

54 | Big Data Simplied
will then look up in its internal table of contents to see where the first block (‘Block 1’) of
‘File1’ is stored. In this case, it happens to be DataNode 1.
The NameNode then forwards this request to the DataNode 1 to read the actual contents from
Block 1, and it is this content that is returned back to the client (Figure 3.6).
For example, three files are in HDFS with the size of a.txt (256 MB), b.txt (289 MB) and c.txt
(370 MB). Thus, HDFS will allocate a total of 8 blocks (default size of a block 128 MB) for these
three files. Here, a.txt will consume 2 blocks, b.txt and c.txt will absorb 3 blocks, respectively.
3.4.3 Fault Tolerance with Replication
Let us assume that a single le has been distributed across multiple nodes in the cluster as
discussed in the last section. Remember that each of these DataNodes in the cluster is commodity
hardware, which means it is prone to failure. There are two challenges to distributed storage.
First, how to manage the failure of DataNodes? Second, how to manage failure of the NameNode?
The fault tolerance strategy, which HDFS uses, is based on a replication factor. It is already
seen that a file is broken up into huge number of blocks distributed across DataNodes in a clus-
ter. No single machine holds the entire data for a single file. Further, every block of a file that is
stored in the cluster is replicated across multiple machines. Replication factor is a configuration
property that can be set. Based on this replication factor, the blocks which belong to a certain
file are replicated or copied to other nodes. The number of copies will depend on the replication
factor has been set.
In the example given in Figure 3.7, note that Block 1 and Block 2 of a file are stored on both
DataNode 1 and DataNode 2. This is an example where the replication factor is set to 2, i.e., each
block needs to have two replicas. Once these replicas are in place, how to get the information
about which DataNodes contain the replicas of a certain block? Well, the replica locations are also
stored in the NameNode. Just like the NameNode stores the mapping of file blocks, it also has a
mapping of the replicas of these blocks.
In the example given in Figure 3.8, the NameNode would also have entries for the replicas of
Block 1 and Block 2 on DataNode 2. Now, while choosing the locations for these replicas, two
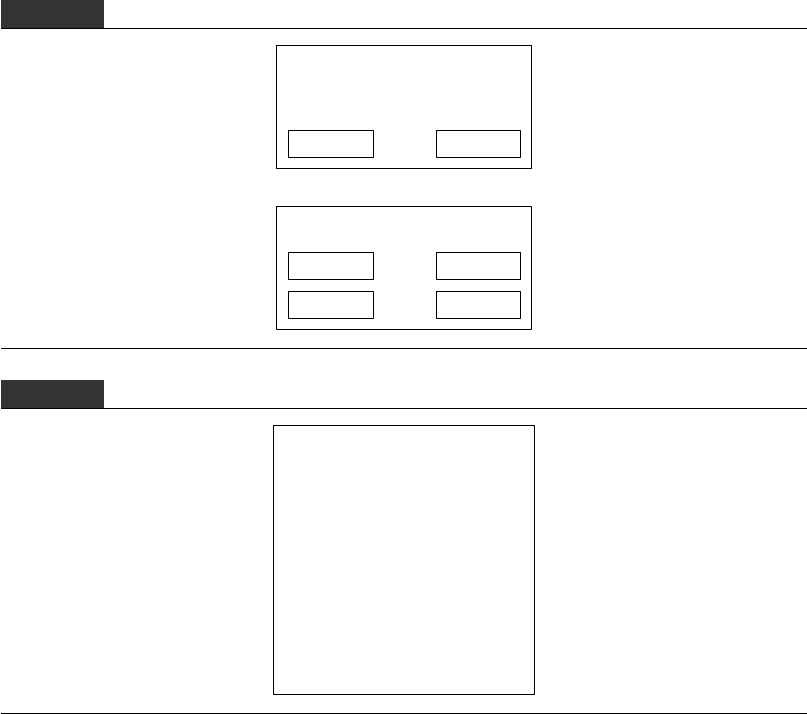
FIGURE 3.6
Step 2 of reading a file in HDFS, such as client reads actual content of
Block1 from DataNode 1
DataNode 1
Block 1 Block 2
NameNode
File 1Block 1 DataNode 1
File 1Block 2 DataNode 1
File 1Block 3 DataNode 2
File 1Block 4 DataNode 2
File 1Block 5 DataNode 3
Client reads contents of Block 1
from DataNode 1
M03 Big Data Simplified XXXX 01.indd 54 5/10/2019 9:57:31 AM
Introducing Hadoop | 55
constraints has to be balanced. On one hand, redundancy needs to be maximized. More is the
number of replicas, more is the redundancy and more is the fault tolerance of the system. On the
other hand, minimize write bandwidth needs to be minimized, which means, writes to locations
which are very far apart from each other must be avoided. It is due to the fact that it will result in
heavy consumption of the intra-cluster bandwidth.
Any cluster within a data centre typically has machines which are stored in racks. Now,
machines on a single rack are close to each other, and they have very high bandwidth connec-
tions between them. Consider a cluster which has machines on three different racks as shown in
Figure 3.9. Nodes on different racks are far away from each other than nodes on the same rack.
Nodes on the same rack are also interconnected. Note that the bandwidth available for write and
read operations between nodes across different racks will be lower than the intra-rack bandwidth.
Now, here is a need for trade-off. To maximize the redundancy of data and increase fault tol-
erance, replication should be carried out across machines on different racks. Replicas should be
stored far away from each other on different nodes where each node is on a different rack. If there
FIGURE 3.7 Replication of blocks
DataNode 1
DataNode 2
Block 1 Block 2
Block 3 Block 4
Block 1 Block 2
FIGURE 3.8 NameNode containing replicas
NameNode
File 1Block 1 DataNode 1
File 1Block 2 DataNode 1
File 1Block 3 DataNode 2
File 1Block 4 DataNode 2
File 1Block 5 DataNode 3
File 1Block 1 DataNode 2
File 1Block 2 DataNode 2
M03 Big Data Simplified XXXX 01.indd 55 5/10/2019 9:57:31 AM

56 | Big Data Simplied
is a catastrophic occurrence like a flood or a technical glitch or loss of power supply to certain
nodes on the cluster, then they will affect the machines on the same rack. If the replicas are on
nodes across racks as shown in Figure 3.10, then it provides better protection against disasters
and technical glitches. On the other hand, to minimize the write bandwidth such that write
operations to HDFS do not clog the interconnectivity between nodes, it is ideal to store replicas
close to each other.
Now, let us look at how a typical
‘write’ operation takes place in Hadoop. Note that the
default replication factor for Hadoop is 3, which means there will be three replicas that needs to
be created by the ‘write’ operation.
There is one node that is responsible for running the replication process as shown in the high-
lighted node of Figure 3.11. This is the NameNode. The NameNode makes all decisions regard-
ing replication of blocks. It periodically receives a Heartbeat and a Blockreport from each of the
DataNodes in the cluster. The receipt of a Heartbeat implies that the DataNode is functioning
properly. A Blockreport contains a list of all blocks on a DataNode.
The NameNode chooses the location for the first replica (as shown in Figure 3.12). Write
operations will first write to this location. The data is then forwarded on to the next replica loca-
tion. If the replica is on a node that is on a different rack, then this write operation has to pass
FIGURE 3.9 Cluster with machines stored in 3 racks
Rack 1 Rack 2 Rack 3
FIGURE 3.10
Maximize redundancy by storing replicas in different nodes in
differentracks
Rack 1 Rack 2 Rack 3
M03 Big Data Simplified XXXX 01.indd 56 5/10/2019 9:57:31 AM

Introducing Hadoop | 57
through the inter-rack connections as demonstrated in Figure 3.13, which are not of very high
bandwidth.
The data will then need to be forwarded further to the third replica. If the third replica is on
a different rack as shown in Figure 3.14, where the inter-rack bandwidth tends to be lesser than
intra-rack bandwidth, then the write operations will be expensive.
FIGURE 3.11 Node for running replication pipeline
Rack 1 Rack 2 Rack 3
FIGURE 3.12 Location of the first replica
Rack 1 Rack 2 Rack 3
FIGURE 3.13 Location of the second replica in a different node in a different rack
Rack 1 Rack 2 Rack 3
M03 Big Data Simplified XXXX 01.indd 57 5/10/2019 9:57:32 AM

58 | Big Data Simplied
Hadoop typically places the third replica on the same rack as the second, however on a differ-
ent node as shown in Figure 3.15. This provides for a compromise between maximizing redun-
dancy and minimizing write bandwidth.
When a client logs onto the cluster and wants to read files, it is directed to the physically
closest node. This can be any of the three replicas. For a write operation, the node that a client
connects to is similarly chosen. The write is then forwarded to two other replicas by the scheme
discussed above.
FIGURE 3.14 Third replica in a different node in a different rack
Rack 1 Rack 2 Rack 3
FIGURE 3.15 Third replica on the same rack but in a different node
Rack 1 Rack 2 Rack 3
Notes
• Default replication factor in Hadoop cluster is always set to 3.
• NameNode receives an acknowledgement signal periodically from each DataNode called
the Heartbeat signal.
• Hadoop configuration files are Hadoop-env.sh, core-site.xml, hdfs-site.xml, mapred-site.
xml and yarn-site.xml.
M03 Big Data Simplified XXXX 01.indd 58 5/10/2019 9:57:32 AM
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.