
1
Learning Objectives
By the end of this chapter, you will be able to:
- Describe the basics of a filesystem
- Navigate a filesystem with command-line tools
- Perform file management tasks using the command line
- Utilize shell history and tab completion to efficiently compose commands
- Utilize shell-editing shortcuts to efficiently work with the command line
- Write and use wildcard expressions to manage groups of files and folders
This chapter gives a brief history of the command line, explains filesystems, and describes how to get into and out of the command line.
Introduction
Today, with the widespread use of computing devices, graphical user interfaces (GUIs) are all-pervasive and easily learned by almost anyone. However, we should not ignore one of the most powerful tools from a bygone era, which is the command-line interface (CLI).
GUIs and CLIs approach user interaction from different angles. While GUIs emphasize user-friendliness, instant feedback, and visual aesthetics, CLIs target automation and repeatability of tasks, and composition of complicated task workflows that can be executed in one shot. These features result in the command line having widespread utility even today, nearly half a century since its invention. For instance, it is useful for web administrators to administer a web server via a shell command-line interface: instead of running a local CLI on your machine, you remotely control one that is running thousands of miles away, as if it were right in front of you. Similarly, it is useful for developers who create the backends of websites. This role requires them to learn how to use a command line, since they often need to replicate the web server environment on their local machine for development.
Even outside the purely tech-oriented professions, almost everyone works with computers, and automation is a very helpful tool that can save a lot of time and drudgery. The CLI is specifically built to help automate things. Consider the task of a graphic designer, who downloads a hundred images from a website and resizes all of them into a standard size and creates thumbnails; a personnel manager, who takes 20 spreadsheet files with personnel data and converts all names to upper case, checking for duplicates; or a web content creator, who quickly replaces a person's name with another across an entire website's content.
Using a GUI for these tasks would usually be tedious, considering that these tasks may need to be performed on a regular basis. Hence, rather than repeating these manually using specific applications, such as a download manager, photo editor, spreadsheet, and so on, or getting a custom application written, the professional in each case can use the command line to automate these jobs, consequently reducing drudgery, avoiding errors, and freeing the person to engage in the more important aspects of their job. Besides this, every new version of a GUI invalidates a lot of what you learned earlier. Menus change, toolbars look different, things move around, and features get removed or changed. It is often a re-learning exercise filled with frustration. On the other hand, much of what we learn about the command line is almost 100% compatible with the command line of 30 years ago, and will remain so for the foreseeable future. Rarely is a feature added that will invalidate what was valid before.
Everyone should use the command line because it can make life so much easier, but there is an aura of mystery surrounding the command line. Popular depictions of command-line users are stereotypical asocial geniuses. This skewed perception makes people feel it is very arcane, complex, and difficult to learn—as if it were magic and out of the reach of mere mortals. However, just like any other thing in the world, it can be learned incrementally step-by-step, and unlike learning GUI programs, which have no connection to one another, each concept or tool you learn in the command line adds up.
Command Line: History, Shells, and Terminology
It is necessary for us to explore a little bit of computing history to fully comprehend the rationale behind why CLIs came into being.
History of the Command Line
At the dawn of the computing age, computers were massive electro-mechanical calculators, with little or no interactivity. Stacks of data and program code in the form of punched cards would be loaded into a system, and after a lengthy execution, punched cards containing the results of the computation would be spit out by the machines.
This was called batch processing (this paradigm is still used in many fields of computing even today). The essence of batch processing is to prepare the complete input dataset and the program code by hand and feed it to the machine in a batch. The computation is queued up for execution, and as soon as it finishes, the output is delivered, following which the next computation in the queue is processed.
As the field progressed, the age of the teletypewriter (TTY) arrived. Computers would take input and produce human—readable output interactively through a typewriter-like device. This was the first time that people sat at a terminal and interacted continuously with the system, looking at results of their computations live.
Eventually, TTYs with paper and mechanical keyboards were replaced by TTYs with text display screens and electronic keyboards. This method of interaction with a computer via a keyboard and text display device is called a command-line interface (CLI), and works as follows:
- The system prompts the user to type a sentence (a command line).
- The system executes the command, if valid, and prints out the results.
- This sequence repeats indefinitely, and the user conducts their work step by step.
In a more generic sense, a CLI is also called a REPL, which stands for Read, Evaluate, Print, Loop, and is defined as follows:
- Read an input command from the user.
- Evaluate the command.
- Print the result.
- Loop back to the first step.
The concept of a REPL is seen in many places—even the flight control computer on NASA's 1998 Deep Space 1 mission spacecraft had a REPL controlled from Earth, which allowed scientists to troubleshoot a failure in real-time and prevent the mission from failing.
Command-Line Shells
CLIs that interface with the operating system are called shells. As shells evolved, they went from being able to execute just one command at a time, to multiple commands in sequence, repeat commands multiple times, re-invoke commands from the past, and so on. Most of this evolution happened in the UNIX world, and the UNIX CLI remains up to date the de facto standard.
There are many different CLIs in UNIX itself, which are analogous to different dialects of a language—in other words, the way they interpret commands from the user varies. These CLIs are called shells because they form a shell between the internals of the operating system and the user.
There are several shells that are widely used, such as the Bourne shell, Korn shell, and C shell, to name a few. Shells for other operating systems such as Windows exist too (PowerShell and DOS). In this book, we will learn a modern reincarnation of the Bourne shell, called Bash (Bourne Again Shell), which is the most widely used, and considered the most standard. The Bash shell is part of the GNU project from the Free Software Foundation that was founded by Richard Stallman, which provides free and open source software.
During this book, we will sometimes introduce common abbreviations for lengthy terms, which the students should get accustomed to.
Command-Line Terminology
Before we can delve into the chapters, we will learn some introductory command-line terms that will come handy throughout the book.
- Commands: They refer to the names that are typed to execute some function. They can be built into the shell or be external programs. Any program that's available on the system is a command.
- Arguments: The strings typed after a command are called its arguments. They tell the command how to operate or what to operate on. They are typically options or names of some data resource such as a file, URL, and so on.
- Switches/Options/Flags: These are arguments that typically start with a single or double hyphen and request a certain optional behavior from a command. Usually, an option has a short form, which is a hyphen followed by a single character, and a longer version of the same option, as a double hyphen followed by an entire word. The long option is easier to remember and often makes the command easier to read. Note that options are always case-sensitive.
The following are some examples of switches and arguments in commands:
ls -l --color --classify
grep -n --ignore-case 'needle' haystack.txt 'my data.txt'
In the preceding snippet, ls and grep are commands, –l, --color, –classify, -n, and --ignore-case are flags, and 'needle', haystack.txt and 'my data.txt' are arguments.
Exploring the Filesystem
The space in which a command line operates is called a filesystem (FS). A lot of shell activity revolves around manipulating and organizing files; thus, learning the basics of filesystems is imperative to learning the command line. In this topic, we will learn about filesystems, and how to navigate, examine, and modify them via the shell. For regular users of computers, some of these ideas may seem familiar, but it is necessary to revisit them to have a clear and unambiguous understanding.
Filesystems
The UNIX design philosophy is to represent every object on a computer as a file; thus, the main objects that we manipulate with a command line are files. There are many different types of file-like objects under UNIX, but for our purposes, we will deal with simple data files, typically ASCII text files, that are human readable.
From this UNIX perspective, the system is accessible under what is termed a filesystem (FS). An FS is a representation of the system that's analogous to a series of nested boxes, each of which is called a directory or folder. Most of us are familiar with this folder structure, which we would have encountered when using a GUI file manager.
A directory that contains another directory is called the parent of the latter. The latter is called a sub-directory of the former. On UNIX-like systems, the outermost directory is called the root directory, and each directory can contain either files or other directories in turn. Some files are not data, but rather represent devices or other resources on the system. To be concise, we will refer to folders, regular files, and special files as FS objects.
Typically, every user of a system has their own distinct home directory, named after the user's name, where they store their own data. Various other directories used by the operating system, called system directories, exist on the filesystem, but we need not concern ourselves with them for the purposes of this book. For the sake of simplicity, we will assume that our entire filesystem resides on only a single disk or partition (although this is not true in general):

Figure 1.1: An illustration of an example structure of a typical filesystem
The notation used to refer to a location in a filesystem is called a path. A path consists of the list of directories that need to be navigated to reach some FS object. The list is separated by a forward slash, which is called a path separator. The complete location of an FS object, including its path from the root directory onward, is called a fully qualified pathname.
Paths can be absolute or relative. An absolute path starts at the root directory, whereas a relative path starts at what is called the current working directory (CWD). Every process that runs on a system is started with its CWD set to some location. This includes the command-line process itself. When an FS object is accessed within the CWD, the name of the object alone is enough to refer to it.
The root directory itself is represented by a single forward slash; thus, any absolute path starts with a single forward slash. The following is an example of an absolute path relative to the root directory:
/home/robin/Lesson1/data/cupressaceae/juniperus/indica
Special syntax is used to refer to the current, parent, and user's home directories:
- ./ refers to the current directory explicitly. The CWD is implicit in many cases, but is useful when the current directory needs to be explicitly specified as an argument to some commands. For instance, the same directory that we've just seen can be expressed relative to the CWD (/home/robin, in this case) as follows: one pathname specifying ./ explicitly and one without:
./Lesson1/data/cupressaceae/juniperus/indica
Lesson1/data/cupressaceae/juniperus/indica
- ../ refers to the parent directory. This can be extended further, such as ../../../, and so on. For instance, the preceding directory can be expressed relative to the parent of the CWD, as follows:
../robin/Lesson1/data/cupressaceae/juniperus/indica
The ../ takes us to one level up to the parent of all the user home directories, and then we go back down to robin and the rest of the path.
- ~/ refers to the home directory of the current user.
~robin/ refers to the home directory of a user called "robin". This is a useful shorthand, because the home directory of a user could be configured to be anywhere in the filesystem. For example, macOS keeps the users' home directories in /Users, whereas Linux systems keep it in /home.
Note
The trailing slash symbol at the end of a directory pathname is optional. The shell does not mandate this. It is usually typed only to make it obvious that it is the name of a directory rather than a file.
Navigating Filesystems
We will now look briefly at the most common commands for moving around the filesystem and examining its contents:
- The cd (change directory) command changes the CWD to the path specified as its argument—if the path is non-existent, it prints an error message. Specifying just a single hyphen as the argument to cd changes the CWD to the last directory that was navigated from.
- The pwd (print working directory) command simply displays the absolute path of the CWD.
- The pushd and popd (push directory and pop directory) commands are used to bookmark the CWD and return to it later, respectively. They work by pushing and popping entries on to an internal directory stack, hence the names pushd and popd. Since they use a stack, you can push multiple values and pop them later in reverse order.
- The tree command displays the hierarchical structure of a directory as a text-based diagram.
- The ls (list) command displays the contents of one or more specified directories (by default, the CWD) in various formats.
- The cat (concatenate) command outputs the concatenation of the contents of the files specified to it. If only one file is specified, it simply displays the file. This is a quick way to look at a file's content, if the files are small. cat can also apply some transformations on its output, such as numbering the lines or suppressing multiple blank lines.
- The less command can be used to interactively scroll through one or more files easily, search for a string, and so on. This command is called a pager (it lets text content be viewed page by page). On most systems, less is configured to be the default pager. Other commands that require a pager interface will request the default pager from the system for this purpose. Here are some of the most useful keyboard shortcuts for less:
(a) The up or down and Page Up or Page Down keys scroll vertically.
(b) The Enter and spacebar keys scroll down by one line and one screenful, respectively.
(c) < and > or g and G characters will scroll to the beginning and end of the file, respectively.
(d) / followed by a string and then Enter searches for the specified string. The occurrences are also highlighted.
(e) n and N jump to the next or previous match, respectively.
(f) Esc followed by u turns off the highlights.
(g) h shows a help screen, with the list of shortcuts and commands that are supported.
(h) q exits the application or exits the help screen if it is being shown.
There are many more features for navigating, searching, and editing that less provides, which we will not cover in this basic introduction.
Commonly Used Options for the Commands
The following options are used with the ls command:
- The -l option (which stands for long list) shows the contents with one entry per line—each column in the listing shows some specific information, namely permissions, link count, owner, group, size, and modification time, followed by the name, respectively. For the purposes of this book, we will only consider the size and the name. Information about the type of each FS object is indicated in the first character of the permissions field. For example, - for a file, and d for a directory.
- The --reverse option sorts the entries in reverse order. This is an example of a long option, where the option is a complete word, which is easy to remember. Long options are usually aliases for short options—in this case, the corresponding short option is -r.
- The --color option is used to make different kinds of FS objects display in different colors—there is no corresponding short option for this.
The following options are used with the tree command:
- The -d option prints only directories and skips files
- The -o option writes the output to a file rather than the display
- The -H option generates a formatted HTML output, and typically would be used along with -o to generate an HTML listing to serve on a website
Before going ahead with the exercises, let's establish some conventions for the rest of this book. Each chapter of this book includes some test data to practice on. Throughout this book, we will assume that each chapter's data is in its own folder called Lesson1, Lesson2, and so on.
In all of the exercises that follow, it is assumed that the work is in the home directory of the logged-in user (here, the user is called robin).
Exercise 1: Exploring Filesystem Contents
In this exercise, we will navigate through a complex directory structure and view files using the commands learned so far. The sample data used here is a dataset of conifer trees, hierarchically structured as per botanic classification, which will be used in future activities and exercises too.
- Open the command-line shell.
- Navigate to the Lesson1 directory and examine the contents of the folder with the ls command:
robin ~ $ cd Lesson1
robin ~/Lesson1 $ ls
data data1
In the preceding code snippet, the part of the first line up to the $ symbol is called a prompt. The system is prompting for a command to be typed. The prompt shows the current user, in this case robin, followed by the CWD ~/Lesson1. The text shown after the command is what the command itself prints as output.
Note
Recall that ~ means the home directory of the current user.
- Use the cd command to navigate to the data directory and examine its contents with ls:
robin ~/Lesson1 $ cd data
robin ~/Lesson1/data $ ls
cupressaceae pinaceae podocarpaceae taxaceae
Note
Notice that the prompt shown afterward displays the new CWD. This is not always true. Depending on the configuration of the system, the prompt may vary, and may even be a simple $ symbol with no other information shown.
- The ls command can be provided with one or more arguments, which are the names of files and folders to list. By default, it lists only the CWD. The following snippet can be used to view the subdirectories within the taxaceae and podocarpaceae directories:
robin ~/Lesson1/data $ ls taxaceae podocarpaceae
podocarpaceae/:
acmopyle dacrydium lagarostrobos margbensonia parasitaxus podocarpus saxegothaea
afrocarpus falcatifolium lepidothamnus microcachrys pherosphaera prumnopitys stachycarpus
dacrycarpus halocarpus manoao nageia phyllocladus retrophyllum sundacarpus
taxaceae/:
amentotaxus austrotaxus cephalotaxus pseudotaxus taxus torreya
The dataset contains a directory for every member of the botanical families of coniferous trees. Here, we can see the top-level directories for each botanical family. Each of these has subdirectories for the genii, and those in turn for the species.
- You can also use ls to request a long output in color, as follows:
robin ~/Lesson1/data $ ls -l --color
total 16
drwxr-xr-x 36 robin robin 4096 Aug 20 14:01 cupressaceae
drwxr-xr-x 15 robin robin 4096 Aug 20 14:01 pinaceae
drwxr-xr-x 23 robin robin 4096 Aug 20 14:01 podocarpaceae
drwxr-xr-x 8 robin robin 4096 Aug 20 14:01 taxaceae
- Navigate into the taxaceae folder, and then use the tree command to visualize the directory structure at this point. For clarity, specify the -d option, which instructs it to display only directories and exclude files:
robin ~/Lesson1/data $ cd taxaceae
robin ~/Lesson1/data/taxaceae $ tree -d
You should get the following output on running the preceding command:

Figure 1.2: The directory structure of the taxaceae folder (not shown entirely)
- cd can be given a single hyphen as an argument to jump back to the last directory that was navigated from:
robin ~/Lesson1/data/taxaceae $ cd taxus
robin ~/Lesson1/data/taxaceae/taxus $ cd -
/home/robin/Lesson1/data/taxaceae
Observe that it prints out the absolute path of the directory it is changing to.
Note
The home directory is stored in /home on UNIX-based systems. Other operating systems such as Mac OS may place them in other locations, so the output of some of the following commands may slightly differ from that shown here.
- We can move upwards in the hierarchy by using .. any number of times. Type the first command that follows to reach the home directory, which is three levels up. Then, use cd - to return to the previous location:
robin ~/Lesson1/data/taxaceae $ cd ../../..
robin ~ $ cd -
/home/robin/Lesson1/data/taxaceae
robin ~/Lesson1/data/taxaceae $
- Use cd without any arguments to go to the home directory. Then, once again, use cd - to return to the previous location:
robin ~/Lesson1/data/taxaceae $ cd
robin ~ $ cd -
/home/robin/Lesson1/data/taxaceae
robin ~/Lesson1/data/taxaceae $
- Now, we will explore commands that help us navigate the folder structure, such as pwd, pushd, and popd. Use the pwd command to display the path of the CWD, as follows:
robin ~/Lesson1/data/taxaceae $ pwd
/home/robin/Lesson1/data/taxaceae
The pwd command may not seem very useful when the CWD is being displayed in the prompt, but it is useful in some situations, for example, to copy the path to the clipboard for use in another command, or to share it with someone.
- Use the pushd command to navigate into a folder, while remembering the CWD:
robin ~/Lesson1/data/taxaceae $ pushd taxus/baccata/
~/Lesson1/data/taxaceae/taxus/baccata ~/Lesson1/data/taxaceae
Use it once again, saving this location to the stack too:
robin ~/Lesson1/data/taxaceae/taxus/baccata $ pushd ../sumatrana/
~/Lesson1/data/taxaceae/taxus/sumatrana ~/Lesson1/data/taxaceae/taxus/baccata ~/Lesson1/data/taxaceae
Using it yet again, now we have three folders on the stack:
robin ~/Lesson1/data/taxaceae/taxus/sumatrana $ pushd ../../../pinaceae/cedrus/deodara/
~/Lesson1/data/pinaceae/cedrus/deodara ~/Lesson1/data/taxaceae/taxus/sumatrana ~/Lesson1/data/taxaceae/taxus/baccata ~/Lesson1/data/taxaceae
robin ~/Lesson1/data/pinaceae/cedrus/deodara $
Notice that it prints out the list of directories that have been saved so far. Since it is a stack, the list is ordered according to recency, with the first entry being the one we just changed into.
- Use popd to walk back down the directory stack, successively visiting the folders we saved earlier. Notice the error message when the stack is empty:
robin ~/Lesson1/data/pinaceae/cedrus/deodara $ popd
~/Lesson1/data/taxaceae/taxus/sumatrana ~/Lesson1/data/taxaceae/taxus/baccata ~/Lesson1/data/taxaceae
robin ~/Lesson1/data/taxaceae/taxus/sumatrana $ popd
~/Lesson1/data/taxaceae/taxus/baccata ~/Lesson1/data/taxaceae
robin ~/Lesson1/data/taxaceae/taxus/baccata $ popd
~/Lesson1/data/taxaceae
robin ~/Lesson1/data/taxaceae $ popd
bash: popd: directory stack empty
The entries on the directory stack are added and removed from the top of the stack as pushd and popd are used, respectively.
- Each of the folders for a species has a text file called data.txt that contains data about that tree from Wikipedia, which we can view with cat. Use the cat command to view the file's content, after navigating into the taxus/baccata directory:
robin ~/Lesson1/data/taxaceae $ cd taxus/baccata
robin ~/Lesson1/data/taxaceae/taxus/baccata $ cat data.txt
The output will look as follows:

Figure 1.3: A screenshot showing a partial output of the data.txt file
Notice that the output from the last command scrolled outside the view rapidly. cat is not ideal for viewing large files. You can scroll through the window manually to see the contents, but this may not extend to the whole output. To view files in a more user-friendly, interactive fashion, we can use the less command.
- Use ls to see that there is a file called data.txt, and then use the less command to view it:
robin ~/Lesson1/data/taxaceae/taxus/baccata $ ls -l
total 40
-rw-r--r-- 1 robin robin 38260 Aug 16 01:08 data.txt
robin ~/Lesson1/data/taxaceae/taxus/baccata $ less data.txt
The output is shown here:

Figure 1.4: A screenshot showing the output of the less command
In this exercise, we have practiced the basic commands used to view directories and files. We have not covered all of the options available with these commands in detail, but what we have learned so far will serve for most of our needs.
Given this basic knowledge, we should be able to find our way around the entire filesystem and examine any file that we wish.
Manipulating a Filesystem
So far, we have looked at commands that only examine directories and files. Now we will learn how to manipulate filesystem objects. We will not be manipulating the contents of files yet, but only their location in the filesystem.
Here are the most common commands that are used to modify a filesystem. The commonly used options for some of these commands are also mentioned:
- mkdir (make directory) creates the directory specified as its argument. It can also create a hierarchy of directories in one shot.
The -p or --parents flag can be used to tell mkdir to create all the parent directories for the path if they do not exist. This is useful when creating a nested path in one shot.
- rmdir (remove directory) is used to remove a directory. It only works if the directory is empty.
The -p or --parents flag works similarly to how it does in mkdir. All the directories along the path that's specified are deleted if they are empty.
- touch is used to create an empty file or update an existing file's timestamp.
- cp (copy) is used to copy files or folders between directories. When copying directories, it can recursively copy all subdirectories, too. The syntax for this command is as follows:
cp <sources> <dest>
Here, <sources> is the paths of one or more files and folders to be copied, and <dest> is the path of the folder where <sources> are copied. This can be a filename, if <sources> is a single filename. The following options can be used with this command:
The -r or --recursive flag is necessary when copying folders. It recursively copies all of the folder's contents to the destination.
The -v or --verbose flag makes cp print out the source and destination pathname of every file it copies.
- mv (move) can be used to rename an object and/or move it to another directory.
Note
The mv command performs both renaming and moving. However, these are not two distinct functions. If you think about it, renaming a file and moving it to a different path on the same disk are the same thing. Inherently, a file's content is not related to its name. A change to its name is not going to affect its contents. In a sense, a pathname is also a part of a file's name.
- rm (remove) deletes a file permanently, and can also be used to delete a directory, recursively deleting all the subdirectories. Unlike sending files to the Trashcan or Recycle Bin in a GUI interface, files deleted with rm cannot be recovered. This command has the following options:
The -r or --recursive flag deletes folders recursively.
The -v or --verbose flag makes rm print out the pathname of every file it deletes.
The -i or --interactive=always options allows review and confirmation before each entry being deleted. Answering n rather than y to the prompts (Enter must be pressed after y or n) will either skip deleting some files or skip entire directories.
-I or --interactive=once prompts only once before removing more than three files, or when removing recursively, whereas -i prompts for each and every file or directory.
Exercise 2: Manipulating the Filesystem
In this exercise, we will learn how to manipulate the FS and files within it. We will modify the directories in the Lesson1 folder by creating, copying, and deleting files/folders using the commands that we learned about previously:
- Open a command-line shell and navigate to the directory for this lesson:
robin ~ $ cd Lesson1/
robin ~/Lesson1 $
- Create some directories, using mkdir, that classify animals zoologically. Type the commands shown in the following snippet:
robin ~/Lesson1 $ mkdir animals
robin ~/Lesson1 $ cd animals
robin ~/Lesson1/animals $ mkdir canis
robin ~/Lesson1/animals $ mkdir canis/familiaris
robin ~/Lesson1/animals $ mkdir canis/lupus
robin ~/Lesson1/animals $ mkdir canis/lupus/lupus
robin ~/Lesson1/animals $ mkdir leopardus/colocolo/pajeros
mkdir: cannot create directory 'leopardus/colocolo/pajeros': No such file or directory
- Notice that mkdir normally creates subdirectories that are only in already-existing directories, so it raises an error when we try to make leopardus/colocolo/pajeros. Use the --parents or -p switch to overcome this error:
robin ~/Lesson1/animals $ mkdir -p leopardus/colocolo/pajeros
robin ~/Lesson1/animals $ mkdir --parents panthera/tigris
robin ~/Lesson1/animals $ mkdir panthera/leo
- Now, use tree to view and verify the directory structure we created:
robin ~/Lesson1/animals $ tree
The directory structure is shown here:

Figure 1.5: The directory structure of the animals folder
- Now use the rmdir command to delete the directories. Try the following code snippets:
robin ~/Lesson1/animals $ rmdir canis/familiaris/
robin ~/Lesson1/animals $ rmdir canis
rmdir: failed to remove 'canis': Directory not empty
robin ~/Lesson1/animals $ rmdir canis/lupus
rmdir: failed to remove 'canis/lupus': Directory not empty
- Notice that it raises an error when trying to remove a directory that is not empty. You need to empty the directory first, removing canis/lupus/lupus, and then use the -p option to remove both canis/lupus and its parent, canis:
robin ~/Lesson1/animals $ rmdir canis/lupus/lupus
robin ~/Lesson1/animals $ rmdir -p canis/lupus
- Now, use tree to view the modified directory structure, as follows:
robin ~/Lesson1/animals $ tree
The directory structure is shown here:

Figure 1.6: A screenshot of the output displaying the modified folder structure of the animals folder
- Create some directories with the following commands:
robin ~/Lesson1/animals $ mkdir -p canis/lupus/lupus
robin ~/Lesson1/animals $ mkdir -p canis/lupus/familiaris
robin ~/Lesson1/animals $ ls
canis leopardus panthera
- Create some dummy files with the touch command, and then view the entire tree again:
robin ~/Lesson1/animals $ touch canis/lupus/familiaris/dog.txt
robin ~/Lesson1/animals $ touch panthera/leo/lion.txt
robin ~/Lesson1/animals $ touch canis/lupus/lupus/wolf.txt
robin ~/Lesson1/animals $ touch panthera/tigris/tiger.txt
robin ~/Lesson1/animals $ touch leopardus/colocolo/pajeros/colocolo.txt
robin ~/Lesson1/animals $ tree
The output will look as follows:

Figure 1.7: A screenshot of the output displaying the revised folder structure of the animals folder
- Use cp to copy the dog.txt and wolf.txt files from the familiaris and lupus directories into a new directory called dogs, as follows:
robin ~/Lesson1/animals $ mkdir dogs
robin ~/Lesson1/animals $ cp canis/lupus/familiaris/dog.txt dogs/
robin ~/Lesson1/animals $ cp canis/lupus/lupus/wolf.txt dogs/
robin ~/Lesson1/animals $ tree
The output will look as follows:
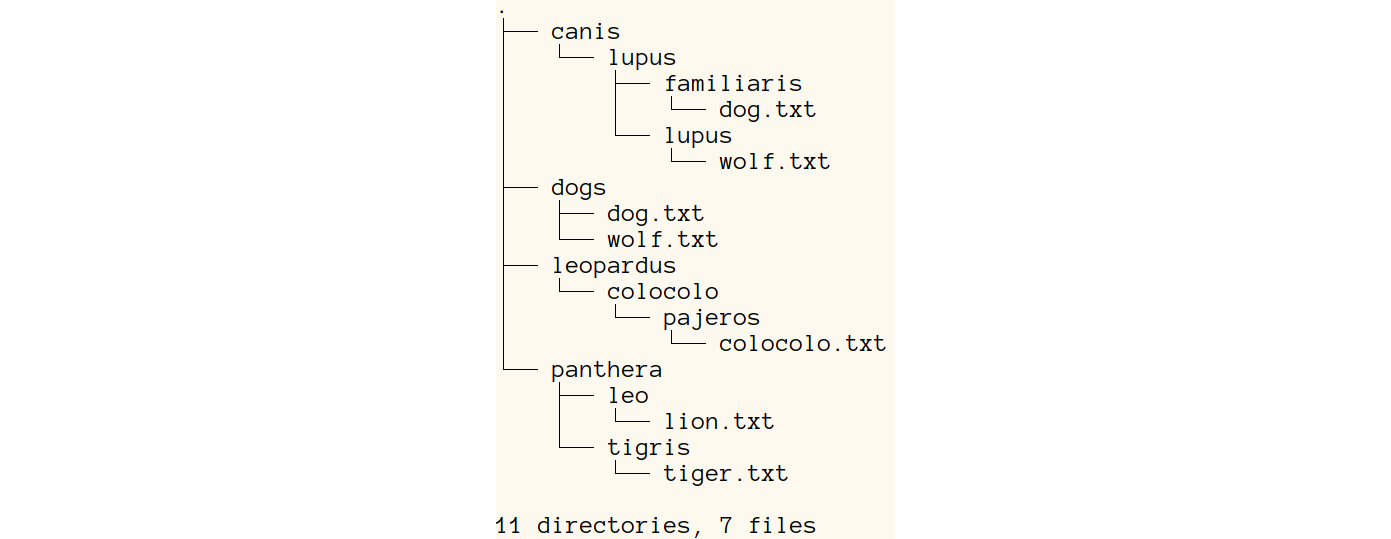
Figure 1.8: A screenshot of the output displaying the revised folder structure of the animals folder, along with the newly copied files
- Now clone the entire panthera directory into a new directory called cats using cp:
robin ~/Lesson1/animals $ mkdir cats
robin ~/Lesson1/animals $ cp -r panthera cats
robin ~/Lesson1/animals $ tree
The output will look as follows:

Figure 1.9: A screenshot of the output displaying the revised folder structure of the animals folder
- Now use the --verbose option with cp to copy the files with verbose progress displayed and print the output using the tree command:
robin ~/Lesson1/animals $ mkdir bigcats
robin ~/Lesson1/animals $ cp -r --verbose leopardus/ panthera/ bigcats
'leopardus/' -> 'bigcats/leopardus'
'leopardus/colocolo' -> 'bigcats/leopardus/colocolo'
'leopardus/colocolo/pajeros' -> 'bigcats/leopardus/colocolo/pajeros'
'leopardus/colocolo/pajeros/colocolo.txt' -> 'bigcats/leopardus/colocolo/pajeros/colocolo.txt'
'panthera/' -> 'bigcats/panthera'
'panthera/tigris' -> 'bigcats/panthera/tigris'
'panthera/tigris/tiger.txt' -> 'bigcats/panthera/tigris/tiger.txt'
'panthera/leo' -> 'bigcats/panthera/leo'
'panthera/leo/lion.txt' -> 'bigcats/panthera/leo/lion.txt'
robin ~/Lesson1/animals $ tree bigcats
The output of the tree command is shown here:

Figure 1.10: A screenshot of the output displaying the folder structure of the animals folder after a recursive directory copy
- Now use mv to rename the animals folder to beasts:
robin ~/Lesson1/animals $ cd ..
robin ~/Lesson1 $ mv animals beasts
robin ~/Lesson1 $ cd beasts
robin ~/Lesson1/beasts $ ls
bigcats canis cats dogs leopardus panthera
- Use mv to move an individual file to a different path. We move dogs/dog.txt to the CWD as fido.txt and move it back again:
robin ~/Lesson1/beasts $ mv dogs/dog.txt fido.txt
robin ~/Lesson1/beasts $ ls
bigcats canis cats dogs fido.txt leopardus panthera
robin ~/Lesson1/beasts $ mv fido.txt dogs/
- Use mv to relocate an entire folder. Move the whole canis folder into dogs:
robin ~/Lesson1/beasts $ mv canis dogs
robin ~/Lesson1/beasts $ tree dogs
The revised folder structure is shown here:

Figure 1.11: A screenshot of the output displaying the folder structure of the animals folder after relocating a folder
- Use the -v or --verbose option with mv to make it report each item being moved. In this case, there was only one file being moved, but this can be a long list:
robin ~/Lesson1/beasts $ mkdir panthers
robin ~/Lesson1/beasts $ mv --verbose panthera panthers
renamed 'panthera' -> 'panthers/panthera'
robin ~/Lesson1/beasts $ tree panthers
The output is shown here:

Figure 1.12: A screenshot of the output displaying the folder structure of the animals folder after moving a folder
- Use tree to view the dogs folder (before we use rm to delete it):
robin ~/Lesson1/beasts $ tree dogs
The output is shown here:

Figure 1.13: A screenshot of the output displaying the folder structure of the animals folder before the deletion of files
- Delete the files one by one with rm:
robin ~/Lesson1/beasts $ rm dogs/fido.txt
robin ~/Lesson1/beasts $ rm dogs/wolf.txt
robin ~/Lesson1/beasts $ rm dogs/canis/lupus/familiaris/dog.txt
robin ~/Lesson1/beasts $ rm dogs/canis/lupus/lupus/wolf.txt
robin ~/Lesson1/beasts $ tree dogs
The output is shown here:

Figure 1.14: The folder structure of the animals folder after the deletion of files
- Remove the complete directory structure with the -r or --recursive switch of rm:
robin ~/Lesson1/beasts $ ls
bigcats cats dogs leopardus panthers
robin ~/Lesson1/beasts $ rm -r dogs
robin ~/Lesson1/beasts $ ls
bigcats cats leopardus panthers
As we can see, the entire dogs directory was silently removed without warning.
- Use the -i flag to remove items interactively. Each individual operation is prompted for confirmation:
Note
Depending on your system configuration, the prompts you see for the following command and the one in step 21 may be in a different order or worded differently. The system will prompt you for every deletion to be performed, regardless.
robin ~/Lesson1/beasts $ rm -r -i panthers
rm: descend into directory 'panthers'? y
rm: descend into directory 'panthers/panthera'? y
rm: descend into directory 'panthers/panthera/leo'? y
rm: remove regular empty file 'panthers/panthera/leo/lion.txt'? n
rm: remove directory 'panthers/panthera/leo'? n
rm: descend into directory 'panthers/panthera/tigris'? n
robin ~/Lesson1/beasts $ ls
bigcats cats leopardus panthers
Now use the -I flag to remove items interactively. Confirmation is asked only a few times, and not for each file:
robin ~/Lesson1/beasts $ rm -r -I bigcats
rm: remove 1 argument recursively? y
robin ~/Lesson1/beasts $ ls
cats leopardus panthers
- Use the -v or --verbose option to make rm report each file or directory that's removed:
robin ~/Lesson1/beasts $ rm -r -v panthers/
removed 'panthers/panthera/leo/lion.txt'
removed directory 'panthers/panthera/leo'
removed 'panthers/panthera/tigris/tiger.txt'
removed directory 'panthers/panthera/tigris'
removed directory 'panthers/panthera'
removed directory 'panthers/'
- Now clear the entire folder we used for this exercise so that we can move on to the next lesson with a blank slate:
robin ~/Lesson1/beasts $ cd ..
robin ~/Lesson1 $ ls
beasts data data1
robin ~/Lesson1 $ rm -r beasts
robin ~/Lesson1 $ ls
data data1
In this exercise, we learned how to change or extend the structure of the filesystem tree. We have yet to learn how to create and manipulate the content within files, which will be covered in future chapters.
Activity 1: Navigating the Filesystem and Viewing Files
For this activity, use the conifer tree dataset that has been supplied as a hierarchy of folders representing each tree's Family, Genus, and Species. Every species has an associated text file called data.txt containing information about the species, which has been mined from a Wikipedia page. Your aim is to navigate this hierarchy via the command line and answer basic questions about certain species by looking it up the data in those text files. Navigate through the directories within the example dataset provided for this lesson and answer the following questions:
- Provide two common names for the species Cedrus Deodara, which belongs to the Pinaceae family.
- Look up information about Abies Pindrow in the Pinaceae family and fill in the following blank: "The name pindrow derives from the tree's name in _______".
- How many species of the Taxus genus in the family Taxaceae are documented in this dataset?
- How many species in total are documented in this dataset?
Follow these steps to complete this activity:
- Use the cd command to navigate to the appropriate folder and use less to read the relevant information.
- Use the cd command to navigate to the appropriate folder and view the file with less. Use the / command to search for the phrase "derives from" and read the rest of the sentence to get the answer.
- Navigate to the right folder and run the tree command, which reports the number of directories in it. Each directory is a species.
- Navigate to the top-level data folder and run the tree command, which reports the number of files. Each file is associated with one species.
The expected answers for the preceding questions are as follows:
- Any two of the following: deodar cedar, Himalayan cedar, deodar, devdar, devadar, devadaru
- Nepali
- 12
- 770
Note
The solution for this activity can be found on page 270.
Activity 2: Modifying the Filesystem
For this activity, you will be using the conifer tree sample dataset that is in the ~/Lesson1/data folder. You need to collect the data for all trees from the family taxaceae and the genus torreya into one folder. Each file should be named <species>.txt, where <species> is the name of the species/folder. Execute the following steps to complete this objective:
- Use the cd command to go into the Lesson1 folder and create a new folder called activity2.
- Navigate to the folder for the genus specified and view the subfolders which represent each species.
- Use the cp command to copy a data file from one sub-directory of the data/taxaceae/torreya folder into the output folder.
- Use the mv command to rename the file as per the species name.
- Repeat steps 3 and 4 for all the species that are requested.
The expected listing of the activity2 folder is as follows:

Figure 1.15: A screenshot of the expected listing of the activity2 folder
Note
The solution for this activity can be found on page 270.
So far, we have explored the space in which a shell command-line operates. In a GUI, we deal with an abstract space of windows, menus, applications, and so on. In contrast, a CLI is based on a lower layer of the operating system, which is the filesystem.
In this topic, we have learned what a filesystem is and how to navigate it, and examined its structure or looked at the contents of files in it using the command line. We also learned how to modify the FS structure and perform simple file management tasks.
We learned how the shell is a way to provide precise, unambiguous, and repeatable instructions to the computer. You may have noticed the fact that most command-line tools perform just one simple function. This stems from one of the UNIX design philosophies: Do only one thing but, do it well. These small commands can be combined like the parts of a machine into constructs that can automate tasks and process data in complex ways.
The focus of this topic was mainly to get familiar with the FS, the arena where most of the command-line work happens. In the next topic, we will learn how to reduce effort when composing commands, making use of several convenience features in Bash.
Shell History Recall, Editing, and Autocompletion
In the previous section, we have experienced the fact that we need to repeatedly type some commands, and often type out the pathnames of files and folders. Indeed, it can get quite tedious if we work with long or hard-to-spell pathnames (both of which are present in our tree dataset). To counter this, we can use a few convenient features of modern command-line shells to reduce typing effort. We will explore these useful keyboard shortcuts for the command line in this section.
The GNU Bash shell uses an interface library called readline. This same interface is used by several programs (for example, gdb, python, and Node.js); hence, what you learn now applies to the CLIs of all those.
The readline interface supports emacs and vi modes. The keyboard shortcuts in these modes are derived from the ones in the iconic editors of those names. Since the default is the emacs mode, we will study only that.
Note
When indicating shortcuts, the convention is to show a combination of the Ctrl key and another key using the caret symbol '^' with the key. For example, Ctrl + C is indicated by ^C.
Command History Recall
The Bash shell retains a history of the past commands that were typed. Depending on the system configuration, anywhere from a few hundred to a few thousand commands could be maintained in the history log. Any command from the history can be brought back and re-executed (after optionally modifying it).
Basic History Navigation Shortcuts
History is accessed by using the following shortcuts:
- The up and down arrow keys move through the command history.
- Esc + < and Esc + > or Page Up and Page Down or Alt + < and Alt + > move to the first and last command in the history. The other shortcuts listed may or may not work depending on the system's configuration.
- Ctrl + S and Ctrl + R let you incrementally search for a command in the history forward and backward, respectively, by typing any substring of the command.
Navigating through the history of past commands with the up and down arrow keys or with Esc + < and Esc + > is quite straightforward. As you navigate, the command appears on the prompt, and can be executed by pressing Enter immediately, or after editing it.
Note
In the aforementioned shortcuts, remember that < and > implies that the Shift key is held down, since these are the secondary symbols on the keyboard.
To view the entire history, we can use the history command:
robin ~ $ history
An example output is shown here:

Figure 1.16: A screenshot of the output displaying the shell command history
This command can perform other tasks related to history management as well, but we will not concern ourselves with that for this book.
Incremental Search
This feature lets you find a command in the history that matches a few characters that you type. To perform a forward incremental search, press Ctrl + S, upon which the shell prompt changes to something like this:
robin ~ $ ^S
(i-search)`':
When we press Ctrl + R instead, we see the following prompt:
robin ~ $ ^R
(reverse-i-search)`':
i-search stands for incremental search. When these prompts are displayed, the shell expects a few characters that appear within a command to be typed. As they are typed, the command which matches those characters as a substring is displayed. If there is more than one command that matches the input, the list of matches can be iterated with Ctrl + R and Ctrl + S backward and forward, respectively.
The incremental search happens from the point where you have currently navigated in the history (with arrow keys and so on). If there are no more matches in the given direction, the prompt changes to something similar to what is shown here:
(failed reverse-i-search)`john': man join
At this point, we can do the following:
- Backspace the search string that was typed, to widen the range of matches and find one.
- Change the search direction. We can press Ctrl + S if we were searching backward or press Ctrl + R if we were searching forward, to return to any previous match that was crossed over.
- Press Esc to exit the search and accept whatever match was shown last.
- Press Ctrl + G to exit the search and leave the command line empty.
Note
On some systems, Ctrl + S does not activate incremental search. Instead, it performs an unrelated function. To make sure it works as we require it to, type the following command once in the console before the exercises here: stty -ixon.
Remember that the search happens relative to the current location in history, so if you start a search without navigating upward in the history, then searching forward would have no effect, since there are no commands after the current history location (that is, the present). This means that searching backward with Ctrl + R is generally the more frequently used and useful feature. Most of the time, a history search comes in handy for retyping a long command from the recent past, or for retrieving a complex command typed long ago, whose details have been forgotten.
As you progress in your command-line knowledge and experience, you will find that although it is easy to compose complicated command lines when you have a certain problem to solve, it is not easy to recollect them after a long period of time has passed. Keeping this in mind, it makes sense to conserve your mental energy, and reuse old commands from history, rather than try to remember or recreate them from scratch. Indeed, it is possible to configure Bash to save your entire history infinitely so that you never lose any command that you ever typed on the shell.
Exercise 3: Exploring Shell History
In this exercise, we will use the history search feature to repeat some commands from an earlier exercise. Make sure that you are in the Lesson1 directory before starting:
- Create a temporary directory called data2 to work with:
robin ~/Lesson1 $ mkdir data2
robin ~/Lesson1 $ cd data2
robin ~/Lesson1/data2 $
- Press Ctrl + R to start a reverse incremental search, and then type "animals". The most recent command with that string will be shown.
- Press Ctrl + R two times to search backward until we get the command we need, and then press Enter to execute it:
(reverse-i-search)`animals': mkdir animals
robin ~/Lesson1/data2 $ mkdir animals
robin ~/Lesson1/data2 $ cd animals
- Find the command that created the directory for the species of the domestic dog canis/lupus/familiaris. The string familiaris is quite unique, so we can use that as a search pattern. Press Esc + < to reach the start of the history and Ctrl + S to start searching forward from that point. Type "fa" and press Ctrl + S two more times to get the command we are searching for. Finally, press Enter to execute it:
(i-search)`fa': mkdir -p canis/lupus/familiaris
robin ~/Lesson1/data2/animals $ mkdir -p canis/lupus/familiaris
- Repeat the same command, except change the directory to create canis/lupus/lupus. Press the up arrow to get the same command again. Change the last word to lupus and press Enter to create the new directory:
robin ~/Lesson1/data2/animals $ mkdir -p canis/lupus/lupus
In this brief exercise, we have seen how to retrieve commands that we typed previously. We can move through the history linearly or search for a command, saving ourselves a lot of retyping.
Command-Line Shortcuts
There are many keyboard shortcuts on Bash that let you modify an already typed command. Usually, it is more convenient to take an existing command from the history and edit it to form a new one, rather than retype everything.
Navigation Shortcuts
The following are some navigation shortcuts:
- The left or right arrow keys, as well as Home or End work as per standard conventions. Ctrl + A and Ctrl + E are alternatives for Home and End.
- Alt + F and Alt + B jump by one word forward and backward, a word being a contiguous string that consists of numbers and letters.
Clipboard Shortcuts
The following are some clipboard shortcuts:
- Alt + Backspace cuts the word to the left of the cursor
- Alt + D cuts the word to the right of the cursor, including the character under the cursor
- Ctrl + W cuts everything to the left of the cursor until a whitespace character is encountered
- Ctrl + K cuts everything from the cursor to the end of the line
- Ctrl + U cuts everything from the cursor to the start of the line, excluding the character under the cursor
- Ctrl + Y pastes what was just cut
- Alt + Y cycles through the previously cut entries one by one (works only after pasting with Ctrl + Y)
Other Shortcuts
The following are some other shortcuts that may come in useful:
- Alt + deletes all whitespace characters that are at the cursor, that is, it joins two words that are separated by whitespaces.
- Ctrl + T swaps the current and previous character. This is useful to correct typos.
- Alt + T swaps the current and previous word.
- Ctrl + Shift + _ undoes the last keypress.
- Alt + R reverts all changes to a line. This is useful to revert a command from history back to what it was originally.
- Alt + U converts the characters from the cursor position until the next word boundary to uppercase.
- Alt + L converts the characters from the cursor position until the next word boundary to lowercase.
- Alt + C capitalizes the first letter of the word under the cursor and moves to the next word.
There are several other shortcuts, but these are the most useful. It is not necessary to memorize all of these, but the navigation and cut/paste shortcuts are certainly worth learning by heart.
Note
The clipboard that the readline interface in Bash uses is distinct from the clipboard provided in the GUI. The two are independent mechanisms and should not be confused with each other. When you use any other command-line interface that uses readline, for example, the Python shell, it gets its own independent clipboard.
Exercise 4: Using Shell Keyboard Shortcuts
In this exercise, we will try out some of the command-line shortcuts. For simplicity, we will introduce the echo command to help with this exercise. This command merely prints out its arguments without causing any side effects. The examples here are contrived to help illustrate the editing shortcuts:
- Run the following command:
robin ~/Lesson1/data2/animals $ echo one two three four five/six/seven
one two three four five/six/seven
- Press the up arrow key to get the same command again. Press Alt + B three times. The cursor ends up at five. Type "thousand" followed by a space, and press Enter to execute the edited command:
robin ~/Lesson1/data2/animals $ echo one two three four thousand five/six/seven
one two three four thousand five/six/seven
- Now use the cut and paste shortcuts as follows: press the up arrow key to get the previous command, press Alt + Backspace to cut the last word seven into the clipboard, press Alt + B twice (the cursor ends up at five), use Ctrl + Y to paste the word that we cut, type a forward slash, and finally press Enter:
robin ~/Lesson1/data2/animals $ echo one two three four thousand seven/five/six/
one two three four thousand seven/five/six/
- Press the up arrow key to get the previous command, press Alt + B four times (the cursor ends up at thousand), press Alt + D to cut that word (notice that an extra space was left behind), press End to go to the end of the line, use Ctrl + Y to paste the word that we cut, and press Enter to execute the command:
robin ~/Lesson1/data2/animals $ echo one two three four seven/five/six/thousand
one two three four seven/five/six/thousand
- Press the up arrow key to get the previous command again, press Alt + B three times (the cursor ends up at five), press Ctrl + K to cut to the end of the line, press Alt + B to go back one word (the cursor ends up at seven), use Ctrl + Y to paste the word that we cut, type a forward slash, and press Enter to execute the command:
robin ~/Lesson1/data2/animals $ echo one two three four five/six/thousand/seven/
one two three four five/six/thousand/seven/
- Press the up arrow key to get the previous command once more, press Alt + B three times (the cursor ends up at six), press Ctrl + U to cut to the start of the line, press Alt + F to move forward one word (the cursor ends up at /thousand), press Ctrl + Y to paste the content we cut earlier, press Home and type echo, and then press the spacebar and then Enter to execute the command:
robin ~/Lesson1/data2/animals $ echo sixecho one two three four five//thousand/seven/
sixecho one two three four five//thousand/seven/
In this exercise, we have explored how to use the editing shortcuts to efficiently construct commands. With some practice, it becomes quite unnecessary to compose a command from scratch. Instead, we compose them from older ones.
Command-Line Autocompletion
We all use auto-suggest on our mobile devices, but surprisingly, this feature has existed on Bash for decades. Bash provides the following context-sensitive completion when you type commands:
- File and pathname completion
- Command completion, which suggests the names of programs and commands
- Username completion
- Options completion
- Customized completion for any program (many programs such as Git add their own completion logic)
Completion is invoked on Bash by entering a few characters and pressing the Tab key. If there is only one possible completion, it is immediately inserted on to the command line; otherwise, the system beeps. Then, if Tab is pressed again, all the possible completions are shown. If the possible completions are too numerous, a confirmation prompt is shown before displaying them.
Note
Depending on the system's configuration, the number of possible command completions seen will vary, since different programs may be installed on different systems.
Exercise 5: Completing a Folder Path
In this exercise, we will explore hands-on how the shell autocompletes folder paths for us:
- Open a new command shell and return to the directory that we recreated from history in the earlier exercise:
robin ~ $ cd Lesson1/data2/animals
robin ~/Lesson1/data2/animals $
- Type cd canis/ and press Tab three times. It completes the command to cd canis/lupus/ and shows two possible completions:
robin ~/Lesson1/data2/animals $ cd canis/lupus/
familiaris/ lupus/
robin ~/Lesson1/data2/animals $ cd canis/lupus/
- Type f and press Tab to choose the completion familiaris:
robin ~/Lesson1/data2/animals $ cd canis/lupus/familiaris/
Exercise 6: Completing a Command
In this exercise, we will use command completion to suggest commands (after each sequence here, clear the command line with Ctrl + U or Alt + Backspace):
- Type "les" and press Tab to produce the completion:
robin ~/Lesson1/data2/animals $ less
- Type "rmd" and press Tab to produce the completion:
robin ~/Lesson1/data2/animals $ rmdir
- If we do not type enough characters, the number of possible completions may be a large one. For instance, type "g" and press Tab twice (it beeps the first time to indicate that there is no single completion). The shell shows a confirmation prompt before showing all possible commands that start with "g", since there are too many:
robin ~/Lesson1/data2/animals $ g
Display all 184 possibilities? (y or n)
In such cases, it is more practical to say n, because poring over so many possibilities is time-consuming, and defeats the purpose of completion.
Exercise 7: Completing a Command using Options
In this exercise, we will use command completion using options to suggest the long options for commands (after each sequence here, clear the command line with Ctrl + U):
- Type "ls --col" and press Tab to produce the completion:
robin ~/Lesson1/data2/animals $ ls --color
- Type "ls --re" and press Tab twice to produce the list of two possible completions:
robin ~/Lesson1/data2/animals $ ls --re
--recursive --reverse
- Then, type "c" and press Tab to select --recursive as the completion:
robin ~/Lesson1/data2/animals $ ls --recursive
After performing these exercises, we have learned how the shell autocompletes text for us based on the context. The autocompletion is extensible, and many programs such as docker and git install completions for their commands, too.
Activity 3: Command-Line Editing
You are provided with the following list of tree species' names:
- Pinaceae Cedrus Deodara
- Cupressaceae Thuja Aphylla
- Taxaceae Taxus Baccata
- Podocarpaceae Podocarpus Alba
Each line has the family, genus, and species written like this: Podocarpaceae Lepidothamnus Intermedius. You need to type out each of these entries and use command-line shortcuts to convert them into a command that prints out the path of the data.txt file associated with the species.
You need to work out the most efficient way to compose a command, reducing typing effort and errors. Use the conifer tree sample data for this chapter that is in the ~/Lesson1/data folder and follow these steps to complete this activity:
- Navigate to the data folder.
- Type out a line from the file manually, for example, Podocarpaceae Lepidothamnus Intermedius.
- Use as few keystrokes as possible to generate a command that prints out the name of the file associated with that species, in this case: echo podocarpaceae/lepidothamnus/intermedius/data.txt.
- Repeat steps 3 and 4 for all the entries.
You should obtain the following paths for the data.txt files for the given species:
pinaceae/cedrus/deodara/data.txt
cupressaceae/thuja/aphylla/data.txt
taxaceae/taxus/baccata/data.txt
podocarpaceae/podocarpus/alba/data.txt
Note
If you are typing any piece of text multiple times, you can save time by typing that only once and then using the cut and paste functionality. You might want to experiment with the behavior of the two "cut word" shortcuts for this particular case. The solution for this activity can be found on page 272.
In this topic, we have examined the more hands-on interactive facilities that command-line shells provide. Without the time-saving features of history, completion, and editing shortcuts, the command line would be very cumbersome. Indeed, some old primitive command shells from the 1980s such as MS-DOS lacked most, if not all, of these features, making it quite a challenge to use them effectively.
Going forward, we will delve deeper into file management operations by utilizing a powerful concept called wildcard expansion, also known as shell globbing.
Shell Wildcards and Globbing
In the preceding exercises and activities, notice that we often perform the same operation on multiple files or folders. The point of a computer is to never have to manually instruct it to do something more than once. If we perform any repeated action using a computer, there is usually some way that it can be automated to reduce the drudgery. Hence, in the context of the shell too, we need an abstraction that lets us handle a bunch of files together. This abstraction is called a wildcard.
The term wildcard originates from card games where a certain card can substitute for whatever card the player wishes. When any command is sent to the shell, before it is executed, the shell performs an operation called wildcard expansion or globbing on each of the strings that make up the command line. The process of globbing replaces a wildcard expression with all file or pathnames that match it.
Note
This wildcard expansion is not performed on any quoted strings that are quoted with single or double quotes. Quoted arguments will be discussed in detail in a future chapter.
Wildcard Syntax and Semantics
A wildcard is any string that contains any of the following special characters:
- A ? matches one occurrence of any character. For example, ?at matches cat, bat, and rat, and every other three letter string that ends with "at".
- A * matches zero or more occurrences of any character. For example, image.* matches image.png, image.jpg, image.bmp.zip, and so on.
- A ! followed by a pair of parentheses containing another wildcard expands to strings that do not match the contained expression.
Note
The exclamation operator is an "extended glob" syntax and may not be enabled by default on your system. To enable it, the following command needs to be executed: shopt -s extglob.
There are a few more advanced shell glob expressions, but we will restrict ourselves to these most commonly used ones for now.
Wildcard Expansion or Globbing
When the shell encounters a wildcard expression on the command line, it is internally expanded to all the files or pathnames that match it. This process is called globbing. Even though it looks as though one wildcard argument is present, the shell has converted that into multiple ones before the command runs.
Note that a wildcard can match paths across the whole filesystem:
- * matches all the directories and files in the current directory
- /* matches everything in the root directory
- /*/* matches everything exactly two levels deep from the root directory
- /home/*/.bashrc matches a file named .bashrc that is in every user's home directory
At this point, a warning is due: this powerful matching mechanism of wildcards can end up matching files that the user never intended if the wildcard was not specified correctly. Hence, you must exercise great care when running commands that use wildcards and modify or delete files. For safety, run echo with the glob expression to view what files it gets expanded to. Once we are sure that the wildcard is correct, we can run the actual command that affects the files.
Note
Since the shell expands wildcards as individual arguments, we can run into a situation where the number of arguments exceeds the limit that the system supports. We should be aware of this limitation when using wildcards.
Let's dive into an exercise and see how we can use wildcards.
Exercise 8: Using Wildcards
In this exercise, we will practice the use of wildcards for file management by creating folders and moving files with specific file formats to those folders.
Note
Some of the commands used in this exercise produce many screenfuls of output, so we only show them partially or not at all.
- Open the command line shell and navigate to the ~/Lesson1/data1 folder:
robin ~ $ cd Lesson1/data1
There are over 11,000 files in this folder, all of which are empty dummy files, but their names come from a set of real-world files.
- Use a wildcard to list all the GIF files: *.gif matches every file that ends with .gif:
robin ~/Lesson1/data1 $ ls *.gif
The output is shown here:

Figure 1.17: A screenshot of the output displaying a list of all GIF files within the folder
- Create a new folder named gif, and use the wildcard representing all GIF files to move all of them into that folder:
robin ~/Lesson1/data1 $ mkdir gif
robin ~/Lesson1/data1 $ mv *.gif gif
- Verify that there are no GIF files left in the CWD:
robin ~/Lesson1/data1 $ ls *.gif
ls: cannot access '*.gif': No such file or directory
- Verify that all of the GIFs are in the gif folder:
robin ~/Lesson1/data1 $ ls gif/
The output is shown here:

Figure 1.18: A screenshot of a partial output of the gif files within the folder
- Make a new folder called jpeg and use multiple wildcard arguments with mv to move all JPEG files into that folder:
robin ~/Lesson1/data1 $ mkdir jpeg
robin ~/Lesson1/data1 $ mv *.jpeg *.jpg jpeg
- Verify with ls that no JPEG files remain in the CWD:
robin ~/Lesson1/data1 $ ls *.jpeg *.jpg
ls: cannot access '*.jpeg': No such file or directory
ls: cannot access '*.jpg': No such file or directory
- List the jpeg folder to verify that all the JPEGs are in it:
robin ~/Lesson1/data1 $ ls jpeg
The output is shown here:

Figure 1.19: A screenshot of a partial output of the .jpeg files within the folder
- List all .so (shared object library) files that have only a single digit as the trailing version number:
robin ~/Lesson1/data1 $ ls *.so.?
The output is shown here:

Figure 1.20: A screenshot of a partial output of the .so files ending with a dot, followed by a one-character version number
- List all files that start with "google" and have an extension;
robin ~/Lesson1/data1 $ ls google*.*
google_analytics.png google_cloud_dataflow.png google_drive.png google_fusion_tables.png google_maps.png google.png
- List all files that start with "a", have the third character "c", and have an extension:
robin ~/Lesson1/data1 $ ls a?c*.*
archer.png archive_entry.h archive.h archlinux.png avcart.png
- List all of the files that do not have the .jpg extension:
robin ~/Lesson1/data1 $ ls !(*.jpg)
The output is shown here:

Figure 1.21: A screenshot of a partial output of the non-.jpeg files in the folder
- Before we conclude this exercise, get the sample data back to how it was before in preparation for the next activity. First, move the files within the jpeg and gif folders back to the current directory:
robin ~/Lesson1/data1 $ mv gif/* .
robin ~/Lesson1/data1 $ mv jpeg/* .
Then, delete the empty folders:
robin ~/Lesson1/data1 $ rm -r gif jpeg
Now, having learned the basic syntax, we can write wildcards to match almost any group of files and paths, so we rarely ever need to specify filenames individually.
Even in a GUI, it takes more effort than this to select groups of files in a file manager (for example, all .gifs) and this can be error-prone or frustrating when hundreds or thousands of files are involved.
Activity 4: Using Simple Wildcards
The supplied sample data in the Lesson1/data1 folder has about 11,000 empty files of various types. Use wildcards to copy each file to a directory representing its category, namely images, binaries, and misc., and count how many of each category exist. Through this activity, you will get familiar with using simple wildcards for file management. Follow these steps to complete this activity:
- Create the three directories representing the categories specified.
- Move all of the files with the extensions .jpg, .jpeg, .gif, and .png to the images folder.
- Move all of the files with the extensions .a, .so, and .so, followed by a period and a version number, into the binaries folder.
- Move the remaining files with any extension into the misc folder.
- Count the files in each folder using a shell command.
You should get the following answers: 3,674 images, 5,368 binaries, and 1,665 misc.
Note
The solution for this activity can be found on page 273.
Activity 5: Using Directory Wildcards
The supplied sample data inside the Lesson1/data folder has a taxonomy of tree species. Use wildcards to get the count of the following:
- The species whose family starts with the character p, and the genus has a as the second character.
- The species whose family starts with the character p, the genus has i as the second character, and species has u as the second character.
- The species whose family as well as genus starts with the character t.
This activity will help you get familiar with using simple wildcards that match directories.
Follow these steps to complete this activity:
- Navigate to the data folder.
- Use the tree command with a wildcard for each of the three conditions to get the count of species.
You should get the following answers: 83 species, 26 species, and 19 species.
Note
The solution for this activity can be found on page 273.
Summary
We have introduced a lot of material in this first chapter, which is probably quite novel to anyone approaching the command line for the first time. Even in this brief exploration, we can start to see how seemingly complicated filesystem tasks can be completed with minimal effort.
In the coming chapter, we will add to our toolbox of useful shell programs that process text data. In later chapters, we will learn about the mechanisms to tie these commands together, such as piping and redirection, to perform complex data-processing tasks. We will also learn about regular expressions and shell expansion constructs that let us manipulate textual data in powerful ways.