
Chapter 5
Exploring Data Analysis
IN THIS CHAPTER
![]() Understanding the exploratory data analysis (EDA) philosophy
Understanding the exploratory data analysis (EDA) philosophy
![]() Describing numeric and categorical distributions
Describing numeric and categorical distributions
![]() Estimating correlation and association
Estimating correlation and association
![]() Testing mean differences in groups
Testing mean differences in groups
![]() Visualizing distributions, relationships, and groups
Visualizing distributions, relationships, and groups
“If you torture the data long enough, it will confess.”
— RONALD COASE
Data science relies on complex algorithms for building predictions and spotting important signals in data, and each algorithm presents different strong and weak points. In short, you select a range of algorithms, you have them run on the data, you optimize their parameters as much as you can, and finally you decide which one will best help you build your data product or generate insight into your problem.
It sounds a little bit automatic and, partially, it is, thanks to powerful analytical software and scripting languages like Python. Learning algorithms are complex, and their sophisticated procedures naturally seem automatic and a bit opaque to you. However, even if some of these tools seem like black or even magic boxes, keep this simple acronym in mind: GIGO. GIGO stands for “Garbage In/Garbage Out.” It has been a well-known adage in statistics (and computer science) for a long time. No matter how powerful the machine learning algorithms you use, you won’t obtain good results if your data has something wrong in it.
Exploratory data analysis (EDA) is a general approach to exploring data sets by means of simple summary statistics and graphic visualizations in order to gain a deeper understanding of data. EDA helps you become more effective in the subsequent data analysis and modeling. In this chapter, you discover all the necessary and indispensable basic descriptions of the data and see how those descriptions can help you decide how to proceed using the most appropriate data transformation and solutions.
 You don’t have to type the source code for this chapter manually. In fact, it’s a lot easier if you use the downloadable source available at
You don’t have to type the source code for this chapter manually. In fact, it’s a lot easier if you use the downloadable source available at www.dummies.com/go/codingaiodownloads. The source code for this chapter appears in the P4DS4D; 13; Exploring Data Analysis.ipynb source code file.
The EDA Approach
EDA was developed at Bell Labs by John Tukey, a mathematician and statistician who wanted to promote more questions and actions on data based on the data itself (the exploratory motif) in contrast to the dominant confirmatory approach of the time. A confirmatory approach relies on the use of a theory or procedure — the data is just there for testing and application. EDA emerged at the end of the ’70s, long before the big data flood appeared. Tukey could already see that certain activities, such as testing and modeling, were easy to make automatic. In one of his famous writings, Tukey said
The only way humans can do BETTER than computers is to take a chance of doing WORSE than them.
This statement explains why your role and tools aren’t limited to automatic learning algorithms but also to manual and creative exploratory tasks. Computers are unbeatable at optimizing, but humans are strong at discovery by taking unexpected routes and trying unlikely but very effective solutions.
EDA goes beyond the basic assumptions about data workability, which actually comprises the Initial Data Analysis (IDA). Up to now, the book has shown how to
- Complete observations or mark missing cases by appropriate features.
- Transform text or categorical variables.
- Create new features based on domain knowledge of the data problem.
- Have at hand a numeric data set where rows are observations and columns are variables.
EDA goes further than IDA. It’s moved by a different attitude: going beyond basic assumptions. With EDA, you
- Describe of your data.
- Closely explore data distributions.
- Understand the relations between variables.
- Notice unusual or unexpected situations.
- Place the data into groups.
- Notice unexpected patterns within groups.
- Take note of group differences.
Defining Descriptive Statistics for Numeric Data
The first actions that you can take with the data are to produce some synthetic measures to help figure out what is going in it. You acquire knowledge of measures such as maximum and minimum values, and you define which intervals are the best place to start.
During your exploration, you use a simple but useful data set called the Fisher’s Iris data set, which contains flower measurements of a sample of 150 irises. You can load it from the Scikit-learn package by using the following code:
from sklearn.datasets import load_irisiris = load_iris()
Having loaded the Iris data set into a variable of a custom Scikit-learn class, you can derive a NumPy nparray and a pandas DataFrame from it:
import pandas as pdimport numpy as npprint 'Your pandas version is: %s' % pd.__version__print 'Your NumPy version is %s' % np.__version__iris_nparray = iris.datairis_dataframe = pd.DataFrame(iris.data, columns=iris.feature_names)iris_dataframe['group'] = pd.Series([iris.target_names[k] for k in iris.target], dtype="category") Your pandas version is: 0.16.0Your NumPy version is 1.9.0
NumPy, Scikit-learn, and especially pandas are packages under constant development, so before you start working with EDA, it’s a good idea to check the product version numbers. Using an old version could cause your output to differ from that shown in the book or cause some commands to fail.
 This chapter presents a series of pandas and NumPy commands that help you explore the structure of data. Even though applying single explorative commands grants you more freedom in your analysis, it’s nice to know that you can obtain most of these statistics using the describe method applied to your pandas DataFrame, such as print iris_dataframe.describe(), when you’re in a hurry.
This chapter presents a series of pandas and NumPy commands that help you explore the structure of data. Even though applying single explorative commands grants you more freedom in your analysis, it’s nice to know that you can obtain most of these statistics using the describe method applied to your pandas DataFrame, such as print iris_dataframe.describe(), when you’re in a hurry.
Measuring central tendency
Mean and median are the first measures to calculate for numeric variables when starting EDA. The output from these functions provides an estimate of when the variables are centered and somehow symmetric.
Using pandas, you can quickly compute both means and medians. Here is the command for getting the mean from the Iris DataFrame:
print iris_dataframe.mean(numeric_only=True) sepal length (cm) 5.843333sepal width (cm) 3.054000petal length (cm) 3.758667petal width (cm) 1.198667
Similarly, here is the command that will output the median:
print iris_dataframe.median(numeric_only=True) sepal length (cm) 5.80sepal width (cm) 3.00petal length (cm) 4.35petal width (cm) 1.30
The median provides the central position in the series of values. When creating a variable, the median unlike the mean is a measure less influenced by anomalous cases or by an asymmetric distribution of values. What you should notice here is that the means are not centered (no variable is zero mean) and that the median of petal length is quite different from the mean, requiring further inspection.
When checking for central tendency measures, you should
- Verify whether means are zero.
- Check whether they are different from each other.
- Notice whether the median is different from the mean.
Measuring variance and range
As a next step, you should check the variance by squaring the value of its standard deviation. The variance is a good indicator of whether a mean is a suitable indicator of the variable distribution.
print iris_dataframe.std() sepal length (cm) 0.828066sepal width (cm) 0.433594petal length (cm) 1.764420petal width (cm) 0.763161
In addition, the range, which is the difference between the maximum and minimum value for each quantitative variable, is quite informative.
print iris_dataframe.max(numeric_only=True)-iris_dataframe.min(numeric_only=True) sepal length (cm) 3.6sepal width (cm) 2.4petal length (cm) 5.9petal width (cm) 2.4
Take notice of the standard deviation and the range with respect to the mean and median. A standard deviation or range that is too high with respect to the measures of centrality (mean and median) may point to a possible problem, with extremely unusual values affecting the calculation.
Working with percentiles
Because the median is the value in the central position of your distribution of values, you may need to consider other notable positions. Apart from the minimum and maximum, the position at 25 percent of your values (the lower quartile) and the position at 75 percent (the upper quartile) are useful for figuring how the data distribution works, and they are the basis of an illustrative graph called a boxplot, which is one of the topics covered in this chapter.
print iris_dataframe.quantile(np.array([0,.25,.50,.75,1])) sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)0.00 4.3 2.0 1.00 0.10.25 5.1 2.8 1.60 0.30.50 5.8 3.0 4.35 1.30.75 6.4 3.3 5.10 1.81.00 7.9 4.4 6.90 2.5
The difference between the upper and lower percentile constitutes the interquartile range (IQR), which is a measure of the scale of variables that are of highest interest. You don’t need to calculate it, but you will find it in the boxplot because it helps to determinate the plausible limits of your distribution. What lies between the lower quartile and the minimum, and the upper quartile and the maximum, are exceptionally rare values that can negatively affect the results of your analysis. Such rare cases are outliers.
Defining measures of normality
The last indicative measures of how the numeric variables used for these examples are structured are skewness and kurtosis:
- Skewness defines the asymmetry of data with respect to the mean. If the skew is negative, the left tail is too long and the mass of the observations are on the right side of the distribution. If the skew is positive, the mass of the observations are on the left side of the distribution.
- Kurtosis shows whether the data distribution, especially the peak and the tails, are of the right shape. If the kurtosis is above zero, the distribution has a marked peak. If it is below zero, the distribution is too flat.
Although reading the numbers can help you determine the shape of the data, taking notice of such measures presents a formal test to select the variables that may need some adjustment or transformation in order to become more similar to the Gaussian distribution. Remember that you also visualize the data later, so this is a first step in a longer process.
As an example, the output shown in the “Measuring central tendency” section earlier in this chapter shows that the petal length feature presents differences between the mean and the median. In this section, you test the same example for kurtosis and skewness in order to determine whether the variable requires intervention.
When performing the kurtosis and skewness tests, you determine whether the p-value is less than or equal 0.05. If so, you have to reject normality, which implies that you could obtain better results if you try to transform the variable into a normal one. The following code shows how to perform the required test:
from scipy.stats import kurtosis, kurtosistest k = kurtosis(iris_dataframe['petal length (cm)'])zscore, pvalue = kurtosistest(iris_dataframe['petal length (cm)'])print 'Kurtosis %0.3f z-score %0.3f p-value %0.3f' % (k, zscore, pvalue) Kurtosis -1.395 z-score -14.811 p-value 0.000 from scipy.stats import skew, skewtest s = skew(iris_dataframe['petal length (cm)'])zscore, pvalue = skewtest(iris_dataframe['petal length (cm)'])print 'Skewness %0.3f z-score %0.3f p-value %0.3f' % (s, zscore, pvalue) Skewness -0.272 z-score -1.398 p-value 0.162
The test results tell you that the data is slightly skewed to the left, but not enough to make it unusable. The real problem is that the curve is much too flat to be bell-shaped, so you should investigate the matter further.
It’s a good practice to test all variables for kurtosis and skewness automatically. You should then proceed to inspect those whose values are the highest visually. Non-normality of a distribution may also conceal different issues, such as outliers to groups that you can perceive only by a graphical visualization.
Counting for Categorical Data
The Iris data set is made of four metric variables and a qualitative target outcome. Just as you use means and variance as descriptive measures for metric variables, so do frequencies strictly relate to qualitative ones.
Because the data set is made up of metric measurements (width and lengths in centimeters), you must render it qualitative by dividing it into bins according to specific intervals. The pandas package features two useful functions, cut and qcut, that can transform a metric variable into a qualitative one:
- cut expects a series of edge values used to cut the measurements or an integer number of groups used to cut the variables into equal-width bins.
- qcut expects a series of percentiles used to cut the variable.
You can obtain a new categorical DataFrame using the following command, which concatenates a binning for each variable:
iris_binned = pd.concat([pd.qcut(iris_dataframe.ix[:,0], [0, .25, .5, .75, 1]),pd.qcut(iris_dataframe.ix[:,1], [0, .25, .5, .75, 1]),pd.qcut(iris_dataframe.ix[:,2], [0, .25, .5, .75, 1]),pd.qcut(iris_dataframe.ix[:,3], [0, .25, .5, .75, 1]),], join='outer', axis = 1)
This example relies on binning. However, it could also help to explore when the variable is above or below a singular hurdle value, usually the mean or the median. In this case, you set pd.qcut to the 0.5 percentile or pd.cut to the mean value of the variable.
Binning transforms numerical variables into categorical ones. This transformation can improve your understanding of data and the machine learning phase that follows by reducing the noise (outliers) or nonlinearity of the transformed variable.
Understanding frequencies
You can obtain a frequency for each categorical variable of the data set, both for the predictive variable and for the outcome, by using the following code:
print iris_dataframe['group'].value_counts() virginica 50versicolor 50setosa 50 print iris_binned['petal length (cm)'].value_counts() [1, 1.6] 44(4.35, 5.1] 41(5.1, 6.9] 34(1.6, 4.35] 31
This example provides you with some basic frequency information as well, such as the number of unique values in each variable and the mode of the frequency (top and freq rows in the output).
print iris_binned.describe() sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)count 150 150 150 150unique 4 4 4 4top [4.3, 5.1] [2, 2.8] [1, 1.6] [0.1, 0.3]freq 41 47 44 41
Frequencies can signal a number of interesting characteristics of qualitative features:
- The mode of the frequency distribution that is the most frequent category
- The other most frequent categories, especially when they are comparable with the mode (bimodal distribution) or if there is a large difference between them
- The distribution of frequencies among categories, if rapidly decreasing or equally distributed
- Rare categories that gather together
Creating contingency tables
By matching different categorical frequency distributions, you can display the relationship between qualitative variables. The pandas.crosstab function can match variables or groups of variables, helping to locate possible data structures or relationships.
In the following example, you check how the outcome variable is related to petal length and observe how certain outcomes and petal binned classes never appear together:
print pd.crosstab(iris_dataframe['group'], iris_binned['petal length (cm)']) petal length (cm) (1.6, 4.35] (4.35, 5.1] (5.1, 6.9] [1, 1.6]groupsetosa 6 0 0 44versicolor 25 25 0 0virginica 0 16 34 0
 The pandas.crosstab function ignores categorical variable ordering and always displays the row and column categories according to their alphabetical order. This nuisance is still present in the pandas version used for this book, 0.16.0, but it may be resolved in the future.
The pandas.crosstab function ignores categorical variable ordering and always displays the row and column categories according to their alphabetical order. This nuisance is still present in the pandas version used for this book, 0.16.0, but it may be resolved in the future.
Creating Applied Visualization for EDA
Up to now, the chapter has explored variables by looking at each one separately. Technically, if you’ve followed along with the examples, you have created a univariate (that is, you’ve paid attention to stand-alone variations of the data only) description of the data. The data is rich in information because it offers a perspective that goes beyond the single variable, presenting more variables with their reciprocal variations. The way to use more of the data is to create a bivariate (seeing how couples of variables relate to each other) exploration. This is also the basis for complex data analysis based on a multivariate (simultaneously considering all the existent relations between variables) approach.
If the univariate approach inspected a limited number of descriptive statistics, then matching different variables or groups of variables increases the number of possibilities. The different tests and bivariate analysis can be overwhelming, and using visualization is a rapid way to limit test and analysis to only interesting traces and hints. Visualizations, using a few informative graphics, can convey the variety of statistical characteristics of the variables and their reciprocal relationships with greater ease.
Inspecting boxplots
Boxplots provide a way to represent distributions and their extreme ranges, signaling whether some observations are too far from the core of the data — a problematic situation for some learning algorithms. The following code shows how to create a basic boxplot using the Iris data set:
boxplots = iris_dataframe.boxplot(return_type='axes')
In Figure 5-1, you see the structure of each variable’s distribution at its core, represented by the 25° and 75° percentile (the sides of the box) and the median (at the center of the box). The lines, the so-called whiskers, represent 1.5 times the IQR (difference between upper and lower quartile) from the box sides (or by the distance to the most extreme value, if within 1.5 times the IQR). The boxplot marks every observation outside the whisker, which is deemed an unusual value.

FIGURE 5-1: A boxplot arranged by variables.
Boxplots are also extremely useful for visually checking group differences. Note in Figure 5-2 how a boxplot can hint that the three groups, setosa, versicolor, and virginica, have different petal lengths, with only partially overlapping values at the fringes of the last two of them.

FIGURE 5-2: A boxplot arranged by groups.
Performing t-tests after boxplots
After you have spotted a possible group difference relative to a variable, a t-test (you use a t-test in situations in which the sampled population has an exact normal distribution) or a one-way analysis of variance (ANOVA) can provide you with a statistical verification of the significance of the difference between the groups’ means.
from scipy.stats import ttest_indgroup0 = iris_dataframe['group'] == 'setosa'group1 = iris_dataframe['group'] == 'versicolor'group2 = iris_dataframe['group'] == 'virginica'print 'var1 %0.3f var2 %03f' % (iris_dataframe['petal length (cm)'][group1].var(), iris_dataframe['petal length (cm)'][group2].var()) var1 0.221 var2 0.304588
The t-test compares two groups at a time, and it requires that you define whether the groups have similar variance or not. So it is necessary to calculate the variance beforehand, like this:
t, pvalue = ttest_ind(iris_dataframe[sepal width (cm)'][group1], iris_dataframe['sepal width (cm)'][group2], axis=0, equal_var=False)print 't statistic %0.3f p-value %0.3f' % (t, pvalue) t statistic -3.206 p-value 0.002
You interpret the pvalue as the probability that the calculated t statistic difference is just due to chance. Usually, when it is below 0.05, you can confirm that the groups’ means are significantly different.
You can simultaneously check more than two groups using the one-way ANOVA test. In this case, the pvalue has an interpretation similar to the t-test:
from scipy.stats import f_onewayf, pvalue = f_oneway(iris_dataframe['sepal width (cm)'][group0], iris_dataframe['sepal width (cm)'][group1], iris_dataframe['sepal width (cm)'][group2])print "One-way ANOVA F-value %0.3f p-value %0.3f" % (f,pvalue) One-way ANOVA F-value 47.364 p-value 0.000
Observing parallel coordinates
Parallel coordinates can help spot which groups in the outcome variable you could easily separate from the other. It is a truly multivariate plot, because at a glance it represents all your data at the same time. The following example shows how to use parallel coordinates.
from pandas.tools.plotting import parallel_coordinatesiris_dataframe['labels'] = [iris.target_names[k] for k iniris_dataframe['group']]pll = parallel_coordinates(iris_dataframe,'labels')
As shown in Figure 5-3, on the x-axis, you find all the quantitative variables aligned. On the y-axis, you find all the observations, carefully represented as parallel lines, each one of a different color given its ownership to a different group.

FIGURE 5-3: Parallel coordinates anticipate whether groups are easily separable.
If the parallel lines of each group stream together along the visualization in a separate part of the graph far from other groups, the group is easily separable. The visualization also provides the means to assert the capability of certain features to separate the groups.
Graphing distributions
You usually render the information that boxplot and descriptive statistics provide into a curve or a histogram, which shows an overview of the complete distribution of values. The output shown in Figure 5-4 represents all the distributions in the data set. Different variable scales and shapes are immediately visible, such as the fact that petals’ features display two peaks.
densityplot = iris_dataframe[iris_dataframe.columns[:4]].plot(kind='density')

FIGURE 5-4: Features’ distribution and density.
Histograms present another, more detailed, view over distributions:
single_distribution = iris_dataframe['petal length (cm)'].plot(kind='hist')
Figure 5-5 shows the histogram of petal length. It reveals a gap in the distribution that could be a promising discovery if you can relate it to a certain group of Iris flowers.
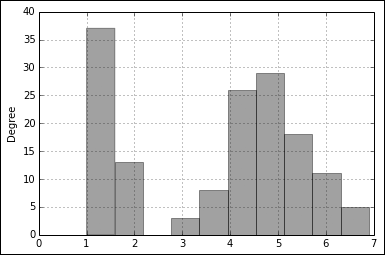
FIGURE 5-5: Histograms can detail better distributions.
Plotting scatterplots
In scatterplots, the two compared variables provide the coordinates for plotting the observations as points on a plane. The result is usually a cloud of points. When the cloud is elongated and resembles a line, you can perceive the variables as correlated. The following example demonstrates this principle.
colors_palette = {0: 'red', 1: 'yellow', 2:'blue'}colors = [colors_palette[c] for c in iris_dataframe['group']]simple_scatterplot = iris_dataframe.plot(kind='scatter', x='petal length (cm)', y='petal width (cm)', c=colors)
This simple scatterplot, represented in Figure 5-6, compares length and width of petals. The scatterplot highlights different groups using different colors. The elongated shape described by the points hints at a strong correlation between the two observed variables, and the division of the cloud into groups suggests a possible separability of the groups.

FIGURE 5-6: A scatterplot reveals how two variables relate to each other.
Because the number of variables isn’t too large, you can also generate all the scatterplots automatically from the combination of the variables. This representation is a matrix of scatterplots. The following example demonstrates how to create one:
from pandas.tools.plotting import scatter_matrixcolors_palette = {0: "red", 1: "yellow", 2: "blue"}colors = [colors_palette[c] for c in iris_dataframe['group']]matrix_of_scatterplots = scatter_matrix(iris_dataframe, figsize=(6, 6), color=colors, diagonal='kde')
In Figure 5-7, you can see the resulting visualization for the Iris data set. The diagonal representing the density estimation can be replaced by a histogram using the parameter diagonal='hist'.

FIGURE 5-7: A matrix of scatterplots displays more information at one time.
Understanding Correlation
Just as the relationship between variables is graphically representable, it is also measurable by a statistical estimate. When working with numeric variables, the estimate is a correlation, and the Pearson correlation is the most famous. The Pearson correlation is the foundation for complex linear estimation models. When you work with categorical variables, the estimate is an association, and the chi-square statistic is the most frequently used tool for measuring association between features.
Using covariance and correlation
Covariance is the first measure of the relationship of two variables. It determines whether both variables have similar behavior with respect to their mean. If the single values of two variables are usually above or below their respective averages, the two variables have a positive association. It means that they tend to agree, and you can figure out the behavior of one of the two by looking at the other. In such a case, their covariance will be a positive number, and the higher the number, the higher the agreement.
If, instead, one variable is usually above and the other variable usually below their respective averages, the two variables are negatively associated. Even though the two disagree, it’s an interesting situation for making predictions, because by observing the state of one of them, you can figure out the likely state of the other (albeit they’re opposite). In this case, their covariance will be a negative number.
A third state is that the two variables don’t systematically agree or disagree with each other. In this case, the covariance will tend to be zero, a sign that the variables don’t share much and have independent behaviors.
Ideally, when you have a numeric target variable, you want the target variable to have a high positive or negative covariance with the predictive variables. Having a high positive or negative covariance among the predictive variables is a sign of information redundancy. Information redundancy signals that the variables point to the same data — that is, the variables are telling us the same thing in slightly different ways.
Computing a covariance matrix is straightforward using pandas. You can immediately apply it to the DataFrame of the Iris data set as shown here:
print iris_dataframe.cov() sepal length (cm) sepal width (cm) petal length (cm) sepal length (cm) 0.685694 -0.039268 1.273682sepal width (cm) -0.039268 0.188004 -0.321713petal length (cm) 1.273682 -0.321713 3.113179petal width (cm) 0.516904 -0.117981 1.296387 petal width (cm)sepal length (cm) 0.516904sepal width (cm) -0.117981petal length (cm) 1.296387petal width (cm) 0.582414
This matrix output shows variables present on both rows and columns. By observing different row and column combinations, you can determine the value of covariance between the variables chosen. After observing these results, you can immediately understand that little relationship exists between sepal length and sepal width, meaning that they’re different informative values. However, there could be a special relationship between petal width and petal length, but the example doesn’t tell what this relationship is because the measure is not easily interpretable.
The scale of the variables you observe influences covariance, so you should use a different, but standard, measure. The solution is to use correlation, which is the covariance estimation after having standardized the variables. Here is an example of obtaining a correlation using a simple pandas method:
print iris_dataframe.corr() sepal length (cm) sepal width (cm) petal length (cm) sepal length (cm) 1.000000 -0.109369 0.871754sepal width (cm) -0.109369 1.000000 -0.420516petal length (cm) 0.871754 -0.420516 1.000000petal width (cm) 0.817954 -0.356544 0.962757 petal width (cm)sepal length (cm) 0.817954sepal width (cm) -0.356544petal length (cm) 0.962757petal width (cm) 1.000000
Now that’s even more interesting, because correlation values are bound between values of –1 and +1, so the relationship between petal width and length is positive and, with a 0.96, it is almost the maximum possible.
You can compute covariance and correlation matrices also by means of NumPy commands, as shown here:
covariance_matrix = np.cov(iris_nparray, rowvar=0, bias=1)correlation_matrix= np.corrcoef(iris_nparray, rowvar=0, bias=1)
In statistics, this kind of correlation is a Pearson correlation, and its coefficient is a Pearson’s r.
Another nice trick is to square the correlation. By squaring it, you lose the sign of the relationship. The new number tells you the percentage of the information shared by two variables. In this example, a correlation of 0.96 implies that 96 percent of the information is shared. You can obtain a squared correlation matrix using this command: print iris_dataframe.corr()**2.
 Something important to remember is that covariance and correlation are based on means, so they tend to represent relationships that you can express using linear formulations. Variables in real-life data sets usually don’t have nice linear formulations. Instead they are highly nonlinear, with curves and bends. You can rely on mathematical transformations to make the relationships linear between variables anyway. A good rule to remember is to use correlations only to assert relationships between variables, not to exclude them.
Something important to remember is that covariance and correlation are based on means, so they tend to represent relationships that you can express using linear formulations. Variables in real-life data sets usually don’t have nice linear formulations. Instead they are highly nonlinear, with curves and bends. You can rely on mathematical transformations to make the relationships linear between variables anyway. A good rule to remember is to use correlations only to assert relationships between variables, not to exclude them.
Using nonparametric correlation
Correlations can work fine when your variables are numeric and their relationship is strictly linear. Sometimes, your feature could be ordinal (a numeric variable but with orderings) or you may suspect some nonlinearity due to non-normal distributions in your data. A possible solution is to test the doubtful correlations with a nonparametric correlation, such as a Spearman correlation (which means that it has fewer requirements in terms of distribution of considered variables). A Spearman correlation transforms your numeric values into rankings and then correlates the rankings, thus minimizing the influence of any nonlinear relationship between the two variables under scrutiny.
As an example, you verify the relationship between sepals’ length and width whose Pearson correlation was quite weak:
from scipy.stats import spearmanrfrom scipy.stats.stats import pearsonrspearmanr_coef, spearmanr_p = spearmanr(iris_dataframe['sepal length (cm)'], iris_dataframe['sepal width (cm)'])pearsonr_coef, pearsonr_p = pearsonr(iris_dataframe['sepal length (cm)'], iris_dataframe['sepal width (cm)'])print 'Pearson correlation %0.3f | Spearman correlation %0.3f' % (pearsonr_coef, spearmanr_coef)Pearson correlation -0.109 | Spearman correlation -0.159
In this case, the code confirms the weak association between the two variables using the nonparametric test.
Considering chi-square for tables
You can apply another nonparametric test for relationship when working with cross tables. This test is applicable to both categorical and numeric data (after it has been discretized into bins). The chi-square statistic tells you when the table distribution of two variables is statistically comparable to a table in which the two variables are hypothesized as not related to each other (the so-called independence hypothesis). Here is an example of how you use this technique:
from scipy.stats import chi2_contingencytable = pd.crosstab(iris_dataframe['group'], iris_binned['petal length (cm)'])chi2, p, dof, expected = chi2_contingency(table.values)print 'Chi-square %0.2f p-value %0.3f' % (chi2, p) Chi-square 212.43 p-value 0.000
As seen before, the p-value is the chance that the chi-square difference is just by chance.
The chi-square measure value depends on how many cells the table has. Do not use the chi-square measure to compare different chi-square tests unless you know for sure that the tables in comparison share the same structure.
The chi-square is particularly interesting for assessing the relationships between binned numeric variables, even in the presence of strong nonlinearity that can fool Person’s r. Contrary to correlation measures, it can inform you of a possible association, but it won’t provide clear details of its direction or absolute magnitude.
Modifying Data Distributions
As a by-product of data exploration, in an EDA phase, you can do the following:
- Obtain new feature creations from the combination of different but related variables.
- Spot hidden groups or strange values lurking in your data.
- Try some useful modifications of your data distributions by binning (or other discretizations such as binary variables).
When performing EDA, you need to consider the importance of data transformation in preparation for the learning phase, which also means using certain mathematical formulas. The following sections present an overview of the most common mathematical formulas used for EDA (such as linear regression). The data transformation you choose depends on the distribution of your data, with a normal distribution being the most common. In addition, these sections highlight the need to match the transformation process to the mathematical formula you use.
Using the normal distribution
The normal, or Gaussian, distribution is the most useful distribution in statistics thanks to its frequent recurrence and particular mathematical properties. It’s essentially the foundation of many statistical tests and models, with some of them, such as the linear regression, widely used in data science.
During data science practice, you’ll meet with a wide range of different distributions — with some of them named by probabilistic theory, others not. For some distributions, the assumption that they should behave as a normal distribution may hold, but for others, it may not, and that could be a problem depending on what algorithms you use for the learning process. As a general rule, if your model is a linear regression or part of the linear model family because it boils down to a summation of coefficients, then both variable standardization and distribution transformation should be considered.
Creating a z-score standardization
In your EDA process, you may have realized that your variables have different scales and are heterogeneous in their distributions. As a consequence of your analysis, you need to transform the variables in a way that makes them easily comparable:
from sklearn.preprocessing import scalestand_sepal_width = scale(iris_dataframe['sepal width (cm)'])
Transforming other notable distributions
When you check variables with high skewness and kurtosis for their correlation, the results may disappoint you. As you find out earlier in this chapter, using a nonparametric measure of correlation, such as Spearman’s, may tell you more about two variables than Pearson’s r may tell you. In this case, you should transform your insight into a new, transformed feature:
tranformations = {'x': lambda x: x, '1/x': lambda x: 1/x, 'x**2': lambda x: x**2, 'x**3': lambda x: x**3, 'log(x)': lambda x: np.log(x)}for transformation in tranformations: pearsonr_coef, pearsonr_p = pearsonr(iris_dataframe['sepal length (cm)'], tranformations[transformation](iris_dataframe['sepal width (cm)'])) print 'Transformation: %s Pearson's r: %0.3f' % (transformation, pearsonr_coef) Transformation: x Pearson's r: -0.109Transformation: x**2 Pearson's r: -0.122Transformation: x**3 Pearson's r: -0.131Transformation: log(x) Pearson's r: -0.093Transformation: 1/x Pearson's r: 0.073
In exploring various possible transformations, using a for loop may tell you that a power transformation will increase the correlation between the two variables, thus increasing the performance of a linear machine learning algorithm. You may also try other, further transformations such as square root np.sqrt(x), exponential np.exp(x), and various combinations of all the transformations, such as log inverse np.log(1/x).