
C H A P T E R 8
Working with XML
Beginning with SQL Server 2005, Microsoft added the XML data type, the XQuery language, and several new functions for working with XML data. XML stands for Extensible Markup Language, and it looks a lot like HTML except that it generally contains data. Companies often use XML to exchange data between incompatible systems or with their vendors and customers. SQL Server also extensively uses XML data to store query plans.
Fully covering XML support in SQL Server would take another complete book, so I’ll just briefly discuss it here. In the past, to work with XML, databases stored the XML data in TEXT columns. The database was just a storage place for the XML data. There was nothing to validate the XML data or to query just part of the XML data. To learn about SQL Server support for XML in depth, check out the book Pro SQL Server 2008 XML by Michael Coles (Apress, 2008).
Converting XML into Data Using OPENXML
There are primarily two ways of handling XML. Either you need to convert an XML document into a rowset (table) or you have a rowset and want to convert it into a XML document. Converting an XML document into a rowset is called shredding and this is the purpose of the OPENXML command. OPENXML must also be used in conjunction with two other commands: sp_xml_preparedocument and sp_xml_removedocument. The first command loads the XML document into memory; this process is expensive and takes one-eighth of SQL Server’s total memory. The command sp_xml_removedocument removes the XML from SQL Server memory and should always be executed at the very end of the transaction. Listing 8-1 shows how this done and Figure 8-1 shows the results from the query.
Listing 8-1. OPENXML Query
DECLARE @hdoc int
DECLARE @doc varchar(1000) = N'
<Products>
<Product ProductID="32565451" ProductName="Bicycle Pump">
<Order ProductID="32565451" SalesID="5" OrderDate="2011-07-04T00:00:00"> <OrderDetail OrderID="10248" CustomerID="22" Quantity="12"/>
<OrderDetail OrderID="10248" CustomerID="11" Quantity="10"/>
</Order>
</Product>
<Product ProductID="57841259" ProductName="Bicycle Seat">
<Order ProductID="57841259" SalesID="3" OrderDate="2011-08-16T00:00:00">
<OrderDetail OrderID="54127" CustomerID="72" Quantity="3"/>
</Order>
</Product>
</Products>';
EXEC sp_xml_preparedocument @hdoc OUTPUT, @doc
SELECT *
FROM OPENXML(@hdoc, N'/Products/Product'),
EXEC sp_xml_removedocument @hdoc;

Figure 8-1. Partial results of the OPENXML query
![]() Note
Note OPENXML, sp_xml_preparedocument, and sp_xml_removedocument are still available in SQL 2012 but are legacy commands. Newer methods such as nodes(), value(), and query() take advantage of the XML data type and are recommended over OPENXML and FORXML. These newer methods are discussed later in the chapter.
Notice that SQL Server predefines the columns in the rowset. These column names are based on the XML edge table format. This format is the default structure for XML represented in table format. Luckily you can modify the column output in order to customize your rowset definitions. You accomplish this by specifying the optional WITH clause in your select statement. Listing 8-2 runs the same OPENXML query but includes the WITH clause and Figure 8-2 shows the results of the OPENXML query.
Listing 8-2. OPENXML Query Using the WITH Clause
DECLARE @hdoc int
DECLARE @doc varchar(1000) = N'
<Products>
<Product ProductID="32565451" ProductName="Bicycle Pump">
<Order ProductID="32565451" SalesID="5" OrderDate="2011-07-04T00:00:00">
<OrderDetail OrderID="10248" CustomerID="22" Quantity="12"/> <OrderDetail OrderID="10248" CustomerID="11" Quantity="10"/>
</Order>
</Product>
<Product ProductID="57841259" ProductName="Bicycle Seat">
<Order ProductID="57841259" SalesID="3" OrderDate="2011-08-16T00:00:00">
<OrderDetail OrderID="54127" CustomerID="72" Quantity="3"/>
</Order>
</Product>
</Products>';
EXEC sp_xml_preparedocument @hdoc OUTPUT, @doc
SELECT *
FROM OPENXML(@hdoc, N'/Products/Product/Order/OrderDetail')
WITH (CustomerID int '@CustomerID',
ProductID int '../@ProductID',
ProductName varchar(30) '../../@ProductName',
OrderID int '@OrderID',
Orderdate varchar(30) '../@OrderDate'),
EXEC sp_xml_removedocument @hdoc;
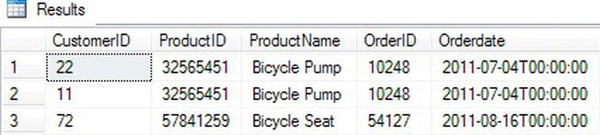
Figure 8-2. Results of the OPENXML query using the WITH clause
In Listing 8-2 you defined the rowpattern as /Products/Product/Order/OrderDetail. You also included the optional ColPattern for each row in the WITH clause. By including the ColPattern you are telling SQL Server to process the XPath using attribute-centric mapping, which is the default method. Another method of mapping XML documents is using element-centric mapping. You’ll look at both methods next. Listing 8-3 shows how to access data using attribute-centric mapping; notice the “1” parameter in the OPENXML statement. Figure 8-3 shows the results.
Listing 8-3. Attribute-Centric Mapping
DECLARE @hdoc int
DECLARE @doc varchar(1000) = N'
<Orders>
<Order OrderID="123458">
<ProductID>32565451</ProductID>
<ProductName>Bicycle Pump</ProductName>
<SalesID>5</SalesID>
<OrderDetail>
<CustomerID>22</CustomerID>
<Quantity>12</Quantity>
</OrderDetail> </Order>
</Orders>';
EXEC sp_xml_preparedocument @hdoc OUTPUT, @doc
SELECT *
FROM OPENXML(@hdoc, N'/Orders/Order', 1)
WITH (ProductID int,
ProductName varchar(30),
SalesID varchar(10),
OrderID int,
CustomerID int);
EXEC sp_xml_removedocument @hdoc;

Figure 8-3. Attribute-centric mapping
You’ve defined your rowpattern as /Orders/Order and, since you’re using attribute-centric mapping, your table includes only the OrderID, which is an in-line attribute of the Order element. Notice the OPENXML query also doesn’t return the CustomerID, which is an attribute of the OrderDetails element.
Now let’s look at the same script but change the OPENXML to element-centric mapping. I’ve highlighted the change in Listing 8-4. Figure 8-4 shows the output when using element-centric mapping.
Listing 8-4. Element-Centric Mapping
DECLARE @hdoc int
DECLARE @doc varchar(1000) = N'
<Orders>
<Order OrderID="123458">
<ProductID>32565451</ProductID>
<ProductName>Bicycle Pump</ProductName>
<SalesID>5</SalesID>
<OrderDetail>
<CustomerID>22</CustomerID>
<Quantity>12</Quantity>
</OrderDetail>
</Order>
</Orders>';
EXEC sp_xml_preparedocument @hdoc OUTPUT, @doc
SELECT *
FROM OPENXML(@hdoc, N'/Orders/Order', 2)
WITH (ProductID int,
ProductName varchar(30), SalesID varchar(10),
OrderID int,
CustomerID int);
EXEC sp_xml_removedocument @hdoc;

Figure 8-4. Element-centric mapping
You’re getting closer to parsing all of the XML into the rowset. OPENXML in Listing 8-4 returns all the attributes of the elements under the Order element. It did not return the OrderID attribute of the Order element or any attributes in the OrderDetails element.
How do you return all the attributes in the XML document? You first have to define ColPatterns for each column in the rowset. Doing so will change the parameter to element-centric mapping. Listing 8-5 shows how this works and Figure 8-5 shows the results.
Listing 8-5. Use of ColPattern in the WITH Clause
DECLARE @hdoc int
DECLARE @doc varchar(1000) = N'
<Orders>
<Order OrderID="123458">
<ProductID>32565451</ProductID>
<ProductName>Bicycle Pump</ProductName>
<SalesID>5</SalesID>
<OrderDetail>
<CustomerID>22</CustomerID>
<Quantity>12</Quantity>
</OrderDetail>
</Order>
</Orders>';
EXEC sp_xml_preparedocument @hdoc OUTPUT, @doc
SELECT *
FROM OPENXML(@hdoc, N'/Orders/Order/OrderDetail')
WITH (ProductID int '../ProductID',
ProductName varchar(30) '../ProductName',
SalesID varchar(10) '../SalesID',
OrderID int '../@OrderID',
CustomerID int 'CustomerID'),
EXEC sp_xml_removedocument @hdoc;

Figure 8-5. Use of ColPattern in WITH clause
You now have all the data. The changes in Listing 8-5 include the ColPattern values but also a change to the rowpattern. The rowpattern is now /Orders/Order/OrderDetail. This allows you to parse the XML document to the lowest element and then work your way up through the XML hierarchy. If any columns are in-line attributes, you will need preface them with an @ sign.
![]() Note When including ColPatterns for columns in your
Note When including ColPatterns for columns in your WITH clause, you don’t need to include the mapping parameter in OPENXML. This is because using ColPattern defaults OPENXML to element-centric mapping.
Retrieving Data as XML Using the FOR XML Clause
As mentioned, XML is normally handled in one of two ways. The first way is when you have a XML document and you need to shred it into a table format. For this method, use the OPENXML command. The other way is to convert table data into a XML document using FOR XML.
The FOR XML clause is actually part of a SELECT statement. A SELECT statement returns data from a table in rowset format. Adding the FOR XML clause at the end converts the rowset data into XML format. The command has four modes and each mode provides you a different level of control. The modes determine how much control you want when converting rowset data containing columns and rows into a XML document consisting of elements and attributes. The four modes are RAW, AUTO, EXPLICIT, and PATH. There are also a number of mode options that will be discussed throughout the chapter.
Throughout this chapter I’ll be discussing the four modes. Each one provides certain advantages and disadvantages. Table 8-1 gives a brief summary of each.

FOR XML RAW
The RAW mode is the simplest mode but provides the least flexibility when generating XML from rowsets. Listing 8-6 shows an example; this mode is an excellent means to quickly generate XML documents from tables. Figure 8-6 shows the initial output and Listing 8-7 shows the results of clicking on the XML hyperlink.
Listing 8-6. Generating XML Using the FOR XML RAW Command
USE AdventureWorks2012;
GO
SELECT TOP 5 FirstName
FROM Person.Person
FOR XML RAW;

Figure 8-6. Using FOR XML RAW
Listing 8-7. XML Output Using the FOR XML RAW Command
<row FirstName="Syed" />
<row FirstName="Catherine" />
<row FirstName="Kim" />
<row FirstName="Kim" />
<row FirstName="Kim" />
As you can tell from the output in Listing 8-7, RAW mode produces a single node “row” for each row returned and each element has a column-based attribute. By default, RAW mode produces an attribute-centric XML document. Remember that attribute-centric XML consists of inline attributes. Also, each node is named row, which is not very helpful when describing the contents of the XML data. To create an element-centric XML document with a more friendly node name, you will need to include the ELEMENTS option along with a node definition. Listing 8-8 shows an example.
Listing 8-8. Creating Element-Centric XML Using XML RAW
--Run this query
USE AdventureWorks2012;
GO
SELECT TOP 5 FirstName, LastName
FROM Person.Person
FOR XML RAW ('NAME'), ELEMENTS
The following is some of the output:
<NAME>
<FirstName>Syed</FirstName>
<LastName>Abbas</LastName>
</NAME>
<NAME>
<FirstName>Catherine</FirstName>
<LastName>Abel</LastName>
</NAME>
<NAME>
<FirstName>Kim</FirstName>
<LastName>Abercrombie</LastName>
</NAME>
<NAME>
<FirstName>Kim</FirstName>
<LastName>Abercrombie</LastName>
</NAME>
<NAME>
<FirstName>Kim</FirstName>
<LastName>Abercrombie</LastName>
</NAME>
In Listing 8-8 the FOR XML RAW clause takes NAME as an input. This defines the node name. The ELEMENTS option converts the columns from attributes to elements within the NAME node.
![]() Note It is possible to mix attribute-centric mapping with element-centric mapping using
Note It is possible to mix attribute-centric mapping with element-centric mapping using FOR XML. To do so requires using nested FOR XML queries. Nested FOR XML queries are beyond the scope of this book. Actually, using the PATH option with nested FOR XML is considered better practice than using the EXPLICIT option. You can get more information at http://msdn.microsoft.com/en-us/library/bb510436(v=SQL.110).aspx.
Keep in mind that even with the ability to use FOR XML RAW to create attribute-centric XML or element-centric XML, the mode still limits your ability to form complex XML documents. FOR XML RAW is well-suited for testing or creating simple XML documents. For more complex XML documents, you will want to work with the other available modes.
FOR XML AUTO
Another option is AUTO mode. This mode is similar to RAW (and just as easy to use) but produces a more complex XML document based on your SELECT query. AUTO creates an element for each table in the FROM clause that has a column in the SELECT clause. Each column in the SELECT clause is represented as an attribute in the XML document. Look at Listing 8-9 to see an example of FOR XML in use. Some example output follows the listing.
--Execute the query
USE AdventureWorks2012;
GO
SELECT CustomerID, LastName, FirstName, MiddleName
FROM Person.Person AS p
INNER JOIN Sales.Customer AS c ON p.BusinessEntityID = c.PersonID
FOR XML AUTO;
The following is an example of the output that you’ll get from executing the query in Listing 8-9:
<c CustomerID="29485">
<p LastName="Abel" FirstName="Catherine" MiddleName="R." />
</c>
<c CustomerID="29486">
<p LastName="Abercrombie" FirstName="Kim" />
</c>
<c CustomerID="29487">
<p LastName="Acevedo" FirstName="Humberto" />
</c>
<c CustomerID="29484">
<p LastName="Achong" FirstName="Gustavo" />
</c>
<c CustomerID="29488">
<p LastName="Ackerman" FirstName="Pilar" />
</c>
<c CustomerID="28866">
<p LastName="Adams" FirstName="Aaron" MiddleName="B" />
</c>
<c CustomerID="13323">
<p LastName="Adams" FirstName="Adam" />
</c>
<c CustomerID="21139">
<p LastName="Adams" FirstName="Alex" MiddleName="C" />
</c>
<c CustomerID="29170">
<p LastName="Adams" FirstName="Alexandra" MiddleName="J" />
</c>
<c CustomerID="19419">
<p LastName="Adams" FirstName="Allison" MiddleName="L" />
</c>
Listing 8-10 shows how AUTO mode converted the tables Customer and Person into elements. SQL Server was intelligent enough to link the corresponding columns as attributes in the respective elements. For example, CustomerID is a column in the Sales.Customer table so AUTO mode created CustomerID as an attribute in the Customer element. The AUTO mode would continue to expand the XML document for each table and column you add to the query.
Now add the ELEMENTS option like you did with RAW mode to see how it affects the XML output.
Listing 8-10. Using AUTO Mode with ELEMENTS Option
--Run the query
USE AdventureWorks2012;
GO
SELECT CustomerID, LastName, FirstName, MiddleName
FROM Person.Person AS Person
INNER JOIN Sales.Customer AS Customer ON Person.BusinessEntityID = Customer.PersonID
FOR XML AUTO, ELEMENTS;
The following is some of the query output from Listing 8-10:
<Customer>
<CustomerID>29485</CustomerID>
<Person>
<LastName>Abel</LastName>
<FirstName>Catherine</FirstName>
<MiddleName>R.</MiddleName>
</Person>
</Customer>
<Customer>
<CustomerID>29486</CustomerID>
<Person>
<LastName>Abercrombie</LastName>
<FirstName>Kim</FirstName>
</Person>
</Customer>
<Customer>
<CustomerID>29487</CustomerID>
<Person>
<LastName>Acevedo</LastName>
<FirstName>Humberto</FirstName>
</Person>
</Customer>
Just as in the example using RAW mode, the ELEMENTS option displays columns as elements for each node instead of the default attribute mapping. One difference is the exclusion of the ElementName option that you saw in the previous RAW mode (RAW(NAME)). You can leave this out because AUTO mode automatically names the nodes after the name of each table; in fact, you will receive a syntax error if you try to use the option.
FOR XML EXPLICIT
The most complicated means to convert table data into XML is by using the FOR XML EXPLICIT mode, but with complexity comes flexibility and control. The complexity lies in the rigorous requirement that you structure your SELECT clause so that the output forms a universal table.
As you can see from previous examples, XML is based on hierarchies. Listing 8-11 shows a Customer element or node and under Customer is a sub-element called Person. Person is a child element of Customer. In order to create a similar XML document using the EXPLICIT mode, you need to define this relationship in the universal table. This is done by creating two columns called Tag and Parent. Think of this as the relationship between manager and employee. A manager would have a tag ID of 1 and the employee would have a tag ID of 2. Since you are only concerned about the manager level in the hierarchy, the manager would have a parent of 0 (NULL) but the employee would have a parent of 1. Listing 8-11 shows a simple example.
Listing 8-11. Using XML FOR EXPLICIT
--Run the query
USE AdventureWorks2012;
GO
SELECT 1 AS Tag,
NULL AS Parent,
CustomerID AS [Customer!1!CustomerID],
NULL AS [Name!2!FName],
NULL AS [Name!2!LName]
FROM Sales.Customer AS C
INNER JOIN Person.Person AS P
ON P.BusinessEntityID = C.PersonID
UNION
SELECT 2 AS Tag,
1 AS Parent,
CustomerID,
FirstName,
LastName
FROM Person.Person P
INNER JOIN Sales.Customer AS C
ON P.BusinessEntityID = C.PersonID
ORDER BY [Customer!1!CustomerID], [Name!2!FName]
FOR XML EXPLICIT;
The results are as follows:
<Customer CustomerID="11000">
<Name FName="Jon" LName="Yang" />
</Customer>
<Customer CustomerID="11001">
<Name FName="Eugene" LName="Huang" />
</Customer>
<Customer CustomerID="11002">
<Name FName="Ruben" LName="Torres" />
</Customer>
<Customer CustomerID="11003">
<Name FName="Christy" LName="Zhu" />
</Customer>
<Customer CustomerID="11004">
<Name FName="Elizabeth" LName="Johnson" />
</Customer>
<Customer CustomerID="11005">
<Name FName="Julio" LName="Ruiz" />
</Customer>
By using the UNION statement you can define different Tag and Parent values in each SELECT clause. This allows you to nest the XML and create hierarchies. In this case you assigned to Customer a Tag of 1 and Parent as NULL. In the next SELECT statement you assigned Name a Tag of 2 and Parent of 1. Table 8-2 shows what the universal table looks like for CustomerID 11008 in Listing 8-11.

In addition to the Tag and Parent values, the ElementName!TagNumber!Attribute defines where in the hierarchy each column exists. The value Customer!1!CustomerID tells you the value belongs with the Customer element, the !1! tells you it is Tag 1 and CustomerID is the attribute.
![]() Note There is an optional value called Directive when creating the universal table. The format is ElementName!TagNumber!Attribute!Directive. They allow you to control how to encode values (ID, IDREF, IDREFS) and how to map string data to XML (hide, element, elementxsinil, xml, xmltext, and cdata). The details of each can be found at
Note There is an optional value called Directive when creating the universal table. The format is ElementName!TagNumber!Attribute!Directive. They allow you to control how to encode values (ID, IDREF, IDREFS) and how to map string data to XML (hide, element, elementxsinil, xml, xmltext, and cdata). The details of each can be found at http://msdn.microsoft.com/en-us/library/ms189068(v=SQL.110).aspx or in Pro T-SQL 2012 Programmer’s Guide (Apress, 2012).
As you can readily see, using the EXPLICIT mode can quickly become cumbersome. What it provides in flexibility it more than makes up in complexity. So for complex XML documents that mix and match attributes and elements, you will want to use the FOR XML PATH mode with nested XML.
FOR XML PATH
As mentioned, if you need to develop complex XML documents from table data, the best tool to use is the FOR XML PATH mode. This is primarily because PATH mode takes advantage of the XPath standard. XPath is a W3C standard for navigating XML hierarchies. XPath includes other useful tools such as XQuery and XPointer.
![]() Note W3C, or World Wide Web Consortium (
Note W3C, or World Wide Web Consortium (www.w3.org), is a group of professionals (both volunteer and paid) who help to define Internet standards. Without a central organization developing standards it would be difficult for the Internet to exist and thrive. XPath is a standard developed for navigating XML documents. This is just one if the items that makes XML such a powerful tool for sharing data between systems around the world running on differing platforms.
Listing 8-12 demonstrates a simple example of the PATH mode. This example runs a SELECT statement against the Prodution.Product table.
Listing 8-12. Simple FOR XML PATH Query
--Run the query
USE AdventureWorks2012;
GO
SELECT p.FirstName,
p.LastName,
s.Bonus,
s.SalesYTD
FROM Person.Person p
JOIN Sales.SalesPerson s
ON p.BusinessEntityID = s.BusinessEntityID
FOR XML PATH
The output from the query in Listing 8-12 will appear as follows:
<row>
<FirstName>Stephen</FirstName>
<LastName>Jiang</LastName>
<Bonus>0.0000</Bonus>
<SalesYTD>559697.5639</SalesYTD>
</row>
<row>
<FirstName>Michael</FirstName>
<LastName>Blythe</LastName>
<Bonus>4100.0000</Bonus>
<SalesYTD>3763178.1787</SalesYTD>
</row>
<row>
<FirstName>Linda</FirstName>
<LastName>Mitchell</LastName>
<Bonus>2000.0000</Bonus>
<SalesYTD>4251368.5497</SalesYTD>
</row>
<row>
<FirstName>Jillian</FirstName>
<LastName>Carson</LastName>
<Bonus>2500.0000</Bonus>
<SalesYTD>3189418.3662</SalesYTD>
</row>
Without any modification, the XML PATH mode will create a simple element-centric XML document. Listing 8-12 produces an element for each row. As always, you may want to complicate things a bit. Listing 8-13 demonstrates how you can easily mix and match element and attribute-centric XML document styles.
Listing 8-13. Defining XML Hierarchy Using PATH Mode
--Run the query
USE AdventureWorks2012;
GO
SELECT p.FirstName "@FirstName",
p.LastName "@LastName",
s.Bonus "Sales/Bonus",
s.SalesYTD "Sales/YTD"
FROM Person.Person p
JOIN Sales.SalesPerson s
ON p.BusinessEntityID = s.BusinessEntityID
FOR XML PATH
The following is some example output:
<row FirstName="Stephen" LastName="Jiang">
<Sales>
<Bonus>0.0000</Bonus>
<YTD>559697.5639</YTD>
</Sales>
</row>
<row FirstName="Michael" LastName="Blythe">
<Sales>
<Bonus>4100.0000</Bonus>
<YTD>3763178.1787</YTD>
</Sales>
</row>
<row FirstName="Linda" LastName="Mitchell">
<Sales>
<Bonus>2000.0000</Bonus>
<YTD>4251368.5497</YTD>
</Sales>
</row>
<row FirstName="Jillian" LastName="Carson">
<Sales>
<Bonus>2500.0000</Bonus>
<YTD>3189418.3662</YTD>
</Sales>
</row>
If you think the SELECT statement in Listing 8-13 looks familiar, you’re right. A similar query was used in Listing 8-5 when navigating an XML document in the OPENXML command using the WITH statement. Keep in mind when mapping columns to a XML document that any column defined with an @ sign becomes an attribute of the node and any column defined with a “/” becomes a separate element. Similar to the OPENXML example, if you add a name value to the PATH mode (FOR XML PATH (‘Product’), you can name the root node from “row” to “Product.” Listing 8-14 shows what this looks like.
Listing 8-14. Simple FOR XML PATH Query with NAME Option
--Run the query
USE AdventureWorks2012;
GO
SELECT ProductID "@ProductID",
Name "Product/ProductName",
Color "Product/Color"
FROM Production.Product
FOR XML PATH ('Product')
The query output is as follows:
<Product ProductID="1">
<Product>
<ProductName>Adjustable Race</ProductName>
</Product>
</Product>
<Product ProductID="2">
<Product>
<ProductName>Bearing Ball</ProductName>
</Product>
</Product>
<Product ProductID="3">
<Product>
<ProductName>BB Ball Bearing</ProductName>
</Product>
</Product>
<Product ProductID="4">
<Product>
<ProductName>Headset Ball Bearings</ProductName>
</Product>
</Product>
<Product ProductID="316">
<Product>
<ProductName>Blade</ProductName>
</Product>
</Product>
When choosing from the legacy XML methods, the PATH mode is the preferred means to generate complex XML documents. It allows for granular control of structuring the document but is not overly complicated as the EXPLICIT mode. Beyond the previous legacy modes Microsoft has developed even more robust methods of generating and handling XML in SQL Server.
XML Data Type
Though OPENXML and FOR XML are still available in SQL 2012, you should utilize them mostly for handling legacy code; I suggest working with the newer methods of handling XML documents. Beginning with SQL 2005, you can define a column as XML when creating a table object. Doing so specifically tells SQL Server to treat the data in the column as XML. You can also use the XML built-in data type when defining variables for stored procedures and functions. Data types are discussed in more detail in Chapter 10. Listing 8-15 creates a sample table with a column defined as a built-in XML data type.
Listing 8-15. Built-in XML Data Type
USE tempdb;
GO
CREATE TABLE ProductList (ProductInfo XML);
You’ll find XML data types scattered throughout the AdventureWorks2012 database. For example, the Person.Person table has two columns defined as XML: AdditionalContactInfo and Demographics. The AdditionalContactInfo column is NULL but is useful for working with XML inserts and updates while the Demographics column shows how the data is, in fact, stored as XML. In the past, this data would be stored as text. Keep in mind the following rules around a column with the XML data type:
- It can’t be used as a primary or foreign key.
- You can’t convert or cast the column to a
textorntext. It is recommended to usevarchar(max)ornvarchar(max).Textandntextwill be deprecated in future versions of SQL Server. - Column can’t be used in a
GROUP BYstatement. - The column size can’t be greater than 2GB.
Let’s now create a table with an XML column and populate it with some data. Type in and execute the code in Listing 8-16.
Listing 8-16. Using XML as a Data Type
USE AdventureWorks2012;
GO
--1
CREATE TABLE #CustomerList (CustomerInfo XML);
--2
DECLARE @XMLInfo XML;
--3
SET @XMLInfo = (SELECT CustomerID, LastName, FirstName, MiddleName
FROM Person.Person AS p
INNER JOIN Sales.Customer AS c ON p.BusinessEntityID = c.PersonID
FOR XML PATH);
--4
INSERT INTO #CustomerList(CustomerInfo)
VALUES(@XMLInfo);
--5
SELECT CustomerInfo FROM #CustomerList;DROP TABLE #CustomerList;
Figure 8-7 shows the results. Statement 1 creates a table with an XML column. Statement 2 declares a variable with the XML data type. Statement 3 saves the information in XML format about each customer from the Sales.Customer and Person.Person tables into a variable. The data comes from the same query that you saw in the previous section. Statement 4 inserts a row into the #CustomerList table using the variable. Query 5 returns the CustomerInfo column from the table without using the FOR XML clause. Since the table stores the data in XML format, the statement looks just like a regular SELECT statement yet returns the data as XML.

Figure 8-7. The results of using the XML data type
![]() Tip When working with large character data types like XML you no longer should use the
Tip When working with large character data types like XML you no longer should use the text or ntext data types. Both of these data types will be deprecated and replaced with varchar(max) and nvarchar(max). The XML data type can’t be converted to text.
XML Methods
XML methods provide ways to handle XML in the XML data type. They allow you to update the XML, convert the XML to rowsets, check whether the XML has nodes, and many other useful options. They provide many of the same functionalities as you saw with the legacy XML commands. Table 8-3 summarizes these methods and I’ll discuss each of them.

Query Method
Use the query() method when you need to extract elements from an XML data type. You have the capability to extract specific elements and create new XML documents. Listing 8-17 demonstrates the use of a simple query() method you will use in this chapter to build on using some of the other methods.
Listing 8-17. Using the query() Method Against XML Data
--Run query
USE AdventureWorks2012;
GO
SELECT Demographics.query('declare namespace ss = "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey";
<Store AnnualSales = "{ /ss:StoreSurvey/ss:AnnualSales }"
BankName = "{ /ss:StoreSurvey/ss:BankName }" />
') AS Result
FROM Sales.Store;
The following is the output:
<Store AnnualSales="800000" BankName="United Security" />
<Store AnnualSales="800000" BankName="International Bank" />
<Store AnnualSales="800000" BankName="Primary Bank & Reserve" />
<Store AnnualSales="800000" BankName="International Security" />
<Store AnnualSales="800000" BankName="Guardian Bank" />
Listing 8-17 brings up a concept not yet discussed: namespaces. Namespaces can be confusing when first learning XML but the concept is simple. XML uses namespaces to uniquely define element and attribute names in an XML document. The classic example is the element <table>. If the XML document is used by a furniture company, <table> would mean a piece of furniture. If the XML document is used by a company writing data modeling software, <table> would mean a database table. In this case, the furniture company and the data modeling company will use different namespaces. In order to facilitate data transfers and communication, all furniture companies may use the same namespace so that <table> always refers to the same thing.
In your query, you refer to the namespace http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey. This namespace was defined for you in the stored XML. In this case, the namespace points to a Microsoft site, but namespaces don’t have to actually point to anything and there is no validation executed against the XML data as a result of including a namespace. They do have to take the format of a URI and this can sometimes be confusing since namespaces (like the one in the query) point to an actual web site. The namespace in Listing 8-17 must be included in your query because the XML data includes it, which makes typed XML (untyped XML has no schema or namespace association).
Once you declare the required namespace, you can then refer to the XML elements using the namespace prefix. In the previous example, you use the prefix /ss to refer to each element. For example, /ss:StoreSurvey/ss:AnnualSales grabs the AnnualSales element from the XML. The braces symbol {} tell the query() method to insert a value into the output.
![]() Note XML can be typed or untyped. What this basically means is whether or not the XML document is associated with a schema. A schema helps to define both the elements and the XMLstructure. We won’t go into detail of the differences in this chapter but more information can be found at
Note XML can be typed or untyped. What this basically means is whether or not the XML document is associated with a schema. A schema helps to define both the elements and the XMLstructure. We won’t go into detail of the differences in this chapter but more information can be found at http://msdn.microsoft.com/en-us/library/ms184277(v=SQL.110).aspx.
The value() Method
The value() method uses XQuery against an XML document to return a scalar value. In the value() statement you specify the data type you want returned. Take a look at Listing 8-18 for a quick example using some of the same data you saw earlier in Listing 8-17. Listing 8-18 shows a query and Figure 8-8 shows the results.
Listing 8-18. Using the value() Method
USE AdventureWorks2012;
GO
SELECT Demographics.value('declare namespace ss =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey";
(/ss:StoreSurvey/ss:BankName)[1]', 'varchar(100)') AS Result
FROM Sales.Store

Figure 8-8. Partial results of using value() method
Listing 8-18 is similar but only pulls the BankName data from the XML data type. The value() method still declares the namespace and also uses the same XQuery syntax. The difference is the value() method pulls back the data as varchar(100) data type and not as an XML document. The other difference to note is the index [1] in the XQuery text. This is required in order to ensure the expression returns a singleton, or a single example of the value (in the event there are different values for BankName in the XML document).
The exist() Method
The exist() method works similarly to the T-SQL EXIST statement. The method will check to see whether or not a value is true or false. If the value is true, it returns a 1; if the value is false, it returns a 0. If the value is NULL, the method returns NULL. Let’s take a look at an example in Listing 8-19 and the results in Figure 8-9.
Listing 8-19. Using the exist() Method
USE AdventureWorks2012;
GO
SELECT Demographics.value('declare namespace ss =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey";
(/ss:StoreSurvey/ss:BankName)[1]', 'varchar(100)') AS LargeAnnualSales
FROM Sales.Store
WHERE Demographics.exist('declare namespace ss = "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey";
/ss:StoreSurvey/ss:AnnualSales [. = 3000000]') = 1
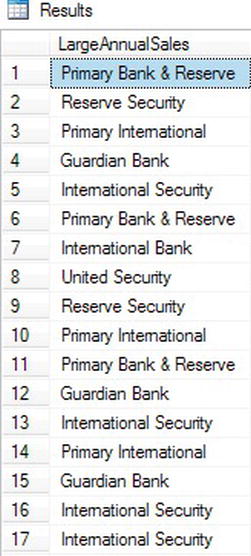
Figure 8-9. Partial output of exist() method
Listing 8-19 begins by using the same value method but then uses the exist() method as filter to only return the BankNames with AnnualSales equal to 3 million. Remember the exist() method returns either 1 if true, 0 if false, or NULL if NULL. Since you are requiring a return of all true values, you set the exist() method to equal 1.
The modify() Method
You will use the modify() method if you want to change XML data stored as an XML data type. The modify() method is similar to using update, insert, and delete commands. One primary difference is the modify() method can only be used in a SET clause. Listing 8-20 shows the different ways to use the modify() method to change data in an XML document assigned to a variable.
Listing 8-20. Inserting, Updating, and Deleting XML Using the modify() Method
DECLARE @x xml =
'<Product ProductID = "521487">
<ProductType>Paper Towels</ProductType>
<Price>15</Price>
<Vendor>Johnson Paper</Vendor>
<VendorID>47</VendorID>
<QuantityOnHand>500</QuantityOnHand>
</Product>'
SELECT @x
/* inserting data into xml with the modify method */
SET @x.modify('
insert <WarehouseID>77</WarehouseID>
into (/Product)[1]')
SELECT @x
/* updating xml with the modify method */
SET @x.modify('
replace value of (/Product/QuantityOnHand[1]/text())[1]
with "250"')
SELECT @x
/* deleting xml with the modify method */
SET @x.modify('
delete (/Product/Price)[1]')
SELECT @x
The first SELECT @x statement produces the original XML as it was declared in the variable. Listing 8-21 repeats the statement.
Listing 8-21. Declaring and Selecting XML Data
--Run the query
DECLARE @x xml =
'<Product ProductID = "521487">
<ProductType>Paper Towels</ProductType>
<Price>15</Price>
<Vendor>Johnson Paper</Vendor>
<VendorID>47</VendorID>
<QuantityOnHand>500</QuantityOnHand>
</Product>'
SELECT @x
The query output appears as follows:
<Product ProductID="521487">
<ProductType>Paper Towels</ProductType>
<Price>15</Price>
<Vendor>Johnson Paper</Vendor>
<VendorID>47</VendorID>
<QuantityOnHand>500</QuantityOnHand>
</Product>
The next two statements in Listing 8-22 uses the modify() method to insert a new element into the XML document and then select the variable. The element you insert is the WarehouseID and you insert it under the Product root.
Listing 8-22. Declaring and Inserting XML Data
--Run the query
SET @x.modify('
insert <WarehouseID>77</WarehouseID>
into (/Product)[1]')
SELECT @x
The results from the INSERT command should look as follows:
<Product ProductID="521487">
<ProductType>Paper Towels</ProductType>
<Price>15</Price>
<Vendor>Johnson Paper</Vendor>
<VendorID>47</VendorID>
<QuantityOnHand>500</QuantityOnHand>
<WarehouseID>77</WarehouseID>
</Product>
The next two statements update the XML by using the REPLACE command and then select the variable. In this example, you change the OnHandQuantity from 500 to 250. In your XQuery, you have to specify the element as a singleton as well as the path, and you also include the text() function. Listing 8-23 shows the query and the results.
Listing 8-23. Declaring and Inserting XML Data
--Run the query
SET @x.modify('
replace value of (/Product/QuantityOnHand[1]/text())[1]
with "250"')
SELECT @x
The following are the results:
<Product ProductID="521487">
<ProductType>Paper Towels</ProductType>
<Price>15</Price>
<Vendor>Johnson Paper</Vendor>
<VendorID>47</VendorID>
<QuantityOnHand>250</QuantityOnHand>
</Product>
The last step in the example shows the DELETE statement in the modify() method. The query uses the familiar DELETE statement along with the XQuery path. In this example, you completely remove the Price element from the XML document. Again, you have to specify the singleton value of [1] in your path. Listing 8-24 shows the query.
Listing 8-24. Declaring and Inserting XML Data
--Run the query
SET @x.modify('
delete (/Product/Price)[1]')
SELECT @x
And the following is the output:
<Product ProductID="521487">
<ProductType>Paper Towels</ProductType>
<Vendor>Johnson Paper</Vendor>
<VendorID>47</VendorID>
<QuantityOnHand>500</QuantityOnHand>
</Product>
Node Method
The final method we’ll discuss is the node method. This method is used when shredding XML stored as a data type into a relational format. Listing 8-25 shows a brief example that we’ll discuss in detail. Figure 8-10 shows the partial result of executing the code in the listing.
Listing 8-25. Shredding XML Using the node() Method
USE AdventureWorks2012;
GO
SELECT Name,
SalesPersonID,
AnnualSales.query('.') AS XMLResult
FROM Sales.Store
CROSS APPLY
Demographics.nodes('declare namespace ss =
"http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey";
/ss:StoreSurvey/ss:AnnualSales') AS NodeTable(AnnualSales)
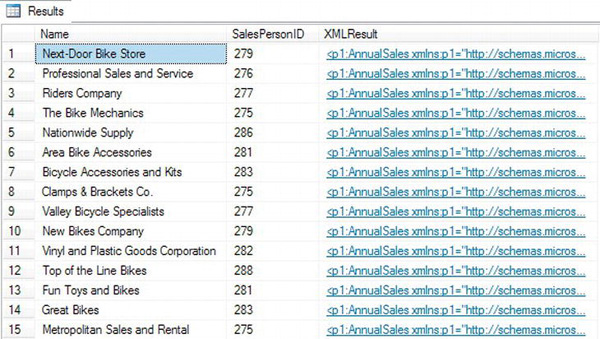
Figure 8-10. Partial result of using the node() method
The first part of the statement executes a familiar SELECT statement against the table. Note that the only way to retrieve data using the node() is to use another XML method. You can use query(), value(), exists(), and nodes() to get the result, but you can’t use the modify() method. For example, the following code shows the section from Listing 8-25 in which the columns are defined in the SELECT clause:
SELECT Name,
SalesPersonID,
AnnualSales.query('.') AS XMLResult
FROM Sales.Store
I’ve provided the column with the aliases of AnnualSales and XMLResult. The XMLResult alias will be used for the column name while the AnnualSales alias will be used as the name for the table created by the node() method.
The second section of the statement begins with the CROSS APPLY command and then the actual node() method statement. The CROSS APPLY command (shown next) allows for the nodes() table to be input for the query() method and then have results combined into a single table.
CROSS APPLY
Demographics.nodes('
declare namespace ss = "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey";
/ss:StoreSurvey/ss:AnnualSales') AS NodeTable(AnnualSales)
The actual node() method format should look familiar by now. You again declare your namespace and access the elements using the XQuery path. When using the node() method, you need to alias the virtual table (in this case NodeTable) and reference the virtual column name in the table, AnnualSales.
EXERCISES
Summary
This chapter only scratches the surface of SQL Server’s capabilities in handling XML data. The XML data and its associated methods allow much greater flexibility and control than the legacy OPENXML and FOR XML commands. I strongly suggest using the new methods of value(), modify(), exist(), and nodes() over the legacy commands especially when implementing the XML data type.