial relationships, or, at a higher level, the spatio-temporal interactions among imaged objects. Indexing through edit types is especially important for storage and retrieval of films and is based on special segmentation techniques that allow to detect boundaries of the syntactic units of the film. It will not be discussed here. In the following we will shortly review the indexing of sequence contents through high-level descriptions (Section 12.3.1), and through representation of spatio-temporal relationships between objects in the frame sequence (Section 12.3.2).
12.3.1 High-level indexing and retrieval
High-level interactions between entities are represented through semantic networks by Walter et al. (1992). Their study concentrates on a formalism for the symbolic representation of physical entities represented in the images, abstract concepts, their dynamic changes and a matching formalism for the representation of deductive rules. Episodes are extracted from a sequence and represented as ensembles of objects and processes. Objects are all material entities and properties or relations between material objects, while processes represent changes of properties and relations between objects over time. Abstract categories of objects are called generic descriptions and particular examples of object categories are referred to as individuals. Individuals may belong to several genera not necessarily at the same time. Genera may be connected by various relations through generalization or attribute links. The representation formalism is referred to as EPEX-F and is a variation of KL-ONE. EPEX-F includes a temporal logic to allow temporal information to be maintained with the objects as lifetime attributes. Retrieval is made textually and supported by a rule system. This approach supports description of episodes at a high semantic level; nevertheless its effectiveness is limited to a small number of objects in the episodes. Queries are easier to be expressed textually than visually due to the abstraction level of relationships between entities.
Davis (1993) indexes video sequences through high-level episodes reflecting the occurrence of typical situations, such as a person running, or drinking from a cup. Indexing is handmade and is obtained by associating a situation icon to each set of frames in which the situation occurs. To retrieve subsequences, icons can be combined visually to define even complex visual queries.
12.3.2 Iconic indexing and querying based on spatial relationships
Arndt and Chang (1989) propose the extension of 2D strings to the indexing of image sequences. Sequences are divided into a number of series where each series represents a continuous sequence of images. Sequence descriptions are obtained by deriving the 2D string for each set of frames where the description keeps constant. Changes that may occur between frames (and in the 2D strings altogether) are marked with the number of frame where changes occur. Sets operators such as addition, deletion of an object, merging and splitting of sets, deletion and addition of sets are used to identify the type of change occurred.
However, such a representation, while effective for indexing image sequences at a lower level with respect to semantic network approaches, does not provide the flexibility needed in representation of image sequences for their retrieval. Two types of problems must be addressed. First, the specificity of image sequence contents, which imposes constraints on the type of representation used. Second, the fact that querying image sequences must be supported at different levels of detail according to the actual knowledge of the user about sequence contents. The first issue requires representations that avoid ambiguities in the description of image contents; the second requires that a language is available supporting different levels of detail and refinement. As to the first issue, in the representation of contents of image sequences, we must take into account that image sequences usually represent 3D dynamic real-world scenes with three-dimensional motions of multiple objects. According to what was discussed for the case of single images, descriptions referring to the original imaged scene (3D scene-based descriptions) are generally needed to avoid representation ambiguities. Image-based descriptions can be considered only in the special cases where all the objects lay on a common plane and the camera is in a normal position with respect to it. In 3D scene-based descriptions, two different descriptions are possible, depending on the reference systems on which symbolic projections are taken. On the one hand, object projections can be evaluated with reference to the Cartesian coordinate system of a privileged point of view, corresponding to the vantage point of the viewing camera (observer-centered description). In this case, images of the same scene, taken from different viewpoints, are associated with distinct 3D scene descriptions. On the other hand, object projections can be evaluated with reference to the coordinate systems associated with individual objects (object-centered description). The overall description of the scene is obtained as the composition of multiple object-centered descriptions, each capturing how one object sees the rest of the scene. Since in the object-centered approach descriptions are independent of the observer point of view, images of a scene, taken from distinct viewpoints, are all associated with the same 3D description. Considering the evolution over time of scene-based descriptions, observer-centered representations lead to a sequence description which is dependent on the observer point of view. Object motion is correctly represented only if the camera is fixed. In the presence of a moving camera, objects may be associated with apparent motions. For instance, camera zooming results in expansive or contractive motions. As a consequence, the description associated with the sequence may include changes in spatial relationships that are not due to the actual motion of the objects. Whereas, object-centered scene descriptions always result in the representation of the actual motion of the objects, both with a fixed and with a moving camera. In this case, the sequence description does not depend on the observer point of view and only represents actual changes in the spatial relationships between objects as occurring in the original imaged scene.
These considerations have been expounded by Del Bimbo et al. (1993b), where a language is also proposed for the symbolic representation of spatio-temporal relationships between objects within image sequences is presented. This language, referred to as Spatio-Temporal Logic (STL), comprises a framework for the qualitative representation of the contents of image sequences, which allows for treatment and operation of content structures at a higher level than pixels or image features. STL extends basic concepts of Temporal Logic (Allen, 1983) and symbolic projection to provide indexing of sequence contents within a unified and cohesive framework. By inheriting from Temporal Logic the native orientation towards qualitative descriptions, this language permits (without imposing) representations with intentional ambiguity and detail refinement, which are especially needed in the expression of queries. Besides, by exploiting the symbolic projection approach, STL supports the description of sequence contents at a lower level of granularity with respect to semantic networks and annotation-based approaches, thus allowing to focus on the actual dynamics represented in the sequence. Temporal properties are expressed as Temporal Logic assertions that capture the evolution over time of spatial relationships occurring in single scenes. These relationships are expressed through an original language, referred to as Spatial Logic, which transposes the concepts of Temporal Logic itself to express relationships between the projections of the objects within individual scenes.
The spatial assertions that capture the properties of the contents of the individual scenes are composed through the Boolean connectives and, or, not and their derived shorthands, and the temporal-until operator unt_t. Boolean connectives have their usual meaning and permit the combination of multiple assertions which refer to any individual scene of the sequence. The temporal-until operator permits to define temporal ordering relationships between the scenes in which different assertions hold. Specifically, temporal until is a binary operator which permits the composition of a pair of assertions q1 and q2 to express that q1 holds along the sequence at least until reaching a scene in which q2 holds. Shorthands of the unt_t operator are the temporal-eventually operator (eve_t) and the temporal-always operator (alw_t). Temporal eventually is a unary operator which permits the composition of an assertion q1 to express that somewhere in the future q1 may hold (nothing is said about what holds until q1 will hold). The temporal-always operator expresses that an assertion q1 will hold from now in the future. Spatial Logic exploits the symbolic projection approach for the description of spatial relationships between objects. It transposes the concepts of Temporal Logic so as to capture the geometric ordering relationships between the projections of the objects within a multi-dimensional scene.
If Φ is a spatial formula defining some positional properties, the spatial assertion of the form (SE, q, en) := Φ (read ⇐ as models) where q is an object possibly extending in more than one region, expresses that the relational property Φ holds in any region containing the object q, considering projections along the en reference axis.
For instance, the assertion (SE, q, x) := p (which is referred to as spatial alignment with respect to the x-axis) expresses that the projection of q on the x-axis is entirely contained in the projection of p.
The assertion (SE, q, x) := (eve_s + p) expresses that every point of the projection of q on the x-axis of the underlying reference system E has at least one point of the projection of p to its right side (s+).
The assertion, (SE, q, x) := (q unt_s + p) expresses that the projection of q on the x-axis extends at least until the beginning of the projection of p.
Composition of the above spatial operators through the Boolean connectives allows the expression of spatial relationships at different levels of detail, which is especially useful in the formulation of queries.
A retrieval system for which exploits such a language for iconic retrieval by example of image sequences is also presented in that paper. In this system sequences are stored with their STL symbolic descriptions associated. Queries are expressed by the user through a visual iconic interface which allows for the creation of sample dynamic scenes reproducing the contents of sequences to be retrieved. Sample scenes are automatically translated into spatio-temporal logic assertions, and retrieval is carried out by checking them against the descriptions of the sequences in the database. An example of retrieval of image sequences based on STL descriptions is shown in Figure 12.2. The pictures in the first column present different steps of the visual query specification (selection of the objects (a)) and motion definition (b), (c): sequences where a car is passing in front of two houses are searched. The pictures in Figure 12.3 show two frames of the retrieved sequences (a), (b).

Figure 12.2 Visual query by example. Specification of a simple dynamic scene: (a) The initial scene; (b), (c) specification of motion by the dragging of the car icon.

Extensions of STL with metric qualifiers to take into account distances, speeds and the like, allow more fitting assertions on visual data and support more precise reasoning on space and time. An extended version of STL referred to as XSTL (eXtended Spatio-Temporal Logic) has been developed and expounded by Del Bimbo and Vicario (1993).
Allen, J.F. Maintaining knowledge about temporal intervals. Communications of the ACM. 1983;26:11.
Arndt, T., Chang, S.-K., Image sequence compression by iconic indexing. IEEE VL′89 Workshop on Visual Languages. Rome, Italy. 1989.
Binaghi, E., Gagliardi, I., Schettini, R. Indexing and fuzzy logic-based retrieval of color images. In: Knuth, Wegner, eds. IFIP Transactions A-7, Visual Database Systems II. Amsterdam, The Netherlands: Elsevier, 1992.
Chang, S.-K., Jungert, E. Pictorial data management based upon the theory of symbolic projections. Journal of Visual Languages and Computing. 1991;2:2.
Chang, S.-K., Liu, S.L. Picture indexing and abstraction techniques for pictorial databases. IEEE Trans. on Pattern Analysis and Machine Intelligence. 1984;PAMI-6:4.
Chang, S.-K., Shi, Q.Y., Yan, C.W. Iconic indexing by 2-D strings. IEEE Trans. on Pattern Analysis and Machine Intelligence. 1987;PAMI-9:3.
Chang, S.-K., Yan, C.W., Dimitroff, D.C., Arndt, T. An intelligent image database system. IEEE Trans. Software Engineering. 1988;14:5.
Costagliola, G., Tortora, G., Arndt, T. A unifying approach to iconic indexing for 2D and 3D scenes. IEEE Trans. on Knowledge and Data Engineering. 1992;4:3.
Also appeared in reduced version in: Proc. IEEE VL′93 Workshop on Visual Languages, Bergen, Norway] Davis, M. Media streams, an iconic visual language for video annotation. Telektronik. 4, 1993.
To appear also in: Del Bimbo, A., Vicario, E., A logical framework for spatio-temporal indexing of image sequences. Chang S.K., Jungert E., eds., eds. Proc. Workshop on Spatial Reasoning. Bergen, Norway. Spatial reasoning. Plenum Press: New York, 1993.
Del Bimbo, M., Campanai, M., Nesi, P. A three-dimensional iconic environment for image database querying. IEEE Trans. Software Engineering. 1993;SE-19:10.
To appear on Del Bimbo, A., Vicario, E., Zingoni, D., Symbolic description and visual querying of image sequences using spatio-temporal logic [Also reduced version in: Proc. IEEE VL′93 Workshop on Visual Languages, Bergen, Norway]. IEEE Trans. on Knowledge and Data Engineering. 1993.
Del Bimbo, A., Vicario, E., Zingoni, D. A spatial logic for symbolic description of image contents. Journal of Visual Languages and Computing. 1994;5:1994.
Del Bimbo, A., Pala, P., Santini, S., Visual image retrieval by elastic deformation of object shapes. Proc. IEEE VL′94 Int. Symp. on Visual Languages. St Louis, Missouri. 1994.
Hirata, K., Kato, T., Query by visual example: Content-based image retrieval. Pirotte A., Delobel C., Gottlob G., eds., eds. Advances in database technology—Proc. EDBT′92. Lecture Notes in Computer Science, 580. Springer Verlag: Berlin, Germany, 1992.
Jungert, E., The observer’s point of view, an extension of symbolic projections. Proc. Int. Conf. on Theories and Methods of Spatio-Temporal Reasoning in Geographic Space. Pisa. Lecture Notes in Computer Science. Springer Verlag: Berlin, Germany, 1992.
Lee, S., Hsu, F. Spatial reasoning and similarity retrieval of images using 2D C-string knowledge representation. Pattern Recognition. 1992;25:3.
Lee, S., Shan, M.K., Yang, W.P. Similarity retrieval of iconic image database. Pattern Recognition. 1989;22:6.
Niblack, W., et al, The QBIC project: Querying images by content using color, texture and shape. Research Report 9203. IBM Res. Div Almaden Res Center, 1993..
Tanimoto, S.L. An iconic/symbolic data structuring scheme. In: Chen C.H., ed. Pattern recognition and artificial intelligence. New York: Academic Press, 1976.
Walter, I.M., Sturm, R. and Lockemann, P.C. (1992) A semantic network based deductive database system for image sequence evaluation. In: Visual database systems II (Eds) Knuth and Wegner). Amsterdam, The Netherlands.