
CHAPTER
4
Web Services

Careful design of the web services layer is critical because if you decide to use web services, this is where most of your business logic will live. Before you jump into implementation of your web services, it is important to consider whether you need them in the first place and what tradeoffs you are willing to make. There are many benefits that come with web services, such as promoting reuse and higher levels of abstraction, but there are also some drawbacks associated with them, such as higher up-front development costs and increased complexity.
To help you make these decisions, I will discuss different approaches to designing and developing web services together with some of their benefits and costs. I will also cover scalability considerations and some best practices of building scalable web services. Before we get into details of how to scale web services, let’s first have a look at different design approaches.
Designing Web Services
Initially, web applications were built using simple, monolithic architecture. At this time, all of the interactions were done using Hypertext Markup Language (HTML) and JavaScript over Hypertext Transfer Protocol (HTTP). Beginning in the mid-2000s, it became increasingly popular to expose alternative ways to interact with web applications by providing different types of application programming interfaces (APIs). This allowed companies to integrate their systems and collaborate on the Web. As the Web got bigger, the need for integration and reuse grew with it, making APIs even more popular. The most recent significant driver for API adoption came in the late 2000s with a massive mobile development wave. Suddenly, everybody wanted a mobile app and it became clear that in many cases, a mobile app was just another user interface to the same data and to the same functions that the existing web applications already had. The popularity of mobile applications helped APIs become a first-class citizen of web development. Let’s now have a look at different ways of designing APIs.
Web Services as an Alternative Presentation Layer
Arguably the oldest approach to developing web services in the context of web applications is to build the web application first and then add web services as an alternative interface to it. In this model, your web application is a single unit with extensions built on top of it to allow programmatic access to your data and functionality without the need to process HTML and JavaScript.
To explain it better, let’s consider an example. If you were building a hotel-booking website, you would first implement the front end (HTML views with some AJAX and Cascading Style Sheets [CSS]) and your business logic (usually back-end code running within some Model View Controller framework). Your website would then allow users to do the usual things like searching for hotels, checking availability, and booking hotel rooms.
After the core functionality was complete, you would then add web services to your web application when a particular need arose. For example, a few months after your product was live, you wanted to integrate with a partner company and allow them to promote your hotels. Then as part of the integration effort you would design and implement web services, allowing your partner to perform certain operations, for example, searching for hotels based on price and availability. Figure 4-1 shows how such a system might look.

Figure 4-1 Monolithic application with a web service extension
As you can see in Figure 4-1, your web application is developed, deployed, and executed as a single unit. It does not mean that you cannot have multiple servers running the exact same copy of the application. It just means that they all run the same codebase in its entirety and that there is no distinction between presentation and service layers. In fact, there is no distinct web services layer in this approach, as web services are part of a single monolithic application.
Web applications like this would usually be developed using a Model View Controller framework (like Symfony, Rails, or SpringMVC), and web services would be implemented as a set of additional controllers and views, allowing clients to interact with your system without having to go through the complexity of HTML/AJAX interactions.
Although you could argue that this approach is immature or even obsolete, I believe that there are still valid reasons for using it in some situations. The main benefit of this approach is that you can add features and make changes to your code at very high speed, especially in early phases of development. Not having APIs reduces the number of components, layers, and the overall complexity of the system, which makes it easier to work with. If you do not have any customers yet, you do not know whether your business model will work, and if you are trying to get the early minimum viable product out the door, you may benefit from a lightweight approach like this.
The second important benefit of this approach is that you defer implementation of any web service code until you have proven that your product works and that it is worth further development. Although you can develop web services very efficiently nowadays, they still add to the up-front cost. For example, when using a monolithic approach, you can simply use your native objects anywhere in your code by passing them around rather than having to add new web service functionality. Managing web service contracts and debugging issues can be very time consuming, making the difference between success and failure of your early project.
Finally, not every web application needs an API, and designing every web application with a distinct web services layer may be just unnecessary overengineering.
On the other hand, for all but the simplest of systems, the monolithic approach is the worst option from a scalability and long-term maintenance point of view. By having all of the code in a single application, you now have to develop and host it all together. It may not be a problem when you have a team of four engineers all working together in a single room, but it becomes very difficult to keep growing such a system past a single engineering team, as everyone needs to understand the whole system and make changes to the same codebase.
As your application grows in size and goes through more and more changes, the flexibility of making quick, ad hoc changes becomes less important. In turn, the separation of concerns and building higher levels of abstraction become much more important. You need to use your judgment and make tradeoffs between the two depending on your situation.
If you decide to use the monolithic approach, you need to be cautious of its potential future costs, like the need for major refactoring or rewrites. As I explained in Chapter 2, keeping coupling under control and functional partitioning are important things to consider when designing for scale. Luckily, the monolithic approach is not the only way to design your applications. Let’s have a look at the opposite end of the spectrum now: the API-first approach.
API-First Approach
The term API-first design is relatively new, and different people may define it slightly differently. I would argue that API-first implies designing and building your API contract first and then building clients consuming that API and the actual implementation of the web service. I would say it does not matter whether you develop clients first or the API implementation first as long as you have the API contract defined beforehand.
The concept of API-first came about as a solution to the problem of multiple user interfaces. It is common nowadays for a company to have a mobile application, a desktop website, a mobile website, and a need to integrate with third parties by giving them programmatic access to the functionality and data of their system.
Figure 4-2 shows how your system might look if you decided to implement each of these use cases separately. You would likely end up with multiple implementations of the same logic spread across different parts of your system. Since your web application, mobile client, and your partners each have slightly different needs, it feels natural to satisfy each of the use cases by providing slightly different interfaces. Before you realize it, you will have duplicate code spread across all of your controllers. You then face the challenge of supporting all of these implementations and applying changes and fixes to each of them separately. An alternative approach to that problem is to create a layer of web services that encapsulates most of the business logic and hides complexity behind a single API contract. Figure 4-3 shows how your application might look when using an API-first approach.
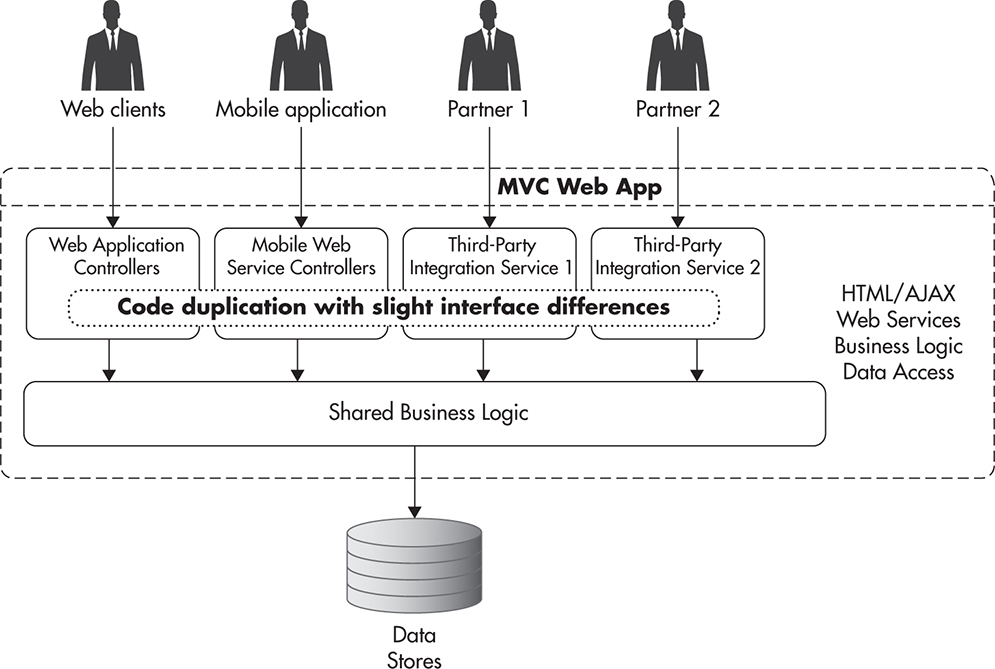
Figure 4-2 Application with multiple clients and code duplication
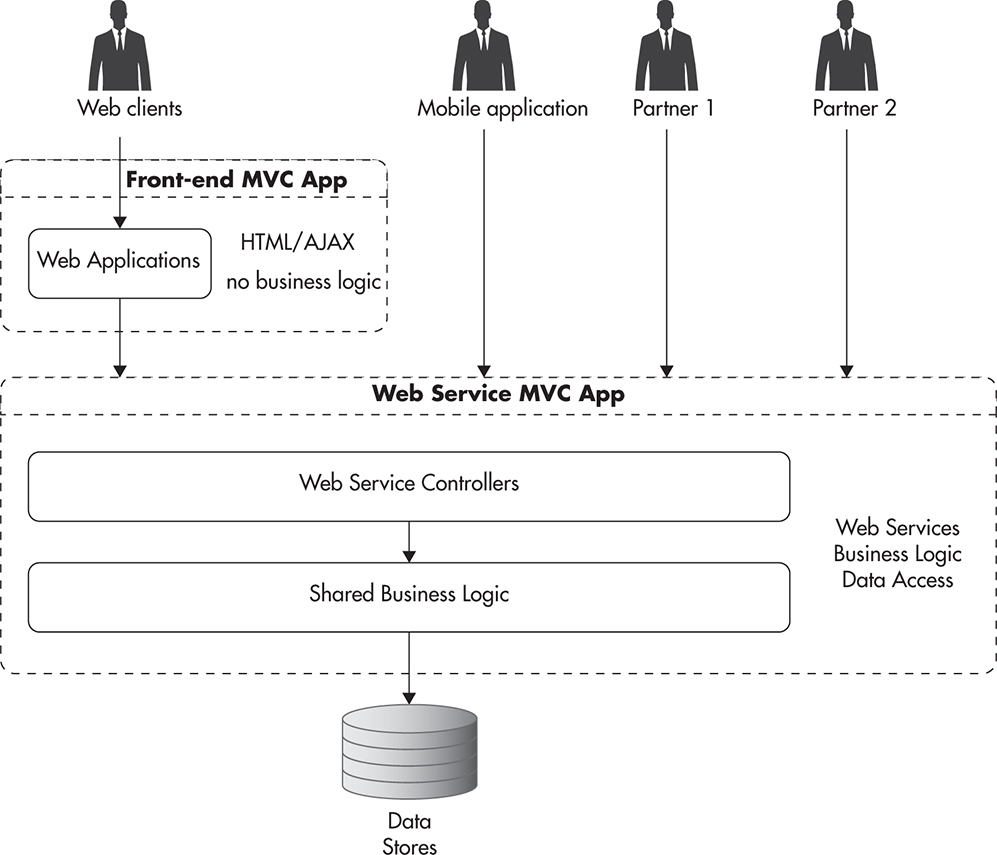
Figure 4-3 API-first application with multiple clients
In this scenario, all of your clients use the same API interface when talking to your web application. There are a few important benefits to this approach. By having a single web service with all of the business logic, you only need to maintain one copy of that code. That in turn means that you need to modify less code when making changes, since you can make changes to the web service alone rather than having to apply these changes to all of the clients.
It is also important to note that most of the complexity and business logic have been pushed away from the client code and into the web services layer. This, in turn, makes developing and changing clients much easier, as they do not have to be concerned with business rules or databases—all they need to do is know how to use a simplified interface of the API.
Having an API can also make it easier to scale your system, as you can use functional partitioning and divide your web services layer into a set of smaller independent web services. By having a higher layer of abstraction, you can decouple your clients from the internals of your web services. This decoupling helps make the system easier to understand, as you can work on the client without the need to understand how the service is implemented, and vice versa—you can work on the web service without worrying how clients are implemented or what do they do with the features your API exposes.
From a scalability point of view, having a separation of concerns helps in scaling clients and services independently. It also allows you to share the load among more servers, as different services can then use different technologies and be hosted independently to better fit their needs.
Unfortunately, the API-first approach is usually much more difficult in practice than it might sound. To make sure you do not overengineer and still provide all of the functionality needed by your clients, you may need to spend much more time designing and researching your future use cases. No matter how much you try, you still take a risk of implementing too much or designing too restrictively. That is mainly because when you are designing your API first, you may not have enough information about the future clients’ needs.
API-first should not be a mantra. Some applications will benefit from it; others will not. I believe one could generalize and say that API-first is better suited for more mature systems and more stable companies than it is for early-phase startups. Developing in this way may be a cleaner way to build software, but it requires more planning, knowledge about your final requirements, and engineering resources, as it takes more experience to design a scalable web service and make it flexible at the same time.
Pragmatic Approach
Rather than following one strategy to build every application you see, I would recommend a more pragmatic approach that is a combination of the two others. I would recommend thinking of the web services layer and service-oriented architecture from day one, but implementing it only when you see that it is truly necessary.
That means that when you see a use case that can be easily isolated into a separate web service and that will most likely require multiple clients performing the same type of functionality, then you should consider building a web service for it. On the other hand, when you are just testing the waters with very loosely defined requirements, you may be better off by starting small and learning quickly rather than investing too much upfront.
To give you an example of how you could judge that, let’s consider an example. If I were to implement a web app for a brand-new startup—let’s say I was building yet another improved selfie-editing website—I would prefer to get a prototype in front of my users as soon as possible. I would prefer to start testing the concept in a matter of weeks rather than going through detailed design, modeling, and implementation of my web services and clients. The reason is that most of these brilliant startup ideas are illusions. Once you put your product in front of the user, you realize that they don’t need it at all or, in the best-case scenario, they need something slightly different, which now you need to cater to. Until you have proven that people are willing to pay their hard-earned cash for what you are about to build, you are taking a risk of wasting time and overengineering.
On the other hand, if I was working in a startup with a few million dollars in funding or a product with a strong paying user base and I had to implement a new supporting product, I might go for the API-first approach. For example, if I was working on an e-commerce website and I had to build a product recommendation engine for an existing shopping cart website, it might be a better choice to hide that complexity behind a web service and start with an API-first approach. By having more stability and faith in my business’s decisions, it would be more important for me to make sure I can maintain and scale my products rather than learn and fail fast. By having recommendation logic encapsulated in the web service, I could provide a simple API and easily integrate these features into my existing website. In addition, it would not matter whether my original website was built with an API-first approach or not, as it would be a client of my service. As long as I can build a fairly decoupled recommendation web service, I do not care how my clients are structured.
Unfortunately, if you go for that hybrid approach, you are in for a game of tradeoffs and self-doubt—either you risk overengineering or you make a mess. As a result of that mixed approach, you are likely going to end up with a combination of tightly coupled small web applications of little business value and a set of web services fulfilling more significant and well-defined needs. Ideally, over time as your company becomes more mature, you can phase out all of the little “messy” prototypes and gradually move toward service-oriented architecture. It may work out well, but it may also become a bit of a mess as you go along. I know that it might sound strange, but trying to take constraints into consideration and making the best decision based on your current knowledge seems like the winning strategy for startups rather than following a single strict rule.
When designing web services, you will also need to choose your architectural style by choosing a type of web service that you want to implement. Let’s have a look at the options available to you.
Types of Web Services
Design and some of the implementation details of web services tend to be a topic of heated debate. I would like to encourage you to keep an open mind to alternatives and reject dogmas as much as it is possible. In that spirit, I would like to discuss two main architectural styles of web services. As we discuss each of the types, I will go into some benefits and drawbacks when it comes to scalability and speed of development, but I would prefer if you made your own judgment as to which style is more suitable for your web application. Let’s have a look at the function-centric architectural style first.
Function-Centric Services
Function-centric web services originated a long time ago—in fact, they go as far back as the early 1980s. The concept of the function-centric approach is to be able to call functions’ or objects’ methods on remote machines without the need to know how these functions or objects are implemented, in what languages are they written, or what architecture are they running on.
A simple way of thinking about function-centric web services is to imagine that anywhere in your code you could call a function (any function). As a result of that function call, your arguments and all the data needed to execute that function would be serialized and sent over the network to a machine that is supposed to execute it. After reaching the remote server, the data would be converted back to the native formats used by that machine, the function would be invoked, and then results would be serialized back to the network abstraction format. Then the result would be sent to your server and unserialized to your native machine formats so that your code could continue working without ever knowing that the function was executed on a remote machine.
In theory, that sounds fantastic; in practice, that was much more difficult to implement across programming languages, central processing unit (CPU) architectures, and run-time environments, as everyone had to agree on a strict and precise way of passing arguments, converting values, and handling errors. In addition, you had to deal with all sorts of new challenges, like resource locking, security, network latencies, concurrency, and contracts upgrades.
There were a few types of function-centric technologies, like Common Object Request Broker Architecture (CORBA), Extensible Markup Language – Remote Procedure Call (XML-RPC), Distributed Component Object Model (DCOM), and Simple Object Access Protocol (SOAP), all focusing on client code being able to invoke a function implemented on a remote machine, but after years of development and standardization processes, SOAP became the dominant technology. It was partially due to its extensibility and partially due to the fact that it was backed by some of the biggest technology companies at the time like IBM, Oracle, Sun, BEA, and Microsoft.
The most common implementation of SOAP is to use XML to describe and encode messages and the HTTP protocol to transport requests and responses between clients and servers. One of most important features of SOAP was that it allowed web services to be discovered and the integration code to be generated based on contract descriptors themselves.
Figure 4-4 shows how integration using SOAP might look. First, the web service provider exposes a set of XML resources, such as Web Service Definition Language (WSDL) files describing methods and endpoints available and definition of data structures being exchanged using XML Schema Definition (XSD) files. These resources become the contract of the web service, and they contain all the information necessary to be able to generate the client code and use the web service. For example, if you developed in Java, you would use special tools and libraries to download the contract and produce the native Java client library. The output would be a set of Java classes, which could then be compiled and used within your application. Behind the scenes, these classes would delegate to SOAP libraries encapsulating all of the data serialization, authentication, routing, and error handling. Your client code would not have to know that it uses a remote web service; it would simply use the Java library that was generated based on the web service contract (WSDL and XSD files).
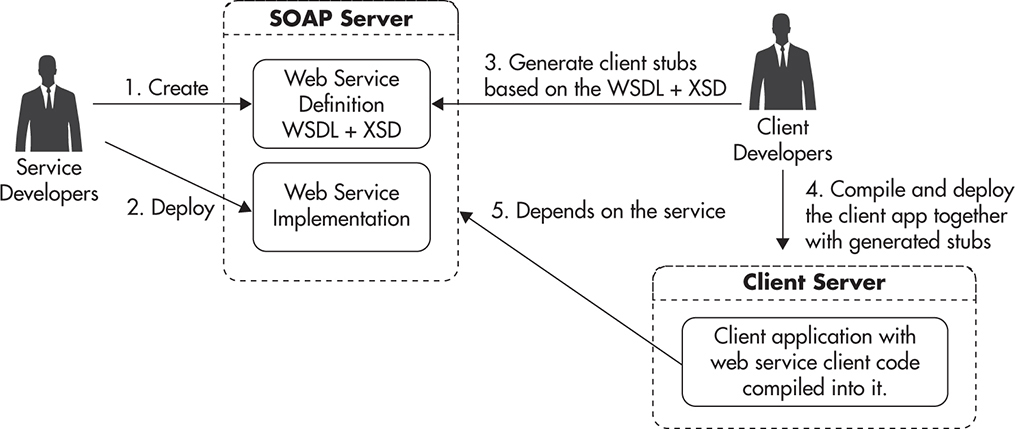
Figure 4-4 SOAP integration flow
Another important feature of the initial SOAP design was its extensibility. Over the years, literally dozens of additional specifications were created, allowing for integration of higher-level features like transactions, support for multiphase commits, and different forms of authentication and encryption. In fact, there were so many of these specifications that people began referring to them as ws-* specifications (from their names like ws-context, ws-coordination, ws-federation, ws-trust, and ws-security). Unfortunately, that richness of features came at a cost of reduced interoperability. Integration between different development stacks became more difficult, as different providers had different levels of support for different versions of ws-* specifications.
In particular, people who worked in the web development space and used dynamic languages like PHP, Ruby, Perl, or even Python found it difficult to integrate with SOAP web services. Developing client code in these technologies was usually possible, but often ran into integration issues. Developing SOAP web services using these technologies was simply not practical, as they did not get the support or funding necessary to develop needed tooling and libraries. Arguably, web technologies were excluded from the SOAP world because none of the giants would implement or support it. As a result, the Web needed an alternative to SOAP to allow integration that was easier and cheaper to implement. This, in turn, led to JavaScript Object Notation (JSON)–based Representational State Transfer (REST) services gaining popularity.
Being able to discover services and define explicit contracts are great parts of SOAP, and I wish I could easily build SOAP services. Unfortunately, the lack of tooling and libraries for dynamic languages makes it impractical to build SOAP services in these technologies. I worked with SOAP using Java and it was fine, but I also worked with it in PHP, and I believe it is not worth the effort.
The interoperability and usability of SOAP can be a concern in some situations, but something even more important to consider in the context of scalability is the fact that you cannot use HTTP-level caching with SOAP. SOAP requests are issued by sending XML documents, where request parameters and method names are contained in the XML document itself. Since the uniform resource locator (URL) does not contain all of the information needed to perform the remote procedure call, the response cannot be cached on the HTTP layer based on the URL alone. This in turn makes SOAP much less scalable in applications where the web service response could be cached by a reverse proxy.
Another serious issue with SOAP when it comes to scalability is that some of the additional ws-* specifications introduce state into the web service protocol, making it stateful. In theory, you could implement a stateless SOAP web service using just the bare minimum of SOAP-related specifications, but in practice, companies often want to use more than that. As soon as you begin supporting things like transactions or secure conversation, you forfeit the ability to treat your web service machines as stateless clones and distribute requests among them.
Although SOAP comes with high complexity and some scalability drawbacks, I learned to respect and like it to some degree. I believe that having a strict contract and ability to discover data types and functions adds significant value in corporate enthronements. If you had to integrate closely with enterprises like banks or insurance companies, you might benefit from SOAP’s advanced security and distributed computing features. On the other hand, I do not think that SOAP is a good technology to develop scalable web services, especially if you work for a startup. SOAP is no longer dominant, and if you are not forced into using it, you probably have little reason to do so, as its complexity and development overhead will slow you down significantly.
Luckily there is an alternative to SOAP. Let’s have a closer look at it now.
Resource-Centric Services
An alternative approach to developing web services focuses around the concept of a resource rather than a function. In function-centric web services, each function can take arbitrary arguments and produce arbitrary values; in resource-centric web services, each resource can be treated as a type of object, and there are only a few operations that can be performed on these objects (you can create, delete, update, and fetch them). You model your resources in any way you wish, but you interact with them in more standardized ways.
REST is an example of a resource-oriented architectural style that was developed in the early 2000s. Since then, it became the de facto standard of web application integration due to its simplicity and lightweight development model.
To understand better how you can model resources using REST, let’s consider an example of an online music website where users can search for music and create public playlists to listen to their favorite songs and share them with their friends. If you were to host such a service, you might want to expose a REST API to allow clients to search for songs and manage playlists. You could then create a “playlists” resource to allow users to create, fetch, and update their lists and a set of additional resources for each list and each song within a list.
It is important to note that REST services use URLs to uniquely identify resources. Once you know the URL of a resource, you need to decide which of the HTTP methods you want to use. Table 4-1 shows the meaning of each HTTP method when applied to the “playlists” resource of a particular user. In general, the GET method is used to fetch information about a resource or its children, the PUT method is used to replace an entire resource or a list by providing a replacement, POST is used to update a resource or add an entry, and DELETE is used to remove objects.

Table 4-1 HTTP Methods Available for the Playlists Resource
Whenever you create a new playlist using the POST request to /playlists/324 resource, you create a new playlist for user 324. The newly created list also becomes available via GET requests sent to the same resource as /playlists/324 is a parent resource for user’s playlists. Table 4-2 shows how you could interact with the /playlists/324/my-favs resource representing a custom music playlist called “my-favs” created by the user 324.

Table 4-2 HTTP Methods Available for the Selected Playlist Resource
The API could also expose additional resources—each representing a song, an album, or an artist—to allow clients to fetch additional metadata. As you can see in Table 4-3, not all methods have to be supported by each resource, as in some cases there may be no way to perform a certain operation. Table 4-3 shows how you could manage individual songs in users’ playlists.

Table 4-3 HTTP Methods Available for Playlist Member Resource
REST services do not have to use JSON, but it is a de facto standard on the Web. It became popular due to its simplicity, compact form, and better readability than XML. Listing 4-1 shows how a web service response might look when you requested a playlist entry using a GET method.
Listing 4-1 Response to GET http://example.org/playlists/324/my-favs/678632

If you wanted to compare REST to SOAP, there are a few important things that stand out. First of all, since you only have four HTTP methods to work with, the structure of REST web services is usually predictable, which also makes it easy to work with. Once you have seen a few REST services, learning to use a new REST API becomes a quick and simple task. If you compare it to SOAP service development, you will find that every web service uses a different set of conventions, standards, and ws-* specifications, making it more challenging to integrate.
From the web service publishers’ perspective, REST is more lightweight than SOAP because all you need to do is create an online wiki with definitions of resources, HTTP methods applicable to each resource, and some request/response examples showing the data model. You can implement the actual REST resources using any web stack, as very little functionality needs to be supported by the REST framework (or a container). It’s basically just an HTTP server with a routing mechanism to map URL patterns to your code. An additional benefit of REST over SOAP is that you will not have to manage the ever-more-complex API contract artifacts like WSDL and XSD files.
From a client point of view, integration with REST service has both drawbacks and benefits. Clients will not be able to auto-generate the client code or discover the web service behavior, which is a drawback. But at the same time, REST services are much less strict, allowing nonbreaking changes to be released to the server side without the need to recompile and redeploy the clients. Another common way to go around the problem of discoverability is for the service provider to build and share client libraries for common languages. This way, client code needs to be written only once and then can be reused by multiple customers/partners. Obviously, this approach puts more burden on the service provider, but allows you to reduce onboarding friction and create even better abstraction than auto-generated code would.
From a security point of view, REST services are much less sophisticated than SOAP. To allow authorized access to REST resources, web services usually require authentication to be performed before using the API. The client would first authenticate (often using OAuth 2) and then provide the authentication token in HTTP headers of each consecutive request. REST services also depend on transport layer security provided by HTTPS (HTTP over TLS Transport Layer Security) rather than implementing their own message encryption mechanisms. These tradeoffs make REST simpler to implement across web development platforms, but it also makes it harder to integrate with enterprises where you need advanced features like exactly-once delivery semantics.
From a scalability point of view, an important benefit of REST web services like the example discussed earlier in this section is that it is stateless and all public operations performed using the GET method can be cached transparently by HTTP caches. The URL of the REST request is all that is needed to route the request, so GET requests can be cached by any HTTP cache between the client and the service. That allows traffic for the most popular resources to be offloaded onto reverse proxies, significantly reducing the load put on your web services and data stores.
As you can probably see, REST is not clearly better than SOAP; it does not replace or deprecate SOAP either—it is just an alternative. From an enterprise perspective, REST may not be mature, strict, and feature rich enough. From a startup perspective, SOAP may be too difficult, strict, and cumbersome to work with. It really depends on the details of your application and your integration needs. Having said that, if all you need is to expose a web service to your mobile clients and some third-party websites, REST is probably a better way to go if you are a web startup, as it is much easier to get started with and it integrates better with web technologies no matter what stack you and your clients are developing on.
Since we have discussed types of web services and different approaches to designing them, let’s now spend some time looking at how to scale them.
Scaling REST Web Services
To be able to scale your web services layer, you will most often depend on two scalability techniques described in Chapter 2. You will want to slice your web services layer into smaller functional pieces, and you will also want to scale by adding clones. Well-designed REST web services will allow you to use both of these techniques.
Keeping Service Machines Stateless
Similar to the front-end layer of your application, you need to carefully deal with application state in your web services. The most scalable approach is to make all of your web service machines stateless. That means you need to push all of the shared state out of your web service machines onto shared data stores like object caches, databases, and message queues. Making web service machines stateless gives you a few important advantages:
![]() You can distribute traffic among your web service machines on a per-request basis. You can deploy a load balancer between your web services and their clients, and each request can be sent to any of the available web service machines. Being able to distribute requests in a round-robin fashion allows for better load distribution and more flexibility.
You can distribute traffic among your web service machines on a per-request basis. You can deploy a load balancer between your web services and their clients, and each request can be sent to any of the available web service machines. Being able to distribute requests in a round-robin fashion allows for better load distribution and more flexibility.
![]() Since each web service request can be served by any of the web service machines, you can take service machines out of the load balancer pool as soon as they crash. Most of the modern load balancers support heartbeat checks to make sure that web service machines serving the traffic are available. As soon as a machine crashes or experiences some other type of failure, the load balancer will remove that host from the load-balancing pool, reducing the capacity of the cluster, but preventing clients from timing out or failing to get responses.
Since each web service request can be served by any of the web service machines, you can take service machines out of the load balancer pool as soon as they crash. Most of the modern load balancers support heartbeat checks to make sure that web service machines serving the traffic are available. As soon as a machine crashes or experiences some other type of failure, the load balancer will remove that host from the load-balancing pool, reducing the capacity of the cluster, but preventing clients from timing out or failing to get responses.
![]() By having stateless web service machines, you can restart and decommission servers at any point in time without worrying about affecting your clients. For example, if you want to shut down a server for maintenance, you need to take that machine out of the load balancer pool. Most load balancers support graceful removal of hosts, so new connections from clients are not sent to that server any more, but existing connections are not terminated to prevent client-side errors. After removing the host from the pool, you need to wait for all of your open connections to be closed by your clients, which can take a minute or two, and then you can safely shut down the machine without affecting even a single web service request.
By having stateless web service machines, you can restart and decommission servers at any point in time without worrying about affecting your clients. For example, if you want to shut down a server for maintenance, you need to take that machine out of the load balancer pool. Most load balancers support graceful removal of hosts, so new connections from clients are not sent to that server any more, but existing connections are not terminated to prevent client-side errors. After removing the host from the pool, you need to wait for all of your open connections to be closed by your clients, which can take a minute or two, and then you can safely shut down the machine without affecting even a single web service request.
![]() Similar to decommissioning, you will be able to perform zero-downtime updates of your web services. You can roll out your changes to one server at a time by taking it out of rotation, upgrading, and then putting it back into rotation. If your software does not allow you to run two different versions at the same time, you can deploy to an alternative stack and switch all of the traffic at once on the load balancer level. No matter what way you choose, stateless web services mean easy maintenance.
Similar to decommissioning, you will be able to perform zero-downtime updates of your web services. You can roll out your changes to one server at a time by taking it out of rotation, upgrading, and then putting it back into rotation. If your software does not allow you to run two different versions at the same time, you can deploy to an alternative stack and switch all of the traffic at once on the load balancer level. No matter what way you choose, stateless web services mean easy maintenance.
![]() By removing all of the application state from your web services, you will be able to scale your web services layer by simply adding more clones. All you need to do is add more machines to the load balancer pool to be able to support more concurrent connections, perform more network I/O, and compute more responses (CPU time). The only assumption here is that your data persistence layer needs to be able to scale horizontally, but we will cover that in Chapter 5.
By removing all of the application state from your web services, you will be able to scale your web services layer by simply adding more clones. All you need to do is add more machines to the load balancer pool to be able to support more concurrent connections, perform more network I/O, and compute more responses (CPU time). The only assumption here is that your data persistence layer needs to be able to scale horizontally, but we will cover that in Chapter 5.
![]() If you are using a cloud hosting service that supports auto-scaling load balancers like Amazon Elastic Load Balancer or Azure Load Balancer, you can implement auto-scaling of your web services cluster in the same way that you did for your front end. Any time a machine crashes, the load balancer will replace it with a new instance, and any time your servers become too busy, it will spin up additional instances to help with the load.
If you are using a cloud hosting service that supports auto-scaling load balancers like Amazon Elastic Load Balancer or Azure Load Balancer, you can implement auto-scaling of your web services cluster in the same way that you did for your front end. Any time a machine crashes, the load balancer will replace it with a new instance, and any time your servers become too busy, it will spin up additional instances to help with the load.
As you can see, keeping web service machines stateless provides a lot of benefits in terms of both scalability and high availability of your system. The only type of state that is safe to keep on your web service machines are cached objects, which do not need to be synchronized or invalidated in any way. By definition, cache is disposable and can be rebuilt at any point in time, so server failure does not cause any data loss. I will discuss caching in more detail in Chapter 6. Any solution that requires consistency to be propagated across your web service machines will increase your latencies or lead to availability issues. To be sure you don’t run into these issues, it is safest to allow your web service machines to store only cached objects that expire based on their absolute Time to Live property. Such objects can be stored in isolation until they expire without the need for your web services to talk to each other.
Any time you need to store any user state on web services, you should look for alternative ways of persisting or distributing that information. Figure 4-5 shows how a stateless service communicates with external data stores, caches, and message queues to get access to persistent data. It is an implementation detail of each of the state-handling components to decide where the state should be persisted. Each of these external persistence stores can be implemented using different technologies suitable for a particular use case, or they could all be satisfied by a single data store.
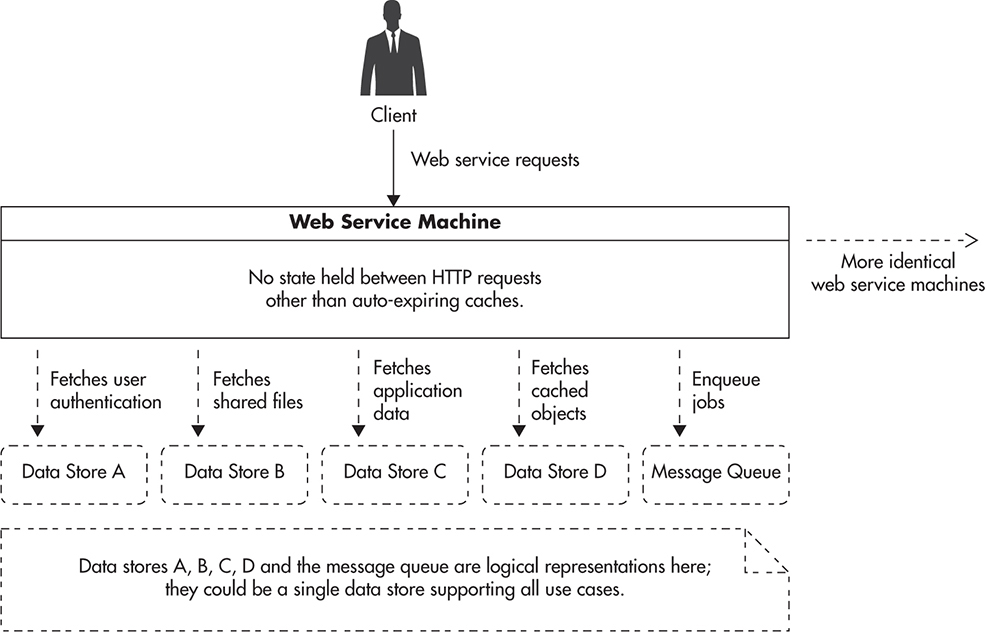
Figure 4-5 Application state pushed out of web service machines
When building stateless web services, you are going to meet a few common use cases where you will need to share some state between your web service machines.
The first use case is related to security, as your web service is likely going to require clients to pass some authentication token with each web service request. That token will have to be validated on the web service side, and client permissions will have to be evaluated in some way to make sure that the user has access to the operation they are attempting to perform. You could cache authentication and authorization details directly on your web service machines, but that could cause problems when changing permissions or blocking accounts, as these objects would need to expire before new permissions could take effect. A better approach is to use a shared in-memory object cache and have each web service machine reach out for the data needed at request time. If not present, data could be fetched from the original data store and placed in the object cache. By having a single central copy of each cached object, you will be able to easily invalidate it when users’ permissions change. Figure 4-6 shows how authorization information is being fetched from a shared in-memory object cache. I will discuss object caches in more detail in Chapter 6; for now, let’s just say that object cache allows you to map any key (like an authentication token) to an object (like a serialized permissions array).
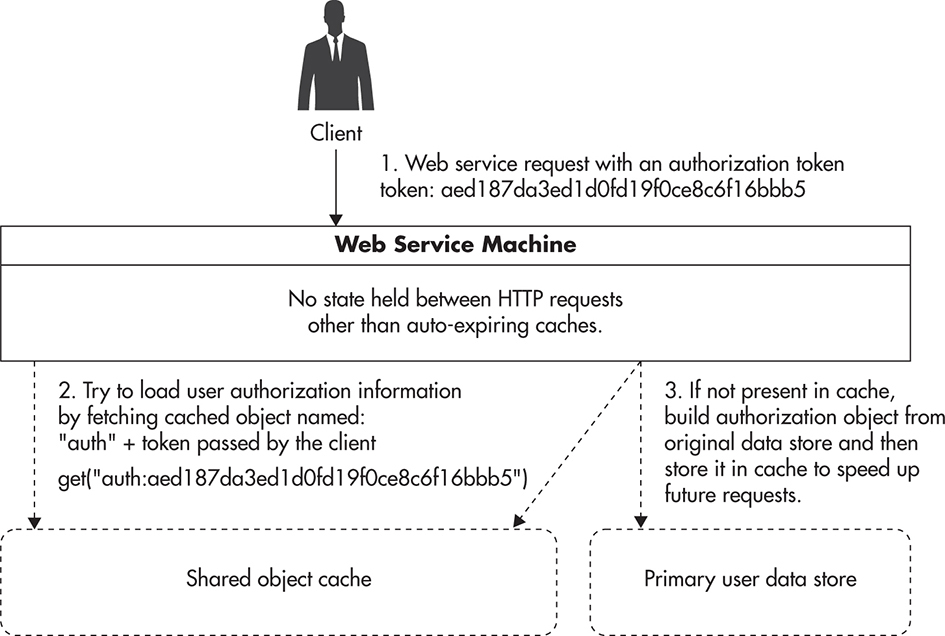
Figure 4-6 Authorization information fetched from shared object cache
Another common problem when dealing with stateless web services is how to support resource locking. As I mentioned in Chapter 3, you can use distributed lock systems like Zookeeper or even build your own simple lock service using a data store of your choice. To make sure your web services scale well, you should avoid resource locks for as long as possible and look for alternative ways to synchronize parallel processes.
Distributed locking is challenging, as each lock requires a remote call and creates an opportunity for your service to stall or fail. This, in turn, increases your latency and reduces the number of parallel clients that your web service can serve. Instead of resource locks, you can sometimes use optimistic concurrency control where you check the state before the final update rather than acquiring locks. You can also consider message queues as a way to decouple components and remove the need for resource locking in the first place (I will discuss queues and asynchronous processing in more detail in Chapter 7).
HINT
If you decide to use locks, it is important to acquire them in a consistent order to prevent deadlocks. For example, if you are locking two user accounts to transfer funds between them, make sure you always lock them in the same order, such as the account with an alphanumerically lower account number gets locked first. By using that simple trick, you can prevent deadlocks from happening and thus increase availability of your service.
If none of these techniques work for you and you need to use resource locks, it is important to strike a balance between having to acquire a lot of fine-grained locks and having coarse locks that block access to large sets of data. When you acquire a lot of fine-grained locks, you increase latency, as you keep sending requests to the distributed locks service. By having many fine-grained locks, you also risk increasing the complexity and losing clarity as to how locks are being acquired and from where. Different parts of the code acquiring many different locks is a recipe for deadlocks. On the other hand, if you use few coarse locks, you may reduce the latency and risk of deadlocks, but you can hurt your concurrency at the same time, as multiple web service threads can be blocked waiting on the same resource lock. There is no clear rule of thumb here—it is just important to keep the tradeoffs in mind.
HINT
The key to scalability and efficient resource utilization is to allow each machine to work as independently as possible. For a machine to be able to make progress (perform computation or serve requests), it should depend on as few other machines as possible. Locks are clearly against that concept, as they require machines to talk to each other or to an external system. By using locks, all of your machines become interdependent. If one process becomes slow, anyone else waiting for their locks becomes slow. When one feature breaks, all other features may break. You can use locks in your scheduled batch jobs, crons, and queue workers, but it is best to avoid locks in the request–response life cycle of your web services to prevent availability issues and increase concurrency.
The last challenge that you can face when building a scalable stateless web service is application-level transactions. Transactions can become difficult to implement, especially if you want to expose transactional guarantees in your web service contract and then coordinate higher-level distributed transactions on top of these services.
A distributed transaction is a set of internal service steps and external web service calls that either complete together or fail entirely. It is similar to database transactions, and it has the same motivation—either all of the changes are applied together to create a consistent view of the world, or all of the modifications need to be rolled back to pretend that transaction was never initiated. Distributed transactions have been a subject of study for many decades, and in simple words they are very difficult to scale and coordinate without sacrificing high availability. The most common method of implementing distributed transactions is the 2 Phase Commit (2PC) algorithm.
An example of a distributed transaction would be a web service that creates an order within an online shop. Figure 4-7 shows how such a distributed transaction could be executed. In this example, the OrderService endpoint depends on PaymentService and FulfillmentService. Failure of any of these web services causes OrderService to become unavailable; in addition, all of the collaborating services must maintain persistent connections and application resources for the duration of the transaction to allow rollback in case any components refuse to commit the transaction.
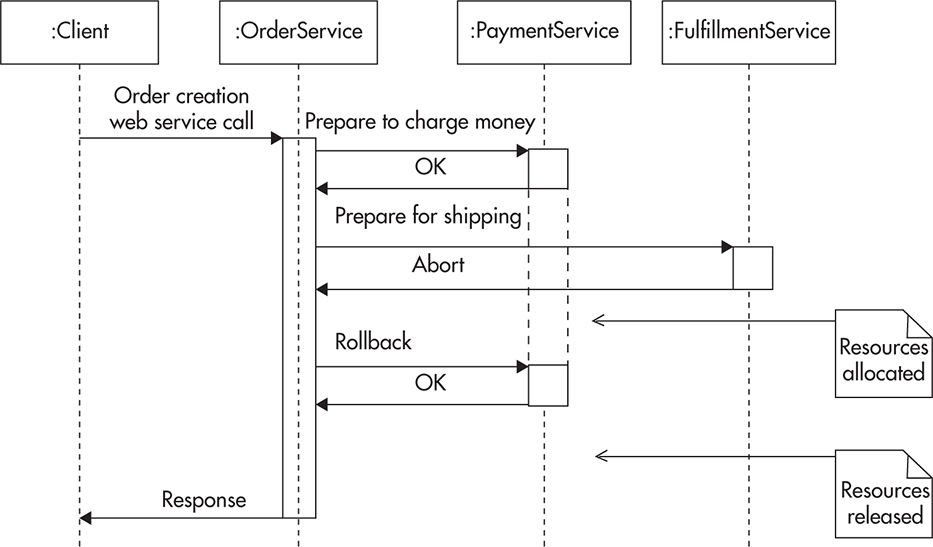
Figure 4-7 Distributed transaction failure
Distributed transactions using 2PCs are notorious for scalability and availability issues. They become increasingly difficult to perform as the number of services involved increases and more resources need to be available throughout the time of the transaction; in addition, the chance of failure increases with each new service. As a simple rule of thumb, I recommend staying away from distributed transactions and consider alternatives instead.
The first alternative to distributed transactions is to not support them at all. It may sound silly, but most startups can live with this type of tradeoff in favor of development speed, availability, and scalability benefits. For example, in a social media website, if you liked someone’s update and a part of your action did not propagate to the search index, users would not be able to search for that specific update in your event stream. Since the core of your system functionality is not compromised, your company may be fine with such a minor inconsistency in return for the time saved developing it and the costs incurred while trying to scale and maintain the solution.
The second alternative to distributed transactions is to provide a mechanism of compensating transaction. A compensating transaction can be used to revert the result of an operation that was issued as part of a larger logical transaction that has failed. Going back to the online store example, your OrderService could issue a request to a PaymentService and then another request to FulfillmentService. Each of these requests would be independent (without underlying transactional support). In case of success, nothing special needs to happen. In case of PaymentService failure, the OrderServcice would simply abort so that FulfillmentService would not receive any requests. Only in the case of PaymentService returning successfully and then FulfillmentService failing would OrderService need to issue an additional PaymentService call to ensure a refund for the previously processed payment. Figure 4-8 shows how such an optimistic approach could be executed.
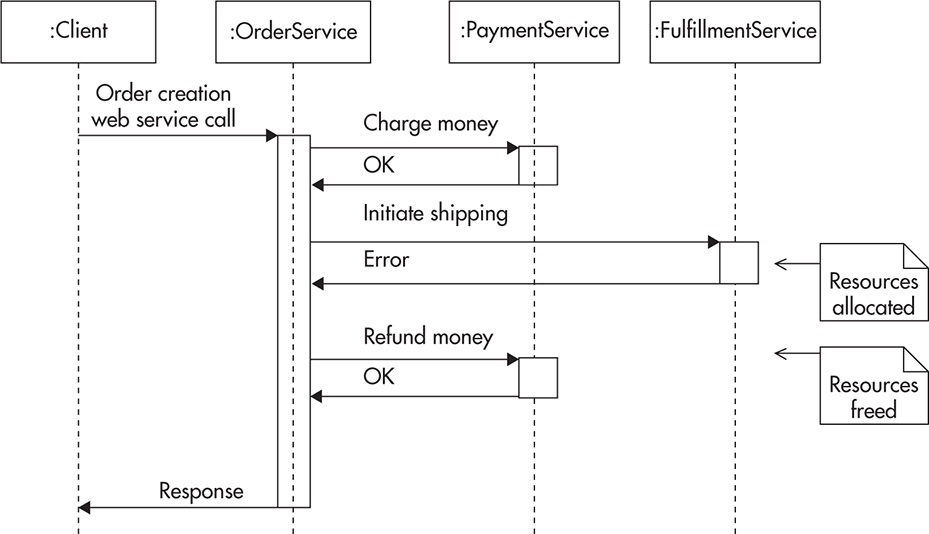
Figure 4-8 Compensating transaction to correct partial execution
The benefit of this approach is that web services do not need to wait for one another; they do not need to maintain any state or resources for the duration of the overarching transaction either. Each of the services responds to a single call in isolation. Only the coordinating web service (here the OrderService) becomes responsible for ensuring data consistency among web services. In addition, the compensating transaction can often be processed asynchronously by adding a message into a queue without blocking the client code.
In all cases, I would first question whether transactions or even locking is necessary. In a startup environment, any complexity like this adds to the overall development and support time. If you can get away with something simpler, like making your application handle failures gracefully rather than preventing them at all cost, it is usually a better choice. You should also try to lean back on your data store as much as possible using its transactional support. Most data stores support atomic operations to some degree, which can be used to implement simple “transactions” or exclusive resource access. I will discuss data stores and transactional support in more detail in Chapter 5.
Caching Service Responses
Another important technique of scaling REST web services is to utilize the power of HTTP protocol caching. HTTP caching is a powerful scalability technique for web applications. Being able to apply the same knowledge, skills, and technologies to scale your web services makes HTTP caching so much more valuable. I will discuss HTTP caching in much more detail in Chapter 6, but let’s quickly discuss how you can leverage it when building REST web services.
As I mentioned before, REST services utilize all of the HTTP methods (like GET and POST) and when implemented correctly, they should respect the semantics of each of these methods. From a caching perspective, the GET method is the most important one, as GET responses can be cached.
The HTTP protocol requires all GET method calls to be read-only. If a web service request was read-only, then it would not leave anything behind. That in turn would imply that issuing a GET request to a web service or not issuing one would leave the web service in the same state. Since there is no difference between sending a request to a web service or not sending one, responses can be cached by proxies or clients and web service calls can be “skipped” by returning a response from the cache rather than asking the web service for the response.
To take advantage of HTTP caching, you need to make sure that all of your GET method handlers are truly read-only. A GET request to any resource should not cause any state changes or data updates.
A good example of how web applications used to notoriously break this property of the GET method was by using the GET method for state changes. In the early 2000s, it was common to see web applications make changes to the database as a result of a GET request. For example, you would be able to unsubscribe from a mailing list by issuing a GET request to a URL like http://example.com/[email protected]. It might be convenient for the developers, but it would obviously change the state of the application, and there would be a clear difference between sending such a request and not sending it at all.
Nowadays it is rare to see REST web services that would break this rule in such an obvious way; unfortunately, there are other, more subtle ways to get in trouble. For example, in one of the companies I used to work for, we were unable to leverage HTTP caching on our front-end web applications because business intelligence and advertising teams depended on the web server logs to generate their reports and calculate revenue sharing. That meant that even if our web applications were implementing GET methods correctly and all of our GET handlers were read-only, we could not add a layer of caching proxies in front of our web cluster, as it would remove a large part of the incoming traffic, reducing the log entries and skewing the reports.
Another subtle way in which you can break the semantics of GET requests is by using local object caches on your web service machines. For example, in an e-commerce web application you might call a web service to fetch details of a particular product. Your client would issue a GET request to fetch the data. This request would then be routed via a load balancer to one of the web service machines. That machine would load data from the data store, populate its local object cache with the result, and then return a response to the client. If product details were updated soon after the cached object was created, another web service machine might end up with a different version of the product data in its cache. Although both GET handlers were read-only, they did affect the behavior of the web service as a whole, since now, depending on which web service machine you connect to, you might see the old or the new product details as each GET request created a snapshot of the data.
Another important aspect to consider when designing a REST API is which resources require authentication and which do not. REST services usually pass authentication details in request headers. These headers can then be used by the web service to verify permissions and restrict access. The problem with authenticated REST endpoints is that each user might see different data based on their permissions. That means the URL is not enough to produce the response for the particular user. Instead, the HTTP cache would need to include the authentication headers when building the caching key. This cache separation is good if your users should see different data, but it is wasteful if they should actually see the same thing.
HINT
You can implement caching of authenticated REST resources by using HTTP headers like Vary: Authorization in your web service responses. Responses with such headers instruct HTTP caches to store a separate response for each value of the Authorization header (a separate cache for each user).
To truly leverage HTTP caching, you want to make as many of your resources public as possible. Making resources public allows you to have a single cached object for each URL, significantly increasing your cache efficiency and reducing the web service load.
For example, if you were building a social music website (like www.grooveshark.com) where users can listen to music and share their playlists, you could make most of your GET handlers public. Would you need to restrict which users can get details of which album, song, artist, or even playlist? Probably not. By making GET methods public, you could ignore user information in your caching layer, thereby reusing objects much more efficiently.
In the early stages of your startup development, you may not need HTTP caching in your web services layer, but it is worth thinking about. HTTP caching is usually implemented in the web services layer in a similar way to how it is done in the front-end layer. To be able to scale using cache, you would usually deploy reverse proxies between your clients and your web service. That can mean a few different things depending on how your web services are structured and how they are used. Figure 4-9 shows how web services are usually deployed with a reverse proxy between web services and the front-end application.
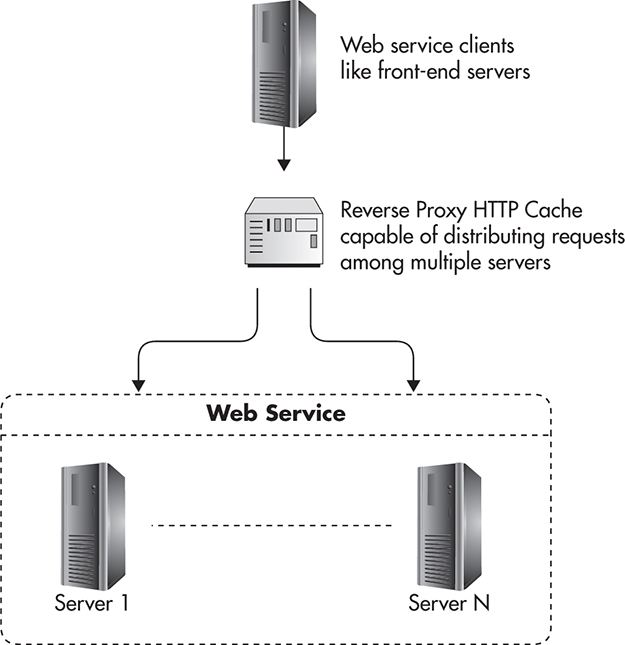
Figure 4-9 Reverse proxy between clients and services
As your web services layer grows, you may end up with a more complex deployment where each of your web services has a reverse proxy dedicated to cache its results. Depending on the reverse proxy used, you may also have load balancers deployed between reverse proxies and web services to distribute the underlying network traffic and provide quick failure recovery. Figure 4-10 shows how such a deployment might look.
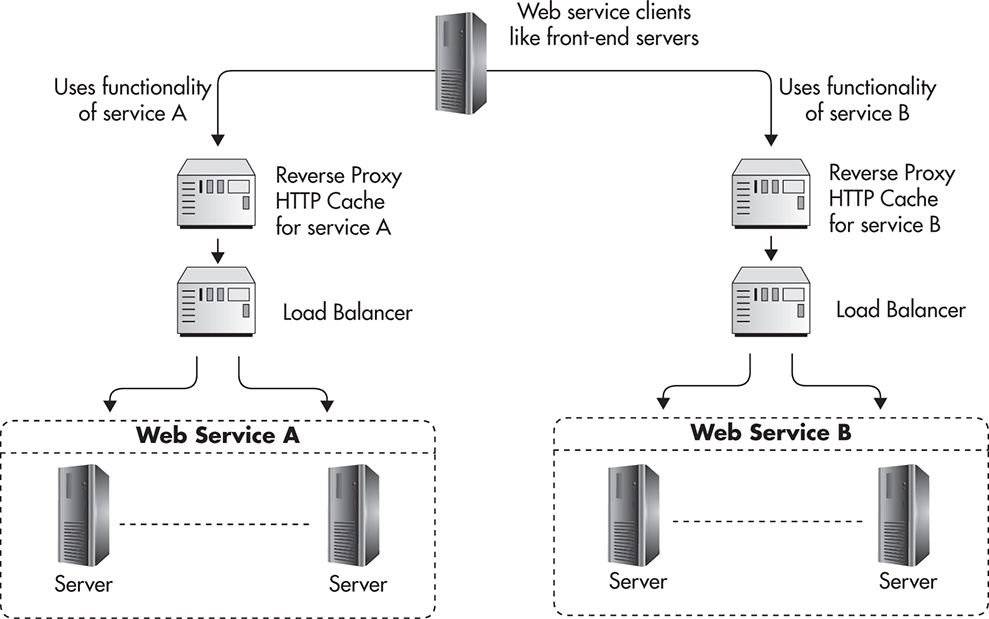
Figure 4-10 Reverse proxy in front of each web service
The benefit of such configuration is that now every request passes via a reverse proxy, no matter where it originated from. As your web services layer grows and your system evolves towards a service-oriented architecture, you will benefit more from this mindset. Treating each web service independently and all of its clients in the same way no matter if they live in the web services layer or not promotes decoupling and higher levels of abstraction. Let’s now discuss in more detail how web service independence and isolation help scalability.
Functional Partitioning
I already mentioned functional partitioning in Chapter 2 as one of the key scalability techniques. At its core, functional partitioning can be thought of as a way to split a large system into a set of smaller, loosely coupled parts so that they can run across more machines rather than having to run on a single, more powerful server. In different areas, functional partitioning may refer to different things. In the context of web services, functional partitioning is a way to split a service into a set of smaller, fairly independent web services, where each web service focuses on a subset of functionality of the overall system.
To explain it better, let’s consider an example. If you were to build an e-commerce website, you could build all of the features into a single web service, which would then handle all of the requests. Figure 4-11 shows how your system might look.
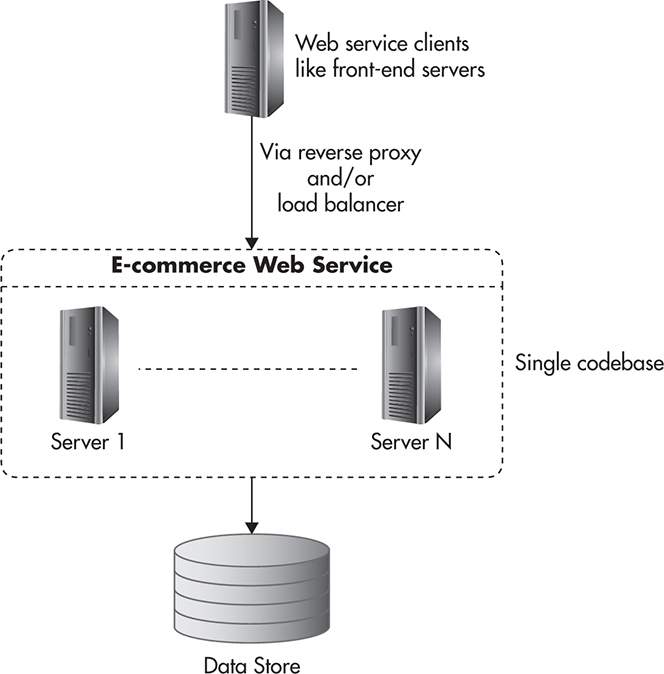
Figure 4-11 Single service
Alternatively, you could split the system into smaller, loosely coupled web services, with each one focusing on a narrow area of responsibility. An example of how you could perform such a split is to extract all of the product catalog–related functionality and create a separate web service for it called ProductCatalogService. Such a service could allow creation, management, and searching for products; their descriptions; prices; and classifications. In a similar way, you could then extract all of the functionality related to the users, such as managing their accounts, updating credit card details, and printing details of past orders, and create a separate UserProfileService.
Rather than having a single large and potentially closely coupled web service, you would end up with two smaller, more focused, and more independent web services: ProductCatalogService and UserProfileService. This would usually lead to decoupling their infrastructures, their databases, and potentially their engineering teams. In a nutshell, this is what functional partitioning is all about: looking at a system, isolating subsets of functionality that are closely related, and extracting that subset into an independent subsystem.
Figure 4-12 shows how these web services might look. The benefit of functional partitioning is that by having two independent subsystems, you could give them at least twice as much hardware, which can be helpful, especially in the data layer and especially when you use classical relational database engines, which are difficult to scale.
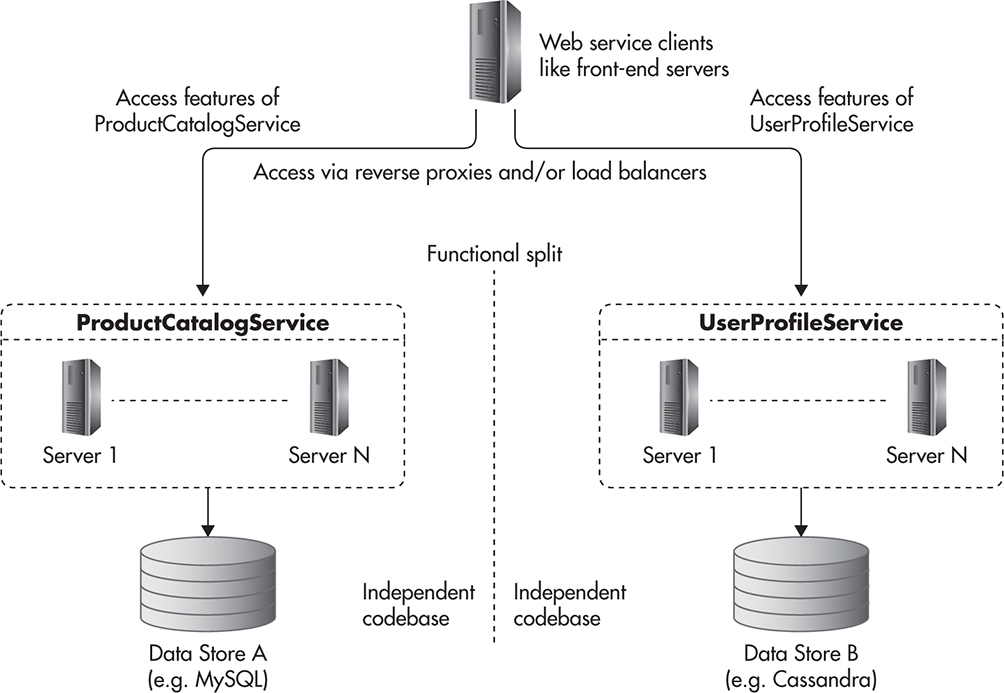
Figure 4-12 Functional partitioning of services
Since you perform functional partitioning by grouping closely related functionality, there are few dependencies between newly created web services. It may happen that a user-related service refers to some products in the product catalog or that some statistics in a product catalog are derived from the user service data, but most of the time, development and changes can be made in isolation, affecting only one of the services. That allows your technology team to grow, as no one needs to know the entire system any more to be able to make changes, and teams can take ownership of one or more web services but do not need to work on the entire codebase.
Another important effect of functional partitioning is that each of these web services can now be scaled independently. When we think about the ProductCatalogService, it will probably receive substantially more read requests than data updates, as every search and every page view will need to load the data about some products. The UserProfileService, on the other hand, will most likely have a completely different access pattern. Users will only ever want to access their own data (which can help in indexing and distributing the data efficiently), and there may be more writes, as you may want to keep track of which users viewed which products. Finally, your data set may be orders of magnitude larger, as the number of users usually grows faster than the number of products in an online store.
All of these differences in access patterns result in different scalability needs and very different design constraints that apply to each of the services. Does it make sense to use the same caching for both of the services? Does it make sense to use the same type of data store? Are both services equally critical to the business, and is the nature of the data they store the same? Do you need to implement both of these vastly different web services using the same technology stack? It would be best if you could answer “no” to these questions. By having separate web services, you keep more options open; you allow yourself to use the best tool for the job and scale according to the needs of each web service rather than being forced to apply the same pattern across the board.
It may not be necessary in small early-phase startups, but as your system grows and you begin to functionally partition your web services layer, you move closer to the service-oriented architecture, where web services are first-class citizens and where single responsibility, encapsulation, and decoupling are applied on a higher level of abstraction. Rather than on a class or component level, you apply the same design principles on the web service level to allow flexibility, reuse, and maintainability of the overall system.
The main challenge that may be an outcome of performing functional partitioning too early or of creating too many partitions is when new use cases arise that require a combination of data and features present in multiple web services. Going back to our e-commerce example, if you had to create a new RecommendationService, you might realize that it depends on the majority of product catalog data and user profile data to build user-specific recommendation models. In such a case, you may end up having much more work than if both of these services shared a single data store and a single codebase because now RecommendationService will need to integrate with two other web services and treat them as independent entities. Although service integrations may be challenging, functional partitioning is a very important scalability technique.
Summary
Well-designed and well-structured web services can help you in many ways. They can have a positive impact on scalability, on the cost of long-term maintenance, and on the local simplicity of your system, but it would be irresponsible to say that they are a must-have or even that every application can benefit from having a web services layer. Young startups work under great uncertainty and tremendous time pressure, so you need to be more careful not to overengineer and not to waste precious time developing too much upfront. If you need services to integrate with third parties or to support mobile clients, build them from the start, but service-oriented architecture and web services begin to truly shine once your tech team grows above the size of one or two agile teams (more than 10 to 20 engineers).
I encourage you to study more on web services46,51 on REST and modern approaches to building web services,20 as well as on SOAP31 and on service-oriented architecture patterns.
Building scalable web services can be done relatively simply by pushing all of the application state out of the web service machines and caching aggressively. I am sure you are already thinking, “So where do we store all of this state?” or “How do we ensure that we can scale these components as much as we scaled front-end and web services layers? These are both great questions, and we are about to begin answering them as we approach the most exciting and most challenging area for scalability, which is scalability of the data layer.