
In Eclipse the file system rules. An Eclipse workspace is mapped to the file system directly and there is no intermediate repository. Users can either change a resource on the file system directly or from inside Eclipse. The resources plug-in provides support for managing a workspace and its resources (see Figure 32.1).
Clients need a way to track a resource in the file system. Resources change during their lifetime: they are created, their contents change, they are replaced with another version, they are deleted, and sometimes recreated. The information about a resource changes over its lifetime, but its identity doesn't. Clients need a simple way to refer to a resource independent of the resource's state in the workspace. We don't want to hold onto stale state, for example, when a file is deleted.
Eclipse addresses this problem by only giving clients access to a handle for a resource, not the full resource. This design is best described as the conjunction of the two structural patterns: Proxy and Bridge. Neither of the patterns alone captures the full intent of the design. The Proxy pattern tells us how to control access to an object and the Bridge pattern tells us how to separate an interface from its implementation. To quote their intent:
Proxy—. “Provide a surrogate or place holder for another object to control access to it”
Bridge (also known as Handle/Body)—. “Decouple an abstraction from its implementation so that the two can vary independently”
The relevant aspect from Proxy is controlling the access to an object. This is the key to avoid clients holding on to stale state. The relevant aspect from Bridge is the strong separation between an interface and its implementation. Both patterns address their problems by introducing a level of indirection. Applied to file-system resources this gives us:
The handle, which acts like a key for a resource.
An info object storing the representation of the file's state. There is only one implementor for each handle and it is therefore an example of a degenerate Bridge.
The handles are defined as interfaces IFile, IFolder, IProject, and IWorkspaceRoot. Figure 32.2 shows their interface hierarchy.

None of the resource interfaces are intended to be implemented by clients. Interfaces are used to define the API, but not so clients can implement the interfaces in different ways.
Let's verify the handle separation with the Spider (Figure 32.3) and explore the file TestFailure.java as presented in the Navigator (Figure 32.4).

From the diagram we can see that a File handle knows only the path to the resource and its containing workspace. It acts like a key to access the file. Here are some interesting characteristics of the resource handles:
They are Value Objects[1] —. small objects whose equality isn't based on identity. Once created, none of their fields ever change. This enables clients to store them in hashed data structures like a
Map. More than one handle can refer to the same resource. Always useIResource.equal()when comparing handles.Handles define the behavior of a resource, but they don't keep any resource state information.
A handle can refer to non-existing resources.
Some operations can be implemented from information stored in the handle only (handle operations). A resource need not exist to successfully execute such an operation. Examples of handle operations are:
getFullPath(),getParent(), andgetProject(). The existence of a resource can be tested withexists(). Operations that depend on the existence of the resource throw aCoreExceptionwhen the resource doesn't exist.Handles are created from a parent handle:
IProject project; IFolder folder= project.getFolder("someFolder");Handles are used to create the underlying resource:
folder.create(...);
The fixture class we used in Circle Two and shown in full in Appendix B illustrates how to use the handle-based API to create resources.
Since a handle is independent of the state in the file system, there is no way for the client to keep a reference to stale state, for example state about a deleted file. Every time you want state for the handle you have to fetch it anew.
Figure 32.5 illustrates the handle/body separation used for resources. In the following explanations we will use UML diagrams to illustrate the pattern stories. We annotate the UML with shaded boxes identifying the pattern being applied.

The handle IResource is API and the ResourceInfo and Resource are internal classes. ResourceInfo is extended to store additional state for projects (ProjectInfo) and the workspace root. This illustrates the strong separation suggested by the Bridge pattern. Eclipse has a lot of freedom when resolving handles to find the corresponding resource state.
When an IResource is created, the resource information is retrieved from the workspace and the path information is stored inside the handle. Figure 32.6 illustrates how the look up is done to find the ProjectInfo for a project:
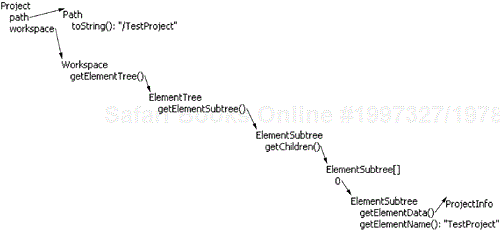
The Eclipse workspace stores the resource info as a complete tree in memory. This tree is referred to as the element tree. The resource info object corresponding to a handle is retrieved by traversing the element tree using the path stored inside the handle. A big advantage of this workspace implementation is that you can navigate the tree of files in almost no time. When you use the file system you have to make many queries to the underlying operating system (OS).
The resources plug-in not only applies handle/body separation for resources, it also applies the same separation for markers. A marker associates attributes with a resource. A marker doesn't store the attributes directly, but only stores a reference to their marker attribute info object. For markers the info object corresponds to the class MarkerInfo. The same coding idioms used for resources are consistently applied to markers:
Markers are created from a handle.
Accessing a marker attribute can throw a
CoreException.
Now that we understand how an individual resource is represented, let's look into the representation of the resource tree.
The Eclipse workspace provides resources stored in the file system. A workspace consists of projects containing folders containing files, as shown in Figure 32.7.

You access the Singleton workspace instance from the static accessor ResourcesPlugin.getWorkspace(). An IWorkspaceRoot represents the top of the resource hierarchy in a workspace.
The workspace is a hierarchical structure and it therefore matches the intent of the Composite pattern well: “Compose object into tree structures to represent part/whole hierarchies. Composite lets clients treat individual objects and compositions of objects uniformly.” Figure 32.8 shows how the implementation of a workspace maps to Composite:

Some observations on the workspace implementation:
IResourceprovides access to its parent. ThegetParent()method is a handle-only operation that can derive the parent from the path stored in the handle.IContaineris the common base interface for the different composite classes. It provides a methodmembers()that returns its children as a typedIResourcearray.
You can traverse a resource tree using the members() method provided by IContainer, but there is a better way.
Traversing a resource tree manually using the members() method results in a lot of control-flow code in clients. The control flow to traverse a resource tree can be extracted with a visitor. When we check the intent of Visitor we find, “Represent an operation to be performed on the elements of an object structure. Visitor lets you define a new operation without changing the classes of the elements on which it operates.” This is all correct. However, the main purpose here is to extract the common control flow and make it generally reusable.
IResourceVisitor is the visitor interface, which is accepted by IResource (see Figure 32.9).

The accept() method implements the resource traversal and calls back the visitor for each resource. The IResourceVisitor interface isn't type-specific; there are no separate methods for visiting a file or a folder. If you need to distinguish between the visited resource types, you can do this inside the visit() method using the getType() method. The code snippet from the Eclipse resource implementation illustrates the use of visitor.
Example . org.eclipse.core.internal.resources/ResourceTree
private void addToLocalHistory(IResource root, int depth) { IResourceVisitor visitor = new IResourceVisitor() { public boolean visit(IResource resource) throws CoreException { if (resource.getType() == IResource.FILE) addToLocalHistory((IFile) resource); return true; } }; try { root.accept(visitor, depth, false); } catch (CoreException e) { } }
Returning true from visit() indicates that the children of a resource should be visited. Returning false stops the traversal at the current resource.
While performance tuning, it was discovered that for some common traversals only a subset of the resource information is actually needed by the visitor. IResourceProxyVisitor was introduced to reduce the information fetched from the file system. It doesn't pass an IResource to the visit() method but an IResourceProxy.
Example . org.eclipse.core.resources/IResourceProxyVisitor
public interface IResourceProxyVisitor { public boolean visit(IResourceProxy proxy) throws CoreException; }
IResourceProxy is an example of a virtual proxy. It creates an expensive object on demand. The expensive object is in this case the full workspace path of a resource. The proxy is only valid during the call of the visit() method.
The Eclipse workspace has another advantage over accessing the file system directly—comprehensive support for observing changes.
Resources in the workspace can change either as a result of manipulating them inside Eclipse or from resynchronizing them with the local file system. In both cases, observing clients need precise change information so that they can update themselves efficiently. To observe changes, the workspace provides a resource listener, which is an Observer variation (see Figure 32.10). Observers register with the workspace, which acts as the subject to be notified about changes.

Internally the notification mechanism is implemented by a NotificationManager (see Figure 32.11).
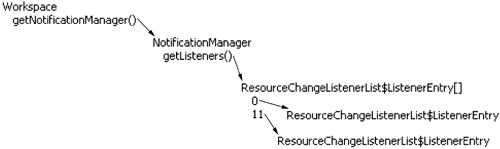
Digging into the implementation of NotificationManager, we find that it is very careful in handling the case of modifications to the listener list during notification. By copying the listener list at the beginning of a notification, it ensures that any modifications to the listener list during the notification will have no effect on the ongoing notification. This is also referred to as making a Safe Copy. The internal class ResourceChangeListenerList implements the listener management.
Example . org.eclipse.core.internal.events/ResourceChangeListenerList
public ListenerEntry[] getListeners() {
if (size == 0)
return EMPTY_ARRAY;
ListenerEntry[] result = new ListenerEntry[size];
System.arraycopy(listeners, 0, result, 0, size);
return result;
}
The observer pattern asks us to decide how to provide details about a change notification. To quote the Observer pattern: “At one extreme, which we call the push model, the subject sends observers detailed information about the change, whether they want it or not. At the other extreme is the pull model; the subject sends nothing but the most minimal notification, and observers ask for details explicitly thereafter.” Changes in a resource tree can be complex, so Eclipse uses the push model and provides detailed information about a change to all observers. Eclipse calls the change information resource deltas (see Figure 32.12).
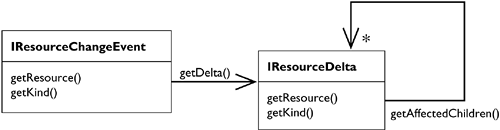
A resource delta describes the change between two states of the workspace tree. It is itself a tree of nodes. Each delta node describes how a resource has changed and provides delta nodes describing the changes to its children. A delta tree is rooted at the workspace root. Here is the resource delta describing a change to the file FailTest.java (see Figure 32.13 and Figure 32.14).

A resource delta has several interesting properties:
A resource delta describes a single change and multiple changes using the same structure.
A resource delta describes complete change information including information about moved resources and marker changes. The method
getMarkerDeltas()returns the changes to markers.It is easy to process a resource delta recursively top-down when updating an observer.
Because a resource delta can be expensive, it is only valid during the call of
resourceChanged().Because resources are just handles to the real resources, a delta can easily describe deleted resources as well.
You can reuse the traversal logic of a resource delta with an IResourceDeltaVisitor:
Any system based on change events is vulnerable to being flooded with resource change events. The common practice to avoid this flooding is to batch changes wherever possible. Changes should be grouped together so that only a single notification is sent out at the end of a single logical change. In Eclipse the batching is achieved using an IWorkspaceRunnable that is passed to the workspace for execution. The action specified by the runnable is then run as an atomic workspace operation. The deltas are accumulated during the operation and broadcast at the end. The snippet below illustrates how to create a marker and set its attributes with an IWorkspaceRunnable so that only one instead of two (creation, setting attributes) notifications are sent out:
Example . org.eclipse.ui.texteditor/MarkerUtilities
public static void createMarker(final IResource resource,
final Map attributes, final String markerType)
throws CoreException {
IWorkspaceRunnable r= new IWorkspaceRunnable() {
public void run(IProgressMonitor monitor) throws CoreException{
IMarker marker= resource.createMarker(markerType);
marker.setAttributes(attributes);
}
};
resource.getWorkspace().run(r, null);
}
An IWorkspaceRunnable is an example of the “Execute Around Method” pattern from Smalltalk[2] adapted to Java. IWorkspace.run() is the execute-around method. Before the runnable is executed, it informs the workspace to start batching. Then the runnable is invoked. Finally, when the runnable is done, IWorkspace.run() informs the workspace to end batching. Without an execute-around method, clients need to explicitly invoke the begin and end methods in the right order. This is error prone. Another benefit of an execute around method is that the begin and end batching methods do not have to be published as API.
Another example of an execute-around method in Eclipse is Platform.run(ISafeRunnable runnable). It invokes the runnable in a protected mode and catches exceptions.
[1] M. Fowler, Patterns of Enterprise Application Architecture, Addison-Wesley, Boston, 2003, p. 486.
[2] See “Execute Around Method” in K. Beck, Smalltalk Best Practice Patterns. Prentice Hall PTR, Upper Saddle River, NJ, 1997.