
Large-scale client-server architecture is ubiquitous on the Internet. Web sites may service thousands of simultaneous clients, with individual servers processing hundreds of clients. Parallelism can be achieved by multiple processes, by multiple threads within a process, by asynchronous I/O and events within a single process thread or by combinations of these approaches. This chapter explores the interaction of threading, forking, network communication and disk I/O on the performance of servers.
Effective deployment of high-performance web servers has become an increasingly important commercial enterprise. Nearly every organization has a web site that serves as an important access point for customers or members. Commercial sites are particularly concerned with handling peak loads and with fault tolerance.
The administrator of a single web server must decide how to distribute data across available disks as well as how many separate processes and separate threads within server processes to create. The effectiveness of different strategies depends on processor and system architecture as well as on the offered load.
Early web servers created a new process to handle each HTTP request. Later web servers, such as Squid [130] and Zeus [137], used a single-process approach to reduce context-switch and synchronization costs. Process creation costs considerably more than thread creation, but thread creation also has some associated costs. Kernel-level thread creation usually costs more than user-level thread creation, but user-level threads must share the kernel resources allocated for a single process.
Creation costs can be offset by preliminary creation of either processes or threads and causing them to wait at a synchronization point until activated. When the process or thread completes its task, it executes another blocking call and resumes waiting. Overhead with this approach depends on the efficiency and scalability of the blocking calls.
Synchronization costs also factor into the efficiency of cache and disk accesses. A single process/single thread architecture that uses asynchronous I/O can be more effective than multiple threads for certain types of cached workloads. Remember that user threads are implemented by a software layer that uses jackets around system calls and manages asynchronous I/O. Sometimes the overhead for this layer is greater than a carefully optimized implementation that directly uses asynchronous I/O. However, event-driven asynchronous I/O is usually more complex to program.
Context-switch costs are another factor in server performance. A switch between user threads within the same process does not incur the overhead of a kernel context switch and can therefore be done quite efficiently. Context switches and synchronization are generally more expensive at the process level than at the thread level.
Chapter 18 introduced three models of client-server communication: the serial-server (Example 18.2), the parent-server (Example 18.3), and the threaded-server (Example 18.6), respectively. Because the parent-server strategy creates a new child process to handle each client request, it is sometimes called process-per-request. Similarly, the threaded-server strategy creates a separate thread to handle each incoming request, so it is often called the thread-per-request strategy.
An alternative strategy is to create processes or threads to form a worker pool before accepting requests. The workers block at a synchronization point, waiting for requests to arrive. An arriving request activates one thread or process while the rest remain blocked. Worker pools eliminate creation overhead, but may incur extra synchronization costs. Also, performance is critically tied to the size of the pool. Flexible implementations may dynamically adjust the number of threads or processes in the pool to maintain system balance.
Example 22.1.
In the simplest worker-pool implementation, each worker thread or process blocks on the accept function, similar to a simple serial server.
for ( ; ; ) {
accept request
process request
}
Although POSIX specifies that accept be thread-safe, not all operating systems currently support thread safety. Alternatively, workers can block on a lock that provides exclusive access to accept, as the next example shows.
Example 22.2.
The following worker-pool implementation places the accept function in a protected critical section so that only one worker thread or process blocks on accept at a time. The remaining workers block at the lock or are processing a request.
for ( ; ; ) {
obtain lock (semaphore or mutex)
accept request
release lock
process request
}
POSIX provides semaphores for interprocess synchronization and mutex locks for synchronization within a process.
Example 22.3.
If a server uses N workers, how many simultaneous requests can it process? What is the maximum number of simultaneous client connections?
Answer:
The server can process N requests simultaneously. However, additional client connections can be queued by the network subsystem. The backlog parameter of the listen function provides a hint to the network subsystem on the maximum number of client requests to queue. Some systems multiply this hint by a fudge factor. If the network subsystem sets its maximum backlog value to B, a maximum of N + B clients can be connected to the server at any one time, although only N clients may be processed at any one time.
Another worker-pool approach for threaded servers uses a standard producer-consumer configuration in which the workers block on a bounded buffer. A master thread blocks on accept while waiting for a connection. The accept function returns a communication file descriptor. Acting as the producer, the master thread places the communication file descriptor for the client connection in the bounded buffer. The worker threads are consumers that remove file descriptors and complete the client communication.
The buffer implementation of the worker pool introduces some interesting measurement issues and additional parameters. If connection requests come in bursts and service time is short, buffering can smooth out responses by accepting more connections ahead than would be provided by the underlying network subsystem. On the other hand, if service time is long, accepted connections languish in the buffer, possibly triggering timeouts at the clients. The number of additional connections that can be accepted ahead depends on the buffer size and the order of the statements synchronizing communication between the master producer and the worker consumers.
Example 22.4.
How many connections ahead can be accepted for a buffer of size M with a master and N workers organized as follows?
Master:
for ( ; ; ) {
obtain a slot
accept connection
copy the file descriptor to slot
signal item
}
Worker:
for ( ; : ) {
obtain an item (the file descriptor)
process the communication
signal slot
}
Answer:
If N ≥ M, then each worker holds a slot while processing the request, and the master cannot accept any connections ahead. For N < M the master can process M – N connections ahead.
Example 22.5.
How does the following strategy differ from that of Exercise 22.4? How many connections ahead can be accepted for a buffer of size M with a master and N workers organized as follows?
Master:
for ( ; ; ) {
accept connection
obtain a slot
copy the file descriptor to slot
signal item
}
Worker:
for ( ; ; ) {
obtain an item (a file descriptor)
signal slot
process the communication
}
Answer:
The strategy here differs from that of Exercise 22.4 in two respects. First, the master accepts a connection before getting a slot. Second, each worker thread immediately releases the slot (signal slot) after copying the communication file descriptor. In this case, the master can accept up to M+1 connections ahead.
Example 22.6.
In what way do system parameters affect the number of connections that are made before the server accepts them?
Answer:
The backlog parameter set by listen determines how many connections the network subsystem queues. The TCP flow control mechanisms limit the amount that the client can send before the server calls accept for that connection. The backlog parameter is typically set to 100 or more for a busy server, in contrast to the old default value of 5 [115].
Example 22.7.
What a priori advantages and disadvantages do worker-pool implementations have over thread-per-request implementations?
Answer:
For short requests, the overhead of thread creation and buffer allocation can be significant in thread-per-request implementations. Also, these implementations do not degrade gracefully when the number of simultaneous connections exceeds system capacity—these implementations usually just keep accepting additional connections, which can result in system failure or thrashing. Worker-pool implementations save the overhead of thread creation. By setting the worker-pool size appropriately, a system administrator can prevent thrashing and crashing that might occur during busy times or during a denial-of-service attack. Unfortunately, if the worker-pool size is too low, the server will not run to full capacity. Hence, good worker-pool deployments need the support of performance measurements.
Example 22.8.
Can the buffer-pool approach be implemented with a pool of child processes?
Answer:
The communication file descriptors are small integer values that specify position in the file descriptor table. These integers only have meaning in the context of the same process, so a buffer-pool implementation with child processes would not be possible.
In thread-per-request architectures, the master thread blocks on accept and creates a thread to handle each request. While the size of the pool limits the number of concurrent threads competing for resources in worker pool approaches, thread-per-request designs are prone to overallocation if not carefully monitored.
Example 22.9.
What is a process-per-request strategy and how might it be implemented?
Answer:
A process-per-request strategy is analogous to a thread-per-request strategy. The server accepts a request and forks a child (rather than creating a thread) to handle it. Since the main thread does not fork a child to handle the communication until the communication file descriptor is available, the child inherits a copy of the file descriptor table in which the communication file descriptor is valid.
The designs thus far have focused on the communication file descriptor as the principal resource. However, heavily used web servers are often limited by their disks, I/O subsystems and memory caches. Once a thread receives a communication file descriptor and is charged with handling the request, it must locate the resource on disk. This process may require a chain of disk accesses.
Example 22.10.
The client request to retrieve /usp/exercises/home.html may require several disk accesses by the OS file subsystem. First, the file subsystem locates the inode corresponding to usp by reading the contents of the web server’s root directory and parsing the information to find usp. Once the file subsystem has retrieved the inode for usp, it reads and parses data blocks from usp to locate exercises. The process continues until the file subsystem has retrieved the actual data for home.html. To eliminate some of these disk accesses, the operating system may cache inodes indexed by pathname.
To avoid extensive disk accesses to locate a resource, servers often cache the inode numbers of the most popular resources. Such a cache might be effectively managed by a single thread or be controlled by a monitor.
Disk accesses are usually performed through the I/O subsystem of the operating system. The operating system provides caching and prefetching of blocks. To eliminate the inefficiency of extra copying and blocking through the I/O subsystem, web servers sometimes cache their most popular pages in memory or in a disk area that bypasses the operating system file subsystem.
This project explores the performance tradeoffs of several server designs and examines the interaction of the implementations during disk I/O and cache access. Section 22.4 describes a test client that standardizes the offered load for different test architectures. Section 22.5 explores the use of multiple client drivers to load a single server. Sections 22.6-22.9 outline a project to compare efficiency of thread-per-request versus process-per-request implementations for different offered loads. Section 22.10 looks at the effect of disk I/O. Later sections discuss how to design experiments and how to write up the results.
This section describes a singleclientdriver program that can be used to present controlled offered loads to servers and to gather statistics. The singleclientdriver program forks a specified number of processes, each of which makes a specified number of connections to a server that is listening on a specified host and port. The singleclientdriver program takes the following command-line arguments.
Hostname of the server
Port number of the server
Number of processes to fork
Number of connections per process
Number of requests per connection
Smallest response size in bytes
Largest response size in bytes
Each process of singleclientdriver sequentially creates a connection, performs the specified communication, and then closes the connection. The communication consists of a specified number of request-response pairs. The process sends a request specifying the size of the desired response and then does a blocking read to wait for that response. The process picks a desired response size that is a random integer between the smallest and largest response size.
The client driver algorithm for processing a connection consists of the following.
Get the time.
Connect to the specified server.
For the number of requests per connection do the following.
Get the time.
Send a request (that includes the desired length of the response).
Read the response.
Get the time.
Close the connection.
Update and save the statistics.
Each request message from a client process consists of a 4-byte message containing the length of the response in network byte order. Each time a client process sends a request, it increments its client message number. After closing a connection, the client increments its connection count and resets the request count to zero. Write your program so that it allows the saving of different levels of detail depending on a loglevel flag. The level can range from only keeping statistics (as described below) to full logging that includes saving the response header information. Take care not to do any output or string processing (e.g., sprintf) between the starting and ending timing statements, since these operations may be comparable in time to the operations that you are timing.
The algorithm glosses over the possibility of a failed connection attempt, which may occur if the server or network experiences congestion. The client should keep track of the number of failed connections. You can handle failed connections by retrying, by continuing, or by aborting the client. Each of these approaches introduces subtle problems for keeping correct statistics. Be sure to think carefully about this issue and devise and document a strategy.
Write a test server program that waits for connection requests from the client driver. After accepting a connection, the test server calls a handleresponse function that takes the communication file descriptor returned from accept as a parameter. The function reads requests from the socket designated by the communication file descriptor and sends response messages. When the function detects that the remote end has closed the socket, it closes the socket and returns. The response message consists of a response identification followed by response data of the specified length. The response identification contains the following three 32-bit integers in network byte order.
Process ID of server process.
Thread number of the thread that processes the message (or 0 for an unthreaded implementation). The thread number is a value that is unique for each thread of the process. The main thread passes this unique identifier to each thread on creation.
Message number. (Messages processed by a particular thread or process are numbered consecutively.)
This simple test server avoids disk accesses by using a previously created buffer with a dummy message to send as a response. The server may need to send the dummy message multiple times to fulfill the length requirement of the request. Think about how large a buffer the server requires and how this might affect the timing of the result. You can pass the address and size of the buffer to the handleresponse function.
Your singleclientdriver program should gather statistics about mean, standard deviation and median of both the connection times and the response times. The sample mean ![]() for a sample of size n is given by the following formula.
for a sample of size n is given by the following formula.
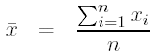
The sample standard deviation is given by the following formula.

For evaluation, combine the statistics of the processes. Calculating combined statistics for the mean and standard deviation is straightforward—just accumulate the number of values, the sum of the values, and the total of the squares of the values.
The median of a distribution is the value in the middle position of the sorted distribution values. (For distributions with an even number of values, the median is the mean of the middle two values.) When distributions are skewed, median times often better reflect behavior than do mean times. Finding the median of combined distributions typically requires that all the values be kept and sorted.
An alternative method of estimating the median of a combined distribution is to keep a histogram of the values for each distribution and then combine the histograms and estimate the median from these. A histogram is an array of counts of the number of times a value falls in a given interval. For unbounded distributions, the last histogram entry accumulates the number of values larger than a specified value. Combine histograms by adding corresponding entries. Estimate the median by accumulating the counts in the bins, starting with the bin representing the smallest value, until the sum reaches ![]() , where n is the number of values in the distribution. The median can be estimated as the midpoint of the range of values corresponding to the bin. You can also use linear interpolation on the range of values counted by the bin containing the median value. You may wish to use histogram approximation for calculating the median in the short form of logging.
, where n is the number of values in the distribution. The median can be estimated as the midpoint of the range of values corresponding to the bin. You can also use linear interpolation on the range of values counted by the bin containing the median value. You may wish to use histogram approximation for calculating the median in the short form of logging.
Test the singleclientdriver for different values of the command-line arguments. You should devise tests in which 5, 10 and 20 simultaneous connections are maintained for a reasonable length of time.
Example 22.11.
What parameters determine the number of simultaneous connections that singleclientdriver offers to the test server?
Answer:
The nominal number of simultaneous connections is the same as the number of child processes. However, during the initial setup period when processes are forked and during the final shutdown period when processes are completing and exiting, the number of connections is unstable. Hence, the individual processes of singleclientdriver should be active long enough to offset these unstable phases. Also, if the number of requests per connection multiplied by the number of bytes per request is too small, each connection will be of short duration and client processes will spend most of their time trying to establish connections rather than communicating. Finally, a given host can only effectively support a limited number of processes performing these activities. To effectively load a server under test conditions, you should run singleclientdriver programs on several hosts at the same time.
A single host, even though it is running multiple threads or processes, may not be able to offer a large enough load to a web server to measure its capacity. Your implementation should have the following features to support running multiple loading clients.
Be able to coordinate the clients to send at the same time.
Be able to collect and analyze combined statistics from all clients.
Be sure that the traffic generated by the clients for synchronization and statistics does not interfere with the traffic being measured.
This section discusses a client-driver design that can be used to put a coordinated load on a server and gather statistics with minimal interference with the measurements.
The design involves two programs: a control driver and a client driver. The control driver controls multiple copies of the client driver and gathers and analyzes statistics from them. The client driver takes an optional port number in addition to the command-line arguments specified in Section 22.4. Without the optional port number, the multiple-client driver behaves like the single-client driver. If the optional port is given, the client communicates with the control driver through this port. The client starts by listening for a connection request on the optional port before loading the server and sends statistical data back over the connection. A synchronization mechanism is set up so that all clients start almost simultaneously and do not send their statistics over the network until all other clients have completed communication with the server.
Copy your singleclientdriver.c into multipleclientdriver.c and compile it as multipleclientdriver. Modify multipleclientdriver to take an additional optional control port number as a command-line argument. If this optional argument is present, multipleclientdriver does the following.
Wait for a connection request from the control host on the control port.
When this request arrives, send the number of child processes to the control host as a 32-bit integer in network byte order.
Create the child processes to load the host.
When loading completes, send a single byte to the control host and wait for a 1-byte response.
When a response from the control host arrives, forward data to the control host in an appropriate format and exit. A format for the data is given below; it includes a special record to indicate that all the data has been sent.
Notice that multipleclientdriver acts as both a client of the server being tested and a server for the control host.
Write a program called controldriver.c to control multipleclientdriver. The first command-line argument of controldriver specifies the port number for communicating with multipleclientdriver. This is followed by one or more command-line arguments specifying the names of the hosts running multipleclientdriver.
The controldriver program does the following.
Establish a connection to each of the hosts specified on the command line, using the given port number. Keep the file descriptors for these connections in an array.
Read a 4-byte integer in network byte order from each connection. Each integer specifies the number of child processes on the corresponding host. Save the integers in an array.
For each connection, read a byte for each process corresponding to that connection. (When all the bytes have been read, all the processes have finished loading the server.)
After receiving all the bytes from all connections, do the following for each process on each connection,
Send a single byte. (This tells a process to start sending its data.)
Read data until no more data is available from that process. The event type
EVENT_TYPE_DATA_ENDcan be used to signify the end of data from a single process.
After receiving all data, analyze and report the results.
One of the important design decisions is the format for the data that multipleclientdriver sends to controldriver. If multipleclientdriver sends raw data, then controldriver can dump the data to a single file for later processing or it can perform analysis itself.
Since controldriver does not necessarily know how much information will be sent from each process, it is simplest if the data is sent in fixed-length records. The controldriver program can store these in a linked list as they come in or write the data to a file. A possible format for a data record is the following.
typedef struct {
int_32 time_sec;
int_32 time_nsec;
int_32 con;
int_32 req;
int_32 pid;
int_32 serv_pid;
int_32 serv_tid;
int_32 serv_msgnum;
int_32 event;
} con_time_t;
All the values in this structure are 4-byte integers in network byte order. Each record represents an event that occurred at one of the multipleclientdriver processes. The first two fields represent the time at which the event took place. These values represent wall clock times on the individual multipleclientdriver hosts, and only differences are relevant since the clocks on these hosts are not assumed to be synchronized. The con and req fields represent the connection number and request number for a given process of multipleclientdriver. Different processes are distinguished by the pid field, which gives the process ID of the process generating the data. The value here is important only in distinguishing data from different processes, since all the processes of a given multipleclientdriver send concurrently. The next three fields are the values returned to the multipleclientdriver from the server being tested. The last field is an indicator of the event. Some possible types include the following.
#define EVENT_TYPE_PROCESS_START 0 #define EVENT_TYPE_CONNECTION_START 1 #define EVENT_TYPE_CONNECTION_END 2 #define EVENT_TYPE_SERVER_LOAD_DONE 3 #define EVENT_TYPE_CLIENT_ALL_DONE 4 #define EVENT_TYPE_CLIENT_FIRST_DATA_SENT 5 #define EVENT_TYPE_CLIENT_LAST_DATA_SENT 6 #define EVENT_TYPE_SERVER_DATA_REQUEST_START 7 #define EVENT_TYPE_SERVER_DATA_REQUEST_END 8 #define EVENT_TYPE_DATA_END 9
The controldriver process can either keep a linked list of events for each multipleclientdriver process or it can store information about which connection the data came from in a single linked list.
An alternative design puts all the parameters in the control program. The multipleclientdriver program takes a single command-line argument: the port number for communicating with the control driver. After establishing the connections, the control driver sends its command-line arguments to each multipleclientdriver. Since both string (hostname) and numeric data (everything else) are to be communicated, a format for this information would need to be specified. If all machines were ASCII-character based, a string that the client would read one character at a time could be sent. An alternative would be to send all data in numeric form (network-byte-ordered integers) by sending the IP address of the server rather than its name.
Since the control driver knows the number of processes on each client, the client driver does not need to send any information back to the control driver until it is ready to send statistics.
The control driver would need more command-line arguments or a configuration file containing the name and port number of the server as well as the number of processes, connections, requests and request size. A configuration file could have one line for each client driver, specifying the name and port number of the client driver as well as the number of processes, connections, requests and connection size. The control program takes the server name, port and configuration file name as command-line arguments. The same configuration file can be used to put loads on different servers.
This section specifies programs to compare the performance of thread-per-request and process-per-request server implementations when disk I/O is not a factor. Write two server programs, thread_per_request and process_per_request, that are to be tested under the same offered load.
The thread_per_request server takes the port number on which to accept connections as a command-line argument. The main thread listens for connection requests and creates a detached thread to handle the communication. The detached thread is passed an array containing the communication file descriptor and a thread number. The thread calls handle_request of Section 22.4.2 and then exits.
Implement a program that uses child processes instead of threads to handle the requests. The process_per_request program is similar to thread_per_request except that the main program waits for completed children (e.g., Example 3.13). Be sure to use the WNOHANG option when waiting so that the server can process concurrent children. Compare the performance of these two approaches as a function of the offered load. Present your results with graphics and a written discussion.
A thread-worker-pool strategy creates a fixed number of workers at the beginning of execution instead of creating a new thread each time a connection is made. Thread-worker-pool implementations have several advantages over thread-per-request implementations.
The cost of creating worker threads is incurred only at startup and does not grow with the number of requests serviced.
Thread-per-request implementations do not limit the number of simultaneous active requests, and the server could run out of file descriptors if requests come in rapid succession. Thread-worker-pool implementations limit the number of open file descriptors based on the number of workers.
Because thread-worker-pool implementations impose natural limits on the number of simultaneous active requests, they are less likely to overload the server when a large number of requests come in.
Write a thread_worker_pool server that takes the listening port number and the number of worker threads as command-line arguments. Create the specified number of worker threads before accepting any connections. Each worker thread calls u_accept and handles the connection directly.
Although POSIX specifies that accept be thread-safe, some systems have not yet complied with this requirement. One way to handle this problem is to do your own synchronization. Use a single statically initialized mutex to protect the call to u_accept. Each thread locks the mutex before calling u_accept and unlocks it when u_accept returns. In this way, at most one thread at a time can be waiting for a connection request. As soon as a request comes in, the worker thread unlocks the mutex, and another thread can begin waiting.
This section describes an implementation of a thread-worker pool that synchronizes on a bounded buffer containing client communication file descriptors. (See, for example, Section 16.5.) The server is a producer that places communication file descriptors in a circular buffer. The worker threads are consumers that wait for the communication file descriptors to become available in the buffer.
Write a worker_pool_buffer server that takes three command-line arguments: the listening port number, the size of the bounded buffer and the number of worker threads in the pool. The threads call the handle_request function to process the communication. Design and run experiments to answer the following questions.
How does the connection time depend on the size of the bounded buffer? What factors influence the result?
How does the number of worker threads influence the server response byte rate?
How sensitive is overall performance to the number of worker threads?
When does worker pool perform better than thread-per-request?
Before running the experiments, write a discussion of how different experimental parameters might influence the results in each case.
Implement a process-worker pool, whereby each worker process blocks on accept. The server takes two command-line arguments: the listening port number and the number of worker processes to fork.
Compare connection times for the process-worker pool with those for the thread pool of Section 22.7. Explore performance as a function of offered load. Explore hybrid designs in which a pool of threaded process workers blocks on accept. Each threaded process maintains a pool of worker threads as in Section 22.7.
Example 22.14.
How would you determine whether the backlog value set by listen affects server performance?
Answer:
The backlog is set in UICI to the value of the MAXBACKLOG constant defined near the top of uici.c in Program C.2. Pick parameters that put a moderate load on the server and recompile with different values of the backlog. UICI uses the default value of 50 if MAXBACKLOG is not defined. You can use the -D option on the compile line to define MAXBACKLOG. Start with this value and then modify it and see if smaller or larger values affect the performance of the server.
Disk accesses can be a million times slower than memory accesses. This section explores the effect of disk I/O on server performance.
To measure this performance, modify the various servers to access the disk rather than a memory buffer to satisfy requests. If your server selects from a small number of request files, your measurements may not be accurate because the operating system buffers file I/O and most of the requests may be satisfied from memory rather than from disk.
One possibility is to create a large number of files whose names are numeric, say, 00000, 00001, 00002, etc. When a request comes in, the server could pick one of these files at random and access it to satisfy the request. Some users might not have enough free disk space to implement this solution.
Another possibility is to use the system files that already exist. The idea is to create a list of the files on the server for which the user has read access. When a request comes in, the server randomly selects one of the files that is large enough to satisfy that request. Care must be taken to ensure that the process of selecting the file does not significantly burden the server.
Program 22.1 illustrates one method of ensuring careful file selection. To enable easy access, the program creates lists of files of different sizes by organizing entries according to the logarithm of their sizes. Each list consists of records that each contain the full pathname and size of a file that is of at least a given size but less than 10 times the given size. The first list contains files of at least 10 bytes, the second has files of at least 100 bytes, etc. Each list contains files 10 times the size of the previous list. If a server receives a request for a resource of size 1234 bytes, it should select at random one of the files from the list of files containing at least 10,000 bytes and transmit the required number of bytes from the selected file. Since each list is an array rather than a linked list, the server uses a random index to directly access the name of the file.
Program 22.1 creates NUMRANGES lists. For NUMRANGES equal to 5, the lists contain files of sizes at least 10, 100, 1000, 10,000 and 100,000 bytes, so makefileinfo can satisfy access requests of up to 100,000 bytes. The makefileinfo program stores the full pathname and size of each file in a record of type fileinfo. Only files whose full pathname is of size at most MAXPATH are inserted in the list. A value of 100 for MAXPATH picks up almost all files on most systems. We avoid using the system value PATH_MAX, which may be 1024 or greater, because this choice takes too much space.
Program 22.1 takes two command-line arguments, the first specifying the base path of the directory tree under which to search for files and the second specifying the number of files to find for each list. The program uses the nftw system function to step through the file system. Each time makefileinfo visits a file, it calls insertfile with the full pathname and other parameters that give information about the file. This function keeps track of how many of the lists are full and returns 1 when all are full. The function nftw stops stepping through the directory tree when insertfile returns a nonzero value.
The function insertfile first checks that it was passed a file rather than a directory by checking the info parameter against FTW_F. It also verifies that the path fits in the list and uses the stat information to make sure that the file is a regular file. If all these conditions are satisfied, insertfile attempts a nonblocking open of the file for reading to make sure that the current process has read access to that file. A nonblocking open guarantees that the attempt does not block. If all these operations are successful, insertfile calls whichlist to determine which list the file should go into. The size of each list is kept in the array filecounts, and the function keeps track of the number of these entries that are equal to the maximum size of the list.
After the list is created, makefileinfo displays a list of counts and then calls showfiles to display the sizes and names of the files in each list. Comment out the call to showfiles after you are convinced that the program is working.
Modify Program 22.1 to make it usable by your servers. Replace the main function with a create_lists function that takes two parameters—the same values as the two command-line arguments of Program 22.1. This function creates the lists. Write an additional function, openfile, that takes a size as a parameter. The openfile function chooses one of the files that is at least as large as the size parameter, opens the file for reading, and returns the open file descriptor. If an error occurs, openfile returns –1 with errno set.
Modify one of the servers from Section 22.6, 22.7, 22.8 or 22.9 so that it satisfies requests from the disk rather than from a memory buffer. The server now takes two additional command-line arguments like those of Program 22.1 and creates the lists before accepting any connection requests. The server should display a message after creating the lists so that you can tell when to start your clients. Compare the results with those of the corresponding server that did not access the disk.
Example 22.1. makefileinfo.c
A program that creates a list of files by walking through a directory tree.
#include <fcntl.h>
#include <ftw.h>
#include <limits.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include "restart.h"
#define MAXPATH 100
#define NUMRANGES 5
typedef struct {
off_t filesize;
char path[MAXPATH+1];
} fileinfo;
static int filecounts[NUMRANGES];
static fileinfo *files[NUMRANGES];
static int maxnum;
static int whichlist(off_t size) {
int base = 10;
int limit;
int lnum;
if (size < base)
return -1;
for (lnum = 0, limit = base*base;
lnum < NUMRANGES - 1;
lnum++, limit *= 10)
if (size < limit)
break;
return lnum;
}
static int insertfile(const char *path, const struct stat *statbuf,
int info, struct FTW *ftwinfo) {
int fd;
int lnum;
static int numfull = 0;
if (info != FTW_F)
return 0;
if (strlen(path) > MAXPATH)
return 0;
if ((statbuf->st_mode & S_IFREG) == 0)
return 0;
if ((fd = open(path, O_RDONLY | O_NONBLOCK)) == -1)
return 0;
if (r_close(fd) == -1)
return 0;
lnum = whichlist(statbuf->st_size);
if (lnum < 0)
return 0;
if (filecounts[lnum] == maxnum)
return 0;
strcpy(files[lnum][filecounts[lnum]].path, path);
files[lnum][filecounts[lnum]].filesize = statbuf->st_size;
filecounts[lnum]++;
if (filecounts[lnum] == maxnum) numfull++;
if (numfull == NUMRANGES)
return 1;
return 0;
}
void showfiles(int which) {
int i;
fprintf(stderr, "List %d contains %d entries
", which, filecounts[which]);
for (i = 0; i < filecounts[which]; i++)
fprintf(stderr, "%*d: %s
",which + 6,files[which][i].filesize,
files[which][i].path);
}
int main(int argc, char *argv[]) {
int depth = 10;
int ftwflags = FTW_PHYS;
int i;
if (argc != 3) {
fprintf(stderr, "Usage: %s directory maxnum
", argv[0]);
return 1;
}
maxnum = atoi(argv[2]);
for (i = 0; i < NUMRANGES; i++) {
filecounts[i] = 0;
files[i] = (fileinfo *)calloc(maxnum, sizeof(fileinfo));
if (files[i] == NULL) {
fprintf(stderr,"Failed to allocate memory for list %d
", i);
return 1;
}
}
fprintf(stderr, "Max number for each range is %d
", maxnum);
if (nftw(argv[1], insertfile, depth, ftwflags) == -1) {
perror("Failed to execute nftw");
return 1;
}
fprintf(stderr, "**** nftw is done
");
fprintf(stderr, "Counts are as follows with sizes at most %d
", maxnum);
for (i = 0; i < NUMRANGES; i++)
fprintf(stderr, "%d:%d
", i, filecounts[i]);
for (i = 0; i < NUMRANGES; i++)
showfiles(i);
return 0;
}
This section provides guidelines for doing a performance study and points out common pitfalls. We focus on the problem of comparing the performance of thread-per-request and worker-pool implementations for servers that do no disk I/O. You are asked to evaluate connection time and response times for the two approaches and to assess the influence of message size on the results. While this book is about UNIX, not performance evaluation, performance-based tuning is often necessary in such systems. In our experience, many excellent programmers do not have a good sense of what to measure, how to measure it, and what they have actually measured after doing the performance study.
All real computer performance studies face the same problem—a large number of hard-to-control variables whose influence on the result is highly nonlinear. Therefore, it is essential to understand the factors that might affect the results before starting to measure.
The first rule of performance measurement is to establish a baseline before varying any parameters. Do you expect the results to be on the order of seconds? Milliseconds? Microseconds? How much will the results vary from measurement to measurement? What influences variability besides the experimental parameters that you are explicitly varying?
Since you are trying to measure the difference in performance between two different strategies, a natural baseline is the time for exchanging a single message stream of the same type as will be used in testing the threaded servers. For example, you might take the reflectclient.c of Program 18.4 and the reflectserver.c of Exercise 18.15 as a starting point for your preliminary measurements. Measure the connection times and times to send and receive messages of different sizes in order to establish the baseline or control for comparing threaded servers. These measurements give a lower bound on the times and the variability of the measurements in the environment that you are working in. Establishing the baseline is an important step in understanding your measurements.
Example 22.15.
We modified the reflecting client of Program 18.4 to measure the time to establish a connection to the reflection server of Exercise 18.15 and to send and receive a 1K message. The client and server were running on two Sun Microsystems Ultra-10 machines with 440 MHz processors that were connected by 100 Mbit/sec Ethernet through a switch. The first run gave a connect time of 120 ms and a round trip response time of 152 ms. Subsequent runs gave connect times of around 3 ms and round trip times of about 1 ms. Can you explain these results?
Answer:
A quick look at u_connect and u_accept suggested that DNS lookup was probably the culprit in the long first initial times. The u_connect function calls name2addr before calling connect. After return from accept, u_accept also contacts DNS to obtain the hostname of the client. Once the names are in the local DNS cache, retrieval is much faster. These results suggest that UICI should probably be modified for measuring timing.
Clearly, the underlying system variability that you observe in single-threaded measurements confounds your ability to distinguish performance differences between the two threading approaches. You can reduce variability by carefully selecting the conditions under which you take measurements. If you have control over the machines in question, you can make sure that no one else is using those machines during your measurements. In many situations, however, you do not have sufficient control of the resources to restrict access. Two other steps are essential in obtaining meaningful answers. First, you should record the conditions under which you performed the measurements and make sure that they did not change significantly over the course of the experiments. Second, when the confounding factors vary significantly over time or you can’t quantify how much they are varying, you need to take many more measurements over extended periods to be sure that your numbers are valid.
Example 22.16.
How might system load contribute to the variability of single-threaded client server communication?
Answer:
Relevant system load parameters are CPU usage, memory usage and network subsystem usage. If the virtual memory system does not have enough pages to accommodate the working sets of the processes running on the system, the system will spend a lot of time swapping disk pages in and out. All network communication on a host passes through the same subsystems, so other processes that are doing network I/O or disk I/O compete for subsystem resources.
Example 22.17.
Investigate the tools for measuring system load on your system. How can you use these tools to characterize the environment for your measurements?
Answer:
System load is hard to control unless you have control over the machines on which the clients and server are running. At a minimum, you should record the system loads immediately before and after your measurements. For long-running measurements, you should periodically record the system load during the run. The UNIX uptime command supplies information about system load. You might also investigate vendor-specific tools such as Sun Microsystems’ perfmeter. The rstatd(1M) service allows remote access to system performance information.
Measurement errors result from side effects whose times are significant compared with the event times that are to be measured (e.g., printing in the timing loop).
Example 22.18.
We measured the time to execute a single
fprintf(stderr, "this is a test");
displaying to the screen in unbuffered form on the system described in Exercise 22.15. The single fprintf took about .25 ms, while an fprintf that outputted five double values took about .4 ms. However, we found that the time for 10,000 executions of the first print statement was highly variable, ranging from 1 to 10 seconds. Give possible explanations for the variability.
Answer:
Although standard error is not buffered from the user perspective, the actual screen device driver buffers output to match the speed of the output device, as the buffer fills up and empties, the time to return from fprintf varies significantly.
Given that the request-response cycle for a 1K packet is about 1 ms for the system and that we are trying to measure additional overhead incurred by threading, the time to execute extraneous print statements can be significant. The sprintf statements may also incur significant overhead for formatting strings. To do careful measurements, you should avoid all printing in timing loops. The next two examples show two common timing-loop errors.
Example 22.19.
What timing errors occur in the following pseudocode for measuring the connection and response times of a server? What happens if you omit the last assignment statement?
get time1 connect to the server get time 2 output time2 - time1 loop write request to the server read response from the server get time3 output time3 - time2 time2 = time3
Answer:
The output of time3 - time2 occurs between the measurement of two successive time3 values, hence this statement is in the timing loop. The program should also not output time2 - time1 between the connect and the first write. A better approach would be to save the times in an array and output them after the measurements are complete. If you omit the time2 = time3 statement, all times are measured from the beginning of the session. The estimates for the request-response cycle won’t mean anything. If you want to measure the time for the total response, move the statement to get the ending time outside the loop.
Example 22.20.
Would outputting to disk during the timing be better or worse than outputting to screen?
Answer:
The outcome is a little hard to predict, but either way it cannot be good. Disk access times are on the order of 10 ms. However, a disk write does not actually go directly to the disk but is usually buffered or cached. If the disk is not local but mounted through NFS, the output introduces network traffic as well as delay. For I/O that must be done during the measurements in such an environment, it is better to use /tmp, which is likely to be located on a local disk.
Example 22.21.
What is wrong with measuring the sending of the request and the receiving of the response individually, such as in the following?
get time1 write request get time2 read response get time3 sendtime = time2 - time1 receivetime = time3 - time2
Answer:
The sendtime is not the time for the message to reach its destination, but the time to copy the information from the user’s variable to system buffers so that the network subsystem can send it. This copying time is usually not meaningful in the context of client-server performance.
Printing inside the timing loop can also occur in the server, as illustrated by the pseudocode in the next example. Direct screen output by the threads has the effect of synchronizing all the threads (the effect gets worse when there are a lot of threads) on each request-response, eliminating parallelism. Use flags and conditional compilation to handle debugging statements.
Example 22.22.
Why does the following pseudocode for a server thread using thread-per-request present a problem for timing measurements?
loop until error: read request write response output a message summarizing the response close connection
Answer:
The output statement, although executed by the server, is effectively in the client’s timing loop. Print statements on the server side have the added problem of implicitly synchronizing the threads on a shared device.
Another inefficiency that can affect timing is the use of an unnecessary select statement in the worker threads. You do not need to use select for request-response situations unless you must control timeouts.
Example 22.23.
What is wrong with the following code segment for writing a block of size BLKSIZE followed by reading a block of the same size?
if (r_write(communfd, buf, BLKSIZE)) < 0)
perror("Failed to write");
else if (r_read(communfd, buf, BLKSIZE) < 0)
perror("Failed to read");
Answer:
The r_write function calls write in a loop until the entire BLKSIZE buffer is written. The r_read function only executes one successful read, so the entire BLKSIZE response may not be read. Thus, a client driver that uses a single r_read call may not correctly time this request-response, particularly for large packets on a wide area network. Worse, the next time the client times a request-response for the connection, it will read the response from the previous request.
The thread-per-request server does not require explicit synchronization, so in theory synchronization isn’t an issue for this server. However, implicit synchronization can occur even for thread-per-request whenever threads share a common resource, such as the screen. Avoid print statements in your server except for debugging or for warning of a serious error condition. Debugging statements should always be enclosed in a conditional compilation clause.
Example 22.24.
The following statement is compiled in the program because DEBUG has been defined.
#define DEBUG 1 #ifdef DEBUG fprintf(stderr, "Sending the message.... "); #endif
To eliminate fprintf, comment out the #define statement or remove it entirely. In the latter case, you can redefine DEBUG by using the -D option on compilation.
The synchronization issues for the worker pool are more complex. The three common implementations for the worker-pool model have different synchronization characteristics. In the most straightforward implementation, each worker thread blocks on accept. This mechanism relies on the availability of a thread-safe accept function with synchronization handled by the library function itself. POSIX specifies that accept should be thread-safe, but not all OS implementations provide a reliable thread-safe accept. A second implementation of worker pool protects accept with a mutex lock, as illustrated schematically in Example 22.25.
Example 22.25.
In the following pseudocode for a worker-pool implementation, the mutex lock effectively forms a barrier allowing one thread at a time to pass through and block on accept.
loop mutex lock (if error, output message to log, clean up and exit) accept (if error, release lock and continue) mutex unlock (if error, output message to log, clean up and exit) process request (if error, output message to log, clean up and continue)
The pseudocode of Example 22.25 indicates what to do in case of error. A common problem occurs in not releasing the lock properly if an error occurs on accept. In this case, the system deadlocks because no other worker can acquire the mutex lock.
The buffer implementation of the worker pool is prone to other performance bottlenecks. For example, if the master producer thread executes pthread_cond_broadcast rather than pthread_cond_signal when it puts an item in the buffer, all waiting threads will be awakened and have to contend for the mutex that controls the items. This implementation puts a significant synchronization load on the server, even for moderate numbers of workers. Producers should avoid broadcasting on slots, and consumers should avoid broadcasting on items.
You can’t rely on timing results from a program that doesn’t work correctly. It is important to catch return values on all library functions, including thread calls. Use the lint utility on your source and pay attention to the output. In particular, do not ignore the implicitly assumed to return int message, suggesting that you are missing header files.
Because the threads are executing in the environment of their parent, threaded servers are prone to memory leaks that are not a problem for servers that fork children. If a thread calls pthread_exit without freeing buffers or closing its communication file descriptor, the server will be saddled with the remnants for the remainder of its lifetime.
Example 22.26.
What memory leaks are possible in the following code?
loop
malloc space for communfd
if malloc fails
quit
accept a client connection
if accept fails
continue
create a thread to handle the communication
if the thread create fails,
continue
Answer:
If accept fails, the space for the communication file descriptor leaks. If the thread create fails, the server leaves an open file descriptor as well as allocated memory.
Example 22.27.
What assumptions does the following code make in casting communfd?
int communfd if ((communfd = u_accept(listenfd, client, MAX_CANON)) == -1) return -1; if (pthread_create(&tid, null, process_request, (void *)communfd)) return -1;
Answer:
The code implicitly assumes that an int can be correctly cast to void *, an assumption that may not be true for all machines.
Memory leaks for threaded servers can occur if any path of execution doesn’t free resources. The thread-per-request threads must free any space that they allocated or that was allocated on their behalf by their parent thread before creation. In addition, they must close the communication file descriptor even if an error occurred.
The worker-pool implementations do not need to allocate memory space for the communication file descriptors, and often they allocate buffers only once. However, the explicit synchronization introduces its own quagmire of error possibilities. Using a single mutex lock for mutual exclusion on the buffer and for tracking items and slots can result in incorrect or extremely delayed synchronization. Failure to synchronize empty slots can result in the server overwriting file descriptors before they are consumed.
Another resource management problem can occur in thread-per-request. When a thread exits, it leaves state and must be waited for unless it is a detached thread. These “zombie” threads are a leak for a long-running server. Finally, you should think seriously about the legitimate causes for a server to exit. In general, a client should not be able to cause a server to exit. The server should only exit if an irrecoverable error due to resources (memory, descriptors, etc.) would jeopardize future correct execution. Remember the Mars Pathfinder!
In most computer performance studies there are too many parameters to vary simultaneously—so usually you can’t run exhaustive tests. If you could, the results would be hard to handle and make sense of. The specific problem that we are considering here has relatively few variables for a performance problem, but even it is complex. Random testing of such a problem generally does not produce insight, and you should avoid it except for debugging. As a first step in formulating testable hypotheses, you should write down the factors that might influence the performance, their probable effect, plausible limits for their sizes, and how these tests should compare with baseline tests.
Example 22.28.
The performance of the thread-per-request server without disk I/O depends on the number of simultaneous requests, the duration of these requests, and the I/O that must be performed during the processing of the request and the response. While the I/O costs probably depend on both the number of messages that are exchanged and their sizes, to first order the total number of bytes exchanged is probably the most important cost. Plausible limits are just that—guesses. One might guess that a server should be able to handle 10 simultaneous streams without a problem. Whether it could handle 100 or a 1000 simultaneous streams is anyone’s guess, but these ranges give a starting point for the measurements.
Example 22.29.
Give performance factors for the worker pool implemented with a mutex lock protecting accept.
Answer:
The factors specified in Example 22.28 are relevant. In addition, the number of threads in the worker pool relative to the number of simultaneous connections should also be important.
The preceding examples and exercises suggest that the most important control variable is the number of simultaneous connections that a server can handle. To measure the server capacity, you will need to be able to control the number of simultaneous connections offered by your driver programs. The client-driver program of Section 22.4 offers parallel loads. Such a client driver running on a single machine might reasonably offer 5 or 10 parallel streams, but is unlikely to sustain 100 parallel streams. Suppose you want to test your server with 10 and 100 parallel streams. A reasonable approach to generating the 100 parallel streams might be to have 10 different hosts generate 10 streams each.
Example 22.30.
Describe the load offered by the client-driver program of Section 22.4 if it forks 10 children that each make 10 connections. Suppose each connection consists of 10 request/response pairs of 100 bytes each.
Answer:
The number of connections per child is far too low to offer a sustained load of 10 simultaneous streams. Forking the 10 children takes sufficiently long and the request streams are sufficiently short that some of the first children will finish or nearly finish before the later children start execution.
Many beginning analysts typically do not take enough measurements to make their studies meaningful and do not account for transient behavior. One approach to eliminating transients is for the loading programs to sustain the load longer than needed and discard the beginning and the end of the record. You can decrease or eliminate the amount that needs to be discarded by synchronizing the children before starting. Children of a single parent can call sigsuspend. The parent can then send a wake-up signal to the process group. For clusters of driver processes running on different machines, the parents can listen for a synchronization server, whose sole job is to initiate connections to the parent drivers. Section 22.5 describes the approach in detail.
To pick parameter values that make sense, you must understand the relationship of the processes/connections/messages values. The number of processes roughly corresponds to the number of parallel connections that are established. However, this assumes steady state. If each client process makes only two connections and sends two messages on each connection, some client processes will probably complete before the client finishes forking all the child processes. The actual length of a run needed to accurately estimate performance is a statistical question beyond the scope of this text. Roughly, the larger the variability in the values, the more measurements you need.
Generally, if the number of threads in the worker pool is greater than the number of request streams, you would expect a worker pool to consistently outperform thread-per-request because it should have less overhead. If the number of request streams exceeds the number of workers, thread-per-request might do better, provided that the system has enough resources. Therefore, if the main variable is offered load, be sure to vary the number of simultaneous request streams from 1 to a value well beyond the number of worker-pool threads. Look, too, for discontinuities in behavior as the number of request streams approaches and exceeds the number of worker-pool threads.
For parameters that influence the system in a highly nonlinear way, it is often useful to measure a few widely separated values. For example, to understand the influence of message size on the performance, you might decide to measure the response as a function of offered load for two different message sizes. Choosing message sizes of 32 bytes and 64 bytes to compare does not give meaningful results because each of these messages always fits into a single physical packet. Although one message is twice as big as the other, the messages are essentially the same size as far as the network is concerned. The network headers on these messages might be comparable to the data in size. You would get more useful information by picking message sizes of 512 bytes and 20 kilobytes, typical sizes for a simple web page and an image, respectively. In addition to being physically meaningful, these sizes exercise different characteristics of the underlying network protocols. A 512-byte message should traverse the network in a single packet even on a wide area network. The 20K message is larger than the typical 8K slow-start limit for TCP, so its transmission should experience some congestion control, at least on a wide area network.
Simple statistical measures such as the mean, median and standard deviation are useful characterizations of behavior. The median is less sensitive to outliers and is often used in network measurements. In general, medians should be smaller and more stable than means for these distributions. If your medians don’t reflect this, you probably are not computing the statistics correctly. If your medians and means are consistently different by an order of magnitude, you should worry! Also, when combining results from multiple clients, don’t take the median of the medians and present that as the median.
Think about how to analyze the data before designing an output format. If you plan to import the data into a spreadsheet, your output format should be spreadsheet-friendly so that you don’t have to manually edit the data before analysis. You may want to output the results in multiple formats, for example, as tables without intermediate text so that the values fall into columns. Combine the numbers from all the client processes for final analysis. Standard deviation or quartiles are good indications of data variability.
You should also consider whether a table of results conveys the message better than a graph. Tables work well when the test consists of a few measurements or if some results are close together while others vary significantly, You can present more than one version if the results are meaningful.
Performance studies are often presented in a technical report. This section describes the key elements of a good technical report and mentions common mistakes. Poor presentation undermines your work, so it pays to put some effort into this aspect of a project. It goes without saying that you should use spelling- and grammar-checking tools. You should also pay attention to the typography and layout, separating sections with subtitles and consistent spacing. No one will have confidence that you have done the technical work correctly if your report is riddled with errors.
Technical reports generally have an abstract that gives an overview of the work and summarizes the principal results. More extensive reports may have a table of contents, a list of figures and an index. Most technical reports include a list of references at the end. Typically, the body of a technical report has an introduction followed by sections describing the design or system architecture, the implementation, the testing or experiments, the results and the conclusions.
The introduction should provide an overview of the topic, without becoming mired in irrelevant detail. You should describe the particular problem being addressed and why it is important. The introduction should also present terminology and background material needed to understand the rest of the report. For example, if you are asked to write a report comparing server performance using thread-per-request and worker-pool implementations, your introduction should explain thread-per-request and worker-pool architectures, but should probably not provide an extensive description of the POSIX thread libraries. After all, the report is about these server strategies, not about POSIX threads. To emphasize the relevance of the topic, you might name well-known software that uses one strategy or the other.
Sometimes a technical report’s introduction includes a review of other work on the topic, comparing results or approaches with those done by others. Other technical papers discuss related works in a separate section after the introduction or after the results, depending on the emphasis of the paper. The introduction usually ends with a paragraph describing the organization of the rest of the report.
The design section of your report should review the implementation of the various parts of the project. Architectural diagrams convey fundamental structure, but badly done diagrams introduce more confusion than clarity. If the architectures are different, the diagrams should not look exactly the same. Use consistent symbols in each diagram and across diagrams in the report. For example, use the same symbol for a thread in each diagram. Don’t use a circle to represent a process in one diagram and a rectangle in another (or, worse, in the same diagram). Don’t use the same symbol to represent a process and a library function. Eliminate unnecessary detail and be sure to provide a legend identifying the symbols.
An implementation details section should not include code—if code is necessary, put it in an appendix. You might include pseudocode or algorithms, if relevant. For example, for a worker-pool implementation using a circular buffer, the placement of the synchronization influences the behavior of the program, so it should be documented in the report.
The testing section should present a detailed description of how you tested the program. (No, “I tested the program and it works” is not an acceptable testing section!) A table of tests keyed to sample output in an appendix makes testing clearer and more convincing. Detail unusual behavior or other problems that you encountered during the development of the program. Explain known bugs that your program has. If you encountered unexpected problems during development, describe these here.
For a technical report that emphasizes performance rather than the development of a system, the description of the design, implementation and testing are often combined into a single section.
Performance studies often have a separate section detailing the procedures used to conduct the performance measurements. The section details the specific conditions under which the program was tested, including the characteristics of the test machines, such as machine architecture, operating system version, type of network, etc. The section should explain the setup for the experiment and the ambient conditions such as the time of day and the network and machine loads. The procedures section should report how the load was established and sustained for the different experiments. The section might also describe how you assembled the measurement data during the computation.
The presentation of the results is the centerpiece of a performance study. Present a clear description of what happened and what was expected to happen. Use graphs and bar charts to compare results from different experiments. For example, if you are comparing thread-per-request and worker-pool implementations, you should plot the corresponding response times for the two architectures on the same graph. Your figures should be labeled, captioned and referred to by number in the text discussion. You should give enough details in your report that someone else could reproduce your results.
Use meaningful units to plot the results. For the server comparison, milliseconds would be good. Don’t use nanoseconds (huge numbers) or seconds (tiny numbers) just because the timer call you happened to use produced those units. Plot consecutive graphs with the same units. Avoid axis labels that contain a large number of digits—change the units. Avoid labeling every tightly spaced tick mark, and use consistent labeling of tick marks. Also plot your graphs in units that are understandable. If you are plotting several curves on the same graph, make sure that the symbols used for the different graphs are clearly distinguishable. Avoid using color if your report will not be printed or viewed in color unless the curves can still be distinguished if reproduced in greyscale. Use legends and in-graph labels to identify the curves and important features.
For this project, plotting response time or connection time versus presented load would be a good starting point for a performance comparison. Plotting response time versus process ID or thread ID displays the variability of the data, but these plots do not show a performance relationship. Variability might be better characterized by the standard deviation.
Often, authors run out of gas before the conclusion section. However, after the abstract, this is the section that many people read first and most carefully. Summarize the overall results of the project, including the principal performance findings. Discuss the strengths and weaknesses of your implementation and experiments. Point out problems that you encountered but did not address, and suggest how this project might be expanded or used in other situations. For course reports, explain what you learned and what you are still confused about. Do not overstate your achievements in the conclusion—let your work stand on its merits. Readers will ascribe more credibility to your conclusions if you are straightforward about the strengths and weaknesses of the study.
The bibliography lists the references that you used. Specify them in a consistent format. You should explicitly reference all the items that appear in the text of the report. The IEEE, the ACM and other professional societies have style files available for most word processors. Pick one of the standard styles.
A classic text in the field of performance analysis is The Art of Computer Systems Performance Analysis: Techniques for Experimental Design, Measurement, Simulation, and Modeling by Jain [59]. Another excellent book is The Practical Performance Analyst by Gunther [45]. Performance Evaluation and Benchmarking with Realistic Applications by Eigenmann [35] emphasizes the collection and analysis of data from standard benchmarks. Web Protocols and Practice by Krishnamurthy and Rexford [66] has some excellent performance case studies characterizing web traffic and web server workload. Capacity Planning for Web Services: Metrics, Models and Methods by Menasce and Almeida devotes an entire book to web server modeling and performance analysis. Finally, Probability and Statistics with Reliability, Queuing and Computer Science Applications, 2nd ed. by Trivedi [126] is an invaluable statistical reference if you plan to go beyond mean and standard deviation in your analysis. For current examples of excellent work in performance evaluation, look at recent proceedings of the ACM Sigmetrics Conferences or the IEEE/ACM Transactions on Networking. “Performance issues of enterprise level web proxies,” by Maltzahn et al. [77] and “Performance issues in WWW servers,” by Nahum et al. [85] are examples of recent articles.