


Logical Architecture
Chapter 1, “Introduction to big data and analytics” on page 1 explained how the data reservoir can help companies meet new expectations for personalized service and in the fictitious company example saw how it can to drive radical improvements in patient care and manufacturing. Chapter 2, “Defining the data reservoir ecosystem” on page 29 described how the business might approach this, looking at culture, ethics, and overall workflow.
This chapter explains how the data reservoir is put together in more detail. It details the different functional areas of the reservoir, their roles, and responsibilities. The chapter also covers some of the key interactions with the reservoir and some considerations you might need to make when creating a data reservoir.
This chapter includes the following sections:
3.1 The data reservoir from outside
Existing processes and systems in the enterprise are already in place supporting the daily business of the organization, whether that is sales, customer service, manufacturing, support, or research and development (R&D). The business of the organization is not going to stop just because of a new data reservoir.
However, with the data reservoir in place, those processes and systems can take advantage of the easier access to data and analytics that the data reservoir offers.
Some core systems primarily provide data to the reservoir, and therefore do not get as much value in return, but the impact on them will be small. In fact, this is a key consideration. Those systems might have stringent 24 x 7 requirements, while the initial deployment of the reservoir might not require the same level of availability.
Other systems and users who are interested in analytics, reporting, and enabling new applications will be able to reap the benefits of this data that is easy to collect, but hard to manage. These systems and users can also be confident that data is not being misused. In addition, the business might decouple this analytical use from the operational systems and ensure that each remains fit for purpose.
This section describes the different kinds of external systems and users that interact with the reservoir. This is not an exhaustive list, but it is intended to provide some ideas of what might be useful to connect, and some of the considerations for doing so. These systems lie outside the control of the reservoir itself. They might be other reservoirs as well. There might also be times when you ask “should this be inside the reservoir or outside?” The answer is that it depends. Existing high quality, governed sources might be best left as is. Organization boundaries might also mean leaving data outside because the intent of the reservoir is to apply consistent governance and management throughout.
The following sections cover the systems that are shown in Figure 3-1 on page 55, starting with the lower left and working clockwise around the data reservoir.

Figure 3-1 Data reservoir’s system context
3.1.1 Other data reservoirs
You might be thinking about setting up your first data reservoir, but it is also worth considering how many you really need. A data reservoir has a governance program that determines how data is managed. It might be that you have distinct operating units that it does not make sense to bring together. Another situation might be that you have operations in different countries where rules around sharing data mean that you want to maintain easy access to data within the country, but have much tighter control over what can move between them to satisfy the applicable laws in each country.
A data reservoir can interact with other data reservoirs in a hierarchical, or peer-to-peer manner depending on the requirements. If for example multiple data reservoirs are needed on a country-by-country basis, you might decide to have a global reservoir that is fed a subset of data from the in-country data reservoirs.
Multiple data reservoirs can also provide a high degree of decoupling. Different rules, policies, and even infrastructure can be used by each country, even though for simplicity you aim to minimize those differences. Typically, a central center of excellence could document a suitable starting template for a reservoir, which could then be customized for each country.
Data reservoirs can supply or use data from each other.
3.1.2 Information sources
An organization such as EbP will have various existing systems responsible for running the business. These systems are already in place and critical to daily operations. As you start building a data reservoir, you will look to these systems to provide data that can then be analyzed.
In the past, the owners of these systems might have had frequent requests to provide regular extracts of data such as a database dump or a spreadsheet. This action could be done in an ad hoc manner or it could have been automated daily. Some other teams were picking up this data for their own use. However, from the point of view of the owner, there is no mechanism to control what happens to the data after it leaves the original system. The owner does not have any knowledge of these factors:
•Who is using their data?
•How many copies are there?
•What business decisions are being made based on their data?
The reservoir aims to provide governance in how data extracted from original systems is later used. The role of the information source is purely to make data available to the reservoir and to let the IT team running those systems get on with what they do best rather than having to respond to random requests for data.
Over time it is likely these sources could also become users of some of the data in the reservoir, adding nuggets of insight to those existing systems. This can be done using some summarized analytical data calculated in the reservoir.
Mobile and other channels
Customers and employees interact with the enterprise's IT systems in many different ways. A few years ago, this might have primarily been a web-based interaction, but these days an increasing proportion of that interaction is coming from mobile devices. These interactions are known as Systems of Engagement because these interactions have evolved beyond simple transactional systems to being much more user-centric and personalized. As the volume of Internet of Things devices takes off, users will also interact more with a myriad of devices such as within their vehicle, their heating systems, and lighting systems. The variety and volume of the data is increasing rapidly. Some data can arrive in batches, but much more can arrive as a stream of data.
Understanding this data, and deriving business value from it is one of the challenges organizations face. Therefore, all of these systems make ideal sources for the data reservoir, which needs to be able to ingest this information rapidly and reliably and ensure that it is made available for investigation and analytical use.
To engage with their users, these systems will also use data from the reservoir. For example, a mobile application might require access to a customer's segmentation or churn propensity. This might be termed summarized analytical data. Given the real-time nature of the interaction, a cache is typically used to minimize any delay to the application and maintain a high level of availability.
Systems of Record
Systems of Record manage the data around the core business of the enterprise. These systems have often been developed as stand-alone applications and can have been in existence for a long time. It is likely they are not subject to a high amount of change or redesign. However, they remain a critical source of data for the reservoir because they provide critical business information such as a list of customers, product inventory, or bank transactions.
Systems of record manage the enterprise's core data, and might include order systems, master data management, and product inventory data.
These systems are carefully managed and in general will be providers of data to the reservoir. Any use of the output from analytical processes in the reservoir by these systems is likely to be through published feeds, which are then fed back into those systems.
New sources
More data is being captured by organizations. Examples of further sources that can be explored include social media and open data.
These sources would not necessarily be seen as useful in their initial form, but by using analytics and merging with other information, can become valuable.
Many weather data sets are now made available. You might feed this information into the data reservoir to make it easy to compare user purchasing decisions with the weather at the time. Or you could look at forecasts to see not how the weather has affected a user's decision, but how what weather they think is coming next will.
Capturing social media feeds, whether by following selective accounts or sampling everything you can get your hands on (though social media) can prove useful in analyzing customer sentiment. Was that new product reviewed favorably? Does it make owners happy?
A flurry of planning applications captured from a town council could be used as an indicator of a stronger economy in a particular area. Could this be a place worth targeting for product sales?
Often it is only after experimenting with this type of data that its value can be understood.
3.1.3 Analytics Tools
Data scientists usually have a solid foundation in computer science, mathematics, and statistics, rather than substantial business knowledge. Their role is to explore different kinds of data to look at patterns so that they can understand the meaning of relationships between sets of data. They often have a thirst for new information sources to develop new ideas on how to gain value from combining that data with other sources. The tools used by the data scientists include capabilities for preparing and transforming data for analysis. They typically work with data in its original (raw) format.
Data can be accessed through the creation of a sandbox copy of the data for the data scientist to use because the data scientist will subset and transform the data as part of their work. Their activity should not affect the shared version of the data in the data reservoir. The sandbox will be accessible as an area in a file system such as Hadoop Distributed File System (HDFS) or accessible by using common mechanisms such as Java Database Connectivity (JDBC) or Open Database Connectivity (ODBC).
As the data scientists explore samples of this data, they will develop analytical models and try them out against test data. Those models can then be deployed to refinery services within the data reservoir or to operational systems outside the data reservoir.
3.1.4 Information curator
Data that is governed needs to have an owner. This person is accountable for the correct management and use of the data. When an information owner agrees to their data being copied into the reservoir, they need to ensure that the management procedures in the data reservoir will provide proper protection for this data. The management procedures are driven by the classifications assigned to the data in the data reservoirs catalog.
The creation of the description of the data in the data reservoir's catalog is called information curation. The information owner is responsible for the accuracy of this definition. However, for enterprise IT systems, the information owner is often a senior person who delegates to an information curator. The information curator understands what that data is and can describe it in an entry in the catalog. Ultimately the success of the reservoir depends on having data that is useful and findable.
The information curator manages the catalog description over time, possibly adding more details as they become known.
3.1.5 Governance, risk, and compliance team
A data reservoir has governance so that data can be relied on. This data needs to be managed and validated.
The information governance, risk, and compliance team will use the catalog to define the governance program and provide a reporting environment to demonstrate compliance to this program.
3.1.6 Line-of-business applications
Individual lines-of-business have developed, and will continue to develop, a myriad of applications. These are not managed by IT and often rely on isolated sets of data for a focused need.
As the data reservoir evolves, these applications can start to have access to a far greater variety of enterprise information than was previously available. The developers of these applications can browse through the catalog of available information sources and have confidence in what the data is, where it came from, and that they can access it in a suitable form.
These applications can access information in the reservoir through service calls and can go through a sandpit environment to isolate their usage from ongoing updates in the reservoir. In some cases, these sandpits can hold raw data sets as seen with the data scientist, but with two distinct differences:
•The line-of-business user is likely to be interested in an entire set of data rather than a sample.
•The line-of-business user might prefer to find data in a more simple or flattened format approach suitable for their need. At one extreme, this might mean something as simple as a flat CSV file for import into a spreadsheet. The View-based Interaction subsystem described in 3.4.4, “View-based interaction” is responsible for providing this simpler format.
3.1.7 Data reservoir operations
The daily operation of the data reservoir is supported by people with these roles:
•Monitor the operation of the reservoir, that is, is it working efficiently?
•Manage metadata in the repository that means ensuring that appropriate classifications schemes are in place
•Deploy changes to the infrastructure components
•Other tasks similar to any IT system
The operations team set up and manage the infrastructure that forms the data reservoir. This team includes the enterprise architect, information steward, data quality analyst, integration developer, and infrastructure operator.
3.2 Overview of the data reservoir details
Previous sections have detailed the users and systems that interact with the data reservoir. This section describes how the reservoir itself is structured from an architectural standpoint and the capabilities it offers.
The data reservoir includes three major parts (Figure 3-2):
•The data reservoir repositories where the data is stored.
•The information management and governance fabric that provides the infrastructure and middleware to operate the data reservoir.
•The data reservoir services provide the mechanisms where data is exchanged between the data reservoir and the systems and people that use it.

Figure 3-2 Top-level structure of the data reservoir
Figure 3-3 shows the major subsystems inside the data reservoir services and the information management and governance fabric that surrounds the data reservoir repositories.

Figure 3-3 Major subsystems in the data reservoir
The data reservoir services contain four subsystems:
•Enterprise IT interaction responsible for the exchange of data with the systems managed by the enterprise IT teams.
•Raw data interaction responsible for the exchange of data with the data scientists and business analyst who are creating analytics.
•Catalog services manage the descriptions of the data in the data reservoir and the definitions of how it is governed.
•View-based interaction responsible for the exchange of data with the line-of-business users.
The Information management and governance fabric has a single subsystem in the logical architecture called Information Integration and Governance.
The sections that follow describe these subsystems in more detail.
3.3 Data reservoir repositories
The data reservoir repositories provide the storage for the data in the reservoir. There are multiple types of data repository, with each being responsible for supporting a different kind of access with the data being stored in a suitable format. A particular data reservoir will not necessarily have every type of repository. It is common for a data reservoir to have multiple instances of a particular type of repository.
Each type of repository must support the appropriate service levels around performance, latency, and availability for the usage it is supporting as shown in Figure 3-4.

Figure 3-4 Types of data reservoir repositories
Different technologies can be used to satisfy the needs of these repositories, such as relational database or HDFS. However, the types are really related to the disposition of the data (that is structure, current or historical values, read/write, or read-only) used rather than the technology applied.
A data repository needs to store new information provided to it. Some transformation can occur to get data into the appropriate format, but this process depends on the data type. This process of storing new data is usually done during a staging to decouple the provider of the data from the repository itself.
A data repository will also support analytics processing deployed in it and calls to access and manage its information from other services. It also needs to publish insight and other relevant information to other reservoir components.
Users will not directly access the data repositories. Instead, access will be through a data reservoir service.
3.3.1 Historical data
This data provides a historical record of activity in the original format of the source. After this data is provisioned in the data reservoir, it is read only.
Operational history is a repository that stores a historical record of data from a system of record. This data will be stored in a similar format to the original operational data and is used for local reporting or as an archive for the system of record. Operational history repositories can also be used for applications that have been decommissioned and the data from which is being kept for compliance or reassurance reasons. Some analytics processes can also use this data.
Audit data contains collections of logs recording activity around who, what, and why in the reservoir, and can be used to understand how data is being used, or more importantly potentially misused. The guards and monitors of the data reservoir create this data.
3.3.2 Harvested data
This type of repository stores data from information sources outside of the data reservoir. This data is then available for processing and use by other reservoir services and external users or application. For example, it can be joined with other data, create subsets, add some analytical data, or be cleansed or otherwise changed into a form different from the original sources that better meets the needs of how it is going to be used.
An information warehouse is a repository that provides a consolidated historical view of data. Often it feeds the reporting data marts that provide dimensional or cube views, and other forms of traditional online analytical processing (OLAP). Its structure is optimized for high-speed analytics, and it contains a related and consolidated set of information.
A deep data repository is optimized to support data in various formats and at a large volume. Data is initially stored schema-less, although over time data structures can be applied, such as by defining hive tables.
Even if the data is largely schema-less, care needs to be taken in deciding how to structure the file and directory structure within HDFS to make it easier for users to use and process the data. This concept is discussed further in Chapter 4, “Developing information supply chains for the data reservoir” on page 75.
This is an ideal place to capture all kinds of ad hoc data that might be available, and offer the data sets for innovative analytical use within the organization
3.3.3 Deposited data
An important aspect for the data reservoir is that it enables its users not only to search for and use data put in the reservoir by others, but also makes it easy for those users to contribute their data back for others to use.
Deposited data consists of these information collections that have been stored in the data reservoir by users. This data can include various different types of data stored in different ways, such as analytics results or intermediate data. This data is often a snapshot and not actively managed or refreshed by other systems in the reservoir.
The depositor of the data is often the data owner and appropriate metadata will be entered by them into the catalog that describes the data to the best of their ability.
3.3.4 Shared operational data
These repositories store a copy of operational data within the organization. On occasion, these are in fact the only copy. Often they are updated from upstream system of record in near real time and the data might be minimally augmented on route to the repository.
Data is stored in the same format as the source and will be used as authoritative by other systems and processes within the reservoir. This data can be stored in one of these types of hubs, depending on the type of data:
•An Asset Hub stores slowly changing operational master data.
This might include customer profiles, product information, and contracts. Within the reservoir and by the reservoir users, this is seen as the authoritative source of master data. Deduplication and other quality improving techniques are applied to this data. Updates are available for publishing.
•An Activity Hub stores recent activity related to a master entity.
This is often rolled up periodically and will be used by analytical process to (for example) understand a customer's recent support calls with an organization or recent orders.
•A Code Hub is a set of code tables or mappings that are used for connecting different information sources.
The Code Hub has a canonical definition of a reference data set such as a country code. Systems that use a country code might use their own definitions, so the code hub helps map between the canonical form and the application-specific definition. This service is made available to systems outside the reservoir.
•A Content Hub contains unstructured data and appropriate metadata in a content management repository.
For example, this can be where you store business documents, legal agreements, and product specifications in their raw form. It might also include documents to publish externally such as to a website or rich media. The rich media can include audio and video such as educational material, announcements, and podcasts.
3.3.5 Descriptive data
This set of repositories is responsible for managing much of the metadata that is used for the reservoir itself to operate. These repositories need to be highly available or the reservoir will not function.
The catalog is one of the most crucial parts of the reservoir because it contains information about the systems and assets within the reservoir and the classification schemes used for those assets. It is used by some automated process to discover governance information such as information classification, by data owners to record details about their data, and by other users of the reservoir shopping for new data to use. It consists of a repository and applications for managing the information stored in the data reservoir. It is accessed through the catalog interfaces.
Information views provide definitions of simplified subsets of information that are geared towards the information user. These are typically done through federation, so this component stores information about the sources and relationships. In addition, the data is related to a semantic model that is also managed here. Search index is an index of data in the reservoir and associated metadata to enable applications to locate information they are after.
3.4 Information integration and governance
The Information Integration and Governance subsystem (Figure 3-5) includes the components necessary for managing and monitoring the use of information in the reservoir, including data mapping, movement, monitoring, and workflow. Its aim is to enforce standards on how information deployment processes are implemented and to provide a set of standard services for aiding these processes.

Figure 3-5 Information integration and governance components
The following are descriptions of the components shown in Figure 3-5:
•Information broker
The Information broker is the runtime server environment for running the integration processes that move data into and out of the data reservoir and between components within the reservoir. It typically includes an extract, transform, and load (ETL) engine for moving around data.
•Code hub
Similar to the code hub found within the shared operational data, this code hub has a canonical definition of a reference data set, such as a country code, and the specific implementation versions of this reference data set. This code hub is used primarily to facilitate transcoding of data coming into the reservoir and data feeds flowing out. Additionally, to support analytics the reference data can map the canonical forms to strings to make it easier for the analytics user and their activities.
•Staging areas
Staging areas are used to manage movement of data into, out of, and around the data reservoir, and to provide appropriate decoupling between systems.
The implementation can include database tables, directories within Hadoop, message queues, or similar structures.
•Operational governance hub
The operational governance hub provides dashboards and reports for reviewing and managing the operation of the data reservoir. Typically it is used by the following groups:
– Information owners and data stewards wanting to understand the data quality issues in the data they are responsible for that have been discovered by the data reservoir.
– Security officers interested in the types and levels of security and data protection issues that have been raised.
– The data reservoir operations team wanting to understand the overall usage and performance of the data reservoir.
•Monitor
Like any piece of infrastructure, it is important to understand how the data reservoir is performing. Are there hotspots? Are you getting more usage than you expected? How are you managing your storage?
The data reservoir has many monitor components deployed that record the activity in the data reservoir along with its availability, functionality, and performance. The management of any alerts that the monitors raise can be resolved using workflow.
•Workflow
Successful use of a data reservoir depends on various processes involving systems, users, and administrators. For example, provisioning new data into the data reservoir might involve an information curator defining the catalog entry to describe and classify the data. An information owner must approve the classifications, and an integration developer must create the data ingestion process. Workflow coordinates the work of these people. For more information, see Chapter 5, “Operating the data reservoir” on page 105.
•Guards
Guards are controls within the reservoir to enforce restrictions on access to data and related protection mechanisms. These guards can include ensuring the requesting user is authorized, data masking being applied, or certain rows of data being filtered out.
3.4.1 Enterprise IT interaction
Figure 3-6 shows the components of the Enterprise IT interaction subsystem.

Figure 3-6 Enterprise IT interaction
This area of the reservoir offers services that are primarily targeted at other enterprise applications and the IT organization rather than business and analytics users:
•Continuous analytics
Continuous analytics integrates and analyzes data in motion to provide real-time insight. This enables insights to be detected in high velocity data from real-time sources. For example, you might want to analyze streaming data from a user's interaction with a website in real-time to suggest a new product offering to them.
– Streaming analytics is the component responsible for running the analytics on streaming data in real-time.
– Event correlation provides for complex event processing based on business events that can occur over an extended period and can correlate these events to develop additional insight. Some of these events can come from insight obtained by the streaming analytics component.
•Service interfaces
Service interfaces provide the ability for outside systems to access data in the reservoir repositories, and for systems within the reservoir to query data from both inside and outside. These interfaces can be REST web services, SQL style through JDBC, or various other forms.
•Data ingestion
The ability to easily import data from a multitude of sources is one of the selling points of the data reservoir. You want to be able to capture anything easily, and to allow decisions about how that data can be used later in the process.
That being said, information needs to be incorporated into the reservoir in a controlled manner. During the process, metadata must be captured. It is also important to ensure appropriate separation between other systems and the reservoir to ensure an issue in one does not impact both. The Information Ingestion component is responsible for managing this. A staging area will often be used as part of the process to support loose coupling and ensure that delays in processing will not affect the source system.
The information ingestion component will apply appropriate policies to the incoming data, including masking, quality validation, deduplication, and will push appropriate metadata to the reservoir catalog.
Data with a known structure can be stored in a more structured repository such as a relational database, whereas less structured or mixed data can end up in a file system such as HDFS.
•Publishing feeds
Publishing feeds are responsible for distributing data from within the data reservoir to other systems external to the reservoir. This can include other analytical systems, other data reservoirs, and systems of record, but all are outside the governance control of the supplying data reservoir. Lineage for the publishing process is captured, but this might be the furthest point lineage reports are available to.
This data can be triggered by upstream changes, or run on a schedule or on demand from a user request.
A subscription table is used to manage the list of sources and the destinations they need to be published to. The destinations can involve populating a table, creating files, or messages to be posted to a queue.
During the publishing process, data transformation can occur, for example by resolving code values to alternate representations
3.4.2 Raw data interaction
Figure 3-7 shows the components of the Raw Data Interaction subsystem.

Figure 3-7 Raw data interaction components
Users of the reservoir do not access data directly. The raw data interaction component supports those who want to access data as it is stored in the reservoir repositories. They will typically be expert users such as data scientists who accessing the data through ODBC or JDBC, or by using files such as in HDFS. They might be doing ad hoc queries, search, simple analytics, or more sophisticated data exploration.
Access control and filtering are done in this layer to ensure adherence to established governance rules, and audit logs are kept of the data accessed. For example, data might need to be masked to remove personally identifiable information. Quality of service rules can also be applied to ensure that users do not overload the repositories with excessive requests that cannot be handled without adversely affecting other workloads.
A sandbox is used to provide a user with a copy of data from selected repositories that allows for a greater level of isolation from changes to the underlying data and to limit the workload impact on the rest of the reservoir. These sandboxes will be managed through their lifecycle according to applicable governance policies.
3.4.3 Catalog interfaces
Figure 3-8 illustrates the catalog interfaces subsystem.

Figure 3-8 The catalog interface subsystem
The catalog interfaces provide information about the data in the data reservoir. This includes details of the information collections (both repositories and views), the meaning and types of information stored, and the profile of the information values within each information collection.
The catalog interfaces make it possible for the users of the reservoir to find the data they need in an appropriate format. This can be data formatted for business users to use in their visualization tools or more complex data geared towards the needs of a data scientist
The data reservoir's catalog also contains definitions of policies, rules, and classifications that govern access to data by users. The interface layer is responsible for adhering to these rules and ensures that users gain access only to the data to which they are entitled. Users are also able to request provisioning of data through the catalog interface.
The catalog interfaces also allow lineage data to be retrieved so that a user can understand where data came from and what it is being used for. This data can be viewed at various levels of detail from a high-level business perspective to a detailed operational view.
Ensuring that the catalog data is available to users of the reservoir in a timely, accessible way, easily searchable, and with appropriate categorization is crucial to the success of a data reservoir. It is a key aspect in ensuring users know what data they are using, helping ensure that the reservoir does not become a data swamp.
An information curator is responsible for ensuring the associated catalog data is accurate and up-to-date and covers concepts for the subject area, and that appropriate classification is in place.
3.4.4 View-based interaction
Figure 3-9 shows the components of the view-based interaction subsystem.

Figure 3-9 View-based interaction components
This subsystem of the data reservoir contains views or copies of the data in the reservoirs repositories that either simplify the structure or improve the labeling of the attributes so they are easy to understand for business users. It provides these benefits:
•Access and feedback
Self-service provisioning helps to get information to business users with minimal delay, known characteristics, and without any additional IT involvement. To support this and improve the usefulness of the reservoir, users are able to request access to additional data and feedback on the data within the reservoir through comments, tagging, rating, and other collaboration. This can be done through interfaces such as the catalog as they search for data, or through other collaboration tools and social media.
Information views provide simplified subsets of the data reservoir repositories that are labeled with business friendly terms (Figure 3-10).

Figure 3-10 Providing views over a data reservoir repository
This component provides the ability for the business user to search for and obtain simple subsets or aggregations of data in a form more geared to them rather than to the structure of the underlying repositories. It is also labeled using business-oriented vocabulary. This makes ad hoc queries, searches, simple analytics, and data exploration much easier for these users.
The data reservoir operations team sets up useful views of data based on the data reservoir's repositories for these business users to access.
•Published
The published subsystem contains the stored copies of data. These copies can be rebuilt as required from data stored in the data reservoir repositories.
•Sandboxes
A sandbox is an area of personal storage where a copy of requested data is placed for the requester to use. These sandboxes are the same as the sandboxes in raw data interaction. They are populated from the simplified information collections designed for business users.
•Reporting data marts
The reporting data marts provide departmental/subject-oriented data marts targeted at supporting frequent line of business reports. The data is often structured as a dimensional model such as star or snowflake, and are easily used by common business reporting packages.
Data in marts will be updated incrementally as new data is made available. typically from an information warehouse.
•Object cache
To improve performance and availability to applications, some views of data can be made available through a cache. The object cache is particularly suited for systems of engagement applications because it is document-oriented, typically using the JSON format.
3.5 Component interactions
Chapter 1, “Introduction to big data and analytics” on page 1 introduced an example pharmaceutical company, EbP, where Erin was trying to address some challenges around a few initiatives being undertaken by the business. Erin proposed a data reservoir architecture to help with these initiatives. This section uses a few aspects of those scenarios to demonstrate how the components in the reservoir interact to fulfill the needs of the business.
In each interaction, the Information Broker is the engine that runs the reference steps. Workflow is used to coordinate different aspects of the process, human or system, and the monitor tracks activity and performance metrics.
3.5.1 Feeding data into the reservoir
Figure 3-11 illustrates how the components within the reservoir collaborate during the process of importing new data into the reservoir.

Figure 3-11 Bringing data into the data reservoir
Bringing data into the data reservoir involves the following steps (Figure 3-11):
•Step 1: Enterprise IT systems deposits data into an interchange area that is shared between the reservoir and Enterprise IT.
This area is managed by the reservoir, and is the handoff point from existing systems. This area is only used by the Data Ingestion subsystem and will not be available to other parts of the reservoir. This interchange area can be a combination of file systems, message queues, and other technologies, and provides isolation between the source systems and the data reservoir.
•Step 2: The data ingestion process for a particular source is started by the information broker in response to an event, a manual request, or a schedule.
•Step 3: The data ingestion process looks up configuration information for the incoming data sets in the subscription table to determine the appropriate destinations.
•Step 4: The data is placed in staging areas for the publishing feeds component for destinations outside the reservoir. This data is in the same format that arrived in the interchange area.
•Step 5: The data is placed in the data repositories inbound staging area, again in the same format that arrived in the interchange area. These repositories then incorporate this new data into their internal storage, performing any necessary transformations.
Operational lineage information from the data ingestion processes is updated in the operational governance hub. This lineage data records the source and destinations of the data along with other pertinent information about the data transformations performed on it.
3.5.2 Publishing feeds from the reservoir
Figure 3-12 looks at the other end of the process and how data within the reservoir is published back to other systems.

Figure 3-12 Publishing data from the data reservoir
Publishing data from the data reservoir involves these steps (Figure 3-12):
•Step 1: The data reservoir repositories publish interesting information to transient information collections. There is one transient information collection for each topic area.
•Step 2: An information deployment process is triggered (manual, scheduled, or on data arrival) to process the data in a transient information collection.
•Step 3: This process uses the subscription table to determine where information is to be distributed to.
•Step 4: The information deployment process posts a copy of the information to each relevant distribution mechanism.
•Step 5: The distribution mechanism can push data to the data ingestion subsystem to push to the data reservoir repositories. This action is how new insights generated by analytics are distributed between the data reservoir repositories.
•Step 6: Users pick up the data from the distribution mechanisms.
Each component also records data that allows operation lineage to be seen through the process.
3.5.3 Information integration and governance
The information integration and governance components collaborate to manage the movement of data within the data reservoir (Figure 3-13).
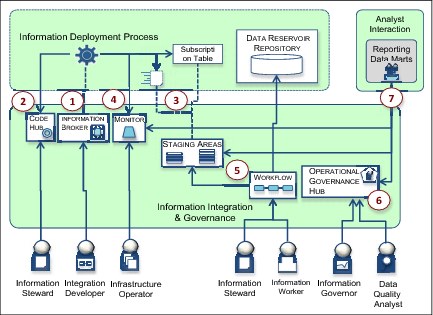
Figure 3-13 Information integration and governance interactions
The components from information integration and governance interact use the following steps (Figure 3-13).
•Step 1: Movement of information around the data reservoir is managed by an information broker. It hosts the integration processes (typically Information Deployment Processes) that transform and copy information in and out of the data reservoir repositories.
•Step 2: The integration processes use a code hub to look up code table mappings.
•Step 3: An integration process locates where to deliver data using a subscription table that lists the destination transient information collections for each relevant destination. The transient information collections are hosted in the staging areas database server.
•Step 4: The movement of information is logged by the monitor.
•Step 5: Errors discovered in the information by an integration process are recorded in a special transient information collection and are processed through stewardship workflows.
•Step 6: The policies that control the management of the data reservoir are managed in the operational governance hub.
•Step 7: Information owners and other users can see reports on the operation of the data reservoir.
3.6 Summary
This chapter provided information about the components that make up the data reservoir architecture. You should now have an understanding of each component, its role, and key interactions. In subsequent chapters, you can explore more about how data, processes, and people interact with the reservoir. Figure 3-14 shows a summary of the components of a data reservoir.

Figure 3-14 Summary of the components of a data reservoir
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.