
Some programs benefit from having a language to describe operations that theycan perform. The Interpreter pattern generally deals with defining a grammar for that language and using that grammar to interpret statements in that language.
When a program presents a number of different but somewhat similar cases that it can deal with, it can be advantageous to use a simple language to describe these cases and then have the program interpret that language. Such cases can be as simple as the Macro language recording facilities that various office suite programs provide or as complex as Visual Basic for Applications (VBA). VBA not only is included in Microsoft Office products but also can be easily embedded in any number of third-party products.
One problem is how to recognize when a language can be helpful. The Macro language recorder records menu and keystroke operations for later playback and just barely qualifies as a language; it might not actually have a written form or grammar. Languages such as VBA, by contrast, are quite complex but are far beyond the capabilities of the individual application developer. Further, embedding commercial languages such as VBA, Java, or SmallTalk usually requires substantial licensing fees—this makes them less attractive to all but the largest developers.
As the Smalltalk Companion notes, recognizing cases in which an Interpreter can be helpful is much of the problem, and programmers without formal language/compiler training often overlook this approach. There aren't many such cases, but there are three in which languages apply:
When you need a command interpreter to parse user commands: The user can type queries of various kinds and obtain a variety of answers.
When the program must parse an algebraic string: This case is fairly obvious. The program is asked to carry out its operations based on a computation in which the user enters an equation of some sort. This often occurs in mathematical-graphics programs, where the program renders a curve or surface based on any equation that it can evaluate. Programs such as Mathematica and graph drawing packages such as Origin work in this way.
When the program must produce varying kinds of output: This case is a little less obvious but far more useful. Consider a program that can display columns of data in any order and sort them in various ways. These programs are often called Report Generators. The underlying data might be stored in a relational database, but the user interface to the report program is usually much simpler then the SQL that the database uses. In fact, in some cases the simple report language might be interpreted by the report program and translated into SQL.
Let's consider a report generator that can operate on five columns of data in a table and return various reports on these data. Suppose that we have the following results from a swimming competition:
Amanda McCarthy 12 WCA 29.28 Jamie Falco 12 HNHS 29.80 Meaghan O'Donnell 12 EDST 30.00 Greer Gibbs 12 CDEV 30.04 Rhiannon Jeffrey 11 WYW 30.04 Sophie Connolly 12 WAC 30.05 Dana Helyer 12 ARAC 30.18
The five column names are frname, lname, age, club, and time. If we consider the complete race results of 51 swimmers, we might want to sort these results by club, by last name, or by age. We could produce several useful reports from these data in which the order of the columns changes as well as the sorting, so a language is one useful way to handle these reports.
We'll define a very simple nonrecursive grammar of the sort
Print lname frname club time Sortby club Thenby time
For the purposes of this example, we define the three verbs given in the grammar as
Print Sortby Thenby
and the five column names as
frname lname age club time
For convenience, we assume that the language is case-insensitive and that its grammar is punctuation-free, amounting in brief to
Print var[var] [sortby var [thenby var]]
Finally, the grammar contains only one main verb, and while each statement is a declaration, it has no assignment statement or computational ability.
Interpreting the language takes place in three steps:
Parse the language symbols into tokens.
Reduce the tokens into actions.
Execute the actions.
We parse the language into tokens by scanning each statement with a StringTokenizer and then substituting a number for each word. Usually parsers push each parsed token onto a stack—we will use that technique here. We implement that Stack class using a Vector, which contains push, pop, top, and nextTop methods to examine and manipulate the stack contents.
After the language is parsed, the stack could look as shown in the following table:
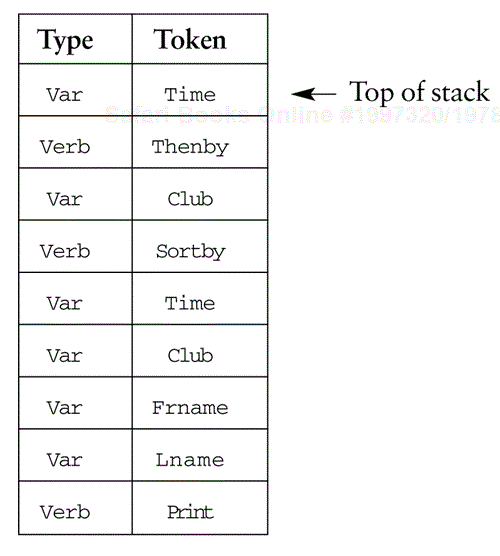
However, we quickly realize that the verb Thenby has no real meaning other than clarification. We'd more likely parse the tokens and skip Thenby altogether. The initial stack then looks like this:
Time Club Sortby Time Club Frname Lname Print
Actually, we do not push just a numeric token onto the stack, but rather a ParseObject that has both a type and a value property.
public class ParseObject {
public static final int VERB=1000, VAR = 1010,
MULTVAR = 1020;
protected int value;
protected int type;
public int getValue() {return value;}
public int getType() {return type;
}
These objects can take on the type VERB or VAR. Then we extend this object into ParseVerb and ParseVar objects, whose value fields can take on PRINT or SORT, for ParseVerb and FRNAME, LNAME, and so on, for ParseVar. For later use in reducing the parse list, we then derive Print and Sort objects from ParseVerb. This gives the hierarchy shown in Figure 18.1.

The parsing process is just the following code, which uses the StringTokenizer and the ParseObjects:
public class Parser implements Command {
private Stack stk;
private Vector actionList;
private KidData kdata;
private Data data;
private JawtList ptable;
private Chain chain;
public Parser(String line) {
stk = new Stack();
actionList = new Vector(); //actions accumulate here
buildStack(line);
buildChain(); //construct the interpreter chain
}
//--------------
public void setData(KidData k, JawtList pt) {
data = new Data(k.getData());
ptable = pt;
}
//--------------
//executes parse and the interpretation of command line
public void Execute() {
while (stk.hasMoreElements()) {
chain.sendToChain (stk);
}
//now execute the verbs
for (int i = 0; i < actionList.size() ; i++) {
Verb v = (Verb)actionList.elementAt(i);
v.setData(data,ptable);
v.Execute();
}
}
//--------------
protected ParseObject tokenize (String s) {
ParseObject obj = getVerb(s);
if (obj == null)
obj = getVar(s);
return obj;
}
//---------------
protected ParseVerb getVerb(String s) {
ParseVerb v;
v = new ParseVerb(s);
if (v.isLegal())
return v.getVerb(s);
else
return null;
}
//--------------
protected ParseVar getVar(String s) {
ParseVar v;
v = new ParseVar(s);
if (v.isLegal())
return v;
else
return null;
}
}
The ParseVerb and ParseVar classes return objects with isLegal set to true if they recognize the word.
public class ParseVerb extends ParseObject {
static public final int PRINT=100, SORTBY=110, THENBY=120;
protected Vector args;
public ParseVerb(String s) {
args = new Vector();
s = s.toLowerCase();
value = -1;
type = VERB
if (s.equal("print")) value = PRINT;
if (s.equals("sortby")) value = SORTBY;
}
//--------------
public ParseVerb getVerb(String s) {
switch (value) {
case PRINT:
return new Print(s)
case SORTBY:
return new Sort(s);
}
return null;
}
The tokens on the stack have the following forms:
Var Var Verb Var Var Var Var Verb
We reduce the stack a token at a time, folding successive Vars into a MultVar class until the arguments are folded into the verb objects, as shown in Figure 18.2.
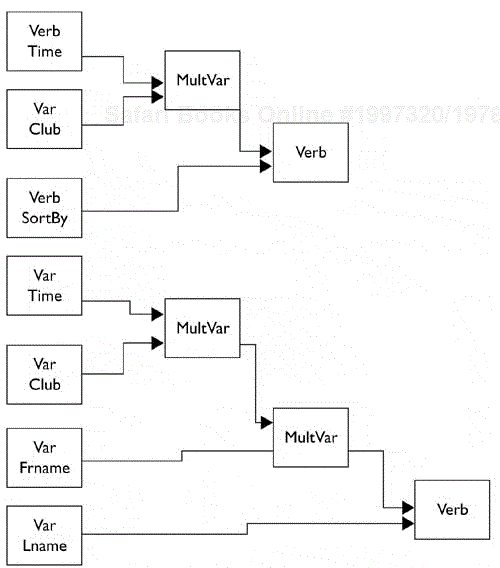
When the stack reduces to a verb, this verb and its arguments are placed in an action list. When the stack is empty, the actions are executed.
Creating a Parser class that is a Command object and executing it when the Go button on the user interface is clicked carry out this entire process.
public void actionPerformed(ActionEvent e) {
Parser p = new Parser (tx.getText());
p.setData(kdata, ptable);
p.Execute();
}
The parser itself just reduces the tokens, as shown earlier. It checks for various pairs oftokens on the stack and reduces each pair to a single one for each of five different cases.
Writing a parser for this simple grammar as a series of if statements is certainly possible. For each of the six possible stack configurations, we reduce the stack until only a verb remains. Then, since we made the Print and Sort verb classes Command objects, we can just execute them one by one as the action list is enumerated.
The real advantage of the Interpreter pattern, however, is its flexibility.Bymaking each parsing case an individual object, we can represent the parse tree as a series of connected objects that reduce the stack successively. Using this arrangement, we can easily change the parsing rules, with few changes tothe program. We just create new objects and insert them into the parse tree.
The participating objects in the Interpreter pattern are:
AbstractExpression. declares the abstract Interpreter operation.
TerminalExpression. interprets expressions containing any of the terminal tokens in the grammar.
NonTerminalExpression. interprets all of the nonterminal expressions in the grammar.
Context. contains the global information that is part of the parser, in this case, the token stack.
Client. builds the syntax tree from the previous expression types and invokes the Interpret operation.
We can construct a simple syntax tree to carry out the parsing of the previous stack. We need only to look for each defined stack configuration and reduce it to an executable form. In fact, the best way to implement this tree is to use a Chain of Responsibility pattern, which passes the stack configuration along between classes until one of them recognizes that configuration and acts on it. You can decide whether a successful stack reduction should end that pass; it is perfectly possible to have several successive chain members work on the stack in a single pass. The processing ends when the stack is empty. Figure 18.3 shows a diagram of the individual parse chain elements.
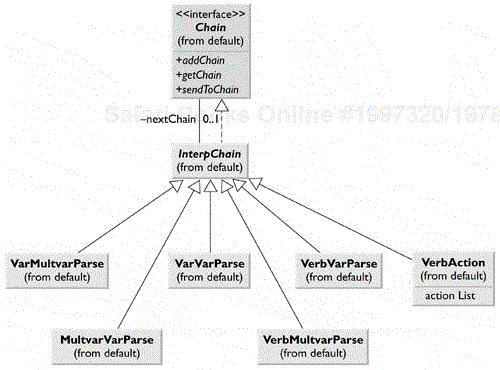
This class structure begins with the AbstractExpression interpreter class InterpChain.
public abstract class InterpChain implements Chain {
private Chain nextChain;
private Stack stk;
//--------------
public void addChain(Chain c) {
nextChain = c: next in the chain of resp
}
//--------------
public abstract boolean interpret();
//--------------
public Chain getChain() {
return nextChain;
}
//--------------
public void sendToChain(Stack stack) {
stk = stack;
if (! interpret()) //interpret the stack
//otherwise, pass the request along the chain
nextChain.sendToChain(stk);
}
//--------------
protected void addArgsToVerb() {
ParseObject v = stk.pop();
ParseVerb verb = (ParseVerb)stk.pop();
verb.addArgs(v); stk.push(verb);
}
//--------------
protected boolean toStack(int cl, int c2) {
return(stk.top().getType() == c1) &&
(stk.nextTop().getType()== c2);
}
}This class also contains the methods for manipulating objects on the stack. Each subclass implements the Interpret operation differently and reduces the stack accordingly. For example, the complete VarVarParse class is as follows:
public class VarVarParse extends InterpChain (
public boolean interpret() {
if (topStack(ParseObject.VAR, ParseObject.VAR)) {
//reduce (Var Var) to Multvar
ParseVar v = (ParseVar)stk.pop();
ParseVar v1 = (ParseVar)stk.pop();
MultVar mv = new MultVar(v1, v);
stk.push(mv);
return true;
} else
return false;
}
}
Thus in this implementation of the pattern the stack constitutes the Context participant. Each of the first five subclasses of InterpChain are NonTerminalExpression participants. The ActionVerb class, which moves the completed verb and action objects to the actionList, is the TerminalExpression participant.
The client object is the Parser class that builds the stack object list from the typed command text and constructs the Chain or Responsibility pattern from the various interpreter classes.
public class Parser implements Command {
Stack stk;
Vector actionList;
KidData kdata;
Data data;
JawtList ptable;
Chain chain;
public Parser(String line) {
stk = new Stack();
actionList = new Vector(); //actions accumulate here
buildStack(line); //construct a stack of tokens
buildChain(); //construct an interpreter chain
}
//--------------
private void buildStack(String line) {
//parse the input tokens and build a stack
StringTokenizer tok = new StringTokenizer(line);
while(tok.hasMoreElements()) {
ParseObject token = tokenizer(tok.nextToken());
if(token != null)
stk.push(token);
}
}
//--------------
private void buildChain() {
chain = new VarVarParse(); //start of the chain
VarMultvarParse vmvp = new VarMultvarParse();
chain.addChain (vmvp);
MultvarVarParse mvvp = new MultvarVarParse();
vmvp.addChain(mvvp);
VerbMultvarParse vrvp = new VerbMultvarParse();
mvvp.addChain(vrvp);
VerbVarParse vvp = new VerbVarParse();
vrvp.addChain(vvp);
VerbAction va = new VerbAction(actionList);
vvp.addChain(va);
}
The class also sends the stack through the chain until it is empty and then executes the verbs that have accumulated in the action list.
//executes parse and interpretation of command line
public void Execute() {
while (stk.hasMoreElements()) {
chain.sendToChain (stk);
}
//now execute the verbs
for (int i =0; i< actionList.size(); i++) {
Verb v = (Verb)actionList.elementAt(i);
v.setData(data, ptable);
v.Execute();
}
}
Figure 18.4shows the final visual program.

Use of the Interpreter pattern has the following consequences:
Whenever you introduce an interpreter into a program, you need to provide a simple way for the program user to enter commands in that language. This can be done via the Macro record button noted previously, or it can be done via an editable text field like the one in the previous program.
Introducing a language and its accompanying grammar requires fairly extensive error checking for misspelled terms or misplaced grammatical elements. This can easily consume a great deal of programming effort unless some template code is available for implementing this checking. Further, effective methods for notifying the users of these errors are not easy to design and implement.
In the Interpreter example in this chapter, the only error handling is that keywords that are not recognized are not converted to ParseObjects and are pushed onto the stack. Thus nothing will happen because the resulting stack sequence probably cannot be parsed successfully. Even if it can, the item represented by the misspelled keyword will not be included.
You can also consider generating a language automatically from a user interface or radio and command buttons and list boxes. While it might seem that having such an interface obviates the necessity for a language, the same requirements of sequence and computation still apply. When you must have a way to specify the order of sequential operations, a language is a good way to do so, even it that language is generated from the user interface.
The Interpreter pattern has the advantage that you can extend or revise the grammar fairly easily once you have built the general parsing and reduction tools. You can also easily add new verbs or variables once the foundation is constructed.
In the simple parsing scheme, shown in the previous Parser class, there are only six cases to consider and they are shown as a series of simple if statements. If you have many more than that, Design Patterns suggests that you create a class for each. This makes language extension easier, but it has the disadvantage of proliferating lots of similar little classes.
Finally, as the grammar's syntax becomes more complex, you run the risk of creating a hard to maintain program.
While interpreters are not commonly used for solving general programming problems, the Iterator pattern discussed in the next chapter is one of the most common ones you'll be using.