


Managing 4-site replication by using CSM
This chapter describes the practical use of the 4-site replication solution with Copy Services Manager. It also describes planned and unplanned Disaster Recovery (DR) scenarios, and back-out scenarios if the recovery fails.
This chapter includes the following topics:
4.1 Overview
In this section, we provide an overview to the Metro Mirror - Global Mirror with a 4-site replication session in CSM. We show how to interpret the overall status of the 4-site session and how to obtain more information. We also explain which operations are applicable and the possible planned and unplanned scenarios.
4.1.1 Exploring the 4-site session
The 4-site session consists of a multi-target session with one Metro Mirror and one Global Mirror leg and a cascaded Global Copy from the Global Mirror target to the fourth site. This configuration results in a set of six different volume roles that are distributed across four sites. In this section, we describe how this session type is presented to the user.
In Figure 4-1, the 4-site session is shown in a normal operational state with replication across all sites.

Figure 4-1 4-site session in normal operational mode
The following information is highlighted in Figure 4-1 on page 22:
•Red box number 1: General information about the state of the session. In this example, we see that the session Status is Normal and the State of the session is Prepared. “Prepared” means that the source to target data transfer is active and all volumes are recoverable at the Metro Mirror and Global Mirror target sites. The active host in this state is in Region A Site 1 accessing the volume set tagged with H1.
•Red box number 2: The topology of the session. We can see the sites H1 to H4 with their name Region_A_site_1, Region_A_site2, Region_B_site3, and Region_B_site4.
The solid blue-colored volume stacks are showing volumes with a consistent, recoverable state whereby the disabled volume stacks are in an inconsistent state. For example, the H4 volumes are Global Copy target volumes, which are per definition inconsistent if I/O is ongoing.
The blue solid arrow indicates synchronous replication (Metro Mirror) while the dashed arrow represents asynchronous replication (Global Copy). Consistent asynchronous replication (Global Mirror), it is indicated with the spinning globe icon in the dashed arrow.
For more information about the icons and states, see IBM Knowledge Center.
•Red box number 3: The participating role pairs in the session are listed. When hovering the mouse over a role pair name, you can see in the topology diagram the corresponding volumes stacks of the role pair highlighted. In this specific state, the following role pairs are participating:
– H1-H2 : Metro Mirror between H1 and H2.
– H1-H3 : Global Copy between H1 and H3.
– H1-J3 : Global Mirror between H1 and J3. Global Mirror consists of the Global Copy H1-H3 and the IBM FlashCopy® H3-J3.
– H3-H4 : Global Copy between H3 and H4.
– H3-J3 : FlashCopy between H3 and J3 (belongs to Global Mirror consistency group formation, which is tracked with H1-J3).
You can identify the role and the status of each pair by the columns of the table.
The non-participating role pairs in the table that is shown at the bottom of Figure 4-1 on page 22 are not participating in the current session state. They are engaged when the session is moved into a different state; for example, when production is started at H2.
4.1.2 General operational steps
In this section, we briefly describe the general operational steps, which are applicable for recovery scenarios. We also give an overview of the operational steps for the major practice scenarios. Practice scenarios can be used to test the recover scenarios regularly.
Operations to a session in the CSM GUI can be triggered by clicking Session Actions: in the session details window, as shown in Figure 4-2.

Figure 4-2 Selecting Session Actions
With the Session Actions: → Commands submenu, CSM offers only those actions that are allowed in the current state of the session. We briefly describe next which operations often are used for specific purposes. These scenarios are described in this chapter.
Recover operations
Recover operations to a different site always are run in the sequence of operation. The following commands are used most often for such operations:
•Suspend
Before a recover operation can be started, replication must be suspended. Suspend means that the current replication is paused.
By using a suspend operation, the copy relations are not deleted; instead, they are maintained in a state where the replication stream is paused and outstanding updates are tracked in a change recording bitmap. The change recording bitmap is used for incremental resynchronization when the replication is resumed. Depending on the replication type and how replication is paused, the targets might not be consistent.
|
Note: By using the Suspend command in CSM, CSM always attempts to pause the replication in a consistent manner, which allows it to receive consistent data at secondary site upon a subsequent Recover or Failover command.
|
Depending on the replication type, a CSM Suspend command uses the required methods to pause replication in a consistent manner:
– For Global Mirror, CSM attempts to pause the Global Mirror master session on the DS8000 storage system with consistency. The Global Mirror master then forms and drains a last consistency group to the Global Mirror targets and then pauses the Global Copy pairs.
– For Metro Mirror, CSM uses the Freeze/Unfreeze mechanism to pause replication consistently across all Metro Mirror pairs that are in the session.
– For Global Copy, the CSM Suspend command converts the Global Copy relations into Metro Mirror relations and uses the Freeze/Unfreeze mechanism after all pairs in the session are fully synchronized.
•Stop
The CSM Stop command pauses the replication inconsistently. Usually this process results in pause commands to the individual PPRC relationships.
The target volumes often are inconsistent and not in a recoverable state after running this command. However, if a Suspend command was not completed and the session remains in a transitional state (such as Suspending), the Stop command makes a final attempt to pause the individual relationships and forces the session into a Suspended state that allows more session commands. In this case, the status section in the session details must be verified (see red box 1 in Figure 4-1 on page 22). If this section shows Recoverable: Yes, the session is consistent. You can also verify the Recoverable state of the individual role pairs to see whether their replication was paused consistently.
•Recover
The Recover command starts the failover process to the site to which production is intended to move. This process includes Copy Services operations for the DS8000 PPRC failover to make the targets accessible and start change recording bitmaps.
The active site indicator in the session also is changed to the target site. For Multi-Target relationships, a Recover command is possible only if replication of both legs was suspended.
|
Note: A Recover command does not restart replication from the target site.
|
•Failover
The Failover command performs many of the same operations as the Recover command. However, it does not change the active site indicator of the session. Therefore, the Failover command does not allow a subsequent Confirm Production command to enable replication start from the target site. Although it can be used only to practice a DR at a dedicated site, it allows practice tests while the other leg of a Multi-Target relationship continues replication and provides DR protection for the production volumes at another site.
•Confirm Production
Confirming the production site gives the user the opportunity to check the status of the data at the recovered site before allowing replication to be started from the recovery site. When the CSM Confirm Production command is performed, no action on the storage systems is triggered. It is a safety feature for the session management to prevent unintended start of replication into the wrong direction after a recovery.
Because the recovery operation might be for practice purposes, a replication restart in original direction is the default start option until the user confirms the production switch and allows that original production site can become a new target site for the replication.
•Start replication
With a Start command, the replication is re-started in the selected directions. The 4-site session allows various start options, depending between which sites replication should be started and what replication type should be used. Although both legs of the multi-target relationship can be started by using a single command and individually, the cascaded replication to the fourth site always must be started by using a separate operation.
Practicing in different sites
A practice scenario offers the possibility to test the production start at another site. The current version of CSM does not provide dedicated practice volumes in the 4-site session. This limitation implies that when a practice was started (for example, at H2), no Metro Mirror data replication within the region is possible if the practice is ongoing. However, the replication to H3 and H4 in the other region continues without any effect.
In contrast to a real DR scenario, which is often started by using the Recover command, a practice scenario might use the Failover command instead.
The Failover command enables a practice DR in a multi-target replication topology while one of the two legs can maintain its replication. The Failover command ensures that the host volumes receive the last possible consistent set of data and makes them available for host access.
Because the active host indicator of the session remains on the original site, the Failover command does not provide the possibility to change the direction of the replication. Therefore, the only possible action after a Failover command is to start the replication in its original direction, when the practice is finished.
4.1.3 State and Status
The session State and the session Status have different meanings and describe the current situation of the session. The status describes the health status with Inactive, Normal, Warning, and Failed, the state describes the momentary operational state of the session. States include the following examples:
•Prepared
The source to target data transfer is active and all pairs are in a state such that the targets can be made consistent and recoverable for planned and unplanned replication events.
•Preparing
The copy sets of the session started the replication, data is synchronizing or resynchronizing. Not all pairs in the session are prepared yet. For Metro Mirror or Global Mirror, this state is a transient state until all pairs become Prepared. For Global Copy, this state is a permanent state because active Global Copy relations cannot provide consistent data at the target site.
•Suspended
Data transfer is temporarily paused. The Recoverable status of the session or the role pair details indicate whether a recovery to the target site is possible. A state of Suspended (Partially) is shown if only one leg of a Multi-Target relationship is suspended while the other leg is still replicating.
•Suspending
A suspend operation is being processed to pause data transfer. This state is a transient state that results in a Suspended state. While the session is in the Suspending state, no other actions are allowed, except the Stop command to finally force the session into a Suspended state.
•Draining
When the cascaded Global Copy relation is being suspended, a drain operation is being processed to transfer the outstanding data to the target volumes before the replication is paused. This operation is valid only if the primary leg of the cascaded relation is Suspended or Target Available to allow consistent replication pause of the cascaded leg.
•Target Available
The targets of a relationship were made accessible for host access. This state is the resulting state after a Recover command.
For more information about states and statuses, see IBM Knowledge Center.
4.1.4 Normal operations
During normal operations, CSM is monitoring the ongoing replication. Depending from where the production is started, the replication type differs. The following replication types are established for the different modes of production operation:
Region A, Site 1 Production is connected to the H1 volumes. Metro Mirror is replicating synchronously to H2 and Global Mirror is started towards Region B, Site 3 (H3/J3). A cascaded Global Copy replicates asynchronously from the H3 to the H4 volumes.
Region A, Site 2 Production is running on the H2 volumes. Metro Mirror is replicating synchronously to H1. In addition, Global Mirror is started to Region B, Site 3 (H3/J3). Finally, a cascaded Global Copy continues replication to the H4 volumes.
Region B, Site 3 Production is running on the H3 volumes. Global Mirror is replicating towards Region A, Site 1 (H1/J1) and Metro Mirror replicates synchronously to H4. A cascaded Global Copy is started from H1 to H2 volumes.
Region B, Site 4 Production is using the H4 volumes. Metro Mirror is replicating data synchronously to the H3 volumes. Global Mirror is started towards Region A, Site 1 (H1/J1). The cascaded Global Copy from H1 to H2 continues to replicate asynchronously.
|
Note: The normal operation status is shown when all replications are started. In some situations, the cascaded Global Copy to the fourth site must be restarted manually. Otherwise, the session stays in a warning state, which indicates that the fourth site does not contain a copy of the latest production data.
The normal operation status is also shown after a recovery operation when the session is in Target Available state as described in the following sections.
|
Detailed Status
In some situations, more detailed status information about a certain session state or status is shown in the session details window (see in Figure 4-3).

Figure 4-3 Detailed Status information
In this example, you see a Detailed Status message that provides more information about the reason for the Warning status of the session.
CSM is maintaining its own state machine where multiple commands are transmitted to the participating storage devices. Instead of a status message as shown in Figure 4-3 in the Detailed Status section, you might also see a sequence of ongoing tasks. Ongoing tasks can be identified by a rotating icon in front of the message.
Console window
For more information about the status, errors, or warnings, the CSM Console window shows a history of all events and command execution. The Console window can be opened by clicking Console in the top menu bar of the CSM window.
As shown in Figure 4-4, the reason for the warning that is shown in Figure 4-3 on page 28 is that the StopH3H4 command was previously issued.

Figure 4-4 Console window
4.2 Planned site failover scenarios
In this section, we explain operations that involve site changes without an acute incident or disaster. A planned switch of production to a different site can be indicated when production is potentially endangered because of maintenance work that is in or close to the computer rooms. Another reason for a planned switch can be testing new applications or application upgrades in a production-like environment at a different site or testing the DR scenarios.
A planned failover is a controlled series of actions and thus typically straightforward because no error conditions exist that must be detected and handled accordingly. The starting position is the completed setup as described in 3.1, “Metro Mirror - Global Mirror with 4-site replication session” on page 10 with Metro/Global Mirror started at site 1 on the H1 volumes.
Planned site or region change scenarios can be performed for all sites of the 4-site session. The CSM 4-site session is organized in a symmetrical topology, which offers the possible production site changes that are listed in Table 4-1.
Table 4-1 Site change possibilities in a 4-site session
|
Current production
|
Next site change
|
Next region change
|
|
H1
|
H2
|
H3
|
|
H2
|
H1
|
H3
|
|
H3
|
H4
|
H1
|
|
H4
|
H3
|
H1
|
As you can see in Table 4-1, production can run at any site. The next possible site change within a region can be done to the corresponding Metro Mirror target volumes. In Table 4-1, they are listed in the Next site change column.
A region change can be done to the corresponding Global Mirror target volumes, which are H1 or H3 volumes, as listed in the Next region change column in Table 4-1. A change to the cascaded Global Copy target volumes (for example, H4 when production runs on H1 or H2) can be done only with a preceding change to the Global Mirror target volumes. It is not necessary to start production I/O on the Global Mirror target volume, but all operational steps in the CSM session must be performed before you can continue subsequent steps to finally switch production to the cascaded target site.
Next, we describe how to operate the different scenarios.
|
Note: For the scenarios that are described next, we assume that the status of the session is Normal with a Prepared state and production is running on H1 volumes.
|
4.2.1 Site failover from H1 to H2
Failing over to Site 2 is the most obvious and simplest site switch. It is a move within one region. This scenario includes the following overall steps:
1. Stop I/O on the host volumes H1.
2. Suspend the session.
3. Recover the session to H2.
4. Start I/O at H2.
5. Confirm Production at H2 in the session.
6. Start session H2->H1 H2->H3.
These steps are described next.
Step 1: Stopping I/O on host site
With a suspend command issued in the session, CSM always ensures that the replication is paused in a way that the target volumes are left in a recoverable state. Depending on the active replication type, different actions on the storage system are performed to accomplish this task (for more information, see 4.1.2, “General operational steps”).
However, when a copy relation is suspended while production is running, the most recent data that is no longer replicated to the target volumes is lost. To ensure that most recent data updates is included on the target volumes, the I/O must be stopped by closing the production at this point.
Step 2: Suspend session
The session is suspended by selecting Commands → Suspend... from the Session Action: button. In the subsequent suspend pop-up window, select the Suspend command and confirm the command preview and information message by clicking Yes, as shown in Figure 4-5.

Figure 4-5 Suspend 4-site session
This suspend action pauses replication consistently on both active legs. It also results in the session status, as shown in Figure 4-6.

Figure 4-6 Suspended session from normal operation on H1
As you can see, the state of the session changed to Suspended state with a Severe status. A Suspended state is always considered with a Severe status because the 4-site session cannot longer transmit any data to Site 2 or Site 3. Nevertheless, as you can see in the solid-colored volume stacks, consistent data exists in H1, H2, and H3. The Suspended state of the session is the final state to achieve in this step.
|
Note: Sessions with many copy sets or with asynchronous replication that is lagging behind can take some time until the suspend operation is finished. During this period, you see that the session shows a transitional state of Suspending, which changes to Suspended after all copy sets are processed.
|
As you can see in Figure 4-6, the Global Copy from H3 to H4 is left untouched during this operation.
Step 3: Recover Session to H2
After the session was successfully suspended, the session can be recovered to H2. To do so, select Commands → Recover... from the Session Actions: button. In the recover pop-up window that opens, select the RevocerH2 command and confirm the command preview and information message with Yes, as shown in Figure 4-7.

Figure 4-7 Recover session to H2 from H1
The result of this action is shown in Figure 4-8.

Figure 4-8 Recovered session at H2
As you can see, the session is now in status Normal. The state of the session is Target Available, which means that the volumes at H2 are now accessible to the host.
Step 4: Start I/O at H2
I/O now can be started by using the H2 volumes. Rather than starting full production immediately at this point, required checks and tests are done. For example, applications and databases are checked to ensure that they can start correctly and their data integrity is verified.
Step 5: Confirm production switch in session
As shown in Figure 4-9, the Commands submenu includes the Start... command. However, the available start commands again restart the replication from H1 volumes.
CSM implemented a confirmation checkpoint to enable replication start into the opposite direction. The start commands for replication from the recovered site are not activated before the production switch is confirmed to the session. To do so, select Commands → Confirm Production at Site 2, as shown in Figure 4-9.

Figure 4-9 Confirmation of production at Site 2
With the confirmation of the production at the new site, the data replication to the other sites (which includes in this case Metro Mirror to H1 and Global Mirror to H3) finally can be started. The pop-up window that is shown in Figure 4-10 explains this process and prompts the user for acknowledgment of the warning message by clicking Yes.

Figure 4-10 Acknowledge the confirmation
Step 6: Start Session H2->H1 H2->H3
After production is confirmed on H2, the 4-site session replication can be started from
Site 2. To do so, select Commands → Start... and then, select the Start H2->H1 H2->H3 command from the subsequent pop-up window, as shown in Figure 4-11.
Site 2. To do so, select Commands → Start... and then, select the Start H2->H1 H2->H3 command from the subsequent pop-up window, as shown in Figure 4-11.

Figure 4-11 Start the session H2->H1 H2->H3
Now the session resynchronizes data from Site 2, as shown in Figure 4-12. The status is Normal, the state of the session is Prepared, and Recoverable:Yes, as shown in the details window.

Figure 4-12 Running replication from Site 2
|
Note: During this scenario, the cascaded Global Copy between H3 and H4 never changed. Therefore, no specific actions are required to continue replication to the fourth site.
|
4.2.2 Region failover from H1 to H3
One of the typical scenarios of a 4-site replication session is a planned failover to the other region. Some customers perform this scenario regularly. One possible reason is to run test operations in the remote region without affecting DR capability in the local region. Other customers are switching production to the other region for a longer period.
The planned region failover is performed by completing the following steps:
1. Stop host I/Os (that is, shutdown hosts).
2. Suspend both active legs of the 4-site session (Metro Mirror and Global Mirror).
3. Recover the session to H3.
4. Start host I/O from the H3 volumes.
5. If start checks were successful, confirm production at Site 3 in the session.
6. Start Metro Mirror and Global Mirror again in opposite direction (H3->H4 and H3->H1).
7. Start cascaded Global Copy to complete 4-site session (H1->H2).
In the following sections, we review the individual steps because some options and considerations are important.
Step 1: Stop host I/Os
To provide most recent data at the other region, I/O is stopped before the replication is suspended.
Step 2: Suspend the 4-site session
The CSM GUI offers Suspend command options to suspend H1->H2 and H1->H3 separately or both mirrors together in a single command. Suspending both mirrors in one or in separate operations provides the same final result. In a planned region failover scenario, you can suspend both mirrors in a single step.
|
Note: In the example that is described next, you can see that the volumes at H3 features a consistent state (solid blue volume stack) after a Suspend H1->H3 command. This state occurs because the DS8000 systems that are used for this session are supporting the Global Mirror pause with consistency function in their microcode.
DS8000 systems that do not support this function cannot provide consistent data on the secondary host volumes of a Global Mirror relation (H3 or H1) right after the Suspend command. In that case, the last Global Mirror consistency group must first be restored on the H3/H1 volumes by using the Failover or Recover command. To provide consistency in this case, a Failover or Recover command must be triggered then.
|

Figure 4-13 4-site session in suspended state with consistent GM targets
Although the data on H3 in this example is consistent, the copy on H4 is still an inconsistent copy because of the nature of Global Copy. Remember, the design point of this 4-site session is not to provide four consistent copies of data, but to establish quickly a Metro Mirror (or HyperSwap) relation in the remote region for immediate HA/DR capabilities after a region failover, as described next.
Step 3: Recover H3
This CSM command ensures that the last Global Mirror consistency group is restored to the H3 volumes to ensure that they are consistent before they are made accessible for hosts.
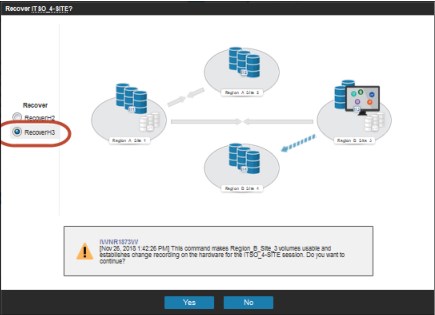
Figure 4-14 Recover Session at H3
Step 4: Start I/Os from H3 volumes
The host systems now can start from these volumes or mount them and perform tests for ensuring production can start and proceed on Site 3. If the decision is made to stay on Site 3, the next step can be performed.
Step 5: Confirm production at Site 3
This step is required as a checkpoint to confirm in the session that Site 3 is the new production site. This action enables the following command options within the Session Actions: menu:
•Re-enable original direction: This option reverts a previous confirm production site operation. It is available if replication was not started from the new production site.
•Start H3->H4 H3->H1: This option establishes the local Metro Mirror and reverses the Global Mirror relation back to Site 1.
Step 6: Start Metro Mirror - Global Mirror relations from Site 3
After production is confirmed at Site 3, the same level of protection as before the region switch is established again. Therefore, the Metro Mirror and Global Mirror and the cascaded Global Copy relation must be restarted. The Multi-Target replication can be restarted by using the Start... → command by selecting Start H3->H4 H3->H1 in the Start command options, as shown in Figure 4-15.
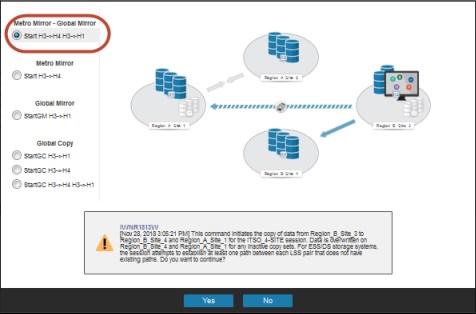
Figure 4-15 Restart replication from site 3
Step 7: Start Global Copy H1->H2
Although the session is recovered to H3 as described in “Step 3: Recover H3” on page 37, the Metro Mirror relation from H1 to H2 was failed over. You can identify this state by the opposite pointing arrows between both sites.
The CSM session details window also shows a warning that replication to the fourth site is not active. To bring the session back into normal operational mode, the now cascaded replication from H1 to H2 must be started as Global Copy by using the StartGC H1->H2 command, as shown in Figure 4-16.

Figure 4-16 Start cascaded replication to H2
4.2.3 Site failover from H3 to H4
Site failover from H3 to H4 works in the same way as described in 4.2.1, “Site failover from H1 to H2” on page 30. The only difference is that production runs at H3 and the local target site is H4. The steps to perform this operation are the same but with different sites:
1. Stop I/O on the host volumes H3.
2. Suspend the session.
3. Recover the session to H4.
4. Start I/O at H4.
5. Confirm Production at H4 in the session.
6. Start session H4->H3 H4->H1.
As a prerequisite for this scenario, the 4-site session must be in Normal status with a Prepared state with production running on H3. Figure 4-17 shows how the session is presented in this mode.

Figure 4-17 Normal operation mode at Site 3
When all steps of this scenario are completed, the session is in a normal operation mode at Site 4 and are presented as shown in Figure 4-18.
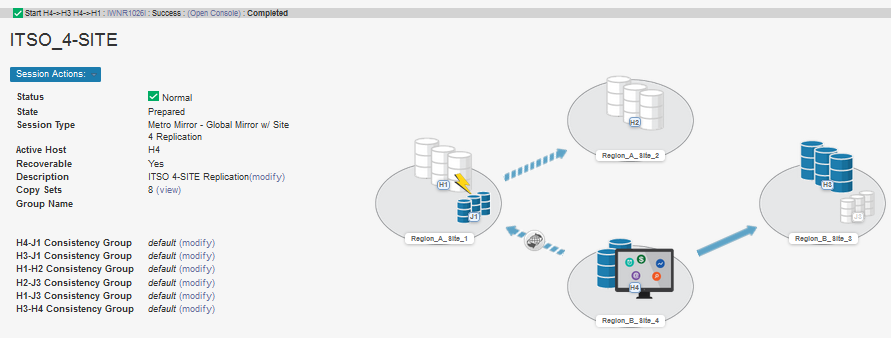
Figure 4-18 Normal operation mode at Site 4
4.2.4 Region failover from H2 to H3
When the session is running at region A site 2 on the H2 volumes, the session established a Metro Mirror relation to H1 and a Global Mirror relation to H3. From this situation, a site failover scenario to the H3 volumes in the other region can be applied.
Typically, a successful site failover from H1 to H2 was operated before. The session must run in normal operation mode at H2 (as shown in Figure 4-12 on page 35) before this failover scenario can be started.
This scenario includes the following steps:
1. Stop I/O at H2.
2. Suspend the session.
3. Recover the session to H3.
4. Start and verify production I/O at H3.
5. Confirm production at H3 in the session.
6. Start session with Start H3->H1 H3->H4.
7. Start Global Copy H1->H2.
4.2.5 Region failover from H4 to H1
A region failover from H4 to H1 corresponds to the process that is described in 4.2.4, “Region failover from H2 to H3”. A successful failover scenario to H4 as described in 4.2.3, “Site failover from H3 to H4” on page 39 must be operated first and production be in normal operational mode at H4.
The process to failover from H4 to H1 includes the following steps:
1. Stop I/O at H4.
2. Suspend the session.
3. Recover the session to H1.
4. Start and verify production I/O at H1.
5. Confirm production at H1 in the session.
6. Start session with Start H1->H3 H1->H2.
7. Start Global Copy H3-> H4.
4.3 Practice scenarios
In this section, we describe how practice scenarios can be implemented by using the 4-site session.
4.3.1 General overview
With the practice scenarios that are described in this section, production data can be made available at one of the target sites while consistent data replication continues to the other target sites. The general approach to achieve this situation is to pause replication with consistency in a first step. This first step can be accomplished by using a Suspend command to the corresponding replication leg. Later, a Failover command is issued to the site where the DR practice test occurs.
In contrast to the site failover scenarios that are described in 4.2, “Planned site failover scenarios” on page 30, the practice scenarios usually do not suspend both replication legs. Therefore, the Recover command is not available to make consistent data accessible on the target site. With the Failover command that is generally used in these practice scenarios, replication can be restarted only in the original direction after the practice tests were completed.
4.3.2 Practice failover at the Metro Mirror target site
Practice failover to the Metro Mirror target site continues Global Mirror replication to the remote region. Also, the cascaded Global Copy to the fourth site in the other region can continue.
If an upcoming disaster situation during the test, a recovery to the remote region must be performed. Depending on which site is the current production site, different commands are required to practice on the Metro Mirror target site. However, the general operational steps are the same for each situation because the 4-site session provides a symmetrical topology.
The following steps are required to practice DR on H2 if production is running on H1. Production continues to be active on H1 with Global Mirror running to H3:
1. Issue Suspend H1-H2.
2. Issue Failover H2.
3. Start host I/O for DR practice test on site 2 by using the H2 volumes.
4. When practice tests are finished, shutdown host I/O on H2 volumes.
5. Issue Start H1->H2 to restart Metro Mirror replication.
The following steps are required to practice DR on H1 if production is running on H2. Production continues to be active on H2 with Global Mirror running to H3:
1. Issue Suspend H2-H1.
2. Issue Failover H1.
3. Start host I/O for DR practice test on site 1 by using the H1 volumes.
4. When practice tests are finished, shutdown host I/O on H1 volumes.
5. Issue Start H2->H1 to restart Metro Mirror replication.
The following steps are required to practice DR on H4 if production is running on H3. Production continues to be active on H3 with Global Mirror running to H1:
1. Issue Suspend H3-H4B.
2. Issue Failover H4B.
3. Start host I/O for DR practice test on site 4 by using the H4 volumes.
4. When practice tests are finished, shutdown host I/O on H4 volumes.
5. Issue Start H3->H4 to restart Metro Mirror replication.
The following steps are required to practice DR on H3 if production is running on H4. Production continues to be active on H4 with Global Mirror running to H1:
1. Issue Suspend H4-H3.
2. Issue Failover H3.
3. Start host I/O for DR practice test on site 3 using the H3 volumes.
4. When practice tests are finished, shutdown host I/O on H3 volumes.
5. Issue Start H4->H3 to restart Metro Mirror replication.
4.3.3 Practice failover at Global Mirror target site
This scenario provides the possibility to perform a DR practice test in the other region at the Global Mirror target site. The Metro Mirror replication in the same region continues without any impact and provides local protection if disaster occurs while the practice tests are ongoing. In that case, a recovery to the Metro Mirror target site must be performed.
|
Note: In the Global Mirror target site practice scenario, a start of the Metro Mirror replication to fourth site is not provided. Rather, the replication to fourth site is suspended to keep a consistent copy of production data at remote region while practice tests are being performed on Global Mirror target site. For more information about performing DR practice tests at a fourth site, see 4.3.4, “Practice failover at fourth site”.
|
This DR practice scenario represents a situation that occurs when both sites within a region are affected by a regional disaster. Depending on which site is the current production site, different commands are required to practice on the Global Mirror target site. However, the general operational steps are the same for each situation because the 4-site session provides a symmetrical topology.
The following steps are required to practice DR on H3 if production is running on H1. Production continues to be active on H1 with Metro Mirror running to H2:
1. Issue Suspend H1-H3.
2. Issue Failover H3.
3. Issue Suspend H3-H4 to keep a consistent production data copy on H4 volumes.
4. Start host I/O for DR practice test on site 3 by using the H3 volumes.
5. When practice tests are finished, shutdown host I/O on H3 volumes.
6. Issue StartGM H1->H3 to restart Global Mirror replication.
7. Issue StartGC H3->H4 to restart Global Copy replication to fourth site.
The following steps are required to practice DR on H3 if production is running on H2. Production continues to be active on H2 with Metro Mirror running to H1:
1. Issue Suspend H2-H3.
2. Issue Failover H3.
3. Issue Suspend H3-H4 to keep a consistent production data copy on H4 volumes.
4. Start host I/O for DR practice test on site 3 by using the H3 volumes.
5. When practice tests are finished, shutdown host I/O on H3 volumes.
6. Issue StartGM H2->H3 to restart Global Mirror replication.
7. Issue StartGC H3->H4 to restart Global Copy replication to fourth site
The following steps are required to practice DR on H1 if production is running on H3. Production continues to be active on H3 with Metro Mirror running to H4:
1. Issue Suspend H3-H1.
2. Issue Failover H1.
3. Issue Suspend H1-H2 to keep a consistent production data copy on H2 volumes.
4. Start host I/O for DR practice test on site 1 by using the H1 volumes.
5. When practice tests are finished, shutdown host I/O on H1 volumes.
6. Issue StartGM H3->H1 to restart Global Mirror replication.
7. Issue StartGC H1->H2 to restart Global Copy replication to fourth site.
The following steps are required to practice DR on H1 if production is running on H4. Production continues to be active on H4 with Metro Mirror running to H3:
1. Issue Suspend H4-H1.
2. Issue Failover H1.
3. Issue Suspend H1-H2 to keep a consistent production data copy on H2 volumes.
4. Start host I/O for DR practice test on site 1 by using the H1 volumes.
5. When practice tests are finished, shutdown host I/O on H1 volumes.
6. Issue StartGM H4->H1 to restart Global Mirror replication.
7. Issue StartGC H1->H2 to restart Global Copy replication to fourth site.
4.3.4 Practice failover at fourth site
With this practice scenario, you can perform DR practice tests on the fourth site without affecting Metro Mirror. Also, Global Mirror can be restarted after a consistent data copy is created on the fourth site. Compared to the previous scenario, this current scenario includes the benefit that remote data protection with Global Mirror can be restarted while DR tests are performed.
Depending on which site is the current production site, different commands are required to practice at the fourth site. As with the previous scenarios, the general operational steps are the same for each situation because the 4-site session provides a symmetrical topology.
The following steps are required to practice DR on H4 if production is running on H1. Production continues to be active on H1 with Metro Mirror running to H2:
1. Issue Suspend H1-H3.
2. If the H1-H3 role pair does not show Recoverable for all pairs, you must issue Failover H3 to restore last Global Mirror consistency group on H3. You can also verify whether the Global Mirror details show that the master was paused with consistency, as shown in Figure 4-19 on page 44. In that case, the H3 volumes are consistent and the Failover H3 can be skipped.
3. Issue Suspend H3-H4.
4. Issue StartGM H1->H3 to restart Global Mirror replication.
5. Issue Failover H4.
6. Start host I/O for DR practice test on site 4 by using the H4 volumes.
7. When practice tests are finished, shutdown host I/O on H4 volumes.
8. Issue StartGC H3->H4 to restart cascaded Global Copy replication.

Figure 4-19 Global Mirror master paused with consistency
The following steps are required to practice DR on H4 if production is running on H2. Production continues to be active on H2 with Metro Mirror running to H1:
1. Issue Suspend H2-H3.
2. If the H2-H3 role pair does not show Recoverable for all pairs, you must issue Failover H3 to restore last Global Mirror consistency group on H3. You can also verify whether the Global Mirror details show that the master was paused with consistency. In that case, the H3 volumes are consistent and the Failover H3 can be skipped.
3. Issue Suspend H3-H4.
4. Issue StartGM H2->H3 to restart Global Mirror replication.
5. Issue Failover H4.
6. Start host I/O for DR practice test on site 4 by using the H4 volumes.
7. When practice tests are finished, shutdown host I/O on H4 volumes.
8. Issue StartGC H3->H4 to restart cascaded Global Copy replication.
The following steps are required to practice DR on H2 if production is running on H3. Production continues to be active on H3 with Metro Mirror running to H4:
1. Issue Suspend H3-H1.
2. If the H1-H3 role pair does not show Recoverable for all pairs, you must issue Failover H1 to restore last Global Mirror consistency group on H1. You can also verify whether the Global Mirror details show that the master was paused with consistency. In that case, the H1 volumes are consistent and the Failover H1 can be skipped.
3. Issue Suspend H1-H2.
4. Issue StartGM H3->H1 to restart Global Mirror replication.
5. Issue Failover H2.
6. Start host I/O for DR practice test on site 2 by using the H2 volumes.
7. When practice tests are finished, shutdown host I/O on H2 volumes.
8. Issue StartGC H1->H2 to restart cascaded Global Copy replication.
The following steps are required to practice DR on H2 if production is running on H4. Production continues to be active on H4 with Metro Mirror running to H3:
1. Issue Suspend H4-H1.
2. If the H1-H4 role pair does not show Recoverable for all pairs, you must issue Failover H1 to restore last Global Mirror consistency group on H1. You can also verify whether the Global Mirror details show that the master was paused with consistency. In that case, the H1 volumes are consistent and the Failover H1 can be skipped.
3. Issue Suspend H1-H2.
4. Issue StartGM H4->H1 to restart Global Mirror replication.
5. Issue Failover H2.
6. Start host I/O for DR practice test on site 2 using the H2 volumes.
7. When practice tests are finished, shutdown host I/O on H2 volumes.
8. Issue StartGC H1->H2 to restart cascaded Global Copy replication.
These procedures, and the procedures that are described in 4.2, “Planned site failover scenarios” on page 30, can be automated. The CSM scheduled tasks feature provides a mechanism to define command sequences for a single or multiple sessions.
Such a defined task can then be run on-demand or scheduled to be run automatically at regular intervals or a predefined schedule.
For more information about scenario automation, see Appendix A., “Automation” on page 67.
An example task to practice DR on H4 if production is running on H1 is provided in A.2.1, “Task to create DR practice copy on H4” on page 79.
4.4 Creating a Golden Copy at fourth site
In a 4-site session, the fourth site in the replication topology is an obvious place for a Golden Copy. The purpose of such a Golden Copy is to create a consistent set of data at a specific time or regular intervals.
For example, a Golden Copy can be used to perform independent application tests where host can run special operations on production data without interrupting normal production. A Golden Copy that is refreshed at regular intervals can be used as a last resort of DR; for example, when recovery to the Metro Mirror and Global Mirror target sites fail. It can also be used as data source to dump a consistent image of the production data to tape without quiescing production. The refresh intervals of a regular Golden Copy determine its Recovery Point Objective (RPO) if it is used to restore production data.
|
Note: The creation and refresh of a Golden Copy is an operational procedure for a CSM 4-site session. It can be performed manually, or scheduled to be run automatically by using a Scheduled Task that is defined for the scenario.
|
For more information about scenario automation, see Appendix A., “Automation” on page 67.
An example task to create a Golden Copy at site 4 is provided in A.2.2, “Task to create regular Golden Copies on H4” on page 83.
In a normal operational mode of the 4-site session, the volumes at the fourth site contain an asynchronous and inconsistent copy of production data, but it can be made consistent on demand. For regular Golden Copy creation, the cascaded Global Copy to fourth site can be in a Suspended or Target Available state and must be restarted first to catch up with the latest production data updates from the Global Mirror target site.
During this scenario, the Metro Mirror replication is not interrupted, which means that it remains in a Prepared state. The Global Mirror replication must be suspended and its target volumes must be made consistent before the latest updates can be drained to the fourth site for a consistent pause of the Global Copy relation.
Depending on which site is the current production site, different commands are required to create a consistent Golden Copy at the fourth site. The general operational steps are the same for each situation since the 4-site session provides a symmetrical topology.
The following steps are required to create a Golden Copy on H4 if production is running on H1. Production continues to be active on H1 with Metro Mirror running to H2:
1. If Global Copy role pair H3-H4 is Suspended or Target Available, issue StartGC H3-H4 and wait for progress completion close to 100%
2. Issue Suspend H1-H3.
3. If the H1-H3 role pair does not show Recoverable for all pairs, you must issue Failover H3 to restore last Global Mirror consistency group on H3. You can also verify whether the Global Mirror details show that the master was paused with consistency, as shown in Figure 4-19 on page 44. In that case, the H3 volumes are consistent and the Failover H3 can be skipped.
4. Issue Suspend H3-H4.
5. Issue StartGM H1->H3 to restart Global Mirror replication.
6. In case you need to access the Golden Copy, issue Failover H4.
The following steps are required to create a Golden Copy on H4 if production is running on H2. Production continues to be active on H2 with Metro Mirror running to H1:
1. If Global Copy role pair H3-H4 is Suspended or Target Available, issue StartGC H3-H4 and wait for progress completion close to 100%.
2. Issue Suspend H2-H3.
3. If the H2-H3 role pair does not show Recoverable for all pairs, you must issue Failover H3 to restore last Global Mirror consistency group on H3. You can also verify whether the Global Mirror details show that the master was paused with consistency, as shown in Figure 4-19 on page 44. In that case, the H3 volumes are consistent and the Failover H3 can be skipped.
4. Issue Suspend H3-H4.
5. Issue StartGM H2->H3 to restart Global Mirror replication.
6. If you must access the Golden Copy, issue Failover H4.
The following steps are required to create a Golden Copy on H2 if production is running on H3. Production continues to be active on H3 with Metro Mirror running to H4:
1. If Global Copy role pair H1-H2 is Suspended or Target Available, issue StartGC H1-H2 and wait for progress completion close to 100%.
2. Issue Suspend H3-H1.
3. If the H3-H1 role pair does not show Recoverable for all pairs, you must issue Failover H1 to restore last Global Mirror consistency group on H1. You can also verify whether the Global Mirror details show that the master was paused with consistency, as shown in Figure 4-19 on page 44. In that case, the H1 volumes are consistent and the Failover H1 can be skipped.
4. Issue Suspend H1-H2.
5. Issue StartGM H3->H1 to restart Global Mirror replication.
6. If you must access the Golden Copy, issue Failover H2.
The following steps are required to create a Golden Copy on H2 if production is running on H4. Production continues to be active on H4 with Metro Mirror running to H3:
1. If Global Copy role pair H1-H2 is Suspended or Target Available, issue StartGC H1-H2 and wait for progress completion close to 100%.
2. Issue Suspend H4-H1B.
3. If the H4-H1 role pair does not show Recoverable for all pairs, you must issue Failover H1 to restore last Global Mirror consistency group on H1. You can also verify whether the Global Mirror details show that the master was paused with consistency, as shown in Figure 4-19 on page 44. In that case, the H1 volumes are consistent and the Failover H1 can be skipped.
4. Issue Suspend H1-H2.
5. Issue StartGM H4->H1 to restart Global Mirror replication.
6. If you must access the Golden Copy, issue Failover H2.
4.5 Unplanned scenarios
Unplanned scenarios are applicable when an incident affects the production and when the data replication is affected, which results in an exposure to disaster recoverability. The most important incidents to consider are effects against the running production. With a well-designed and tested two-, three- or four site solution, several types of production effects can be resolved by a suitable evasive action.
Determining which evasive action is the right one depends on the type of effect. Table 4-2 lists a few examples of possible generic incidents. It is primarily dependent upon the type of implemented and available redundancy.
However, it is also important to understand what type of effect occurred. When you compare examples for Number 3 and 4 in Table 4-2, you can see that the same actions are applicable for different effects.
It is also important to understand which type of redundancy was implemented. Example 2 and 3 have the same effect; however, because the implemented redundancy is presumably slightly different, the actions are fundamentally different.
You might also notice that the following terms are used with recovery of unplanned incidents in this section and in other places in this publication:
•High Availability (HA)
HA covers the outage of a single, often local component. By providing redundancy for the production data processing and I/O flow, the outage can be resolved mostly concurrently and automated by host cluster technologies, such as IBM PowerHA®, GDPS, or z/OS HyperSwap.
•Disaster Recovery (DR)
DR covers the resolution of an outage of more than one single component or essential infrastructure components. DR actions requires manual interventions by the operational personnel and might require to switch production workload to a different location because of a local or regional disaster.
Also known is the term Continuous Availability (CA), which combines in some implementations DR and HA and offers automatically triggered actions for specific incident types. One example is the combination of a 4-site replication with GDPS, which can include HA and DR for storage and operating system platforms and network components to switch various infrastructure components that are based on policies and incident types.
Table 4-2 Examples of considerable generic incidents
|
Number
|
Impact
|
Redundancy
|
Type
|
Possible action
|
|
1
|
Component failures of the local host
|
Locally available
|
HA
|
Component redundancy or automated failover action at the host
No storage actions
|
|
2
|
Local host down
|
Redundant host available,
Local storage accessible
|
HA
|
Host failover
No storage actions
|
|
3
|
Local host down
|
Redundant host available,
remote storage accessible and prepared
|
DR
|
Remote host failover
Storage failover
|
|
4
|
Local [Network | Power | Air condition |... ] down
|
Redundant host available,
remote storage accessible and prepared
|
DR
|
Remote host failover
Storage failover
|
|
5
|
Remote storage unavailable
|
No other storage available
|
Exposed DR
|
Fix problem to restore DR capability
|
|
6
|
Remote Storage unavailable
|
More Storage available
|
Degraded DR
|
DR capability maintained with 3-site or 4-site replication
|
4.5.1 Outage of the production site
An outage at the primary site is the most serious incident that affects production because of the probability that the entire production fails. In this case, a failover to another production site is required. A primary production site outage can occur for many reasons, including the following examples:
•Access loss to primary storage because of hardware failure or loss of all I/O paths to the storage systems
•Server crash, where no HA functions are available or all HA functions failed
•Infrastructure components failed, such as power, network, or air conditioning
|
Important: Before taking any action, ensure that the incident is thoroughly analyzed and the root cause is understood. It might not be only a single incident, but a chain of incidents that occur over time, which is known as a rolling disaster.
For example, when CSM recognizes and reports that it lost access to a storage system, it does not necessarily mean that the storage system is down or that the I/O path to the storage is interrupted.
|
For more information about the management of HA implementations with CSM and z/OS HyperSwap, see Chapter 7, “Managing z/OS HyperSwap with Copy Services Manager”, of Best Practices for DS8000 and z/OS HyperSwap with Copy Services Manager, SG24-8431.
The following example shows an outage at the primary site, where we assume that the primary system is no longer available. We also assume that the host lost access to the primary storage and CSM also lost connection the storage systems that are hosting the H1 volumes.
The CSM 4-site session presents a status as shown in Figure 4-20 on page 50. In the red rectangle at top Figure 4-20 on page 50, the overall status of the session is summarized. In this situation, the following three entries are most important:
Status: Severe The session is in a severe state, as expected when access to primary storage is down.
State: Prepared The session is prepared for a data recovery on another site.
Recoverable: Yes Acknowledgment that the session is recoverable.
With this information, we can conclude that a recovery to H2 or H3 is feasible.

Figure 4-20 Status when primary storage failed
In addition, we see the error message that is related to the severe session state, as shown in the second red rectangle in Figure 4-20. In this case, we see that the CSM connection to the primary storage system is lost.
Finally, in the lower red rectangle that is shown in Figure 4-20, we see which role pairs of the session are affected. In this case, all role pairs with H1 as a source are affected. The Error Count column indicates how many copy sets are affected. Comparing this number with the total number of copy sets in the session, we can state that all copy sets are affected. You can find the total number of copy sets in the session status, which is marked by the rectangle at the top of Figure 4-20.
|
Attention: CSM recognizes only that it cannot connect to the primary storage systems. Only when the host looses I/O access to the storage as well we can say that the primary storage system or all its connection paths failed.
|
Recovering the session
When a failed session status was detected as described in previous example, the primary aim in this situation is to recover production to another site. In our example, the following options are available with a CSM 4-site session:
Recover at H2 H2 is a Metro Mirror target site, which should provide the most resent update of the production data.
Recover at H3 H3 is the Global Mirror target site, which can provide the last consistency group with a certain RPO. The RPO can be obtained by clicking the Global Mirror Info tab in the session overview.
Recover at H4 While a recovery at H4 site is possible, H4 cannot provide a better RPO than H3 and more actions are required. A recovery at H4 requires a recovery of H3 volumes to the latest Global Mirror consistency group before H4 volumes can become consistent for recovery. Starting production at H4 also implies that sufficient host resources are installed at this site. While H4 provides a perfect site to practice DR while Global Mirror can stay active, it is good practice to recover at H2 or H3, where consistent data can be provided directly after the Recover operation and less operational steps are required in an unplanned scenario.
Because we now analyzed the status of the session, we are ready to start with the recovery procedure. In our example, we describe the scenario for an unplanned recovery at H2.
The following steps are required to perform this recovery in a 4-site session:
1. Pause the session replication.
2. Recover at H2.
3. Confirm H2 as new production site in the session.
4. Start Global Mirror replication from H2 to H3.
Starting production I/O on H2 volumes can be done before or after starting Global Mirror replication to H3. If you want to keep a consistent set of data on H3 as backup for a failed production start on H2, restart Global Mirror after verification of a successful production start from H2 volumes. However, if you want to protect your production restart with a recoverable copy, restart Global Mirror before you perform production start on H2 volumes.
Step 1: Pause the session replication
Even when all I/O to the storage system stops, a Suspend command attempts to pause remaining pairs of the session in a consistent manner. To suspend the session, select Session Action: → Commands... → Suspend .... In the Suspend window, select Suspend (see Figure 4-5 on page 31) and confirm by clicking Yes.
The progress of the Suspend command can be see in the console window. When the primary storage system is disconnected or is gone completely, CSM cannot process the Suspend command; therefore, the consistent pause fails and the session remains in the transient Suspending state, which allows only a few subsequent actions.
In such situations, the command often finished with errors to H1, and a subsequent recover action is not offered by CSM. In this case, a subsequent Stop command (see Figure 4-21 on page 52 and Figure 4-22 on page 52) is required to bring the 4-site session in the Suspended state to continue recovering the session.

Figure 4-21 Stopping the session
After selecting Session Actions: → Commands → Stop..., you can select the Stop command in the subsequent window to pause both replication legs of the session, as shown in Figure 4-22.

Figure 4-22 Stop command to stop both replication legs from H1
|
Note: Even if the Stop command cannot issue the necessary commands to the failed primary storage system, it forces the session state to Suspended to allow subsequent recovery actions. These actions do not rely on communication capability to the failed primary storage system.
|
Step 2: Recover at H2
After the session is in Suspended state, a recovery at H2 can be performed. For more information about how to perform that recovery scenario, see “Step 3: Recover Session to H2” on page 33.
After a recover operation, the state of the session changes from Suspended to Target Available, as shown in Figure 4-23 on page 53. This state denotes that the H2 volumes are now ready for host access from site 2.
|
Note: Even if the recovery was processed successfully, the session status is still Severe if the connection to the H1 storage system was not restored.
|

Figure 4-23 Recovered Session to H2
Step 3: Confirm production at H2
Now the production I/O can be started on H2 volumes. After verification that everything is up and running, the production switch to H2 must be confirmed to the session to enable subsequent start commands from H2.
Step 4: Start Global Mirror H2->H3
Although H1 was not yet recovered from the failure, the session is now ready to start Global Mirror from H2 to H3 to restore remote DR capability, as shown in Figure 4-24. This action is usually an incremental resynchronization between the former multi-target sites. Global Mirror consistency group formation starts after the resynchronization is completed.

Figure 4-24 Start Global Mirror from H2 to H3
The session is running production now at H2 if H1 is still in a failed state. Remote DR capability was restored; however, because H1 storage systems are still disconnected and the Metro Mirror replication cannot be restarted, the session remains in a Suspended (Partial) state, which is reported with a Severe status, as shown in Figure 4-25. The production is now running in a DR mode.

Figure 4-25 Recovered Session at H2 after failure at H1
Restore normal operational mode for the production
You can bring the production back into a normal operational mode by restarting Metro Mirror replication from H2 to H1. To start this process, the storage systems hosting the H1 volumes must be accessible for CSM and the PPRC paths must be reestablished. The connection state from CSM to the H1 storage systems can be obtained in the main menu by selecting Storage → Storage Devices, as shown in Figure 4-26.

Figure 4-26 Select Storage system from main menu
The table in the Storage Systems tab (see Figure 4-27 on page 55) lists the overall connection status for each storage system from the local CSM server and from the other CSM server if a secondary CSM server is connected and in an active HA relationship with the local CSM server. The local status represents the connection state from the current CSM server (which you are logged in to) to the listed storage systems.
If the connection is degraded or disconnected, you can click the storage system name to see a more detailed connection status for the selected storage system. Alternatively, you can click the Connections tab to see a more detailed table that lists all connection types per storage system with their corresponding status.

Figure 4-27 Showing local connection status of storage systems
Next, the PPRC path status between H2 and H1 must be verified. Select Path → DS8000 Paths from the CSM main menu, as shown in Figure 4-28.

Figure 4-28 View DS8000 PPRC Path
The ESS/DS Paths table that is shown in Figure 4-29 represents the established logical PPRC paths for each storage system. The Errors column shows if any of the established paths is in an error condition, which is an indicator that the underlying physical link that is used for the logical PPRC paths is not in a healthy state. The paths that are listed here are the established paths from or to the selected storage system.

Figure 4-29 View path status of the storage system at H1
|
Important: In case of PPRC Freeze actions that might be processed by CSM or other automation software (for example, z/OS HyperSwap) to pause Metro Mirror relationships consistently, all PPRC paths between a frozen LSS pair are removed. Therefore, the paths count might be less than expected after a recovery operation. You do not have to reestablish the removed PPRC paths manually in that case. The paths are reestablished automatically by CSM when you restart the replication between the systems. It is recommended to make a DS8000 Port Pairing CSV definition that CSM uses all defined port pairs to establish the required logical PPRC path between managed LSS pairs.
|
To verify path details of a specific storage system, click the storage system name hyperlink to display its Paths table, as shown in Figure 4-30. All paths are listed with their status information and physical connection ports. All paths should show a Normal state. If they do not show this state, more investigation is needed. Most likely, the physical connection between the ports of the failed paths still features connectivity issues that must be analyzed.

Figure 4-30 Status of all paths of selected storage system
|
Note: If the storage environment on the failed site compromises more than one storage system, the procedure that was described in this section must be repeated for each storage system.
|
When all connections are restored, the procedure to restart Metro Mirror for a normal operational mode at site 2 in the local region can be started.
Start session H2->H1 H2->H3
This step is same as described in “Step 6: Start Session H2->H1 H2->H3” on page 35. Depending on the duration of the outage at site 1 and how long production was running at site 2, a reasonable number of out-of-sync tracks might exist for the Metro Mirror relation from H2 to H1. These out-of-sync tracks must be transmitted to H1 before the Metro Mirror pairs go into a Prepared state. While this process is ongoing, the session remains in the Preparing state.
When the session reaches the normal operational mode at site 2, the production has the same level of protection as is in normal operational mode at site 1. Keeping the production in this mode can be considered and the decision to switch production back to site 1 can be postponed to a later time.
Switch production back to H1
After the decision is made to switch production back to site 1, the procedure continues with a planned site failover from H2 to H1 with following steps:
1. Pause replication of session.
2. Recover at H1.
|
Attention: At this point, the H1 storage volumes are accessible the first time after the outage. We recommend to thoroughly perform all necessary health checks to verify that the production can be started at the H1 volumes.
|
3. Confirm production at H1 to the session.
4. Select Start session H1->H2 H1->H3.
This scenario is similar to the scenario that is described in 4.2.1, “Site failover from H1 to H2” on page 30. Because the 4-site session includes a symmetrical topology, you can use the same steps, but exchange the H1 and H2 roles in the commands.
4.5.2 Outage of a target site
In general, the outage of a target site does not require any immediate actions if the primary production is not affected.
When one of the target sites of the 4-site replication fails, the session still provides a healthy replication to another region or site and degraded DR capability is still being maintained. The strategy to resolve an outage of a target site does not involve a site recovery, but is to discover the reason for the outage and to fix the problem to restore full DR capabilities.
After the problem is resolved, the session can be restored to a normal operational mode by issuing a Start H1->H2 H1->H3 command, or if only site 4 failed, by issuing a StartGC H3->H4 command.
An outage of a target site can occur for several reasons, including the following examples:
•The CSM server lost connection to a storage system at a target site.
•Connectivity or replication problems exist between storage system pairs.
•A target storage system or even the complete target site is down.
Other reasons might need to be considered, but most likely problems with a target site are based on connection issues. Figure 4-31 shows an example of a severe session situation when a problem exists at the Metro Mirror target site H2.

Figure 4-31 Failure on the Metro Mirror replication to H2
Although the session state remained Prepared in this case, the session status changed from Normal to Severe, which indicates that a problem exists. In the session topology diagram that is shown in Figure 4-32, you can see that the replication arrow has a red error sign. You can also see in the role pair table the error counts for the role pair H1-H2 as marked by the red rectangle. When clicking the link for this role pair, the role pair details window opens, as shown in Figure 4-32.

Figure 4-32 Disclose error message in Role Pair window
The role pair details windows allows you to view the detailed error message for each pair by hovering the mouse pointer to the link named Show, as you can see in the lower right corner of Figure 4-32 on page 58. The pop-up window displays many details about the pair and a link to the detailed description of the error message. In some cases, the error message contains a hardware reason code. The hardware reason code is usually presenting another hyperlink to get more details what type of problem this code is representing on the underlying hardware.
When the Global Mirror target site is affected, the session shows a Severe status and the asynchronous replication arrow shows an error sign, as shown in Figure 4-33.

Figure 4-33 Failure on the Global Mirror replication to H3
Depending on the error scenario, the session state might still show Prepared or changed to Suspended (Partial). The Metro Mirror replication can continue in that case and the session is still in a state to recover at H2.
From a DR perspective, this situation is potentially more critical than an outage of the Metro Mirror target site because production is replicated only within one region. Therefore, the data is still protected within the region from primary site outages, but not from regional outages that affect site 1 and 2.
When the Global Copy to fourth site is affected, the session represents a Severe status, but often remains in a Prepared state because the Metro Mirror and the Global Mirror replication remain prepared for a recovery at H2 or H3.
From a DR perspective, this outage is the least critical target site outage because local and remote recoverability is not affected. After the problem at fourth site is resolved, the normal operational mode can be restored by using the StartGC H3->H4 command.
4.6 Back-out scenarios
Back-out scenarios are operations that are suitable when something went wrong during a recovery scenario. It means to bring back production in the original site or in another site of the 4-site session.
In some cases, a back-out must be prepared; for example, by providing backup data as tape back up or by a so-called Golden Copy on another site of the session. In the case of an error or a failure during the recovery operation, the backup or Golden Copy can be used to restore data into the failed recovery site to retry a recovery operation. A Golden Copy can be considered as a consistent set of data that is available on another site from the time the disaster occurred or from a previous consistent set of data set that was created and conserved from external changes.
After a site or replication failure, the CSM 4-site session indicates with the role pair recoverability if the targets are consistent or can be made consistent with the Recover command. Such a consistent set of data at any target site can be used to attempt recovery on that site, or to consider this consistent set of data as Golden Copy and replicate it to the wanted recovery site for another production recovery attempt.
|
Note: Storage system data replication does not replace data backups on tape or other media. Logical data errors on the source volumes, such as accidental data deletion or logical data corruption, cannot be recovered with data replication because the last consistency point of replicated data usually does not go back far enough before the incident occurred.
|
In a 4-site replication, data is distributed across four different places. In general, this data in the different places can be used for production recovery. However, to make this data usable for a back-out, the data must be made consistent first. The session status and the corresponding role pairs must indicate that the targets are recoverable.
In general, the recovery can fail in the following areas:
•A failure during the storage recovery scenario, which is run through CSM.
•A failure in post recovery procedures; for example, when applications are started.
In this phase, the storage recovery of the session was completed successfully. Control is now at the host or server operations. The next CSM operation is to confirm the production at the new site when the host operation is acknowledged.
In this phase, the storage recovery of the session was completed successfully. Control is now at the host or server operations. The next CSM operation is to confirm the production at the new site when the host operation is acknowledged.
In a CSM 4-site session, back-out approaches can be many-fold and extend the scope of this publication. For simplicity, we describe the following common back-out approaches for a few recovery failure scenarios:
•The easiest back-out approach often is to recover the session and the production to a different site than originally intended. For example, when recovery on the Metro Mirror target site fails, perform a recovery on the Global Mirror target site.
•Restart production from the original site. This approach is possible only for a planned site recovery failure when the original site and data is still available.
•A more complex back-out approach is to restore a Golden Copy from another site to the failed recovery site and retry the production recovery. For example, when recovery to the Global Mirror target site failed, restore a Golden Copy from the fourth site to reattempt production recovery.
|
Note: Before any recovery is attempted on the Global Mirror target site, a Golden Copy at fourth site requires that Global Copy is consistently paused after the Global Mirror target volumes are consistent. This operation can occur at regular intervals, or just after a Recover command is issued to the Global Mirror target site before host I/O is restarted for production recovery. If Global Copy is still in Preparing state after a Recover to Global Mirror target site, it is good practice to issue a Suspend command to the Global Copy role pair right after the Recover command is completed.
|
4.6.1 Back-out to H1 from planned H2 recovery
In this scenario, we assume that something went wrong during a planned recovery at the Metro Mirror target site in the same region (in this example, the H2 volumes at site 2). The original recover scenario is described in 4.2.1, “Site failover from H1 to H2” on page 30. We assume that an unresolvable problem occurred while production was started at H2. In this case, production can be switched back to H1.
We assume that the session state is Target Available with H2 as the active host site. The process includes the following overall steps:
1. Stop host I/O on H2 volumes.
2. If the CSM session is Confirmed Production on H2, issue Re-enable original direction in the 4-site session, as shown in Figure 4-34

Figure 4-34 Re-enable session into original direction
3. Start host I/O on H1 volumes to restart production on original site.
|
Note: If something goes wrong during production start on H1, another back-out recovery at H3 or H4 is possible if Global Mirror replication was not restarted.
|
4. After successful production start on H1 is confirmed, you can issue the Start H1->H2 H1->H3 command to restart replication and return the session to a normal operational mode.
4.6.2 Back-out to H3 from unplanned H2 recovery
In this scenario, we assume that something went wrong during an unplanned recovery at the Metro Mirror target site in the same region (in this example, the H2 volumes at site 1). The original recovery scenario is described in 4.5.1, “Outage of the production site” on page 49. We assume that an unresolvable problem occurred while production was started at H2 and site 1 is still unavailable. In this case, production recovery can be attempted on the H3 volumes at site 3 in the other region.
We assume that the session state is Target Available with H2 as the active host site. The process includes the following overall steps:
1. Stop host I/O on H2 volumes.
2. If the CSM session Confirmed Production at H2, issue Re-enable original direction in the 4-site session, as shown in Figure 4-34 on page 61. The Recover H3 command is then reenabled.
3. Issue Recover H3 and wait until the session state changes to Target Available with H3 as active host
|
Attention: Do not yet start host I/O at H3 at this point.
|
4. Complete the following steps to prepare a Golden Copy at fourth site as last recovery resort:
a. If the Global Copy to fourth site is still active and in Preparing state, issue Suspend H3-H4 to create a Golden Copy at site 4. Wait until the session completed the Draining state and returns to a Target Available state with a paused H3-H4 replication.
b. If the Global Copy to fourth site is Suspended or Target Available, you can refresh a Golden Copy by completing the following steps:
i. Confirm Production at H3 in the session to enable the start commands from H3.
ii. Issue StartGC H3-H4 and wait until the H3-H4 role pair changes to Preparing state with a Global Copy progress close to 100%, or issue Start H3->H4 and wait until the H3-H4 role pair changes to a Prepared state. The session state changes to Suspended (Partial) after replication was restarted on the H3-H4 role pair.
iii. Issue Suspend H3-H4 to create a consistent Golden Copy on H4 volumes. Verify that the H4 volumes indicate consistent recoverable data, as shown in Figure 4-35 on page 63, which is marked with red rectangles that are labeled with 1.
5. After a Golden Copy exists on H4 volumes, start host I/O on H3 volumes for production recovery.
6. After the successful production start from H3 volumes is confirmed, issue Confirm Production at H3 in the session if it was not done during Golden Copy creation.
7. The Golden Copy on H4 volumes is no longer required and local replication can be restarted. Issue Start H3->H4 and wait for the H3-H4 role pair to change to a Prepared state to restore local recoverability. The session state remain Suspended (Partial) if the Global Mirror relation is not restarted yet.
|
Note: You might see a detailed status warning in the session details window, as shown in the red rectangle that is labeled as 2 in Figure 4-35. If another recovery at H4 is required in this state, a full copy from H4 back to H1 is required upon replication restart. This copy is necessary because the multi-target replication from H3 to H1 was not started yet, which enables an incremental resynchronization between its targets (H4 and H1 in this case).
|
8. After the problems at site 1 are resolved, restore remote recoverability by using StartGM H3->H1 and wait until the Global Mirror role pair forms consistency groups. The session state changes to Prepared, with a status of Warning because the 4-site replication was not fully restored yet.
9. Restore replication to the fourth site by issuing StartGC H1-H2 and wait until the session status changes back to Normal.

Figure 4-35 Golden Copy created at H4 after Recover H3
4.6.3 Back-out to H4 from unplanned H3 recovery
Now, we assume that an unplanned recovery failed at H3 after a region A outage that affects site 1 and 2. We also assume that the production cannot be started successfully at site 3 in region B, but that a Golden Copy is available on H4 volumes as last recovery resort. For more information about creating or refreshing a Golden Copy during recovery to H3, see 4.6.2, “Back-out to H3 from unplanned H2 recovery”.
We assume that the session state is Target Available with H3 as the active host site and a Golden Copy exists on the H4 volumes. The H3-H4 role pair is in a Suspended state, as shown in Figure 4-35. Complete the following steps:
1. Stop host I/O on H3.
2. Issue Recover H4 and wait until the session is in a Target Available state with H4 as the active host site.
3. Start host I/O on H4 to recover production from H4 volumes.
4. After the successful production start from H4 volumes is confirmed, issue Confirm Production at H4 in the session.
5. Issue Start H4->H3 and wait for the H3-H4 role pair to change to a Prepared state to restore local recoverability. The session state remains Suspended (Partial) if the Global Mirror relation is not yet restarted.
6. After problems at site 1 are resolved, restore remote recoverability by using StartGM H4->H1 and wait until the Global Mirror role pair forms consistency groups. The session state changes to Prepared, with a status of Warning because the 4-site replication is not fully restored yet.
|
Note: If the multi-target replication was never started from H3 to H1 volumes after a H3 recovery (because of site 1 outage), the Global Mirror start from H4 to H1 might require a full data copy. This issue is also indicated as a detailed status warning in the session details window, as shown in the red rectangle that is labeled with a 2 in Figure 4-35 on page 63.
|
7. Restore replication to the fourth site by using StartGC H1-H2 and wait until the session status changes back to Normal.
4.6.4 Back-out to restored Golden Copy from unplanned H3 recovery
We assume that an unplanned recovery failed at H3 after a region A outage, which affects site 1 and 2. We also assume that the production cannot be started successfully at site 3 in region B, but that a Golden Copy is available on H4 volumes as last recovery resort. For more information about creating or refreshing a Golden Copy during recovery to H3, see 4.6.2, “Back-out to H3 from unplanned H2 recovery”.
Instead of performing a back-out recovery at H4 as described in 4.6.3, “Back-out to H4 from unplanned H3 recovery” on page 63, you can also restore the Golden Copy from H4 to H3 for another back-out recovery at H3. This scenario provides following advantages to the back-out recovery at H4:
•You do not have to change host I/O path or start configuration for the back-out recovery because the recovery is attempted from the same H3 volumes again.
•You can prevent a full copy that might become necessary when Global Mirror is restarted from H4 volumes.
•You maintain a Golden Copy at H4 for another back-out recovery if the recovery attempt fails again on H3 volumes.
For this scenario, we assume that the session state is Target Available with H3 as the active host site and a Golden Copy exists on the H4 volumes. The H3-H4 role pair is in a Suspended state, as shown in Figure 4-35 on page 63. Complete the following steps:
1. Stop host I/O on H3.
2. Issue Recover H4 and wait until the session is in a Target Available state with H4 as the active host site.
|
Important: Do not start host I/O at H4 at this point.
|
3. Issue Confirm Production at H4 in the session.
4. Issue Start H4->H3 and wait for the H3-H4 role pair to change to a Prepared state. The session state changes to Suspended (Partial).
5. Issue Suspend H4-H3 and wait until the session state changes to Suspended.
6. Issue Recover H3 and wait until the session is in a Target Available state with H3 as the active host site.
7. Start host I/O on H3 volumes for another production recovery attempt.
8. After the successful production start from H3 volumes is confirmed, issue Confirm Production at H3 to enable start commands from H3 volumes.
9. The Golden Copy on H4 volumes is no longer required and local replication can be restarted. Issue Start H3->H4 and wait for the H3-H4 role pair to change to a Prepared state to restore local recoverability. The session state remains Suspended (Partial) if the Global Mirror relation is not restarted yet.
10. After the problems at site 1 are resolved, restore remote recoverability by using StartGM H3->H1 and wait until the Global Mirror role pair forms consistency groups. The session state changes to Prepared, with a status of Warning because the 4 site replication was not fully restored yet.
11. Restore replication to the fourth site by using StartGC H1-H2 and wait until the session status changes back to Normal.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.