
This chapter introduces the ideas of communication, concurrency and asynchronous operation at the operating system level and at the application level. Handling such program constructs incorrectly can lead to failures with no apparent cause, even for input that previously seemed to work perfectly. Besides their added complexity, many of today’s applications run for weeks or months, so they must properly release resources to avoid waste (so-called leaks of resources). Applications must also cope with outrageously malicious user input, and they must recover from errors and continue running. The Portable Operating System Interface (POSIX) standard is an important step toward producing reliable applications. Programmers who write for POSIX-compliant systems no longer need to contend with small but critical variations in the behavior of library functions across platforms. Most popular UNIX versions (including Linux and Mac OS X) are rapidly moving to support the base POSIX standard and various levels of its extensions.
Computer power has increased exponentially for nearly fifty years [73] in many areas including processor, memory and mass-storage capacity, circuit density, hardware reliability and I/O bandwidth. The growth has continued in the past decade, along with sophisticated instruction pipelines on single CPUs, placement of multiple CPUs on the desktop and an explosion in network connectivity.
The dramatic increases in communication and computing power have triggered fundamental changes in commercial software.
Large database and other business applications, which formerly executed on a mainframe connected to terminals, are now distributed over smaller, less expensive machines.
Terminals have given way to desktop workstations with graphical user interfaces and multimedia capabilities.
At the other end of the spectrum, standalone personal computer applications have evolved to use network communication. For example, a spreadsheet application is no longer an isolated program supporting a single user because an update of the spreadsheet may cause an automatic update of other linked applications. These could graph the data or perform sales projections.
Applications such as cooperative editing, conferencing and common whiteboards facilitate group work and interactions.
Computing applications are evolving through sophisticated data sharing, realtime interaction, intelligent graphical user interfaces and complex data streams that include audio and video as well as text.
These developments in technology rely on communication, concurrency and asynchronous operation within software applications.
Asynchronous operation occurs because many computer system events happen at unpredictable times and in an unpredictable order. For example, a programmer cannot predict the exact time at which a printer attached to a system needs data or other attention. Similarly, a program cannot anticipate the exact time that the user presses a key for input or interrupts the program. As a result, a program must work correctly for all possible timings in order to be correct. Unfortunately, timing errors are often hard to repeat and may only occur once every million executions of a program.
Concurrency is the sharing of resources in the same time frame. When two programs execute on the same system so that their execution is interleaved in time, they share processor resources. Programs can also share data, code and devices. The concurrent entities can be threads of execution within a single program or other abstract objects. Concurrency can occur in a system with a single CPU, multiple CPUs sharing the same memory, or independent systems running over a network. A major job of a modern operating system is to manage the concurrent operations of a computer system and its running applications. However, concurrency control has also become an integral part of applications. Concurrent and asynchronous operations share the same problems—they cause bugs that are often hard to reproduce and create unexpected side effects.
Communication is the conveying of information by one entity to another. Because of the World Wide Web and the dominance of network applications, many programs must deal with I/O over the network as well as from local devices such as disks. Network communication introduces a myriad of new problems resulting from unpredictable timings and the possibility of undetected remote failures.
The remainder of this chapter describes simplified examples of asynchronous operation, concurrency and communication. The buffer overflow problem illustrates how careless programming and lack of error checking can cause serious problems and security breaches. This chapter also provides a brief overview of how operating systems work and summarizes the operating system standards that are used in the book.
Operating systems manage system resources: processors, memory and I/O devices including keyboards, monitors, printers, mouse devices, disks, tapes, CD-ROMs and network interfaces. The convoluted way operating systems appear to work derives from the characteristics of peripheral devices, particularly their speed relative to the CPU or processor. Table 1.1 lists typical processor, memory and peripheral times in nanoseconds. The third column shows these speeds slowed down by a factor of 2 billion to give the time scaled in human terms. The scaled time of one operation per second is roughly the rate of the old mechanical calculators from fifty years ago.
Table 1.1. Typical times for components of a computer system. One nanosecond (ns) is 10–9 seconds, one microsecond (μs) is 10–6 seconds, and one millisecond (ms) is 10–3 seconds.
item | time | scaled time in human terms (2 billion times slower) | ||
|---|---|---|---|---|
processor cycle | 0.5 ns | (2 GHz) | 1 | second |
cache access | 1 ns | (1 GHz) | 2 | seconds |
memory access | 15 ns | 30 | seconds | |
context switch | 5,000 ns | (5 μs) | 167 | minutes |
disk access | 7,000,000 ns | (7 ms) | 162 | days |
quantum | 100,000,000 ns | (100 ms) | 6.3 | years |
Disk drives have improved, but their rotating mechanical nature limits their performance. Disk access times have not decreased exponentially. The disparity between processor and disk access times continues to grow; as of 2003 the ratio is roughly 1 to 14,000,000 for a 2-GHz processor. The cited speeds are a moving target, but the trend is that processor speeds are increasing exponentially, causing an increasing performance gap between processors and peripherals.
The context-switch time is the time it takes to switch from executing one process to another. The quantum is roughly the amount of CPU time allocated to a process before it has to let another process run. In a sense, a user at a keyboard is a peripheral device. A fast typist can type a keystroke every 100 milliseconds. This time is the same order of magnitude as the process scheduling quantum, and it is no coincidence that these numbers are comparable for interactive timesharing systems.
Example 1.1.
A modem is a device that permits a computer to communicate with another computer over a phone line. A typical modem is rated at 57,600 bps, where bps means “bits per second.” Assuming it takes 8 bits to transmit a byte, estimate the time needed for a 57,600 bps modem to fill a computer screen with 25 lines of 80 characters. Now consider a graphics display that consists of an array of 1024 by 768 pixels. Each pixel has a color value that can be one of 256 possible colors. Assume such a pixel value can be transmitted by modem in 8 bits. What compression ratio is necessary for a 768-kbps DSL line to fill a screen with graphics as fast as a 57,600-bps modem can fill a screen with text?
Answer:
Table 1.2 compares the times. The text display has 80 × 25 = 2000 characters so 16,000 bits must be transmitted. The graphics display has 1024 × 768 = 786,432 pixels so 6,291,456 bits must be transmitted. The estimates do not account for compression or for communication protocol overhead. A compression ratio of about 29 is necessary!
Observe from Table 1.1 that processes performing disk I/O do not use the CPU very efficiently: 0.5 nanoseconds versus 7 milliseconds, or in human terms, 1 second versus 162 days. Because of the time disparity, most modern operating systems do multiprogramming. Multiprogramming means that more than one process can be ready to execute. The operating system chooses one of these ready processes for execution. When that process needs to wait for a resource (say, a keystroke or a disk access), the operating system saves all the information needed to resume that process where it left off and chooses another ready process to execute. It is simple to see how multiprogramming might be implemented. A resource request (such as read or write) results in an operating system request (i.e., a system call). A system call is a request to the operating system for service that causes the normal CPU cycle to be interrupted and control to be given to the operating system. The operating system can then switch to another process.
Example 1.2.
Explain how a disk I/O request might allow the operating system to run another process.
Answer:
Most devices are handled by the operating system rather than by applications. When an application executes a disk read, the call issues a request for the operating system to actually perform the operation. The operating system now has control. It can issue commands to the disk controller to begin retrieving the disk blocks requested by the application. However, since the disk retrieval does not complete for a long time (162 days in relative time), the operating system puts the application’s process on a queue of processes that are waiting for I/O to complete and starts another process that is ready to run. Eventually, the disk controller interrupts the CPU instruction cycle when the results are available. At that time, the operating system regains control and can choose whether to continue with the currently running process or to allow the original process to run.
UNIX does timesharing as well as multiprogramming. Timesharing creates the illusion that several processes execute simultaneously, even though there may be only one physical CPU. On a single processor system, only one instruction from one process can be executing at any particular time. Since the human time scale is billions of times slower than that of modern computers, the operating system can rapidly switch between processes to give the appearance of several processes executing at the same time.
Consider the following analogy. Suppose a grocery store has several checkout counters (the processes) but only one checker (the CPU). The checker checks one item from a customer (the instruction) and then does the next item for that same customer. Checking continues until a price check (a resource request) is needed. Instead of waiting for the price check and doing nothing, the checker moves to another checkout counter and checks items from another customer. The checker (CPU) is always busy as long as there are customers (processes) ready to check out. This is multiprogramming. The checker is efficient, but customers probably would not want to shop at such a store because of the long wait when someone has a large order with no price checks (a CPU-bound process).
Now suppose that the checker starts a 10-second timer and processes items for one customer for a maximum of 10 seconds (the quantum). If the timer expires, the checker moves to another customer even if no price check is needed. This is timesharing. If the checker is sufficiently fast, the situation is almost equivalent to having one slower checker at each checkout stand. Consider making a video of such a checkout stand and playing it back at 100 times its normal speed. It would look as if the checker were handling several customers simultaneously.
Example 1.3.
Suppose that the checker can check one item per second (a one-second processor cycle time in Table 1.1). According to this table, what would be the maximum time the checker would spend with one customer before moving to a waiting customer?
Answer:
The time is the quantum that is scaled in the table to 6.3 years. A program may execute billions of instructions in a quantum—a bit more than the number of grocery items purchased by the average customer.
If the time to move from one customer to another (the context-switch time) is small compared with the time between switches (the CPU burst time), the checker handles customers efficiently. Timesharing wastes processing cycles by switching between customers, but it has the advantage of not wasting the checker resources during a price check. Furthermore, customers with small orders are not held in abeyance for long periods while waiting for customers with large orders.
The analogy would be more realistic if instead of several checkout counters, there were only one, with the customers crowded around the checker. To switch from customer A to customer B, the checker saves the contents of the register tape (the context) and restores it to what it was when it last processed customer B. The context-switch time can be reduced if the cash register has several tapes and can hold the contents of several customers’ orders simultaneously. In fact, some computer systems have special hardware to hold many contexts at the same time.
Multiprocessor systems have several processors accessing a shared memory. In the checkout analogy for a multiprocessor system, each customer has an individual register tape and multiple checkers rove the checkout stands working on the orders for unserved customers. Many grocery stores have packers who do this.
Concurrency occurs at the hardware level because multiple devices operate at the same time. Processors have internal parallelism and work on several instructions simultaneously, systems have multiple processors, and systems interact through network communication. Concurrency is visible at the applications level in signal handling, in the overlap of I/O and processing, in communication, and in the sharing of resources between processes or among threads in the same process. This section provides an overview of concurrency and asynchronous operation.
The execution of a single instruction in a program at the conventional machine level is the result of the processor instruction cycle. During normal execution of its instruction cycle, a processor retrieves an address from the program counter and executes the instruction at that address. (Modern processors have internal parallelism such as pipelines to reduce execution time, but this discussion does not consider that complication.) Concurrency arises at the conventional machine level because a peripheral device can generate an electrical signal, called an interrupt, to set a hardware flag within the processor. The detection of an interrupt is part of the instruction cycle itself. On each instruction cycle, the processor checks hardware flags to see if any peripheral devices need attention. If the processor detects that an interrupt has occurred, it saves the current value of the program counter and loads a new value that is the address of a special function called an interrupt service routine or interrupt handler. After finishing the interrupt service routine, the processor must be able to resume execution of the previous instruction where it left off.
An event is asynchronous to an entity if the time at which it occurs is not determined by that entity. The interrupts generated by external hardware devices are generally asynchronous to programs executing on the system. The interrupts do not always occur at the same point in a program’s execution, but a program should give a correct result regardless of where it is interrupted. In contrast, an error event such as division by zero is synchronous in the sense that it always occurs during the execution of a particular instruction if the same data is presented to the instruction.
Although the interrupt service routine may be part of the program that is interrupted, the processing of an interrupt service routine is a distinct entity with respect to concurrency. Operating-system routines called device drivers usually handle the interrupts generated by peripheral devices. These drivers then notify the relevant processes, through a software mechanism such as a signal, that an event has occurred.
Operating systems also use interrupts to implement timesharing. Most machines have a device called a timer that can generate an interrupt after a specified interval of time. To execute a user program, the operating system starts the timer before setting the program counter. When the timer expires, it generates an interrupt that causes the CPU to execute the timer interrupt service routine. The interrupt service routine writes the address of the operating system code into the program counter, and the operating system is back in control. When a process loses the CPU in the manner just described, its quantum is said to have expired. The operating system puts the process in a queue of processes that are ready to run. The process waits there for another turn to execute.
A signal is a software notification of an event. Often, a signal is a response of the operating system to an interrupt (a hardware event). For example, a keystroke such as Ctrl-C generates an interrupt for the device driver handling the keyboard. The driver recognizes the character as the interrupt character and notifies the processes that are associated with this terminal by sending a signal. The operating system may also send a signal to a process to notify it of a completed I/O operation or an error.
A signal is generated when the event that causes the signal occurs. Signals can be generated either synchronously or asynchronously. A signal is generated synchronously if it is generated by the process or thread that receives it. The execution of an illegal instruction or a divide-by-zero may generate a synchronous signal. A Ctrl-C on the keyboard generates an asynchronous signal. Signals (Chapter 8) can be used for timers (Chapter 10), terminating programs (Section 8.2), job control (Section 11.7) or asynchronous I/O (Section 8.8).
A process catches a signal when it executes a handler for the signal. A program that catches a signal has at least two concurrent parts, the main program and the signal handler. Potential concurrency restricts what can be done inside a signal handler (Section 8.6). If the signal handler modifies external variables that the program can modify elsewhere, then proper execution may require that those variables be protected.
A challenge for operating systems is to coordinate resources that have greatly differing characteristic access times. The processor can perform millions of operations on behalf of other processes while a program waits for a disk access to complete. Alternatively, the process can avoid blocking by using asynchronous I/O or dedicated threads instead of ordinary blocking I/O. The tradeoff is between the additional performance and the extra programming overhead in using these mechanisms.
A similar problem occurs when an application monitors two or more input channels such as input from different sources on a network. If standard blocking I/O is used, an application that is blocked waiting for input from one source is not able to respond if input from another source becomes available.
A traditional method for achieving concurrent execution in UNIX is for the user to create multiple processes by calling the fork function. The processes usually need to coordinate their operation in some way. In the simplest instance they may only need to coordinate their termination. Even the termination problem is more difficult than it might seem. Chapter 3 addresses process structure and management and introduces the UNIX fork, exec and wait system calls.
Processes that have a common ancestor can communicate through pipes (Chapter 6). Processes without a common ancestor can communicate by signals (Chapter 8), FIFOs (Section 6.3), semaphores (Sections 14.2 and 15.2), shared address space (Section 15.3) or messages (Section 15.4 and Chapter 18).
Multiple threads of execution can provide concurrency within a process. When a program executes, the CPU uses the program counter to determine which instruction to execute next. The resulting stream of instructions is called the program’s thread of execution. It is the flow of control for the process. If two distinct threads of execution share a resource within a time frame, care must be taken that these threads do not interfere with each other. Multiprocessor systems expand the opportunity for concurrency and sharing among applications and within applications. When a multithreaded application has more than one thread of execution concurrently active on a multiprocessor system, multiple instructions from the same process may be executed at the same time.
Until recently there has not been a standard for using threads, and each vendor’s thread package behaved differently. A thread standard has now been incorporated into the POSIX standard. Chapters 12 and 13 discuss this new standard.
How many CPUs does a typical home computer have? If you think the answer is one, think again. In early machines, the main CPU handled most of the decision making. As machine design evolved, I/O became more complicated and placed more demands on the CPU. One way of enhancing the performance of a system is to determine which components are the bottlenecks and then improve or replicate these components. The main I/O controllers such as the video controller and disk controller took over some of the processing related to these peripherals, relieving the CPU of this burden. In modern machines, these controllers and other I/O controllers have their own special purpose CPUs.
What if after all this auxiliary processing has been offloaded, the CPU is still the bottleneck? There are two approaches to improving the performance. Admiral Grace Murray Hopper, a pioneer in computer software, often compared computing to the way fields were plowed in the pioneer days: “If one ox could not do the job, they did not try to grow a bigger ox, but used two oxen.” It was usually cheaper to add another processor or two than to increase the speed of a single processor. Some problems do not lend themselves to just increasing the number of processors indefinitely. Seymour Cray, a pioneer in computer hardware, is reported to have said, “If you were plowing a field, which would you rather use? Two strong oxen or 1024 chickens?”
The optimal tradeoff between more CPUs and better CPUs depends on several factors, including the type of problem to be solved and the cost of each solution. Machines with multiple CPUs have already migrated to the desktop and are likely to become more common as prices drop. Concurrency issues at the application level are slightly different when there are multiple processors, but the methods discussed in this book are equally applicable in a multiprocessor environment.
Another important trend is the distribution of computation over a network. Concurrency and communication meet to form new applications. The most widely used model of distributed computation is the client-server model. The basic entities in this model are server processes that manage resources, and client processes that require access to shared resources. (A process can be both a server and a client.) A client process shares a resource by sending a request to a server. The server performs the request on behalf of the client and sends a reply to the client. Examples of applications based on the client-server model include file transfer (ftp), electronic mail, file servers and the World Wide Web. Development of client-server applications requires an understanding of concurrency and communication.
The object-based model is another model for distributed computation. Each resource in the system is viewed as an object with a message-handling interface, allowing all resources to be accessed in a uniform way. The object-based model allows for controlled incremental development and code reuse. Object frameworks define interactions between code modules, and the object model naturally expresses notions of protection. Many of the experimental distributed operating systems such as Argus [74], Amoeba [124], Mach [1], Arjuna [106], Clouds [29] and Emerald [11] are object based. Object-based models require object managers to track the location of the objects in the system.
An alternative to a truly distributed operating system is to provide application layers that run on top of common operating systems to exploit parallelism on the network. The Parallel Virtual Machine (PVM) and its successor, Message Passing Interface (MPI), are software libraries [10, 43] that allow a collection of heterogeneous workstations to function as a parallel computer for solving large computational problems. PVM manages and monitors tasks that are distributed on workstations across the network. Chapter 17 develops a dispatcher for a simplified version of PVM. CORBA (Common Object Request Broker Architecture) is another type of software layer that provides an object-oriented interface to a set of generic services in a heterogeneous distributed environment [104].
The 1950s and early 1960s brought batch processing, and the mid-to-late 1960s saw deployment of operating systems that supported multiprogramming. Time-sharing and real-time programming gained popularity in the 1970s. During the 1980s, parallel processing moved from the supercomputer arena to the desktop. The 1990s was the decade of the network—with the widespread use of distributed processing, email and the World Wide Web. The 2000s appears to be the decade of security and fault-tolerance. The rapid computerization and the distribution of critical infrastructure (banking, transportation, communication, medicine and government) over networks has exposed enormous vulnerabilities. We have come to rely on programs that were not adequately designed or tested for a concurrent environment, written by programmers who may not have understood the implications of incorrectly working programs. The liability disclaimers distributed with most software attempts to absolve the manufacturers of responsibility for damage—software is distributed as is.
But, lives now depend on software, and each of us has a responsibility to become attuned to the implications of bad software. With current technology, it is almost impossible to write completely error-free code, but we believe that programmer awareness can greatly reduce the scope of the problem. Unfortunately, most people learn to program for an environment in which programs are presented with correct or almost correct input. Their ideal users behave graciously, and programs are allowed to exit when they encounter an error.
Real-world programs, especially systems programs, are often long-running and are expected to continue running after an error (no blue-screen of death or reboot allowed). Long-running programs must release resources, such as memory, when these resources are no longer needed. Often, programmers release resources such as buffers in the obvious places but forget to release them if an error occurs.
Most UNIX library functions indicate an error by a return value. However, C makes no requirement that return values be checked. If a program doesn’t check a return value, execution can continue well beyond the point at which a critical error occurs. The consequence of the function error may not be apparent until much later in the execution. C also allows programs to write out of the bounds of variables. For example, the C runtime system does not complain if you modify a nonexistent array element—it writes values into that memory (which probably corresponds to some other variable). Your program may not detect the problem at the time it happened, but the overwritten variable may present a problem later. Because overwritten variables are so difficult to detect and so dangerous, newer programming languages, such as Java, have runtime checks on array bounds.
Even software that has been in distribution for years and has received heavy scrutiny is riddled with bugs. For example, an interesting study by Chou et al. [23] used a modified compiler to look for 12 types of bugs in Linux and OpenBSD source code. They examined 21 snapshots of Linux spanning seven years and one snapshot of OpenBSD. They found 1025 bugs in the code by using automatic scanning techniques. One of the most common bugs was the failure to check for a NULL return on functions that return pointers. If the code later uses the returned pointer, a core dump occurs.
Commercial software is also prone to bugs. Software problems with the Therac-25 [71], a medical linear accelerator used to destroy tumors, resulted in serious accidents.
Another problem is the exponential growth in the number of truly malicious users who launch concerted attacks on servers and user computers. The next section describes one common type of attack, the buffer overflow.
This section presents a simplified explanation of buffer overflows and how they might be used to attack a computer system. A buffer overflow occurs when a program copies data into a variable for which it has not allocated enough space.
Example 1.4 shows a code segment that may have a buffer overflow. A user types a name in response to the prompt. The program stores the input in a char array called buf. If the user enters more than 79 bytes, the resulting string and string terminator do not fit in the allocated variable.
Example 1.4.
The following code segment has the possibility of a buffer overflow.
char buf[80];
printf("Enter your first name:");
scanf("%s", buf);
Your first thought in fixing this potential overflow might be to make buf bigger, say, 1000 bytes. What user’s first name could be that long? Even if a user decides to type in a very long string of characters, 1000 bytes should be large enough to handle all but the most persistent user. However, regardless of the ultimate size that you choose, the code segment is still susceptible to a buffer overflow. The user simply needs to redirect standard input to come from an arbitrarily large file.
Example 1.5 shows a simple way to fix this problem. The format specification limits the input string to one less than the size of the variable, allowing room for the string terminator. The program reads at most 79 characters into buf but stops when it encounters a white space character. If the user enters more than 79 characters, the program reads the additional characters in subsequent input statements.
Example 1.5.
The following code segment does not have a buffer overflow.
char buf[80];
printf("Enter your first name:");
scanf("%79s", buf);
To understand what happens when a buffer overflow occurs, you need to understand how programs are laid out in memory. Most program code is executed in functions with local variables that are automatic. While the details differ from machine to machine, programs generally allocate automatic variables on the program stack.
In a typical system, the stack grows from high memory to low memory. When a function is called, the lower part of the stack contains the passed parameters and the return address. Higher up on the stack (lower memory addresses) are the local automatic variables. The stack may store other values and have gaps that are not used by the program at all. One important fact is that the return address for each function call is usually stored in memory after (with larger address than) the automatic variables.
When a program writes beyond the limits of a variable on the stack, a buffer overflow occurs. The extra bytes may write over unused space, other variables, the return address or other memory not legally accessible to your program. The consequences can range from none, to a program crash and a core dump, to unpredictable behavior.
Program 1.1 shows a function that can have a buffer overflow. The checkpass function checks whether the entered string matches "mypass" and returns 1 if they match, and 0 otherwise.
Example 1.1. checkpass.c
A function that checks a password. This function is susceptible to buffer overflow.
#include <stdio.h>
#include <string.h>
int checkpass(void){
int x;
char a[9];
x = 0;
fprintf(stderr,"a at %p and
x at %p
", (void *)a, (void *)&x);
printf("Enter a short word: ");
scanf("%s", a);
if (strcmp(a, "mypass") == 0)
x = 1;
return x;
}
Figure 1.1 shows a possible organization of the stack for a call to checkpass. The diagram assumes that integers and pointers are 4 bytes. Note that the compiler allocates 12 bytes for array a, even though the program specifies only 9 bytes, so that the system can maintain a stack pointer that is aligned on a word boundary.
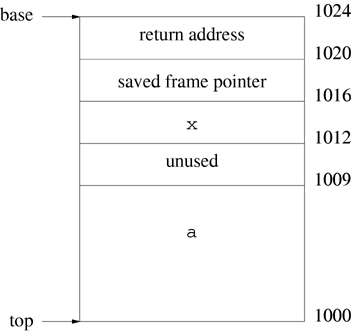
If the character array a is stored on the stack in lower memory than the integer x, a buffer overflow of a may change the value of x. If the user enters a word that is slightly longer than the array a, the overflow changes the value of x, but there is no other effect. Exactly how long the entered string needs to be to cause a problem depends on the system. With the memory organization of Figure 1.1, if the user enters 12 characters, the string terminator overwrites one byte of x without changing its value. If the user enters more than 12 characters, some of them overwrite x, changing its value. If the user enters 13 characters, x changes to a nonzero value and the function returns 1, no matter what characters are entered.
If the user enters a long password, the return address is overwritten, and most likely the function will try to return to a location outside the address space of the program, generating a segmentation fault and core dump. Buffer overflows that cause an application program to exit with a segmentation fault can be annoying and can cause the program to lose unsaved data. The same type of overflow in an operating system function can cause the operating system to crash.
Buffer overflows in dynamically allocated buffers or buffers with static storage can also behave unpredictably. One of our students wrote a program that appeared to show an error in the C library. He traced a segmentation fault to a call to malloc and was able to show that the program was working until the call to malloc. The program had a segmentation fault before the call to malloc returned. He eventually traced the problem to a type of buffer overflow in which the byte before a buffer dynamically allocated by a previous malloc call was overwritten. (This can easily happen if a buffer is being filled from the back and a count is off by one.) Overwriting control information stored in the heap caused the next call to malloc to crash the program.
Security problems related to buffer overflows have been known for over a decade. They first acquired national attention when on November 2, 1988, Robert Morris released a worm on the Internet. A worm is a self-replicating, self-propagating program. This program forced many system administrators to disconnect their sites from the Internet so that they would not be continually reinfected. It took several days for the Internet to return to normal. One of the methods used by the Morris worm was to exploit a buffer overflow in the finger daemon. This daemon ran on most UNIX machines to allow the display of information about users.
In response to this worm, CERT, the Computer Emergency Response Team, was created [24]. The CERT Coordination Center is a federally funded center of Internet security expertise that regularly publishes computer security alerts.
Programs that are susceptible to buffer overflow are still being written, in spite of past experiences. The first six CERT advisories in 2002 describe buffer overflow flaws in various computer systems, including Common Desktop Environment for the Sun Solaris operating environment (a windowing system), ICQ from AOL (an instant messaging program used by over 100 million users), Simple Network Management Protocol (a network management protocol used by many vendors), and Microsoft Internet Explorer. In 1999 Steve Ballmer, the CEO of Microsoft, was quoted as saying, “You would think we could figure out how to fix buffer overflows by now.” The problem is not that we do not know how to write correct code, the problem is that writing correct code takes more care than writing sloppy code. As long as priorities are to produce code quickly, sloppy code will be produced. The effects of poor coding are exacerbated by compilers and runtime systems that don’t enforce range checking.
There are many ways in which buffer overflows have been used to compromise a system. Here is a possible scenario. The telnet program allows a user to remotely log in to a machine. It communicates over the network with a telnet daemon running on the remote machine. One of the functions of the telnet daemon is to query for a user name and password and then to create a shell for the user if the password is correct.
Suppose the function in the telnet daemon that requests and checks a password returns 1 if the password is correct and 0 otherwise, similar to the checkpass function of Program 1.1. Suppose the function allocates a buffer of size 100 for the password. This might seem reasonable, since passwords in UNIX are at most 8 bytes long. If the program does not check the length of the input, it might be possible to have input that writes over the return value (x in Program 1.1), causing a shell to be created even if the password is incorrect.
Any application that runs with root privileges and is susceptible to a buffer overflow might be used to create a shell with root privileges. The implementation is technical and depends on the system, but the idea is relatively simple. First, the user compiles code to create a shell, something like the following code.
execvl("/bin/sh", "/bin/sh", NULL);
exit(0);
The user then edits the compiled code file so that the compiled code appears at exactly the correct relative position in the file. When the user redirects standard input to this file, the contents of the file overwrite the return address. If the bytes that overwrite the return address happen to correspond to the address of the execvl code, the function return creates a new user shell. Since the program is already running with the user ID of root, the new shell also runs with this user ID, and the ordinary user now has root privileges. The vulnerability depends on getting the bytes in the input file exactly right. Finding the address of the execvl is not as difficult as it might first appear, because most processor instruction sets support a relative addressing mode.
Not too long ago, two distinct and somewhat incompatible “flavors” of UNIX, System V from AT&T and BSD from Berkeley coexisted. Because no official standard existed, there were major and minor differences between the versions from different vendors, even within the same flavor. Consequently, programs written for one type of UNIX would not run correctly or sometimes would not even compile under a UNIX from another vendor.
The IEEE (Institute of Electronic and Electrical Engineers) decided to develop a standard for the UNIX libraries in an initiative called POSIX. POSIX stands for Portable Operating System Interface and is pronounced pahz-icks, as stated explicitly by the standard. IEEE’s first attempt, called POSIX.1, was published in 1988. When this standard was adopted, there was no known historical implementation of UNIX that would not have to change to meet the standard. The original standard covered only a small subset of UNIX. In 1994, the X/Open Foundation published a more comprehensive standard called Spec 1170, based on System V. Unfortunately, inconsistencies between Spec 1170 and POSIX made it difficult for vendors and application developers to adhere to both standards.
In 1998, after another version of the X/Open standard, many additions to the POSIX standard, and the threat of world-domination by Microsoft, the Austin Group was formed. This group included members from The Open Group (a new name for the X/Open Foundation), IEEE POSIX and the ISO/IEC Joint Technical Committee. The purpose of the group was to revise, combine and update the standards. Finally, at the end of 2001, a joint document was approved by the IEEE and The Open Group. The ISO/IEC approved this document in November of 2002. This specification is referred to as the Single UNIX Specification, Version 3, or IEEE Std. 1003.1-2001, POSIX. In this book we refer to this standard merely as POSIX.
Each of the standards organizations publishes copies of the standard. Print and electronic versions of the standard are available from IEEE and ISO/IEC. The Open Group publishes the standard on CD-ROM. It is also freely available on their web site [89]. The copy of the standard published by the IEEE is in four volumes: Base Definitions [50], Shell and Utilities [52], System Interfaces [49] and Rationale [51] and is over 3600 pages in length.
The code for this book was tested on three systems: Solaris 9, Redhat Linux 8 and Mac OS 10.2. Table 1.3 lists the extensions of POSIX discussed in the book and the status of implementation of each on the tested systems. This indication is based on the man pages and on running the programs from the book, not on any official statement of compliance.
Table 1.3. POSIX extensions supported by our test systems.
code | extension | Solaris 9 | Redhat 8 | Mac OS 10.2 |
|---|---|---|---|---|
AIO | asynchronous input and output | yes | yes | no |
CX | extension to the ISO C standard | yes | yes | yes |
FSC | file synchronization | yes | yes | yes |
RTS | realtime signals extension | yes | yes | no |
SEM | semaphores | yes | unnamed only | named only |
THR | threads | yes | almost | yes |
TMR | timers | yes | yes | no |
TPS | thread execution scheduling | yes | yes | yes |
TSA | thread stack address attribute | no | no | no |
TSF | thread-safe functions | yes |
| yes |
XSI | XSI extension | yes | yes | timers, |
| 199506 | 199506 | 198808 | |
A POSIX-compliant implementation must support the POSIX base standard. Many of the interesting aspects of POSIX are not part of the base standard but rather are defined as extensions to the base standard. Table E.1 of Appendix E gives a complete list of the extensions in the 2001 version of POSIX. Appendix E applies only to implementations that claim compliance with the 2001 version base standard. These implementations set the symbol _POSIX_VERSION defined in unistd.h to 200112L. As of the writing of this book, none of the systems we tested used this value. Systems that support the previous version of POSIX have a value of 199506L. Differences between the 1995 and 2001 standards for features supported by both are minor.
The new POSIX standard also incorporates the ISO/IEC International Standard 9899, also referred to as ISO C. In the past, minor differences between the POSIX and ISO C standards have caused confusion. Often, these differences were unintentional, but differences in published standards required developers to choose between them. The current POSIX standard makes it clear that any differences between the published POSIX standard and the ISO C standard are unintentional. If any discrepancies occur, the ISO C standard takes precedence.
Most general operating systems books present an overview and history of operating systems. Recommended introductions include Chapter 1 of Modern Operating Systems by Tanenbaum [122] or Chapters 1 to 3 of Operating Systems Concepts by Silberschatz et al. [107]. Chapters 1 and 2 of Distributed Systems: Concepts and Design by Coulouris et al. discuss design issues for distributed systems [26]. Distributed Operating Systems by Tanenbaum [121] also has a good overview of distributed systems issues, but it provides fewer details about specific distributed systems than does [26]. See also Distributed Systems: Principles and Paradigms by Van Steen and Tanenbaum [127].
Advanced Programming in the UNIX Environment by Stevens [112] is a key technical reference on the UNIX interface to use in conjunction with this book. Serious systems programmers should acquire the POSIX Std. 1003.1 from the IEEE [50] or the Open Group web site [89]. The standard is surprisingly readable and thorough. The rationale sections included with each function provide a great deal of insight into the considerations that went into the standard. The final arbiter of C questions is the ISO C standard [56].
The CERT web site [24] is a good source for current information on recently discovered bugs, ongoing attacks and vulnerabilities. The book Know Your Enemy: Revealing the Security Tools, Tactics, and Motives of the Blackhat Community edited by members of the Honeynet Project [48] is an interesting glimpse into the realm of the malicious.