
Chapter 23. FinOps for the Container World
To support the adoption of microservice architectures, containers have gained popularity. Over the last few years, the number of container environments being run by organizations has rapidly increased. Managing a single running container instance is quite simple, but running hundreds, thousands, or tens of thousands of containers across many server instances becomes difficult. Thus, along came orchestration solutions like Kubernetes, which enable DevOps teams to maintain the configuration and orchestrate the deployment and management of fleets of containers.
Since containers and container orchestrators are becoming a popular choice for many teams, it’s vital to understand the fundamental impact of these containerized workloads on FinOps practices.
The most important reason this impacts FinOps so much is that most container environments are complex shared environments. Shared resources like containers—which run on shared cloud compute instances—cause challenges with cost allocation, cost visibility, and resource optimization. In the containerized world, traditional FinOps cost allocation doesn’t work the way it does with just virtual machines (VMs). You can’t simply allocate the cost of a resource to a tag or label, because each cloud or on-premises resource may be running a constantly shifting set of multiple containers, each supporting a different application. They also may be attached to different cost centers around the organization. Not to worry, though. In this chapter we’ll look at changes and adjustments that will allow you to successfully operate your FinOps practice in the container world.
Containers 101
Let’s quickly run through the basics for anyone not familiar with containers. It will also be helpful to create a common understanding of these components throughout this chapter.
Containers are, quite simply, a way to package software. All of the requirements and settings are baked into a deployable image. Container orchestration tools like Kubernetes help engineers deploy containers to servers in a manageable and maintainable way.
There are a few key terms we will use throughout this chapter:
- Image
- A snapshot of a container with the software that needs to be run.
- Container
- An instance of a container image; you can have multiple copies of the same image running at the same time.
- Server instance/node
- A server (e.g., EC2 instance, VM, physical server).
- Pod
- This is a Kubernetes concept. A pod consists of at least one container but can also contain a group of containers and treats them as a single block of resources that can be scheduled and scaled on the cluster.
- Container orchestration
- An orchestrator manages the cluster of server instances and also maintains the lifecycle of containers/pods. Part of the container orchestrator is the scheduler, which schedules a container/pod to run on a server instance. Examples include Kubernetes or AWS Elastic Container Service (ECS).
- Cluster
- A group of server instances, managed by container orchestration.
- Namespace
- Another Kubernetes concept, a namespace is a mechanism for isolating groups of resources within a single cluster where pods/containers can be deployed separately from other namespaces.
A Kubernetes cluster (see Figure 23-1) consists of a number of nodes (server instances) that run containers inside pods. Each pod can be made up of a varying number of containers. The nodes themselves support namespaces used to isolate groups of pods.

Figure 23-1. Basic view of a Kubernetes cluster
The Move to Container Orchestration
Engineers make the decision to move to containers for a multitude of reasons including availability, reliability, scalability, and ease of management. Remember, FinOps is about making sure that you are doing what’s best for the business, continuously balancing between cost and technical needs. Cost is not the only driver for the migration to containers, but having the ability to cost out an application in a container model and a VM model (with all attendant costs and implications on both sides) is helpful context to provide the business.
When you change from a large number of individual cloud server instances to a cluster orchestration solution like Kubernetes, you usually end up with a smaller number of larger servers. By packing multiple container workloads into these larger servers (also known as bin packing), you can gain efficiency through better resource utilization by running many containers isolated on the same node.
An analogy might help you picture this idea: each server instance in a cluster is like a game of Tetris. Containers are the blocks of different shapes and sizes, and the container orchestrator is trying to place as many of these “blocks” (containers) into the servers as possible.
Platforms like Kubernetes allow you to set different resource guarantees, allowing you to pack more containers onto a server instance, which we’ll cover in more depth later in the chapter.
You lose visibility into the individual costs of each container when running multiple containers on a single server instance, since the cloud service provider will provide billing data only for the usage of the underlying server instance. When a server instance is running multiple containers, you need more information in order to divide up the usage costs.
In other words, each cloud resource that’s shared by multiple workloads needs to have supplemental data, so it can show how much of the cloud resource was used by each workload. Containers do not consume servers equally. Some containers can be configured to use more of a server instance than others. Some containers run for weeks or months. But research shows that most containers often run for short periods, less than 12 hours on average, and some might only run for a few seconds. With different sized containers coming and going at different rates, taking infrequent snapshots of your cluster usage won’t provide sampling sufficient for the detailed cost allocation you need. Detailed data that tracks all the containers as they come and go will help you identify how the individual server costs are to be divided, and how much of the server was used by a container for service A versus a container for service B. You will see what this data looks like in “Container Proportions”.
One of the difficulties collecting this data, though, is the sheer volume of it. The cloud billing data files are already extremely large, but you may have many times the number of containers as VMs, and each one may shift around from resource to resource many times, creating a new line of data each time. It is a difficult challenge that requires some specialized tooling if you aim to solve it in a detailed and granular way.
FinOps practitioners need to prepare teams for the impact of shared resources on cost visibility and cost allocation processes. It’s vital to have a clear understanding of the requirements needed to maintain successful FinOps practices in the container world, and then to be sure they get implemented by the DevOps team.
The Container FinOps Lifecycle
When you look at the challenges that containerization poses for FinOps—cost visibility, cost showback/chargeback, and cost optimization—you quickly realize that you’re encountering the same difficulties you faced as you moved into the cloud. Containers represent another layer of virtualization, also called containerization, on top of cloud virtualization. While this might feel like you have moved backward, keep in mind that you have already accumulated all the knowledge, processes, and practices necessary to solve these challenges. You simply need to base your approach on how you solved for the cloud in the first place.
Therefore, you can divide the containerization FinOps challenges into the same inform, optimize, and operate lifecycle that you applied to the broader cloud FinOps.
Container Inform Phase
Your first focus should be to generate reporting that enables you to determine the cost of individual containers on the clusters that teams are operating. In other words, you need to build visibility into your container spending.
Cost Allocation
You will be charged by a cloud service provider for every server instance that makes up a cluster. When containers are deployed into a cluster, they consume some amount of the cluster’s resource capacity, such as CPU, memory, and storage. Even if the processes inside the container don’t consume all of what was provisioned for that container, in some cases it blocks other containers from using this capacity, and therefore you have to pay for it. It’s just like when you provision a server with your cloud service provider. You pay for that server resource, whether you use it or not. The network traffic costs from and to your services is a challenge on its own and should be included as well. Network costs attributed to a single node or server instance may be supporting a number of containers, and the related costs will need to be split up by each individual container’s usage. Network becomes a form of shared costs that require an equitable distribution model, ideally by evaluating the actual network traffic volume of each container and allocating the network costs based on these amounts.
To allocate the individual costs of a container that runs on a cluster, you’ll need some way to determine how much of the underlying server the individual container consumed. We’ll cover this more in the next section.
You also need to take into account the satellite costs of a running cluster. Management nodes, data stores used to track cluster states, software licensing, backups, and disaster recovery costs are part of your cost allocation strategies. These overhead costs are all part of running clusters and must be taken into account in your cost allocation strategy.
Container Proportions
The biggest issue with governing clusters is that you’re sharing underlying resources, so you can’t get complete visibility into allocation by using your cloud bill alone. Remember, a cloud service provider can only observe metrics provided by the VM hypervisors, not operating systems or processes, unless you’re using their managed service offerings. This lack of visibility means providers are unable to track your containers and how much of the server they use. So for your FinOps team to divide the underlying server costs out to the right teams and services, you need the teams who run the container clusters to report on which containers are running on each server instance. By recording the proportion each container is using of each of your servers, you can enrich your cloud billing data.
Custom container proportions
Measuring the proportion consumed by each container of the underlying cloud server instance is a complex process. But you can start by using the amount of vCPU and memory used.
Table 23-1 shows an example to help you understand this data.
In the table, there’s a server instance with four vCPU and 8 GB memory that costs $1 per hour. This server is part of a cluster, and during a particular hour runs containers 1–4.
| ServerID | Container ID | Service label | vCPU | Mem (GB) | Time (mins) | Proportion |
|---|---|---|---|---|---|---|
| i-123456 | 1 | A | 1 | 2 | 60 | 25% |
| i-123456 | 2 | A | 1 | 2 | 60 | 25% |
| i-123456 | 3 | B | 0.5 | 1 | 60 | 12.5% |
| i-123456 | 4 | C | 1 | 2 | 15 | 6.25% |
The proportion calculation appears pretty simple when you look at containers 1 and 2. They use a quarter of the vCPU and memory for the whole billing hour, so you allocate a quarter of the server costs. As both of these containers are running for the same service (A), you allocate 50% of the server costs to service A.
Container 3 appears to have a similar story. However, this time it’s using even less of the server.
When you get to container 4, you see that it’s using 25% of the server instance, but this time only for 15 minutes of the hour (25%). That reduces its proportion data when you multiply it by the time: 0.25 × 0.25 = 6.25%.
There are cases where the proportion of metrics isn’t neatly symmetrical to the underlying server, which causes problems when you are calculating the proportions. We’ve seen two main approaches for solving this issue:
- Most impactful metric
- If a container uses more vCPU than memory, that ratio is used to calculate the proportion.
- Weighted metrics
- Weight the metrics (vCPU, memory, etc.) first and then use them to calculate the proportions.
While we recommend starting with vCPU and memory, they’re not the only metrics that could be important when you’re determining the proportions for your containers. You may need to take into account other metrics, such as local disk usage, GPU, and network bandwidth. Depending on the types of workloads scheduled onto a cluster, the overall metric weighting that is most relevant to specific clusters could be different. It is also important to note that with Kubernetes there is a difference between requested resources and consumed. Often a pod will use fewer resources than it requests, but the opposite can also occur. When measuring the proportions of usage, we recommend you use the greater of the requested resources and the consumed resources by the workload.
Even if you allocate the costs of your clusters in the previous manner, you can still end up with unallocated capacity costs. It’s unlikely your clusters will be 100% used—or requested—all of the time by the running containers, which leaves excess capacity that has not been allocated—nor is it being used.
Figure 23-2 shows a single server instance that has an hourly cost of $40. On this node there are two running containers. Team A and B get allocated $15 and $11 of the costs, respectively, even though some amount of their requested capacity within their container is unused and could be considered waste. There is still $14 of spare node capacity (allocatable capacity) on the server instance that needs to be assigned to someone’s budget.
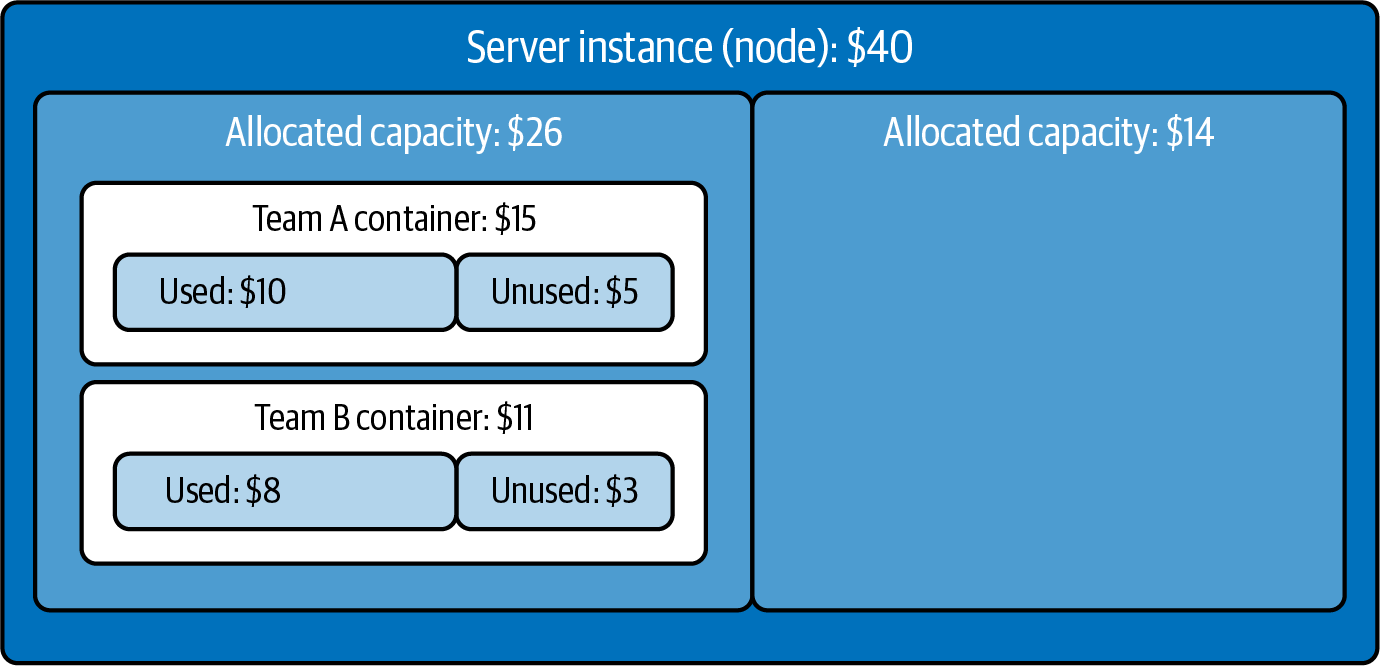
Figure 23-2. Unallocated capacity on a server instance/node
We have not yet seen a standard approach to allocating the excess, allocatable node capacity. One option is to have the team managing the server instance itself cover the cost; another is to spread the cost of the allocatable node capacity equitably between all the containers within the node based on their respective proportion of usage of the overall node.
Tip
Reserved capacity is a soft limit, and pods are able to exceed its set limits if there is additional allocatable capacity remaining within the node. As such, the amount of capacity that a pod consumes can be more than 100% of its reserved capacity. This means that the pod’s portion of the overall node’s costs would increase during the period of use, and less of the unreserved node capacity would be left unused.
This leaves the question of who should pay for the excess capacity: the team managing the cluster or the teams who own the workloads running on the server instances?
Having spent time with organizations that are successfully allocating their container costs, we’ve identified two main strategies for assigning these unallocated costs when they exist:
- Assigning the idle costs to a central team (recommended option)
Since you need an allocation strategy to make sure that your cluster costs can be 100% allocated, some organizations take those excess capacity costs and assign them to the team that runs the cluster. These teams have their budget and forecasts on cluster costs, so by mapping the excess capacity costs to them, you incentivize the group to optimize the container scheduling, reduce the size of the cluster as permitted by the workload, and keep cluster waste to a minimum, thereby reducing those excess capacity costs.
The team running and administering the cluster gets visibility into the allocatable costs on cluster/node level. In most cases the actual usage through the deployed services/pods is dependent on the resource requests that are set by the actual users like the platform team running the platform services for everyone and the developer teams with their respective applications. The platform team is positioned best to rightsize the cluster, switch to other instance types, or set up a cluster autoscaler to overall reduce the allocatable costs by better sizing the cluster, which increases efficient utilization of the cluster’s resources.
David Sterz, Mindcurv, Container Cost Allocation Working Group lead
- Distributing the idle costs to the teams using the cluster (alternative option)
- The second strategy is to distribute the excess capacity costs to the teams running containers on the cluster. You determine what gets distributed, and where, by using the same proportion data you use to allocate the costs of the containers. This method avoids the need for a central catch-all budget for the excess capacity costs.
Before deciding on an approach for allocating the excess capacity costs, we recommend you engage both the teams running the clusters and the teams consuming the clusters, so you can reach agreement on how to proceed.
Container proportions in Google Cloud
When you use custom machine types, Google Cloud charges for vCPU and memory separately, so if these are the metrics you’re going to use for container cost allocation, you don’t need to determine the proportion of the underlying server consumed by a container. If you record just the vCPU and memory allocated to each container that runs on your cluster, you can use the normal Google Cloud pricing table to allocate charges to each container. Your total cluster costs will be represented as an overall vCPU and memory charge. When you subtract the recorded container costs from these values, you are left with the unused cluster costs.
When you are using predefined machine types, however, you will need to record custom proportion data for each container, as previously discussed.
Tags, Labels, and Namespaces
Like server instances, containers without any identifiers make it hard from the outside to determine what is what. Realistically, you could end up with hundreds or even thousands of small containers. Having a tagging/labeling strategy will enable you to categorize your usage. Remember, you deal with containers in the same FinOps pattern as native cloud, which we hope you are getting used to by now. So it’s not surprising that your standard cloud tagging strategy will apply nicely to containers.
In the container world, you can tag/label your containers. These tags form the identification that you use to allocate costs. Namespaces allow you to group resources within a single cluster. Creating namespaces for teams, or for specific services, allows you to create a coarse-grained cost allocation group.
Containers or pods themselves can also be labeled when they are launched, providing a more fine-grained cost allocation mechanism if needed, though the ability to see these labels and divide cost with them is done with tools outside the cloud billing data.
Container Optimize Phase
Like the inform phase, the optimize phase in the container world is a direct adaptation of your original FinOps practices built for cloud platforms.
At first glance, it might seem that containerization solves the rightsizing problem. After all, having more things running on the same server instance appears more cost-effective. But as you’ve seen so far, it’s a complex task to measure whether or not you are getting savings from your clusters.
We have heard FinOps practitioners state, “Now that you’ve moved to containers, you don’t need to rightsize.” Or “Idle resources are no longer an issue.” While there are some elements of truth to these statements, they don’t tell the full story. Let’s take a look at how your FinOps practices have to evolve in order to be successful.
Cluster Placement
If you run all of your containers within one cluster, you may not be able to optimize the cluster for different environments. Running development containers on spot instances, or in a region that is closer to developers, is easier when they run on a development-specific cluster. And further, it helps if you run this development cluster in a development account separate from production.
The alternative is to run multiple clusters, but running too many clusters can be hard to manage and isn’t cost-efficient. Each cluster will have management overhead, both in terms of cloud resources and staff time needs. In addition, it’s harder to maximize cluster utilization when you have workloads spread out over many clusters. The more containers are spread across clusters, the less chance containers will fill your running servers, which means lower utilization.
Finding a balance here is just as important as finding the balance of accounts for the cloud resources that we discussed previously. Working alongside the teams that are managing and using your clusters is the best method of finding the happy medium between smaller domain-specific clusters and larger general clusters within your organization.
Container Usage Optimization
Now we’ll work through adapting the usage optimizations discussed in a broader optimize phase of the FinOps lifecycle.
Tip
There is a shared responsibility model for optimizing containers: centralized teams running the cluster are responsible for the sizing of the cluster, including horizontal/vertical rightsizing and workload placement, whereas teams running containers within the cluster are responsible for setting and using the appropriate amount of requested or guaranteed capacity.
Centralize the rightsizing of clusters
The responsibility for the optimizations in this section typically falls to the centralized teams managing the clusters and server instances.
If you find that your clusters aren’t cost-efficient, the most likely causes are poor scheduling and underutilized cluster resources. Cluster instances that remain running after all running containers have stopped, or only one or a few containers running on a large cluster instance, will mean that the instance is largely underutilized—leading to higher costs per cluster and a need to rightsize.
In the container world, there are multiple strategies that need to be applied by your central cluster management team for rightsizing:
- Horizontal rightsizing
- This refers to how well you pack your containers onto your server instances. The tighter things are packed together, the fewer server instances you need to run at a given point in time. When this is done correctly, your clusters can scale in the number of instances needed while realizing cost savings by avoiding running server instances that you don’t need. Container orchestrators should be looking for opportunities to relocate containers to increase utilization of server instances while freeing up server instances that can be removed from the cluster—using autoscaling—when the load drops. Tracking the amount of unused cluster capacity over time allows you to measure changes in the scheduling engines. If you then update/tune the scheduler so that it manages to pack your containers onto fewer server instances, you can measure the increased efficiency.
- Vertical rightsizing
- This refers to changing the size of server instances. While you should expect a container orchestrator to pack your containers onto as few servers as possible, there are other factors to consider. For high availability, some containers should be running on different underlying server instances. If this leaves your server instances underutilized, resizing the server instances to use less vCPU and memory will lower costs.
- Workload matching
- If your container workloads aren’t matching your vCPU-to-memory ratio (using more memory than vCPU, for example), then there’s no memory for a container to use when there is free server vCPU. When your data tells you that your server’s balance between vCPU and memory doesn’t match your container workload, you can run a server instance type that is a better match (e.g., one with more memory per vCPU) at a reduced hourly rate, thereby lowering costs. It is possible to use a mix of server configurations within the cluster and assign workloads to the servers that best match the container workload.
Decentralize the rightsizing of containers/pods
Teams running containers within a pod are responsible for correctly sizing their requests of capacity from the clusters.
Even within containers that have been efficiently bin packed, there’s a risk that individual containers scheduled onto your clusters will be inactive. As you now know, containers consume a portion of cluster resources, so if a container is larger than needed, it will be less cost-efficient.
Instead of tracking server utilization metrics looking for idle server instances, teams are now required to track container utilization metrics to identify unused container instances. Again, similar concepts used to address idle server instances apply to containers.
Cluster orchestration solutions like Kubernetes allow you to request different resource class allocations on the scheduled containers called quality of service (QoS) classes. Each QoS class brings with it different models for allocating capacity and affecting the related allocation of costs:
- Guaranteed resource allocation
- For critical service containers, you might use guaranteed resource allocation to ensure that a set amount of vCPU and memory is available to the pod at all times. You can think of guaranteed resource allocation as reserved capacity. The size and shape of the container do not change. This class has the highest potential for idle costs for containers when set to high and the actual usage is low.
- Burstable resource allocation
- Spiky workloads can benefit from having access to more resources only when required, letting the pod use more resources than initially requested when the capacity is available on the underlying server instance. Burstable resource allocation is more like the burstable server instances offered by some cloud service providers (burstable performance instances like the T3 from AWS or the F4 from Google Cloud), which give you a base level of performance but allow the pod to burst when needed. While this is an easy way to start, more cost-efficient with a low request on resources but no limits, it can also lead to spiky unforeseeable resource consumption that can harm other workloads or a decrease in service performance due to the lack of available resources.
- Best-effort resource allocation
- Additionally, development/test containers can use best-effort resource allocation, which allows the pod to run while there is excess capacity but stops it when there isn’t. This class is similar to preemptible VMs in Google Cloud or spot instances in AWS. From a purely cost-efficient point of view, that class is the best as it has zero idle costs; however, there is absolutely no guarantee resources will be available at any time, and it should be used with caution for only specific workloads on production systems.
When the container orchestrator allocates a mix of pods with different resource allocation guarantees onto each server instance, you get higher server instance utilization. You can allocate a base amount of resources to fixed resource pods, along with some burstable pods that may use up the remainder of the server resources, and some best-effort pods to use up any spare capacity that becomes available.
Server Instance Rate Optimization
Unless you are using serverless clusters—which we will look into next—your clusters are made up of regular cloud server instances.
If your clusters run a lot of best-effort or restartable pods, there’s the option to run part of the cluster with spot instances. Spot instances let you take advantage of possibly massive savings from your cloud service provider. But running them inside a cluster requires you to consider the added risk that your server instances—and the pods they’re running—could be stopped by the cloud service provider with little notice.
These server instances can be requested, just like any other instance. Just because you run cluster orchestration software like Kubernetes doesn’t mean you should exclude your clusters from normal reservation/commitment programs. Often, we see containerization lead to more stable cloud server instances. Containers can come and go without changing your cloud servers overall. This can mean simpler reservation planning and overall better reservation utilization. Reserving the instances that are running all the time can lead to savings well over 50%, as we discussed in Chapter 17.
Container Operate Phase
As you go through the broader FinOps operate phase in this part of the book, you should consider how many of the operations that you perform at a cloud resource level can be applied to the container world. Scheduling development containers to be turned on and off around business hours, finding and removing idle containers, and maintaining container labels/tags by enforcement are just some of the one-to-one parallels you can draw from the broader FinOps operate phase.
Serverless Containers
Serverless containers, offered by cloud service providers like Fargate for AWS, add an interesting twist to your FinOps strategies around containers. With self-managed clusters you need to consider the cost impact of running more clusters. There’s an added cost and maintenance requirement of management compute nodes for each cluster, which can lead engineering teams to opt for fewer clusters in centralized accounts.
With the cluster management layer being managed by the cloud service provider and the compute nodes being abstracted away from you, there’s less need to centralize your workloads. In the serverless world, tracking the efficiency of the scheduler and measuring how well your containers are being packed onto the cluster instances isn’t an issue. This responsibility has been offloaded to the cloud service provider. Monitoring for overprovisioned containers is still a requirement, however, as today’s offerings for serverless containers allow only certain sizes of vCPU and memory combinations.
Cost allocation is done for you, as each container task is charged directly by the cloud service provider. This is because they can now see what containers are running on the servers. Therefore, the challenge of proportioning costs and dividing shared resources is removed. When a container is running on a server instance inside your account, removing the container creates free space on the cluster but doesn’t reduce costs until the compute node is removed from the cluster altogether. With serverless containers, when they’re removed, you stop being charged.
This may sound like good news, but as with everything in FinOps, there are multiple considerations. For example, having the cloud service provider manage the cluster means there are fewer configuration items that your teams can tune, which might keep you from optimizing the cluster for your workloads.
Conclusion
The problems with containers are similar to the issues you initially face when moving into the cloud, so you can use the existing FinOps practices to solve these issues.
To summarize:
Containerization won’t let you avoid FinOps, given that FinOps principles still apply and that the need to manage costs is just as important for containerized applications.
Unless you’re using the cloud service–managed containerization platforms, you will need to gather supplemental data about how your servers are used by the running containers.
Tracking the proportions of server instances your containers consume and pairing that information with your cloud bill enables true cost allocation.
Containerization does not necessarily mean efficient: monitoring server usage and performing rightsizing and scheduler optimizations will be required.
Serverless orchestration reduces the FinOps overhead of allocating costs, but comes with a high potential for increased costs.
The next chapter digs into the process of building partnerships with your engineering teams.