
The C++ Standard Library provides a selection of different data structures called containers that you can use to store data. Containers work in tandem with algorithms, described in Chapter 4. Containers and algorithms are designed in such a way that they do not need to know about each other. The interaction between them is accomplished with iterators. All containers provide iterators, and algorithms only need iterators to be able to perform their work.
This chapter starts by explaining the concept of iterators followed by a description of all containers.
Because this book is a quick reference, it is impossible to discuss all containers in depth. The std::vector container is explained in more detail compared to the others. Once you know how to work with one container, you know how to work with others.
Iterators <iterator>
Iterators are the glue
between containers and algorithms. They provide a way to enumerate all elements of a container in a uniform way without having to know any details about the container. The following list briefly mentions the most important iterator categories
provided by the Standard, and the subsequent table explains all the operations possible on them:
- Forward (F): An input iterator that supports forward iteration
- Bidirectional (B): A forward iterator that can move forward and backward
- Random (R): A bidirectional iterator that support jumping to elements at arbitrary indexes
In the following table, T is an iterator type
, a and b are instances of T, t is an instance of the type to which T points to, and n is an integer.
Operation | Description | F | B | R |
|---|---|---|---|---|
T a, ∼T(), T b(a), b = a
| Default constructor, destructor, copy constructor, copy assignment. | ■ | ■ | ■ |
a == b, a != b
| Equality and inequality operators. | ■ | ■ | ■ |
*a, a->m, *a = t, *a++ = t
| Dereferencing. | ■ | ■ | ■ |
++a, a++, *a++
| Incrementing operators. | ■ | ■ | ■ |
--a, a--, *a--
| Decrementing operators. | □ | ■ | ■ |
a[n]
| Random access. | □ | □ | ■ |
a + n, n + a, a - n, a += n, a -= n
| Arithmetic operators. Advance an iterator forward or backward. | □ | □ | ■ |
a - b
| Calculate the distance between iterators. | □ | □ | ■ |
a < b, a > b,
a <= b, a >= b
| Inequality operators. | □ | □ | ■ |
From this, it is obvious that random iterators are very similar to C++ pointers. In fact, pointers into a regular C-style array satisfy all requirements for a random iterator and can therefore be used with the algorithms from Chapter 4 as well. Also, certain containers, sequential containers in particular, likely define their iterators as typedefs for regular pointers. For more complex data structures, though, this is not possible, and iterators are implemented as small classes.
All Standard Library compliant containers must provide an iterator and const_iterator member type. Additionally, containers that support reverse iteration must provide the reverse_iterator and const_reverse_iterator member types. For example, the reverse iterator type for a vector of integers is std::vector<int>::reverse_iterator.
Iterator Tags
An iterator tag is an empty type used to differentiate between the different iterator categories seen earlier. The Standard defines std::
category
_iterator_tag types for the following values of category: forward, bidirectional, and random_access. The type trait expression std::iterator_traits<Iter>::iterator_category evaluates to the iterator tag type of the given iterator type Iter. This can be used by generic algorithms to optimize their implementation based on the category of its iterator arguments. For example, the std::distance() method explained in an upcoming section uses the iterator tag to choose between an implementation that linearly calculates the distance between two iterators and a more efficient one that simply subtracts two iterators.
If you implement your own iterators, you should therefore specify its tag. You can do this either by adding a typedef Tag iterator_category to your implementation, where Tag is one of the iterator tags, or by specializing std::iterator_traits for your type to provide the correct tag type.
Non-Member Functions to Get Iterators
All containers support member functions that return various iterators. However, the Standard also provides non-member functions that can be used to get such iterators. In addition, these non-member functions work the same way on containers, C-style arrays, and initializer_lists. The provided non-member functions are as follows:
Non-Member Function | Description |
|---|---|
begin() / end()
| Returns an iterator to the first, or, respectively, one past the last element |
cbegin() / cend()
|
const versions of begin() and end()
|
rbegin() / rend()
| Returns a reverse iterator to the last, or, respectively, one before the first element |
crbegin() / crend()
|
const versions or rbegin() and rend()
|
Dereferencing the iterators returned by
the const versions, also called const iterators, results in const references and therefore cannot be used to modify the elements in the container or array. A
reverse
iterator allows you to traverse a container’s elements in reverse order: starting with the last element and going toward the first element. When you increment a reverse iterator, it actually moves to the previous element in the underlying container.
Here is an example of how to use such non-member functions on a C-style array:
int myArray[] = { 1,2,3,4 };
auto beginIter = std::cbegin(myArray);
auto endIter = std::cend(myArray);
for (auto iter = beginIter; iter != endIter; ++iter) {
std::cout << *iter << std::endl;
}
However, instead of this, it is recommended that you use a range-based for loop to iterate over all elements of a C-style array or Standard Library container. It is much shorter and clearer. For example:
int myArray[] = { 1,2,3,4 };
for (const auto& element : myArray) {
std::cout << element << std::endl;
}
You cannot always use the range-based for loop version, though. If you want to loop over the elements and remove some of them, for instance, then you need the iterator version.
Non-Member Operations on Iterators
The following non-member operations
exist to perform random-access operations on all types of iterators. When called on iterators that are not known to support random access (see also earlier), the implementation automatically falls back to a method that works for that iterator (for example, a linear traversal):
- std::distance(iter1, iter2): Returns the distance between two iterators.
- std::advance(iter, dist): Advances an iterator by a given distance and returns nothing. The distance can be negative if the iterator is bidirectional or random access.
- std::next(iter, dist): Equivalent to advance(iter, dist) and returns iter.
- std::prev(iter, dist): Equivalent to advance(iter, -dist) and returns iter. Only works for bidirectional and random-access iterators.
Sequential Containers
The following sections describe the five sequential containers: vector, deque, array, list, and forward_list. At the end is a reference with all available methods supported by these containers.
std::vector <vector>
A vector stores its elements contiguously in memory. It is comparable to a heap-allocated C-style array, except that it is safer and easier to use because vector automatically releases its memory and grows to accommodate new elements.
Construction
Like all Standard Library containers, vector is templated on the type of object stored in it. The following piece of code shows how to define a vector of integers:
std::vector<int> myVector;
Initial elements can be specified using a braced initializer:
std::vector<int> myVector1 = { 1,2,3,4 };
std::vector<int> myVector2{ 1,2,3,4 };
You can also construct a vector with a certain size. For example:
std::vector<int> myVector(100, 12);
This creates myVector containing 100 elements with value 12. The second parameter is optional. If you omit it, new elements are zero-initialized, which is 0 for the case of integers.
Iterators
vector supports random-access iterators
. You use the begin() or cbegin() member to get a non-const or const iterator to the first element in the vector. The end() and cend() methods are used to get an iterator to one past the last element. rbegin() and crbegin() return a reverse iterator to the last element, and rend() and crend() return a reverse iterator to one before the first element.
As always, you can also use the equivalent non-member functions explained earlier, such as std::begin(), std::cbegin(), and so on.
Accessing Elements
Elements in a vector can be accessed using operator[], which returns a reference to an element at a specific zero-based index, making it behave exactly as with C-style arrays. For example:
No bounds-checking is performed when using operator[]. If you need bounds-checking, use the at() method, which throws an std::out_of_range exception if the given index is out of bounds.
front() can be used to get a reference to the first element, and back() returns a reference to the last element.
Adding Elements
One way to add elements
to a vector is to use push_back(). For example, adding two integers to myVector can be done as follows:
std::vector<int> myVector;
myVector.push_back(11);
myVector.push_back(2);
Another option is to use the insert() method, which requires an iterator to the position before which the new element should be inserted. For example:
Just like any modifying operation, insertion generally invalidates existing iterators. So when inserting in a loop, the following idiom should be used:
This works because insert() returns a valid iterator pointing to the inserted element (more generally, to the first inserted element, discussed shortly). If you do use a loop, make sure you do not cache the end iterator, because insert() might invalidate it.
insert() can also be used to insert a range of elements anywhere in the vector or to concatenate (append) two vectors. When using insert(), you do not have to resize the vector yourself. For example:
Two additional overloads of insert() provide insertion of initializer lists or a given number of copies of a certain element. Using the same v1 as before:
Instead of constructing
a new element and then passing it to insert() or push_back(), elements can also be constructed in place using an emplacement method, such as emplace() or emplace_back(). The former, emplace(), is the counterpart of a single-element insert(), the latter of push_back(). Suppose you have a vector of Person objects. You can add a new person at the back in these two similar ways:
persons.push_back(Person("Sheldon", "Cooper"));
persons.emplace_back("Leonard", "Hofstadter");
The arguments to emplacement functions are perfectly forwarded to the element’s constructors. Emplacement is generally more efficient if it avoids the creation of a temporary object, as in the previous example. This is particularly interesting if copying is expensive or may even be the only way to add elements if they cannot be copied.
On a related note, addition and insertion members of containers generally have full support for moving elements into containers, again to avoid the creation of unnecessary copies (move semantics is explained in Chapter 2). For example:
Person person("Howard", "Wolowitz");
persons.push_back(std::move(person));
Size and Capacity
A vector has a size, returned by size(), which is the number of elements contained in the vector. Use empty() to check whether a vector is empty or not. Take care, though, not to confuse empty() with clear(): the former returns a Boolean, and the latter removes all elements.
A vector can be resized with resize(). For example:
std::vector<int> myVector;
myVector.resize(100, 12);
This sets the size of the vector to 100 elements. If new elements have to be created, they are initialized with 12. The second parameter is again optional; when omitted, new elements are zero-initialized.
In addition to a size, a vector also has a capacity, returned by capacity(). The capacity is the total number of elements it can store (including the elements already in the vector) without having to allocate more memory. If more elements are added than allowed by the capacity, the vector must perform a reallocation because it needs to store all elements contiguously in memory. Reallocation means that a new, bigger block of memory is allocated and that all current elements in the vector are transferred to the new location (they are moved if moving is supported and known not to throw; otherwise they are copied; see Chapter 2).
If you know
how many elements you are going to add, it is crucial for performance to preallocate sufficient capacity to avoid reallocation. Failure to do so will cause a significant performance hit. This can be done using reserve():
myVector.reserve(100);
Note that this does not reserve capacity for 100 extra elements; it simply ensures that the total capacity of myVector is at least 100. Reserving capacity for a non-empty vector to store 100 extra elements should be done as follows:
myVector.reserve(myVector.size() + 100);
Removing Elements
The last element
in a vector can be removed using pop_back(), and erase() is used to remove other elements. There are two overloads of erase():
- erase(iter): Removes the element to which the given iterator points
- erase(first, last): Removes the range of elements given by the two iterators, so [first, last)
When you remove elements, the size of the vector changes, but its capacity does not. If you want to reclaim unused memory, you can use shrink_to_fit(). This is just a hint, though, which may be ignored by an implementation: for example, for performance reasons.
To remove all elements, use clear(). This again does not affect capacity. A classic idiom to clear a container while guaranteeing its memory is reclaimed is to swap with an empty one:
The formerly
empty container is then destroyed, containing all elements, leaving the original one empty. This idiom is often also written more briefly as follows:
Remove-Erase Idiom
If you need to remove a number of elements from a vector, you can write your own loop to iterate over all the elements. The following example removes all elements equal to 2 from a vector:
If you do use a loop as shown here, make sure you do not cache the end iterator because erase() will invalidate it. To avoid this and other mistakes, it is always recommended that you use standard algorithms instead of hand-written loops. When you want to remove multiple elements, you can use the remove-erase idiom. This pattern first uses the std::remove() or std::remove_if() algorithm. As Chapter 4 explains, these algorithms do not actually remove elements. Instead, they move all elements that need to be kept toward the beginning, maintaining the relative order of these elements. The algorithms return an iterator to one past the last element to be kept. The next step usually is to call erase() on the container to really erase the elements starting from the iterator returned by remove() or remove_if() to the end. For example:
The call to
remove() in the second line moves all elements to keep toward the beginning of the vector. The contents of the other elements (that is, those to remove) can be different depending on your compiler.
The previous remove() and erase() calls can also be combined into one line:
vec.erase(std::remove(begin(vec), end(vec), 2), end(vec));
Caution
In the remove-erase idiom, do not forget to specify the end iterator as second parameter to erase(), as marked in bold in the previous examples. Otherwise you will only delete one element!
std::vector<bool>
vector<bool> is a specialization of vector<T> for Boolean elements. It allows C++ Standard Library implementations to store the Boolean values in a space-efficient way, but this is not a requirement. It has the same interface as vector<T>, with the addition of a
flip() method
to flip all the bits in the vector<bool>.
This specialization is similar to the std::bitset discussed later. The difference is that a bitset has a fixed size, whereas a vector<bool> can dynamically grow and shrink as needed.
Both vector<bool> and bitset are recommended only to save memory; otherwise, use a vector<std::uint_fast8_t>: this generally has superior performance when it comes to, for example, accessing, traversing, or assigning values.
Complexity
The complexity
of common operations on a vector is as follows:
- Insertion: Amortized constant O(1) at the end; otherwise linear in the distance from the insertion point to the end of the vector, O(N)
- Deletion: O(1) at the end, otherwise linear in the distance to the end of the vector O(N)
- Access: O(1)
Even though
list and forward_list, discussed later, have better theoretical insertion and deletion complexities, vector is typically faster in practice and should therefore be your default sequential container. When in doubt, always use a profiler to compare their performance for your application.
std::deque <deque>
A deque is a double-ended queue
, a container similar to a vector that supports efficient insertion and deletion both at the beginning and at the end. The Standard does not require deque elements to be stored contiguously in memory, so reallocation done by a deque may be cheaper than for a vector. Nevertheless, deque supports random access and random-access iterators.
The operations on a deque are almost the same as for a vector, with a few minor differences. A deque does not have the concept of capacity because it does not have to store its elements contiguously, so none of the methods related to capacity are available. Moreover, a deque provides a
push_front() and pop_front()
in addition to push_back() and pop_back().
Here is an example of using a deque:
Complexity
The complexity
of common operations on a deque is as follows:
- Insertion: Amortized constant O(1) at the beginning and end; otherwise linear in the distance from the insertion point to the beginning or end O(N)
- Deletion: O(1) at the beginning or end; otherwise linear in the distance to the beginning or end O(N)
- Access: O(1)
std::array <array>
An array is a container with a fixed size specified at compile time as a template argument, supporting random-access iterators
. For an array, both
size() and max_size()
return the same.
The following defines an array of three integers
:
std::array<int, 3> myArray;
These integers are uninitialized. This is different from all other containers, which zero-initialize their elements by default. This is because a std::array is designed to be as close as possible to a C array. Of course, you can also initialize elements when defining an array. The number of initialization values must equal the size of the array or less. If you specify more values, you get a compilation error. Elements for which no value is specified are zero initialized. For example:
This also implies that the following zero-initializes all elements:
There is one special method, fill(), which fills the array with a certain value. For example: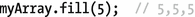
For arrays, this may be more efficient than the generic std::fill() algorithm explained in Chapter 4.
Complexity
- Insertion: Not possible
- Deletion: Not possible
- Access: O(1)
std::list and std::forward_list <list>, <forward_list>
A list stores its elements as a doubly linked list, whereas a forward_list stores them as a singly linked list. Both therefore store elements non-contiguously in memory.
A first downside is that random access therefore is not possible in constant time. Because of this, operator[] is not supported. To access a specific element, you always have to perform a linear search using iterators. list supports bidirectional iterators, so you can start at the beginning or the end; forward_list only supports forward iterators, so you always need to start at the beginning. Once you are at the correct place in the container, though, insertion and deletion at that place are efficient because they only need to modify a couple of links.
A second downside is that elements may become scattered in memory, which is bad for locality and hurts performance due to an increased number of cache misses.
Tip
Because of the aforementioned downsides, only use a list or forward_list instead of a vector if a profiler shows that it is more efficient for your use case.
The operations supported by list and forward_list are similar to those of a vector, with some minor differences. A list or forward_list does not have a capacity, so none of the capacity-related methods are supported. Both support front(), which returns a reference to the first element. A list also supports back() returning a reference to the last element.
Complexity
Both list and forward_list have similar complexities:
- Insertion: O(1) once you are at the correct position
- Deletion: O(1) once you are at the correct position
- Access: O(1) to access the first (for list and forward_list) or last (only for list) element; otherwise O(N)
List-Specific Algorithms
Due to the nature of how list and forward_list store their elements, they provide a couple of member functions that implement specific algorithms
. The following table lists the provided algorithms for list (L) and forward_list (F):
Operation | L | F | Description |
|---|---|---|---|
merge()
| ■ | ■ | Merges two sorted lists. The list that is merged in is emptied. |
remove()
| ■ | ■ | Removes elements from the list that match a given value. |
remove_if()
| ■ | ■ | Removes elements from the list that satisfy a given predicate. |
reverse()
| ■ | ■ | Reverses the contents of the list. |
sort()
| ■ | ■ | Sorts the elements. |
splice()
| ■ | □ | Moves elements from another list before a given position. |
splice_after()
| □ | ■ | Moves elements from another list after a given position. |
unique()
| ■ | ■ | Replaces consecutive duplicates with a single element. |
For all of these
algorithms except splice() and splice_after(), generic versions are available that are explained in Chapter 4. These generic versions work on all types of containers, but the list containers provide special implementations that are more efficient.
Here is an example of using some of these list algorithms:
Sequential Containers Reference
The following subsections give an overview of all the operations supported by vector (V), deque (D), array (A), list (L), and forward_list (F), divided into categories.
Iterators
Operation | V | D | A | L | F | Description |
|---|---|---|---|---|---|---|
begin()
end()
| ■ | ■ | ■ | ■ | ■ | Returns an iterator to the first or one past the last element |
cbegin()
cend()
| ■ | ■ | ■ | ■ | ■ |
const versions of begin() and end()
|
rbegin()
rend()
| ■ | ■ | ■ | ■ | □ | Returns a reverse iterator to the last element or one before the first element |
crbegin()
crend()
| ■ | ■ | ■ | ■ | □ |
const versions of rbegin() and rend()
|
before_begin()
| □ | □ | □ | □ | ■ | Returns an iterator to the element right before the element returned by begin()
|
cbefore_begin()
| □ | □ | □ | □ | ■ |
const version of before_begin()
|
Size and Capacity
Operation | V | D | A | L | F | Description |
|---|---|---|---|---|---|---|
size()
| ■ | ■ | ■ | ■ | □ | Returns the number of elements |
max_size()
| ■ | ■ | ■ | ■ | ■ | Returns the maximum number of elements that can be stored in the container |
resize()
| ■ | ■ | □ | ■ | ■ | Resizes the container |
empty()
| ■ | ■ | ■ | ■ | ■ | Returns true if the container is empty, false otherwise |
capacity()
| ■ | □ | □ | □ | □ | Returns the current capacity of the container |
reserve()
| ■ | □ | □ | □ | □ | Reserves capacity |
shrink_to_fit()
| ■ | ■ | □ | □ | □ | Hint to reduce the capacity of the container to match its size |
Access
Operation | V | D | A | L | F | Description |
|---|---|---|---|---|---|---|
operator[]
| ■ | ■ | ■ | □ | □ | Returns a reference to an element at a given index position. No bounds-checking is performed on the index. |
at()
| ■ | ■ | ■ | □ | □ | Returns a reference to an element at a given index position. If the given index position is out of bounds, an std::out_of_range exception is thrown. |
data()
| ■ | □ | ■ | □ | □ | Returns a pointer to the data of the vector or array. This is useful to pass the data to legacy C-style array APIs. In older code, you often see the equivalent &myContainer[0]. |
front()
| ■ | ■ | ■ | ■ | ■ | Returns a reference to the first element. Undefined behavior on an empty container. |
back()
| ■ | ■ | ■ | ■ | □ | Returns a reference to the last element. Undefined behavior on an empty container. |
Modifiers
Operation | V | D | A | L | F | Description |
|---|---|---|---|---|---|---|
assign()
| ■ | ■ | ■ | ■ | ■ | Replaces the contents of the container with • N copies of a given value, or • Copies of elements from a given range, or • Elements from a given initializer_list
|
clear()
| ■ | ■ | □ | ■ | ■ | Deletes all elements; size becomes zero. |
emplace()
| ■ | ■ | □ | ■ | □ | Constructs a single new element in place before the element pointed to by a given iterator. The iterator argument is followed by zero or more arguments that are just forwarded to the element’s constructor. |
emplace_back()
| ■ | ■ | □ | ■ | □ | Constructs a single new element in place at the end. |
emplace_after()
| □ | □ | □ | □ | ■ | Constructs a single new element in place after an existing element. |
emplace_front()
| □ | ■ | □ | ■ | ■ | Constructs a single new element in place at the beginning. |
erase()
| ■ | ■ | □ | ■ | □ | Erases elements. |
erase_after()
| □ | □ | □ | □ | ■ | Erases an element after an existing iterator position. |
fill()
| □ | □ | ■ | □ | □ | Fills the container with a given element. |
insert()
| ■ | ■ | □ | ■ | □ | Inserts one or more elements before the element pointed to by a given iterator. |
insert_after()
| □ | □ | □ | □ | ■ | Inserts one or more elements after the element pointed to by a given iterator. |
push_back()
pop_back()
| ■ | ■ | □ | ■ | □ | Adds an element at the end, or, respectively, removes the last element. |
push_front()
pop_front()
| □ | ■ | □ | ■ | ■ | Adds an element at the beginning, or, respectively, removes the first element. |
swap()
| ■ | ■ | ■ | ■ | ■ | Swaps the contents of two containers in constant time, except for arrays, where it needs linear time. |
Non-Member Functions
All sequential containers support the following non-member functions
:
Operation | Description |
|---|---|
==, !=, <, <=, >, >=
| Compares values in two containers (lexicographically) |
std::swap()
| Swaps the contents of two containers |
The <array> header
defines one additional non-member function, std::get<Index>(), and helper types std::tuple_size and std::tuple_element, which are equivalent to the same function and types defined for tuples and pairs explained in Chapter 2.
std::bitset <bitset>
A
bitset
is a container storing a fixed number of bits. The number of bits is specified as a template parameter. For example, the following creates a bitset with 10 bits, all initialized to 0:
std::bitset<10> myBitset;
The values for the individual bits can be initialized by passing an integer to the constructor or by passing in a string representation of the bits. For example:
std::bitset<4> myBitset("1001");
A bitset can be converted to an integer or a string with to_ulong(), to_ullong(), and to_string().
Complexity
- Insertion: Not possible
- Deletion: Not possible
- Access: O(1)
Reference
Access
Operation | Description |
|---|---|
all()
any()
none()
| Returns true if all, at least one, or, respectively, none of the bits are set. |
count()
| Returns the number of bits that are set. |
operator[]
| Accesses a bit at a given index. No bounds-checking is performed. |
test()
| Accesses a bit at a given index. Throws std::out_of_range if the given index is out of bounds. |
==, !=
| Returns true if two bitsets are equal, or, respectively, not equal. |
size()
| Returns the number of bits the bitset can hold. |
to_string()
to_ulong()
to_ullong()
| Converts a bitset to a string, unsigned long, or, respectively, unsigned long long.
|
Operations
Operation | Description |
|---|---|
flip()
| Flips the values of all the bits |
reset()
| Sets all bits or a bit at a specific position to false
|
set()
| Sets all bits to true or a bit at a specific position to a specific value |
In addition, bitset supports all bitwise operators: ∼, &, &=, ^, ^=, |, |=, <<, <<=, >>, and >>=.
Container Adaptors
Container adaptors are
built on top of other containers to provide a different interface. They prevent you from directly accessing the underlying container and force you to use their special interface. The following three sections give an overview of the available container adaptors—queue, priority_queue, and stack—followed by a section that gives an example and a reference section.
std::queue <queue>
A
queue
represents a container that has first-in first-out (FIFO)
semantics. You can compare it to a queue at a night club. A person who arrived before you will be allowed to enter before you.
A queue needs access to the front and the back, so the underlying container must support back(), front()
, push_back(), and pop_front()
. The standard list and deque support these methods and can be used as underlying containers. The default container is the deque. Here is the template definition of queue:
template<class T, class Container = std::deque<T>>
class queue;
The complexity
for a queue is as follows:
- Insertion: O(1) for list as underlying container; amortized O(1) for deque
- Deletion: O(1) for list and deque as underlying container
- Access: Not possible
std::priority_queue <queue>
A
priority_queue
is similar to a queue but stores the elements according to a priority. The element with highest priority is at the front of the queue. In the case of a night club, VIP members get higher priority and are allowed to enter before non-VIPs.
A priority_queue needs random access on the underlying container and only needs to be able to modify the container at the back, not the front. Therefore, the underlying container must support random access, front(), push_back(), and pop_back(). The vector and deque are available options, with the vector being the default underlying container. Here is the template definition of priority_queue:
template<class T,
class Container = std::vector<T>,
class Compare = std::less<typename Container::value_type>>
class priority_queue;
To determine the priority, elements are compared using a functor object of the type specified as the Compare template type parameter. By default, this is std::less, explained in Chapter 2, which, unless specialized, forwards to operator< of the element type T. A Compare instance can optionally be provided to the priority_queue constructor; if not, one is default-constructed.
The complexity for a priority_queue is as follows:
- Insertion: Amortized O(log(N)) for vector or deque as underlying container
- Deletion: O(log(N)) for vector and deque as underlying container
- Access: Not possible
std::stack <stack>
A
stack
represents a container that has last-in first-out (LIFO)
semantics. You can compare it to a stack of plates in a self-service restaurant. Plates are added at the top, pushing down other plates. A customer takes a plate from the top, which is the last added plate on the stack.
For implementing LIFO semantics, a stack requires the underlying container to support back(), push_back(), and pop_back(). The vector, deque, and list are available options for the underlying container, with deque being the default one. Here is the template definition of stack:
template<class T, class Container = std::deque<T>>
class stack;
The complexity for a stack is as follows:
- Insertion: O(1) for list as underlying container, amortized O(1) for vector and deque
- Deletion: O(1) for list, vector and deque as underlying container
- Access: Not possible
Example
The following example demonstrates how to use the container adaptors. The table after the code shows the output of the program when the container, cont, is defined as a queue, priority_queue, or, respectively, stack:
queue<Person>
|
priority_queue<Person>
|
stack<Person>
|
|---|---|---|
Doug B Phil W Stu P Alan G | Stu P1
Doug B Phil W Alan G | Alan G Stu P Phil W Doug B |
Reference
Operation | Description |
|---|---|
emplace()
|
Queue: Constructs a new element in place at the back.
Priority queue: Constructs a new element in place.
Stack: Constructs a new element in place at the top. |
empty()
| Returns true if empty, false otherwise. |
front()
back()
|
Queue: Returns a reference to the first or last element.
Priority queue: n/a
Stack: n/a |
pop()
|
Queue: Removes the first element from the queue.
Priority queue: Removes the highest-priority element.
Stack: Removes the top element. |
push()
|
Queue: Inserts a new element at the back of the queue.
Priority queue: Inserts a new element.
Stack: Inserts a new element at the top. |
size()
| Returns the number of elements. |
swap()
| Swaps the contents of two queues or stacks. |
top()
|
Queue: n/a
Priority queue: Returns a reference to the element with the highest priority.
Stack: Returns a reference to the element at the top. |
queue and
stack
support the same set of non-member functions as the sequential containers: ==, !=, <, <=, >, >=, and std::swap(). priority_queue only supports the std::swap() non-member function.
Ordered Associative Containers
std::map and std::multimap <map>
A map is a data structure that stores key-value pairs, using the pair utility class explained in Chapter 2. The elements are ordered according to the key. That is, when iterating over all elements contained in an ordered associative container, they are enumerated in an order with increasing key values
, not in the order these elements were inserted. For a map there can be no duplicate keys, whereas a multimap supports duplicate keys.
When defining a map, you need to specify both the key type and the value type. You can immediately initialize a map with a braced initializer:
std::map<Person, int> myMap{ {Person("Jenne"), 1}, {Person("Bart"), 2} };
Iterators
for a map<Key,Value> or multimap<Key,Value> are bidirectional and point to a pair<Key,Value>. For example:
operator[]
can be used to access elements in a map. If a requested element does not exist, it is default constructed, so it can also be used to insert elements:
myMap[Person("Peter")] = 3;
You can add more elements to the map with insert():
myMap.insert(std::make_pair(Person("Marc"), 4));
There are several versions of the
insert() method
:
std::pair<iterator, bool> insert(pair)
- Inserts the given key-value pair. A pair is returned with an iterator pointing to either the inserted element (a key-value pair) or the already-existing element, and a Boolean that is true if a new element was inserted or false otherwise.
iterator insert(iterHint, pair)
- Inserts the given key-value pair. An implementation may use the given hint to start searching for an insertion position. An iterator is returned that points to the inserted element or to the element that prevented the insertion.
void insert(iterFirst, iterLast)
- Inserts the key-value pairs from the range [iterFirst, iterLast).
void insert(initializerList)
- Inserts the key-value pairs from the given initializer_list.
There is also an
emplace() method
that allows you to construct a new key-value pair in place. It returns a pair<iterator, bool> similar to the first insert() method in the previous list. For example:
myMap.emplace(Person("Anna"), 4);
To avoid the creation of all temporary objects, though, you must use so-called piecewise construction, as explained in the section on pairs in Chapter 2:
myMap.emplace(std::piecewise_construct,
std::forward_as_tuple("Anna"), std::forward_as_tuple(4));
std::set and std::multiset <set>
A set is similar to a
map, but it does not store pairs, only unique keys without values (this is how the Standard defines it, and we will as well: some may prefer to think of it as values without keys though). A multiset supports duplicate keys.
There is only one template type parameter: the key type. The insert() method takes a single key instead of a pair. For example:
There are overloads of insert() similar to those for map and multimap.
An iterator for a set or multiset is bidirectional and points to the actual key, not to a pair, as is the case for map and multimap. Keys are always sorted.
Searching
If you want to find out whether a certain key is in an associative container, you can use these:
- find(): Returns an iterator to the found element (a key-value pair for maps) or the end iterator if the given key is not found.
- count(): Returns the number of keys matching the given key. For map or set, this can only be 0 or 1, whereas for multimap or multiset, this can be larger than 1.
Order of Elements
The ordered associative containers store their elements in an ordered
fashion. By default, std::less<Key> is used for this ordering, which, unless specialized, relies on operator< of the Key type. You can change the comparison functor type by specifying a Compare template type parameter. Unless a concrete Compare functor instance is passed to the container’s constructors, one is default-constructed. Here are the more complete template definitions of all ordered associative containers:
template<class Key, class Value, class Compare = std::less<Key>>
class map;
template<class Key, class Value, class Compare = std::less<Key>>
class multimap;
template<class Key, class Compare = std::less<Key>>
class set;
template<class Key, class Compare = std::less<Key>>
class multiset;
Tip
The preferred functors for use with ordered associative containers are the so-called transparent operator functors (see Chapter 2)—for example, std::less<> (short for std::less<void>)—because this improves performance for heterogeneous lookups. A classic example is lookups with string literals for std::string keys: std::less<> then avoids the creation of temporary std::string objects. A set with string keys and a transparent operator functor, for instance, is declared as follows: std::set<std::string, std::less<>> mySet;.
Complexity
The complexity
for all four ordered associative containers is the same:
- Insertion: O(log(N))
- Deletion: O(log(N))
- Access: O(log(N))
Reference
The following subsections give an overview of all the operations supported by map (M), multimap (MM), set (S), and multiset (MS), divided into categories.
Iterators
All ordered associative containers support the same set of iterator-related methods as supported by the vector container: begin(), end(), cbegin(), cend(), rbegin(), rend(), crbegin(), and crend().
Size
All associative containers support the following methods
:
Operation | Description |
|---|---|
empty()
| Returns true if the container is empty, false otherwise |
max_size()
| Returns the maximum number of elements that can be stored |
size()
| Returns the number of elements |
Access and Lookup
Operation | M | MM | S | MS | Description |
|---|---|---|---|---|---|
at()
| ■ | □ | □ | □ | Returns a reference to an element with the given key. If the given key does not exist, an std::out_of_range exception is thrown. |
operator[]
| ■ | □ | □ | □ | Returns a reference to an element with the given key. It default constructs an element with the given key if one does not exist already. |
count()
| ■ | ■ | ■ | ■ | Returns the number of elements that match a given key. |
find()
| ■ | ■ | ■ | ■ | Finds an element matching a given key. |
lower_bound()
| ■ | ■ | ■ | ■ | Returns an iterator to the first element with a key not less than a given key. |
upper_bound()
| ■ | ■ | ■ | ■ | Returns an iterator to the first element with a key greater than a given key. |
equal_range()
| ■ | ■ | ■ | ■ | Returns a range of elements that match a given key as a pair of iterators. The range is equivalent to calling lower_bound() and upper_bound(). For map or set, this range can only contain 0 or 1 elements.
|
Modifiers
All associative containers support the following methods:
Operation | Description |
|---|---|
clear()
| Clears the container. |
emplace()
| Constructs a new element in place. |
emplace_hint()
| Constructs a new element in place. An implementation may use the given hint to start searching for the insertion position. |
erase()
| Removes an element at a specific position, a range of elements, or all elements matching a given key. |
insert()
| Inserts new elements. |
swap()
| Swaps the contents of two containers. |
Observers
All ordered associative containers support the following observers
:
Operation | Description |
|---|---|
key_comp()
| Returns the key compare functor |
value_comp()
| Returns the functor used to compare key-value pairs based on their keys |
Non-Member Functions
All ordered associative containers support the same set of non-member functions
as the sequential containers: operator==, !=, <, <=, >, >=, and std::swap().
Unordered Associative Containers <unordered_map>, <unordered_set>
There are four unordered associative containers:
unordered_map
,
unordered_multimap
,
unordered_set
, and
unordered_multiset
. They are similar to the ordered associative containers (map, multimap, set, and multiset), except that they do not order the elements but instead store them in buckets in a hash map. The interfaces are similar to the corresponding ordered associative containers, except that they expose hash-specific interfaces related to the hash policy and buckets.
Hash Map
A
hash map
or hash table is an efficient data structure storing its elements in buckets.2 Conceptually, the map contains an array of pointers to buckets, which are in turn arrays or linked lists of elements. Through a mathematical formula called hashing, a hash integer number is calculated, which is then transformed into a bucket index. Two elements resulting in the same bucket index are stored inside the same bucket.
A hash map allows for very fast retrieval of elements. To retrieve an element, calculate its hash value, which results in the bucket number. If there are multiple elements in that bucket, a quick (generally linear) search is performed in that single bucket to find the right element.
Template Type Parameters
The unordered associative containers allow you to specify your own hasher and your own definition of how to decide whether two keys are equal by specifying extra template type parameters
. Here are the template definitions for all unordered associative containers:
template<class Key, class Value, class Hash = std::hash<Key>,
class KeyEqual = std::equal_to<Key>> class unordered_map;
template<class Key, class Value, class Hash = std::hash<Key>,
class KeyEqual = std::equal_to<Key>> class unordered_multimap;
template<class Key, class Hash = std::hash<Key>,
class KeyEqual = std::equal_to<Key>> class unordered_set;
template<class Key, class Hash = std::hash<Key>,
class KeyEqual = std::equal_to<Key>> class unordered_multiset;
Hash Functions
If too many keys result in the same hash (bucket index), the performance of a hash map deteriorates. In the worst case, all elements end up in the same bucket and all lookup and insertion operations become linear. Details of writing proper hash functions fall outside the scope of this book.
The Standard provides the following std::hash template (the base template is defined in <functional> but is included also in the <unordered_xxx> headers):
template<class T> struct hash;
Specializations are provided for several types, such as bool, char, int, long, double, and std::string. If you want to calculate a hash of your own object types, you can implement your own hashing functor class. However, we recommend that you implement a specialization of std::hash instead.
The following is an example of how you could implement a std::hash specialization for the Person class defined in the introduction chapter. It uses the standard std::hash specialization for string objects to calculate the hash of the first and last name. Both hashes are then combined by a XOR operation. Simply XORing values generally does not give sufficiently randomly distributed integers, but if both operands are already hashes, it can be considered acceptable:
Note
Although adding types or functions to the std namespace is generally disallowed, adding specializations is perfectly legal. Note also that the recommendation we made in Chapter 2 to specialize std::swap() in the type’s own namespace does not extend to std::hash: because std::hash is a class rather than a function (like swap()), ADL does not apply (see the discussion in Chapter 2).
Complexity
The complexity
for all four unordered associative containers is the same:
- Insertion: O(1) on average, O(N) worst case
- Deletion: O(1) on average, O(N) worst case
- Access: O(1) on average, O(N) worst case
Reference
All unordered associative containers support the same methods as the ordered associative containers, except reverse iterators, lower_bound(), and upper_bound(). The following subsections give an overview of all additional operations supported by
unordered_map (UM)
, unordered_multimap (UMM), unordered_set (US), and unordered_multiset (UMS), divided into categories.
Observers
All unordered associative containers support the following observers:
Operation | Description |
|---|---|
hash_function()
| Returns the hash function used for hashing keys |
key_eq()
| Returns the function used to perform an equality test on keys |
Bucket Interface
All unordered associative containers support the following bucket interface
:
Operation | Description |
|---|---|
begin(int)
end(int)
| Returns an iterator to the first or one past the last element in the bucket with given index |
bucket()
| Returns the index of the bucket for a given key |
bucket_count()
| Returns the number of buckets |
bucket_size()
| Returns the number of elements in the bucket with a given index |
cbegin(int)
cend(int)
|
const versions of begin(int) and end(int)
|
max_bucket_count()
| Returns the maximum number of buckets that can be created
|
Hash Policy
All unordered associative containers support the following hash policy methods
:
Operation | Description |
|---|---|
load_factor()
| Returns the average number of elements in a bucket. |
max_load_factor()
| Returns or sets the maximum load factor. If the load factor exceeds this maximum, more buckets are created. |
rehash()
| Sets the number of buckets to a specific value and rehashes all current elements. |
reserve()
| Reserves a number of buckets to accommodate a given number of elements without exceeding the maximum load factor. |
Non-Member Functions
All unordered associative containers only support operator==, operator!=, and std::swap() as non-member functions
.
Allocators
All containers except array and bitset support another template type parameter we have not shown yet—one that allows you to specify an allocator
type. This always has a default value, though, and you should normally simply ignore it. It is there in cases when you want to have more control over how memory for the container is allocated. So, in theory, you could write your own allocator and pass it to the container. This is an advanced topic that falls outside the scope of this book.
For example, the complete definition of the vector template is as follows:
template<class T, class Allocator = allocator<T>>
class vector;
Footnotes
1
The way operator< is defined for Person in the Introduction chapter causes the VIP and non-VIP persons in the priority_queue to be in reverse alphabetical order: people with an alphabetically higher name get a higher priority.
2
Technically, you could easily implement a hash map without buckets: for example, using so-called open addressing. The way the standard unordered containers are defined, though, strongly suggests the use of a separate chaining method, which is therefore what we describe here.