
Threads <thread>
Threads are the basic building blocks to be able to write code that runs in parallel.
Launching a New Thread
To run any function pointer, functor, or lambda expression
in a new thread of execution, pass it to the constructor of std::thread, along with any number of arguments. For example, these two lines are equivalent:
std::thread worker1(function, "arg", anotherArg);
std::thread worker2([=] { function("arg", anotherArg); });
The function with its arguments is called in a newly launched thread of execution prior to returning from the thread’s constructor
.
Both the function and its arguments must first be copied or moved (for example, for temporary objects or if std::move() is used) to memory accessible to this new thread. Therefore, to pass a reference as an argument, you first have to make it copyable: for example, by wrapping it using std::ref() / std::cref(). Of course, you can also simply use a lambda expression with capture-by-reference. Functors, reference wrappers, and lambda expressions are all discussed in detail in Chapter 2.
The thread class does not offer any facilities to retrieve the function’s result. On the contrary, its return value is ignored, and std::terminate() is called if it raises an uncaught exception (which by default terminates the process: see Chapter 8). Retrieving function results is made easier though using the constructs defined in the <future> header, as detailed later in this chapter.
Tip
To asynchronously execute a function and retrieve its result later, std::async()
(defined in <future>) is recommended over thread. It typically is both easier and more efficient (implementations of async() likely use a thread pool). Reserve the use of threads for longer-running concurrent tasks that do not necessarily return a result.
A Thread’s Lifetime
A std::thread is said to be joinable if it is associated with a thread of execution. This property is queried using joinable(). threads initialized with a function start out joinable, whereas default-constructed ones start out non-joinable. After that, thread instances can be moved and swapped as expected. Copying thread objects, however, is not possible. This ensures that at all times, at most one thread instance represents a given thread of execution. A handle to the underlying native thread representation may be obtained through the optional native_handle() member.
The two most important facts to remember about std::threads are as follows:
- A thread remains joinable even after the thread function has finished executing.
- If a thread object is still joinable when it is destructed, std::terminate() is called from its destructor.
So, to make sure the latter does not happen, always make sure to eventually call one of the following functions on each joinable thread:
- join(): Blocks until the thread function has finished executing
- detach(): Disassociates the thread object from the possibly continuing thread of execution
Note that detaching a thread is the only standard way to asynchronously execute a function in a fire-and-forget manner.
A std::thread offers no means to terminate, interrupt, or resume the underlying thread of execution. Stopping the thread function or otherwise synchronizing with it must therefore be accomplished using other means, such as mutexes or condition variables, both discussed later in this chapter.
Thread Identifiers
Each active thread has a unique thread::id, which offers all operations you typically need for thread identifiers:
- They can be outputted to string streams (for example, for logging purposes).
- They can be compared using == (for example, for testing / asserting a function is executed on some specific thread).
- They can be used as keys in both ordered and unordered associative containers: all comparison operators (<, >=, and so on) are defined, as is a specialization of std::hash().
If a std::thread object is joinable, you can call get_id() on it to obtain the identifier of the associated thread. All non-joinable threads have an identifier that equals the default-constructed thread::id. To get the identifier for the currently active thread, you can also call the global std::this_thread::get_id() function.
Utility Functions
The static std::thread::hardware_concurrency() function
returns the number of concurrent threads (or an approximation thereof) supported by the current hardware, or zero if this cannot be determined. This number may be larger than the number of physical cores: if the hardware, for instance, supports simultaneous multithreading (branded by Intel as Hyper-Threading), this will be an even multiple of (typically twice) the number of cores.
In addition to get_id(), the std::this_thread namespace contains three additional functions to manipulate the current thread of execution:
- yield() hints the implementation to reschedule, allowing other active threads to continue their execution.
- sleep_for(duration) and sleep_until(time_point) suspend the current thread for or until a given time; the timeouts are specified using types from <chrono> described in Chapter 2.
Exceptions
Unless noted here, all
functions in <thread> are declared noexcept. Several std::thread members call native system functions to manipulate native threads. If those fail, a std::
system_error
is thrown with one of the following error codes (see Chapter 8 for more information on system_errors and error codes):
- resource_unavailable_try_again if a new native thread cannot be created in the constructor
- invalid_argument if join() or detach() is called on a non-joinable thread
- no_such_process if join() or detach() is called and the thread is not valid
- resource_deadlock_would_occur if join() is called on a joinable thread from the corresponding thread of execution
Failure to allocate
storage in the constructor may also be reported by throwing an instance of std::bad_
alloc
or a class that derives from bad_alloc.
Futures <future>
The
<future> header
provides facilities to retrieve the result (value or exception) from a function that is being, will be, or has executed, typically in a different thread. Conceptually, a thread-safe communications channel is set up between a single provider and one or more return objects (T may be void or a reference type):
The shared state is an internal reference-counted object, shared between a single provider and one or more return objects. The provider asynchronously stores a result into its shared state, which is then said to be ready. The only way to acquire this result is through one of the corresponding return objects.
Return Objects
All return objects
have a synchronous get() function that blocks until the associated shared state is ready and then either returns the provided value (may be void) or rethrows the provided exception in the calling thread.
To wait until the result is ready without actually retrieving it, use one of the wait functions: wait(), wait_until(time_point), or wait_for(duration). The former waits indefinitely, and the latter two wait no longer than a timeout specified using one of the types defined in <chrono> (Chapter 2).
A return object that is associated with a shared state is said to be valid. Validity may be checked using valid(). A valid future cannot be constructed directly but must always be obtained from the shared state’s single provider.
There are two important limitations with std::futures:
- There can be only one valid future per shared state, just as there can only be one provider. That is, each provider allows the creation of only one future, and futures can never be copied, only moved (futures cannot be swapped, either).
- get() can only be called once; that is, calling get() releases the future’s reference to the shared state, making the future non-valid. Calling get() again after this throws an exception. Which exceptions are raised and when is summarized at the end of the section.
A shared_future is completely equivalent to a future, but without these two limitations: that is, they can be copied, and get() may be called more than once. A
shared_future
is obtained by calling share() on a future. This can again be done only once, because it invalidates the future. But once you have a shared_future, more can be created by copying it. Here is an overview:
Providers
The <future> library offers three different providers: std::async(), packaged_tasks, and promises. This section discusses each in turn. As example workload for asynchronous computations, we use the following greatest-common-divisor function:
Async
Calling std::async()
schedules the asynchronous execution of a given function before returning a std::future object that can be used to retrieve the result:
As with the std::thread constructor, virtually any type of function or function object can be used, and both the function and its arguments are moved or copied to their asynchronous execution context.
The result of the function call is put into the shared state as soon as the function is finished executing. If the function throws an exception, the exception is caught and put into the shared state; and if it succeeds, the return value is moved there.
The standard defines additional overrides of std::async() that take an instance of std::launch as a first argument. Supported values include at least the following enum values (implementations are allowed to define more):
- With std::launch::async, the function is executed as if in a new thread of execution, although implementations may employ, for example, a thread pool to improve performance.
- With std::launch::deferred, the function is not executed until get() is called on one of the return objects for this call of async(). The function is executed in the first thread that calls get().
These options can be combined using the | operator. For instance, the combination async | deferred encourages the implementation to exploit any available concurrency but allows to defer until get() is called if there is insufficient concurrency available. This combination is also the default policy used when no explicit launch policy is specified.
There is one important caveat when using a launch policy that includes async (that is, also with the default policy). Conceptually, the thread that executes the asynchronous function is owned by the shared state, and the destructor of the shared state joins with it. As a consequence, the following becomes a synchronous execution of f():
This is because the destruction of the temporary future returned by async() blocks until f() is finished executing (the destruction of the internal shared state joins with the thread in which f() runs).
Tip
To launch a function without waiting for its result, a.k.a. fire-and-forget, create a std::thread object and detach() it.
Packaged Tasks
A
packaged_task
is a functor that executes a given function when its operator() is called and then stores the result (that is, a value or an exception) into a shared state. This can, for instance, be used to acquire the result of a function executed by a std::thread (recall that the return value of a thread’s function is ignored and that std::terminate() is called should the function throw an exception):
A packaged_task constructed with any function, functor, or lambda expression has an associated shared state and is therefore said to be valid(); a default-constructed task is not valid(). A single future to get() the function’s result can be obtained using get_future().
Like all providers, a packaged_task cannot be copied, only moved or swapped. This is why, in the previous example, we had to move the task functor to the thread (after first obtaining its future). It is, however, the only provider that can be used more than once: reset() on a valid packaged_task releases its old shared state and associates it with a freshly created one. Resetting a non-valid task throws an exception.
There is one additional member function, make_ready_at_thread_exit(), which executes the task’s function just like operator() would, except that it does not make the shared state ready until the calling thread exits. This is done after, and used to avoid race conditions with, the destruction of all thread-local objects:
Promises
A promise is similar to a future but represents the input side of the communication channel rather than the output side. Where a future has a blocking get() function, a promise offers nonblocking set_value() and set_exception() functions.
A new promise is default constructed and cannot be copied, only moved or swapped. From each promise, a single future can be obtained using get_future(). If a second is requested, an exception is thrown. Here is an example:
There is also a second set of member functions to fill in the result: set_value_at_thread_exit() and set_exception_at_thread_exit(). These again postpone making the shared state ready until the calling thread exits, thus ensuring that this occurs after the destruction of any thread-local objects.
Exceptions
Most functions in the
<future> header
throw an exception if misused. Because the behavior is consistent across all provider and return objects, this single section provides the overview. The following discussion refers to standard exception classes as well as the concepts of error codes and categories
, all of which are explained in detail in Chapter 8.
As usual, default and move constructors, move-assignment operators, and swap() functions are declared noexcept, and of course destructors never throw exceptions either. Apart from these, only the valid() functions are noexcept.
Most other member functions
of provider and return objects throw a std::future_error in case of an error, a subclass of std::logic_error. More similar to a std::system_error, though, a future_error also has a code() member that returns an std::error_code, in this case one for which the category() equals std::future_category() (whose name() equals "future"). For future_errors, the value() of the error_code always equals one of the four values of the error code enum class
std::future_
errc
:
- broken_promise, if get() is called on a return object for a shared state that was released by its provider—because its destructor, move-assignment, or reset() function was called—without first making the shared state ready.
- future_already_retrieved, if get_future() is called twice on the same provider (without a reset() for a packaged_task).
- promise_already_satisfied, if the shared state is made ready multiple times, either by a set function or by re-executing a packaged_task.
- no_state, if any member except the nonthrowing ones listed earlier is called on a provider without an associated state. For non-valid() return objects, implementations are encouraged to do the same.
When using an async launch policy,
async()
may throw a system_error with error code resource_unavailable_try_again if it fails to create a new thread.
Mutual Exclusion <mutex>
Mutexes (short for mutual exclusion) are synchronization objects used to prevent or restrict concurrent accesses to shared memory and other resources, such as peripheral devices, network connections, and files.
Asides from a large selection of mutex and lock types, the <mutex> header also defines std::call_once(), which is used to ensure that a given function is called only once. The call_once() utility is introduced at the end of this section.
Mutexes and Locks
Basic usage of a std::mutex object m is as follows:
The
lock() function
blocks until the thread has acquired ownership of a mutex. For a basic std::mutex object, only a single thread is granted exclusive ownership at any given time. The intention is that only threads that own a given mutex are allowed to access the resources guarded by it, thus preventing data races. A thread retains this ownership until it releases it by calling unlock(). Upon unlocking, another thread that is blocked on the mutex, if any, is woken up and granted ownership. The order in which threads are woken up is undefined.
It is critical that any and all successful calls to a lock function are paired with a call to unlock(). To ensure this is done in a consistent and exception-safe manner, you should avoid calling these lock and unlock functions directly and use the Resource Acquisition Is Initialization (RAII) idiom instead. For this, the Standard Library offers several lock classes. The simplest, leanest lock is lock_guard, which simply calls lock() in its constructor and unlock() in its destructor:
Example

The result is 2,000. Removing the lock_guard almost certainly results in a value less than 2,000, unless of course your system cannot execute threads concurrently.
Mutex Types
The Standard Library offers several flavors of mutexes, each with additional capabilities compared to the basic std::mutex. More restricted mutex types can typically be implemented more efficiently.
Mutex Type | Recursive | Timeouts | Sharing | Header |
|---|---|---|---|---|
mutex
| No | No | No |
<mutex>
|
recursive_mutex
| Yes | No | No |
<mutex>
|
timed_mutex
| No | Yes | No |
<mutex>
|
recursive_timed_mutex
| Yes | Yes | No |
<mutex>
|
shared_timed_mutex
| No | Yes | Yes |
<shared_mutex>
|
shared_mutex
1
| No | No | Yes |
<shared_mutex>
|
Common Functionality
In addition to the
lock() and unlock() functions
explained earlier, all mutex types also support try_lock(), a nonblocking version of lock(). It returns true if ownership can be acquired instantly; otherwise, it returns false.2
Implementations may also offer a
native_handle() member
, returning a handle to the underlying native object.
None of the mutex types allow copying, moving, or swapping.
Recursion
Recursive
mutexes (a.k.a. reentrant mutexes) allow lock functions to be called by threads that already own the mutex. When doing so, locking immediately succeeds. Take care, though: to release ownership, unlock() has to be called once per successful invocation of a lock function. As always, it is therefore best to use RAII lock objects.
For non-recursive mutex types, the behavior of locking an already-owned mutex is undefined as per the standard, but it may very well lead to a deadlock.
Timeouts
Timed mutexes add two extra lock functions that block until a given timeout: try_lock_for(duration) and try_lock_until(time_point). As usual, the timeouts are specified using types defined in <chrono>, explained in Chapter 2. Both functions return a Boolean: true if ownership of the mutex was acquired successfully, or false if the specified timeout occurred first.
Sharing Ownership <shared_mutex>
Many types of shared resources can safely be accessed concurrently as long as they are not modified. For shared memory, for instance, multiple threads can safely read from a given location, as long as there is no thread writing to it at the same time. Restricting read access to a single thread in such scenarios is overly conservative and may harm performance.
The
<shared_mutex> header
therefore defines mutexes that support shared locking, on top of the exclusive locking scheme they have in common with all other mutex types. Such mutexes are also commonly known as readers-writers mutexes or multiple-readers/single-writers mutexes.
A thread that intends to modify / write to a resource must acquire
exclusive ownership
of the mutex. This is done using the exact same set of functions or lock objects as used for all mutex types. Threads that only want to inspect / read from a resource, however, can acquire shared ownership. The members for acquiring shared ownership are completely analogous to their counterparts for exclusive ownership, except that in their names lock is replaced with lock_shared; that is, they are named lock_shared(), try_lock_shared_for(), and so on. Shared ownership is released using unlock_shared().
No exclusive ownership is granted while one or more threads have acquired shared ownership, and vice versa. The Standard does not define the order in which ownership is granted or in which threads are unblocked in any way.
The shared locks defined by the Standard currently do not support upgrading ownership from shared to exclusive, or downgrading from exclusive to shared, without unlocking first.
Lock Types
There are three lock types provided by the standard: std::lock_guard, unique_lock, and shared_lock.
std::lock_guard
lock_guard
is a trivial, textbook RAII-style template class: by default, it locks a mutex in its constructor and unlocks it in its destructor. The only additional member is a constructor intended to be used with a mutex already owned by the calling thread. This constructor is called by passing the global std::adopt_lock constant:
std::lock_guard<std::mutex> lock(m, std::adopt_lock);
std::unique_lock
Although lock_guard is easy and optimally efficient, it is limited in functionality. To facilitate more advanced scenarios, the standard defines
unique_lock
.
The basic usage is the same:
std::unique_lock<std::mutex> lock(m);
However, unique_lock has several additional features compared to a lock_guard, including these:
- A unique_lock can be moved and swapped (but of course not copied).
- It has a release() function to disassociate it from the underlying mutex without unlocking it.
- The mutex() member returns a pointer to the underlying mutex.
What really sets unique_lock apart, though, is that it offers functions to release and (re)acquire ownership of the mutex. Specifically, it supports the exact same set of locking functions as the underlying mutex type: lock(), try_lock(), and unlock(), plus the timed locking functions for timed mutex types. The locking functions of unique_lock may be called only once, even if the underlying mutex is recursive, or an exception will be thrown. To check whether the unique_lock will unlock upon destruction, call owns_lock() (unique_lock also casts to a Boolean with this value).
In addition to the obvious constructor with a given mutex, the unique_lock class supports three alternative constructors where you pass an additional constant:
- adopt_lock: Used when the mutex is already owned by the current thread (analogous to the equivalent lock_guard constructor).
- defer_lock: Signals not to lock during construction; one of the locking functions may be used to lock the mutex later.
- try_to_lock: Tries to lock during construction, but does so without blocking should it fail. owns_lock() can be used to check whether it succeeded.
std::shared_lock <shared_mutex>
Both lock_guard and unique_lock manage exclusive ownership of mutexes. To reliably manage shared ownership, <shared_mutex> defines std::shared_lock, which is completely equivalent to unique_lock, except that it acquires / releases shared ownership. Even though they acquire shared ownership, the names of its locking and unlocking members do not contain shared. This is done to ensure that a shared_lock satisfies the requirements for other utilities such as std::lock() and std::condition_variable_any, both discussed later.
Locking Multiple Mutexes
As soon as threads need to acquire ownership of multiple mutexes at the same time, the risk of deadlocks becomes imminent. Different techniques may be employed to prevent such deadlocks: for example, locking the mutexes in all threads in the same order (error-prone), or so-called try-and-back-off schemes. The Standard Library offers templated helper functions instead to facilitate this:
std::lock(lockable1, lockable2, ..., lockableN);
This function blocks until ownership is acquired for all lockable objects passed to it. These can be mutexes (which, after locking, you should transfer to RAII locks using their adopt_lock constructors), but also unique_ or shared_locks (for example, constructed with defer_lock). Although the standard does not specify how this should be achieved, if all threads use std::lock(), there are no deadlocks.
Of course, a nonblocking std::try_lock() equivalent of std::lock() exists as well. It calls try_lock() on all objects in the order they are passed and returns the 0-based index of the first try_lock() that fails, or -1 if they all succeed. If it fails to lock an object, any objects that were locked already are unlocked again first.
Exceptions
Using a mutex
before it is fully constructed or after it has been destructed results in undefined behavior. If used properly, only the functions mentioned next may throw an exception.
For mutexes, all lock() and lock_shared() functions (not the try_ variants) may throw a
system_error
with one of these error codes (see Chapter 8):
- operation_not_permitted, if the calling thread has insufficient privileges.
- resource_deadlock_would_occur if the implementation detects that a deadlock would occur. Deadlock detection is only optional, though: never rely on this!
- device_or_resource_busy if it failed to lock because the underlying handle is already locked. For nonrecursive mutexes only of course, but again: detection is only optional.
Any locking functions with timeouts, including the try_ variants, may also throw timeout-related exceptions.
By extension, both std::lock() and the constructors and locking functions of RAII locks may throw the same exceptions as well. Any of the RAII locking functions (including the try_ variants) are guaranteed to throw a system_error with resource_deadlock_would_occur if owns_lock() == true (even if the underlying mutex is recursive), and their unlock() members will throw one with operation_not_permitted if owns_lock() == false.
If any locking function throws an exception, it is guaranteed that no mutex
was locked.
Calling a Function Once <mutex>
std::call_once()
is a thread-safe utility function to ensure other functions are called at most once. This is useful, for example, for implementing the lazy initialization idiom:
std::once_flag flag;
...
std::call_once(flag, initialise, "a string argument");
Only a single thread that calls call_once() with a given instance of std::once_flag—a default-constructible, non-copyable, non-moveable helper class—effectively executes the function passed alongside it. Any subsequent calls have no effect. If multiple threads concurrently call call_once() with the same flag, all but one is suspended until the one executing the function has finished doing so. Recursively calling call_once() with the same flag results in undefined behavior.
Any return value of the function is ignored. If running the function throws an exception, this is thrown in the calling thread, and another thread is allowed to execute with the flag again. If there are threads blocked, one of them is woken up.
Note that call_once() is typically more efficient than, and should be preferred at all times over, the error-prone, double-checked locking (anti-)pattern.
Tip
Function-local statics (a.k.a. magic statics) have exactly the same semantics as call_once() but may be implemented even more efficiently. So although call_once() can readily be used for a thread-safe implementation of the singleton design pattern (left as an exercise for you), the use of function-local statics is advised instead:
Singleton& GetInstance() {
static Singleton instance;
return instance;
}
Condition Variables <condition_variable>
A condition variable is a synchronization primitive that allows threads to wait until some user-specified condition becomes true. A condition variable always works in tandem with a mutex. This mutex
is also intended to prevent races between checking and setting the condition, which is inherently done by different threads.
Waiting for a Condition
Suppose the following variables are somehow shared between threads:
std::mutex m;
std::condition_variable cv;
bool ready = false;
Then the archetypal pattern for waiting until ready becomes true is
To wait using a condition_variable, a thread must first lock the corresponding mutex using a std::unique_lock<std::mutex>.3 As
wait() blocks
the thread, it also unlocks the mutex: this allows other threads to lock the mutex in order to satisfy the shared condition. When a waiting thread is woken up, before returning from wait(), it always first locks the mutex again using the unique_lock, making it safe to recheck the condition.
Caution
Although threads waiting on a condition variable normally remain blocked until a notification is done on that variable (discussed later), it is also possible (albeit unlikely) for them to wake up spontaneously at any time without notification. These are called spurious wakeups. This phenomenon makes it critical to always check the condition in a loop as in the example.
Alternatively, all wait functions
have an overload that takes a predicate function as an argument: any function or functor that returns a value that can be evaluated as a Boolean may be used. The loop in the example, for instance, is equivalent to
cv.wait(lock, [&]{ return ready; });
There are two sets of additional wait functions that never block longer than a given timeout:
wait_until(time_point) and wait_for(duration)
. The timeouts are, as always, expressed using types defined in the <chrono> header. The return value of wait_until() and wait_for() is as follows:
- The versions of the functions without a predicate return a value from the enum class std::cv_status: either timeout or no_timeout.
- The overloads that do take a predicate function return a Boolean: true if the predicate returns true after a notification, a spurious wakeup, or when the timeout is reached; otherwise, they return false.
Notification
Two notification functions
are provided: notify_all(), which unblocks all threads waiting on a condition variable, and notify_one(), which unblocks only a single thread. The order in which multiple waiting threads are woken up is unspecified.
Notification normally occurs because the condition has changed:
{ std::lock_guard<std::mutex> lock(m);
ready = true;
}
cv.notify_all();
Note that the notifying thread is not required to own the mutex when calling a notification function. In fact, the first thing any unblocked thread does is attempt to lock the mutex, so releasing ownership prior to notification may actually improve performance.4
There is one more notification function, but it is a nonmember function and has the following signature:
void std::notify_all_at_thread_exit(condition_variable& cv,
unique_lock<mutex> lock);
It is to be called while the mutex is already owned by the calling thread through the given unique_lock, and while no thread is waiting on the condition variable using a different mutex; otherwise, the behavior is undefined. When called, it schedules the following sequence of operations upon thread exit, after all thread-local objects have been deleted:
lock.unlock();
cv.notify_all();
Exceptions
The constructor of a condition variable may throw a std::bad_alloc if insufficient memory is available, or a std::system_error with resource_unavailable_try_again as an error code if the condition variable cannot be created due to a non-memory-related resource limitation.
Destructing a condition variable upon which a thread is still waiting results in undefined behavior.
Synchronization
Informally, for a single-threaded program, an optimizing implementation (the combination of a compiler, the memory caches, and the processor) is bound by the as-if rule. Essentially, in a well-formed program, instructions may be reordered, omitted, invented, and so on, at will, as long as the observable behavior (I/O operations and such) of the program is as if the instructions were executed as written.
In a multithreaded program, however, this does not suffice. Without proper synchronization, concurrently accessing shared resources inevitably causes data and other races, even if each individual thread adheres to the as-if rule.
Although a full, formal description of the memory model is out of the scope of this Quick Reference, this chapter provides a brief informal introduction to the synchronization constraints imposed by the different constructs, focusing on the practical implications when writing multithreaded programs. We introduce all essential synchronization principles first using mutexes. Recall the following:
First, synchronization constructs introduce constraints on the code reorderings that are allowed within a single thread of execution. Locking and unlocking a mutex, for example, injects special instructions, respectively called acquire and release fences. These instructions tell the implementation (not just the compiler, but also all hardware executing the code!) to respect these rules: no code may move up an acquire fence or down a release fence. Together, this ensures that no code is executed outside the critical section, the section between lock() and unlock().
Second, fences impose constraints between different threads of execution. This can be reasoned about as restrictions on the allowed interleavings of instructions of concurrent threads into a hypothetical single instruction sequence. Releasing ownership of a mutex in one thread, for example, is said to synchronize with acquiring it in another: essentially, in any interleaving, the former must occur before the latter. Combined with the intra-thread constraints explained earlier, this implies that the entire critical section of the former thread is guaranteed to be fully executed before the latter thread enters its critical section.
For condition variables, the
synchronization properties are implied by the operations on the corresponding mutexes.
For std::threads, the following applies:
- When launching a thread, its constructor injects a release fence, which synchronizes with the beginning of the execution of the thread function. This implies that you can write to shared memory (for example, to initialize it or to pass input) before launching a thread and then safely (without extra synchronization) access it from within the thread function.
- Conversely, the end of a thread’s function execution synchronizes with the acquire fence inside its join() function. This ensures that the joining thread can safely read all shared data written by the thread function.
Finally, for the constructs in the <future> header, making the shared state ready through a provider contains a release fence, which synchronizes with the acquire fence inside the get() of a return object of the same shared state. So not only can the thread that calls get() safely read the result (luckily), but it can also safely read any other values written by the provider. So a future<void>, for example, can be used to wait until a thread has finished asynchronously writing to shared memory. Or a future<T*> may point to an entire data structure created by the provider function.
Note
All this may be summarized as follows: the behavior of unsynchronized data races (threads concurrently accessing memory with at least one writing) is undefined. However, as long as you consistently use the synchronization constructs provided by the Standard Library, your program will generally behave exactly as expected.
Atomic Operations <atomic>
First and foremost, the <atomic> header defines two types of atomic variables, special variables whose operations are atomic or data-race free: std::atomic<T> and std::atomic_flag. In addition, it provides some low-level functions to explicitly introduce fences, as explained at the end of this section.
Atomic Variables
Variables of the std::atomic<T> type mostly behave like regular T variables—thanks to the obvious constructors and assignment and cast operators—offering a restricted set of fine-grained atomic operations with specific memory-consistency properties. More details follow shortly, but first we introduce the template specializations of atomic<T>.
Template Specializations and Typedefs
The atomic<T> template may be used at least with any trivially copyable5 type T, and specializations are defined for Booleans as well as all other integral types and pointer types T*. The latter two offer additional operations, as described later.
For the Boolean and integral specializations, convenience typedefs are defined. For std::atomic<xxx>, these mostly equal std::atomic_xxx. Specifically, this is true for xxx equal to bool, char, char16_t, char32_t, wchar_t, short, int, long, or any integral type defined in <cstdint> (see Chapter 1). For the remaining integral types, the typedef abbreviates the first words of the xxx type:
typedef
|
xxx
|
typedef
|
xxx
|
|---|---|---|---|
std::atomic_schar
std::atomic_uchar
std::atomic_ushort
std::atomic_uint
|
signed char
unsigned char
unsigned short
unsigned int
|
std::atomic_ulong
std::atomic_llong
std::atomic_ullong
|
unsigned long
long long
unsigned long long
|
Common Atomic Operations
The default constructor of an
atomic<T>
variable behaves exactly like the declaration of a regular T variable: that is, it generally does not initialize the value; only static or thread-local atomic variables are zero-initialized. A constructor to initialize with a given T value is present as well. This initialization is not atomic, though: concurrent access from another thread, even through atomic operations, is a data race. Atomic variables cannot be copied, moved, or swapped.
All atomic<T> types have both an assignment operator accepting a T value and a cast operator to convert to T, and can therefore be used as regular T variables:
Equivalent to these operators are the
store() and load() members
. The last two lines of the previous code snippet, for example, can also be written as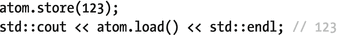
Either way, these operations are atomic or, in other words, data-race free. That is, if one thread concurrently stores a value into an atomic variable while another is loading from it, the latter sees either the old value from prior to the store or the newly stored value, but nothing in between (no half-written values). Or, in technical speak, there are no torn reads. Similarly, when two threads concurrently each store a value, one of these values is fully stored; there are never torn writes. With regular variables, such scenarios are data races and therefore result in undefined behavior, including the possibility of torn reads and writes.
All atomic variables also offer a few less obvious atomic operations,
exchange() and compare_exchanges
. These member functions behave as if implemented as follows:
T exchange(T newVal) {
T oldVal = load();
store(newVal);
return oldVal;
}
|
bool compare_exchange(T& oldVal, T newVal) {
if (load() == oldVal) {
store(newVal); return true;
} else {
oldVal = load(); return false;
}}
|
Naturally, though, both operations are again atomic. That is, they (conditionally) exchange the value in such a way that no thread may concurrently store another value during the exchange or experience a torn read.
There is no actual member named compare_exchange. Instead, there are two different variants: compare_exchange_weak() and compare_exchange_strong(). The only (subtle) difference is that the former is allowed to spuriously fail: that is, sporadically return false even when a valid exchange could be done. This “weak” variant may be slightly faster than the “strong” variant but is intended to be used only in a loop. The latter is intended to be used as a stand-alone statement.
The exchange() and compare_exchange operations are key building blocks in the implementation of lock-free data structures: thread-safe data structures that do not use blocking mutexes. This is an advanced topic, best left to experts. Still, a classical example is adding a new node in the beginning of a singly linked list:
All operations introduced in this section are atomic for any base type T. For types such as Booleans, integers, and pointers, most compilers simply generate a few special instructions that guarantee atomicity (most current CPUs support this). If so, lock_free() returns true. For other types, atomic variables mostly resort to mutex-like constructs
to accomplish atomicity. For such types, lock_free() returns false.
Take care: although atomic variables ensure that loads and stores are atomic, this does not make the operations on the underlying object atomic. In the following example, if another thread concurrently calls GetLastName() on the person object, then there is a data race with SetLastName():
Atomic Operations for Integral and Pointer Types
Certain template specializations offer additional operators that atomically update the variable. The selection is based on which atomic instructions current hardware generally supports (no multiplication, for example):
- Atomic integral variables: ++, --, +=, -=, &=, |=, ^=
- Atomic pointer variables: ++, --, +=, -=
Both pre- and postfix versions of ++ and -- are supported. For the other operators, equivalent non-operator members are again available as well: respectively, fetch_add(), fetch_sub(), fetch_and(), fetch_or(), and fetch_xor().
Synchronization
In addition to atomicity, a lesser-known property of atomic variables is that they offer the same kind of synchronization guarantees as, for example, mutexes or threads. Specifically, all operations that write to a variable (store(), exchanges, fetch_xxx(), and so on) contain release fences that synchronize with the acquire fences in operations that read from the same variable (load(), exchanges, fetch_xxx(), and so forth). This enables the following idiom, which initializes a potentially complex object or data structure before storing it in a shared atomic variable:
Any thread that loads the pointer to the new object (a Person in this example) can safely read all other memory it points to as well (the name strings for example), as long as this was completely written prior to the release fence.
All atomic operations (except the operators, of course) accept an extra, optional std::memory_order parameter (or parameters), allowing the caller to fine-tune the memory order constraints. Possible values are memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel, and memory_order_seq_cst (the default). The first option, memory_order_relaxed, for instance, denotes that the operation simply has to be atomic and that no further memory-order constraints are required. The often subtle differences between the other options fall outside the scope of this book. Unless you are an expert, our recommendation is that you stick with the default values at all times. Otherwise, you risk introducing subtle bugs.
Atomic Flags
The std::atomic_
flag
is a simple, guaranteed lock-free, atomic, Boolean-like type. It can only be default constructed and cannot be copied, moved, or swapped. It is not specified whether the default constructor initializes the flag. The only initialization that is guaranteed to work is this exact expression:
An atomic_flag offers only two other members:
- void clear(): Atomically sets the flag to false
- bool test_and_set(): Atomically sets the flag to true while returning its previous value
Both functions have synchronization properties similar to atomic_bools and again accept an optional std::memory_order parameter as well.
Nonmember Functions
For compatibility with C, <atomic> defines nonmember counterparts for all member functions of std::atomic<T> and std::atomic_flag: atomic_init(), atomic_load(), atomic_fetch_add(), atomic_flag_test_and_set(), and so on. As a C++ programmer, you normally never need any of these: simply use the classes’ member functions.
Fences
The <atomic> header also provides two functions to explicitly create acquire and/or release fences: std::atomic_thread_fence()
and std::atomic_signal_fence()
. The concept of fences is as explained earlier this chapter. Both take a std::memory_order argument to specify the desired fence type: memory_order_release for a release fence, either memory_order_acquire or memory_order_consume for an acquire fence, and memory_order_acq_rel and memory_order_seq_cst for fences that are both acquire and release fences, with the latter option denoting the fence has to be the sequentially consistent variant (the difference in their semantics falls outside the scope of this book). A fence with memory_order_relaxed has no effect.
The difference between the two functions is that the latter only restrict reorderings between a thread and a signal handler executed in the same thread. The latter only constrains the compiler but does not inject any instructions to constrain the hardware (memory caches and CPU).
Caution
Using explicit fences is discouraged: atomic variables or other synchronization constructs have more interesting synchronization properties and should generally be preferred instead.
Footnotes
2
Although normally uncommon, try_lock() is allowed to spuriously fail: that is, return false even though the mutex is not owned by any other thread. Take that into account when designing more advanced synchronization scenarios.
3
With condition_variable, this exact lock and mutex type must be used. To use other standard types, or any object with public lock() and unlock() functions, the more general std::condition_variable_any class is declared, which is otherwise analogous to condition_variable.
4
Some care must be taken: it introduces a window for race conditions between setting the condition and the notification of waiting threads. In certain cases, notifying while holding the lock may actually lead to more predictable results and avoid subtle races. When in doubt, it is best to not unlock the mutex when notifying, because the performance impact is likely to be minimal.
5
A trivially copyable type has no nontrivial copy/move constructor/assignment, no virtual functions or bases, and a trivial destructor. Essentially, these are the types that can safely be bit-wise copied (for example, using memcpy()).