
When we first began to write this chapter, we were asked whether we could use a word other than canonicalization—after all, canonicalization cannot be found in most dictionaries. However, the term is used heavily in the computer industry, and several security issues involve canonicalization problems, so we decided it was the best fit for what we describe in this chapter.
Canonicalization refers to the process of converting data into its “canonical” representation—its simplest or most basic form. Take a name, for instance: Bryan can be represented in more than one way, including Brian, BrYaN, Br%79an (%79 is hexadecimal for the ASCII value of the letter y), or even ![]() (which uses different Latin letters). The main point is that often there is more than one way to represent data.
(which uses different Latin letters). The main point is that often there is more than one way to represent data.
In this chapter, we discuss why you should be concerned with canonicalization issues, the general testing approach for finding common file and Web-based canonicalization issues, different encodings that can be used to bypass security validations, and other techniques to fool the logic of parsers.
If your application does not use the canonical form of a name when it makes security decisions, you might have security bugs. Lots of known security bulletins involve canonicalization issues. Attackers will use the same techniques discussed throughout this chapter to work around specific blocks an application is attempting to make. An application’s parser might be able to handle some checks, but often will ignore other representations of the same data. This mistake can lead to security vulnerabilities that an attacker will exploit. Following is an example of a canonicalization vulnerability in Microsoft ASP.NET that could allow an attacker unauthorized access.
On February 8, 2005, Microsoft released a security bulletin for a canonicalization vulnerability in ASP.NET. Normally, when you access a Web site, the address looks something like http://www.contoso.com/default.aspx; however, sometimes a forward slash (/) or a backslash () can be used to represent the same path.
In this vulnerability, an attacker could bypass the security of an ASP.NET Web site because the parser in ASP.NET did not map the request to the correct URL. So if a Web site secured a request to http://www.example.com/secure/default.aspx using ASP.NET to prevent unauthorized access, an attacker could bypass the security check by accessing the site using http://www.example.com/securedefault.aspx instead.
More Info
For more information about this vulnerability, see http://www.microsoft.com/technet/security/bulletin/ms05-004.mspx.
The main methodology in testing for canonicalization issues is to determine whether your application is making security decisions based on a name of a resource, and then try to trick the parser by using other variations of that same name. Here are the basic steps to follow when looking for canonicalization issues:
Identify places where your application uses data to make security decisions or presents the user with data to make a security decision.
Try alternate representations of data to see whether you can bypass the check, such as using a forward slash instead of a backslash or tabs instead of spaces.
Use different encodings, which are discussed later in this chapter, to attempt to trick the parser.
Can you think of how many ways there are to represent a path to a single file? Look at the following examples:
Although this might seem like a lot of different ways to access the same file, more variations could be created. The following sections discuss examples like these, but the preceding list helps illustrate how easy it can be to make a bad security decision based only on the name of a resource.
Directory traversal occurs when an attacker references the parent or root folder as part of the filename and/or path and is able to coerce the target application into processing something that would otherwise be off limits to the attacker. This type of vulnerability is extremely common because many system calls programmers use automatically resolve relative file paths. For example, if a Web application must block requests to /secret, it might parse incoming requests to see whether the root folder name is equivalent to secret. Perhaps the developer understands and accounted for different encoding techniques and case-sensitivity issues in the application’s request-processing code, but can you think of a way that directory traversal techniques might fool the parser? If the request is to http://www.example.com/somedir/../secret, the parser would compare somedir to secret and so this request would not be blocked, but the canonical form of the path is /secret, which results in a canonicalization bug.
Table 12-1 shows some common symbols that can be used to help traverse directories. By including the symbols listed in the table, the following are considered equivalent:
C:WINDOWS
.WINDOWS...WINDOWS.system32drivers....system32...
Table 12-1. Common Symbols Used in Directory Traversal
Symbol | Description |
|---|---|
... (dot dot dot) | Obscure method of traversing up two directory levels or of referring to the same directory. |
.. (dot dot) | Traverses up one directory level. |
. (dot) | Refers to the same directory. |
Leading forward slash (/) or backslash () | Refers to the root directory. |
Even if an application is doing something that seems straightforward, such as blocking files based on the extension, it can be difficult to determine all of the valid possibilities that an attacker could use to bypass your check. Take the following C# sample code, for example:
// Filename is specified from user input, so block
// if it is an .exe file.
if (filename.EndsWith(".exe") == true)
{
allowUpload = false; // Block upload.
}
else
{
allowUpload = true; // Allow upload.
}This example seems pretty simple: most filenames have an extension, so checking the end of the filename for the extension you want to block seems like a good check. But the preceding code might overlook some problems. The first is that it is always better to use a “white-list” (or “allow-list”) approach when making security decisions. In this case, the code should check only for the files it allows, and then block everything else. That issue aside, there are canonicalization issues that would allow an attacker to bypass the extension check, thus causing allowUpload to equal true. For instance, if the user specified a file with any of the following extensions, and if the file is not in canonical form first, the preceding code would fail to block an .exe file from being uploaded to the server:
.exe. (trailing dot)
.EXE (different casing)
.exe%20 (hexadecimal representation of a trailing space)
Issues with trailing characters are discussed in more detail later in this chapter. The point here is to show how easy it is to bypass even filename extension checks.
At the command prompt, when you type the name of an executable, are you sure you know what application will run? Obviously, you can run applications that are not located in the current working folder. The Windows operating system launches executable files in an order based on extension precedence. If executables with the same filename but different extension exist in the same directory, the Windows operating system will launch them in the following order:
.com files
.exe files
.bat files
Because most applications do not use files with a .com extension any more, attackers can create Trojan applications that use the same filename as a legitimate executable and place the bogus file in the same directory as the actual executable. For instance, if an application is installed in C:Application and contains an executable called Program.exe, attackers might get their code to run by placing a malicious Program.com, which uses the uncommon .com extension, in the same directory. To prevent this, your application should use the full path when referring to files. Also, permissions should be set properly on the Application folder so this attack is not possible. Permissions are discussed further in Chapter 13.
Some examples of trailing characters that could cause canonicalization problems where mentioned previously. In certain environments, an illegal trailing character might be removed automatically from the filename by the system before the file is actually accessed. This behavior has caused many applications to parse filenames improperly when such characters as a dot (.) or forward slash (/) are appended to the filename. Remember, as a tester you are trying to fool the parser by providing values that slip past data validation checks, yet that are still considered the same in canonical form. Here are more ways you might be able to bypass a trailing characters check by appending characters to the extension:
.exe. (trailing dot)
.exe (trailing space after extension)
. exe (space after dot)
.exex (trailing other character)
.exe%08 (trailing nonprintable character, such as a BACKSPACE)
.e&xe (embedded ampersand)
.txt%00 (trailing null character)
.txt%0d%0a.exe (embedded carriage return/line feed, or CRLF)
.txt .exe (embedded newline character, useful in spoofing attempts because .exe is moved to the next line)
Because an application might even strip out characters from the middle of the filename, you might be able to use that behavior to bypass any checks. For instance, we tested an application that removed ampersands (&) from the filenames. It also blocked users from uploading certain file types. Unfortunately, it checked the extension prior to sanitizing the filename. Can you see the problem? We attempted to upload a file called evilfile.e&xe, and the parser did not block the filename based on the extension. Then the parser removed the “illegal” character from the filename, allowing evilfile.exe to be uploaded.
The NTFS file system supports multiple data streams for a file, meaning even though the file’s content is in the main data stream, you can create a new stream associated with the file that can be accessed as well. To create or access the additional stream, append a colon and the name of the stream to the file. Let’s look at an example. You can create a file called test.txt on the command line with the following syntax:
echo hello > test.txt
Now you can add additional content to a new data stream called newstream:
echo world > text.txt:newstream
To view the contents of the streams, use the more command. Notice the following output shows how you can access the different streams:
D:examples>more < test.txt hello D:examples>more < test.txt::$DATA hello D:examples>more < test.txt:newstream world D:examples>more < test.txt:newstream:$DATA world
Probably the most well known NTFS data stream vulnerability was the one in Microsoft Internet Information Server (IIS) 4.0 that revealed the source of the Active Server Pages (ASP) file when a user would browse to a file and append ::$DATA to the filename. Essentially, IIS did not render the contents through the ASP engine because it did not recognize the extension as the correct type; thus, it simply showed the contents of the file to the user.
More Info
For more information about this bug, see http://www.microsoft.com/technet/security/bulletin/MS98-003.asp (without the ::$DATA, of course).
Depending on how the application determines the file extension, specifying alternate data streams, such as ::$DATA, might bypass any checks. And because the data stream can also contain information, there might be a way to get an application to process that data as well. For instance, imagine that an application parses a file upon being uploaded to the server and removes all malicious input. However, there could also be data stored in the alternative data stream that would not be parsed.
Depending on the file type, including an extension might not matter on certain operating systems. For instance, you might think that on all systems Microsoft Office PowerPoint files use the .ppt extension, and that when you click a .ppt file, the file will attempt to open in PowerPoint. Some systems open files in the correct application regardless of the filename extension because the application uses the GetClassFile API to determine how to handle the file. For example, if you create a PowerPoint file called Example.ppt and rename it to Example.ext, the file will still open in PowerPoint when you double-click it. To understand why this works, refer to http://msdn.microsoft.com/library/en-us/com/html/dc3cb263-7b9a-45f9-8eab-3a88aa9392db.asp, but this example illustrates how relying only on the extension in a filename could lead to problems.
Because there are so many different ways a file or path could be represented, security decisions based on names will likely lead to canonicalization issues. Following are additional issues that programmers commonly overlook when they attempt to block certain files and paths from being accessed.
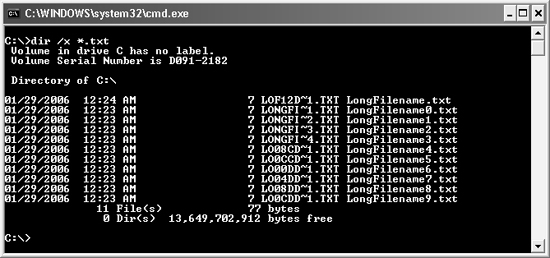
In the early days of MS-DOS and the FAT file system, filenames were restricted to using a maximum of eight characters with a three-character extension, known as 8.3 filenames. Now, file systems such as FAT32 and NTFS allow for long filenames, too. To maintain backward compatibility, the NTFS and FAT32 file systems automatically generate the 8.3 representation of a filename as well as the long filename. For example, if you have a file on your FAT32 or NTFS Windows system called LongFilename.txt, LONGFI~1.TXT will also get generated.
As you might imagine, an application that makes decisions based on a specified path and filename might somehow become vulnerable if the equivalent short filename can be specified. So if the developer checks LongFilename.txt and LONGFI~1.TXT, that should be good enough when making a security decision, right? Not exactly! The general format of the 8.3 naming convention is to include the first six characters of the long filename followed by a tilde (~), an incremental number, and then the three-digit extension. As such, a developer might use a regular expression that checks for the six characters, tilde, and then a digit to attempt to plug the hole. But this method has flaws, too. If files already exist in the same directory with filenames that start with the same first six characters of the long filename, the naming convention for the autogenerated 8.3 name changes. Look at Figure 12-1. In this example, 10 files named LongFilename0.txt to LongFilename9.txt were created before LongFilename.txt was created. As you can see, the 8.3 filename for LongFilename.txt is LOF12D~1.TXT.
Although developers can continue to refine the checks, they will more than likely miss several other cases. Instead, the canonical form and system APIs should be used when you are making decisions based off the name. Also, do not forget to combine this knowledge with what you learned earlier in this chapter about bypassing filename extension checks. For instance, if an e-mail application is supposed to block .exe attachments, what do you think happens when you can create a file called runme.exempt and e-mail it as an attachment to a recipient? The filename extension check might be bypassed, but the short filename version for the attachment file is runme~1.exe.
The file system of some operating systems, such as UNIX, is case-sensitive, meaning myfile, MyFile, and MYFILE are considered different filenames and can be located in the same directory. The Windows NTFS file system, however, is not case-sensitive, but does preserve the case of filenames. If your application restricts certain filenames, consider using alternate casing to attempt to bypass any of the casing checks.
Note
Systems that use the Portable Operating System Interface for UNIX (POSIX) on Windows perform case-sensitive name comparison on files.
Another common casing problem involves internationalization issues concerning certain characters. In the following C# code, the lowercase values of two strings are compared in a case-insensitive manner:
if (folder.ToLower() == "private")
{
throw new UnauthorizedAccessException();
}
else
{
// Allow access
}Sometimes functions, such as ToUpper or ToLower, are used to compare strings. In many cases, the preceding code might not cause a problem. However, because the system locale is used to make the conversion, the code might not work as expected in other locales, for example, Turkish. In English, there are 26 unique letters in the alphabet that can be uppercase or lowercase, such as i or I. Turkish, on the other hand, has four i’s: ![]() and i. As such, if your application prevents access to a folder called private by using code like what’s shown in the preceding example, it won’t work properly on a system set to the Turkish locale because calling ToLower on a folder called PRIVATE would result in private. Notice, the i is not dotted. The comparison would fail because in the Turkish locale, i and I are one uppercase-lowercase equivalent and i and I are another. Attackers can take advantage of this functionality if they are able to specify the encoding or if they target users of the Turkish locale.
and i. As such, if your application prevents access to a folder called private by using code like what’s shown in the preceding example, it won’t work properly on a system set to the Turkish locale because calling ToLower on a folder called PRIVATE would result in private. Notice, the i is not dotted. The comparison would fail because in the Turkish locale, i and I are one uppercase-lowercase equivalent and i and I are another. Attackers can take advantage of this functionality if they are able to specify the encoding or if they target users of the Turkish locale.
Another MS-DOS feature that also made it into the Windows operating system for backward compatibility is the use of device names. These are reserved words that refer to devices, such as COM1 for the first communications port. Examples of several device names include AUX, COM0, COM1, COM2, COM3, COM4, COM5, COM6, COM7, COM8, COM9, CON, LPT0, LPT1, LPT2, LPT3, LPT4, LPT5, LPT6, LPT7, LPT8, LPT9, NUL, PRN, and CLOCK$.
Applications that allow a user to specify filenames without ensuring the filename is not equivalent to a DOS device name can experience denial of service (DoS) attacks. For example, imagine if your application creates a file based on a name that is provided by the user. If the user specifies a name such as COM1 for the file, the application would try talking with the communication port instead of the file.
On January 8, 2005, Dennis Rand discovered a DoS in Novell eDirectory 8.7.3 if a DOS device name was specified when requesting a URL, such as http://www.example.com:8008/COM1. If an attacker made a request to a vulnerable server, the service would stop until it was restarted. Although the problem has been resolved, it shows that such vulnerabilities still exist. You can read more about this vulnerability at http://cirt.dk/advisories/cirt-33-advisory.pdf.
Note
Device name vulnerabilities are not limited to the Windows operating system; other operating systems such as UNIX also have device names that could lead to similar attacks; /dev/ttyp0, /dev/hda1, and /dev/cd0 are just a few.
If your application takes a filename as input, here are some variations you might want to test (replace COM1 with various device names):
COM1:other
Other.COM1
COM1.ext
http://www.example.com/COM1
c:somefolderCOM1file.txt
Tip
Some filenames need to be created with the CreateFile or CreateFileW API because they cannot be created using the Windows shell. There are also many illegal characters for file and folder names that you can use those APIs to create. Refer to http://msdn.microsoft.com/library/en-us/fileio/fs/naming_a_file.asp for more information about naming a file.
A Universal Naming Convention (UNC) share allows access to file and printer resources on both local and remote machines. UNC shares are treated as part of the file system, and users can access them by using a mapped drive letter or the UNC path. For example, if you have a file share named public on a machine called FranksMachine, you could create a mapped drive on a system that runs the Windows operating system by using the command net use x: \FranksMachinepublic. This would allow you to access the files on the newly mapped X drive, or you could use the UNC path notation \FranksMachinepublic to access the share.
Some applications might do simple checking to make sure that a file path specifies a UNC share, whereas other applications might allow only drive letters to be used. Either of these methods could be bypassed. Let’s say a backup application wants the backup file specified to be on a local machine. The developer might check that the first character of the path is an alphabetic character followed by a colon. Do you see a problem with this assumption? If a UNC share is mapped to a drive letter, the check will allow the file to be saved to a network share—that isn’t what the developer intended.
On the other hand, an application feature might allow saving only to a network share by using the UNC path method (to prevent a user from saving data to the local machine). If the machine on which the application is running has no UNC shares, the application shouldn’t allow the file to be saved. If the only check the developer includes is to look for two backslashes (\) at the beginning of the path, that does not ensure that only a UNC path is used because it simply ensures that the path begins with two backslashes and it does not protect the application from saving data to the local machine. Here are a few ways a malicious user could supply a path that meets the requirement of starting with two backslashes, but that still allows access to the local machine:
\FranksMachineC$
\127.0.0.1C$
\MACHINE_IP_ADDRESSC$
\?UNC127.0.0.1C$
\?c:
C$ represents a default hidden share for the C drive, also known as an administrative share. Also, ADMIN$ maps to the Windows directory. The Windows operating system automatically creates these default shares for all the local hard disk volumes and requires the user to be an administrator to access the share. Even if the administrative shares are deleted, they are re-created after you stop and start the Server service or restart the computer. To find all the shares on a machine, type net share in a command prompt. You can prevent the Windows operating system from creating these shares automatically by using the AutoShareServer and AutoShareWks registry key settings (http://support.microsoft.com/default.aspx?scid=kb;en-us;816524).
When an application is provided a filename to open, but the path is not specified, you are at the mercy of the operating system to determine which file is started. Also, if your application links to dynamic-link libraries (DLLs) without specifying the full path to the file, your application might load a malicious file rather than the one you where expecting—put in a different way, Trojan DLLs that allow arbitrary code execution. This flaw has caused problems with several applications.
Generally, the search path for loading a DLL is the following:
The set of preinstalled DLLs, such as KERNEL32.DLL and USER32.DLL
The current directory of the executable
The current working directory
The Windows system directory
The Windows directory
The directories specified by the PATH environment variable
Note
Microsoft Windows XP Service Pack 1 (SP1) and later and Windows Server 2003 change the search path so that the system directories are searched first, and then the current directory is searched. However, systems that are upgraded to Microsoft Windows XP SP1 or Windows Server 2003 still default to using the previous search algorithm when loading a DLL. It is best to make sure that you specify the full path of the file you wish to use, rather than letting the operating system decide which file to open.
To find out how your application is loading certain files, you can try the following checks:
Perform a code review to look for places where files are opened. Pay attention to how the name can be manipulated by the attacker. Look for APIs such as LoadLibrary, LoadLibraryEx, CreateProcess, CreateProcessAsUser, CreateProcessWithLogon, WinExec, ShellExecute, SearchPath, CreateFile, CreateFileW, CreateFileA, and the like to make sure the full path is specified and is quoted. Also, APIs that allow command-line arguments to be specified separately, such as CreateProcess, ideally should do so instead of passing the arguments as part of the process path.
Use Microsoft Application Verifier to make sure CreateProcess and similar APIs are called properly. Refer to http://www.microsoft.com/technet/prodtechnol/windows/appcompatibility/appverifier.mspx for more information on Application Verifier.
Attach to a running process in the debugger and see where modules and files are actually loaded from.
Some of the topics mentioned in the preceding section on file-based canonicalization issues, such as directory traversal and dealing with file extensions, also apply to Web-based applications. However, Web applications are more complex because of encoding or issues in handling URLs. In either case, great care must be taken to ensure that security decisions made off of a name are tested thoroughly.
When you read about the canonicalization issues that files have, you saw how variations like c:file.txt, \?c: est.txt, and c:windows...file.TxT could all be used to refer to the same file. With Web-based applications, encoding issues add to the problem of making security decisions based on a name. For instance, consider the following values:
%41
%u0041
%C1%81
%uFF21
%EF%BC%A1
A
All of the preceding values are equivalent to the ASCII character A, and this isn’t even a complete list. These variations illustrate some of the types of encodings that are covered in this section, including URL escaping, HTML encoding, overlong UTF-8, and more. As a security tester, you should realize how canonicalization typically offers many variations that can fool parsers if the parsers are not comparing the canonical form of the value—resulting in a security bug.
You are probably most familiar with using ASCII characters, such as A, B, #, and !. Each ASCII character has a decimal value, and those values can be converted to hexadecimal. Table 12-2 shows several ASCII values with their decimal and hexadecimal values.
More Info
A complete ASCII character code chart can be found at http://msdn.microsoft.com/library/en-us/vsintro7/html/_pluslang_ASCII_Character_Codes.asp.
Hexadecimal escape codes are just another way to represent a character. In URLs, hexadecimal characters are often used to represent some of the nonprintable characters. For example, an ampersand (&) in a URL usually is a delimiter between the name/value pairs in a query string, such as http://www.example.com/file.aspx?name1=value1&name2=value2. What happens if one of the values contains an ampersand? The programmer would not want the application to mistake the ampersand in the value for another name/value pair delimiter, so the hexadecimal escape code for the ampersand (%26) can be used. Thus, the URL would be http://www.example.com/file.aspx?name1=some%26value.
If an application fails to decode the escape characters first, and then makes a security decision based on the name, a security vulnerability might be imminent. In the ASP.NET path validation vulnerability mentioned at the beginning of the chapter, Microsoft Internet Explorer automatically replaced the backslash () with a forward slash (/) if you made a request to http://www.example.com/securesomefile.aspx. However, if you replaced the backslash with %5C (the hex value for the backslash), the request would succeed and enable you to access somefile.aspx.
The ASCII character examples in the preceding section are all 1-byte long, but many languages in the world require more than one byte to represent a character. The 8-bit Unicode Transformation Format (UTF-8) is a common encoding used for Internet URLs. UTF-8 is a variable-byte encoding scheme that allows different character sets, such as 2-byte Unicode (UCS-2; this encoding is discussed shortly), to be encoded. The following are common places where UTF-8 encodings are used:
URLs
Multipurpose Internet Mail Extensions (MIME) encodings
XML documents
Text files
More Info
For more information about the format of UTF-8, refer to RFC 2279 at http://www.faqs.org/rfcs/rfc2279.html.
Because UTF-8 can be used to encode a character with more than one byte, it can also represent a single-byte character by using any of the UTF-8 character mappings. Generally, all UTF-8 characters are shown in the shortest form, but it is possible for an attacker to use a nonshort form of a character encoding, which is known as overlong UTF-8 encoding. An attacker can use the overlong form hopefully to trick the parser, which should accept only the shortest form. Let’s look at an example. The UTF-8 representation of a forward slash (/) is 0x2F. The overlong UTF-8 equivalent of this value is any one of the following:
0xC0 0xAF
0xE0 0x80 0xAF
0xF0 0x80 0x80 0xAF
0xF8 0x80 0x80 0x80 0xAF
0xFC 0x80 0x80 0x80 0x80 0xAF
0xFE 0x80 0x80 0x80 0x80 0x80 0xAF
If the UTF-8 parser does not use the shortest form, it might consider all these representations as the same, leading to a canonicalization issue.
Using an overlong UTF-8 sequence is another way attackers can try to trick the parser into thinking a value is something else when it is actually equivalent in canonical form. To generate an overlong UTF-8 encoding of a character, you can use the tool called OverlongUTF, which is included on this book’s companion Web site. Figure 12-2 shows the overlong UTF-8 encodings of the forward slash.

Another encoding that can be used in URLs is called UCS-2 Unicode encoding. It is a lot like hexadecimal and UTF-8, but uses the format %uNNNN, where NNNN is the Unicode character value in hexadecimal. Look at the forward slash (/) character again, which had the hexadecimal value %2F. This value is the same as its UCS-2 encoding of %u002F. Having fun yet?
In Figure 12-2, notice the output also shows 0x2F has equivalent values of U+FF0F and %uFF0F. The latter two representations are the wide Unicode equivalent called the full-width version. Overlong UTF can be used to show whether a full-width version of the character is available. If there is, you can use the full-width value in hopes of fooling the parser.
You can also use the UTF-8 encoding format to represent the UCS-2 Unicode value. For example, %uFFOF in UTF-8 format is %EF%BC%8F. And, of course, even that is subject to overlong UTF-8 sequences.
You might consider trying other types of encodings, depending on your application. For instance, UTF-7 and UCS-4 can sometimes fool certain parsers. Chapter 10, gives an example of how UTF-7 can be used to encode data to fool parsers. For instance, if a Web site tries to block certain HTML tags by stripping out angle brackets (< and >), it might still be vulnerable to attack if another encoding could be used.
Internet Explorer has a feature that attempts to autoselect the encoding for a Web site. If the Web page contains characters in the first 200 bytes that use a specific encoding, Internet Explorer defaults to using that encoding unless the request explicitly specifies a particular encoding. So if the browser can be forced to use UTF-7, the attacker can use the UTF-7 encoding of the angle brackets (+ADw- and +AD4-) to bypass the filter an application might use. Normally, UTF-7 is used for mail and news transports, but that does not mean an attacker won’t use it to attempt to fool your application.
More Info
For more information about UTF-7 encoding, refer to RFC 1642 (http://www.faqs.org/rfcs/rfc1642.html).
To make matters more interesting, values can even be double-encoded in an attempt to bypass code in which the developer fails to fully decode the data. The process of double encoding takes a character from the string and essentially encodes it twice. This usually causes a problem when the application decodes the data in one place and then later decodes it again. Normally, this is not a problem when using the application because the input is not double-encoded. Look at the following examples:
Encoding the letter A one time results in A = %41.
Encoding each character in the %41 sequence results in % = %25, 4 = %34, and 1 = %31.
If you encode the A once, and then encode the percent sign, you end up with %2541.
If you encode just the 4 instead of the percent sign, you get %%341.
If you encode all the characters in %41, you get %25%34%31.
When you use the preceding technique to double-encode values, the following URLs are equivalent:
http://example/file.asp
http://example/file.%41sp
http://example/file.%2541sp
http://example/file.%%341sp
http://example/file.%25%34%31sp
Chapter 10 discusses cross-site scripting attacks in great detail, but canonicalization techniques can be used to fool parsers that are attempting to block script. Remember, if your application wants to prevent malicious data, it should accept only the safe values by using an allow list and fail on everything else. Otherwise, cases are likely to be missed.
For example, some Web applications attempt to block malicious script by looking for values such as “<script>” or “javascript:” and removing them from the input. If you can fool the parser into allowing an equivalent value to a restricted value, you will have found a bug. Let’s look at different ways characters can be represented in HTML.
The decimal value of a forward slash (/) is 47 and the hexadecimal value is 0x2F. If you create HTML files with the following content, they will all be equivalent:
<a href=“http://www.contoso.com”>Regular Value</a>
<a href=“http://www.contoso.com”>Decimal Value</a>
<a href=“http://www.contoso.com”>Hexadecimal Value</a>
You can also omit the semicolon and pad the beginning of the value with zeros, such as http://www.contoso.com. By using HTML escape codes for characters, you might be able to fool the parser that is supposed to block the malicious values. On June 3, 2004, GreyMagic published a security advisory against Yahoo!’s Web-based e-mail service. The Yahoo! mail service attempted to remove any malicious script in an e-mail; however, it missed a variation that allowed the following HTML to be embedded in an e-mail message:
<div style="background-image:url(jav
ascript:alert())">Hi!</div>
Tip
You can use the tool Web Text Converter, which is included on the book’s Web site, to escape a string or convert an escaped string back to a more readable format.
You can also escape certain characters by using a special value known as a named entity. For instance, an ampersand can be escaped as & as well as by using the decimal (&), hexadecimal (&), and UCS-2 (@) escape codes. Table 12-3 shows a few examples of HTML entities that are commonly used. A complete list is available at http://www.w3.org/TR/REC-html40/sgml/entities.html.
As mentioned earlier, a URL can use different types of encodings to represent characters. The common encodings that could lead to issues when parsing a URL include hexadecimal, UTF-8, overlong UTF-8, and UCS-2. If your application parses the URL to make security decisions, be sure to try the different encoding techniques to try and fool the parser.
In addition to encoding issues for URLs, other common problems include these:
Improper handling of SSL URLs
Improper handling of domain name parsing
Improper handling of credentials in a URL
Improper handling of a forward slash versus a backslash
We often hear people claim that their applications are secure because they use SSL. Throughout this book, you will read how SSL does not offer protection against such attacks as cross-site scripting, SQL injection, among others. In addition, applications that do not handle the URL properly when dealing with SSL also have problems. For example, to access a Web site using SSL, the https: protocol is used. If you search your source code for http:, you might find code like the following:
if (url.StartsWith("http:") == true)
{
// Handle URL.
}
else
{
// Invalid URL format, so return false.
return false;
}If so, your application might not be properly handling URLs that use SSL. Also, imagine if the code was supposed to return an error if the URL started with http:. The check could be bypassed by using https: instead. You’ll need to decide the intention of the check because the developer might have forgotten to check both http: and https:.
If your application makes decisions based on parsing the domain name, you must consider a few things. For example, how might a developer implement a check in an application to allow connections only to intranet sites? One method might be to check to make sure the Web site name does not contain any dots, such as http://contoso. This idea might seem reasonable because most Internet addresses either have one or more dots, for example, http://contoso.com, or they are in the IP address form http://207.46.130.108; but this check isn’t good enough. Other ways to fool the parser include the following:
Encoding the URL
Using dotless IP addresses
Using Internet Protocol version 6 (IPv6) formats
Important
Some browsers also allow a dot at the end of the domain name, so http://www.microsoft.com and http://www.microsoft.com. would both work. This technique could fool some parsers, especially if your application has a block list for domains.
Remember how values can be encoded to represent the same character? Depending on how the parser works, encoding an Internet address might be able to bypass the check for dots. To accomplish this exploit, %2E can be used in place of the dot because it is the hexadecimal equivalent of the dot. So the URL looks like http://contoso%2Ecom—no dots, and the check passes.
When you type in a human-readable Web address, the name resolves to an IP address. An Internet Protocol version 4 (IPv4) address is broken up into four segments that each use numbers in the range of 0 to 255. You can usually use this address to access the Web site. The IP address can then be converted into dotless form using different formats.
For example, to convert an IP address in the form of a.b.c.d (where a, b, c, and d are numbers ranging from 0 to 255) into a DWORD (32-bit) value, use the formula:
DWORD Dot-less IP = (a × 16777216) + (b × 65536) + (c + 256) + d
In this example, running 207.46.130.108 through this formula results in the value 3475931756. Browsing to http://3475931756 is the same as browsing to http://207.46.130.108.
Another method involves converting the IP address to a hexadecimal address. To accomplish this conversion, change each of the four segments from the decimal to the hexadecimal value. Using the hex format, the IP address 207.46.130.108 becomes 0xCF.0x2E.0x82.0x6C. You can then omit the dots and simply precede the beginning of the address with 0x, which results in another form of the dotless IP address: http://0xCF2E826C.
The main point is, do not make assumptions about whether the domain is on the Internet or intranet based on whether there are dots in the name. IPv6 introduces additional problems, especially because it uses colons (:) instead of dots.
Although many details about the IPv6 format are beyond the scope of this book, if your application supports this format, there are some interesting canonicalization issues you should consider.
IPv4 supports only 4.3 × 109 (or 4.3 billion) addresses; the world is slowly running out of IPv4 address spaces. IPv6, which supports 3.4 × 1038 addresses, was introduced to alleviate the problem. IPv6 uses 128-bit addresses in the format xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx (hexadecimal). IPv6 allows the zeros to be compressed or trimmed, so you can have the following:
:0000: can be compressed to :000:
:000: can be compressed to :00:
:00: can be compressed to :0:
:0: can be compressed to ::
The general rule is that a group of four zeros can be reduced to two colons as long as there isn’t more that one double colon in an address. This means 0000:0000:0000:0000:0000:0000 :0000:0001 can be reduced to simply ::1, which is also known as the loopback address.
Also, a sequence of four bytes at the end of the IPv6 address can be written in decimal format for compatibility reasons. So the following are also the same:
0000:0000:0000:0000:0000:0000:0102:0304
::102:304
::1.2.3.4
More Info
As the Internet continues to grow, more applications will need to support IPv6—which introduces additional security threats. For more information about IPv6 format, see http://www.faqs.org/rfcs/rfc3513.html.
Some Web browsers allow the user name and password to be supplied as part of the URL by using the following format:
http://username:password@server/resource.ext
This syntax can be used when users log on to a site that uses basic authentication, but it can lead to all sorts of problems. For example, look at the following URLs:
http://[email protected]
http://www.contoso.com%40www.example.com
http://www.contoso.com%40%77%77%77%2E%65%78%61%6D%70%6C%65%2E%63 %6F%6D
Where do you think they go to? All of them take you to http://www.example.com. This method of representing a URL can help in exploiting spoofing attacks, which are discussed in Chapter 6. However, think about ways this technique might fool a parser. For example, perhaps an application that is preparing to open a resource on a server wants to display the name of the server in case the user wants to cancel the action. The application verifies that the URL begins with http:// or https://, and then displays all the characters until the first nonalphanumeric character, hyphen (-), dot (.), colon (:), or the end of the string is reached. In this simple example, the application would miss the case of the percent sign (%) and at sign (@), and thus would display the incorrect server name to the user.
When testing for canonicalization issues, it might seem overwhelming for you to attempt all of the different ways to represent data. The following list provides some basic testing tips to help you get started looking for canonicalization issues.
If your application processes links or URLs that can be specified by an attacker, try different types of protocols to see what the attacker could accomplish.
If your application installs a protocol handler, try to inject arbitrary command-line arguments.
If your application processes a filename that is supplied by the user, try using different DOS device names, such as COM1.txt, file.COM1, and so forth.
When creating files for the application to use, use the CreateFile or CreateFileW API to create illegal filenames that the Windows shell won’t allow.
Use directory traversal techniques to attempt to access files from locations you shouldn’t be able to access.
Try using both the short and long versions of filenames.
Try inserting and appending encoded special characters, such as tabs, spaces, nulls, and CR/LFs.
Attempt to access files using different techniques, such as by UNC or \?.
Add illegal characters to the value to see what happens.
Use encoding techniques, such as UTF-8, UCS-2, and overlong UTF-8, to try to fool the parser.
Use double-encoding techniques, especially if you notice the application decodes the values.
Express your HTML characters using different escape codes; especially try padding with zeros.
Making security decisions based only on a name is a bad idea! As you have read, a value might be represented many ways in an equivalent format. If parsers do not handle values in their simplest forms, applications will have canonicalization issues. We have seen developers attempt to fix canonicalization bugs by adding another special case to look for when parsing; that is the wrong approach because it is extremely hard to catch all cases using that method.
Developers can avoid most canonicalization issues in their applications if they list the characters that are allowed rather than using a block list to block the bad characters. If you know specifically the input your application should allow, make sure it accepts only that input and rejects all else. Trying to block known bad input is more than likely to be error prone because the developer probably does not know the many different ways bad input can be represented, and any filters could be bypassed.