
Chapter 5
Identity and Access Management (IAM)
This chapter covers the following topics:
Access Control Process: Concepts discussed include the steps of the access control process.
Physical and Logical Access to Assets: Concepts discussed include access control administration, information access, systems access, device access, facilities access, and application access.
Identification and Authentication Concepts: Concepts discussed include knowledge factors, ownership factors, characteristic factors, location factors, time factors, single- versus multifactor authentication, and device authentication.
Identification and Authentication Implementation: Concepts discussed include separation of duties, least privilege/need-to-know, default to no access, directory services, single sign-on, federated identity management (IdM), session management, registration proof and registration of identity, credential management systems, Remote Authentication Dial-In User Service (RADIUS), Terminal Access Controller Access Control System Plus (TACACS+), accountability, and just-in-time (JIT).
Identity as a Service (IDaaS) Implementation: Concepts discussed include the considerations when implementing IDaaS.
Third-Party Identity Services Integration: This section details how to integrate third-party identity services in an enterprise, including on-premises, cloud, federated, and hybrid identity services.
Authorization Mechanisms: This section covers permissions, rights, and privileges; access control models; and access control policies.
Provisioning Life Cycle: This section describes the provisioning life cycle; identity and account management; user, system, and service account access review; account transfers; account revocation; role definition; and privilege escalation.
Access Control Threats: Concepts discussed include password threats, social engineering threats, DoS/DDoS, buffer overflow, mobile code, malicious software, spoofing, sniffing and eavesdropping, emanating, backdoor/trapdoor, access aggregation, and advanced persistent threat (APT).
Prevent or Mitigate Access Control Threats: This section describes ways to prevent or mitigate access control threats.
Identity and access management (IAM) is mainly concerned with controlling access to assets and managing identities. These assets include computers, equipment, networks, and applications. Security professionals must understand how to control physical and logical access to the assets and manage identification, authentication, and authorization systems. Finally, the access control threats must be addressed.
Identity and access management involves how access management works, why IAM is important, and how IAM components and devices work together in an enterprise. Access control allows only properly authenticated and authorized users, applications, devices, and systems to access enterprise resources and information. It includes facilities, support systems, information systems, network devices, and personnel. Security professionals use access controls to specify which users can access a resource, which resources can be accessed, which operations can be performed, and which actions will be monitored with or without giving an advanced warning. Once again, the CIA triad is important in providing enterprise IAM.
Foundation Topics
Access Control Process
Although many approaches to implementing access controls have been designed, all the approaches generally involve the following steps:

Identify resources.
Identify users.
Identify the relationships between the resources and users.
Identify Resources
This first step in the access control process involves identifying all resources in the IT infrastructure by deciding which entities need to be protected. When identifying these resources, you must also consider how the resources will be accessed. You can use the following questions as a starting point during resource identification:
Will this information be accessed by members of the general public?
Should access to this information be restricted to employees only?
Should access to this information be restricted to a smaller subset of employees?
Keep in mind that data, applications, services, servers, and network devices are all considered resources. Resources are any organizational asset that users can access or request access to. In access control, resources are often referred to as objects, and the requesting service or person as a subject.
Identify Users
After identifying the resources, an organization should identify the users who need access to the resources. The organization may also identify devices and services that will need access to resources. A typical security professional must manage multiple levels of users who require access to organizational resources. During this step, only identifying the users, devices, and services is important. The level of access these users will be given will be analyzed further in the next step. In access control, users, devices, and services are often referred to as subjects.
As part of this step, you must analyze and understand the users’ needs and then measure the validity of those needs against organizational needs, policies, legal issues, data sensitivity, and risk.
Remember that any access control strategy and the system deployed to enforce it should avoid complexity. The more complex an access control system is, the harder that system is to manage. In addition, anticipating security issues that could occur in more complex systems is much harder. As a security professional, you must balance the organization’s security needs and policies with the needs of the users. If a security mechanism that you implement causes too much difficulty for the user, the user might engage in practices that subvert the mechanisms that you implement. For example, if you implement a password policy that requires a very long, complex password, users might find remembering their passwords to be difficult. Users might then write their passwords on sticky notes that are attached to their monitor or keyboard.
Identify the Relationships Between Resources and Users
The final step in the access control process is to define the access control levels that need to be in place for each resource and the relationships between the resources and users, devices, and services. For example, if an organization has defined a web server as a resource, general employees might need a less restrictive level of access to the resource than the public and a more restrictive level of access to the resource than the web development staff. In addition, the web service may need access to certain resources, such as a database, to provide customers with the appropriate data after proper authentication. Access controls should be designed to support the business functionality of the resources that are being protected. Controlling the actions that can be performed for a specific resource based on a user’s, device’s, or service’s role is vital.
Physical and Logical Access to Assets
Access control is all about using physical or logical controls to control who or what has access to a network, system, or device. It also involves what type of access is given to the information, network, system, device, or facility. Access control is primarily provided using physical and logical controls.
Physical access focuses on controlling access to a network, system, or device. In most cases, physical access involves using access control to prevent users from being able to touch network components (including wiring), systems, or devices. Although locks are the most popular physical access control method to prevent access to devices in a data center, other physical controls, such as guards and biometrics, should also be considered, depending on the needs of the organization and the value of the asset being protected.
Logical controls, also known as technical controls, limit the access a user has through software or hardware components. Authentication, logs, and encryption are examples of logical controls.
When installing an access control system, security professionals should understand who needs access to the asset being protected and how those users actually access the asset. When multiple users need access to an asset, the organization should implement defense in depth using a multilayer access control system. For example, users wanting access to the building may only need to sign in with a security guard. However, to access the locked data center within the same building, users would need a smart card. Both of these examples would be physical access controls. To protect data on a single server within the building (but not in the data center), the organization would need to deploy such mechanisms as authentication, encryption, and access control lists (ACLs) as logical access controls but could also place the server in a locked server room to provide physical access control.
When deploying physical and logical access controls, security professionals must understand the access control administration methods and the different assets that must be protected and their possible access controls.
Access Control Administration
Access control administration occurs in two basic manners: centralized and decentralized.
Centralized
In centralized access control, a central department or personnel oversee the access for all organizational resources. This administration method ensures that user access is controlled in a consistent manner across the entire enterprise and applies to every single employee, including the CEO. However, centralized access control can be slow because all access requests have to be processed by the central entity. Any hack or disruption in the central entity’s security can also disrupt the entire organization.
Decentralized
In decentralized access control, personnel closest to the resources, such as department managers and data owners, oversee the access control for individual resources. This administration method ensures that those who know the data control the access rights to the data. However, decentralized access control can be hard to manage because there is no single entity responsible for configuring access rights. Decentralized access control thereby loses the uniformity and fairness of security.
Some companies may implement a hybrid approach that includes both centralized and decentralized access control. In this deployment model, centralized administration is used for basic access, but granular access to individual assets, such as data on a departmental server, is handled by the data owner as decentralized access.
Information
To fully protect information that is stored on an organization’s network, servers, or other devices, security professionals must provide both physical and logical access controls. The physical access controls, such as placing devices in a locked room, protect the devices on which the information resides. The logical access controls—such as deploying data or drive encryption, transport encryption, ACLs, and firewalls—protect the data from unauthorized access.
The value of the information being protected will likely determine the controls that an organization is willing to deploy. For example, regular correspondence on a client computer will likely not require the same controls as financial data stored on a server. For the client computer, the organization may simply deploy a local software firewall and appropriate ACL permissions on the local folders and files. For the server, the organization may need to deploy more complex measures, including drive encryption, transport encryption, ACLs, and other measures.
Systems
To fully protect the systems that the organization uses, including client and server computers, security professionals may rely on both physical and logical access controls. However, some systems, like client computers, may be deployed in such a manner that only minimal physical controls are used. If a user is granted access to a building, that user may find client computers being used in nonsecure cubicles throughout the building. For these systems, a security professional must ensure that the appropriate authentication mechanisms are deployed. If confidential information is stored on the client computers, data encryption should also be deployed. But only the organization can best determine which controls to deploy on individual client computers.
When it comes to servers, determining which access controls to deploy is usually a more complicated process. Security professionals should work with the server owner, whether it is a department head or an IT professional, to determine the value of the asset and the needed protection. Of course, most servers should be placed in a locked room that has restricted access. In many cases, this will be a data center or server room. However, servers can be deployed in regular locked offices if necessary. In addition, other controls should be deployed to ensure that the system is fully protected. The access control needs of a file server are different from those of a web server or database server. It is vital that the organization perform a thorough assessment of the data that is being processed and stored on the system before determining which access controls to deploy. If limited resources are available, security professionals must ensure that their most important systems have more access controls than other systems.
Devices
As with systems, physical access to devices is best provided by placing the devices in a secure room. Logical access to devices is provided by implementing the appropriate ACL or rule list, authentication, and encryption, as well as securing any remote interfaces that are used to manage the device. In addition, security professionals should ensure that the default accounts and passwords are changed or disabled on all devices.
For any IT professionals that need to access the device, a user account should be configured for the professional with the appropriate level of access needed. If a remote interface is used, make sure to enable encryption, such as SSL, to ensure that communication via the remote interface is not intercepted and read. Security professionals should closely monitor vendor announcements for any devices to ensure that the devices are kept up to date with the latest security patches and firmware updates.
Facilities
With facilities, the primary concern is physical access, which can be provided using locks, fencing, bollards, guards, and closed-circuit television (CCTV). Many organizations think that such measures are enough. But with today’s advanced industrial control systems and the Internet of Things (IoT), organizations must also consider any devices involved in facility security. If an organization has an alarm/security system that allows remote viewing access from the Internet, the appropriate logical controls must be in place to prevent a malicious user from accessing the system and changing its settings or from using the system to gain inside information about the facility layout and day-to-day operations. If the organization uses an industrial control system (ICS), logical controls should also be a priority. Security professionals must work with organizations to ensure that physical and logical controls are implemented appropriately to ensure that the entire facility is protected.
Applications
Applications are installed digitally on devices. Logical access involves controlling who can digitally access or install applications on a device. For organizations, these applications may require that security professionals use IAM solutions to permit or deny access to users and roles. Permission may be limited to using the application or may be as expansive as allowing the users to install applications. These applications may use enterprise IAM or an in-application mechanism. Security professionals may need to use group policies to control the ability to install the applications on Windows devices. Physical access to applications is a slightly different matter. Some applications are installed via digital media. Security professionals should ensure that the media is stored in a secured location, such as a locked filing cabinet. Physical access to an application can also be obtained by gaining physical access to a device on which the application is installed. Devices should be configured to enter sleep or standby mode after a certain amount of user inactivity. In addition, users should be trained to digitally lock their devices when they leave their desks. This would ensure that an unauthorized user is not able to access the application.
Security professionals should help establish the appropriate physical and logical controls for all applications.
Identification and Authentication Concepts
To be able to access a resource, a user, device, or service must profess an identity, provide the necessary credentials, and have the appropriate rights to perform the tasks to be completed. The first step in this process is called identification, which is the act of a user, device, or service professing an identity to an access control system. Often, this is part of the hiring process, whereby a user provides a photo ID for identity verification.
Authentication, the second part of the process, is the act of validating a user, device, or service with a unique identifier by providing the appropriate credentials. When trying to differentiate between the two, security professionals should know that identification identifies the user, device, or service and authentication verifies that the identity provided by the user, device, or service is valid. Authentication is usually implemented through a password provided at login. When a user, device, or service logs in to a system, the login process should validate the login after the user, device, or service supplies all the input data.
After a user, device, or service is authenticated, the user, device, or service must be granted the rights and permissions to resources. The process is referred to as authorization.
The most popular forms of user identification—either issued by an organization or self-generated by users—include user IDs or user accounts, account numbers, and personal identification numbers (PINs).
NIST SP 800-63
NIST Special Publication (SP) 800-63 provides a suite of technical requirements for federal agencies implementing digital identity services, including an overview of identity frameworks; using authenticators, credentials, and assertions in digital systems. In July 2017, NIST finalized the four-volume SP 800-63 entitled “Digital Identity Guidelines.” The four volumes in this SP are as follows:
SP 800-63 Digital Identity Guidelines: Provides the risk assessment methodology and an overview of general identity frameworks, using authenticators, credentials, and assertions together in a digital system, and a risk-based process of selecting assurance levels. SP 800-63 contains both normative and informative material.
SP 800-63A Enrollment and Identity Proofing: Addresses how applicants can prove their identities and become enrolled as valid subjects within an identity system. It provides requirements for processes by which applicants can both proof and enroll at one of three different levels of risk mitigation in both remote and physically present scenarios. SP 800-63A contains both normative and informative material.
SP 800-63B Authentication and Life Cycle Management: Addresses how an individual can securely authenticate to a credential service provider (CSP) to access a digital service or set of digital services. This volume also describes the process of binding an authenticator to an identity. SP 800-63B contains both normative and informative material.
SP 800-63C Federation and Assertions: Provides requirements on the use of federated identity architectures and assertions to convey the results of authentication processes and relevant identity information to an agency application. Furthermore, this volume offers privacy-enhancing techniques to share information about a valid, authenticated subject, and describes methods that allow for strong multifactor authentication (MFA) while the subject remains pseudonymous to the digital service. SP 800-63C contains both normative and informative material.
Specifically in SP 800-63B, passwords fall into the category of memorized secrets. Memorized secret and other password guidelines are given that may or may not differ greatly from those that were given in the past and we are following today:
Memorized secrets should be at least 8 characters in length if chosen by the subscriber or at least 6 characters in length if chosen randomly by the CSP or verifier.
Verifiers should require subscriber-chosen memorized secrets to be at least 8 characters in length and should be allowed to include all printing ASCII characters, the space character, and Unicode characters.
Memorized secrets that are randomly chosen by the CSP or by the verifier should be at least 6 characters in length and should be generated using an approved random bit generator.
Memorized secret verifiers should not permit the subscriber to store a “hint” that is accessible to an unauthenticated claimant. Verifiers should not prompt subscribers to use specific types of information (e.g., “What was the name of your first pet?”) when choosing memorized secrets.
When processing requests to establish and change memorized secrets, verifiers should compare the prospective secrets against a list that contains values known to be commonly used, expected, or compromised. For example, the list may include but is not limited to passwords obtained from previous breach corpuses, dictionary words, repetitive or sequential characters (e.g., “aaaaaa” or “1234abcd”), and context-specific words, such as the name of the service, the username, and derivatives thereof.
Verifiers should offer guidance to the subscriber, such as a password-strength meter, to assist the user in choosing a strong memorized secret.
Verifiers should implement a rate-limiting mechanism that effectively limits the number of failed authentication attempts that can be made on the subscriber’s account.
Verifiers should not impose other composition rules (e.g., requiring mixtures of different character types or prohibiting consecutively repeated characters) for memorized secrets. Verifiers should not require memorized secrets to be changed arbitrarily (e.g., periodically). However, verifiers should force a change if there is evidence of compromise of the authenticator.
Verifiers should permit claimants to use “paste” functionality when entering a memorized secret, thereby facilitating the use of password managers, which are widely used and in many cases increase the likelihood that users will choose stronger memorized secrets.
To assist the claimant in successfully entering a memorized secret, the verifier should offer an option to display the secret—rather than a series of dots or asterisks—until it is entered.
The verifier should use approved encryption and an authenticated protected channel when requesting memorized secrets to provide resistance to eavesdropping and man-in-the-middle attacks.
Verifiers should store memorized secrets in a form that is resistant to offline attacks. Memorized secrets should be salted and hashed using a suitable one-way key derivation function. The salt should be at least 32 bits in length and be chosen arbitrarily so as to minimize salt value collisions among stored hashes. Both the salt value and the resulting hash should be stored for each subscriber using a memorized secret authenticator.
According to NIST SP 800-63B, passwords remain a very widely used form of authentication despite widespread frustration with the use of passwords from both a usability and security standpoint. Humans, however, have only a limited ability to memorize complex, arbitrary secrets, so they often choose passwords that can be easily guessed. To address the resultant security concerns, online services have introduced rules in an effort to increase the complexity of these memorized secrets. The most notable form of these is composition rules, which require the user to choose passwords constructed using a mix of character types, such as at least one digit, uppercase letter, and symbol. However, analyses of breached password databases reveal that the benefit of such rules is not nearly as significant as initially thought, although the impact on usability and memorability is severe. A different and somewhat simpler approach, based primarily on password length, is presented in SP 800-63B.
Many attacks associated with the use of passwords are not affected by password complexity and length. Keystroke logging, phishing, and social engineering attacks are equally effective on lengthy, complex passwords as simple ones.
Password length has been found to be a primary factor in characterizing password strength. Passwords that are too short yield to brute-force attacks as well as to dictionary attacks using words and commonly chosen passwords.
The minimum password length that should be required depends to a large extent on the threat model being addressed. Online attacks where the attacker attempts to log in by guessing the password can be mitigated by limiting the rate of login attempts permitted. To prevent an attacker (or a persistent claimant with poor typing skills) from easily inflicting a denial-of-service attack on the subscriber by making many incorrect guesses, passwords need to be complex enough that rate limiting does not occur after a modest number of erroneous attempts but does occur before there is a significant chance of a successful guess.
Users should be encouraged to make their passwords as lengthy as they want, within reason. Since the size of a hashed password is independent of its length, there is no reason not to permit the use of lengthy passwords (or passphrases) if the user wishes. Extremely long passwords (perhaps megabytes in length) could conceivably require excessive processing time to hash, so it is reasonable to have some limit.
Composition rules are commonly used in an attempt to increase the difficulty of guessing user-chosen passwords. Research has shown, however, that users respond in very predictable ways to the requirements imposed by composition rules. For example, a user who might have chosen the word “password” as a password may choose “Password1” if required to include an uppercase letter and a number, or “Password1!” if a symbol is also required.
Users also express frustration when attempts to create complex passwords are rejected by online services. Many services reject passwords with spaces and various special characters. In some cases, not accepting certain special characters might be an effort to avoid attacks, like SQL injection, that use the characters as reserved words in SQL programming language. But a properly hashed password would not be sent intact to a database in any case, so such precautions are unnecessary. Users should also be able to include space characters to allow the use of phrases. Spaces themselves, however, add little to the complexity of passwords and may introduce usability issues (e.g., the undetected use of two spaces rather than one), so it may be beneficial to remove repeated spaces in typed passwords prior to verification.
Most users’ password choices can be somewhat predictable depending on their hobbies and social interactions, so attackers are likely to guess passwords that have been successful in the past. They include dictionary words and passwords from previous breaches, such as the “Password1!” discussed in the previous example. For this reason, it is recommended that passwords chosen by users be compared against a “black list” of unacceptable passwords that the organization has adopted and documented. This list should include passwords from previous breach corpuses, dictionary words, and specific words (such as the name of the service itself) that users are likely to choose. Because user choice of passwords will also be governed by a minimum length requirement, this dictionary need only include entries meeting that requirement.
Highly complex memorized secrets introduce a new potential vulnerability: they are less likely to be memorable, and it is more likely that they will be written down or stored electronically in an unsafe manner. Although these practices are not necessarily vulnerable, statistically some methods of recording such secrets will be. Preventing such a vulnerability is an additional motivation not to require excessively long or complex memorized secrets.
Another factor that determines the strength of memorized secrets is the process by which they are generated. Secrets that are randomly chosen (in most cases by the verifier and are uniformly distributed) will be more difficult to guess or brute-force attack than user-chosen secrets meeting the same length and complexity requirements.
Five Factors for Authentication
After establishing the user, device, or service identification method, an organization must decide which authentication method to use.
Authentication methods are divided into five broad categories:
Knowledge factor authentication: Something a person knows
Ownership factor authentication: Something a person has or possesses
Characteristic factor authentication: Something a person is
Location factor authentication: Somewhere a person is
Time factor authentication: The time a person is authenticating
Knowledge Factors
As briefly described in the preceding section, knowledge factor authentication is authentication that is provided based on something that a person knows. Although the most popular form of authentication used by this category is password authentication, other knowledge factors can be used, including date of birth, mother’s maiden name, key combination, or PIN.
Password Types and Management
As mentioned earlier, password authentication is the most popular authentication method implemented today. However, password types can vary from system to system. Understanding all the types of passwords that can be used is vital. Passwords and other knowledge factors are referred to as memorized secrets in NIST SP 800-63.
The types of passwords that you should be familiar with include
Standard word or simple passwords: As the name implies, these passwords consist of single words that often include a mixture of upper- and lowercase letters and numbers. The advantage of this password type is that it is easy to remember. A disadvantage of this password type is that it is easy for attackers to crack or break, resulting in a compromised account.
Combination passwords: This password type uses a mix of dictionary words, usually two unrelated words. These are also referred to as composition passwords. Like standard word passwords, they can include upper- and lowercase letters and numbers. An advantage of this password is that it is harder to break than simple passwords. A disadvantage is that it can be hard to remember.
Static passwords: This password type is the same for each login. It provides a minimum level of security because the password never changes. It is most often seen in peer-to-peer networks.
Complex passwords: This password type forces a user to include a mixture of upper- and lowercase letters, numbers, and special characters. For many organizations today, this type of password is enforced as part of the organization’s password policy. An advantage of this password type is that it is very hard to crack. A disadvantage is that it is harder to remember and can often be much harder to enter correctly than standard or combination passwords.
Passphrase passwords: This password type requires that a long phrase be used. Because of the password’s length, it is easier to remember but much harder to attack, both of which are definite advantages. Incorporating upper- and lowercase letters, numbers, and special characters in this type of password can significantly increase authentication security.
Cognitive passwords: This password type is a piece of information that can be used to verify an individual’s identity. This information is provided to the system by answering a series of questions based on the user’s life, such as favorite color, pet’s name, mother’s maiden name, and so on. An advantage to this type is that users can usually easily remember this information. The disadvantage is that someone who has intimate knowledge of the person’s life (spouse, child, sibling, and so on) might be able to provide this information as well.
One-time passwords: Also called a dynamic password, this type of password is used only once to log in to the access control system. This password type provides the highest level of security because the one-time passwords can be used just once and discarded within a certain timeframe or after they are used.
Graphical passwords: Also called CAPTCHA, which stands for Completely Automated Public Turing test to tell Computers and Humans Apart, passwords, this type of password uses graphics as part of the authentication mechanism. One popular implementation requires a user to enter a series of characters in the graphic displayed. This implementation ensures that a human is entering the password, not a robot. Another popular implementation requires users to select the appropriate graphic for their accounts from a list of graphics shown to the users. The list changes dynamically every time a user tries to log in.
Numeric passwords: This type of password includes only numbers. Keep in mind that the choices of a password are limited by the number of digits allowed. For example, if all passwords are four digits, then the maximum number of password possibilities is 10,000, from 0000 through 9999. After an attacker realizes that only numbers are used, cracking user passwords would be much easier because all the possibilities for a certain number of digits can be easily known.
Passwords are considered weaker than passphrases, one-time passwords, token devices, and login phrases. After an organization has decided which type of password to use, the organization must establish its password management policies.
Password management considerations include
Password life: How long the password will be valid. For most organizations, passwords are valid for 60 to 90 days.
Password history: How long before a password can be reused. Password policies usually remember a certain number of previously used passwords.
Authentication period: How long a user can remain logged in. If a user remains logged in for the period without activity, the user will be automatically logged out.
Password complexity: How the password will be structured. Most organizations require upper- and lowercase letters, numbers, and special characters.
Password length: How long the password must be. Most organizations require longer passwords and set their own length.
Password masking: Prevents a password from being learned through shoulder surfing by obscuring the characters entered.
As part of password management, organizations should establish a procedure for changing passwords. Most organizations implement a service that allows users to automatically reset their password before the password expires. In addition, most organizations should consider establishing a password reset policy in cases where users have forgotten their password or passwords have been compromised. A self-service password reset approach allows users to reset their own passwords without the assistance of help desk employees. An assisted password reset approach requires that users contact help desk personnel for help in changing their passwords.
Password reset policies can also be affected by other organizational policies, such as account lockout policies. Account lockout policies are security policies that organizations implement to protect against attacks that are carried out against passwords. Organizations often configure account lockout policies so that user accounts are locked after a certain number of unsuccessful login attempts. If an account is locked out, the system administrator might need to unlock or re-enable the user account. Security professionals should also consider encouraging organizations to require users to reset their passwords if their accounts have been locked or after a password has been used for a certain amount of time (often 90 days). For most organizations, all the password policies, including account lockout policies, are implemented at the enterprise level on the servers that manage the network. Account lockout policies are most often used to protect against brute-force or dictionary attacks.
Depending on which servers are used to manage the enterprise, security professionals must be aware of the security issues that affect user account and password management. Two popular server operating systems are Linux and Windows.
For Linux, passwords are stored in the /etc/passwd or /etc/shadow file. Because the /etc/passwd file is a text file that can be easily accessed, you should ensure that any Linux servers use the /etc/shadow file where the passwords in the file can be protected using a hash. The root user in Linux is a default account that is given administrative-level access to the entire server. If the root account is compromised, all passwords should be changed. Access to the root account should be limited only to system administrators, and root login should be allowed only via a local system console, not remotely.
For Windows computers that are in workgroups, the Security Accounts Manager (SAM) stores user passwords in a hashed format. However, known security issues exist with a SAM, including the ability to dump the password hashes directly from the registry. You should take all Microsoft-recommended security measures to protect this file. If you manage a Windows network, you should change the name of the default Administrator account or disable it. If this account is retained, make sure that you assign it a password. The default Administrator account might have full access to a Windows server.
Ownership Factors
Ownership factor authentication is authentication that is provided based on something that a person has. Ownership factors can include token devices, memory cards, phones, keys, fobs, and smart cards.
Synchronous and Asynchronous Token Devices
The token device (often referred to as a password generator) is a handheld device that presents the authentication server with the one-time password. If the authentication method requires a token device, the user must be in physical possession of the device to authenticate. So although the token device provides a password to the authentication server, the token device is considered an ownership authentication factor because its use requires ownership of the device.
Two basic token device authentication methods are used: synchronous or asynchronous. A synchronous token generates a unique password at fixed time intervals with the authentication server. An asynchronous token generates the password based on a challenge/response technique with the authentication server, with the token device providing the correct answer to the authentication server’s challenge.
A token device is usually implemented only in very secure environments because of the cost of deploying the token device. In addition, token-based solutions can experience problems if they include a battery because of the battery lifespan of the token device.
Memory Cards
A memory card is a swipe card that is issued to valid users. The card contains user authentication information. When the card is swiped through a card reader, the information stored on the card is compared to the information that the user enters. If the information matches, the authentication server approves the login. If it does not match, authentication is denied.
Because the card must be read by a card reader, each computer or access device must have its own card reader. In addition, the cards must be created and programmed. Both of these steps add complexity and cost to the authentication process. However, it is often worth the extra complexity and cost for the added security it provides, which is a definite benefit of this system. However, the data on the memory cards is not protected, a weakness that organizations should consider before implementing this type of system. Memory-only cards can be counterfeited.
Smart Cards
Similar to a memory card, a smart card accepts, stores, and sends data but can hold more data than a memory card. Smart cards, often known as integrated circuit cards (ICCs), contain memory like a memory card but also contain an embedded chip like bank or credit cards. Smart cards use card readers. However, the data on the smart card is used by the authentication server without user input. To protect against lost or stolen smart cards, most implementations require the user to input a secret PIN, meaning the user is actually providing both a knowledge (PIN) and ownership (smart card) authentication factor.
Two basic types of smart cards are used: contact cards and contactless cards. Contact cards require physical contact with the card reader, usually by swiping. Contactless cards, also referred to as proximity cards, simply need to be in close proximity to the reader. Hybrid cards are available that allow a card to be used in both contact and contactless systems.
For comparative purposes, security professionals should remember that smart cards have processing power due to the embedded chips. Memory cards do not have processing power. Smart card systems are much more reliable than memory card systems.
Smart cards are even more expensive to implement than memory cards. Many organizations prefer smart cards over memory cards because they are harder to counterfeit and the data on them can be protected using a variety of encryption methods.
Characteristic Factors
Characteristic factor authentication is authentication that is provided based on something that a person is. Biometric technology is the technology that allows users to be authenticated based on physiological or behavioral characteristics. Physiological characteristics include any unique physical attribute of the user, including iris, retina, and fingerprints. Behavioral characteristics measure a person’s actions in a situation, including voice patterns and data entry characteristics.
Biometric technologies are now common in some of the most popular operating systems. Examples include Windows Hello and Apple’s Touch ID and Face ID technologies. As a security professional, you need to be aware of such new technologies as they are deployed to provide added security. Educating users on these technologies should also be a priority to ensure that users adopt these technologies as they are deployed.
Physiological Characteristics
Physiological systems use a biometric scanning device to measure certain information about a physiological characteristic. You should understand the following physiological biometric systems:
Fingerprint
Finger scan
Hand geometry
Hand topography
Palm or hand scans
Facial scans
Retina scans
Iris scans
Vascular scans
A fingerprint scan usually scans the ridges of a finger for matching. A special type of fingerprint scan called minutiae matching is more microscopic in that it records the bifurcations and other detailed characteristics. Minutiae matching requires more authentication server space and more processing time than ridge fingerprint scans. Fingerprint scanning systems have a lower user acceptance rate than many systems because users are concerned with how the fingerprint information will be used and shared.
A finger scan extracts only certain features from a fingerprint. Because a limited amount of the fingerprint information is needed, finger scans require relatively less server space or processing time than any type of fingerprint scan.
A hand geometry scan usually obtains size, shape, or other layout attributes of a user’s hand but can also measure bone length or finger length. Two categories of hand geometry systems are mechanical and image-edge detective systems. Regardless of which category is used, hand geometry scanners require less server space and processing time than fingerprint or finger scans.
A hand topography scan records the peaks and valleys of the hand and its shape. This system is usually implemented in conjunction with hand geometry scans because hand topography scans are not unique enough if used alone.
A palm or hand scan combines fingerprint and hand geometry technologies. It records fingerprint information from every finger as well as hand geometry information.
A facial scan records facial characteristics, including bone structure, eye width, and forehead size. This biometric method uses eigenfeatures or eigenfaces. Neither of these methods actually captures a real picture of a face. With eigenfeatures, the distance between facial features is measured and recorded. With eigenfaces, measurements of facial components are gathered and compared to a set of standard eigenfaces. For example, a person’s face might be composed of the average face plus 21 percent from eigenface 1, 83 percent from eigenface 2, and –18 percent from eigenface 3. Many facial scan biometric devices use a combination of eigenfeatures and eigenfaces for better security.
A retina scan scans the retina’s blood vessel pattern. A retina scan is considered more intrusive than an iris scan.
An iris scan scans the colored portion of the eye, including all rifts, coronas, and furrows. Iris scans have a higher accuracy than any other biometric scan.
A vascular scan scans the pattern of veins in the user’s hand or face. Although this method can be a good choice because it is not very intrusive, physical injuries to the hand or face, depending on which the system uses, could cause false rejections.
Behavioral Characteristics
Behavioral systems use a biometric scanning device to measure a person’s actions. You should understand the following behavioral biometric systems:
Signature dynamics
Keystroke dynamics
Voice pattern or print
Signature dynamics measure stroke speed, pen pressure, and acceleration and deceleration while users write their signatures. Dynamic signature verification (DSV) analyzes signature features and specific features of the signing process.
Keystroke dynamics measure the typing pattern that a user uses when inputting a password or other predetermined phrase. In this case, even if the correct password or phrase is entered but the entry pattern on the keyboard is different, the user will be denied access. Flight time, a term associated with keystroke dynamics, is the amount of time it takes to switch between keys. Dwell time is the amount of time you hold down a key.
Voice pattern or print measures the sound pattern of a user stating a certain word. When the user attempts to authenticate, that user will be asked to repeat those words in different orders. If the pattern matches, authentication is allowed.
Biometric Considerations
When considering biometric technologies, security professionals should understand the following terms:
Enrollment time: The process of obtaining the sample that is used by the biometric system. This process requires actions that must be repeated several times.
Feature extraction: The approach to obtaining biometric information from a collected sample of a user’s physiological or behavioral characteristics.
Biometric accuracy: The most important characteristic of biometric systems. It is how correct the overall readings will be.
Biometric throughput rate: The rate at which the biometric system will be able to scan characteristics and complete the analysis to permit or deny access. The acceptable rate is 6–10 subjects per minute. A single user should be able to complete the process in 5–10 seconds.
Biometric acceptability: The likelihood that users will accept and follow the system.
False rejection rate (FRR): A measurement of valid users that will be falsely rejected by the system. This is called a Type I error.
False acceptance rate (FAR): A measurement of the percentage of invalid users that will be falsely accepted by the system. This is called a Type II error. Type II FAR errors are more dangerous than Type I FRR errors.
Crossover error rate (CER): The point at which FRR equals FAR. Expressed as a percentage, this is the most important metric. It shows the accuracy at which the system functions.
When analyzing biometric systems, security professionals often refer to a Zephyr chart that illustrates the comparative strengths and weaknesses of biometric systems. However, you should also consider how effective each biometric system is and its level of user acceptance. The more popular biometric methods are ranked here by effectiveness, with the most effective being first:
Iris scan
Retina scan
Fingerprint
Hand print
Hand geometry
Voice pattern
Keystroke pattern
Signature dynamics
The more popular biometric methods ranked by user acceptance follow, with the methods that are ranked more popular by users being first:
Voice pattern
Keystroke pattern
Signature dynamics
Hand geometry
Hand print
Fingerprint
Iris scan
Retina scan
When considering FAR, FRR, and CER, smaller values are better. FAR errors are more dangerous than FRR errors. Security professionals can use the CER for comparative analysis when helping their organization decide which system to implement. For example, voice print systems usually have higher CERs than iris scans, hand geometry, or fingerprints.
Figure 5-1 shows the biometric enrollment and authentication process.

Figure 5-1 Biometric Enrollment and Authentication Process
Location Factors
Location factor authentication provides a means of authenticating the user based on the location from which the user is authenticating. This could include the computer or device the person is using or the geographic location based on GPS coordinates. The primary appeal to this type of authentication is that it limits the user to logging in from those certain locations only. This type of authentication is particularly useful in large manufacturing environments for users who should log in to only certain terminals in the facility.
Geo-fencing is one example of the use of location factors. With geo-fencing, devices operate correctly following is a list of within the geo-fence boundaries. If a device enters or exits the geo-fenced area, an alert is generated and sent to the operator.
Time Factors
Time factor authentication authenticates a user based on the time and/or date the user is authenticating. For example, if certain users work only a set schedule, you can configure their accounts to allow them to log in only during those set work hours. However, keep in mind that such a limitation could cause administrative issues if overtime hours are allowed. Some organizations implement this type of authentication effectively by padding the allowed hours with an hour or two leeway for the start and end times. Credit cards use this feature effectively to protect their customers. If transactions take place in a short timeframe from geographically dispersed locations, credit cards will often block the second transaction.
Single-Factor Versus Multifactor Authentication
Authentication usually ensures that a user provide at least one factor from the five categories, which is referred to as single-factor authentication. An example would be providing a username and password at login. Two-factor authentication (2FA) ensures that the user provides two of the five factors. An example of two-factor authentication would be providing a username, password, and smart card at login. Three-factor authentication ensures that a user provides three factors. An example of three-factor authentication would be providing a username, password, smart card, and fingerprint at login. For authentication to be considered strong authentication, a user must provide factors from at least two different categories. (Note that the username is the identification factor, not an authentication factor.)
The term multifactor authentication (MFA) is often used when more than one authentication factor is used. So two-factor or three-factor authentication may be referred to as multifactor authentication.
You should understand that providing multiple authentication factors from the same category is still considered single-factor authentication. For example, if a user provides a username, password, and the user’s mother’s maiden name, single-factor authentication is being used. In this example, the user is still only providing factors that are something a person knows.
Device Authentication
Device authentication, also referred to as endpoint authentication, is a form of authentication that relies on the identity of the device as part of the authentication process. With device authentication, the identity of the device from which a user logs in is included as part of the authentication process, thereby providing two-factor authentication using the device and user’s credentials. If the user then attempts to log in from a different device, the authentication system recognizes that a new device is being used and asks the user to provide extra authentication verification information, usually an answer to a security question. The user is usually then given the option to include this device in the authentication (if the device is a private device) or not (if the device is a public device). In this manner, the device itself becomes a security token and, as such, becomes a “something you have” authentication factor.
Security professionals should not confuse device authentication with a system that uses a known mobile device or email to provide a one-time password or PIN needed for authentication. When a system transmits the one-time password or PIN that must be used as part of authentication to a mobile device or via email, this is just another authentication factor, not device authentication. With this system, the user registers a mobile device number or email address with the authentication system. When the user logs in, that user usually provides two factors of authentication. After authentication of the initial factors is completed, the one-time password or PIN is transmitted to the known device or email, which the user must input as part of a second authentication interface.
Identification and Authentication Implementation
Identification and authentication are necessary steps to providing authorization. Authorization is the point after identification and authentication at which a user is granted the rights and permissions to resources. The next sections cover important components in authorization: separation of duties, least privilege/need-to-know, default to no access, directory services, single sign-on (including Kerberos, SESAME, federated identity management, and security domains), session management, registration proof, and registration of identity, credential management systems, and accountability.
Separation of Duties
Separation of duties is an important concept to keep in mind when designing an organization’s authentication and authorization policies. Separation of duties prevents fraud by distributing tasks and their associated rights and privileges between two or more users. This separation helps deter fraud and collusion because any fraudulent act can occur only if there is collusion. A good example of separation of duties is authorizing one person to manage backup procedures and another to manage restore procedures.
Separation of duties is associated with dual controls and split knowledge. With dual controls, two or more users are authorized and required to perform certain functions. For example, a retail establishment might require two managers to open the safe. Split knowledge ensures that no single user has all the information to perform a particular task. An example of a split control is the military’s requiring two individuals to each enter a unique combination to authorize missile firing.
Least Privilege/Need-to-Know
The principle of least privilege requires that a user or process is given only the minimum required access needed to perform a particular task. Its main purpose is to ensure that users have access only to the resources they need and are authorized to perform only the tasks they need to perform. To properly implement the least privilege principle, organizations must identify all users’ jobs and restrict users only to the identified privileges.
The need-to-know principle is closely associated with the privilege allocation given to the users. Although least privilege seeks to reduce access to a minimum, the need-to-know principle actually defines what the minimum privileges for each job or business function are. Excessive privileges become a problem when a user has more rights, privileges, and permissions than that user needs to do the job. Excessive privileges are hard to control in large environments.
In a common implementation of the least privilege and need-to-know principles, for example, a system administrator is issued both an administrative-level account and a normal user account. In most day-to-day functions, the administrator should use the normal user account. When needing to perform administrative-level tasks, the system administrator should use the administrative-level account. If the administrator uses the administrative-level account while performing routine tasks, the admin risks compromising the security of the system and user accountability.
Organizational rules that support the principle of least privilege include the following:
Keep the number of administrative accounts to a minimum.
Administrators should use normal user accounts when performing routine operations.
Permissions on tools that are likely to be used by attackers should be as restrictive as possible.
To more easily support the least privilege and need-to-know principles, users should be divided into groups to facilitate the confinement of information to a single group or area. This process is referred to as compartmentalization.
Default to No Access
During the authorization process, you should configure an organization’s access control mechanisms so that the default level of security is to default to no access. This means that if nothing has been specifically allowed for a user or group, then the user or group cannot access the resource. The best security approach is to start with no access and add rights based on a user’s need to know and least privilege needed to accomplish his daily tasks.
Directory Services
A directory service is a database designed to centralize data management regarding network subjects and objects. A typical directory contains a hierarchy that includes users, groups, systems, servers, client workstations, and so on. Because the directory service contains data about users and other network entities, it can be used by many applications that require access to that information.
The most common directory service standards are
X.500
X.400
Active Directory Domain Services (AD DS)
X.500 uses the Directory Access Protocol (DAP). In X.500, the distinguished name (DN) provides the full path in the X.500 database where the entry is found. The relative distinguished name (RDN) in X.500 is an entry’s name without the full path.
Based on X.500’s DAP, LDAP is simpler than X.500. LDAP supports DN and RDN, but includes more attributes such as the common name (CN), domain component (DC), and organizational unit (OU) attributes. Using a client/server architecture, LDAP uses TCP port 389 to communicate. If advanced security is needed, LDAP over SSL communicates via TCP port 636.
X.400 is mainly for message transfer and storage. It uses elements to create a series of name/value pairs separated by semicolons. X.400 has gradually been replaced by Simple Mail Transfer Protocol (SMTP) implementations.
Microsoft’s implementation of LDAP is Active Directory Domain Services (AD DS), which stores and organizes directory data into trees and forests. It also manages logon processes and authentication between users and domains and allows administrators to logically group users and devices into organizational units.
Single Sign-on
In a single sign-on (SSO) environment, a user enters login credentials once and can access all resources in the network. The Open Group Security Forum has defined many objectives for an SSO system. Some of the objectives for the user sign-on interface and user account management include the following:
The interface should be independent of the type of authentication information handled.
The creation, deletion, and modification of user accounts should be supported.
Support should be provided for a user to establish a default user profile.
Accounts should be independent of any platform or operating system.
SSO provides many advantages and disadvantages when it is implemented.
Advantages of an SSO system include
Users are able to use stronger passwords.
User and password administration is simplified.
Resource access is much faster.
User login is a one-time effort and can be more efficient.
Users need to remember only one set of login credentials.
Disadvantages of an SSO system include
After obtaining system access through the initial SSO login, a user is able to access all resources to which that user is granted access. Although this is also an advantage for the user (only one login needed), it is also considered a disadvantage because only one sign-on can compromise all the systems that participate in the SSO network.
If a user’s credentials are compromised, attackers will have access to all resources to which the user has access.
Although the discussion on SSO so far has been mainly about how it is used for networks and domains, SSO can also be implemented in web-based systems. Enterprise access management (EAM) provides access control management for web-based enterprise systems. Its functions include accommodation of a variety of authentication methods and role-based access control.
SSO can be implemented in Kerberos, SESAME, OpenID Connect (OIDC)/Open Authorization (Oauth), Security Assertion Markup Language (SAML), and federated identity management environments. Security domains can then be established to assign SSO rights to resources.
Kerberos
Kerberos is an authentication protocol that uses a client/server model developed by MIT’s Project Athena. It is the default authentication model in recent editions of Windows Server and is also used in Apple, Oracle, and Linux operating systems. Kerberos is an SSO system that uses symmetric key cryptography, and it provides confidentiality and integrity.
Kerberos assumes that messaging, cabling, and client computers are not secure and are easily accessible. In a Kerberos exchange involving a message with an authenticator, the authenticator contains the client ID and a timestamp. Because a Kerberos ticket is valid for a certain time, the timestamp ensures the validity of the request.
In a Kerberos environment, the Key Distribution Center (KDC) is the repository for all user and service secret keys. The client sends a request to the authentication server (AS), which might or might not be the KDC. The AS forwards the client credentials to the KDC. The KDC authenticates clients to other entities on a network and facilitates communication using session keys. The KDC provides security to clients or principals, which are users, network services, and software. Each principal must have an account on the KDC. The KDC issues a ticket-granting ticket (TGT) to the principal. The principal will send the TGT to the ticket-granting service (TGS) when the principal needs to connect to another entity. The TGS then transmits a ticket and session keys to the principal. The set of principles for which a single KDC is responsible is referred to as a realm.
Some advantages of implementing Kerberos include the following:
User passwords do not need to be sent over the network.
Both the client and server authenticate each other.
The tickets passed between the server and client are time-stamped and include lifetime information.
The Kerberos protocol uses open Internet standards and is not limited to proprietary codes or authentication mechanisms.
Some disadvantages of implementing Kerberos include the following:
KDC redundancy is required if providing fault tolerance is a requirement. The KDC is a single point of failure.
The KDC must be scalable to ensure that performance of the system does not degrade.
Session keys on the client machines can be compromised.
Kerberos traffic needs to be encrypted to protect the information over the network.
All systems participating in the Kerberos process must have synchronized clocks.
Kerberos systems are susceptible to password-guessing attacks.
Figure 5-2 shows the ticket-issuing process for Kerberos.
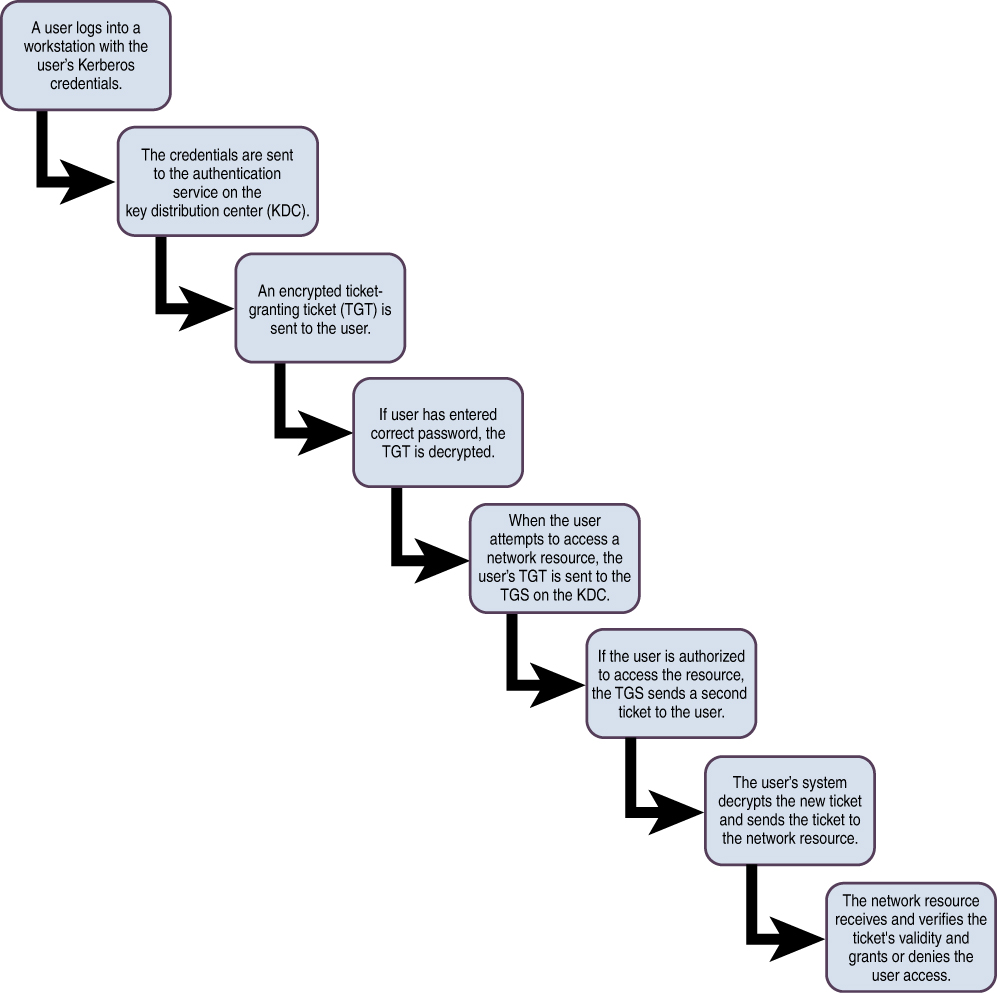
Figure 5-2 Kerberos Ticket-Issuing Process
SESAME
The Secure European System for Applications in a Multi-vendor Environment (SESAME) project extended the functionality of Kerberos to fix its weaknesses. SESAME uses both symmetric and asymmetric cryptography to protect interchanged data. SESAME uses a trusted authentication server at each host.
SESAME uses Privileged Attribute Certificates (PACs) instead of tickets. It incorporates two certificates: one for authentication and one for defining access privileges. The trusted authentication server is referred to as the Privileged Attribute Server (PAS), which performs roles similar to the KDC in Kerberos. SESAME can be integrated into a Kerberos system.
OpenID Connect (OIDC)/Open Authorization (Oauth)
Open Authorization (OAuth) is an access delegation standard that applications can use to ensure secure delegated access over HTTPS. It authorizes devices, APIs, servers, and applications with access tokens rather than credentials. OAuth allows an end user’s account information to be used by third-party services, such as a social media application, without exposing the user’s password. OAuth uses JavaScript Object Notation (JSON) data interchange.
OpenID Connect (OIDC) is an identity layer built on top of the OAuth 2.0 framework. It allows third-party applications to verify the identity of the end user and to obtain basic user profile information.
Whereas OAuth 2.0 is about resource access and sharing, OIDC is about user authentication.
Security Assertion Markup Language (SAML)
Security Assertion Markup Language (SAML) allows users to access multiple web applications using one set of login credentials, thereby providing SSO. It passes authentication data in a set format between two parties, usually an identity provider (IdP) and a web application. SAML uses Extensible Markup Language (XML) format.
In a comparison of SAML and OAuth, SAML provides more control to enterprises to keep their SSO logins more secure, whereas OAuth is better on mobile devices.
Federated Identity Management (IdM)
A federated identity is a portable identity that can be used across businesses and domains. In federated identity management (FIM), each organization that joins the federation agrees to enforce a common set of policies and standards. These policies and standards define how to provision and manage user identification, authentication, and authorization. Federated identity management uses two basic models for linking organizations within the federation: the cross-certification model and trusted third-party (or bridge) model. Through this model, an SSO system can be implemented.
In the cross-certification federated identity model, each organization certifies that every other organization is trusted. This trust is established when the organizations review each other’s standards. Each organization must verify and certify through due diligence that the other organizations meet or exceed standards. One disadvantage of cross certification is that the number of trust relationships that must be managed can become a problem. In addition, verifying the trustworthiness of other organizations can be time-consuming and resource intensive.
In the trusted third-party (or bridge) federated identity model, each organization subscribes to the standards of a third party. The third party manages verification, certification, and due diligence for all organizations. This model is usually the best if an organization needs to establish federated identity management relationships with a large number of organizations.
Security Assertion Markup Language (SAML) 2.0 is an SAML standard that exchanges authentication and authorization data between organizations or security domains. It uses an XML-based protocol to pass information about a principal between an SAML authority and a web service via security tokens. In SAML 2.0, there are three roles: the principal or user, the identity provider, and the service provider. The service provider requests identity verification from the identity provider. SAML is very flexible because it is based on XML. If an organization implements enterprise SAML identity federation, the organization can select which identity attributes to share with another organization.
Security Domains
A domain is a set of resources that is available to a subject over a network. Subjects that access a domain include users, processes, and applications. A security domain is a set of resources that follows the same security policies and is available to a subject. The domains are usually arranged in a hierarchical structure of parent and child domains.
Session Management
Session management ensures that any instance of identification and authentication to a resource is managed properly. This process includes managing desktop sessions and remote sessions.
Desktop sessions should be managed through a variety of mechanisms. Screensavers allow computers to be locked if left idle for a certain period of time. To reactivate a computer, the user must log back in. Screensavers are one kind of timeout mechanism, and other timeout features may also be used, such as shutting down or placing a computer in hibernation after a certain period. Session or logon limitations allow organizations to configure how many concurrent sessions a user can have. Schedule limitations allow organizations to configure the time during which a user can access a computer.
Remote sessions usually incorporate some of the same mechanisms as desktop sessions. However, remote sessions do not occur at the computer itself. Rather, they are carried out over a network connection. Remote sessions should always use secure connection protocols. In addition, if users will only be connecting remotely from certain computers, the organization may want to implement some type of rule-based access that allows only certain connections.
Registration, Proof, and Establishment of Identity
A proof of identity process involves collecting and verifying information about an individual to prove that the person who has a valid account is who that person claims to be. Establishment is the process of determining what that user’s identity will be. Proofing is the act of ensuring that a person is who that person claims to be, and registration is the act of entering the identity into the IAM solution. The most basic method of proof of identity is providing a driver’s license, passport, or some other government-issued identification. Proof of identity is performed before user account creation. Once proof of identity is completed, the user is issued a credential, and authentication factors are determined and recorded, which is referred to as identify establishment. Setting up the user’s account in the IAM solution, such as Active Directory, is an example of registration. From that point forward, authentication occurs each time the user logs in using the issued credential.
The National Institute of Standards and Technology (NIST) has issued documents that provide guidance on proof of identity:
FIPS Publication 201-2, “Personal Identity Verification (PIV) of Federal Employees and Contractors”: This document specifies the architecture and technical requirements for a common identification standard for federal employees and contractors. This publication includes identification, security, and privacy requirements and personal identity verification system guidelines.
NIST SP 800-79-2, “Guidelines for the Authorization of Personal Identity Verification Card Issuers (PCI) and Derived PIV Credential Issuers (DPCI)”: This document includes preparation guidelines, issuer control implementation guidelines, and issuer control life cycle guidelines.
Both of these NIST publications are intended to guide federal government agencies in their proof of identity efforts and can also be used by private organizations to aid in the development of their own systems.
Credential Management Systems
Users are often required to remember usernames, passwords, and other authentication information for a variety of organizations. They often use the same authentication credentials across multiple platforms, which makes online identity theft and fraud easier to commit. After a set of credentials has been discovered on one online system, attackers often use the same set of credentials on another organization’s systems to see if they can gain access. Along with this problem comes an organization’s own internal issue for maintaining different credentials for users needing access to multiple systems with different credentialing systems. Factor in the increasing use of mobile devices, and you have a recipe for disaster.
Credential management systems allow organizations to establish an enterprisewide user authentication and authorization framework. Organizations should employ security professionals to design, deploy, and manage secure credential management systems. The business requirements for a credential management system should include individual privacy protection guidelines, automated identity solutions, security, and innovation. Some of the guidelines of a credential management system include the following:
Use strong passwords.
Automatically generate complex passwords.
Implement password history.
Use access control mechanisms, including the who, what, how, and when of access.
Implement auditing.
Implement backup and restore mechanisms for data integrity.
Implement redundant systems within the credential management systems to ensure 24/7/365 access.
Implement credential management group policies or other mechanisms offered by operating systems.
When an organization implements a credential management system, separation of duties becomes even more important because the centralized credential management system can be used to commit fraud. Security professionals should provide guidance on how the separation should occur to best protect the organization and its assets.
Remote Authentication Dial-In User Service (RADIUS)/Terminal Access Controller Access Control System Plus (TACACS+)
RADIUS authenticates and logs remote network users, while TACACS+ most commonly provides administrator access to network devices, like routers and switches. Both protocols provide centralized authentication, authorization, and accounting (AAA) services on a network.
TACACS+ is more reliable than RADIUS. It supports authorization of commands. Finally, all TACACS+ communication is encrypted, whereas RADIUS authentication encrypts only the password.
However, RADIUS is an open standard and can be used with all types of devices, while TACACS+ works only with Cisco products. The accounting support in RADIUS is more robust than that provided by TACACS+.
Accountability
Accountability is an organization’s ability to hold users responsible for the actions they perform before and after they are authorized. To ensure that users are accountable for their actions, organizations must implement auditing and other accountability mechanisms.
Organizations could implement any combination of the following components:
Strong identification: All users should have their own accounts. Group or role accounts cannot be traced back to a single individual.
Strong authentication: Multifactor authentication is best. At minimum, two-factor authentication should be implemented.
Monitoring: User actions should be monitored, including login, privilege use, and other actions. Users should be warned as part of a no-expectation-of-privacy statement that all actions can be monitored.
Audit logs: Audit logs should be maintained and stored according to organizational security policies. Administrators should periodically review these logs and adjust authorizations of users accordingly.
Although organizations should internally implement these accountability mechanisms, they should also periodically have a third party perform audits and tests. Third-party audit is important because the third party that is not part of the organization can provide objectivity that internal personnel often may fail to provide.
Auditing and Reporting
Auditing and reporting ensure that users are held accountable for their actions, but an auditing mechanism can report only on events that it is configured to monitor. Security professionals should monitor network events, system events, application events, user events, and keystroke activity. Keep in mind that any auditing activity might impact the performance of the system being monitored. Organizations must find a balance between auditing important events and activities and ensuring that device performance is maintained at an acceptable level. Also, organizations must ensure that any monitoring that occurs is in compliance with all applicable laws and the auditors are given written permission before an audit is conducted.
When designing an auditing mechanism, security professionals should remember the following guidelines:
Develop an audit log management plan that includes mechanisms to control the log size, backup processes, and periodic review plans.
Ensure that the ability to delete an audit log is a two-person control that requires the cooperation of at least two administrators. This strategy ensures that a single administrator is not able to delete logs that might hold incriminating evidence.
Monitor all high-privilege accounts (including all root users and administrative-level accounts).
Ensure that the audit trail includes who processed the transaction, when the transaction occurred (date and time), where the transaction occurred (which system), and whether the transaction was successful or not.
Ensure that deleting the log and deleting data within the logs cannot occur unless the user has the appropriate administrative-level permissions.
Audit trails detect computer penetrations and reveal actions that identify misuse. As a security professional, you should use the audit trails to review patterns of access to individual objects. To identify abnormal patterns of behavior, you should first identify normal patterns of behavior. Also, you should establish the clipping level, which is a baseline of user errors above which violations will be recorded. For example, your organization might choose to ignore the first invalid login attempt, knowing that initial failed login attempts are often due to user error. Any further invalid login attempts after the first would be recorded because they could be a sign of an attack. A common clipping level that is used is three failed login attempts. For security purposes, any failed login attempt above the limit of three would be considered malicious. In most cases, a lockout policy would lock out a user’s account after this clipping level is reached.
Audit trails deter attacker attempts to bypass the protection mechanisms that are configured on a system or device. As a security professional, you should specifically configure the audit trails to track system/device rights or privileges being granted to a user, and data additions, deletions, or modifications.
Finally, audit trails must be monitored, and automatic notifications should be configured. If no one monitors the audit trail, then the data recorded in the audit trail is useless. Certain actions should be configured to trigger automatic notifications. For example, you might want to configure an email alert to occur after a certain number of invalid login attempts because invalid login attempts might be a sign that a brute-force password attack is occurring.
Just-In-Time (JIT)
Just-In-Time (JIT) access enables organizations to grant access to applications or systems for predetermined periods of time, on an as-needed basis. With JIT provisioning, if a user does not already have an account in a target application, the IAM system creates the account for a user on the fly when the user first accesses the application. JIT uses the SAML protocol to transmit information from the identity provider to the web application. The web application receives the information from the identity provider via SAML assertions.
Using a cloud identity provider with JIT is the most streamlined approach because admins can configure application permissions by role or group and revoke application access from one central location. Although setting up a JIT configuration between the identity and service providers can be tedious, administrative effort will be saved in the long run when each user is provisioned automatically.
Identity as a Service (IDaaS) Implementation
Identity as a Service (IDaaS) provides a set of identity and access management functions to target systems on customers’ premises and/or in the cloud. IDaaS includes identity governance and administration (IGA), which provides the ability to provision identities held by the service to target applications. It includes user authentication, single sign-on (SSO), and authorization enforcement. IDaaS services are divided into two categories: web access software for cloud-based applications and cloud-delivered legacy identity management services. Web IDaaS applications do not work with on-premises applications. Most IDaaS deployments offer SSO authentication, federated identities, remote administration, and internal directory service integration. IDaaS is different from identity and access management (IAM) solutions, which are operated from within the organization’s own network via bundled software and hardware. IAM solutions may use Active Directory and LDAP.
If organizations consider IDaaS deployment, they should primarily be concerned with service availability, identity data protection, and trusting a third party with a critical business function. They should also be concerned with regulatory compliance. Moving identity management to the cloud brings up a whole host of questions for the organization regarding auditing, ensuring compliance of regulations, and what happens if disclosures occur.
An organization should perform a comprehensive risk analysis prior to implementing and deploying any IDaaS service. After performing the risk analysis, the organization should determine which identities should be placed on the IDaaS solution.
Third-Party Identity Services Integration
If an organization decides to deploy a third-party identity service, including cloud computing solutions, security practitioners must be involved in the integration of that implementation with internal services and resources. This integration can be complex, especially if the provider solution is not fully compatible with existing internal systems. Most third-party identity services provide cloud identity, directory synchronization, and federated identity. Examples of these services include the Amazon Web Services (AWS) Identity and Access Management (IAM) service and Oracle Identity Management.
Third-party identity services include on-premises, cloud, federated, and hybrid services. These three service types are discussed throughout this chapter.
Authorization Mechanisms
Authorization mechanisms are systems an organization deploys to control which systems a user or device can access. Authorization mechanisms include access control models and access control policies.
Permissions, Rights, and Privileges
Permissions are granted or denied at the file, folder, or other object level. Common permission types include Read, Write, Execute, and Full Control. Data custodians or administrators will grant users permissions on a file or folder based on the owner’s request to do so.
Rights allow administrators to assign specific privileges and logon rights to groups or users. Rights manage who is allowed to perform certain operations on an entire computer or within a domain, rather than a particular object within a computer. While user permissions are granted by an object’s owner, user rights are assigned using a computer’s local security policy or a domain security policy. User rights apply to user accounts, whereas permissions apply to objects.
Rights include the ability to log on to a system interactively, which is a logon right, or the ability to back up files, which is considered a privilege. User rights are divided into two categories: privileges and logon rights. Privileges are the right of an account, such as a user or group account, to perform various system-related operations on the local computer, such as shutting down the system, loading device drivers, or changing the system time. Logon rights control how users are allowed access to the computer, including logging on locally or through a network connection or whether as a service or as a batch job.
Conflicts can occur in situations where the rights that are required to administer a system overlap the rights of resource ownership. When rights conflict, a privilege is allowed to override a permission.
Access Control Models
An access control model is a formal description of an organization’s security policy. Access control models are implemented to simplify access control administration by grouping objects and subjects. Subjects are entities that request access to an object or data within an object. Users, programs, and processes are subjects. Objects are entities that contain information or functionality. Computers, databases, files, programs, directories, and fields are objects. A secure access control model must ensure that secure objects cannot flow to a less secure subject.
The access control models and concepts that you need to understand include the following:
Discretionary access control
Mandatory access control
Role-based access control
Rule-based access control
Attribute-based access control
Content-dependent versus context-dependent access control
Risk-based access control
Access control matrix
Capabilities table
ACL
Discretionary Access Control
In discretionary access control (DAC), the owner of the object specifies which subjects can access the resource. DAC is typically used in local, dynamic situations. The access is based on the subject’s identity, profile, or role. DAC is considered to be a need-to-know control.
DAC can be an administrative burden because the data custodian or owner grants access privileges to the users. Under DAC, a subject’s rights must be terminated when the subject leaves the organization. Identity-based access control is a subset of DAC and is based on user identity or group membership.
Nondiscretionary access control is the opposite of DAC. In nondiscretionary access control, access controls are configured by a security administrator or other authority. The central authority decides which subjects have access to objects based on the organization’s policy. In nondiscretionary access control, the system compares the subject’s identity with the objects’ access control list.
Mandatory Access Control
In mandatory access control (MAC), subject authorization is based on security labels. MAC is often described as prohibitive because it is based on a security label system. Under MAC, all that is not expressly permitted is forbidden. Only administrators can change the category of a resource.
MAC is more secure than DAC. DAC is more flexible and scalable than MAC. Because of the importance of security in MAC, labeling is required. Data classification reflects the data’s sensitivity. In a MAC system, a clearance is a subject’s privilege. Each subject and object is given a security or sensitivity label. The security labels are hierarchical. For commercial organizations, the levels of security labels could be confidential, proprietary, corporate, sensitive, and public. For government or military institutions, the levels of security labels could be top secret, secret, confidential, and unclassified.
In MAC, the system makes access decisions when it compares the subject’s clearance level with the object’s security label.
Role-Based Access Control
In role-based access control (RBAC), each subject is assigned to one or more roles. Roles are hierarchical. Access control is defined based on the roles. RBAC can be used to easily enforce minimum privileges for subjects. An example of RBAC is implementing one access control policy for bank tellers and another policy for loan officers.
RBAC is not as secure as the previously mentioned access control models because security is based on roles. RBAC usually has a much lower cost to implement than the other models and is popular in commercial applications. It is an excellent choice for organizations with high employee turnover. RBAC can effectively replace DAC and MAC because it allows you to specify and enforce enterprise security policies in a way that maps to the organization’s structure.
RBAC is managed in four ways: non-RBAC, limited RBAC, hybrid RBAC, and full RBAC. In non-RBAC, no roles are used. In limited RBAC, users are mapped to single application roles, but some applications do not use RBAC and require identity-based access. In hybrid RBAC, each user is mapped to a single role, which gives them access to multiple systems, but each user can be mapped to other roles that have access to single systems. In full RBAC, users are mapped to a single role as defined by the organization’s security policy, and access to the systems is managed through the organizational roles.
Rule-Based Access Control
Rule-based access control facilitates frequent changes to data permissions and is defined in RFC 2828. Using this method, a security policy is based on global rules imposed for all users. Profiles are used to control access. Many routers and firewalls use this type of access control and define which packet types are allowed on a network. Rules can be written allowing or denying access based on packet type, port number used, MAC address, and other parameters. Rules can be added, edited, or deleted as required.
Attribute-Based Access Control
Attribute-based access control (ABAC) grants or denies user requests based on arbitrary attributes of the user and arbitrary attributes of the object, and environment conditions that may be globally recognized. NIST SP 800-162 was published to define and clarify ABAC.
According to NIST SP 800-162, ABAC is an access control method where subject requests to perform operations on objects are granted or denied based on assigned attributes of the subject, assigned attributes of the object, environment conditions, and a set of policies that are specified in terms of those attributes and conditions. An operation is the execution of a function at the request of a subject upon an object. Operations include read, write, edit, delete, copy, execute, and modify. A policy is the representation of rules or relationships that make it possible to determine whether a requested access should be allowed, given the values of the attributes of the subject, object, and possibly environment conditions. Environment conditions are the operational or situational context in which access requests occur. Environment conditions are detectable environmental characteristics. Environment characteristics are independent of subject or object, and may include the current time, day of the week, location of a user, or the current threat level.
Figure 5-3 shows a basic ABAC scenario according to NIST SP 800-162.
As specified in NIST SP 800-162, there are characteristics or attributes of a subject such as name, date of birth, home address, training record, and job function that may, either individually or when combined, comprise a unique identity that distinguishes that person from all others. These characteristics are often called subject attributes.
Like subjects, each object has a set of attributes that help describe and identify it. These traits are called object attributes and are sometimes referred to as resource attributes. Object attributes are typically bound to their objects through reference, by embedding them within the object, or through some other means of assured association such as cryptographic binding.
Figure 5-3 NIST SP 800-162 Basic ABAC Scenario
ACLs and RBAC are in some ways special cases of ABAC in terms of the attributes used. ACLs work on the attribute of “identity.” RBAC works on the attribute of “role.” The key difference with ABAC is the concept of policies that express a complex Boolean rule set that can evaluate many different attributes. While it is possible to achieve ABAC objectives using ACLs or RBAC, demonstrating access control requirements compliance is difficult and costly due to the level of abstraction required between the access control requirements and the ACL or RBAC model. Another problem with ACL or RBAC models is that if the access control requirements need to be changed depending on business demands or user changes, it may be difficult to identify all the places where the ACL or RBAC implementation needs to be updated.
ABAC relies on the assignment of attributes to subjects and objects, and the development of policy that contains the access rules. Each object within the system must be assigned specific object attributes that characterize the object. Some attributes pertain to the entire instance of an object, such as the owner. Other attributes may apply only to parts of the object.
Each subject that uses the system must be assigned specific attributes. Every object within the system must have at least one policy that defines the access rules for the allowable subjects, operations, and environment conditions to the object. This policy is normally derived from documented or procedural rules that describe the business processes and allowable actions within the organization. The rules that bind subject and object attributes indirectly specify privileges (i.e., which subjects can perform which operations on which objects). Allowable operation rules can be expressed through many forms of computational language such as
A Boolean combination of attributes and conditions that satisfy the authorization for a specific operation
A set of relations associating subject and object attributes and allowable operations
After object attributes, subject attributes, and policies are established, objects can be protected using ABAC. Access control mechanisms mediate access to the objects by limiting access to allowable operations by allowable subjects. The access control mechanism assembles the policy, subject attributes, and object attributes; then it renders and enforces a decision based on the logic provided in the policy. Access control mechanisms must be able to manage the process required to make and enforce the decision, including determining what policy to retrieve, which attributes to retrieve in what order, and where to retrieve attributes. The access control mechanism must then perform the computation necessary to render a decision.
The policies that can be implemented in an ABAC model are limited only to the degree imposed by the computational language and the richness of the available attributes. This flexibility enables the greatest breadth of subjects to access the greatest breadth of objects without having to specify individual relationships between each subject and each object.
While ABAC is an enabler of information sharing, the set of components required to implement ABAC gets more complex when deployed across an enterprise. At the enterprise level, the increased scale requires complex and sometimes independently established management capabilities necessary to ensure consistent sharing and use of policies and attributes and the controlled distribution and employment of access control mechanisms throughout the enterprise.
Content-Dependent Versus Context-Dependent
Content-dependent access control makes access decisions based on the data contained within the object. With this access control, the data that a user sees might be different from the actual data, based on the policy and access rules that are applied.
Context-dependent access control is based on subject or object attributes or environmental characteristics. These characteristics can include location or time of day. An example of context-dependent access control is administrators implementing a security policy that checks to see whether a user can log in only from a particular workstation and during certain hours of the day.
Security experts consider a constrained user interface as another method of access control. An example of a constrained user interface is a shell, which is a software interface to an operating system that implements access control by limiting the system commands that are available. Another example is database views that are filtered based on user or system criteria. Constrained user interfaces can be content- or context-dependent based on how the administrator constrains the interface.
Risk-Based Access Control
Risk-based access control uses risk probability to make access decisions. It performs a risk analysis to estimate the risk value related to each access request. The estimated risk value is then compared against access policies to determine the access decision.
With risk-based access control, the access granted can be based on the risk factors of the individual connection. For example, a user connecting to a resource via the local network would not be considered as risky as a user connecting via a mobile device connected to a coffee shop wireless network. If risk-based access control were deployed, it would see the mobile device as a greater risk and could require another authentication factor than that required for a local connection. In addition, with risk-based access control, an organization could allow the system to learn about user patterns and behaviors and thereby lessen stringent controls over time based on that data.
Risk-based access includes an external authorization service (EAS), a runtime authorization service, and an attribute collection service. The EAS provides policy enforcement by taking the request data and sending an authorization decision request to the risk-based access authorization service. The runtime authorization service stores the policy, calculates the risk score, and makes the access decision. The attribute collection service collects web browser and location attributes from the user.
Let’s look at an example. Suppose a company employee named Michael works normal Monday through Friday business hours from the central office. He always accesses the corporate network using his company-issued laptop or mobile phone. This connection would be seen as a low-risk connection, and normal organizational username/password authentication would suffice. However, when Michael travels for business and attempts to connect to the corporate network from his hotel via a free Wi-Fi, risk-based access control policies could request secondary authentication factors from Michael based on this new Internet connection. Even if the new connection were from the same device, the policy could notice several risks, including a new location or new login hours.
For organizations with a large enterprise, security professionals should provide guidance on those times when risk-based access control should be considered and how it could benefit these organizations.
Access Control Matrix
An access control matrix is a table that consists of a list of subjects, a list of objects, and a list of the actions that a subject can take upon each object. The rows in the matrix are the subjects, and the columns in the matrix are the objects. Common implementations of an access control matrix include a capabilities table and an ACL.
Capabilities Table
A capability corresponds to a subject’s row from an access control matrix. A capability table lists the access rights that a particular subject has to objects. A capability table is about the subject.
ACL
An ACL corresponds to an object’s column from an access control matrix. An ACL lists all the access rights that subjects have to a particular object; an ACL is about the object.
Figure 5-4 shows an access control matrix and how a capability and ACL are part of it.
Figure 5-4 Access Control Matrix
Access Control Policies
An access control policy defines the method for identifying and authenticating users and the level of access that is granted to users. Organizations should put access control policies in place to ensure that access control decisions for users are based on formal guidelines. If an access control policy is not adopted, organizations will have trouble assigning, managing, and administering access management.
Provisioning Life Cycle
Organizations should create a formal process for creating, changing, and removing users, which is the provisioning life cycle. This process includes user approval, user creation, user creation standards, and authorization. Users should sign a written statement that explains the access conditions, including user responsibilities. Finally, access modification and removal procedures should be documented.
User accounts are not the only types of accounts security professionals may need to provision. Security professionals also need to understand systems and service accounts.
A system account is generally thought of in two ways. System accounts are often created for actual devices or services, including computers, routers, and firewalls. These system accounts allow organizations to track the devices and assign them security policies and directory service policies. In addition, a system account is an account created during operating system installation. It is considered a user account but often performs operating system functions. System administrators also log in to some system accounts, such as the Windows Administrator account or the UNIX/Linux root account. System accounts are generally privileged accounts. Security professionals should, at minimum, rename these default admin and operating system accounts and ensure that the default password is changed.
A service account is an account created explicitly to provide a security context for services running on Windows or Unix computers. The security context determines the service’s ability to access local and network resources. Services that need accounts include Domain Name System (DNS), HyperText Transfer Protocol (HTTP), File Transfer Protocol (FTP), and Dynamic Host Configuration Protocol (DHCP). Services that should not be running on a computer should be disabled and have the service accounts deleted.
Provisioning
User provisioning policies should be integrated as part of human resources management. Human resources policies should include procedures whereby the human resources department formally requests the creation or deletion of a user account when new personnel are hired or terminated.
Identity and Account Management
Identity and account management is vital to any authentication process. As a security professional, you must ensure that your organization has a formal procedure to control the creation and allocation of access credentials or identities. If invalid accounts are allowed to be created and are not disabled, security breaches will occur. Most organizations implement a method to review the identification and authentication process to ensure that user accounts are current. Questions that are likely to help in the process include
Is a current list of authorized users, devices, and services and their access maintained and approved?
Are passwords changed at least every few days (e.g., 90 days) or earlier if needed?
Are inactive user, device, and service accounts disabled after a specified period of inactivity?
Any identity management procedure must include processes for creating (provisioning), changing and monitoring (reviewing), and removing users, devices, and services from the access control system (revoking). This procedure is referred to as the provisioning life cycle. When initially establishing a user account, new users should be required to provide valid photo identification and should sign a statement regarding password confidentiality. For device and service accounts, the device or service owner should request account creation. User, device, and service accounts must be unique. Policies should be in place that standardize the structure of user, device, and service accounts. For example, all user accounts should be firstname.lastname or some other structure. This structure ensures that users within an organization will be able to determine a new user’s identification, mainly for communication purposes. Device and service naming conventions should also be adopted.
After creation, accounts should be monitored to ensure that they remain active. Inactive accounts should be automatically disabled after a certain period of inactivity based on business requirements. In addition, any termination policy should include formal procedures to ensure that all accounts are disabled or deleted. Elements of proper account management include the following:
Establish a formal process for establishing, issuing, and closing accounts.
Periodically review accounts.
Implement a process for tracking access authorization.
Periodically rescreen personnel in sensitive positions.
Periodically verify the legitimacy of accounts.
Account reviews are a vital part of account management. Accounts should be reviewed for conformity with the principle of least privilege. (The principle of least privilege is explained earlier in this chapter.) Account reviews can be performed on an enterprisewide, systemwide, or application-by-application basis. The size of the organization will greatly affect which of these methods to use. As part of account reviews, organizations should determine whether all accounts are active.
User, System, and Service Account Access Review
Account review should be performed periodically to determine that all accounts that have been created are still being used. If a user, system, or service account is inactive for a certain period, it is always best to disable that account and wait for a user request to renew. When no requests for renewal are made, the disabled accounts are usually deleted after a certain period. After an account is deleted, any objects owned by the account may remain in the current state, meaning no new users can be given permissions nor can current permissions be changed. Having this period when an account is disabled prior to deletion allows administrators to identify those objects and transfer their ownership to another user or system account.
Account Transfers
Accounts, particularly user accounts, may need to be periodically transferred within an organization. This is most often the case when personnel move from one department or role to another. Procedures should be written so that the user account is granted the appropriate permissions for the new department or role. In addition, any unneeded permissions from the old department or role should be removed. Following this procedure ensures that privilege creep does not occur. Privilege creep, also referred to as permissions creep, occurs when an employee moves between roles in an organization and keeps the access or permissions of the previous role.
Account Revocation
Account revocation, also referred to as deprovisioning, is the process of removing an account from a device or enterprise. Because accounts are assigned unique IDs in most operating systems, it is very important that security professionals ensure that accounts are no longer needed prior to deletion. Countless stories exist where accounts were deleted and then access to certain resources was lost. Even if an administrator re-creates an account with the same account name, it will not have the same unique ID that was assigned to the original account. Therefore, the administrator would still be unable to access resources owned by the original account.
Organizations should adopt formal policies on account revocation. These policies should be implemented as part of any employee termination policy.
Role Definition
Role definition is the process of establishing what roles are needed and documenting the permissions and privileges of those roles. Roles may be organizational or departmental. Roles will then need to be created and assigned the appropriate rights.
After roles are defined and created, user or group accounts must be assigned to the roles. It is important that security professionals ensure that appropriate procedures are in place for adding users or groups to roles. However, having procedures in place for removing users or groups from roles is just as important. These procedures also act as a protection against privilege creep, mentioned earlier.
Regular monitoring of the roles should occur to ensure that a particular role is assigned only to those accounts that belong in that role and that all created roles are still valid. Roles can be created in applications, devices, and computers.
Privilege Escalation
Privilege escalation, also referred to as privilege creep or permissions creep, is a situation in which a user account has accumulated permissions over time, thereby resulting in an account with unnecessary elevated permissions and privileges. It most often is the result of a user being granted new permissions without having current permissions examined and revoked as needed. User accounts with this condition are a security hole just waiting for an attacker to exploit.
Two types of privilege escalation can occur: horizontal and vertical. In horizontal privilege escalation, a hacker uses the privilege escalation account to access other accounts that have the same permissions. In vertical privilege escalation, a valid user or hacker uses the privilege escalation account to obtain more privileges, such as through a system or administrative account. This is the most worrying form of privilege escalation because the hacker can cause immense system damage, change account settings, access sensitive and confidential information, and even disseminate malware throughout the network.
Managed service accounts should be carefully monitored for privilege escalation. Because these accounts are critical to the operation of the service, security administrators are often reluctant to remove permissions.
In addition, privilege escalation may result in the compromise of an administrator-level account. It is important that users use their account with administrator-level permissions only when tasks that require those permissions must be completed. In other cases, they should use the lower-level account. This includes the default Administrator account in Windows and the root account in Linux.
When it comes to working with Linux, there are two ways to run administrative applications: (1) change over to the super user, also known as the root account, using the su command with a known password for the root or super user account, or (2) use the sudo command. With the sudo command, the user uses their regular or another user account but with root privilege. However, with the su command, the user is actually logged in to the root account. Also, the root privilege in the sudo command is valid only for a temporary amount of time. When that time expires, the user has to input a password again to regain root privilege.
Security professionals should ensure that use of the su command is greatly restricted. While the sudo command is a better choice, users should still use it only when it is strictly necessary.
Access Control Threats
Access control threats directly impact the confidentiality, integrity, and availability of organizational assets. The purpose of most access control threats is to cause harm to an organization. Because harming an organization is easier to do from within its network, outsiders usually first attempt to attack any access controls that are in place.
Access control threats that security professionals should understand include
Password threats
Social engineering threats
DoS/DDoS
Buffer overflow
Mobile code
Malicious software
Spoofing
Sniffing and eavesdropping
Emanating
Backdoor/trapdoor
Password Threats
A password threat is any attack that attempts to discover user passwords. The two most popular password threats are dictionary attacks, brute-force attacks, birthday attacks, rainbow table attacks, and sniffer attacks.
The best countermeasures against password threats are to implement complex password policies, require users to change passwords on a regular basis, employ account lockout policies, encrypt password files, and use password-cracking tools to discover weak passwords.
Dictionary Attack
A dictionary attack occurs when attackers use a dictionary of common words to discover passwords. An automated program uses the hash of the dictionary word and compares this hash value to entries in the system password file. Although the program comes with a dictionary, attackers also use extra dictionaries that are found on the Internet.
You should implement a security rule that says that a password must not be a word found in the dictionary file to protect against these attacks. You can also implement an account lockout policy so that an account is locked out after a certain number of invalid login attempts.
Brute-Force Attack
Brute-force attacks are more difficult to carry out because they work through all possible combinations of numbers and characters. A brute-force attack is also referred to as an exhaustive attack. It carries out password searches until a correct password is found. These attacks are also very time-consuming.
Birthday Attack
A birthday attack compares the values that attackers have against a set of password hashes for which they know the passwords. Eventually, the attackers will find a password that matches. To protect against birthday attacks, implement encryption on the transmission. The attack gets its name from the likelihood of a group of users using the same password, similar to the likelihood of a group of users assembled in a room, having the same birthday, often referred to as the birthday paradox.
Rainbow Table Attack
A rainbow table attack is similar to a birthday attack in that comparisons are used against known hash values. However, in a rainbow attack, a rainbow table is used that contains the cryptographic hashes of passwords. Using an up-to-date hashing algorithm (versus one that is outdated) is the first step in protecting against this type of attack. Salting is the process of randomizing each hash by adding random data that is unique to each user to their password hash, so even the same password has a unique hash.
Sniffer Attack
A sniffer attack in the context of password attacks simply uses a sniffer to capture an unencrypted or plaintext password. Security professionals should periodically use sniffers to see whether they can determine passwords using these tools. Encryption of the password transmission prevents this type of attack.
Social Engineering Threats
Social engineering attacks occur when attackers use believable language and user gullibility to obtain user credentials or some other confidential information. Social engineering threats that you should understand include phishing/pharming, shoulder surfing, identity theft, and dumpster diving.
The best countermeasure against social engineering threats is to provide user security awareness training. This training should be required and must occur on a regular basis because social engineering techniques evolve constantly.
Phishing/Pharming
Phishing is a social engineering attack in which attackers try to learn personal information, including credit card information and financial data. This type of attack is usually carried out by implementing a fake website that very closely resembles a legitimate website. Users enter data, including credentials, on the fake website, allowing the attackers to capture any information entered. Spear phishing is a phishing attack carried out against a specific target by learning about the target’s habits and likes. Spear phishing attacks take longer to carry out than phishing attacks because of the information that must be gathered. Whaling is a type of phishing that specifically targets high-level executives or other high-profile individuals. Vishing is a type of phishing that uses a phone system or VoIP technologies. The user initially receives a call, text, or email that says to call a specific number and provide personal information such as name, birth date, Social Security number, and credit card information.
Pharming is similar to phishing, but it actually pollutes the contents of a computer’s DNS cache so that requests to a legitimate site are actually routed to an alternate site.
Caution users against using any links embedded in email messages, even if the message appears to have come from a legitimate entity. Users should also review the address bar any time they access a site where their personal information is required to ensure that the site is correct and that SSL is being used, which is indicated by an HTTPS designation at the beginning of the URL address.
Shoulder Surfing
Shoulder surfing occurs when an attacker watches a user enter login or other confidential data. To avoid the attack, a corporation should encourage users to always be aware of who is observing their actions. Implementing privacy screens helps to ensure that data entry cannot be recorded.
Identity Theft
Identity theft occurs when someone obtains personal information, including driver’s license number, bank account number, and Social Security number, and uses that information to assume the identity of the individual whose information was stolen. After the identity is assumed, the attack can go in any direction. In most cases, attackers open financial accounts in the user’s name. Attackers also can gain access to the user’s valid accounts.
Dumpster Diving
Dumpster diving occurs when attackers examine garbage contents to obtain confidential information, such as personnel information, account login information, network diagrams, and organizational financial data.
Organizations should implement policies for shredding documents that contain this information.
DoS/DDoS
A denial-of-service (DoS) attack occurs when attackers flood a device with enough requests to degrade the performance of the targeted device. Some popular DoS attacks include SYN floods and teardrop attacks.
A distributed DoS (DDoS) attack is a DoS attack that is carried out from multiple attack locations. Vulnerable devices are infected with software agents, called zombies. They turn the vulnerable devices into botnets, which then carry out the attack. Because of the geographically distributed bots and the very nature of the attack, identifying all the attacking botnets is virtually impossible. The botnets also help to hide the original source of the attack.
Buffer Overflow
Buffers are portions of system memory that are used to store information. A buffer overflow occurs when the amount of data that is submitted to the application is larger than the buffer can handle. Typically, this type of attack is possible because of poorly written application or operating system code. This attack can result in an injection of malicious code.
To protect against this issue, organizations should ensure that all operating systems and applications are updated with the latest service packs, updates, and patches. In addition, programmers should properly test all applications to check for overflow conditions. Finally, programmers should use input validation to ensure that the data submitted is not too large for the buffer.
Mobile Code
Mobile code is any software that is transmitted across a network to be executed on a local system. Examples of mobile code include Java applets, JavaScript code, and ActiveX controls. Mobile code includes security controls, Java sandboxes, and ActiveX digital code signatures. Malicious mobile code can be used to bypass access controls.
Organizations should ensure that users understand the security concerns of malicious mobile code. Users should download mobile code only from legitimate sites and vendors.
Malicious Software
Malicious software, also called malware, is any software that is designed to perform malicious acts.
The following are the five classes of malware you should understand:
Virus: Any malware that attaches itself to another application to replicate or distribute itself.
Worm: Any malware that replicates itself, meaning that it does not need another application or human interaction to propagate.
Trojan horse: Any malware that disguises itself as a needed application while carrying out malicious actions.
Spyware: Any malware that collects private user data, including browsing history login credentials, website data, or keyboard input.
Ransomware: Any malware that prevents or limits users’ access to their systems or devices. Usually, it forces victims to pay the ransom for the return of system access.
The best defense against malicious software is to implement antivirus and anti-malware software. Today most vendors package these two types of software in the same package. Keeping antivirus and anti-malware software up to date is vital. Doing so includes ensuring that the latest virus and malware definitions are installed.
Spoofing
Spoofing, also referred to as masquerading, occurs when communication from an attacker appears to come from trusted sources. Spoofing examples include IP spoofing and hyperlink spoofing. The goal of this type of attack is to obtain access to credentials or other personal information.
A man-in-the-middle attack uses spoofing as part of the attack. Some security professionals consider phishing attacks as a type of spoofing attack.
Sniffing and Eavesdropping
Sniffing, also referred to as eavesdropping, occurs when an attacker inserts a device or software into the communication medium that collects all the information transmitted over the medium. Network sniffers are used by both legitimate security professionals and attackers.
Organizations should monitor and limit the use of sniffers. To protect against their use, you should encrypt all inbound and outbound traffic on the network.
Emanating
Emanations are electromagnetic signals that are emitted by an electronic device. Attackers can target certain devices or transmission mediums to eavesdrop on communication without having physical access to the device or medium.
The TEMPEST program, initiated by the United States and UK, researches ways to limit emanations and standardizes the technologies used. Any equipment that meets TEMPEST standards suppresses signal emanations using shielding material. Devices that meet TEMPEST standards usually implement an outer barrier or coating, called a Faraday cage or Faraday shield. TEMPEST devices are most often used in government, the military, or in law enforcement.
Backdoor/Trapdoor
A backdoor or trapdoor is a mechanism implemented in many devices or applications that gives the user who uses the backdoor unlimited access to the device or application. Privileged backdoor accounts are the most common method of backdoor that you will see today.
Most established vendors no longer release devices or applications with this security issue. You should be aware of any known backdoors in the devices or applications you manage.
Access Aggregation
Access aggregation is a term that is often used synonymously with privilege creep. Access aggregation occurs when users gain more access across more systems. It can be intentional, as when single sign-on is implemented, or unintentional, when users are granted more rights without first checking and considering the rights that they already have. Privilege or authorization creep occurs when users are given new rights without having their old rights revoked. So privilege creep is actually a subset of access aggregation.
To protect against access aggregation, organizations should implement permissions/rights policies that review an account when permissions or rights changes—both in escalation and de-escalation—are requested. Administrators should ensure that any existing permissions or rights that the user no longer needs are removed. For example, if a user is moving from the accounting department to the sales department, the user account should no longer have permissions or rights to accounting resources.
Security professionals should work with data owners and data custodians to ensure that the appropriate policies are implemented.
Advanced Persistent Threat
An advanced persistent threat (APT) is an attack in which an unauthorized person gains access to a network and remains for a long period of time with the intention being to steal data. An APT does not aim to cause damage to the network or organization. Its main aim is to gain access to valuable information.
After attackers gain access to the network, they usually set up a backdoor. To prevent discovery, the attackers may erase logs (also known as covering their tracks), rewrite code, and employ other sophisticated evasion techniques. Some APTs are so complex that they require a full-time administrator. The attackers will work to establish backdoors with each successful breach of an internal system.
The best method to detect APTs is to look for anomalies or large amounts of data transfers in outbound data.
Prevent or Mitigate Access Control Threats
Because access control threats are so widespread, organizations must do all they can to protect their access control systems, including deploying anti-malware, firewalls, intrusion detection and prevention, and other defense tools. Security professionals should encourage their organizations to deploy the following measures to prevent or mitigate access control threats:
Deploy physical access controls for all systems and devices.
Control and monitor access to password files.
Encrypt password files.
Deploy an enterprisewide strong password policy.
Deploy password masking on all operating systems and applications.
Deploy multifactor authentication.
Deploy account lockout on prolonged inactivity.
Deploy auditing for access controls.
Deploy a user account management policy to ensure that user accounts are created and removed as necessary.
Provide user security awareness training that specifically focuses on access control.
Exam Preparation Tasks
As mentioned in the section “About the CISSP Cert Guide, Fourth Edition” in the Introduction, you have a couple of choices for exam preparation: the exercises here, Chapter 9, “Final Preparation,” and the exam simulation questions in the Pearson Test Prep practice test software.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 5-1 lists a reference of these key topics and the page numbers on which each is found.
Table 5-1 Key Topics for Chapter 5
Key Topic Element | Description | Page Number |
List | Access control process | 536 |
List | Five factors for authentication | 546 |
List | Password types | 547 |
List | Password management considerations | 548 |
List | Physiological characteristics | 552 |
Section | Behavioral Characteristics | 553 |
Section | Biometric Considerations | 554 |
Biometric Enrollment and Authentication Process | 556 | |
Lists | Advantages and disadvantages of SSO | 561 |
Lists | Advantages and disadvantages of Kerberos | 562 |
Kerberos Ticket-Issuing Process | 563 | |
List | Auditing mechanism guidelines | 569 |
NIST SP 800-162 Basic ABAC Scenario | 576 | |
Section | Provisioning Life Cycle | 580 |
List | Five classes of malware | 589 |
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
advanced persistent threat (APT)
attribute-based access control (ABAC)
context-dependent access control
cross-certification federated identity model
discretionary access control (DAC)
federated identity management (FIM)
Lightweight Directory Access Protocol (LDAP)
mandatory access control (MAC)
multifactor authentication (MFA)
role-based access control (RBAC)
Secure European System for Applications in a Multi-vendor Environment (SESAME)
Answer Review Questions
1. Which of the following is not an example of a knowledge authentication factor?
Password
Mother’s maiden name
City of birth
Smart card
2. Which of the following statements about memory cards and smart cards is false?
A memory card can be a swipe card that contains user authentication information.
Memory cards are also known as integrated circuit cards (ICCs).
Smart cards contain memory and an embedded chip.
Smart card systems are more reliable than memory card systems.
3. Which biometric method is most effective as far as accuracy?
Iris scan
Retina scan
Fingerprint
Hand print
4. What is a Type I error in a biometric authentication system?
Crossover error rate (CER)
False rejection rate (FRR)
False acceptance rate (FAR)
Throughput rate
5. Which access control model is a desirable model used by routers and firewalls to control access to secure networks?
Discretionary access control
Mandatory access control
Role-based access control
Rule-based access control
6. Which threat is not considered a social engineering threat?
Phishing
Pharming
DoS attack
Dumpster diving
7. Which of the following statements best describes an IDaaS implementation?
Ensures that any instance of identification and authentication to a resource is managed properly.
Collects and verifies information about an individual to prove that the person who has a valid account is who that person claims to be.
Provides a set of identity and access management functions to target systems on customers’ premises and/or in the cloud.
Exchanges authentication and authorization data between organizations or security domains.
8. Which of the following is an example of multifactor authentication?
Username and password
Username, retina scan, and smart card
Retina scan and finger scan
Smart card and security token
9. You decide to implement an access control policy that requires that users log on from certain workstations within your organization’s facility. Which type of authentication factor are you implementing?
Knowledge factor
Location factor
Ownership factor
Characteristic factor
10. Which threat is considered a password threat?
Buffer overflow
Sniffing
Spoofing
Brute-force attack
11. Which session management mechanisms are often used to manage desktop sessions?
Screensavers and timeouts
FIPS 201.2 and NIST SP 800-79-2
Bollards and locks
KDC, TGT, and TGS
12. Which of the following is a major disadvantage of implementing an SSO system?
Users are able to use stronger passwords.
Users need to remember the login credentials for a single system.
User and password administration are simplified.
If a user’s credentials are compromised, an attacker can access all resources.
13. Which type of attack is carried out from multiple locations using zombies and botnets?
TEMPEST
DDoS
Backdoor
Emanating
14. Which type of attack is one in which an unauthorized person gains access to a network and remains for a long period of time with the intention of stealing data?
APT
ABAC
Access aggregation
FIM
15. Which of the following is a formal process for creating, changing, and removing users that includes user approval, user creation, user creation standards, and authorization?
NIST SP 800-63
Centralized access control
Decentralized access control
Provisioning life cycle
Answers and Explanations
1. d. Knowledge factors are something a person knows, including passwords, mother’s maiden name, city of birth, and date of birth. Ownership factors are something a person has, including a smart card.
2. b. Memory cards are not also known as integrated circuit cards (ICCs). Smart cards are also known as ICCs.
3. a. Iris scans are considered more effective as far as accuracy than retina scans, fingerprints, and hand prints.
4. b. A Type I error in a biometric system is false rejection rate (FRR). A Type II error in a biometric system is false acceptance rate (FAR). Crossover error rate (CER) is the point at which FRR equals FAR. Throughput rate is the rate at which users are authenticated.
5. d. Rule-based access control is a desirable model used by routers and firewalls to control access to networks. The other three types of access control models are not usually implemented by routers and firewalls.
6. c. A denial-of-service (DoS) attack is not considered a social engineering threat. The other three options are considered to be social engineering threats.
7. c. An Identity as a Service (IDaaS) implementation provides a set of identity and access management functions to target systems on customers’ premises and/or in the cloud. Session management ensures that any instance of identification and authentication to a resource is managed properly. A proof of identity process collects and verifies information about an individual to prove that the person who has a valid account is who that person claims to be.
8. b. Using a username, retina scan, and smart card is an example of multifactor authentication. The username is something you know, the retina scan is something you are, and the smart card is something you have.
9. b. You are implementing a location factor, which is based on where a person is located when logging in.
10. d. A brute-force attack is considered a password threat.
11. a. Desktop sessions can be managed through screensavers, timeouts, logon, and schedule limitations. FIPS PUB 201.2 and NIST SP 800-79-2 are documents that provide guidance on proof of identity. Physical access to facilities can be provided securely using locks, fencing, bollards, guards, and CCTV. In Kerberos, the Key Distribution Center (KDC) issues a ticket-granting ticket (TGT) to the principal. The principal sends the TGT to the ticket-granting service (TGS) when the principal needs to connect to another entity.
12. d. If a user’s credentials are compromised in a single sign-on (SSO) environment, attackers have access to all resources to which the user has access. All other choices are advantages to implementing an SSO system.
13. b. A distributed DoS (DDoS) attack is a DoS attack that is carried out from multiple attack locations. Vulnerable devices are infected with software agents, called zombies. They turn the vulnerable devices into botnets, which then carry out the attack. Devices that meet TEMPEST standards implement an outer barrier or coating, called a Faraday cage or Faraday shield. A backdoor or trapdoor is a mechanism implemented in many devices or applications that gives the user who uses the backdoor unlimited access to the device or application. Emanations are electromagnetic signals that are emitted by an electronic device. Attackers can target certain devices or transmission mediums to eavesdrop on communication without having physical access to the device or medium.
14. a. An advanced persistent threat (APT) is an attack in which an unauthorized person gains access to a network and remains for a long period of time with the intention of stealing data. Attribute-based access control (ABAC) grants or denies user requests based on arbitrary attributes of the user and arbitrary attributes of the object, and environment conditions that may be globally recognized. Access aggregation is a term that is often used synonymously with privilege creep. Access aggregation occurs when users gain more access across more systems. In federated identity management (FIM), each organization that joins the federation agrees to enforce a common set of policies and standards. These policies and standards define how to provision and manage user identification, authentication, and authorization.
15. d. The provisioning life cycle is a formal process for creating, changing, and removing users. This process includes user approval, user creation, user creation standards, and authorization. Users should sign a written statement that explains the access conditions, including user responsibilities. NIST SP 800-63 provides a suite of technical requirements for federal agencies implementing digital identity services, including an overview of identity frameworks; and using authenticators, credentials, and assertions in digital systems. In centralized access control, a central department or personnel oversee the access for all organizational resources. This administration method ensures that user access is controlled in a consistent manner across the entire enterprise. In decentralized access control, personnel closest to the resources, such as department managers and data owners, oversee the access control for individual resources.