
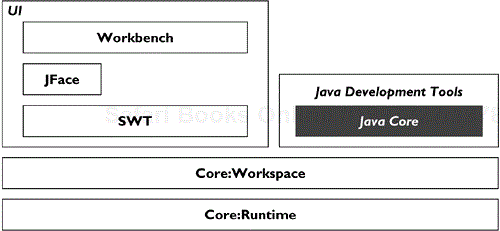
The Eclipse core workspace is programming-language agnostic. It provides API to a workspace containing projects, files, and folders. The JDT core builds on top of the workspace and provides APIs for navigating and analyzing the workspace from a Java angle (see Figure 33.1).
The JDT core defines a Java nature that configures projects with an incremental Java builder. A project with a Java nature is a Java project. Each Java project maintains class-path information in a .classpath file. The class path captures the location of the source code, the libraries used, and the output locations for generated-class files.
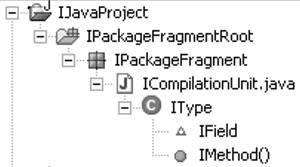
The resource structure is defined in terms of files and folders. The Java-centric view on resources is defined in terms of Java elements. The Java-element-based view on resources is referred to as the Java model. The Package Explorer presents the structure of the Java model, as shown in Figure 33.2.
Clients navigating Java code need to have a uniform Java-centric API that is different from the resource interface. This is a typical setup for the Adapter pattern. Its intent states: “Convert an interface of a class into another interface clients expect. Adapter lets classes work together that couldn't otherwise because of incompatible interfaces.” It is the first sentence of the intent that is of relevance for Java elements. IJavaElement plays the Adapter role and IResource is the adaptee (see Figure 33.3).

IJavaElement doesn't attempt to hide the fact that it is an adapter. It provides access to its adaptee with the accessor getCorrespondingResource(). Not all Java elements have a corresponding resource. The Java model also provides access to
Java elements that reside in JARs outside of the workspace and have no corresponding resource. An example is the JDK's rt.jar.
Java elements representing methods contained in a compilation unit. For this reason,
IJavaElementprovides additional accessor methods likegetResource(). It returns the innermost resource enclosing this element.
IJavaElement allows us to navigate from Java elements to their resources. However, clients also need to be able to navigate from a resource to a corresponding Java element. Java core provides an API Façade, JavaCore (see Figure 33.4). It provides static factory methods to create IJavaElements.
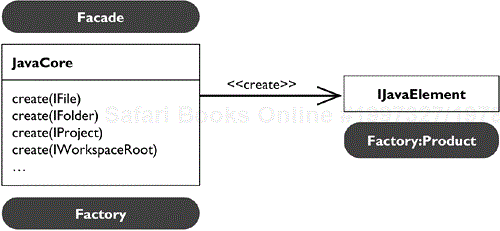
Notice that the create() methods do not really create a Java project, compilation unit, or package. They only return a handle to a corresponding Java element. The handles are lightweight value objects used to reference Java elements. The Java model may create any number of handles for an element. Next, let's take a look at the handle design in more detail.
Java elements use the same handle/body separation as is used for referencing resources (see Figure 33.5).
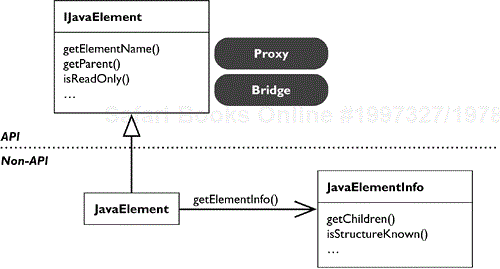
IJavaElement is the handle and JavaElementInfo is the body. IJavaElement defines the common behavior for Java elements. Several of its methods are handle-only methods, for example, getElementName() and getParent().
Figure 33.6 illustrates the element info structure for a compilation unit.

In contrast to the resource handle/body design, the one used in the Java model is much more involved. The main concern is scalability with regard to memory footprint. The Java model is much finer-grained than a resource tree. It supports navigation down to methods inside a compilation unit which requires Eclipse to parse the source of the corresponding file. Having a complete Java element tree in memory would be very expensive. The following observations help us solve the footprint problem:
Users typically only have a subset of the element tree expanded in the UI.
Users only have a small number of compilation units open in an editor or expanded in a Java view.
The element info can be computed based on the resource info.
It is therefore possible to consider the Java element infos as cached information for Java elements only. The implementation can maintain a bounded least-recently-used cache of element infos. The handle IJavaElement acts as the key into the cache. The Java model swaps out element infos to make room for other elements. Unsaved changes can never be swapped out. This might require growing the cache so isn't strictly bounded.
This, in fact, makes Java elements virtual proxies for the element info. The handle's bodies are virtualized and created on demand. In addition to all the other benefits of a handle-based design discussed above, handles naturally enable this virtualization without having to introduce yet another concept.
JavaElementInfos store the cached structure and attributes for a particular Java element. There is a class hierarchy of JavaElementInfos for the different kinds of Java elements, as illustrated by the following snapshot of its subclasses (see Figure 33.7).
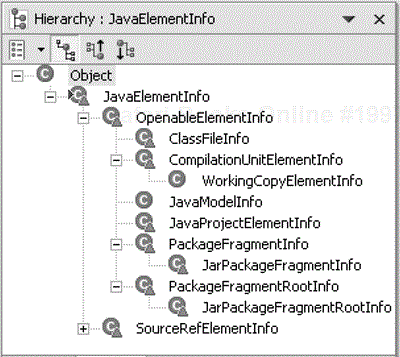
Elements that have their element info stored in the cache are said to be “open.” The Java model transparently opens Java elements as the client navigates the element tree.
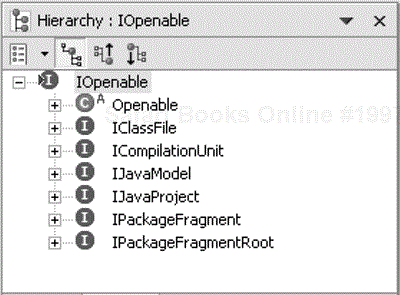
Java elements that need to be opened before they can be accessed implement the IOpenable interface (see Figure 33.8).
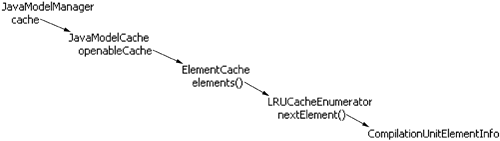
The element cache is maintained by an internal singleton JavaModelManager (see Figure 33.9).
You can observe the opening activity by enabling a Java model tracing option, as shown in Figure 33.10. You have to enable both the debug and debug/javamodel tracing options of the org.eclipse.jdt.core plug-in.
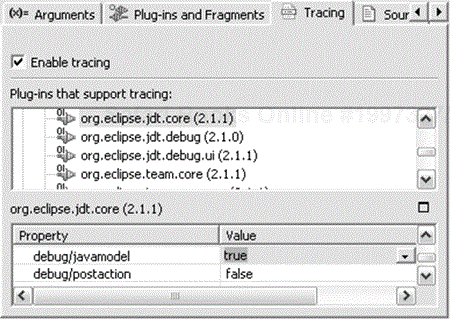
For example, when opening a source file and a class file we get the following trace:
OPENING Element (Thread[main,6,main]): [Working copy] Test.java [in [default] [in [projectroot] [in Foo]]] -> Package cache size = 502 -> Openable cache filling ratio = 0.35% OPENING Element (Thread[main,6,main]): AboutDialog.class [in junit.awtui [in C:/eclipse
Another interesting aspect of the handle/body implementation is that you can create an externalized form of a handle for an IJavaElement. The method IJavaElement.getHandleIdentifier() returns a string representation that is stable across sessions and that you can use to make persistent references to Java elements. The JavaCore provides a factory method, JavaCore.create(String), that can recreate the corresponding handle. This is an instance of the Memento pattern.
In contrast to the resource tree, the Java element tree is a part-whole structure with a fixed structure. It isn't just a recursive composition. Therefore, the Java element tree isn't a Composite in the pure sense. However, the composite nature of the tree can still be factored out using a Java interface IParent. Figure 33.11 shows the Java element tree interfaces and their structure.

All the interfaces are tagged with the same comment as IResources: “This interface is not intended to be implemented by clients.”
The IParent interface defines the composite interface with the methods getChildren() and hasChildren(). Notice that IParent isn't defined to extend IJavaElement. Peeking at the implementors of IParent we can see that they all implement IJavaElement. It would be possible therefore to have IParent extend IJavaElement, which gives the more typical Composite structure.
Why have both getChildren() and hasChildren()? The reason is performance. It is straightforward to implement hasChildren() in terms of getChildren(). However, it is often sufficient to know whether there are children at all. For example, when deciding whether a tree node should have a “+” to indicate it can be expanded, all you need to know is whether there are children, but you don't have to retrieve all of them. In particular, when it is expensive to compute the children, you can use hasChildren() to optimistically answer whether or not children exist.
We have covered almost all of the key interfaces of the Java model in the above diagram. One interface we haven't mentioned yet is ISourceReference. ISourceReference is mixed into all Java elements that have associated source. It provides access to the source range of a Java element.
We have already discussed the motivation for separating the type hierarchy information from Java elements in Chapter 17. The sub- and supertypes define an association between types. To implement this relationship in an efficient way, and in particular to compute it only when needed, the basic pattern “Objectify Associations”[1] was applied. However, in the case of the type hierarchy, an entire collection of associations was reified into a separate object (see Figure 33.12).
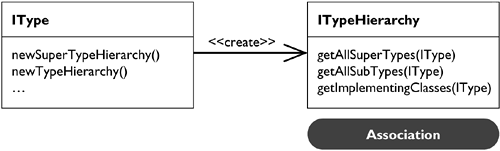
Having factory methods for creating either the super type hierarchy or the complete type hierarchy allows clients to choose which association they want. This is important because computing the super type hierarchy is much cheaper than computing a complete hierarchy.
In contrast to the workspace, the Java model doesn't provide Visitors to traverse its structure. There wasn't an urgent need to have such a visitor. More importantly, given the lazy nature of the Java model, using a visitor is often not the most efficient way to traverse the Java element tree. For example, finding a method by traversing the Java model starting at the root and then drilling down to methods is expensive. It will fully populate the element info caches.
You can perform search operations much faster by using Search. Search keeps an index of the Java elements contained in compilation units. It allows you to quickly find Java elements without having to create all of the element infos.
A recursive traversal of the Java element tree can be done using the IParent interface:
IJavaElement element;
IJavaElement[] children;
if (element instanceof IParent) {
IParent parent= (IParent)element;
children= parent.getChildren();
}
The support for tracking changes to Java elements is symmetrical to the workspace support for tracking changes to resources (see Figure 33.13).
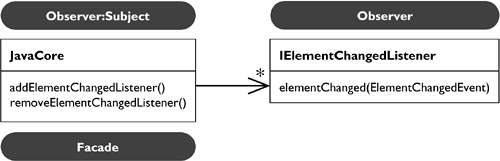
In contrast to the workspace, clients register the listeners with the JavaCore Façade. A listener receives an ElementChangedEvent, which carries a IJavaElementDelta (see Figure 33.14).
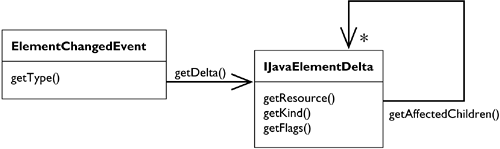
Resource deltas are always rooted at the top of the resource tree. Java element deltas don't make this guarantee. For example, deltas sent out while the user edits a compilation unit in the editor are rooted at the compilation unit. A Java element delta is only valid during a notification, so that its allocated resources can be freed after the event is processed.
The Java model provides the execute-around method JavaCore.run(IWorkspaceRunnable, IProgressMonitor) for batching change notifications. This method is the analog to IWorkspace.run() provided by the workspace.
Type hierarchies are not part of the element tree. To track changes in type hierarchies the Java model provides a separate change listener (see Figure 33.15). It is used when a type hierarchy is displayed in a view and needs to be updated as the source code is changing. For a type hierarchy, no detailed information about the change in the form of a delta is provided.

Next we consider the common pattern used by the Java core to return results.
The Java core provides several services that need to report their results as they are computed or discovered. However, it should be up to the clients to decide how to handle the results and how to store them. Here are some examples:
The search engine accepts a search pattern and reports matches.
Code assist analyzes possible completions at the current cursor location and reports them to the client.
Validating a compilation unit during typing needs to report problems as they are discovered by the Java builder.
This problem of separating the process of computing a result from its representation is the intent of the Builder pattern: “Separate the construction of a complex object from its representation so that the same construction process can create different representations.” Computing the result is done by what the pattern calls a Director and the handling of results is delegated to a Builder.
The Java core uses a naming convention for Builders. The corresponding interface or class names have the suffix Requestor or Collector. Let's look at two examples.
The Java core maintains an index of references and declarations to Java elements. It provides the class SearchEngine for searching elements matching a pattern in a specified scope (see Figure 33.16). The search pattern and the scope are created with factory methods. Using factory methods enables the hiding of the corresponding implementation classes. Search patterns can be combined to form simple logical expressions. The factory method createOrSearchPattern() takes two patterns and combines them into an or pattern. Behind the scenes we can recognize a use of the Interpreter pattern to represent and interpret these logical expressions.
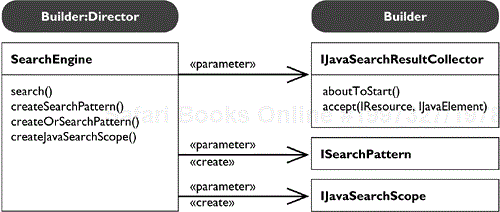
The SearchEngine acts as the Director and notifies its Builder, the IJavaSearchResultCollector, when a match is found. Before a search starts, the SearchEngine informs the builder with aboutToStart(). The actual matches are then reported with accept().
Figure 33.17 illustrates the different result collectors playing the role of a Builder.
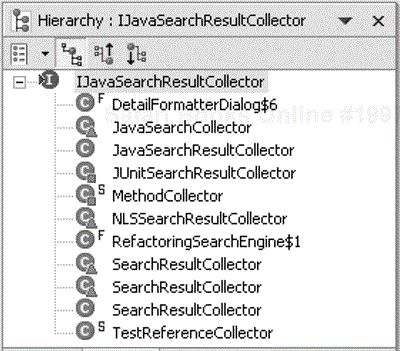
Code Assist follows the Builder pattern to report results as well (see Figure 33.18). Code Assist performs code completions at a given textual position inside a compilation unit.
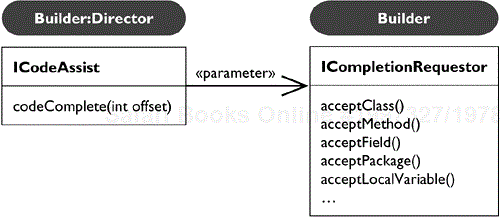
Code Assist reports its findings to the Builder ICompletionRequestor. The results are reported specifically to the type of the completion element.
The Java model supports navigating the Java element tree. However, the model is too coarse-grained to allow for a detailed analysis of code. The Java core provides access to a compilation unit's abstract syntax tree (AST). An AST represents the result of parsing and analyzing the compilation unit. Figure 33.19 shows the AST for the following compilation unit.
Example . TestFailure
import junit.framework.TestCase;
public class TestFailure extends TestCase {
public void testFailure() {
fail();
}
}
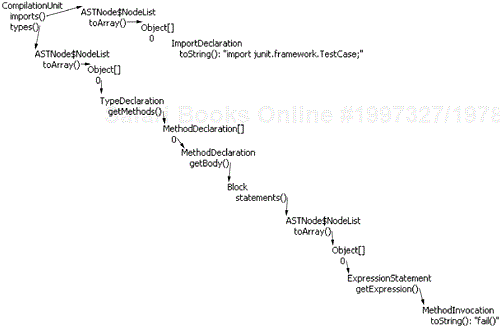
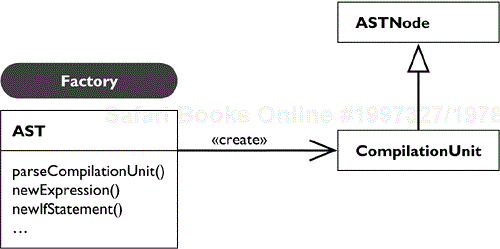
Each node of the AST represents an element of the program and keeps track of its source range and its bindings. A binding represents references to named entities as seen by the compiler. The AST nodes are defined in a hierarchy descending from ASTNode. An AST is constructed from a compilation unit or class file with the help of the factory class AST, as shown in Figure 33.20.
There is a different AST node for each Java source-code construct (see Figure 33.21).
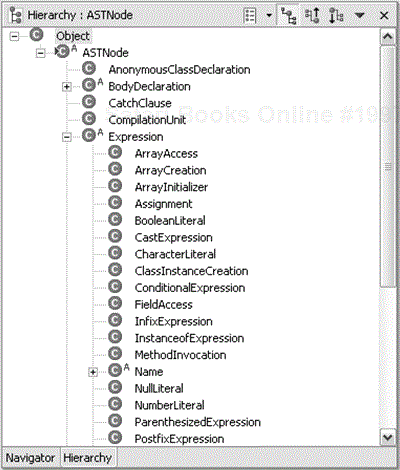
The reason for creating an AST is to analyze a compilation unit. To do the analysis, you traverse the AST and perform actions depending on the node type. AST analysis is a prototypical use of Visitor. The key consideration for applying Visitor is whether the class hierarchy defining the node structure is stable. Adding a new class to the node hierarchy would make it difficult to maintain a Visitor since existing Visitors would need to be modified. The source constructs of a language are stable (at least between major releases).
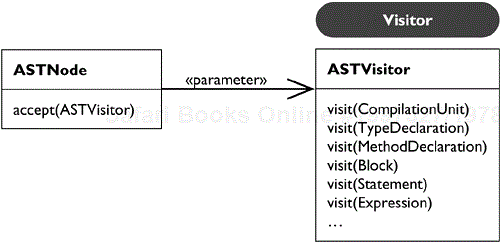
Therefore the node hierarchy remains stable and Visitor is useful. The AST API provides an abstract class, ASTVisitor. The ASTVisitor defines a visit method for each node type (see Figure 33.22).
The ASTVisitor provided by Java core comes with some Visitor implementation variations that are worth mentioning. Implementing a generic visitor that isn't interested in most node types is painful. A client has to override over sixty methods. For this reason the ASTVisitor provides two generic visit methods: preVisit(ASTNode) and postVisit(ASTNode). Clients can override these two methods to perform a non-type-specific traversal of an AST. For example, counting all nodes in an AST can be done with the following simple visitor:
Example . CountingVisitor
class CountingVisitor extends ASTVisitor { int count= 0; public void postVisit(ASTNode node) { count++; } public int getCount() { return count; } }
It can then be called as follows:
CompilationUnit cu; CountingVisitor visitor= new CountingVisitor(); cu.accept(visitor); System.out.println(visitor.getCount());
The other interesting variation is that ASTVistor provides both a visit() and an endVisit() method:
The method
visit()is called before descending into a node. Clients can returnfalsefromvisit()when they don't want to descend into a particular node.The method
endVisit()is called after all the descendent nodes are visited.
Here is an example illustrating the use of visit() and endVisit(). Let's assume we want to collect a metric, the number of method invocations in each method. To simplify the example, let's further assume that no local or anonymous types are used. (Handling these types properly requires storing the method count in a stack.) Below is the visitor implementation for this simplified scenario:
class CallsPerMethodVisitor extends ASTVisitor { int callCount= 0; public boolean visit(MethodDeclaration node) { callCount= 0; return super.visit(node); } public void endVisit(MethodDeclaration node) { System.out.println("calls in "+node.getName()+":"+ callCount); } public boolean visit(MethodInvocation node) { callCount++; return true; } }