


Developing information supply chains for the data reservoir
The thinking is that data has mass and therefore attracts more data through gravity. A successful data reservoir will attract increasing amounts of data. The information supply chain documents data flows so data does not disappear. Instead, it is visible and accessible for data reservoir users.
This chapter describes how to design the flow of data through the data reservoir by using information supply chains. An information supply chain describes the flow of a particular type of data from its original source through various systems to the point where it is used. It maps the movement of data from one or more information sources through the reservoir repositories and other stores to one or more users.
This chapter also describes the information supply chains designed for the data reservoir, and the considerations and best practices around implementing them for a particular organization. There are a number of stages to this effort:
•Identifying the subject areas that need to be represented in the data reservoir.
•Determining the potential sources for the data.
•Working with the information zones to identify which repositories need data from each subject area.
•Design the data reservoir refineries to link the sources with the data reservoir repositories and the users.
|
Data reservoir: The data reservoir manages data with different levels of quality and trustworthiness that potentially contains sensitive information. Well-designed information supply chains ensure that the origin of data and the processing that it has received are well understood so that users can decide whether the data they discover in the data reservoir is suitable for their needs.
|
This chapter includes the following sections:
4.1 The information supply chain pattern
The IBM developerWorks article Patterns of Information Management1 discusses the information supply chain as a pattern to address the problem “An organization needs to process information to fulfill its purpose. How is the flow of information coordinated throughout the organization's people and systems?” The solution is to design and manage well-defined flows of information that start from the points where information is collected for the organization and links them to the places where key users receive the information they need.
An information supply chain typically begins where people or monitoring devices enter data into an IT system. This system processes and stores the data. The data is then copied to other systems for processing and over time it spreads to a number of different systems. The path that the data flows is the information supply chain.
Figure 4-1 shows a simple diagram of the information supply chain.

Figure 4-1 Schematic diagram of an information supply chain
The data entering the information supply chain comes from the information user and the information supply. This source can be another information supply chain outside of the control of the organization, such as from sensors or other devices that generate data.
The information collections are the places where this data is stored. In the data reservoir context, these are the data reservoirs, sources, repositories, sandboxes, and published data stores.
The information processes transform and derive new data for the information supply chain, and copy the data between the information collections. This processing is called information provisioning. In the data reservoir context, the following are the information processes:
•The data refinery processes that run in the enterprise IT interaction subsystem
•The analytics that run in the data reservoir
The information nodes are the infrastructure services that support the information collections and processes.
An information supply chain is the flow of a particular type of data through an organization's systems, from its original introduction, typically either through a user interface (UI) or external feed to its various users.
Another way of looking at an information supply chain is that it is the stories that you tell to transform the raw data into something useful. The information supply chain takes data of a particular kind with potentially different levels of quality and trustworthiness and levels of sensitivity and delivers it in various forms to different users.
Theoretically, the scope of an information supply chain is from the moment data is created through to every user of that data. However, the scope here is defined as an information supply chain to the systems and users that are within a particular sphere of influence. For this publication, the scope is to the data reservoir itself and the systems and people that connect to it.
4.2 Standard information supply chains in the data reservoir
Typically there is a different information supply chain for each subject area that the organization has. The simplicity of the data reservoir architecture means that many information supply chains will follow the same path through the data reservoir components. This section describes these standard data flows.
4.2.1 Information supply chains for data from enterprise IT systems
Enterprise IT provides the data reservoir with data that records how the organization is operating. Its inclusion in the data reservoir is a critical step for supporting the analytics that drive the business. The data scientists and analytics can copy this data into the data reservoir by using deposited data. However, this just adds a snapshot of this data. Ideally, this data is brought in through reliable, ongoing, automated processes so that the data reservoir becomes an authoritative source of a wide range of enterprise data.
This section describes the information supply chains that automate the importing of data into the data reservoir and the publication of data from the data reservoir. These automated processes are maintained by enterprise IT.
Enterprise data delivery information supply chain
Figure 4-2 shows the flow of data from enterprise IT systems into the data reservoir repositories where it can be used in various ways.
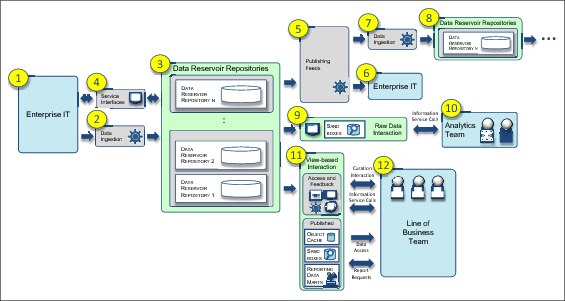
Figure 4-2 Enterprise data delivery information supply chain
The following are the steps in the enterprise data delivery information supply chain flow (Figure 4-2):
•Item 1: Data is generated through activity in the enterprise IT systems and external sources.
•Item 2: Data is copied into the data reservoir repositories through the data refinery processes in the data ingestion subsystem.
•Item 3: Data is stored in one or more data reservoir repositories.
•Item 4: Data may be accessed and updated through service interfaces.
•Item 5: Data from the data reservoir repositories, potentially augmented by analytics, is pushed into the publishing feeds subsystem for distribution.
•Item 6: The data refinery processes in publishing feeds can push the data back into the enterprise IT systems or to external feeds.
•Item 7: Alternatively, publishing feeds can push the data into data ingestion so that it is stored in other data reservoir repositories.
•Item 8: Typically, this is a flow of data from the shared operational data to either the historical data or harvested data repositories.
•Item 9: Enterprise IT data can be extracted from the data reservoir repositories through the Raw Data Interaction subsystem.
•Item 10: This Raw Data Interaction subsystem enables the analytics team to explore the data and create analytics from it. The analytics team benefit from the enterprise data by being able to explore, find, and use it in the raw data sandboxes.
•Item 11: Enterprise IT data from the data reservoir repositories can be accessed through the View-based Interaction subsystem. This action can be done either directly through information views or through the published data stores that have been populated by using data refinery processes from the data reservoir repositories.
•Item 12: The line-of-business (LOB) teams can then view simplified versions of the data. The LOB team is not as technical as the analytics team, and use the view-based interactions to work with simplified subsets of the data that are meaningful to them.
Continuous analytics information supply chain
Events and messages from enterprise IT can also be processed in real time by the data reservoir, rather than stored for later processing. This real-time processing occurs in the Continuous Analytics subsystem and the results of its processing are distributed both inside and outside of the data reservoir (Figure 4-3).
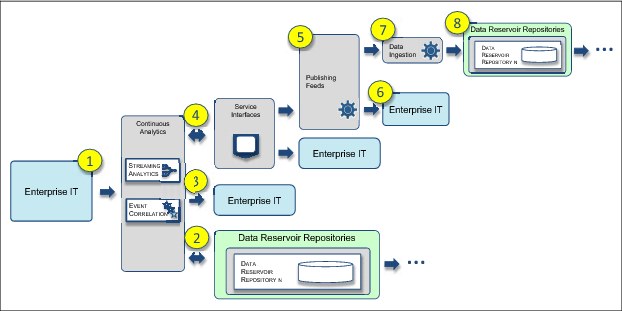
Figure 4-3 Continuous Analytics information supply chain
The continuous analytics information supply chain consists of these items (Figure 4-3)
•Item 1: New events or streaming data from enterprise IT are fed to the data reservoir and picked up by Continuous Analytics.
•Item 2: Continuous Analytics can look up data in the data reservoir repositories to correlate and interpret the incoming data.
•Item 3: The resulting events can be sent back to enterprise IT directly.
•Item 4: Results can also be pushed through the services interfaces for broader delivery. The service interfaces provide a layer of isolation between the continuous analytics processes and the delivery destination.
•Item 5: The results of the continuous analytics processes can be sent as a publishing feed.
•Item 6: The publishing feed can push data to enterprise IT.
•Item 7: The publishing feed can push data to the Data Ingestion subsystem.
•Item 8: The data ingestion processes store the new insight in the data reservoir repositories.
The choices in the different paths to publish new insights provide options on how frequently the data is published and the mechanisms used.
4.2.2 Information supply chain for descriptive data
The data reservoir is heavily dependent on the catalog and related descriptive data to ensure that the data it is managing is properly governed and understood.
This descriptive data itself requires proper management to perform its job correctly.
Figure 4-4 shows the information supply chain for descriptive data.

Figure 4-4 Metadata information supply chain
The metadata information supply chain consists of these items (Figure 4-4):
•Item 1: The governance risk and compliance team set up the policies, rules, and classifications using the catalog interfaces.
•Item 2: The information curators describe and classify the data that they own.
•Item 3: Both the governance definitions and the descriptions of information sources are stored in the catalog.
•Item 4: The search index is continuously updated with the results of indexing scans on the data reservoir repositories (including the catalog).
•Item 5: The data reservoir operations team manually maintains the information views.
•Item 6: The analytics team and LOB teams can then understand the data with the understanding that it meets company policies.
4.2.3 Information supply chain for auditing the data reservoir
Internally, the data reservoir continuously monitors the activity in the reservoir and the requests for data from people and systems external to the data reservoir. This monitoring activity generates a lot of data that can be analyzed and audited. Figure 4-5 shows the flow of data for auditing the data reservoir.

Figure 4-5 Data reservoir auditing information supply chain
The data reservoir auditing Information Supply Chain consists of the following items (Figure 4-5):
•Item 1: Much of the audit data is captured by monitoring processes. These processes watch the access of data in the data reservoir repositories, and monitor steps in the data refinery processes that create the operational lineage information for the data reservoir data.
•Item 2: This data is stored in an Audit Data repository.
•Item 3: The guards that are enforcing access control can also record both successful and unsuccessful access attempts in an Audit Data repository, depending on the repository being accessed.
•Item 4: Audit data is regularly consolidated into reports for the governance, risk, and compliance team.
•Item 5: The analytics team can generate additional analytics by exploring the values stored in the audit data. These analytics can be deployed into the audit data repositories to detect suspicious activity.
4.2.4 Information supply chain for deposited data
An important aspect of the data reservoir is that it offers a place for teams to store their own data sources and the results of their analysis in the data reservoir without needing help from the Data Reservoir Operations team. This data is stored in deposited data. So the last information supply chain is one that is a simple service-oriented style of access to the deposited data repositories (Figure 4-6).

Figure 4-6 Deposited Data Information Supply Chain
The Deposited Data Information Supply Chain consists of the following items (Figure 4-6)
•Item 1: The analytics team are storing and retrieving their sources of data.
•Item 2: This data is stored in the Deposited Data repositories.
•Item 3: Similarly, the LOB teams can store and retrieve their files and the files that others (such as the analytics team) have shared with them.
Deposited data provides an effective mechanism for the analytics team to share the results of their work with the LOB. Analytics that have ongoing value can then be pushed into production in the data reservoir. This is a process that involved the Data Reservoir Operations team to do the following activities:
•Verify that there is no unexpected impact of the analytics on the existing production environment.
•Provision any additional data that the analytics requires in the data reservoir repositories.
•Arrange for the deployment of the analytic model in the appropriate data reservoir repository or data refinery process.
•Ensure that the resulting insight can be used by the business.
4.3 Implementing information supply chains in the data reservoir
Designing the information supply chains for a specific data reservoir deployment requires specific consideration of the existing sources and the use cases for the data reservoir. A wide range of integration technology can be used to access, move, transform, and store data. Any of this technology can be used in a data reservoir, if it is able to honor the governance rules defined in the catalog and produce appropriate auditing and lineage reporting to ensure that the data reservoir can demonstrate its compliance.
The following section covers some of the architecture considerations for a specific data reservoir deployment.
4.3.1 Erin's perspective
Erin Overview, the enterprise architect, needs to be reassured on her thinking around the data stored in the data reservoir. As the enterprise architect, Erin needs to design the data reservoir so that the data is well-managed and governed along each of the information supply chains. Doing so helps the people using the data reservoir to understand where data came from and how trustworthy it is.
The data reservoir typically starts empty, and data repositories and sources are added as required in an ongoing manner. Erin is looking to understand more around the information supply chains. She wants to know how the data moves from outside the reservoir into and around the reservoir. She also wants to use the concept of information zones in the data reservoir to help her manage the data usage for the various users.
Erin shows simpler versions of the data to Tom Tally, the accounts manager. She would like Tom to see the data in a way that is natural to him. Erin would like to introduce a semantic layer with simple views to ease the data consumption for Tom. At the same time, she would like to give Callie Quartile access to the raw data she needs to understand how the new drugs they are developing work.
4.3.2 Deciding on the subject areas that the data reservoir needs to support
A subject area is a category or topic of information that has business value. Erin decides which subject areas the data reservoir needs to support from the use cases and the users. She identifies patients, suppliers, customers, orders, genomes, clinical trials, manufacturing schedules, deliveries, and invoices as the subject areas that will appear in the Eightbar Pharmaceuticals data reservoir.
Of each subject area, she asks the following questions:
•Where are the likely sources of this information? If Erin does not know, then what investigations does she need to do to identify likely sources?
•Are there any cultural or ethical considerations around accessing each source?
•What is the scope (instances), coverage (attributes), and quality of each of these sources? On what basis does Erin know this?
•Who owns the source? Who does Erin need to ask for permission to access the source? Does Erin need to arrange new agreements with the owner?
•What technology is required to access the data sources? How does the data reservoir connect to it? Does Erin need to arrange for new credentials to be set up for access?
•What is the operational load and availability of the source? When can Erin get the data, and what are the restrictions? On what basis can Erin be sure that this level of service will meet her near-term and future needs?
•What is the volume of this data? What is the volatility of this data? These answers tell Erin how much it would cost to copy and how much ongoing refreshing is required.
•Who are the likely users of this data?
– What are their requirements for scope, coverage, and quality?
– What tools are they using? What structure (formats) do they need the data in to support their tools?
– When do they need this data (the required availability) and how much processing are they going to perform on it?
Typically, the information supply chain is different for each subject area. However, the simplicity of the data reservoir architecture means that many information supply chains will follow the same path through the data reservoir components. This analysis will show the mix of the different subject areas in each data repository and the different subject areas that need to be extracted from each source.
4.3.3 Information sources: The beginning of the information supply chain
This section covers more details about the information sources. Sources are the supplier of much of the data for the data reservoir.
Systems of record, engagement, and insight
Systems of record are operational systems that support the day-to-day operations of the business. There are many systems of record, each specialized for a single purpose. As a result, their data is tightly scoped to the business functions that they support. These systems are used to hold the version of the truth that the part of the business it supports needs to operate. The data associated with the many systems of record is vital to have in the data reservoir.
Systems of engagement are the systems that interact directly with people and support various activities. This ability makes them an important source of information for the data reservoir to understand what an individual is doing and how they are doing it.
Systems of insight (such as the data reservoir) also generate important information that needs to be fed into the system of record and systems of engagement. For example, the data reservoir can generate scores that indicate customer churn rates and who the high value customers are, which would be important for the system of record that is supporting a customer service organization.
What data is needed from a source?
To answer this question, look at the data.
All data
While deciding what data you want to bring into the data reservoir, you might decide that you want all available data in the enterprise. Taking in all data gives the organization the greatest amount of freedom to process that data and you will not be missing any information. But what do you mean by all data? Do you want to bring in every data source that has ever been created?
Pragmatic selection of data
Typically, the data reservoir contains all of the data that the organization would like to share or retain for future analysis.
As you bring in data from new and existing information sources, any data that you can ignore means that you avoid the following situations:
•Moving it with data refinery services
•Being concerned about exposing it inappropriately
•Tracking that data in the reservoir or dealing with lifetime considerations.
It makes sense to filter out data that is unlikely to be used. As you use the data in the data repositories to make insights, you can improve how you filter data, based on usage statistics. For streaming sources (such as Twitter feeds) there will be a large amount of data, much of which you are not interested in. In this case, you need to target the data you require by using rules or analytics models to pick out subsets of the data.
Characteristics of sources
The data reservoir can use many styles and types of data.
Structured data
The structured data can be readily queried, and joined and merged by, for example, using SQL on relational databases. There can be many different types of structured data, including relational and dimensional, each with their own set of data types. Structured data coerces applications to store specific data, which can be useful to force data into a consistent representation. Applications can then readily use this standardized structured data.
The prevalence of mobile devices (such as smartphones, tablets, and wearable devices) and the rise of the Internet of Things means that there is a continual creation of data. Many devices typically produce structured data. However, this structure is typically not correlated with other sources.
Semi-structured data
Most of the new data created each year is semi-structured data such as social media, email, documents, video, audio, and pictures. For example, people typically produce text-based data. In order to be useful, this data has associated headers (describing where and when the data was created) along with the text-based data.
Documents can be stored in JavaScript Object Notation (JSON). JSON has structure but is not as rigid as structured data (relational databases have defined schemas). Each JSON document can have a different shape. To query JSON document stores, it can be useful to use a SQL-like paradigm and pick out parts of documents that fit a particular shape. This approach makes the JSON easier to use, by applying a structured lens on the data to pick out what is interesting.
With this data, there is often a small amount of identification information such as a social media handle. Using social and mobile technologies, individuals are empowered to create their own content and interactions. This data can create a better sense of someone's life than ever before. This data is increasingly used by organizations to get the fuller view of a person. You can use the data reservoir to store this data and correlate it with other sources.
Techniques such as text analytics are required to pick out relevant information. This semi-structured data can take the following forms:
•Documents (such as a web page) or a word-processing document.
•Streamed data (such as data from your car). Streamed data often needs to be accumulated over time in a data repository so that a historical view can be taken. If the amount of data is very large, rules are often needed to look for and extract meaningful data. This extracted data is stored in the data reservoir. In addition to existing structured information about an entity, new attributes can be found in the streamed data.
Time series data is streamed data that is accumulated over time in the data reservoir. Analytics done on time series data allows trends and repeating patterns to be identified. These trends and periodicities allow predictions and forecasts to be made.
Recent information and roll ups of information are useful for real-time analytics. Information decays, so its value decreases if it is not acted on in a timely manner. Ideally the time window that is used for recent information needs to be large enough to show short-term interesting patterns, but also be performant. Data from different subject areas will become obsolete (decay) will at different rates. This rate of decay will determine how frequently.
4.3.4 Position of data repositories in the information supply chain
There are often questions on whether existing analytical repositories should be adopted into the data reservoir or kept as information sources with selective content copied into the data reservoir as required.
Should your warehouse be in the data reservoir?
If the organization sees their existing warehouse as an analytics source, then this data needs to be represented in the data reservoir.
If the existing information warehouse is well-maintained and managed and there are processes to ensure that the data within it are of good quality, then it makes sense to adopt this information warehouse into the data reservoir and use it as a reliable data repository of data.
If the contents of the information warehouse cannot be confidently relied on, then leave it outside of the data reservoir and treat it a data source. Picking out the pieces of data and refining them in the reservoir might be a good option. If the existing data management practice has failed once, it will fail again unless it is changed. Often, focusing on a smaller scope of data is required to create new well-managed information warehouses in the data reservoir that are fit for purpose.
Enterprise data warehouses are typically large. When adopting an existing enterprise data warehouse into the reservoir, there is a choice on how much of its data to catalog. Some or all of the data in the warehouse can be cataloged. The cataloged data is then available to users and analytics of the data reservoir. If the existing warehouse is poor quality, overloaded, or does not contain relevant data, then it is best left out.
Master data management (MDM) and the data reservoir
In life, when you meet someone new you discover some basic information about them from what you can immediately see and maybe what you have heard about them. You then make assumptions based on that data. If you ask the person’s name and then speak to them with someone else's name, they might be offended and feel that you are not interested in them. As you talk with them, you find out more things about them, such as:
•Marital status
•Attitudes about gender
•What job they have
They might feel that some of this information is private and should not be disclosed. As you discover more information, you might have suggestions or insights that might be useful. If all goes well and the person feels respected, you build trust and a relationship. The relationship they have with an organization that knows things about them is similar. You need to be sure that you build relationships based on well managed, appropriate information that you are confident in, so your interactions with them are ethical and wanted.
MDM
Operational data typically is in specialized applications that are each only visible to a small part of the enterprise. Data about people and organization, products, services, and assets that are core to the working of the business is often duplicated in each of these applications and over time becomes inconsistent.
Master data management (MDM) takes a holistic view of the end-to-end information supply chain and considers how to keep this high value data synchronized in the different systems. Often this type of data is being updated in different silos, where a silo has a constrained view of the data. MDM solves this problem by creating a consolidated view of this data in an operational hub that is called the asset hub, and provides common ways of accessing that hub that the whole enterprise can use.
MDM has processes that allow these high value entities to be normalized, not duplicated, and synchronized with other copies of the same data.
|
Information value: High value data about people, organizations, products, services, and assets that drive a business is needed in the data reservoir because it is the data necessary to develop high value analytics. This data is typically present in many of the data reservoir repositories.
Companies move from customer data being spread over many silos to a single MDM operational hub for personal data. This operational hub contains the high value business data. You need the master data so that analytics get access to the up-to-date data, but you do not necessarily need a separate MDM hub.
|
The inclusion of an asset hub inside the data reservoir is decided by these factors:
•Whether the organization has an asset hub
•Whether they need operational access to it.
•Is the data in the correct format for the users?
For example, you know that you need to use customer data as a basis to be able to treat each person effectively. Do you put the asset hub for customer data into the data reservoir or set it up as a source?
The answer is a political one, not a technical one. It is about who owns customer data. If it is owned by the operational systems of record team, then it is unlikely that the asset hub itself can be included in the data reservoir. However, the data from it can be included.
The asset hub is often a critical operational system and the change management around it is strict so that the customer data can be replicated into the data reservoir. This copy in the data reservoir is read-only. In addition, there can be established governance practices around the asset hub that differ from those in the data reservoir.
For Eightbar Pharmaceuticals, Erin could have chosen to have one of these configurations:
•Read-only patient asset hub with patient data in the reservoir, and to keep the writable data updated by using an asset hub outside the reservoir.
•An updateable asset hub in the reservoir governed by the catalog.
For Erin, the patient details and medical records are owned by the hospital, which supplies this data to Erin in the medical health record. The medical health record is a read-only replication of the patient data from the hospital.
4.3.5 Information supply chain triggers
Every movement of data is initiated with some form of trigger. This trigger can come from the source system, the target system, or an independent information broker or scheduler. The result of the trigger causes a data refinery process to start. Figure 4-7 shows the different types of triggers.

Figure 4-7 Triggering data movement
Triggering data movement can include the following activities (Figure 4-7):
•Manual requests: Allowing authorized users to bring in data to the reservoir.
•Scheduled extract: This could be an overnight extraction of a day's activity into the reservoir.
•Information service call: For an application to push data into the data reservoir.
•Change data capture: As a result of an update to stored data in the information source.
•External feed: A push of data from an external party.
•Queued message: A push of a message or event from an information source.
The trigger starts processing that makes the data available to the enterprise IT interaction subsystem, where it is picked up and processed appropriately.
4.3.6 Creating data refineries
Processes inside the data reservoir called data refineries, take data and process it to change its structure, move it between data stores, add new insights, and link related information together. These processes are also used to bring data into the data reservoir and publish data out of the data reservoir.
A core principle of the data reservoir is that users do not have direct access to the data reservoir repositories. The data refinery processes are the only processes that can access and update the data reservoir repositories.
Data refinery processes capture lineage information about the data they are moving and transforming so it is possible to trace where data originated. Data refinery processes also honor the governance classifications defined for the data in the catalog by implementing the associated governance rules. As such, they are key processes in creating robust governance in the data reservoir.
Styles of data refinery
The data reservoir reference architecture supports many types of data refinery process, of which these are some examples:
•ETL bulk load and delta load
Extract, transform, and load (ETL) is a technology for moving large amounts of data between data stores. ETL jobs are composed of sequences of data transformations (splits and merges are also possible in the flow).
For example, the initial import of data from a new information source or the population of a new data reservoir repository might be performed by using an ETL job. Then incremental updates to the information sources can also be moved into the reservoir by using ETL jobs. Traditionally, ETL jobs have been run on structured sources. More recently, ETL engines such as IBM InfoSphere DataStage® can also run with Hadoop sources and targets.
•Trickle feed
Trickle feeds are used when small changes occur in an information source that need to be sent to the data reservoir. Replication and messaging are two approaches in addition to ETL to implement a trickle feed.
•Replication
Replication monitors changes to the information source and triggers a data flow when new data is stored. In this case, no complex transformations occur. This approach has little effect on the information source system both in terms of performance and change to its logic.
•Messaging
Messaging is a push mechanism from the information source system. Data is packaged as a message and deposited on a queue that acts as an intermediary. The data reservoir monitors the queue and picks up new messages as they arrive. Using message queues provides an intermediary between the sender and the receiver, enabling them to exchange data even if they are operating at different times of the day.
A messaging paradigm has these advantages:
– Messages can be sent synchronously or asynchronously. This method allows control over when information flows. Synchronous processing of messages is simple to implement, but the receiving system might not be ready to process the message, so it blocks the sender. Asynchronous message allows the sender to send and not be blocked. The message is processed some time later when the receiver is ready.
– Messaging systems (for example, IBM MQ2) ensure delivery and scale.
– It might be more efficient to batch up messages or send them independently.
The data refineries of the data reservoir implement any transformations that are required during the trickle feed.
Validation
Refinery services can be called to validate that data is of the shape and content expected. For example, addresses can be validated to ensure that they represent an actual location. Errors are raised as exceptions that are sent to the team responsible for the original information source so that team can correct them.
Data shaping or transformation
To improve the raw data, you often need to normalize it and make it self-consistent. Data refinery services do this sort of shaping. This action involves filtering, normalizing, and dealing with nulls and trailing blanks.
One way to ensure that data values are normalized is to use reference data. Reference data provides a standard set of values for certain fields. For example, it can be useful to hold a standard definition of country codes and use this reference data to ensure that country code fields comply. Variations of “US”, “USA”, and “United States” could all be resolved to the same reference data value. This means that users get much more consistent data.
It is important to understand that making data consistent is not the same thing as raising the quality of data. Raising the quality of data might take a person who understands the context of the data and can make a meaningful assessment. As a company embraces a semantic definition of concepts, it is possible to make inferences about the meanings of new concepts. Using cognitive analytics technology solutions allows users to interact with the system in natural language in a more meaningful way.
Adding smarts into the information supply chain: Analytics in action
As you create supply chains in your data reservoir, it is useful to think of the information supply chain itself as an analytics project. This means that you should look to capture metrics of the supply chain to assess how it is doing and whether it is meeting the needs of the data reservoir.
So what do you want from the information supply chain? Each information supply chain has an expected service level agreement (SLA). The following items could be considered:
•Operational efficiency: Collecting metrics around the amount of data, the time for transformation, the time taken, and the number of concurrent jobs means you can see how the supply chain is doing. A real-time dashboard or report provide descriptive analytics. It is worth taking the time to understand which roles might need to see which reports and make sure that the reports are matched to the role.
•Seeing how quality and consistency metrics change.
•Using analytics to highlight possible fraudulent activity in the supply chain.
•Using analytics to answer the business questions such as am I getting a return on investment from the supply chains I have?
•Using metrics to spot when you are running out of capacity such as processing power, network bandwidth, or memory, which indicates that more data repositories might be required.
•Metrics and lineage information from the supply chains and their interpretation are part of the story to ensure that audits can be passed, legal standards are complied with, and ethical practices are occurring.
After you have the data and can spot anomalies in the supply chain, you can start making decisions on how to change the supply chain. Deploying analytic scoring models into the supply chain to give up-to-date information to enable real-time decisions to be made should improve the supply chain efficiency.
4.3.7 Information virtualization
Information virtualization is a technique that provides consumable data to people and systems irrespective of how the data is physically stored or structured. Information virtualization is used for two purposes in the data reservoir:
•The View-based Interaction subsystem uses information virtualization to provide consumable versions of data to its users.
•The Data Reservoir Repositories subsystem uses information virtualization to augment the data that is stored in the data reservoir repositories.
The techniques to implement information virtualization are varied and depend on these factors:
•The location of the data
•How compatible the format of the stored data is to the needs of the user
•How frequently the requests for data will be
•How much capacity is available in the systems that store the data to service these queries
There are two basic approaches:
•Accessing the data in place through a simplifying view or API
•Copying the required subset of data to a new location where the users can access it
Many organizations want to avoid copying data, particularly when a required information source is too large and too volatile to make it feasible to copy. The data reservoir can represent this data as cataloged information views over its contents so that data can be located, understood, and accessed on demand. For this to work, the information source must be available when the data reservoir users need it, and able to support the additional workload that the data reservoir brings.
If the information source is not able to support the needs of the data reservoir users directly, then its data should be copied into the data reservoir repositories. For example, Eightbar Pharmaceuticals chose to use an object cache for the information for patients and medical staff for use by the systems of engagement. This choice was made because the availability requirements for systems of engagement are high and it is easy to achieve high availability with a simple object cache. Also, the object cache limits the data that is exposed to the systems of engagement.
When combining data from multiple sources, there are two approaches to consider:
•Copy sources to a single data reservoir repository and join the data sources on demand
•Use federation to query and create federated views, leaving the data in place
Copy sources centrally and join
Creating a copy of each source centrally and then joining them together means that all the data is in the same ecosystem, for example Hadoop or a relational database. After the data is copied, it is located together so joins do not involve excessive network traffic.
Federated Views
Federation returns data from multiple repositories using a single query. It manages logical information schemas that the caller uses. Using federation to query and create federated views, leaving the data in place, means that data does not have to be moved. This approach can be simpler and can handle a variety of data sources both in size and structure. Federation is an up-to-date (within practical limits) “don't move the data” paradigm. Also, federated views can help with authorization by only showing the parts of the data that are allowed to be seen.
Using federation is not magic, so it is worth thinking about sampling the data to reduce the amount of data that needs to flow. Being careful that complete table scans on large tables are not required to support the federated view. Consider caching as a way to keep some data locally to aid performance at the expense of the data being up-to-date. Consider copying the data using ETL, if you do not want the data to change underneath you. This gives you a point in time snap shot of the data that might be more useful to train an analytic model on in combination with the federated view.
Pragmatically for proof-of-concept and discovery activities, federation is often the quickest way to get going with data.
4.3.8 Service interfaces
Service interfaces provide direct access to a part of an information supply chain. They represent points in an information supply chain where information can both be injected and extracted.
In the data reservoir, the service interfaces are one of these types:
•RESTful information services provide simple operations (such as create, update, query, and delete) on named data objects. These data objects are typically stored in the shared operational data repositories.
•Services to initiate processes to manage the data reservoir.
•Services to run particular types of analytics.
Following is an example of using the service interfaces.
Harry Hopeful's data needs
Many people use spreadsheets to hold their data successfully. They are easy to use. The disadvantage is that a spreadsheet is a personal store of data that is not designed for sharing. As individuals exchange spreadsheets, multiple slightly different versions can be produced as each person changes it. It is possible that this spreadsheet data is never shared or stored for future analytics.
This section shows how Harry can move from working purely with spreadsheets to a mobile application that uses cloud services to manage his data in the data reservoir. This means that the data is moved into historical data repositories, so analytics can be performed. The information services around the reservoir allow mobile applications to access the data.
This change of emphasis from data locked up in a silo (such as a spread sheet) to the data being liberated in the data reservoir resonates across many industries and roles (Figure 4-8).

Figure 4-8 Harry Hopeful's spreadsheet usage
Harry Hopeful visits consultants in hospitals and their own practices to sell them products. He is used to working with spreadsheets that he keeps up-to-date manually. Locked in these spreadsheets are years of experience on how and when to approach different types of sales situations. Harry is approaching retirement and is happy to make his spreadsheet data available in the data reservoir so it can be used to develop some analytics that will help guide and train less experienced sales people.
The data reservoir holds the history of Harry's sales visits. Current data, along with recommendations, are fed into the object cache, which in turn feeds information to Harry's tablet. Harry works more on his tablet, and has an app on the tablet that uses location services to determine who Harry is visiting, in which case a draft sales visit is created for Harry to confirm.
The plan is to send a recommendation to Harry and have him confirm whether they are valid or useful. The aim is to improve the recommendations through Harry's feedback so they can be used with other, less experienced sales people.
This is an example of using data and calculated insight published from the data reservoir for new applications. These applications feed the results of using the data reservoir's content back into the data reservoir to improve the analytics.
4.3.9 Using information zones to identify where to store data in the data reservoir repositories
You have considered the subject areas in the data reservoir and the likely information sources. This section considers how the users will use the data reservoir and how data needs to be organized in the data reservoir repositories.
An information zone is a collection of data elements that are prepared for a particular workload, quality of services, and user group. In this way, data is grouped for the same usage: Scoping content in the catalog so that different types of users see the data that is most relevant to their needs.
Information zones are helpful when thinking about information supply chains as they identify the different destinations that the information supply chain must serve.
Information zones are also an implementation time hint to the data reservoir architect as to what SLA should be present in the target data repository, ensuring the data repository is deployed onto infrastructure with the correct characteristics and services. Some information zones overlap on the same data element. However, it might be necessary for the same data element to be copied (and possibly reformatted) and stored in a different repository to make it more consumable in another information zone.
|
Data reservoir repositories: The data reservoir repositories can each exist in multiple information zones, meaning the information zones overlap. A large number of overlaps is a sign that there are many opportunities to share data. This must be balanced with the need to structure and place data on an infrastructure platform that suits the workload using it.
|
There are three broad types of information zones:
•Traditional IT information zones: These information zones reflect the publication of enterprise IT data into the data reservoir. This zone includes the deep data, information warehouses, and their reporting data marts.
•Self-Service information zones: These information zones provide data to the line of business (LOB) users that have simple structure and are labeled using business relevant terminology. The self-service zones should not require deep IT skills to understand the data and its structure.
•Analytics information zones: These zones contain the data that underpins all the steps in the analytics lifecycle.
Traditional IT zones
The traditional IT zones describe how data flows from the enterprise IT systems into the data reservoir. They include these zones:
•The landing area zone
•The integrated warehouse and marts zone
•The shared operational information zone
•The audit zone
•The archive zone
•The descriptive data zone
The landing zone
The landing area zone contains raw data just received from the applications and other sources. Figure 4-9 shows the landing zone in the context of the data reservoir. This data has the following characteristics:
•Minimal verification and reformatting performed on it.
•Date and time stamps added.
•Optionally, information is added around where the information came from and who authored it.

Figure 4-9 The landing area zone
The systems of record do not know about the staging areas, only the interchange area that is on the boundary of the reservoir. Only the data refineries use the staging areas. The interchange area is not in the landing zone because this is not a place where users can get data.
The integrated warehouse and marts zone
The integrated warehouse and marts zone contains consolidated and summarized historical information that is managed for reporting and analytics. It spans the information warehouse and reporting data marts repositories.
This zone is populated and managed using traditional data warehousing practices.
Figure 4-10 shows Operational History and Deep Data repositories feeding into the Information Warehouse. The Information Warehouse can feedback derived information into the Deep Data repository.

Figure 4-10 Integrated warehouse and marts zone
Reporting data marts are created from the Information Warehouse to create simple subsets of data suitable to drive reports.
Shared operational information zone
The shared operational information zone has the data reservoir repositories that contain consolidated operational information that is shared by multiple systems. This zone includes the asset hubs, content hubs, code hubs, and activity hubs.
Service interfaces are typically available to access these repositories from outside the data reservoir.
Data from the shared operational information zone is also used to help correlate and validate data inside the data reservoir. Data can also be fed to this zone through Data Ingestion and distributed from this zone through the Publishing Feeds. It can also receive new data through the service interfaces.
Figure 4-11 shows three interactions between the shared operational data and deep data.
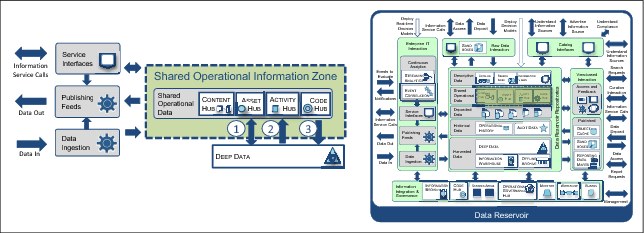
Figure 4-11 Shared operational information zone
The shared operational information zone consists of these items (Figure 4-11):
•Item 1: Service interfaces between the asset hub and the deep data repository, matching master data with new sources.
•Item 2: Pushing recent activity from deep data into the activity hub. The following are other patterns of keeping the activity hub and deep data up-to-date as new activity comes into the reservoir:
– A refinery process updates the activity hub, and the deep data is then periodically updated depending on how up to date the activity in deep data needs to be. It might be that deep data only needs to be updated overnight.
– As a new activity comes into the data reservoir, refinery processes update the activity hub and the deep data. This keeps deep data as up to date as the activity hub.
•Item 3: Standardize and map code values. For example, standardizing country codes means that data can be more easily correlated. If possible, standardization of code values should be pushed back to the source systems. Over time, the data coming into the reservoir becomes more standardized, reducing the standardization work that the reservoir needs to do.
The audit data zone
The Audit Data Zone maps to the audit data repository in the Historical Data subsystem. It is fed from the governance processes and logs the activity of the data reservoir. The audit log data comes predominantly from the information brokers, monitors, and guards (Figure 4-12).

Figure 4-12 Audit data zone
The archive data zone
The operational systems (system of record or system of engagement) run the daily business. They are continually updating data and deleting old data that they do not need any more (for example, completed activities). For analytics, you need to capture this historical data and store it for investigations, audit, and understanding historical trends. This ability is one of the roles of the data reservoir.
From the perspective of the operational systems, the data reservoir is its archive. The data reservoir itself has an archive as well. The archive data zone holds data that is archived from the data reservoir (Figure 4-13).

Figure 4-13 Archive data zone
Data is kept online in the data reservoir while its users need it. Then it is shifted to the offline archive (Figure 4-13) in the harvested data subsystem. The Archive Data Zone of the data reservoir is the offline archive plus space in the Deep Data repository for data that is about to go into the offline archive.
From the perspective of the data scientist building analytical models, the data reservoir is much like a museum. Artifacts that are no longer being used in daily life are curated and can be accessed by visitors to gain an understanding of the past. In a similar way, data from the operational systems is curated and stored in the data reservoir. Data scientists and reporting mechanisms accesses this data to gain an understanding of the past. When data scientists are performing data mining, they are looking to learn the lessons from the past to predict how best to react in similar circumstances when they occur in the future.
Not all artifacts are displayed in a museum. The museum needs to store many artifacts in its archive (an area that visitors cannot access without special permissions). Similarly, the data reservoir has an offline archive where data no longer useful to the data scientist or reporting or other analytical processing is stored. This offline archive in the data reservoir is only retained for regulatory reasons and is unlikely to be needed by the data scientists.
Data is moved into and deleted from the archives based on retention classifications set in the catalog. The archiving process is managed by the data refineries and monitored from information integration and governance.
The descriptive data zone
The descriptive data zone contains the data stored in the descriptive data repositories.
The purpose of this zone is to provide descriptions of the reservoir content. This zone includes the catalog content, plus search indexes and information views used by the View-based Interaction subsystem (Figure 4-14).

Figure 4-14 Descriptive data zone
Self-service zones
The self-service zones contain the data that is used by LOB teams as they access the data reservoir through the view-based interaction subsystem. These zones include:
•The information delivery zone
•The deposited data zone
•The test data zone
The information delivery zone
The information delivery zone stores information that has been prepared for use by the lines of business. Typically this zone contains a simplified view of information that can be easily understood and used by spreadsheets and visualization tools.
This zone is in the published data stores in the View-based Interaction subsystem, or includes data accessed through the information views (Figure 4-15).

Figure 4-15 Information delivery zone
The deposited data zone
The deposited data zone is an area for the users of the data reservoir to store and share files. These files are stored in the Deposited Data subsystem.
The person depositing the data is its owner (until ownership is transferred to someone else). That person is responsible for the correct classification of the data in the catalog so that access control and other protection mechanisms operate correctly.
Deposited data can be accessed from both the Raw Data Interaction and View-based Interaction subsystems (Figure 4-16).
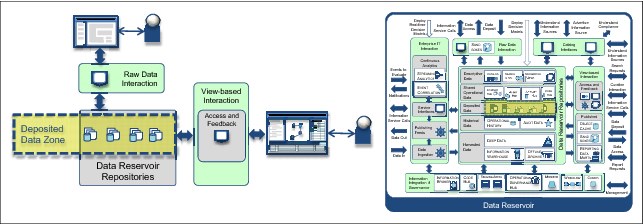
Figure 4-16 Deposited data zone
The test data zone
The test data zone (Figure 4-17) is in the deep data repository. It provides test data prepared for application developers.
•This data can be subsets of other information collections in the data reservoir that have been selected to test a broad range of conditions in new application code.
•It can be selectively masked or jumbled to hide personal information.

Figure 4-17 Test data zone
Analytics zone
The analytics zones show the data usage during the development and execution of analytics.
The Discovery Zone
The discovery zone (Figure 4-18) contains data that is potentially useful for analytics. Data scientist and experienced analysts from the line-of-business typically perform these steps:
•Browse the catalog to locate the data in the discovery zone that they want to work with.
•Understand the characteristics of the data from the catalog description.
•Populate a sandbox with interesting data.
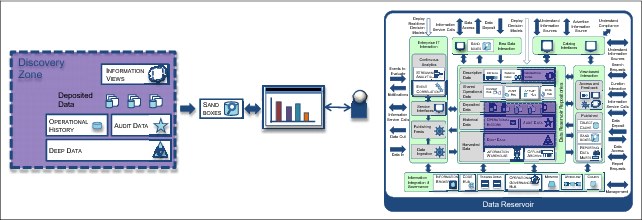
Figure 4-18 Discovery zone
The exploration zone
The exploration zone contains the data that the analysts and data scientists are working with to analyze a situation or create analytics. This data is stored in sandboxes that are managed by the data reservoir. These sandboxes are fed from the discovery zone.
The users of this zone browse, reformat, and summarize data to understand how a process works, locate unusual values (outliers), and identify interesting patterns of data for use with a new analytical algorithm. This is a place where data can be played with, so different combinations of data can be brought together in new ways to drive data mining. This zone can work with subsets of the data (for example, using different sampling strategies) to create the new combinations quickly and facilitate the iterative way of working that the data scientist needs when finding and preparing data, and training analytics models (Figure 4-19).

Figure 4-19 Exploration zone
The analytics production zone
The analytics production zone defines where the analytics production workloads are in the data reservoir repositories.
This can vary between each data reservoir. In the initial deployment, it might even be empty. As new analytics are deployed into production, the scope of this zone grows.
The value of this zone is in identifying where production SLAs needs to be maintained. See Figure 4-20.
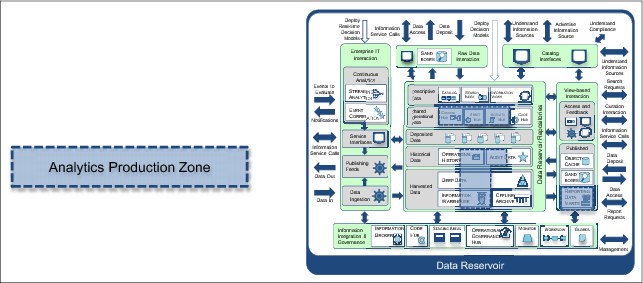
Figure 4-20 Analytics production zone
The derived insight zone
The derived insight zone identifies data that has been created as a result of production analytics. This data is unique to the data reservoir and might need additional procedures for backup and archive.
This data might also need distributing to other systems, both inside and outside of the data reservoir, for the business to act on the insight. Examples of this insight are the propensity to be fraudulent of a supplier or the propensity to leave the trial for a patent. See Figure 4-21.

Figure 4-21 Derived insight zone
Information supply chains and zones
So how does the information supply chain fit with the information zones? The information zones show where the data used by each type of user is located. Thus, the information zones show which of the data reservoir repositories (destinations) that the information supply chains must serve.
4.4 Summary
Information supply chains are the flows of data from its original introduction in an IT system to its user. This chapter describes how to identify the subject areas that meet the needs of the use cases and users of the data reservoir. Next, the usage of the reservoir was considered with the information zones, followed by identifying data sources for the subject areas. Information source characteristics were reviewed. Matching up the usage and the sources allows you to identify gaps that the information supply chain fill. The various information supply chains that involve the data reservoir were described for enterprise data, metadata, deposited data, and audit data.
Master data can be an anchor used to hang information, handling identifiers and correlation centrally. The chapter covered information refineries, the information processes in the data reservoir. Finally, it described consumption of data from the reservoir by information services and information virtualization.
1 Patterns of Information Management, Mandy Chessell, https://www.ibm.com/developerworks/community/wikis/home?lang=en#!/wiki/W4108ee665aa0_4201_8931_923a96c3653a/page/Information%20Supply%20Chain
2 For more details about IBM MQ go to this web address: http://www.ibm.com/software/products/en/ibm-mq
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.