
The Data Vault 2.0 Methodology
Abstract
The Data Vault 2.0 Methodology introduces unique concepts to the development of data warehouses and is based on several agile data warehouse methodologies and techniques, including CMMI, Six Sigma, TQM, SDLC, and Function Point Analysis. This chapter introduces the basics of these standards and explains how the Data Vault 2.0 methodology brings them together. This chapter focuses on the project practices of the Data Vault 2.0 methodology.
Keywords
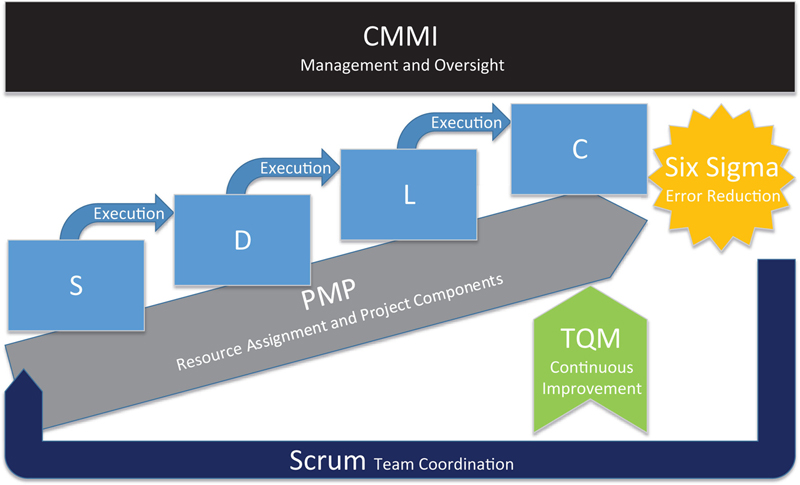
3.1. Project Planning





3.1.1. Capability Maturity Model Integration
3.1.1.1. Capability Levels
3.1.1.2. Maturity Levels
3.1.1.3. Advancing to Maturity Level 5
3.1.1.4. Integrating CMMI in the Data Vault 2.0 Methodology
Table 3.1
Mapping the Data Vault 2.0 Methodology to CMMI Maturity Levels
| Level | Maturity Level | Data Vault 2.0 Methodology |
| 1 | Initial chaos | N/A |
| 2 | Managed | Predefined Document Templates |
| Implementation Standards | ||
| Pattern Based Architecture | ||
| 3 | Defined | Defined Project Process |
| 4 | Quantitatively managed | Estimates and Actuals Captured |
| Measured Lead Times | ||
| Measured complexity | ||
| Measured defects | ||
| 5 | Optimizing | Automation tools |
| Rapid delivery | ||
| Reduced cost | ||
| Parallel teams |

3.1.2. Managing the Project
3.1.2.1. Scrum


3.1.2.2. Iterative Approach

3.1.2.3. Product and Sprint Backlog

3.1.2.4. Integrating Scrum with the Data Vault 2.0 Methodology
3.1.3. Defining the Project

3.1.3.1. Agile Requirements Gathering
3.1.4. Estimation of the Project
3.1.4.1. Function Point Analysis

3.1.4.2. Measuring with Function Points
3.1.4.3. Function Point Analysis for Data Warehousing
3.1.4.4. Boundaries in Data Warehousing

3.1.4.5. Estimating Size
Table 3.2
Mapping Data Warehouse Components to Function Point Types [58]
| DWH Component | Function Point Type |
| Staging tables | External interface file (EIF) |
| Target table | Internal logic file (ILF) |
| Fact table | Internal logic file (ILF) |
| Dimension table | Internal logic file (ILF) |
| Lookup table | Internal logic file (ILF) |
| Mapping | External input (EI) |
| Process alert | External output (EO) |
Table adapted by author from “Function Points Based Estimation Model for Data Warehouses,” by Karthikeyan Sankaran. Copyright by Enterprise Warehousing Solutions, Inc. (www.EWSolutions.com) Reprinted with permission.
3.1.4.6. Assessing ETL Complexity Factors

3.1.4.7. Applying Function Point Analysis to Data Warehousing
Table 3.3
Person Hours per Function Point
| Complexity Factor | Person Hours per Function Point |
| Easy | 0.1 |
| Moderate | 0.2 |
| Difficult | 0.7 |
Table 3.4
Function Points and Level of Effort
| Item | Complexity Factor | Estimated Function Points | Estimated Total Hours |
| Build Outs | Build Outs | Build Outs | Build Outs |
| Stage Load | Easy | 2 | 0.2 |
| Hub Load | Easy | 2 | 0.2 |
| Link Load | Easy | 3 | 0.3 |
| Thin Satellite Load | Easy | 3 | 0.3 |
| Wide Satellite Load | Moderate | 4 | 0.8 |
| Dimension Load | Difficult | 4 | 2.8 |
| Fact Load | Moderate | 4 | 0.8 |
| Report Build | Difficult | 5 | 3.5 |
| Unit Tests | Unit Tests | Unit Tests | Unit Tests |
| Stage Load | Easy | 1 | 0.1 |
| Hub Load | Easy | 1 | 0.1 |
| Link Load | Easy | 1 | 0.1 |
| Satellite Load | Easy | 2 | 0.2 |
| Dimension Load | Moderate | 2 | 0.4 |
| Fact Load | Easy | 2 | 0.2 |
| Report Build | Moderate | 4 | 0.4 |

3.1.4.8. Function Points for Enterprise Data Warehouse
3.2. Project Execution
Table 3.5
Agile Delivery Objective
| Week | Activities |
| Week 1 | Design & Develop |
| Week 2 | Manage & Test |
| Week 3 | Deployment & Acceptance |
3.2.1. Traditional Software Development Life-Cycle

3.2.1.1. Requirements Engineering
3.2.1.2. Design
3.2.1.3. Implementation and Unit Testing
3.2.1.4. Integration and System Testing

3.2.1.5. Operation and Maintenance
3.2.2. Applying Software Development Life-Cycle to the Data Vault 2.0 Methodology
Table 3.6
Agile Project Plan
| ID | WBS | Task Name | Duration | Predecessors |
| 1 | 3 | Agile Delivery of Single Requirements | 58 hrs | |
| 2 | 3.1 | Choose Report to Produce (Scope) | 0.5 hrs | |
| 3 | 3.2 | Estimate Work Effort | 0.5 hrs | 2 |
| 4 | 3.3 | Fill in Risk Assessment | 0.5 hrs | 3 |
| 5 | 3.4 | Identify Source/Stage Tables for Report | 4 hrs | 4 |
| 6 | 3.4.1 | Source to Requirements Matrix | 4 hrs | |
| 7 | 3.5 | Design ER Data Vault Model | 2 hrs | 3 |
| 8 | 3.6 | Add Attributes to ER Data Vault Model | 6 hrs | 7 |
| 9 | 3.7 | Create ETL Data Vault Loads | 4 hrs | 8 |
| 10 | 3.7.1 | Create Hub Loads | 1 hr | |
| 11 | 3.7.2 | Create Link Loads | 1 hr | |
| 12 | 3.7.3 | Create Satellite Loads | 2 hrs | |
| 13 | 3.8 | Design Data Mart Model for Report | 4 hrs | 3 |
| 14 | 3.9 | Create ETL Data Vault to Information Mart | 16 hrs | 13 |
| 15 | 3.9.1 | Build Dimension Loads | 8 hrs | |
| 16 | 3.9.2 | Build Fact Loads | 8 hrs | 15 |
| 17 | 3.10 | Build Report and Produce Output | 8 hrs | 13 |
| 18 | 3.11 | Create Source-to-Target Report for Project Documentation | 2 hr | 5;8;13 |
| 19 | 3.12 | Unit Test | 4 hrs | 17 |
| 20 | 3.13 | Record Actual Effort | 0.5 hrs | |
| 21 | 3.14 | Sign-off | 1 hr | 20 |
| 22 | 3.15 | Deploy to Test Environment | 2 hrs | |
| 23 | 3.16 | Run User Acceptance Test | 2 hrs | |
| 24 | 3.17 | Deploy to Production | 1 hr | 22;23 |


3.2.3. Parallel Teams
3.2.4. Technical Numbering
Table 3.7
Requirements to Information Mart Tables Example
| Requirements to Target Map | |
| XREF | |
| Requirement Document: | MyDoc |
| Table |
| Logical Name | Physical Name | Business Key | Passenger | Airplane Utilization | Connections |
| Passenger Information | PASSENGER | X | |||
| Connections | CONNECTION | X | |||
| Airplanes | AIRPLANE | X | X |
Table 3.8
Example Acronyms for Artifact Types
| Document Type | Acronym |
| Business Requirements | B2.2 |
| Technical Requirement | T5.1 |
| Organizational Breakdown Structure | O3.3 |
| Process Breakdown Structure | P2.4 |
| Data Breakdown Structure | D23.2 |
| Work Breakdown Structure | W9.9 |
| Change Requests | C25.5 |
3.3. Review and Improvement
3.3.1. Six Sigma

Table 3.9
Sigma Table [55]
| Sigma | Defects per Million | Yield |
| 0.0 | 933,193.0 | 6.7 % |
| 0.5 | 841,345.0 | 15.9 % |
| 1.0 | 691,462.0 | 30.9 % |
| 1.1 | 655,422.0 | 34.5 % |
| 1.2 | 617,911.0 | 38.2 % |
| 1.3 | 579,260.0 | 42.1 % |
| 1.4 | 539,828.0 | 46.0 % |
| 1.5 | 500,000.0 | 50.0 % |
| 2.0 | 308,538.0 | 69.1 % |
| 2.5 | 158,655.0 | 84.1 % |
| 3.0 | 66,807.0 | 93.32 % |
| 4.0 | 6,210.0 | 99.379 % |
| 5.0 | 233.0 | 99.977 % |
| 6.0 | 3.4 | 99.9997 % |


3.3.1.1. Applying Six Sigma to Software
3.3.1.2. Six Sigma Framework
3.3.1.3. DMAIC Improvement

3.3.1.4. Applying Six Sigma to Data Warehousing
3.3.2. Total Quality Management

3.3.2.1. Data Quality Dimensions
Table 3.10
Data Quality Dimensions [51-53]
| Dimension | Definition |
| Accessibility | Indicates the extent to which the data is available or easily and quickly retrievable by the business user |
| Appropriate Amount of Data | Provides information about the appropriate volume of data for the business user’s task |
| Believability | Indicates the extent to which the data is believed to be true and credible by the business user |
| Completeness | Defined by the extent of available data, that is, not missing data and if the data is available in sufficient breadth and depth for the task of the business user. It is defined as expected comprehensiveness. Optional data that is missing doesn’t affect the completeness of the data. |
| Concise Representation | Indicates if the data is represented in a compact format |
| Conformity | Indicates if the data is represented in the same, consistent format if available at multiple locations. It ensures that standard data definitions are met, including data type, size and format |
| Ease of Manipulation | Determines if the data is easy to manipulate and apply to different tasks |
| Free-of-Error | Indicates if the data is free of errors and therefore correct and reliable |
| Integrity | Indicates if the data is valid across data relationships |
| Interpretability | Indicates if the data is using the right language, symbols, definitions, and units |
| Objectivity | Defines the extent to which the data is unbiased, unprejudiced, and impartial |
| Relevancy | Indicates if the data is applicable and helpful for the business user’s task |
| Reputation | Provides information about the reputation of the data source or content |
| Security | Indicates if the data is properly secured in terms of properly restricted access |
| Timeliness | Provides information about the business user’s perception regarding the up-to-dateness of the data |
| Understandability | Indicates if the data is easily to comprehend by the business user |
| Uniqueness | Ensures that data is not stored redundantly |
| Value-Added | Provides information about the benefit and advantage of the data for the business user |
3.3.2.2. Total Data Quality Management

3.3.2.3. Data Warehouse Quality
