
Chapter 3. Electronic Discovery
James O. Holley, Paul H. Luehr, Jessica Reust Smith and Joseph J. Schwerha IV
Contents
Introduction to Electronic Discovery63
Legal Context66
Case Management74
Identification of Electronic Data78
Forensic Preservation of Data83
Data Processing106
Production of Electronic Data130
Conclusion132
Cases132
References132
Introduction to Electronic Discovery
Electronic discovery or “e-discovery” is the exchange of data between parties in civil or criminal litigation. The process is largely controlled by attorneys who determine what data should be produced based on relevance or withheld based on claims of privilege. Forensic examiners, however, play crucial roles as technical advisors, hands-on collectors, and analysts.
Some examiners view electronic discovery as a second-class endeavor, void of the investigative excitement of a trade secret case, an employment dispute, or a criminal “whodunit.” These examiners, however, overlook the enormous opportunities and challenges presented by electronic discovery. In sheer economic terms, e-discovery dwarfs traditional digital forensics and will account for $10.67 billion in estimated revenues by 2010 (Socha & Gelbman, 2008a).
This financial projection reflects the high stakes in e-discovery, where the outcome can put a company out of business or a person in jail. Given the stakes, there is little room for error at any stage of the e-discovery process—from initial identification and preservation of evidence sources to the final production and presentation of results. Failing to preserve or produce relevant evidence can be deemed spoliation, leading to fines and other sanctions.
In technical terms, electronic discovery also poses a variety of daunting questions: Where are all the potentially relevant data stored? What should a company do to recover data from antiquated, legacy systems or to extract data from more modern systems like enterprise portals and cloud storage? Does old data need to be converted? If so, will the conversion process result in errors or changes to important metadata? Is deleted information relevant to the case? What types of false positives are being generated by keyword hits? Did the tools
In Coleman v. Morgan Stanley, after submitting a certificate to the court stating that all relevant e-mail had been produced, Morgan Stanley found relevant e-mail on 1600 additional backup tapes. The judge decided not to admit the new e-mail messages, and based on the company's failure to comply with e-discovery requirements, the judge issued an “adverse inference” to the jury, namely that they could assume Morgan Stanley had engaged in fraud in the underlying investment case. As a result, Morgan Stanley was ordered to pay $1.5 billion in compensatory and punitive damages. An appeals court later overturned this award, but the e-discovery findings were left standing, and the company still suffered embarrassing press like the The Wall Street Journal article, “How Morgan Stanley botched a big case by fumbling e-mails” (Craig, 2005).
Confusion over terminology between lawyers, forensic examiners, and lay people add to the complexity of e-discovery. For instance, a forensic examiner may use the term “image” to describe a forensic duplicate of a hard drive, whereas an IT manager may call routine backups an “image” of the system, and a lawyer may refer to a graphical rendering of a document (e.g., in TIFF format) as an “image.” These differing interpretations can lead to misunderstandings and major problems in the e-discovery process, adding frustration to an already pressured situation.
Fortunately, the industry is slowly maturing and establishing a common lexicon. Thanks to recent definitions within the 2006 amendments to the U.S. Federal Rules of Civil Procedure (F.R.C.P.), attorneys and examiners now typically refer to e-discovery data as ESI—short for Electronically Stored Information. This term is interpreted broadly and includes information stored on magnetic tapes, optical disks, or any other digital media, even if it is not technically stored in electronic form. In addition, George Socha and Thomas Gelbman have created a widely accepted framework for e-discovery consulting known as the Electronic Discovery Reference Model (EDRM). Shown in Figure 3.1, the EDRM breaks down the electronic discovery process into six different stages.
 |
| Figure 3.1 Diagram of the Electronic Discovery Reference Model showing stages from left to right (Socha & Gelbman, 2008a). |
The first EDRM stage involves information management and the process of “getting your electronic house in order to mitigate risk & expenses should electronic discovery become an issue.” (Socha & Gelbman, 2008a). The next identification stage marks the true beginning of a specific e-discovery case and describes the process of determining where ESI resides, its date range and format, and its potential relevance to a case. Preservation and collection cover the harvesting of data using forensic or nonforensic tools. The processing stage then covers the filtering of information by document type, data range, keywords, and so on, and the conversion of the resulting data into more user-friendly formats for review by attorneys. At this stage, forensic examiners may be asked to apply their analysis to documents of particular interest to counsel. During production, data are turned over to an opposing party in the form of native documents, TIFF images, or specially tagged and encoded load files compatible with litigation support applications like Summation or Concordance. Finally, during the presentation stage, data are displayed for legal purposes in depositions or at trial. The data are often presented in their native or near-native format for evidentiary purposes, but specific content or properties may be highlighted for purposes of legal argument and persuasion.
The Electronic Discovery Reference Model outlines objectives of the processing stage, which include: “1) Capture and preserve the body of electronic documents; 2) Associate document collections with particular users (custodians); 3) Capture and preserve the metadata associated with the electronic files within the collections; 4) Establish the parent-child relationship between the various source data files; 5) Automate the identification and elimination of redundant, duplicate data within the given dataset; 6) Provide a means to programmatically suppress material that is not relevant to the review based on criteria such as keywords, date ranges or other available metadata; 7) Unprotect and reveal information within files; and 8) Accomplish all of these goals in a manner that is both defensible with respect to clients’ legal obligations and appropriately cost-effective and expedient in the context of the matter.”
This chapter explores the role of digital forensic examiners throughout these phases of e-discovery, particularly in large-scale cases involving disputes between organizations. It addresses the legal framework for e-discovery as well as unique forensic questions that arise around case management, identification and collection of ESI, and culling and production of data. Finally, this chapter describes common pitfalls in the complex, high-stakes field of e-discovery, with the goal of helping both new and experienced forensic examiners safely navigate this potential minefield.
Legal Context
In the past few years, the complexity of ESI and electronic discovery has increased significantly. The set of governing regulations has become so intricate that even professionals confess that they do not understand all the rules. A 2008 survey of in-house counsel found that 79% of the 203 respondents in the United States and 84% of the 200 respondents in the United Kingdom were not up to date with ESI regulations (Kroll Ontrack, 2008). Although it is beyond the scope of this chapter to cover all aspects of the legal context of discovery of ESI, the points that are most relevant to digital investigators are presented in this section.
This chapter focuses on the requirements of the United States, but digital examiners should be aware that even more stringent requirements may be present when evidence is in foreign countries. Most of Europe, for example, affords greater privacy protections to individuals in the workplace. Therefore, in countries such as France, it is often necessary to obtain the consent of an employee before conducting a search on his or her work computer. The very acts of imaging and reviewing a hard drive also may be subject to different country-specific regulations. Spanish rules, for instance, may require examiners to image a hard drive in the presence of a public notary, and analysis may be limited to information derived from specific keyword searches, not general roaming through an EnCase file. Thus, a civil examination in that country may look more like a computer search, which is subject to a criminal search warrant in the United States. For more information on conducting internal investigations in European Union countries, see Howell & Wertheimer (2008).
Legal Basis for Electronic Discovery
In civil litigation throughout the United States, courts are governed by their respective rules of civil procedure. Each jurisdiction has its own set of rules, but the rules of different courts are very similar as a whole. 1 As part of any piece of civil litigation, the parties engage in a process called discovery. In general, discovery allows each party to request and acquire relevant, nonprivileged information in possession of the other parties to the litigation, as well as third parties (F.R.C.P. 26(b)). When that discoverable information is found in some sort of electronic or digital format (i.e., hard disk drive, compact disc, etc.), the process is called electronic discovery or e-discovery for short.
1For the purposes of this chapter, we are concentrating on the Federal Rules of Civil Procedure; however, each state has its own set of civil procedures.
The right to discover ESI is now well established. On December 1, 2006, amended F.R.C.P. went into effect and directly addressed the discovery of ESI. Although states have not directly adopted the principles of these amendments en masse, many states have changed their rules to follow the 2006 F.R.C.P. amendments.
ESI Preservation: Obligations and Penalties
Recent amendments to various rules of civil procedure require attorneys—and therefore digital examiners—to work much earlier, harder, and faster to identify and preserve potential evidence in a lawsuit. Unlike paper documents that can sit undisturbed in a filing cabinet for several years before being collected for litigation, many types of ESI are more fleeting. Drafts of smoking-gun memos can be intentionally or unwittingly deleted or overwritten by individual users, server-based e-mail can disappear automatically following a system purge of data in a mailbox that has grown too large, and archived e-mail can disappear from backup tapes that are being overwritten pursuant to a scheduled monthly tape rotation.
Just how early attorneys and digital examiners need to act will vary from case to case, but generally they must take affirmative steps to preserve relevant information once litigation or the need for certain data is foreseeable. In some cases like employment actions, an organization may need to act months before a lawsuit is even filed. For example, in Broccoli v. Echostar Communications, the court determined that the defendant had a duty to act when the plaintiff communicated grievances to senior managers one year before the formal accusation. Failure to do so can result in severe fines and other penalties such as described next.
The seminal case of Zubulake v. UBS Warburg outlined many ESI preservation duties in its decision. Laura Zubulake was hired as a senior salesperson to UBS Warburg. She eventually brought a lawsuit against the company for gender discrimination, and she requested, “all documents concerning any communication by or between UBS employees concerning Plaintiff.” UBS produced about 100 e-mails and claimed that its production was complete, but Ms. Zubulake's counsel learned that UBS had not searched its backup tapes. What began as a fairly mundane employment action turned into a grand e-discovery battle, generating seven different opinions from the bench and resulting in one of the largest jury awards to a single employee in history.
The court stated that “a party or anticipated party must retain all relevant documents (but not multiple identical copies) in existence at the time the duty to preserve attaches, and any relevant documents created thereafter,” and outlined three groups of interested parties who should maintain ESI:
▪ Primary players: Those who are “likely to have discoverable information that the disclosing party may use to support its claims or defenses” (F.R.C.P. 26(a)(1)(A)).
▪ Assistants to primary players: Those who prepared documents for those individuals that can be readily identified.
▪ Witnesses: “The duty also extends to information that is relevant to the claims or defenses of any party, or which is ‘relevant to the subject matter involved in the action’” (F.R.C.P. 26(b)(1)).
The Zubulake court realized the particular difficulties associated with retrieving data from backup tapes and noted that they generally do not need to be saved or searched, but the court noted:
[I]t does make sense to create one exception to this general rule. If a company can identify where particular employee documents are stored on backup tapes, then the tapes storing the documents of “key players” to the existing or threatened litigation should be preserved if the information contained on those tapes is not otherwise available. This exception applies to all backup tapes.
In addition to clarifying the preservation obligations in e-discovery, the Zubulake case revealed some of the penalties that can befall those who fail to meet these obligations. The court sanctioned UBS Warburg for failing to preserve and produce e-mail backup tapes and important messages, or for producing some evidence late. The court required the company to pay for additional depositions that explored how data had gone missing in the first place. The jury heard testimony about the missing evidence and returned a verdict for $29.3 million, including $20.2 million in punitive damages.
The Zubulake court held the attorneys partially responsible for the lost e-mail in the case and noted, “[I]t is not sufficient to notify all employees of a litigation hold and expect that the party will then retain and produce all relevant information. Counsel must take affirmative steps to monitor compliance so that all sources of discoverable information are identified and searched.” (Zubulake v. UBS Warburg, 2004). Increasingly, attorneys have taken this charge to heart and frequently turn to their digital examiners to help assure that their discovery obligations are being met.
Rather than grappling with these challenges every time new litigation erupts, some organizations are taking a more strategic approach to prepare for e-discovery and engage in data-mapping before a case even begins. The two most fundamental aspects of being prepared for e-discovery are knowing the location of key data sources and ensuring that they meet regulatory requirements while containing the minimum data necessary to support business needs. The data-mapping process involves identifying pieces of data that are key to specific and recurring types of litigation (e.g., personnel files that are relevant to employment disputes). In turn, organizations attempt to map important pieces of data to functional categories that are assigned clear backup and retention policies. Organizations can then clean house and expunge unnecessary data, not to eliminate incriminating digital evidence, but to add greater efficiency to business operations and to reduce the amount of time and resources needed to extract and review the data for litigation.
In the best of all worlds, the data-mapping process cleanses a company of redundant data and rogue systems and trains employees to store their data in consistent forms at predictable locations. In a less perfect world, the data-mapping process still allows a company to think more carefully about its data and align an organization's long-term business interests with its recurring litigation concerns. For example, the data-mapping process may prompt an organization to create a forensic image of a departing employee's hard drive, especially when the employee is a high-ranking officer or is leaving under a cloud of suspicion.
Determining Violations of the Electronic Discovery Paradi
As pointed out by the Zubulake decision, the consequences of failing to preserve data early in a case can be severe. Under F.R.C.P. Rule 37, a court has broad latitude to sanction a party in a variety of ways. Of course, courts are most concerned about attorneys or litigation parties that intentionally misrepresent the evidence in their possession, as seen in the Qualcomm case.
In Qualcomm Inc. v. Broadcom Corp., the underlying dispute centered on whether Qualcomm could claim a patent to video compression technology after it allegedly had participated in an industry standards-setting body known as the Joint Video Team (JVT). Qualcomm brought a lawsuit against Broadcom claiming patent infringement, but the jury ultimately returned a unanimous verdict in favor of Broadcom.
During all phases of the case, Qualcomm claimed that it had not participated in the JVT. Qualcomm responded to numerous interrogatories and demands for e-mails regarding its involvement in the JVT. When a Qualcomm witness eventually admitted that the company had participated in the JVT, over 200,000 e-mails and other ESI were produced linking Qualcomm to the JVT! The court determined that Qualcomm had intentionally and maliciously hidden this information from Broadcom and the court. As a result Qualcomm had to pay sanctions (including attorney fees) of over $8 million and several attorneys for Qualcomm were referred to the State Bar for possible disciplinary action.
The following 10 recommendations are provided for investigators and in-house counsel to avoid the same fate as Qualcomm (Roberts, 2008):
1. Use checklists and develop a standard discovery protocol;
2. Understand how and where your client maintains paper files and electronic information, as well as your client's business structures and practices;
3. Go to the location where information is actually maintained—do not rely entirely on the client to provide responsive materials to you;
4. Ensure you know what steps your client, colleagues, and staff have actually taken and confirm that their work has been done right;
5. Ask all witnesses about other potential witnesses and where and how evidence was maintained;
6. Use the right search terms to discover electronic information;
7. Bring your own IT staff to the client's location and have them work with the client's IT staff, employ e-discovery vendors, or both;
8. Consider entering into an agreement with opposing counsel to stipulate the locations to be searched, the individuals whose computers and hard copy records are at issue, and the search terms to be used;
9. Err on the side of production;
10. Document all steps taken to comply with your discovery protocol.
This is a useful and thorough set of guidelines for investigators to use for preservation of data issues, and can also serve as a quick factsheet in preparing for depositions or testimony.
Initial Meeting, Disclosures, and Discovery Agreements
In an effort to make e-discovery more efficient, F.R.C.P. Rule 26(f) mandates that parties meet and discuss how they want to handle ESI early in a case.
Lawyers often depend on digital examiners to help them prepare for and navigate a Rule 26(f) conference. The meeting usually requires both technical and strategic thinking because full discovery can run counter to cost concerns, confidentiality or privacy issues, and claims of privilege. For example, an organization that wants to avoid costly and unnecessary restoration of backup tapes should come to the table with an idea of what those tapes contain and how much it would cost to restore them. At the same time, if a party might be embarrassed by personal information within deleted files or a computer's old Internet history, counsel for that party might be wise to suggest limiting discovery to specific types of active, user documents (.DOC, .XLS, .PDF, etc.). Finally, privilege concerns can often be mitigated if the parties can agree on the list of attorneys that might show up in privileged documents, if they can schedule sufficient time to perform a privilege review, and if they allow each other to “claw back” privileged documents that are mistakenly produced to the other side.
The initial meetings between the parties generally address what ESI should be exchanged, in what format (e.g., native format versus tiffed images; electronic version versus a printout, on CD/DVD versus hard drive delivery media), what will constitute privileged information, and preservation considerations. Lawyers must make ESI disclosures to each other and certify that they are correct. This process is especially constructive when knowledgeable and friendly digital investigators can help lawyers understand their needs, capabilities, and costs associated with various ESI choices. The initial meeting may result in an agreement that helps all the parties understand their obligations. This same agreement can help guide the parties if a dispute should arise.
Consider the case of Integrated Service Solutions, Inc. v. Rodman. Integrated Service Solutions (ISS) brought a claim against Rodman, which in turn required information from a nonparty, VWR. VWR was subpoenaed to produce ESI in connection with either ISS or Rodman. VWR expressed its willingness to provide data but voiced several objections, namely that the subpoena was too broad, compliance costs were too great, and that ISS might obtain unfettered access to its systems (all common concerns).
VWR and ISS were able to reach a compromise in which ISS identified particular keywords, PricewaterhouseCoopers (PwC) conducted a search for $10,000, and VWR reviewed the resulting materials presented by PwC. However, the relationship between VWR and ISS deteriorated, and when VWR stated that it did not possess information pertinent to the litigation, ISS responded that it was entitled to a copy of each file identified by the search as well as a report analyzing the information.
The case went before the court, which looked at the agreement between the parties and held that ISS should receive a report from PwC describing its methods, the extent of VWR's cooperation, and some general conclusions. The court also held that VWR should pay for any costs associated with generating the report.
This case underscores several key principals of e-discovery. First, even amicable relationships between parties involved in e-discovery can deteriorate and require judicial intervention. Second, digital investigators should be sensitive to the cost and disclosure concerns of their clients. Third, digital examiners may be called upon to play a neutral or objective role in the dispute, and last, the agreement or contract between the parties is crucial in establishing the rights of each party.
Assessing What Data Is Reasonably Accessible
Electronic discovery involves more than the identification and collection of data because attorneys must also decide whether the data meets three criteria for production, namely whether the information is (1) relevant, (2) nonprivileged, and (3) reasonably accessible (F.R.C.P. 26(b)(2)(B)). The first two criteria make sense intuitively. Nonrelevant information is not allowed at trial because it simply bogs downs the proceedings, and withholding privileged information makes sense in order to protect communications within special relationships in our society, for example, between attorneys and clients, doctors and patients, and such. Whether information is “reasonably accessible” is harder to determine, yet this is an important threshold question in any case.
In the Zubulake case described earlier, the employee asked for “all documents concerning any communications by or between UBS employees concerning Plaintiff,” which included “without limitation, electronic or computerized data compilations,” to which UBS argued the request was overly broad. In that case Judge Shira A. Scheindlin, United States District Court, Southern District of New York, identified three categories of reasonably accessible data: (1) active, online data such as hard drive information, (2) near-line data to include robotic tape libraries, and (3) offline storage such CDs or DVDs. The judge also identified two categories of data generally not considered to be reasonably accessible: (1) backup tapes and (2) erased, fragmented, and damaged data. Although there remains some debate about the reasonable accessibility of backup tapes used for archival purposes versus disaster recovery, many of Judge Scheindlin's distinctions were repeated in a 2005 Congressional report from the Honorable Lee H. Rosenthal, Chair of the Advisory Committee on the Federal Rules of Civil Procedure (Rosenthal, 2005), and Zubulake's categories of information still remain important guideposts (Mazza, 2007).
The courts use two general factors—burden and cost—to determine the accessibility of different types of data. Using these general factors allows the courts to take into account challenges of new technologies and any disparity in resources among parties (Moore, 2005). If ESI is not readily accessible due to burden or cost, then the party possessing that ESI may not have to produce it (see F.R.C.P. 26(b)). Some parties, however, make the mistake of assessing the burden and cost on their own and unilaterally decide not to preserve or disclose data that is hard to reach or costly to produce. In fact, the rules require that a party provide “a description by category and locations, of all documents” with potentially relevant data, both reasonably and not reasonably accessible (F.R.C.P. 26(a)(1)(B)). This allows the opposing side a chance to make a good cause showing to the court why that information should be produced (F.R.C.P. 26(a)(2)(B)).
These rules mean that digital examiners may have to work with IT departments to change their data retention procedures and schedules, even if only temporarily, until the parties can negotiate an ESI agreement or a court can decide what must be produced. The rules also mean that digital examiners may eventually leave behind data that they would ordinarily collect in many forensic examinations, like e-mail backups, deleted files, and fragments of data in unallocated space. These types of data may be relatively easy to acquire in a small forensic examination but may be too difficult and too costly to gather for all custodians over time in a large e-discovery case.
Utilizing Criminal Procedure to Accentuate E-Discovery
In some cases, such as lawsuits involving fraud allegations or theft of trade secrets, digital examiners may find that the normal e-discovery process has been altered by the existence of a parallel criminal investigation. In those cases, digital examiners may be required to work with the office of a local US Attorney, State Attorney General, or District Attorney, since only these types of public officials, and not private citizens, can bring criminal suits.
There are several advantages to working with a criminal agency. The first is that the agency might be able to obtain the evidence quicker than a private citizen could. For example, in United States v. Fierros-Alaverez, the police officer was permitted to search the contents of a cellular phone during a traffic stop. Second, the agency has greater authority to obtain information from third parties. Third, there are favorable cost considerations since a public agency will not charge you for their services. Finally, in several instances, information discovered in a criminal proceeding can be used in a subsequent civil suit.
Apart from basic surveillance and interviews, criminal agencies often use four legal tools to obtain evidence in digital investigations—a hold letter, a subpoena, a ‘d’ order, and a search warrant. 2
2Beyond the scope of this chapter are pen register orders, trap and trace orders, or wire taps that criminal authorities can obtain to collect real-time information on digital connections and communications. These tools seldom come into play in a case that has overlapping e-discovery issues in civil court.
A criminal agency can preserve data early in an investigation by issuing a letter under 18 U.S.C. 2703(f) to a person or an entity like an Internet Service Provider (ISP). Based on the statute granting this authority, the notices are often called “f letters” for short. The letter does not actually force someone to produce evidence but does require they preserve the information for 90 days (with the chance of an additional 90 day extension). This puts the party with potential evidence on notice and buys the agency some time to access that information or negotiate with the party to surrender it.
Many criminal agencies also use administrative or grand jury subpoenas to obtain digital information as detailed in Federal Rules of Criminal Procedure Rule 17. The subpoenas may be limited by privacy rights set forth in the Electronic Communication Privacy Act (18 U.S.C. § 2510). Nevertheless, criminal agencies can often receive data such as a customer's online account information and method of payment, a customer's record of assigned IP numbers and account logins or session times, and in some instances the contents of historic e-mails.
Another less popular method of obtaining evidence is through a court “d” order, under 18 U.S.C. §2703(d). This rule is not used as often because an official must be able to state with “specific and articulateable” facts that there is a reasonable belief that the targeted information is pertinent to the case. However, this method is still helpful to obtain more than just subscriber information—data such as Internet transactional information or a copy of a suspect's private homepage.
Search warrants are among the most powerful tools available to law enforcement agencies (see Federal Rules of Criminal Procedure Rule 41). Agents must receive court approval for search warrants and must show there is probable cause to believe that evidence of a specified crime can be found on a person or at a specific place and time. Search warrants are typically used to seize digital media such as computer hard drives, thumb drives, DVDs, and such, as well as the stored content of private communications from e-mail messages, voicemail messages, or chat logs.
Despite the advantages of working a case with criminal authorities, there are some potent disadvantages that need to be weighed. First, the cooperating private party loses substantial control over its case. This means that the investigation, legal decisions (i.e., venue, charges, remedies sought, etc.), and the trial itself will all be controlled by the government. Second, and on a corollary note, the private party surrenders all control over the evidence. When government agents conduct their criminal investigation, they receive the information and interpret the findings, not the private party. If private parties wish to proceed with a civil suit using the same evidence, they will typically have to wait until the criminal case has been resolved.
It is imperative for digital examiners to understand the legal concepts behind electronic discovery, as described earlier. You likely will never know more than a lawyer who is familiar with all the relevant statutes and important e-discovery court decisions; however, your understanding of the basics will help you apply your art and skills and determine where you can add the most value.
Case Management
The total volume of potentially relevant data often presents the greatest challenge to examiners in an e-discovery case. A pure forensic matter may focus on a few documents on a single 80 GB hard drive, but an e-discovery case often encompasses a terabyte or more of data across dozens of media sources. For this reason, e-discovery requires examiners to become effective case managers and places a premium on their efficiency and organizational skills. These traits are doubly important considering the tight deadlines that courts can impose in e-discovery cases and the high costs that clients can incur if delays or mistakes occur.
Effective case management requires that examiners establish a strategic plan at the outset of an e-discovery project, and implement effective and documented quality assurance measures throughout each step of the process. Problems can arise from both technical and human errors, and the quality assurance measures should be sufficiently comprehensive to identify both. Testing and verification of tools’ strengths and weaknesses before using them in case work is critical, however it should not lull examiners into performing limited quality assurance of the results each time the tool is used (Lesemann & Reust, 2006).
Effective case management requires that examiners plan ahead. This means that examiners must quickly determine where potentially relevant data reside, both at the workstation and enterprise levels. As explained in more detail later in this chapter (see the section, “Identification of Electronic Data”), a sit-down meeting with a client's IT staff, in-house counsel, and outside counsel can help focus attention on the most important data sources and determine whether crucial information might be systematically discarded or overwritten by normal business processes. Joining the attorneys in the interviews of individual custodians can also help determine if data are on expected media like local hard drives and file servers or on far-flung media like individual thumb drives and home computers. This information gathering process is more straightforward and efficient when an organization has previously gone through a formal, proactive data-mapping process, and knows where specific data types reside in their network.
Whether examiners are dealing with a well-organized or disorganized client, they should consider drafting a protocol that describes how they intend to handle different types of data associated with their case. The protocol can address issues such as what media should be searched for specific file types (e.g., the Exchange server for current e-mail, or hard drives and home directories for archived PST, OST, MSG, and EML files), what tools can be used during collection, whether deleted data should be recovered by default, what keywords and date ranges should be used to filter the data, and what type of deduplication should be applied (e.g., eliminating duplicates within a specific custodian's data set, or eliminating duplicates across all custodians’ data). Designing a protocol at the start of the e-discovery process increases an examiner's efficiency and also helps manage the expectations of the parties involved.
A protocol can also help attorneys and clients come to terms with the overall volume and potential costs of e-discovery. Often it will be the digital examiner's job to run the numbers and show how the addition of even a few more data custodians can quickly increase costs. Though attorneys may think of a new custodian as a single low-cost addition to a case, that custodian probably has numerous sources of data and redundant copies of documents across multiple platforms. The following scenario shows how this multiplicative effect can quickly inflate e-discovery costs.
One Custodian's Data:
Individual hard drive = 6GB of user data
Server e-mail = 0.50GB
Server home directory data = 1GB
Removable media (thumb drives) = 0.50GB
Blackberries, PDAs = 0GB (if synchronized with e-mail)
Scanned paper documents = 1GB
Backup tapes – e-mail for 12 mo × 0.50GB = 6GB
Backup tapes – e-docs for 12 mo × 1.0GB = 12GB
Potential data for one additional custodian = 28GB
Est. processing cost (at $1,500/GB) = $42,000
Digital examiners may also be asked how costly and burdensome specific types of information will be to preserve, collect, and process. This assessment may be used to decide whether certain data are “reasonably accessible,” and may help determine if and how preservation, collection, processing, review, and production costs should be shared between the parties. Under Zubulake, a court will consider seven factors to determine if cost-shifting is appropriate (Zubulake v. UBS Warburg):
1. The extent to which the request is specifically tailored to discover relevant information.
2. The availability of such information from other sources.
3. The total cost of production, compared to the amount in controversy.
4. The total cost of production, compared to the resources available to each party.
5. The relative ability of each party to control costs and its incentive to do so.
6. The importance of the issues at stake in the litigation.
7. The relative benefits to the parties of obtaining the information.
In an attempt to cut or limit e-discovery costs, a client will often volunteer to have individual employees or the company's own IT staff preserve and collect documents needed for litigation. This can be acceptable in many e-discovery cases. As described in more detail later, however, examiners should warn their clients and counsel of the need for more robust and verifiable preservation if the case hinges on embedded or file system metadata, important dates, sequencing of events, alleged deletions, contested user actions, or other forensic issues.
If an examiner is tasked with preserving and collecting the data in question, the examiner should verify that his or her proposed tools are adequate for the job. A dry run on test data is often advisable because there will always be bugs in some software programs, and these bugs will vary in complexity and importance. Thus it is important to verify, test, and document the strengths and weaknesses of a tool before using it, and apply approved patches or alternative approaches before collection begins.
Effective case management also requires that examiners document their actions, not only at the beginning, but also throughout the e-discovery process. Attorneys and the courts appreciate the attention to detail applied by most forensic examiners, and if an examiner maintains an audit trail of his or her activities, it often mitigates the impact of a problem, if one does arise.
In a recent antitrust case, numerous employees with data relevant to the suit had left the client company by the time a lawsuit was filed. E-mail for former employees was located on Exchange backups, but no home directories or hard drives were located for these individuals. Later in the litigation, when the opposing party protested the lack of data available on former employees, the client's IT department disclosed that data for old employees could be found under shared folders for different departments. The client expressed outrage that this information had not been produced, but digital examiners who had kept thorough records of their collections and deliveries were able to show that data for 32 of 34 former employees had indeed been produced, just under the headings of the shared drives not under individual custodian names. Thus, despite miscommunications about the location of data for former employees, careful record-keeping showed that there was little missing data, and former employee files had been produced properly in the form they were ordinarily maintained, under Federal Rules of Civil Procedure Rule 34.
Documenting one's actions also helps outside counsel and the client track the progress of e-discovery. In this vein, forensic examiners may be accustomed to tracking their evidence by media source (e.g., laptop hard drive, desktop hard drive, DVD), but in an e-discovery case, they will probably be asked to track data by custodian, as shown in Table 3.1. This allows attorneys to sequence and prepare for litigation events such as a document production or the deposition of key witnesses. A custodian tracking sheet also allows paralegals to determine where an evidentiary gap may exist and helps them predict how much data will arrive for review and when.
Case management is most effective when it almost goes unnoticed, allowing attorneys and the client to focus their attention on the substance and merits of their case, not the harrowing logistical and technical hurdles posed by the e-discovery process in the background. As described earlier, this means that examiners should have a thorough understanding of the matter before identification and preservation has begun, as well as a documented quality assurance program for collecting, processing, and producing data once e-discovery has commenced.
Identification of Electronic Data
Before the ESI can be collected and preserved, the sources of potentially relevant and discoverable ESI must be identified. Although the scope of the preservation duty is typically determined by counsel, the digital investigator should develop a sufficient understanding of the organization's computer network and how the specific custodians store their data to determine what data exists and in what locations. Oftentimes this requires a more diligent and iterative investigation than counsel expects, however it is a vital step in this initial phase of e-discovery.
A comprehensive and thorough investigation to identify the potentially relevant ESI is an essential component of a successful strategic plan for e-discovery projects. This investigation determines whether the data available for review is complete, and if questions and issues not apparent at the outset of the matter can be examined later down the road (Howell, 2005). A stockpile of media containing relevant data being belatedly uncovered could call into question any prior findings or conclusions reached, and possibly could lead to penalties and sanctions from the court.
There are five digital storage locations that are the typical focus of e-discovery projects (Friedberg & McGowan, 2006):
▪ Workstation environment, including old, current, and home desktops and laptops
▪ Personal Digital Assistants (PDAs), such as the BlackBerry® and Treo®
▪ Removable media, such as CDs, DVDs, removable USB hard drives, and USB “thumb” drives
▪ Server environment, including file, e-mail, instant messaging, database, application and VOIP servers
▪ Backup environment, including archival and disaster recovery backups
Although these storage locations are the typical focus of e-discovery projects, especially those where the data are being collected in a corporate environment, examiners should be aware of other types of storage locations that may be relevant such as digital media players and data stored by third parties (for example, Google Docs, Xdrive, Microsoft SkyDrive, blogs, and social networking sites such as MySpace and Facebook).
Informational interviews and documentation requests are the core components of a comprehensive and thorough investigation to identify the potentially relevant ESI in these five locations, followed by review and analysis of the information obtained to identify inconsistencies and gaps in the data collected. In some instances a physical search of the company premises and off-site storage is also necessary.
Informational Interviews
The first step in determining what data exist and in what location is to conduct informational interviews of both the company IT personnel and the custodians. It is helpful to have some understanding of the case particulars, including relevant data types, time period, and scope of preservation duty before conducting the interviews. In addition, although policy and procedure documentation can be requested in the IT personnel interviews, it may be helpful to request them beforehand so they can be reviewed and any questions incorporated into the interview. Documenting the information obtained in these interviews is critical for many reasons, not least of which is the possibility that the investigator may later be required to testify in a Rule 30(b)(6) deposition.
For assistance in structuring and documenting the interviews, readers might develop their own interview guide. Alternatively, readers might consult various published sources for assistance. For example, Kidwell et al. (2005) provide detailed guides both for developing Rule 26 document requests and for conducting Rule 30(b)(6) depositions of IT professionals. Another source for consideration is a more recent publication of the Sedona Conference (Sedona Conference, 2008).
IT Personnel Interviews
The goal of the IT personnel interviews is to gain a familiarity and understanding with the company network infrastructure to determine how and where relevant ESI is stored.
When conducting informational interviews of company IT personnel, IT management such as the CIO or Director of IT will typically be unfamiliar with the necessary infrastructure details, but should be able to identify and assemble the staff that have responsibility for the relevant environments. Oftentimes it is the staff “on the ground” who are able to provide the most accurate information regarding both the theoretical policies and the practical reality. Another point to keep in mind is that in larger companies where custodians span the nation if not the world, there may be critical differences in the computer and network infrastructure between regions and companies, and this process is complicated further if a company has undergone recent mergers and acquisitions. Suggested questions to ask IT personnel are:
▪ Is there a centralized asset inventory system, and if so, obtain an asset inventory for the relevant custodians. If not, what information is available to determine the history of assets used by the relevant custodians?
▪ Regarding workstations, what is the operating system environment? Are both desktops and laptops issued? Is disk or file level encryption used? Are the workstations owned or leased? What is the refresh cycle and what steps are taken prior to the workstations being redeployed? Are users permitted to download software onto their workstations? Are software audits performed on the workstations to determine compliance?
▪ Regarding PDAs and cell phones, how are the devices configured and synchronized? Is it possible that data, such as messages sent from a PDA, exist only on the PDA and not on the e-mail server? Is the BlackBerry® server located and managed in-house?
▪ What are the policies regarding provision and use of removable media?
▪ Regarding general network questions, are users able to access their workstations/e-mail/file shares remotely and if so what logs are enabled? What are the Internet browsing and computer usage policies? What network shares are typically mapped to workstations? Are any enterprise storage and retention applications implemented such as Symantec Enterprise Vault®? Is an updated general network topology or data map available? Are outdated topologies or maps available for the duration of the relevant time period?
▪ Regarding e-mail servers, what are their numbers, types, versions, length of time deployed and locations? What mailbox size or date restrictions are in place? Is there an automatic deletion policy in place? What logging is enabled? Are employees able to replicate or archive e-mail locally to their workstations or to mapped network shares?
▪ Regarding file servers, what are the numbers, types, versions, locations, length of time deployed, data type stored, and departments served. Do users have home directories? Are they restricted by size? What servers provide for collaborative access, such as group shares or SharePoint®? To which shares and/or projects do the custodians have access?
▪ Regarding the backup environment, what are the backup systems used for the different server environments? What are the backup schedules and retention policies? What is the date of the oldest backup? Have there been any “irregular” backups created for migration purposes or “test” servers deployed? What steps are in place to verify the success of the backup jobs?
▪ Please provide information on any other data repositories such as database servers, application servers, digital voicemail storage, legacy systems, document management systems, and SANs.
▪ Have there been any other prior or on-going investigations or litigation where data was preserved or original media collected by internal staff or outside vendors? If so, where does this data reside now?
Obtaining explicit answers to these questions can be challenging and complicated due to staff turnover, changes in company structure, and lack of documentation. On the flip side when answers are provided (especially if just provided orally), care must be taken to corroborate the accuracy of the answers with technical data or other reliable information.
Custodian Interviews
The goal of the custodian interviews is to determine how and where the custodians store their data. Interviews of executive assistants may be necessary if they have access to the executive's electronic data. Suggested questions to ask are:
▪ How many laptops and desktops do they currently use? For how long have they used them? Do they remember what happened to the computers they used before, if any? Do they use a home computer for company-related activities? Have they ever purchased a computer from the company?
▪ To what network shares do they have access? What network shares are typically mapped to a drive letter on their workstation(s)?
▪ Do they have any removable media containing company-related data?
▪ Do they have a PDA and/or cell phone provided by the company?
▪ Do they use encryption?
▪ Do they use any instant messaging programs? Have they installed any unapproved software programs on their workstation(s)?
▪ Do they archive their mail locally or maintain a copy on a company server or removable media?
▪ Do they access their e-mail and/or files remotely? Do they maintain an online storage account containing company data? Do they use a personal e-mail address for company related activities, including transfer of company files?
The information and documentation obtained through requests and the informational interviews can assist in creating a graphical representation of the company network for the relevant time period. Although likely to be modified as new information is learned, it will serve as an important reference throughout the e-discovery project. As mentioned earlier, some larger corporations may have proactively generated a data map that will serve as the starting point for the identification of ESI.
Analysis and Next Steps
Review and analysis of the information obtained is essential in identifying inconsistencies and gaps in the data identification and collection. In addition, comparison of answers in informational interviews with each other and against the documentation provided can identify consistent, corroborative information between sources, which is just as important to document as inconsistencies. This review and analysis is not typically short and sweet, and is often an iterative process that must be undertaken as many times as new information is obtained, including after initial review of the data collected and from forensic analysis of the preserved data.
E-discovery consultants had been brought in by outside counsel to a national publicly-held company facing a regulatory investigation into its financial dealings, and were initially tasked with identifying the data sources for custodians in executive management. Counsel had determined that any company-issued computer used by the custodians in the relevant date range needed to be collected, thereby necessitating investigation into old and home computers. Without an updated, centralized asset tracking system, company IT staff had cobbled together an asset inventory from their own memory and from lists created by previous employees and interns. The inventory showed that two Macintosh laptops had been issued to the Chief Operations Officer (COO), however only one had been provided for preservation by the COO, and he maintained that he had not been issued any other Macintosh laptop. The e-discovery consultants searched through the COO's and his assistant's e-mail that had already been collected, identifying e-mail between the COO and the IT department regarding two different Macintosh laptops, and then found corresponding tickets in the company helpdesk system showing requests for technical assistance from the COO. When confronted with this evidence, the COO “found” the laptop in a box in his attic and provided it to the digital investigator. Subsequent analysis of the laptop showed extensive deletion activity the day before the COO had handed over the laptop.
There are many challenges involved in identifying and collecting ESI, including the sheer number and variety of digital storage devices that exist in many companies, lack of documentation and knowledge of assets and IT infrastructure, and deliberate obfuscation by company employees. Only through a comprehensive, diligent investigation and analysis you are likely to identify all relevant ESI in preparation for collection and preservation.
In a standard informational interview, investigators were told by the IT department in the Eastern European division of an international company that IT followed a strict process of wiping the “old” computer whenever a new computer was provided to an employee. The investigators attempted to independently verify this claim through careful comparison of serial numbers and identification of “old” computers that had been transferred to new users. This review and analysis showed intact user accounts for Custodian A on the computers being used by Custodian B. The investigators ultimately uncovered rampant “trading” and “sharing” of assets, together with “gifting” of assets by high level executives to subordinate employees, thereby prompting a much larger investigation and preservation effort.
Forensic Preservation of Data
Having conducted various informational interviews and having received and reviewed documents, lists and inventories from various sources to create an initial company data map, the next step for counsel is to select which of the available sources of ESI should be preserved and collected. The specific facts of the matter will guide counsel's decision regarding preservation. Federal Rules of Evidence Rule 26(b)(1) allows that parties “may obtain discovery regarding any non-privileged matter that is relevant to any party's claim or defense – including the existence, description, nature, custody, condition, and location of any documents or other tangible things and the identity and location of persons who know of any discoverable matter.”
Once counsel selects which sources of ESI are likely to contain relevant data and should be preserved in the matter, the next two phases of the electronic discovery process as depicted in Figure 3.1 include preservation and collection. Preservation includes steps taken to “ensure that ESI is protected against inappropriate alteration or destruction” and collection is the process of “gathering ESI for future use in the electronic discovery process…”
Preservation for electronic discovery has become a complicated, multi-faceted, steadily-changing concept in recent years. Starting with the nebulous determination of when the duty to preserve arises, then continuing into the litigation hold process (often equated to the herding of cats) and the staggering volumes of material which may need to be preserved in multiple global locations, platforms and formats, the task of preservation is an enormous challenge for the modern litigator. Seeking a foundation in reasonableness, wrestling with the scope of preservation is often an exercise in finding an acceptable balance between offsetting the risks of spoliation and sanctions related to destruction of evidence, against allowing the business client to continue to operate its business in a somewhat normal fashion. (Socha & Gelbman, 2008b)
Although the EDRM defines “preservation” and “collection” as different stages in electronic discovery for civil litigation, it has been our experience that preservation and collection must be done at the same time when conducting investigations, whether the underlying investigation is related to a financial statement restatement, allegations of stock option backdating, alleged violations of the Foreign Corrupt Practices Act, or other fraud, bribery, or corruption investigation. Given the volatile nature of electronic evidence and the ability of a bad actor to quickly destroy that evidence, a digital investigator's perspective must be different.
Electronic evidence that is not yet in the hands of someone who recognizes its volatility (i.e., the evidence has not been collected) and who is also absolutely committed to its protection has not really been preserved, regardless of the content of any preservation notice corporate counsel may have sent to custodians.
Besides the case cited, we have conducted numerous investigations where custodians, prior to turning over data sources under their control, have actively taken steps to destroy relevant evidence in contravention of counsels’ notice to them to “preserve” data. These steps have included actions like:
▪ Using a data destruction tool on their desktop hard drive to destroy selected files
▪ Completely wiping their entire hard drive
▪ Reinstalling the operating system onto their laptop hard drive
▪ Removing the original hard drive from their laptop and replacing it with a new, blank drive
▪ Copying relevant files from their laptop to a network drive or USB drive and deleting the relevant files from their laptop
▪ Printing relevant files, deleting them from the computer, and attempting to wipe the hard drive using a data destruction tool
▪ Setting the system clock on their computer to an earlier date and attempting to fabricate electronic evidence dated and timed to corroborate a story
▪ Sending themselves e-mail to attempt to fabricate electronic evidence
▪ Physically destroying their laptop hard drive with a hammer and reporting that the drive “crashed”
▪ Taking boxes of relevant paper files from their office to the restroom and flushing documents down the toilet
▪ Hiding relevant backup tapes in their vehicle
▪ Surreptitiously removing labels from relevant backup tapes, inserting them into a tape robot, and scheduling an immediate out-of-cycle backup to overwrite the relevant tapes
▪ Purchasing their corporate owned computer from the company the day before a scheduled forensic collection and declaring it “personal” property not subject to production
We were retained by outside counsel as part of the investigation team examining the facts and circumstances surrounding a financial statement restatement by an overseas bank with US offices. The principal accounting issue focused on the financial statement treatment of certain loans the bank made and then sold. It was alleged that certain bank executives routinely made undisclosed side agreements with the purchasers to buy back loans that eventually defaulted after the sale. Commitments to buy back defaulted loans would have an affect on the accounting treatment of the transactions. Faced with pending regulatory inquiries, in-house counsel sent litigation hold notices to custodians and directed IT staff to preserve relevant backup tapes. The preservation process performed by IT staff simply included temporarily halting tape rotations. But no one actually took the relevant tapes from IT to lock them away. In the course of time, IT ran low on tape inventory for daily, weekly and monthly backups. Eventually, IT put the relevant tapes back into rotation. By the time IT disclosed to in-house counsel that they were rotating backup tapes again, more than 600 tapes potentially holding relevant data from the time period under review had been overwritten. The data, which had been temporarily preserved at the direction of counsel was never collected and was eventually lost.
Forensic examiners might use a wide variety of tools, technologies, and methodologies to preserve and collect the data selected by counsel, depending on the underlying data source. 3 Regardless of the specific tool, technology, or methodology, the forensic preservation process must meet certain standards, including technical standards for accuracy and completeness, and legal standards for authenticity and admissibility.
3Research performed by James Holley identified 59 hardware and software tools commercially or publicly available for preserving forensic images of electronic media (Holley, 2008).
Historically, forensic examiners have relied heavily on creating forensic images of static media to preserve and collect electronic evidence. 4 But more and more often, relevant ESI resides on data sources that can not be shut down for traditional forensic preservation and collection, including running, revenue generating servers or multi-Terabyte Storage Area Networks attached to corporate servers.
4“Static Media” refers to media that are not subject to routine changes in content. Historically, forensic duplication procedures included shutting down the computer, removing the internal hard drive, attaching the drive to a forensic write blocker, and preserving a forensic image of the media. This process necessarily ignores potentially important and relevant volatile data contained on the memory of a running computer. Once the computer is powered down, the volatile memory data are lost.
Recognizing the evolving nature of digital evidence, the Association of Chief Police Officers has published its fourth edition of The Good Practice Guide for Computer-Based Electronic Evidence (ACPO, 2008). This guide was updated to take into account that the “traditional ‘pull-the-plug’ approach overlooks the vast amounts of volatile (memory-resident and ephemeral) data that will be lost. Today, digital investigators are routinely faced with the reality of sophisticated data encryption, as well as hacking tools and malicious software that may exist solely within memory. Capturing and working with volatile data may therefore provide the only route towards finding important evidence.” Additionally, with the advent of full-disk encryption technologies, the traditional approach to forensic preservation is becoming less and less relevant. However, the strict requirement to preserve and collect data using a sound approach that is well documented, has been tested, and does not change the content of or metadata about electronic evidence if at all possible, has not changed.
Preserving and Collecting E-mail from Live Servers
Laptop, desktop, and server computers once played a supporting role in the corporate environment: shutting them down for traditional forensic imaging tended to have only a minor impact on the company. However, in today's business environment, shutting down servers can have tremendously negative impacts on the company. In many instances, the company's servers are not just supporting the business—they are the business. The availability of software tools and methodologies capable of preserving data from live, running servers means that it is no longer absolutely necessary to shut down a production e-mail or file server to preserve data from it. Available tools and methodologies allow investigators to strike a balance between the requirements for a forensically sound preservation process and the business imperative of minimizing impact on normal operations during the preservation process (e.g., lost productivity as employees sit waiting for key servers to come back online or lost revenue as the company's customers wait for servers to come back online).
Perhaps the most requested and most produced source of ESI is e-mail communication. Counsel is most interested to begin reviewing e-mail as soon as practicable after forensic preservation. Because the content of e-mail communications might tend to show that a custodian knew or should have known certain facts; or took, should have taken, or failed to take certain action; proper forensic preservation of e-mail data sources is a central part of the electronic discovery process. In our experience over the last 10 years conducting investigations, the two most common e-mail infrastructures we've encountered are Microsoft Exchange Server (combined with the Microsoft Outlook e-mail client) and Lotus Domino server (combined with the Lotus Notes e-mail client). There are, of course, other e-mail servers/e-mail clients in use in the business environment today. But those tend to be less common. In the course of our investigations, we've seen a wide variety of e-mail infrastructures, including e-mail servers (Novell GroupWise, UNIX Sendmail, Eudora Internet Mail Server and Postfix) and e-mail clients (GroupWise, Outlook Express, Mozilla, and Eudora). In a few cases, the company completely outsourced their e-mail infrastructure by using web-based e-mail (such as Gmail or Hotmail) or AOL mail for their e-mail communications.
Preserving and Collecting E-mail from Live Microsoft Exchange Servers
To preserve custodian e-mail from a live Microsoft Exchange Server, forensic examiners typically take one of several different approaches, depending on the specific facts of the matter. Those approaches might include:
▪ Exporting a copy of the custodian's mailbox from the server using a Microsoft Outlook e-mail client
▪ In older versions of Exchange, exporting a copy of the custodian's mailbox from the server using Microsoft's Mailbox Merge utility (Exmerge)
▪ In Exchange 2007, exporting a copy of the custodian's mailbox using the Exchange Management Shell
▪ Exporting a copy of the custodian's mailbox from the server using a specialized third-party tool (e.g., GFI PST-Exchange Email Export wizard)
▪ Obtaining a backup copy of the entire Exchange Server “Information Store” from a properly created full backup of the server
▪ Temporarily shutting down Exchange Server services and making a copy of the Exchange database files that comprise the Information Store
▪ Using a software utility such as F-Response™ or EnCase Enterprise to access a live Exchange Server over the network and copying either individual mailboxes or an entire Exchange database file
Microsoft Exchange stores mailboxes in a database comprised of two files: priv1.edb and priv1 .stm. The priv1.edb file contains all e-mail messages, headers, and text attachments. The priv1.stm file contains multimedia data that are MIME encoded. Similarly, public folders are stored in files pub1.edb and pub1.stm. An organization may maintain multiple Exchange Storage Groups, each with their own set of databases. Collectively, all databases associated with a given Exchange implementation are referred to as an Information Store, and for every .EDB file there will be an associated .STM file (Buike, 2005).
Each approach has its advantages and disadvantages. When exporting a custodian's mailbox using Microsoft Outlook, the person doing the exporting typically logs into the server as the custodian. This can, under some circumstances, be problematic. One advantage of this approach, though, is that the newer versions of the Outlook client can create very large (>1.7GB) Outlook e-mail archives. For custodians who have a large volume of mail in their accounts, this might be a viable approach if logging in as the custodian to collect the mail does not present an unacceptable risk. One potential downside to this approach is that the Outlook client might not collect deleted e-mail messages retained in the Microsoft Exchange special retention area called “the dumpster,” which is a special location in the Exchange database file where deleted messages are retained by the server for a configurable period of time. Additionally, Outlook will not collect any part of any “double-deleted” message. Double-deleted is a term sometimes used to refer to messages that have been soft-deleted from an Outlook folder (e.g., the Inbox) into the local Deleted Items folder and then deleted from the Deleted Items folder. These messages reside essentially in the unallocated space of the Exchange database file, and are different from hard-deleted, which bypass the Deleted Items folder altogether during deletion. Using Outlook to export a custodian's mailbox would not copy out any recoverable double-deleted messages or fragments of partially overwritten messages.
One advantage of using the Exmerge utility to collect custodian e-mail from a live Exchange server is that Exmerge can be configured to collect deleted messages retained in the dumpster and create detailed logs of the collection process. However, there are at least two main disadvantages to using Exmerge. First, even the latest version of Exmerge cannot create Outlook e-mail containers larger than 1.7GB. For custodians who have a large volume of e-mail in their account, the e-mail must be segregated into multiple Outlook containers, each less than about 1.7GB. Exmerge provides a facility for this, but configuring and executing Exmerge multiple times for the task and in a manner that does not miss messages can be problematic. Second, Exmerge will not collect any part of a double-deleted message that is not still in the dumpster. So there could be recoverable deleted messages or fragments of partially overwritten messages that Exmerge will not copy out.
Exmerge can be run with the Exmerge GUI or in batch mode from the command line. The screenshots in Figure 3.2, Figure 3.3 and Figure 3.4 show the steps to follow to extract a mailbox, including the items in the Dumpster, using the Exmerge GUI.
 |
| Figure 3.2 |
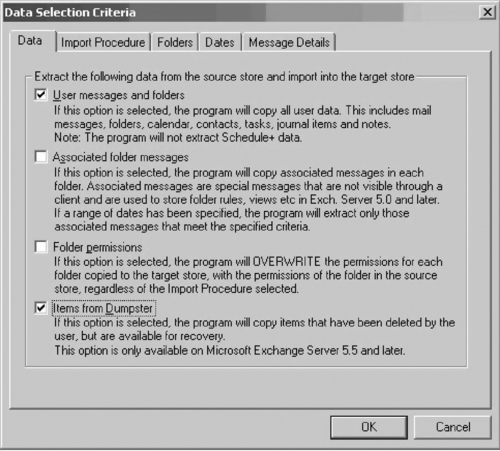
 |
| Figure 3.4 |
To enable the maximum logging level for Exmerge, it is necessary to edit the Exmerge.ini configuration file, setting LoggingLevel to the value 3.
With the release of Exchange Server 2007, Microsoft did not update the Exmerge utility. Instead, the latest version of Exchange Server includes new command-line functionality integrated into the Exchange Management Shell essentially to replace Exmerge.
The Exchange Management Shell provides a command-line interface and associated command-line plug-ins for Exchange Server that enable automation of administrative tasks. With the Exchange Management Shell, administrators can manage every aspect of Microsoft Exchange 2007, including mailbox moves and exports. The Exchange Management Shell can perform every task that can be performed by Exchange Management Console in addition to tasks that cannot be performed in Exchange Management Console. (Microsoft, 2007a)
The Exchange Management Shell PowerShell (PS) Export-Mailbox command-let (cmdlet) can be used either to export out specific mailboxes or to cycle through the message store, allowing the investigator to select the mailboxes to be extracted. By default, the Export-Mailbox cmdlet copies out all folders, including empty folders and subfolders, and all message types, including messages from the Dumpster. For a comprehensive discussion of the Export-Mailbox cmdlet and the permissions required to run the cmdlet see Microsoft (2007b).
The following is the command to export a specific mailbox, “[email protected],” to a PST file named jsmith.pst:
Export-Mailbox -Identity [email protected] -PSTFolderpath c:jsmith.pst
The following is the command to cycle through message store “MailStore01” on server named “EXMAIL01,” allowing the investigator to select the mailboxes to be extracted:
Get-Mailbox -Database EXMAIL01MailStore01 | Export-Mailbox -PSTFolderpath c:pst”
The screenshots in Figure 3.5, Figure 3.6 and Figure 3.7 show the steps to follow to cycle through message store “EMT” on the Exchange server named “MAIL2,” allowing the investigator to select the mailboxes to be extracted.
 |
| Figure 3.5 |
 |
| Figure 3.6 |
 |
| Figure 3.7 |
(Note: The following screen captures were taken during a live investigation, however the names have been changed to protect custodian identities.)
The most complete collection from a Microsoft Exchange Server is to collect a copy of the Information Store (i.e., the priv1.edb file and its associated .STM file for the private mailbox store as well as the pub1.edb and associated .STM file for the Public Folder store). The primary advantage of collecting the entire information store is that the process preserves and collects all e-mail in the store for all users with accounts on the server. If during the course of review it becomes apparent that new custodians should be added to the initial custodian list, then the e-mail for those new custodians has already been preserved and collected.
Traditionally, the collection of these files from the live server would necessitate shutting down e-mail server services for a period of time because files that are open for access by an application (i.e., the running Exchange Server services) cannot typically be copied from the server. E-mail server services must be shut down so the files themselves are closed by the exiting Exchange application and they are no longer open for access. This temporary shutdown can have a negative impact on the company and the productivity of its employees. However, the impact of shutting down e-mail server services is rarely as significant as shutting down a revenue-producing server for traditional forensic imaging. In some cases, perhaps a process like this can be scheduled to be done off hours or over a weekend to further minimize impact on the company.
More recently, software utilities such as F-Response™ can be used to access the live Exchange Server over the network and to preserve copies of the files comprising the Information Store. F-Response (to enable access to the live server) coupled with EnCase® Forensic or AccessData's FTK Imager® could be used to preserve the .EDB and .STM files that comprise the Information Store. Alternatively, F-Response coupled with Paraben's Network E-mail Examiner™ could be used to preserve individual mailboxes from the live server.
F-Response (www.f-response.com/) is a software utility based on the iSCSI standard that allows read-only access to a computer or computers over an IP network. The examiner can then use his or her tool of choice to analyze or collect data from the computer. Different types of licenses are available, and the example shown in Figure 3.8, Figure 3.9, Figure 3.10, Figure 3.11 and Figure 3.12 (provided by Thomas Harris-Warrick) is shown using the Consultant Edition, which allows for multiple computers to be accessed from one examiner machine.

 |
| Figure 3.10 |

 |
| Figure 3.12 |
The examiner's computer must have the iSCSI initiator, F-Response and the necessary forensic collection or analysis tools installed, and the F-Response USB dongle inserted in the machine. The “target” computer must be running the “F-Response Target code,” which is an executable than can be run from a thumb drive.
1. Start F-Response NetUniKey Server
The first step is to initiate the connection from the examiner's computer to the target computer, by starting the F-Response NetUniKey server. The IP address and port listed are the IP and port listening for validation requests from the target computer(s).
2. Start F-Response Target Code on Target Computer
Upon execution of the F-Response Target code, a window will appear requesting the IP address and port of the examiner's machine that is listening for a validation request. After entering in this information, the window in Figure 3.9 will appear. The host IP address, TCP address, username and password must be identified.
3. Consultant Connector
The next step involves opening and configuring the iSCSI Initiator, which used to be completed manually. F-Response has released a beta version of Consultant Connector, however, which completes this process for you, resulting in read-only access to the hard drive of the target computer.
4. Preservation of EDB File
The Microsoft Exchange Server was live when accessed with F-Response, and it was not necessary to shut down the server during the collection of the EDB file using FTK Imager (see additional detail, further, on FTK Imager).
Another approach to collecting the .EDB and .STM files might be to collect a very recent full backup of the Exchange Server Information Store if the company uses a backup utility that includes an Exchange Agent. The Exchange Agent software will enable the backup software to make a full backup of the Information Store, including the priv1.edb file, the pub1.edb file, and their associated .STM files.
Once the Information Store itself or the collective .EDB and .STM files that comprise the Information Store are preserved and collected, there are a number of third-party utilities on the market today that can extract a custodian's mailbox from them. Additionally, if the circumstances warrant, an in-depth forensic analysis of the .EDB and .STM files can be conducted to attempt to identify fragments of partially overwritten e-mail that might remain in the unallocated space of the .EDB or .STM files.
This was the case in an arbitration. The central issue in the dispute was whether the seller had communicated certain important information to the buyer prior to the close of the transaction. The seller had received this information from a third party prior to close. The buyer claimed to have found out about the information after the close and also found out the seller possessed the information prior to close. The buyer claimed the seller intentionally withheld the information. An executive at the seller company had the information in an attachment to an e-mail in their inbox. Metadata in the Microsoft Outlook e-mail client indicated the e-mail had been forwarded. However, the Sent Items copy of the e-mail was no longer available. The employee claimed the addressee was an executive at the buyer company. The buyer claimed the recipients must have been internal to the seller company and that the buyer did not receive the forwarded e-mail.
The seller company hired us to conduct an exhaustive search for a copy of the forwarded e-mail throughout their own internal e-mail archives, including forensic images of all key executives’ laptop and desktop computers as well as a forensic examination of the current e-mail server and e-mail server backup tapes. The purpose of the examination was to attempt to determine the addressees of the forwarded e-mail. The buyer company refused to examine their own archives and refused to allow a forensic examination of their computers. Both Exmerge and Paraben's Network E-mail Examiner found the e-mail in the Inbox of the seller employee—neither tool found a copy of the forwarded message. However, a forensic examination of the .EDB file uncovered fragments of the relevant e-mail in the unallocated space of the seller's .EDB file. These fragments allowed the seller company to substantiate their claim of forwarding the message to the buyer. Although this kind of in-depth forensic recovery of fragments of a deleted e-mail is not always necessary, if the central issue might be decided by a single e-mail, the effort might be worthwhile.
In addition, some companies have been deploying enterprise level e-mail storage and management applications that they anticipate using not only to store and manage the company's e-mail data, but also to respond to discovery requests. In some cases, the application houses much of the archived e-mail data for the custodians, and could also be configured to maintain a copy of every e-mail that enters or leaves the Exchange environment, regardless of whether a user later deleted the e-mail from their account on the Exchange server. A forensic examiner may need to preserve data from these applications and should determine the tool's functionality and configuration from the company IT department to assist in this process. The importance of verifying the application's ability to provide accurate and complete information is discussed in Howell (2009).
Preserving and Collecting E-mail from Lotus Domino Server
Unlike Exchange Server, where e-mail is contained in a unified database storage file (i.e., the priv1.edb file) and must be extracted from the .EDB file into .PST files for processing into a review environment, on Lotus Domino server each custodian will have their own separate e-mail file (IBM, 2007). Each custodian will have a Lotus Notes data file on the server that holds the custodian's e-mail, as well as other Lotus Notes items (e.g., Calendar items, To-Do lists, etc.). A complete collection from the live Lotus Domino server can be as simple as making a copy of each .NSF file assigned to a custodian. However, consider collecting .NSF files for all e-mail users at the time. If during the course of reviewing a custodian's e-mail it becomes apparent that new custodians should be added to the initial custodian list, you'll be better able to respond to the needs of the matter if e-mail for those new custodians has already been preserved and collected.
At least three considerations come to mind when working with Lotus Domino.
1. A custodian's .NSF file might not have a name that clearly links it to the custodian. For instance, the .NSF file for custodian Joe Smith could be called 123456.nsf. To confirm that you preserve the correct mail files, consider asking for a custodian/e-mail file cross reference.
2. Unlike Exchange, where the .EDB and .STM files are always open for access by Exchange Server services, each .NSF file should be open for access only during a replication event. Copying the .NSF files off the server should generally not be hampered by open file access and shutting down e-mail server services should not be necessary. One exception to this is the case where a custodian does not have a replica of his or her e-mail on the local computer: the custodian could access his or her e-mail directly from the server copy. In that case, the .NSF file on the server might be open for access by the custodian's copy of Lotus Notes on his or her laptop/desktop as long as the Lotus Notes application is active. The custodian might need to close Lotus Notes on the laptop or desktop to release the .NSF file on the server.
3. Lotus Notes .NSF files can be protected with local encryption such that the user's ID file and password are required to open the .NSF file and access the e-mail data. After the .NSF has been opened in Lotus Notes using the ID file and password, the protection can be removed by creating a copy of the database file without encryption. Individual messages may also be protected even if the entire database file is not, and in most instances the ID file and password used at the time the message was protected must be used to decrypt the message. Messages that are individually protected have a value of “1“ in the Lotus Notes field “Encrypted,“ which can be used to identify the messages if necessary.
Most of the electronic discovery review tools on the market today can take as input a native Lotus Notes .NSF file for processing into their review environment, so the .NSF files typically do not require further processing.
The tools commonly used to complete this collection could be as simple and cost-effective as xxcopy™ (see the next section for more details) or as complex as an EnCase Enterprise e-discovery suite.
Preserving and Collecting Home Drives and Departmental Shares5
5By “home drive” we mean that personal network space assigned to a custodian for individual or personal use. Other than a system administrator with privileged access to the file server housing the home drives, only the custodian should be able to read files from and write files to their home drive. Contrast this with a departmental share where all employees assigned to a department (e.g., Finance, HR, Accounting, IT, etc.) map the departmental share to their local computer and have permission to read from and write to the shared space.
Several tools are available to the forensic examiner for preserving and collecting data from live file servers. Two of the more robust tools are FTK Imager by AccessData, which is free, and xxcopy, which is free for noncommercial use, and licensed for commercial use.
FTK Imager, which has a “lite” version that can be run on a server from CD or USB without installing the software on the server, has several advantages over xxcopy. First, FTK Imager can preserve certain metadata about files and folders and it containerizes the data into evidence containers. This protects the data and the metadata from accidental modification. Additionally, since FTK Imager is a forensic tool, it provides an opportunity to identify and attempt to recover deleted files from the live server.
Using FTK Imager to preserve logical data, such as a custodian's home directory, from a live server is a simple process. The screenshot in Figure 3.13 shows the opening screen of FTK Imager and adding the live server as a logical drive.

Once the drive has been added as an evidence item, the files, including deleted files, are available for review and export as a logical image (AD1) (Figure 3.14).

After identifying the destination directory and filename of the local image file to be exported, the user can choose to generate a directory listing of all the files in the image, which is recommended for documentation and quality assurance purposes (Figure 3.15).

After the preservation is completed, a results window will open informing the user if the process was successful or not (Figure 3.16). This information, including a hash value for the logical image itself, is included in a log file that is automatically generated and saved in the destination directory. The generation of a hash value is another advantage of FTK Imager over xxcopy.
 |
| Figure 3.16 |
The AD1 logical image file should always be opened in FTK Imager after completion to verify that the data was preserved accurately and completely.
The other useful tool for preserving logical files is xxcopy™ by Pixielab, Inc. (www.xxcopy.com/), which is based on the Microsoft xcopy command that can be used to preserve data from file servers. The xxcopy utility can be configured to generate a detailed log of the copying process, and can preserve the date and time metadata for the files and folders of both the original files being copied, and the copy of the files. In addition, xxcopy recently added Unicode support with version 2.97.3, the previous lack of which was a major disadvantage as xxcopy would not always log folders that were not copied due to Unicode characters in the folder name. However, xxcopy has several disadvantages compared with FTK Imager:
▪ xxcopy does not place the files it copies into a “container.” The files remain loose files in a file system, subject to accidental change during future processing.
▪ xxcopy will not copy open files from the server. If a custodian has a file in his or her home drive open for editing—including a .PST or .NSF e-mail container—xxcopy will not copy the open file. However, if the optional logging facility is enabled during the copy process, xxcopy will add an entry in its log file for each live file it failed to copy.
▪ xxcopy does not calculate and preserve in its log a cryptographic hash of the files it copies. xxcopy relies on the MS Windows operating system to make complete and accurate copies of files. If MS Windows fails to make a complete and accurate copy of a file and also fails to report that the copy process failed, then xxcopy cannot determine that a copy of a file is incomplete.
▪ xxcopy cannot identify and recover any recently deleted files during the copy process (except files and folders that are still in the Recycle Bin).
An example xxcopy command line for preserving live server data from the folder S:Jessica Smith Files to the folder D:ES55Jessica Smith Files is provided here:
xxcopy /H /K /E /PB /oAD:ES55Jsmith-log.log /TCA /TCC /TCW “S:Jessica Smith Files” “D:ES55Jessica Smith Files”
An explanation of each switch used in this command follows. A full listing of the command line switches available can be found at www.xxcopy.com/xxcopy25.htm.
▪ /H includes hidden and system files
▪ /K maintains attributes
▪ /E includes subdirectories and empty directories
▪ /PB show progress bar
▪ /oA appends to error log in specified location
▪ /TCA preserves last accessed dates
▪ /TCC preserves creation dates
▪ /TCW preserves last modified dates
The xxcopy progress bar provides some indication of the time required to complete the copying process (Figure 3.17).

The xxcopy log, specified using the /oA switch, provides information on whether the copy process is successful or not. In addition to review of this log, the examiner should always perform an independent comparison of number of files to be copied and number of files copied to ensure the copy process was accurate and complete (Figure 3.18).
 |
| Figure 3.18 |
There are other tools that are somewhat similar to xxcopy, including the Microsoft software utility Robocopy and Microsoft Backup; however each has its disadvantages for collections when compared to both FTK Imager and xxcopy. Robocopy is the most similar to xxcopy, and has the same disadvantages, namely that it does not containerize the files it copies, will not copy open files from the server, and does not calculate a cryptographic hash of the files it copies. Robocopy, however, has an additional disadvantage—although it preserves date-time metadata on the copies of the files it makes, it updates the access date of the original files left behind (Figure 3.19). This certainly contravenes a fundamental forensic principle to not alter the original data if at all possible, and for this reason, given the other options available, we do not recommend using Robocopy to preserve data from a live server.
 |
| Figure 3.19 |
Another utility, called Microsoft Backup, differs from xxcopy and Robocopy in that it does “containerize” the files it backs up into a .BKF file. However, Microsoft Backup shares the same fundamental flaw as Robocopy, where it preserves date-time metadata on the copies of the files it makes, but updates the access date of the original files left behind. For this reason, given the other options available, we do not recommend using Microsoft Backup to preserve data from a live server.
Of course, do not forget about the backup tapes of the servers. A full backup made during the timeframe of interest and before anyone was aware of an investigation or litigation may be the only place to find some files that were deleted from the server either intentionally or in the normal course of business. Backup tapes are a crucial source of this historical data.
Preserving and Collecting Data from Transactional Systems and Databases
Preserving and collecting data from complex transactional or database systems (e.g., SAP, Oracle Financials, JD Edwards, Equity Edge, etc.) offers the forensic examiner a challenge. Traditional forensic imaging and backup tapes may preserve the data, but will generally not make the data accessible and useable to a third party. Additionally, in most cases, the forensic examiner will not be qualified to run the application that houses and interacts with the data and the application itself will not likely have facilities for conducting the required data analytics supporting the investigation or litigation. Those factors together mean that generally, preserving and collecting the data in a useable fashion will mean extracting it from its proprietary environment and importing it into a nonproprietary environment.
The extraction process will generally be driven by the requirements of the litigation or investigation, including defining applicable date constraints, selecting specific accounting codes or company codes, and finalizing data sources (e.g., accounts payable, accounts receivable, journal entries, or data from CRM systems, ERP systems, or HR systems, etc.). In some cases, the database system may contain standard reporting modules that can be run to extract data from the system in a text file format. In other cases, the forensic examiner will work with a programmer or administrator of the database system to develop customized reports or queries. The output of the report or query process will be the data selected for collection and preservation transformed into a flat text-based format able to be uploaded into a nonproprietary database environment.
An important aspect of the extraction process will be an independent review of the extraction/report queries before they are run to verify they do not include unapproved constraints that might restrict the extracted data. Additional queries should also be run whose outputs constitute quality control checks of the output data to be compared to corresponding queries of the data after import into the new environment. This is typically accomplished with row or record counts as well as control totals of numeric fields. After importing the data into a nonproprietary database system, the count of imported rows or records can be compared to the count of exported rows or records and the sum of an imported numeric field can be compared to the control total calculated of that same field prior to extraction. This enables the forensic examiner to evaluate the import process and verify the imported data matches the output of the approved queries. Absent these kinds of quality control procedures, there could be import errors that go undetected. These errors could have an impact on the output of analytical procedures executed on the data.
As with e-mail server and file server data, backup tapes of the database or transactional data systems can be very important. For instance, some financial systems retain detailed records for only a few fiscal years and, at some scheduled process, drop the detailed records and maintain only summary data afterward. Available full backups of the system might be the only mechanism for recovering some detailed records that have been deleted by the system after their defined retention period.
Preserving and Collecting Data from Other Data Sources
There are a variety of other data sources that will be sought in the course of formal discovery, including data from cell phones or personal digital assistants that might be synchronized with a custodian's laptop e-mail client as well as entertainment devices like iPods. Personal digital devices can store hundreds of gigabytes of data and are likely candidates for preservation and collection for review and production. As technology progresses and capabilities like WiFi, digital video/audio/photograph, and GPS are integrated into the devices, they will store more and more information relevant to what a person knew and when they knew it or the actions a person took or failed to take.
The targeted data on a new generation cell phone or PDA is likely to be e-mail, calendar items, call logs, GPS location information to correlate with other timing data; videos or photographs taken with the camera or stored on the phone; and other types of user data a custodian might store on their cell phone or PDA. Additionally, the phones will contain a type of data not usually found on a personal computer—the ubiquitous text message. In the normal configuration, text messages sent from phone to phone bypass the corporate e-mail server and are not recorded there. So the data will likely be found only on the cell phone itself.
Software tools allowing preservation and collection of cell phone and PDA data are becoming more readily available, even as the number of different models of phones and devices expands. Once the data are preserved and collected, the traditional user data will be processed for review and production just like any other user data. However, another type of analysis will likely be important for an investigation, including whether the user data on the cell phone or PDA is consistent with user data from other sources. Additionally, the call logs, text messages, and GPS information might be analyzed and correlated with other information to reconstruct a timeline of key events.
Evidence Chain of Custody and Control
A key aspect of electronic data preservation and collection in formal discovery is initiating and maintaining chain of custody and control of the electronic data. A well-documented chain of custody process allows the data to be submitted as evidence in a court or other legal or administrative proceeding. The Federal Rules of Evidence Rule 1001 states, “If data are stored in a computer or similar device, any printout or other output readable by sight, shown to reflect the data accurately, is an ‘original’.” A well-documented chain of custody process will be required to demonstrate that the data preserved and collected has not changed since the preservation and collection and that any printouts of the data are accurate reflections of the original data. Absent good chain of custody procedures, an adverse party might raise a claim as to the accuracy of the data in an effort to have the data withheld from admission.
The legal requirement that the data preserved and collected accurately reflect the original has many implications in the technical application of electronic discovery. For instance, if original data on a file server are preserved using a simple copy–paste procedure, the content of the copy will likely be an accurate representation of the original, but the metadata about the original will be changed on the copy. If at some time in the future the matter requires an inspection of the Date Created of a key document, the copy preserved with a copy–paste procedure will not have the same Date Created as the original, even if the content of the copy is digitally identical to the original. This is not to suggest that preservation and collection via a copy–paste procedure automatically makes electronic evidence inadmissible. After all, the content of the copy will most likely be identical to the content of the original and a printout from the copy will likely accurately reflect the original. But the means used to preserve and collect the data, if not a more robust forensic procedure, can have an impact on your future use of the data and metadata when electronic discovery questions are necessarily formatted into forensic analysis questions.
Preserving and Collecting Backup Tapes
Many of the systems covered in earlier paragraphs of this section are routinely backed up by a company for disaster recovery purposes. It will be important for the forensic examiner to understand the universe of available backup tapes for each of the systems, when tapes are rotated, which tapes are kept long term, and when tapes are destroyed. At the initial stages of the matter, the company should provide (or in some cases be compelled to create new) a complete backup tape inventory for both current systems and during the relevant time period (if different) detailing at least the following information:
▪ Tape identifier/label
▪ Tape format (e.g., DDS, LTO, DLT, etc.)
▪ Backup date/time
▪ Names(s) of server(s)/system(s) targeted for backup
▪ Type of backup on the tape (e.g., a full backup, incremental or differential)
▪ Current location of the tape (e.g., in the backup device, in the server room, in off-site storage, etc.)
▪ Scheduled rotation
It is not unusual for a company to make full backups of their systems on a weekly basis during the weekend hours and to make incremental or differential backups during the work week. Full backups of large data sets can take time and resources away from the servers, and incremental or differential backups only back up the subset of data that changed since the last full backup. Most companies will keep weekly or monthly full backups for some period of time and might keep an annual full backup for a number of years. In the highly regulated financial and pharmaceutical industries, we typically find that month-end and year-end backup tapes are kept much longer than in the nonregulated industries.
Backup tapes can be a contentious issue. In one matter we worked on, a company in a highly regulated industry had more than 30,000 backup tapes in off-site storage. Compounding the matter, the company did not have a reliable inventory of the tapes that described in any detail the contents of the tapes such that some tapes could be eliminated from the pool of tapes to be reviewed. Because any of the tapes might have held relevant nonprivileged data, all tapes were initially cataloged to provide a suitable inventory from which to make selections for data restoration and processing. Had the company kept a reliable log of tapes in off-site storage, including some indication of what was on a tape or even what backup tape media types (e.g., DDS, DLT, DLT IV) were used to back up servers containing relevant data, the company could have saved a considerable amount of money on tape processing.
Do not underestimate the value of backup tapes. Though processing them can take time, they contain a snapshot of the server at a period of time before the litigation or investigation began, before anyone knew data on the systems might be produced to another party, and before someone or some process might have deleted potentially relevant and nonprivileged data.
Data Processing
Having preserved and collected perhaps a mountain of data for counsel to review, the next phase of the electronic discovery process is—naturally—data processing. Although data processing will be focused on accomplishing many objectives discussed in the introductory section of this chapter, the overarching goals for data processing are data transformation and data reduction. The data must be transformed into a readable format so that counsel can review the data for relevancy and privilege and the volume of data must be reduced, typically through filtering for file types, duplicates, date, and keywords, in a manner that does not compromise the completeness of any future production.
The Enron case highlights the steady growth in both volume and importance of electronic data in corporate environments. Andrew Rosen, President of ASR Data Acquisition and Analysis, a computer forensics firm hired by Arthur Andersen to preserve electronic records and to attempt to recover deleted computer records related to the matter, estimated his firm preserved approximately “268 terabytes—roughly 10 times the amount of data stored by the Library of Congress” in the form of hundreds of hard drives. All that data had to be reviewed. If all the digital content were printable ASCII text printed singled sided, reviewers would have to look at 76.9 billion pages of paper—a stack more than 4,857 miles tall (Holley, 2008).
The forensic examiner's role in this phase of the e-discovery process ultimately depends on the processing strategy for review purposes decided by counsel. An examiner is typically involved with extracting the user files from the preserved data, including the forensic images and the data preserved from servers, using a tool such as EnCase Forensic. Filtering the data for duplicates, date, and keywords, and transforming the data to a reviewable format can be performed either by examiners using forensic software or other processing tools, or with an electronic discovery database. These electronic discovery databases are robust, comprehensive database platforms. Most are able to perform filtering for file type, duplicates, date, and keywords. Other advanced systems also provide advanced analytics such as concept searching, concept categorization, e-mail thread analysis, “near” duplicate identification, and/or social networking analysis. These database platforms facilitate counsel review and ultimate production by either hosting the data online or by outputting responsive data to load files for review with in-house review tools such as Concordance or Summation.
There are many different processing strategies for review purposes employed by counsel. Counsel considers many factors when deciding on a strategy, and though discussion of all of these factors are outside the scope of this chapter, we have found that data volume, costs, and upcoming production deadlines are the most frequent factors considered. Three of the more common approaches are:
▪ Upload all the user files extracted from the preserved data into an electronic discovery database and perform the data filtering in the database.
▪ Use forensic software or other processing tools such as dtSearch to filter the data and transform it into reviewable format.
▪ Use a hybrid approach where the extracted data is first reduced through filtering with forensic software or other processing tools and then is uploaded into an electronic discovery database for review and/or further filtering.
Forensic examiners should understand how data are uploaded, stored, and searched in the electronic discovery databases both because they are often responsible for providing the data to be uploaded, and also for instances where they are required to either assist with formulating the keywords or perform quality assurance on the results, as further described in the production section of this chapter. It is even more imperative for forensic examiners to understand the tools they use to extract user files from preserved data, filter for duplicates, date, and keyword, and transform for review. The focus of this section is on performing these tasks and completing the necessary quality assurance to ensure accurate and complete results.
Exctracting and Processing Data from Forensic Images
For almost every matter, counsel will have a list of custodians and will direct forensic images of custodian laptop and desktop computers to be preserved. Processing data from those forensic images into a review environment can be a technically complex procedure with many decision points. Counsel must determine which file types are most likely to be relevant; whether processing will include attempts to identify and recover deleted files; how to handle compressed or encrypted files; what level of forensic review, if any, will be accomplished for high priority and/or lower priority custodians; whether attempts will be made to identify and recover fragments of deleted files from unallocated space; whether personal data will be excluded from upload into the review environment; and more.
Certain types of data may be identified as relevant only after a diligent forensic examiner reviews the forensic image(s) in a case. Therefore, forensic examiners must have an understanding of the case background and what kind of ESI is being sought in order to identify relevant items when they come across them. Furthermore, forensic examiners should not become overly reliant on rote checklists and automated methods for extracting predetermined file types, or they risk missing entire classes of relevant items. Such an oversight could lead to incomplete productions, and provide grounds for sanctions as discussed in the legal section earlier in this chapter.
Relevant File Types
One of the first decisions counsel must make that has an impact on data reduction is to determine which file types are potentially relevant to the matter. In almost every matter, e-mail and office documents will be processed into the review environment. But there are other matters where unique file types play a part. If a custodian works in an engineering department, for example, the engineering drawings themselves (which can be quite large when created in a computer-aided design (CAD) application) might be relevant and they would be extracted for review. However, they might be excluded from extraction if the dispute does not center on the CAD drawings themselves.
In one matter we worked on, digital camera pictures in JPEG file format were relevant to the dispute. Counsel asked us to design a processing methodology for extracting the digital camera JPEG files from the forensic image while ignoring typical web page JPEG graphic files. Since the files have the same extension, a simple search for all .JPG files would extract too many files for counsel to review. Complicating this was the fact that some of the relevant digital camera images were also in the web cache folders. But counsel had no interest in reviewing all the typical JPEG images that continue to proliferate in the web cache folders. Our approach to the process involved analyzing samples of the relevant digital camera pictures, developing signatures from them that identified them distinctly from web page image files, and analyzing file system activity patterns when web page images are created on the hard drive. Using those data elements, we were able to isolate the web page images from all other JPEG files, significantly reducing the number of JPEG files counsel had to review in the matter.
Extracting files from forensic images is typically done using a variety of techniques, but the most complete technique checks a file's signature instead of a file's extension. A file signature refers to a unique sequence of data bytes at the beginning of a file that identifies the file as a specific file type. For instance, a file whose first four bytes are “%PDF” can be identified as a likely Adobe Acrobat Portable Document Format file, even if its extension is not .PDF. The file signature will be a better indicator of the file's contents than is its extension. This is especially important where a company maps a custodian's local My Documents folder to their network home drive and has implemented Client Side Caching. In this situation, all documents in the My Documents folder actually reside on a file server housing the custodian's home drive. Local copies of the files are available to the custodian to be opened and edited when the custodian is offline, but the local copies of the file are not actually contained in the My Documents folder, they do not have their real document names, and they have no extensions. The Microsoft Windows operating system maintains a local database that maps the actual files to the names the custodian expects to see. In actuality, the files are contained in the C:WindowsCSC folder and they have names like 80001E6C or 80001E60 without extensions. An extraction procedure that relies exclusively on extensions will not identify the relevant files in the Client Side Cache folder. Additionally, if a custodian has renamed file extensions in an effort to hide files (e.g., renaming myfile.doc to myfile.tmp) then the renamed files will not be extracted if the extraction procedure looks exclusively for file extensions.
Identifying and Recovering Deleted Files and Folders
Forensic tools commonly available today have robust capabilities to identify and recover deleted files in the normal course of processing. As discussed in the legal section of this chapter, Rule 26(a)(2)(B) exempts from discovery information that is “not reasonably accessible” and the Advisory Committee identified deleted data that requires computer forensics to restore it as one data source that might not be reasonably accessible. Whether or not to include recoverable deleted files in a discovery effort is a decision that ultimately needs to be made by counsel.
Compressed or Encrypted Files
Compressed file archives (e.g., zip, rar, tar, cab, 7z, etc.) will be extracted and examined to determine if they contain relevant file types. The processing must be able to recursively extract files from the archive because a compressed archive can be included in another compressed archive. Encrypted or password-protected files need to be identified and a log generated. Once notified, counsel will decide whether additional actions such as attempts to “crack” the password or approaching the respective custodian are necessary.
Nontext-Based Files
Counsel will decide whether nontext-based files such as TIFF images of scanned documents or PDF files will be extracted and processed into review. Typically, a well-constructed keyword search through the nontext data will not find hits because the files are not encoded in a text format. Therefore, searching the nontext-based files will require either running an Optical Character Recognition (OCR) program against the images to render the text of the pages or manual/visual review.
Forensic Review of High Priority Custodian Computers
If allegations or suspicions of potential evidence tampering exist, there are a number of forensic questions that could be answered for each of the custodians at issue.
▪ Is this actually the custodian's computer? Do they have a user profile on the system? When was the user profile first created and used? When was the user profile last used? If the system has an asset tag, does the asset tag agree with information contained in the company's asset tracking database?
▪ Does it appear that someone may have used a data destruction tool on the hard drive to destroy files?
▪ When was the operating system installed? Does that correlate with IT records about this computer asset?
▪ Is there evidence suggesting the custodian copied files to a network drive or external drive and deleted the files?
▪ Is there evidence to suggest someone may have tampered with the system clock?
▪ Is there evidence to suggest any massive deletion of files from the system prior to imaging?
Although it might not be practical to conduct this forensic analysis by default on all hard drives for all custodians, it could provide valuable information if conducted on the hard drives of the most critical custodians. Indeed, the ability to answer these types of questions is one reason why creating a forensic image of computers is the preferred method of data preservation compared to preserving only active files or custodian-selected files.
Recovering Fragments of Deleted Files from Unallocated Space
Any frequently used computer is likely to have hundreds of thousands, if not millions, of file fragments in the computer's unallocated space. In civil discovery matters though, these file fragments are rarely seen as “reasonably accessible” and therefore not necessary to be recovered and processed into a review environment. That can be seen as an extraordinary effort and can be an expensive proposition. However, for investigations, it might be appropriate for the most important custodians. Fragments of files recovered from unallocated space will not have file system metadata associated with them—therefore you will not necessarily be able to determine with any certainty when a file was created, modified, accessed, or deleted. In fact, you might not even be able to determine that the fragment was part of a document that the user deleted. File fragments can be created in many ways that do not relate to a custodian deleting files, including:
▪ The custodian accessing or opening a file whose content is subsequently temporarily cached to the local hard drive
▪ The custodian or the Microsoft operating system optimizing the hard drive, moving files from one location on disk to another and leaving fragments of the files in their old location
▪ A virus program quarantining and then deleting a file that is subsequently partially overwritten
▪ Microsoft Office or an e-mail application creating and then deleting temporary files that are subsequently partially overwritten, resulting in a fragment
▪ The WinZIP compression and archiving program creating and deleting temporary copies of files that have been extracted for viewing, which are subsequently partially overwritten
If the file is of a type that contains embedded metadata, for example Microsoft Office files and Adobe Acrobat files, this embedded information may be able to be recovered. This embedded metadata can include dates of creation, modification, last saved, and last printed, as well as the author. These dates would not necessarily correspond to the file system metadata. Because file fragments often provide almost no information that can help determine when they were created, by whom or by what process they were created, and how they came to be file fragments, great care must be used when examining them and making judgments about them.
Isolating Personal Data
Some custodians use their company-owned computer as if it were their own personal computer. We've worked on matters where custodians have stored their personal income tax records, private family pictures, social security records, and immigration and naturalization records on the company's computer. In some cases, counsel has requested that this data not be extracted from the forensic image nor processed into the review environment. This might be problematic if the custodian's personal data are comingled with company data, and is often best achieved through the creation of a detailed protocol signed off on by the custodian and the company's counsel. Similar issues often arise when the custodian list includes a company's Board of Directors and the board member has not been diligent in keeping board-related data separate from the data generated from his or her day-to-day job at his or her respective employer. In some cases, a detailed protocol that specifies the identification of relevant board-related data, through performing the collection, preservation, and processing on site at the respective board member's home or employer may be necessary.
Exploring Web Usage
Counsel may be particularly interested in whether the primary custodians might have used web-based e-mail services in an effort to circumvent the company e-mail system. Additionally, Instant Messaging services and proxy services will be important to review for the most important custodians. Counsel may also ask that recoverable web mail message and Instant Message chat logs be extracted from the images and processed into the review environment.
We worked on one Foreign Corrupt Practices Act investigation looking into the practices of an overseas office of a US company. The overseas executives of the company used their corporate e-mail accounts for their normal day-to-day activities, but used free web-based e-mail accounts to conduct their illegal activities. We recovered web mail from one executive that specifically identified topics to be discussed only via the web mail service and indicating the executive knew the US offices had the ability to monitor all corporate e-mail servers and traffic globally.
Over time we've developed the following high-level work flow for processing forensic images supporting electronic discovery matters. This work flow is designed to be used with the EnCase forensic software. You might adapt the work flow to your local needs and tools:
1. Update chain of custody documents as necessary.
2. Update evidence database as necessary.
3. Review forensic preservation memo as necessary.
4. Prepare backup copy of forensic image as necessary.
5. Create new EnCase case and add/import image.
6. Adjust case time zone settings as necessary.
7. Validate sector count and verify image hash.
8. Validate logical data structures.
9. Run recover folders tool.
10. Hash all files and validate file signatures.
11. Export EnCase all files list.
12. Filter active user files.
13. Export EnCase active user files list.
14. Copy folders—filtered active user files.
15. Filter active e-mail files.
16. Export EnCase active e-mail files list.
17. Copy folders—filtered active e-mail files.
18. Filter deleted user files.
19. Export EnCase deleted user files list.
20. Copy folders—filtered deleted user files.
21. Filter deleted e-mail.
22. Export EnCase deleted e-mail files list.
23. Copy folders—filtered deleted e-mail.
24. Identify web mail files.
25. Export EnCase web mail list.
26. Export web mail.
27. Verify file counts—user files, e-mail archives, recovered deleted data, web mail.
28. Verify total size on disk.
29. MD5 sum all exported files—save hash log.
30. Import EnCase all files list into SQL.
31. Import EnCase filtered files list(s) into SQL.
32. Import hash log into SQL.
33. Quality check hash log against EnCase filtered file list(s).
34. Convert e-mail as necessary.
35. Save conversion logs.
36. Quality check e-mail conversion process.
37. Recover deleted e-mail from active and deleted e-mail containers.
38. Count all extracted files by type.
39. Count all mail files and mail items inside the files.
40. Quality check all forensic processing.
41. Send to e-discovery team for processing into review:
▪ Extracted active user files
▪ Extracted active e-mail containers/archives
▪ Extracted active web mail
▪ Recovered deleted user files
▪ Recovered deleted e-mail containers/archives
▪ Recovered deleted e-mail from e-mail containers
▪ Processing logs and counts
▪ Converted e-mail
▪ Forensic processing documentation
42. Update chain of custody documents as necessary.
43. Update evidence database as necessary.
44. Prepare forensic processing memo for binder.
Processing Data from Live E-mail, File Servers, and Backup Tapes
Data preserved and collected from live e-mail and file servers present very few processing challenges to the forensic examiner. E-mail extracted from the live Exchange and Domino e-mail servers will likely proceed directly into the filtering stage without further preprocessing. If the e-mail comes from some other system (e.g., GroupWise, UNIX Sendmail, etc.) and the review tool does not support the native e-mail in that format, then the forensic examiner might convert the e-mail into PST format prior to processing. This conversion should be done only when absolutely necessary as the conversion process is a prime opportunity to introduce data loss and/or corruption. Many tools exist to do this conversion, but it is important to choose carefully and test the tool's e-mail conversion and logging capabilities. The conversion process must not lose e-mail or attachments, must maintain e-mail-attachment relationships, must not change important metadata elements, and must fully document the conversion process. After the conversion has taken place, there should be significant quality assurance steps taken to ensure that the conversion was accurate and complete.
Files preserved and collected from live file servers will likely be processed using the same procedures as for forensic images. The files will be subjected to the same selection and filtering criteria so that there is a consistent approach to user files. The process is typically simpler, however, as there is much less comingling of user files with system files than on forensic images.
When processing backup tapes, it is not uncommon for counsel to ask a vendor to first catalog select tapes to test the accuracy of the company's tape inventory. Particularly if some sampling will be done of the tapes, counsel must be confident that the sampling methodology is relying on a sound inventory as its basic starting point. Cataloging a selection of tapes and comparing the actual results to expected results will provide a measure of confidence that the tape inventory is accurate or will suggest that the tape inventory is not reliable. Once the data from specific e-mail and file server backup tapes are restored, then the data will be processed using the same tools and methods as for the live server e-mail and live file server data.
Data Reduction through Deduplication
Deduplication can reduce the load on counsel, who typically will review documents for relevance and privilege prior to production. Deduplication essentially identifies, using some algorithm, that a file presented to the processing tool is a copy of a file already in the data set for review. Once a file is identified as a duplicate of another file already in review, the new file can be suppressed (although the tool should not “forget” that it found the duplicate).
There are essentially two major deduplication methodologies: per-custodian deduplication and global deduplication. In the per-custodian model, all data for custodian Mike is deduped only against other data also preserved and collected from Mike's data sources. If a file exists on Mike's hard drive and a copy of the file is recovered from Mike's home drive on the live file server and several copies of the file are restored from multiple backup tapes of the file server, then counsel should expect to see and review only one copy of the file for Mike. Other custodians might also have a copy of the file, but Mike's copy will not be deduped against Jane's copy. Likewise, an e-mail contained in Mike's Sent Items folder will be deduped only against other e-mail sources for Mike. If several instances of the e-mail server are restored from backup tape, and a copy of the e-mail exists in Mike's account on each restored tape, then counsel should expect to see the e-mail only once in their review of Mike's data. Recipients of the e-mail who are custodians and who have not deleted the e-mail may also have a copy of the e-mail in their holdings.
The other major deduplication methodology is global deduplication. In this methodology, once the first copy of a unique file is identified using a specific deduplication algorithm, all other copies of that same file will be considered duplicates regardless of custodian. If both Mike and Jane have a copy of a file on their hard drive, the first one to be processed will be added to the review environment and the second one will be suppressed (although the tool should not “forget” that it found the duplicate).
Careful attention should be paid to the technical implementation of the deduplication algorithm. For e-documents, the most common algorithm used to identify duplicates is the MD5 hash. Identifying e-mail duplicates is slightly more complicated as tools typically identify duplicates by hashing the values of a number of different e-mail fields (e.g., sender, recipient, cc, bcc, subject, body text, attachment titles) in a predetermined order. Therefore, depending on the fields used by the tool, there may be different determinations between tools of what is and is not a duplicate e-mail. Not only that, but in some tools the fields used to deduplicate are optional, so different fields can be chosen for different projects.
A commercially available tool had a number of different optional fields available to deduplicate Lotus Notes e-mail, including author, recipients, date and time, number of attachments, and e-mail body. It was only through use of the tool and review of the results that it became obvious not all fields were being used as deduplication criteria, regardless of whether or not they were chosen by the user. Consultation with the developer revealed that there was a “bug” in the tool whereby with Lotus Notes e-mail the e-mail body was not being used to compare potential duplicates, even if the e-mail body was selected by the user as one of the criteria. This bug was specific to deduplication of Lotus Notes e-mail and not Microsoft Outlook. This bug obviously had the capacity to erroneously eliminate unique messages through the deduplication process, an unacceptable situation. Fortunately this bug was identified before the processing was finalized and we were able to ensure that the complete data set was provided to counsel.
The testing and validation of tools with a robust test set that is representative of different e-mail types and real-world scenarios is very important. However, it is not realistic to require testing of every possible scenario before using a tool, nor is it possible to test every type of human error that could take place. This is another reason why it is imperative to perform the necessary quality assurance steps at every step of the electronic discovery process.
Some of the deduplication tools keep detailed records of their automated deduplication decisions, making it relatively easy to show that multiple custodians had a copy of a specific document. However other tools make a deduplication decision and then do not log the fact that the duplicate file existed, or the process of saving the log is not automatic and must be performed manually after each data set has been processed. If Jane has a copy of a file processed into the review environment and later another copy of the same file is processed for Mike, a record should be created and saved that documents Mike had a copy of the file.
Custodian level deduplication is generally preferred by counsel because it allows a wide variety of review strategies to be developed. First, counsel might assign an associate to perform a first-level review of all documents in Mike's holdings to develop a detailed understanding of Mike's communication patterns, including topics on which Mike routinely provides comments and insights, as well as topics of conversation where he is typically only an observer. A reviewer focused on understanding Mike's role in and actions on behalf of a company will need to have access to all of Mike's documents. In a global deduplication methodology, if a document was first processed for Jane and later processed for Mike and Mike's copy was suppressed as a duplicate, the associate might not know Mike had a copy of the document, even if the application did record the fact. Custodian level deduplication also allows for custodian-specific searches to be performed.
Other review strategies certainly exist. Counsel might assign an associate to do a first level review of all documents related to a specific transaction, regardless of custodian or all documents related to a specific period of time to get a sense for official corporate actions in a specific fiscal quarter. Counsel may also determine that the time and cost savings generated by using a global deduplication methodology, resulting in less documents to review, is more important than immediately being able to determine which custodian had which document in their data set. This is often the strategy chosen if counsel is confident that the information on what custodian had which document can be provided at a later date if necessary. Typically, for global deduplication to meet counsel's long-term needs, the application must track and facilitate some level of access to the original document for every custodian that held the document.
Data Reduction through Keyword Searching
Keyword searching provides perhaps the greatest potential to drastically reduce the data volume to a manageable, reviewable level. However it is also a process that if not performed correctly has the potential to significantly impact the completeness and accuracy of the data provided to counsel for review and included in the ultimate production.
Almost every major electronic discovery database platform provides some facility both for preculling, where the data is searched and only responsive data made available for review by counsel, and searching in the review environment, which can be performed by or for counsel.
As mentioned earlier, forensic examiners should understand how data are uploaded, stored, and searched in the electronic discovery databases both because they are often responsible for providing the data to be uploaded (especially if their company owns a proprietary electronic discovery database), and also for instances where they are required to either assist with formulating the keywords or perform quality assurance on the results.
When the forensic examiner is performing the keyword searching, understanding the searching process of the tool used is even more crucial. This understanding is important from a technical perspective to ensure that the keyword search results are accurate and complete, and also to identify crux areas of the process that would benefit from vigorous quality assurance. In addition, understanding the searching process is also important from the perspective of assisting counsel with developing an effective keyword search strategy. There are three core components of the searching process that must be understood:
▪ How the tool indexes the document content, and how documents that cannot be indexed are handled
▪ The data sources being searched
▪ How to formulate a smart, targeted keyword list with the tool's specific keyword syntax and advanced searching capabilities
Additional details on these three core components follow. A comprehensive test example using the tool dtSearch Desktop is also included, to provide additional demonstrative information and highlight the importance of understanding the three core components and performing quality assurance at each step of the searching process.
The dtSearch suite includes a range of indexing and searching products including dtSearch Desktop, dtSearch Network, and dtSearch Web, all of which are based on dtSearch's text retrieval engine. In our experience, we have found that dtSearch is a robust, highly configurable indexing and searching tool for electronic documents and many types of e-mail, including Microsoft Outlook. dtSearch also makes the engine available to developers to allow users to create added functionality if necessary. dtSearch is able to identify certain documents it could not index because of corruption or specific types of encryption and password protection, but does not identify documents with unsearchable text, such as scanned PDF files. Additionally, dtSearch is not able to index Lotus Notes e-mail or perform deduplication. The configurable nature of dtSearch can become a liability if the user is not diligent about reviewing the settings before conducting the index and search.
Proper planning and consideration of indexing preferences in relation to the keywords being searched is essential before beginning the indexing, as is documentation of the preferences being used to ensure consistency among data sets and to answer questions that may arise in the future. The consequences of errors in the search process are often high, including providing an incomplete production to counsel when the mistake is overlooked and work having to be redone when the mistake is caught.
In the following example, dtSearch Desktop was used to index four Microsoft Outlook .PST files consisting of publicly available Enron data and test data generated by the authors.
1. Setting the Indexing Preferences
After the keyword list has been finalized and a searching strategy determined, the first step in using any searching tool that utilizes an indexing engine is to set the indexing preferences. Depending on the tool, the examiner may be able to choose how certain letters and characters are indexed. As shown in Figure 3.20, in dtSearch each letter and character can either be indexed as a letter, space, or hyphen, or be ignored.
2. Creating an Index
When creating the index through the dtSearch Index Manager, the user has the option to index the data with case and/or accent sensitivity. In most cases, you will not want to index the data with case or accent sensitivities to ensure that a complete set of responsive data is identified. However, when the client has requested small acronym keywords such as NBC or ABC, this may result in too many false positives. One solution would be to index the data twice, once with case sensitivity turned on and one without. The small acronym keywords could be searched in the case-sensitive index and all other keywords searched in the noncase-sensitive index.
Choosing the Detailed index logging option will generate a log of all items indexed and all items not indexed, or only partially indexed (Figure 3.21).

3. Index Summary Log
When the index has finished, a log can be viewed that summarizes the number of files indexed and the number of files not indexed, or only partially indexed. A more detailed log that lists each file can also be accessed. Figure 3.22A and FIGURE 3.22B depicts the summary log and then the more detailed log listing the two items only partially indexed.
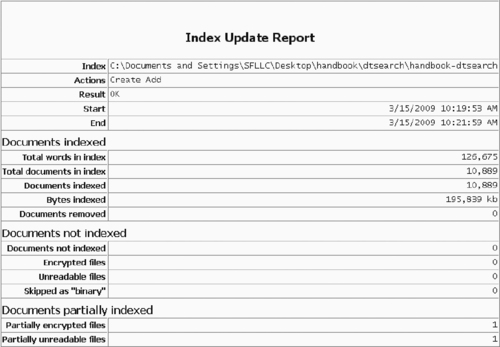

When the original messages are located, it is determined that the attachment to the message with the subject “Ken Lay Employment Agreement” is corrupt, and the attachment to the message with the subject “RE: Target” is password protected. As they are listed under partially indexed, the e-mail itself and any other attachments to the e-mail would have been successfully indexed.
The items either not indexed or only partially indexed should be documented as exceptions to the search process, and either provided to the client for review or further work performed in an attempt to make them available for searching (such as cracking the password protection on the file).
4. Keyword Searching
After the data have been indexed and any exceptions noted, the data can be keyword searched. dtSearch can import a list of keywords, or keywords can be run one at a time in the Search window. Figure 3.23 shows a search for the keyword “apples & oranges” using the Search window, with no files retrieved as responsive.

However, remember that the ampersand symbol “&” is by default indexed as a space, and is also a special search symbol meaning “synonym.” For example, the keyword “fast&” would also return as responsive the word “quickly.” Therefore the previous search is not searching literally for the term “apples & oranges” but is interpreting the search as an incorrect synonym search. If the keyword is changed to “apples oranges”, responsive e-mail items are identified as shown in Figure 3.24. These types of errors are a common mistake when the user does not fully understand dtSearch's search syntax, and highlight the importance of performing a test with a known dataset, indexed with the preferences being used in the case, and searching for the case search terms.
Similarly, it is important to note that dtSearch cannot index the content of files with no searchable text (dtSearch does index the metadata for these files), and also does not identify them as being only partially indexed. As shown in Figure 3.25, the keyword “written agreement” identifies no hits when searching a scanned PDF containing the keyword.
We have implemented work-arounds to this issue by running a grep command through the dtSearch index files themselves to identify PDF files containing a small number of indexed words.
5. Copying Out Results
After the keyword search, responsive files can be copied out, preserving the folder structure as well as dates of creation, modification, and last access as shown in Figure 3.26. Always check the folder to which the data was copied to ensure that the number of files copied out is accurate.

How Documents Are Indexed
There are a number of different indexing engines available on the market today. The indexing engine prepares the documents for searching generally by creating a full-text index of the contents of the documents. Some indexing tools also index metadata about the documents and make the metadata searchable as well (e.g., document names and document properties). The more advanced indexing tools understand compound document formats and provide a capability to search the contents of compound documents.
Given the wide variety of file types and ways they can be damaged or secured, tools used for keyword searching will not be able to index certain file types that are relevant to a case, due to corruption, lack of searchable text (e.g., scanned PDF), encryption, or password protection. It is important to know what file types your tool cannot search and how the tool deals with files it cannot index. Detailed logging of the files the tool can and cannot index is an important feature to enable both a thorough evaluation of the tools’ capabilities, as well as an adequate quality assurance review of the results.
Some tools have more fundamental limitations that forensic examiners must be cognizant of in order to avoid mistakes. For instance, some tools used to perform keyword searches in e-discovery support only ASCII keyword searching and cannot be used to search for keywords in Unicode format. As another example, some tools index data in such a way that a keywords can be case sensitive. Some keyword search tools used to index and search the data necessarily rely on many other software programs to process the data. For example, searching Microsoft Outlook data almost always requires the use of the Outlook API. Therefore, tool testing and validation should not be limited to any specific e-discovery tool, but should include the programs they incorporate. A good example of this is the Microsoft Outlook bug where the body of e-mails created with pre 2003 versions of Outlook are blank when opened with an unpatched version of Outlook 2003. The tool did not index contents of these e-mails, but the failure was not a flaw of limitation of the tool itself. Because the unpatched version of Microsoft Outlook provided no data to the index engine, the tool had no data to index. This was a failure of the Outlook API upon which the tool relied.
In addition to the basic functionality of keyword searching tools, the index settings are a key component of the indexing engine. Most have dictionaries of noise words that will not be indexed (e.g., “and”, “if”, “because”) and also enable you to build a custom dictionary of noise words that can be project- or matter-specific. Other configuration options might include how specific characters such as “&”, “.”, “-“, and “,” are indexed. For example, in dtSearch hyphenated words can be indexed in one of four ways. First, hyphens can be indexed as spaces, such that first-class would be indexed as “first” and “class” with each word separately searchable. Second, by treating the hyphens themselves as searchable, “first-class” would be indexed only as “first-class”. A search for “first” or “class” would not find “first-class”. Third, by ignoring hyphens, “first-class” would be indexed as “firstclass”. And finally, “first-class” might be indexed all three ways to enable a more thorough search. Some index settings might enable you to index field names in XML files and index NTFS Summary Information Streams along with the document content.
Still other options might enable you to completely ignore certain languages or to include in the index several different languages. The tool's approach to indexing punctuation will be important to keyword construction. If the tool indexes the period, then you would be able to search for “Ph.D” or “gmail.com”. But if the tool does not index periods, then search terms constructed to find e-mail addresses must not use the period. In addition, some tools use the ampersand as a special character (e.g., synonym), so using a keyword with an ampersand will not return that keyword.
What the Data Sources Are
Developing a robust search strategy requires an understanding of the types of documents to be searched and their content. Search terms designed to comb through formal corporate documents will be different than search terms designed to parse through more informal e-mail communications where custodians might routinely use abbreviations or slang terminology. Effectively searching through even more informal communications mediums like instant messaging might require using search terms that are almost unrecognizable as words (e.g., “r u there”, or “doin?”, or “havin sup with my peeps”).
Developing Targeted Keywords
The initial keyword list is usually generated by counsel, however the forensic examiner can and should provide guidance and insight into the formulation of keywords and what keywords could generate an excessive number of false positives. A careful review of each keyword on the list and consideration of what it is designed to uncover and what it is designed to accomplish should be performed to ensure the most precise results possible. For example, in one case we worked on, counsel developed a list of key terms containing over 800 words. The list was not well focused, and returned hundreds of thousands of false positive results. Similarly, very short keywords (e.g. acronyms and other terms that are only two or three characters) can also be problematic. The same situation occurs when the contents of document metadata is not taken into account (for example searching Microsoft Word documents for “Microsoft”), or keywords that are included in standard nomenclature such as the disclaimer wording at the bottom of most company e-mails.
Certain keywords that may not generate excessive false positives in one data set will do so in another. To provide some insight into the number of responsive documents before the results are produced for review, it can be helpful to generate for counsel a keyword hit summary report detailing the number of hits and/or the number of documents per keyword. Oftentimes the keyword list is subject to negotiation between the two parties, and this keyword search summary report can be used to show cause for reconsideration or editing of certain keywords due to the number of hits they would generate.
When counsel must also review documents both for relevance and for privilege, it is typical for counsel to develop two or more distinct keyword lists. One list of terms will help counsel to identify potentially privileged materials for privilege review. This list typically contains names of the outside law firms that have been retained by the company for legal advice in the past, as well as the names and e-mail addresses of attorneys from the firms who have been involved in privileged communications with the company's executives and staff. Additionally, the list will likely contain the names and e-mail addresses of in-house counsel. Other words might help counsel find and review documents related to specific issues where the company sought legal advice in the past, including “legal advice”, “privileged”, “work product”, “work-product”, and perhaps other terms.
Before keywords are finalized it can be beneficial for the examiner to review the data before running the search. In instances where counsel provides a custodian's company e-mail address and asks for all e-mails to and from that e-mail address, it may be prudent to review the data to try and determine whether the custodian's e-mail address changed at any point due to changes in company e-mail address nomenclature (e.g., “[email protected]” changed to “[email protected]”), the custodian's change of department (e.g., “[email protected]” or “[email protected]”), or a change of name. In addition, depending on a number of factors including the mail server configuration and method of collection, the custodian's e-mail address is not always preserved in the specific e-mail field. The field is populated with the custodian's name (e.g., “Smith, John”) but the link between the name and the e-mail address has been lost. For Outlook mail, Figure 3.27 depicts the error generated when the e-mail is viewed and the custodian name clicked in an attempt to view the e-mail address.
 |
| Figure 3.27 |
A search for the e-mail address “[email protected]” would not return an e-mail with only the custodian's name in the field as responsive if this link had been lost.
Counsel will construct the other list of terms specifically to find documents potentially relevant to the matter under review. The keyword list should not be taken lightly—attorney review hours flow from the list. To the extent key terms can be precisely developed to focus on the matter under review, attorney review hours will be saved.
We have conducted a number of investigations that can be similarly categorized (e.g., stock option back dating, revenue recognition, FCPA compliance, etc.). We've examined the keywords used in those matters to explore which keywords across the matters tended to uncover documents that an attorney subsequently marked as a HOT document and which data sources tended to contain the HOT documents. We've used this historical data to assist counsel in developing not only a prioritized custodian list, but also a prioritized data preservation and collection plan and a prioritized data processing and review plan.
Advanced Keyword Searching Concepts
Keywords can lead counsel to relevant documents; however simple keywords like “revenue” or “recognition” can lead to a tremendous volume of irrelevant documents—expending significant attorney time in the review process. If the real issue is a company's standard revenue recognition policies and how they were implemented or circumvented in specific cases, then the matter may require more complex keyword searching capabilities. Typically, this is accomplished with keyword completion, Boolean expressions, keyword stemming, phonic searching, field searching, and keyword synonym capabilities.
Keyword Completion
Keyword completion allows a search term to specify how a keyword must start but does not specify how the word must end. For example, “rev*” (where the * represents the unspecified part of the term) will find “revenue”, “revolution”, “revocation”, and any other word that starts with “rev”. The keyword “rec*” will find “recognize”, “recognition”, “recreation”, and any other word that begins with “rec”. When used alone, keyword completion tends to be overinclusive. But when combined with other advanced search capabilities, keyword completion allows some powerful search capabilities where the precise use of a single word might not be known.
Boolean Expressions
With Boolean expressions, a complex keyword can be constructed to narrow the focus of the search. The Boolean expression may typically include AND, OR, NOT, and WITHIN. For example, rev* w/5 rec* will find all occurrences of the word “revenue” when it occurs within five words of “recognition”, but it will not find single occurrences of either word.
Keyword Stemming
Keyword stemming is a capability to extend a search to find variations of a word. For example, the keyword “implement” would find “implemented” and “implementing” if the stemming rules are properly constructed.
Phonic Searching
Phonic searching extends a search to find phonetic variations of a word (i.e., other words that sound like the search term and start with the same letter. For example, a phonic search for “Smith” would return “Smyth”, “Smythe”, and “Smithe”. Phonic searches can return false positives, but can also help find documents where spelling errors occurred.
Keyword Synonym Searching
Synonym searching extends a search to return synonyms of the keywords. Typically, the process relies on a thesaurus created either by the search team or supplied by a vendor. Synonym searching can also return false positives, but might help the reviewers understand more about the language and phrases certain custodians use.
Keyword Field Searching
Field searching allows for keywords to be searched against only certain parts, or fields, of a document. For example, an e-mail address could be searched against only the “From” field of an e-mail data set to identify all e-mails sent from that address. This search would not find the e-mail address keyword in the e-mail body or in any of the other fields such as “To,” “CC,” or “BCC.”
As the keywords become more complex, the need for quality assurance at each step of the searching process becomes increasingly important. The keyword list should be reviewed by multiple people for typographical and syntax errors, complex terms should be tested to ensure they are formulated correctly, and the results reviewed for completeness and accuracy.
Data Reduction through Advanced Analytics
As mentioned briefly before, on the market today are e-discovery database platforms with advanced analytical capabilities that go well beyond traditional keyword or Boolean searching. Concept searching, concept categorization or “clustering,” e-mail thread analysis, near duplicate analysis, social networking analysis, and other types of advanced analytics enable counsel to further reduce the mountain of electronic files for review, quickly identifying and focusing on the more relevant files. The addition of these advanced analytical capabilities allow for automatic identification and grouping of documents based on their topic or concept rather than on specific keywords.
There are a number of approaches that various tools take to enable more advanced analytics. For example, Autonomy uses Information Theory and Bayesian Inference to put mathematical rigor into their analytics engine. 6 Bayesian inference techniques enable the development of advanced algorithms for recognizing patterns in digital data. Although Autonomy supports traditional keyword searching and Boolean searching with which counsel is very likely familiar, the software also employs mathematically complex algorithms to recognize patterns occurring in communications and to group documents based on those patterns. The software “learns” from the content it processes and groups documents based on statistical probability that they relate to the same concept. As more data is processed, the software continues to learn and the probabilities are refined. Using this approach, Autonomy allows counsel to begin reviewing the documents most likely to contain relevant material first and then to migrate their review to other material as new information emerges.
6See www.autonomy.com/content/Technology/autonomys-technology-unique-combination-technologies/index.en.html.
Cataphora takes a different approach to enabling advanced search and analytics by using standard and custom ontologies as well as a branch of mathematics called Lattice Theory (Stallings, 2003). Originally a term used by philosophers, ontology “refers to the science of describing the kinds of entities in the world and how they are related.” (Smith, Welty, McGuinness, 2004). As defined by Tom Gruber, “In the context of computer and information sciences, an ontology defines a set of representational primitives with which to model a domain of knowledge or discourse. The representational primitives are typically classes (or sets), attributes (or properties), and relationships (or relations among class members)” (Liu & Ozsu, 2009). By precisely defining individuals, classes (or sets, collections, types or kinds of things), attributes, relations, functions, restrictions, rules, axioms (or assertions), and events that can occur in a domain, an ontology models a domain. That complex model can then be applied to a data set and the data can be visualized based on the model. For example, an ontology about baseball might describe “bat,” “ball,” “base,” “park,” “field,” “score,” and “diamond” and the interactions among those things whereas an ontology about jewelry might describe “cut,” “color,” “clarity,” “carat,” “ring,” “diamond,” “bride,” “engagement,” and “anniversary.” Using this ontology, documents related to the baseball diamond would be grouped together, but grouped separately from documents related to a jewelry business. In a dispute with another jeweler, one party might quickly identify and mark as nonresponsive all the documents related to baseball, even though they contain the keyword “diamond.”
Attenex takes yet another approach to grouping documents and also presents a visual depiction of their content to reviewers. During processing, Attenex identifies nouns and noun phrases and groups documents based on the frequency with which words commonly appear together based on statistical analysis. In the visual depiction of the related documents, the word or phrase that causes the documents to group together is directly available to the reviewer. In this manner, documents that contain similar content—though not necessarily identical content—are visually grouped together to enable counsel to review them all at essentially the same time.
Stroz Friedberg's e-discovery database platform Stroz Discovery (www.strozlic.com) implements two approaches to categorize documents. The first approach uses pattern matching and rules-based analysis to encapsulate the logic contained within a reviewer's coding manual. In another approach, statistical algorithms are used to build a classification model from a sample learning-set that was coded by the client. The software learns how counsel coded the learning- set, develops a classification model based on what it sees, then applies the model to new, uncoded documents. These technologies can also be used in a hybrid of automatic and manual coding to suggest document codes or to pre-annotate documents prior to counsel reviewing the documents (see Figure 3.28, provided by Christopher Cook).

There are other applications used in e-discovery that provide advanced analytics. A summary discussion of these applications, including aspects that set them apart from one another, is beyond the scope of this chapter. Consult the 2008 Socha-Gelbmann Electronic Discovery Survey (www.sochaconsulting.com/2008survey/) for a review of software providers and service providers. The Sedona Conference has also published an excellent summary of different technologies that hold promise for data reduction in e-discovery (Sedona Conference, 2007).
Forensic examiners should be aware that these technologies and applications exist, as they can be useful when performing analysis in other contexts such as determining document distribution and identifying different versions of documents in a theft of intellectual property case.
Data Transformation and Review
After the data processing has been completed, the next phase is transformation of the data into a format for counsel review, and then the subsequent review of that data by counsel. Forensic examiners are typically not involved in the data transformation and review phases, especially in instances where data was processed with an e-discovery database platform that will also host the data for review by counsel. It is also our experience that forensic examiners are not often asked to “transform” the data for review, which is typically done by creating a load file so the responsive data can be uploaded into a review tool such as Concordance or Summation. In instances where this is requested, there are tools such as Discovery Assistant that can perform this process. As with any tool, the examiner should ensure that he or she has a thorough understanding of how the tool functions, and performs sufficient quality assurance to ensure a complete and accurate result.
Production of Electronic Data
Data identified by the attorneys to produce to the opposing party is often provided after having been converted to an image format such as Adobe PDF or TIFF, and is delivered with a corresponding load file containing associated fielded information about each file. A digital examiner or investigator may be asked to verify the accuracy and completeness of the information before it is produced to the opposing party. In these instances, the following quality assurance steps should be included:
▪ Data Volume: The examiner should verify that the number and types of files to be produced equals the number in the production set. For example, in most load files original single documents are broken up into document families, with each member of the document family having its own row or entry in the load file. In this way, an e-mail message would be recorded in one row of the load file, and the attachment to the e-mail would be recorded in a different row, with one of the fields for both entries documenting the e-mail and attachment relationship. Therefore if the examiner is attempting to confirm that 400 e-mails were included in the production, and there are 700 entries in the load file, the examiner would need to further segregate the e-mails and their attachments to ensure an accurate count and comparison.
▪ Metadata: The examiner should verify that the metadata recorded in the load file is consistent and accurate. This is often achieved through reviewing a suitable sample set, as the sheer number of files in the production datasets precludes the ability to review each metadata field for each file. This review should encompass both an overall general review of the fields and format, and a comparison of specific documents and their corresponding metadata in the load file to verify that the load file information accurately represents the metadata of the native file. The examiner should check that all required fields are present and populated with valid information in a consistent format. Special attention should be paid to the date fields to ensure that all dates are formatted consistently, especially in cases where data from multiple countries were processed.
▪ Image Files: If documents have been converted to file formats such as TIFF or PDF, the examiner should review a suitable sample set to verify that the image file accurately represents the native file.
▪ Text Fields or Files: In instances where documents have been converted to image files, the text of a document can be included for searching purposes either as a field in the load file or as a separate text file. If this is the case, the examiner should review a suitable sample set to confirm that the text provided is complete and accurate.
▪ Exception Files: The examiner should verify that any files not provided in the production dataset were listed as an exception file, and accurately identified as such. There are some files, such as database files, that, due to their format, are not able to be converted to an image file. The examiner should discuss with the attorneys how best to handle these files; one option is to provide the files in native format.
Digital examiners had been tasked with completing quality assurance of production load files of native e-documents and e-mail that had been created by an outside e-discovery vendor, and were to be delivered to the government regulatory agency. By performing the preceding quality assurance steps on the production load files, the digital examiners identified missing data and inaccurate fields, including missing nonmessage items such as calendar items and notes in the native Lotus Notes database files, that the vendor had not processed nor listed on the exception report, inconsistent date formats populated in the date fields, such that some entries were recorded as DD/MM/YYYY and some recorded as MM/DD/YYYY, and inconsistent field headers between different load files. The examiners reported these anomalies to the vendor who reproduced accurate and complete load files.
Conclusion
The e-discovery field is complex, and the technical and logistical challenges routinely found in large e-discovery projects can test even the most experienced digital forensic examiner. The high stakes nature of most e-discovery projects leave little room for error at any stage of the process—from initial identification and preservation of evidence sources to the final production and presentation of results—and to be successful an examiner must understand and be familiar with their role at each stage. The size and scope of e-discovery projects require effective case management, and essential to effective case management is establishing a strategic plan at the outset, and diligently implementing constructive and documented quality assurance measures throughout each step of the process.
Cases
Broccoli v. Echostar Communications, 229 F.R.D. 506 (D. MD 2005)
Coleman (Parent) Holdings, Inc. v. Morgan Stanley & Co., Inc., 2005 WL 679071 (Fla. Cir. Ct. Mar. 1, 2005), rev'd on other grounds, Morgan Stanley & Co. Inc. v. Coleman (Parent) Holdings, Inc., 955 So.2d 1124 (Fla. Dist. Ct. App. 2007)
Integrated Service Solutions, Inc. v. Rodman, Civil Action No. 07-3591 (E.D. Pa. November 03, 2008)
United States v. Fierros-Alaverez, 2008 WL 1826188 (D. Kan. April 23, 2008)
Qualcomm Inc. v. Broadcom Corp., 548 F.3d 1004 (Cal. 2008)
Zubulake v. UBS Warburg LLC, 217 F.R.D. 309, 322 (S.D.N.Y. 2003)
Zubulake v. UBS Warburg LLC, No. 02 Civ. 1243 (SAS), 2004 U.S. Dist. LEXIS 13574, at *35 (S.D.N.Y. July 20, 2004)
References
ACPO, The Good Practice Guide for Computer-based Electronic evidence. 4th ed. (2008) ; Available online atwww.7safe.com/electronic_evidence/.
Buike, R., Understanding the exchange information store. (2005) MSExchange.org; Available online atwww.msexchange.org/articles/Understanding-Exchange-Information-Store.html.
Craig, S., How Morgan Stanley botched a big case by fumbling emails, The Wall Street Journal (2005) A1.
Federal rules of evidence, Available online atwww.law.cornell.edu/rules/fre/rules.htm.
Friedberg, E.; McGowan, M., Electronic discovery technology, In: (Editors: Cohen, A.; Lender, D.) Electronic discovery: Law and practice (2003) Aspen Publishers.
Holley, J., A framework for controlled testing of software tools and methodologies developed for identifying, preserving, analyzing and reporting electronic evidence in a network environment. (2008) ; Available online atwww.infosec.jmu.edu/reports/jmu-infosec-tr-2008-005.php.
Howell, B., Strategic planning at outset of e-discovery can save money in the end, Digital Discovery & e-Evidence 5 (2) (2005).
Howell, B.; Wertheimer, L., Data detours in internal investigations in EU countries, International Law & Trade (2008).
Howell, B., Lawyers on the Hook: Counsel's professional responsibility to provide quality assurance in electronic discovery, Journal of Securities Law, Regulation & Compliance 2 (3) (2009).
IBM, The History of Notes and Domino. (2007) ; Available online atwww.ibm.com/developerworks/lotus/library/ls-NDHistory/.
Kidwell, B.; Neumeier, M.; Hansen, B., Electronic discovery. (2005) Law Journal Press.
Kroll Ontrack, ESI Trends Report. (2008) .
Lesemann, D.; Reust, J., No one likes surprises in e-discovery projects. And quality assurance and strategic planning can reduce their number, Digital Discovery & e-Evidence 6 (9) (2006).
Mazza, M.; Quesada, E.; Sternberg, A., In pursuit of FRCP1: Creative approaches to cutting and shifting the costs of discovery of electronically stored information, 13 Rich, J.L. & Tech. 11 (2007) 101.
Microsoft, Using the Exchange Management Shell. (2007) Microsoft TechNet; Available online athttp://technet.microsoft.com/en-us/library/bb123778.aspx.
Microsoft, How to Export Mailbox Data. (2007) Microsoft TechNet; Available online athttp://technet.microsoft.com/en-us/library/bb266964.aspx.
Moore, J.W., Moore's federal practice. 3rd ed. (2000) LexisNexis.
National Institute of Standards and Technology, Digital Data Acquisition Tool Specification, Version 4. (2004) ; Available online atwww.cftt.nist.gov/disk_imaging.htm.
Roberts, K., Qualcomm fined for “monumental” e-discovery violations—possible sanctions against counsel remain pending. (2008) Litigation News Online, American Bar Association; Available online atwww.abanet.org/litigation/litigationnews/2008/may/0508_article_qualcomm.html.
Rosenthal, L.H., Memorandum from Honorable Lee H. Rosenthal Chair, Advisory Committee on the Federal Rules of Civil Procedure to Honorable David F. Levi, Chair, Standing Committee on Rules of Practices and Procedure (May 27, 2005). (2005) ; Available online atwww.uscourts.gov/rules/supct1105/Excerpt_CV_Report.pdf.
Sedona Conference, The Sedona conference best practices commentary on search and retrieval methods. (2007) ; Available online atwww.thesedonaconference.org/dltForm?did=Best_Practices_Retrieval_Methods___revised_cover_and_preface.pdf.
Sedona Conference, “Jumpstart Outline”: Questions to ask your client and your adversary to prepare for preservation, rule 26 obligations, court conferences and requests for production, May 2008. (2008) ; Available online atwww.thesedonaconference.org/dltForm?did=Questionnaire.pdf.
Smith, M.K.; Welty, C.; McGuinness, D.L., OWL web ontology language guide. (2004) ; Available online atwww.w3.org/TR/2004/REC-owl-guide-20040210/ #StructureOfOntologies.
Socha, G.; Gelbman, T., 2008 Socha-Gelbman electronic discovery survey report. (2008) .
Socha, G.; Gelbman, T., Preservation node. Available online atwww.edrm. net/wiki/index.php/Preservation_Node (2008).
Stallings, W., Cryptography and network security: Principles and practice. 3rd ed. (2003) Addison-Wesley.
Tamer, O.M.; Ling, L., Encyclopedia of database systems. (2009) Springer; (in press). Seehttp://tomgruber.org/writing/ontology-definition-2007.htm.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.