
Operating systems organize raw storage devices in file systems so that applications can use high-level operations rather than low-level device calls to access information. UNIX file systems are tree structured, with nodes representing files and arcs representing the contains relationship. UNIX directory entries associate filenames with file locations. These entries can either point directly to a structure containing the file location information (hard link) or point indirectly through a symbolic link. Symbolic links are files that associate one filename with another. This chapter also introduces functions for accessing file status information and directories from within programs.
Operating systems organize physical disks into file systems to provide high-level logical access to the actual bytes of a file. A file system is a collection of files and attributes such as location and name. Instead of specifying the physical location of a file on disk, an application specifies a filename and an offset. The operating system makes a translation to the location of the physical file through its file systems.
A directory is a file containing directory entries that associate a filename with the physical location of a file on disk. When disks were small, a simple table of filenames and their positions was a sufficient representation for the directory. Larger disks require a more flexible organization, and most file systems organize their directories in a tree structure. This representation arises quite naturally when the directories themselves are files.
Figure 5.1 shows a tree-structured organization of a typical file system. The square nodes in this tree are directories, and the / designates the root directory of the file system. The root directory is at the top of the file system tree, and everything else is under it.
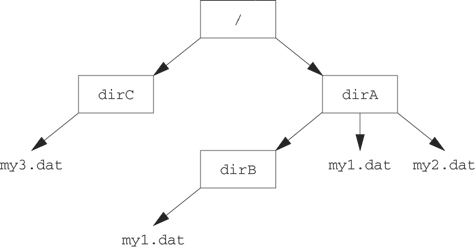
The directory marked dirA in Figure 5.1 contains the files my1.dat, my2.dat and dirB. The dirB file is called a subdirectory of dirA because dirB is a directory contained in dirA of the file system tree. Notice that dirB also contains a file named my1.dat. Clearly, the filename is not enough to uniquely specify a file.
The absolute or fully qualified pathname specifies all of the nodes in the file system tree on the path from the root to the file itself. The absolute path starts with a slash (/) to designate the root node and then lists the names of the nodes down the path to the file within the file system tree. The successive names are separated by slashes. The file my1.dat in dirA in Figure 5.1 has the fully qualified pathname /dirA/my1.dat, and my1.dat in dirB has the fully qualified pathname /dirA/dirB/my1.dat.
A program does not always have to specify files by fully qualified pathnames. At any time, each process has an associated directory, called the current working directory, that it uses for pathname resolution. If a pathname does not start with /, the program prepends the fully qualified path of the current working directory. Hence, pathnames that do not begin with / are sometimes called relative pathnames because they are specified relative to the fully qualified pathname of the current directory. A dot (.) specifies the current directory, and a dot-dot (..) specifies the directory above the current directory. The root directory has both dot and dot-dot pointing to itself.
Example 5.1.
After you enter the following command, your shell process has the current working directory /dirA/dirB.
cd /dirA/dirB
Example 5.2.
Suppose the current working directory of a process is the /dirA/dirB directory of Figure 5.1. State three ways by which the process can refer to the file my1.dat in directory dirA. State three ways by which the process can refer to the file my1.dat in directory dirB. What about the file my3.dat in dirC?
Answer:
Since the current working directory is /dirA/dirB, the process can use /dirA/my1.dat, ../my1.dat or even ./../my1.dat for the my1.dat file in dirA. Some of the ways by which the process can refer to the my1.dat file of dirB include my1.dat, /dirA/dirB/my1.dat, ./my1.dat, or ../dirB/my1.dat. The file my3.dat in dirC can be referred to as /dirC/my3.dat or ../../dirC/my3.dat.
The PWD environment variable specifies the current working directory of a process. Do not directly change this variable, but rather use the getcwd function to retrieve the current working directory and use the chdir function to change the current working directory within a process.
The chdir function causes the directory specified by path to become the current working directory for the calling process.
SYNOPSIS #include <unistd.h> int chdir(const char *path); POSIX
If successful, chdir returns 0. If unsuccessful, chdir returns –1 and sets errno. The following table lists the mandatory errors for chdir.
| cause |
|---|---|
| search permission on a |
| a loop exists in resolution of |
| the length of |
| a component of |
| a component of the pathname is not a directory |
Example 5.3.
The following code changes the process current working directory to /tmp.
char *directory = " /tmp";
if (chdir(directory) == -1)
perror("Failed to change current working directory to /tmp");
Example 5.4.
Why do ENOENT and ENOTDIR represent different error conditions for chdir?
Answer:
Some of the components of path may represent symbolic links that have to be followed to get the true components of the pathname. (See Section 5.4 for a discussion of symbolic links.)
The getcwd function returns the pathname of the current working directory. The buf parameter of getcwd represents a user-supplied buffer for holding the pathname of the current working directory. The size parameter specifies the maximum length pathname that buf can accommodate, including the trailing string terminator.
SYNOPSIS #include <unistd.h> char *getcwd(char *buf, size_t size); POSIX
If successful, getcwd returns a pointer to buf. If unsuccessful, getcwd returns NULL and sets errno. The following table lists the mandatory errors for getcwd.
| cause |
|---|---|
|
|
|
|
If buf is not NULL, getcwd copies the name into buf. If buf is NULL, POSIX states that the behavior of getcwd is undefined. In some implementations, getcwd uses malloc to create a buffer to hold the pathname. Do not rely on this behavior.
You should always supply getcwd with a buffer large enough to fit a string containing the pathname. Program 5.1 shows a program that uses PATH_MAX as the buffer size. PATH_MAX is an optional POSIX constant specifying the maximum length of a pathname (including the terminating null byte) for the implementation. The PATH_MAX constant may or may not be defined in limits.h. The optional POSIX constants can be omitted from limits.h if their values are indeterminate but larger than the required POSIX minimum. For PATH_MAX, the _POSIX_PATH_MAX constant specifies that an implementation must accommodate pathname lengths of at least 255. A vendor might allow PATH_MAX to depend on the amount of available memory space on a specific instance of a specific implementation.
Example 5.1. getcwdpathmax.c
A complete program to output the current working directory.
#include <limits.h>
#include <stdio.h>
#include <unistd.h>
#ifndef PATH_MAX
#define PATH_MAX 255
#endif
int main(void) {
char mycwd[PATH_MAX];
if (getcwd(mycwd, PATH_MAX) == NULL) {
perror("Failed to get current working directory");
return 1;
}
printf("Current working directory: %s
", mycwd);
return 0;
}
A more flexible approach uses the pathconf function to determine the real value for the maximum path length at run time. The pathconf function is one of a family of functions that allows a program to determine system and runtime limits in a platform-independent way. For example, Program 2.10 uses the sysconf member of this family to calculate the number of seconds that a program runs. The sysconf function takes a single argument, which is the name of a configurable systemwide limit such as the number of clock ticks per second (_SC_CLK_TCK) or the maximum number of processes allowed per user (_SC_CHILD_MAX).
The pathconf and fpathconf functions report limits associated with a particular file or directory. The fpathconf takes a file descriptor and the limit designator as parameters, so the file must be opened before a call to fpathconf. The pathconf function takes a pathname and a limit designator as parameters, so it can be called without the program actually opening the file. The sysconf function returns the current value of a configurable system limit that is not associated with files. Its name parameter designates the limit.
SYNOPSIS #include <unistd.h> long fpathconf(int fildes, int name); long pathconf(const char *path, int name); long sysconf(int name); POSIX
If successful, these functions return the value of the limit. If unsuccessful, these functions return –1 and set errno. The following table lists the mandatory errors.
| cause |
|---|---|
|
|
| a loop exists in resolution of |
Program 5.2 shows a program that avoids the PATH_MAX problem by first calling pathconf to find the maximum pathname length. Since the program does not know the length of the path until run time, it allocates the buffer for the path dynamically.
Example 5.2. getcwdpathconf.c
A program that uses pathconf to output the current working directory
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
long maxpath;
char *mycwdp;
if ((maxpath = pathconf(".", _PC_PATH_MAX)) == -1) {
perror("Failed to determine the pathname length");
return 1;
}
if ((mycwdp = (char *) malloc(maxpath)) == NULL) {
perror("Failed to allocate space for pathname");
return 1;
}
if (getcwd(mycwdp, maxpath) == NULL) {
perror("Failed to get current working directory");
return 1;
}
printf("Current working directory: %s
", mycwdp);
return 0;
}
A user executes a program in a UNIX shell by typing the pathname of the file containing the executable. Most commonly used programs and utilities are not in the user’s current working directory (e.g., vi, cc). Imagine how inconvenient it would be if you actually had to know the locations of all system executables to execute them. Fortunately, UNIX has a method of looking for executables in a systematic way. If only a name is given for an executable, the shell searches for the executable in all possible directories listed by the PATH environment variable. PATH contains the fully qualified pathnames of important directories separated by colons.
Example 5.5.
The following is a typical value of the PATH environment variable.
/usr/bin:/etc:/usr/local/bin:/usr/ccs/bin:/home/robbins/bin:.
This specification says that when you enter a command your shell should search /usr/bin first. If it does not find the command there, the shell should next examine the /etc directory and so on.
Remember that the shell does not search subdirectories of directories in the PATH unless they are also explicitly specified in the PATH. If in doubt about which version of a particular program you are actually executing, use which to get the fully qualified pathname of the executable. The which command is not part of POSIX, but it is available on most systems. Section 5.5 describes how you can write your own version of which.
It is common for programmers to create a bin directory for executables, making bin a subdirectory of their home directories. The PATH of Example 5.5 contains the /home/robbins/bin directory. The bin directory appears before dot (.), the current directory, in the search path leading to the problem discussed in the next exercise.
Example 5.6.
A user develops a program called calhit in the subdirectory progs of his or her home directory and puts a copy of the executable in the bin directory of the same account. The user later modifies calhit in the progs directory without copying it to the bin directory. What happens when the programmer tries to test the new version?
Answer:
The result depends on the value of the PATH environment variable. If the user’s PATH is set up in the usual way, the shell searches the bin directory first and executes the old version of the program. You can test the new version with ./calhit.
Resist the temptation to put the dot (.) at the beginning of the PATH in spite of the problem mentioned in Exercise 5.6. Such a PATH specification is regarded as a security risk and may lead to strange results when your shell executes local programs instead of the standard system programs of the same name.
Directories should not be accessed with the ordinary open, close and read functions. Instead, they require specialized functions whose corresponding names end with "dir": opendir, closedir and readdir.
The opendir function provides a handle of type DIR * to a directory stream that is positioned at the first entry in the directory.
SYNOPSIS #include <dirent.h> DIR *opendir(const char *dirname); POSIX
If successful, opendir returns a pointer to a directory object. If unsuccessful, opendir returns a null pointer and sets errno. The following table lists the mandatory errors for opendir.
| cause |
|---|---|
| search permission on a path prefix of |
| a loop exists in resolution of |
| the length of |
| a component of |
| a component of |
The DIR type, which is defined in dirent.h represents a directory stream. A directory stream is an ordered sequence of all of the directory entries in a particular directory. The order of the entries in a directory stream is not necessarily alphabetical by file name.
The readdir function reads a directory by returning successive entries in a directory stream pointed to by dirp. The readdir returns a pointer to a struct dirent structure containing information about the next directory entry. The readdir moves the stream to the next position after each call.
SYNOPSIS #include <dirent.h> struct dirent *readdir(DIR *dirp); POSIX
If successful, readdir returns a pointer to a struct dirent structure containing information about the next directory entry. If unsuccessful, readdir returns a NULL pointer and sets errno. The only mandatory error is EOVERFLOW, which indicates that the value in the structure to be returned cannot be represented correctly. The readdir function also returns NULL to indicate the end of the directory, but in this case it does not change errno.
The closedir function closes a directory stream, and the rewinddir function repositions the directory stream at its beginning. Each function has a dirp parameter that corresponds to an open directory stream.
SYNOPSIS #include <dirent.h> int closedir(DIR *dirp); void rewinddir(DIR *dirp); POSIX
If successful, the closedir function returns 0. If unsuccessful, it returns –1 and sets errno. The closedir function has no mandatory errors. The rewinddir function does not return a value and has no errors defined.
Program 5.3 displays the filenames contained in the directory whose pathname is passed as a command-line argument.
Example 5.3. shownames.c
A program to list files in a directory.
#include <dirent.h>
#include <errno.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
struct dirent *direntp;
DIR *dirp;
if (argc != 2) {
fprintf(stderr, "Usage: %s directory_name
", argv[0]);
return 1;
}
if ((dirp = opendir(argv[1])) == NULL) {
perror ("Failed to open directory");
return 1;
}
while ((direntp = readdir(dirp)) != NULL)
printf("%s
", direntp->d_name);
while ((closedir(dirp) == -1) && (errno == EINTR)) ;
return 0;
}
Example 5.7.
Run Program 5.3 for different directories. Compare the output with that from running the ls shell command for the same directories. Why are they different?
Answer:
The ls command sorts filenames in alphabetical order. The readdir function displays filenames in the order in which they occur in the directory file.
Program 5.3 does not allocate a struct dirent variable to hold the directory information. Rather, readdir returns a pointer to a static struct dirent structure. This return structure implies that readdir is not thread-safe. POSIX includes readdir_r as part of the POSIX:TSF Extension, to provide a thread-safe alternative.
POSIX only requires that the struct dirent structure have a d_name member, representing a string that is no longer than NAME_MAX. POSIX does not specify where additional information about the file should be stored. Traditionally, UNIX directory entries contain only filenames and inode numbers. The inode number is an index into a table containing the other information about a file. Inodes are discussed in Section 5.3.
This section describes three functions for retrieving file status information. The fstat function accesses a file with an open file descriptor. The stat and lstat functions access a file by name.
The lstat and stat functions each take two parameters. The path parameter specifies the name of a file or symbolic link whose status is to be returned. If path does not correspond to a symbolic link, both functions return the same results. When path is a symbolic link, the lstat function returns information about the link whereas the stat function returns information about the file referred to by the link. Section 5.4 explains symbolic links. The buf parameter points to a user-supplied buffer into which these functions store the information.
SYNOPSIS #include <sys/stat.h> int lstat(const char *restrict path, struct stat *restrict buf); int stat(const char *restrict path, struct stat *restrict buf); POSIX
If successful, these functions return 0. If unsuccessful, they return –1 and set errno. The restrict modifier on the arguments specifies that path and buf are not allowed to overlap. The following table lists the mandatory errors for these functions.
| cause |
|---|---|
| search permission on a |
| an error occurred while reading from the file system |
| a loop exists in resolution of |
| the length of the pathname exceeds |
| a component of |
| a component of the path prefix is not a directory |
| the file size in bytes, the number of blocks allocated to file or the file serial number cannot be represented in the structure pointed to by |
The struct stat structure, which is defined in sys/stat.h, contains at least the following members.
dev_t st_dev; /* device ID of device containing file */
ino_t st_ino; /* file serial number */
mode_t st_mode; /* file mode */
nlink_t st_nlink; /* number of hard links */
uid_t st_uid; /* user ID of file */
gid_t st_gid; /* group ID of file */
off_t st_size; /* file size in bytes (regular files) */
/* path size (symbolic links) */
time_t st_atime; /* time of last access */
time_t st_mtime; /* time of last data modification */
time_t st_ctime; /* time of last file status change */
Example 5.8. printaccess.c
The following function displays the time that the file path was last accessed.
#include <stdio.h>
#include <time.h>
#include <sys/stat.h>
void printaccess(char *path) {
struct stat statbuf;
if (stat(path, &statbuf) == -1)
perror("Failed to get file status");
else
printf("%s last accessed at %s", path, ctime(&statbuf.st_atime));
}
Example 5.9. printaccessmodbad.c
What is wrong with the following function that attempts to print both the access time and the time of modification of a file? How would you fix it?
#include <stdio.h>
#include <time.h>
#include <sys/stat.h>
void printaccessmodbad(char *path) {
struct stat statbuf;
if (stat(path, &statbuf) == -1)
perror("Failed to get file status");
else
printf("%s accessed: %s modified: %s", path,
ctime(&statbuf.st_atime), ctime(&statbuf.st_mtime));
}
Answer:
The string returned by ctime ends with a newline, so the result is displayed on 2 lines. More importantly, ctime uses static storage to hold the generated string, so the second call to ctime will probably write over the string containing the access time. To solve the problem, save the access time in a buffer before calling ctime the second time, as in the following code. An alternative would be to use two separate print statements. After the strncpy call, the string is terminated at the position that would have contained the newline.
printaccessmod.c
#include <stdio.h>
#include <string.h>
#include <time.h>
#include <sys/stat.h>
#define CTIME_SIZE 26
void printaccessmod(char *path) {
char atime[CTIME_SIZE]; /* 26 is the size of the ctime string */
struct stat statbuf;
if (stat(path, &statbuf) == -1)
perror("Failed to get file status");
else {
strncpy(atime, ctime(&statbuf.st_atime), CTIME_SIZE - 1);
atime[CTIME_SIZE - 2] = 0;
printf("%s accessed: %s modified: %s", path, atime,
ctime(&statbuf.st_mtime));
}
}
The fstat function reports status information of a file associated with the open file descriptor fildes. The buf parameter points to a user-supplied buffer into which fstat writes the information.
SYNOPSIS #include <sys/stat.h> int fstat(int fildes, struct stat *buf); POSIX
If successful, fstat returns 0. If unsuccessful, fstat returns –1 and sets errno. The following table lists the mandatory errors for fstat.
| cause |
|---|---|
|
|
| an I/O error occurred while reading from the file system |
| the file size in bytes, the number of blocks allocated to file or the file serial number cannot be represented in the structure pointed to by |
The file mode member st_mode specifies the access permissions of the file and the type of file. Table 4.1 on page 105 lists the POSIX symbolic names for the access permission bits. POSIX specifies the macros of Table 5.1 for testing the st_mode member for the type of file. A regular file is a randomly accessible sequence of bytes with no further structure imposed by the system. UNIX stores data and programs as regular files. Directories are files that associate filenames with locations, and special files specify devices. Character special files represent devices such as terminals; block special files represent disk devices. The ISFIFO tests for pipes and FIFOs that are used for interprocess communication.Chapter 6 discusses special files, and Chapter 14 discusses interprocess communication based on message queues, semaphores and shared memory.
Example 5.10. isdirectory.c
The isdirectory function returns true (nonzero) if path is a directory, and false (0) otherwise.
#include <stdio.h>
#include <time.h>
#include <sys/stat.h>
int isdirectory(char *path) {
struct stat statbuf;
if (stat(path, &statbuf) == -1)
return 0;
else
return S_ISDIR(statbuf.st_mode);
}
Table 5.1. POSIX macros for testing for the type of file. Here m is of type mode_t and the value of buf is a pointer to a struct stat structure.
macro | tests for |
|---|---|
| block special file |
| character special file |
| directory |
| pipe or FIFO special file |
| symbolic link |
| regular file |
| socket |
| message queue |
| semaphore |
| shared memory object |
Disk formatting divides a physical disk into regions called partitions. Each partition can have its own file system associated with it. A particular file system can be mounted at any node in the tree of another file system. The topmost node in a file system is called the root of the file system. The root directory of a process (denoted by /) is the topmost directory that the process can access. All fully qualified paths in UNIX start from the root directory /.
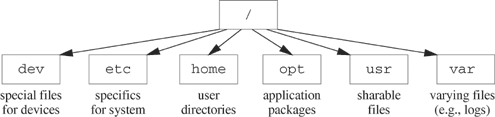
Figure 5.2 shows a typical root file system tree containing some of the standard UNIX subdirectories. The /dev directory holds specifications for the devices (special files) on the system. The /etc directory holds files containing information regarding the network, accounts and other databases that are specific to the machine. The /home directory is the default directory for user accounts. The /opt directory is a standard location for applications in System V Release 4. Look for include files in the /usr/include directory. The /var directory contains system files that vary and can grow arbitrarily large (e.g., log files, or mail when it arrives but before it has been read). POSIX does not require that a file system have these subdirectories, but many systems organize their directory structure in a similar way.
POSIX does not mandate any particular representation of files on disk, but traditionally UNIX files have been implemented with a modified tree structure, as described in this section. Directory entries contain a filename and a reference to a fixed-length structure called an inode. The inode contains information about the file size, the file location, the owner of the file, the time of creation, time of last access, time of last modification, permissions and soon.
Figure 5.3 shows the inode structure for a typical file. In addition to descriptive information about the file, the inode contains pointers to the first few data blocks of the file. If the file is large, the indirect pointer is a pointer to a block of pointers that point to additional data blocks. If the file is still larger, the double indirect pointer is a pointer to a block of indirect pointers. If the file is really huge, the triple indirect pointer contains a pointer to a block of double indirect pointers. The word block can mean different things (even within UNIX). In this context a block is typically 8K bytes. The number of bytes in a block is always a power of 2.

Example 5.11.
Suppose that an inode is 128 bytes, pointers are 4 bytes long, and the status information takes up 68 bytes. Assume a block size of 8K bytes and block pointers of 32 bits each. How much room is there for pointers in the inode? How big a file can be represented with direct pointers? Indirect? Double indirect? Triple indirect?
Answer:
The single, double, and triple indirect pointers take 4 bytes each, so 128 - 68 - 12 = 48 bytes are available for 12 direct pointers. The size of the inode and the block size depend on the system. A file as large as 8192 × 12 = 98, 304 bytes can be represented solely with direct pointers. If the block size is 8K bytes, the single indirect pointer addresses an 8K block that can hold 8192 ÷ 4 = 2048 pointers to data blocks. Thus, the single indirect pointer provides the capability of addressing an additional 2048 × 8192 = 16, 777, 216 bytes or 16 megabytes of information. Double indirect addressing provide 2048 × 2048 pointers with the capability of addressing an additional 32 gigabytes. Triple indirect addressing provides 2048 × 2048 × 2048 pointers with the capability of addressing an additional 64 terabytes. However, since 20483 = 233, pointers would need to be longer than 4 bytes to fully address this storage.
Example 5.12.
How large a file can you access using only the single indirect, double indirect, and triple indirect pointers if the block size is 8K bytes and pointers are 64 bits?
Answer:
A block can now hold only 1024 pointers, so the single indirect pointer can address 1024 × 8192 = 8,388,608 bytes. Double indirect addressing provides 1024 × 1024 pointers with the capability of addressing an additional 8 gigabytes. Triple indirect addressing provides 1024 × 1024 × 1024 pointers with the capability of addressing an additional 8 terabytes.
Example 5.13.
How big can you make a disk partition if the block size is 8K bytes and pointers are 32 bits? How can bigger disks be handled? What are the tradeoffs?
Answer:
32-bit addresses can access approximately 4 billion blocks (4,294,967,296 to be exact). 8K blocks give 245 ≈ 3.5 × 1013 bytes. With a block address of fixed size, there is a tradeoff between maximum partition size and block size. Larger blocks mean a larger partition for a fixed address size. The block size usually determines the smallest retrievable unit on disk. Larger blocks can be retrieved relatively more efficiently but can result in greater internal fragmentation because of partially filled blocks.
The tree-structured representation of files is fairly efficient for small files and is also flexible if the size of the file changes. When a file is created, the operating system finds free blocks on the disk in which to place the data. Performance considerations dictate that blocks of the same file should be located close to one another on the disk to reduce the seek time. It takes about twenty times as long to read a 16-megabyte file in which the data blocks are randomly placed than one in which the data blocks are contiguous.
When a system administrator creates a file system on a physical disk partition, the raw bytes are organized into data blocks and inodes. Each physical disk partition has its own pool of inodes that are uniquely numbered. Files created on that partition use inodes from that partition’s pool. The relative layout of the disk blocks and inodes has been optimized for performance.
POSIX does not require that a system actually represent its files by using inodes. The ino_t st_ino member of the struct stat is now called a file serial number rather than an inode number. POSIX-compliant systems must provide the information corresponding to the mandatory members of the struct stat specified on page 155, but POSIX leaves the actual implementation unspecified. In this way, the POSIX standard tries to separate implementation from the interface.
A directory is a file containing a correspondence between filenames and file locations. UNIX has traditionally implemented the location specification as an inode number, but as noted above, POSIX does not require this. The inode itself does not contain the filename. When a program references a file by pathname, the operating system traverses the file system tree to find the filename and inode number in the appropriate directory. Once it has the inode number, the operating system can determine other information about the file by accessing the inode. (For performance reasons, this is not as simple as it seems, because the operating system caches both directory entries and inode entries in main memory.)
A directory implementation that contains only names and inode numbers has the following advantages.
Changing the filename requires changing only the directory entry. A file can be moved from one directory to another just by moving the directory entry, as long as the move keeps the file on the same partition or slice. (The
mvcommand uses this technique for moving files to locations within the same file system. Since a directory entry refers to an inode on the same partition as the directory entry itself,mvcannot use this approach to move files between different partitions.)Only one physical copy of the file needs to exist on disk, but the file may have several names or the same name in different directories. Again, all of these references must be on the same physical partition.
Directory entries are of variable length because the filename is of variable length. Directory entries are small, since most of the information about each file is kept in its inode. Manipulating small variable-length structures can be done efficiently. The larger inode structures are of fixed length.
UNIX directories have two types of links—links and symbolic links. A link, sometimes called a hard link, is a directory entry. Recall that a directory entry associates a filename with a file location. A symbolic link, sometimes called a soft link, is a file that stores a string used to modify the pathname when it is encountered during pathname resolution. The behavioral differences between hard and soft links in practice is often not intuitively obvious. For simplicity and concreteness, we assume an inode representation of the files. However, the discussion applies to other file implementations.
A directory entry corresponds to a single link, but an inode may be the target of several of these links. Each inode contains the count of the number of links to the inode (i.e., the total number of directory entries that contain the inode number). When a program uses open to create a file, the operating system makes a new directory entry and assigns a free inode to represent the newly created file.
Figure 5.4 shows a directory entry for a file called name1 in the directory /dirA. The file uses inode 12345. The inode has one link, and the first data block is block 23567. Since the file is small, all the file data is contained in this one block, which is represented by the short text in the figure.
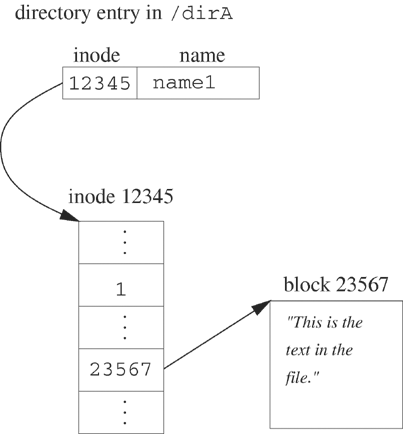
You can create additional links to a file with the ln shell commandor the link function. The creation of the new link allocates a new directory entry and increments the link count of the corresponding inode. The link uses no other additional disk space.
When you delete a file by executing the rm shell command or by calling the unlink function from a program, the operating system deletes the corresponding directory entry and decrements the link count in the inode. It does not free the inode and the corresponding data blocks unless the operation causes the link count to be decremented to 0.
The link function creates a new directory entry for the existing file specified by path1 in the directory specified by path2.
SYNOPSIS #include <unistd.h> int link(const char *path1, const char *path2); POSIX
If successful, the link function returns 0. If unsuccessful, link returns –1 and sets errno. The following table lists the mandatory errors for link.
| cause |
|---|---|
| search permission on a prefix of |
|
|
| a loop exists in resolution of |
| number of links to file specified by |
| the length of |
| a component of either path prefix does not exist, or file named by |
| directory to contain the link cannot be extended |
| a component of either path prefix is not a directory |
| file named by |
|
|
| link named by |
Example 5.15.
The following shell command creates an entry called name2 in dirB containing a pointer to the same inode as /dirA/name1.
ln /dirA/name1 /dirB/name2
The result is shown in Figure 5.5.
Example 5.16.
The following code segment performs the same action as the ln shell command of Example 5.15.
#include <stdio.h>
#include <unistd.h>
if (link("/dirA/name1", "/dirB/name2") == -1)
perror("Failed to make a new link in /dirB");
Figure 5.4 shows a schematic of /dirA/name1 before the ln command of Example 5.15 or the link function of Example 5.16 executes. Figure 5.5 shows the result of linking.
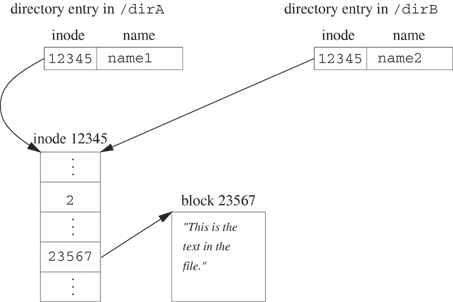
The ln command (or link function) creates a link (directory entry) that refers to the same inode as dirA/name1. No additional disk space is required, except possibly if the new directory entry increases the number of data blocks needed to hold the directory information. The inode now has two links.
The unlink function removes the directory entry specified by path. If the file’s link count is 0 and no process has the file open, the unlink frees the space occupied by the file.
SYNOPSIS #include <unistd.h> int unlink(const char *path); POSIX
If successful, the unlink function returns 0. If unsuccessful, unlink returns –1 and sets errno. The following table lists the mandatory errors for unlink.
| cause |
|---|---|
| search permission on a component of the path prefix is denied, or write permission is denied for directory containing directory entry to be removed |
| file named by |
| a loop exists in resolution of |
| the length of |
| a component of |
| a component of the path prefix is not a directory |
| file named by |
|
|
Example 5.17.
The following sequence of operations might be performed by a text editor when editing the file /dirA/name1.
Open the file
/dirA/name1.Read the entire file into memory.
Close
/dirA/name1.Modify the memory image of the file.
Unlink
/dirA/name1.Open the file
/dirA/name1(create and write flags).Write the contents of memory to the file.
Close
/dirA/name1.
How would Figures 5.4 and 5.5 be modified if you executed this sequence of operations on each configuration?
Answer:
After these operations were applied to Figure 5.4, the new file would have the same name as the old but would have the new contents. It might use a different inode number and block. This is what we would expect. When the text editor applies the same set of operations to the configuration of Figure 5.5, unlinking removes the directory entry for /dirA/name1. The unlink reduces the link count but does not delete the file, since the link /dirB/name2 is still pointing to it. When the editor opens the file /dirA/name1 with the create flag set, a new directory entry and new inode are created. We now have /dirA/name1 referring to the new file and /dirB/name2 referring to the old file. Figure 5.6 shows the final result.
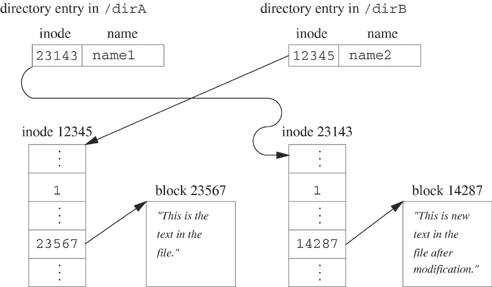
Figure 5.6. Situation after a text editor changes a file. The original file had inode 12345 and two hard links before editing (i.e., the configuration of Figure 5.5).
Example 5.18.
Some editors back up the old file. One possible way of doing this is with the following sequence of operations.
Open the file
/dirA/name1.Read the entire file into memory.
Close
/dirA/name1.Modify the memory image of the file.
Rename the file
/dirA/name1 /dirA/name1.bak.Open the file
/dirA/name1(create and write flags).Write the contents of memory to the file.
Close
/dirA/name1.
Describe how this strategy affects each of Figures 5.4 and 5.5.
Answer:
Starting with the configuration of Figure 5.4 produces two distinct files. The file /dirA/name1 has the new contents and uses a new inode. The file /dirA/name1.bak has the old contents and uses the old inode. For the configuration of Figure 5.5, /dirA/name1.bak and /dirB/name2 point to the old contents using the old inode. The second open creates a new inode for dirA/name1, resulting in the configuration of Figure 5.7.

The behavior illustrated in Exercises 5.17 and 5.18 may be undesirable. An alternative approach would be to have both /dirA/name1 and /dirB/name2 reference the new file. In Exercise 5.22 we explore an alternative sequence of operations that an editor can use.
A symbolic link is a file containing the name of another file or directory. A reference to the name of a symbolic link causes the operating system to locate the inode corresponding to that link. The operating system assumes that the data blocks of the corresponding inode contain another pathname. The operating system then locates the directory entry for that pathname and continues to follow the chain until it finally encounters a hard link and a real file. The system gives up after a while if it doesn’t find a real file, returning the ELOOP error.
Create a symbolic link by using the ln command with the -s option or by invoking the symlink function. The path1 parameter of symlink contains the string that will be the contents of the link, and path2 gives the pathname of the link. That is, path2 is the newly created link and path1 is what the new link points to.
SYNOPSIS #include <unistd.h> int symlink(const char *path1, const char *path2); POSIX
If successful, symlink returns 0. If unsuccessful, symlink returns –1 and sets errno. The following table lists the mandatory errors for symlink.
| cause |
|---|---|
| search permission on a component of the path prefix of |
|
|
| an I/O error occurred while reading from or writing to the file system |
| a loop exists in resolution of |
| the length of |
| a component of |
| directory to contain the link cannot be extended, or the file system is out of resources |
| a component of the path prefix for |
| the new symbolic link would reside on a read-only file system |
Example 5.19.
Starting with the situation shown in Figure 5.4, the following command creates the symbolic link /dirB/name2, as shown in Figure 5.8.
ln -s /dirA/name1 /dirB/name2

Example 5.20.
The following code segment performs the same action as the ln -s of Example 5.19.
if (symlink("/dirA/name1", "/dirB/name2") == -1)
perror("Failed to create symbolic link in /dirB");
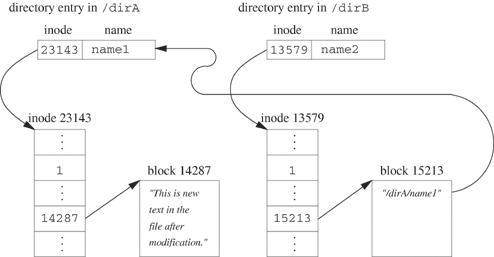
Unlike Exercise 5.17, the ln command of Example 5.19 and the symlink function of Example 5.20 use a new inode, in this case 13579, for the symbolic link. Inodes contain information about the type of file they represent (i.e., ordinary, directory, special, or symbolic link), so inode 13579 contains information indicating that it is a symbolic link. The symbolic link requires at least one data block. In this case, block 15213 is used. The data block contains the name of the file that /dirB/name2 is linked to, in this case, /dirA/name1. The name may be fully qualified as in this example, or it may be relative to its own directory.
Example 5.21.
Suppose that /dirA/name1 is an ordinary file and /dirB/name2 is a symbolic link to /dirA/name1, as in Figure 5.8. How are the files /dirB/name2 and /dirA/name1 related after the sequence of operations described in Exercise 5.17?
Answer:
/dirA/name1 now refers to a different inode, but /dirB/name2 references the name dirA/name1, so they still refer to the same file, as shown in Figure 5.9. The link count in the inode counts only hard links, not symbolic links. When the editor unlinks /dirA/name1, the operating system deletes the file with inode 12345. If other editors try to edit /dirB/name2 in the interval during which /dirA/name1 is unlinked but not yet created, they get an error.
Example 5.22.
How can the sequence of operations in Exercise 5.17 be modified so that /dirB/name2 references the new file regardless of whether this was a hard link or a symbolic link?
Answer:
The following sequence of operations can be used.
Open the file
/dirA/name1.Read the entire file into memory.
Close
/dirA/name1.Modify the memory image of the file.
Open the file
/dirA/name1with theO_WRONLYandO_TRUNCflags.Write the contents of memory to the file.
Close
/dirA/name1.
When the editor opens the file the second time, the same inode is used but the contents are deleted. The file size starts at 0. The new file will have the same inode as the old file.
Example 5.23.
Exercise 5.22 has a possibly fatal flaw: If the application or operating system crashes between the second open and the subsequent write operation, the file is lost. How can this be prevented?
Answer:
Before opening the file for the second time, write the contents of memory to a temporary file. Remove the temporary file after the close of /dirA/name1 is successful. This approach allows the old version of the file to be retrieved if the application crashes. However, a successful return from close does not mean that the file has actually been written to disk, since the operating system buffers this operation. One possibility is to use a function such as fsync after write. The fsync returns only after the pending operations have been written to the physical medium. The fsync function is part of the POSIX:FSC Extension.
Example 5.24.
Many programs assume that the header files for the X Window System are in /usr/include/X11, but under Sun’s Solaris operating environment these files are in the directory /usr/openwin/share/include/X11. How can a system administrator deal with the inconsistency?
Answer:
There are several ways to address this problem.
Copy all these files into
/usr/include/X11.Move all the files into
/usr/include/X11.Have users modify all programs that contain lines in the following form.
#include <X11/xyz.h>
Replace these lines with the following.
#include, "/usr/openwin/share/include/X11/xyz.h"
Have users modify their makefiles so that compilers look for header files in the following directory.
/usr/openwin/share/include
Create a symbolic link from
/usr/include/X11to the following directory./usr/openwin/share/include/X11
All the alternatives except the last have serious drawbacks. If the header files are copied to the directory /usr/include/X11, then two copies of these files exist. Aside from the additional disk space required, an update might cause these files to be inconsistent. Moving the files (copying them to the directory /usr/include/X11 and then deleting them from /usr/openwin/share/include/X11) may interfere with operating system upgrades. Having users modify all their programs or makefiles is unreasonable. Another alternative not mentioned above is to use an environment variable to modify the search path for header files.
Example 5.25.
Because of a large influx of user mail, the root partition of a server becomes full. What can a system administrator do?
Answer:
Pending mail is usually kept in a directory with a name such as /var/mail or /var/spool/mail, which may be part of the root partition. One possibility is to expand the size of the root partition. This expansion usually requires reinstallation of the operating system. Another possibility is to mount an unused partition on var. If a spare partition is not available, the /var/spool/mail directory can be a symbolic link to any directory in a partition that has sufficient space.
Example 5.26.
Starting with Figure 5.8, execute the command rm /dirA/name1. What happens to /dirB/name2?
Answer:
This symbolic link still exists, but it is pointing to something that is no longer there. A reference to /dirB/name2 gives an error as if the symbolic link /dirB/name2 does not exist. However, if later a new file named /dirA/name1 is created, the symbolic link then points to that file.
When you reference a file representing a symbolic link by name, does the name refer to the link or to the file that the link references? The answer depends on the function used to reference the file. Some library functions and shell commands automatically follow symbolic links and some do not. For example, the rm command does not follow symbolic links. Applying rm to a symbolic link removes the symbolic link, not what the link references. The ls command does not follow symbolic links by default, but lists properties such as date and size of the link itself. Use the -L option with ls to obtain information about the file that a symbolic link references. Some operations have one version that follows symbolic links (e.g., stat) and another that does not (e.g., lstat). Read the man page to determine a particular function’s behavior in traversing symbolic links.
The which command is available on many systems. It takes the name of an executable as a command-line argument and displays the fully qualified pathname of the corresponding executable. If the argument to which contains a path specifier (/), which just checks to see if this path corresponds to an executable. If the argument does not contain a path specifier, which uses the PATH environment variable to search directories for the corresponding executable. If which locates the executable, it prints the fully qualified path. Otherwise, which prints an message indicating that it could not find the executable in the path.
Implement a which command. If no path-specifier character is given, use getenv to get the PATH environment variable. Start by creating a fully qualified path, using each component of the PATH until an appropriate file is found. Write a checkexecutable function with the following prototype.
int checkexecutable(char *name);
The checkexecutable function returns true if the given file is executable by the owner of the current process. Use geteuid and getegid to find the user ID and group ID of the owner of the process. Use stat to see if this user has execute privilege for this file. There are three cases to consider, depending on whether the user is the owner of the file, in the same group as the file or neither.
The which command of the csh shell also checks to see if an alias is set for the command-line argument and reports that alias instead of searching for an executable. See if you can implement this feature.
Some systems have a facility called biff that enables mail notification. When a user who is logged in receives mail, biff notifies the user in some way (e.g., beeping at the terminal or displaying a message). UNIX folklore has it that biff’s original author had a dog named Biff who barked at mail carriers.
Program 5.4 shows the code for a C program called simplebiff.c that beeps at the terminal at regular intervals if the user ostudent has pending mail. The program beeps by sending a Ctrl-G (ASCII 7) character to standard error. Most terminals handle the receipt of Ctrl-G by producing a short beep. The program continues beeping every 10 seconds, until it is killed or the mail file is removed. This simple version assumes that if the mail file exists, it has mail in it. On some systems the mail file may exist but contain zero bytes when there is no mail. Program 8.10 on page 281 gives a version that does not have this problem.
Example 5.27.
The following command starts simplebiff.
simplebiff &
The & tells the shell to run simplebiff in the background so that ostudent can do something else.
Example 5.28.
What happens if you execute the command of Example 5.27 and then log off?
Answer:
The simplebiff program continues to run after you log off, since it was started in the background. Execute ps -a to determine simplebiff’s process ID. Kill the simplebiff process by entering the command kill -KILL pid. Make sure simplebiff is gone by doing another ps -a.
Example 5.4. simplebiff.c
A simple program to notify ostudent of pending mail.
#include <errno.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#define MAILFILE "/var/mail/ostudent"
#define SLEEPTIME 10
int main(void) {
int mailfd;
for( ; ; ) {
if ((mailfd = open(MAILFILE, O_RDONLY)) != -1) {
fprintf(stderr, "%s", "�07");
while ((close(mailfd) == -1) && (errno == EINTR)) ;
}
sleep(SLEEPTIME);
}
}
Mail is usually stored in a file in the /var/mail or /var/spool/mail directory. A file in that directory with the same name as the user’s login name contains all unread mail for that user. If ostudent has mail, an open of /var/mail/ostudent succeeds; otherwise, the open fails. If the file exists, the user has unread mail and the program beeps. In any case, the program sleeps and then repeats the process indefinitely.
Example 5.29.
Run Program 5.4 after replacing the user name and mail directory names so that they are appropriate for your system.
Program 5.4 is not very general because the user name, mail directory and sleep time are hardcoded. In addition, the stat function provides more information about a file without the overhead of open.
Example 5.31.
On some systems, a user’s new mail file always exists but has zero bytes if the user has no mail. Modify simplebiff to account for this case.
The POSIX-approved way of getting the user name is to call getuid to find out the user ID and then call getpwuid to retrieve the user’s login name. The getpwuid function takes the user’s numerical ID as a parameter and retrieves a passwd structure that has the user’s name as a member.
SYNOPSIS #include <pwd.h> struct passwd *getpwuid(uid_t uid); POSIX
If unsuccessful, getpwuid returns a NULL pointer and sets errno.
The struct passwd structure is defined in pwd.h. The POSIX base definition specifies that the struct passwd structure have at least the following members.
char *pw_name /* user's login name */ uid_t pw_uid /* numerical user ID */ gid_t pw_gid /* numerical group ID */ char *pwd_dir /* initial working directory */ char *pw_shell /* program to use as shell */
Example 5.32.
Find out the base directory name of the directory in which unread mail is stored on your system. (The base directory in Program 5.4 is /var/mail/.) Construct the pathname of the unread mail by concatenating the base mail directory and the program’s user name. Use getuid and getpwuid in combination to determine the user name at run time.
The directory used for mail varies from system to system, so you must determine the location of the system mail files on your system in order to use simplebiff. A better version of the program would allow the user to specify a directory on the command line or to use system-specific information communicated by environment variables if this information is available. The POSIX:Shell and Utilities standard specifies that the sh shell use the MAIL environment variable to determine the pathname of the user’s mail filefor the purpose of incoming mail notification. The same standard also specifiesthat the MAILCHECK environment variable be used to specify how often (in seconds) the shell should check for the arrival of new messages for notification. The standard states that the default value of MAILCHECK should be 600.
Example 5.33.
Rewrite Program 5.4 so that it uses the value of MAILCHECK for the sleep time if that environment variable is defined. Otherwise, it should use a default value of 600.
Example 5.34.
Rewrite your program of Exercise 5.33 so that it uses the value passed on the command line as the pathname for the user’s mailbox. If simplebiff is called with no command-line arguments, the program should use the value of the MAIL environment variable as the pathname. If MAIL is undefined and there were no command-line arguments, the program should use a default path of /var/mail/user. Use the method of Exercise 5.32 to find the value of user.
Example 5.35.
Rewrite Program 5.4 so that it has the following synopsis.
simplebiff [-s n] [-p pathname]
The [ ] in the synopsis indicates optional command-line arguments. The first command-line argument specifies a sleep interval. If -s n is not provided on the command line and MAILCHECK is not defined, use thevalue of SLEEPTIME as a default. The -p pathname specifies a pathname for the system mail directory. If this option is not specified on the command line, use the MAIL environment variable value as a default value. If MAIL is not defined, use the MAILFILE defined in the program. Read the man page for the getopt function and use it to parse the command-line arguments.
The simplebiff program informs the user of incoming mail. A user might also want to be informed of changes in other files such as the Internet News files. If a system is a news server, it probably organizes articles as individual files whose pathname contains the newsgroup name.
Example 5.36.
A system keeps its news files in the directory /var/spool/news. Article 1034 in newsgroup comp.os.unix is located in the following file.
/var/spool/news/comp/os/unix/1034
The following exercises develop a facility for biffing when any file in a list of files changes.
Write a function called
lastmodthat returns the time at which a file was last modified. The prototype forlastmodis as follows.time_t lastmod(char *pathname);
Use
statto determine the last modification time. Thetime_tis time in seconds since 00:00:00 UTC, January 1, 1970. Thelastmodfunction returns –1 if there is an error and setserrnoto the error number set bystat.Write a main program that takes a pathname as a command-line argument and calls
lastmodto determine the time of last modification of the corresponding file. Usectimeto print out thetime_tvalue in a readable form. Compare the results with those obtained fromls -l.Write a function called
convertnewsthat converts a newsgroup name to a fully qualified pathname. The prototype ofconvertnewsis as follows.char *convertnews(char *newsgroup);
If the environment variable
NEWSDIRis defined, use it to determinethe path. Otherwise, use/var/spool/news. (Callgetenvto determine whether the environment variable is defined.) For example, if the newsgroup iscomp.os.unixandNEWSDIRis not defined, the pathname is the following./var/spool/news/comp/os/unix
The
convertnewsfunction allocates space to hold the converted string and returns a pointer to that space. (A common error is to return a pointer to an automatic variable defined withinconvertnews.) Do not modifynewsgroupinconvertnews. Theconvertnewsreturns aNULLpointer and setserrnoif there was an error.Write a program that takes a
newsgroupname and asleeptimevalue as command-line arguments. Print the time of the last modification of thenewsgroupand then loop as follows.Sleep for
sleeptime.Test to see whether the
newsgrouphas been modified.If the
newsgroupdirectory has been modified, print a message with thenewsgroupname and the time of modification.
Test the program on several newsgroups. Post news to a local newsgroup to verify that the program is working. The
newsgroupdirectory can be modified both by news arrival and by expiration. Most systems expire news in the middle of the night.Generalize your
newsbiffprogram so that it reads in a list of files to be tracked from a file. Your program should store the files and their last modification times in a list. (For example, you can modify the list object developed in Section 2.9 for this purpose.) Your program should sleep for a specified number of seconds and then update the modification times of the files in the list. If any have changed, print an informative message to standard output.
The exercises in this section develop programs to traverse directory trees in depth-first and breadth-first orders. Depth-first searches explore each branch of a tree to its leaves before looking at other branches. Breadth-first searches explore all the nodes at a given level before descending lower in the tree.
Example 5.37.
For the file system tree in Figure 5.1 on page 146, depth-first ordering visits the nodes in the following order.
/
dirC
my3.dat
dirA
dirB
my1.dat
my1.dat
my2.dat
The indentation of the filenames in Example 5.37 shows the level in the file system tree. Depth-first search is naturally recursive, as indicated by the following pseudocode.
depthfirst(root) {
for each node at or below root
visit node;
if node is a directory
depthfirst(node);
}
Example 5.38.
For the file system tree in Figure 5.1, breadth-first order visits the nodes in the following order.
/ /dirC /dirA /dirC/my3.dat /dirA/dirB /dirA/my1.dat /dirA/my2.dat /dirA/dirB/my1.dat
Breadth-first search can be implemented with a queue similar to the history queue of Program 2.8 on page 47. As the program encounters each directory node at a particular level, it enqueues the complete pathname for later examination. The following pseudocode assumes the existence of a queue. The enqueue operation puts a node at the end of the queue, and the dequeue operation removes a node from the front of the queue.
breadthfirst(root){
enqueue(root);
while (queue is not empty) {
dequeue(&next);
for each node directly below next:
visit the node
if node is a directory
enqueue(node)
}
}
Example 5.39.
The UNIX du shell command is part of the POSIX:UP Extension. The command displays the sizes of the subdirectories of the tree rooted at the directory specified by its command-line argument. If called with no directory, the du utility uses the current working directory. If du is defined on your system, experiment with it. Try to determine which search strategy it uses to traverse the tree.
Develop a program called mydu that uses a depth-first search strategy to display the sizes of the subdirectories in a tree rooted at the specified file.
Write a function called
depthfirstapplythat has the following prototype.int depthfirstapply(char *path, int pathfun(char *path1));
The
depthfirstapplyfunction traverses the tree, starting atpath. It applies thepathfunfunction to each file that it encounters in the traversal. Thedepthfirstapplyfunction returns the sum of the positive return values ofpathfun, or –1 if it failed to traverse any subdirectory of the directory. An example of a possiblepathfunis thesizepathfunfunction specified in the next part.Write a function called
sizepathfunthat has the following prototype.int sizepathfun(char *path);
The
sizepathfunfunction outputspathalong with other information obtained by callingstatforpath. Thesizepathfunreturns the size in blocks of the file given bypathor -1 ifpathdoes not correspond to an ordinary file.Use
depthfirstapplywith thepathfungiven bysizepathfunto implement the following command.showtreesize pathname
The
showtreesizecommand writespathnamefollowed by its total size to standard output. Ifpathnameis a directory, the total size corresponds to the size of the entire subtree rooted atpathname. Ifpathnameis a special file, print an informative message but no size.Write a command called
myduthat is called with a command-line argumentrootpathas follows.mydu rootpath
The
myduprogram calls a modifieddepthfirstapplywith the functionsizepathfun. It outputs the size of each directory followed by its pathname. The size of the directory does not count the size of subtrees of that directory. The program outputs the total size of the tree at the end and exits.Write
breadthfirstapplythat is similar todepthfirstapplybut uses a breadth-first search strategy.